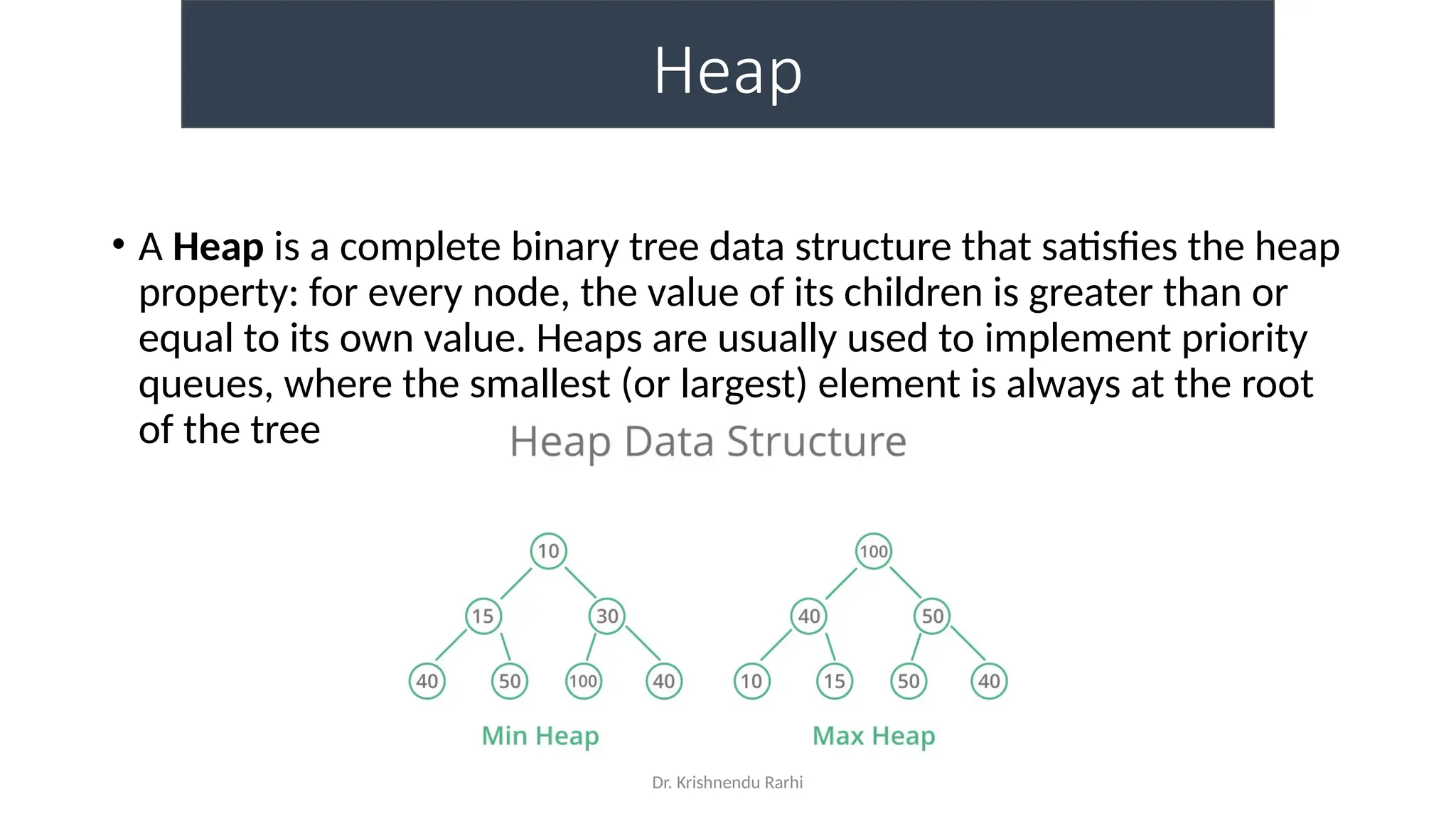
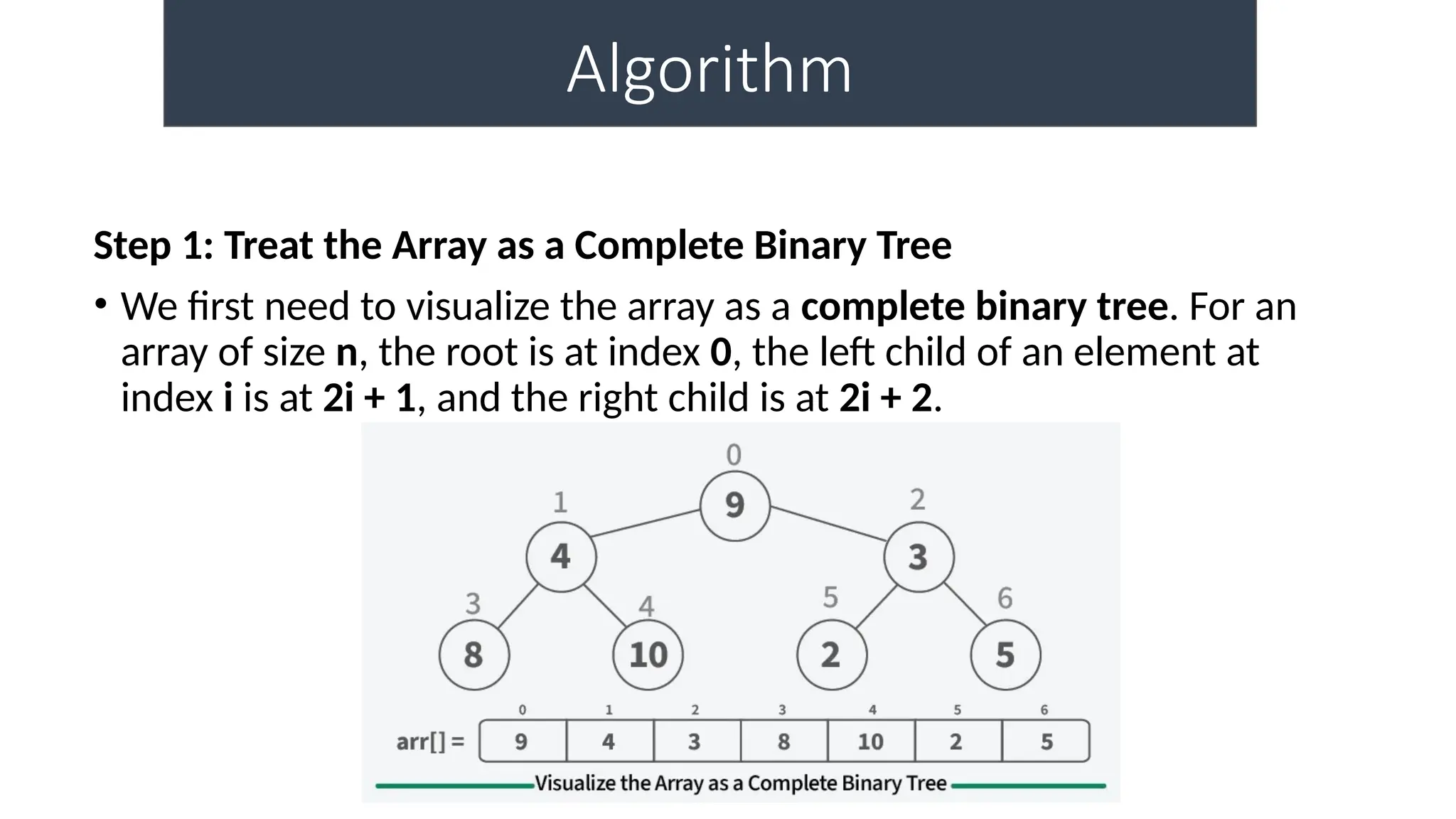
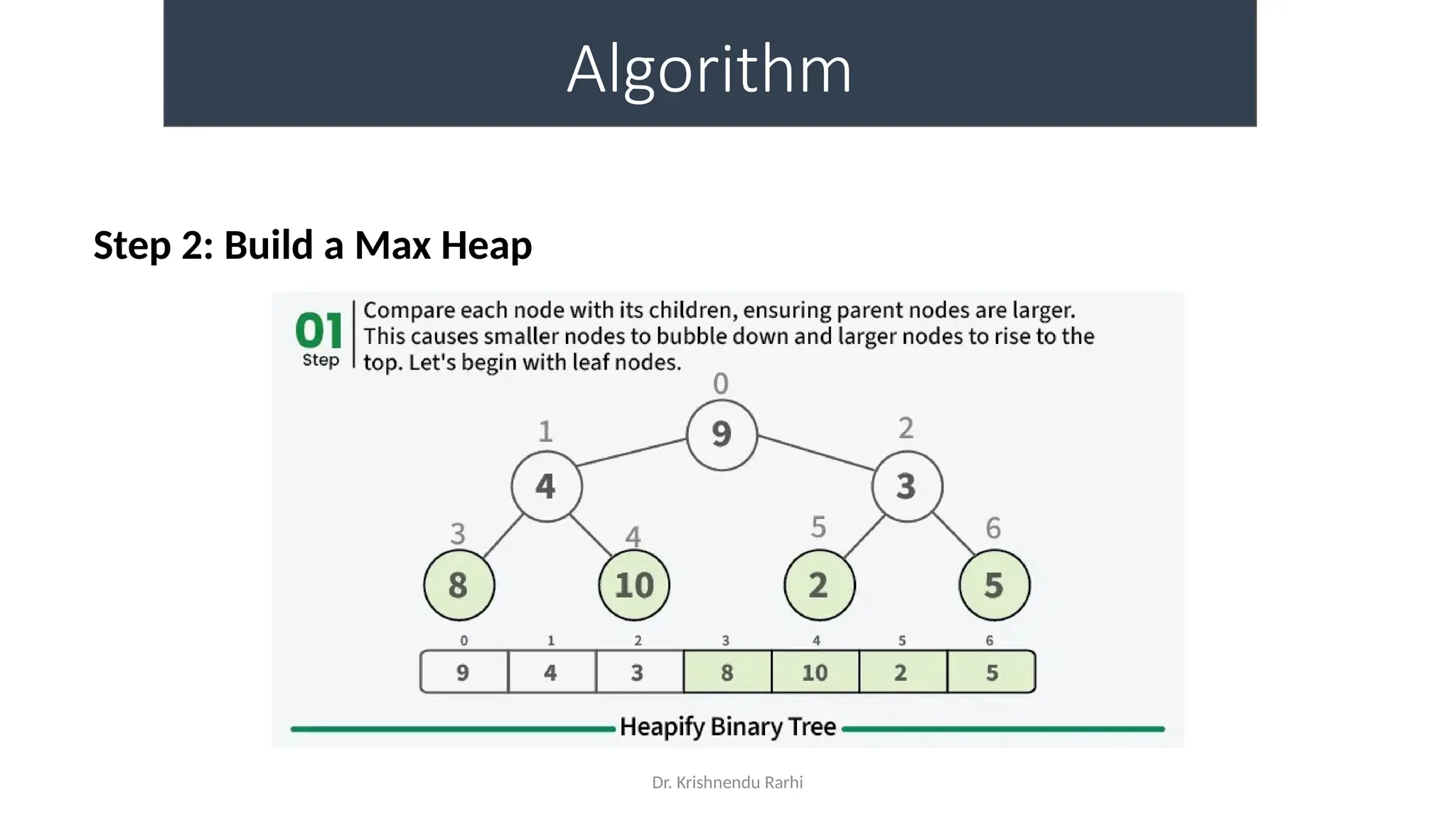
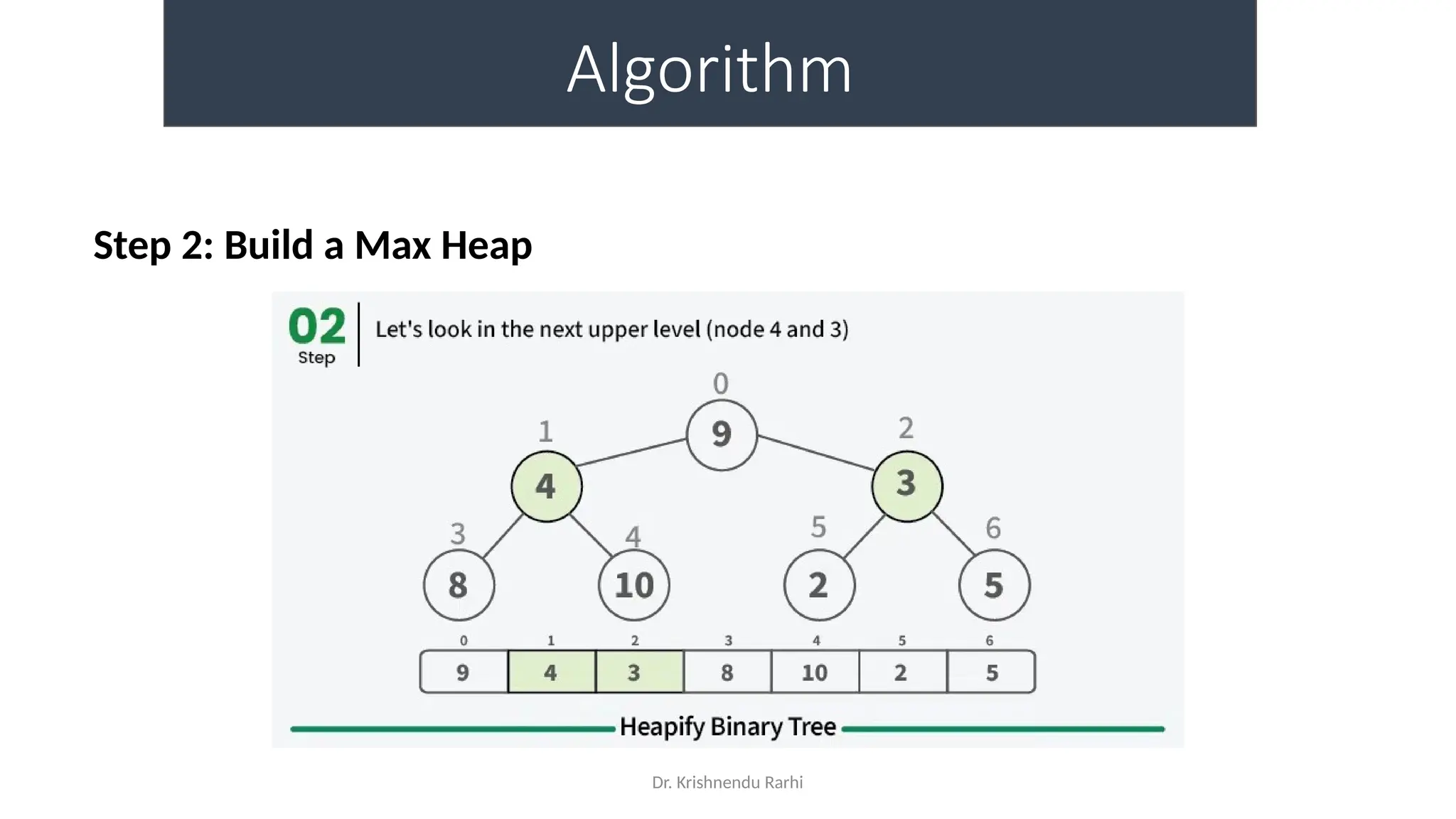
The document discusses heaps as a complete binary tree structure that supports priority queues, highlighting their properties, operations (insertion, deletion, and heapify), and implementations. It outlines the advantages of heaps, such as time and space efficiency, and their applications in tasks like priority queues, sorting algorithms, and job scheduling. Additionally, it touches on hashing as a method for efficient data storage and retrieval, explaining its components and functioning.








