Download as PDF, PPTX






![Ever Changing Structure of Data
● One of your data centers
upgrade to IPv6 192.168.0.4
© 2014 StreamSets, Inc.
fe80::21b:21ff:fe83:90fa
M0137: User {jonsmith} granted access to {accounts}
M0137: [jonsmith] granted access to [sys.accounts]
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”
}
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”,
“phone”: “(408) 555-1212”
}
● Application developer
changes logs (again)
● JSON data may contain
more attributes than
expected](https://image.slidesharecdn.com/dataaggregationatscaleusingapacheflume-141029171908-conversion-gate01/75/Data-Aggregation-At-Scale-Using-Apache-Flume-7-2048.jpg)

















![Ever Changing Structure of Data
● One of your data centers
upgrade to IPv6 192.168.0.4
© 2014 StreamSets, Inc.
fe80::21b:21ff:fe83:90fa
M0137: User {jonsmith} granted access to {accounts}
M0137: [jonsmith] granted access to [sys.accounts]
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”
}
{
“first”:”jon”,
“last”:”smith”,
“add1”:”123 Main St.”,
“add2”:”Ste - 4”,
“city”:”Little Town”,
“state”:”AZ”,
“zip”: “12121”,
“phone”: “(408) 555-1212”
}
● Application developer
changes logs (again)
● JSON data may contain
more attributes than
expected](https://crownmelresort.com/image.slidesharecdn.com/dataaggregationatscaleusingapacheflume-141029171908-conversion-gate01/75/Data-Aggregation-At-Scale-Using-Apache-Flume-7-2048.jpg)

























