Download as PDF, PPTX




![7
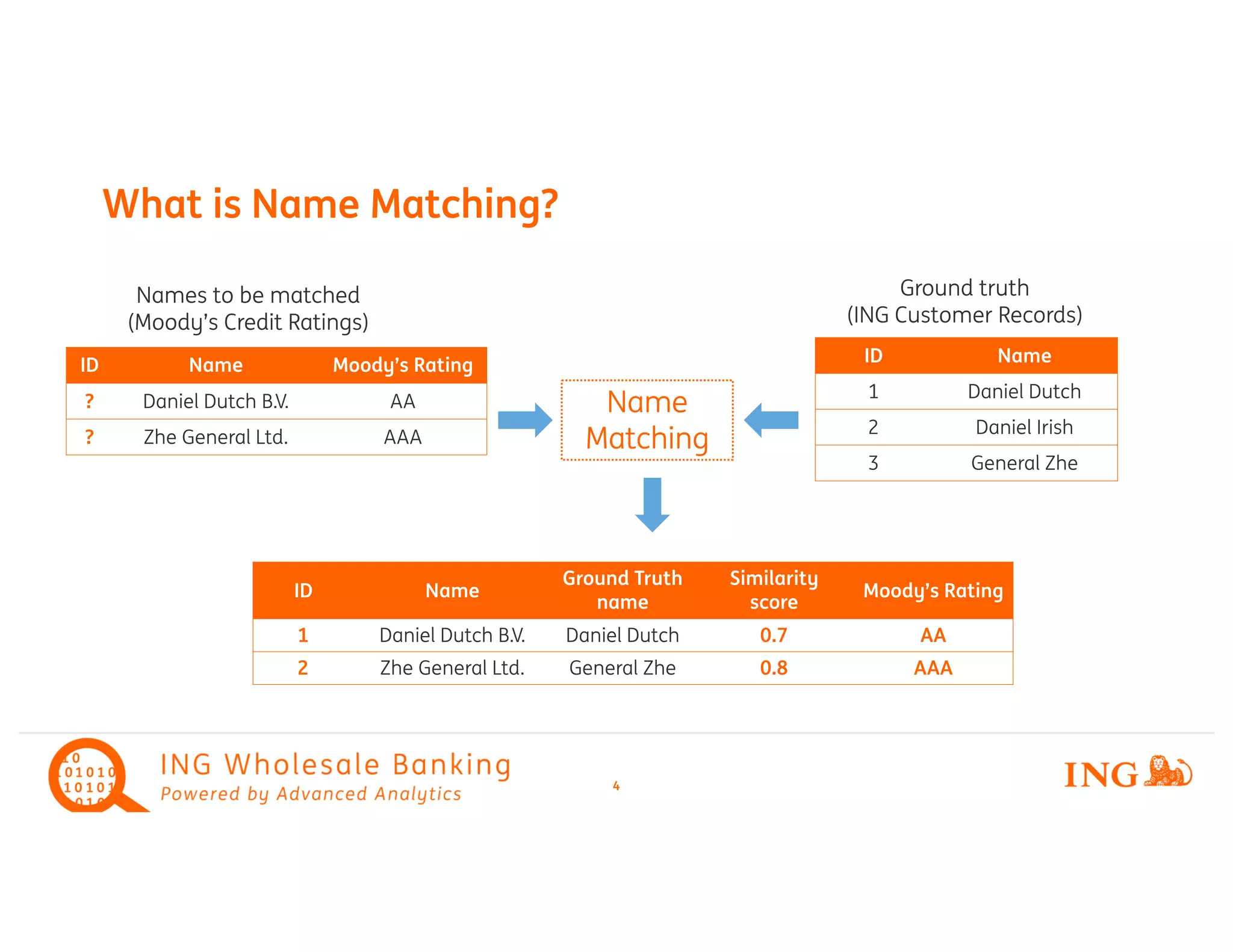
Name Matching Pipeline
Step 2
Vectorization
Step 1
preprocessing
Names
Daniel Dutch
Daniel Irish
Zhe General
Names
Daniel
Dutch B.V.
GT
NM
Names Sparse Vector
Daniel Dutch [0, 0.2, …, 0.8, …]
Daniel Irish [0, 0.2, 0.6, …, 0]
Zhe General [0.6, 0, …, 0, 0.9]
GT
NM
Names Sparse Vector
Daniel
Dutch B.V.
[0, 0.3, …, 0.7, …]
Names GT name Score
Daniel
Dutch B.V.
Daniel Dutch 0.8
Daniel Irish 0.7
Step 3
Cosine similarity
Names GT name Score
Daniel
Dutch B.V.
Daniel Dutch 0.8
Step 4
Candidate selection](https://image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-7-2048.jpg)


