Downloaded 23 times

![Instruct.KR Summer 2025 Meetup
Hygeun Oh
( , Zerohertz)
q / Machine Learning Engineer ( ) .
qPython Kubernetes , MLOps .
qNeovim .
q ML .
0. ...
[1] https://github.com/Zerohertz
GitHub[1]
1/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-2-2048.jpg)

![Instruct.KR Summer 2025 Meetup
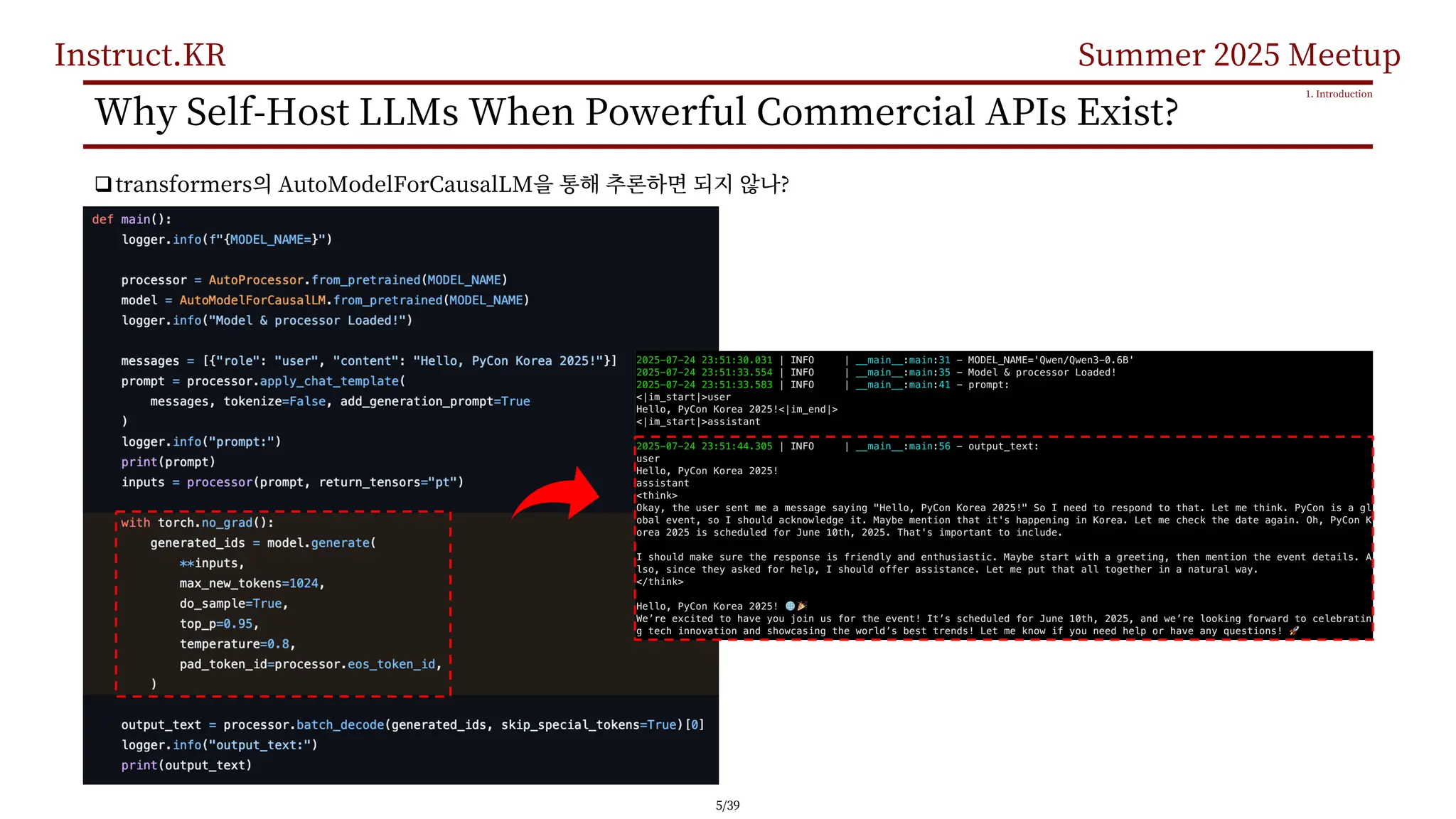
Why Self-Host LLMs When Powerful Commercial APIs Exist?
q :
q / :
q : , ,
qAPI : , ,
1. Introduction
[2] https://artificialanalysis.ai/
[2]
4/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-5-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
qvLLM history
§ 2023 2 9 , GitHub CacheFlow[3]
§ 2023 6 17 , vLLM [4]
§ 2023 9 12 , UC Berkeley Sky Computing Lab “Efficient Memory Management for Large Language Model Serving with
PagedAttention” [5]
§ 2025 6 19 , GitHub star 50k
§ 2025 7 24 , v0.10.0 release
qLicense: Apache-2.0[6]
qv of vLLM[7]
1. Introduction
[3] https://github.com/vllm-project/vllm/commit/e7d9d9c08c79b386f6d0477e87b77a572390317d
[4] https://github.com/vllm-project/vllm/commit/0b98ba15c744f1dfb0ea4f2135e85ca23d572ae1
[5] https://github.com/vllm-project/vllm/blob/main/LICENSE
[6] https://arxiv.org/abs/2309.06180
[7] https://github.com/vllm-project/vllm/issues/835
6/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-7-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
1. Introduction
[8] https://www.star-history.com/
[8]
7/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-8-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
1. Introduction
[8] https://www.star-history.com/
[8]
8/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-9-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
q LLM
§ State-of-the-art throughput:
§ Continuous batching:
q
§ PagedAttention [6]: Attention key/value
§ Optimized CUDA kernels: FlashAttention[9], FlashInfer[10]
§ Chunked prefill [11], Speculative decoding[12]
q
§ HuggingFace :
§ : ,
§ : Tensor, pipeline (Ray ), data, expert parallelism
q API
§ OpenAI-Compatible API: AI (e.g., LangChain, Gemini CLI, …)
§ Streaming output:
§ Prefix caching, Multi-LoRA
1. Introduction
[6] https://arxiv.org/abs/2309.06180
[9] https://github.com/vllm-project/flash-attention
[10] https://github.com/flashinfer-ai/flashinfer
[11] https://docs.vllm.ai/en/v0.9.2/configuration/optimization.html#chunked-prefill_1
[12] https://docs.vllm.ai/en/v0.9.2/features/spec_decode.html
9/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-10-2048.jpg)
![Instruct.KR Summer 2025 Meetup
How to serving LLM with vLLM?
qInstallation
§ Local (CPU)
§ GPU [13]
qvllm serve
1. Introduction
[13] https://docs.vllm.ai/en/v0.9.2/deployment/docker.html
10/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-11-2048.jpg)

