Downloaded 31 times


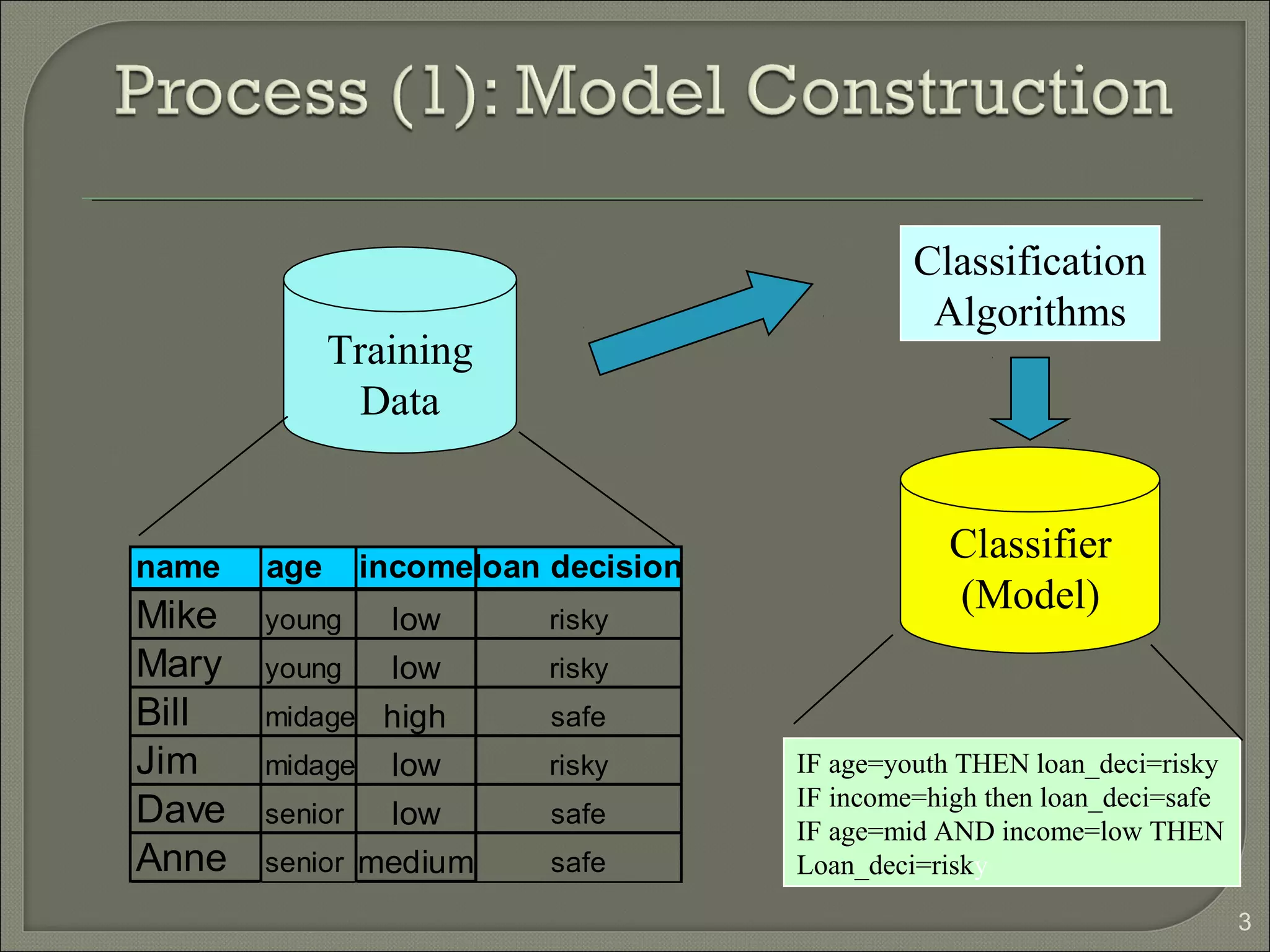
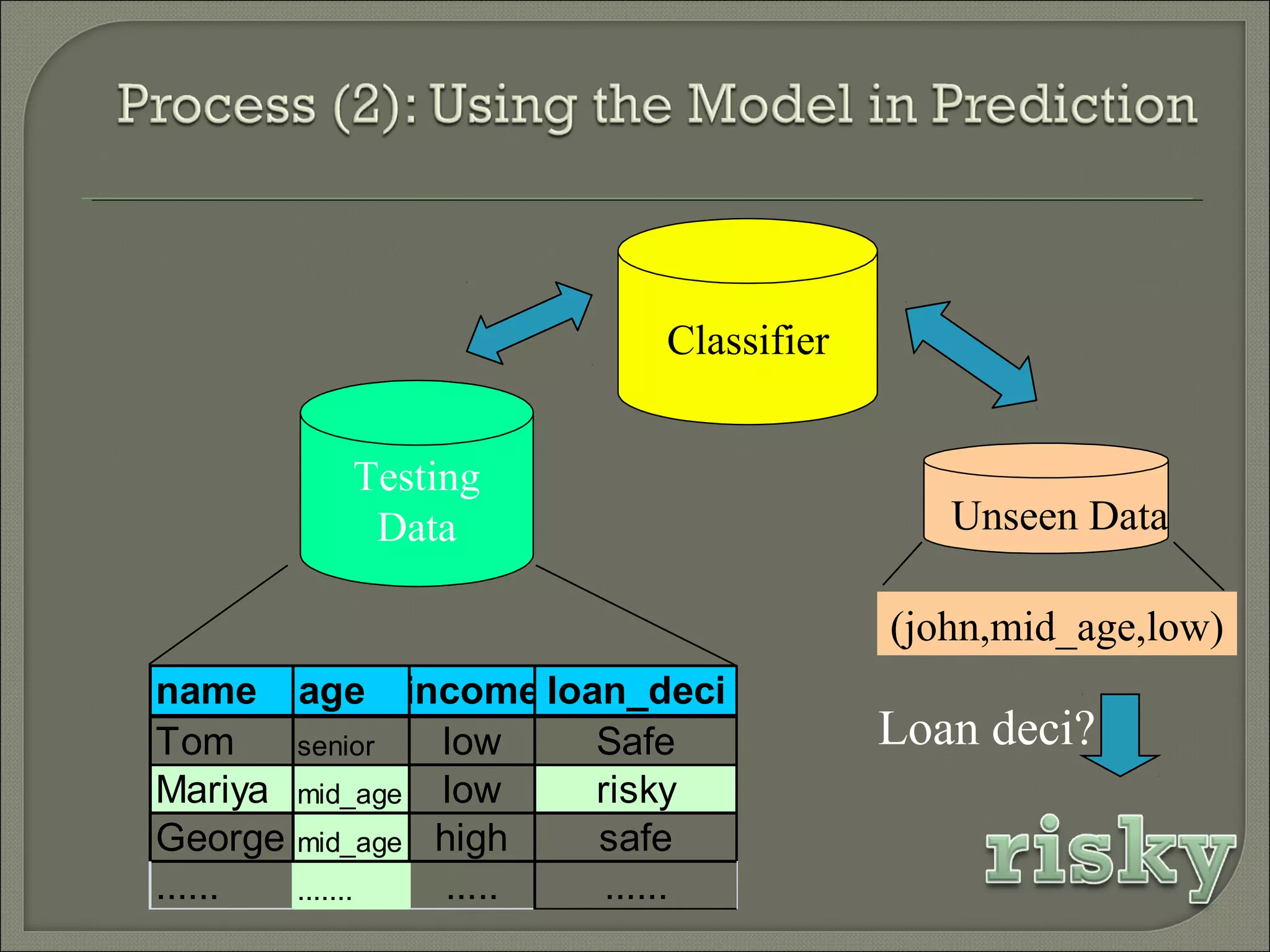







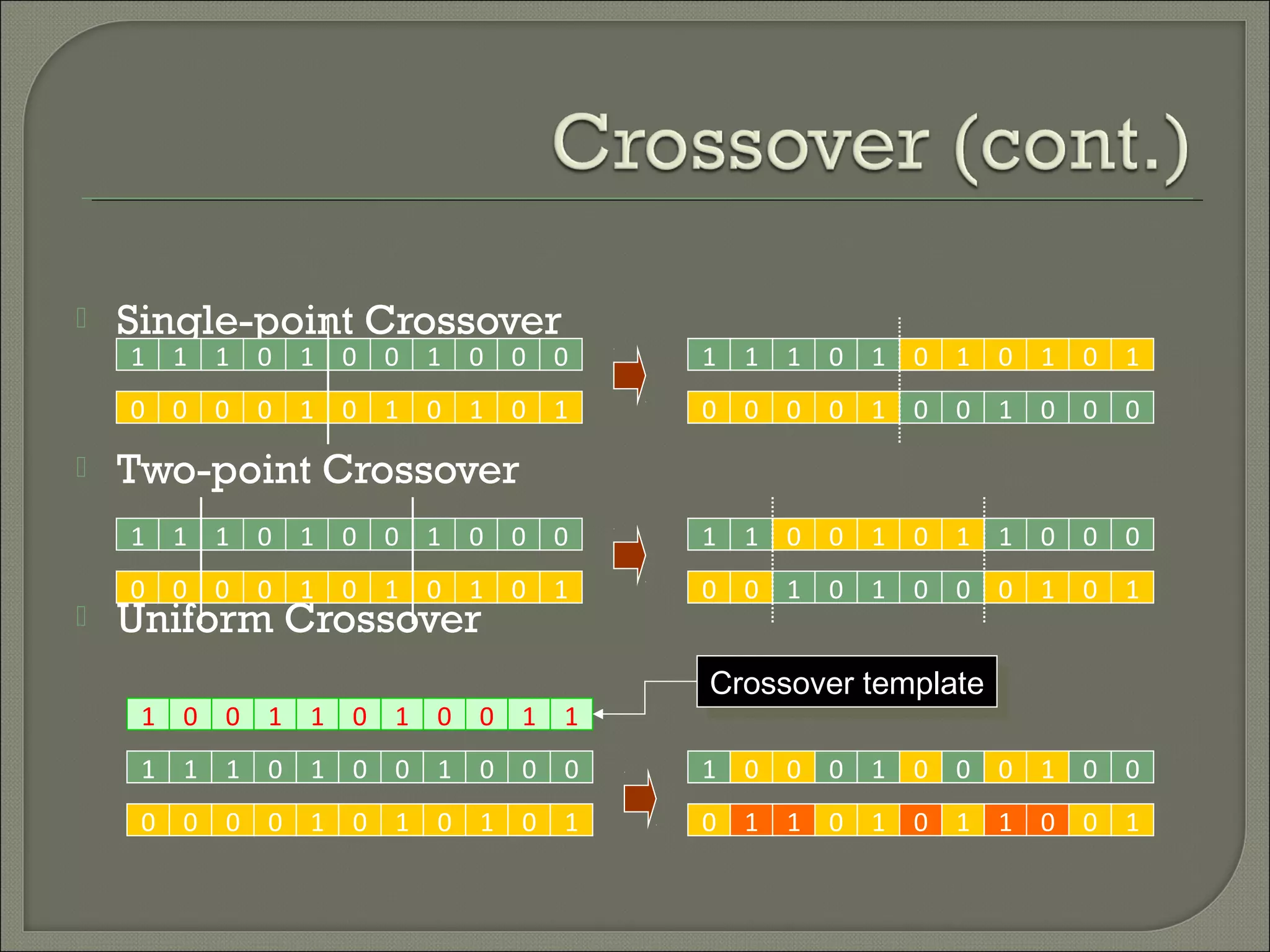

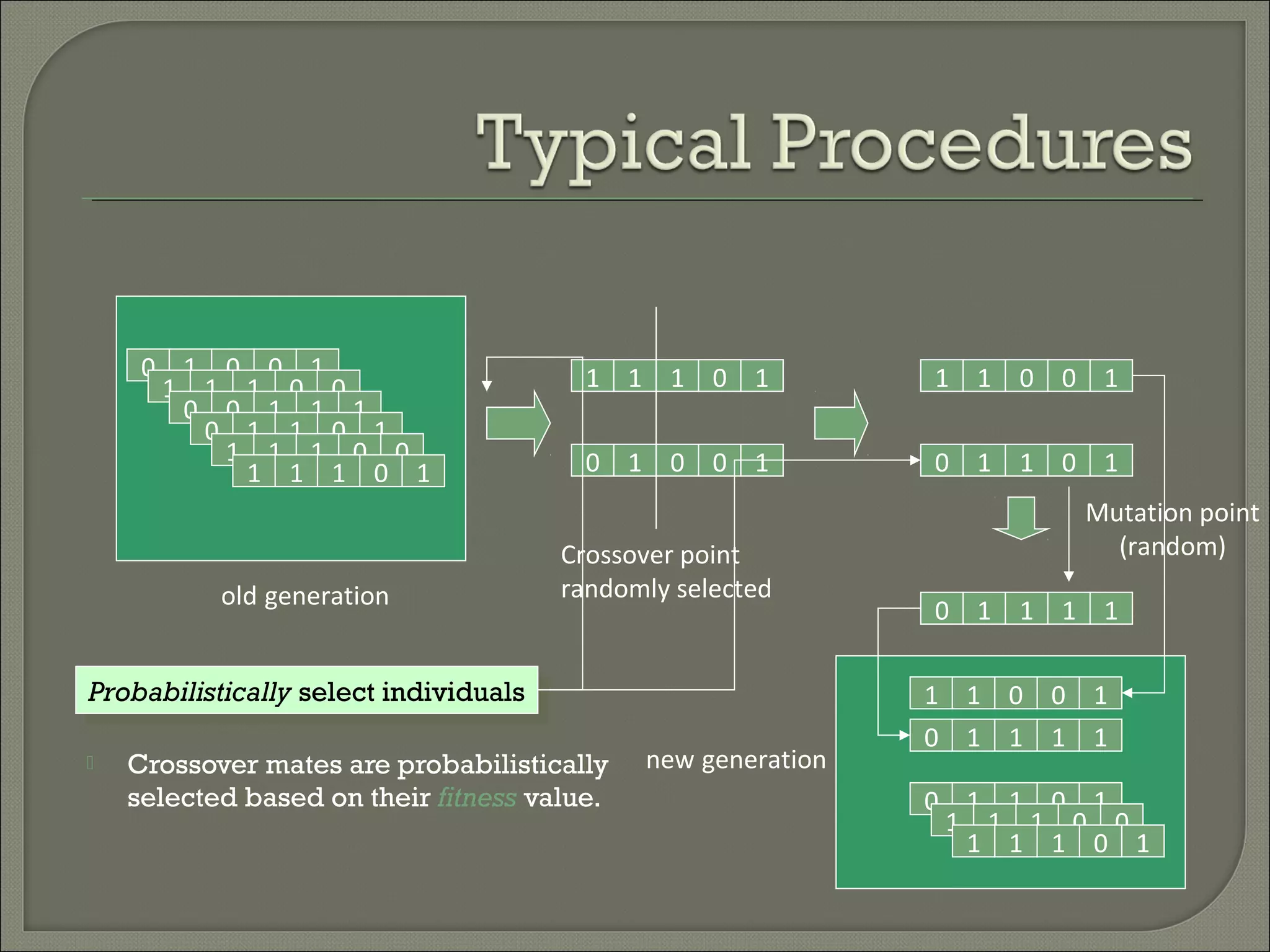
