



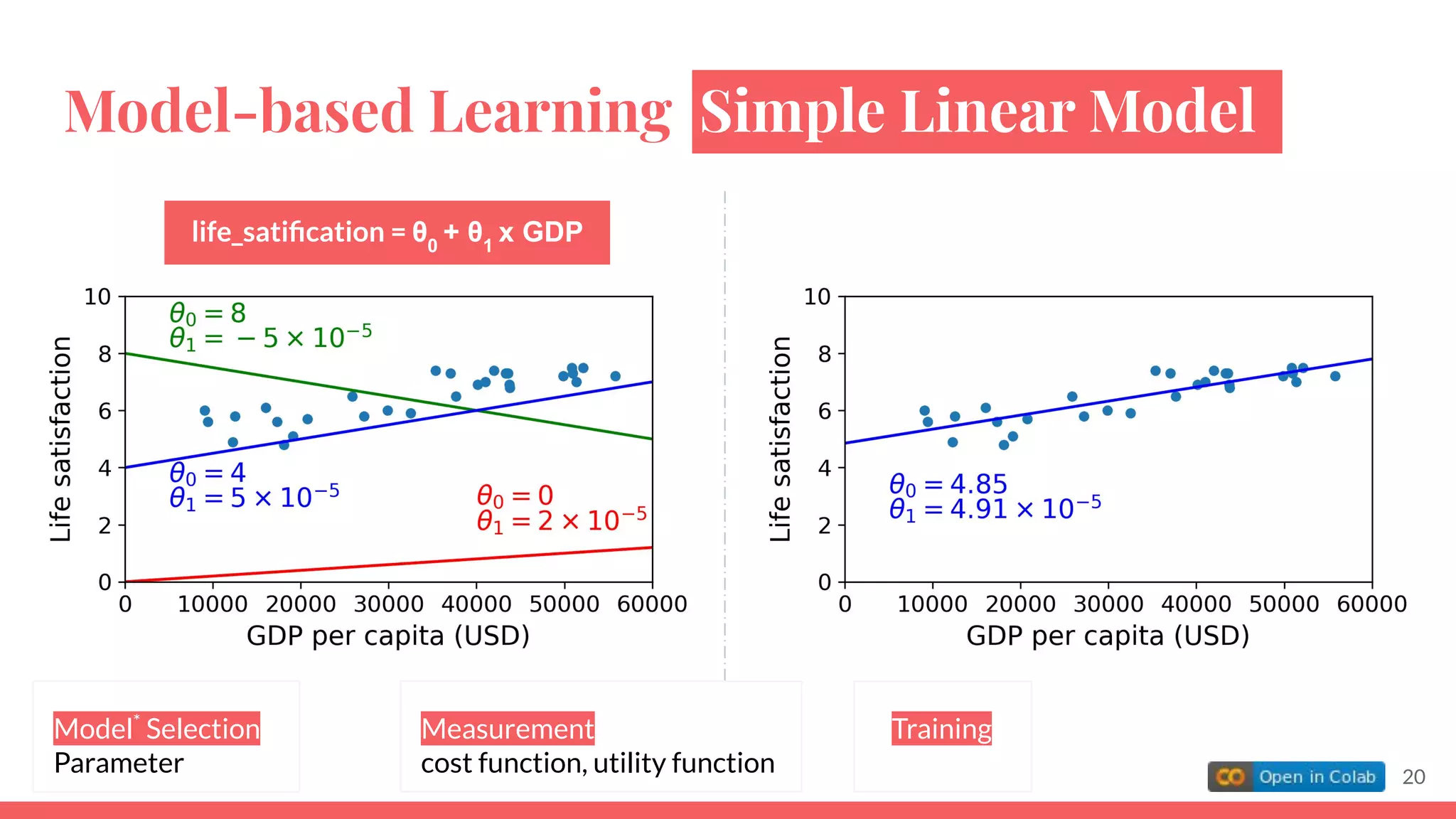











![import numpy as np
import pandas as pd
import sklearn.linear_model # import sklearn.neighbors
# Load the data
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='t', encoding='latin1',
na_values="n/a")
# Prepare the data
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# Select a linear model
model = sklearn.linear_model.LinearRegression() # model = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[22587]] # Cyprus' GDP per capita
