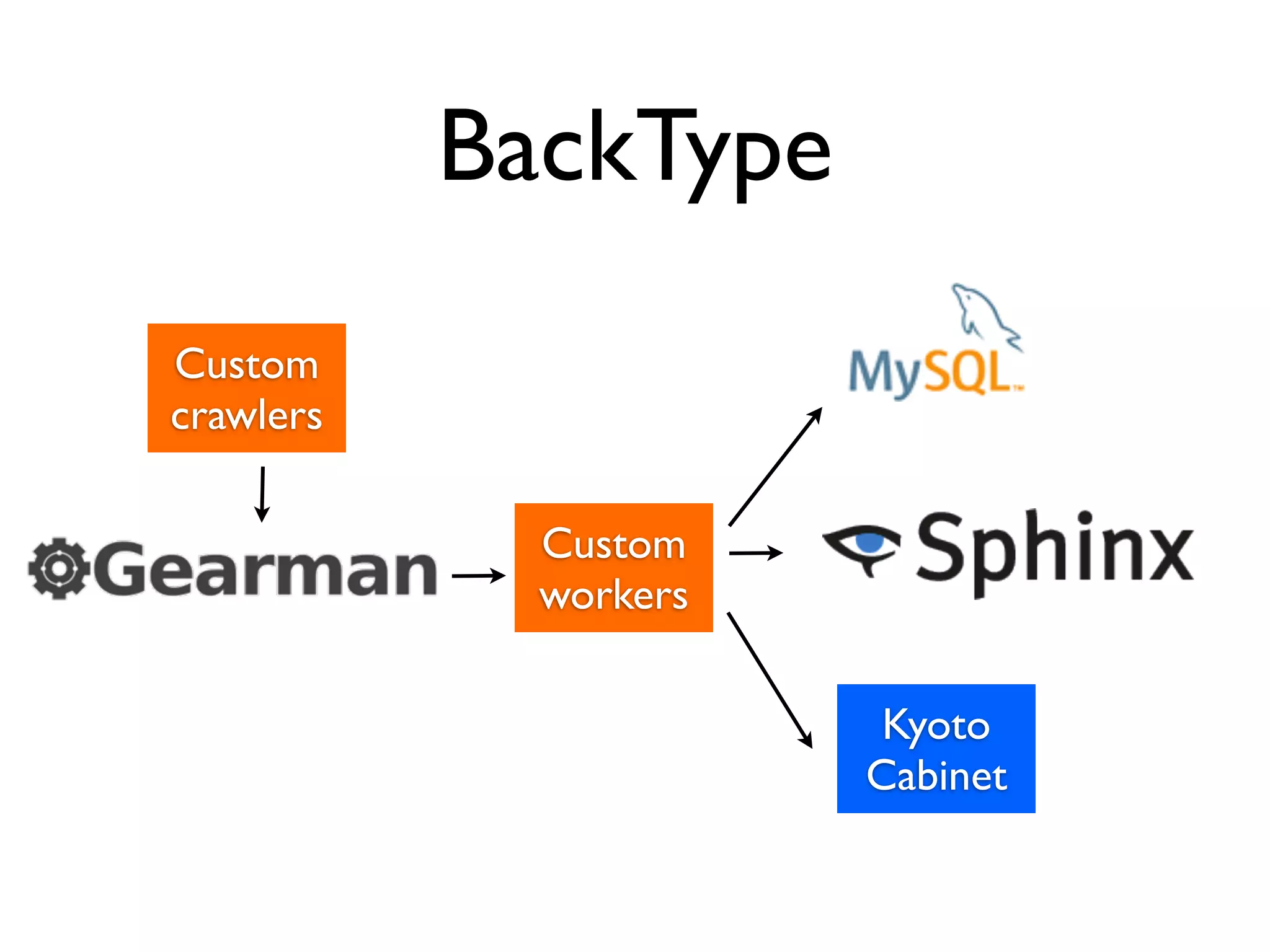
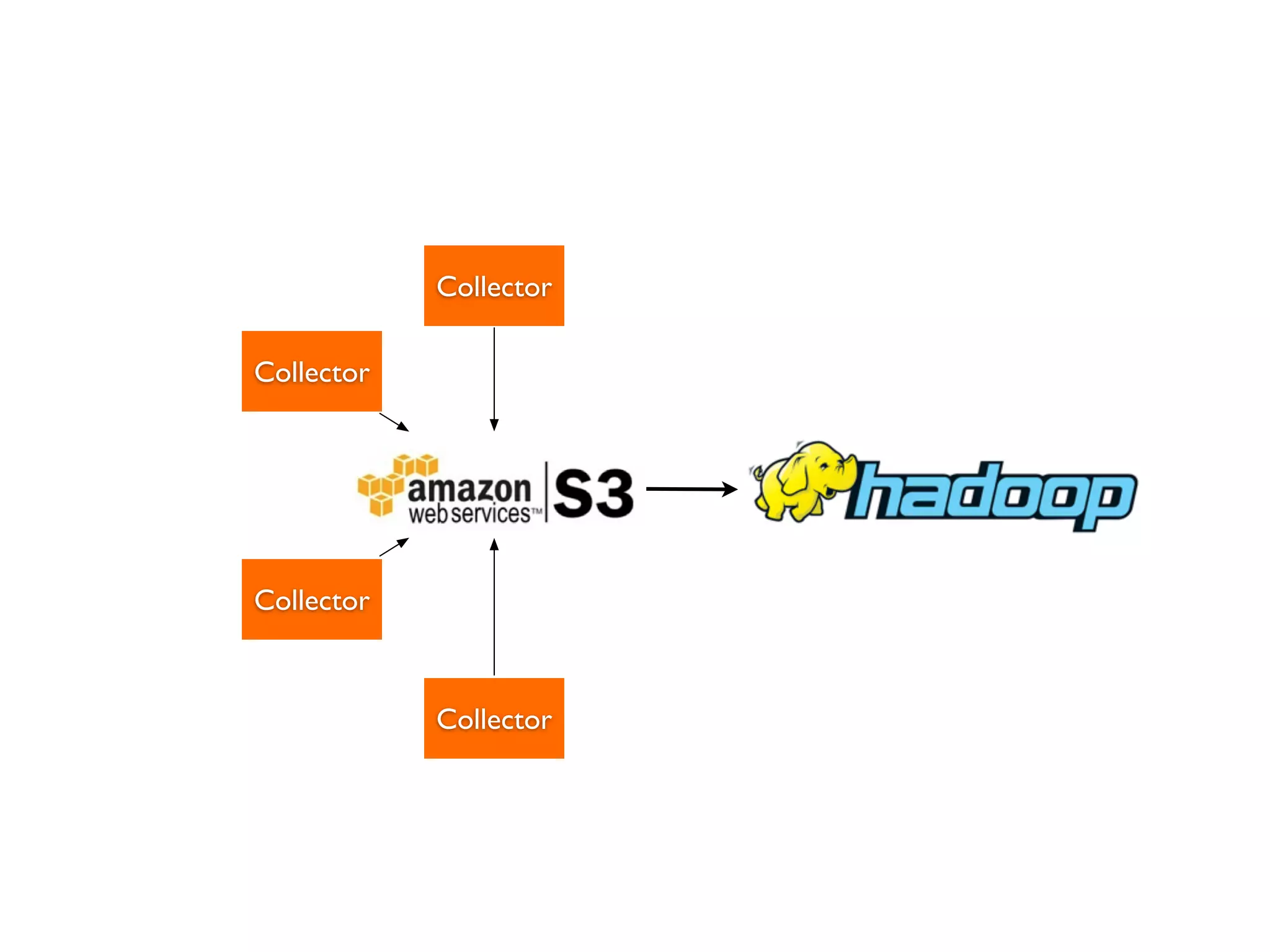
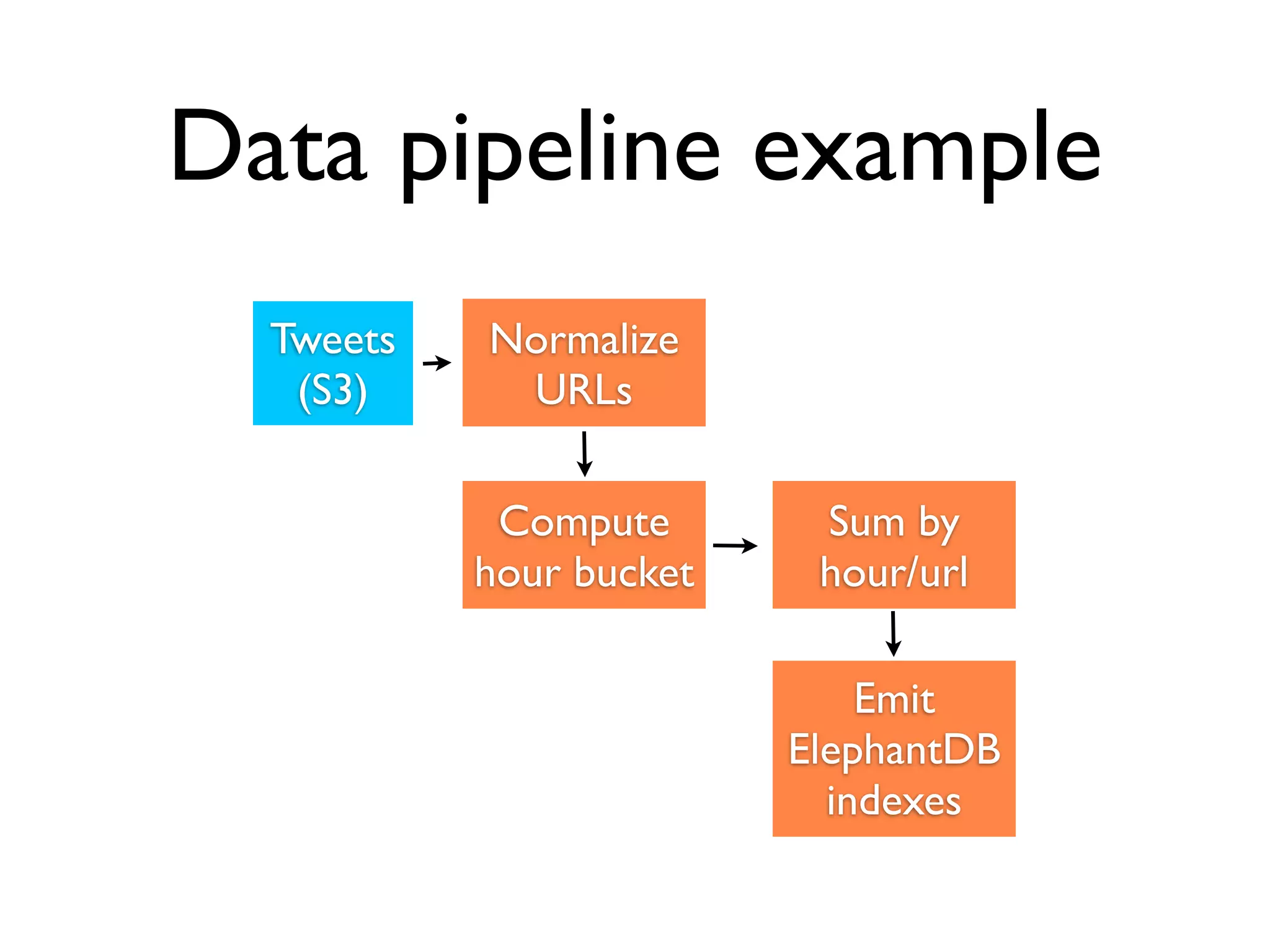
