Download as PDF, PPTX






























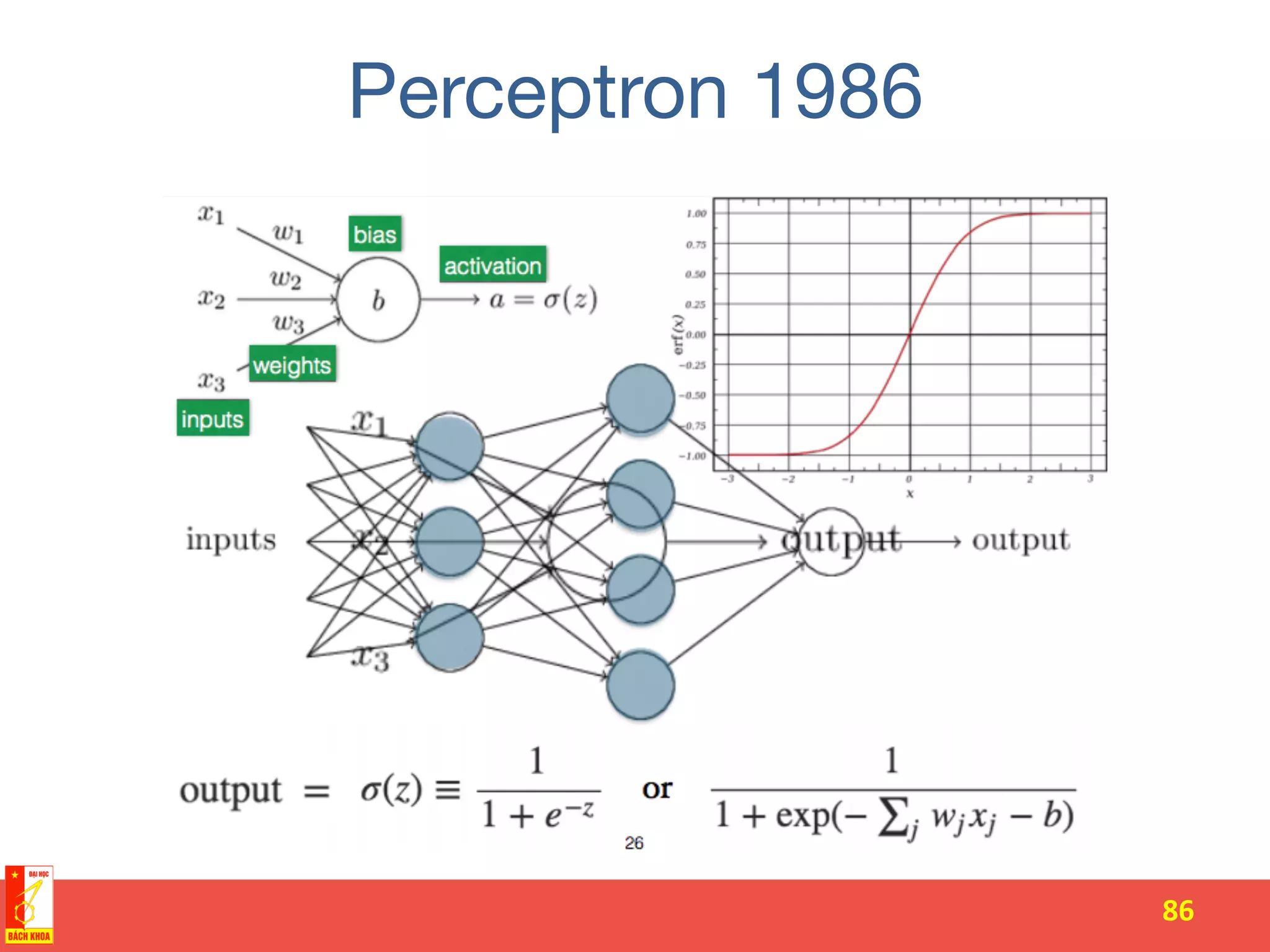
![• The tanh(z) function is a rescaled version of
the sigmoid, and its output range is [ − 1,1]
instead of [0,1].
69](https://image.slidesharecdn.com/neuralnetworkanddeeplearning-150915170327-lva1-app6892/75/From-neural-networks-to-deep-learning-69-2048.jpg)

















































































![• The tanh(z) function is a rescaled version of
the sigmoid, and its output range is [ − 1,1]
instead of [0,1].
69](https://crownmelresort.com/image.slidesharecdn.com/neuralnetworkanddeeplearning-150915170327-lva1-app6892/75/From-neural-networks-to-deep-learning-69-2048.jpg)



























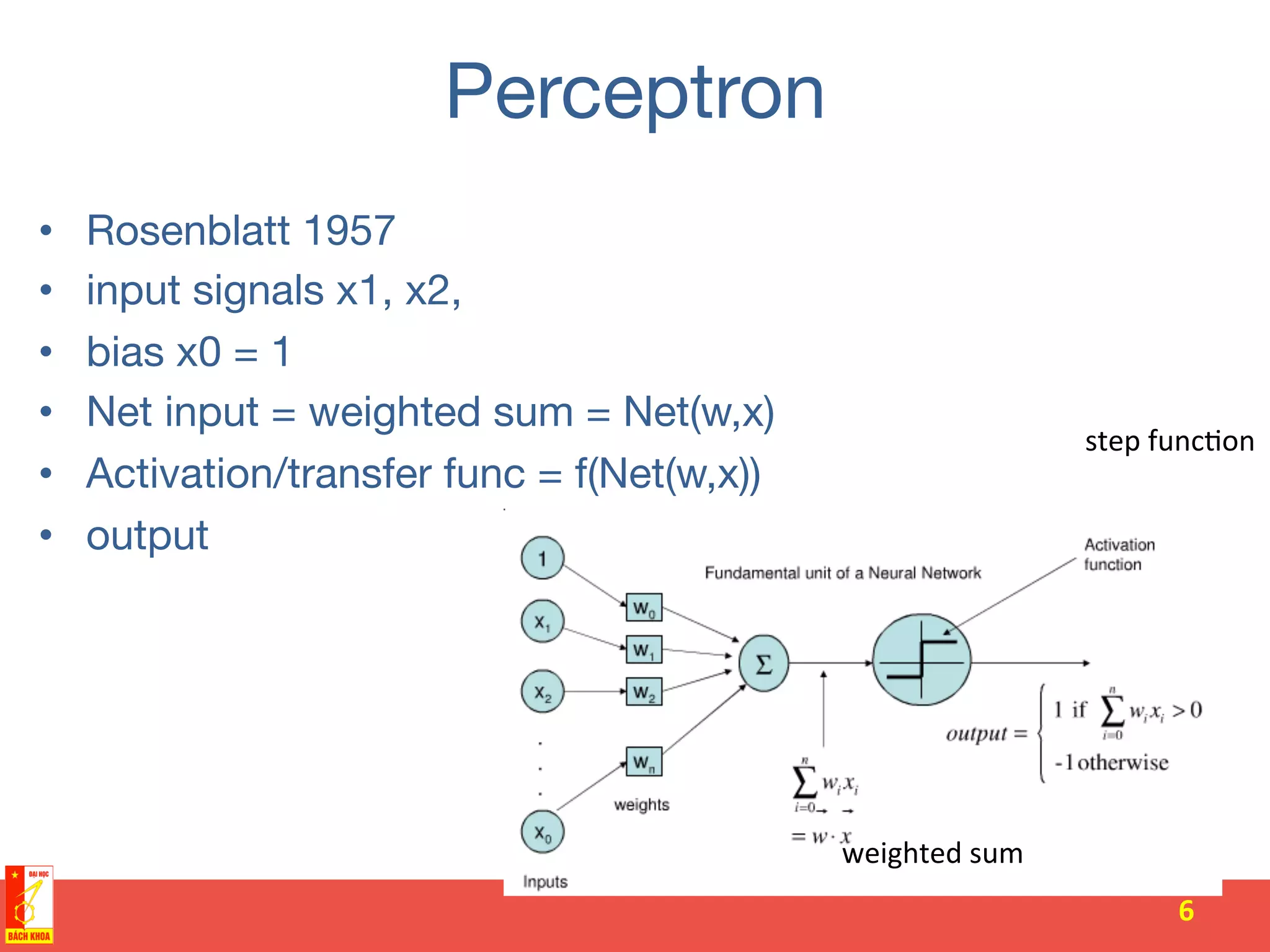
