Download as PDF, PPTX


























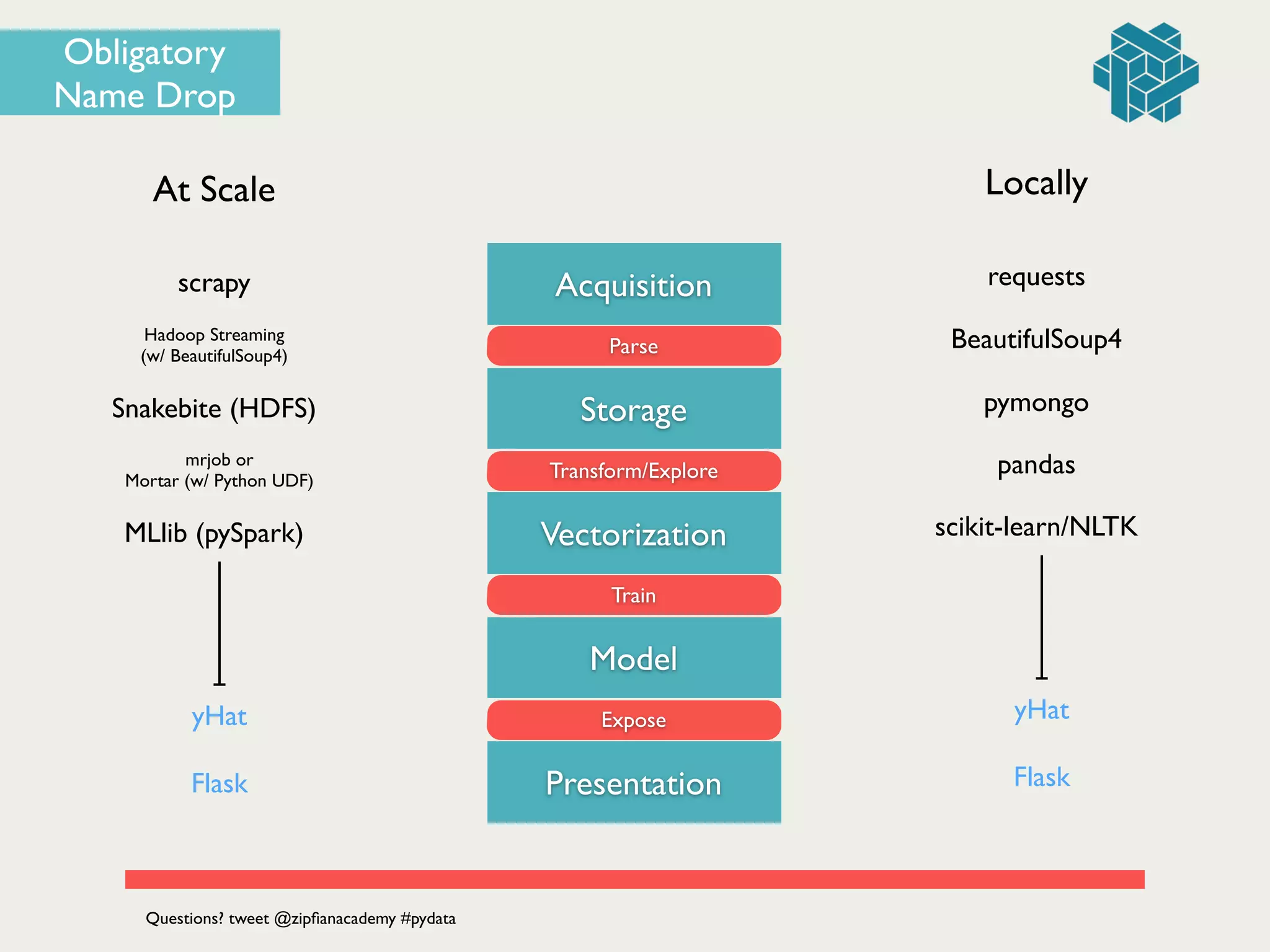



![# parse resulting JSON and insert into a mongoDB collection!
for content in api.json()['response']['docs']:!
if not collection.find_one(content):!
collection.insert(content)!
!
!
# only returns 10 per page!
"There are only %i docuemtns returned 0_o" % !
! len(api.json()[‘response']['docs'])!
Questions? tweet @zipfianacademy #pydata
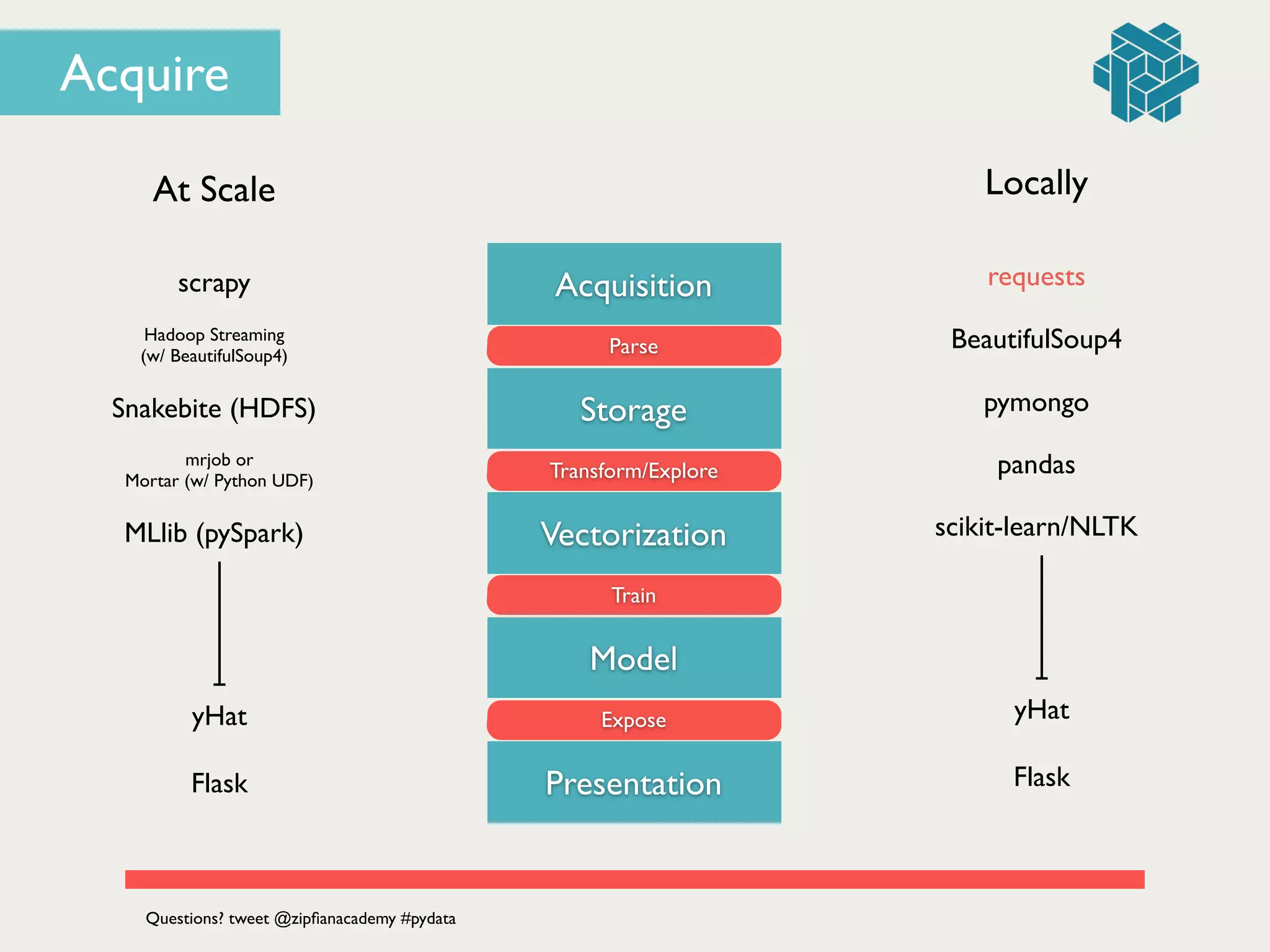
Acquire](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-44-2048.jpg)
![# there are many more than 10 articles however!
total_art = articles_left = api.json()['response']['meta']['hits']!
!
!
print "There are currently %s articles in the NYT archive" % total_art!
!
!
#=> There are currently 15277775 articles in the NYT archive
Questions? tweet @zipfianacademy #pydata
Acquire](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-45-2048.jpg)