![Instruct.KR Summer 2025 Meetup
OpenAI API Spec[14]
q/v1/models[15]
2. OpenAI-Compatible Server
[14] https://docs.vllm.ai/en/v0.9.2/serving/openai_compatible_server.html
[15] https://platform.openai.com/docs/api-reference/models/list
[16] https://platform.openai.com/docs/api-reference/chat/create
q/v1/chat/completions[16]
12/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-13-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Tool calling
qOpenAI
2. OpenAI-Compatible Server
[17] https://github.com/openai/openai-python/blob/v1.97.1/src/openai/types/shared_params/function_definition.py#L13-L45
[17]
13/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-14-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Tool calling
q“--tool-call-parser” parser [18, 19]
2. OpenAI-Compatible Server
[18] https://docs.vllm.ai/en/v0.9.2/features/tool_calling.html
[19] https://qwen.readthedocs.io/en/latest/deployment/vllm.html#parsing-tool-calls
14/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-15-2048.jpg)
![Instruct.KR Summer 2025 Meetup
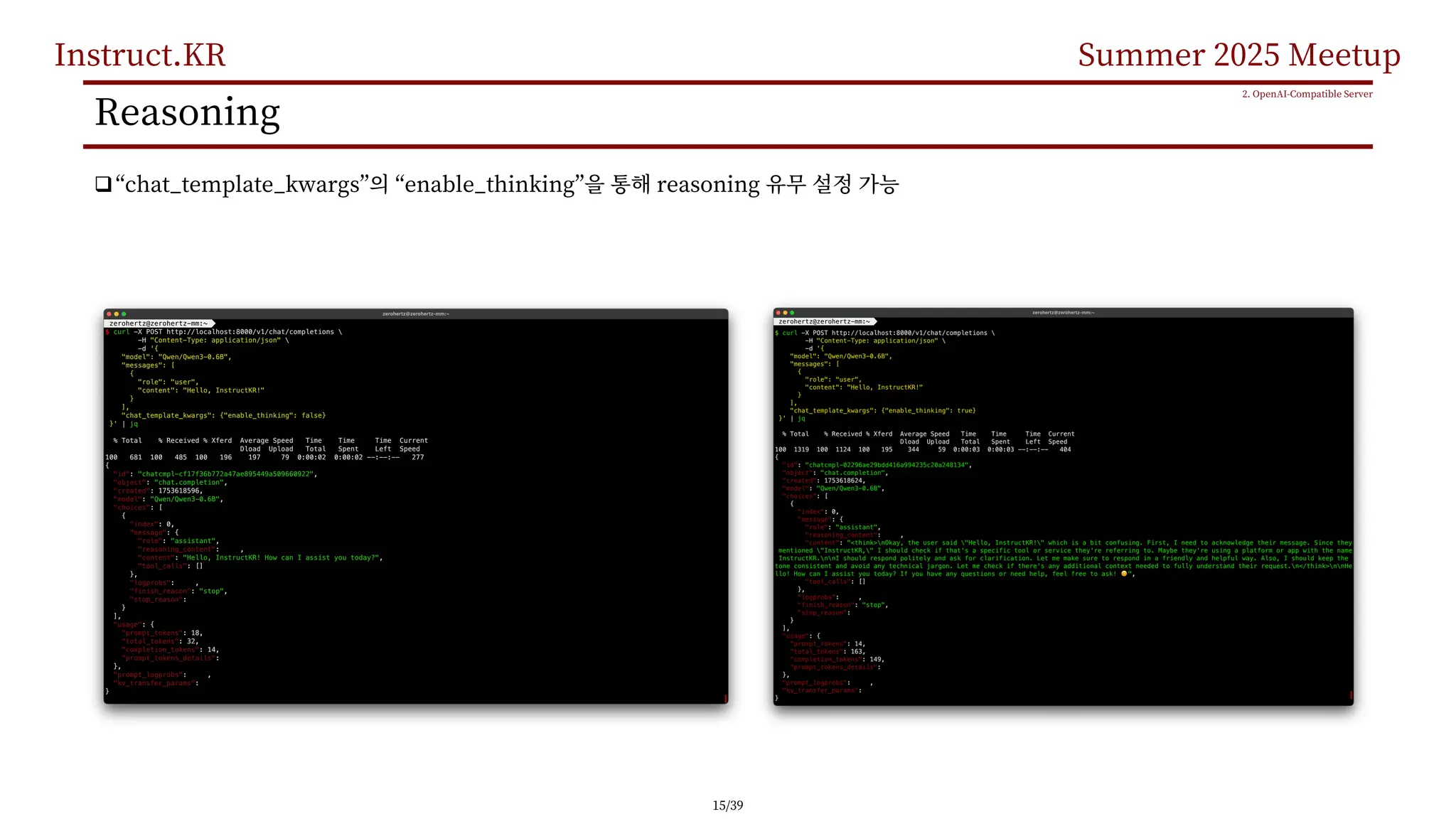
Reasoning
q“--reasoning-parser” parser [20, 21]
q “--enable-reasoning” deprecated[22]
2. OpenAI-Compatible Server
[20] https://docs.vllm.ai/en/v0.9.2/features/reasoning_outputs.html
[21] https://qwen.readthedocs.io/en/latest/deployment/vllm.html#parsing-thinking-content
[22] https://github.com/vllm-project/vllm/blob/v0.9.2/vllm/engine/arg_utils.py#L626-L634
16/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-17-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Template
q tokenizer_config.json “chat_template”
2. OpenAI-Compatible Server
[23] https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/tokenizer_config.json#L230
[23]
17/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-18-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Template
q“--chat-template” chat template [24]
2. OpenAI-Compatible Server
[24] https://docs.vllm.ai/en/v0.9.2/serving/openai_compatible_server.html#chat-template_1
[25] https://github.com/vllm-project/vllm/tree/main/examples
[25]
18/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-19-2048.jpg)

