Download as PDF, PPTX





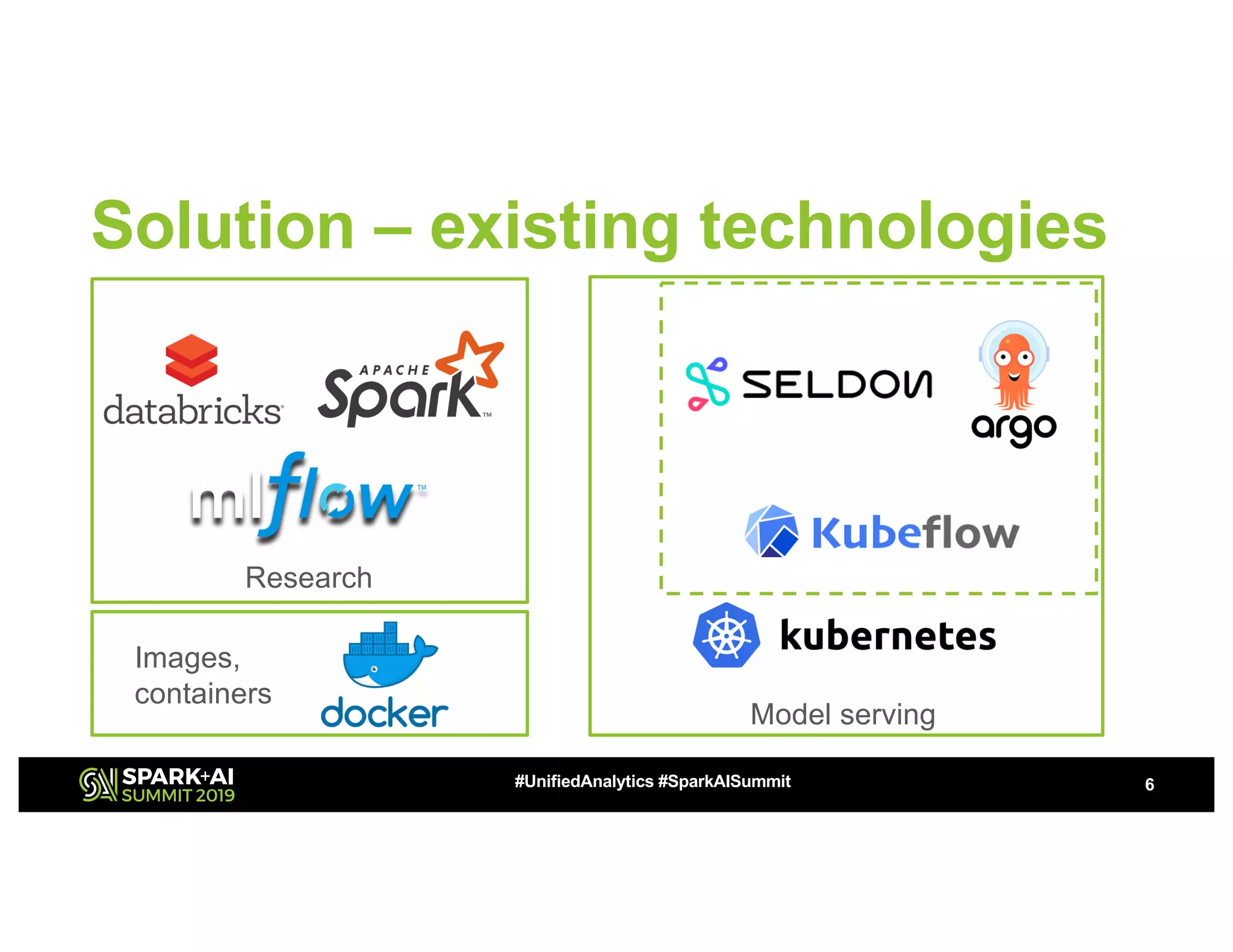




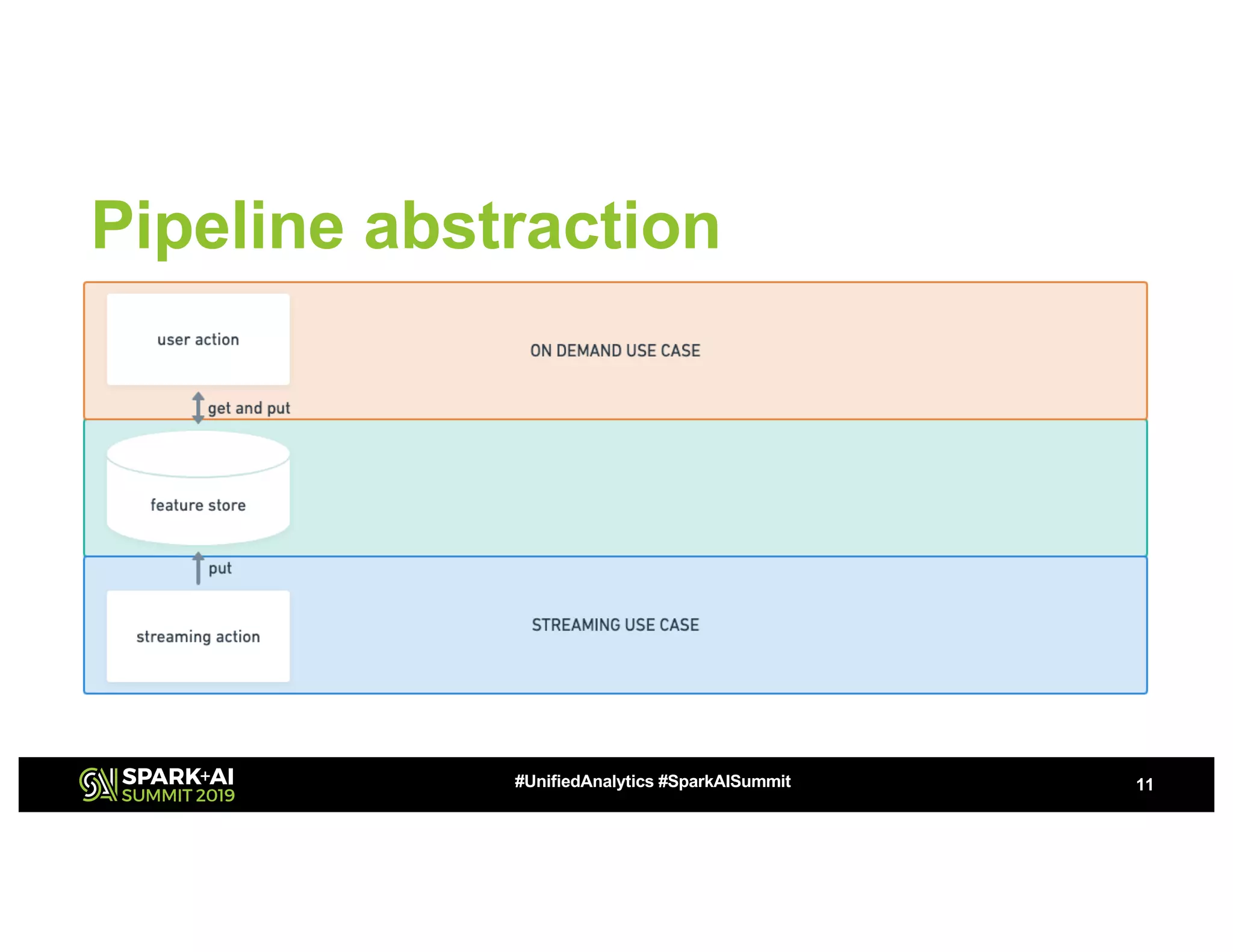
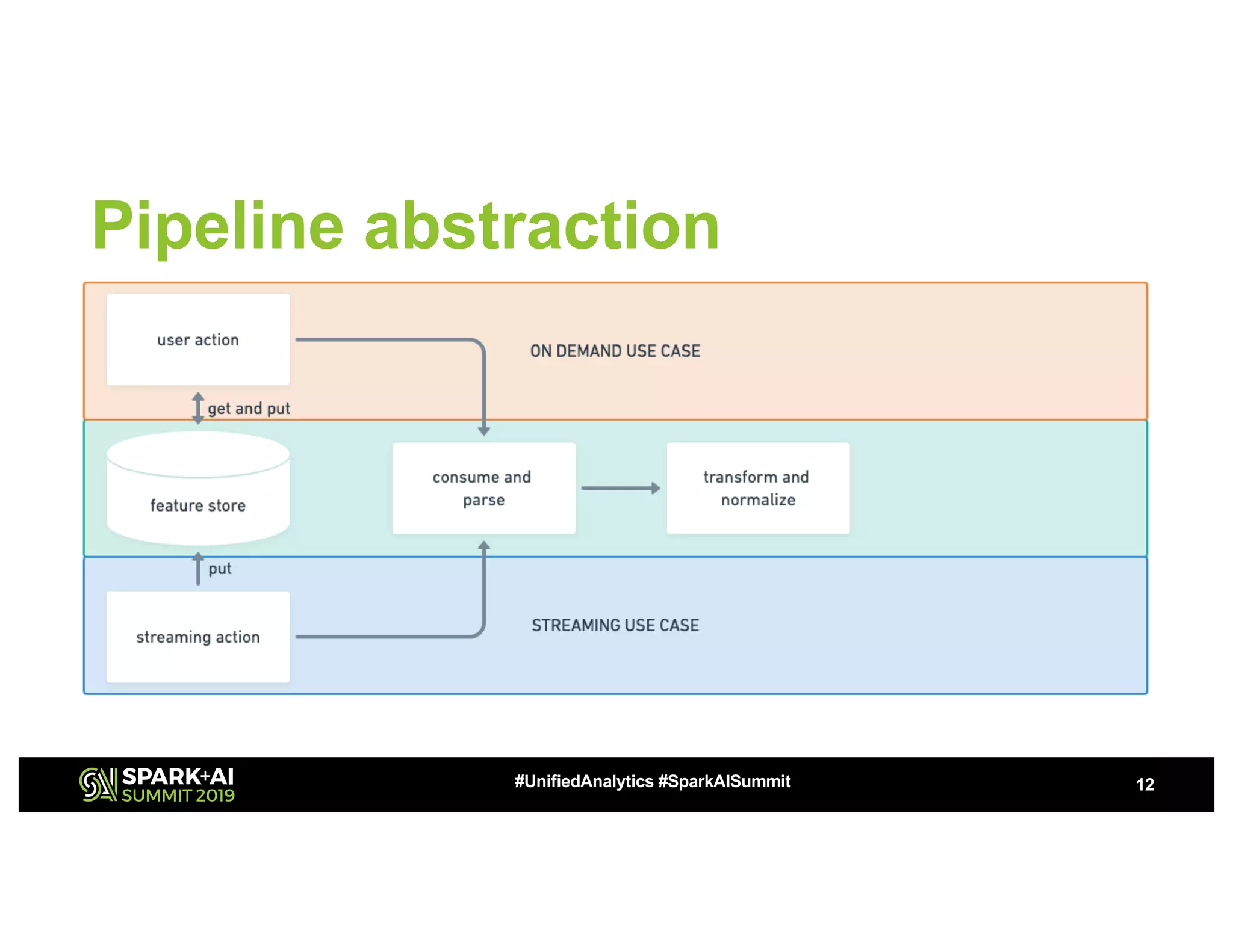
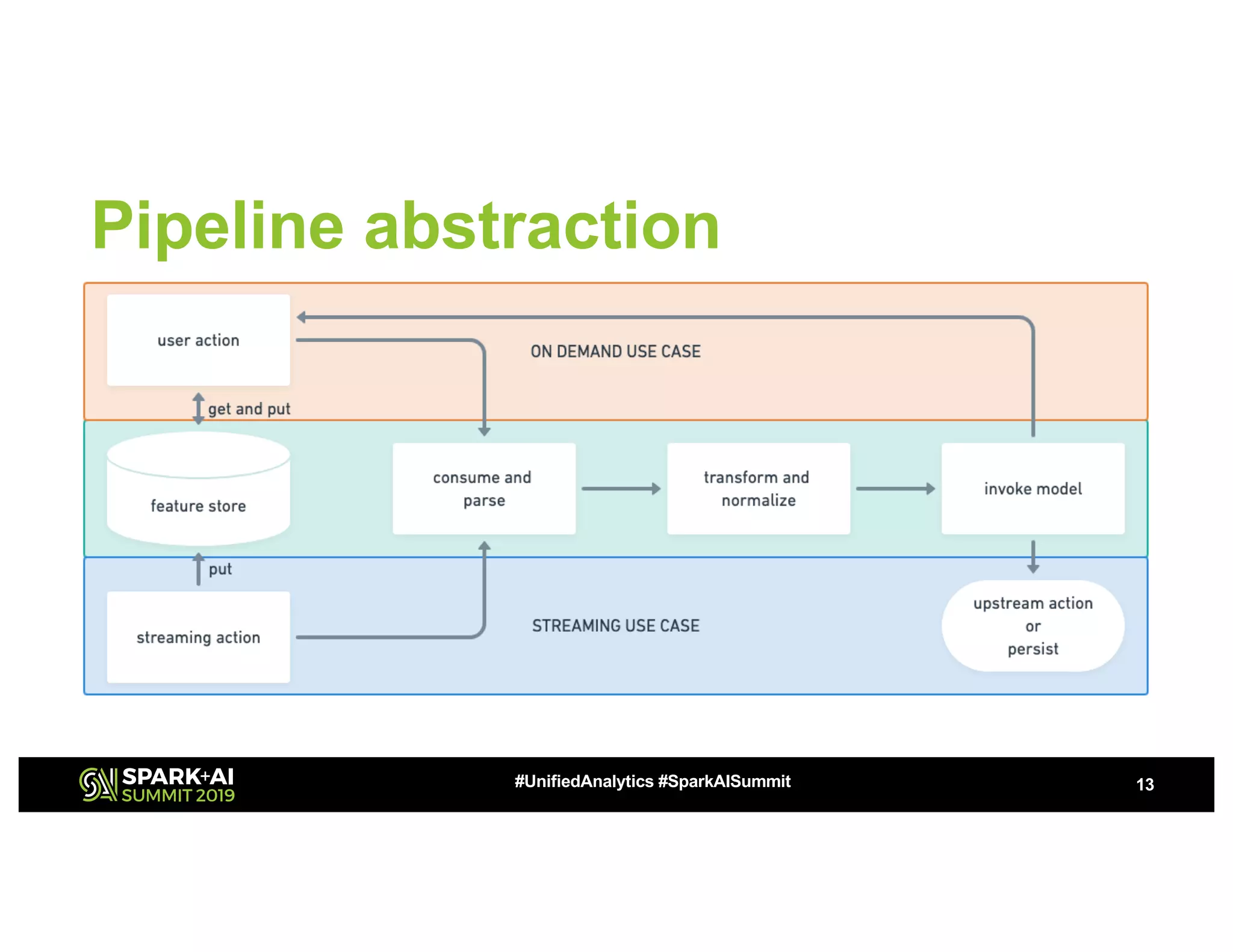
