Download as PDF, PPTX


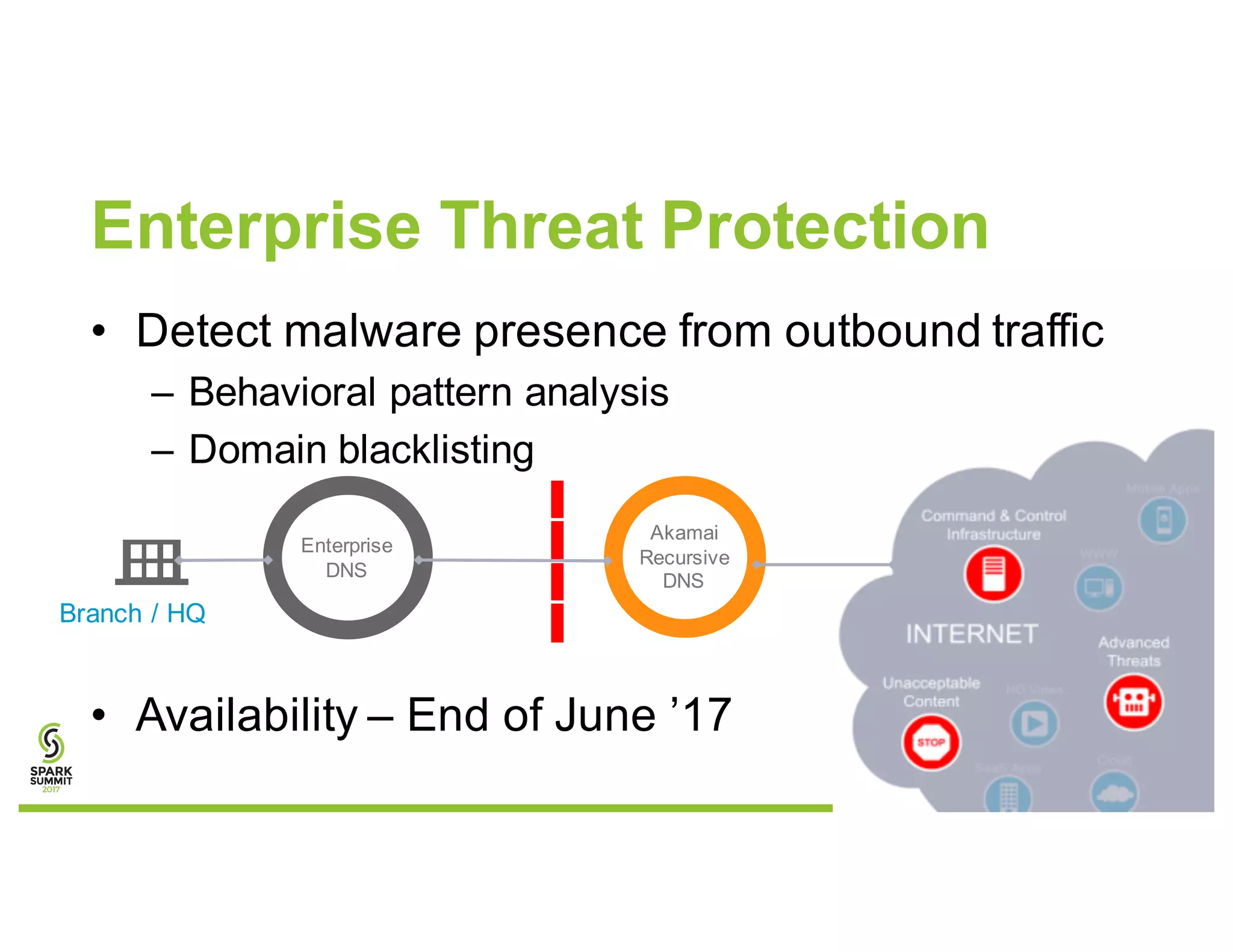
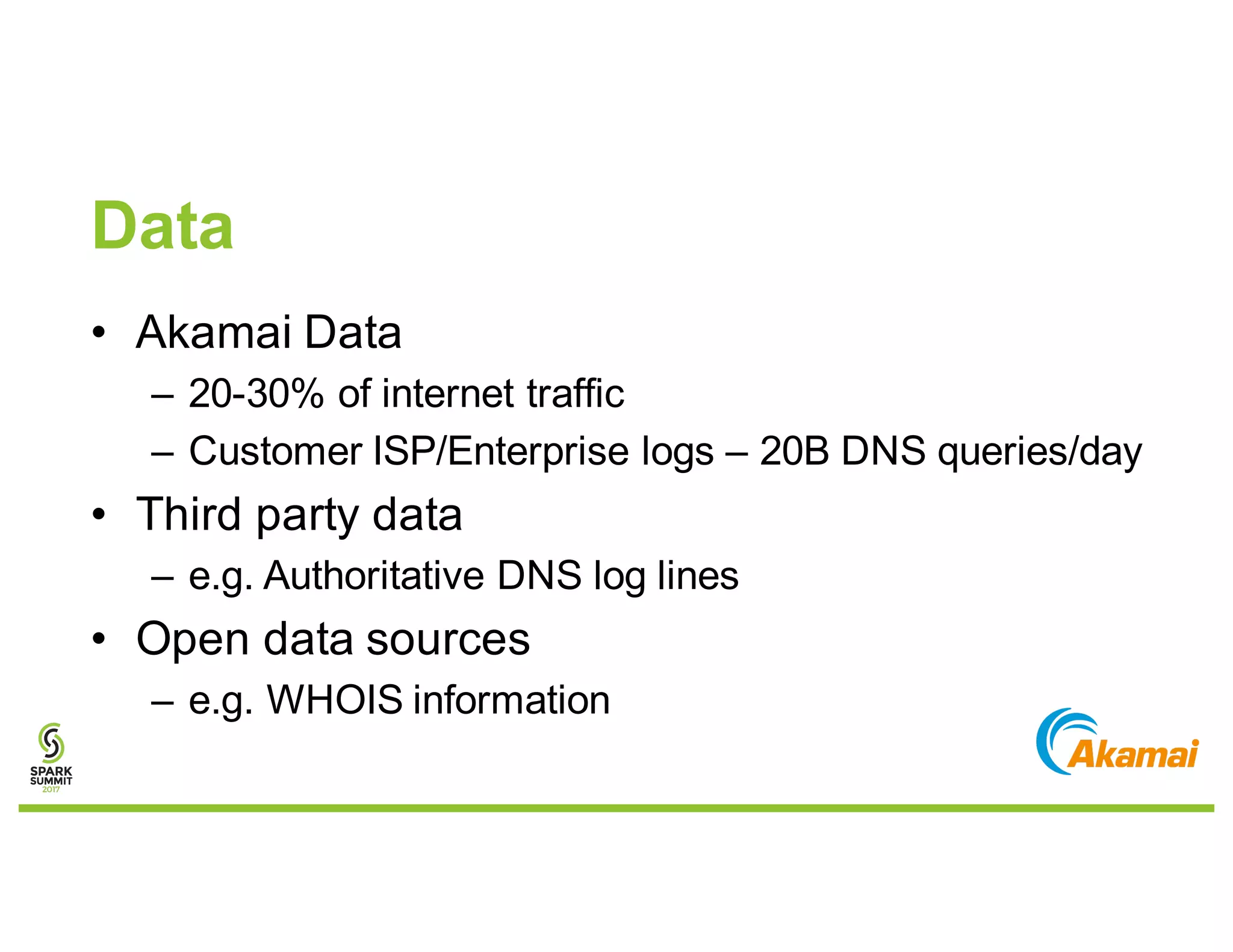
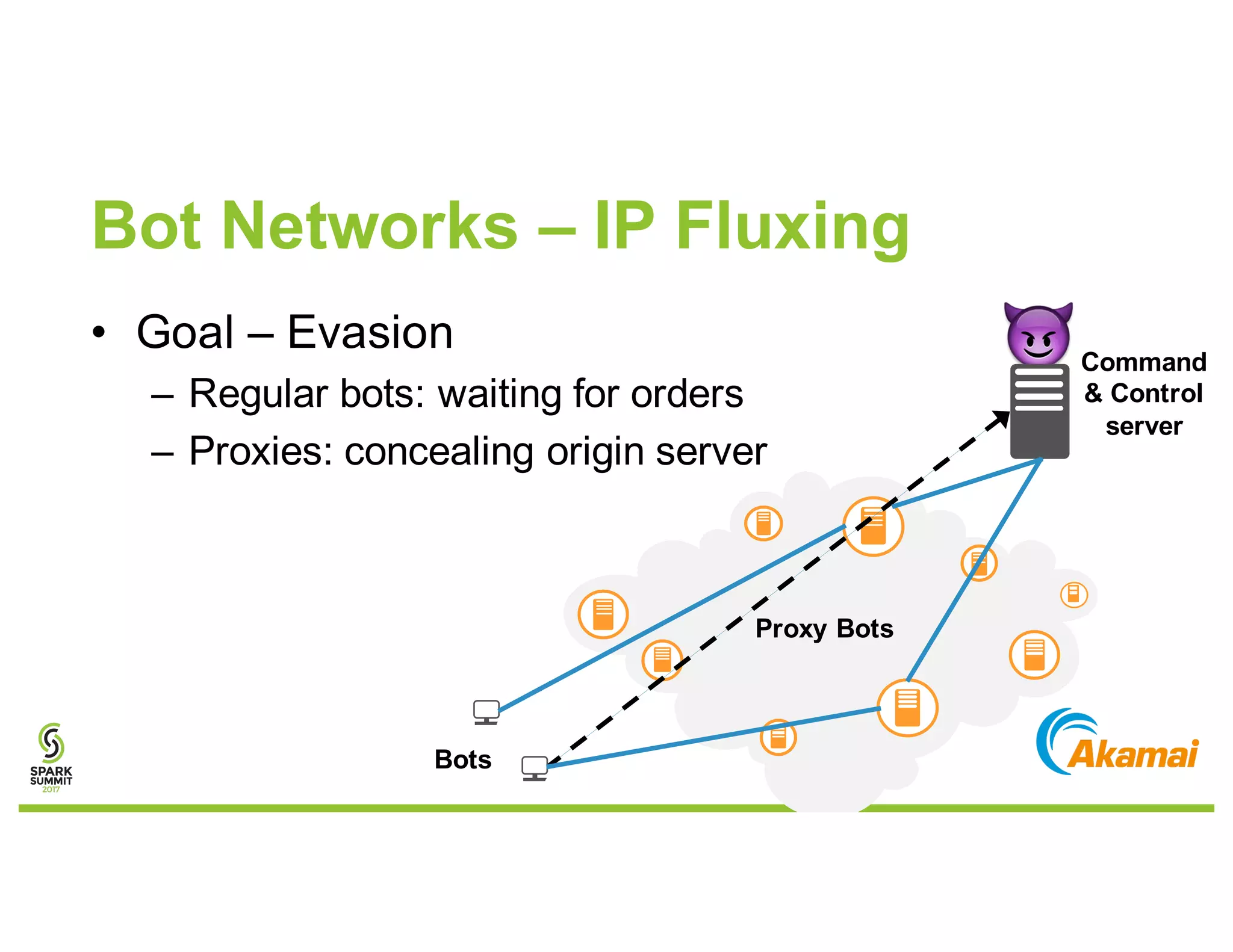