![Instruct.KR Summer 2025 Meetup
KV Cache, PagedAttention
qKV Cache[26]
§ Autoregressive token sequence
→ time complexity: 𝑂 𝑛!
§ Key/Value (KV cache)
→ time complexity: 𝑂 𝑛
qPagedAttention[6, 27, 28]
§ (OS) virtual memory
§ KV cache memory memory fragmentation
→ memory /
§ Block memory page table (logical continuity) memory
§ page mapping memory non-continuous
3. Architecture
[26] https://huggingface.co/blog/not-lain/kv-caching
[6] https://arxiv.org/abs/2309.06180
[27] https://docs.vllm.ai/en/v0.9.2/design/kernel/paged_attention.html
[28] https://blog.vllm.ai/2023/06/20/vllm.html
[29] https://github.com/HandsOnLLM/Hands-On-Large-Language-Models/blob/main/chapter03/Chapter%203%20-%20Looking%20Inside%20LLMs.ipynb
Value Token 1
Value Token 2
Value Token 3
Value Token 4
𝑉
Query Token 1
Query Token 2
Query Token 3
Query Token 4
𝑄
Key
Token
1
Key
Token
2
Key
Token
3
Key
Token
4
𝐾!
𝑄"𝐾"
𝑄!𝐾"
𝑄#𝐾"
𝑄$𝐾"
𝑄"𝐾!
𝑄!𝐾!
𝑄#𝐾!
𝑄$𝐾!
𝑄"𝐾#
𝑄!𝐾#
𝑄#𝐾#
𝑄$𝐾#
𝑄"𝐾$
𝑄!𝐾$
𝑄#𝐾$
𝑄$𝐾$
𝑄𝐾!
× = ×
[29]
[6]
20/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-21-2048.jpg)
![Instruct.KR Summer 2025 Meetup
V0 Engine vs. V1 Engine
q Optimized Execution Loop & API Server: EngineCore AsyncLLM API server, token CPU GPU model
q Simple & Flexible Scheduler: “prefill”, “decode” , “{request_id: num_tokens}” token chunked-prefill, caching, decoding
q Zero-Overhead Prefix Caching: Hash+LRU cache cache hit rate 0% 1%
q Clean Architecture for Tensor-Parallel Inference: Worker caching diff , scheduler, worker IPC overhead
q Efficient Input Preparation: Persistent batch tensor diff , Numpy CPU overhead
q torch.compile & Piecewise CUDA Graphs: Model CUDA graph kernel customizing
q Enhanced Support for Multimodal LLMs: image , image hash KV cache, encoder cache chunked-prefill
q FlashAttention 3: batch attention kernel
q VLLM_USE_V1=1 V1 Engine
3. Architecture
[30] https://docs.vllm.ai/en/v0.9.2/design/arch_overview.html
[31] https://docs.vllm.ai/en/v0.9.2/usage/v1_guide.html
[32] https://github.com/vllm-project/vllm/issues/18571
[33] https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
21/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-22-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Completions
qvLLM /v1/chat/completions [34]
2. OpenAI-Compatible Server
[34] https://zerohertz.github.io/vllm-openai-2/#Conclusion
22/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-23-2048.jpg)

