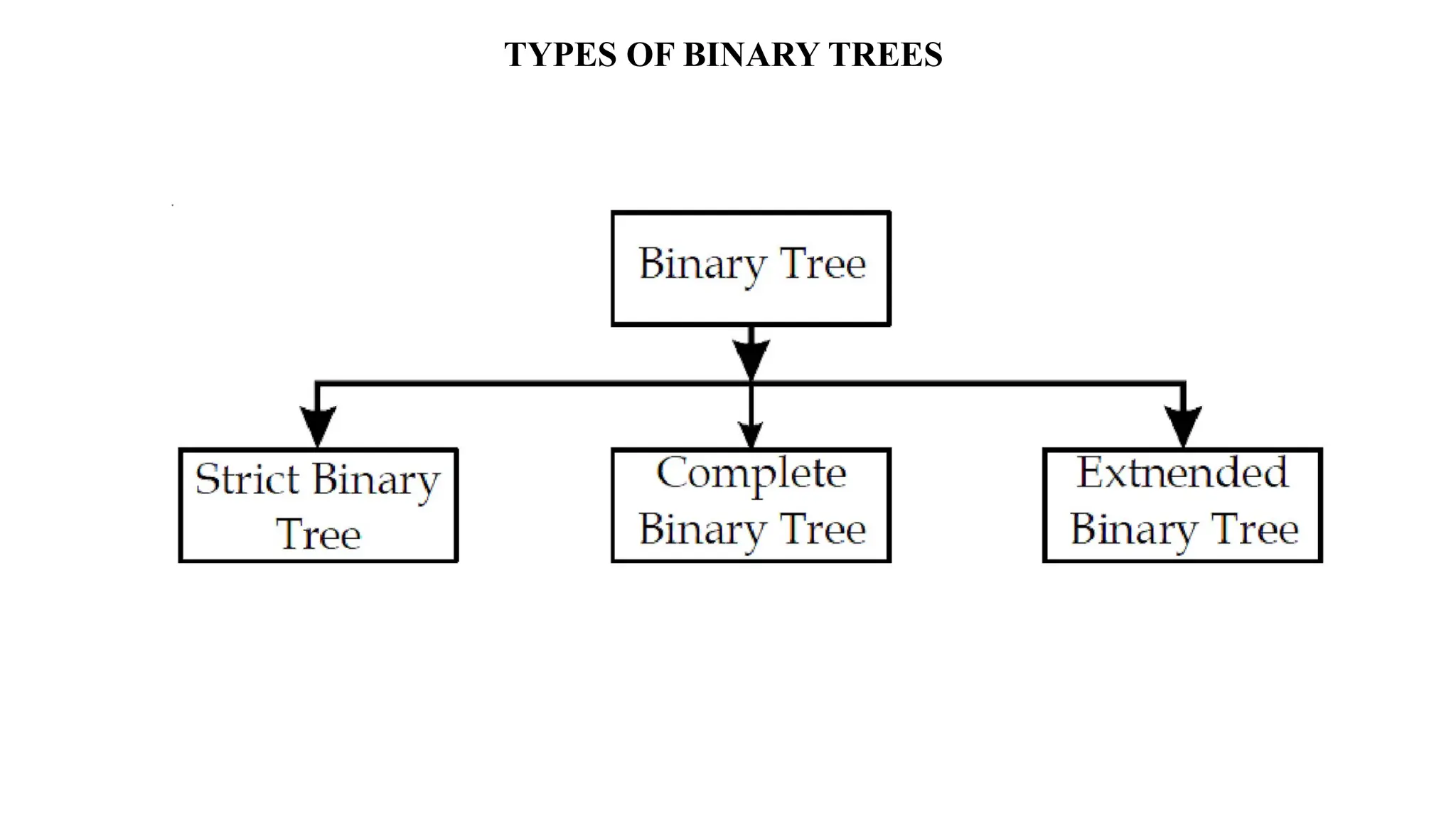