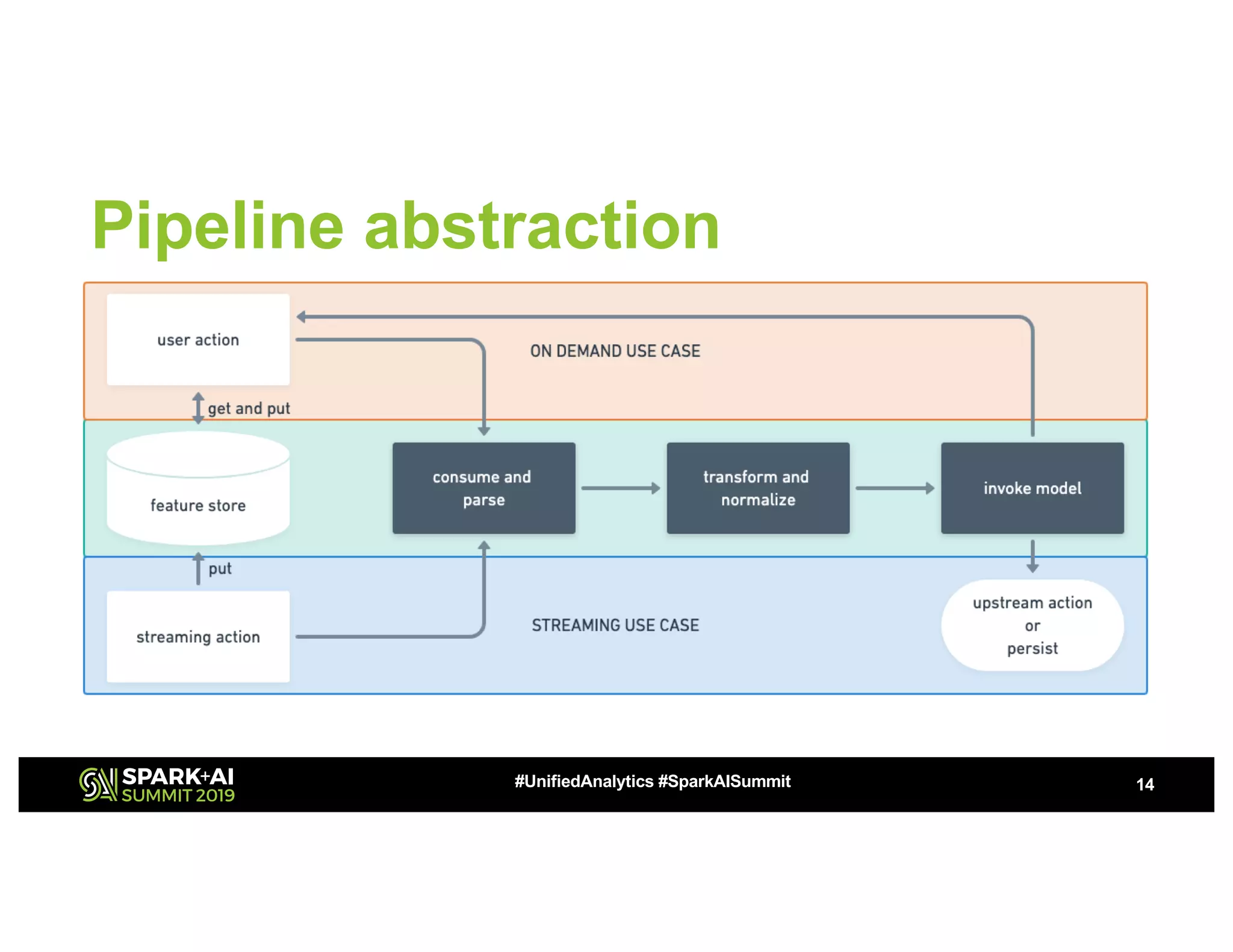
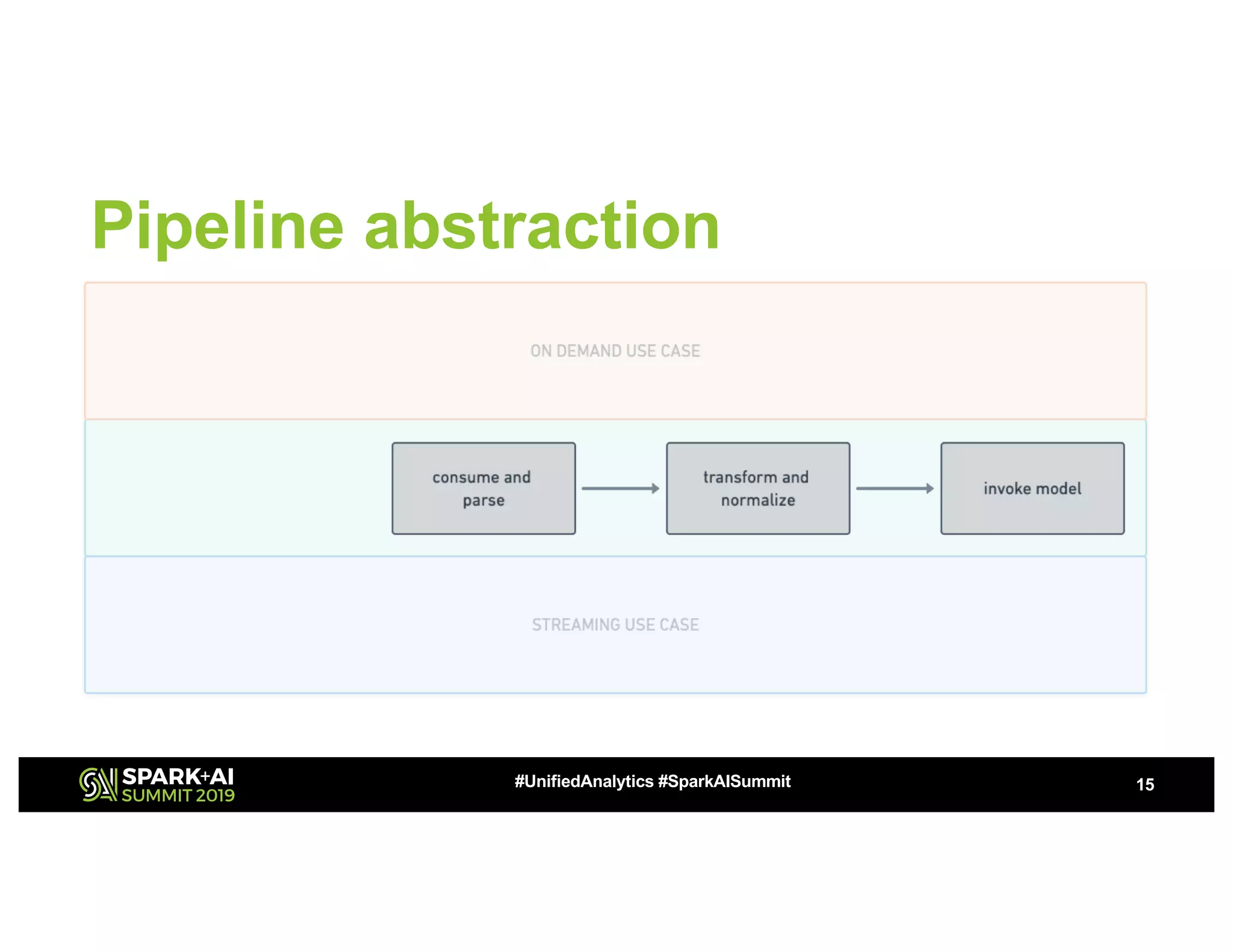
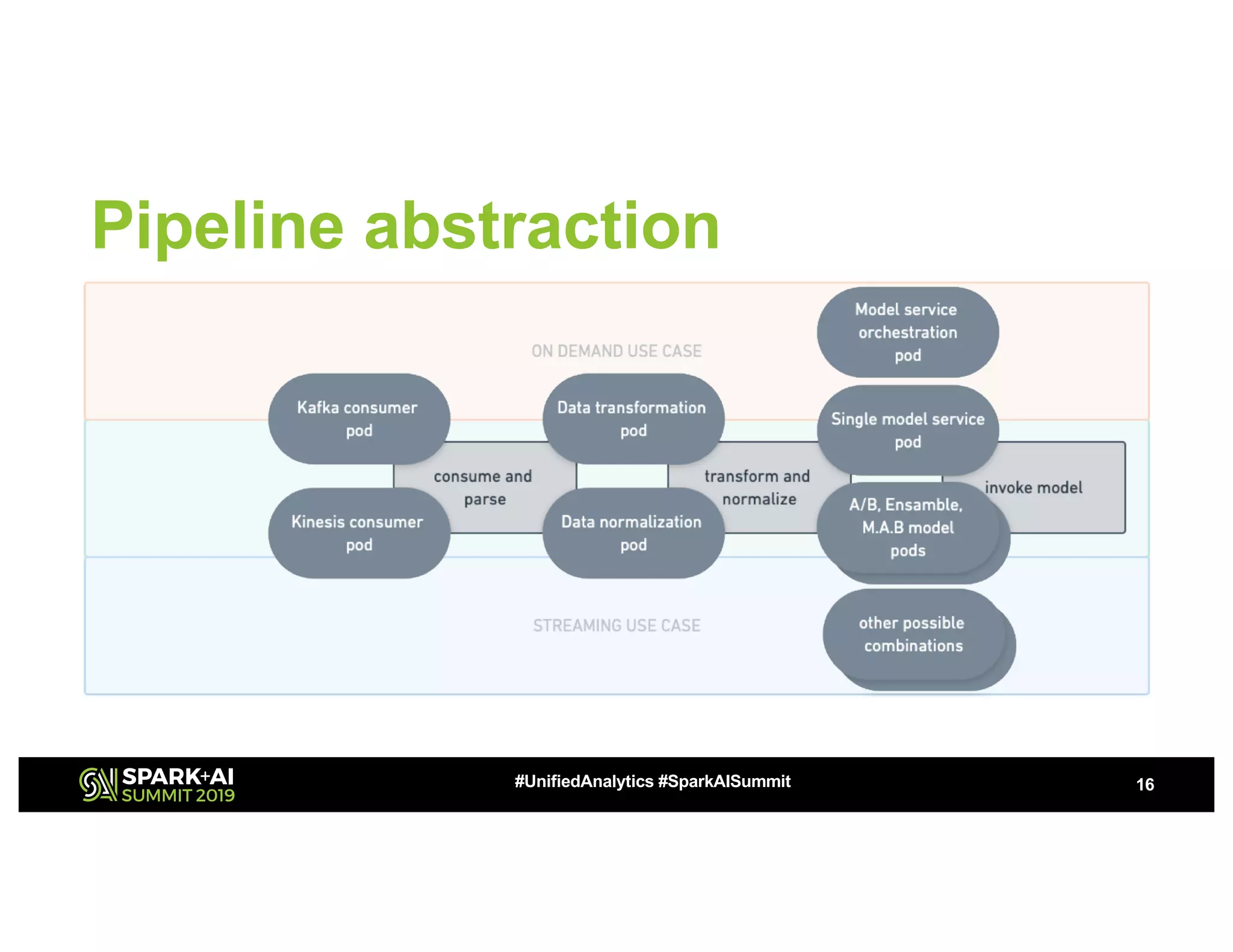
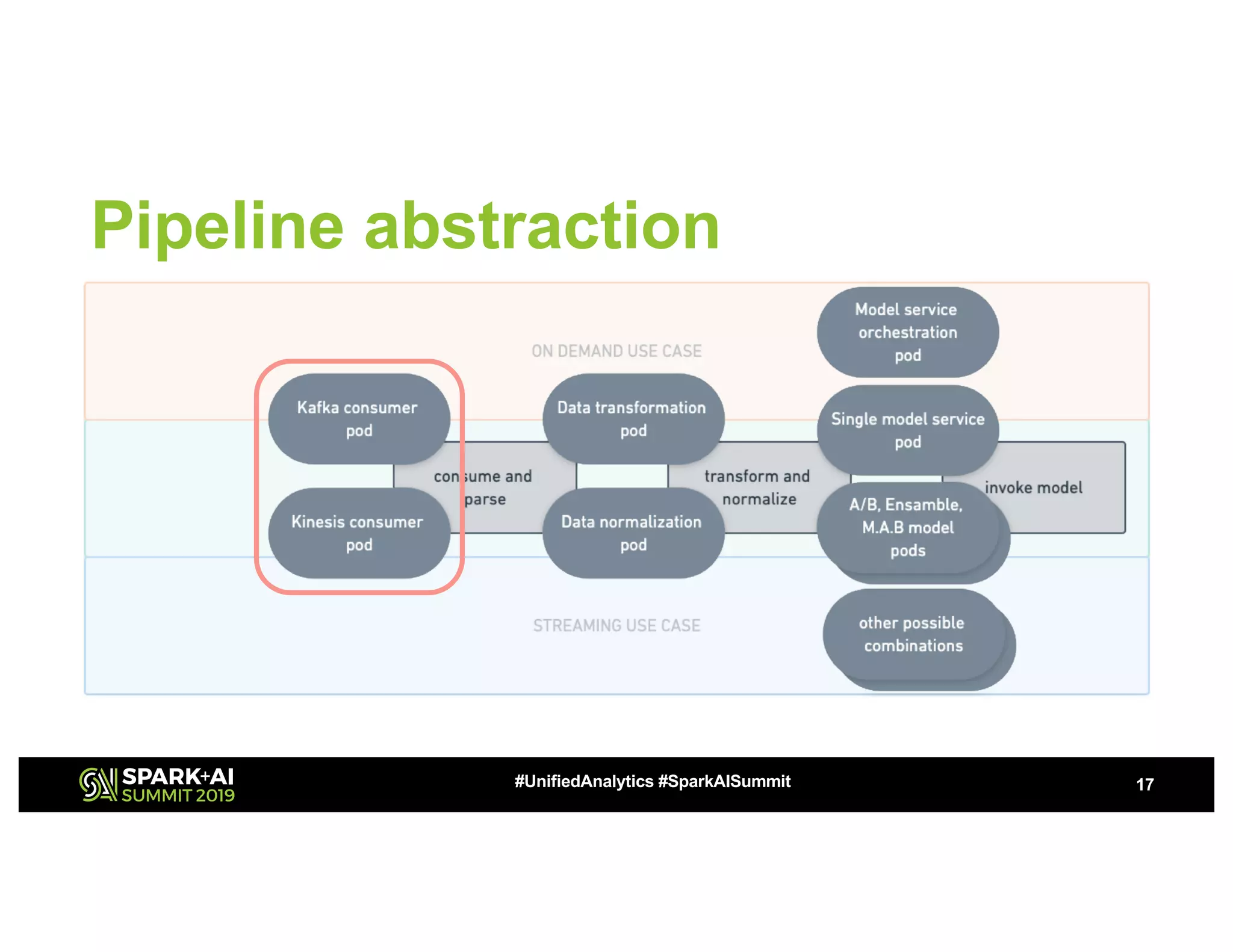
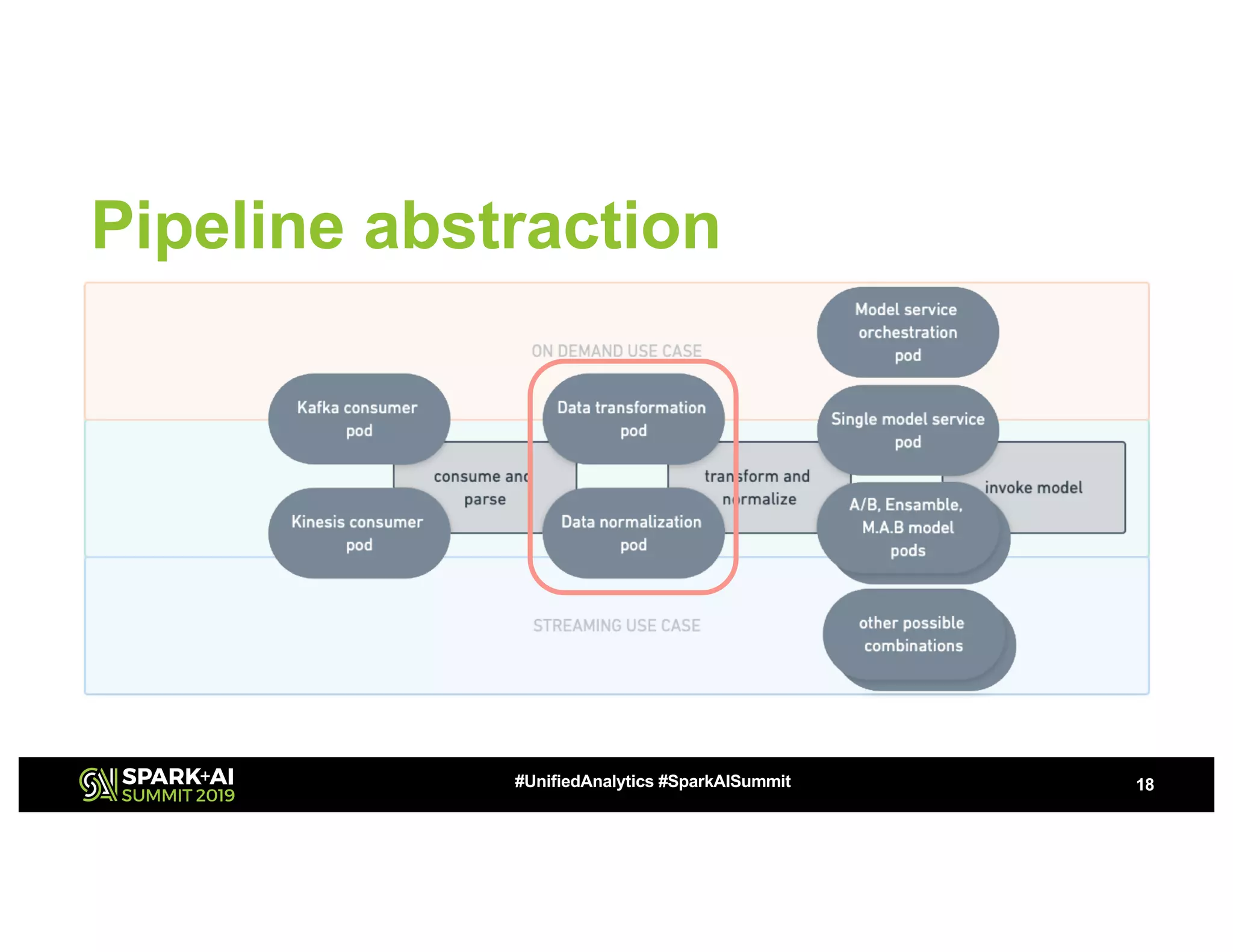