![Instruct.KR Summer 2025 Meetup
LoRA Adapters
qLoRA (Low-Rank Adaptation)[35]
§ model weight low-rank matrix (𝐴, 𝐵)
§ Δ𝑊 = 𝐵𝐴 model data
qStatic serving LoRA adapters
qDynamic serving LoRA adapters
4. Production Deployment
[35] https://docs.vllm.ai/en/v0.9.2/features/lora.html
[36] https://arxiv.org/abs/2106.09685
[36]
24/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-25-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Parallelism Strategies[37]
qTensor Parallelism (TP)
§ model layer model parameter GPU
→ Model GPU single node
→ KV cache GPU memory pressure
qPipeline Parallelism (PP)
§ Model layer GPU model
→ Model node
→ Layer tensor sharding model
qExpert Parallelism (EP)
§ Mixture of Experts (MoE) model
→ “--enable-expert-parallel” MoE layer tensor parallelism expert parallelism
→ MoE model
→ GPU expert
qData Parallelism (DP)
§ GPU model batch
→ model GPU
→ Model
→ batch
4. Production Deployment
[37] https://docs.vllm.ai/en/v0.9.2/configuration/optimization.html#parallelism-strategies
26/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-27-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qRay cluster [38]
§ VLLM_HOST_IP[39]: vLLM node IP
§ GLOO_SOCKET_IFNAME[40]: PyTorch Gloo bakcend network interface
§ NCCL_IB_DISABLE[41]: NCCL InfiniBand (IB) network
4. Production Deployment
[38] https://docs.vllm.ai/en/v0.9.2/examples/online_serving/run_cluster.html
[39] https://docs.vllm.ai/en/v0.9.2/usage/security.html
[40] https://docs.pytorch.org/docs/stable/distributed.html#common-environment-variables
[41] https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html#nccl-ib-disable
Head Node
Worker Node
27/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-28-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qMulti-Node Multi-GPU[42, 43]
(tensor parallel plus pipeline parallel inference)
§ If your model is too large to fit in a single node, you can use tensor
parallel together with pipeline parallelism.
§ The tensor parallel size is the number of GPUs you want to use in
each node, and the pipeline parallel size is the number of nodes
you want to use.
§ E.g., if you have 16 GPUs in 2 nodes (8 GPUs per node), you can set
the tensor parallel size to 8 and the pipeline parallel size to 2.
qTP 16 vs. TP 8 + PP 2
4. Production Deployment
[42] https://docs.vllm.ai/en/v0.9.2/serving/distributed_serving.html
[43] https://blog.vllm.ai/2025/02/17/distributed-inference.html
28/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-29-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qRDMA (Remote Direct Memory Access)[44]
§ Network node memory CPU, cache, data
§ E.g., InfiniBand, RoCE, iWARP
qInfiniBand[45]
§ RDMA native CPU node memory
§ switch network adapter (Host Channel Adapter, HCA) (Ethernet network architecture)
qRoCEv2 (RDMA over Converged Ethernet v2)[44]
§ ethernet network RDMA protocol
4. Production Deployment
[44] https://zerohertz.github.io/distributed-computing-rdma-roce/
[45] https://developer.nvidia.com/gpudirect
29/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-30-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
4. Production Deployment
[46] https://docs.vllm.ai/en/v0.9.2/serving/distributed_serving.html#gpudirect-rdma
[46]
30/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-31-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Deployment with GPU Cluster (Kubernetes)
qKubernetes [47]
§ Model store, Network, IPC,
qAIBrix[48, 49, 50, 51]
§ vLLM cloud native control plane
§ LoRA , LLM gateway routing, autoscaler, KV cache, …
qProduction-stack[52, 53, 54, 55]
§ vLLM LLM production codebase
§ LMCache KV cache , prefix-aware routing, Helm chart , …
4. Production Deployment
[47] https://docs.vllm.ai/en/v0.9.2/deployment/k8s.html
[48] https://github.com/vllm-project/aibrix
[49] https://arxiv.org/abs/2504.03648
[50] https://blog.vllm.ai/2025/02/21/aibrix-release.html
[51] https://aibrix.readthedocs.io/latest/
[52] https://github.com/vllm-project/production-stack
[53] https://docs.vllm.ai/en/v0.9.2/deployment/integrations/production-stack.html
[54] https://blog.vllm.ai/2025/01/21/stack-release.html
[55] https://blog.vllm.ai/production-stack/
31/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-32-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Deployment with GPU Cluster (Kubernetes)
qLWS (LeaderWorkerSet)[56, 57]
§ Kubernetes Leader-Worker architecture
CRD controller
4. Production Deployment
[56] https://docs.vllm.ai/en/v0.9.2/deployment/frameworks/lws.html
[57] https://github.com/kubernetes-sigs/lws
32/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-33-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Observability (Prometheus + Grafana)
q“/metrics” vLLM server Prometheus format metric [58, 59]
§ vllm:request_success_total: (EOS max )
§ vllm:request_queue_time_seconds: queue
§ vllm:request_prefill_time_seconds: prefill
§ vllm:request_decode_time_seconds: decoding
§ vllm:request_max_num_generation_tokens: token
§ …
qGrafana dashboard
4. Production Deployment
[58] https://docs.vllm.ai/en/v0.9.2/usage/metrics.html
[59] https://docs.vllm.ai/en/v0.9.2/examples/online_serving/prometheus_grafana.html
33/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-34-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Benchmark
q“vllm bench” CLI benchmark [60]
4. Production Deployment
[60] https://docs.vllm.ai/en/v0.9.2/cli/index.html#bench
[61] https://docs.vllm.ai/en/v0.9.2/contributing/profiling.html
[62] https://github.com/vllm-project/vllm/tree/v0.9.2/benchmarks
[63] https://github.com/vllm-project/guidellm
[64] https://arxiv.org/pdf/2502.06494
qvLLM repository benchmarks [61, 62]
qvLLM project Guidellm [63, 64]
34/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-35-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Issues
qGloo connectFullMesh failed with…[65]
§ Multi node process GLOO
→ “GLOO_SOCKET_IFNAME” interface
4. Production Deployment
[65] https://github.com/vllm-project/vllm/discussions/11353
[66] https://github.com/vllm-project/vllm/issues/17652#issuecomment-2867891239
[67] https://flashinfer.ai/2024/02/02/cascade-inference.html
qQwen model token [66, 67]
§ FlashInfer kernel cascade inference
→ “--disable-cascade-attn”
35/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-36-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Roadmap Q3 2025[68]
qV1 Engine
§ V0 Engine
§ Core scheduler
§ Async scheduling, multi-modal
qLarge Scale Serving
§ Mixture-of-Experts (MoE) model scale-out serving
§ autoscaling
qModels
§ framework (training, authoring) tokenizer, configuration, processor
§ Sparse attention mechanism
§ 1B
qUse Cases
§ RLHF
→ resharding
→ Multi-turn scheduling
§ Evaluation
→ Batching order full determinism (with/without prefix cache)
§ Batch Inference
→ Prefix caching scale-out data parallel router
→ CPU KV cache offloading
5. Wrap-up
[68] https://github.com/vllm-project/vllm/issues/20336
37/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-38-2048.jpg)