print(model.predict(X_new)) # outputs [[ 5.96242338]]
Train a linear model using Scikit-Learn
43](https://image.slidesharecdn.com/handson-ml-ch1-210721104434/75/Hands-on-ML-CH1-43-2048.jpg)













































![import numpy as np
import pandas as pd
import sklearn.linear_model # import sklearn.neighbors
# Load the data
oecd_bli = pd.read_csv(datapath + "oecd_bli_2015.csv", thousands=',')
gdp_per_capita = pd.read_csv(datapath + "gdp_per_capita.csv",thousands=',',delimiter='t', encoding='latin1',
na_values="n/a")
# Prepare the data
country_stats = prepare_country_stats(oecd_bli, gdp_per_capita)
X = np.c_[country_stats["GDP per capita"]]
y = np.c_[country_stats["Life satisfaction"]]
# Select a linear model
model = sklearn.linear_model.LinearRegression() # model = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)
# Train the model
model.fit(X, y)
# Make a prediction for Cyprus
X_new = [[22587]] # Cyprus' GDP per capita
print(model.predict(X_new)) # outputs [[ 5.96242338]]
Train a linear model using Scikit-Learn
43](https://crownmelresort.com/image.slidesharecdn.com/handson-ml-ch1-210721104434/75/Hands-on-ML-CH1-43-2048.jpg)





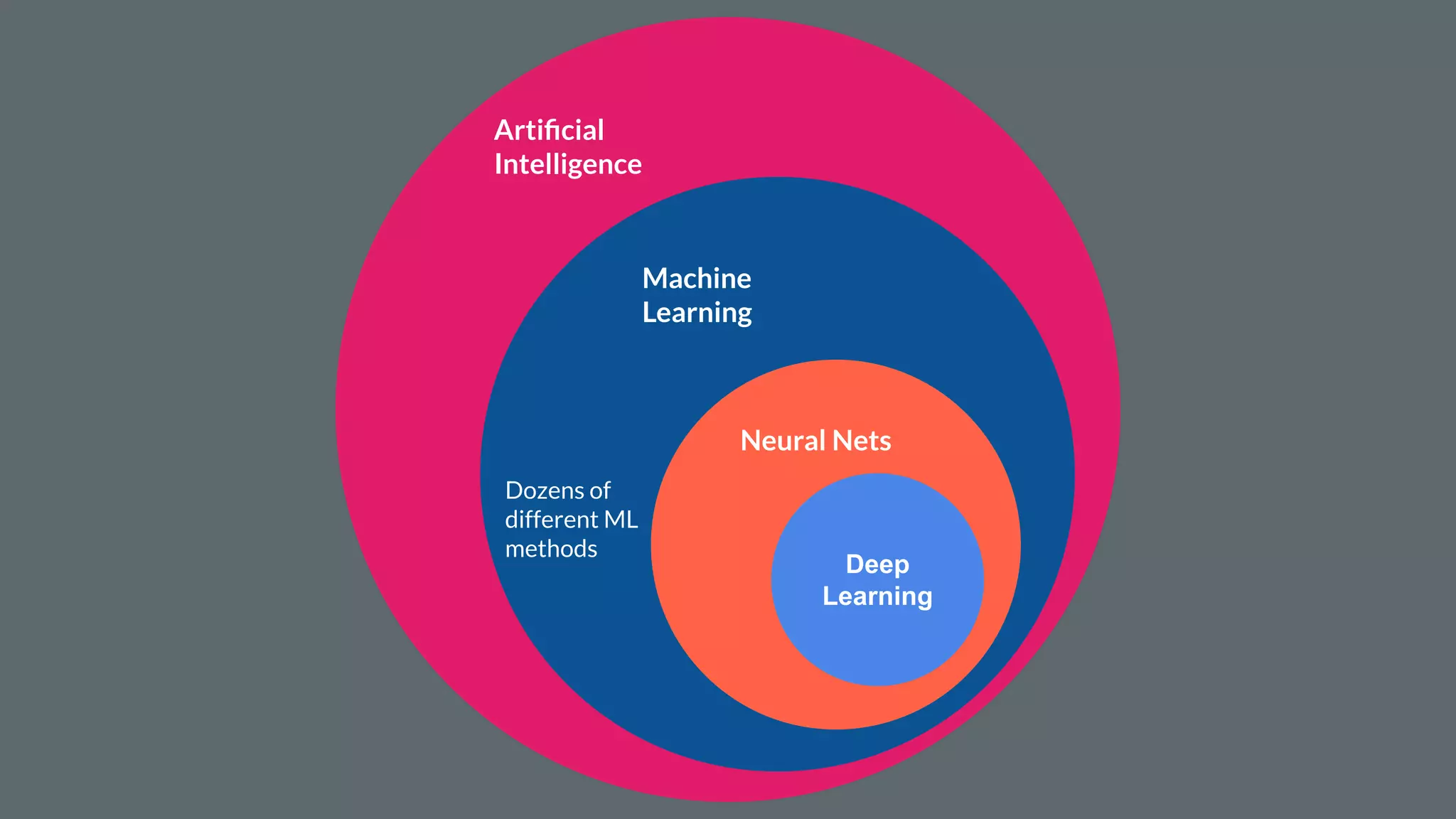
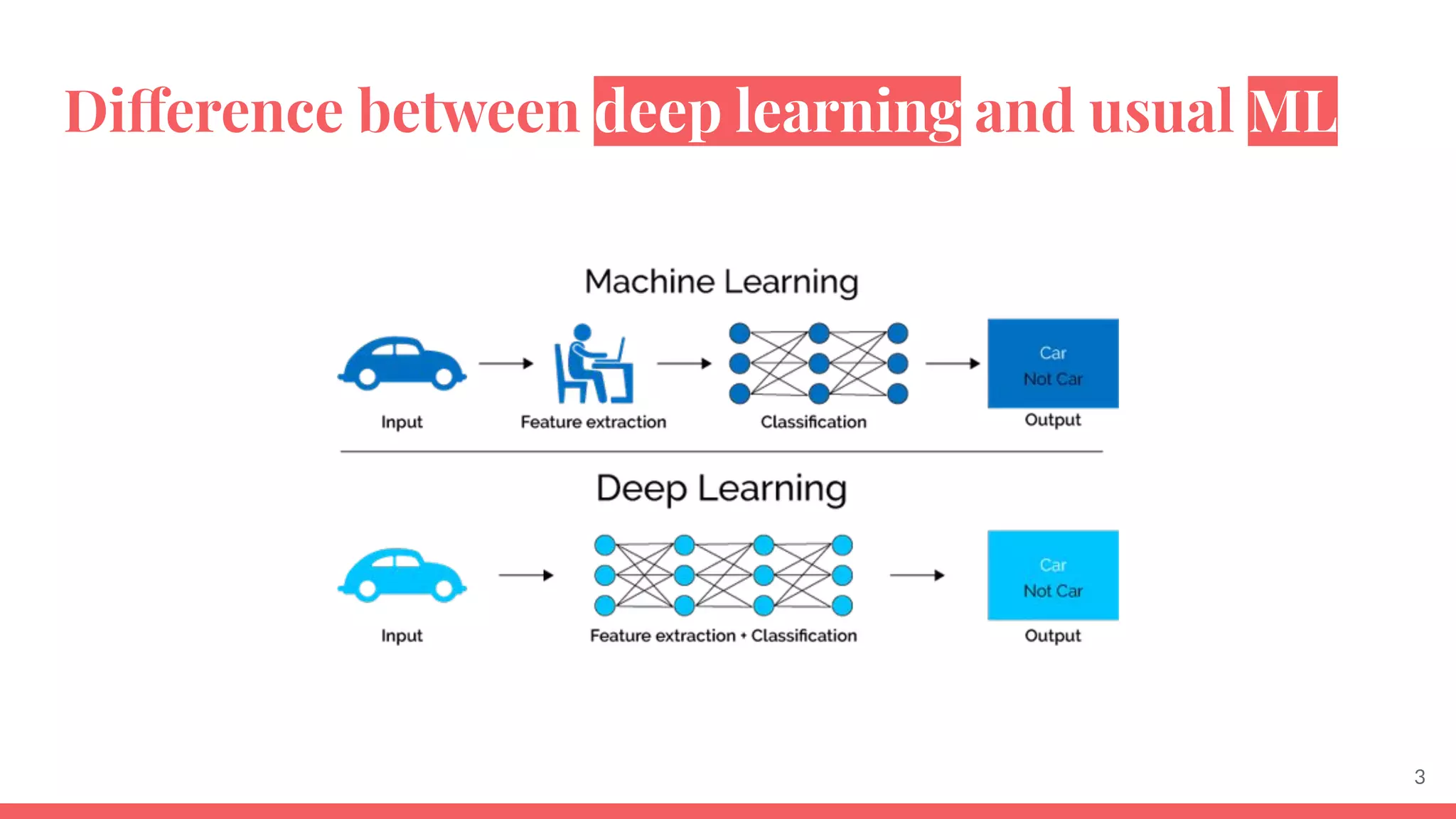
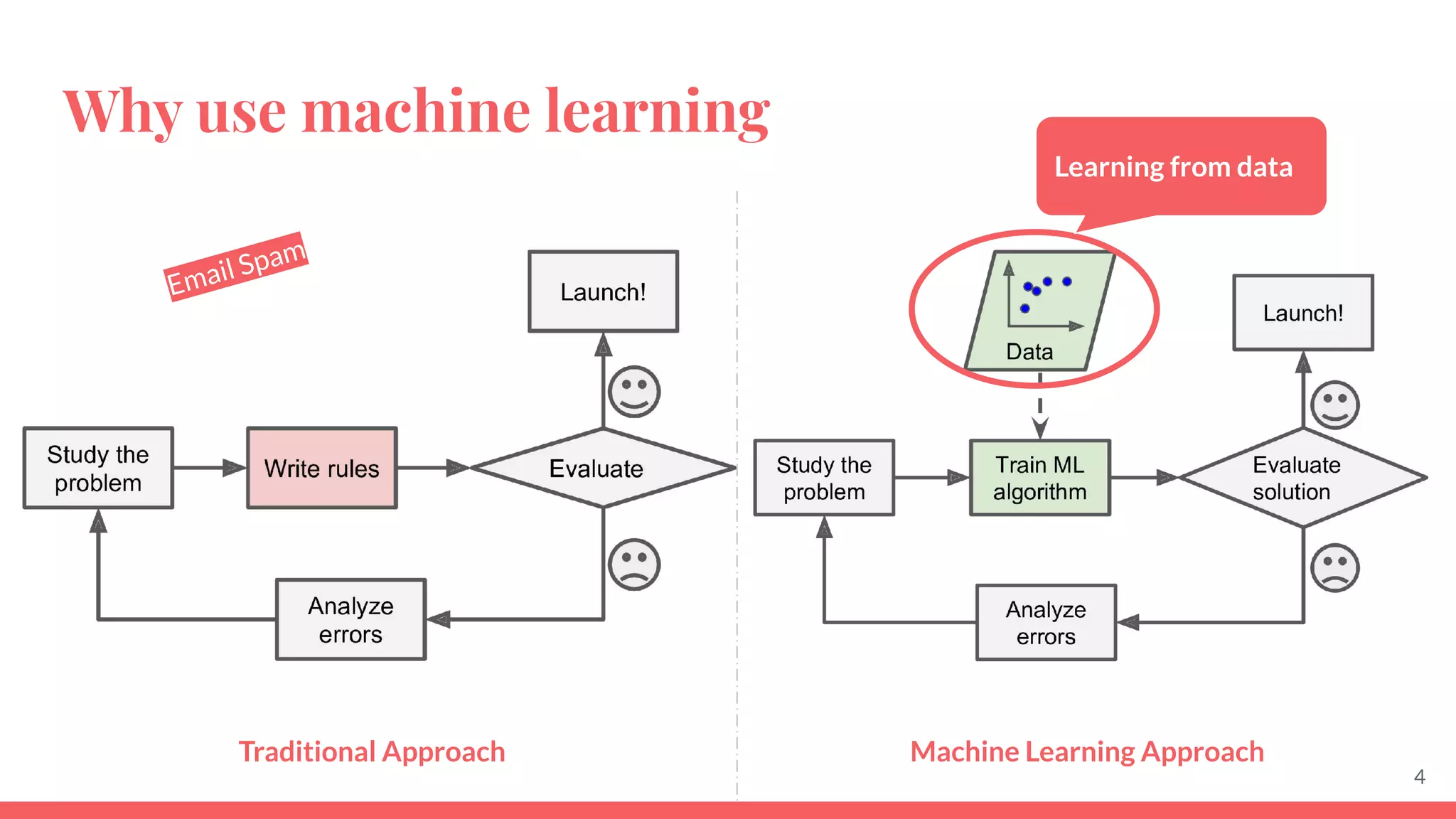
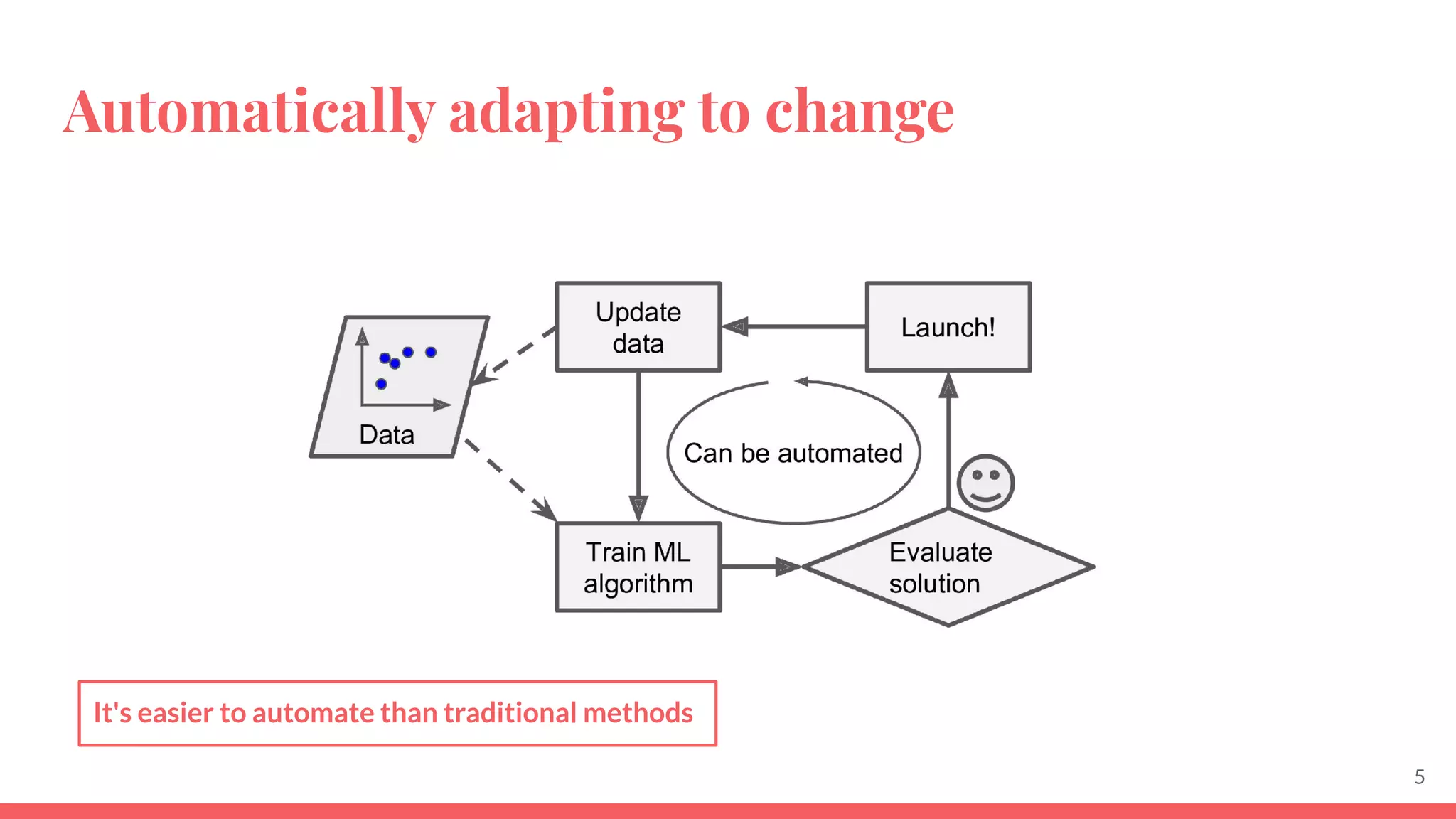
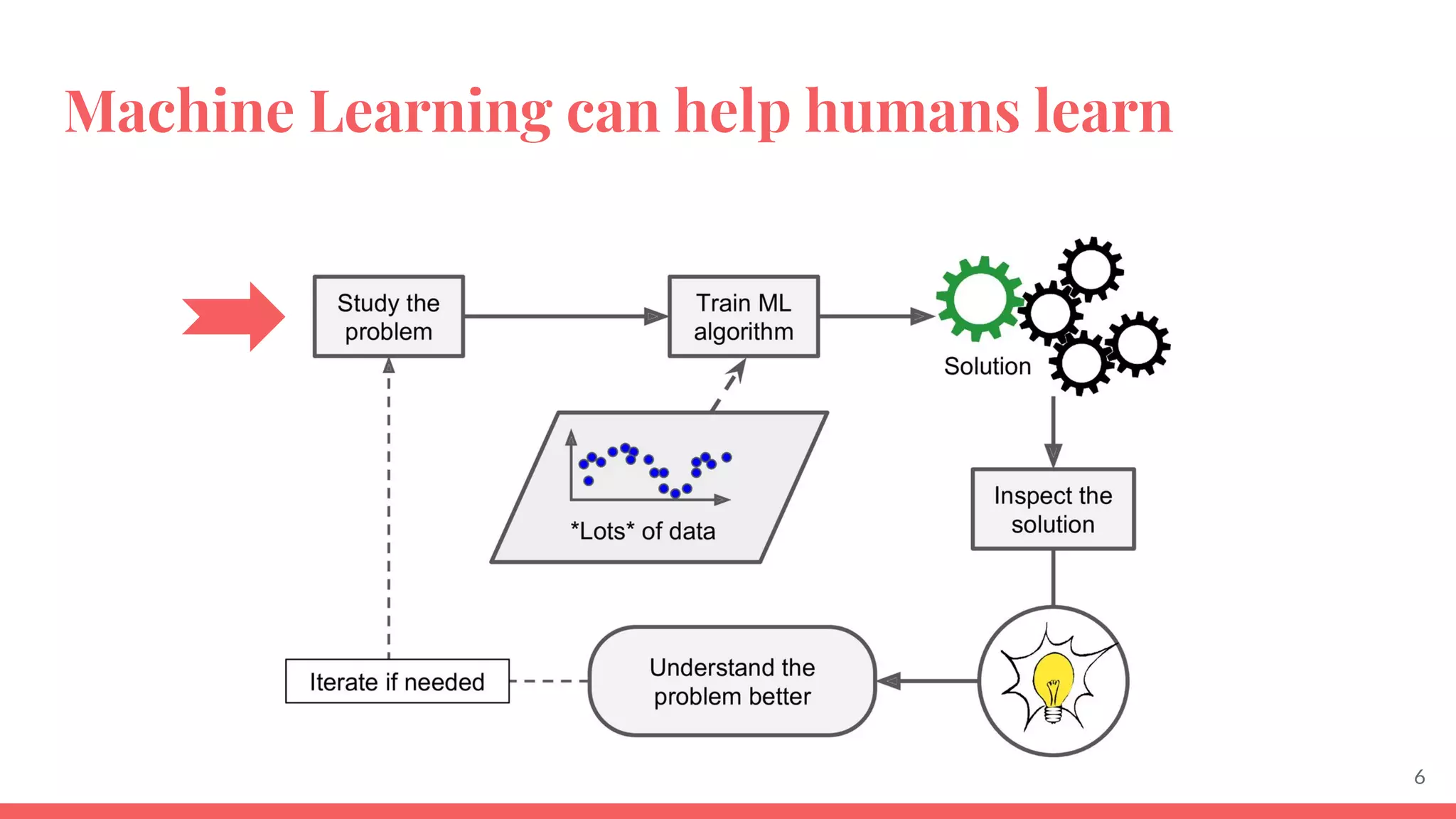
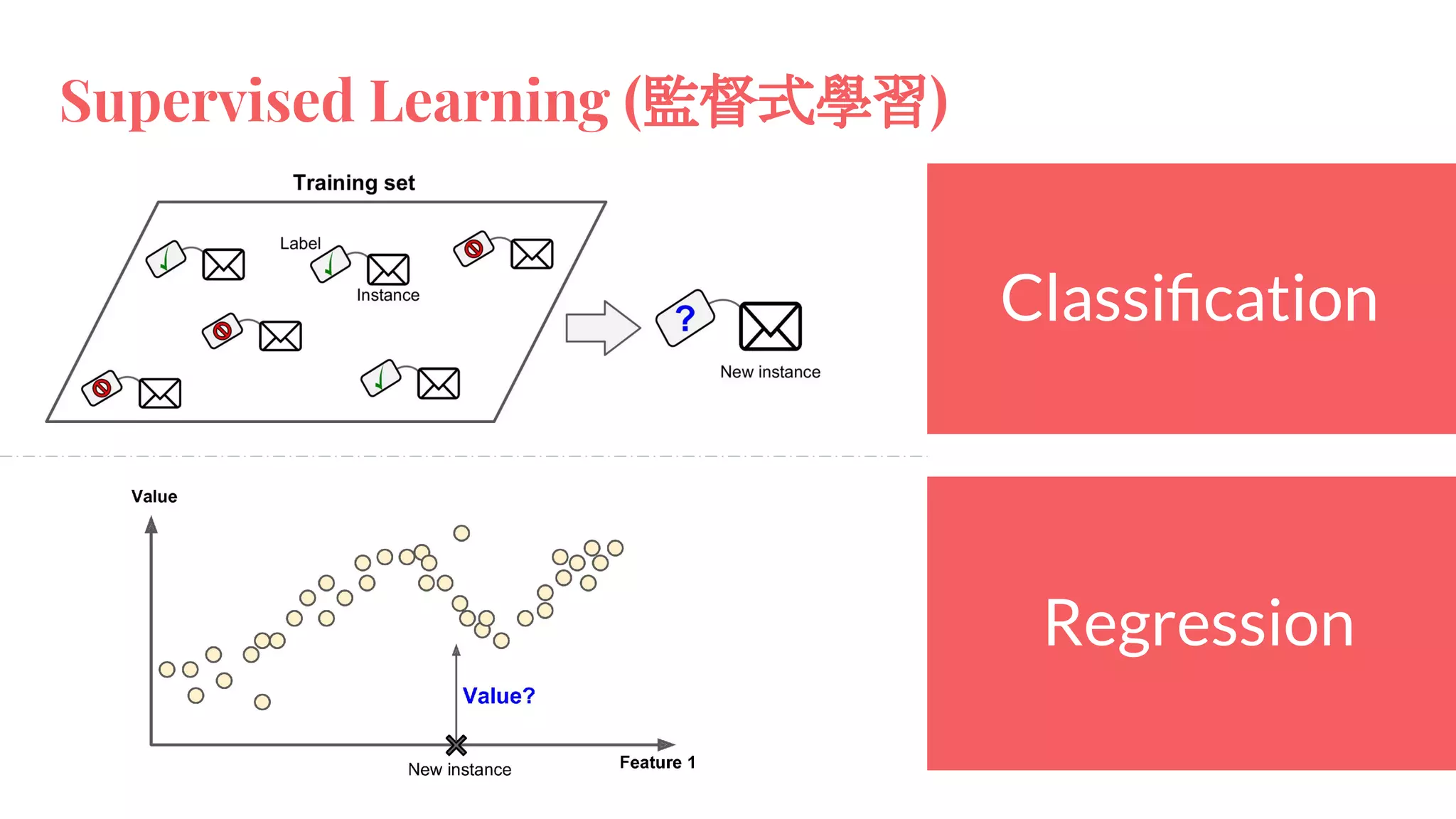
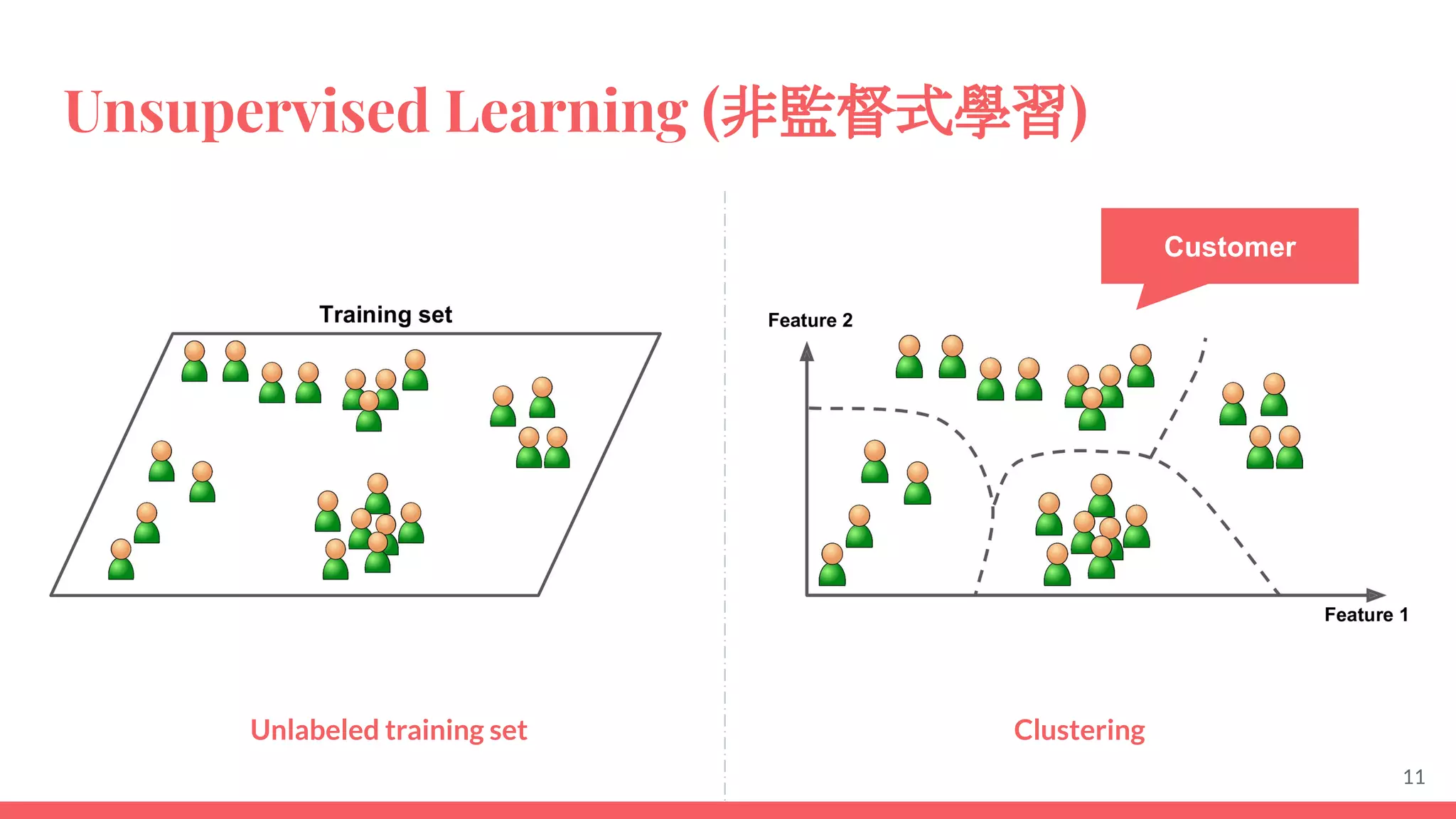