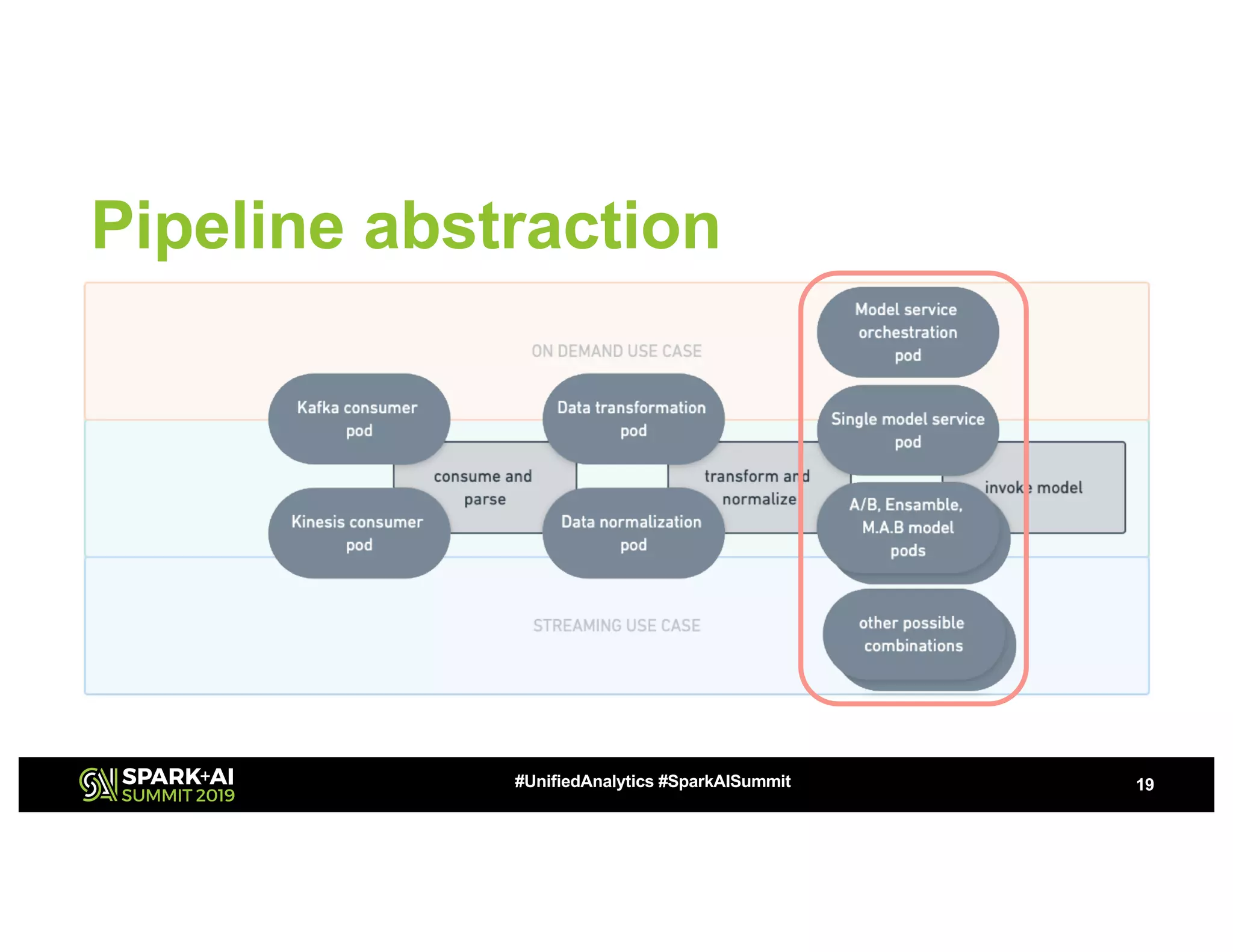
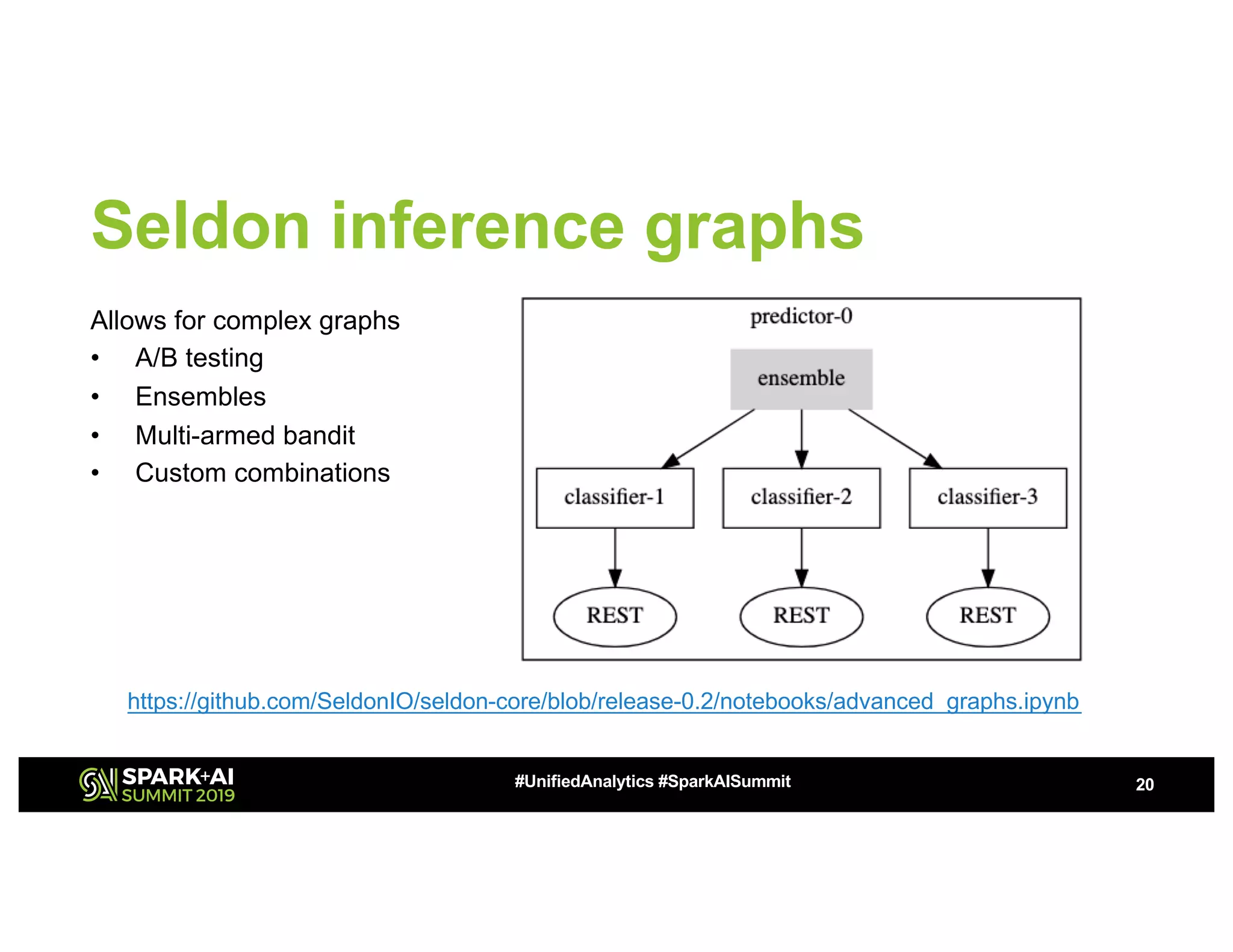


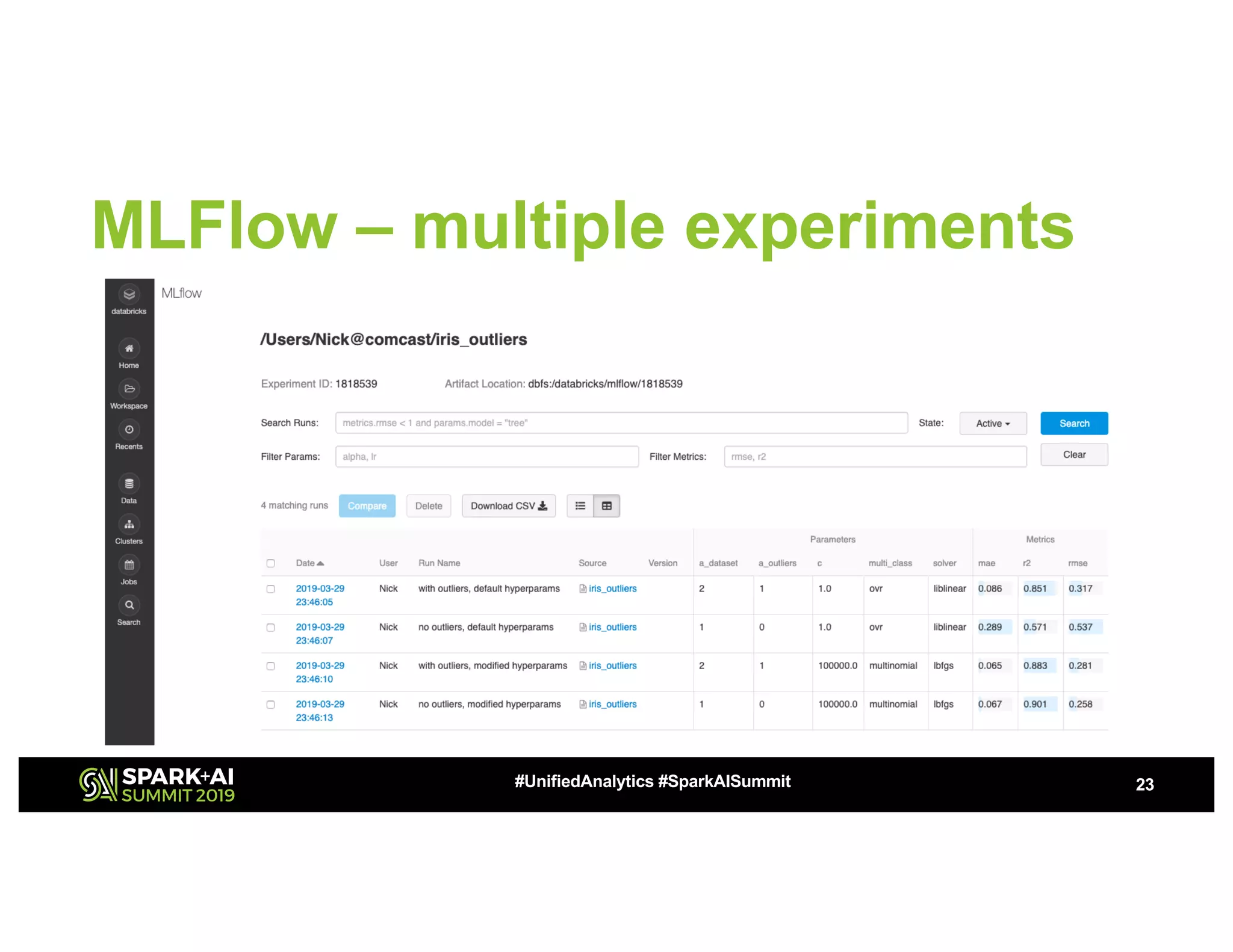
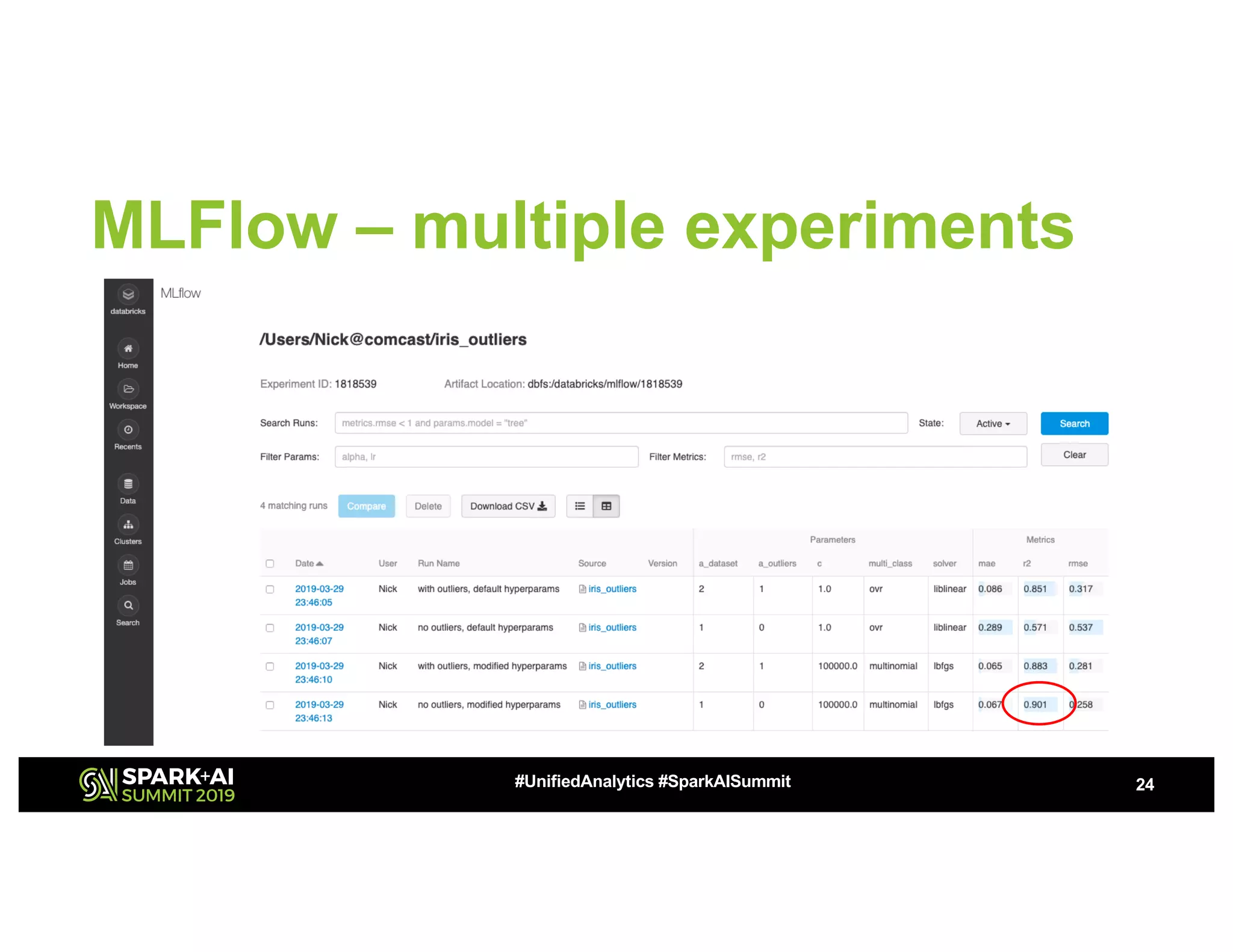
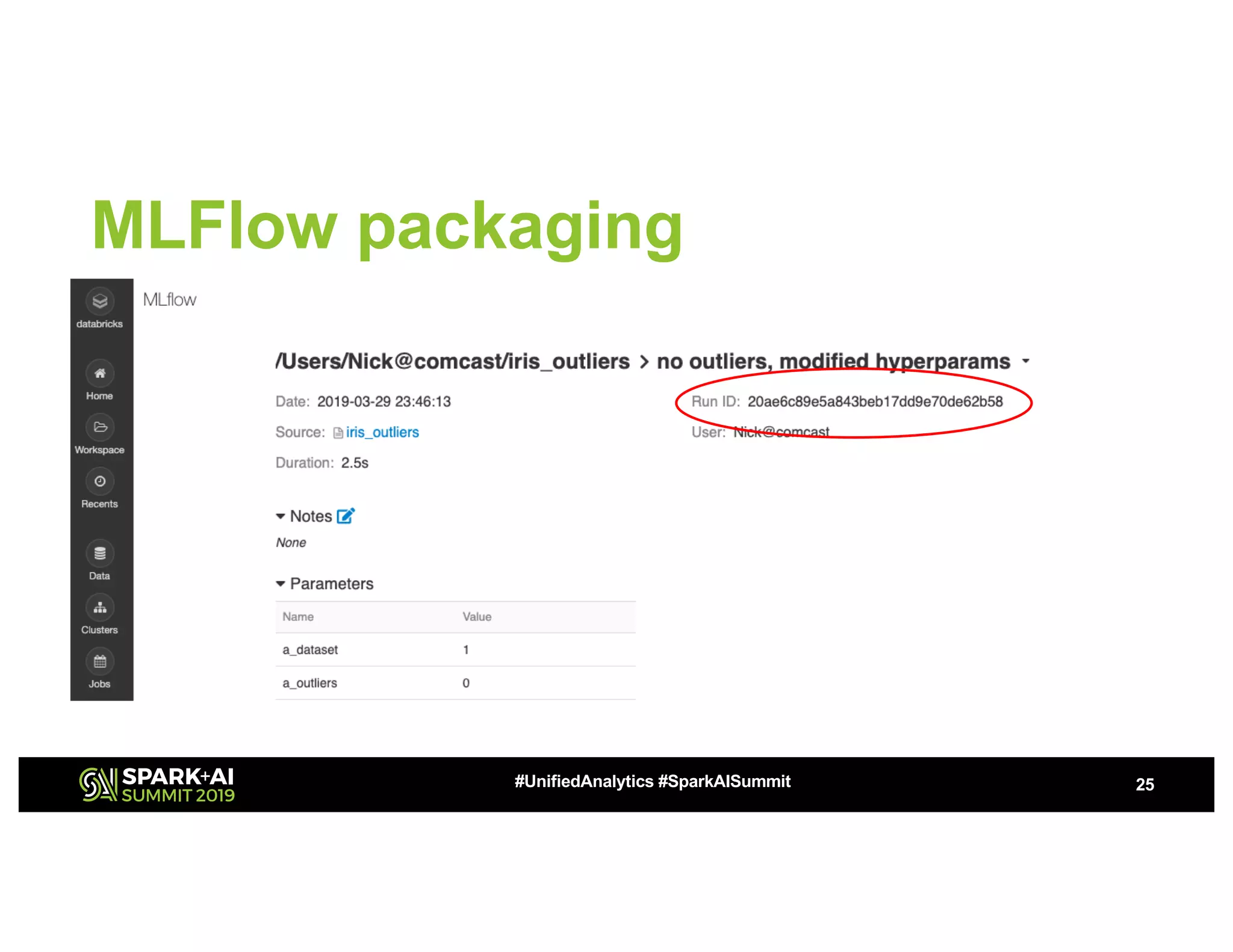
