Download as PDF, PPTX









































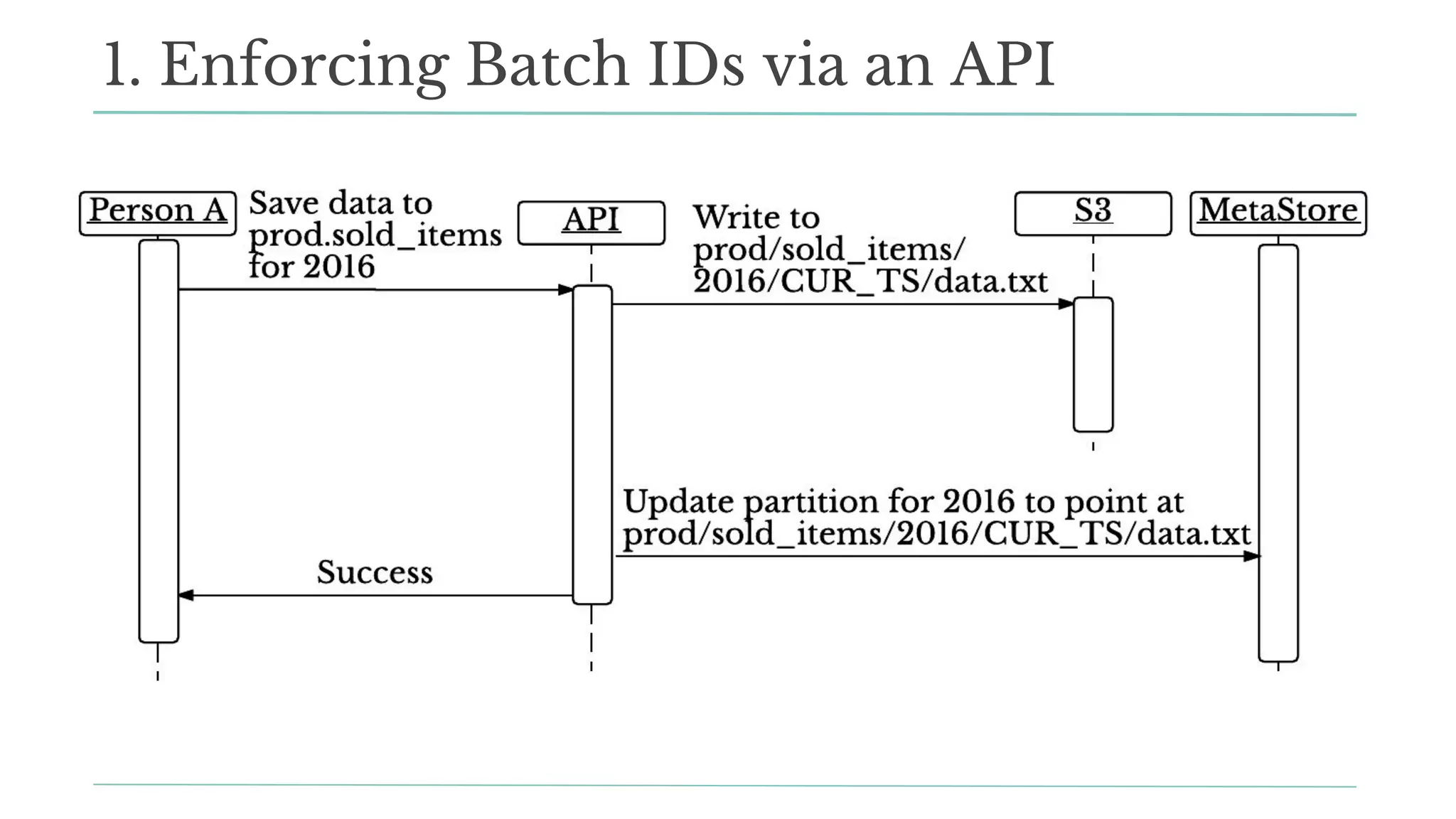
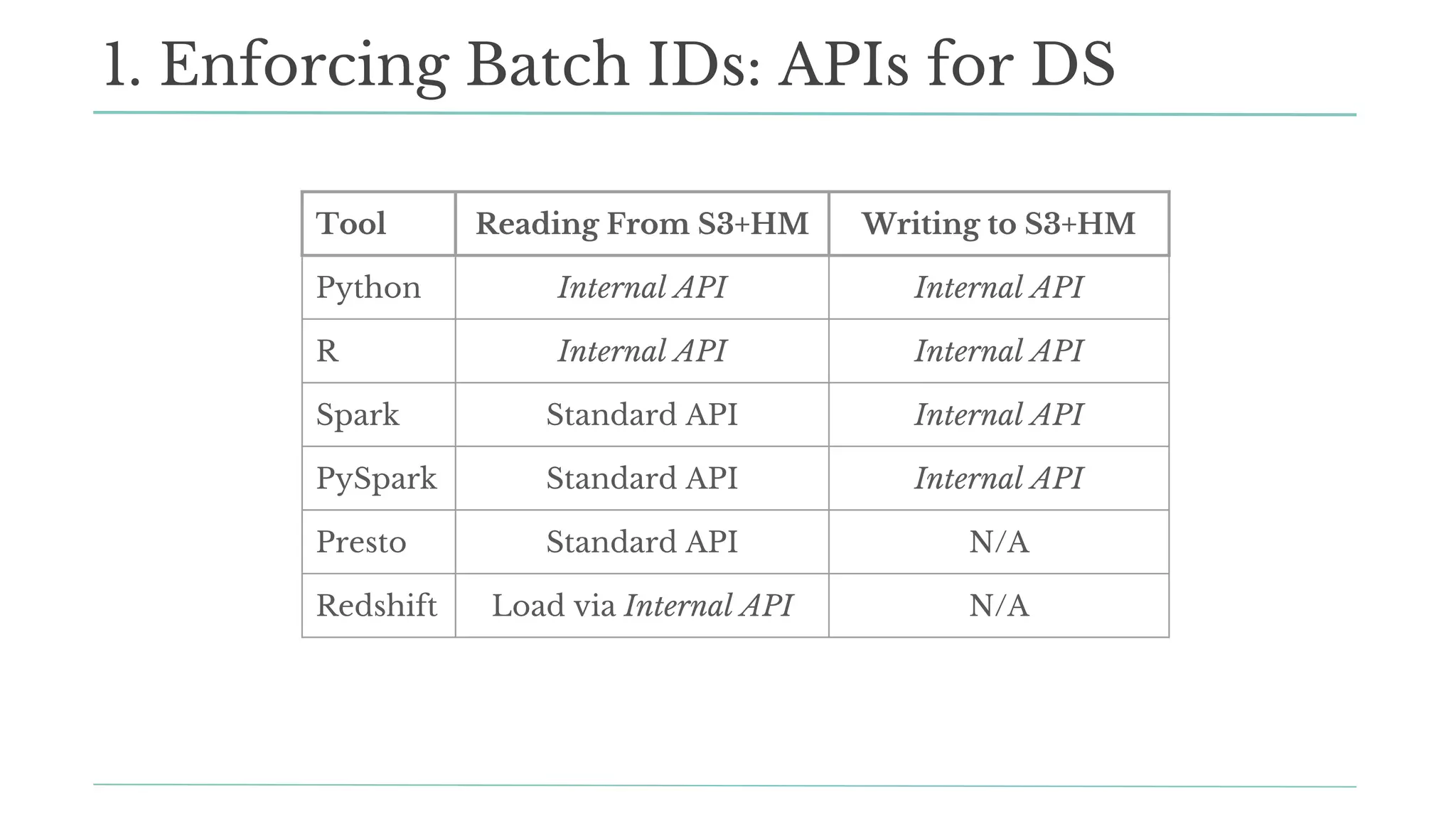
![Python:
store_dataframe(df, dest_db, dest_table, partitions=[‘2016’])
df = load_dataframe(src_db, src_table, partitions=[‘2016’])
R:
sf_writer(data = result,
namespace = dest_db,