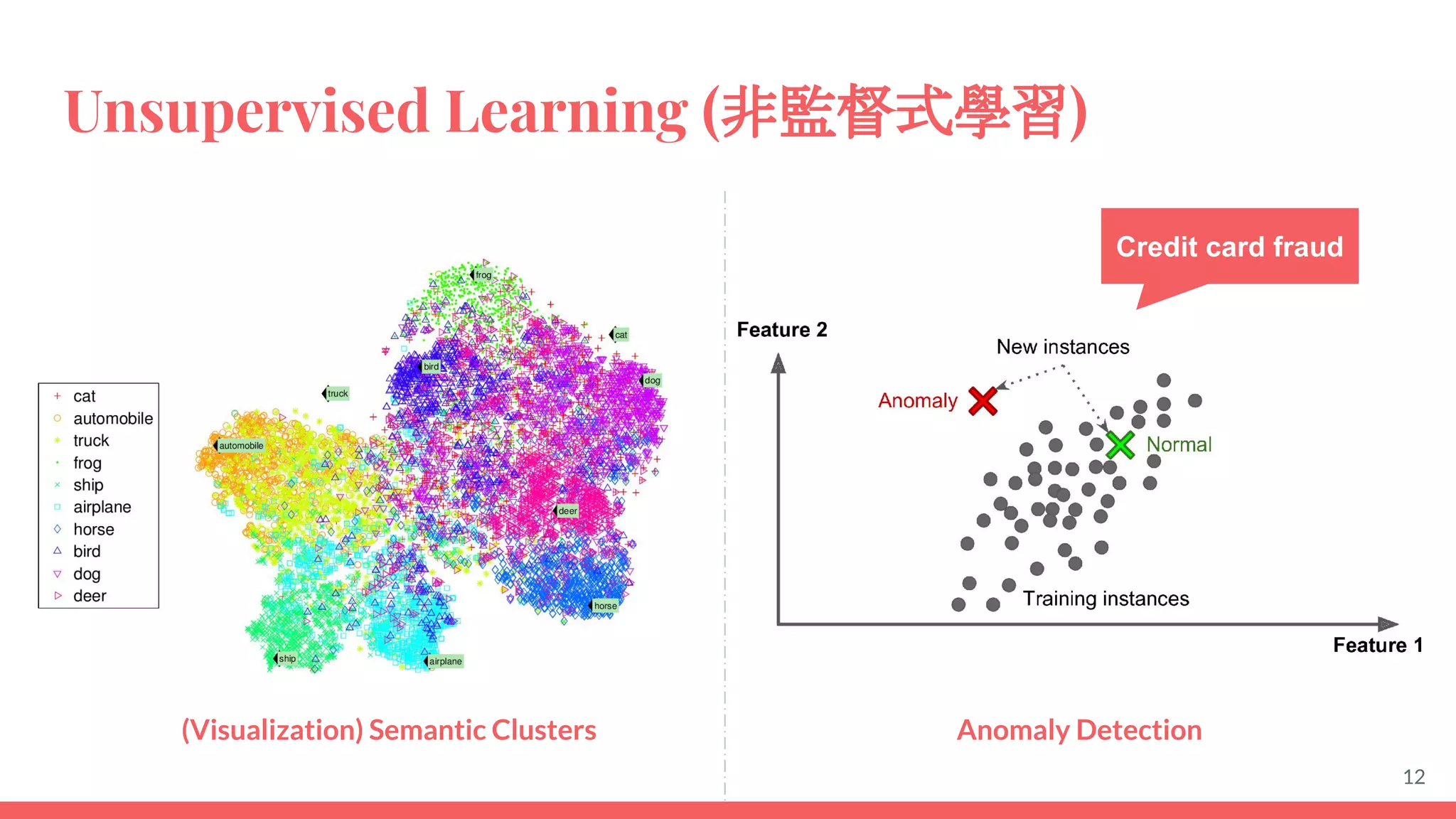
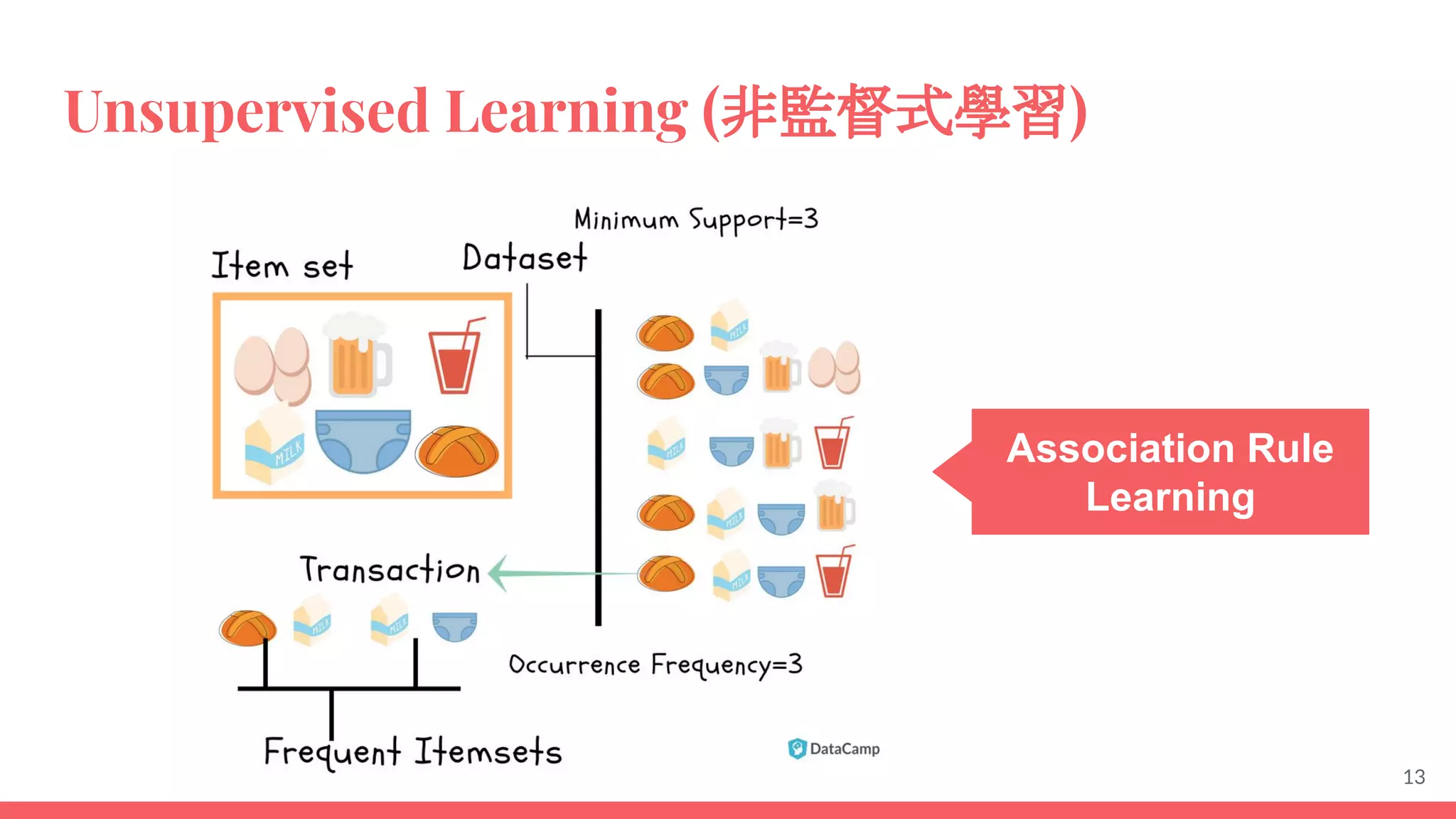
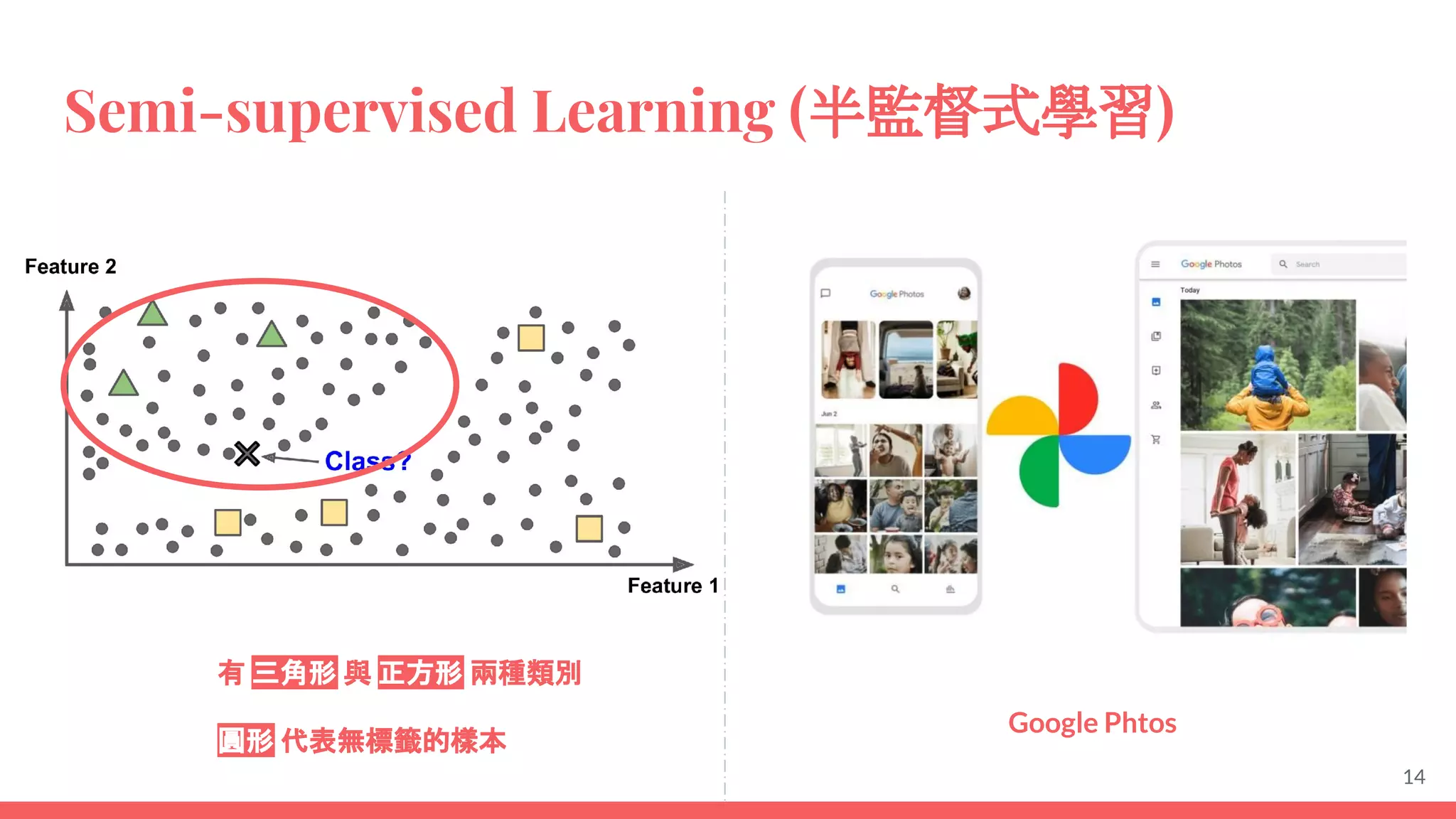
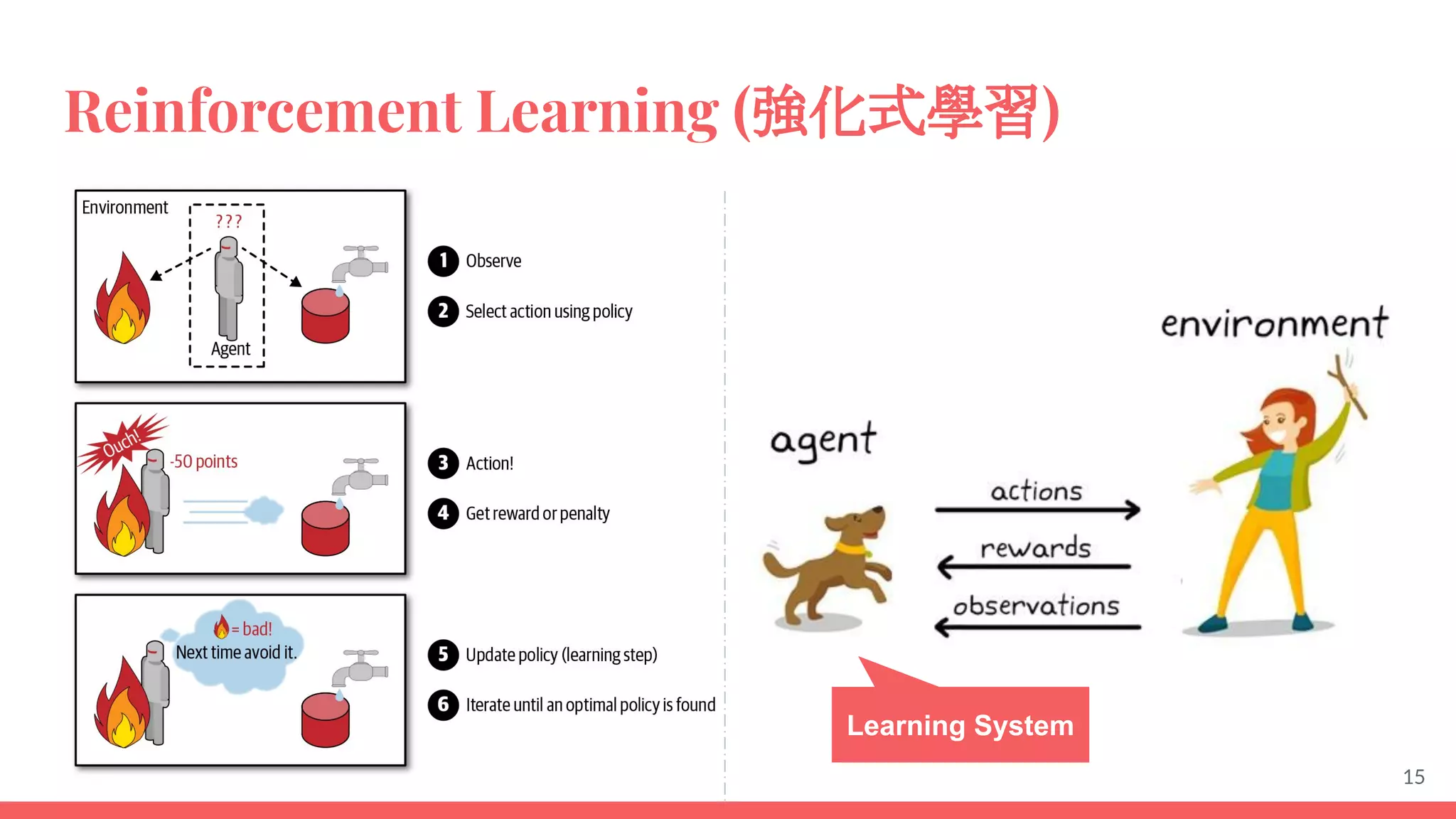
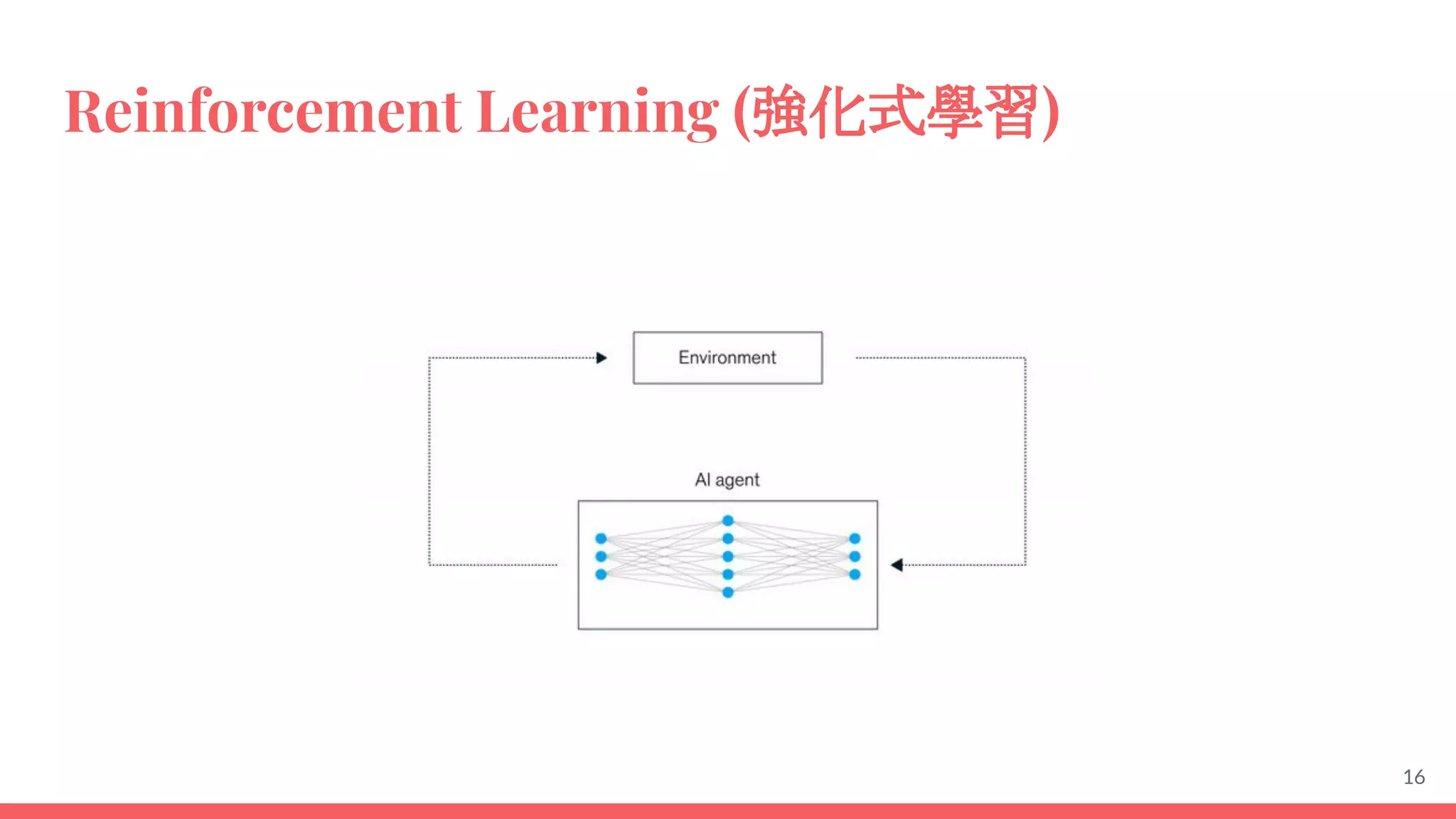
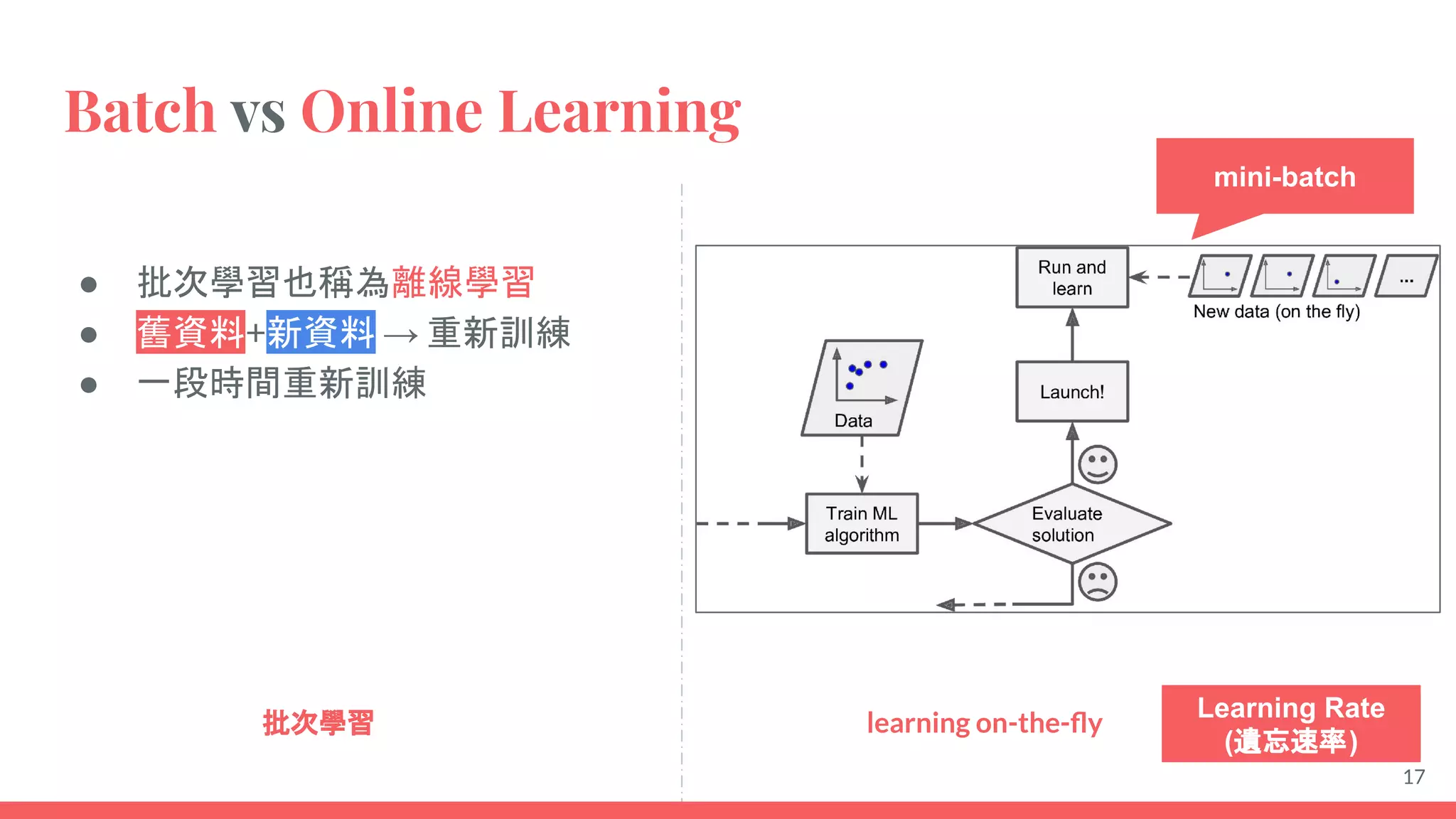
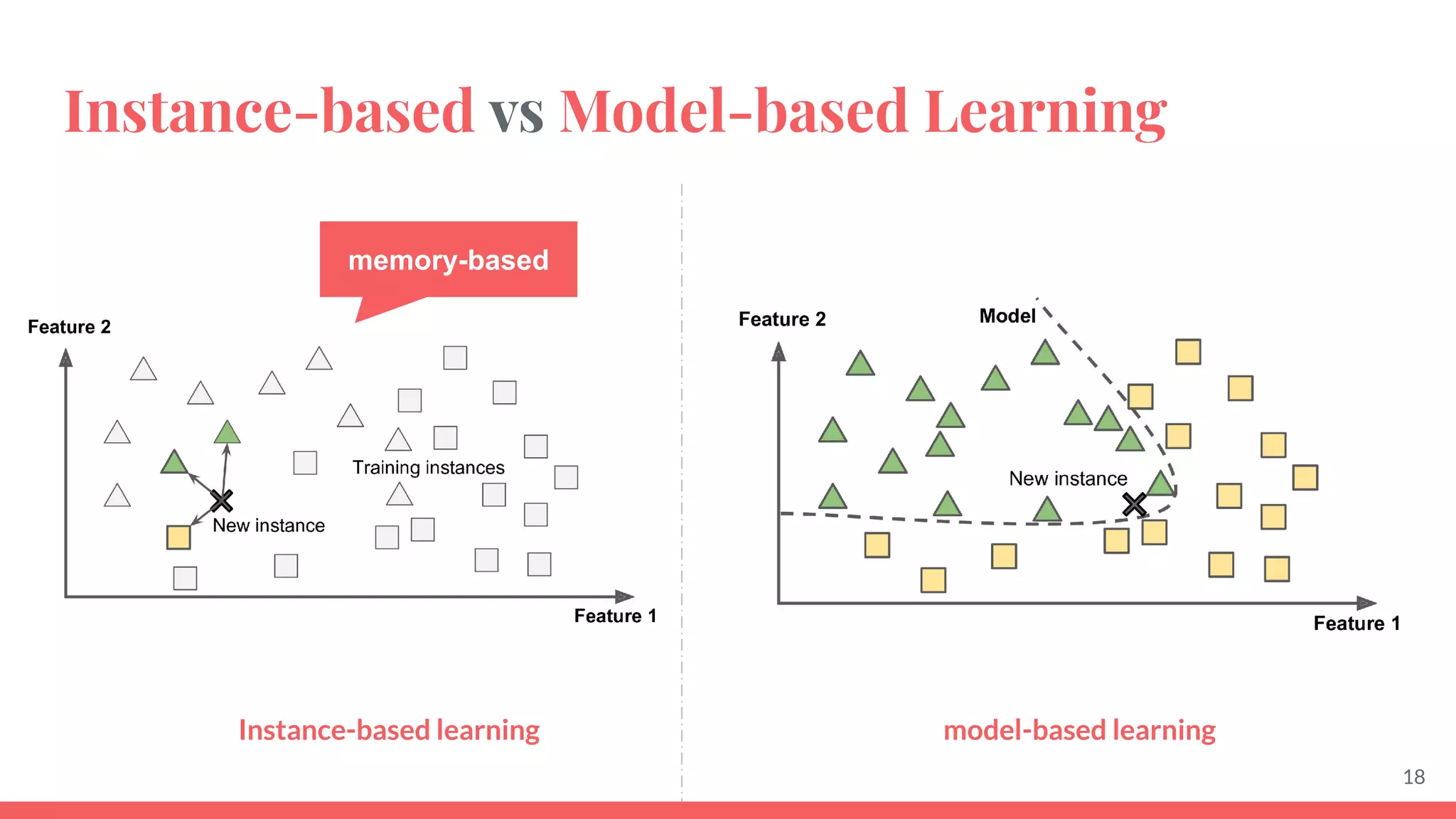
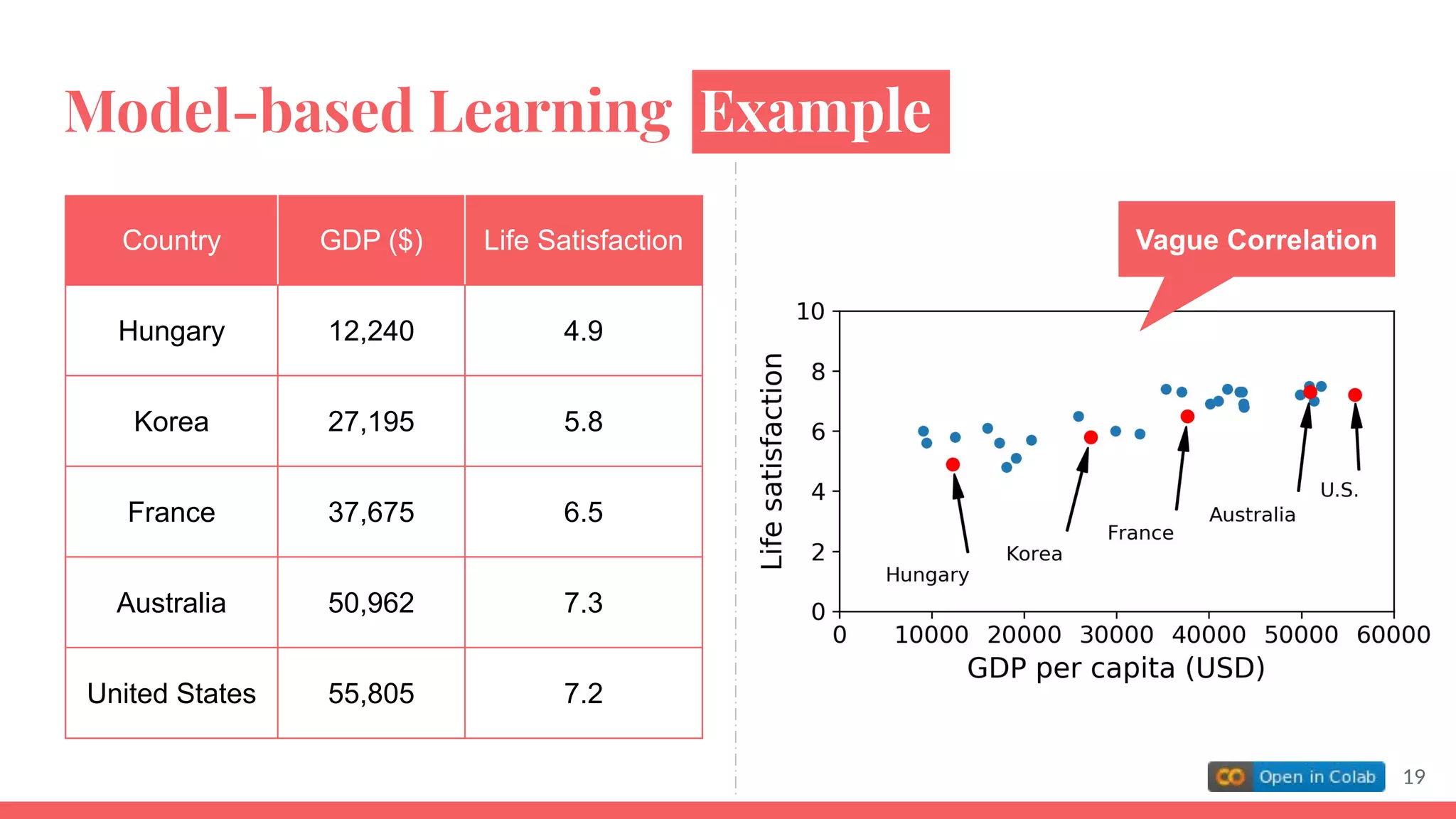
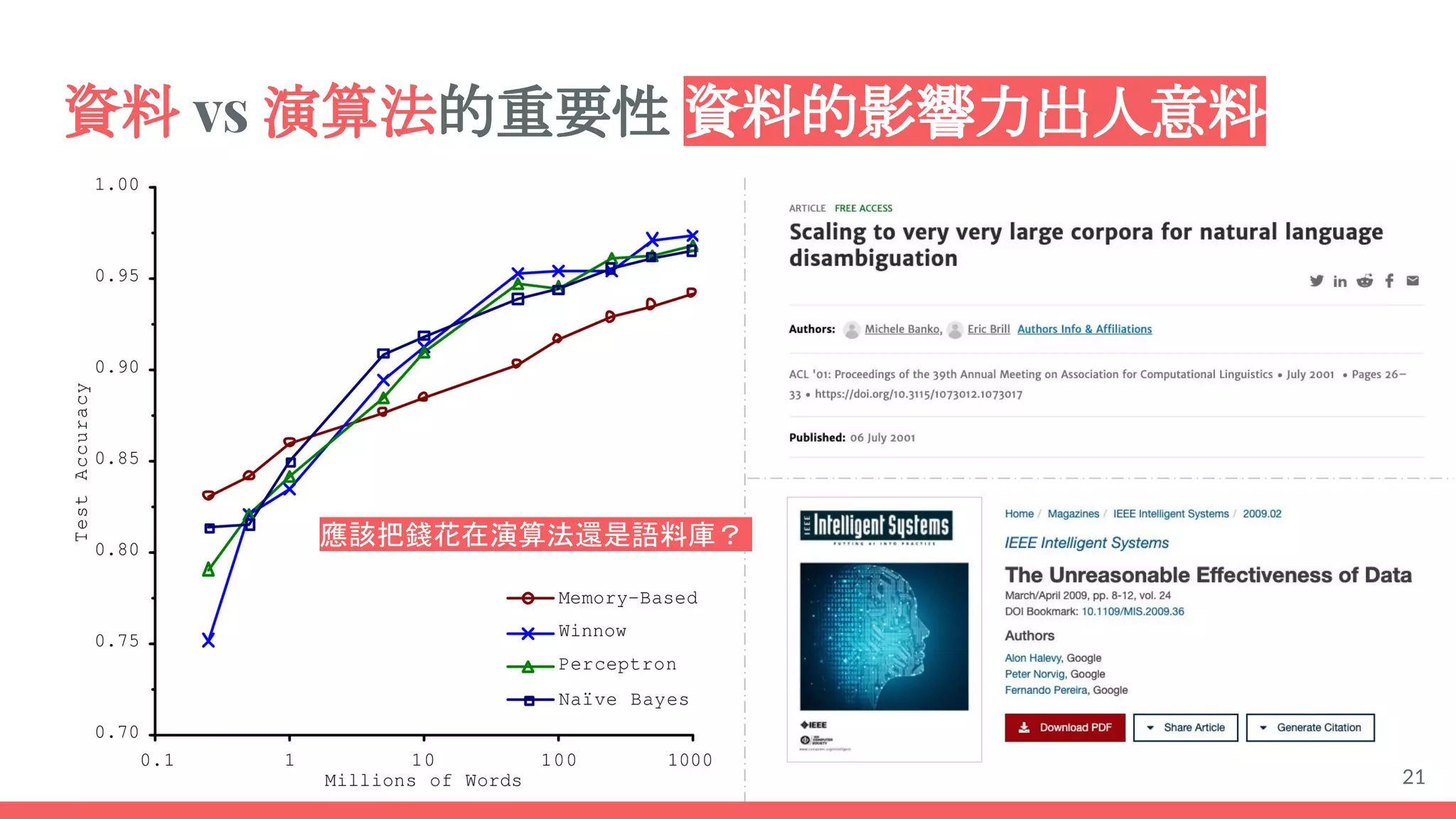
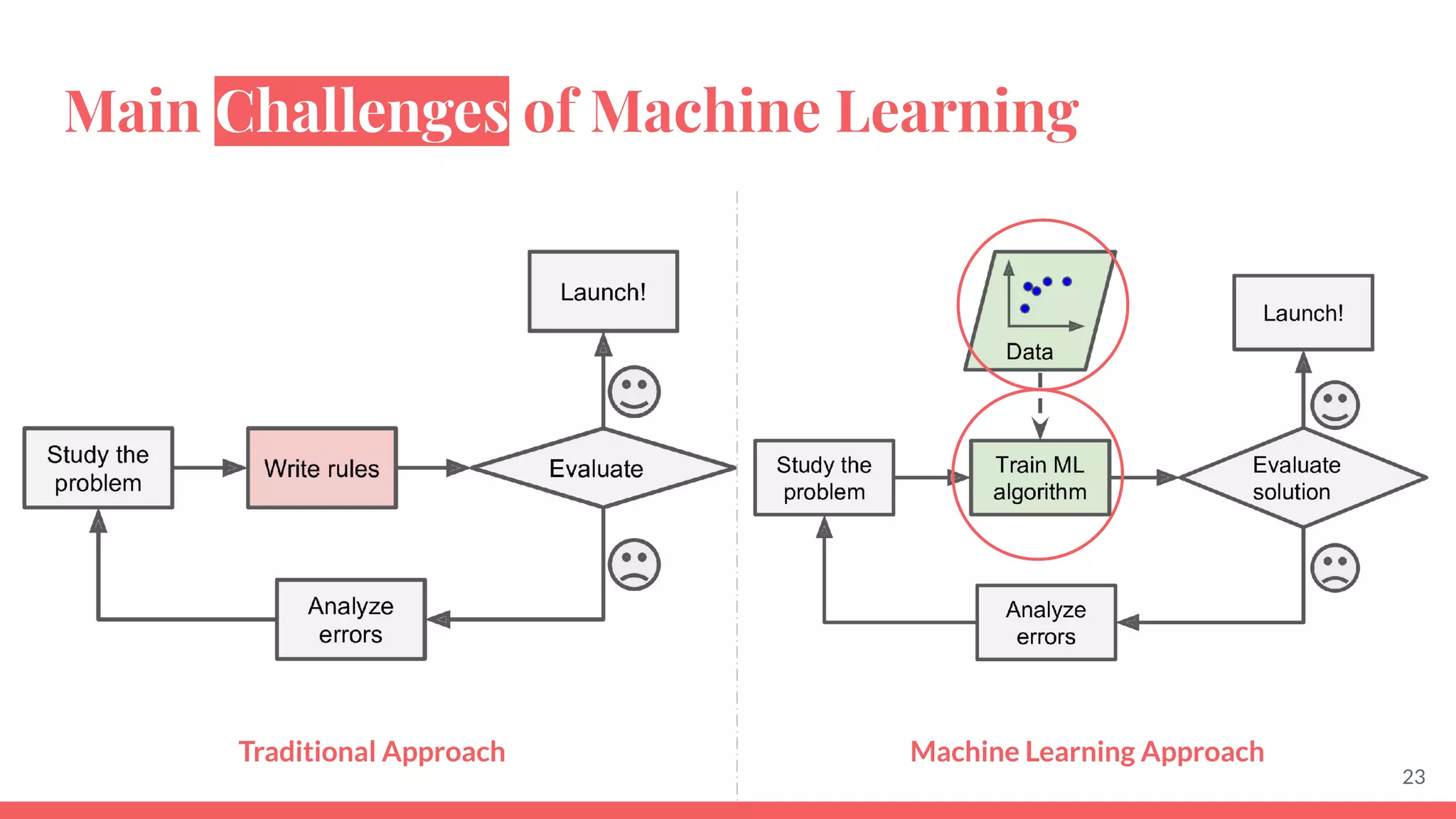
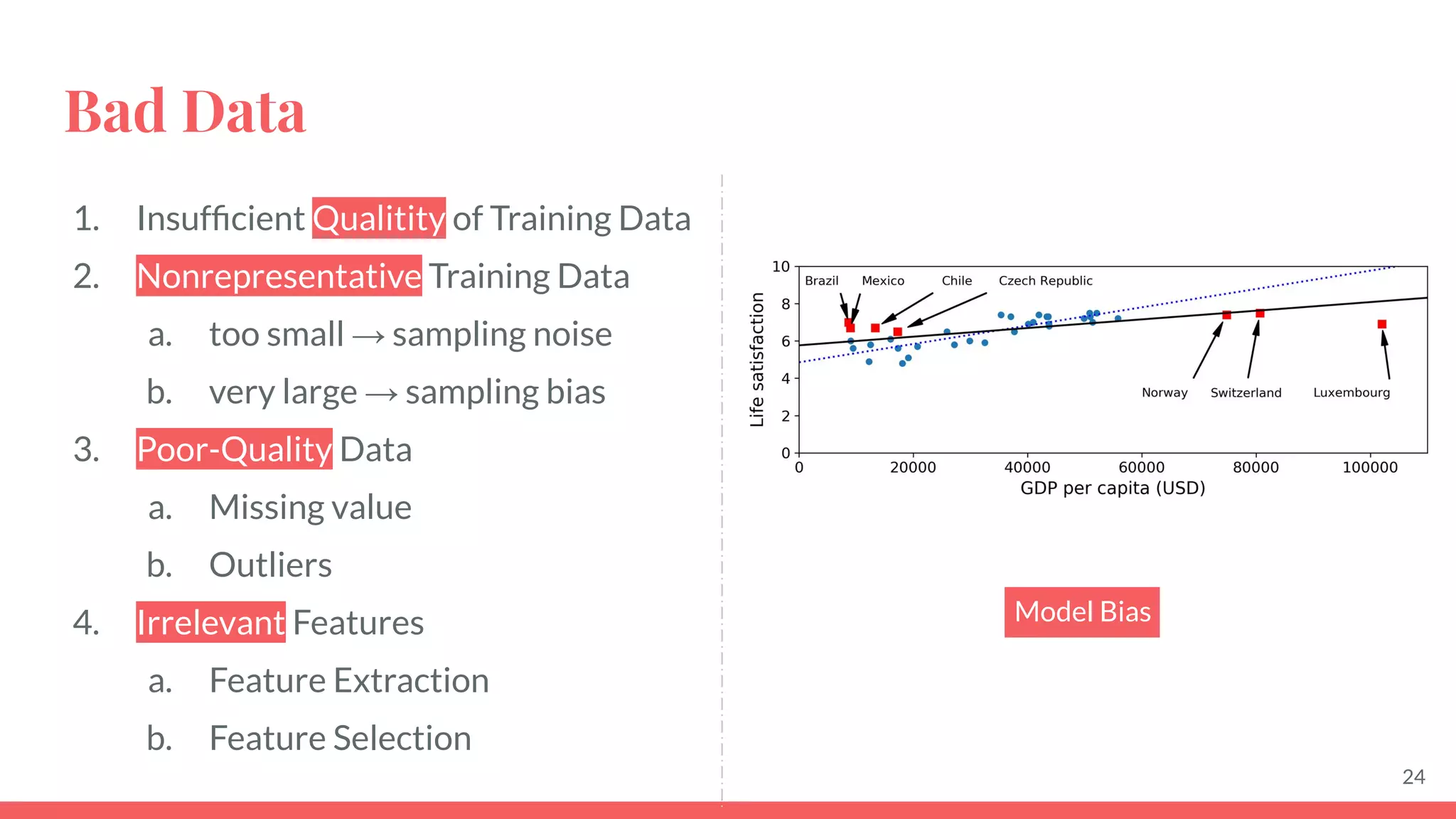
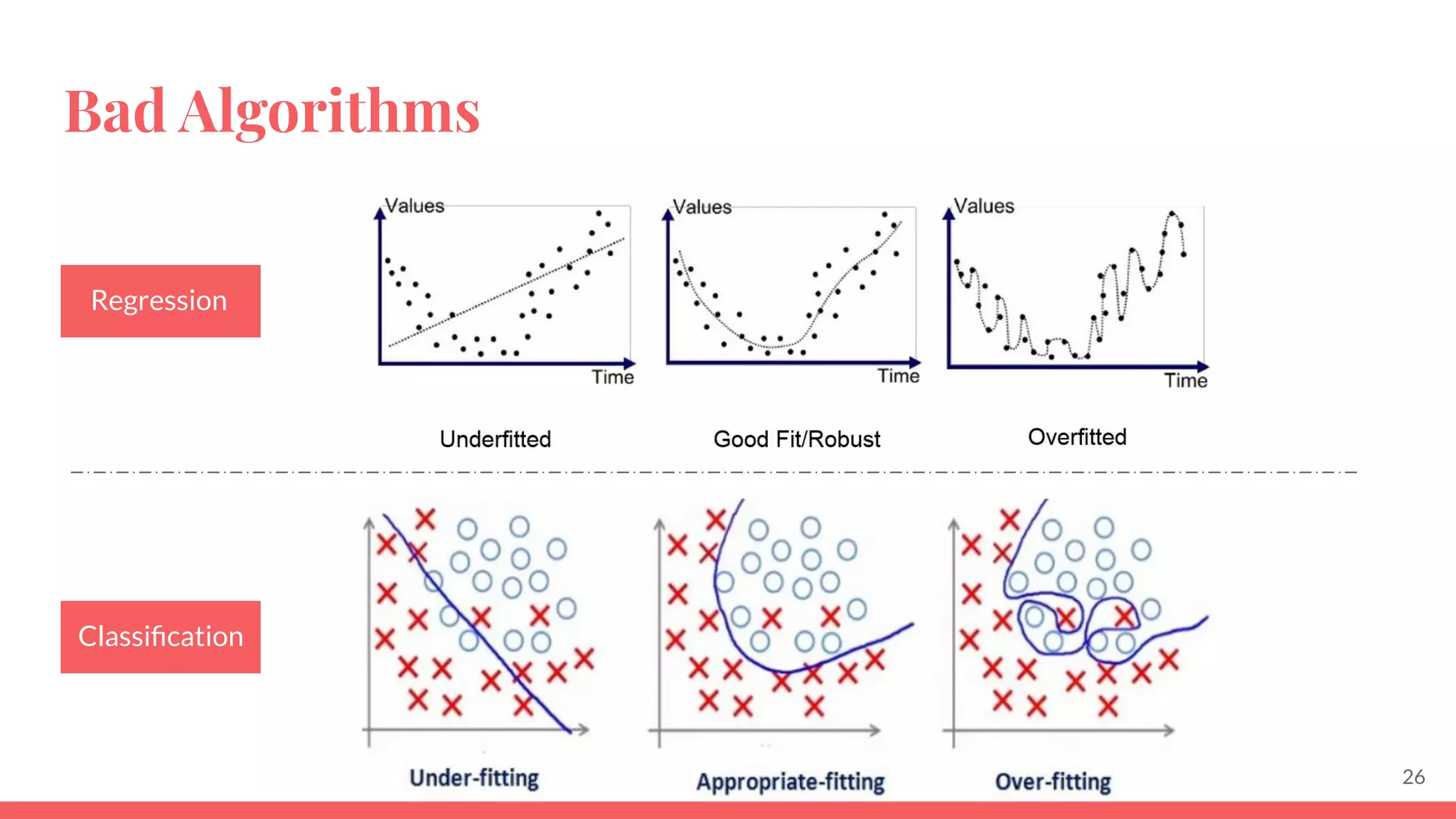
