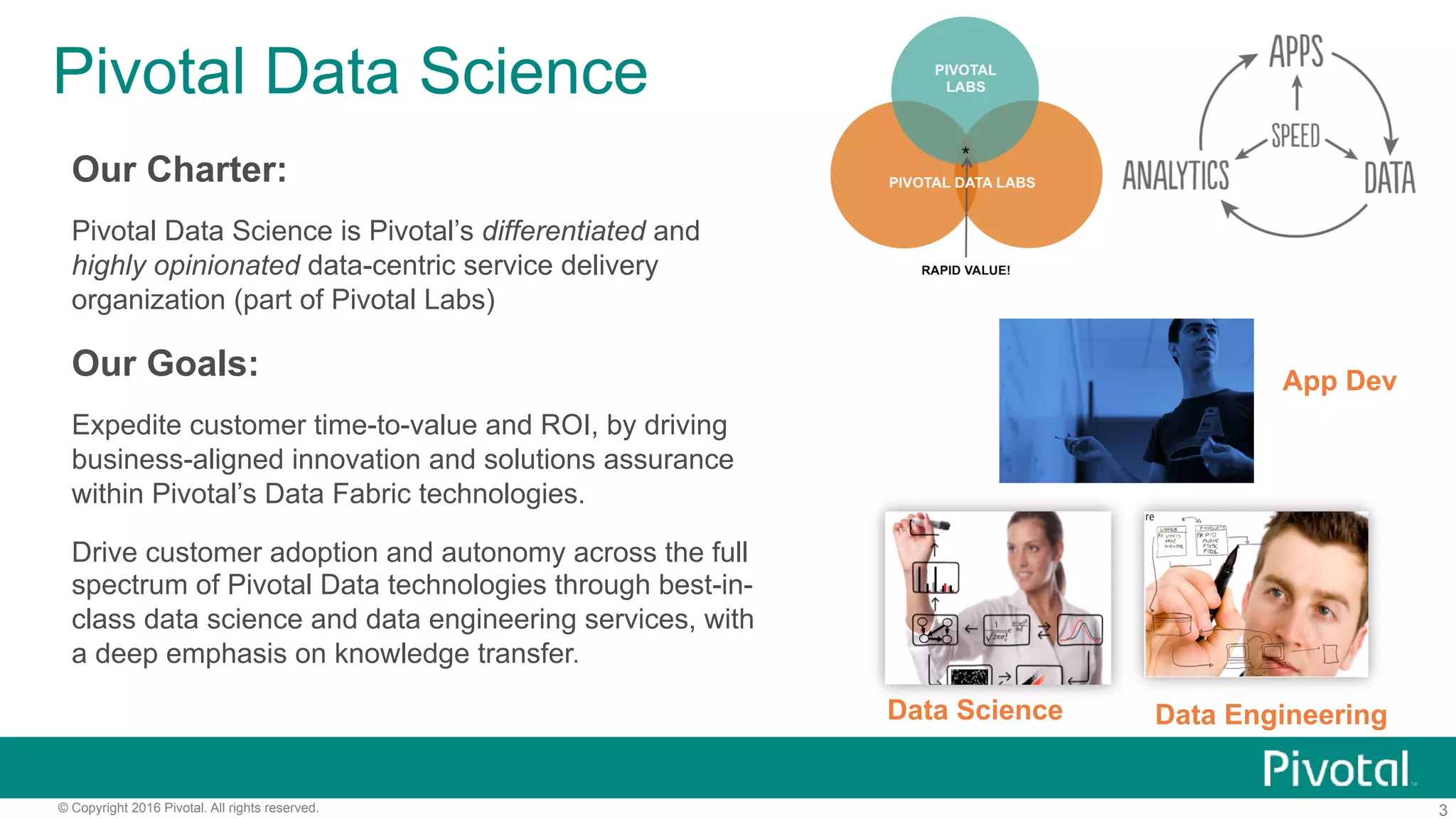
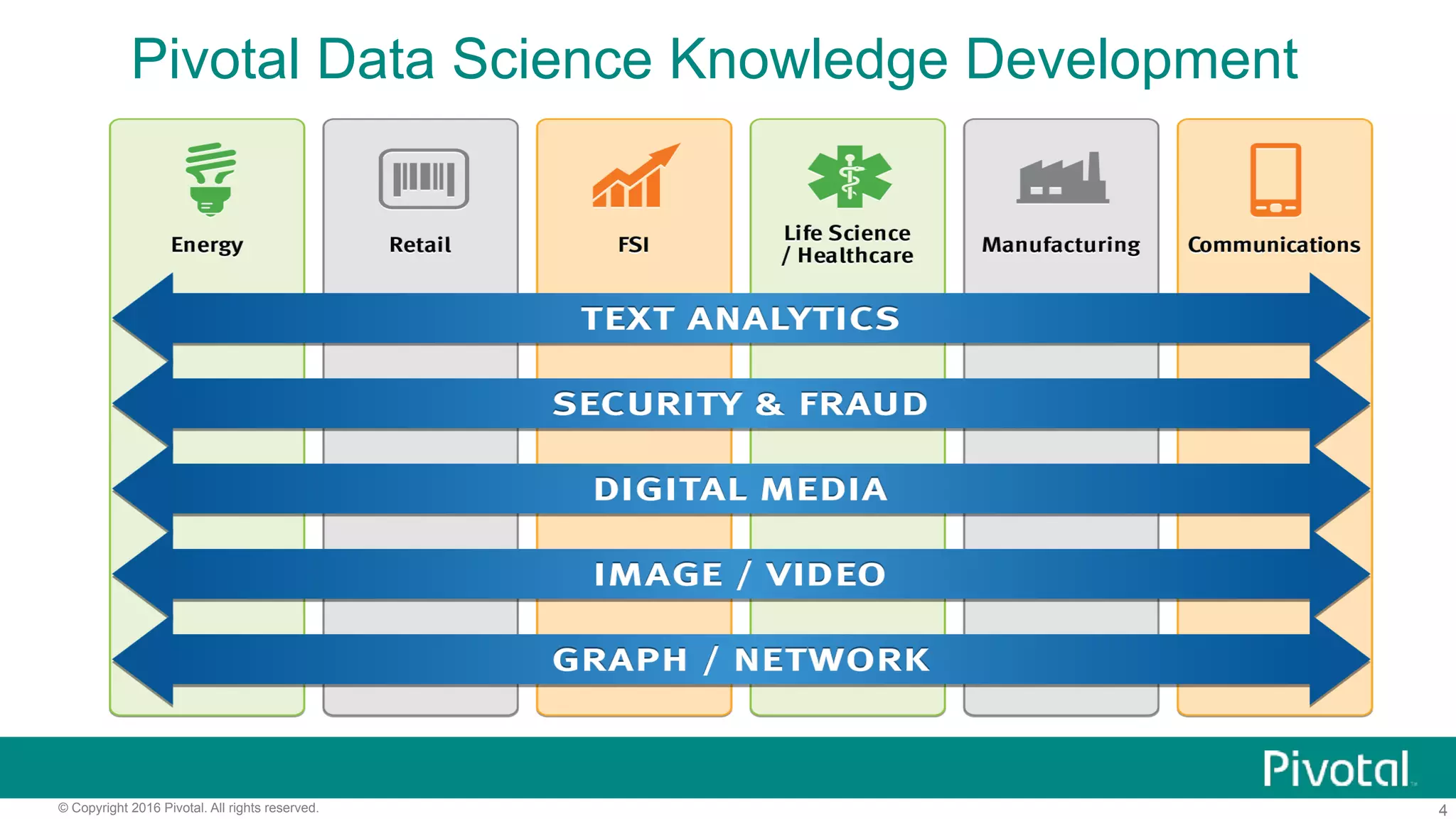
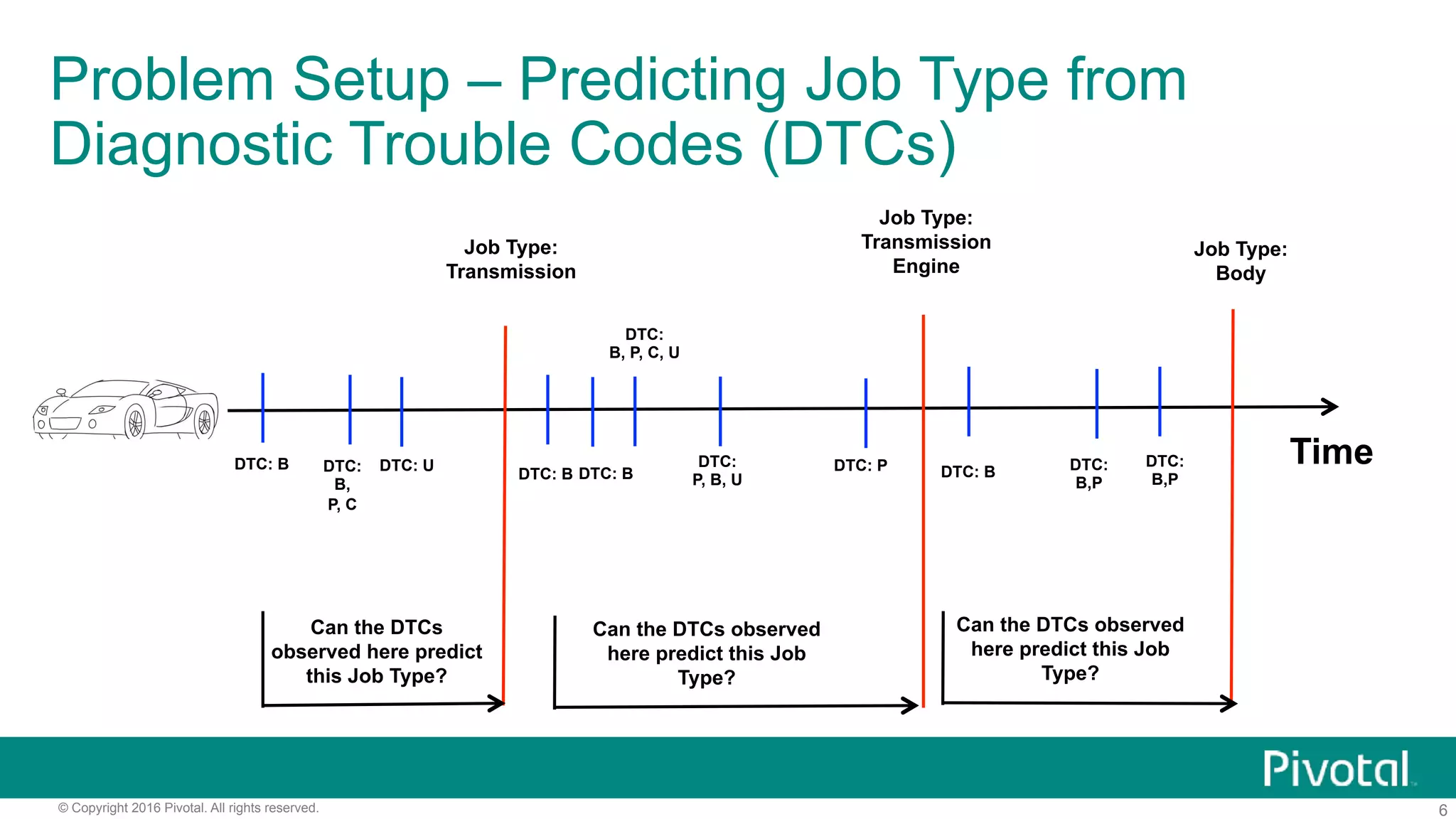
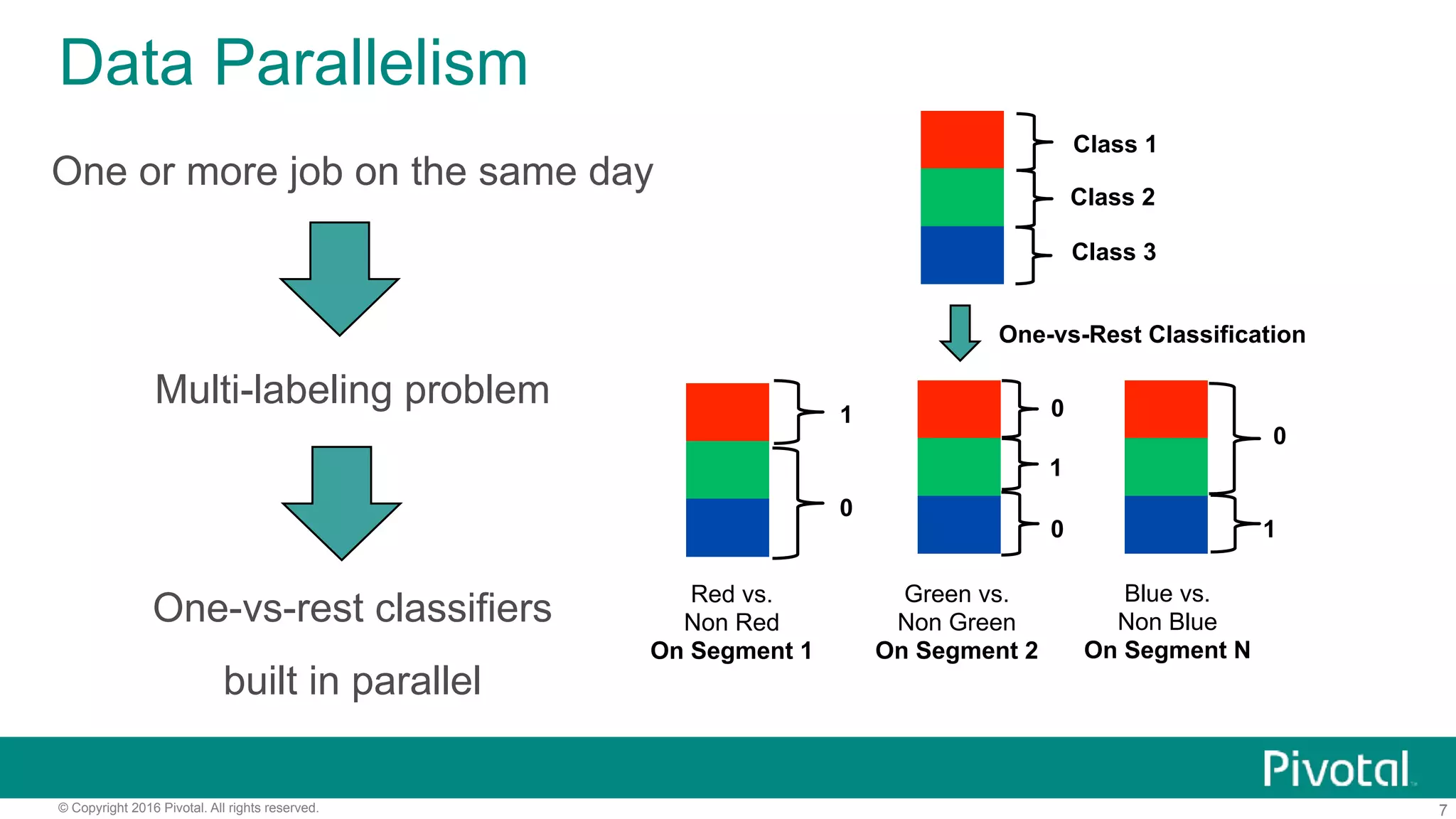
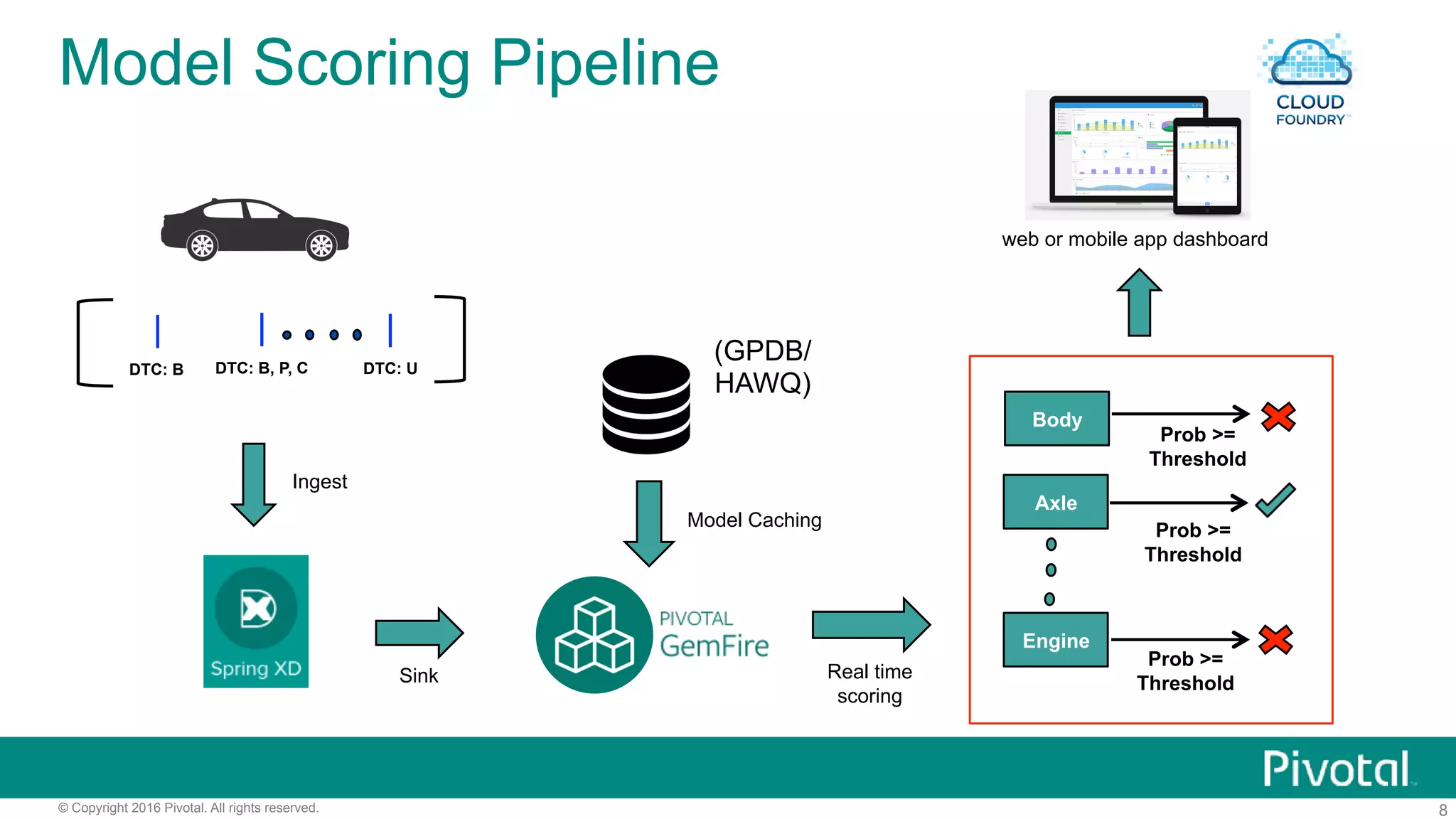
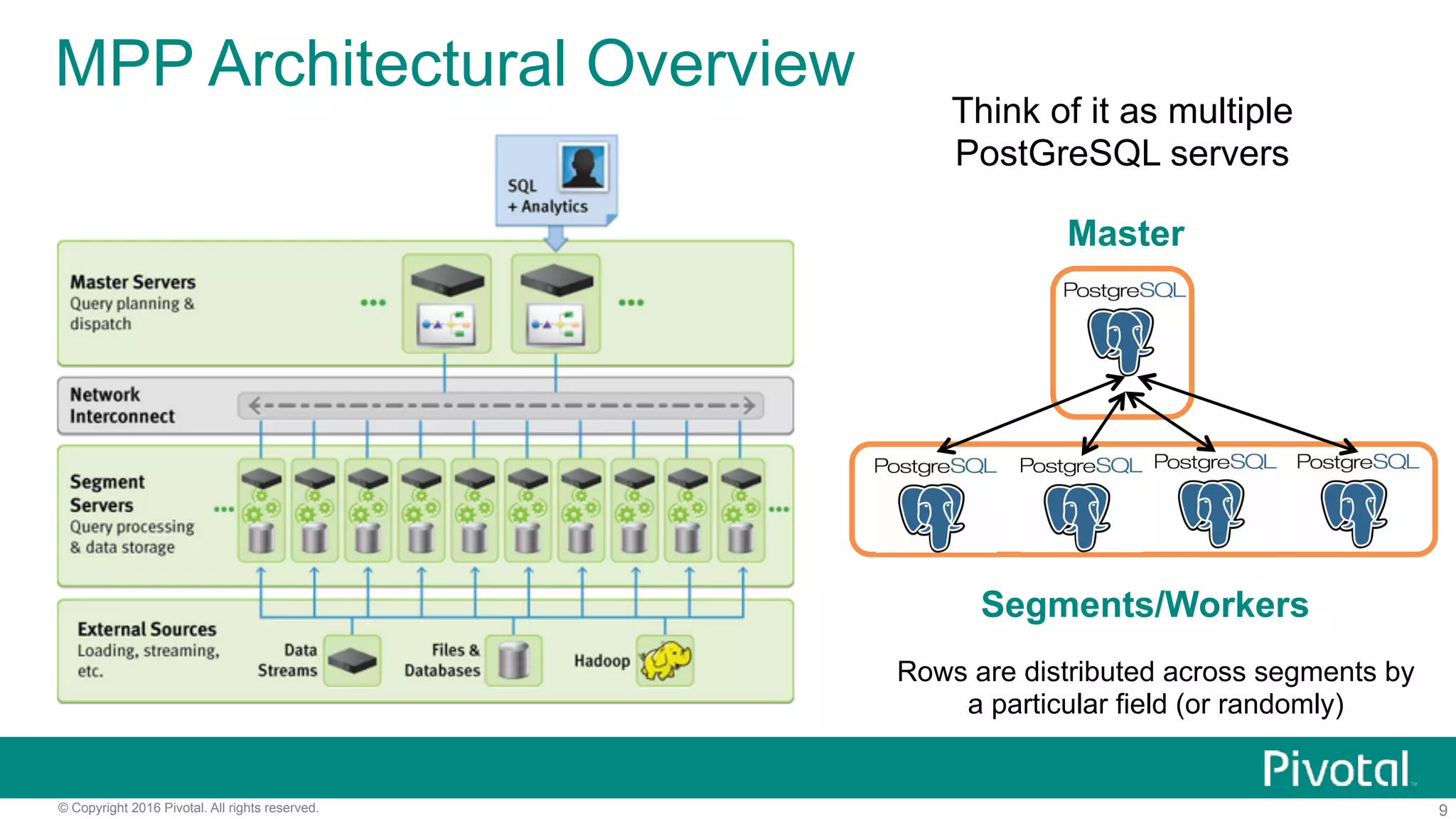
The document outlines pivotal data science's approach to data science at scale using MPP databases, emphasizing real-world applications