![# let us loop (and hopefully not hit our rate limit)!
while articles_left > 0 and page_count < max_pages:!
more_articles = requests.get(url + "&page=" + str(page) + "&end_date=" + str(last_date))!
print "Inserting page " + str(page)!
# make sure it was successful!
if more_articles.status_code == 200:!
for content in more_articles.json()['response']['docs']:!
latest_article = parser.parse(content['pub_date']).strftime("%Y%m%d")!
if not collection.find_one(content) and content['document_type'] == 'article':!
print "No dups"!
try:!
print "Inserting article " + str(content['headline'])!
collection.insert(content)!
except errors.DuplicateKeyError:!
print "Duplicates"!
continue!
else:!
print "In collection already”!
! ! …
Iteration 0.5
Questions? tweet @zipfianacademy #pydata
Acquire](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-49-2048.jpg)


![Acquire
# now we can get some content!!
#limit = 100!
limit = 10000!
!
for article in collection.find({'html' : {'$exists' : False} }):!
if limit and limit > 0:!
if not article.has_key('html') and article['document_type'] == 'article':!
limit -= 1!
print article['web_url']!
html = requests.get(article['web_url'] + "?smid=tw-nytimes")!
!
if html.status_code == 200:!
soup = BeautifulSoup(html.text)!
!
# serialize html!
collection.update({ '_id' : article['_id'] }, { '$set' : !
! ! ! ! ! ! ! ! ! ! ! ! ! { 'html' : unicode(soup), 'content' : [] } !
! ! ! ! ! ! ! ! ! ! ! ! } )!
!
for p in soup.find_all('div', class_='articleBody'):!
collection.update({ '_id' : article['_id'] }, { '$push' : !
! ! ! ! ! ! ! ! ! ! ! ! ! ! { 'content' : p.get_text() !
! ! ! ! ! ! ! ! ! ! ! ! ! } })!
Questions? tweet @zipfianacademy #pydata](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-52-2048.jpg)
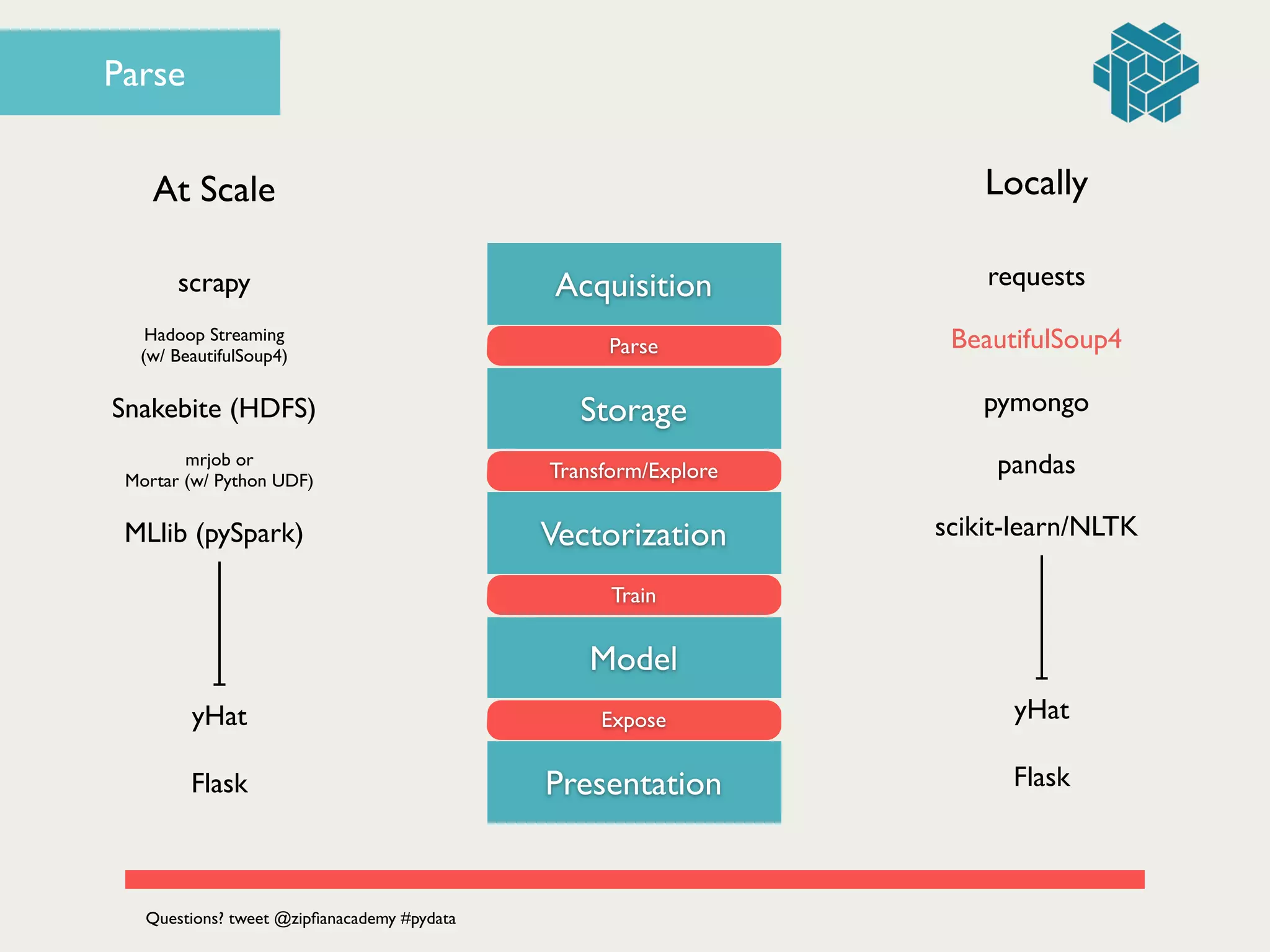

