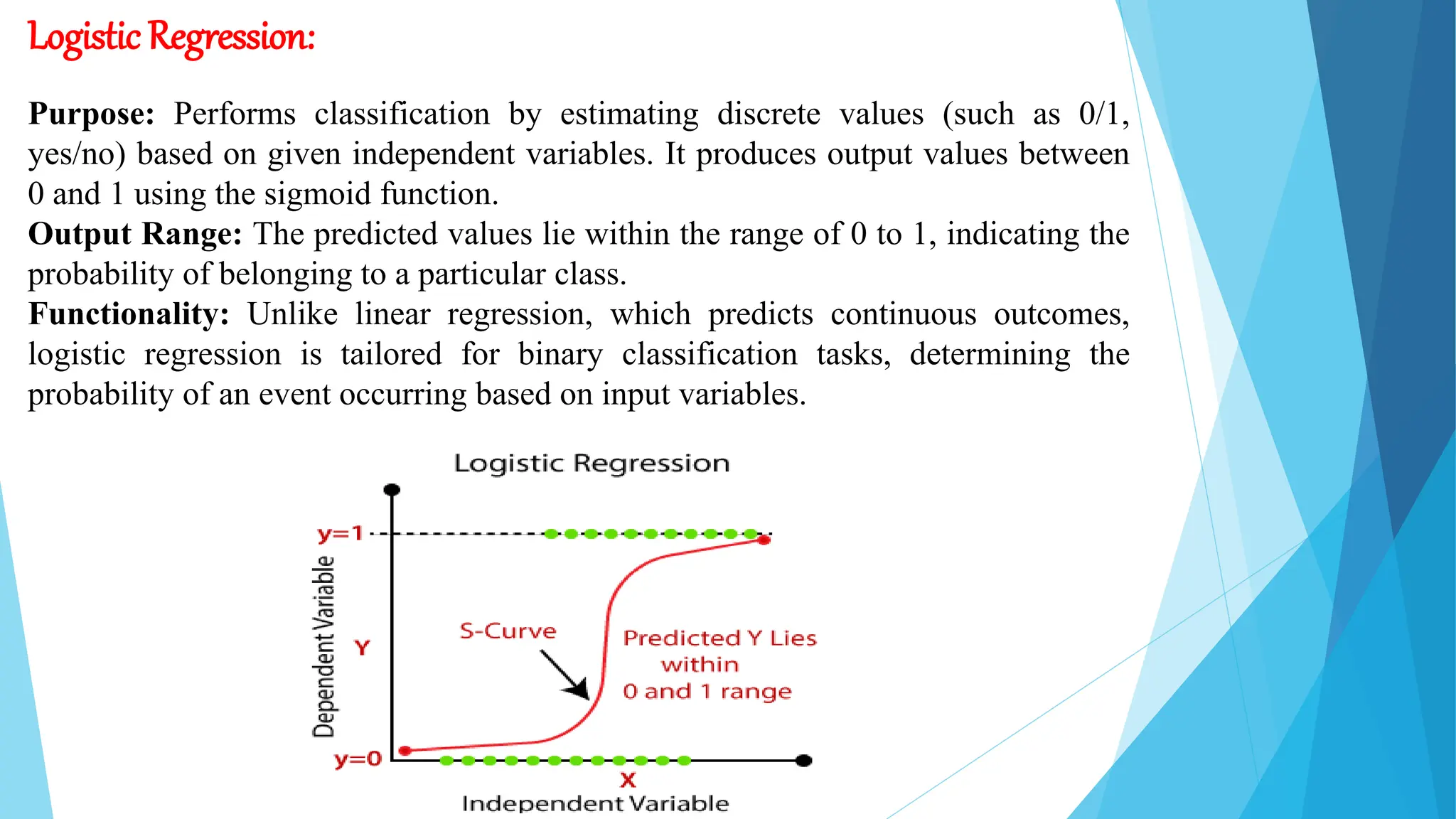
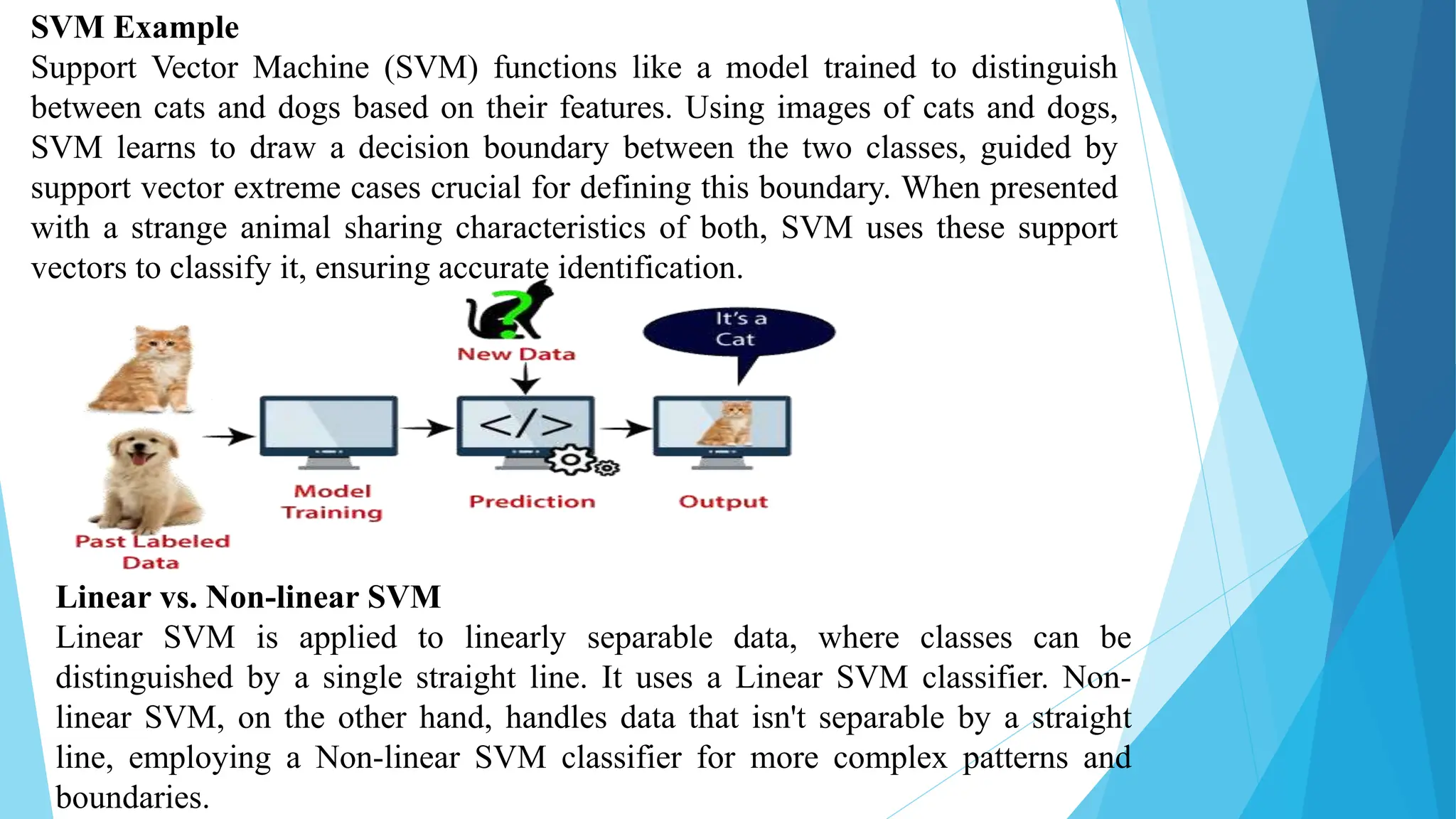
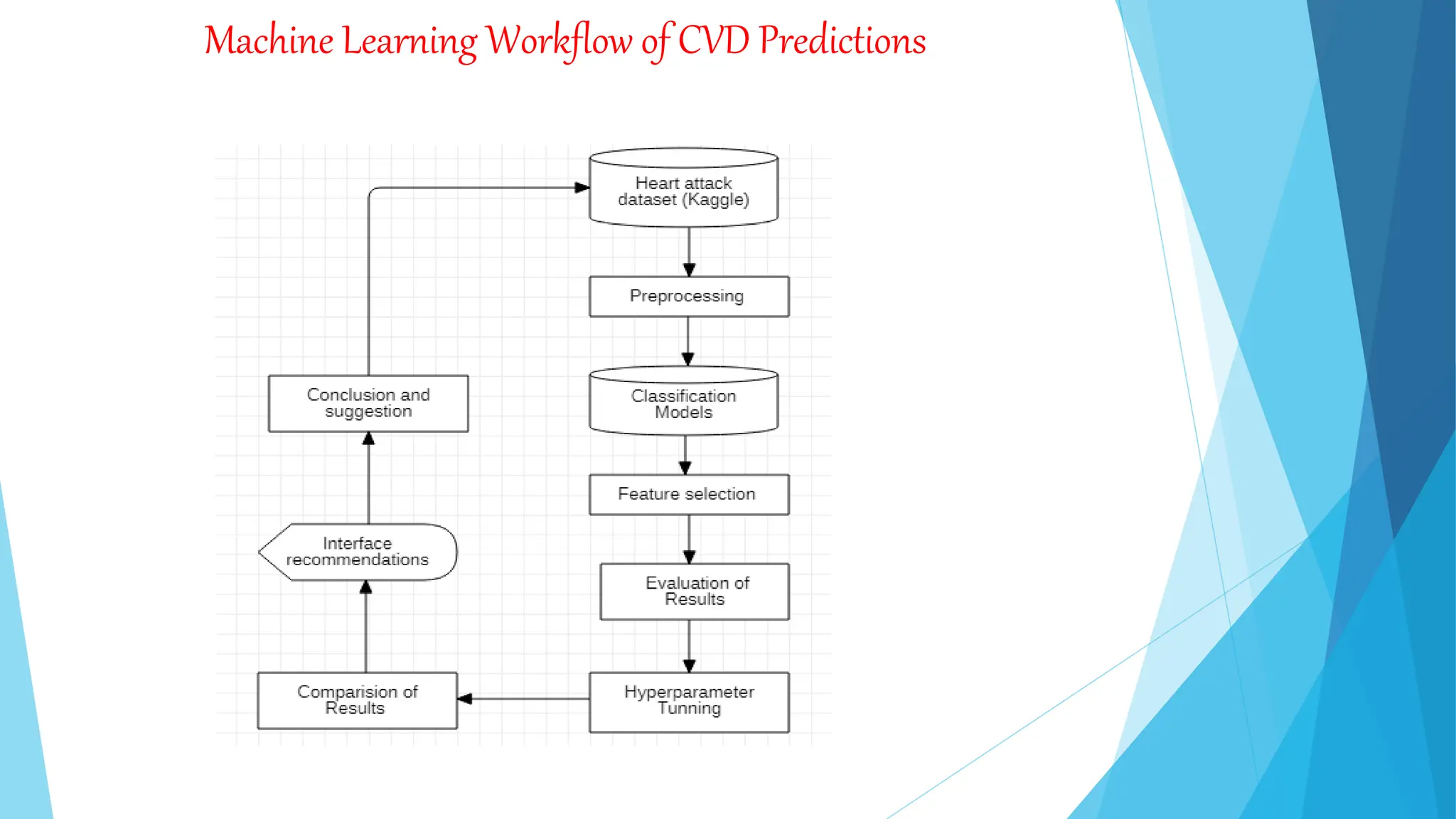
The document outlines a lecture on machine learning, differentiating it from artificial intelligence and explaining its various types: supervised, unsupervised, and reinforcement learning. It elaborates on specific algorithms such as k-NN, decision trees, random forests, and support vector machines, detailing their functions and applications across different domains. Additionally, it discusses the historical development of machine learning and its applications in sectors like healthcare, finance, transportation, and agriculture.










![How does K-NN work?
Suppose we have a new data point and we need to put it in the
required category. Consider the given image:
