Downloaded 67 times



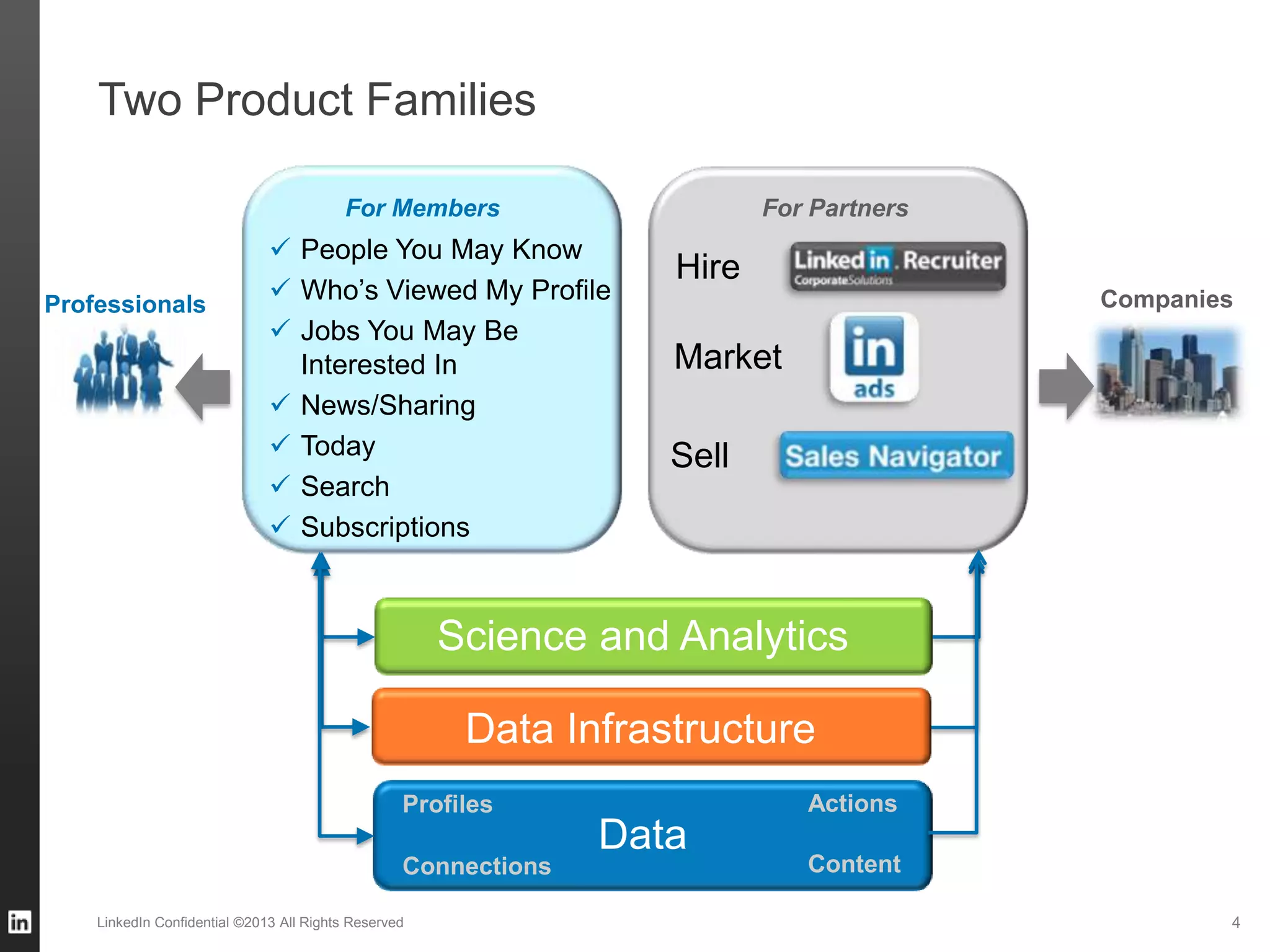
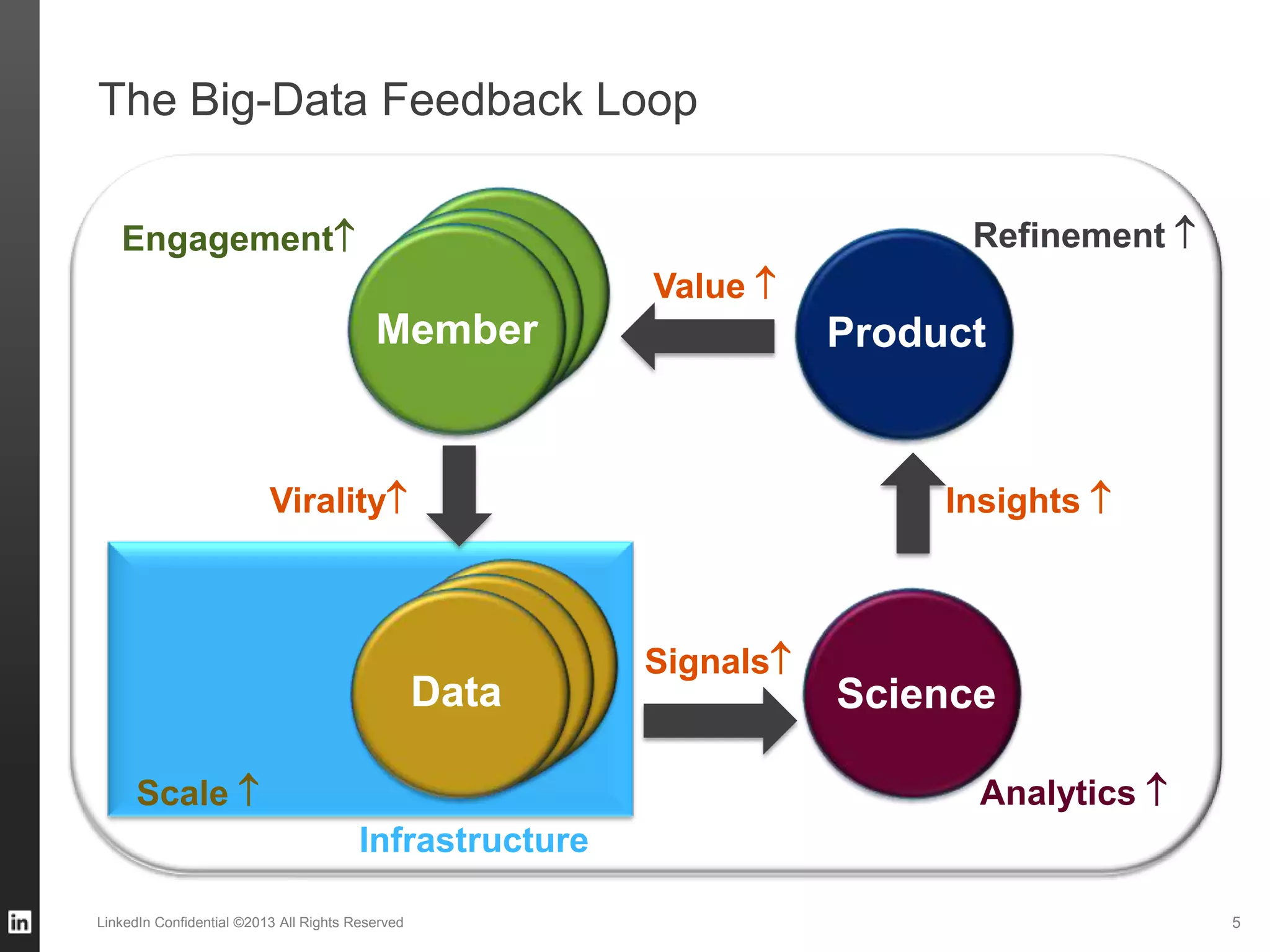