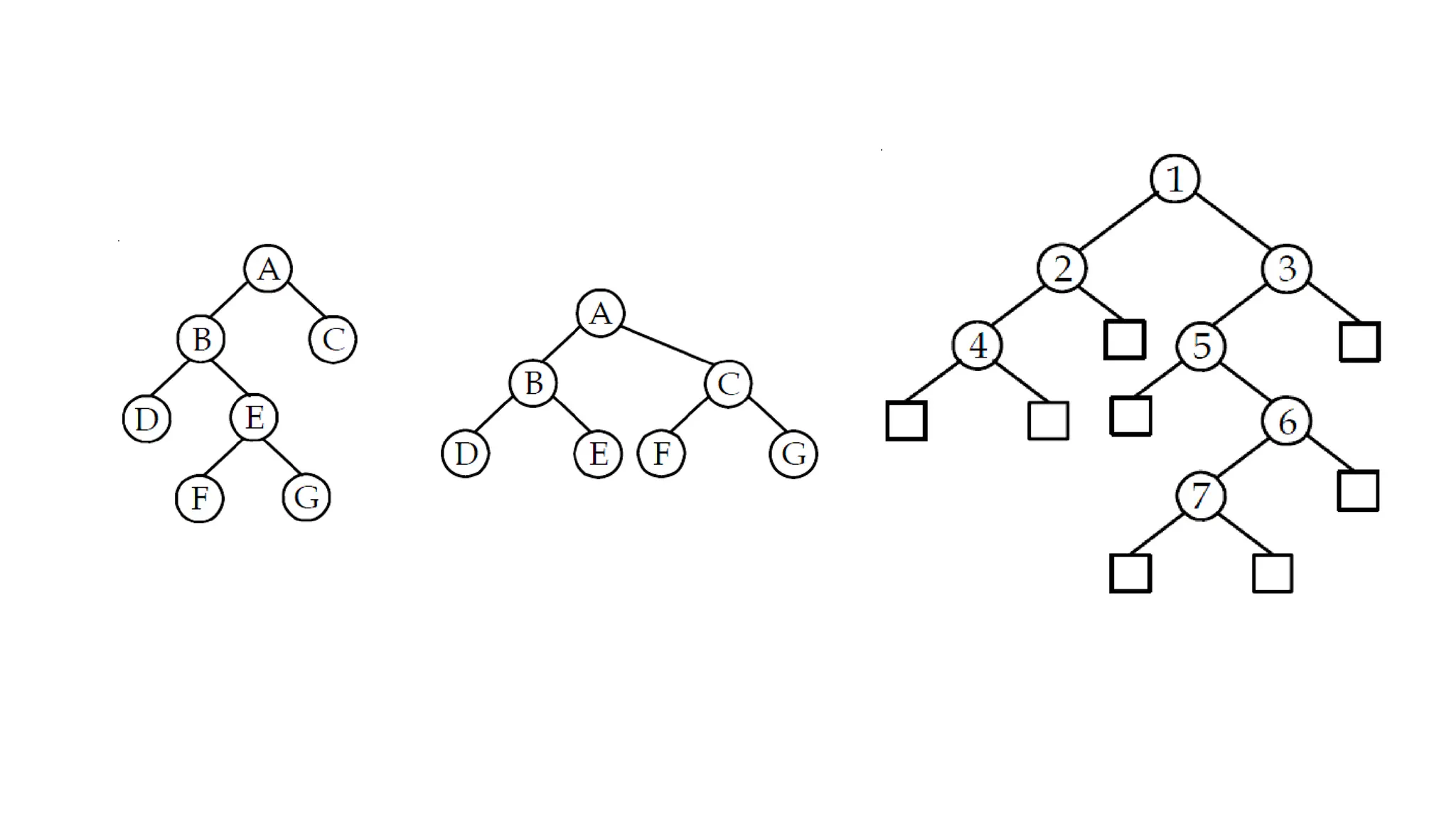
