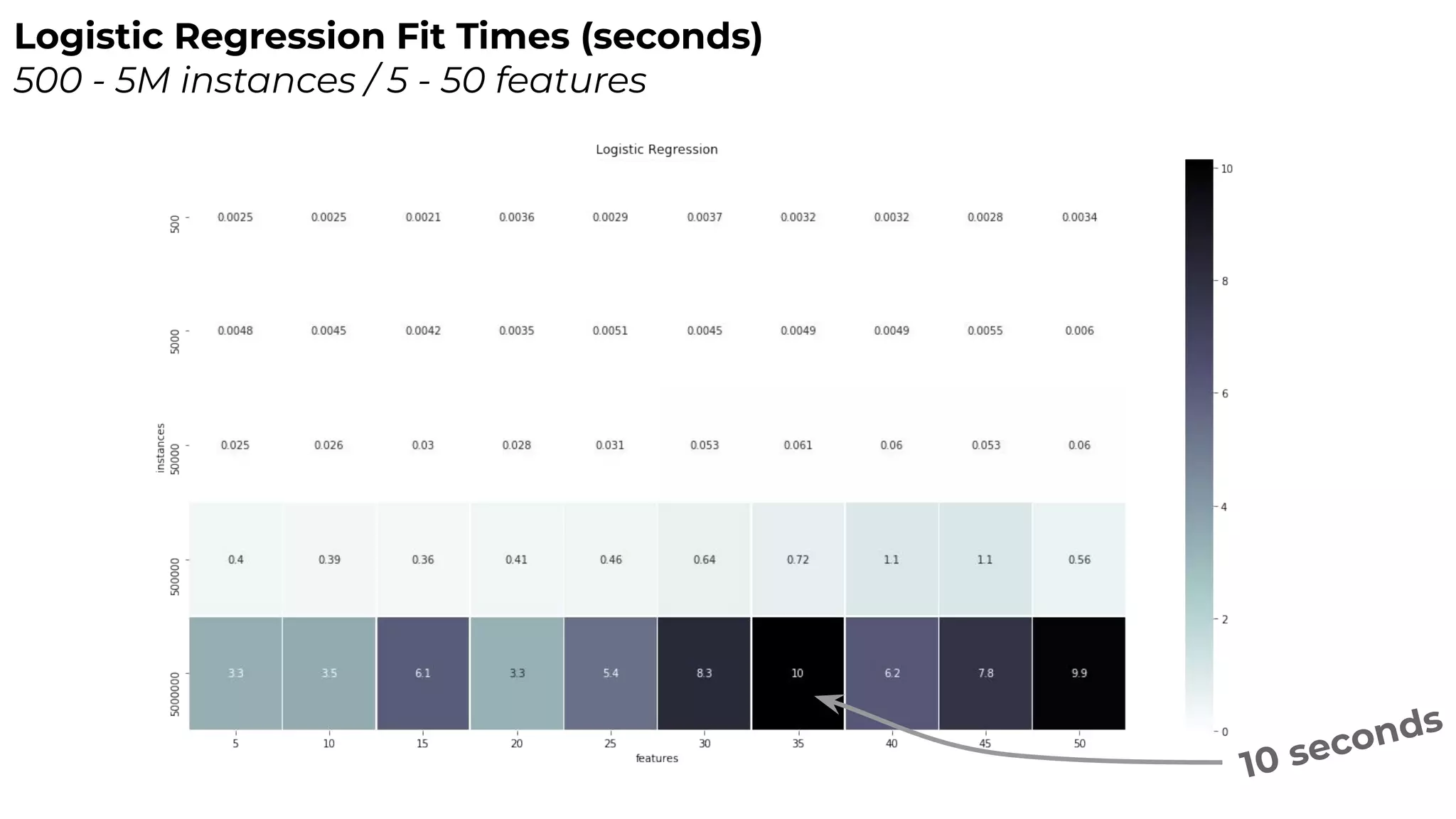
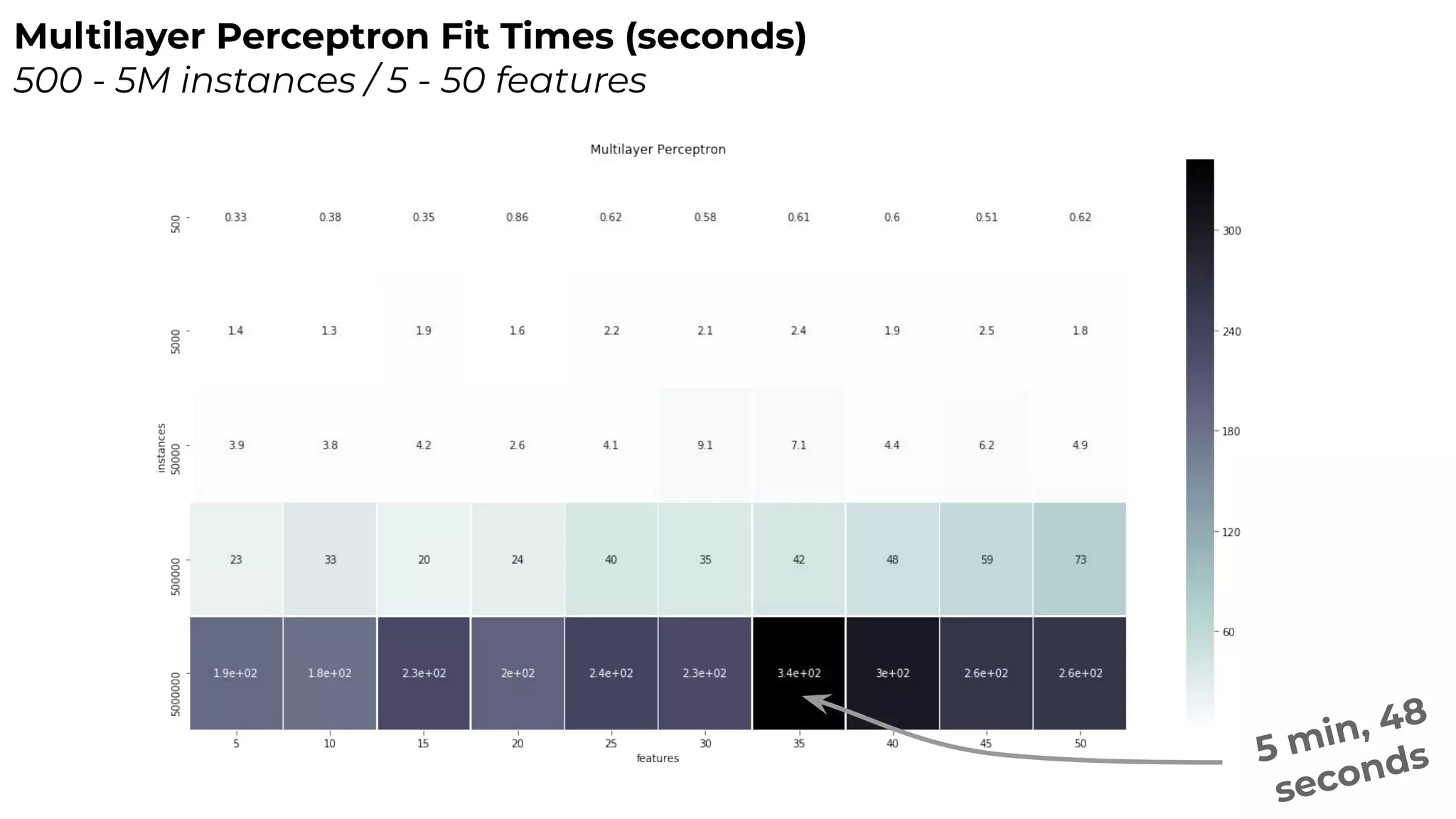
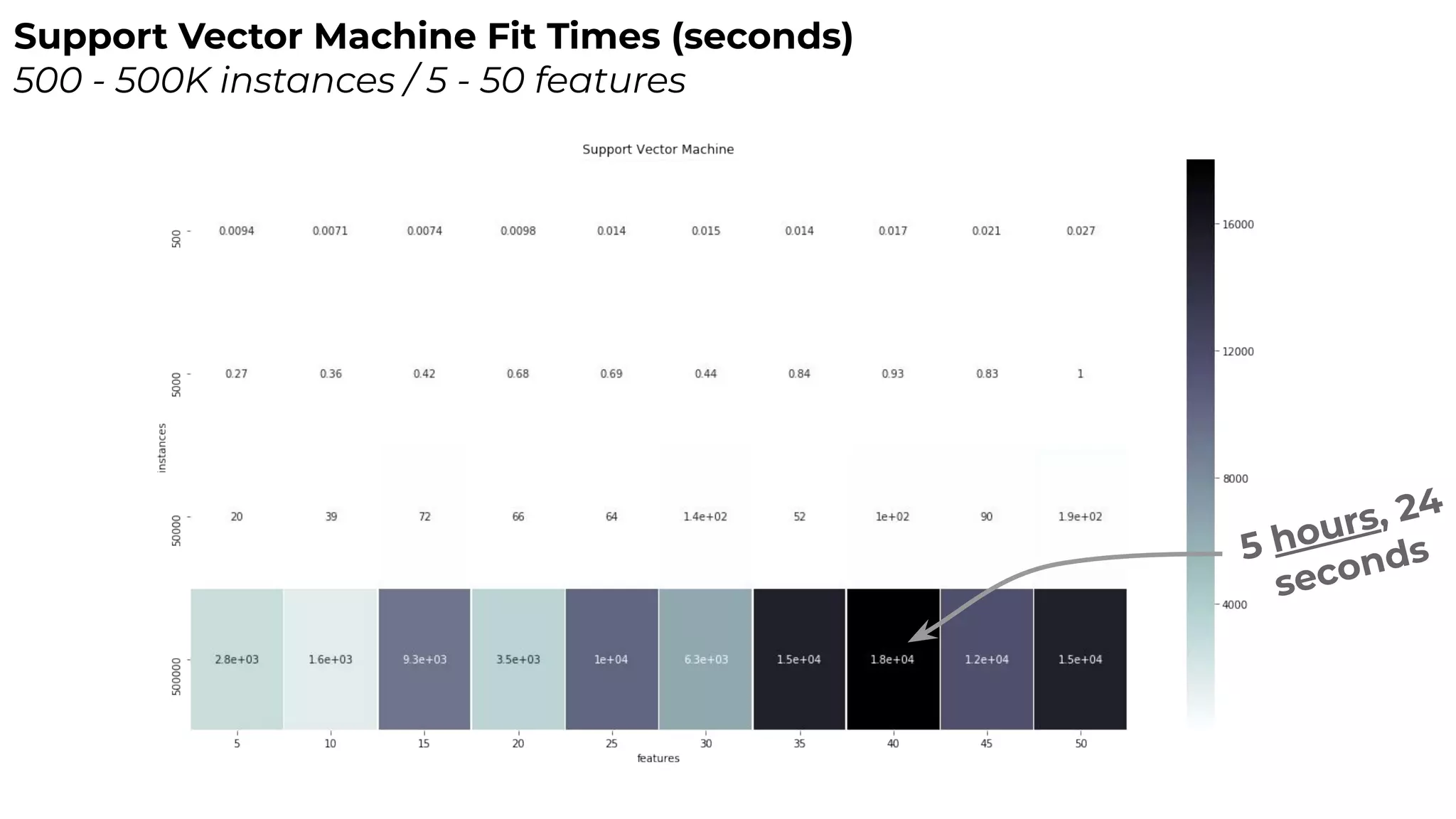
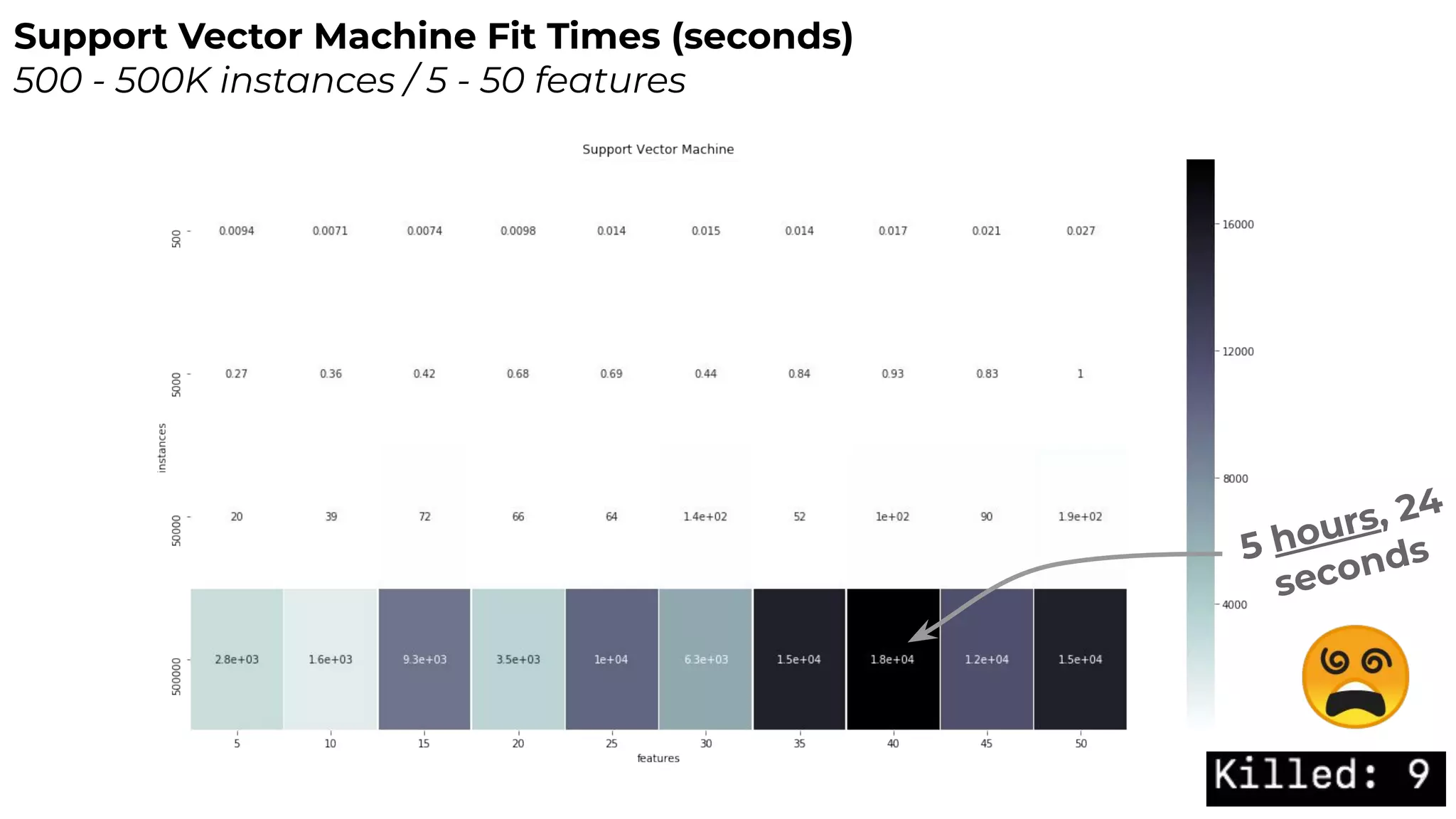