![Dr. Krishnendu Rarhi
Heap- Implementation
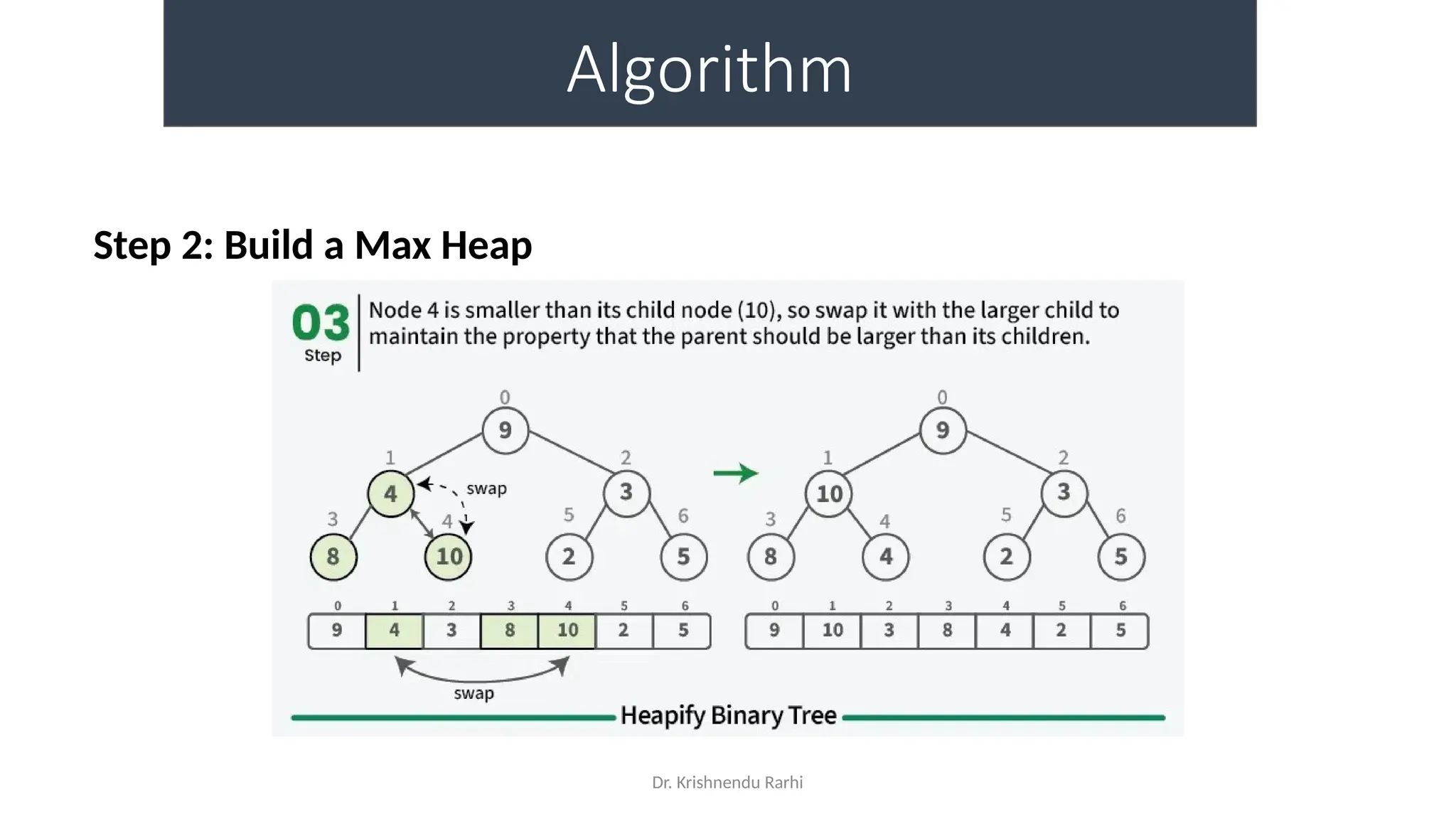
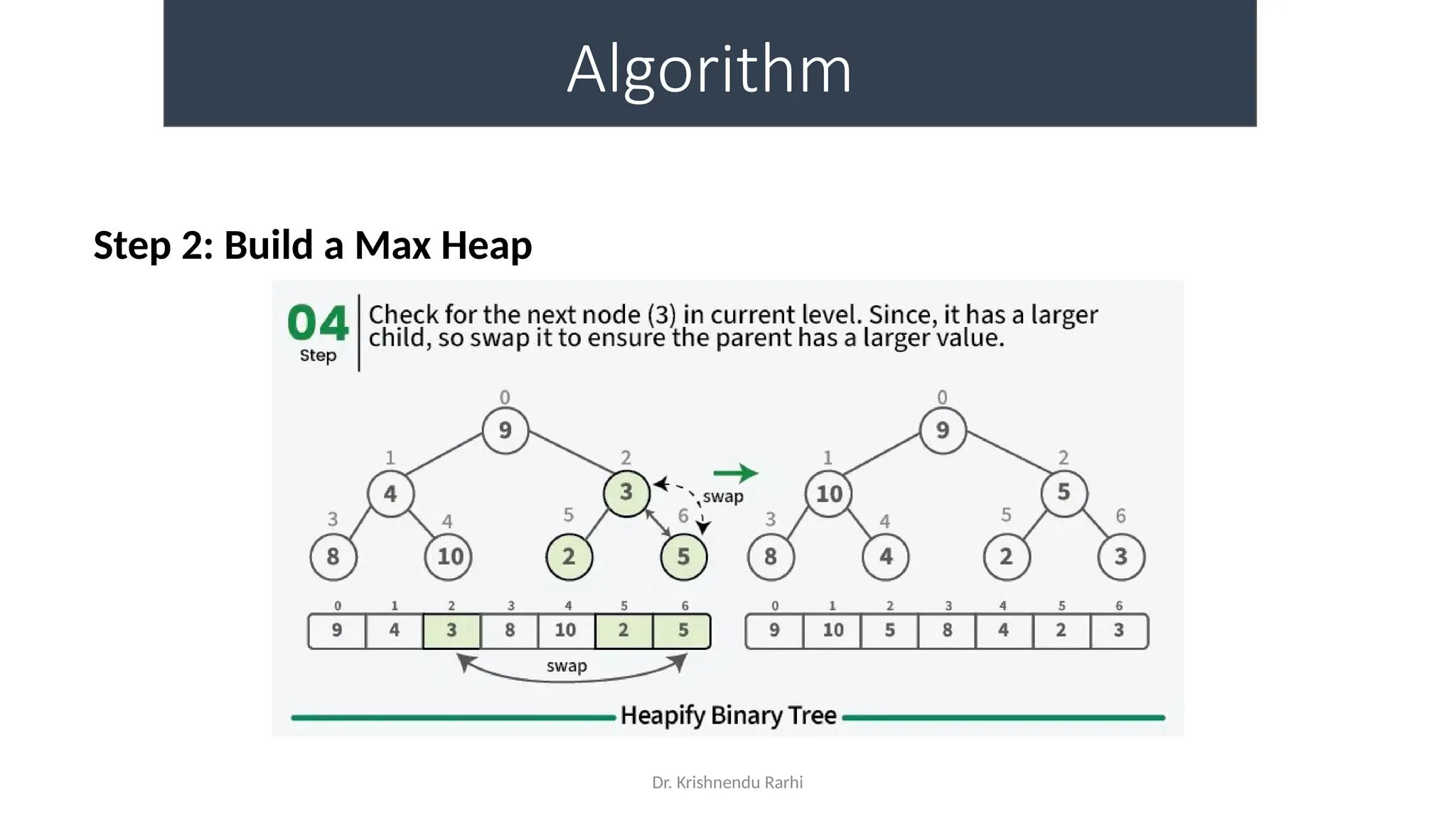
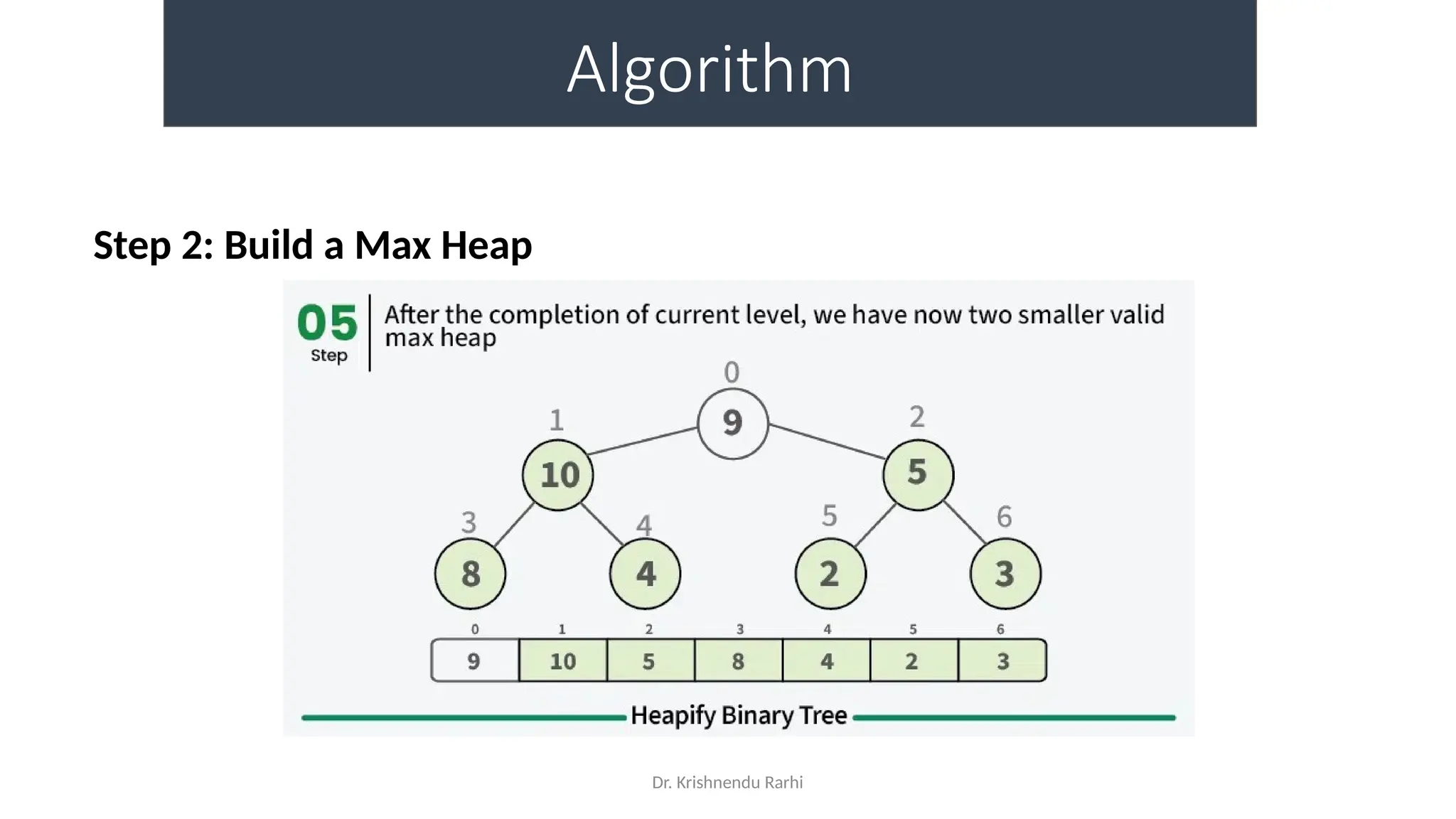
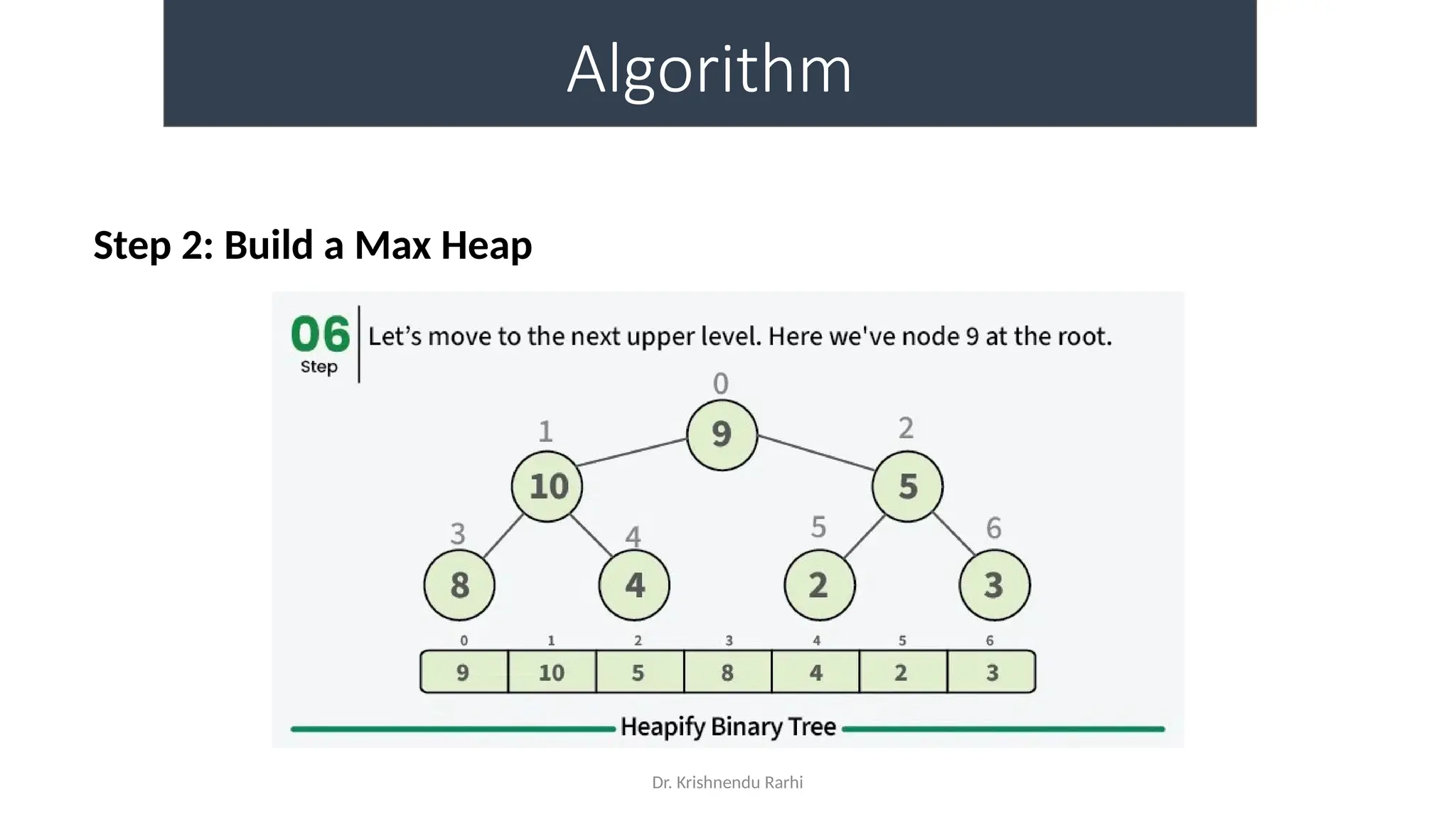