![# parse HTML content of articles!
for article in collection.find({'html' : {'$exists' : True} }):!
print article['web_url']!
soup = BeautifulSoup(article['html'], 'html.parser')!
arts = soup.find_all('div', class_='articleBody')!
!
if len(arts) == 0:!
arts = soup.find_all('p', class_=‘story-body-text')!
!
! ! …
Questions? tweet @zipfianacademy #pydata
Parse](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-55-2048.jpg)
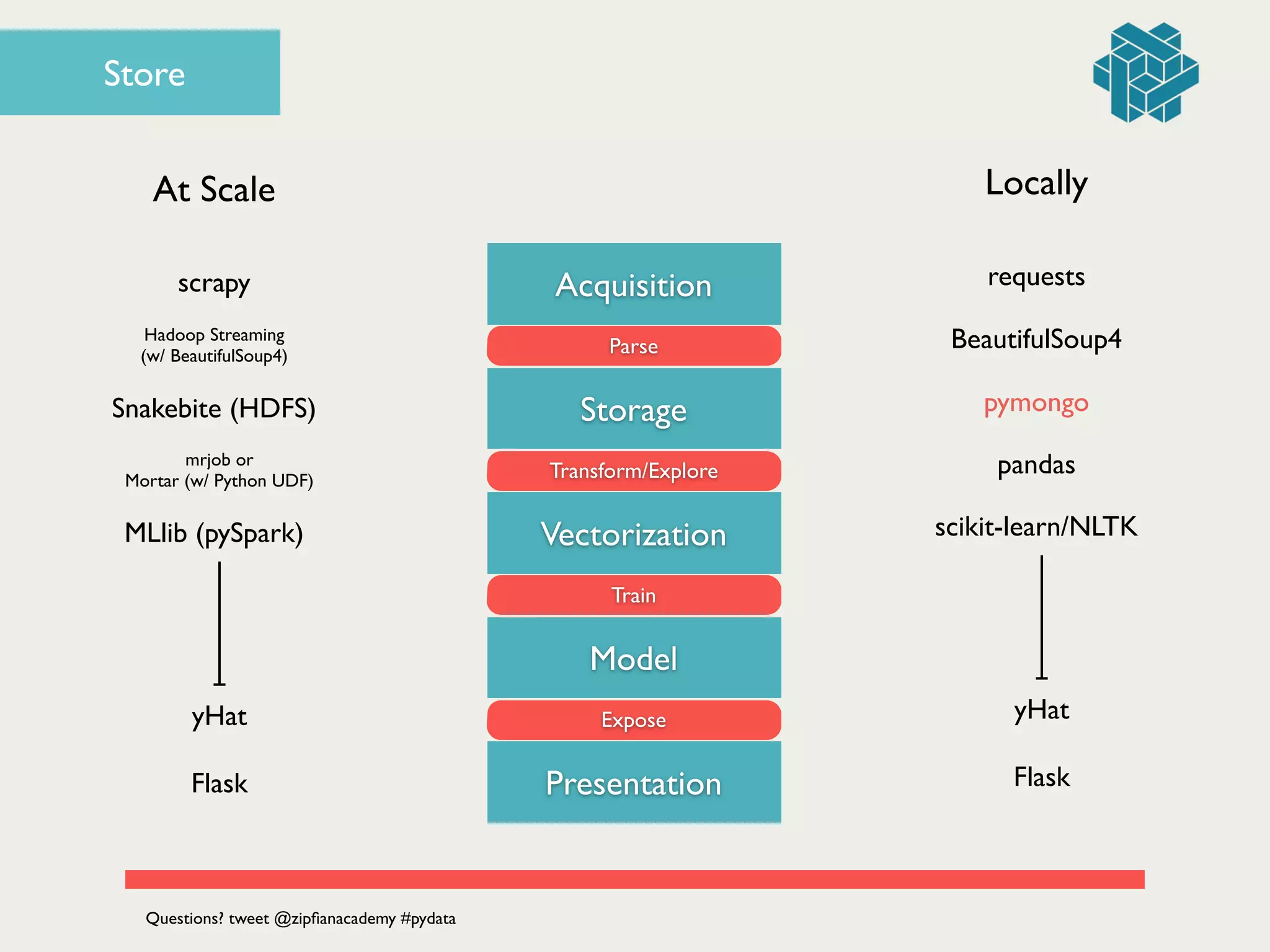
![for p in arts:!
collection.update({ '_id' : article['_id'] }, { '$push' : !
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! { 'content' : p.get_text() } !
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! })!
Questions? tweet @zipfianacademy #pydata
Store](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-57-2048.jpg)
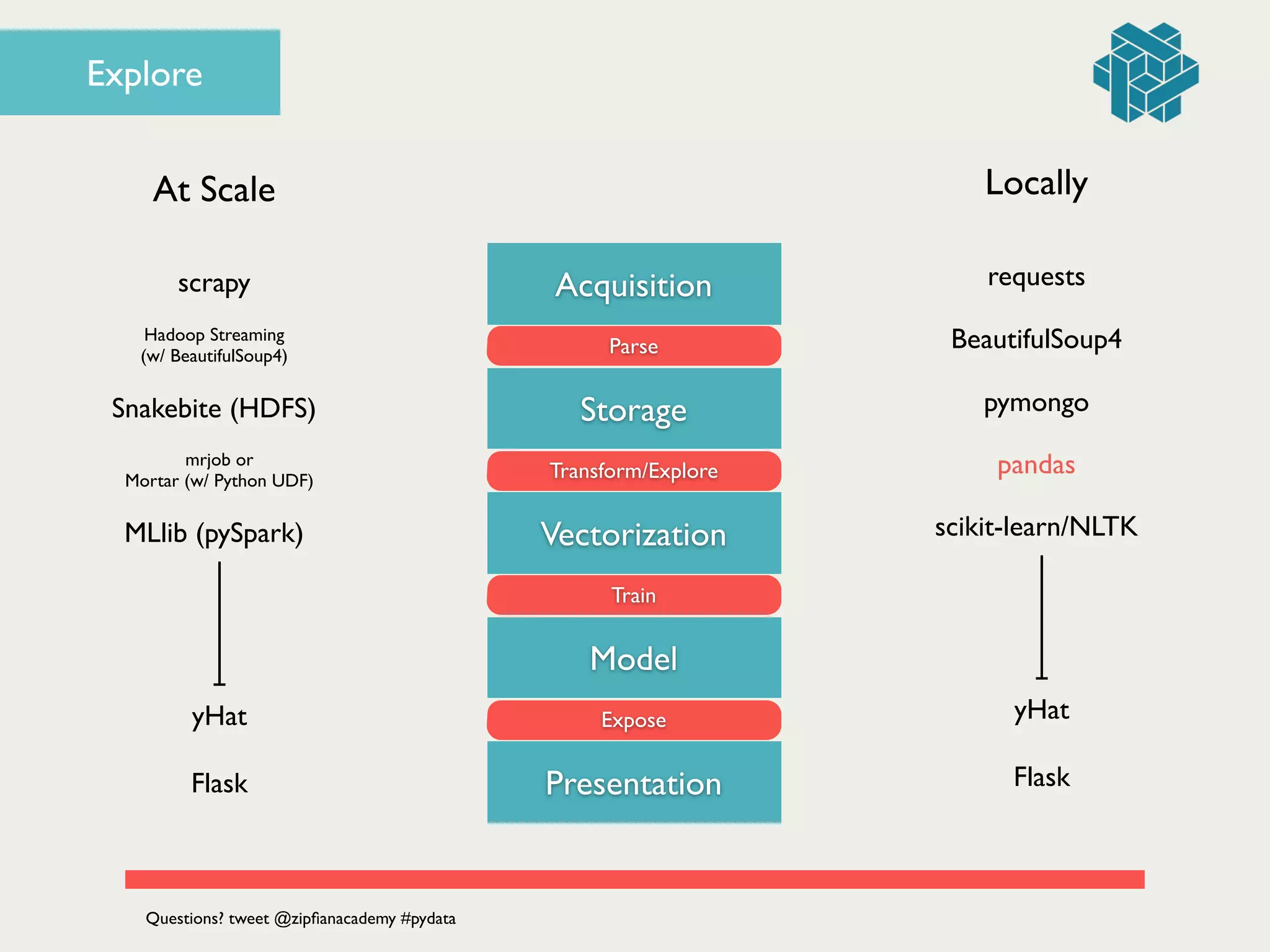