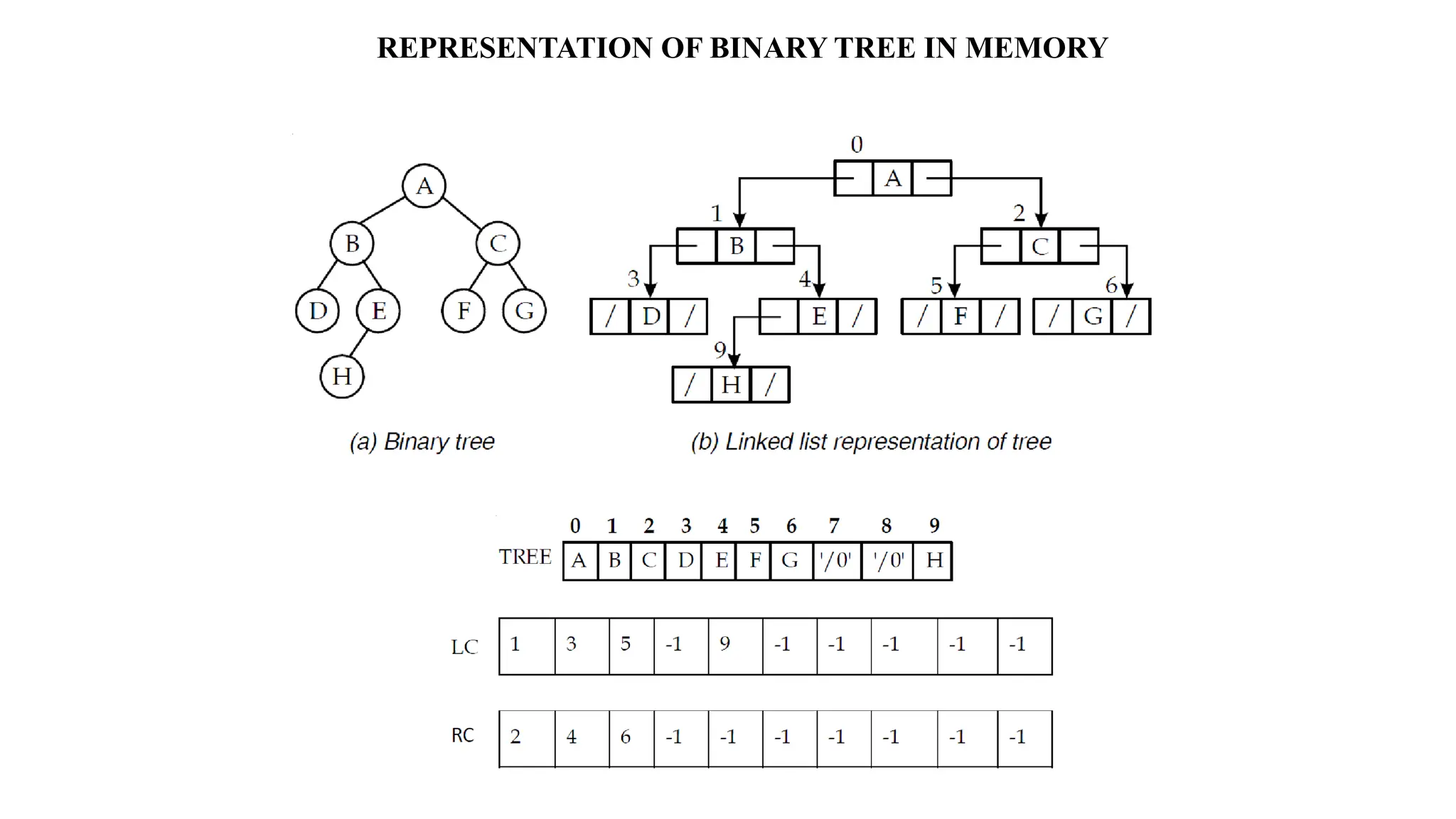