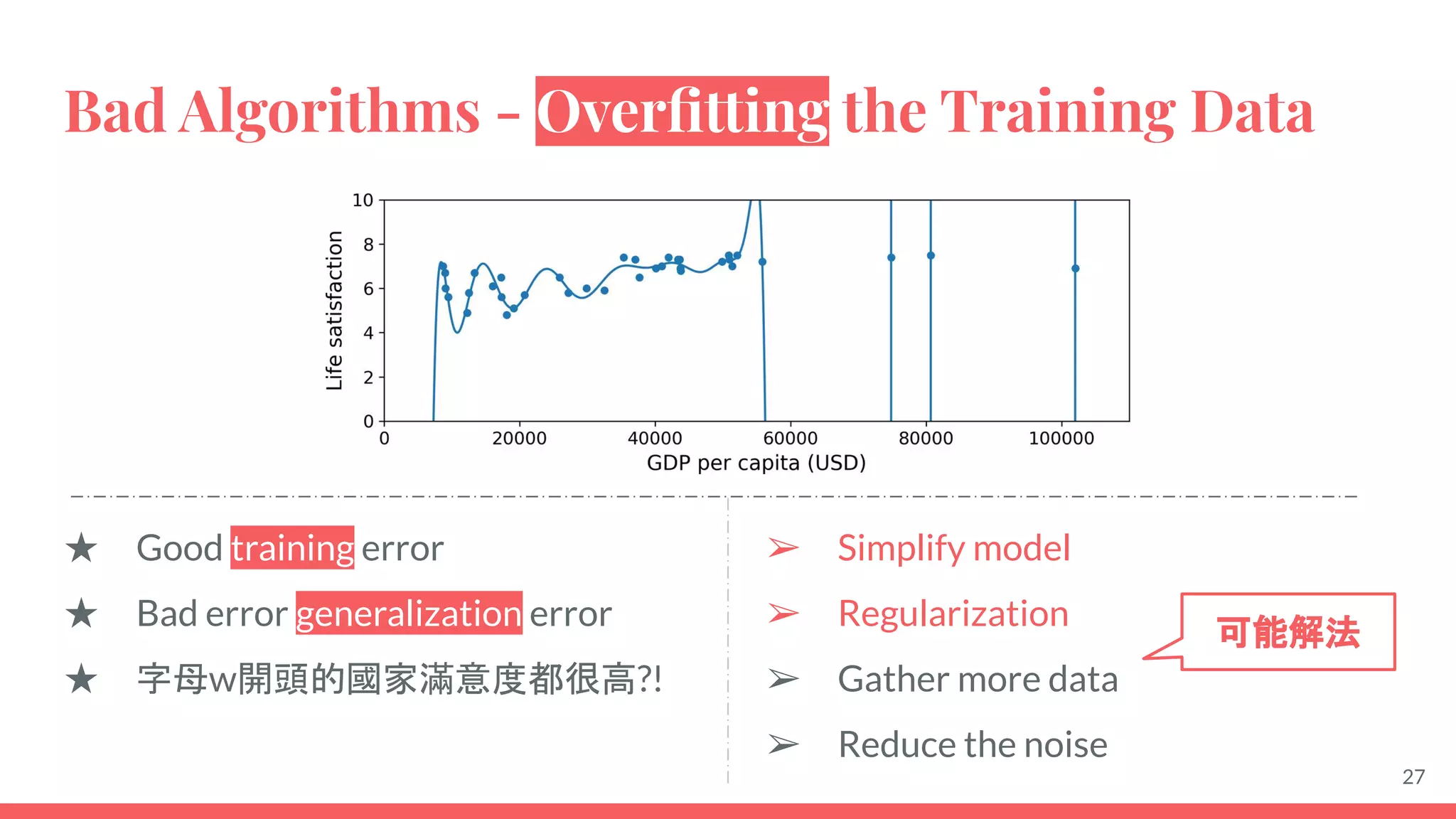
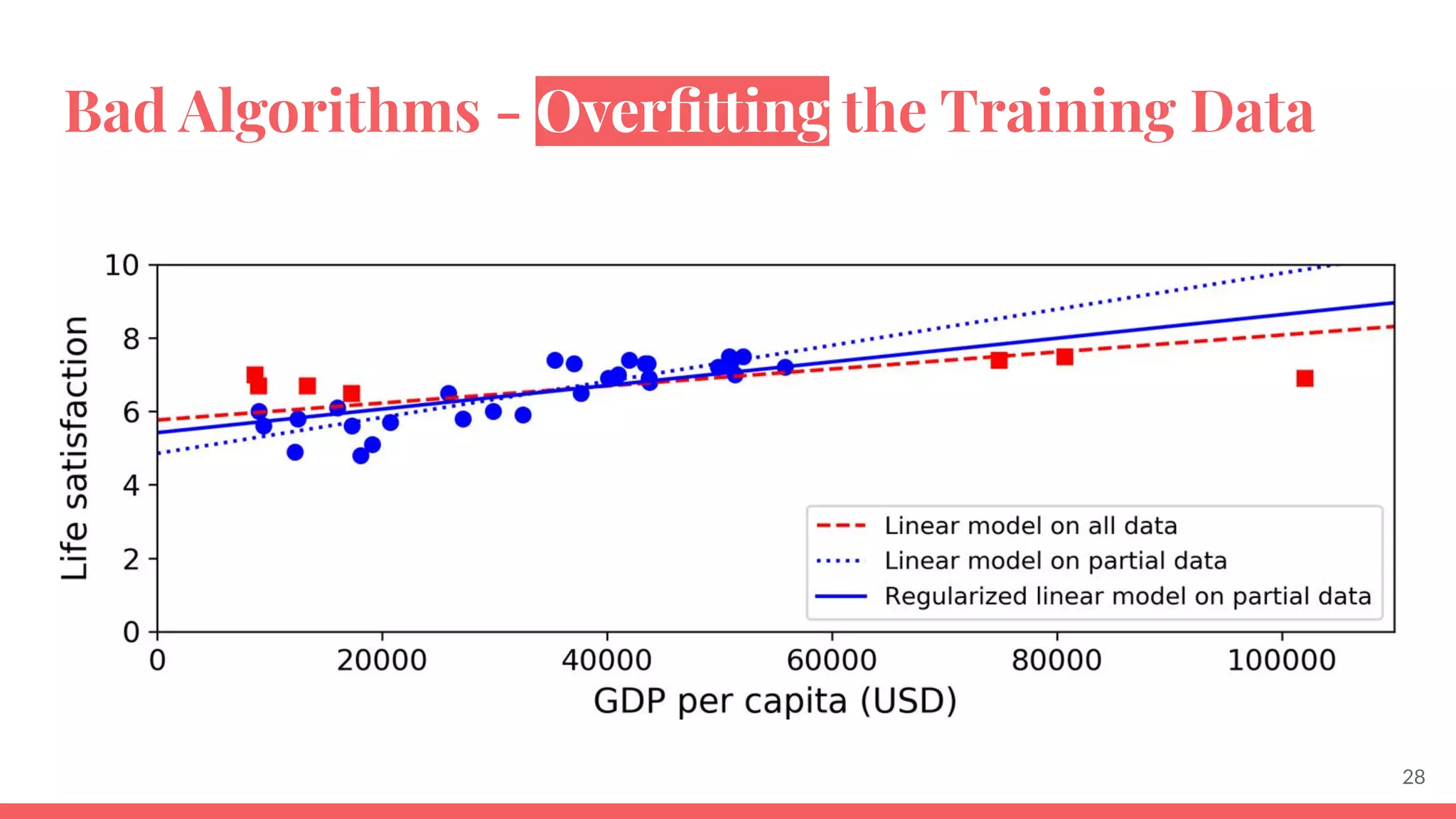
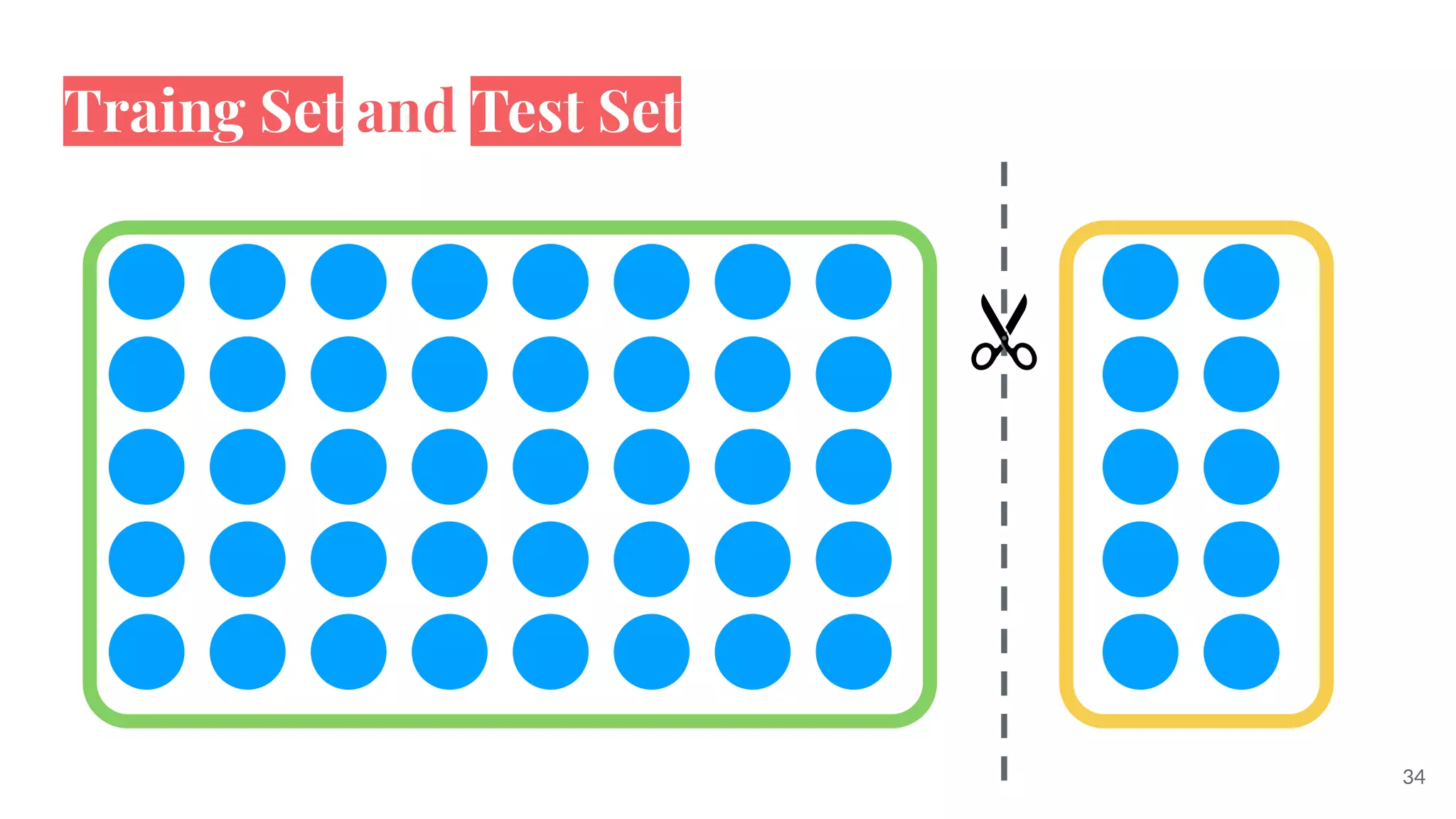
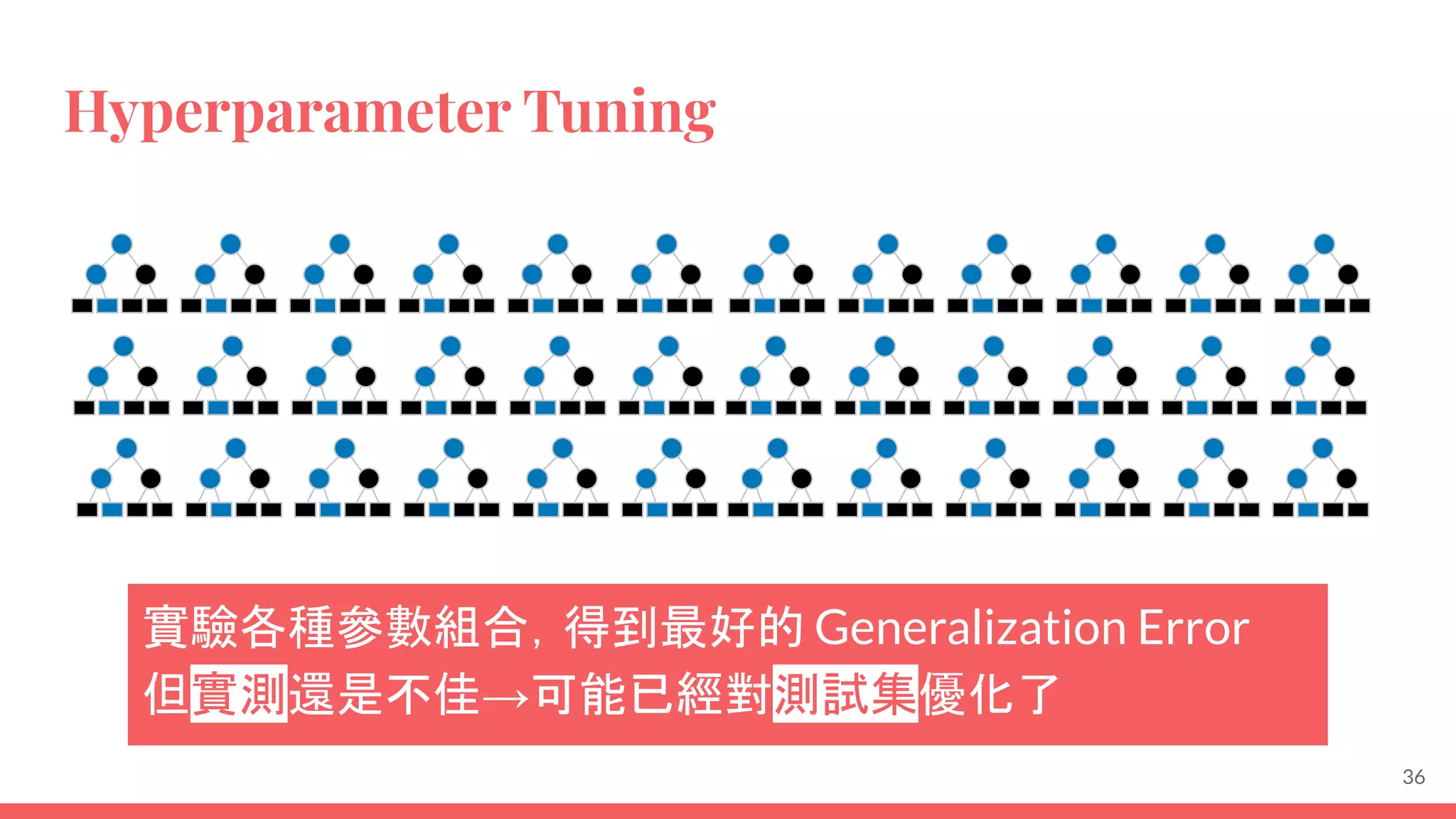
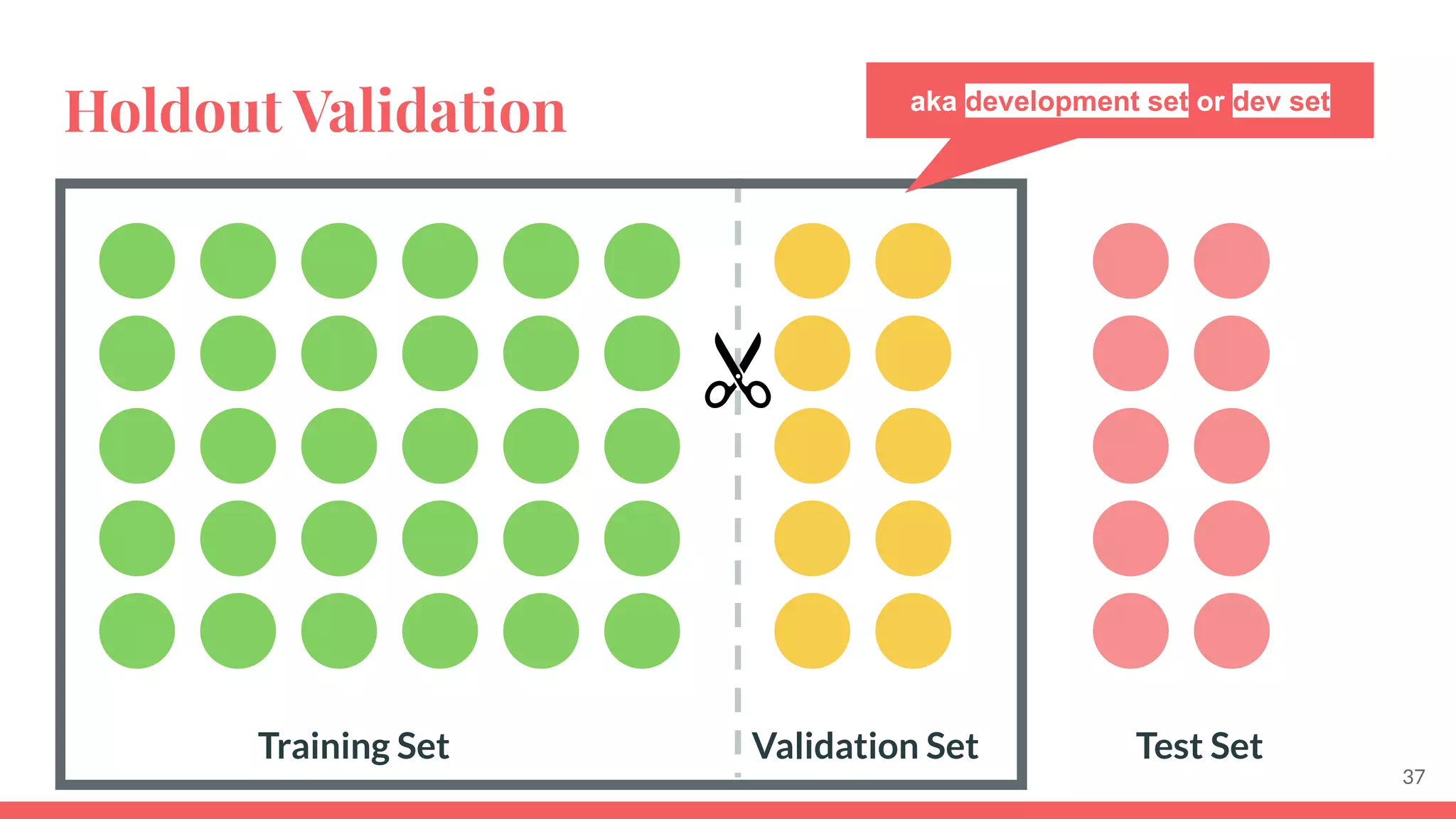
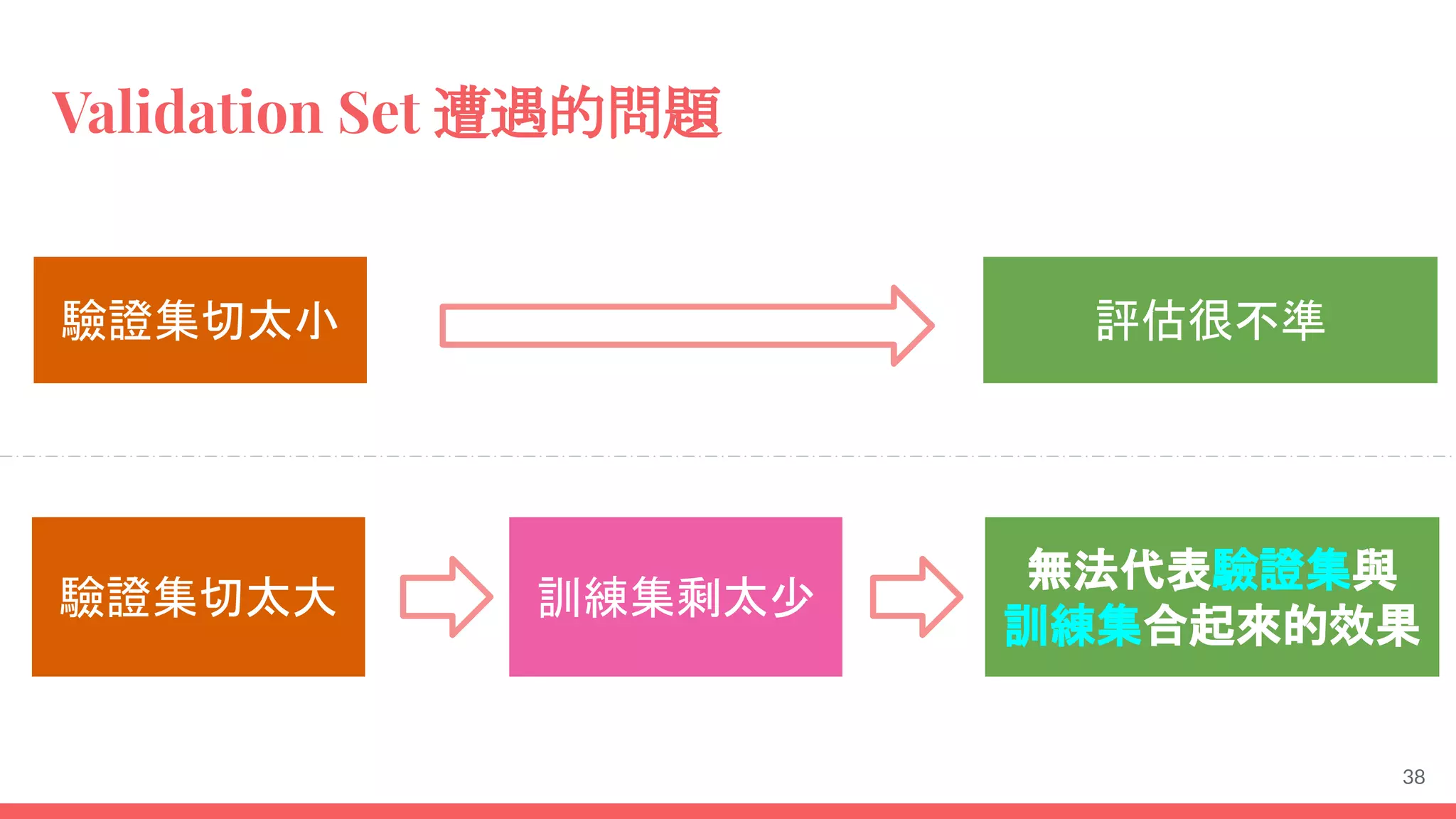
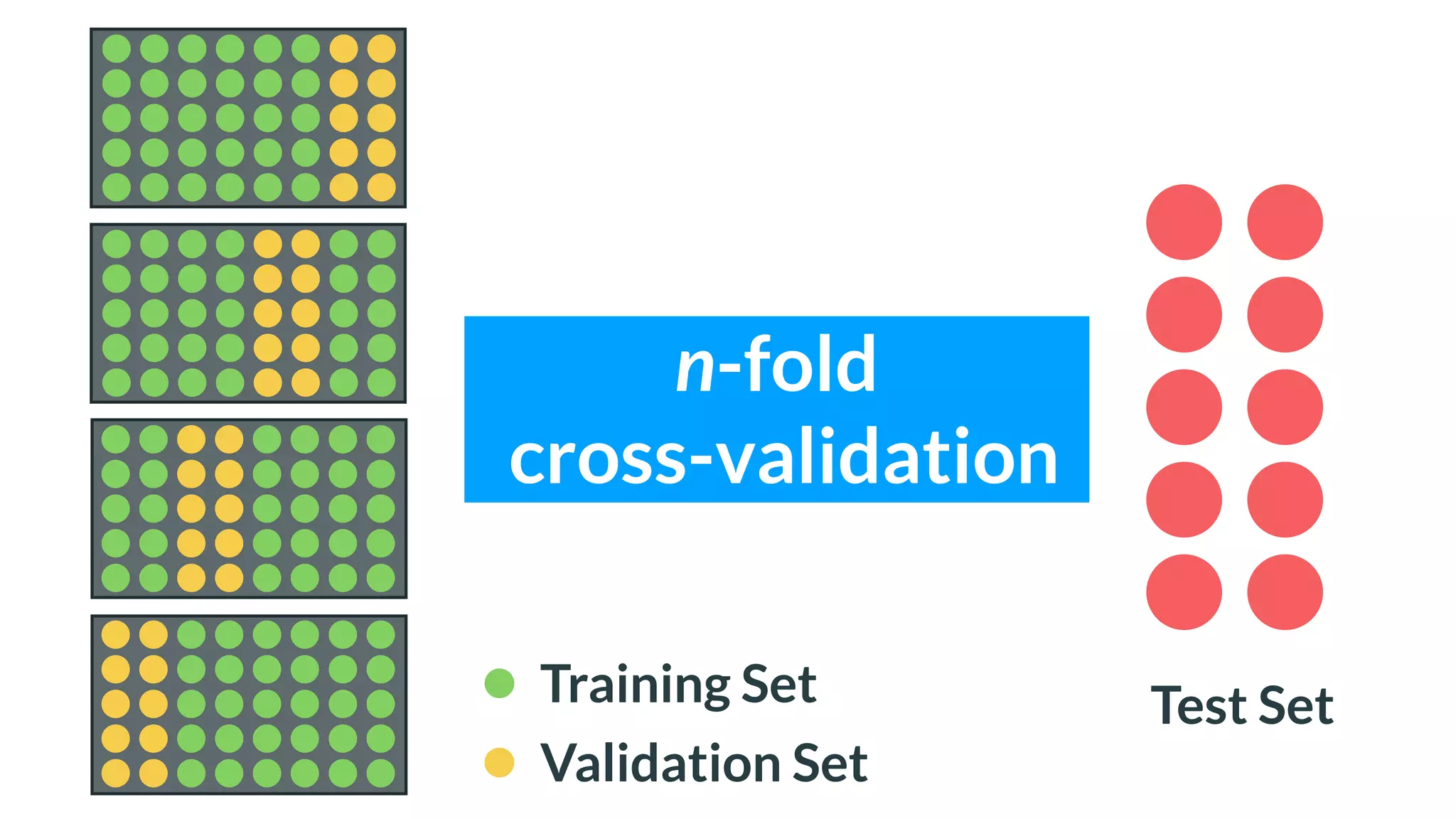
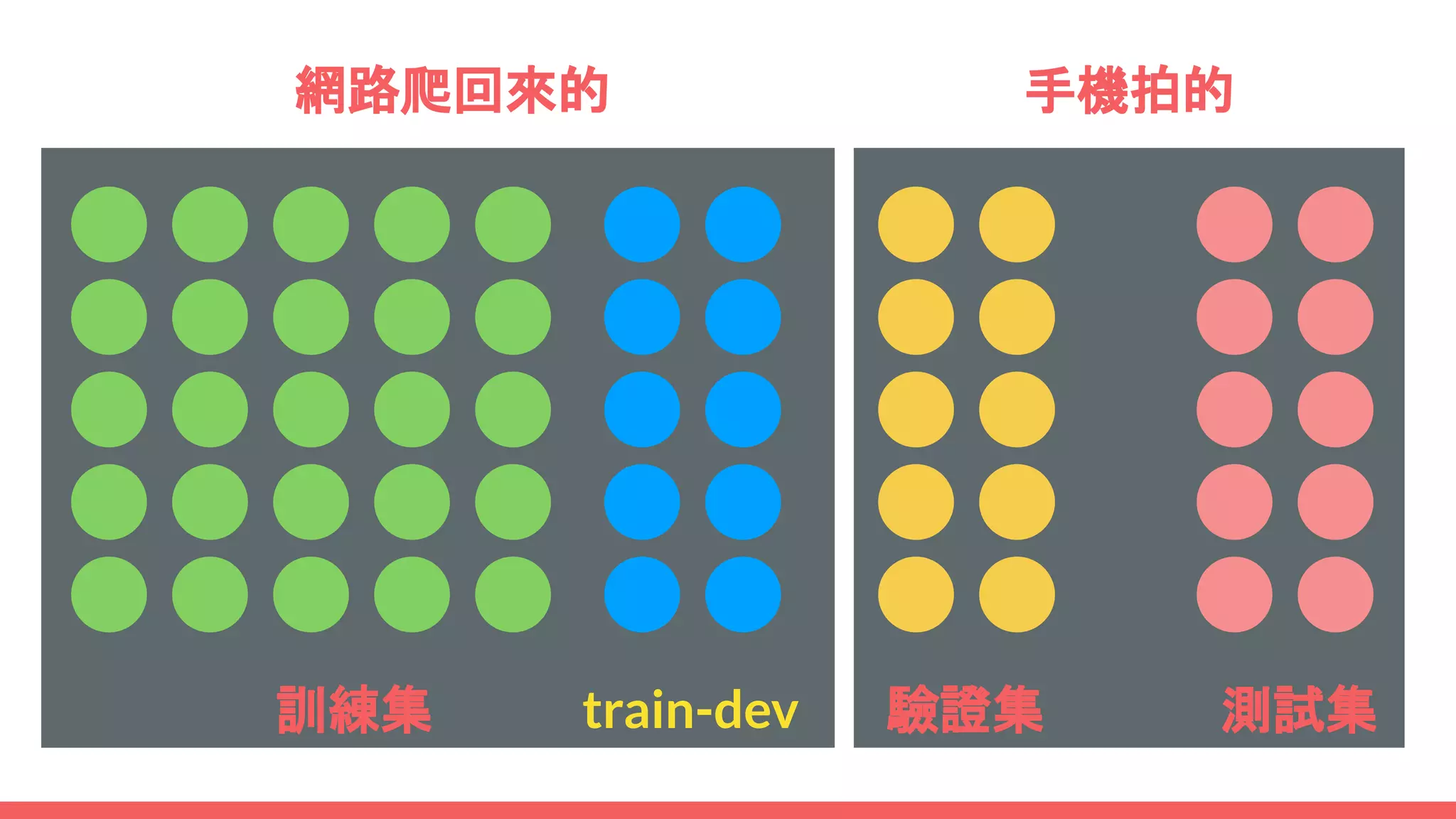
This document provides an overview of machine learning concepts including: - The differences between deep learning, neural networks, machine learning, and artificial intelligence. - Examples of machine learning applications such as image classification, text summarization, and fraud detection. - The main types of machine learning including supervised, unsupervised, semi-supervised, and reinforcement learning. - Common challenges in machine learning like bad data, overfitting, and underfitting models. - Methods for evaluating machine learning models like validation sets and cross-validation.





























![[系列活動] 手把手的深度學實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidedlfinal1216-171213041058-thumbnail.jpg?width=640&height=640&fit=bounds)

![[系列活動] 手把手的深度學習實務](https://cdn.slidesharecdn.com/ss_thumbnails/slidesharestepbystepdl-161213072731-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC x TAAI 2016] 林守德 / 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/md-161124235136-thumbnail.jpg?width=640&height=640&fit=bounds)






















