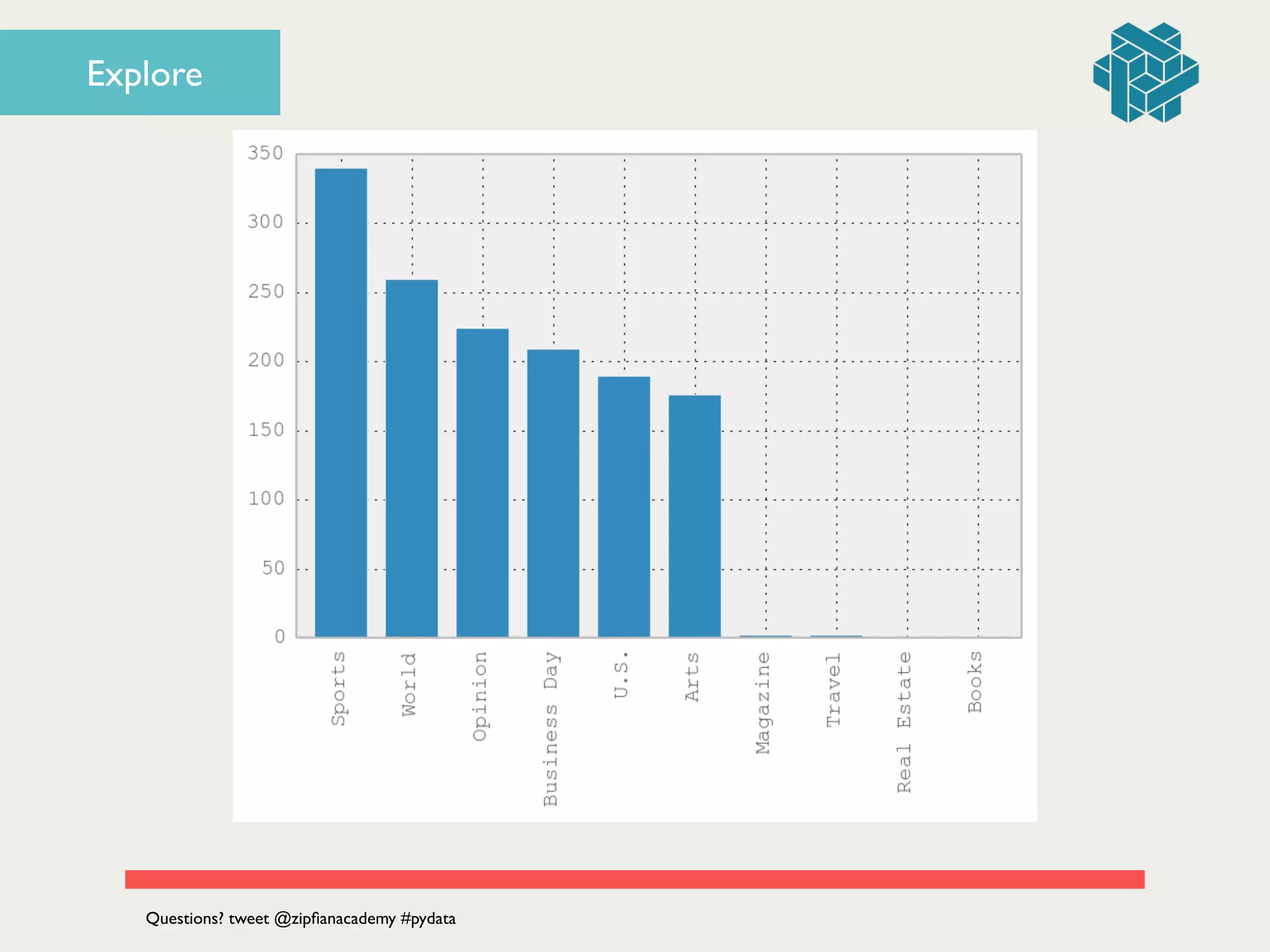
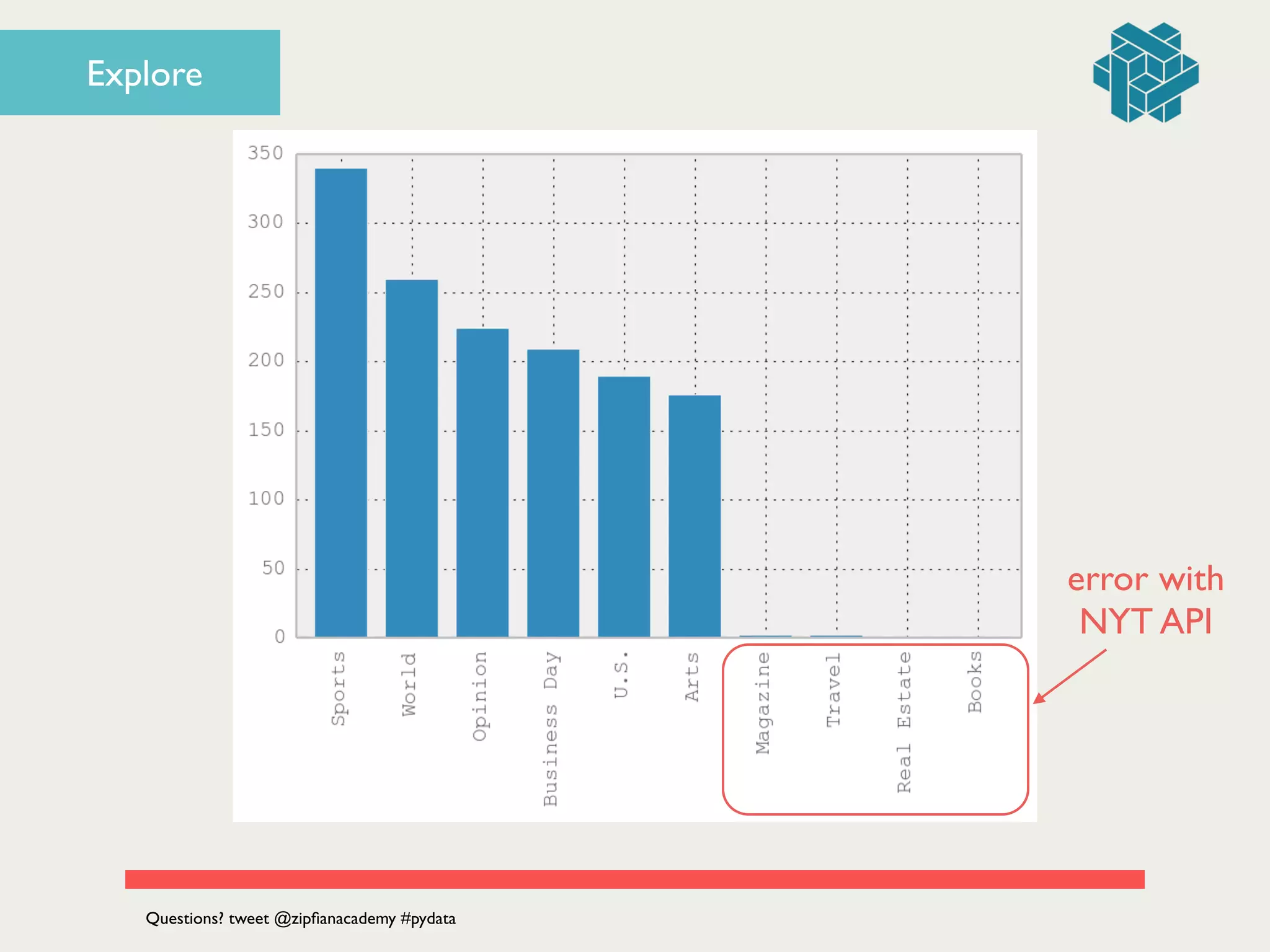
![articles.describe()!
# ! ! text section!
# count 1405 1405!
# unique 1397 10!
!
fig = plt.figure()!
# histogram of section counts!
articles['section'].value_counts().plot(kind='bar')
Questions? tweet @zipfianacademy #pydata
Explore](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-60-2048.jpg)


![Vectorize
wnl = nltk.WordNetLemmatizer()!
!
def tokenize_and_normalize(chunks):!
words = [ tokenize.word_tokenize(sent) for sent in
tokenize.sent_tokenize("".join(chunks)) ]!
flatten = [ inner for sublist in words for inner in sublist ]!
stripped = [] !
!
for word in flatten: !
if word not in stopwords.words('english'):!
try:!
stripped.append(word.encode('latin-1').decode('utf8').lower())!
except:!
print "Cannot encode: " + word!
!
no_punks = [ word for word in stripped if len(word) > 1 ] !
return [wnl.lemmatize(t) for t in no_punks]!
Questions? tweet @zipfianacademy #pydata](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-66-2048.jpg)
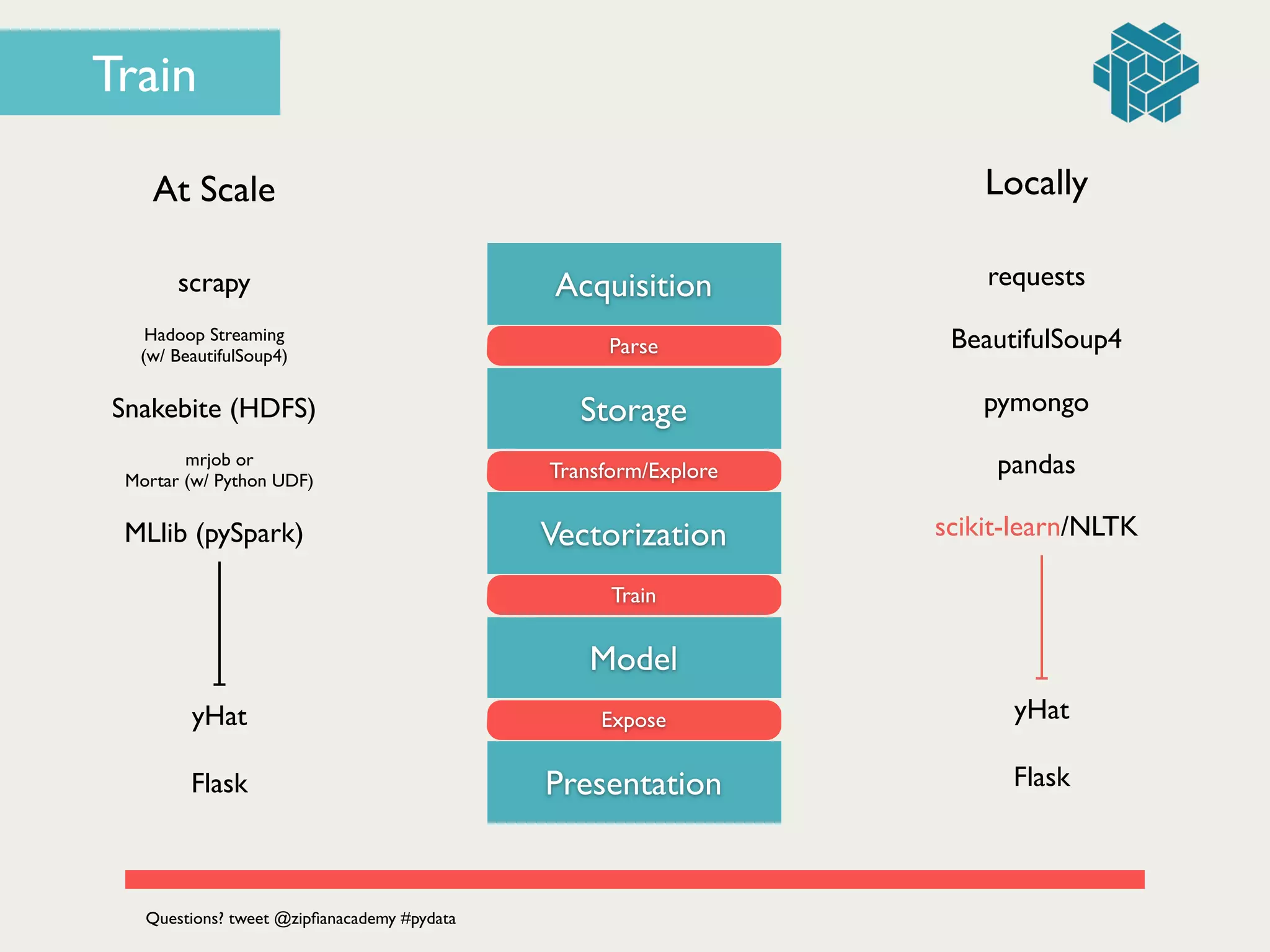