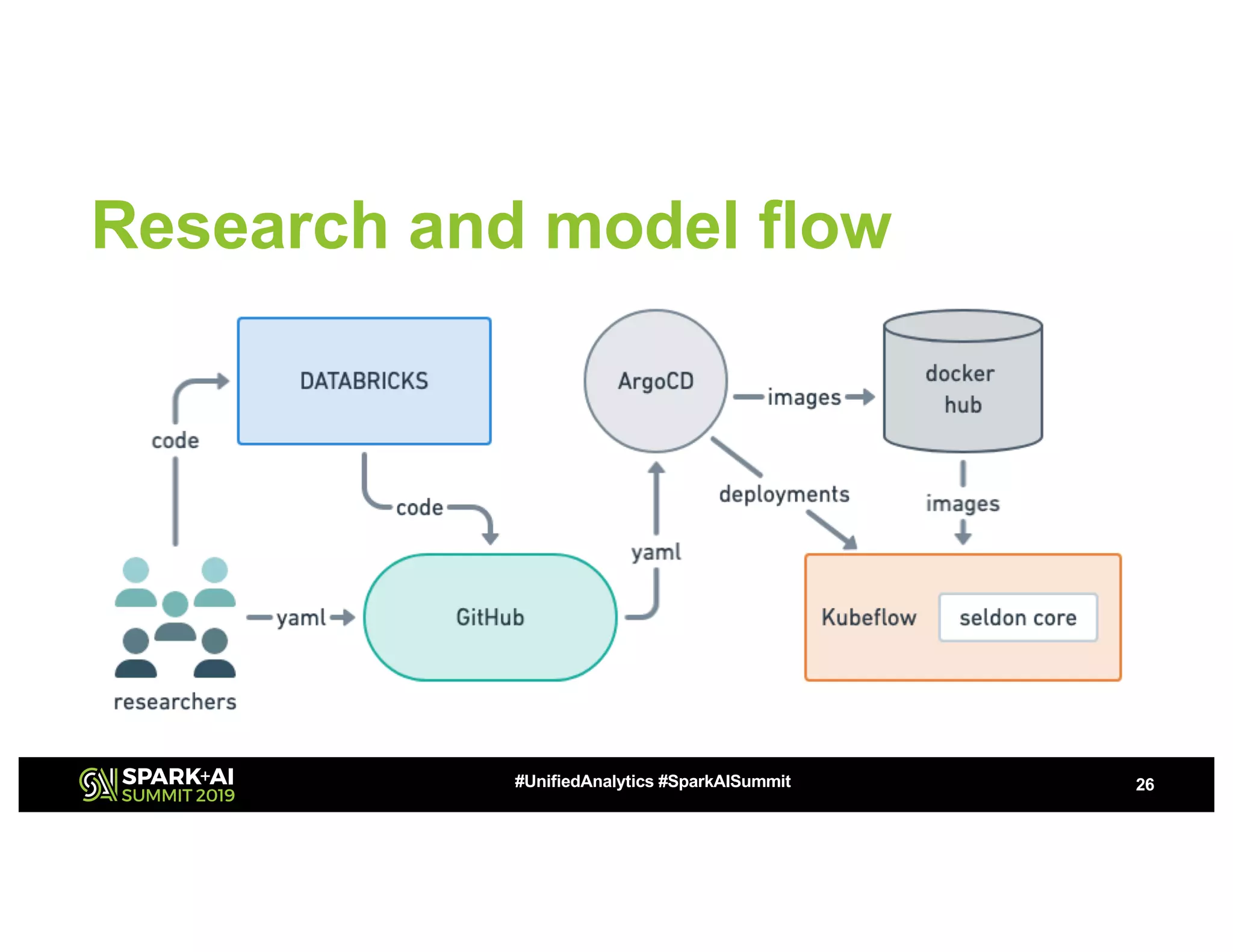
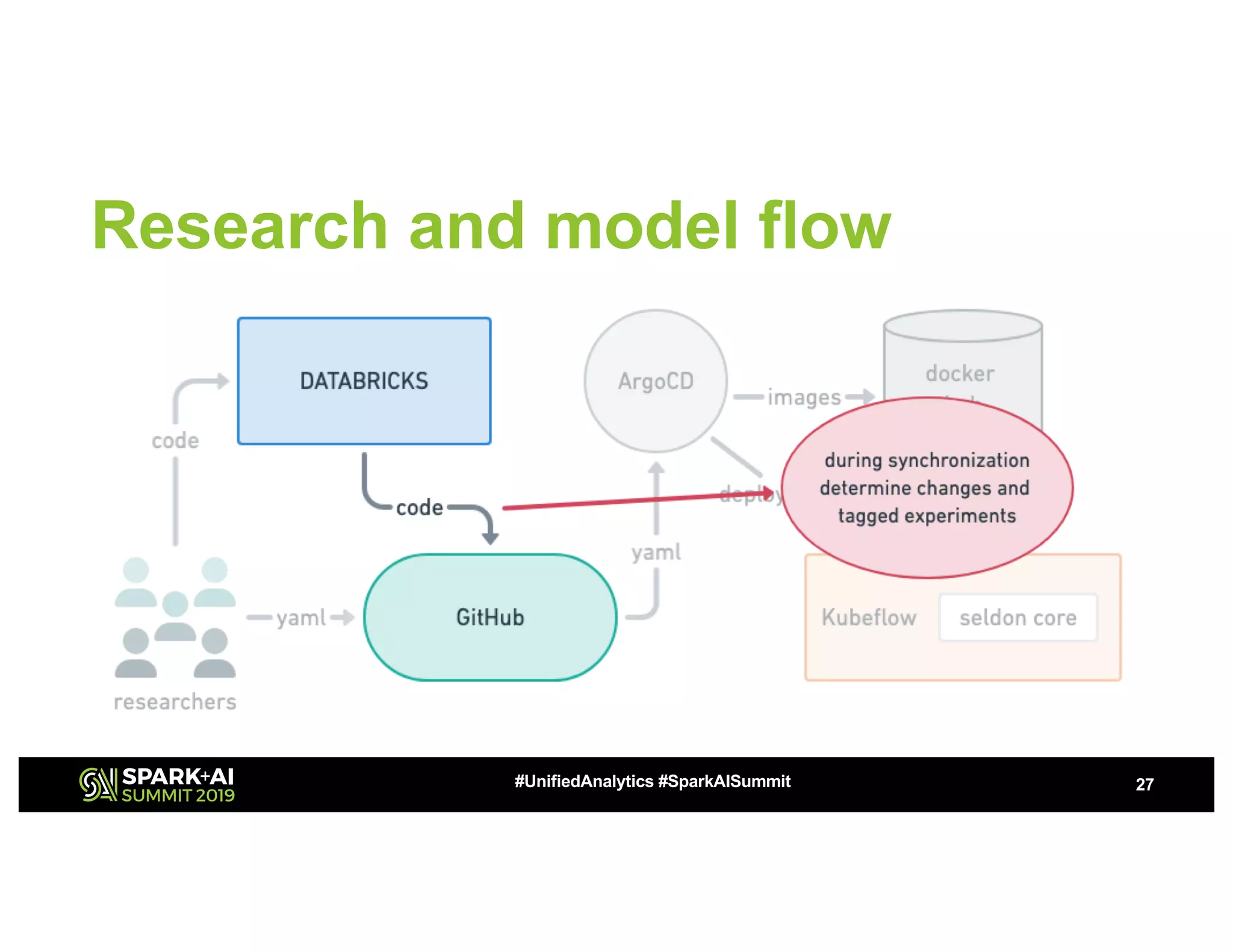
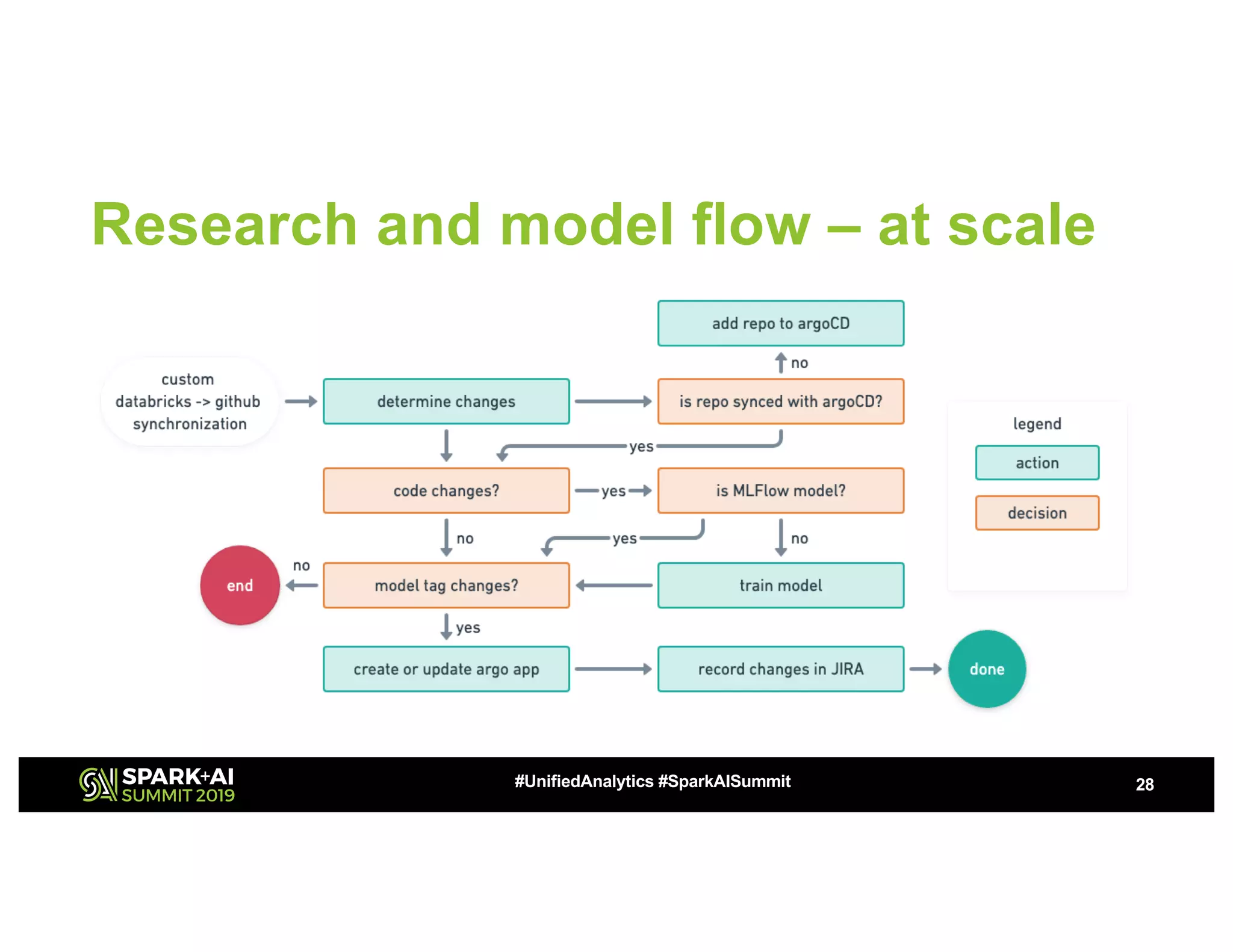
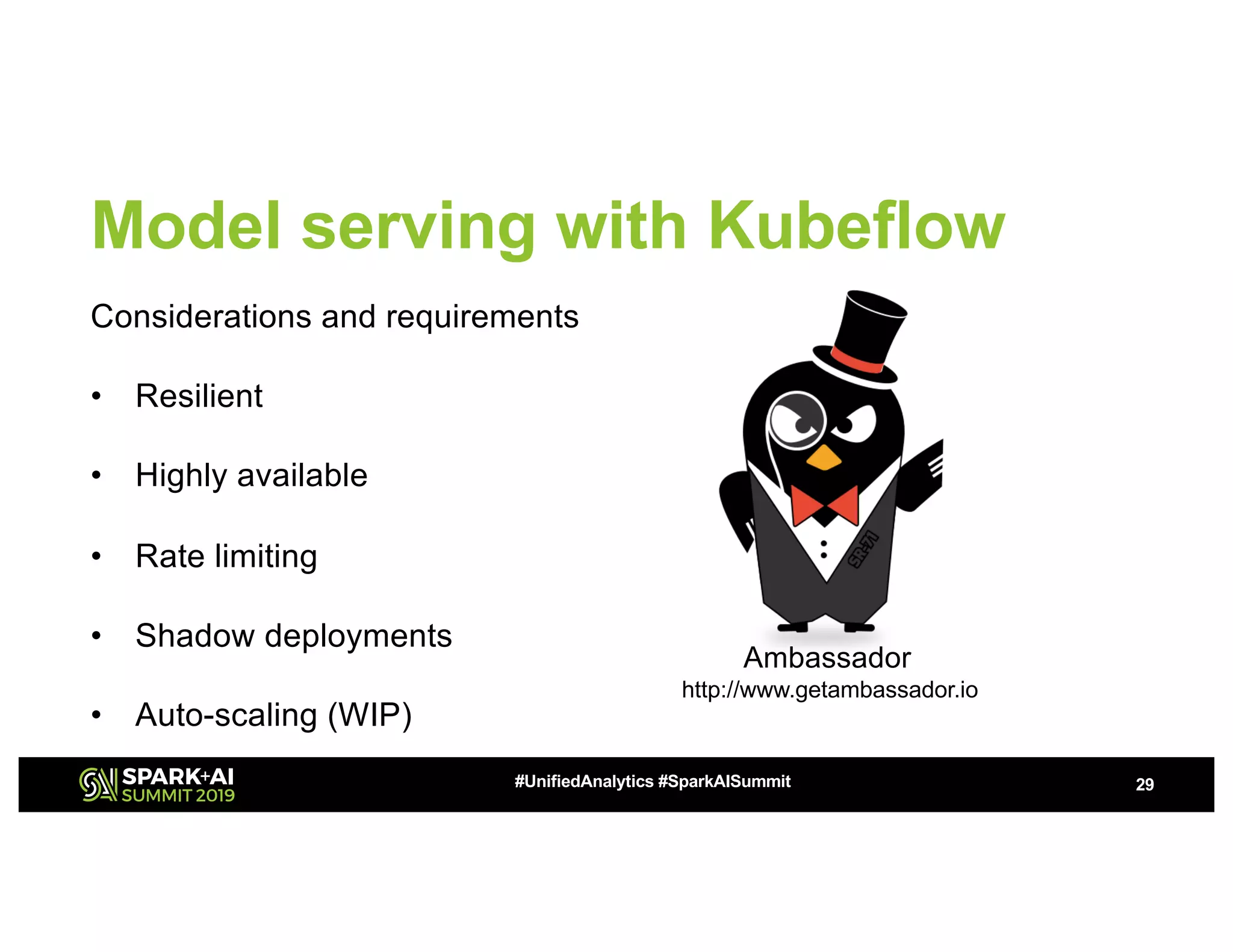
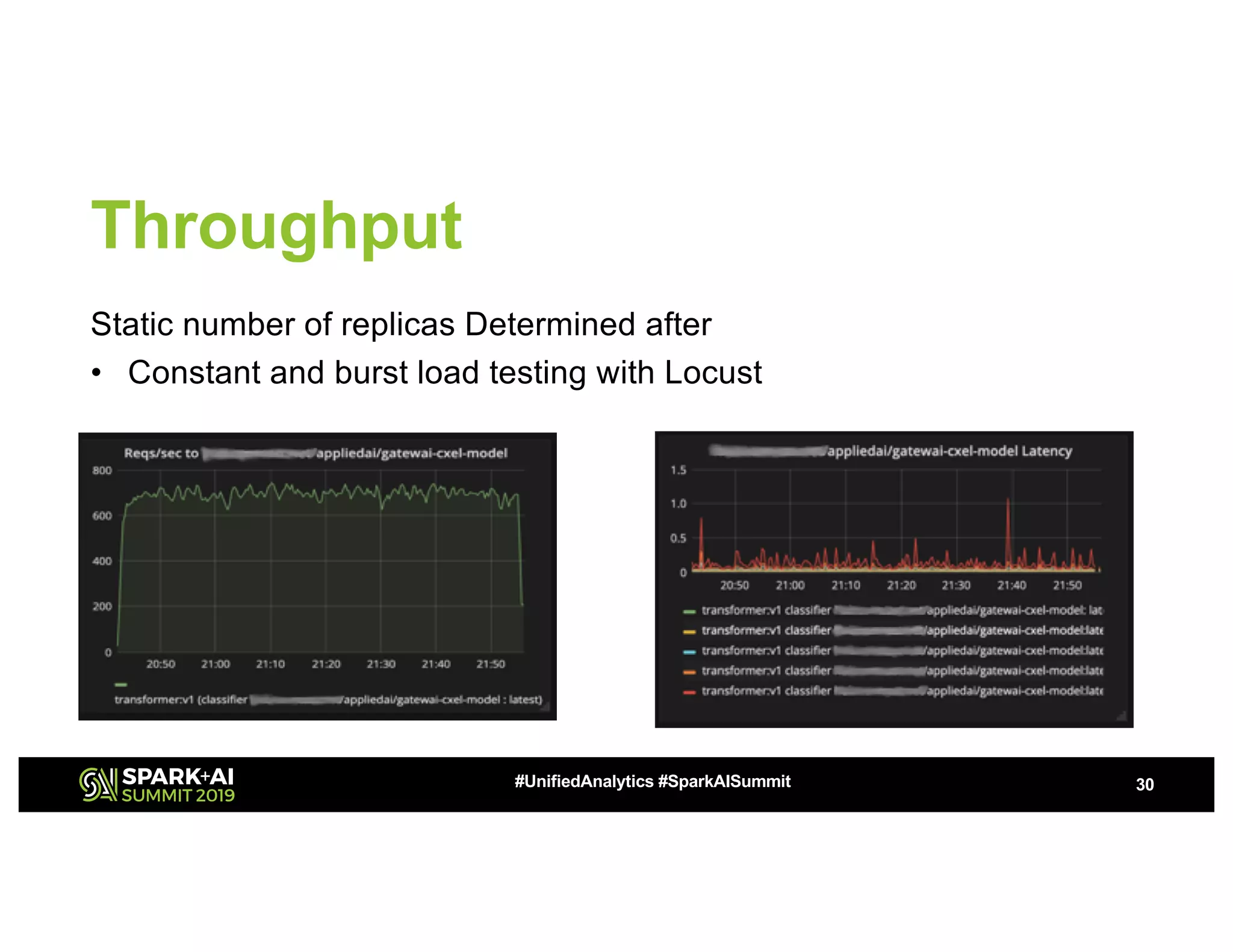