such as predictive maintenance for connected vehicles, insurance claim predictions, and customer churn analysis. It discusses the use of an open source data science toolkit and includes technical details about machine learning, data processing, and inference models. Furthermore, it highlights the integration of structured and unstructured data analytics along with the development of user-defined functions for in-database analytics.









![21© Copyright 2016 Pivotal. All rights reserved.
User Defined Functions (UDFs) in PL/Python
Ÿ Procedural languages need to be installed on each database used.
Ÿ Syntax is like normal Python function with function definition line replaced by SQL wrapper.
Alternatively like a SQL User Defined Function with Python inside.
CREATE
FUNCTION
seasonality
(x
float[])
RETURNS
float[]
AS
$$
import
statsmodels.api
as
sm
s
=
sm.tsa.seasonal_decompose(x).seasonal
return
s
$$
LANGUAGE
plpythonu;
SQL wrapper
SQL wrapper
Normal Python](https://image.slidesharecdn.com/structuredataworkshop-160309233201/75/Data-Science-at-Scale-on-MPP-databases-Use-Cases-Open-Source-Tools-21-2048.jpg)
























![21© Copyright 2016 Pivotal. All rights reserved.
User Defined Functions (UDFs) in PL/Python
Ÿ Procedural languages need to be installed on each database used.
Ÿ Syntax is like normal Python function with function definition line replaced by SQL wrapper.
Alternatively like a SQL User Defined Function with Python inside.
CREATE
FUNCTION
seasonality
(x
float[])
RETURNS
float[]
AS
$$
import
statsmodels.api
as
sm
s
=
sm.tsa.seasonal_decompose(x).seasonal
return
s
$$
LANGUAGE
plpythonu;
SQL wrapper
SQL wrapper
Normal Python](https://crownmelresort.com/image.slidesharecdn.com/structuredataworkshop-160309233201/75/Data-Science-at-Scale-on-MPP-databases-Use-Cases-Open-Source-Tools-21-2048.jpg)








































