Firstly, we will choose the number of neighbors, so we will
choose the k=5.
Next, we will calculate the Euclidean distance between the
data points. The Euclidean distance is the distance between
two points, which we have already studied in geometry. It
can be calculated as: √[(x2 – x1)2 + (y2 – y1)2]
By calculating the Euclidean distance we got the nearest
neighbors, as three nearest neighbors in category A and two
nearest neighbors in category B.
As we can see the 3 nearest neighbors are from category A,
hence this new data point must belong to category A.](https://image.slidesharecdn.com/demolect-1-240725032239-12fc6d13/75/demo-lecture-for-foundation-class-for-btech-11-2048.jpg)


















![How does K-NN work?
Suppose we have a new data point and we need to put it in the
required category. Consider the given image:
Firstly, we will choose the number of neighbors, so we will
choose the k=5.
Next, we will calculate the Euclidean distance between the
data points. The Euclidean distance is the distance between
two points, which we have already studied in geometry. It
can be calculated as: √[(x2 – x1)2 + (y2 – y1)2]
By calculating the Euclidean distance we got the nearest
neighbors, as three nearest neighbors in category A and two
nearest neighbors in category B.
As we can see the 3 nearest neighbors are from category A,
hence this new data point must belong to category A.](https://crownmelresort.com/image.slidesharecdn.com/demolect-1-240725032239-12fc6d13/75/demo-lecture-for-foundation-class-for-btech-11-2048.jpg)


























































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)