resource = dest_table,
partitions = c(as.integer(opt$ETL_DATE)))
df <- sf_reader(namespace = src_db,
resource = src_table,
partitions = c(as.integer(opt$ETL_DATE)))
1. Enforcing Batch IDs: APIs for DS](https://image.slidesharecdn.com/scalingdsatsf-171027042508/75/Data-Day-Seattle-2017-Scaling-Data-Science-at-Stitch-Fix-66-2048.jpg)























































































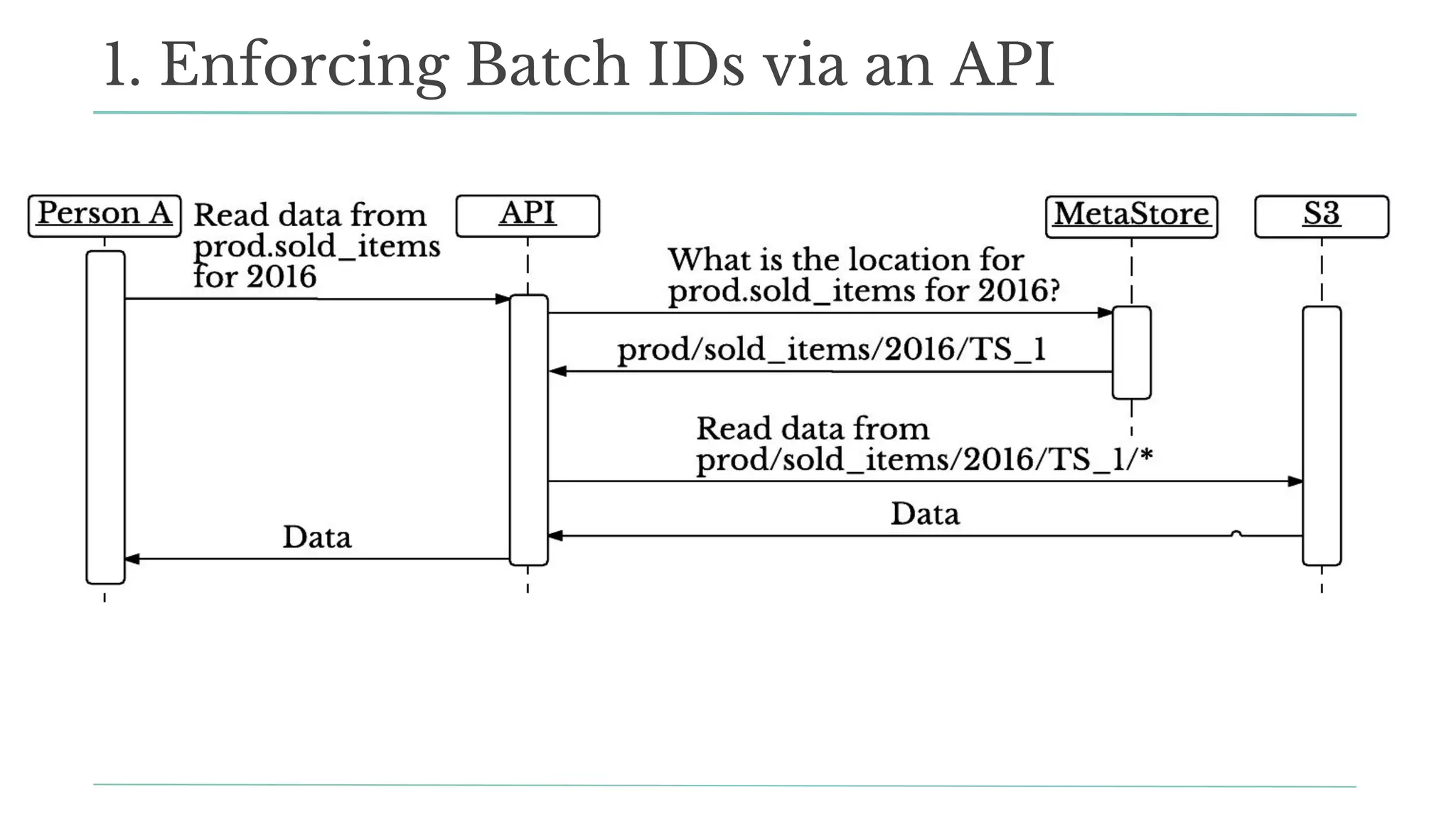
![Python:
store_dataframe(df, dest_db, dest_table, partitions=[‘2016’])
df = load_dataframe(src_db, src_table, partitions=[‘2016’])
R:
sf_writer(data = result,
namespace = dest_db,