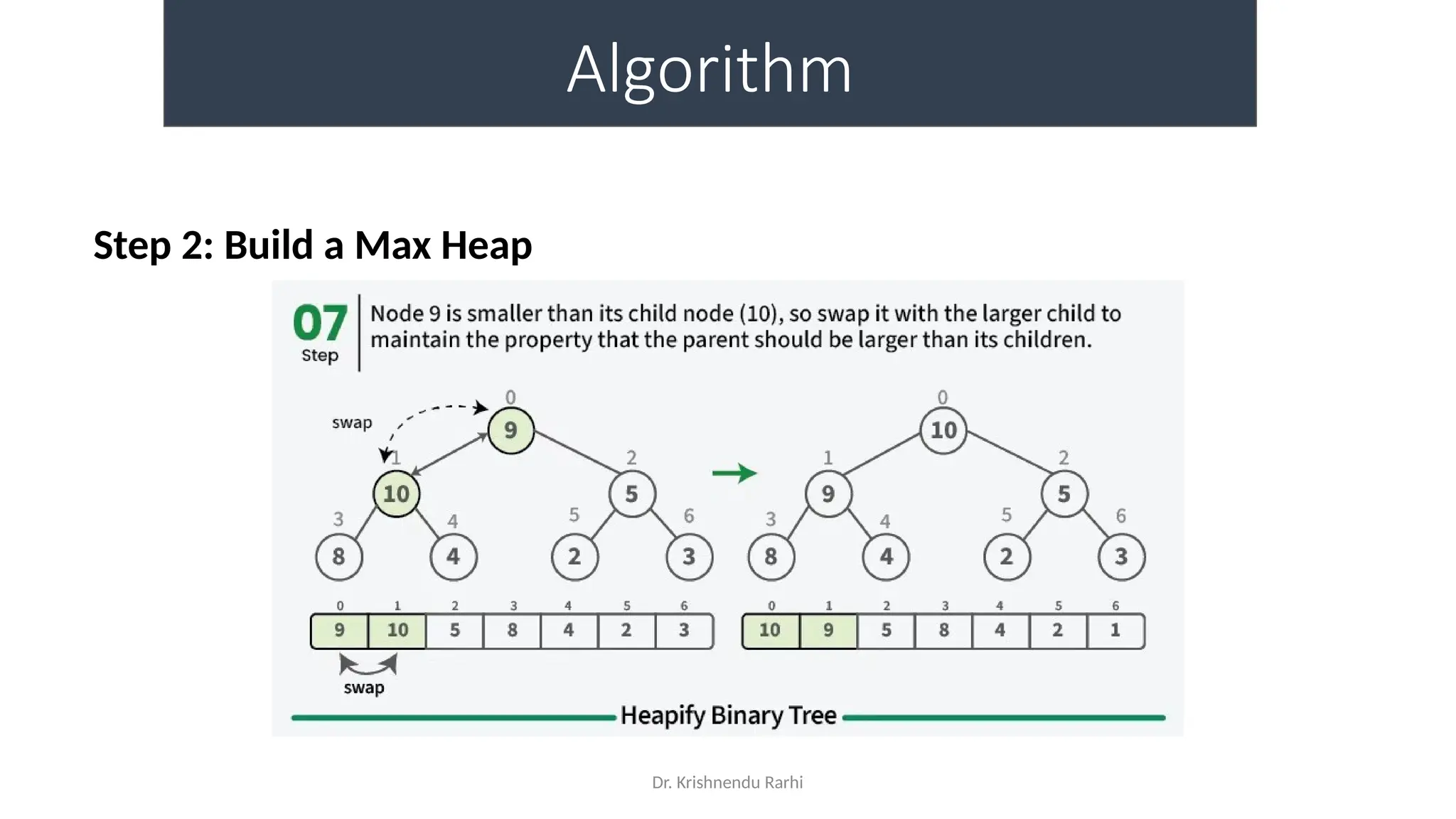
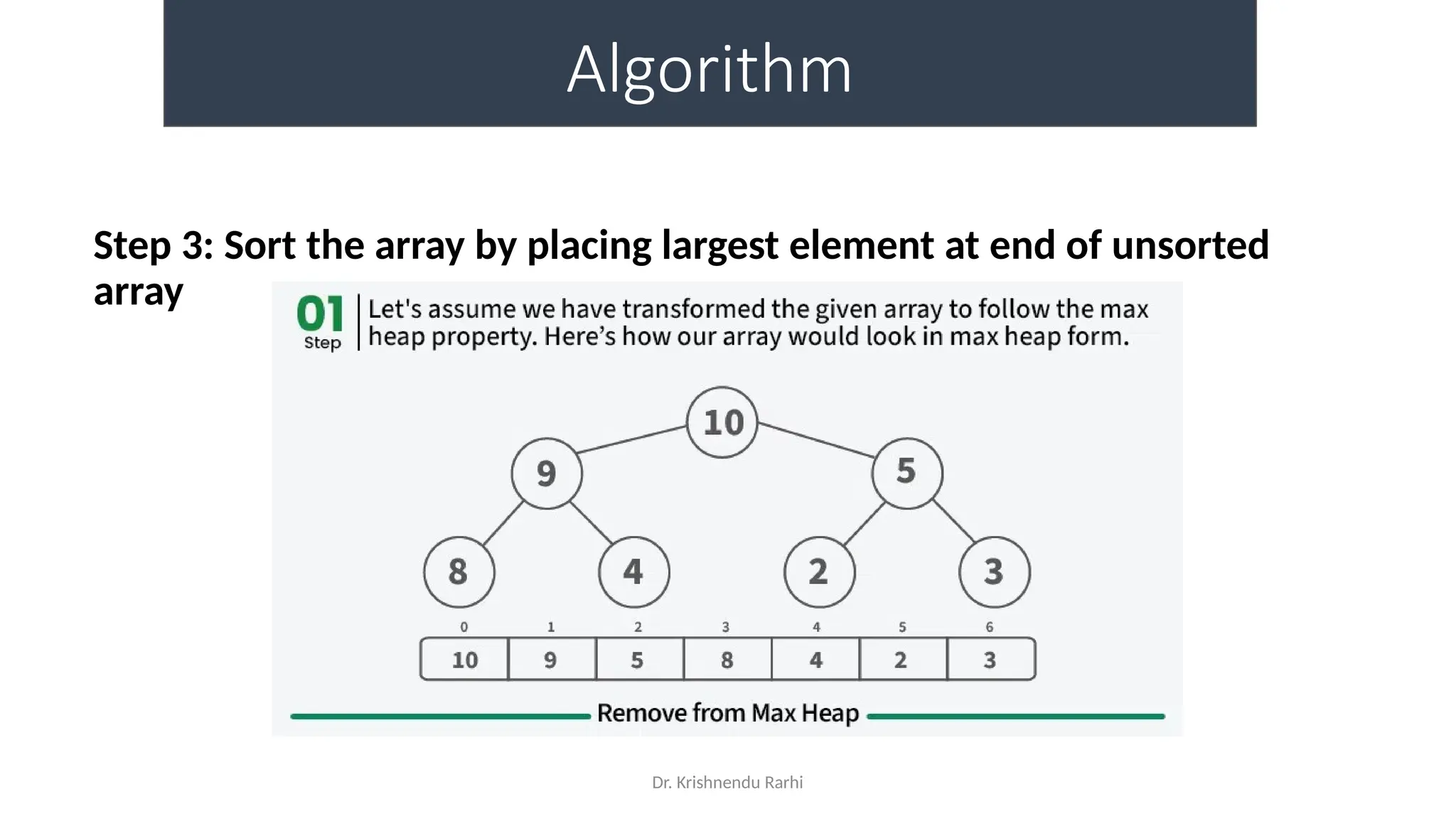
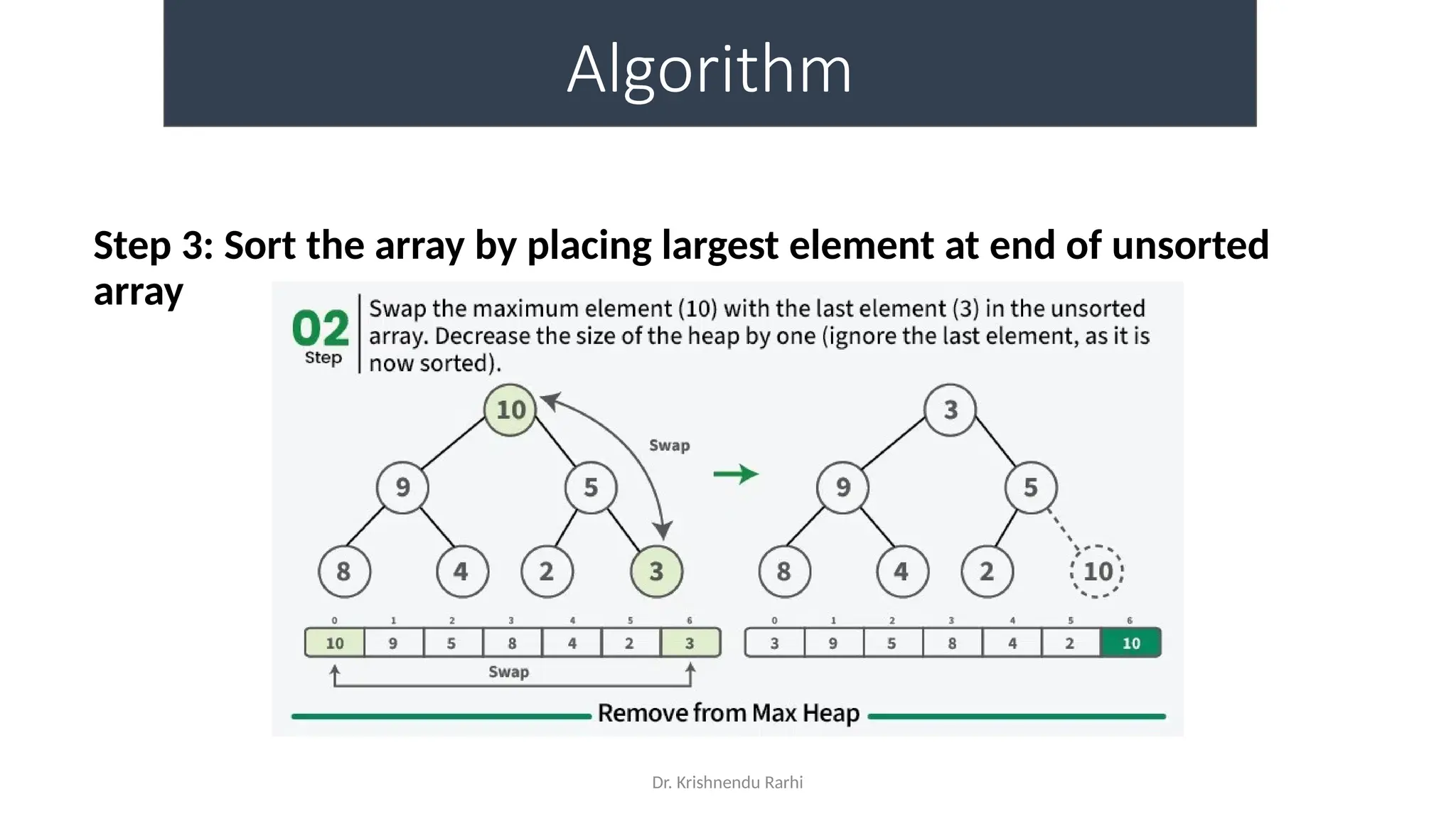
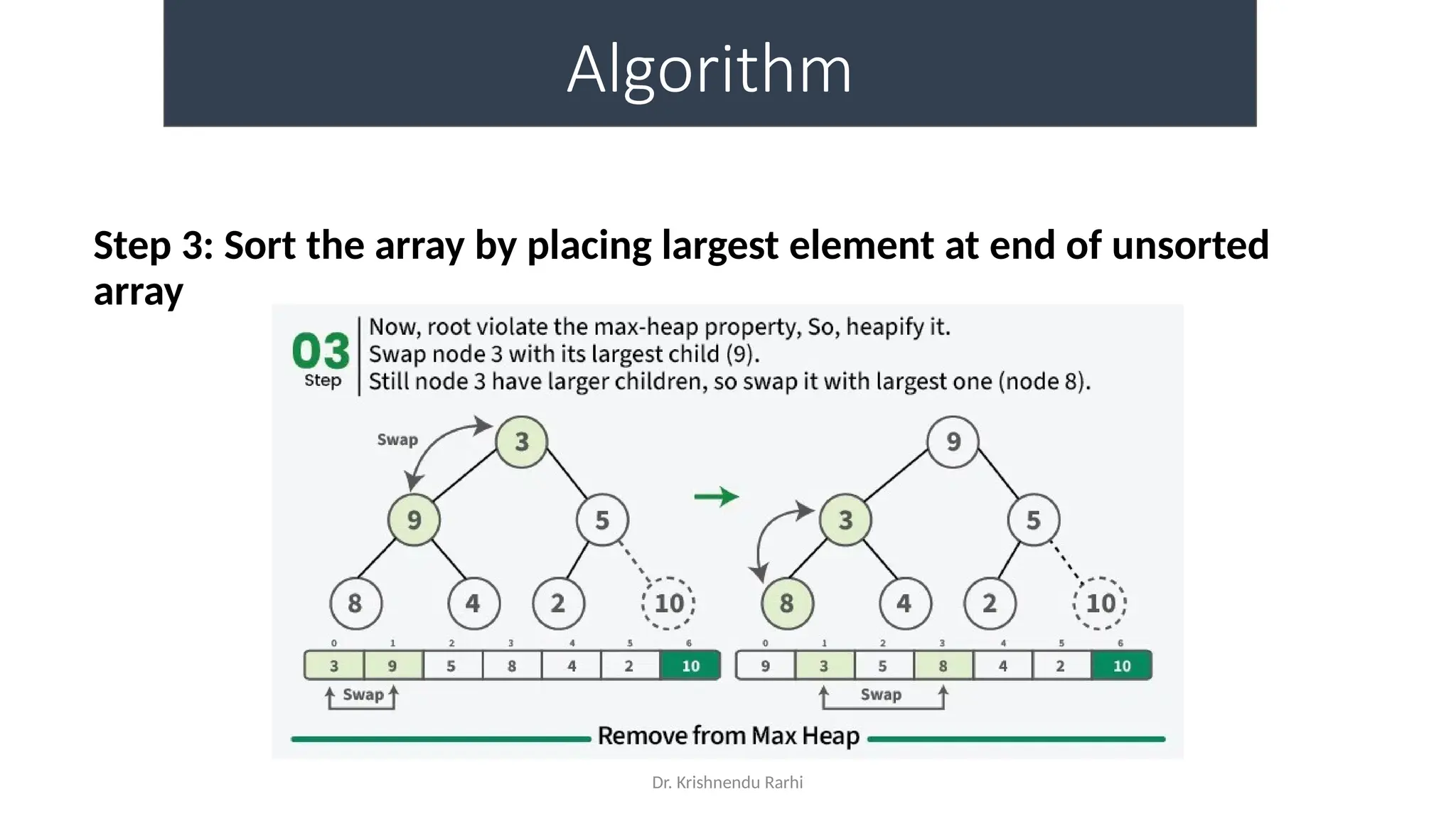
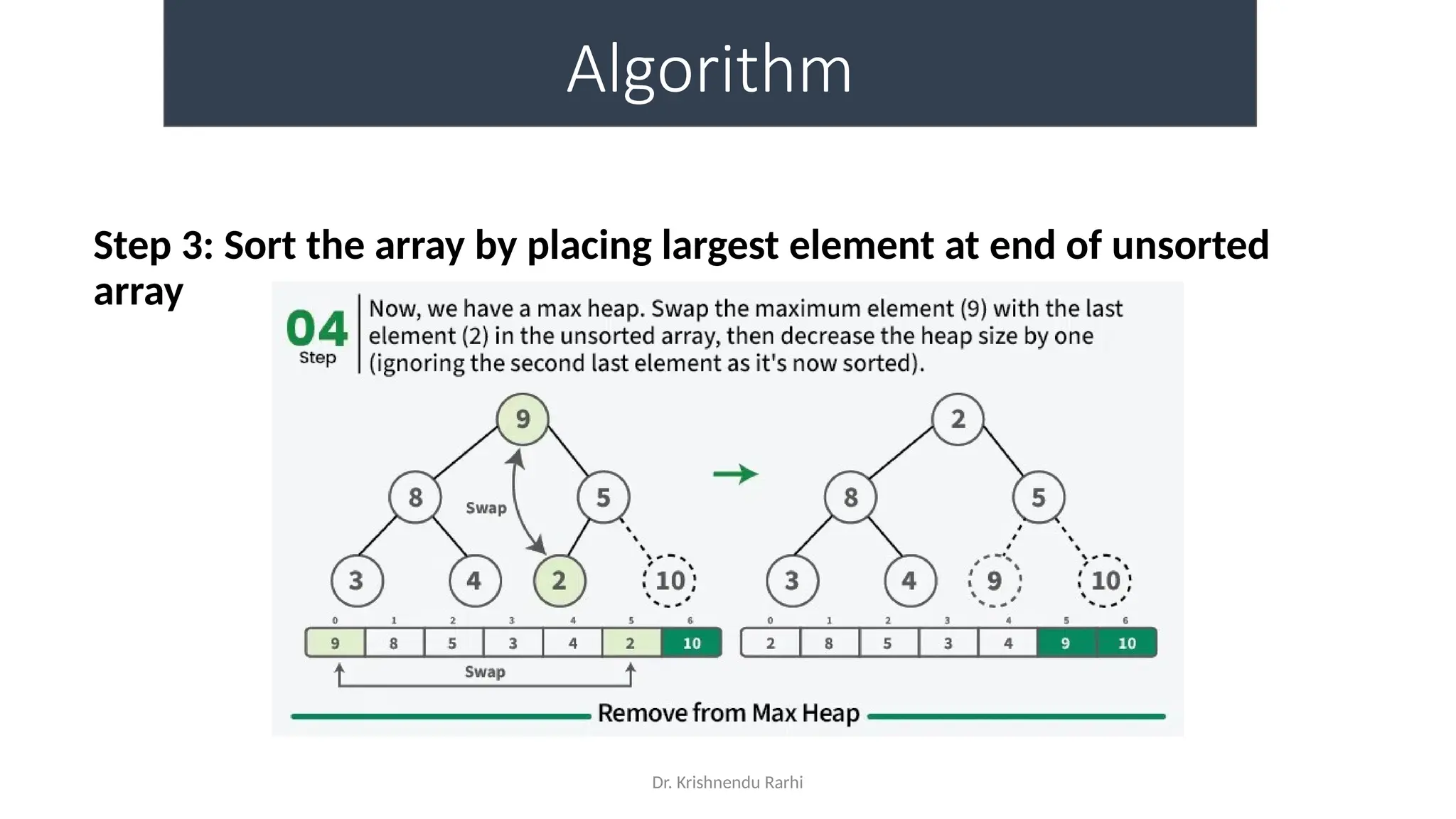
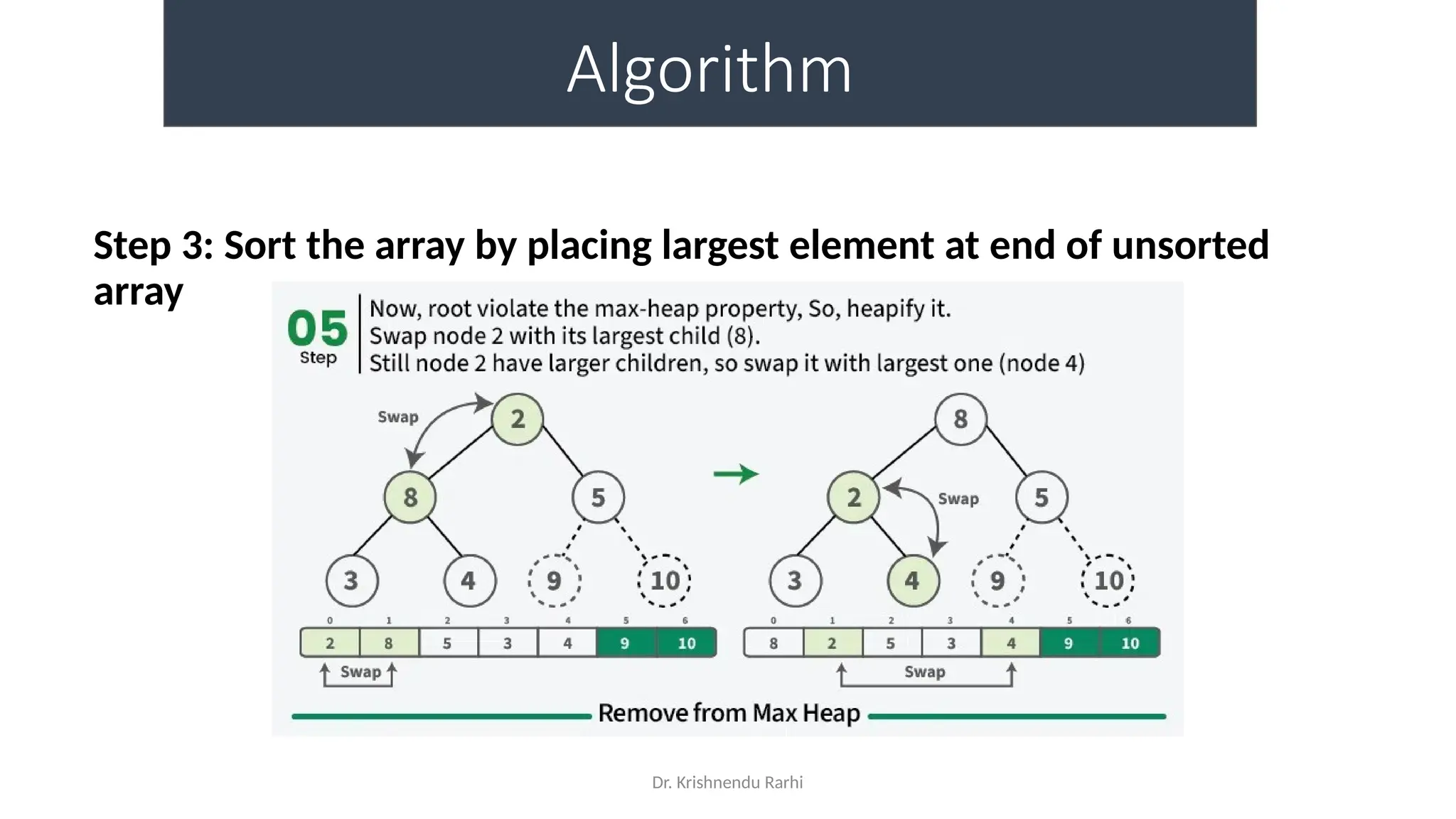