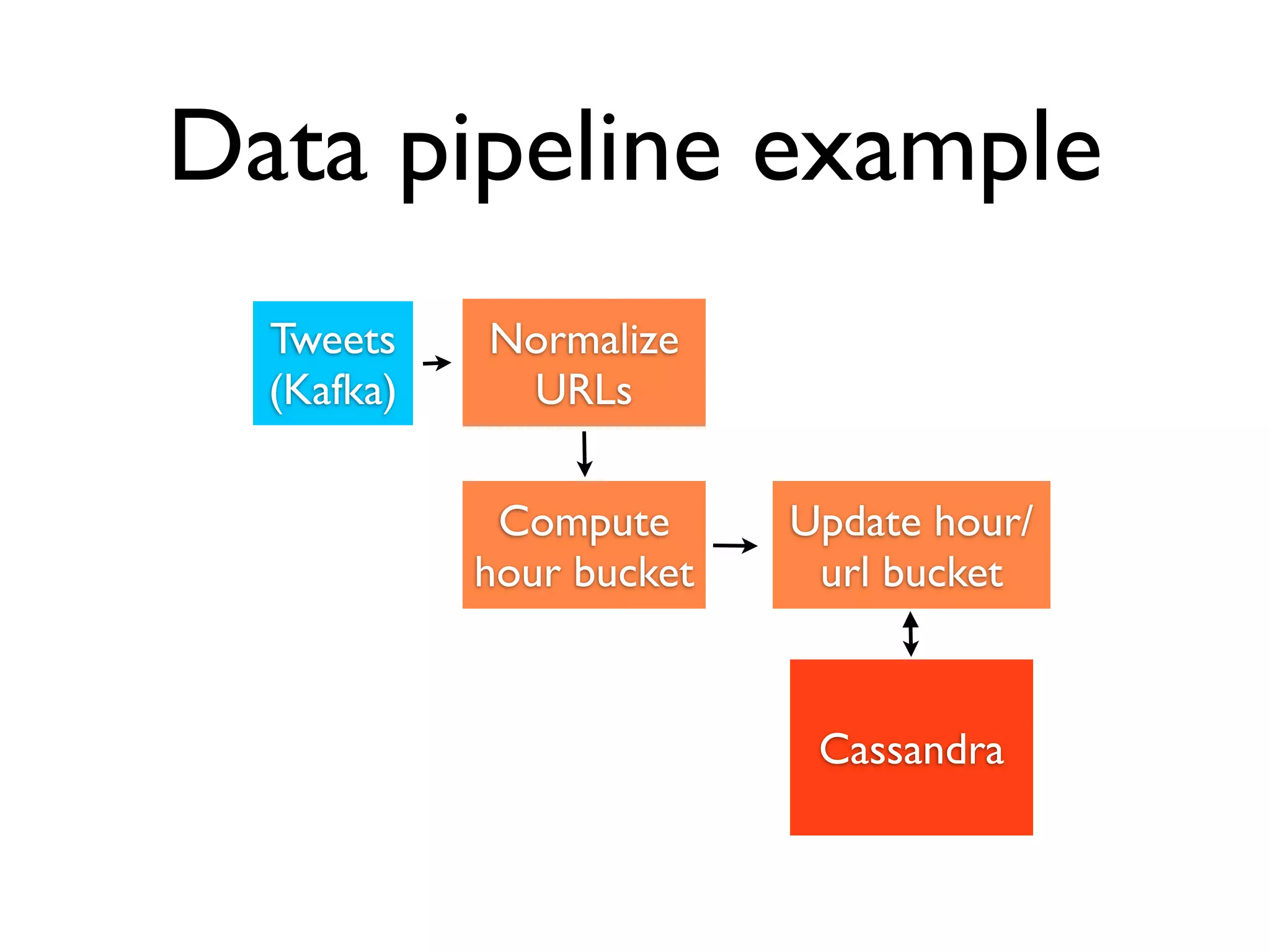
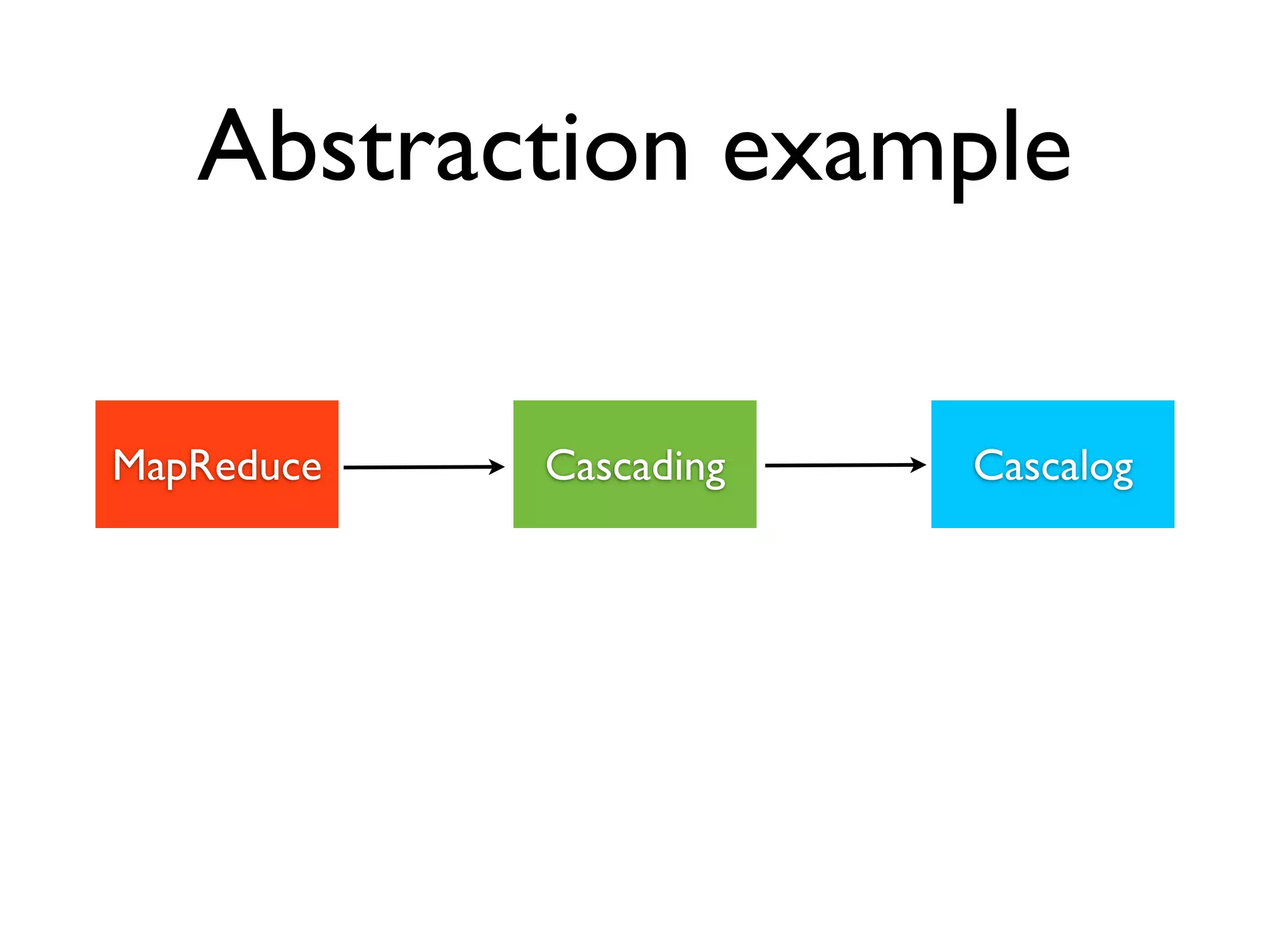
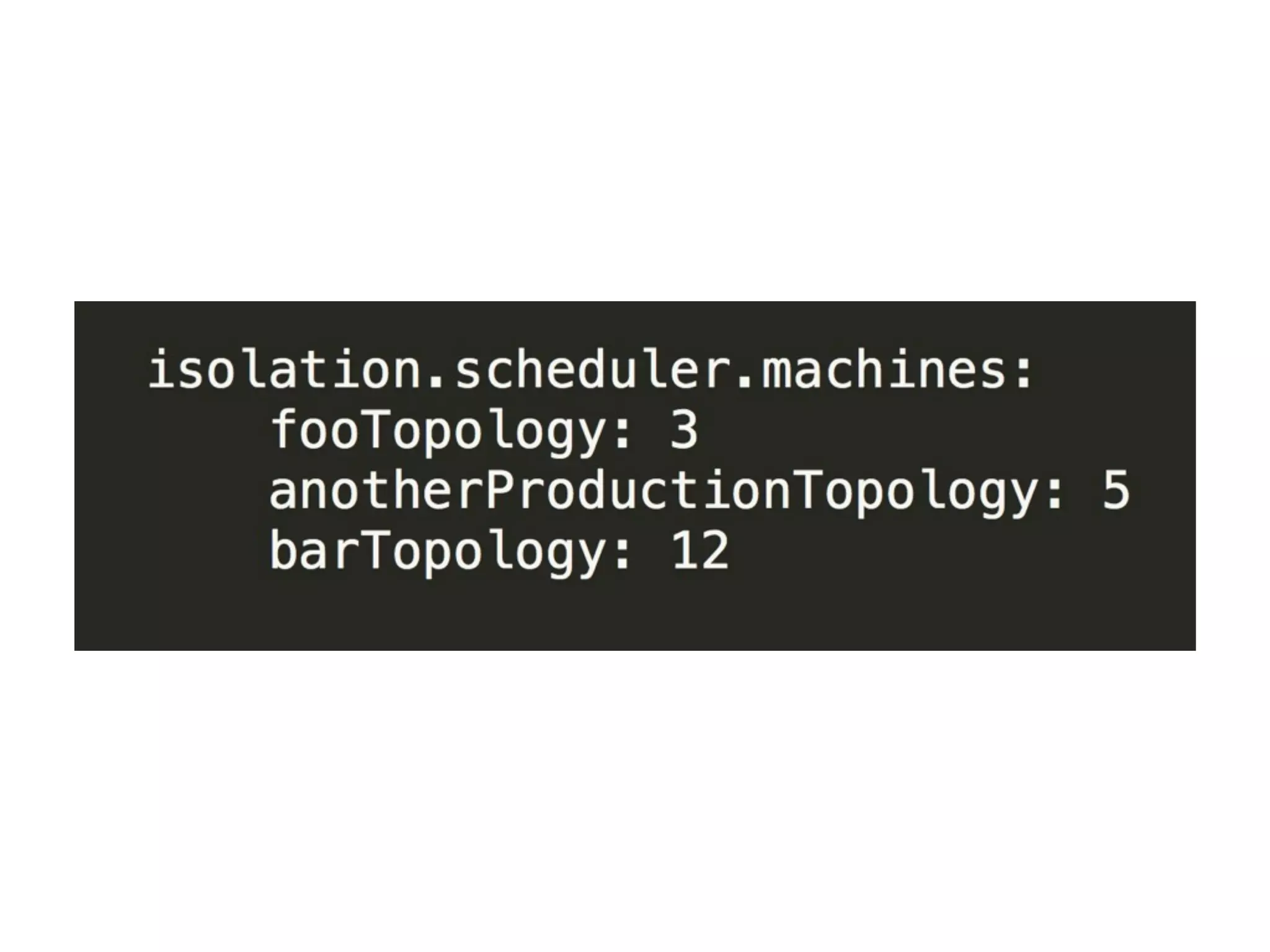
This document discusses data engineering. It defines data engineering as software engineering focused on dealing with large amounts of data. It explains why data engineering has become important now due to advances in technology and economics. The document then discusses data engineering concepts like distributed systems, parallel processing, and databases. It provides an example of a data pipeline that collects tweets and processes them. Finally, it discusses qualities of an ideal data engineer.