resource = dest_table,
partitions = c(as.integer(opt$ETL_DATE)))
df <- sf_reader(namespace = src_db,
resource = src_table,
partitions = c(as.integer(opt$ETL_DATE)))
1. Enforcing Batch IDs: APIs for DS](https://crownmelresort.com/image.slidesharecdn.com/scalingdsatsf-171027042508/75/Data-Day-Seattle-2017-Scaling-Data-Science-at-Stitch-Fix-66-2048.jpg)







































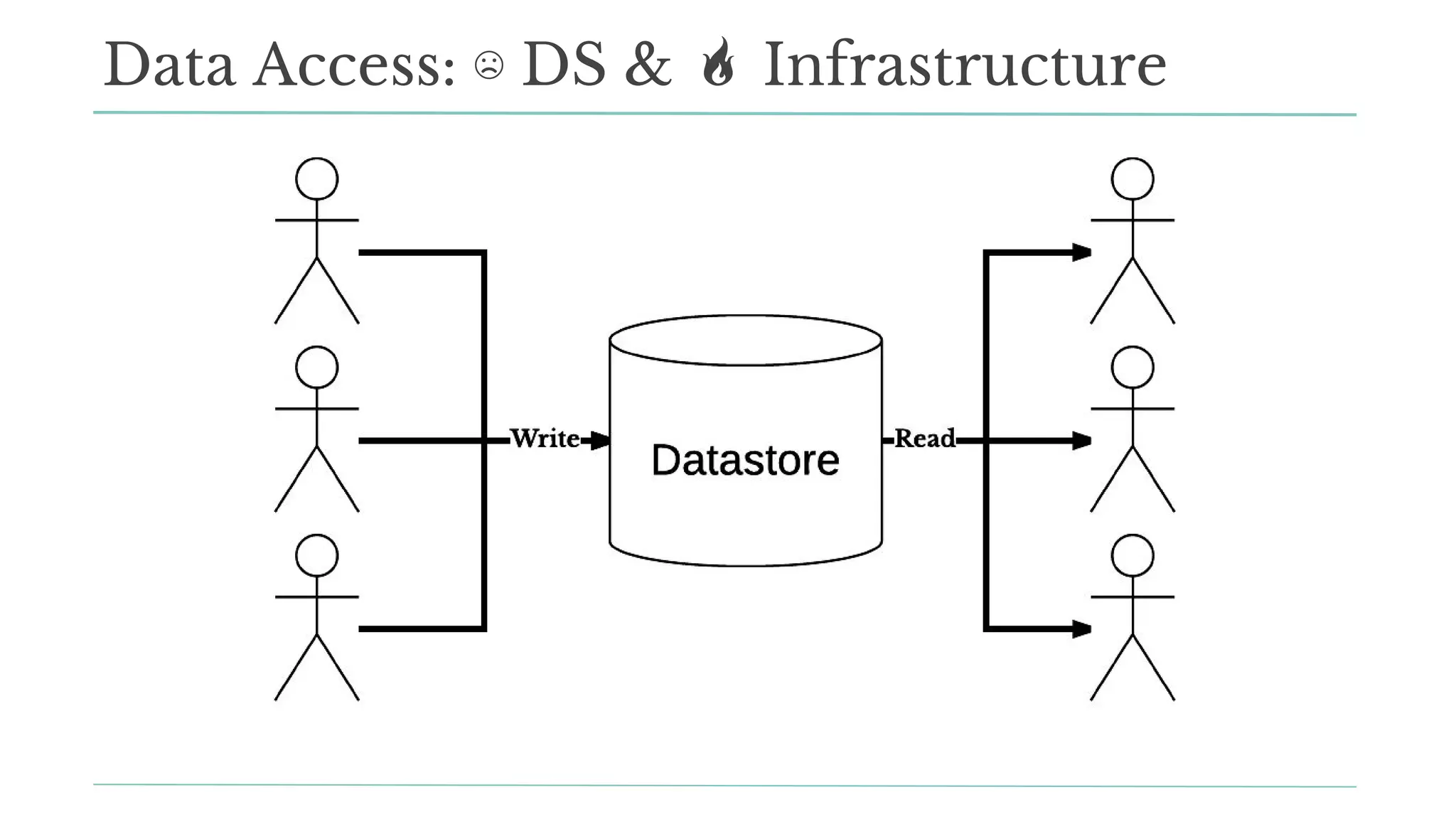
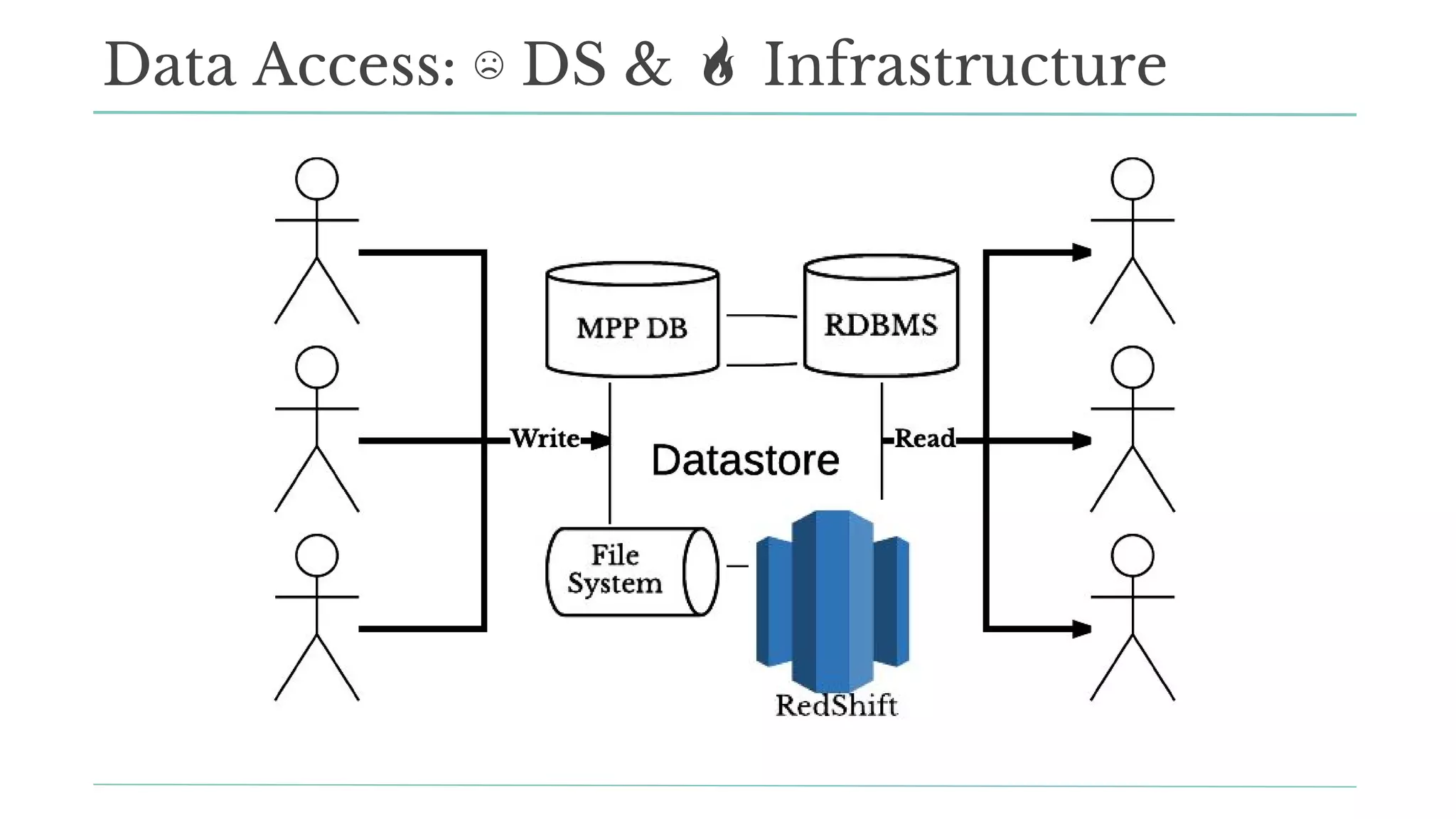
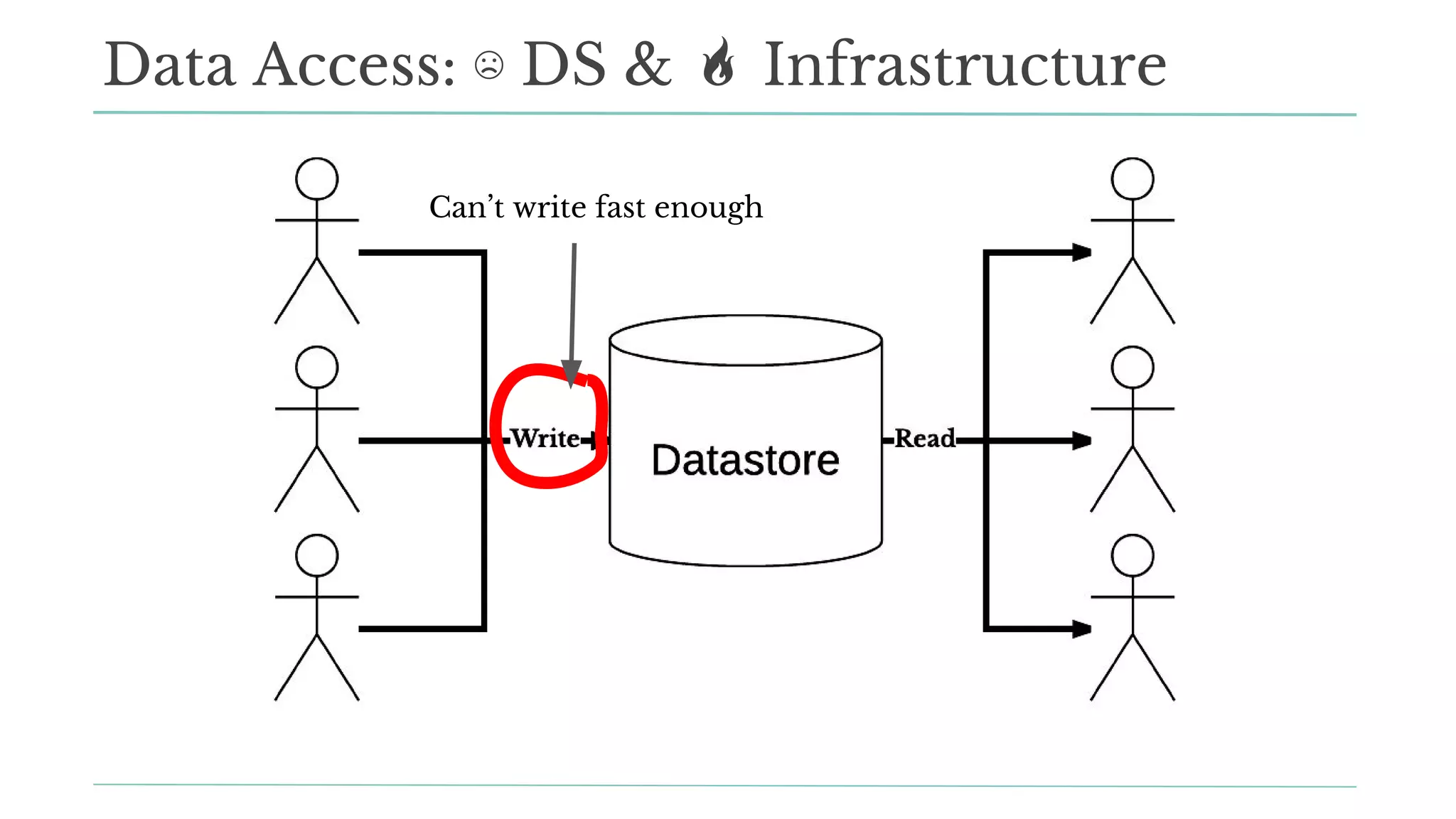
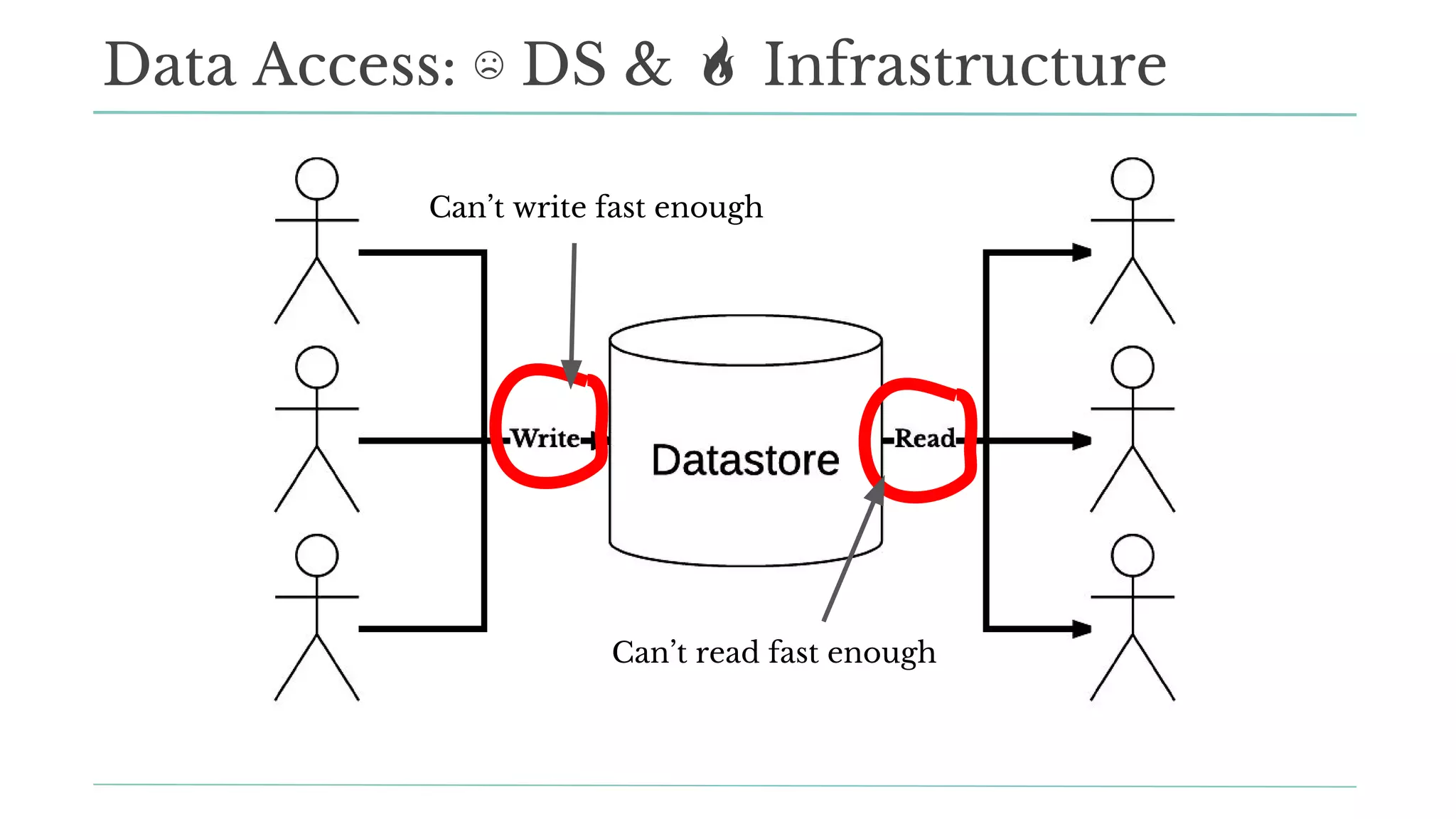
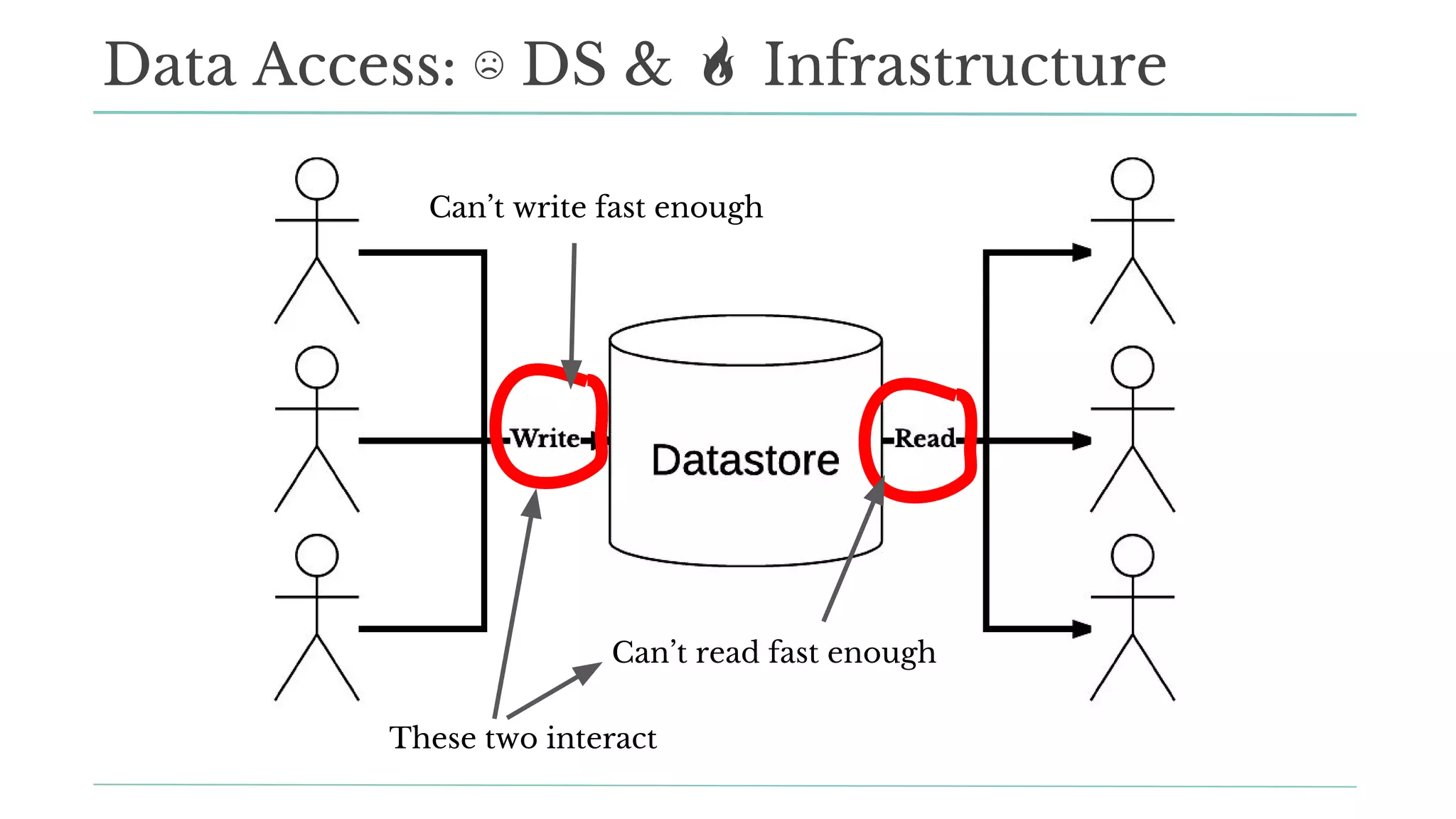
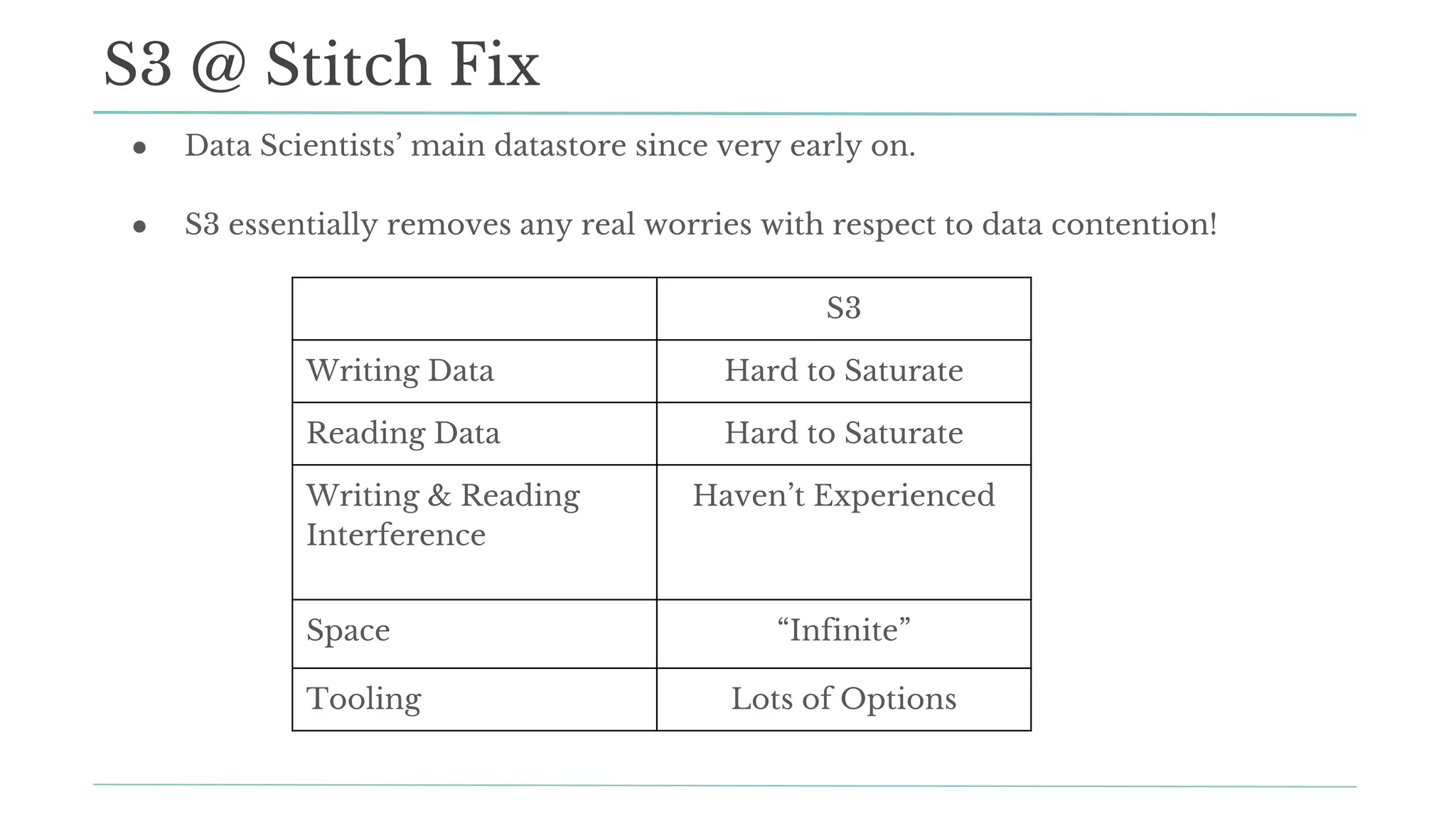