![11
Final spark ML pipeline: elegant and easily maintainable
stages += [Preprocessor(params['preprocessor'], input_col=params['name_col’],
output_col='preprocessed')]
stages += [RegexTokenizer(inputCol='preprocessed', outputCol='tokens', pattern=r"w+", gaps=False)]
stages += [NGram(inputCol='tokens', outputCol='ngram_tokens', n=params['ngram'])]
stages += [CountVectorizer(inputCol='ngram_tokens', outputCol='tf', vocabSize=2<<24)]
stages += [NormalizedTfidf(count_col="tf", token_col="ngram_tokens", output_col="features”)]
stages += [CosSimMatcher(num_candidates=params['num_candidates'],
cos_sim_lower_bound=params['cos_sim_lower_bound'],
index_col=params['index_col'],
name_col=params['name_col'],
chunk_size=params['chunk_size’])]
snm = load_pickle(params['supervised_model_filename'], params['supervised_model_path'])
stages += [SupervisedNMTransformer(snm)]
self.pipeline = Pipeline(stages=stages)](https://image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-11-2048.jpg)











![28
Spark ML pipeline: standard + customized stages
Step Stage Customized Description
Example input
HANS Investment B.V., Willem
Barentszstraat
1 Preprocessing Y
• Strip punctuation
• Accents to unicode
• All characters to lower case
• Shorthands and abbreviations replacement
hans investment bv willem
barentszstr
2 Tokenizer N Splits the input string by white spaces
[hans, investment, by, willem,
barentszstr]
3 NGram N
Converts the input tokens into an array of n-
grams
[hans, investment, by, willem,
barentszstr]
4 CountVectorizer N Extracts a vocabulary from document collections (5, [0, 1, 2, 3, 4], [1.0, 1,0, 1.0, 1.0, 1.0])
5
Normalized
TFIDF
Y
Compute the Term Frequency Inverse Document
Frequency (TF-IDF). We need a custom stage to
deal with previously unseen tokens.
(5, [0, 1, 2, 3, 4], [0.5, 0.1, 0.01, 0.2,
0.8])
6
Cosine
Similarity
Y
Compute cosine similarity between input and
ground truth
7
Candidate
selection
Y Pick the most similar names by supervised model](https://image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-28-2048.jpg)






![7
Name Matching Pipeline
Step 2
Vectorization
Step 1
preprocessing
Names
Daniel Dutch
Daniel Irish
Zhe General
Names
Daniel
Dutch B.V.
GT
NM
Names Sparse Vector
Daniel Dutch [0, 0.2, …, 0.8, …]
Daniel Irish [0, 0.2, 0.6, …, 0]
Zhe General [0.6, 0, …, 0, 0.9]
GT
NM
Names Sparse Vector
Daniel
Dutch B.V.
[0, 0.3, …, 0.7, …]
Names GT name Score
Daniel
Dutch B.V.
Daniel Dutch 0.8
Daniel Irish 0.7
Step 3
Cosine similarity
Names GT name Score
Daniel
Dutch B.V.
Daniel Dutch 0.8
Step 4
Candidate selection](https://crownmelresort.com/image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-7-2048.jpg)



![11
Final spark ML pipeline: elegant and easily maintainable
stages += [Preprocessor(params['preprocessor'], input_col=params['name_col’],
output_col='preprocessed')]
stages += [RegexTokenizer(inputCol='preprocessed', outputCol='tokens', pattern=r"w+", gaps=False)]
stages += [NGram(inputCol='tokens', outputCol='ngram_tokens', n=params['ngram'])]
stages += [CountVectorizer(inputCol='ngram_tokens', outputCol='tf', vocabSize=2<<24)]
stages += [NormalizedTfidf(count_col="tf", token_col="ngram_tokens", output_col="features”)]
stages += [CosSimMatcher(num_candidates=params['num_candidates'],
cos_sim_lower_bound=params['cos_sim_lower_bound'],
index_col=params['index_col'],
name_col=params['name_col'],
chunk_size=params['chunk_size’])]
snm = load_pickle(params['supervised_model_filename'], params['supervised_model_path'])
stages += [SupervisedNMTransformer(snm)]
self.pipeline = Pipeline(stages=stages)](https://crownmelresort.com/image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-11-2048.jpg)
