![class DocumentClassifier(YhatModel):!
@preprocess(in_type=dict, out_type=dict)!
def execute(self, data):!
featureBody = vectorizer.transform([data['content']])!
result = multi_bayes.predict(featureBody)!
list_res = result.tolist()!
return {"section_name": list_res}!
!
clf = DocumentClassifier()!
yh = Yhat("jonathan@zipfianacademy.com", “xxxxxx",!
! ! ! ! ! ! ! ! ! ! ! ! ! "http://cloud.yhathq.com/")!
yh.deploy("documentClassifier", DocumentClassifier, globals())
Questions? tweet @zipfianacademy #pydata
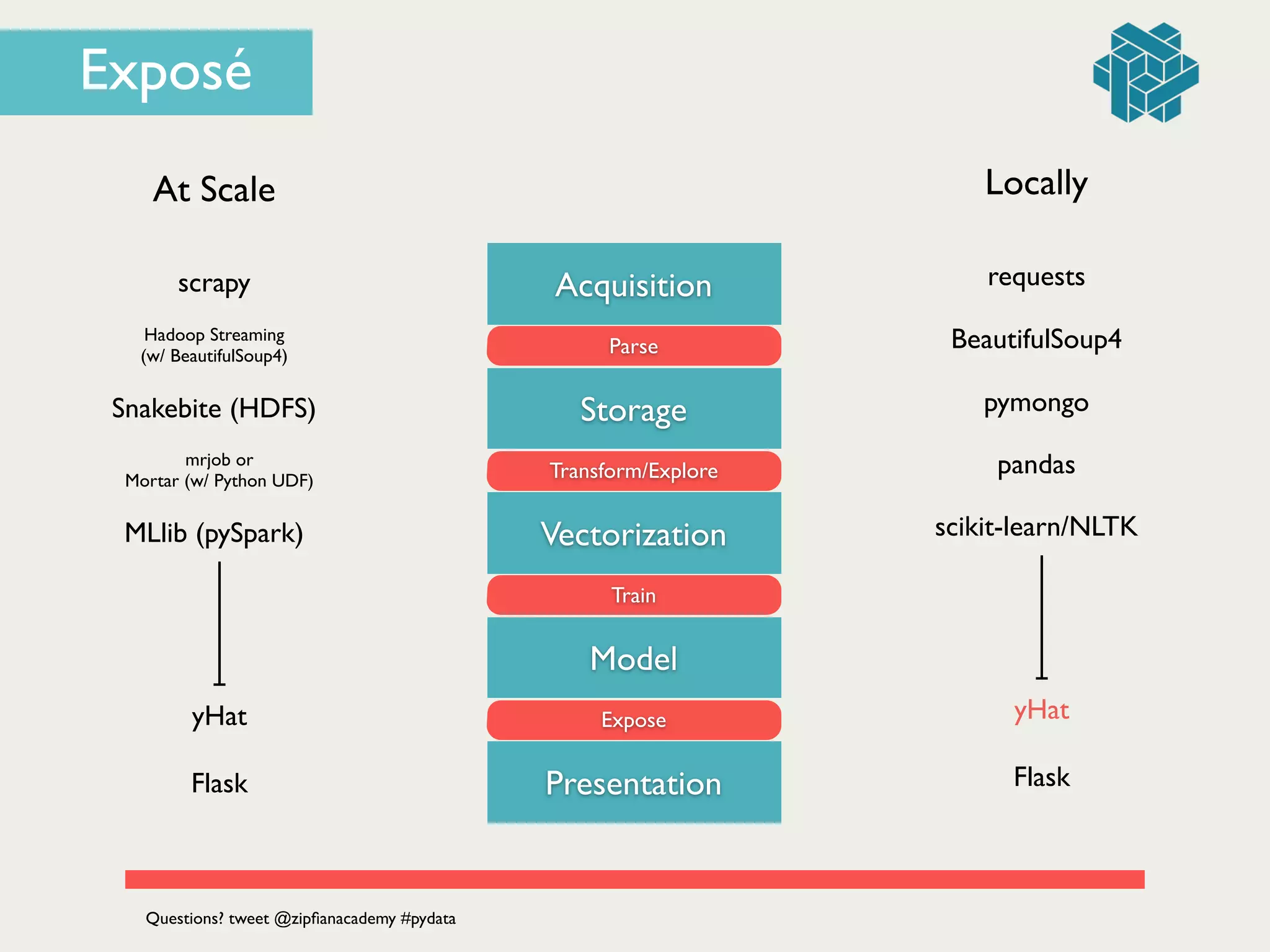
Exposé](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-83-2048.jpg)

![yh = Yhat("<USERNAME>", "<API KEY>", "http://cloud.yhathq.com/")
!
@app.route('/')
def index():
return app.send_static_file('index.html')
!
@app.route('/predict', methods=['POST'])
def predict():
article = request.form['article']
results = yh.predict("documentClf", { 'content': article })
return jsonify({"results": results})
Questions? tweet @zipfianacademy #pydata
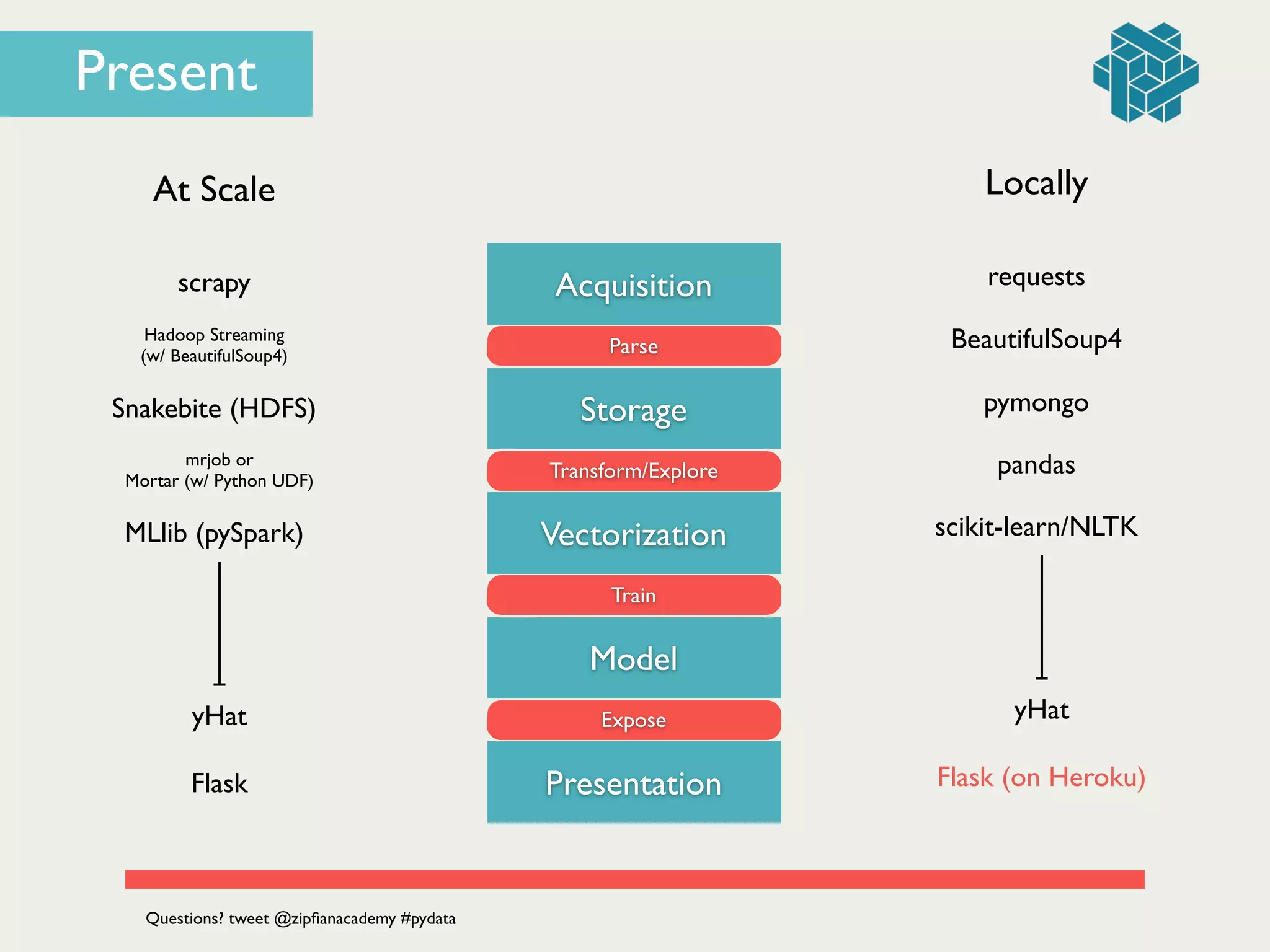
Present](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-86-2048.jpg)





















