Download as PDF, PPTX



























This document covers a presentation on building data quality pipelines using Apache Spark and Delta Lake, emphasizing the significance of addressing dirty data which costs companies significantly. The speakers outline key design decisions for creating a robust system that meets specific business needs while facilitating ease of use for developers. Conclusively, it highlights the benefits of building custom solutions over off-the-shelf products, particularly in enhancing data ingestion processes.
Presentation on creating data quality pipelines using Apache Spark and Delta Lake.
Bios of speakers Sandy May and Darren Fuller, tech champions in data engineering and passionate about Spark and Azure.
Outline of the presentation covering problems, needs, solutions, investigation, and learning.
Overview of data quality problems, highlighting costs of dirty data ($3 trillion) and challenges faced by data scientists.
Discussion on whether to build or buy data quality solutions, examining ownership, features, and cost considerations.
Key design decisions for data quality solutions including cross-cloud capability and tool usage.
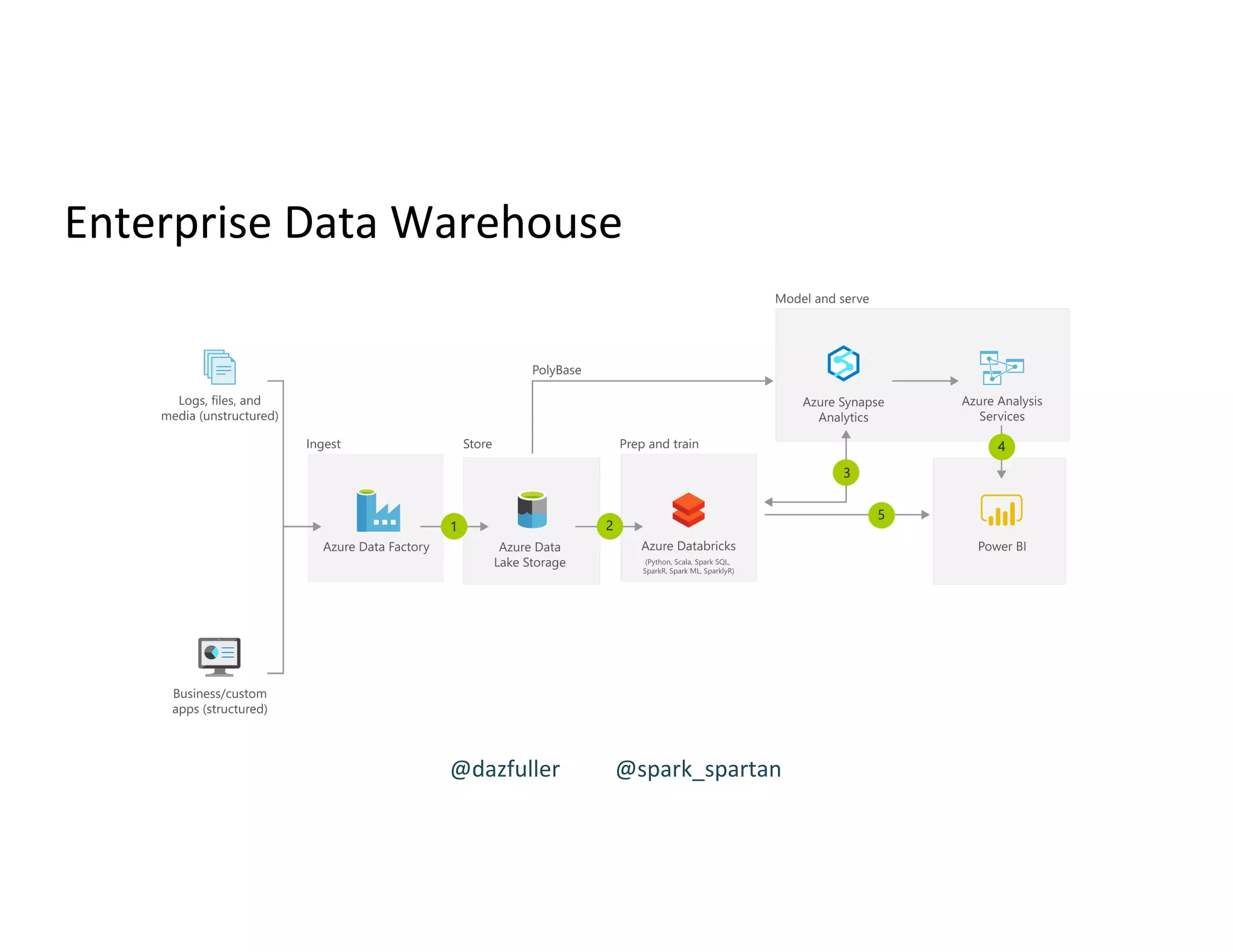
Concept of Enterprise Data Warehouse and its relevance in data management.
Call to action for the audience to engage in building data quality solutions.
Final recap of the presentation discussing the effectiveness of building data quality solutions.
Conclusions about the quick and effective build of data quality solutions, emphasizing business needs.
Open floor for audience questions related to the presentation.
Closing remarks encouraging feedback and reviews from the audience.





































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)

