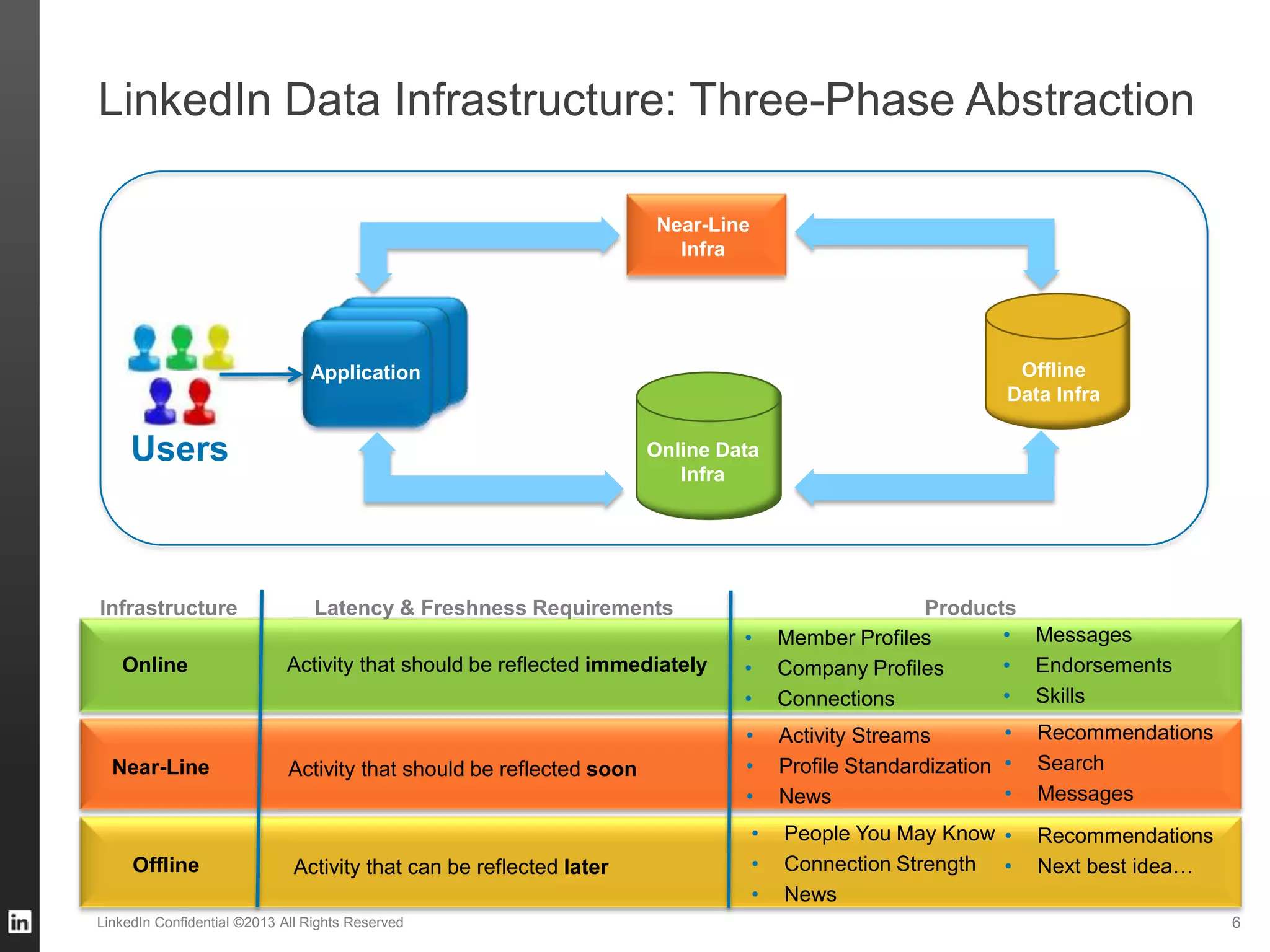
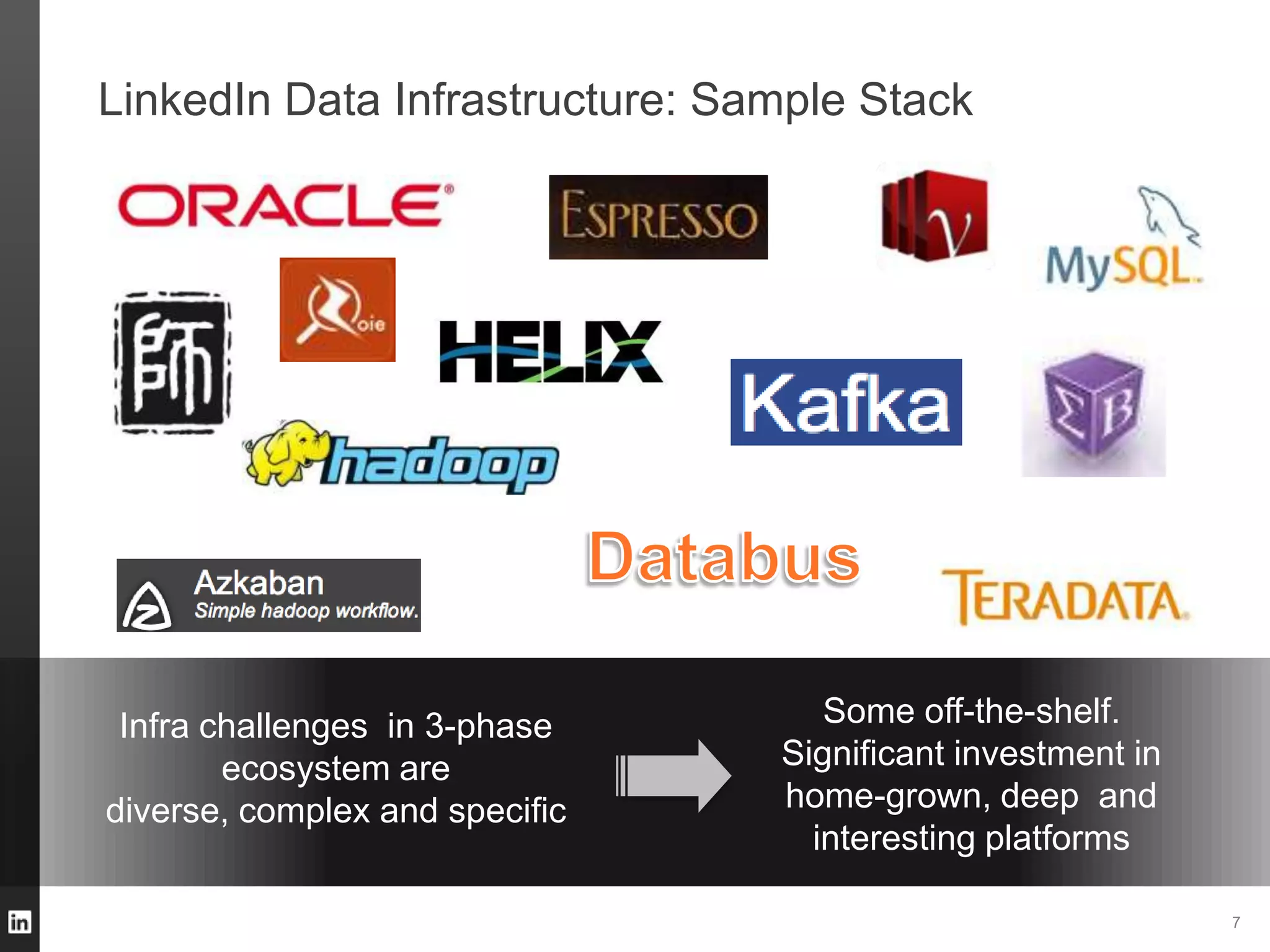

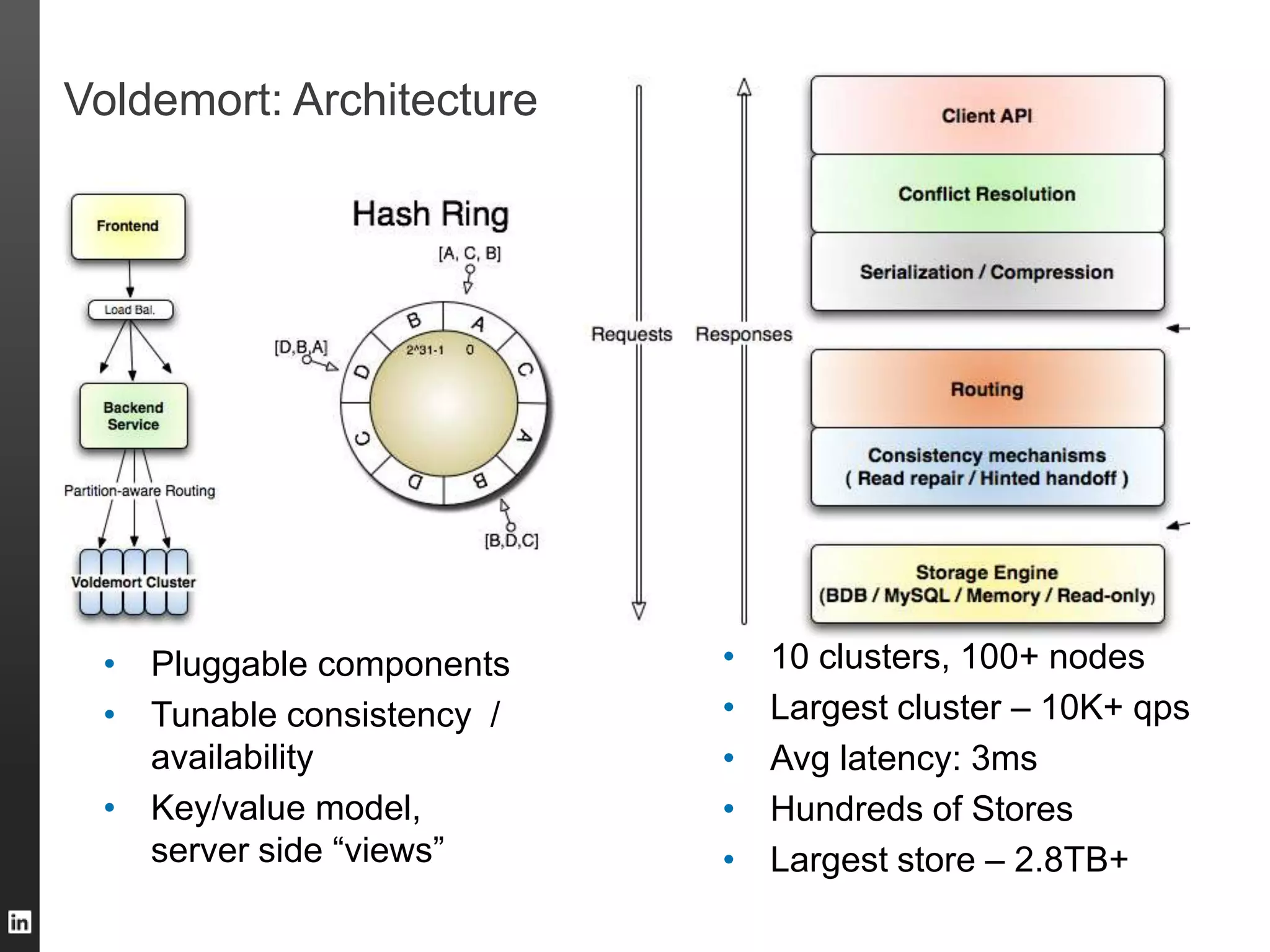