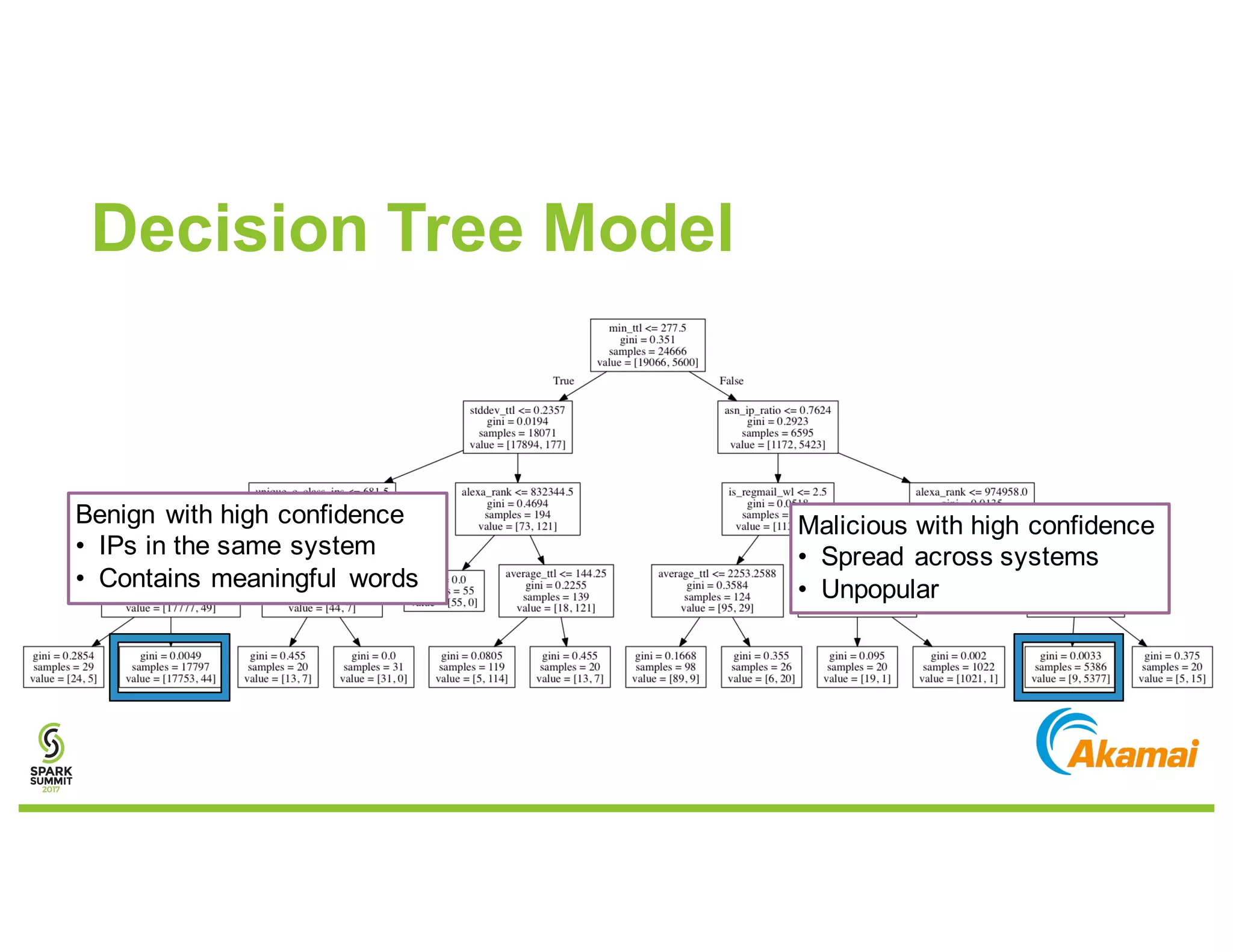
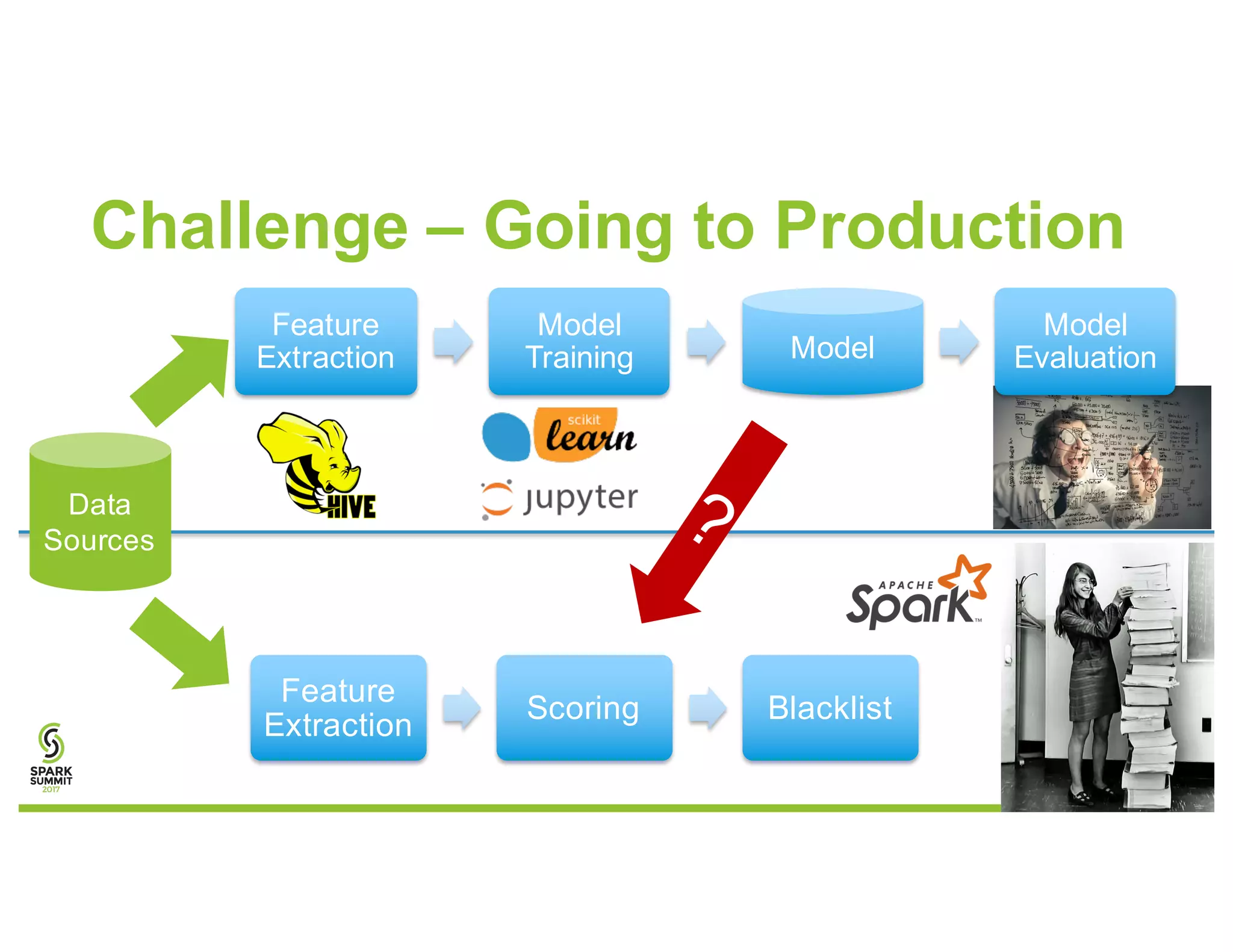






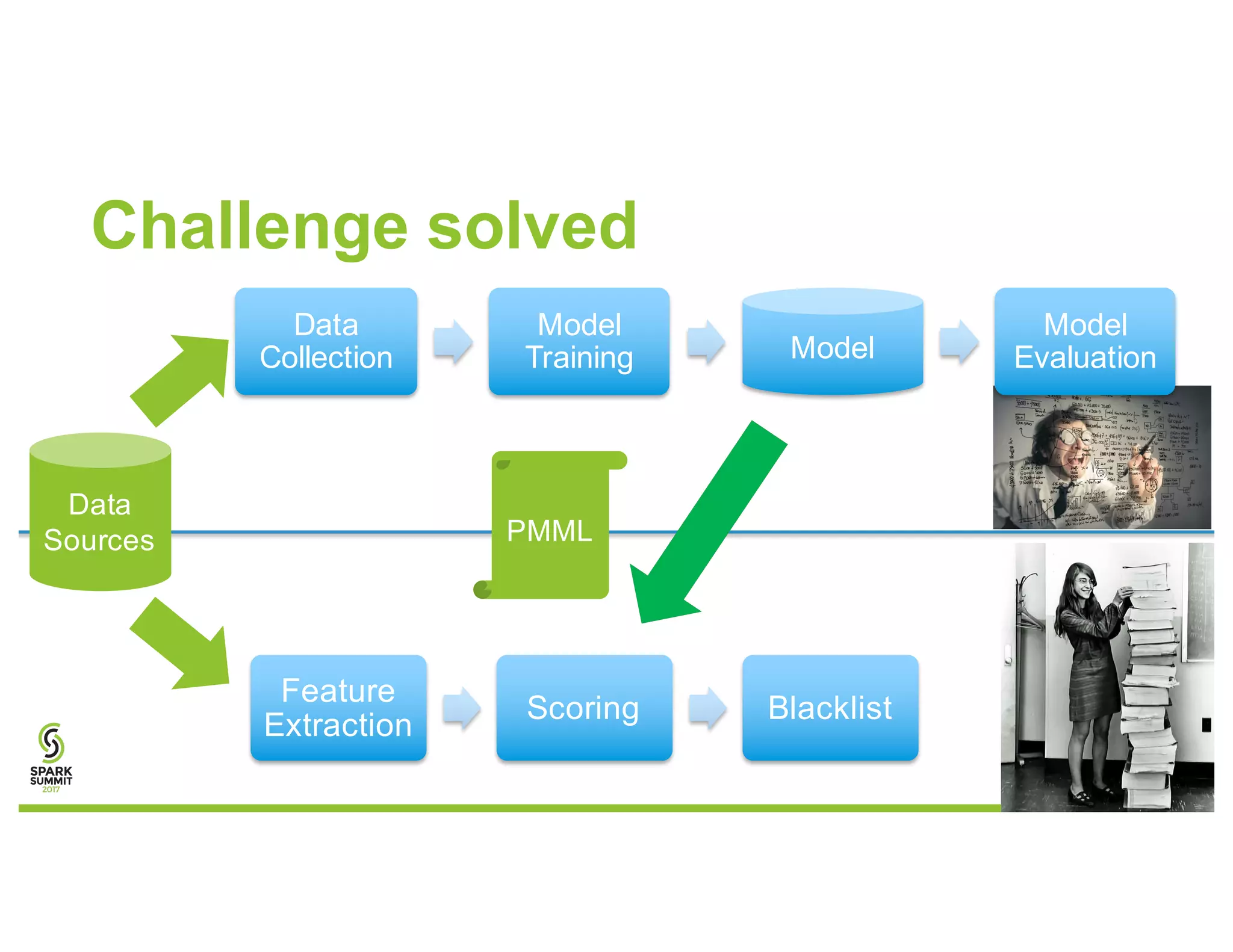


















The document discusses methods for detecting botnets using data analysis techniques, including behavioral pattern analysis and domain blacklisting. It highlights the challenges of model training and implementation in production environments, proposing solutions such as using Scala/Spark pipelines and the predictive model markup language (PMML) for efficient model export. Key lessons learned emphasize the importance of adapting workflows based on scale and utilizing existing frameworks for model management.




































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