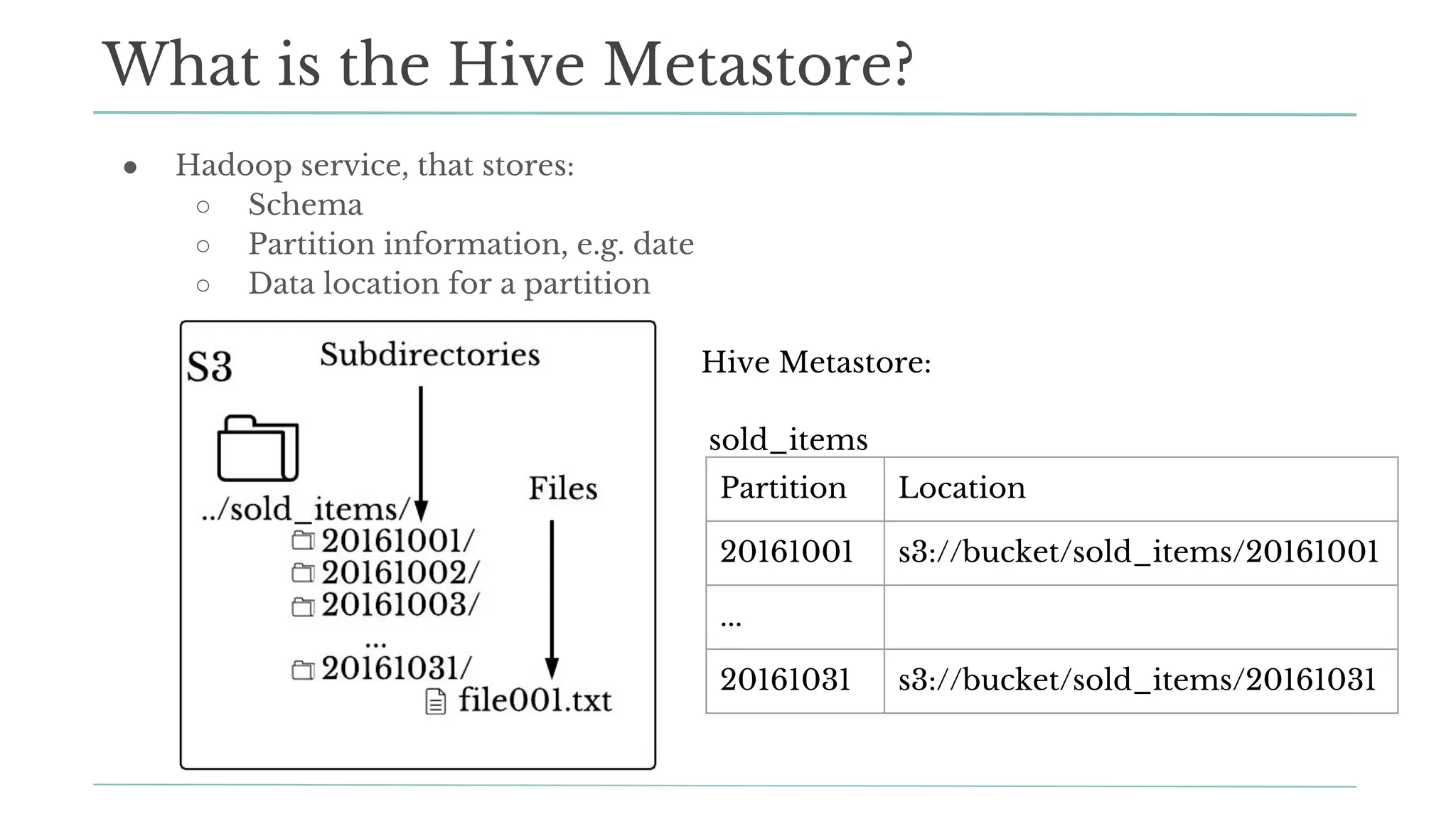
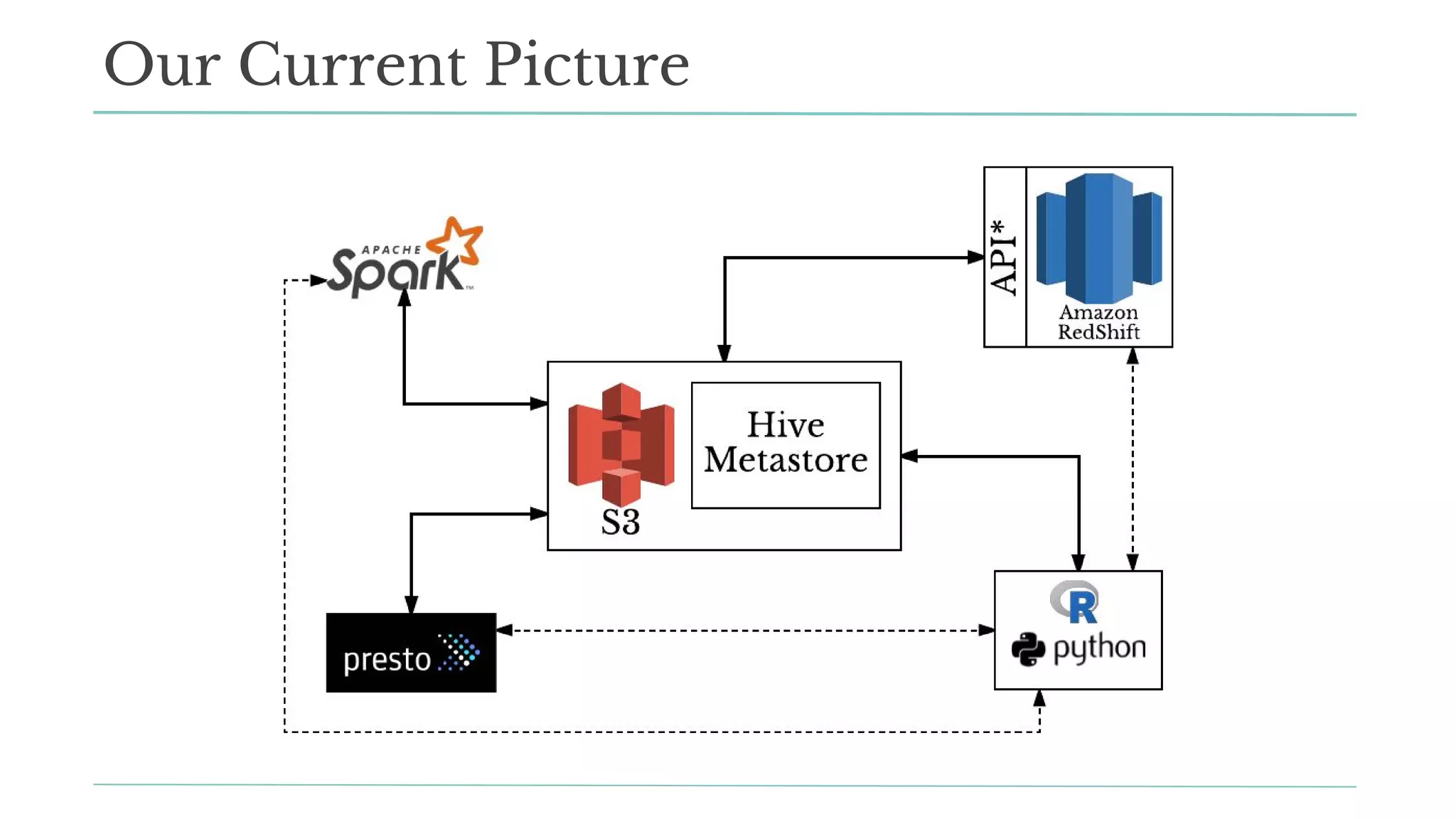
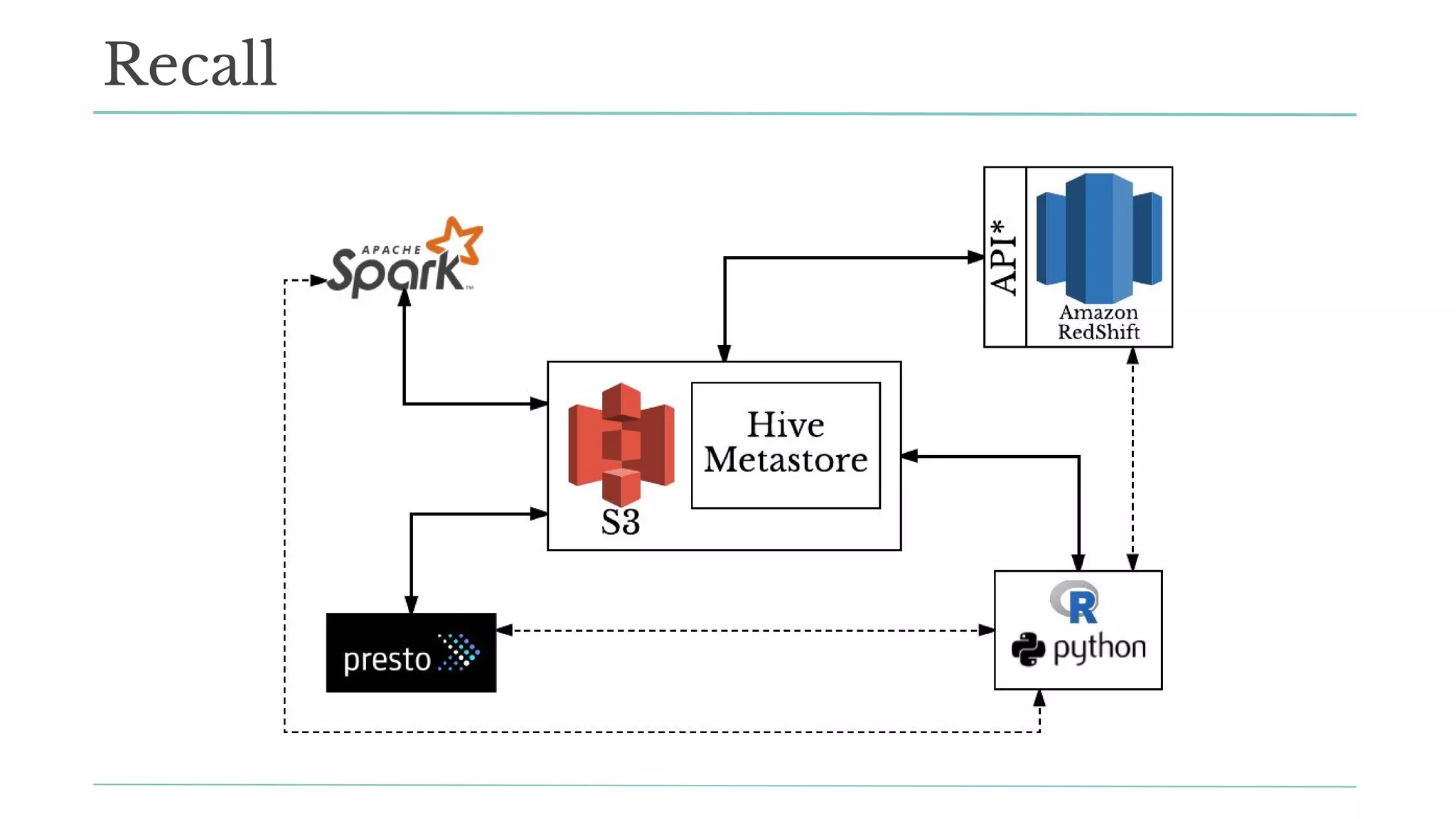
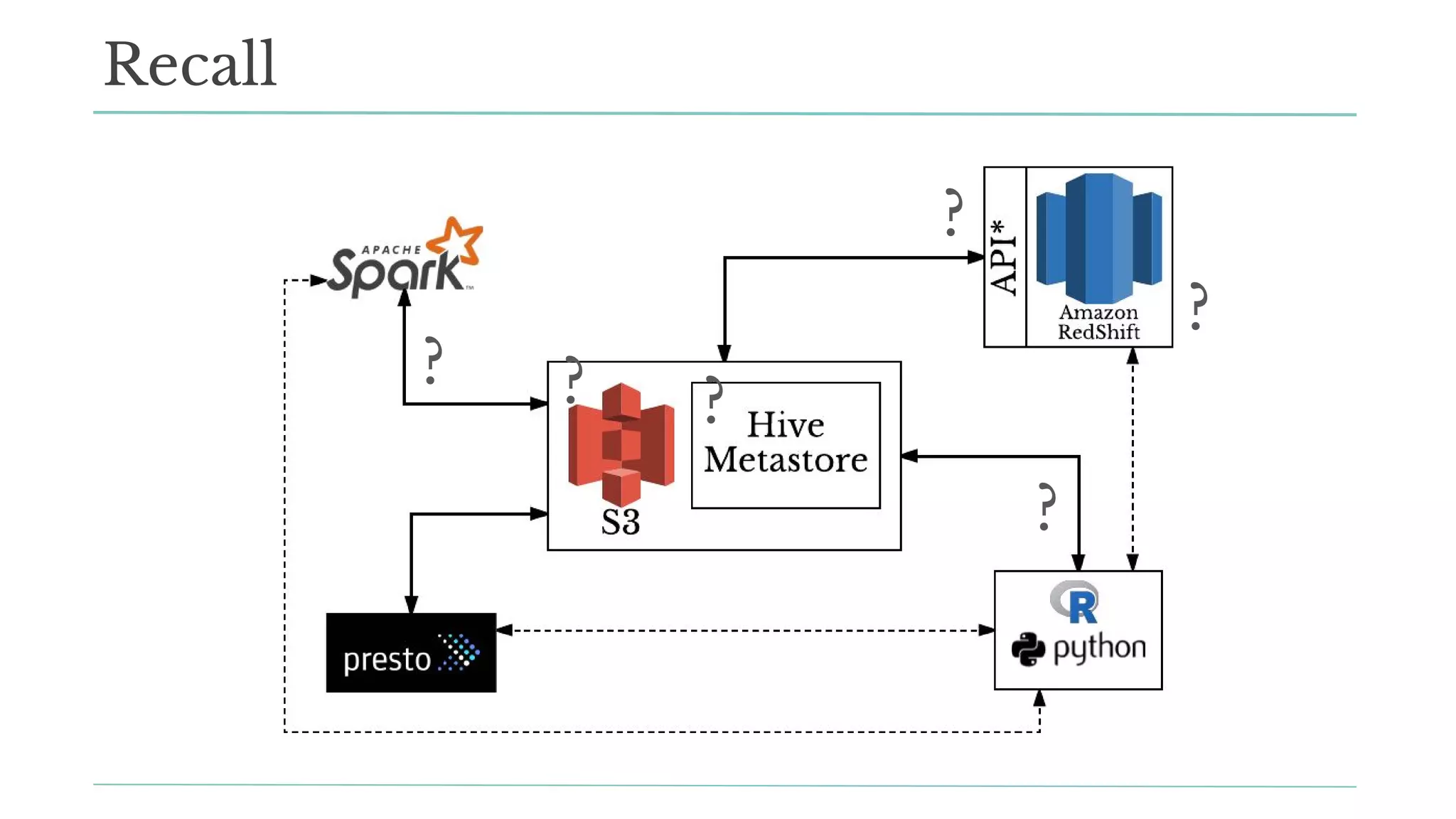
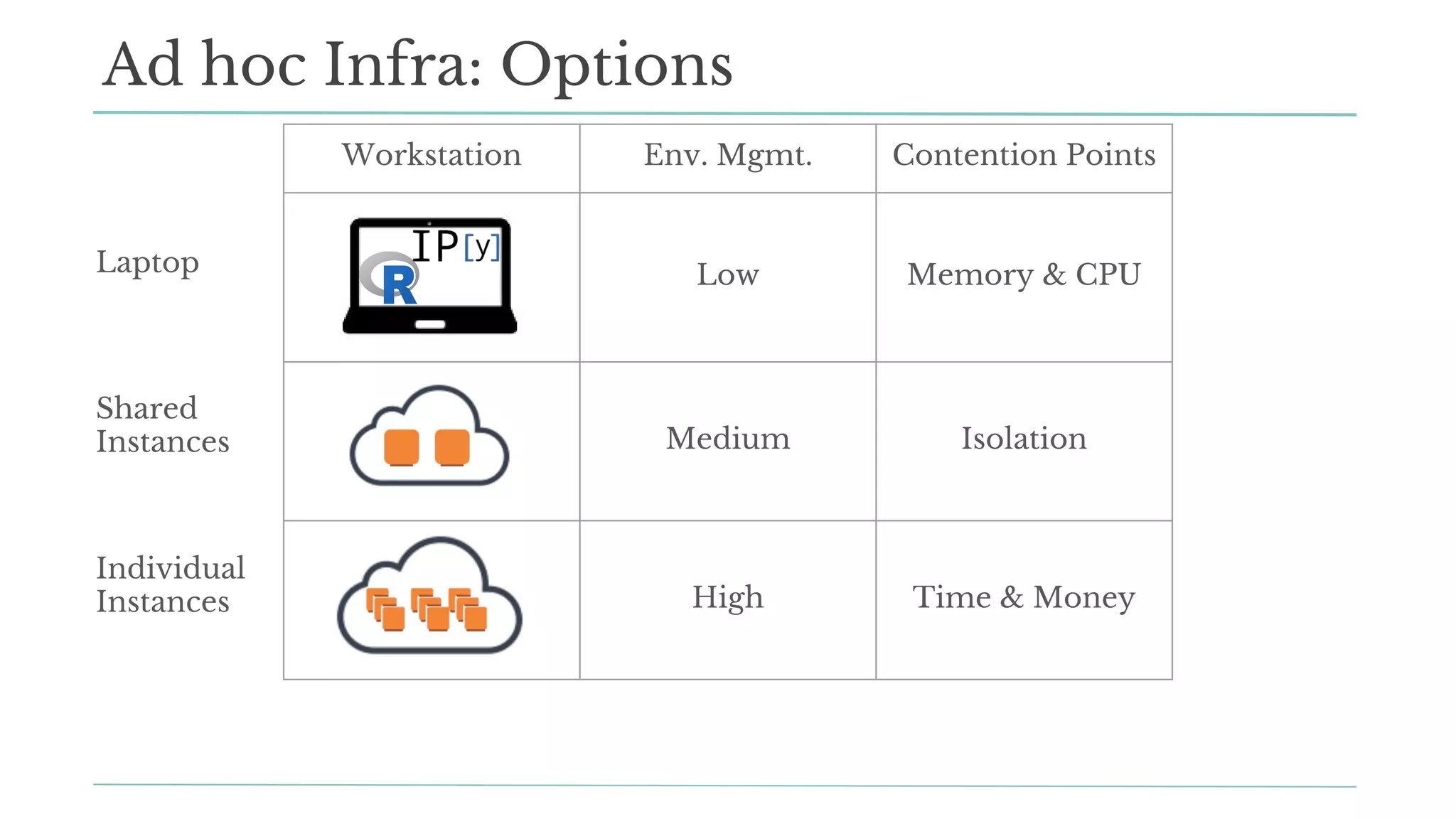
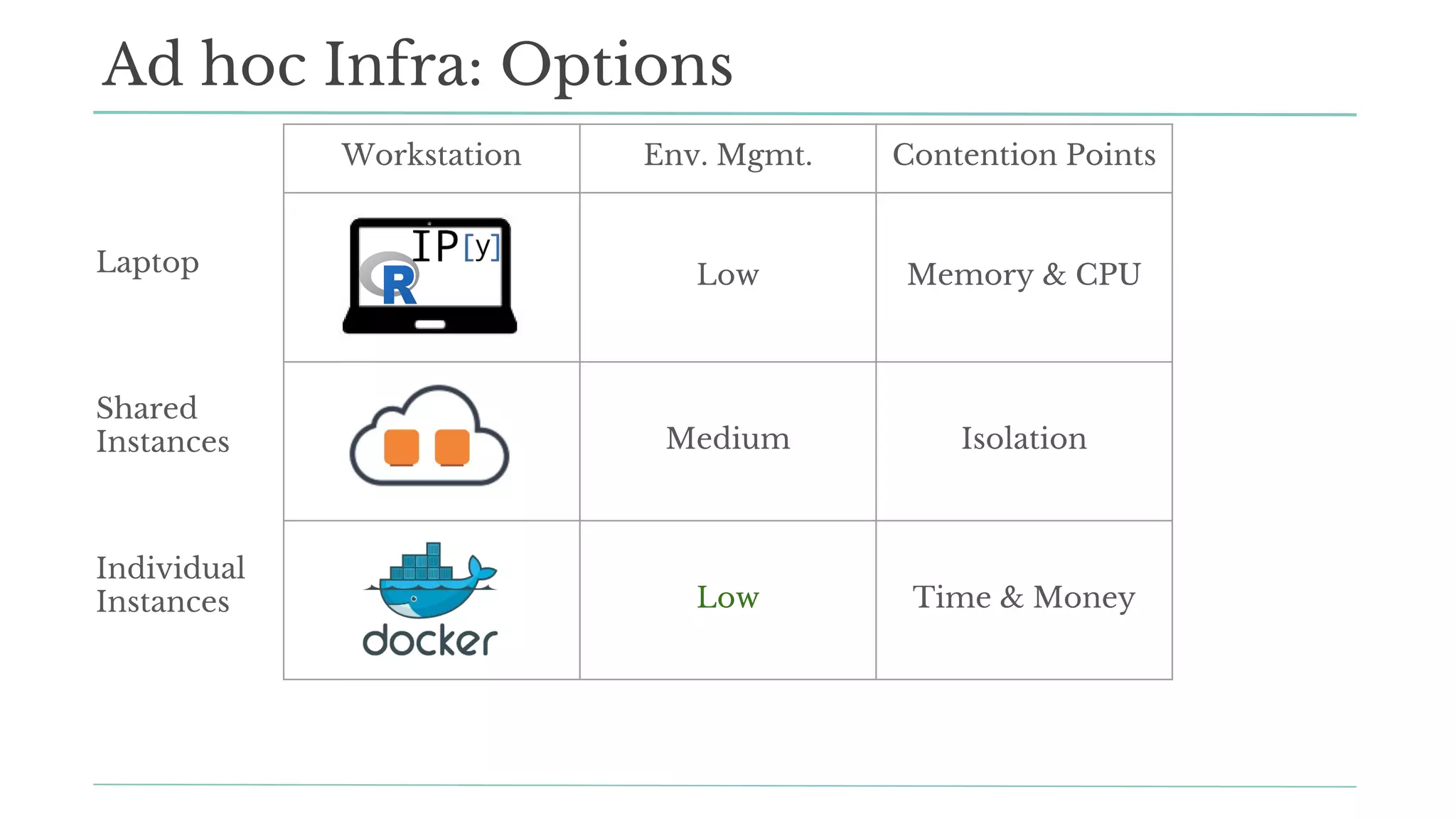
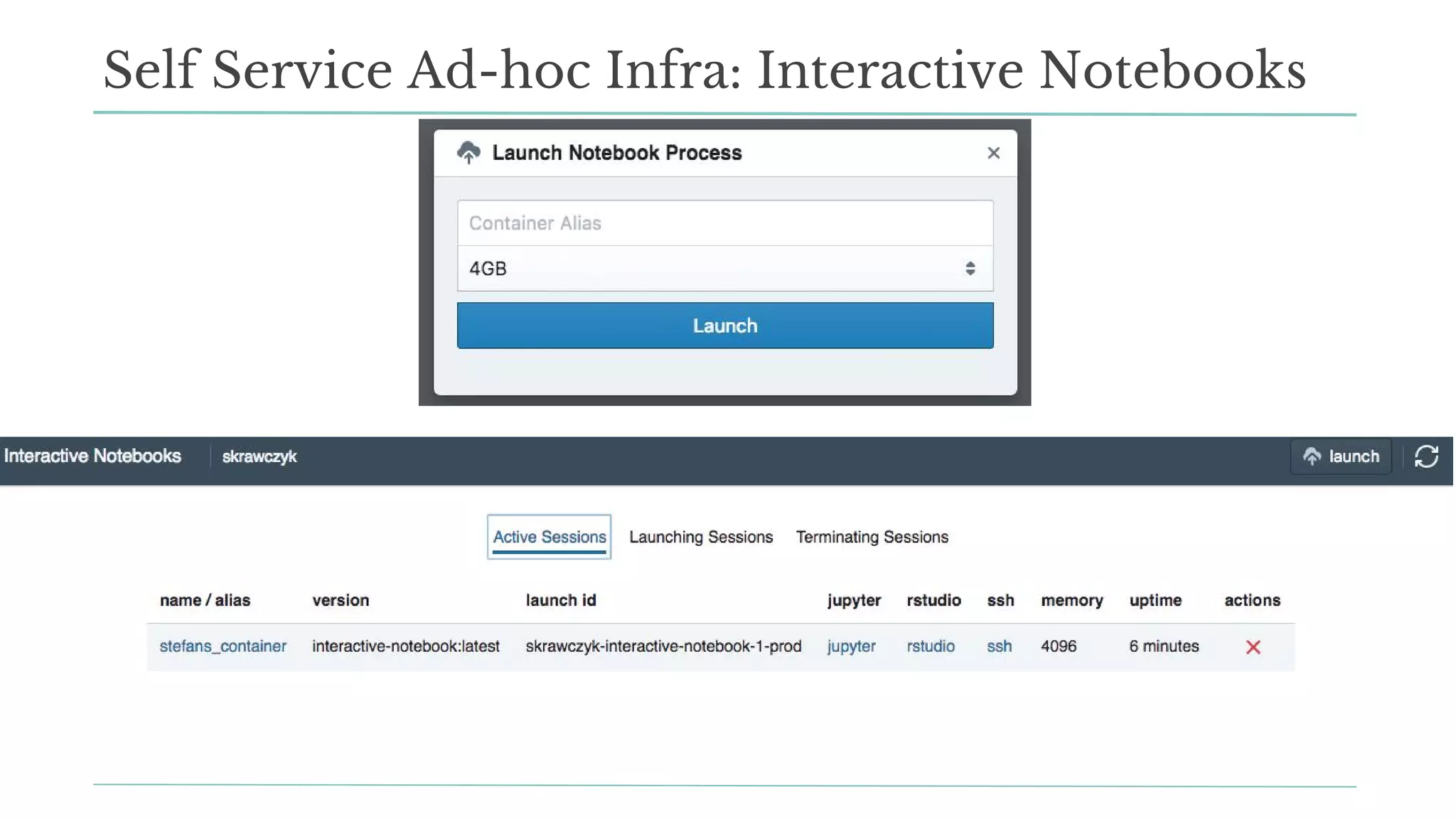
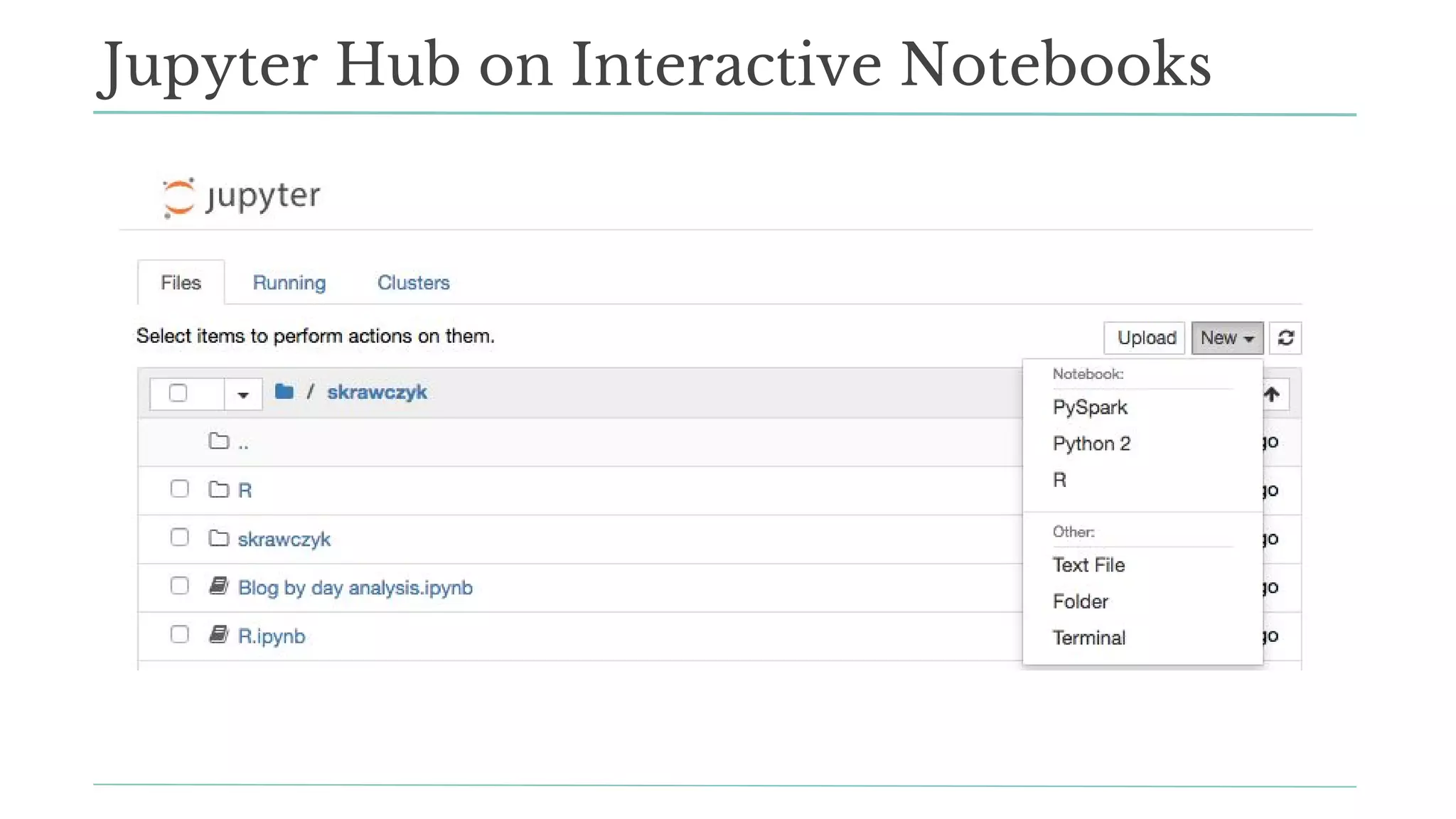