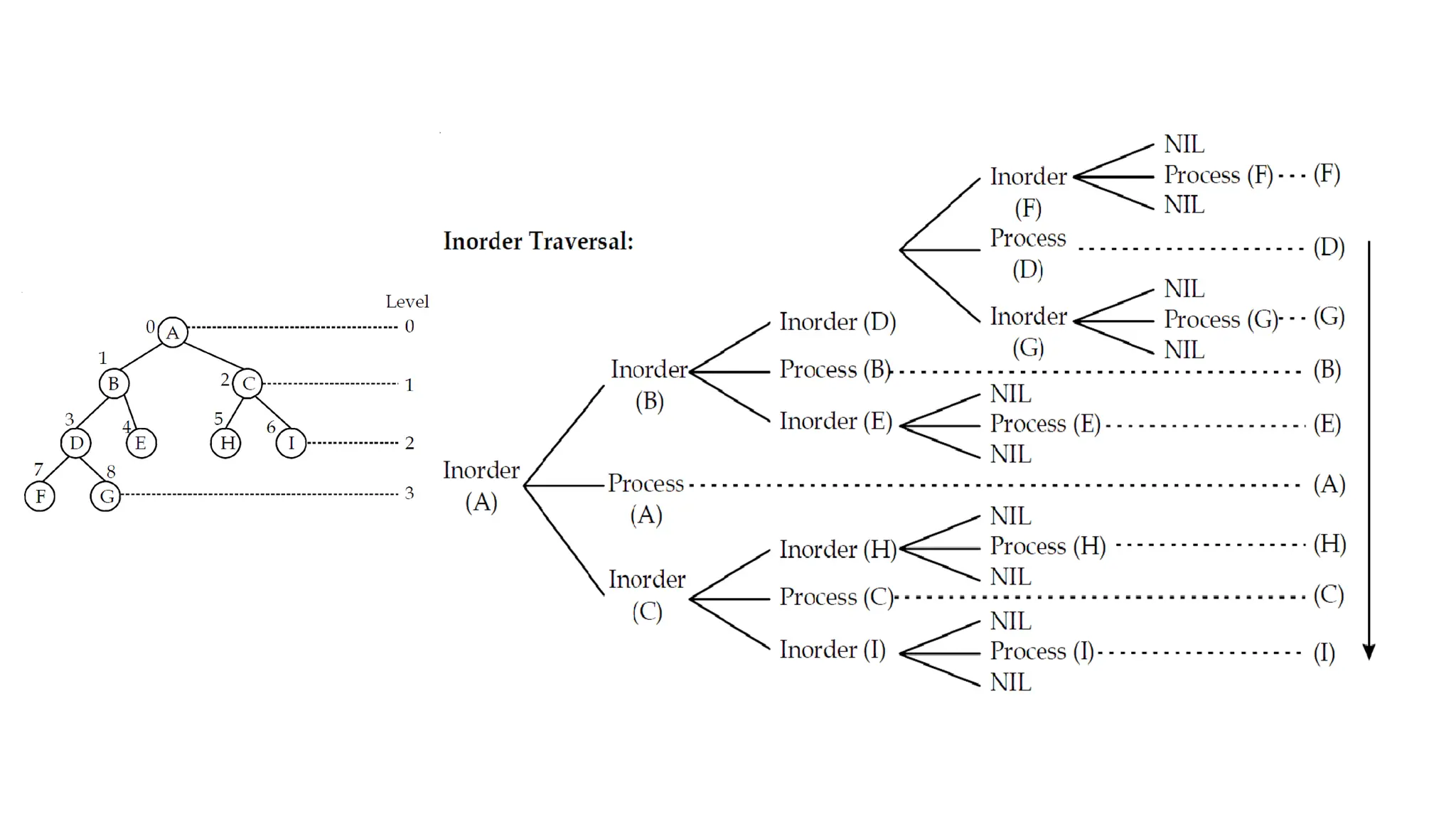
