Downloaded 39 times








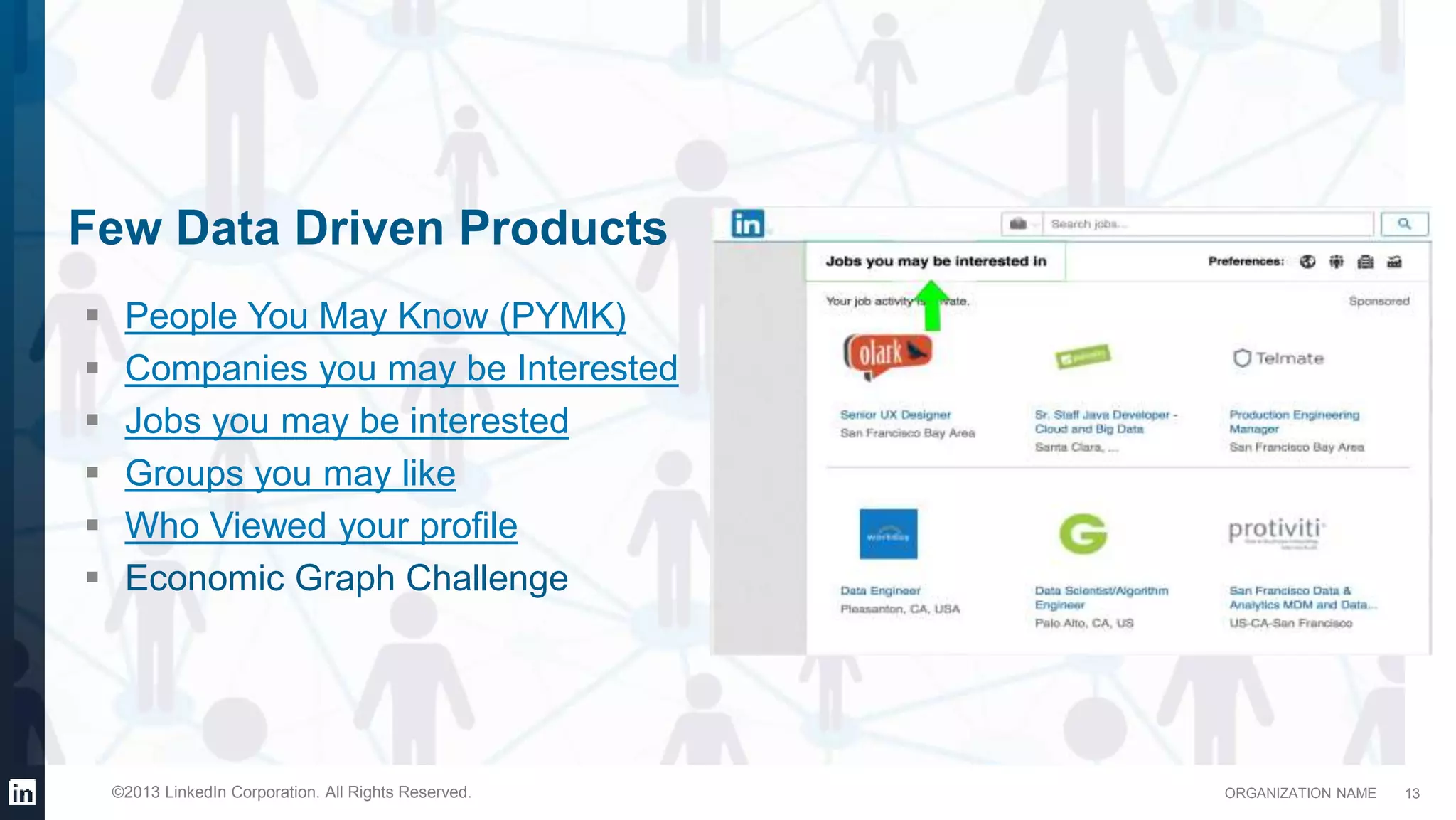
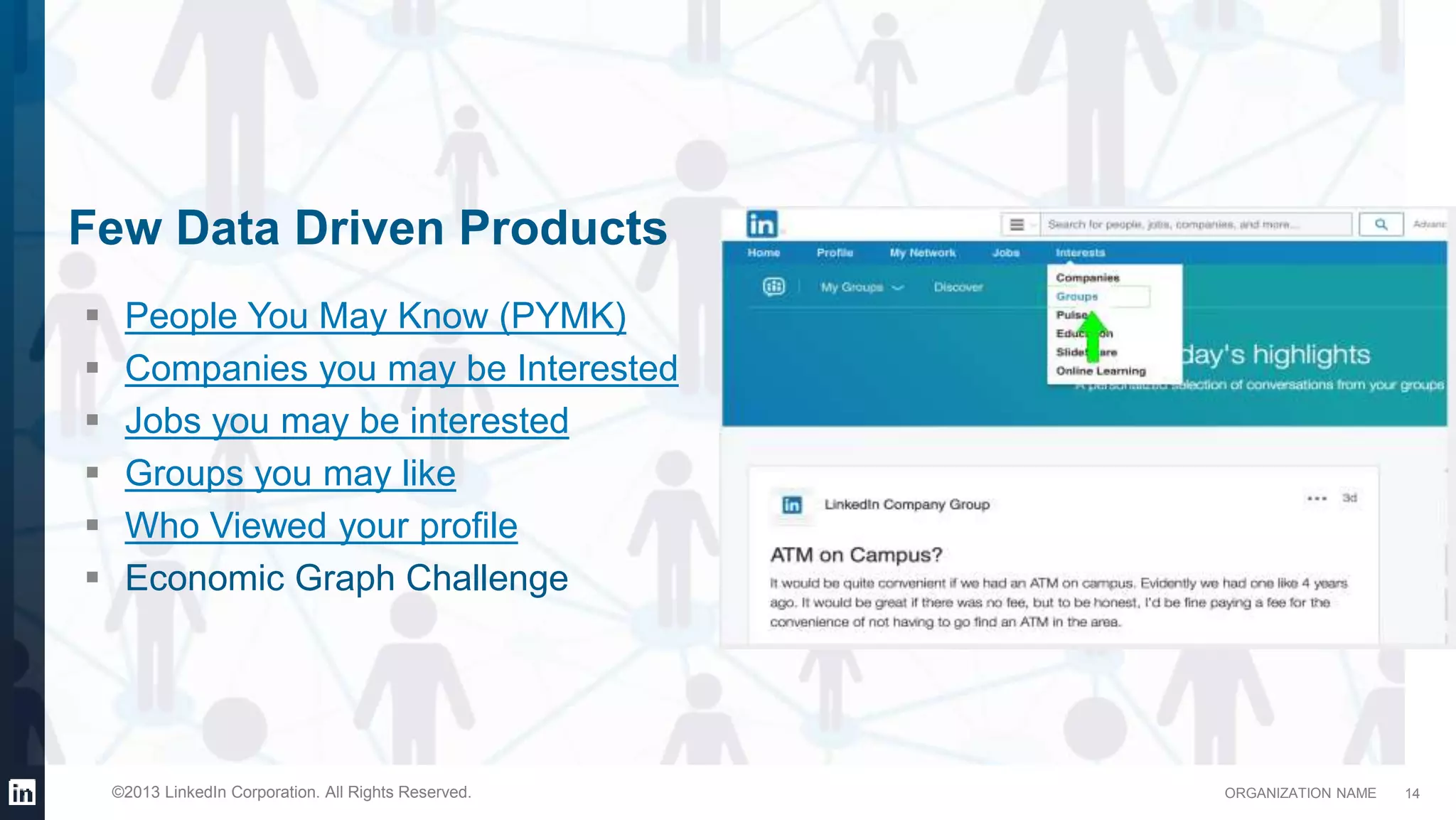
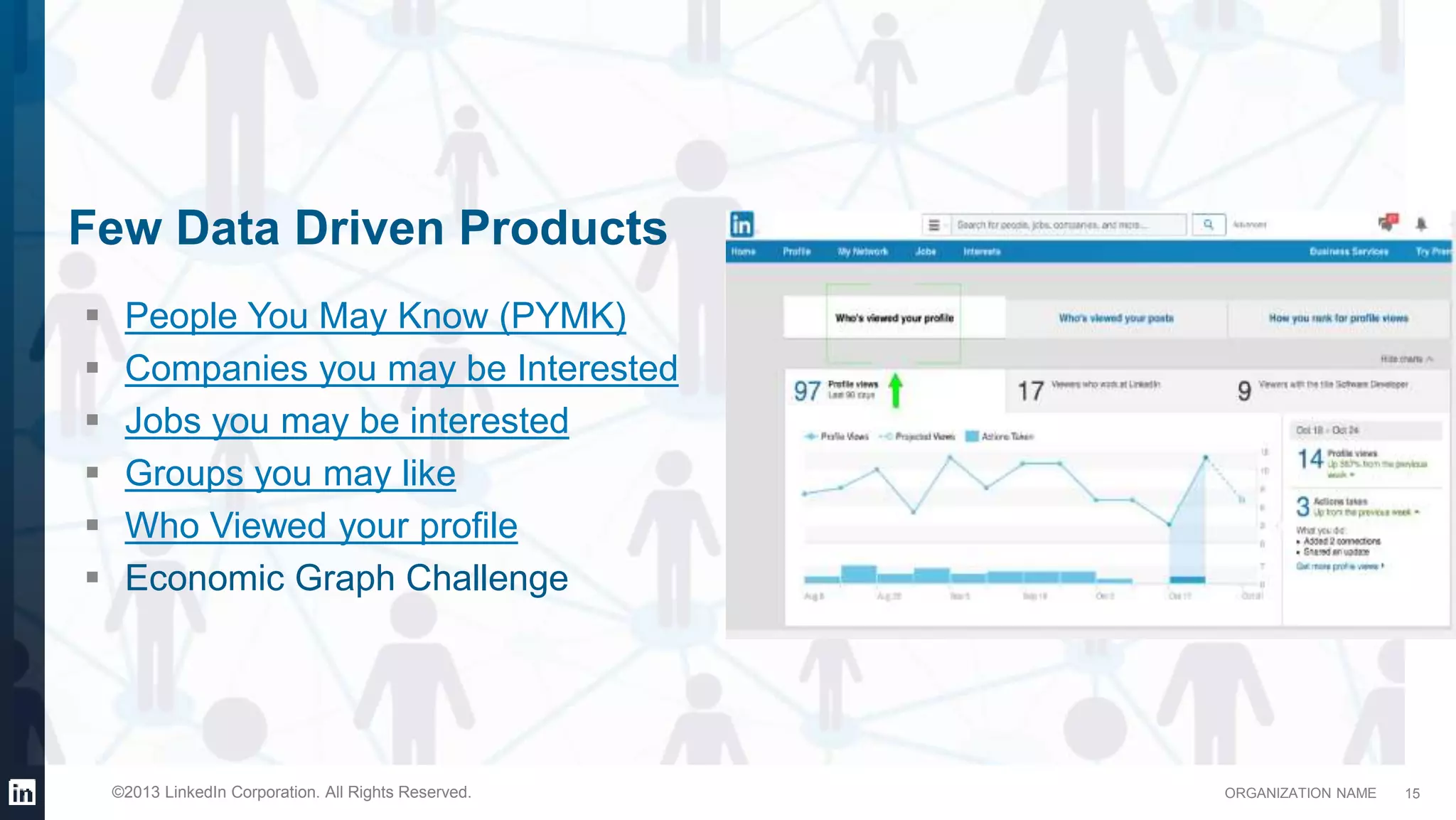