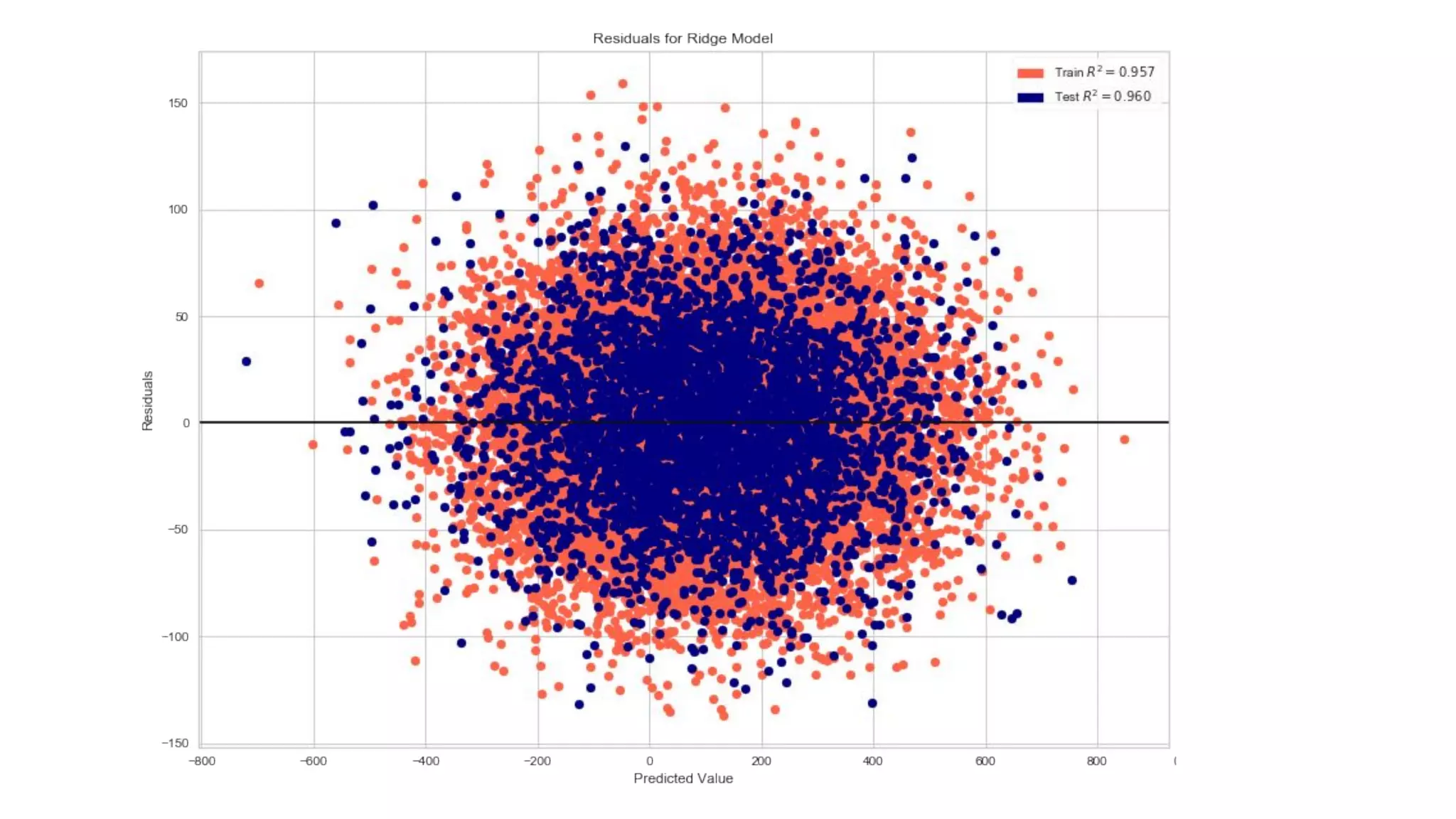
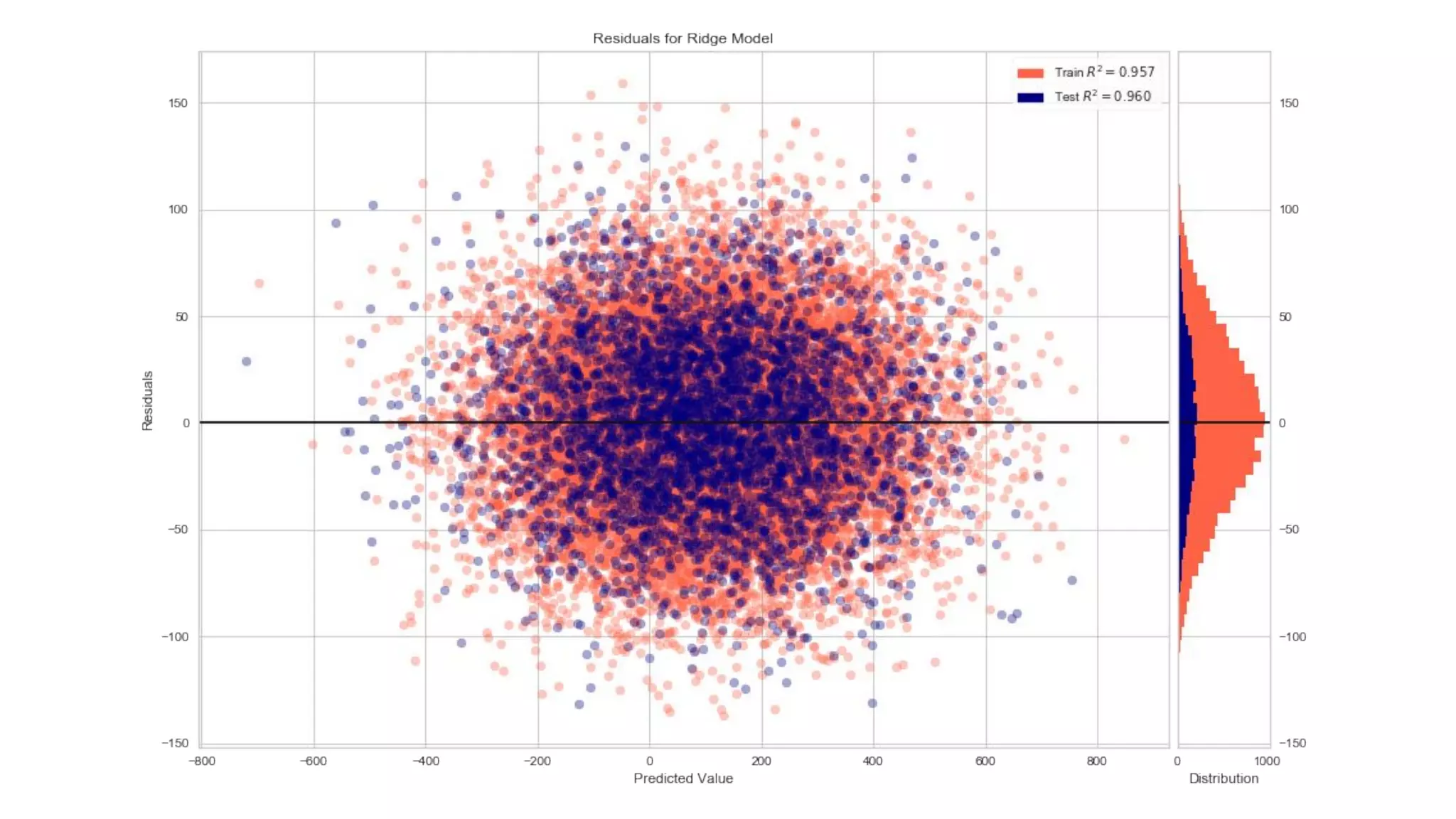
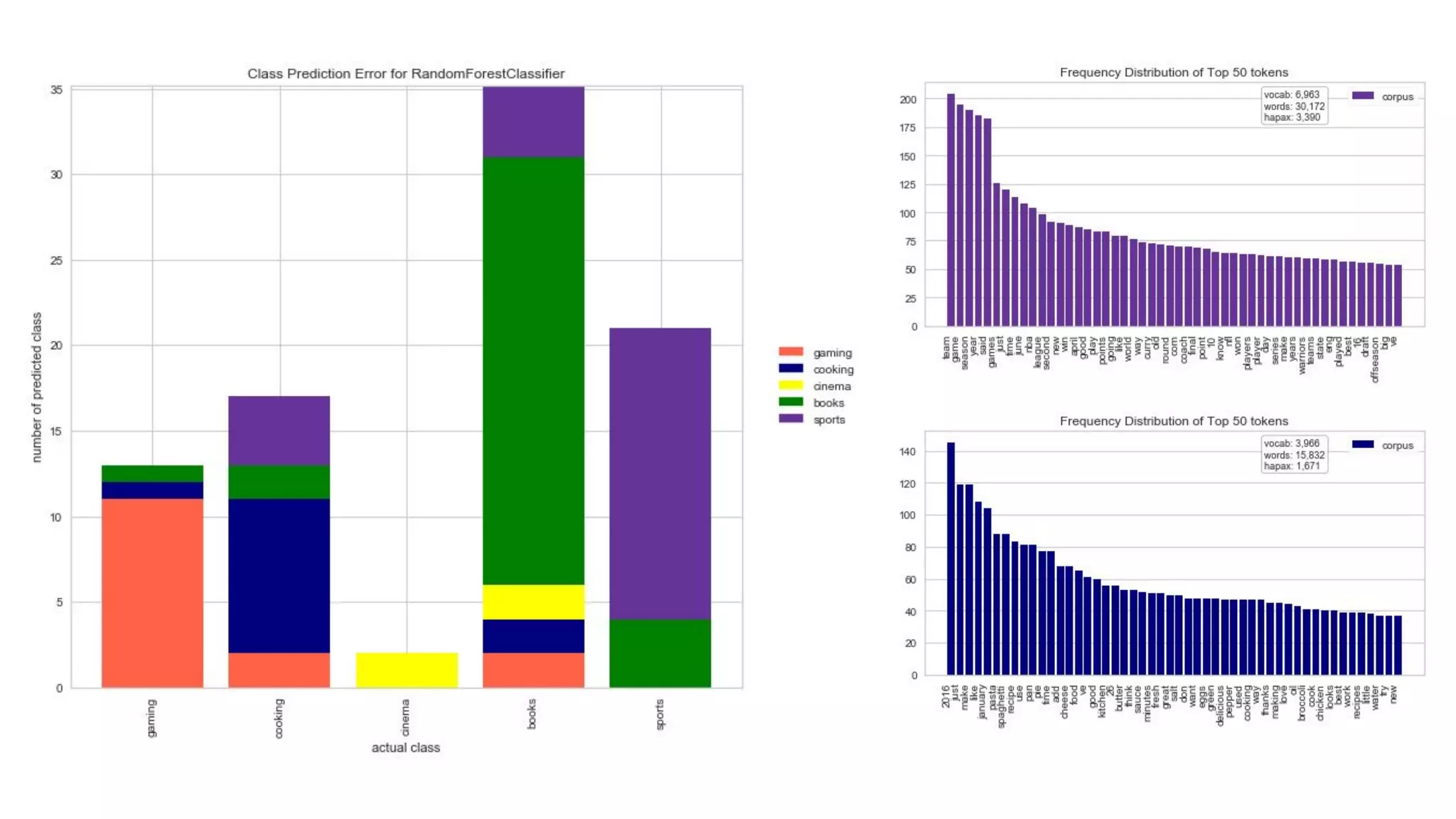