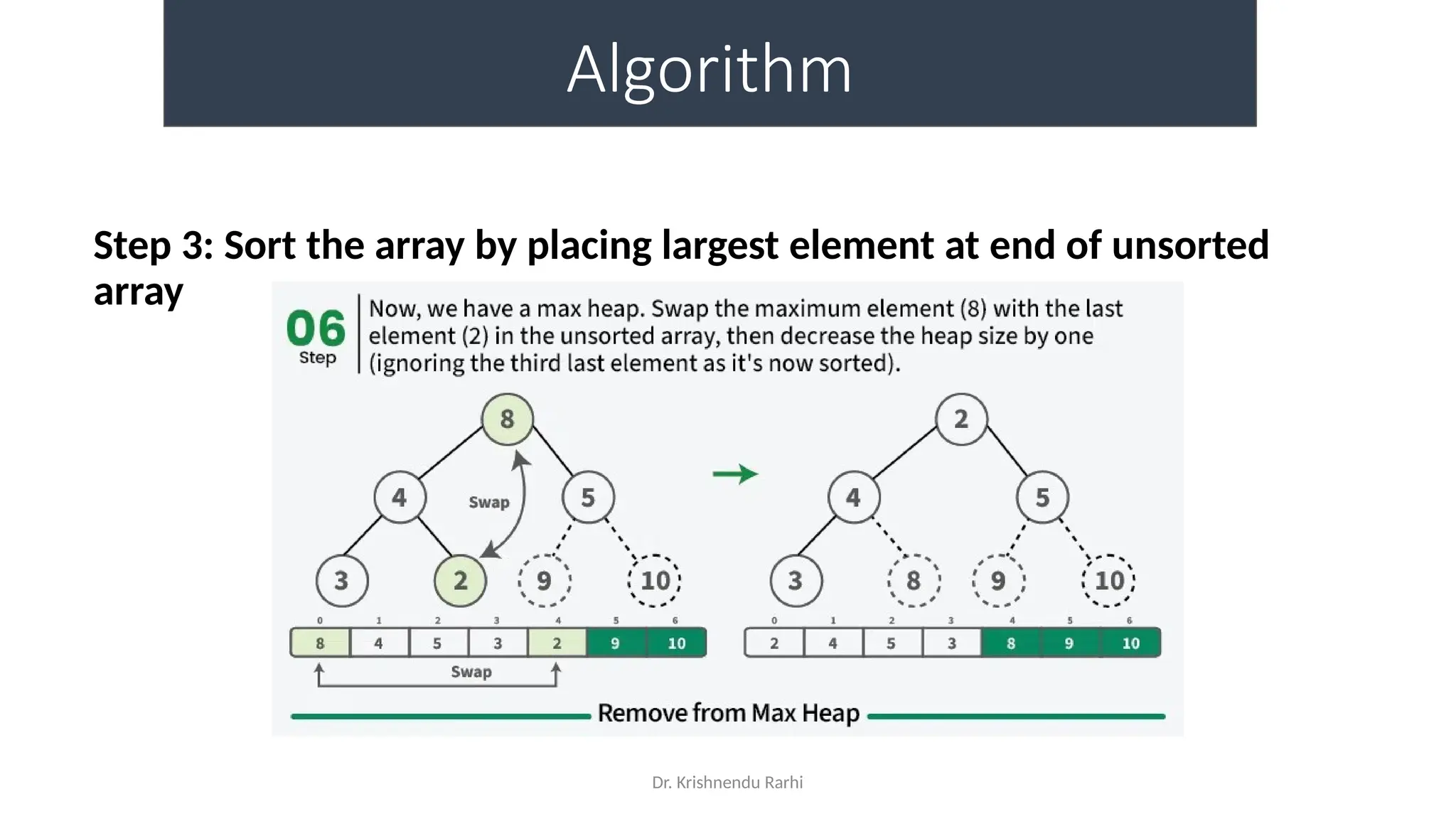
• maxHeapify is the function responsible for restoring the property of the
Max Heap. It arranges the node i, and its subtrees accordingly so that the
heap property is maintained.
• Suppose we are given an array, arr[] representing the complete binary tree. The
left and the right child of ith
node are in indices 2*i+1 and 2*i+2.
• We set the index of the current element, i, as the ‘MAXIMUM’.
• If arr[2 * i + 1] > arr[i], i.e., the left child is larger than the current value, it is set as
‘MAXIMUM’.
• Similarly if arr[2 * i + 2] > arr[i], i.e., the right child is larger than the current value,
it is set as ‘MAXIMUM’.
• Swap the ‘MAXIMUM’ with the current element.