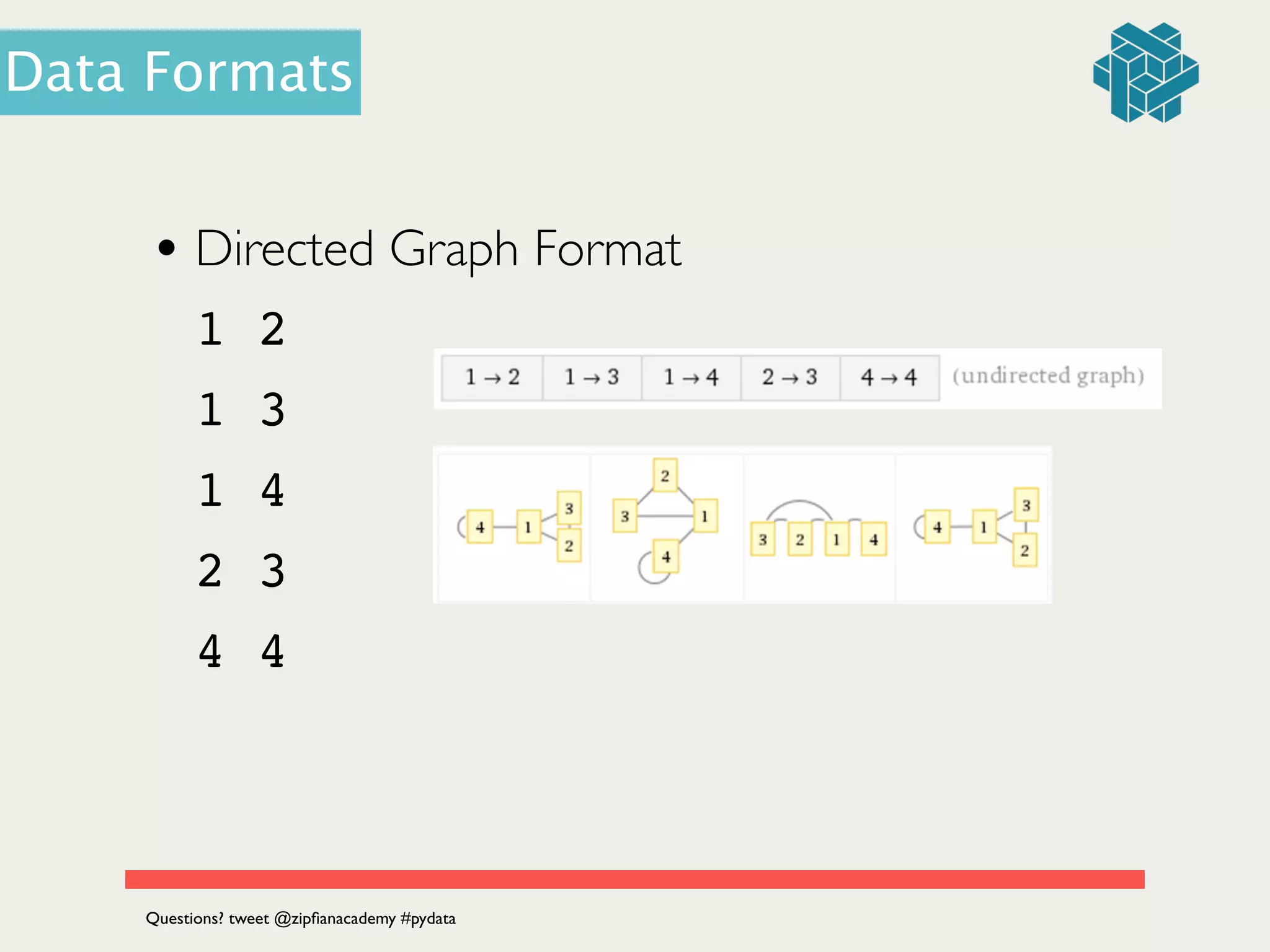
![• JSON is made up of hash tables and arrays
• Hash tables: { “foo” : 1, “bar” : 2, baz : “3” }
• Arrays: [1, 2, 3]
• Arrays of arrays: [[1, 2, 3], [‘foo’, ‘bar’, ‘baz’]]
• Array of hashes: [{‘foo’:1, ‘bar’:2}, {‘baz’:3}]
• Hashes of hashes: {‘foo’: {‘bar’: 2, ‘baz’: 3}}
Questions? tweet @zipfianacademy #pydata
Data Formats](https://image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-113-2048.jpg)


















































![# parse resulting JSON and insert into a mongoDB collection!
for content in api.json()['response']['docs']:!
if not collection.find_one(content):!
collection.insert(content)!
!
!
# only returns 10 per page!
"There are only %i docuemtns returned 0_o" % !
! len(api.json()[‘response']['docs'])!
Questions? tweet @zipfianacademy #pydata
Acquire](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-44-2048.jpg)
![# there are many more than 10 articles however!
total_art = articles_left = api.json()['response']['meta']['hits']!
!
!
print "There are currently %s articles in the NYT archive" % total_art!
!
!
#=> There are currently 15277775 articles in the NYT archive
Questions? tweet @zipfianacademy #pydata
Acquire](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-45-2048.jpg)



![# let us loop (and hopefully not hit our rate limit)!
while articles_left > 0 and page_count < max_pages:!
more_articles = requests.get(url + "&page=" + str(page) + "&end_date=" + str(last_date))!
print "Inserting page " + str(page)!
# make sure it was successful!
if more_articles.status_code == 200:!
for content in more_articles.json()['response']['docs']:!
latest_article = parser.parse(content['pub_date']).strftime("%Y%m%d")!
if not collection.find_one(content) and content['document_type'] == 'article':!
print "No dups"!
try:!
print "Inserting article " + str(content['headline'])!
collection.insert(content)!
except errors.DuplicateKeyError:!
print "Duplicates"!
continue!
else:!
print "In collection already”!
! ! …
Iteration 0.5
Questions? tweet @zipfianacademy #pydata
Acquire](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-49-2048.jpg)


![Acquire
# now we can get some content!!
#limit = 100!
limit = 10000!
!
for article in collection.find({'html' : {'$exists' : False} }):!
if limit and limit > 0:!
if not article.has_key('html') and article['document_type'] == 'article':!
limit -= 1!
print article['web_url']!
html = requests.get(article['web_url'] + "?smid=tw-nytimes")!
!
if html.status_code == 200:!
soup = BeautifulSoup(html.text)!
!
# serialize html!
collection.update({ '_id' : article['_id'] }, { '$set' : !
! ! ! ! ! ! ! ! ! ! ! ! ! { 'html' : unicode(soup), 'content' : [] } !
! ! ! ! ! ! ! ! ! ! ! ! } )!
!
for p in soup.find_all('div', class_='articleBody'):!
collection.update({ '_id' : article['_id'] }, { '$push' : !
! ! ! ! ! ! ! ! ! ! ! ! ! ! { 'content' : p.get_text() !
! ! ! ! ! ! ! ! ! ! ! ! ! } })!
Questions? tweet @zipfianacademy #pydata](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-52-2048.jpg)


![# parse HTML content of articles!
for article in collection.find({'html' : {'$exists' : True} }):!
print article['web_url']!
soup = BeautifulSoup(article['html'], 'html.parser')!
arts = soup.find_all('div', class_='articleBody')!
!
if len(arts) == 0:!
arts = soup.find_all('p', class_=‘story-body-text')!
!
! ! …
Questions? tweet @zipfianacademy #pydata
Parse](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-55-2048.jpg)

![for p in arts:!
collection.update({ '_id' : article['_id'] }, { '$push' : !
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! { 'content' : p.get_text() } !
! ! ! ! ! ! ! ! ! ! ! ! ! ! ! })!
Questions? tweet @zipfianacademy #pydata
Store](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-57-2048.jpg)


![articles.describe()!
# ! ! text section!
# count 1405 1405!
# unique 1397 10!
!
fig = plt.figure()!
# histogram of section counts!
articles['section'].value_counts().plot(kind='bar')
Questions? tweet @zipfianacademy #pydata
Explore](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-60-2048.jpg)





![Vectorize
wnl = nltk.WordNetLemmatizer()!
!
def tokenize_and_normalize(chunks):!
words = [ tokenize.word_tokenize(sent) for sent in
tokenize.sent_tokenize("".join(chunks)) ]!
flatten = [ inner for sublist in words for inner in sublist ]!
stripped = [] !
!
for word in flatten: !
if word not in stopwords.words('english'):!
try:!
stripped.append(word.encode('latin-1').decode('utf8').lower())!
except:!
print "Cannot encode: " + word!
!
no_punks = [ word for word in stripped if len(word) > 1 ] !
return [wnl.lemmatize(t) for t in no_punks]!
Questions? tweet @zipfianacademy #pydata](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-66-2048.jpg)
















