Download as PDF, PPTX





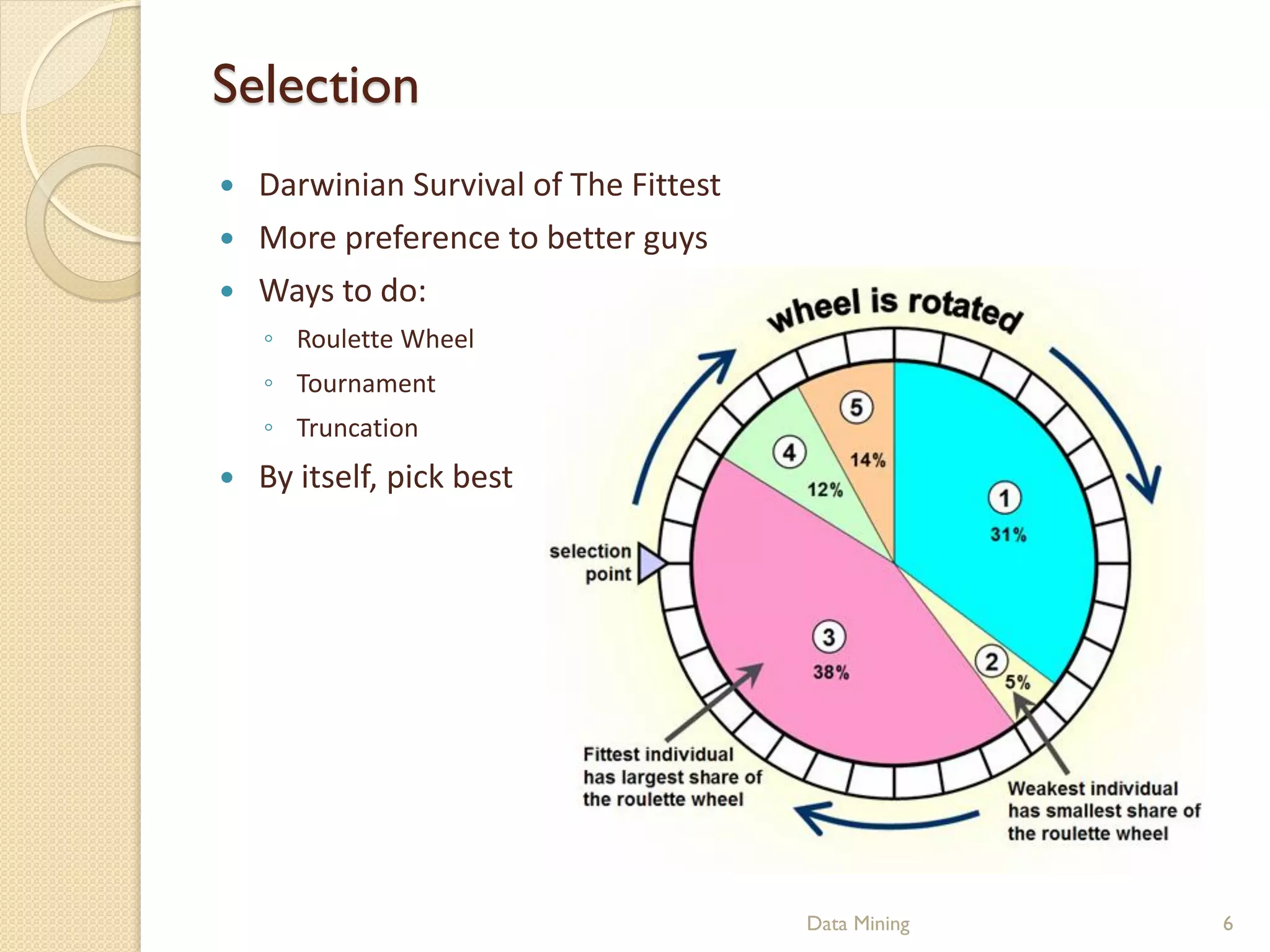


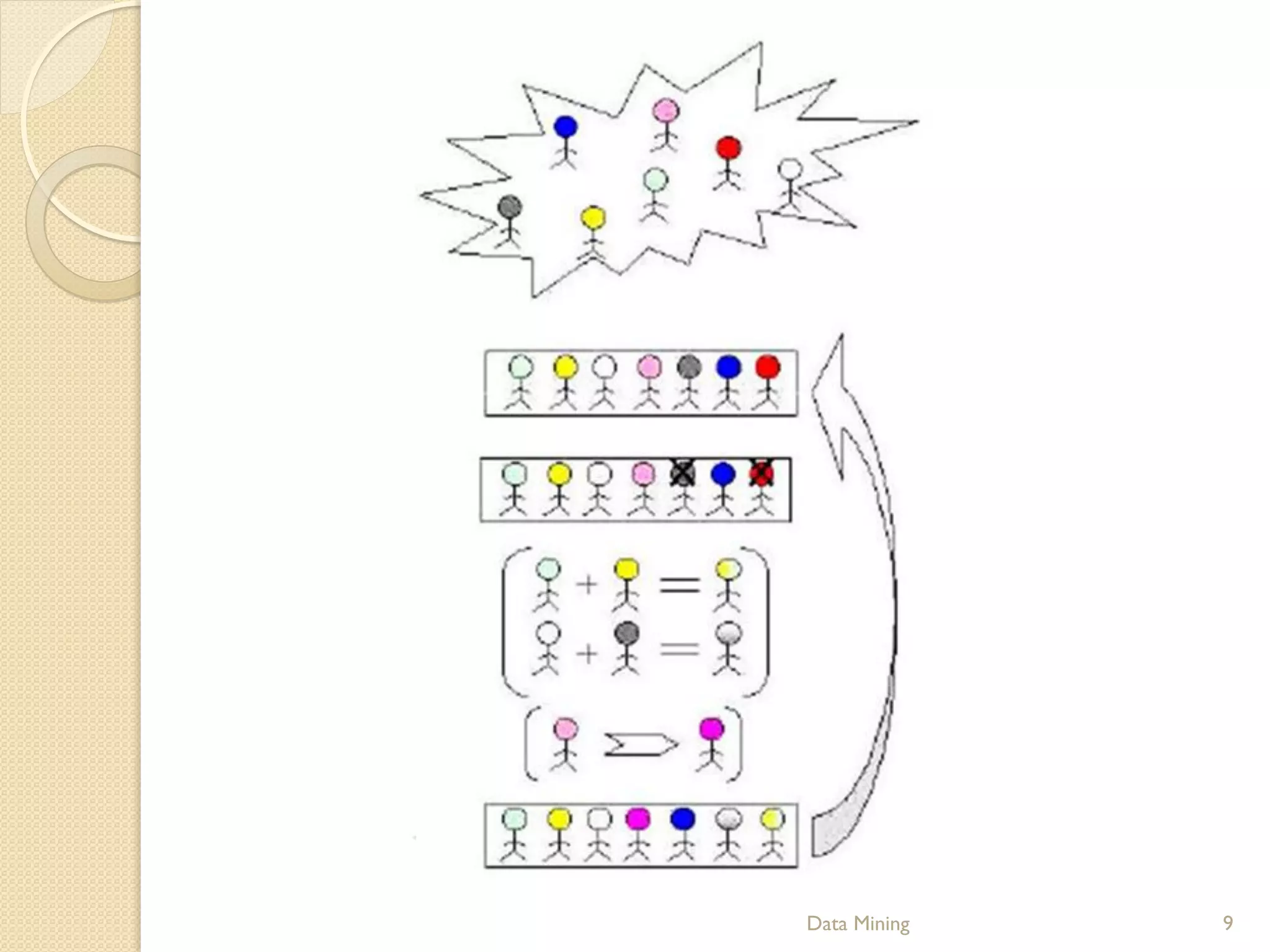
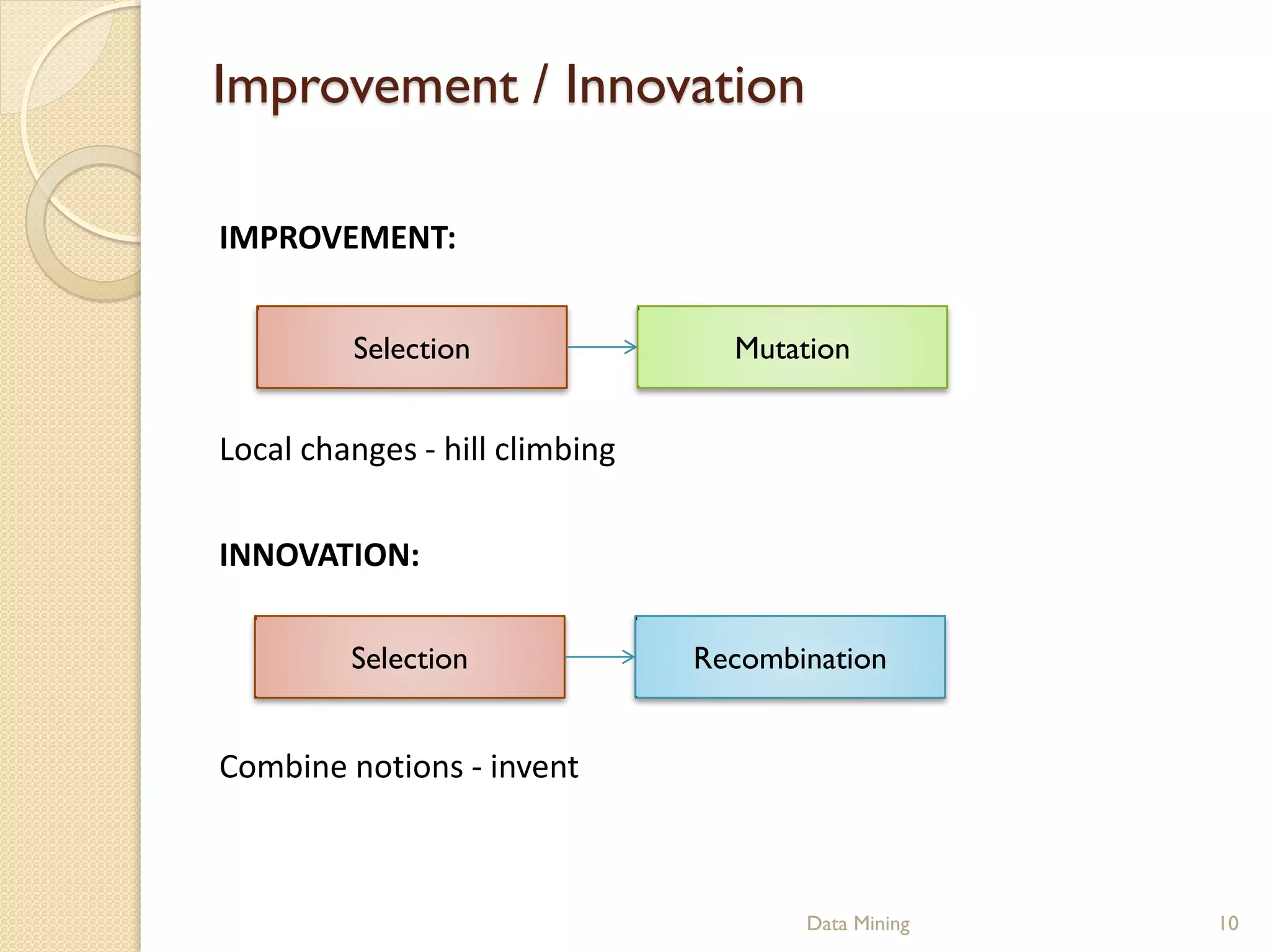









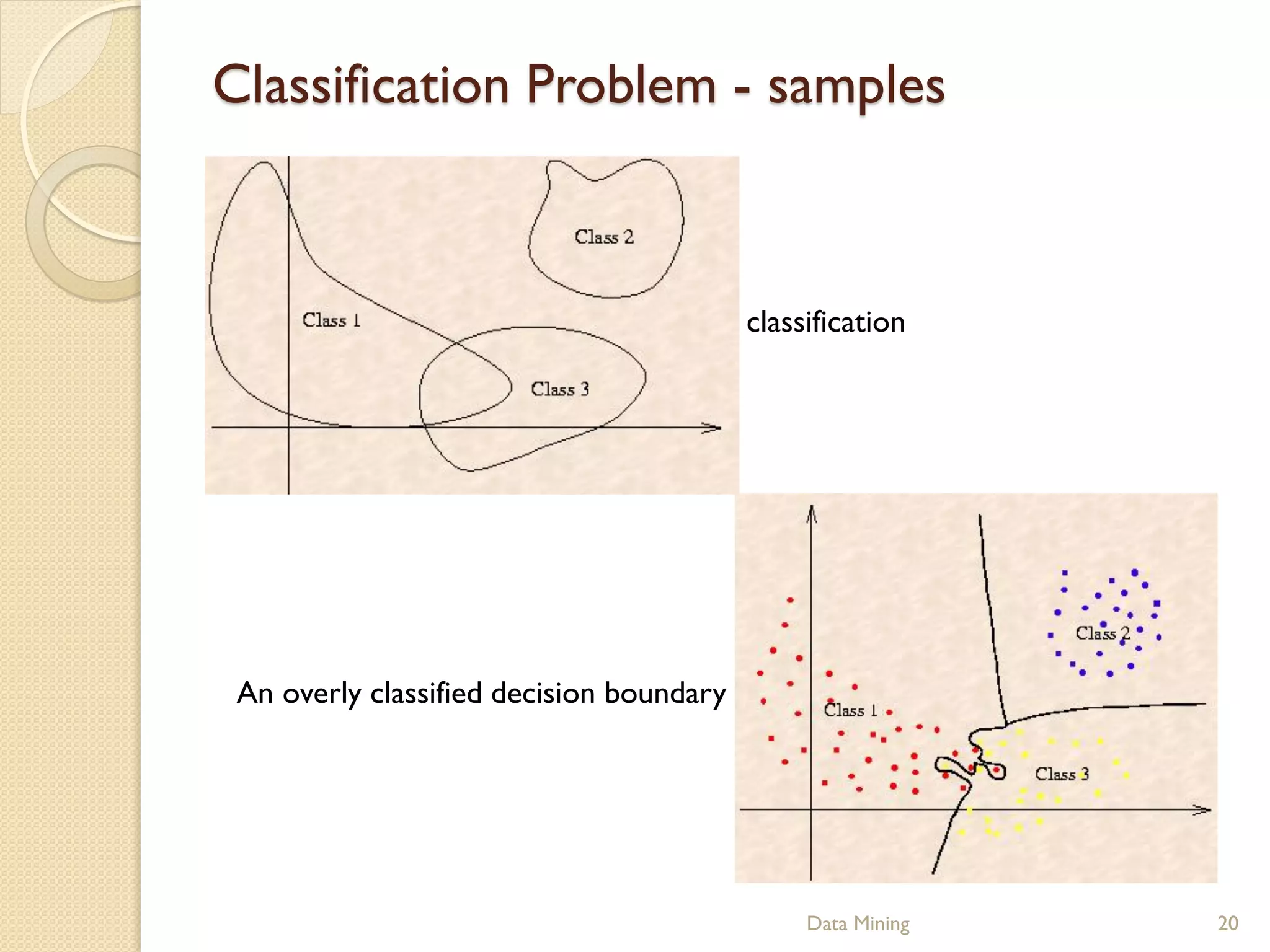































This document provides an introduction to genetic algorithms. It explains that genetic algorithms are inspired by Darwinian evolution and use processes like selection, crossover and mutation to iteratively improve a population of potential solutions. It discusses how genetic algorithms can be used for optimization problems and classification in data mining. Examples of genetic algorithm applications like the traveling salesman problem are also presented to illustrate genetic algorithm concepts and processes.























































