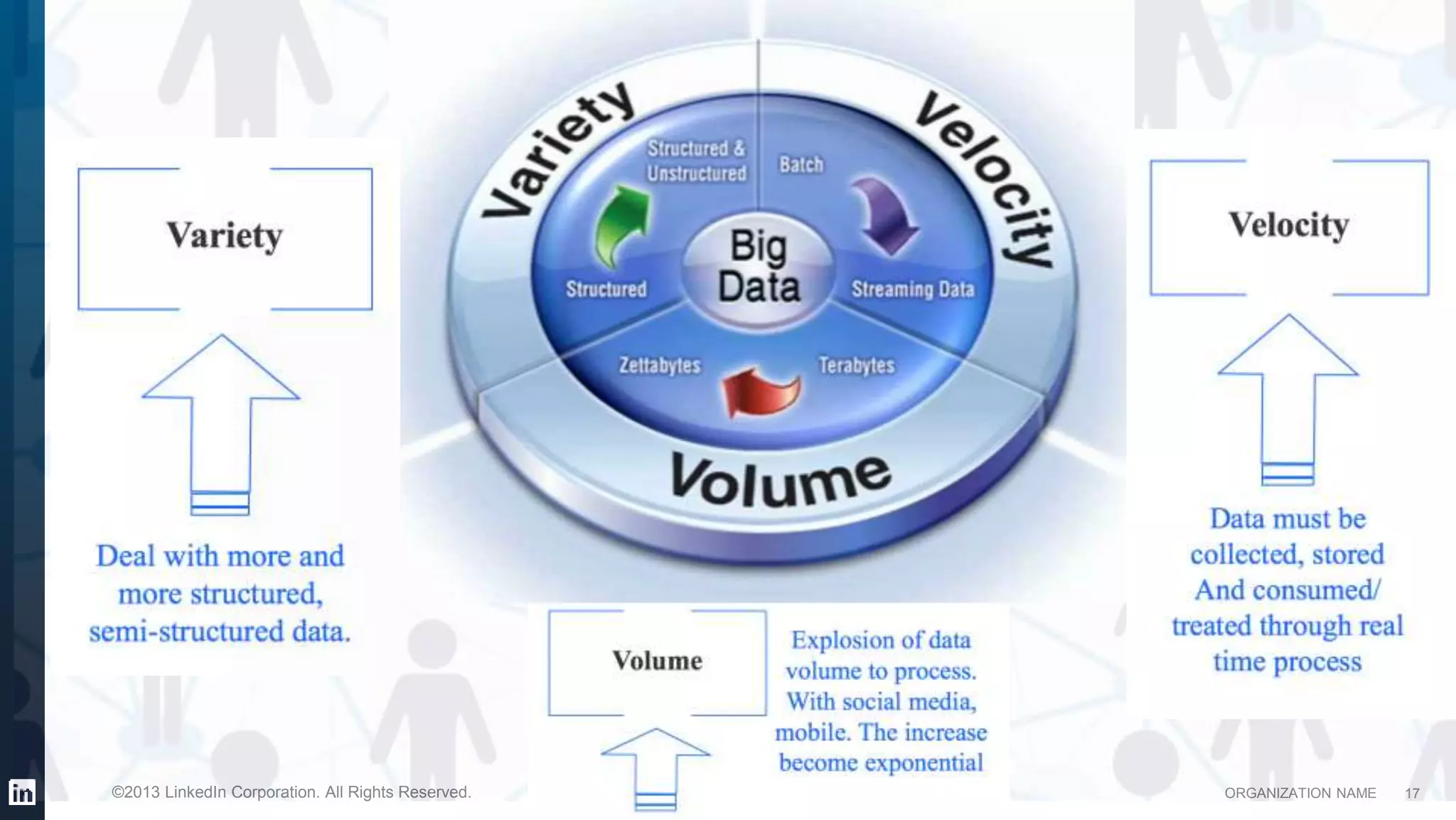


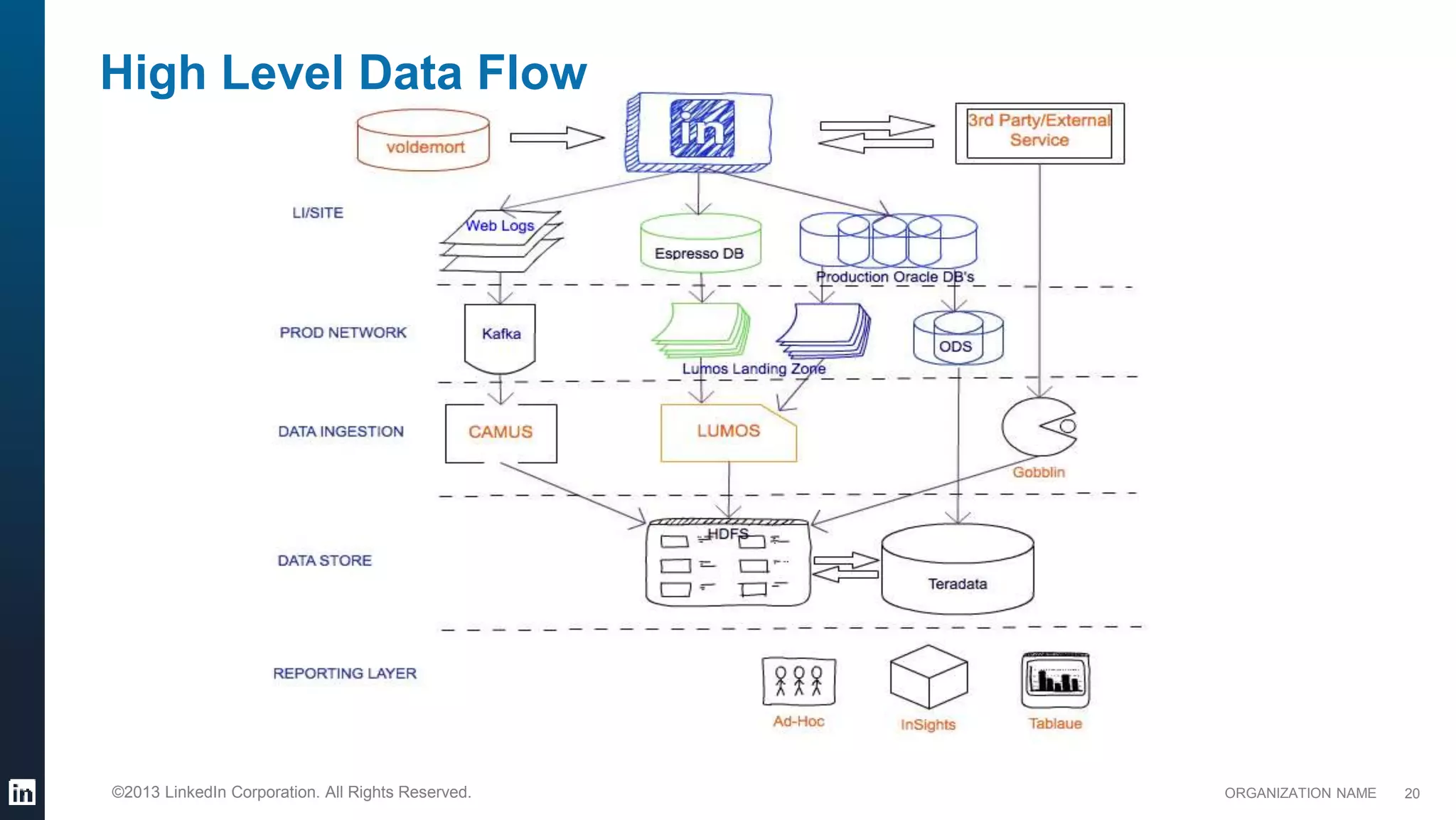

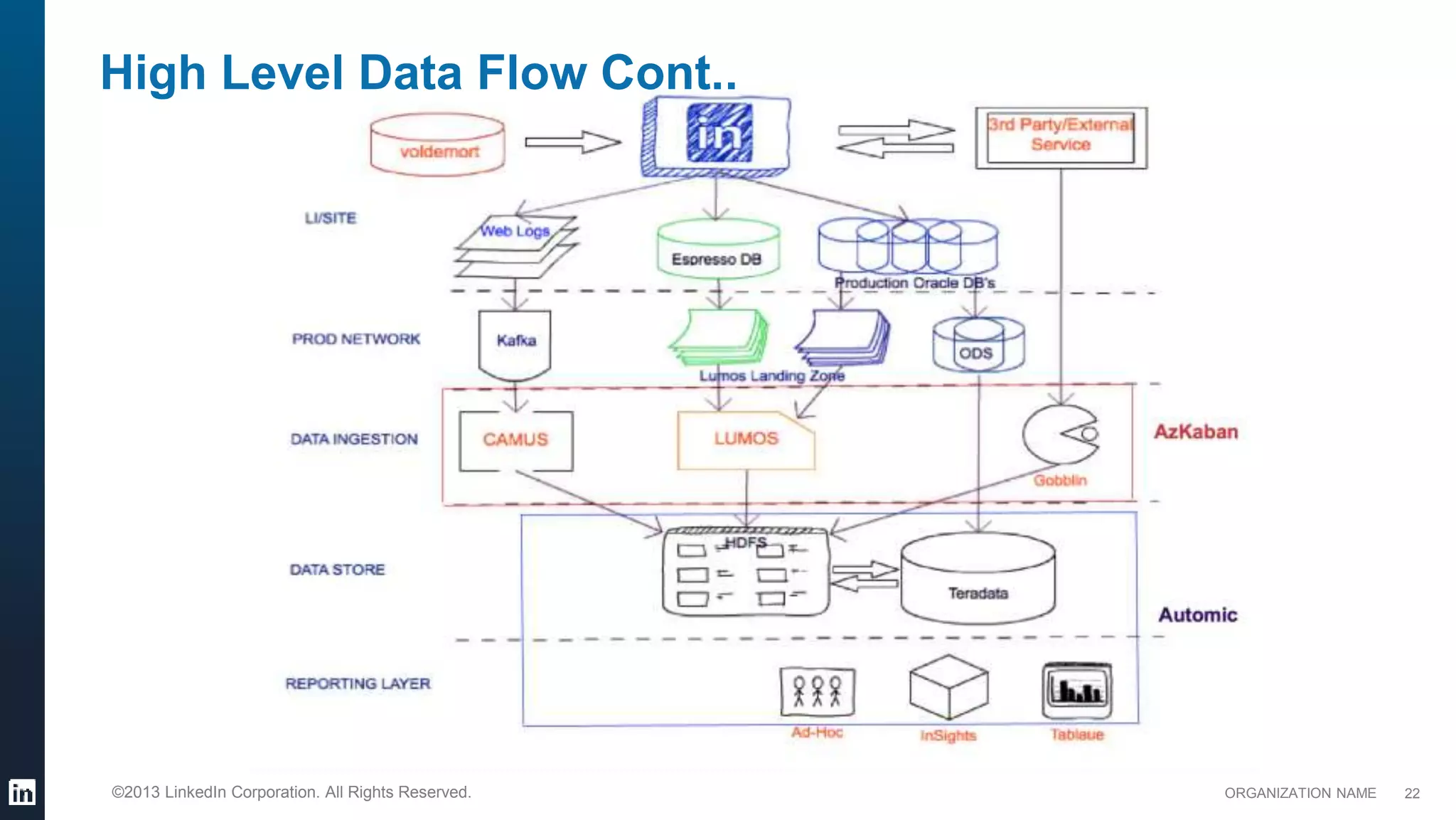

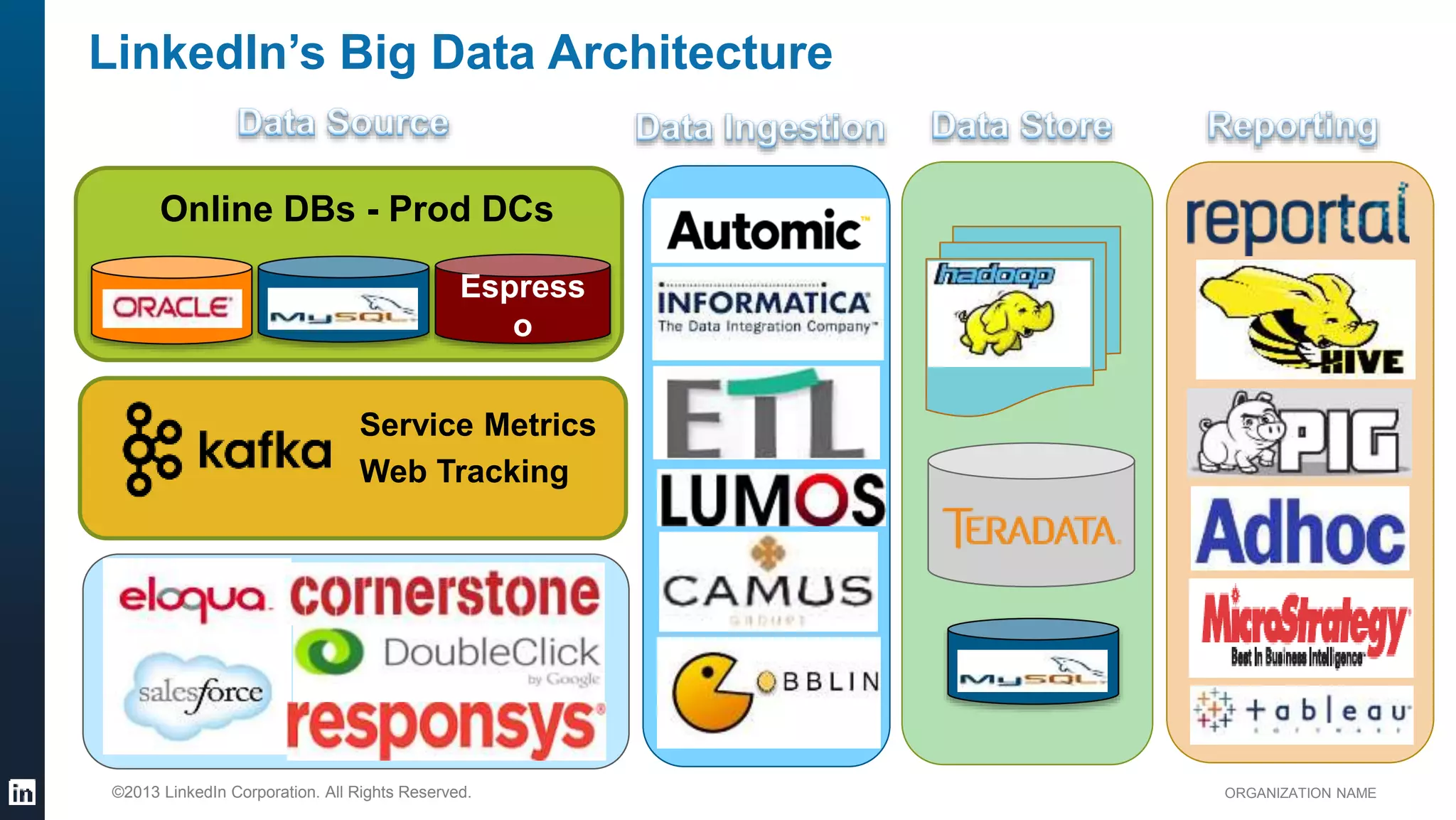
