Download to read offline








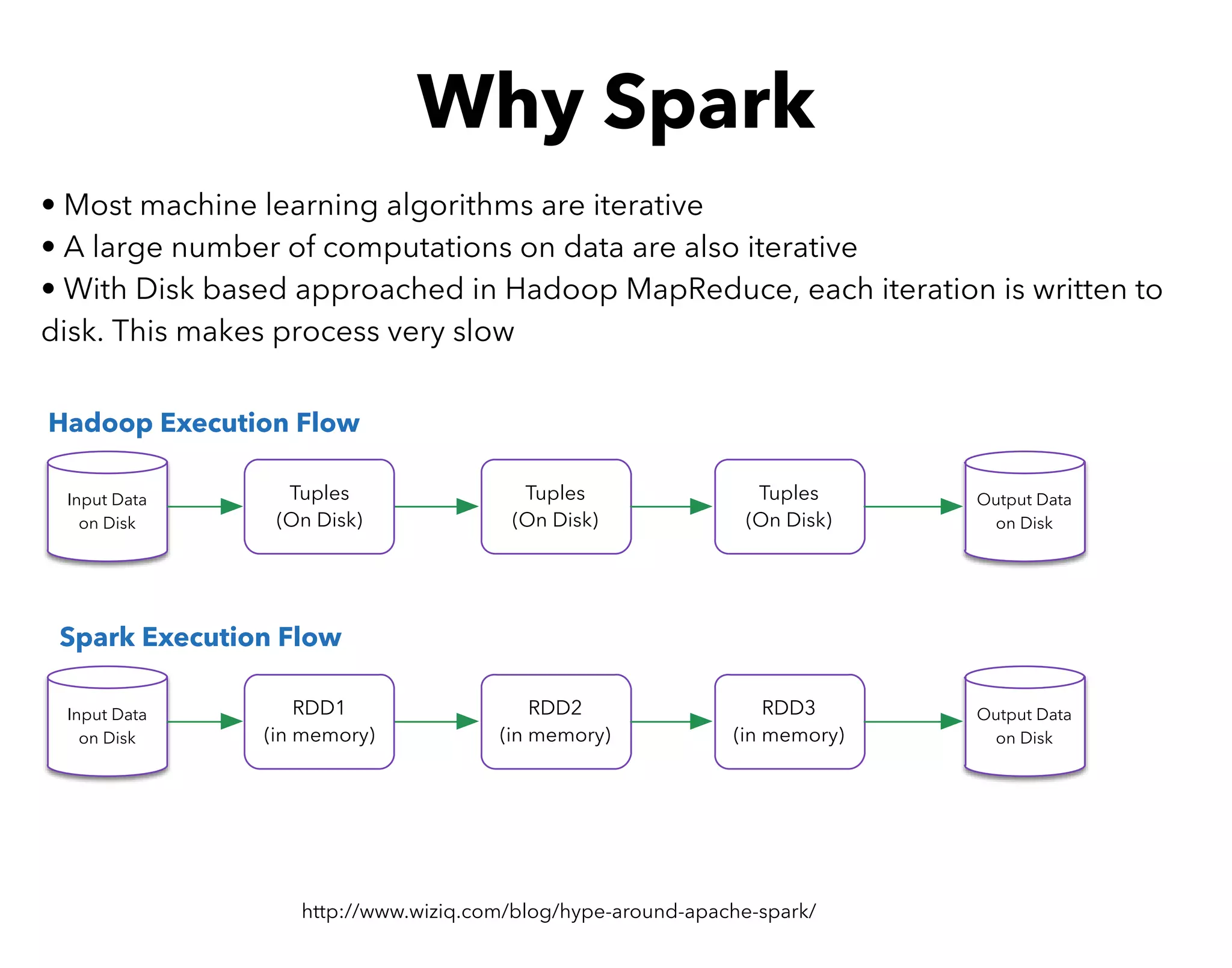



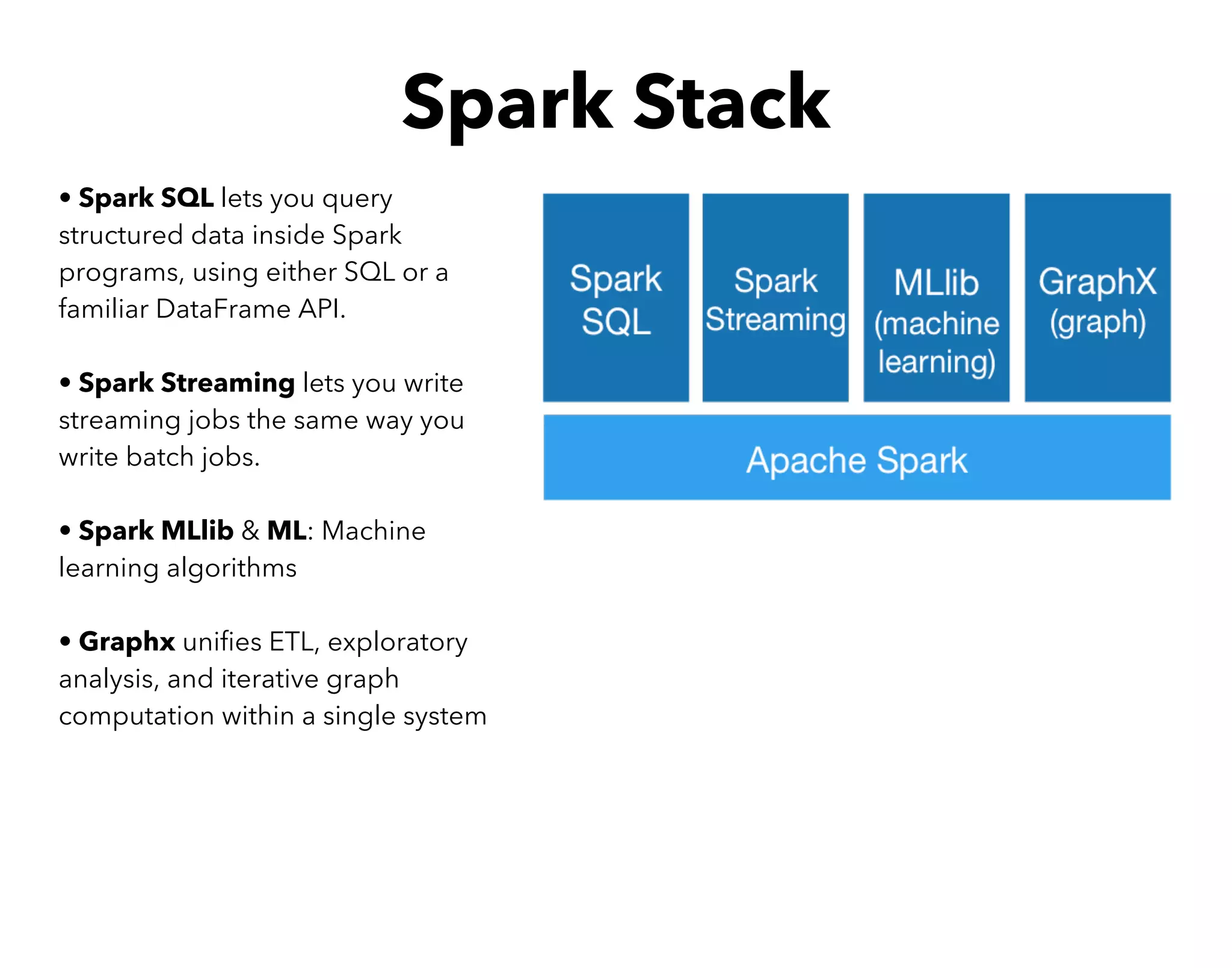

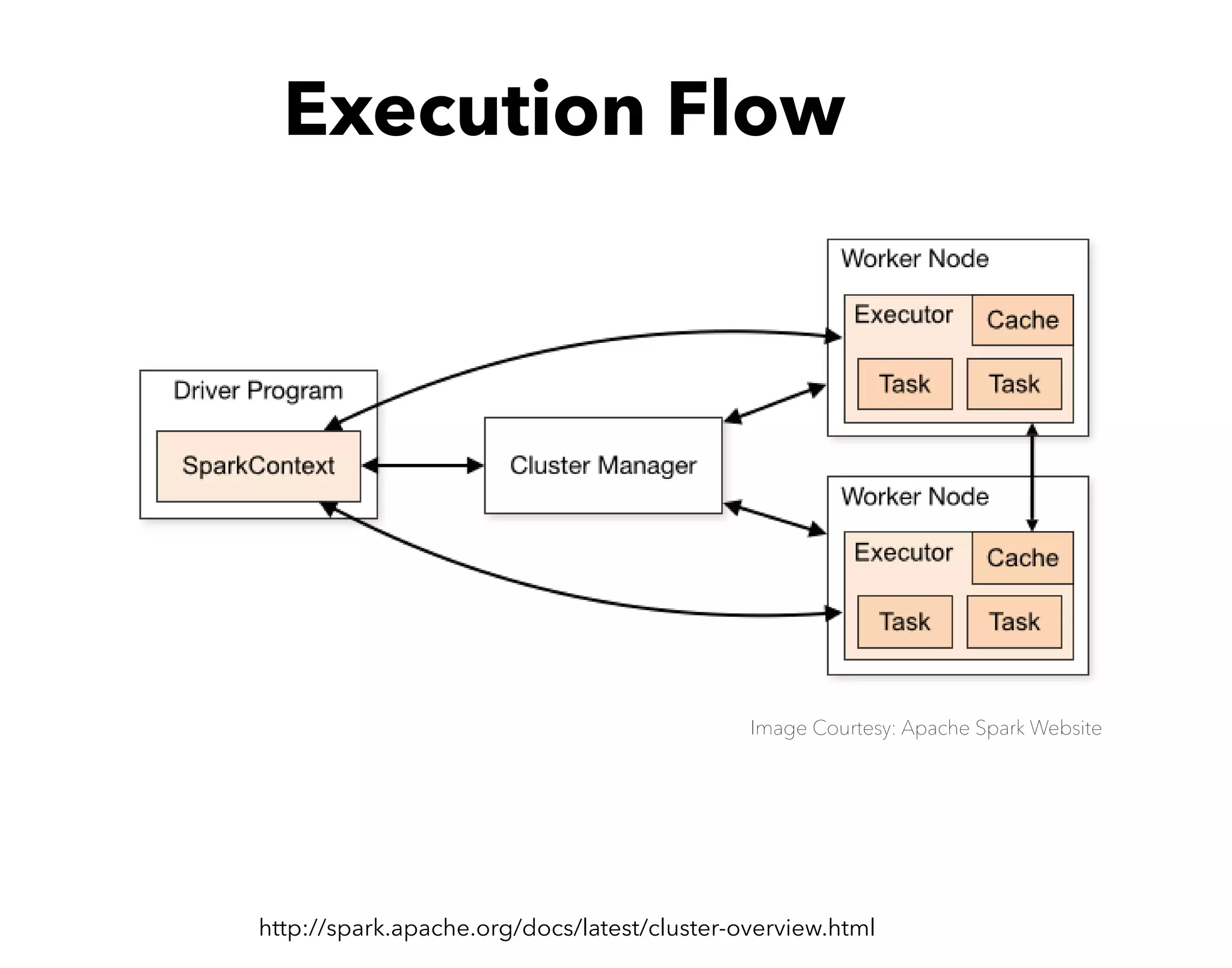

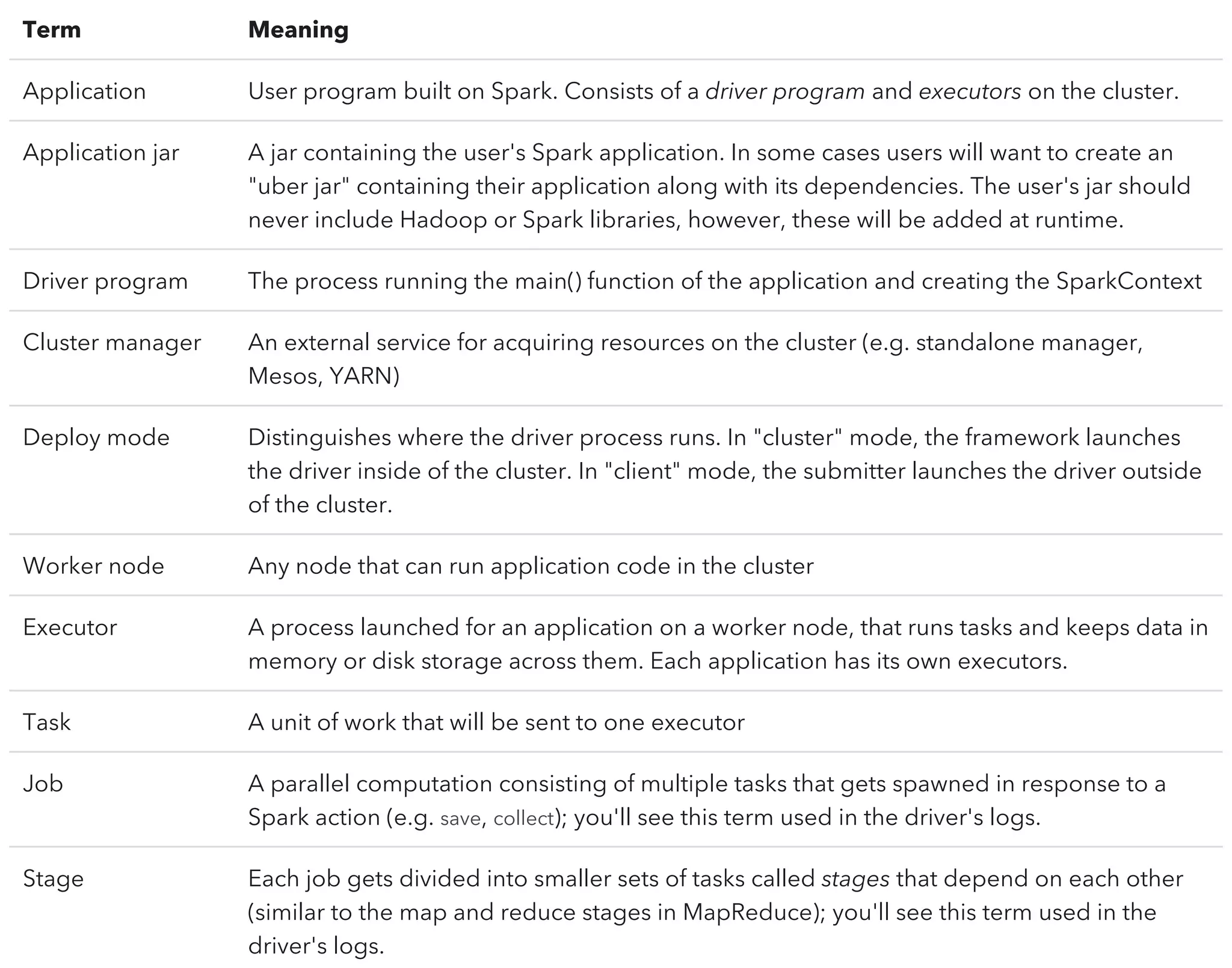






























This document serves as an introductory guide to Apache Spark, detailing the necessary installations and features of the Spark framework. It covers basic operations, execution flow, and key terms, emphasizing Spark's efficiency for iterative computations and its capabilities in machine learning, data streaming, and SQL queries. The content includes hands-on exercises for practical learning and an overview of deployment options and monitoring tools.




































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)