![28
Spark ML pipeline: standard + customized stages
Step Stage Customized Description
Example input
HANS Investment B.V., Willem
Barentszstraat
1 Preprocessing Y
• Strip punctuation
• Accents to unicode
• All characters to lower case
• Shorthands and abbreviations replacement
hans investment bv willem
barentszstr
2 Tokenizer N Splits the input string by white spaces
[hans, investment, by, willem,
barentszstr]
3 NGram N
Converts the input tokens into an array of n-
grams
[hans, investment, by, willem,
barentszstr]
4 CountVectorizer N Extracts a vocabulary from document collections (5, [0, 1, 2, 3, 4], [1.0, 1,0, 1.0, 1.0, 1.0])
5
Normalized
TFIDF
Y
Compute the Term Frequency Inverse Document
Frequency (TF-IDF). We need a custom stage to
deal with previously unseen tokens.
(5, [0, 1, 2, 3, 4], [0.5, 0.1, 0.01, 0.2,
0.8])
6
Cosine
Similarity
Y
Compute cosine similarity between input and
ground truth
7
Candidate
selection
Y Pick the most similar names by supervised model](https://crownmelresort.com/image.slidesharecdn.com/8zhesundanielvanderende-180614201225/75/Large-Scale-Fuzzy-Name-Matching-with-a-Custom-ML-Pipeline-in-Batch-and-Streaming-Zhe-Sun-and-Daniel-Vanderende-28-2048.jpg)