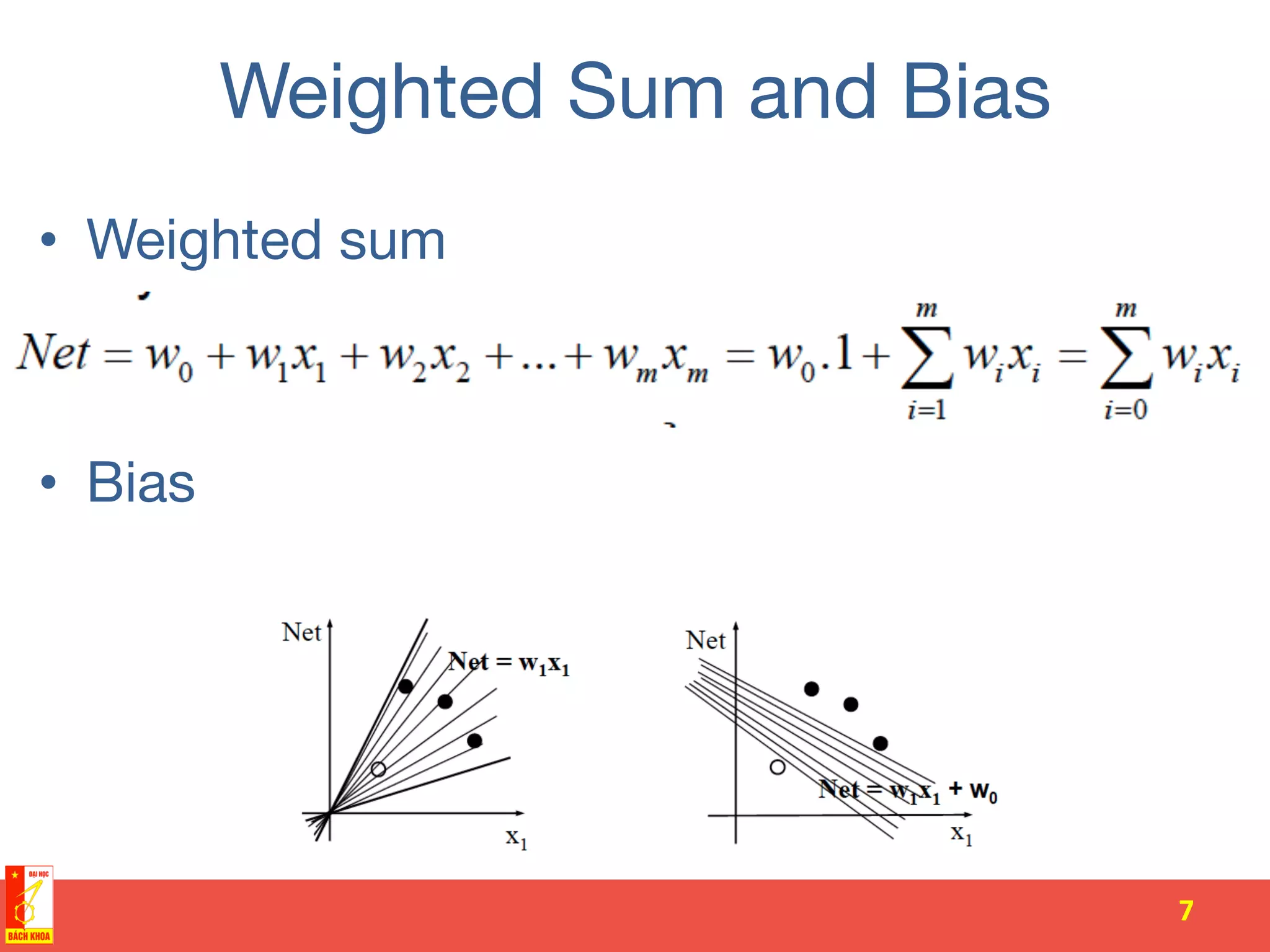
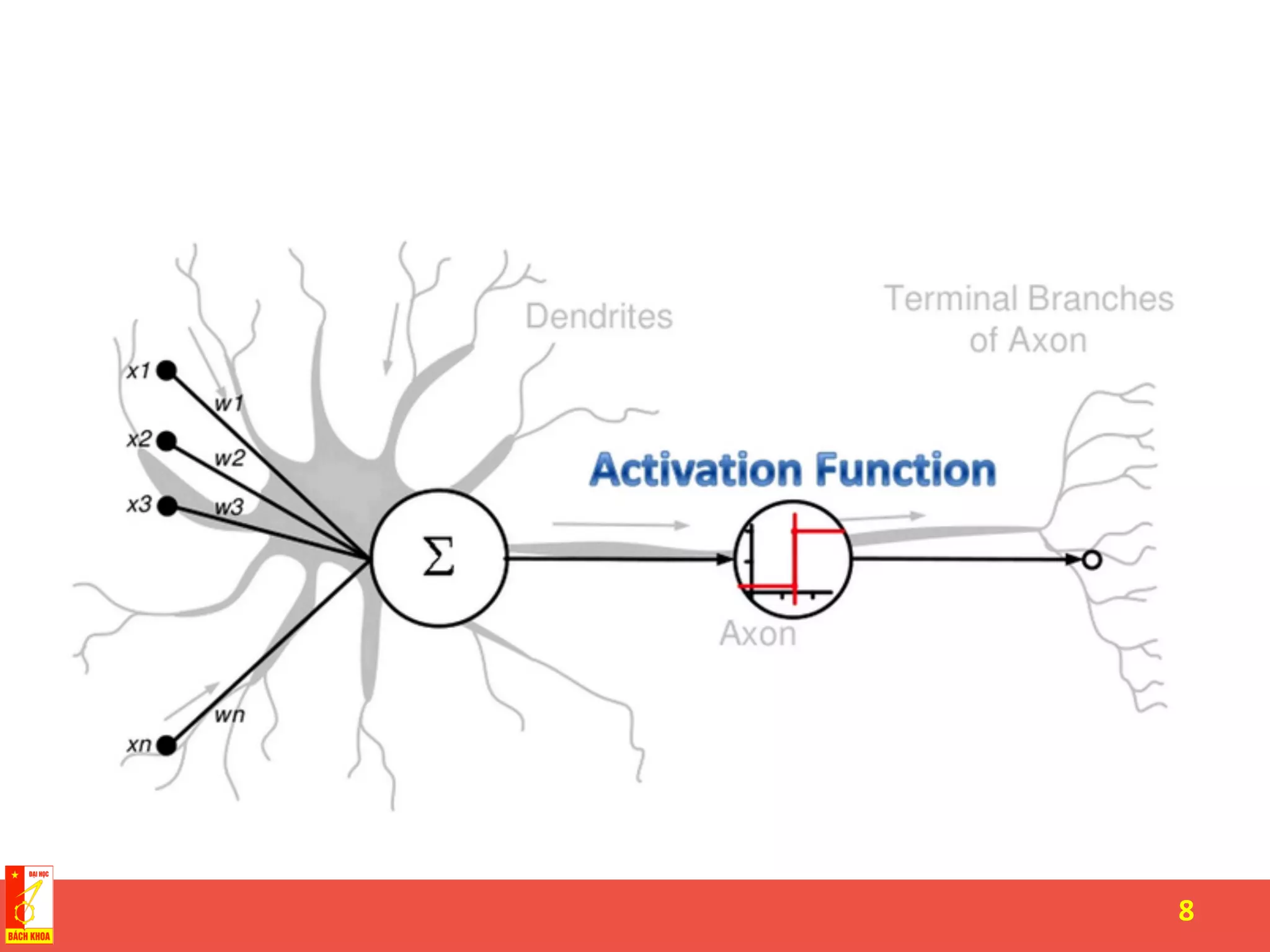
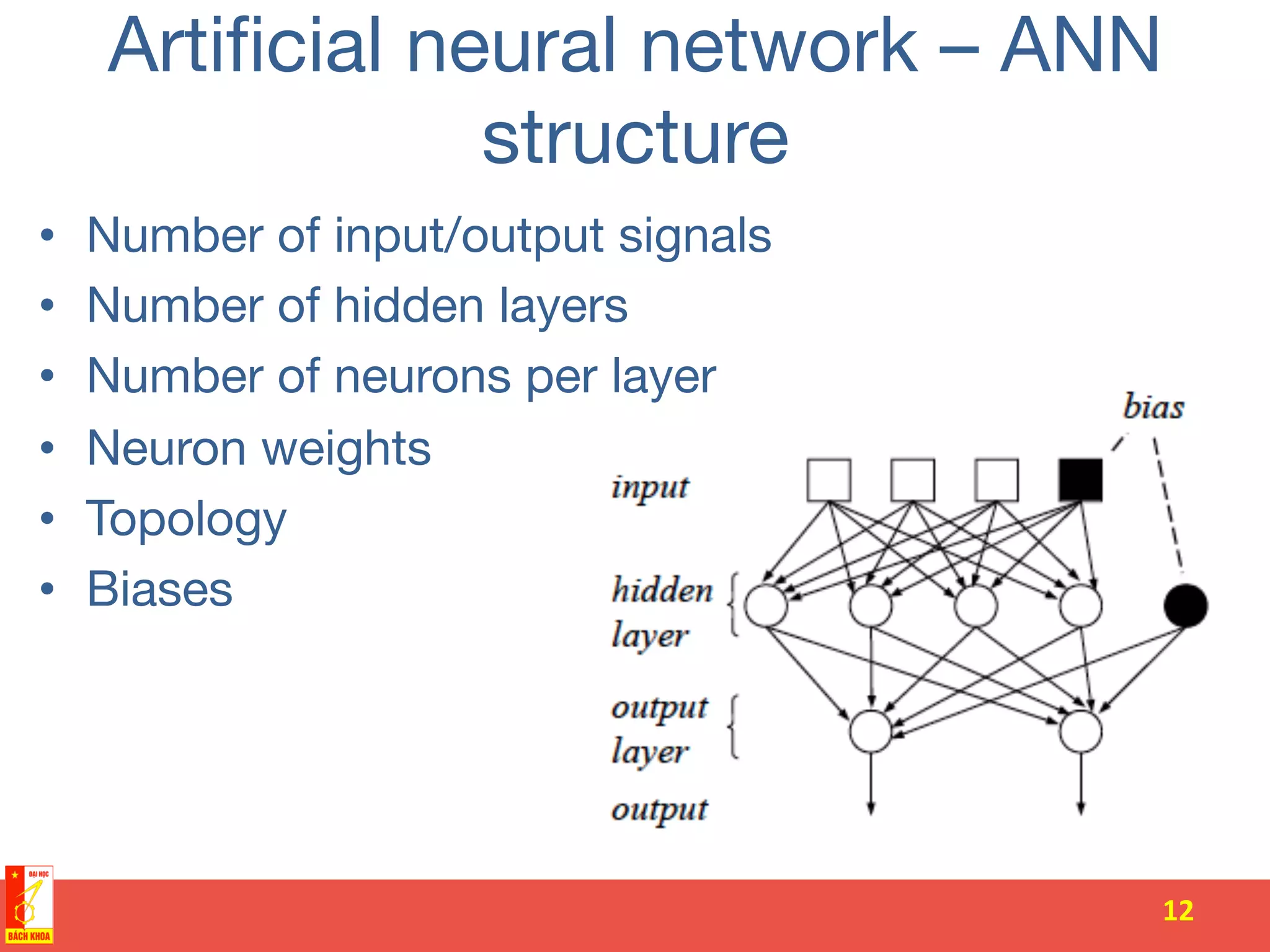
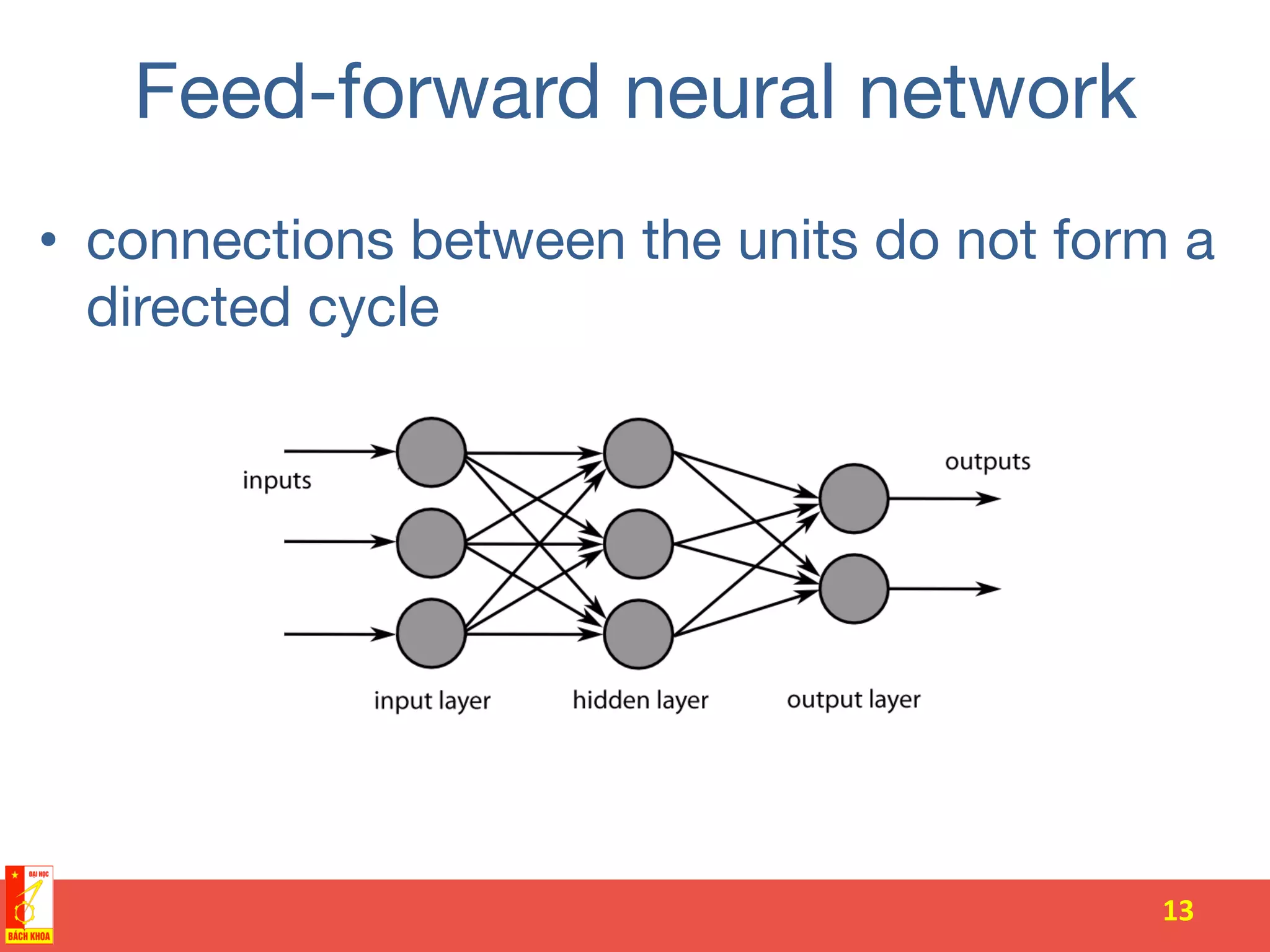
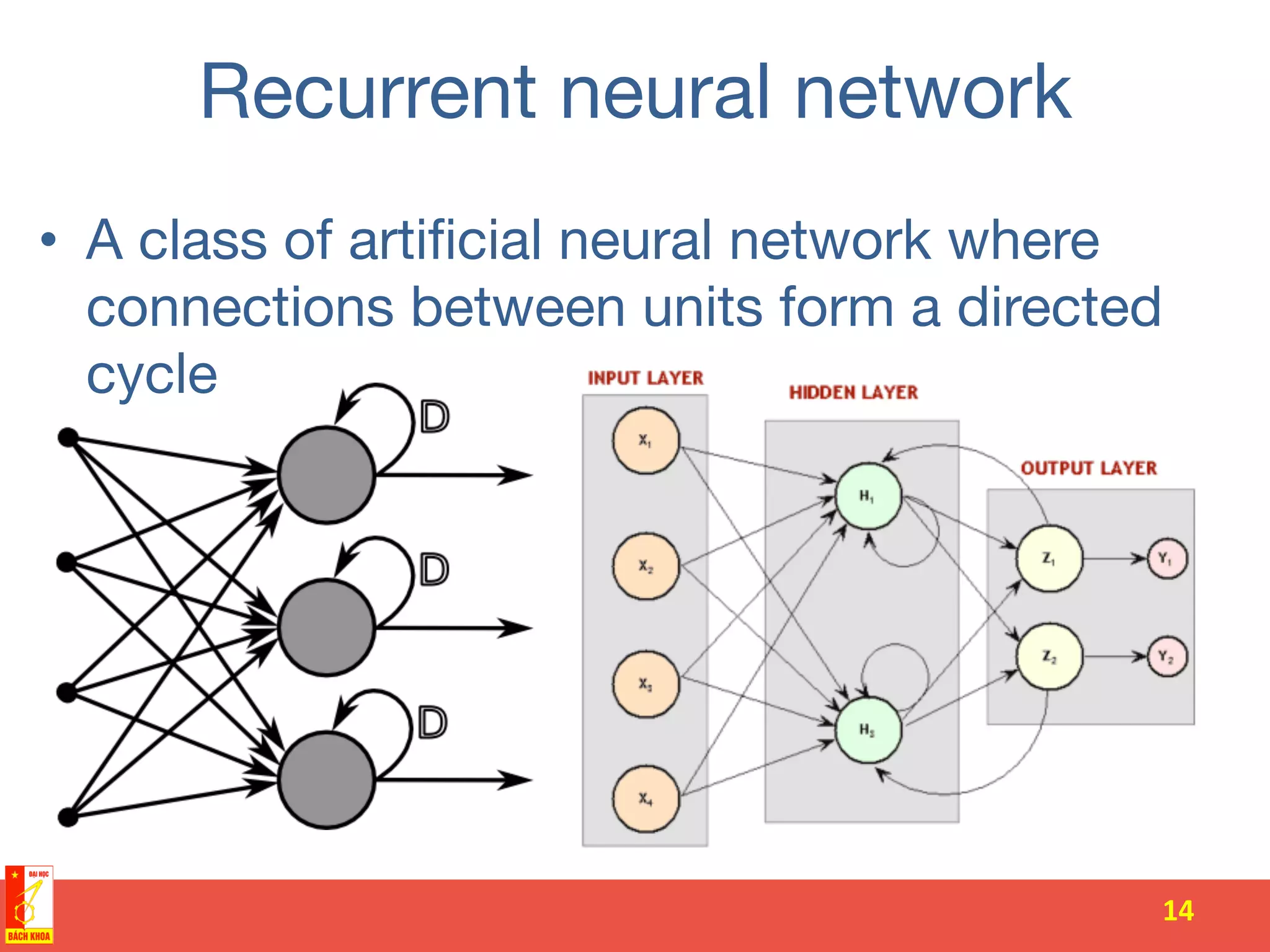
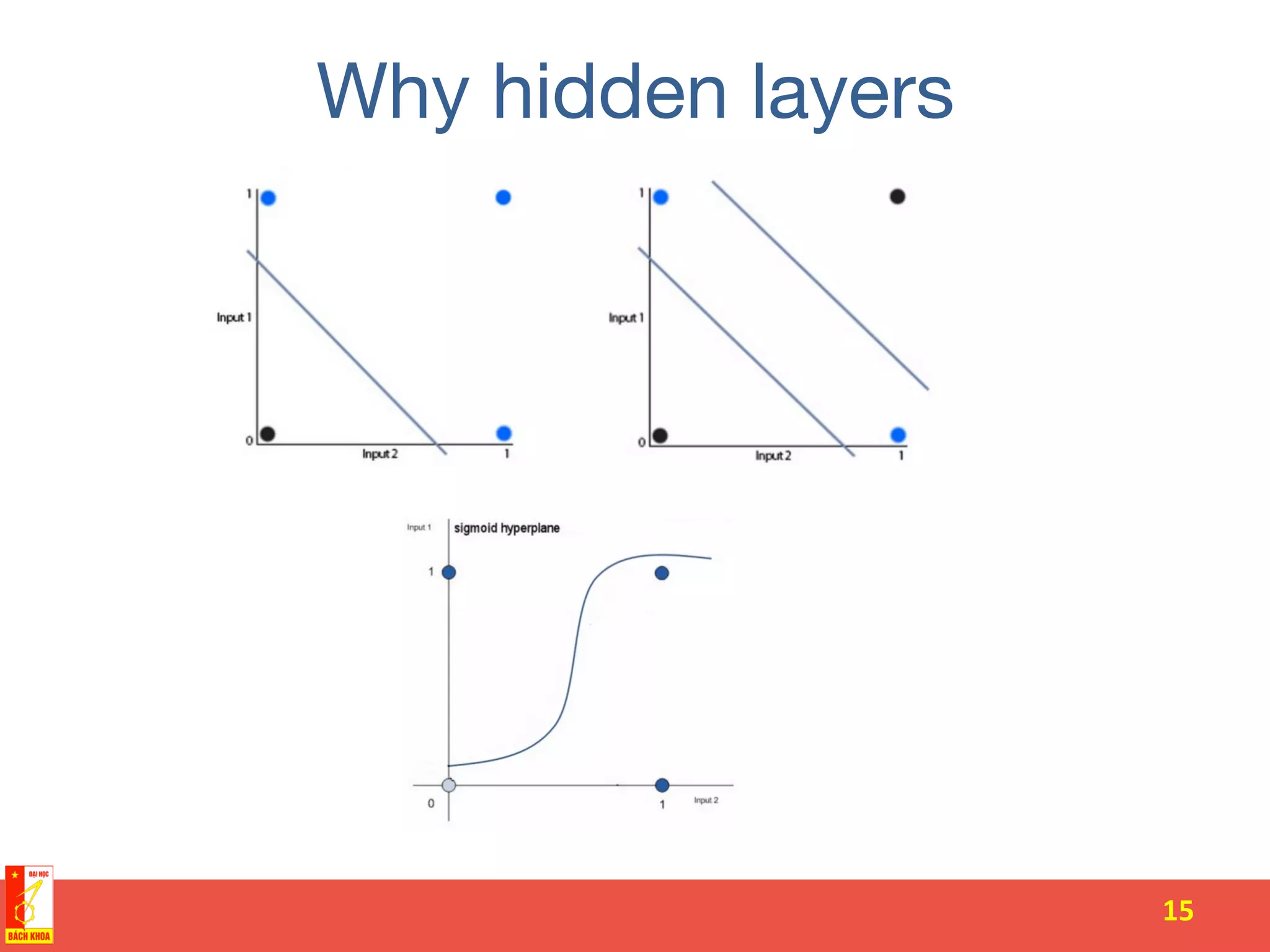
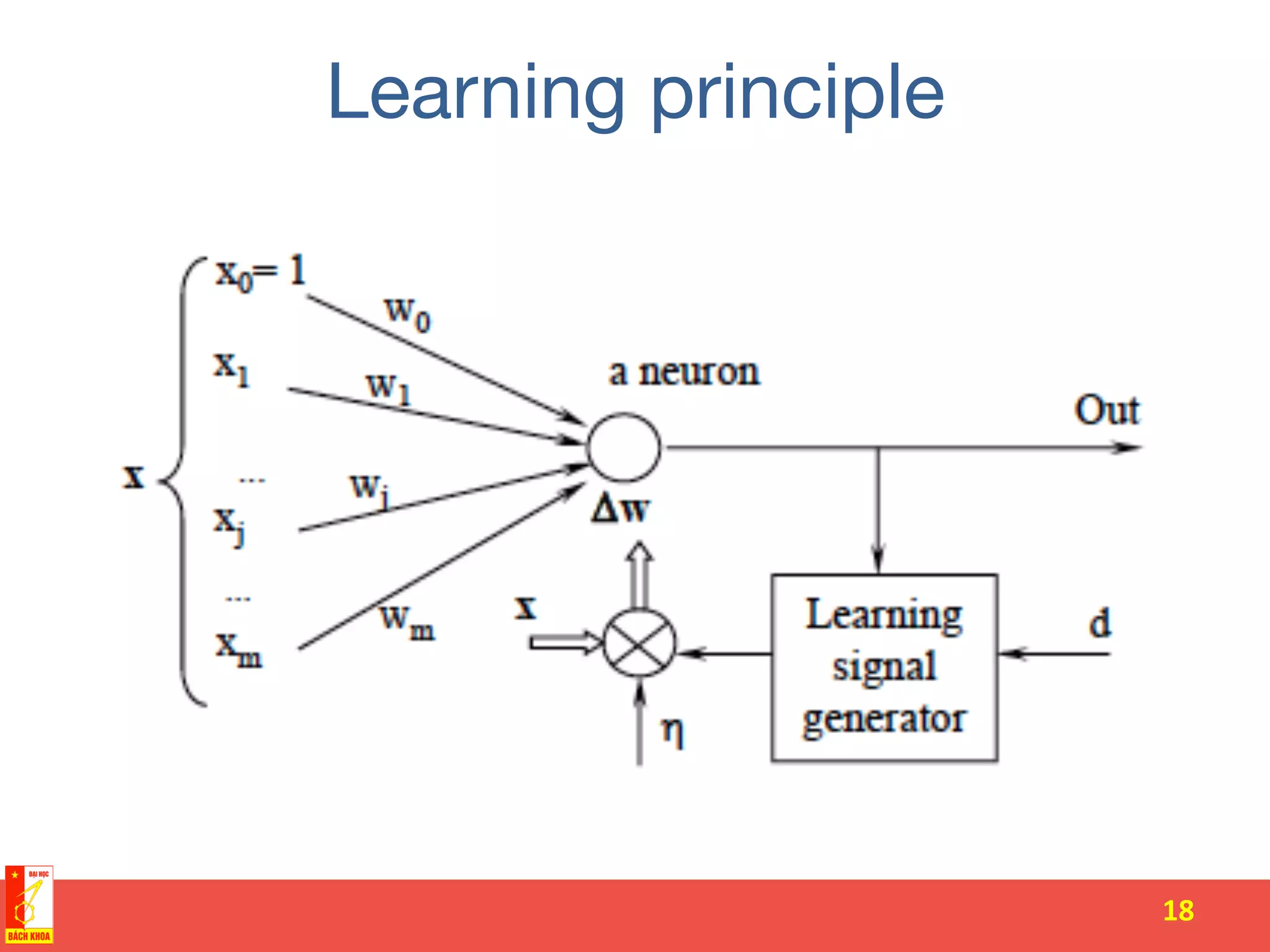