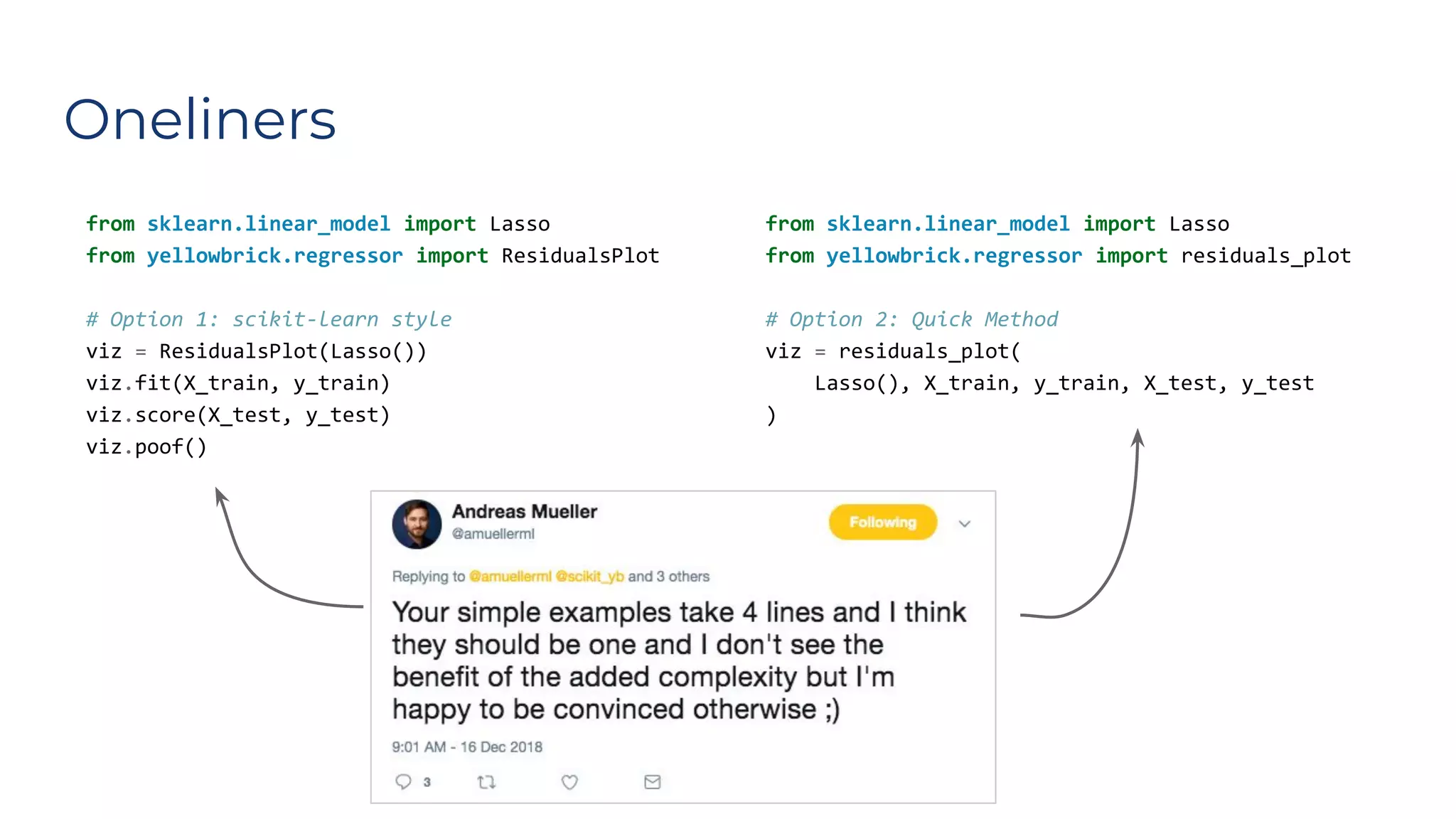
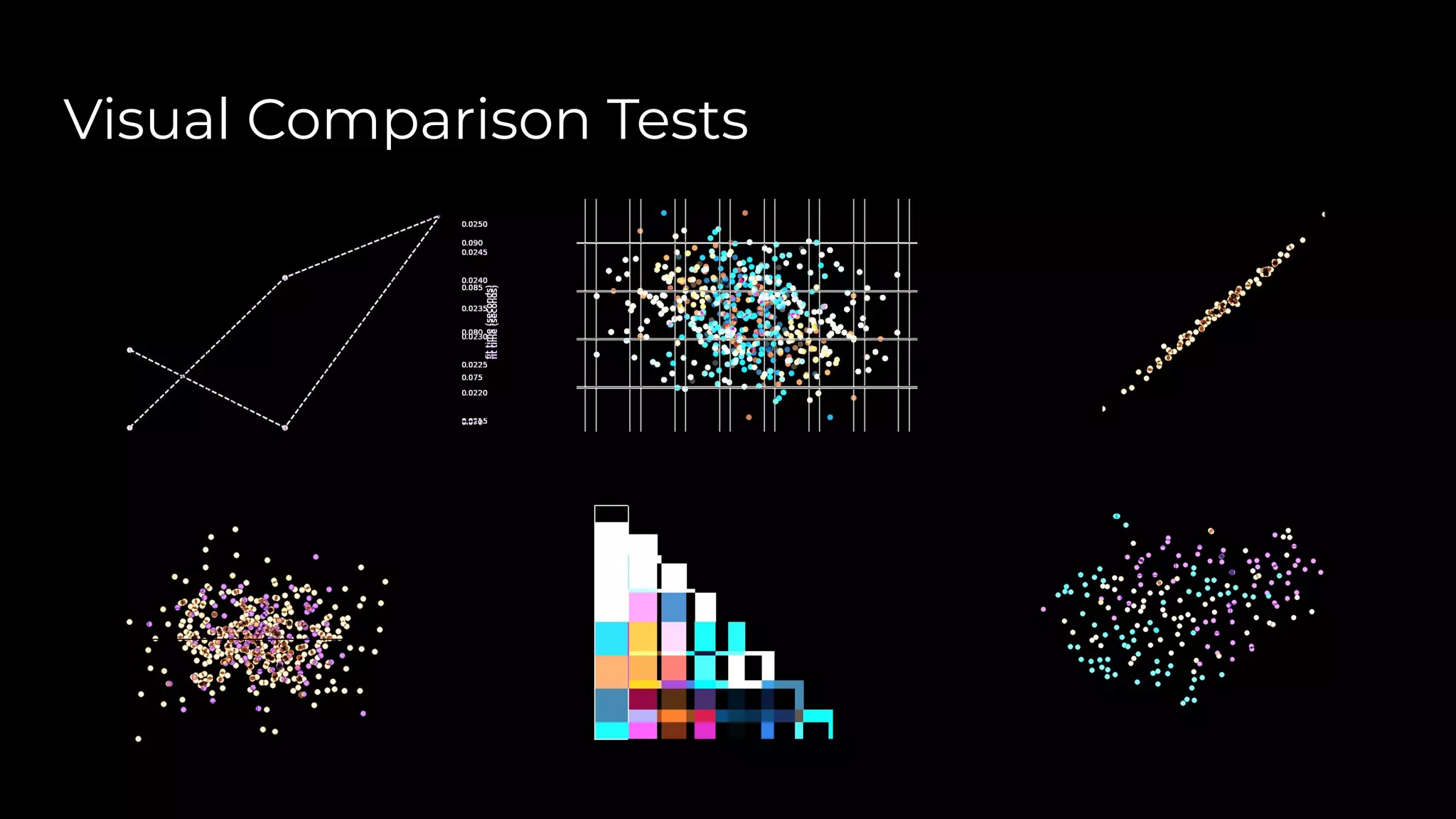
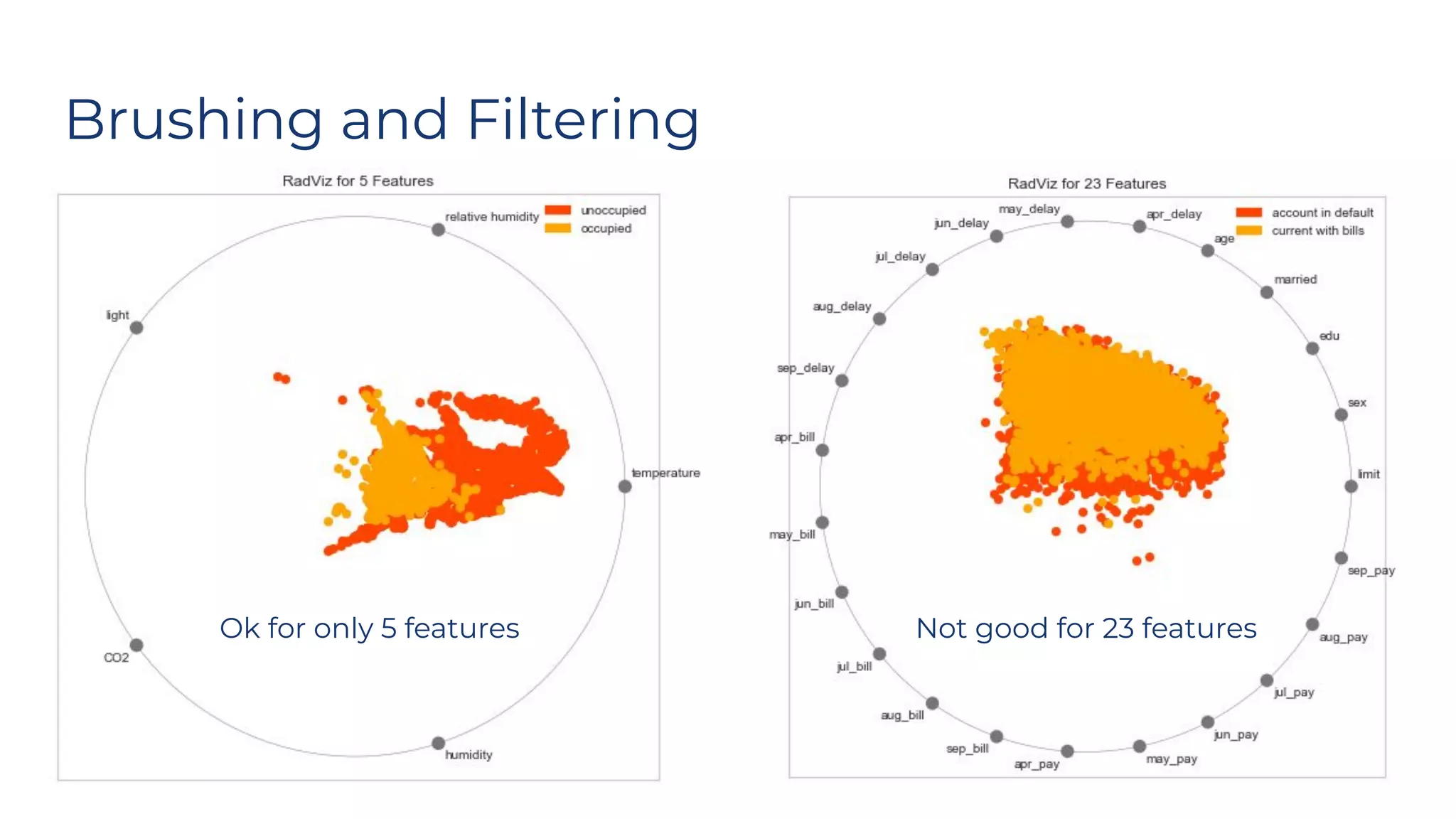
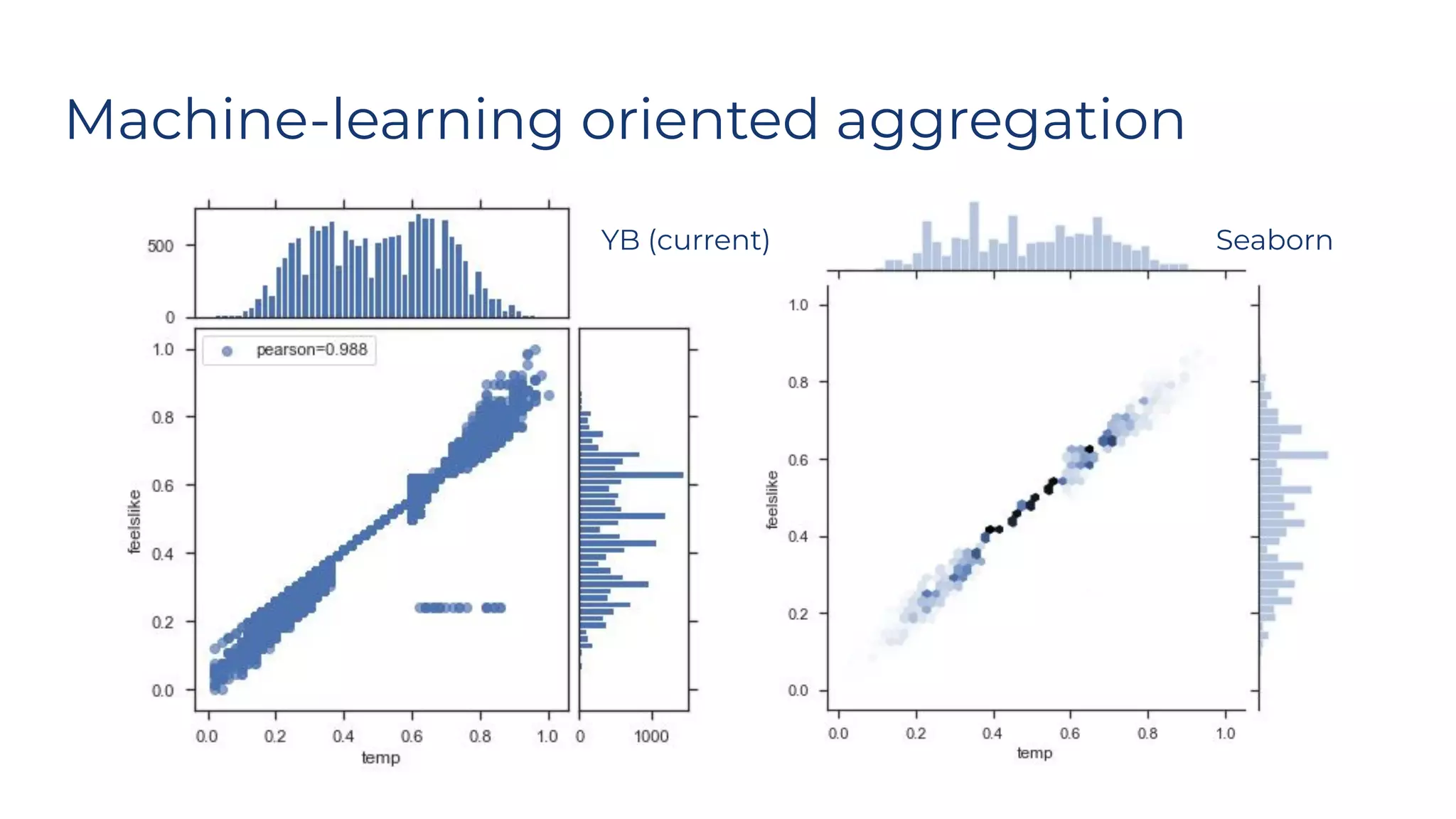