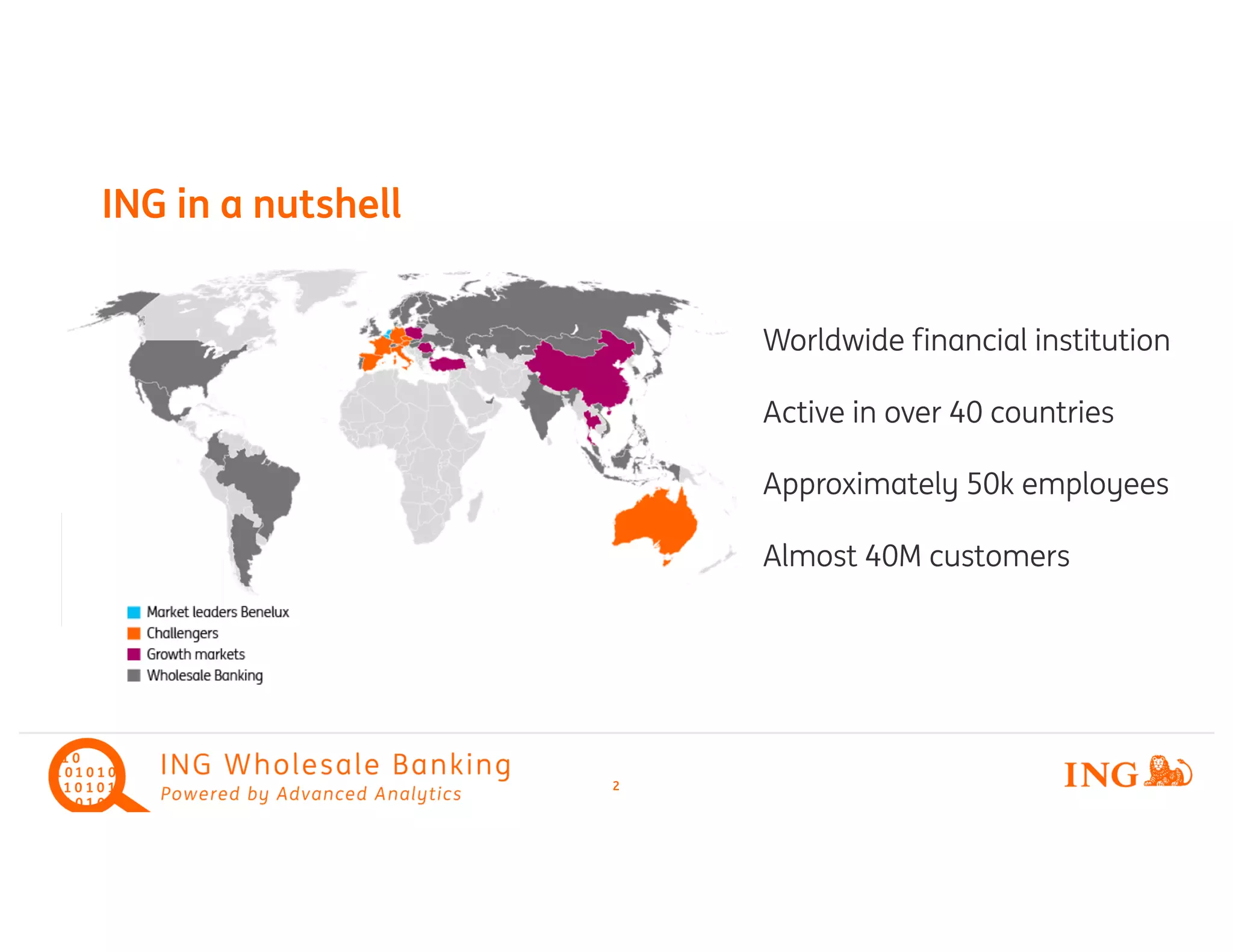
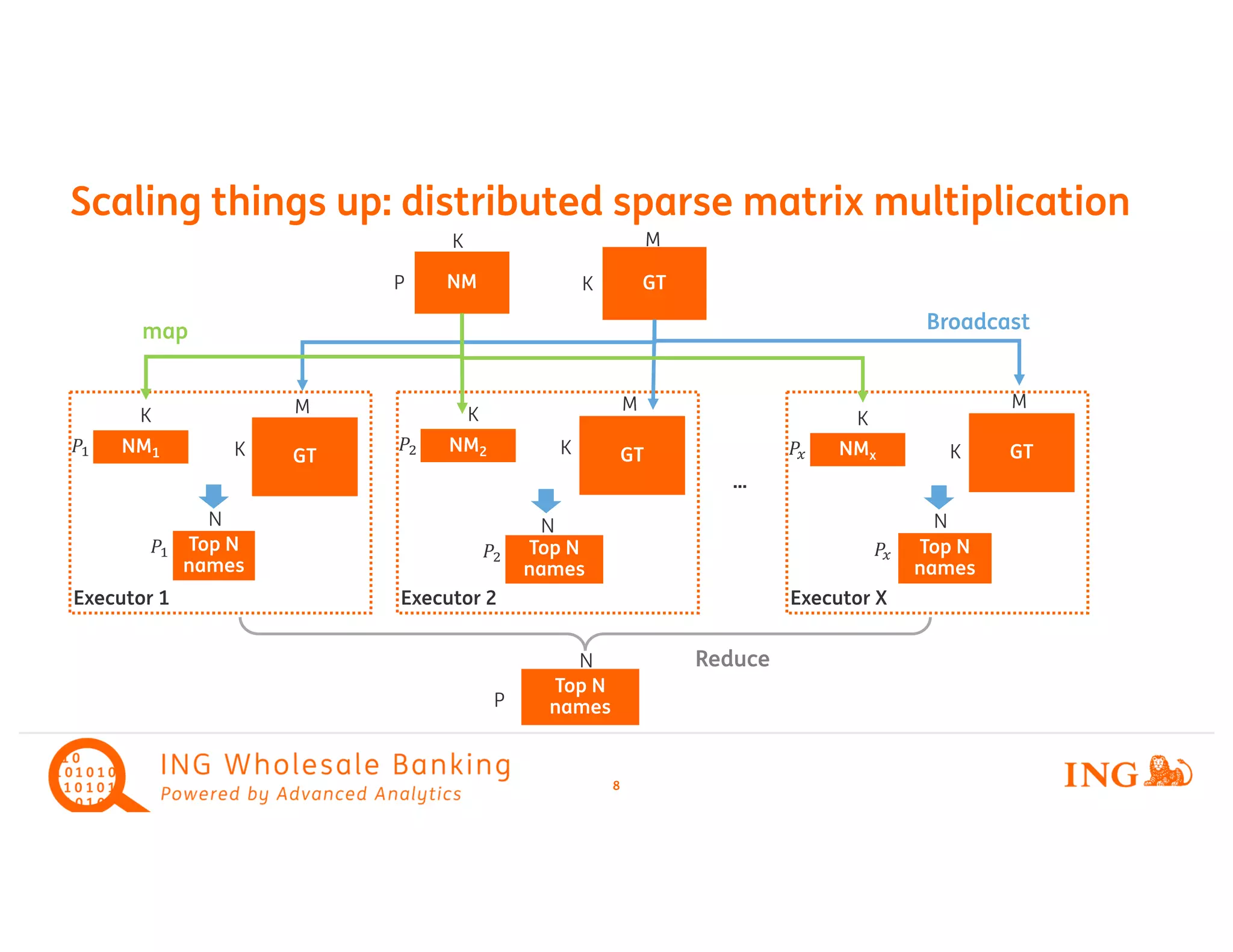
The document discusses a large-scale fuzzy name matching system implemented at ING for wholesale banking, highlighting the use of advanced analytics and machine learning techniques. It details the name matching process, including preprocessing, tokenization, vectorization, and the use of cosine similarity to efficiently match 160 million names to a ground truth of 10 million names. The implementation leverages Spark ML and structured streaming to optimize performance and provides insights into challenges faced and solutions applied during development.























































