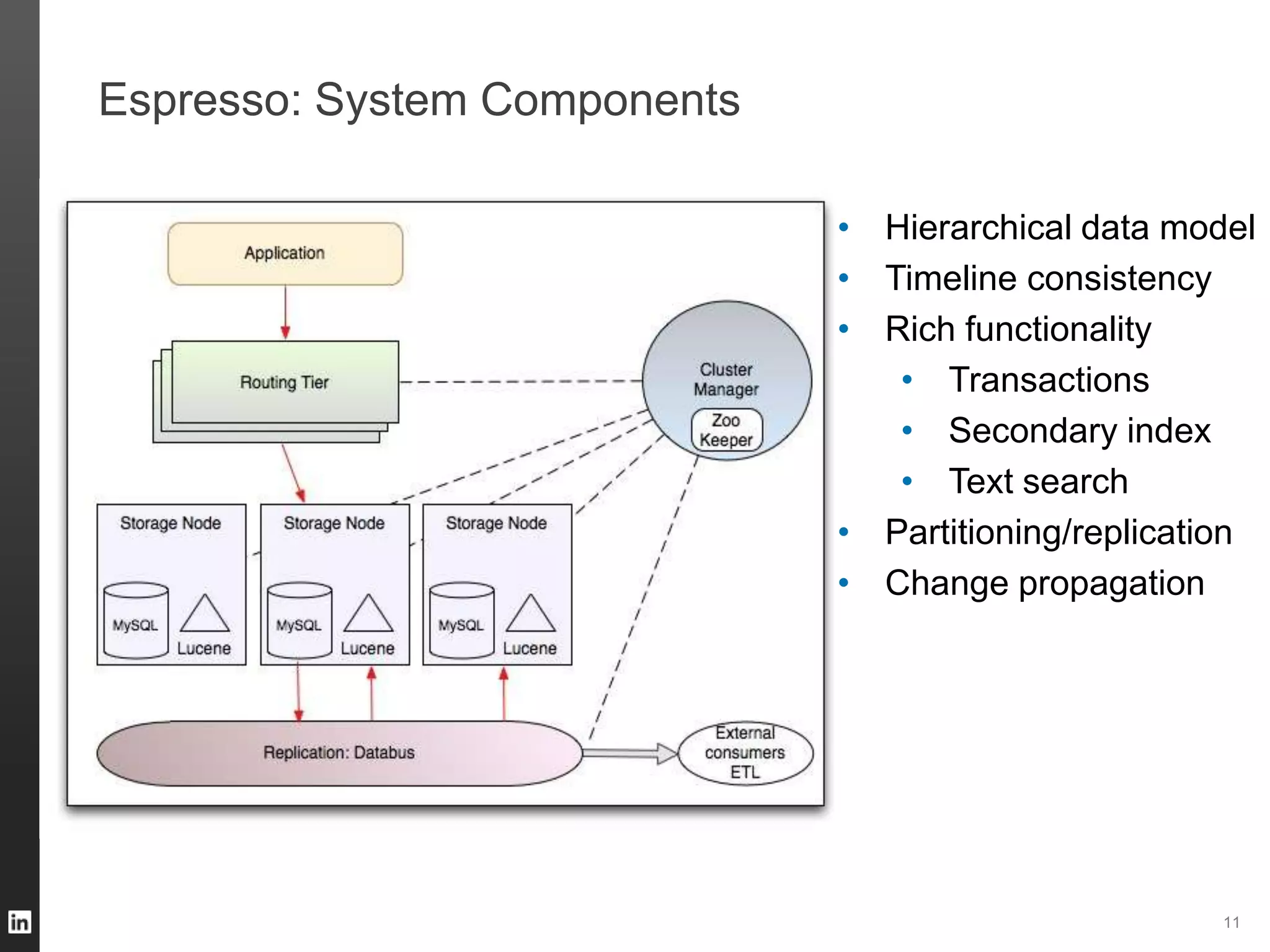
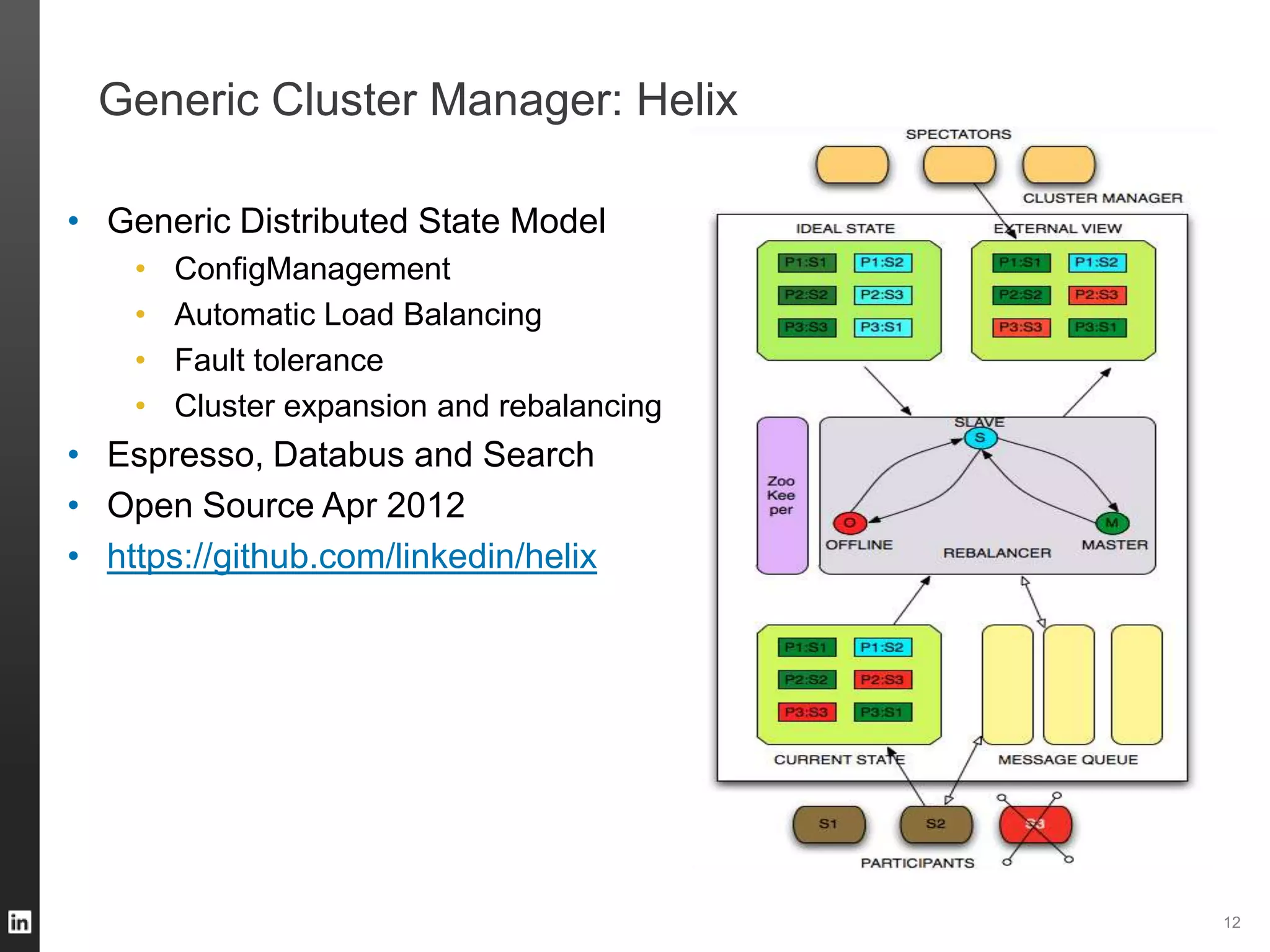

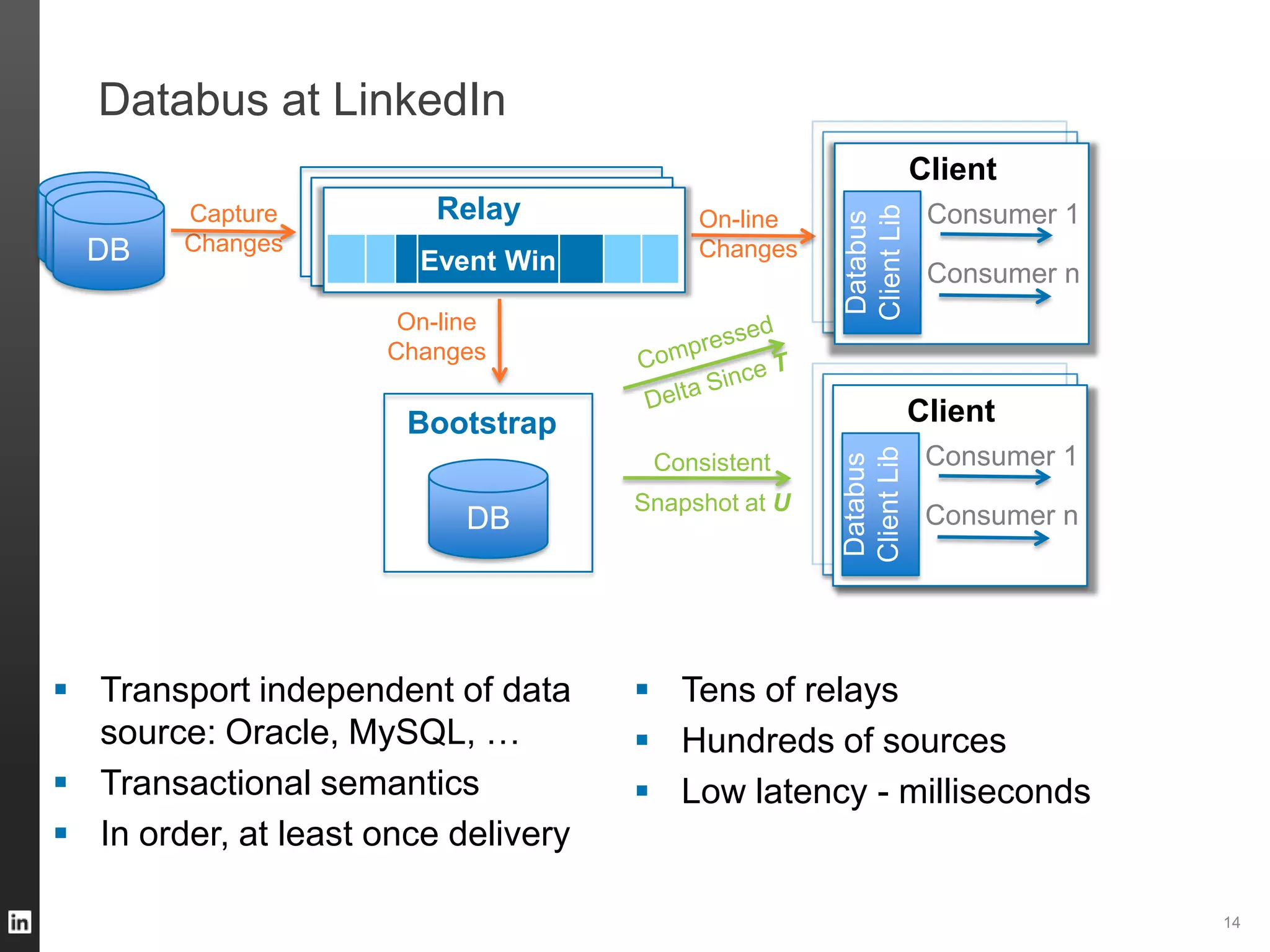