![Instruct.KR Summer 2025 Meetup
vLLM Meetup in Korea[69, 70]
5. Wrap-up
[69] https://discuss.pytorch.kr/t/8-19-vllm-meetup/7401
[70] https://lu.ma/cgcgprmh
39/39](https://image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-40-2048.jpg)


![Instruct.KR Summer 2025 Meetup
Hygeun Oh
( , Zerohertz)
q / Machine Learning Engineer ( ) .
qPython Kubernetes , MLOps .
qNeovim .
q ML .
0. ...
[1] https://github.com/Zerohertz
GitHub[1]
1/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-2-2048.jpg)


![Instruct.KR Summer 2025 Meetup
Why Self-Host LLMs When Powerful Commercial APIs Exist?
q :
q / :
q : , ,
qAPI : , ,
1. Introduction
[2] https://artificialanalysis.ai/
[2]
4/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-5-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Why vLLM?
qvLLM history
§ 2023 2 9 , GitHub CacheFlow[3]
§ 2023 6 17 , vLLM [4]
§ 2023 9 12 , UC Berkeley Sky Computing Lab “Efficient Memory Management for Large Language Model Serving with
PagedAttention” [5]
§ 2025 6 19 , GitHub star 50k
§ 2025 7 24 , v0.10.0 release
qLicense: Apache-2.0[6]
qv of vLLM[7]
1. Introduction
[3] https://github.com/vllm-project/vllm/commit/e7d9d9c08c79b386f6d0477e87b77a572390317d
[4] https://github.com/vllm-project/vllm/commit/0b98ba15c744f1dfb0ea4f2135e85ca23d572ae1
[5] https://github.com/vllm-project/vllm/blob/main/LICENSE
[6] https://arxiv.org/abs/2309.06180
[7] https://github.com/vllm-project/vllm/issues/835
6/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-7-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
1. Introduction
[8] https://www.star-history.com/
[8]
7/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-8-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
1. Introduction
[8] https://www.star-history.com/
[8]
8/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-9-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Why vLLM?
q LLM
§ State-of-the-art throughput:
§ Continuous batching:
q
§ PagedAttention [6]: Attention key/value
§ Optimized CUDA kernels: FlashAttention[9], FlashInfer[10]
§ Chunked prefill [11], Speculative decoding[12]
q
§ HuggingFace :
§ : ,
§ : Tensor, pipeline (Ray ), data, expert parallelism
q API
§ OpenAI-Compatible API: AI (e.g., LangChain, Gemini CLI, …)
§ Streaming output:
§ Prefix caching, Multi-LoRA
1. Introduction
[6] https://arxiv.org/abs/2309.06180
[9] https://github.com/vllm-project/flash-attention
[10] https://github.com/flashinfer-ai/flashinfer
[11] https://docs.vllm.ai/en/v0.9.2/configuration/optimization.html#chunked-prefill_1
[12] https://docs.vllm.ai/en/v0.9.2/features/spec_decode.html
9/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-10-2048.jpg)
![Instruct.KR Summer 2025 Meetup
How to serving LLM with vLLM?
qInstallation
§ Local (CPU)
§ GPU [13]
qvllm serve
1. Introduction
[13] https://docs.vllm.ai/en/v0.9.2/deployment/docker.html
10/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-11-2048.jpg)