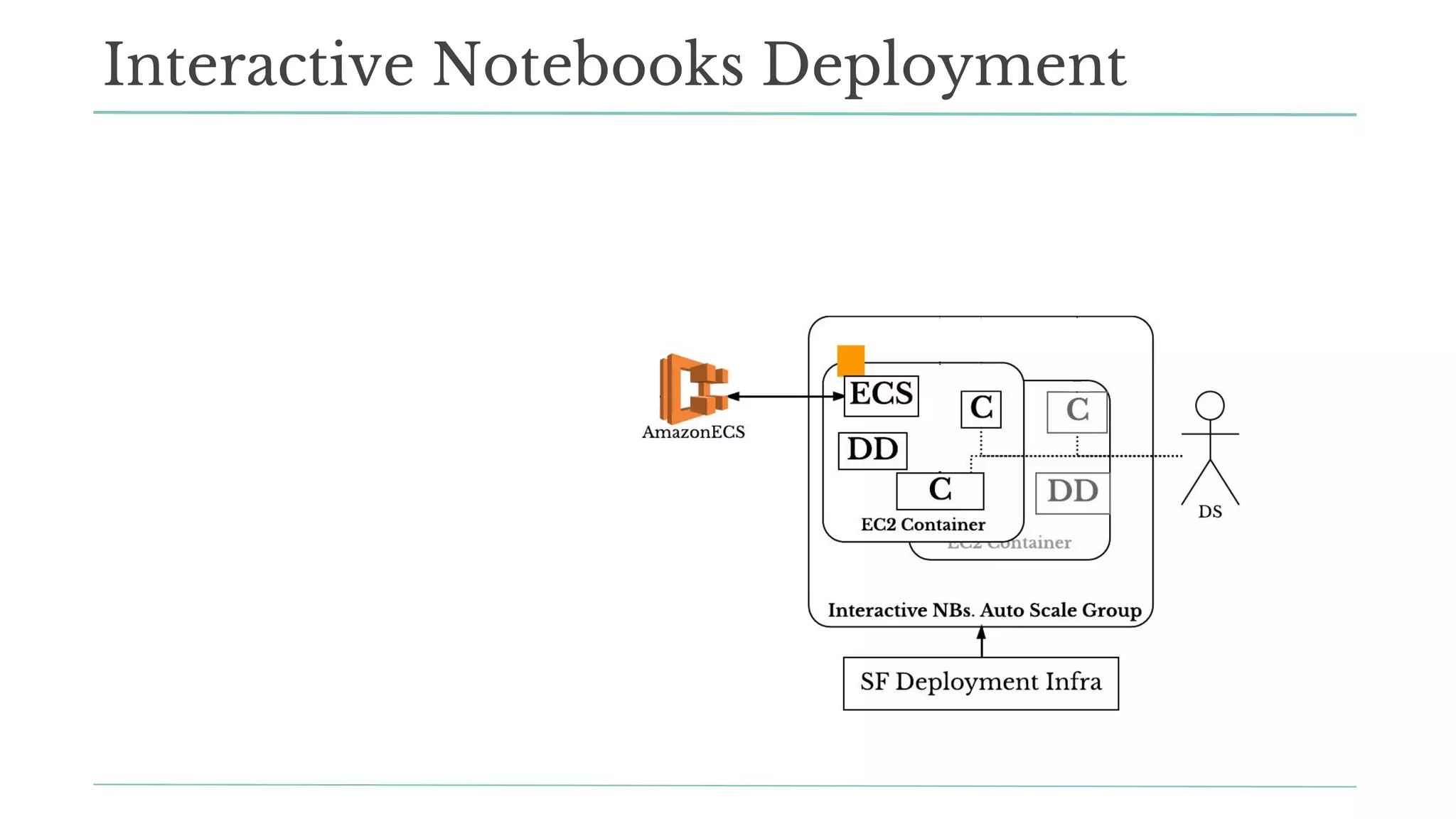
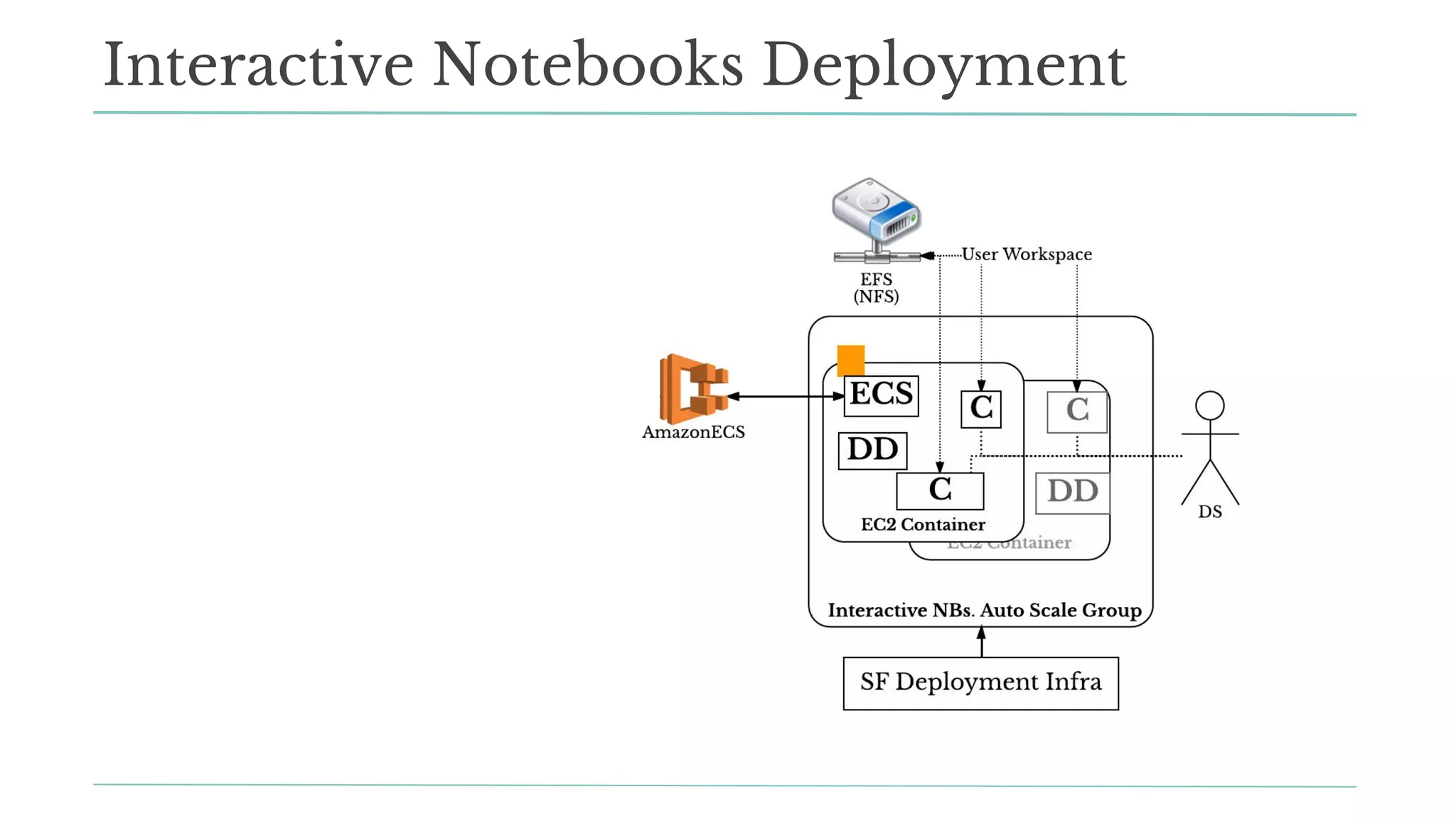
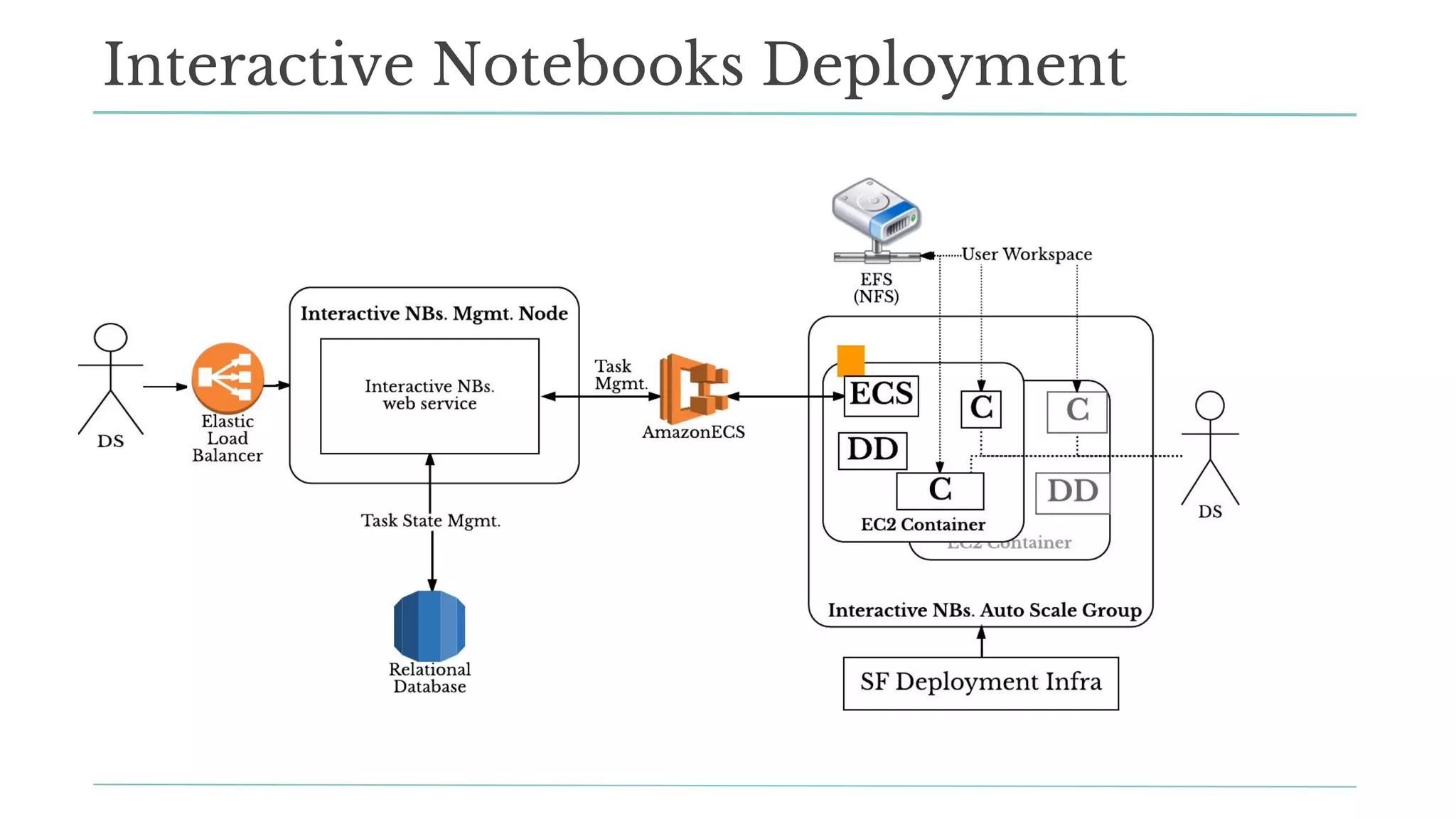
The document outlines how Stitch Fix scales data science by managing data access and computational resources for its approximately 80 data scientists. It emphasizes the use of Amazon S3 for storage, the Hive Metastore for data consistency, and the implementation of Docker for providing a consistent working environment. By creating internal APIs and leveraging cloud technology, Stitch Fix aims to reduce contention between data scientists and enhance their productivity.



































