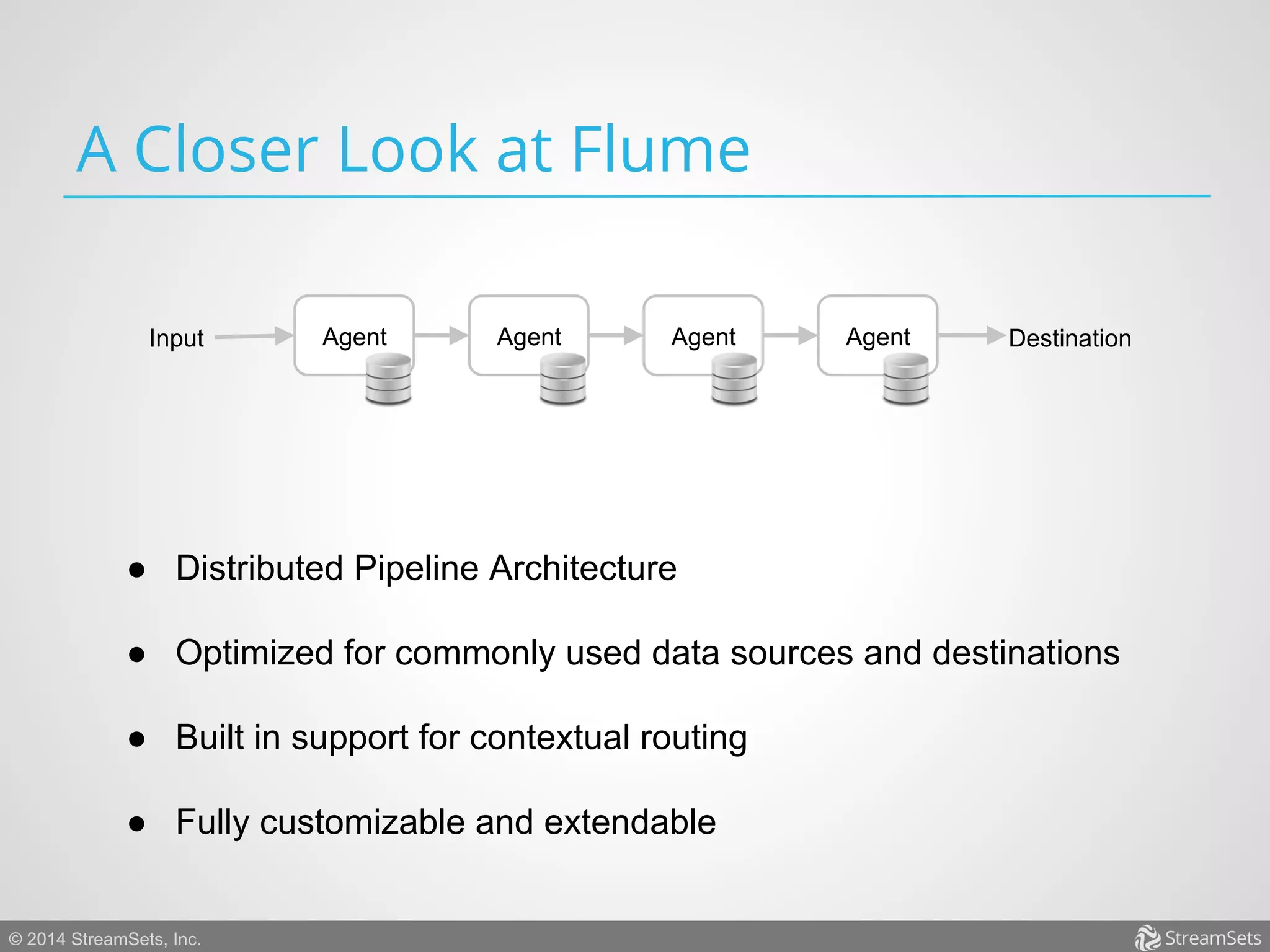
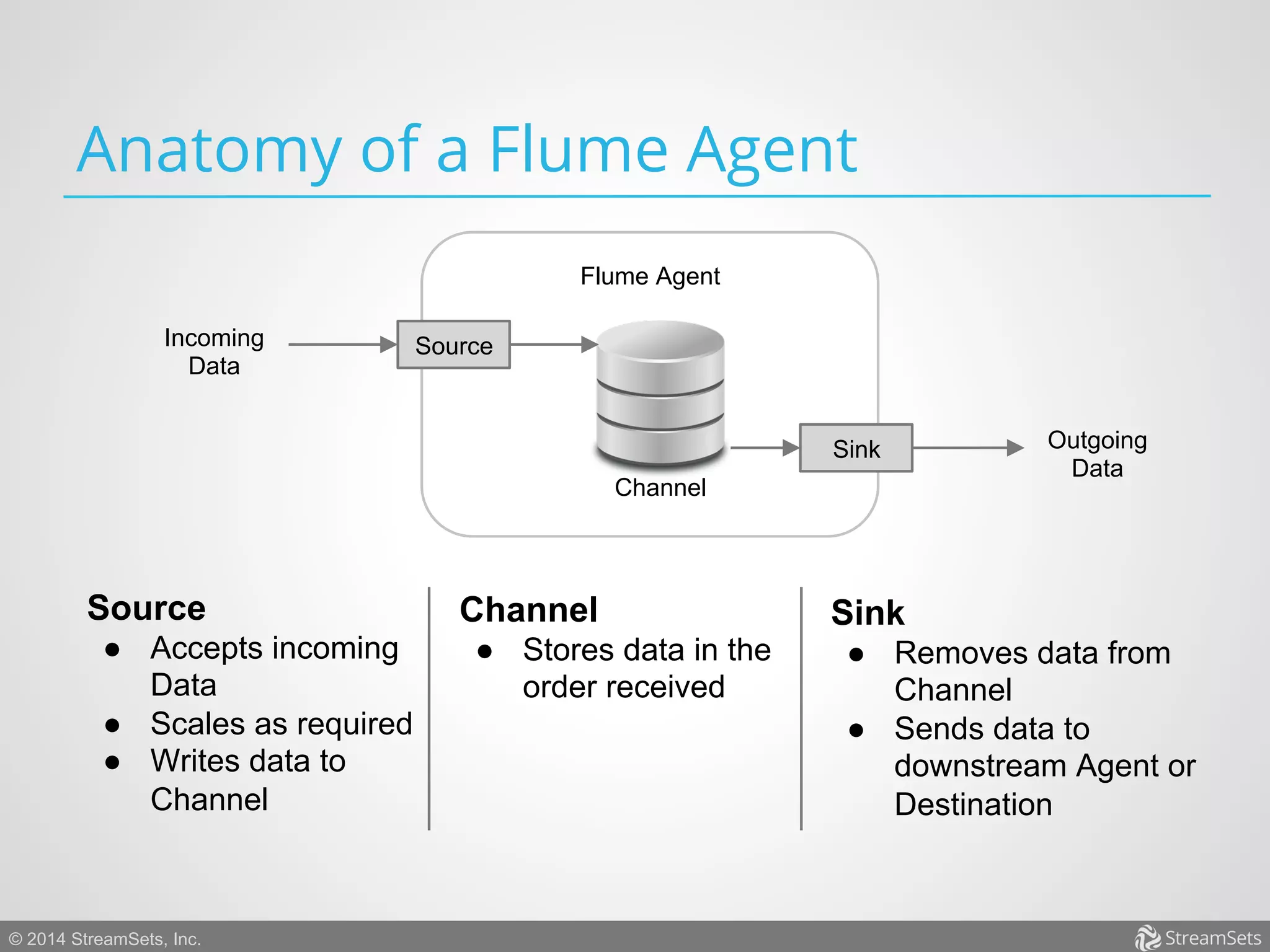
Apache Flume is an open-source, reliable data ingestion system designed for large-scale data aggregation in the big data ecosystem, capable of handling continuous data production from various sources. It features customizable and extensible architecture with a distributed pipeline, ensuring transactional guarantees and scalability. Although it effectively manages large volumes of data, it has limitations such as handling poison events and centralized configuration needs.












































