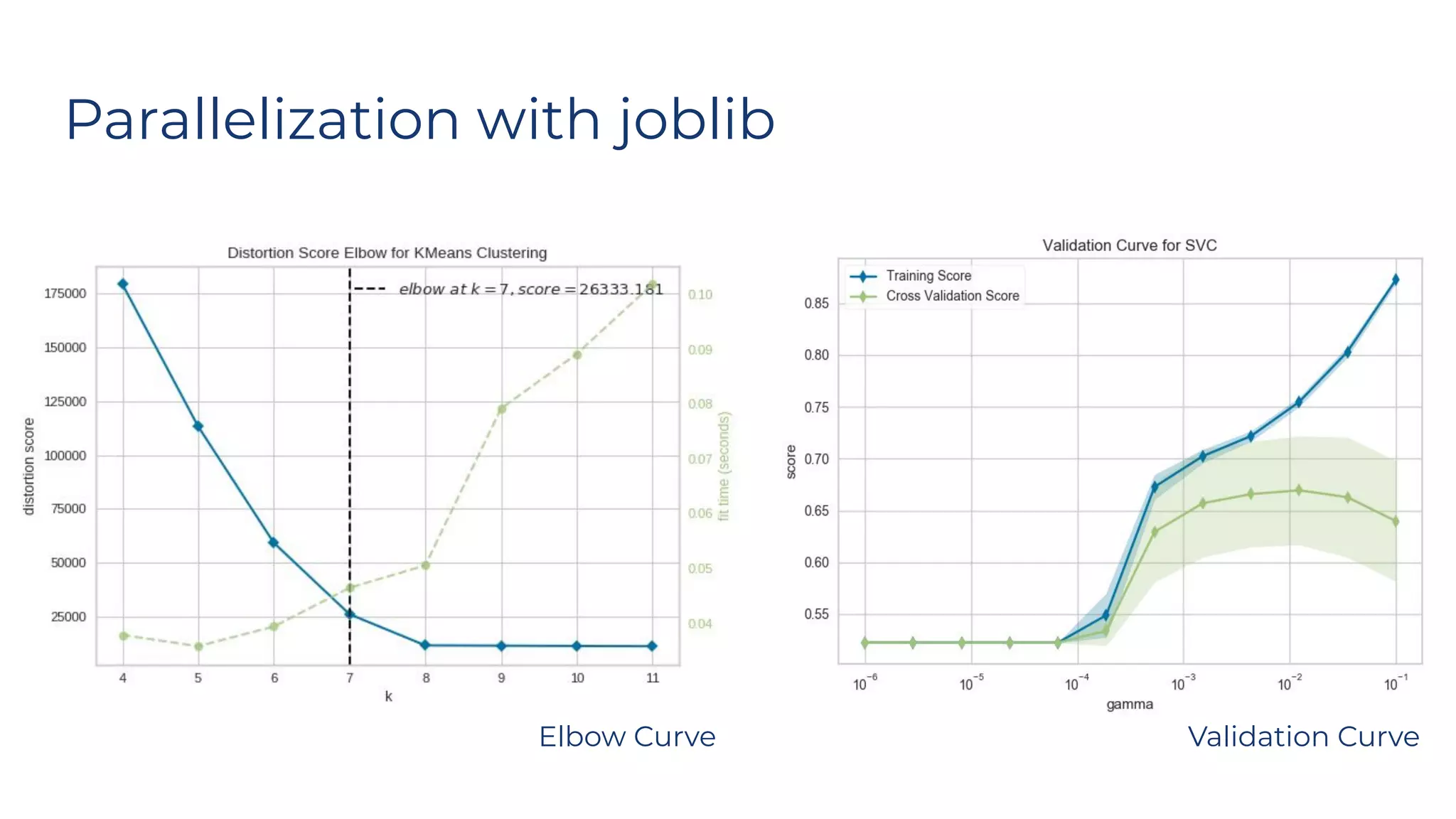
Dr. Rebecca Bilbro discusses visual diagnostics at scale using three datasets, highlighting the challenges of large datasets in machine learning such as feature variance and fit times for different models. The talk emphasizes the importance of model visualization and introduces components of the Scikit-learn and Yellowbrick libraries for effective data analysis and visualization. The presentation concludes with insights on optimizing machine learning pipelines and the use of visualizations to guide model selection.