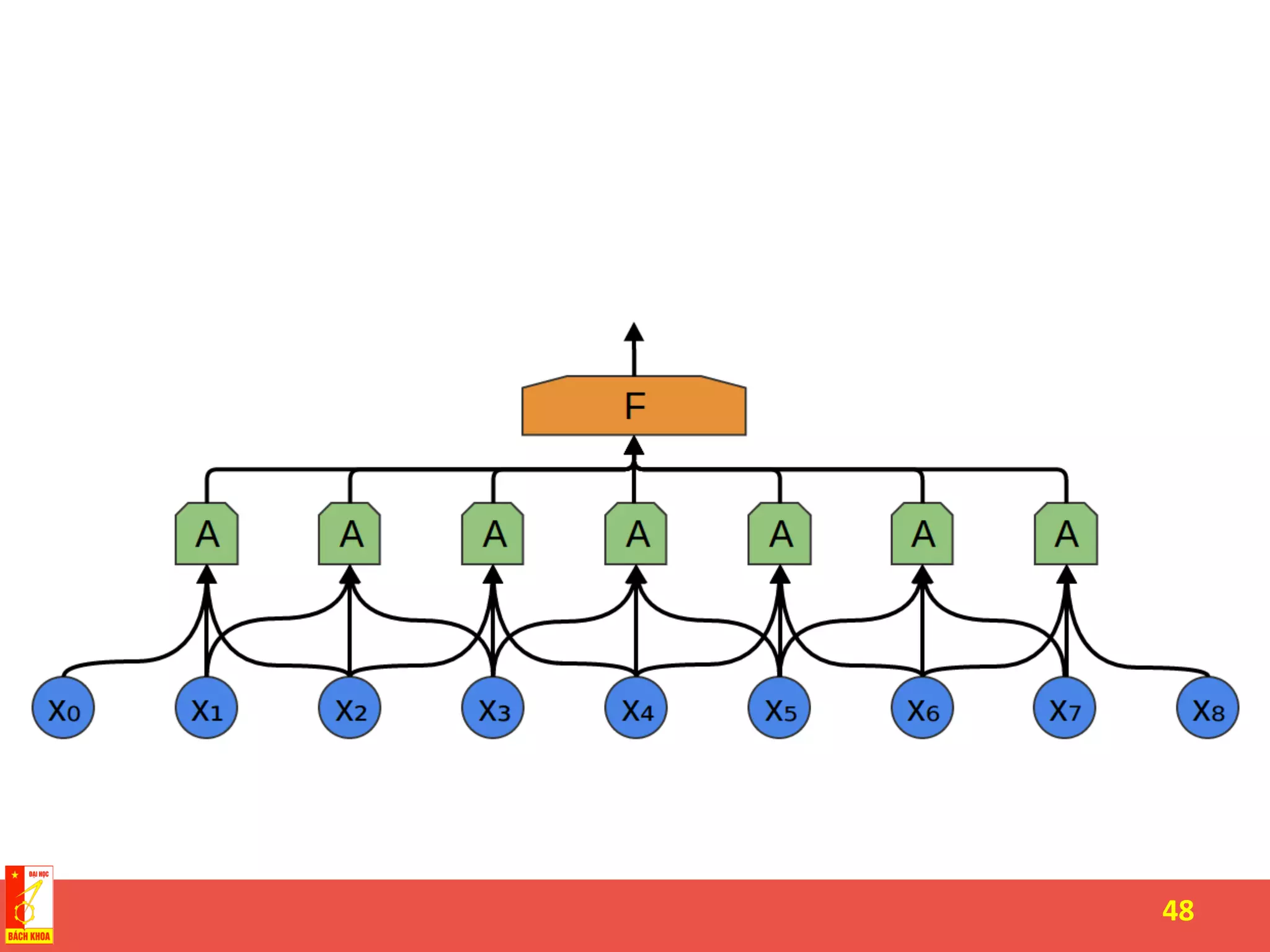
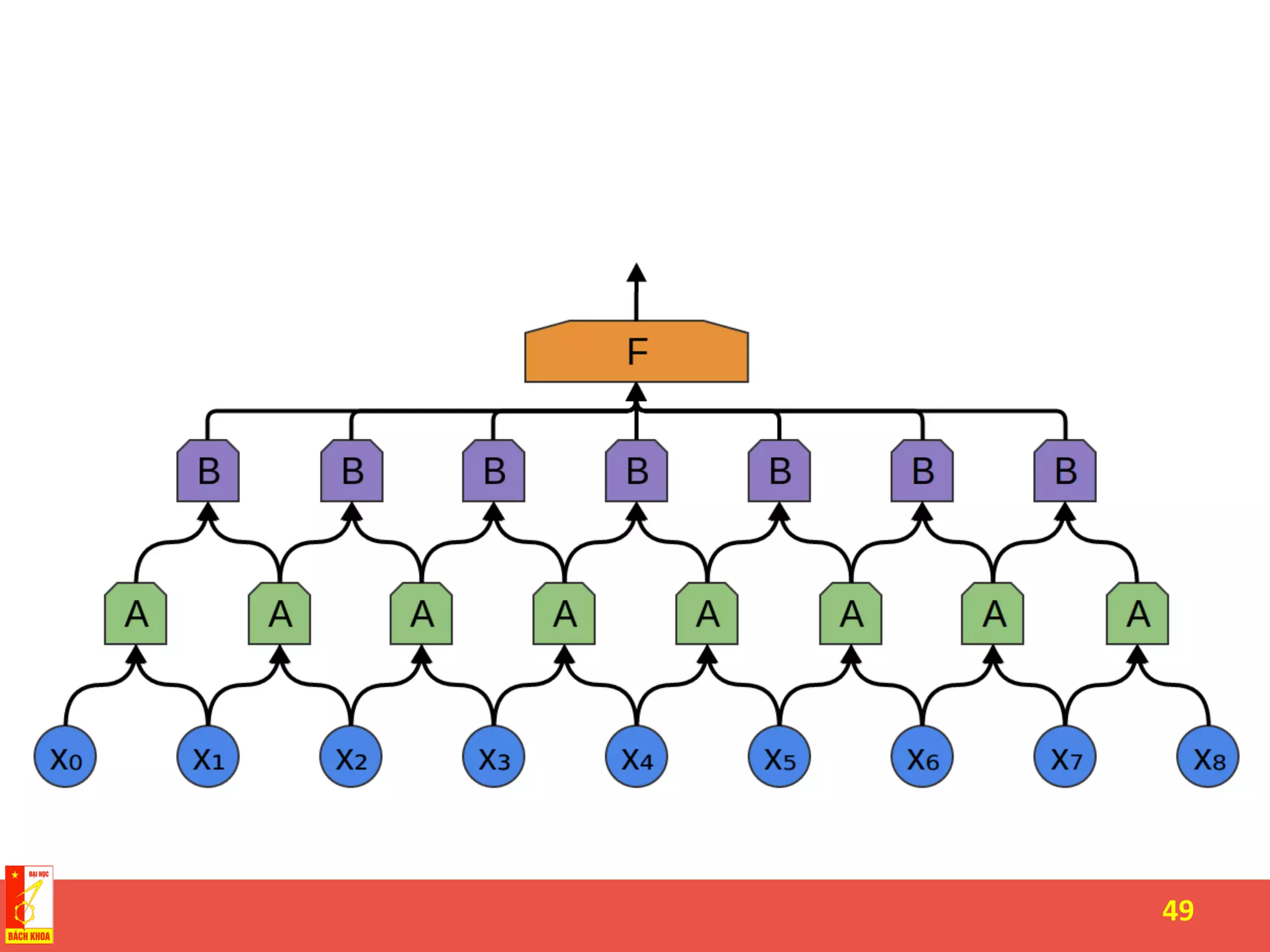
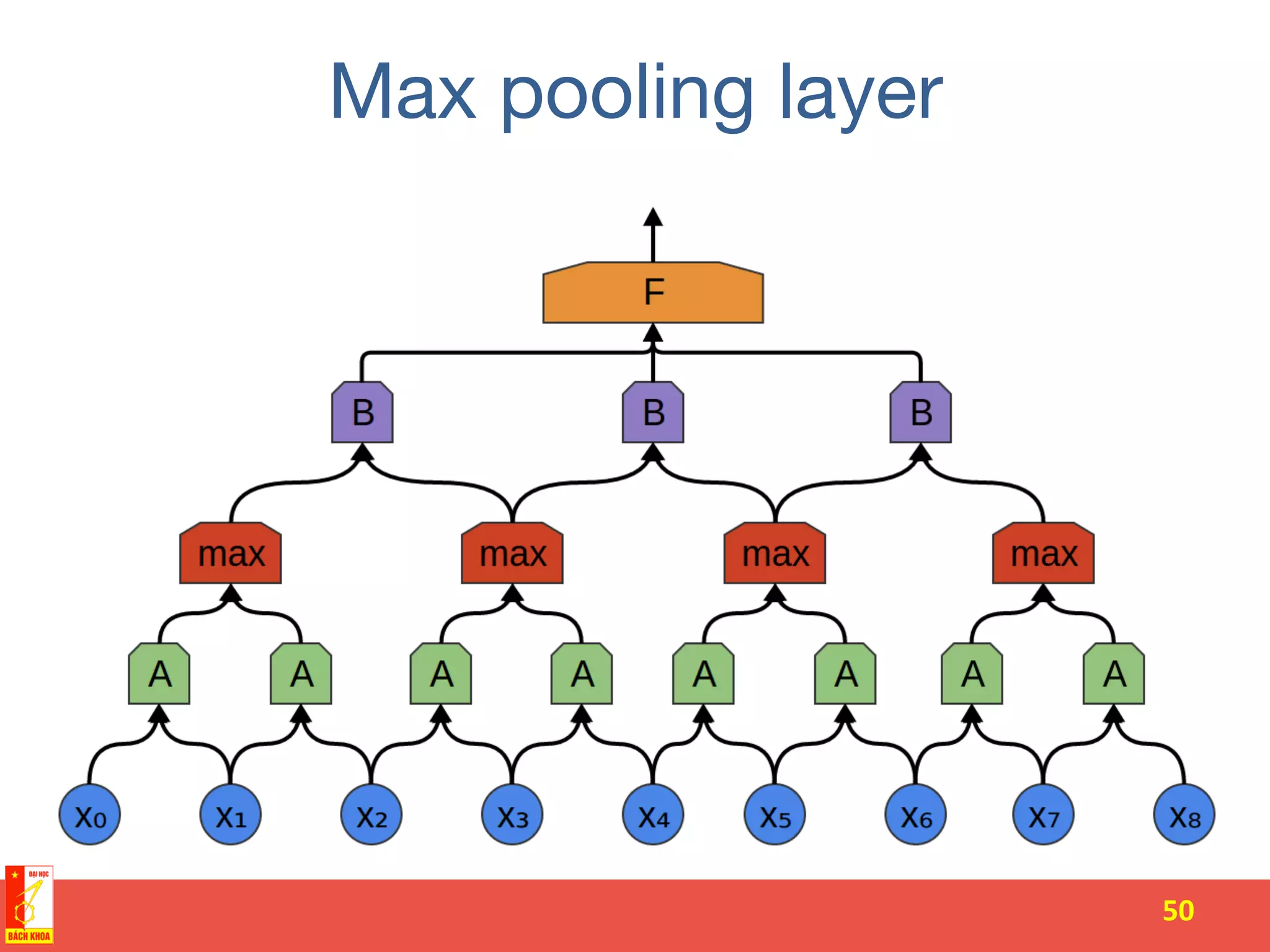
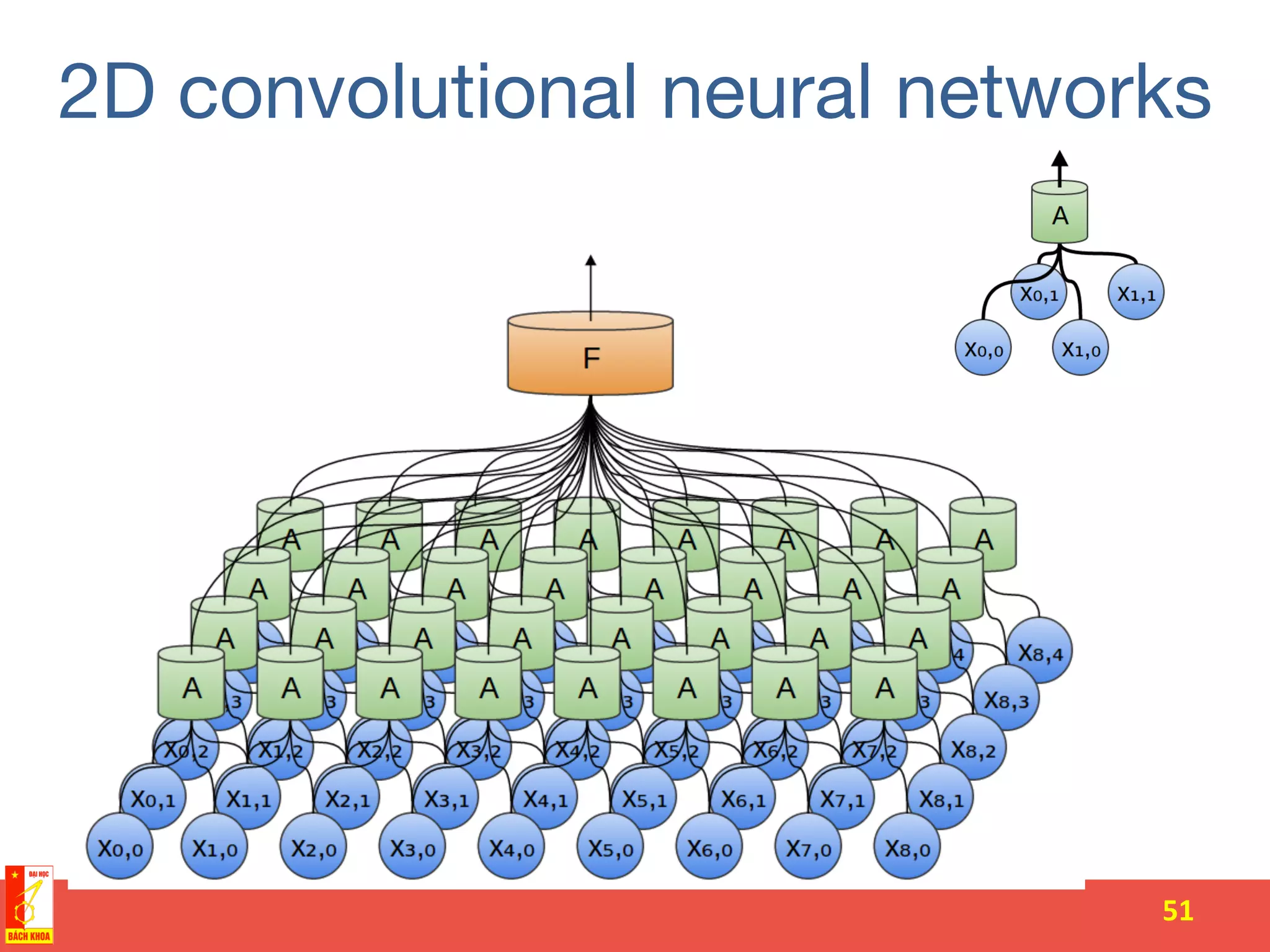
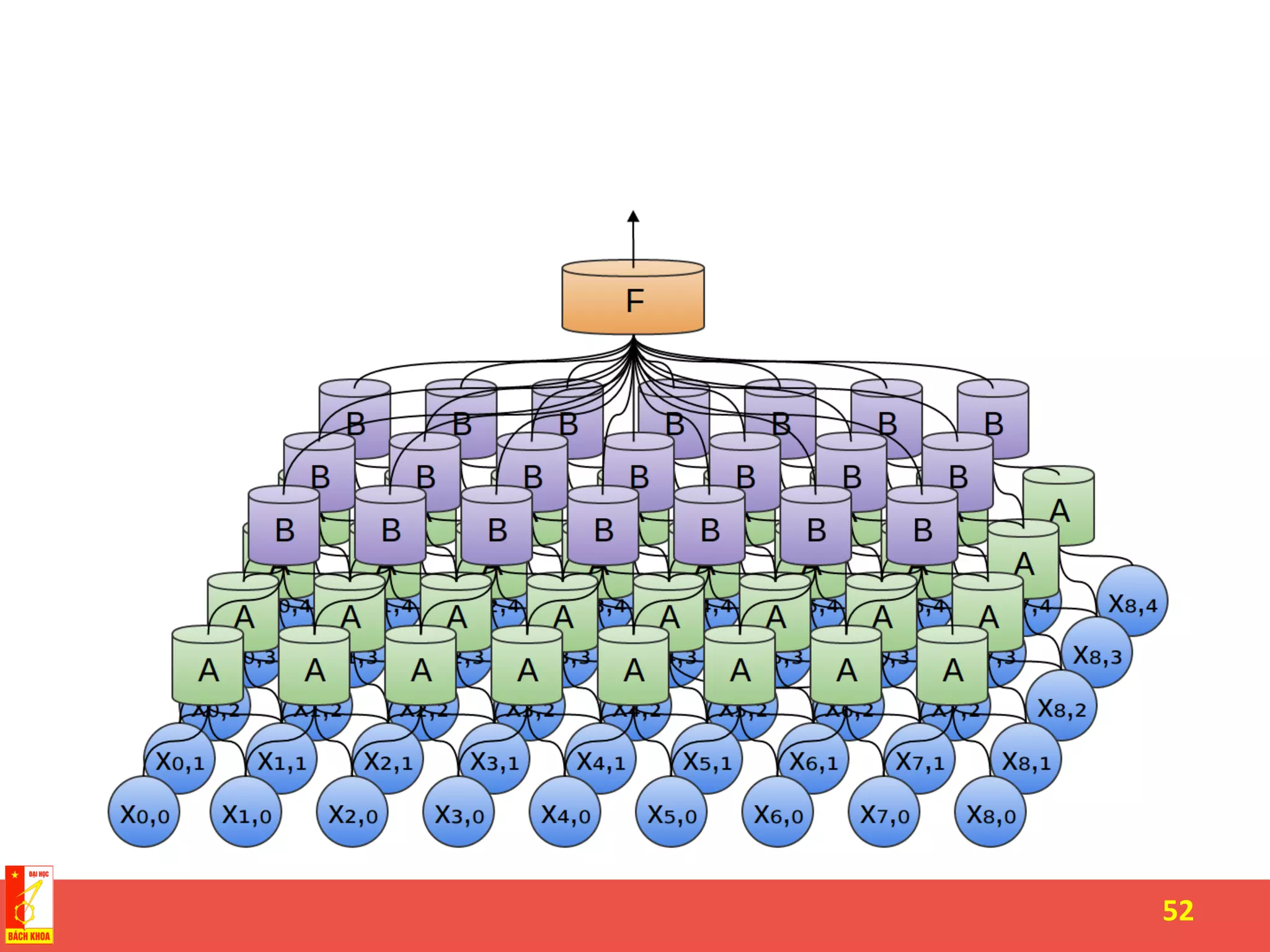
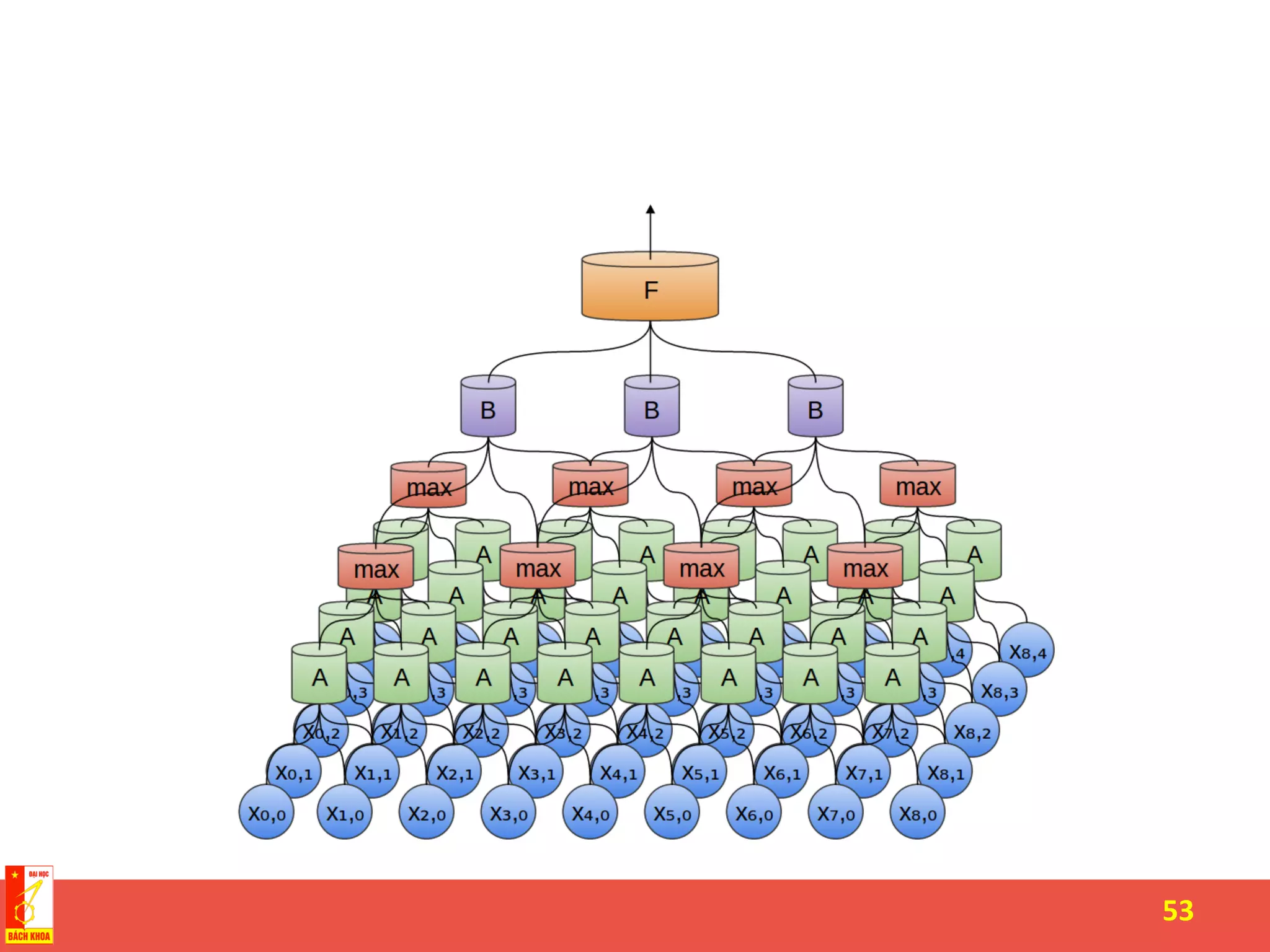