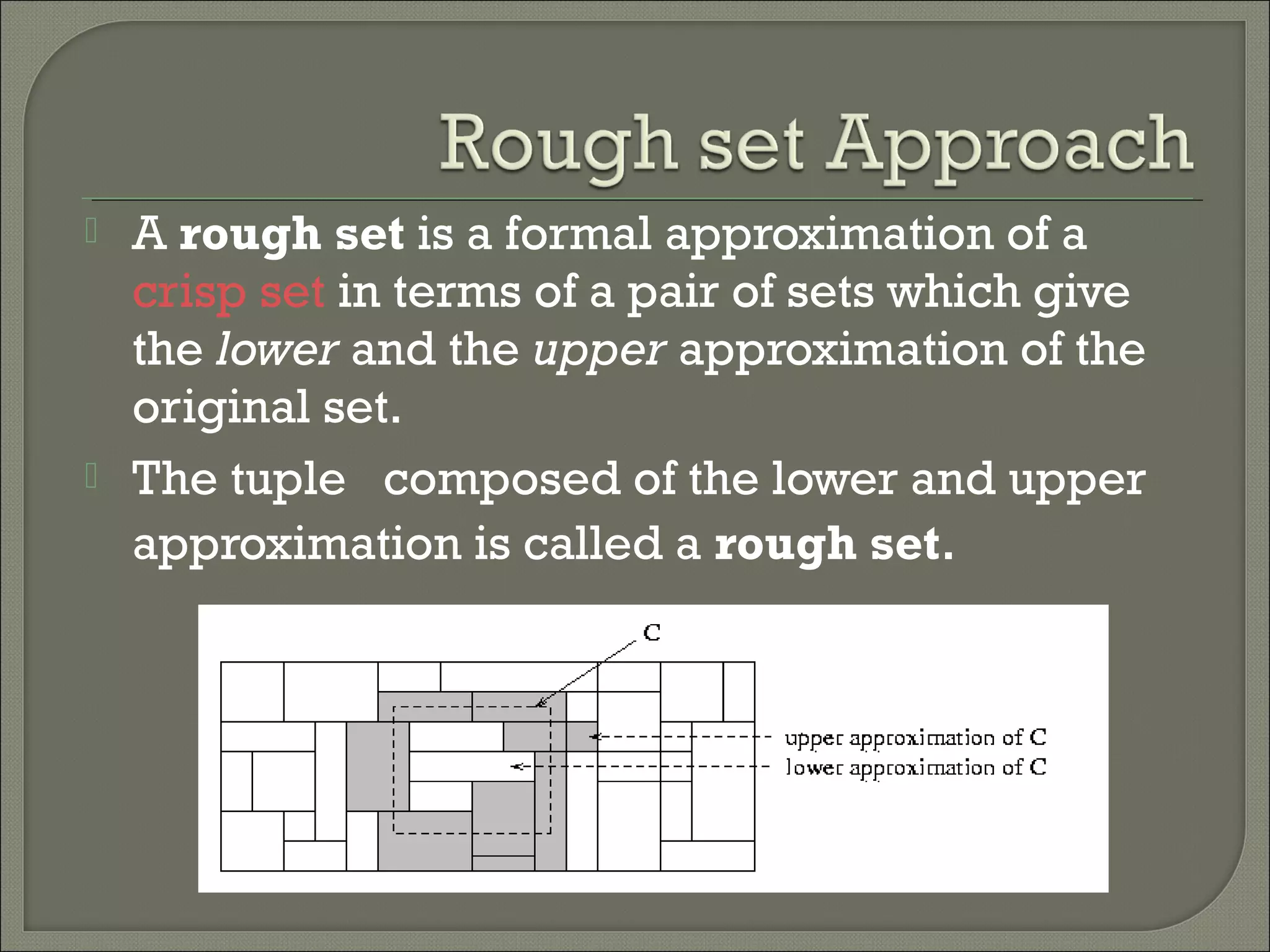
























1) Classification is a process of predicting categorical class labels based on a training set of data. It involves constructing a model from the training data and using that model to classify new unseen data. 2) Common classification algorithms include decision trees, naive Bayes classifiers, k-nearest neighbors, logistic regression, and artificial neural networks. Genetic algorithms and rough set theory can also be applied to classification problems. 3) Fuzzy logic classification allows attributes to have fuzzy membership in multiple classes rather than just one class. It assigns truth values between 0 and 1 to represent degree of membership and applies multiple applicable rules to classify new data.



































