![Instruct.KR Summer 2025 Meetup
OpenAI API Spec[14]
q/v1/models[15]
2. OpenAI-Compatible Server
[14] https://docs.vllm.ai/en/v0.9.2/serving/openai_compatible_server.html
[15] https://platform.openai.com/docs/api-reference/models/list
[16] https://platform.openai.com/docs/api-reference/chat/create
q/v1/chat/completions[16]
12/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-13-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Tool calling
qOpenAI
2. OpenAI-Compatible Server
[17] https://github.com/openai/openai-python/blob/v1.97.1/src/openai/types/shared_params/function_definition.py#L13-L45
[17]
13/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-14-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Tool calling
q“--tool-call-parser” parser [18, 19]
2. OpenAI-Compatible Server
[18] https://docs.vllm.ai/en/v0.9.2/features/tool_calling.html
[19] https://qwen.readthedocs.io/en/latest/deployment/vllm.html#parsing-tool-calls
14/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-15-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Reasoning
q“--reasoning-parser” parser [20, 21]
q “--enable-reasoning” deprecated[22]
2. OpenAI-Compatible Server
[20] https://docs.vllm.ai/en/v0.9.2/features/reasoning_outputs.html
[21] https://qwen.readthedocs.io/en/latest/deployment/vllm.html#parsing-thinking-content
[22] https://github.com/vllm-project/vllm/blob/v0.9.2/vllm/engine/arg_utils.py#L626-L634
16/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-17-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Template
q tokenizer_config.json “chat_template”
2. OpenAI-Compatible Server
[23] https://huggingface.co/Qwen/Qwen3-0.6B/blob/main/tokenizer_config.json#L230
[23]
17/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-18-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Template
q“--chat-template” chat template [24]
2. OpenAI-Compatible Server
[24] https://docs.vllm.ai/en/v0.9.2/serving/openai_compatible_server.html#chat-template_1
[25] https://github.com/vllm-project/vllm/tree/main/examples
[25]
18/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-19-2048.jpg)

![Instruct.KR Summer 2025 Meetup
KV Cache, PagedAttention
qKV Cache[26]
§ Autoregressive token sequence
→ time complexity: 𝑂 𝑛!
§ Key/Value (KV cache)
→ time complexity: 𝑂 𝑛
qPagedAttention[6, 27, 28]
§ (OS) virtual memory
§ KV cache memory memory fragmentation
→ memory /
§ Block memory page table (logical continuity) memory
§ page mapping memory non-continuous
3. Architecture
[26] https://huggingface.co/blog/not-lain/kv-caching
[6] https://arxiv.org/abs/2309.06180
[27] https://docs.vllm.ai/en/v0.9.2/design/kernel/paged_attention.html
[28] https://blog.vllm.ai/2023/06/20/vllm.html
[29] https://github.com/HandsOnLLM/Hands-On-Large-Language-Models/blob/main/chapter03/Chapter%203%20-%20Looking%20Inside%20LLMs.ipynb
Value Token 1
Value Token 2
Value Token 3
Value Token 4
𝑉
Query Token 1
Query Token 2
Query Token 3
Query Token 4
𝑄
Key
Token
1
Key
Token
2
Key
Token
3
Key
Token
4
𝐾!
𝑄"𝐾"
𝑄!𝐾"
𝑄#𝐾"
𝑄$𝐾"
𝑄"𝐾!
𝑄!𝐾!
𝑄#𝐾!
𝑄$𝐾!
𝑄"𝐾#
𝑄!𝐾#
𝑄#𝐾#
𝑄$𝐾#
𝑄"𝐾$
𝑄!𝐾$
𝑄#𝐾$
𝑄$𝐾$
𝑄𝐾!
× = ×
[29]
[6]
20/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-21-2048.jpg)
![Instruct.KR Summer 2025 Meetup
V0 Engine vs. V1 Engine
q Optimized Execution Loop & API Server: EngineCore AsyncLLM API server, token CPU GPU model
q Simple & Flexible Scheduler: “prefill”, “decode” , “{request_id: num_tokens}” token chunked-prefill, caching, decoding
q Zero-Overhead Prefix Caching: Hash+LRU cache cache hit rate 0% 1%
q Clean Architecture for Tensor-Parallel Inference: Worker caching diff , scheduler, worker IPC overhead
q Efficient Input Preparation: Persistent batch tensor diff , Numpy CPU overhead
q torch.compile & Piecewise CUDA Graphs: Model CUDA graph kernel customizing
q Enhanced Support for Multimodal LLMs: image , image hash KV cache, encoder cache chunked-prefill
q FlashAttention 3: batch attention kernel
q VLLM_USE_V1=1 V1 Engine
3. Architecture
[30] https://docs.vllm.ai/en/v0.9.2/design/arch_overview.html
[31] https://docs.vllm.ai/en/v0.9.2/usage/v1_guide.html
[32] https://github.com/vllm-project/vllm/issues/18571
[33] https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
21/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-22-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Chat Completions
qvLLM /v1/chat/completions [34]
2. OpenAI-Compatible Server
[34] https://zerohertz.github.io/vllm-openai-2/#Conclusion
22/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-23-2048.jpg)