![class DocumentClassifier(YhatModel):!
@preprocess(in_type=dict, out_type=dict)!
def execute(self, data):!
featureBody = vectorizer.transform([data['content']])!
result = multi_bayes.predict(featureBody)!
list_res = result.tolist()!
return {"section_name": list_res}!
!
clf = DocumentClassifier()!
yh = Yhat("jonathan@zipfianacademy.com", “xxxxxx",!
! ! ! ! ! ! ! ! ! ! ! ! ! "http://cloud.yhathq.com/")!
yh.deploy("documentClassifier", DocumentClassifier, globals())
Questions? tweet @zipfianacademy #pydata
Exposé](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-83-2048.jpg)


![yh = Yhat("<USERNAME>", "<API KEY>", "http://cloud.yhathq.com/")
!
@app.route('/')
def index():
return app.send_static_file('index.html')
!
@app.route('/predict', methods=['POST'])
def predict():
article = request.form['article']
results = yh.predict("documentClf", { 'content': article })
return jsonify({"results": results})
Questions? tweet @zipfianacademy #pydata
Present](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-86-2048.jpg)


























![• JSON is made up of hash tables and arrays
• Hash tables: { “foo” : 1, “bar” : 2, baz : “3” }
• Arrays: [1, 2, 3]
• Arrays of arrays: [[1, 2, 3], [‘foo’, ‘bar’, ‘baz’]]
• Array of hashes: [{‘foo’:1, ‘bar’:2}, {‘baz’:3}]
• Hashes of hashes: {‘foo’: {‘bar’: 2, ‘baz’: 3}}
Questions? tweet @zipfianacademy #pydata
Data Formats](https://crownmelresort.com/image.slidesharecdn.com/dataengineering101buildingyourfirstdataproductbyjonathandinu-140613094459-phpapp01/75/Data-Engineering-101-Building-your-first-data-product-by-Jonathan-Dinu-PyData-SV-2014-113-2048.jpg)