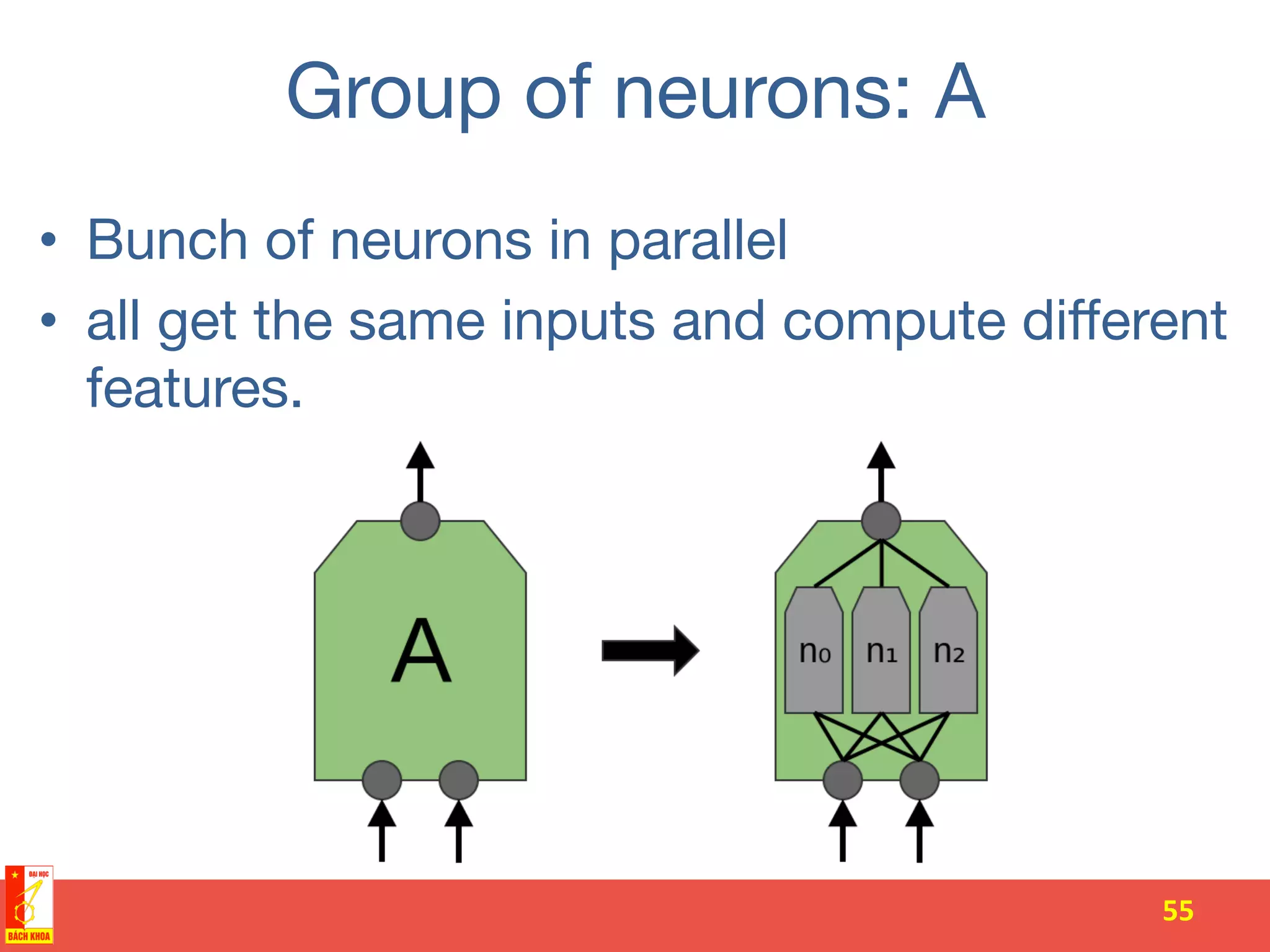
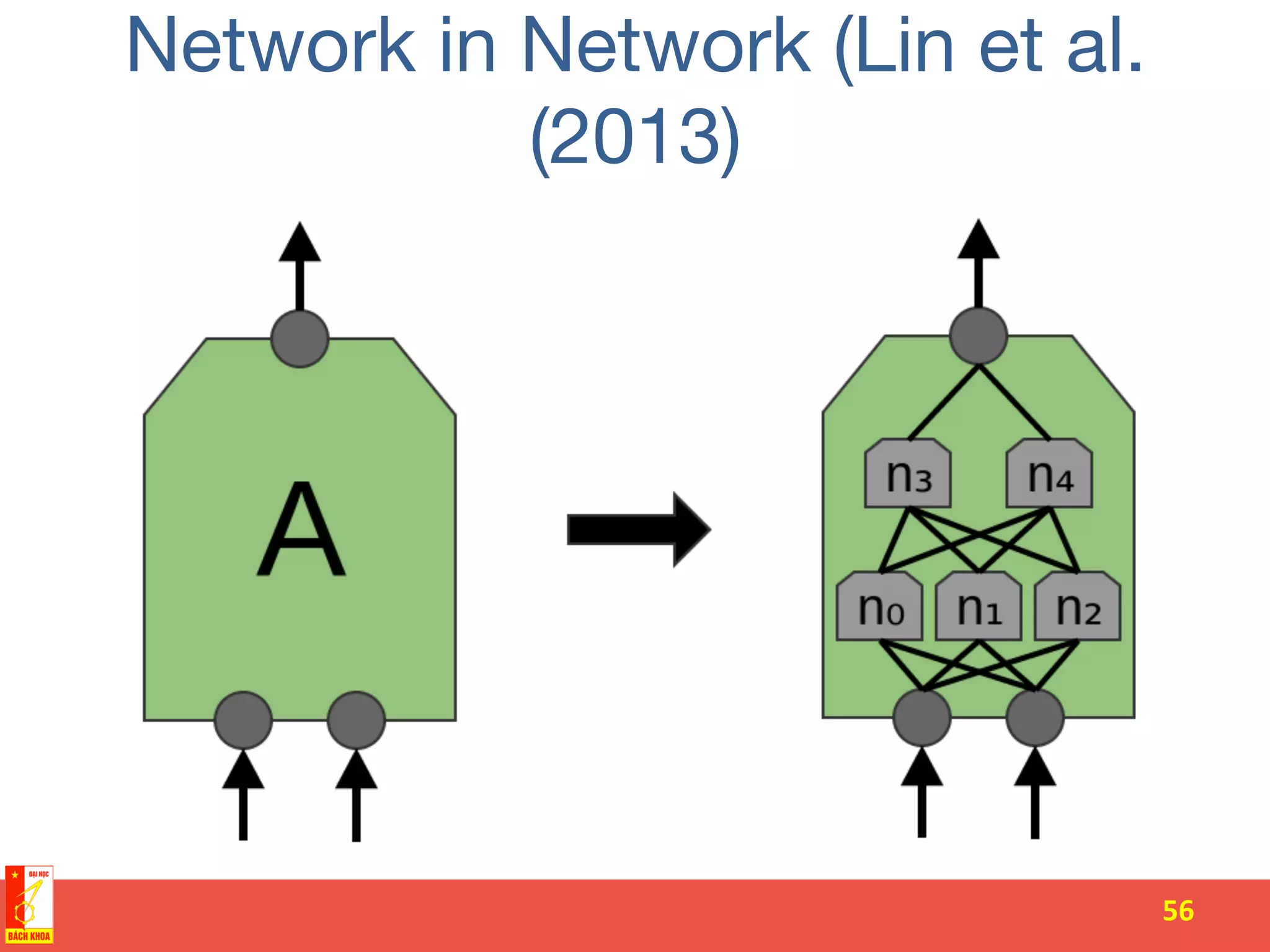
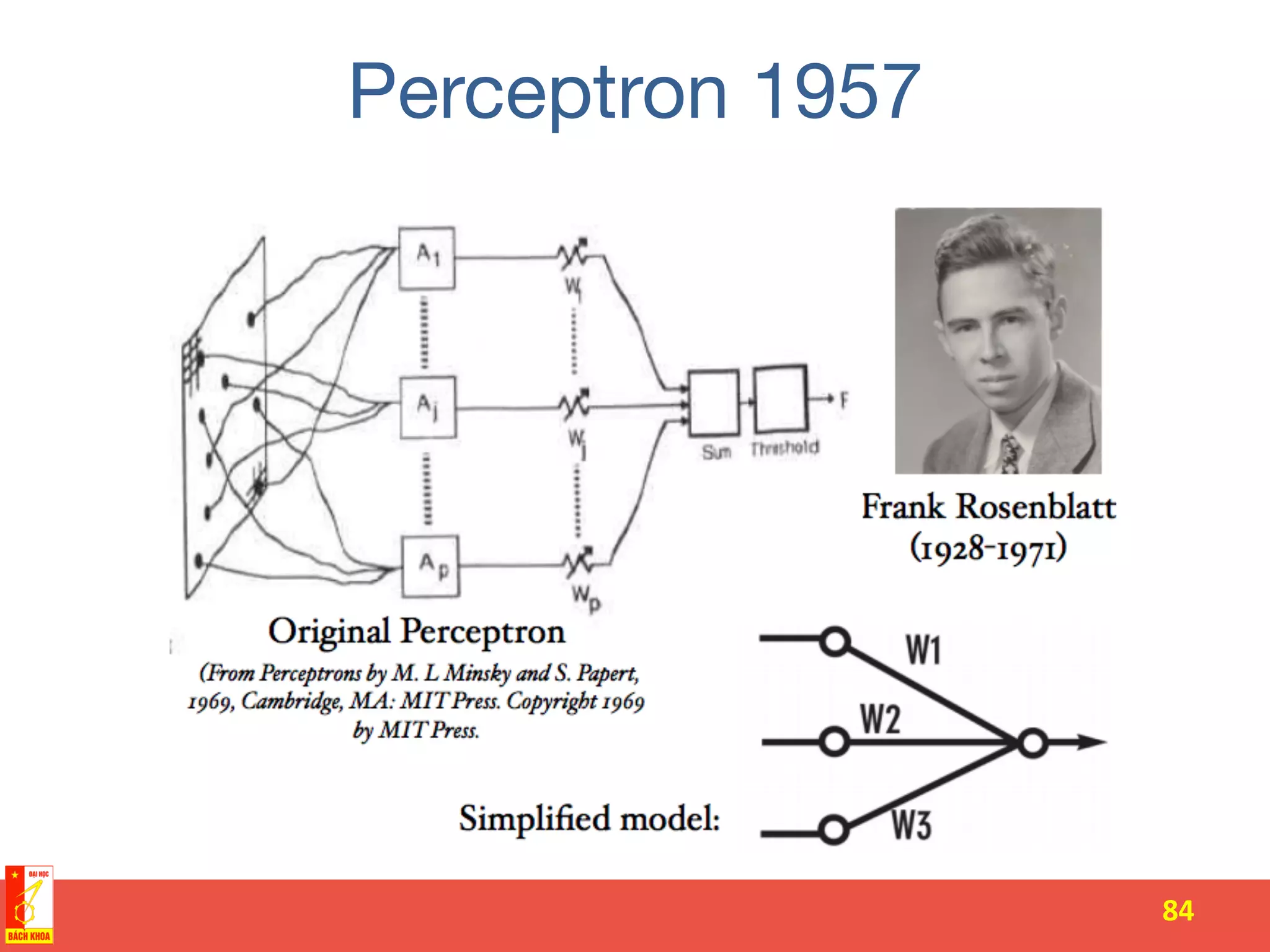
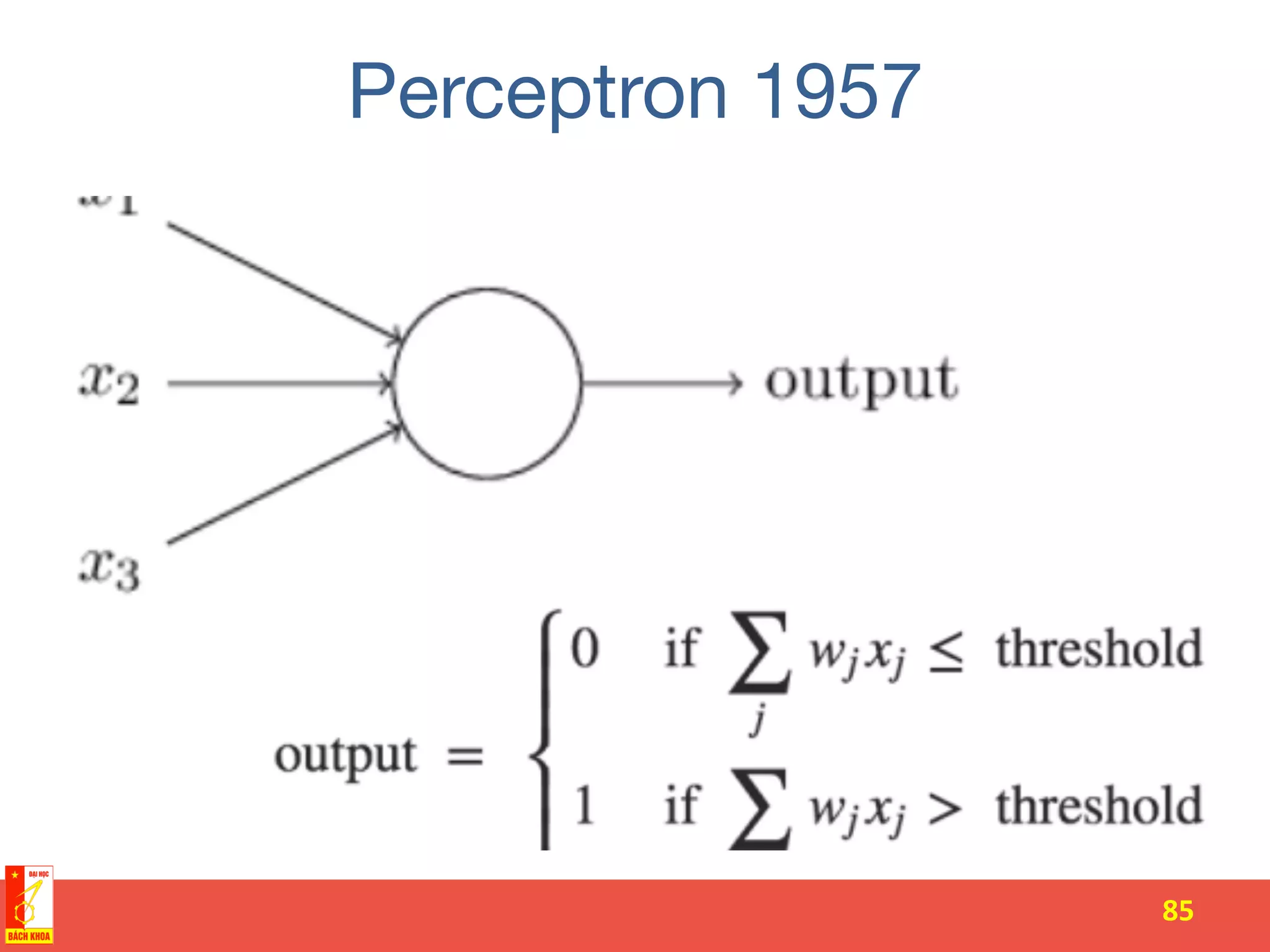
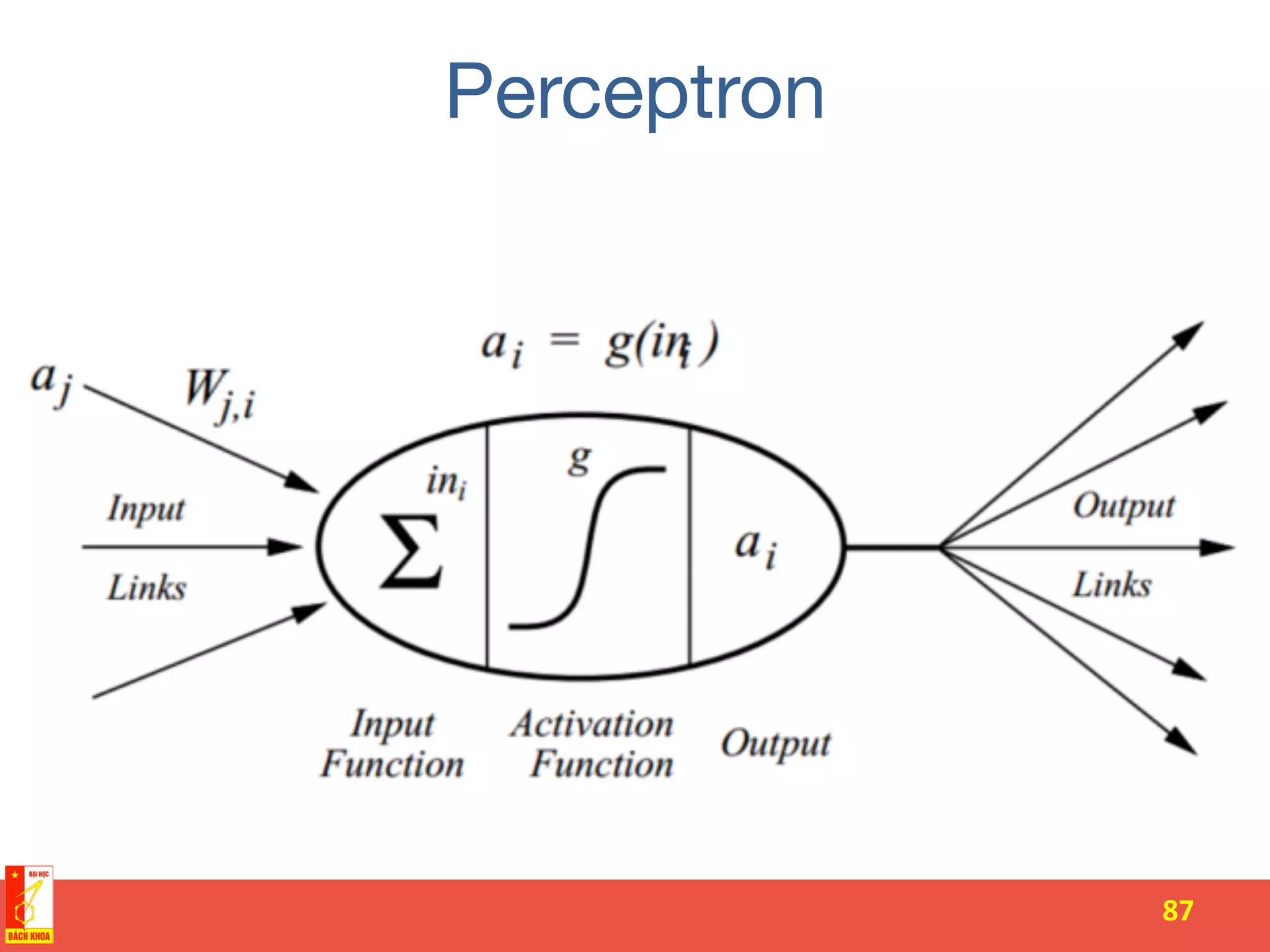
The document discusses the history and development of artificial neural networks and deep learning. It describes early neural network models like perceptrons from the 1950s and their use of weighted sums and activation functions. It then explains how additional developments led to modern deep learning architectures like convolutional neural networks and recurrent neural networks, which use techniques such as hidden layers, backpropagation, and word embeddings to learn from large datasets.























































