![Instruct.KR Summer 2025 Meetup
LoRA Adapters
qLoRA (Low-Rank Adaptation)[35]
§ model weight low-rank matrix (𝐴, 𝐵)
§ Δ𝑊 = 𝐵𝐴 model data
qStatic serving LoRA adapters
qDynamic serving LoRA adapters
4. Production Deployment
[35] https://docs.vllm.ai/en/v0.9.2/features/lora.html
[36] https://arxiv.org/abs/2106.09685
[36]
24/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-25-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Parallelism Strategies[37]
qTensor Parallelism (TP)
§ model layer model parameter GPU
→ Model GPU single node
→ KV cache GPU memory pressure
qPipeline Parallelism (PP)
§ Model layer GPU model
→ Model node
→ Layer tensor sharding model
qExpert Parallelism (EP)
§ Mixture of Experts (MoE) model
→ “--enable-expert-parallel” MoE layer tensor parallelism expert parallelism
→ MoE model
→ GPU expert
qData Parallelism (DP)
§ GPU model batch
→ model GPU
→ Model
→ batch
4. Production Deployment
[37] https://docs.vllm.ai/en/v0.9.2/configuration/optimization.html#parallelism-strategies
26/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-27-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qRay cluster [38]
§ VLLM_HOST_IP[39]: vLLM node IP
§ GLOO_SOCKET_IFNAME[40]: PyTorch Gloo bakcend network interface
§ NCCL_IB_DISABLE[41]: NCCL InfiniBand (IB) network
4. Production Deployment
[38] https://docs.vllm.ai/en/v0.9.2/examples/online_serving/run_cluster.html
[39] https://docs.vllm.ai/en/v0.9.2/usage/security.html
[40] https://docs.pytorch.org/docs/stable/distributed.html#common-environment-variables
[41] https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html#nccl-ib-disable
Head Node
Worker Node
27/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-28-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qMulti-Node Multi-GPU[42, 43]
(tensor parallel plus pipeline parallel inference)
§ If your model is too large to fit in a single node, you can use tensor
parallel together with pipeline parallelism.
§ The tensor parallel size is the number of GPUs you want to use in
each node, and the pipeline parallel size is the number of nodes
you want to use.
§ E.g., if you have 16 GPUs in 2 nodes (8 GPUs per node), you can set
the tensor parallel size to 8 and the pipeline parallel size to 2.
qTP 16 vs. TP 8 + PP 2
4. Production Deployment
[42] https://docs.vllm.ai/en/v0.9.2/serving/distributed_serving.html
[43] https://blog.vllm.ai/2025/02/17/distributed-inference.html
28/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-29-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
qRDMA (Remote Direct Memory Access)[44]
§ Network node memory CPU, cache, data
§ E.g., InfiniBand, RoCE, iWARP
qInfiniBand[45]
§ RDMA native CPU node memory
§ switch network adapter (Host Channel Adapter, HCA) (Ethernet network architecture)
qRoCEv2 (RDMA over Converged Ethernet v2)[44]
§ ethernet network RDMA protocol
4. Production Deployment
[44] https://zerohertz.github.io/distributed-computing-rdma-roce/
[45] https://developer.nvidia.com/gpudirect
29/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-30-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Multi-node Distributed Inference
4. Production Deployment
[46] https://docs.vllm.ai/en/v0.9.2/serving/distributed_serving.html#gpudirect-rdma
[46]
30/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-31-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Deployment with GPU Cluster (Kubernetes)
qKubernetes [47]
§ Model store, Network, IPC,
qAIBrix[48, 49, 50, 51]
§ vLLM cloud native control plane
§ LoRA , LLM gateway routing, autoscaler, KV cache, …
qProduction-stack[52, 53, 54, 55]
§ vLLM LLM production codebase
§ LMCache KV cache , prefix-aware routing, Helm chart , …
4. Production Deployment
[47] https://docs.vllm.ai/en/v0.9.2/deployment/k8s.html
[48] https://github.com/vllm-project/aibrix
[49] https://arxiv.org/abs/2504.03648
[50] https://blog.vllm.ai/2025/02/21/aibrix-release.html
[51] https://aibrix.readthedocs.io/latest/
[52] https://github.com/vllm-project/production-stack
[53] https://docs.vllm.ai/en/v0.9.2/deployment/integrations/production-stack.html
[54] https://blog.vllm.ai/2025/01/21/stack-release.html
[55] https://blog.vllm.ai/production-stack/
31/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-32-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Deployment with GPU Cluster (Kubernetes)
qLWS (LeaderWorkerSet)[56, 57]
§ Kubernetes Leader-Worker architecture
CRD controller
4. Production Deployment
[56] https://docs.vllm.ai/en/v0.9.2/deployment/frameworks/lws.html
[57] https://github.com/kubernetes-sigs/lws
32/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-33-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Observability (Prometheus + Grafana)
q“/metrics” vLLM server Prometheus format metric [58, 59]
§ vllm:request_success_total: (EOS max )
§ vllm:request_queue_time_seconds: queue
§ vllm:request_prefill_time_seconds: prefill
§ vllm:request_decode_time_seconds: decoding
§ vllm:request_max_num_generation_tokens: token
§ …
qGrafana dashboard
4. Production Deployment
[58] https://docs.vllm.ai/en/v0.9.2/usage/metrics.html
[59] https://docs.vllm.ai/en/v0.9.2/examples/online_serving/prometheus_grafana.html
33/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-34-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Benchmark
q“vllm bench” CLI benchmark [60]
4. Production Deployment
[60] https://docs.vllm.ai/en/v0.9.2/cli/index.html#bench
[61] https://docs.vllm.ai/en/v0.9.2/contributing/profiling.html
[62] https://github.com/vllm-project/vllm/tree/v0.9.2/benchmarks
[63] https://github.com/vllm-project/guidellm
[64] https://arxiv.org/pdf/2502.06494
qvLLM repository benchmarks [61, 62]
qvLLM project Guidellm [63, 64]
34/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-35-2048.jpg)
![Instruct.KR Summer 2025 Meetup
Production Issues
qGloo connectFullMesh failed with…[65]
§ Multi node process GLOO
→ “GLOO_SOCKET_IFNAME” interface
4. Production Deployment
[65] https://github.com/vllm-project/vllm/discussions/11353
[66] https://github.com/vllm-project/vllm/issues/17652#issuecomment-2867891239
[67] https://flashinfer.ai/2024/02/02/cascade-inference.html
qQwen model token [66, 67]
§ FlashInfer kernel cascade inference
→ “--disable-cascade-attn”
35/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-36-2048.jpg)