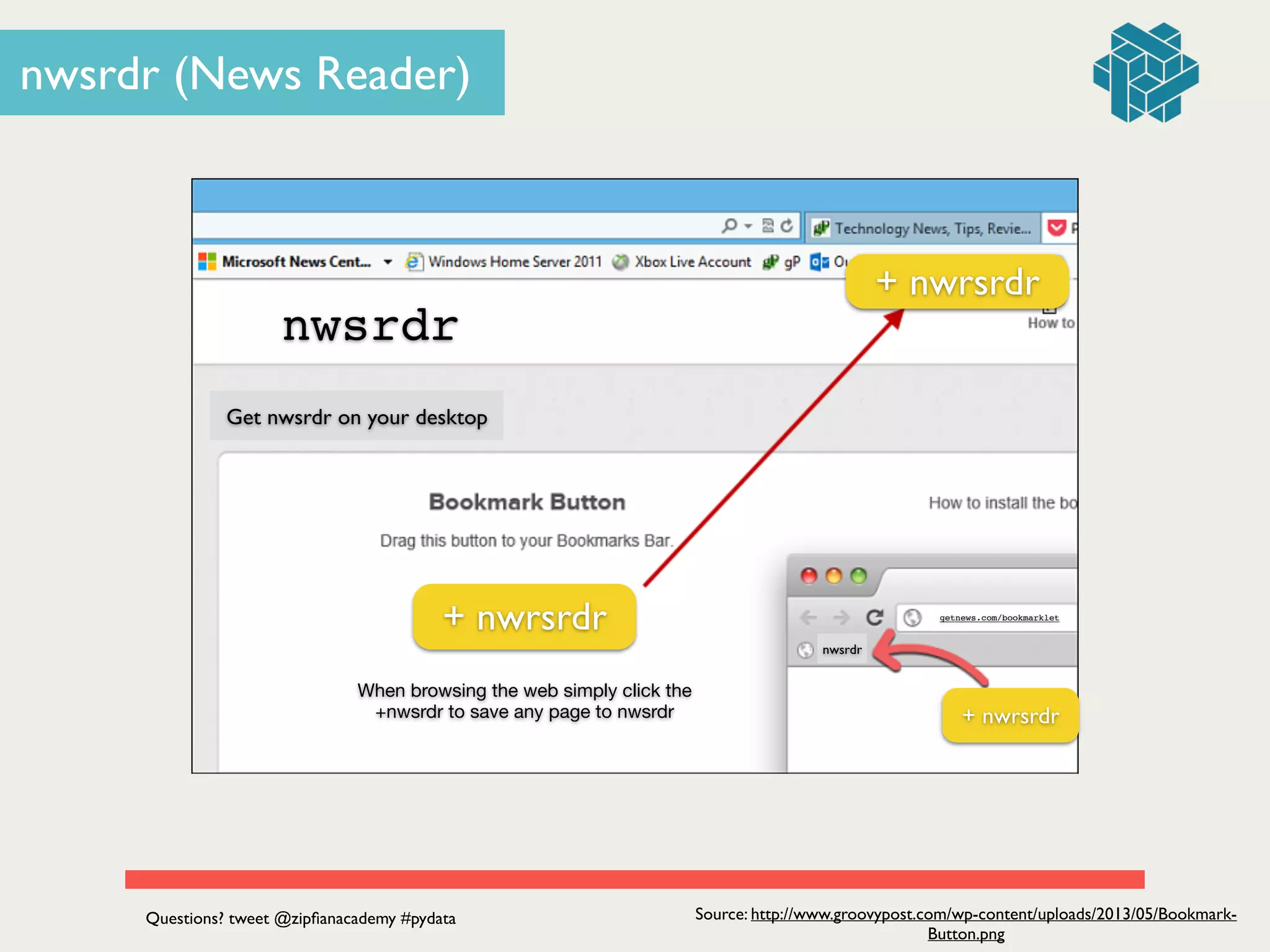
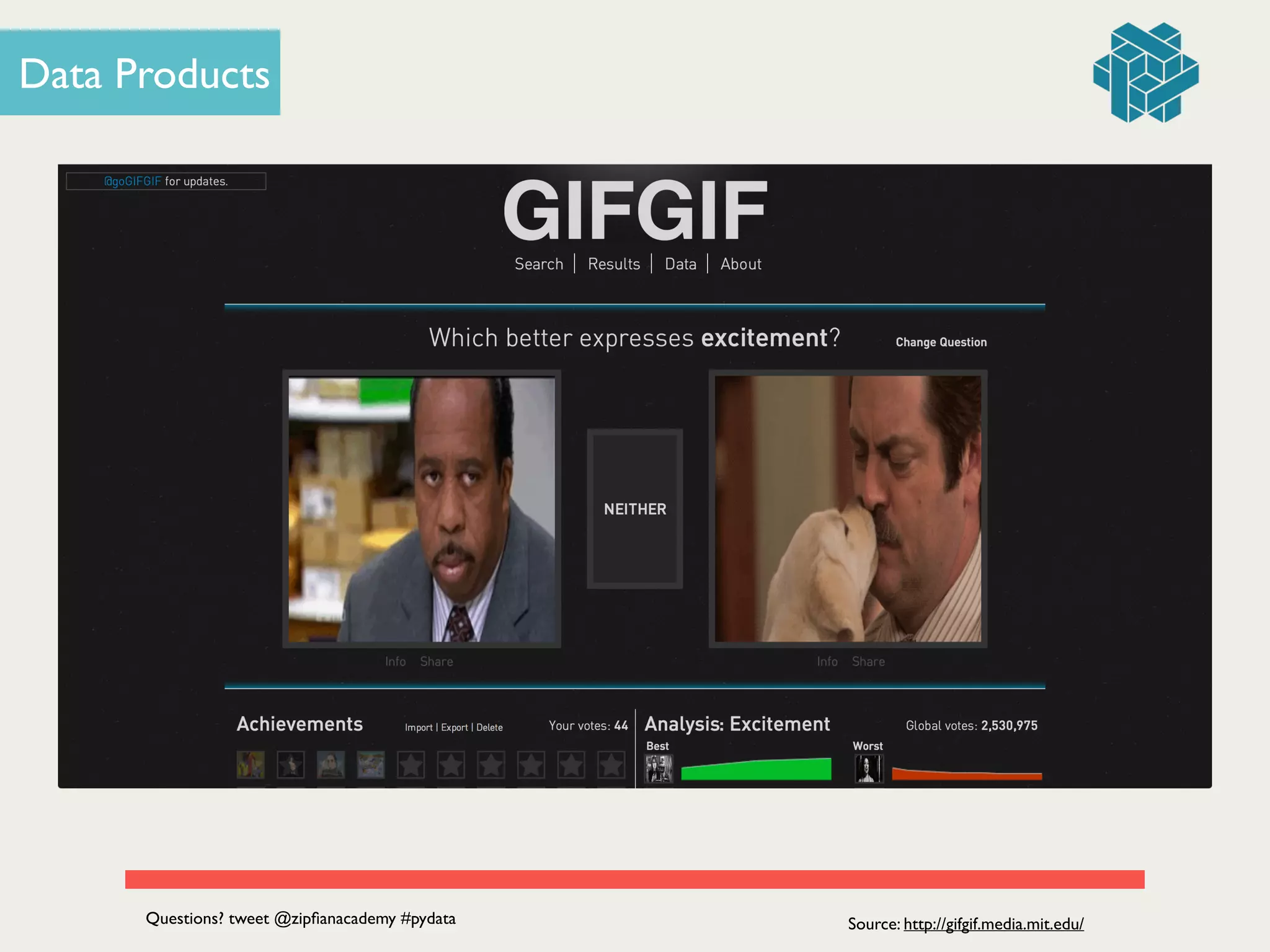
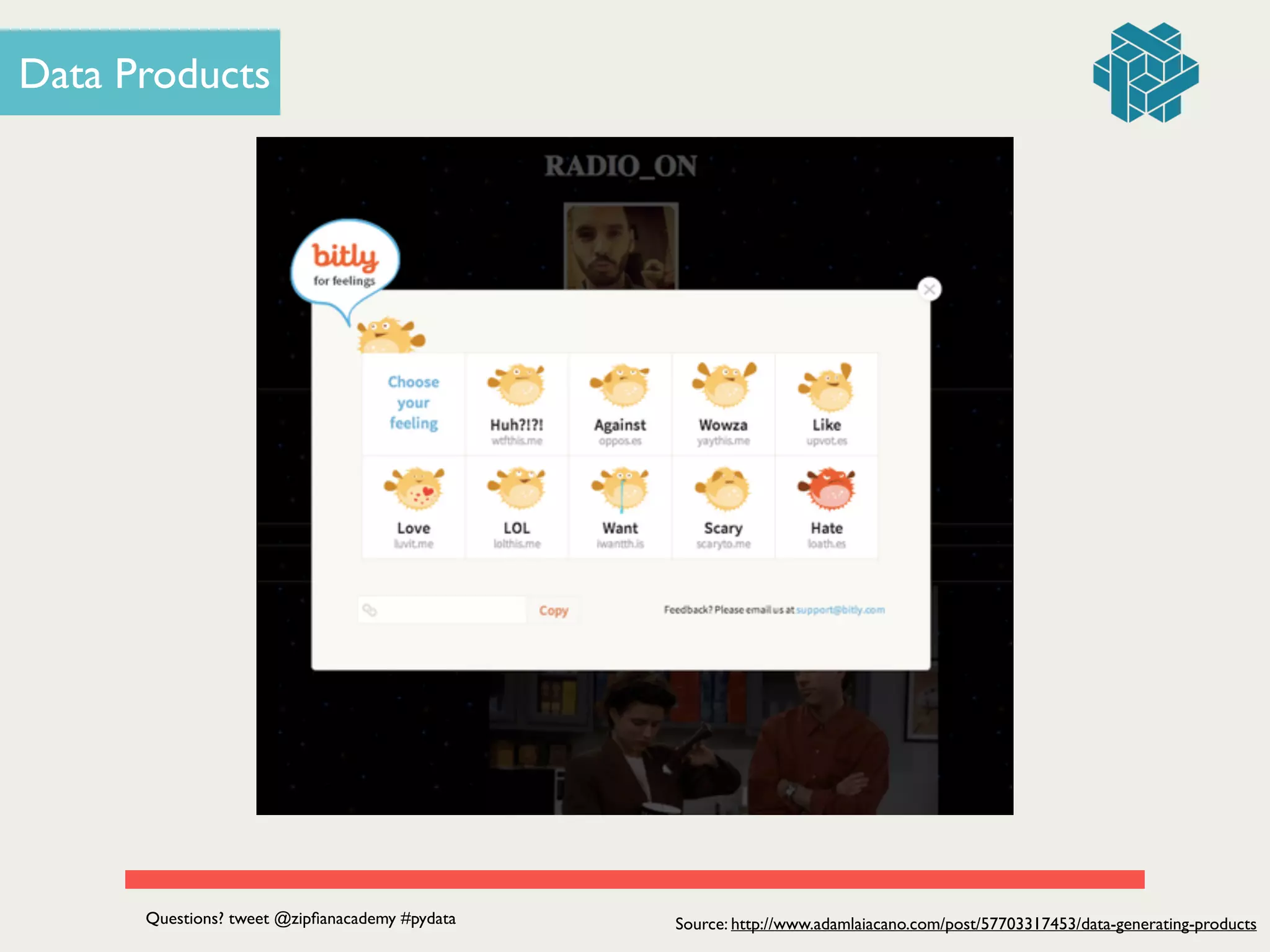
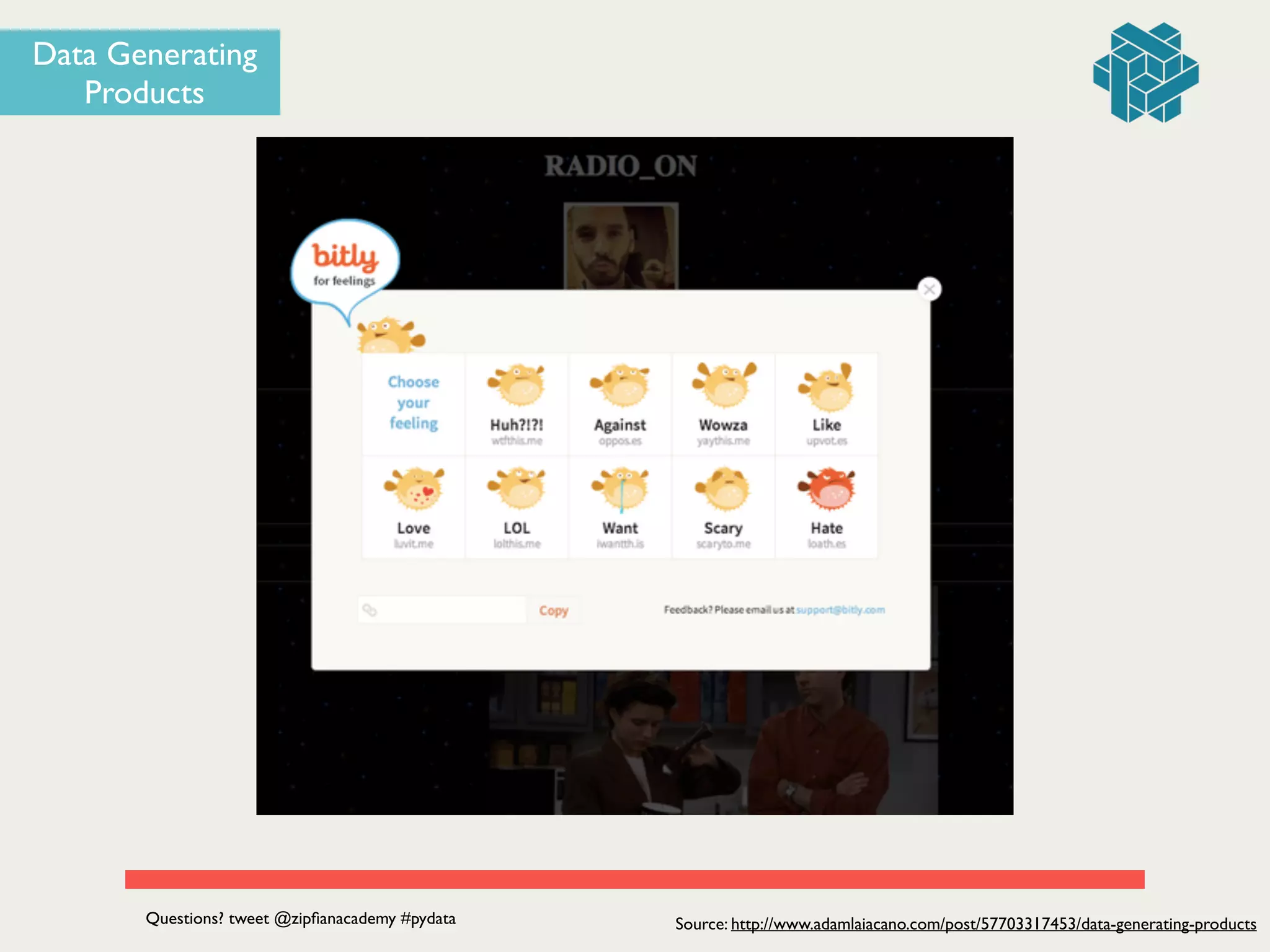
The document presents a seminar led by Jonathan Dinu on the fundamentals of data engineering and building a data product, focusing on the development of a news reader application called 'nws rdr.' It details the processes of data acquisition, pipeline construction, and the implementation of machine learning techniques such as Naive Bayes and collaborative filtering. The seminar also includes a Q&A section and emphasizes the value of data products in enhancing user experiences.



































