![import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from yellowbrick.features import ParallelCoordinates
data = load_iris()
oz = ParallelCoordinates(ax=axes[idx], fast=True)
oz.fit_transform(data.data, data.target)
oz.finalize()
Each point drawn individually
as connected line segment
With standardization
Points grouped by class, each class
drawn as single segment](https://image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-15-2048.jpg)

![class Estimator(object):
def fit(self, X, y=None):
"""
Fits estimator to data.
"""
# set state of self
return self
def predict(self, X):
"""
Predict response of X
"""
# compute predictions pred
return pred
class Transformer(Estimator):
def transform(self, X):
"""
Transforms the input data.
"""
# transform X to X_prime
return X_prime
class Pipeline(Transfomer):
@property
def named_steps(self):
"""
Returns a sequence of estimators
"""
return self.steps
@property
def _final_estimator(self):
"""
Terminating estimator
"""
return self.steps[-1]
The scikit-learn API
self.X](https://image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-18-2048.jpg)

![=========================================== test session starts ============================================
platform darwin -- Python 3.7.1, pytest-5.0.0, py-1.8.0, pluggy-0.12.0
rootdir: /Users/rbilbro/pyjects/yb, inifile: setup.cfg
plugins: flakes-4.0.0, cov-2.7.1
collected 932 items
tests/__init__.py s... [ 0%]
tests/base.py s [ 0%]
tests/conftest.py s [ 0%]
tests/fixtures.py s [ 0%]
tests/images.py s [ 0%]
tests/rand.py s [ 0%]
tests/test_base.py s............ [ 2%]
...........................................................................................................
...........................................................................................................
...........................................................................................................
...........................................................................................................
tests/test_utils/test_target.py s............ [ 68%]
tests/test_utils/test_timer.py s..... [ 68%]
tests/test_utils/test_types.py s.................................................................... [ 70%]
....x................................x.............................................................. [ 72%]
.... [ 73%]
tests/test_utils/test_wrapper.py s....
===================== 854 passed, 72 skipped, 6 xfailed, 33 warnings in 225.96 seconds =====================](https://image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-22-2048.jpg)

![from yellowbrick.features import Rank2D
from yellowbrick.pipeline import VisualPipeline
from yellowbrick.model_selection import CVScores
from yellowbrick.regressor import PredictionError
viz_pipe = VisualPipeline([
('rank2d', Rank2D(features=features, algorithm='covariance')),
('prederr', PredictionError(model)),
('cvscores', CVScores(model, cv=cv, scoring='r2'))
])
Visual
Pipelines](https://image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-27-2048.jpg)

















![import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from yellowbrick.features import ParallelCoordinates
data = load_iris()
oz = ParallelCoordinates(ax=axes[idx], fast=True)
oz.fit_transform(data.data, data.target)
oz.finalize()
Each point drawn individually
as connected line segment
With standardization
Points grouped by class, each class
drawn as single segment](https://crownmelresort.com/image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-15-2048.jpg)


![class Estimator(object):
def fit(self, X, y=None):
"""
Fits estimator to data.
"""
# set state of self
return self
def predict(self, X):
"""
Predict response of X
"""
# compute predictions pred
return pred
class Transformer(Estimator):
def transform(self, X):
"""
Transforms the input data.
"""
# transform X to X_prime
return X_prime
class Pipeline(Transfomer):
@property
def named_steps(self):
"""
Returns a sequence of estimators
"""
return self.steps
@property
def _final_estimator(self):
"""
Terminating estimator
"""
return self.steps[-1]
The scikit-learn API
self.X](https://crownmelresort.com/image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-18-2048.jpg)



![=========================================== test session starts ============================================
platform darwin -- Python 3.7.1, pytest-5.0.0, py-1.8.0, pluggy-0.12.0
rootdir: /Users/rbilbro/pyjects/yb, inifile: setup.cfg
plugins: flakes-4.0.0, cov-2.7.1
collected 932 items
tests/__init__.py s... [ 0%]
tests/base.py s [ 0%]
tests/conftest.py s [ 0%]
tests/fixtures.py s [ 0%]
tests/images.py s [ 0%]
tests/rand.py s [ 0%]
tests/test_base.py s............ [ 2%]
...........................................................................................................
...........................................................................................................
...........................................................................................................
...........................................................................................................
tests/test_utils/test_target.py s............ [ 68%]
tests/test_utils/test_timer.py s..... [ 68%]
tests/test_utils/test_types.py s.................................................................... [ 70%]
....x................................x.............................................................. [ 72%]
.... [ 73%]
tests/test_utils/test_wrapper.py s....
===================== 854 passed, 72 skipped, 6 xfailed, 33 warnings in 225.96 seconds =====================](https://crownmelresort.com/image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-22-2048.jpg)




![from yellowbrick.features import Rank2D
from yellowbrick.pipeline import VisualPipeline
from yellowbrick.model_selection import CVScores
from yellowbrick.regressor import PredictionError
viz_pipe = VisualPipeline([
('rank2d', Rank2D(features=features, algorithm='covariance')),
('prederr', PredictionError(model)),
('cvscores', CVScores(model, cv=cv, scoring='r2'))
])
Visual
Pipelines](https://crownmelresort.com/image.slidesharecdn.com/visualdiagnosticsatscaleeuroscipy-190905093215/75/EuroSciPy-2019-Visual-diagnostics-at-scale-27-2048.jpg)



































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)
