![Instruct.KR Summer 2025 Meetup
Roadmap Q3 2025[68]
qV1 Engine
§ V0 Engine
§ Core scheduler
§ Async scheduling, multi-modal
qLarge Scale Serving
§ Mixture-of-Experts (MoE) model scale-out serving
§ autoscaling
qModels
§ framework (training, authoring) tokenizer, configuration, processor
§ Sparse attention mechanism
§ 1B
qUse Cases
§ RLHF
→ resharding
→ Multi-turn scheduling
§ Evaluation
→ Batching order full determinism (with/without prefix cache)
§ Batch Inference
→ Prefix caching scale-out data parallel router
→ CPU KV cache offloading
5. Wrap-up
[68] https://github.com/vllm-project/vllm/issues/20336
37/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-38-2048.jpg)

![Instruct.KR Summer 2025 Meetup
vLLM Meetup in Korea[69, 70]
5. Wrap-up
[69] https://discuss.pytorch.kr/t/8-19-vllm-meetup/7401
[70] https://lu.ma/cgcgprmh
39/39](https://crownmelresort.com/image.slidesharecdn.com/2025instructkrsummermeetuphyogeunoh-250802031615-aba93fd1/75/Open-Source-LLMs-from-vLLM-to-Production-Instruct-KR-Summer-Meetup-2025-40-2048.jpg)


# Title - Open Source LLMs, from vLLM to Production - 오픈소스 LLM, vLLM으로 Production까지 # Session - Instruct.KR Summer Meetup (August 2, 2025, Sat, 13:00 - 18:00 KST) # Location - Inflearn Pangyo Office (5F, Building 3, Startup Campus, 20, Pangyo-ro 289beon-gil, Bundang-gu, Seongnam-si, Gyeonggi-do, Republic of Korea - 인프런 판교 오피스 (경기도 성남시 분당구 판교로289번길 20 스타트업캠퍼스 3동 5F) # GitHub Repository - https://github.com/Zerohertz/Instruct_KR_2025_Summer_Meetup_vLLM































![[DSC DACH 24] AI and XR - Ivan Voras](https://cdn.slidesharecdn.com/ss_thumbnails/dscdach2024-aiandxr-241008090719-297f455a-thumbnail.jpg?width=640&height=640&fit=bounds)



