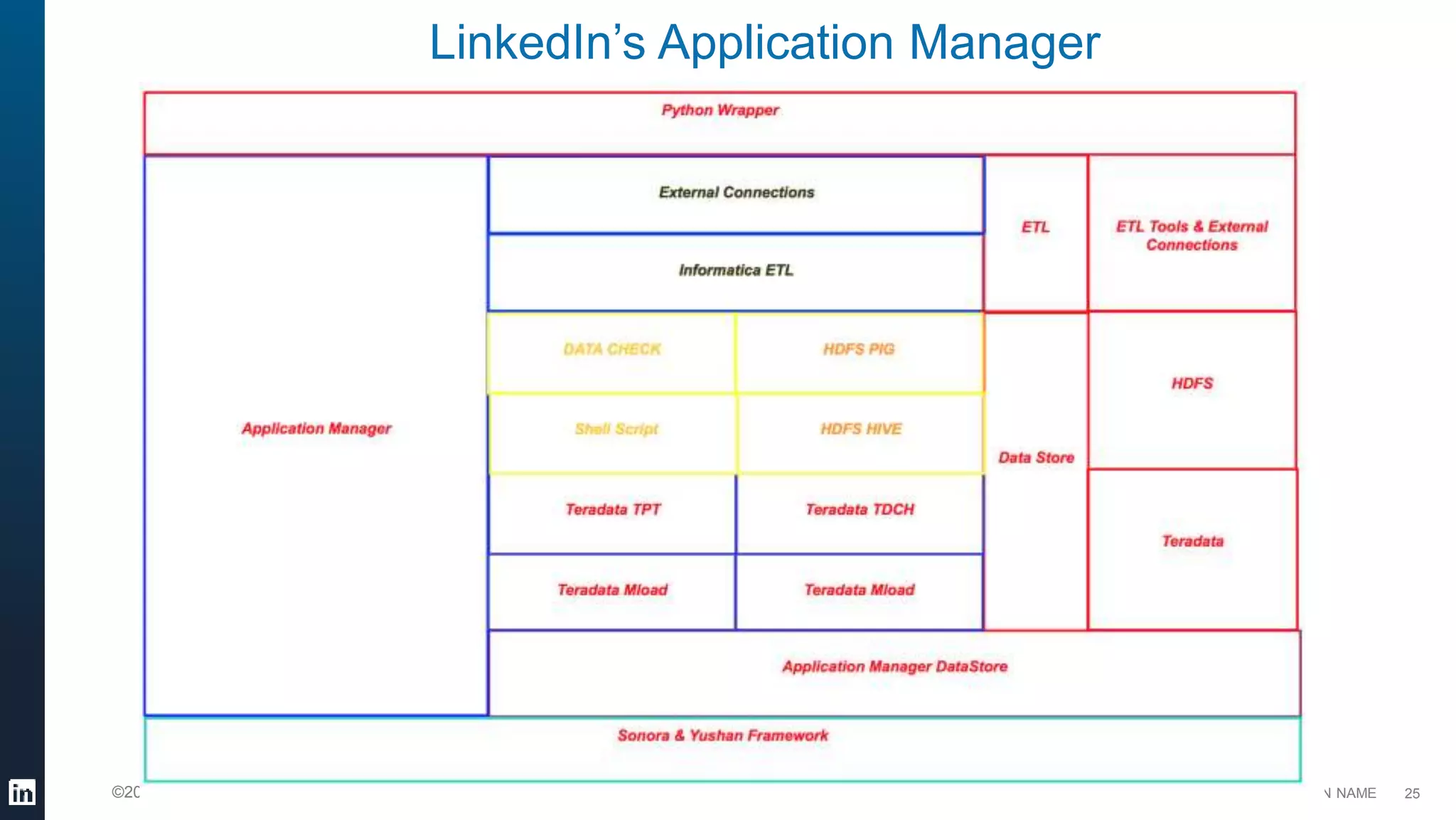

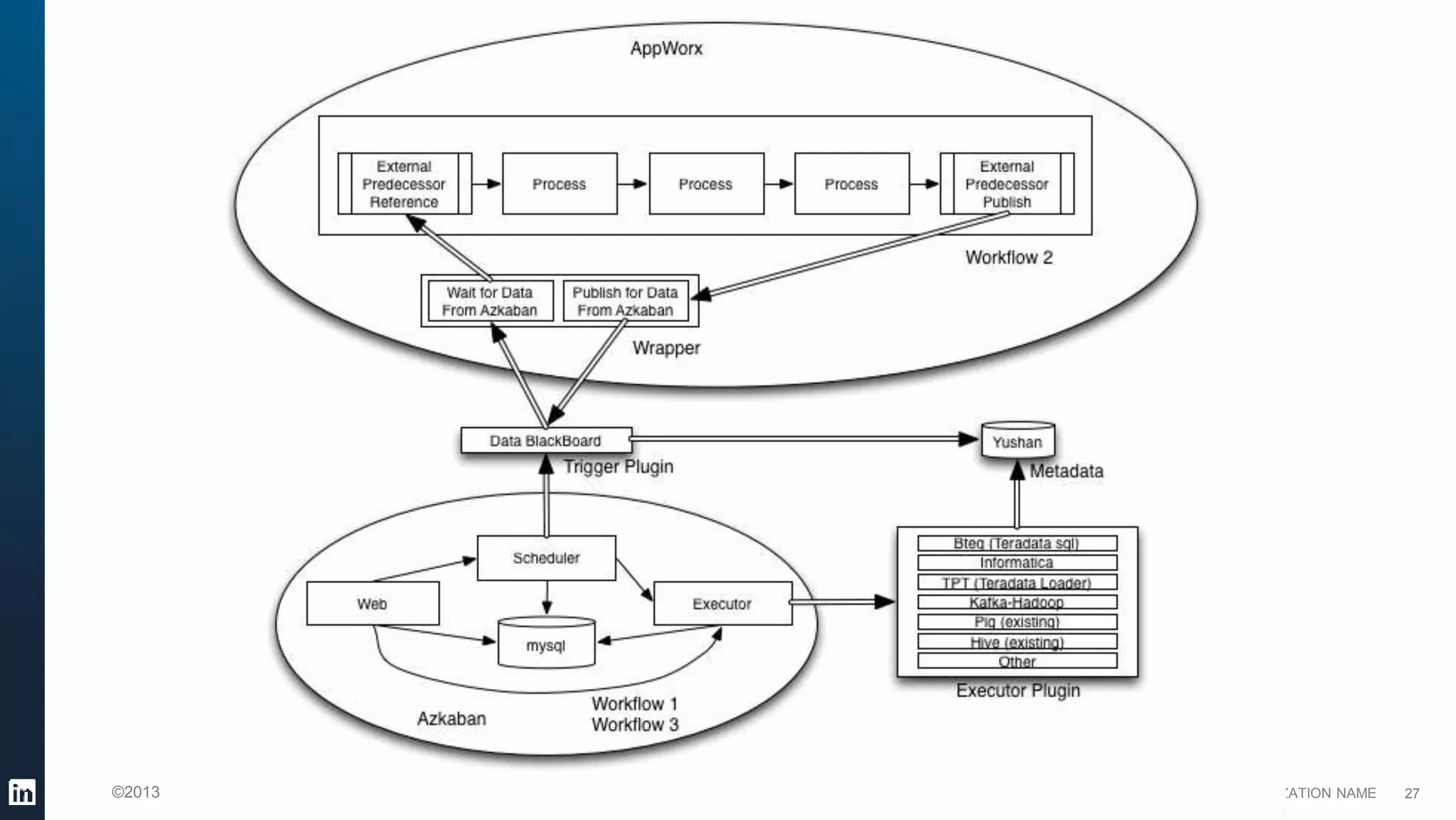
































This document provides an overview of LinkedIn's use of big data. It discusses how data is important for LinkedIn's products and services. It describes LinkedIn's big data ecosystem, including tools used for data ingestion (Camus, Gobblin) and scheduling workflows (Azkaban). It provides details on the types and volumes of data handled, including over 900 Kafka topics ingesting 10TB of data daily, 300+ online database tables in Hadoop totaling 8TB, and a 186TB Teradata data warehouse. Automic tools help schedule external, Hadoop, and Teradata ETL jobs.


























![[Webinar] Modern Network Compliance: How to Get Proactive with Compliance Val...](https://cdn.slidesharecdn.com/ss_thumbnails/2021oct26-modernnetworkcomplianceseries4-final-211026213803-thumbnail.jpg?width=640&height=640&fit=bounds)





































