• Repeat steps 2 to 5 till the property of the heap is restored.](https://image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-10-2048.jpg)













![Dr. Krishnendu Rarhi
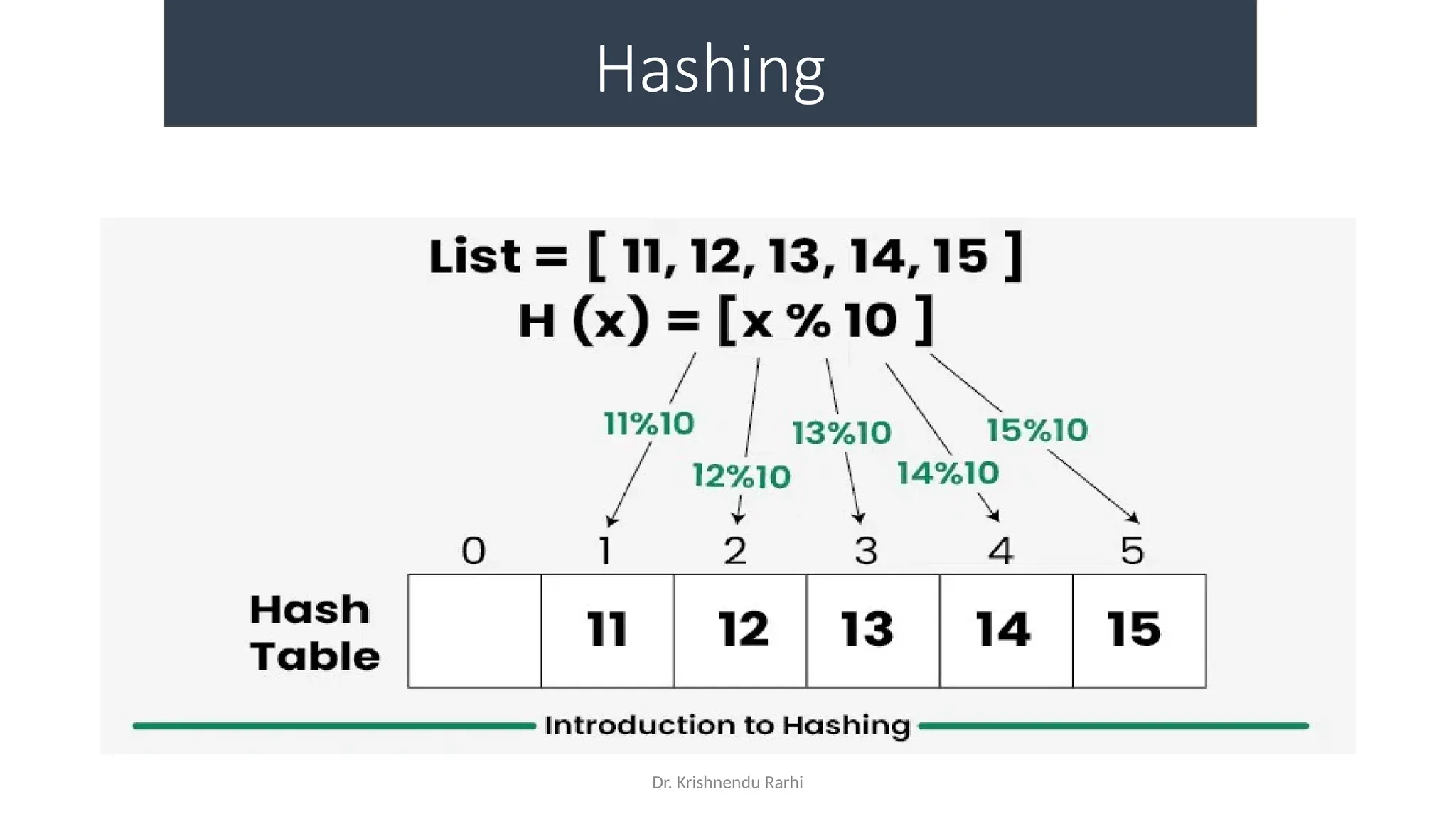
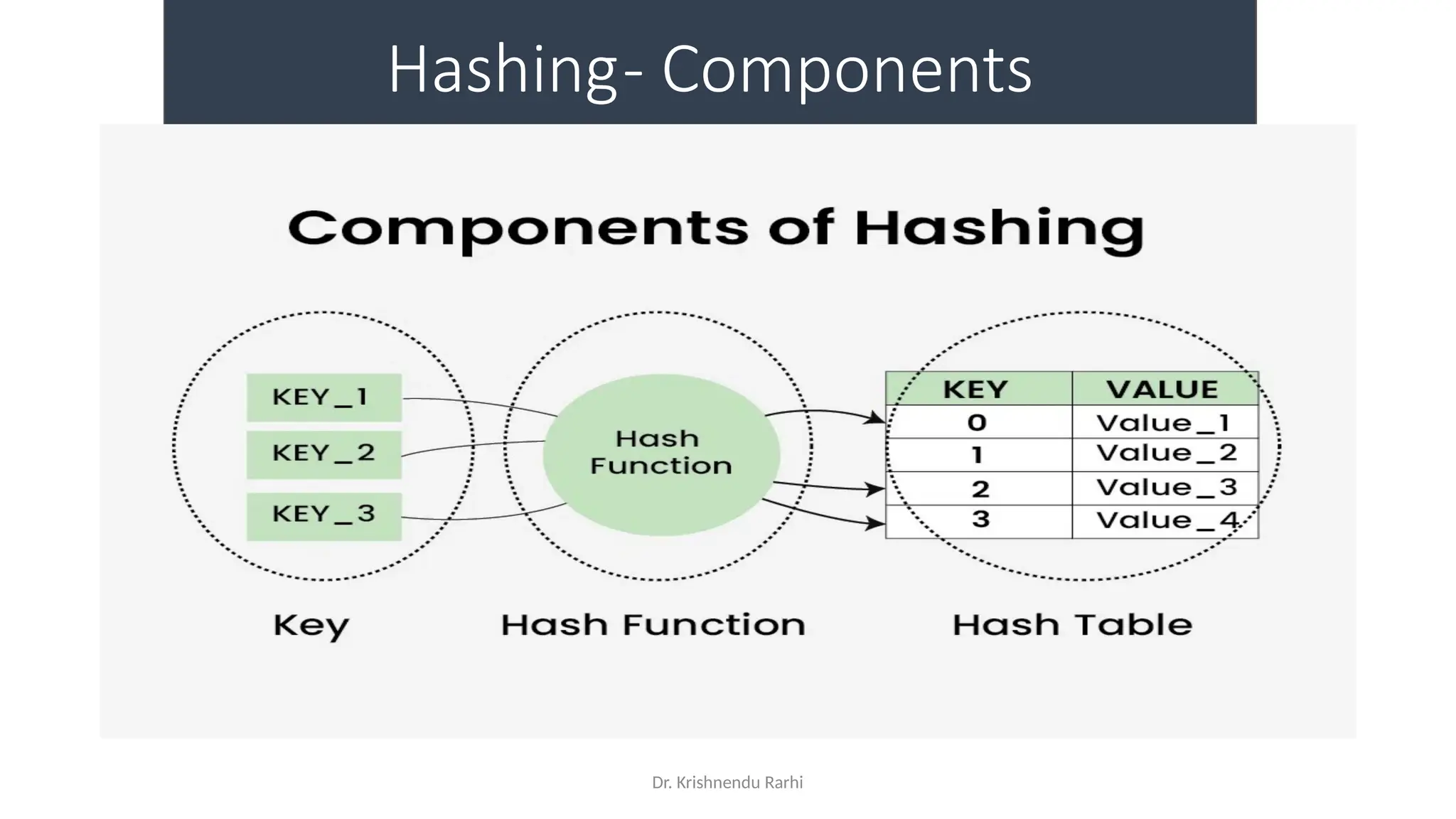
Hash Function
• A hash function is a function that takes an input (or ‘message’) and
returns a fixed-size string of bytes. The output, typically a number, is
called the hash code or hash value. The main purpose of a hash
function is to efficiently map data of arbitrary size to fixed-size values,
which are often used as indexes in hash tables
• For example: Consider an array as a Map where the key is the index
and the value is the value at that index. So for an array A if we have
index i which will be treated as the key then we can find the value by
simply looking at the value at A[i]](https://image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-40-2048.jpg)












![Dr. Krishnendu Rarhi
Collision Handling
• Linear Probing
• Calculate the hash key. i.e. key = data % size
• Check, if hashTable[key] is empty
• store the value directly by hashTable[key] = data
• If the hash index already has some value then
• check for next index using key = (key+1) % size
• Check, if the next index is available hashTable[key] then store the value.
Otherwise try for next index.
• Do the above process till we find the space.](https://image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-53-2048.jpg)





















![Dr. Krishnendu Rarhi
Heap- Implementation
• maxHeapify is the function responsible for restoring the property of the
Max Heap. It arranges the node i, and its subtrees accordingly so that the
heap property is maintained.
• Suppose we are given an array, arr[] representing the complete binary tree. The
left and the right child of ith
node are in indices 2*i+1 and 2*i+2.
• We set the index of the current element, i, as the ‘MAXIMUM’.
• If arr[2 * i + 1] > arr[i], i.e., the left child is larger than the current value, it is set as
‘MAXIMUM’.
• Similarly if arr[2 * i + 2] > arr[i], i.e., the right child is larger than the current value,
it is set as ‘MAXIMUM’.
• Swap the ‘MAXIMUM’ with the current element.
• Repeat steps 2 to 5 till the property of the heap is restored.](https://crownmelresort.com/image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-10-2048.jpg)





























![Dr. Krishnendu Rarhi
Hash Function
• A hash function is a function that takes an input (or ‘message’) and
returns a fixed-size string of bytes. The output, typically a number, is
called the hash code or hash value. The main purpose of a hash
function is to efficiently map data of arbitrary size to fixed-size values,
which are often used as indexes in hash tables
• For example: Consider an array as a Map where the key is the index
and the value is the value at that index. So for an array A if we have
index i which will be treated as the key then we can find the value by
simply looking at the value at A[i]](https://crownmelresort.com/image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-40-2048.jpg)












![Dr. Krishnendu Rarhi
Collision Handling
• Linear Probing
• Calculate the hash key. i.e. key = data % size
• Check, if hashTable[key] is empty
• store the value directly by hashTable[key] = data
• If the hash index already has some value then
• check for next index using key = (key+1) % size
• Check, if the next index is available hashTable[key] then store the value.
Otherwise try for next index.
• Do the above process till we find the space.](https://crownmelresort.com/image.slidesharecdn.com/lecture3-fileorganization-241205171958-fbce6b3a/75/Lecture-3-Data-Structure-File-Organization-53-2048.jpg)








































































![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)