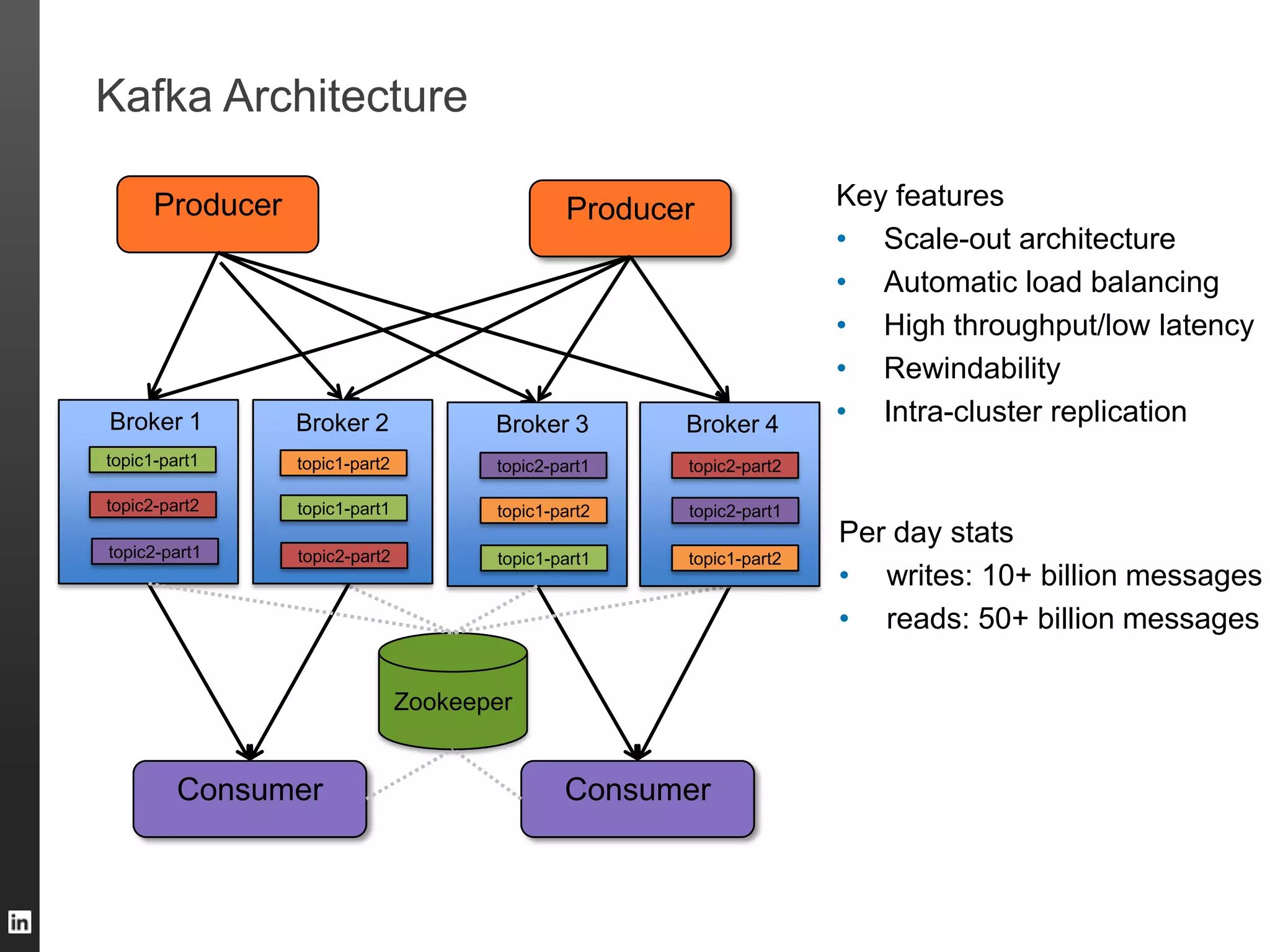


















The document outlines LinkedIn's data infrastructure, discussing its three-phase abstraction of online, near-line, and offline data handling. It highlights key solutions like Voldemort, Espresso, Databus, and Kafka for managing data efficiently while maintaining high availability and low latency. The challenges of building infrastructure in a hyper-growth environment are addressed, emphasizing the need for a balance between specialized and generic efforts.



































