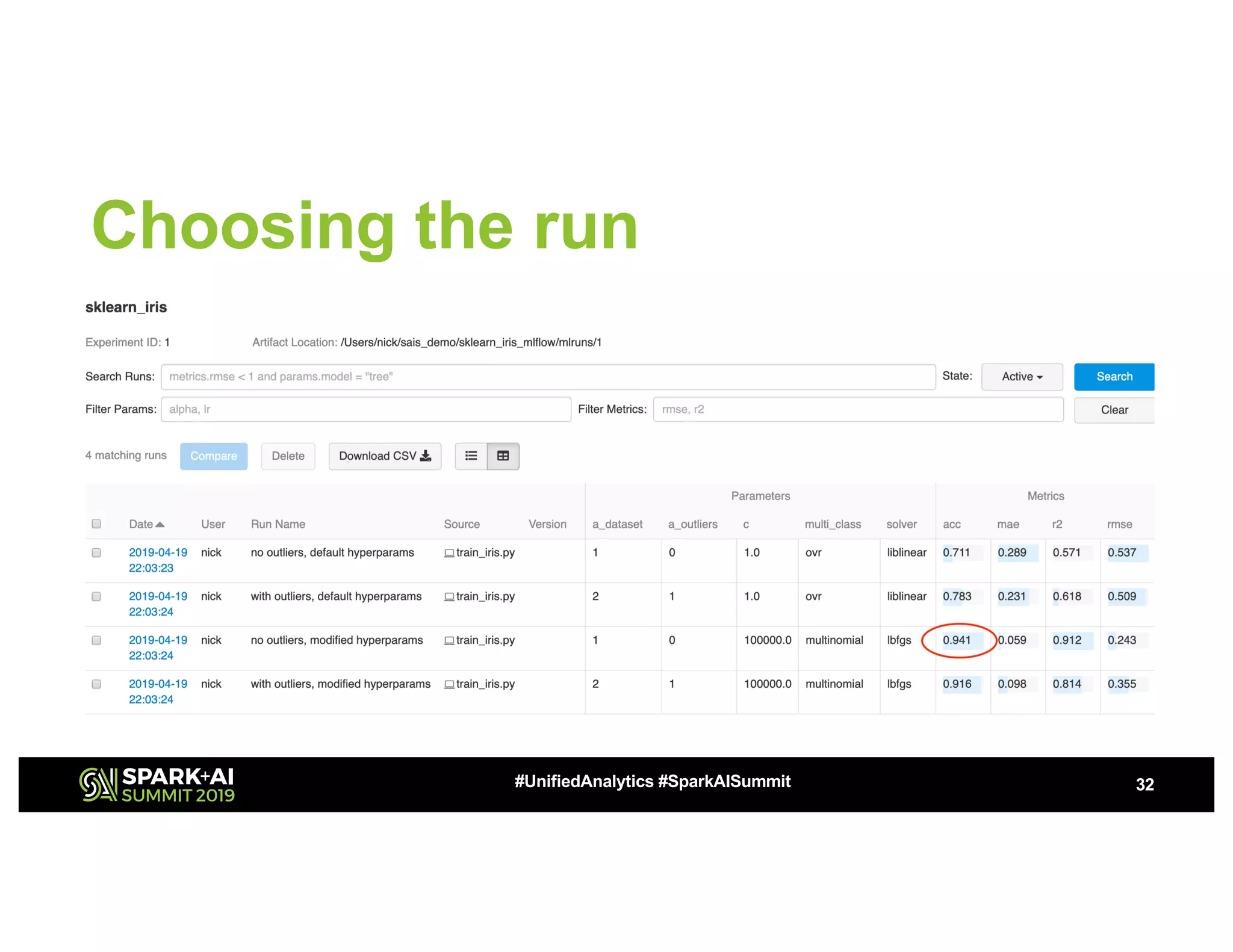
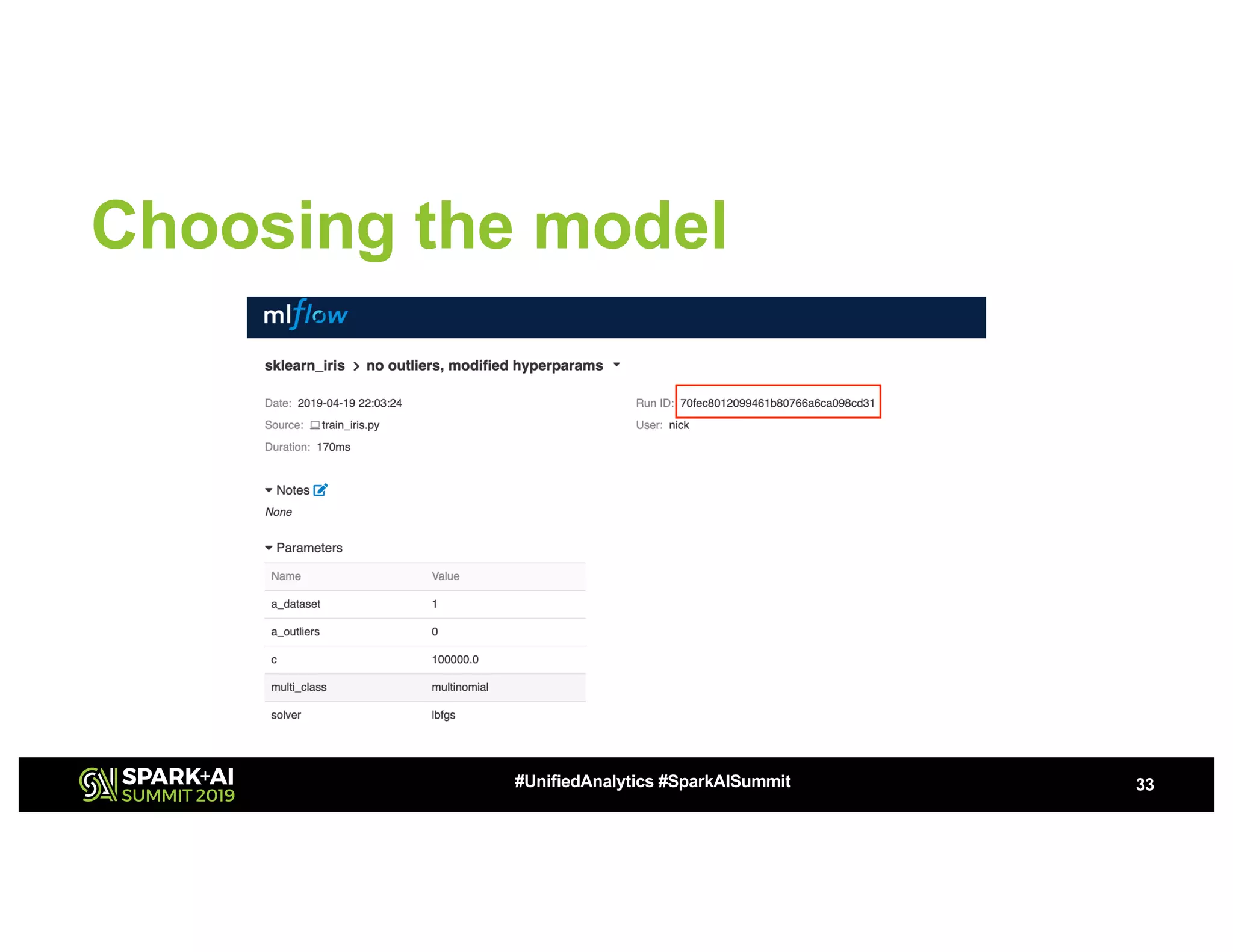




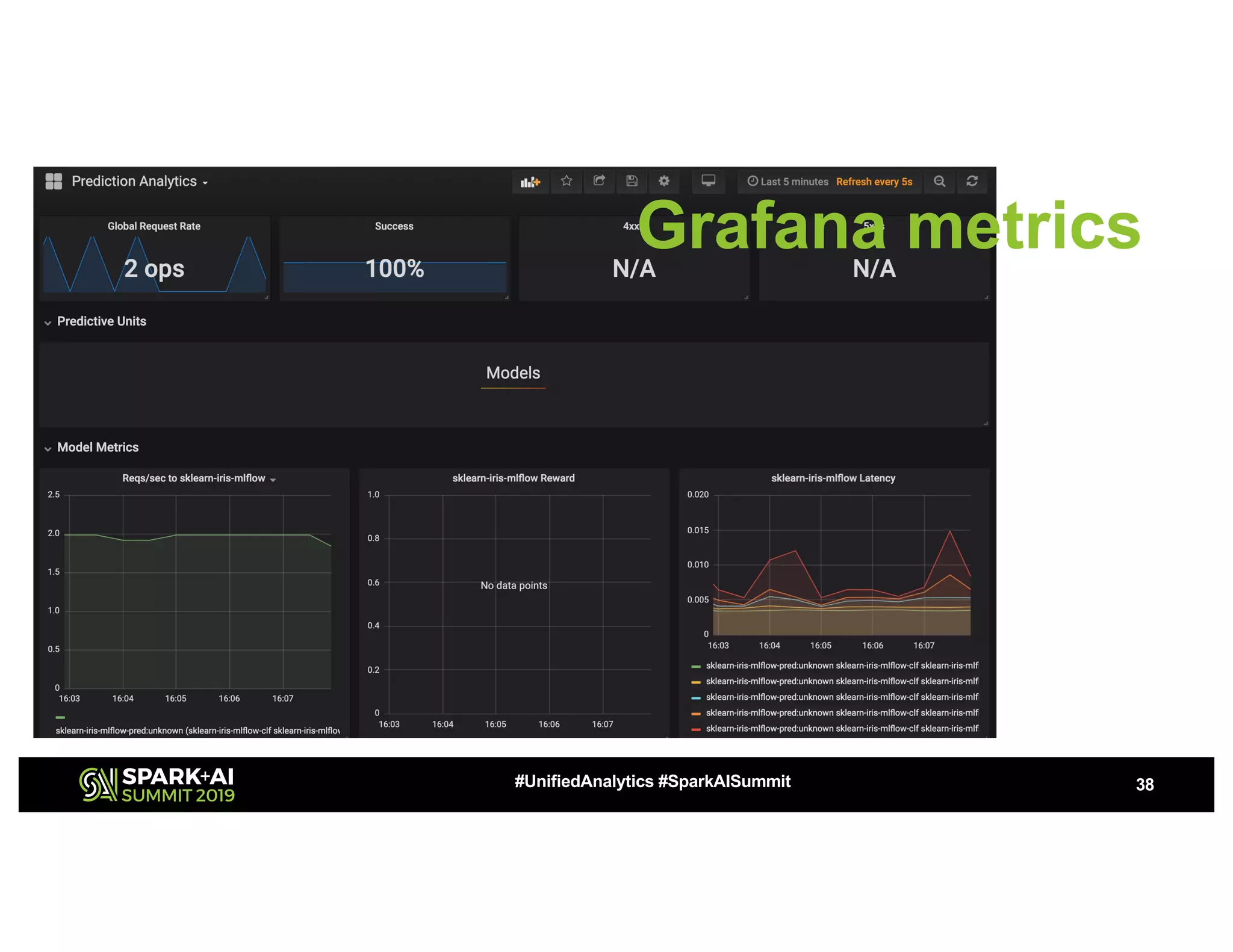











































This document summarizes a presentation about utilizing MLFlow and Kubernetes to build an enterprise machine learning platform. It discusses challenges that motivated building such a platform, like lack of model management and difficult deployments. The solution presented abstracts data pipelines into modular components to standardize workflows. It also uses MLFlow to package and track models and experiments, and Kubernetes with Kubeflow to deploy models at scale. A demo shows implementing model serving with these tools.




































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