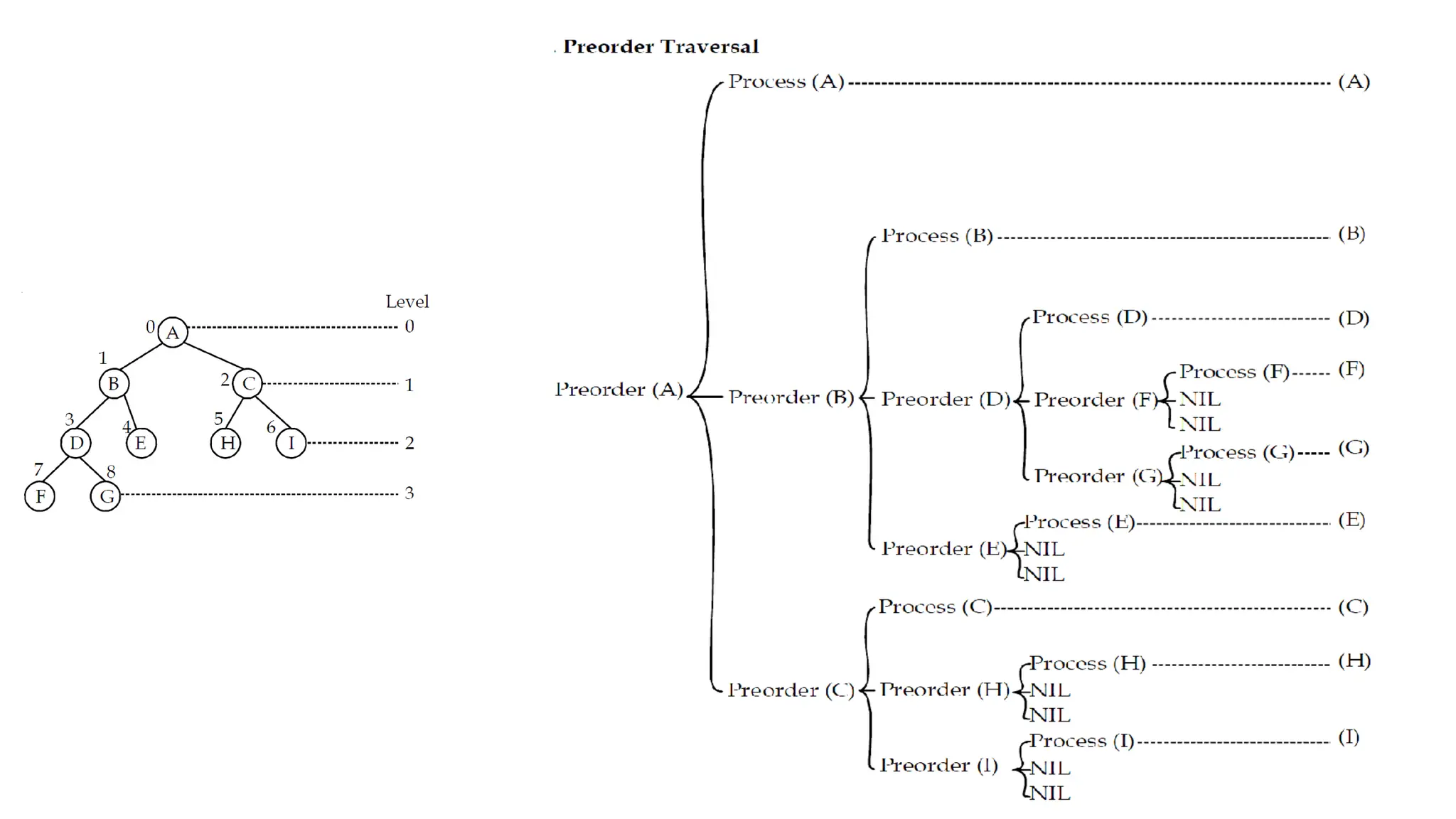
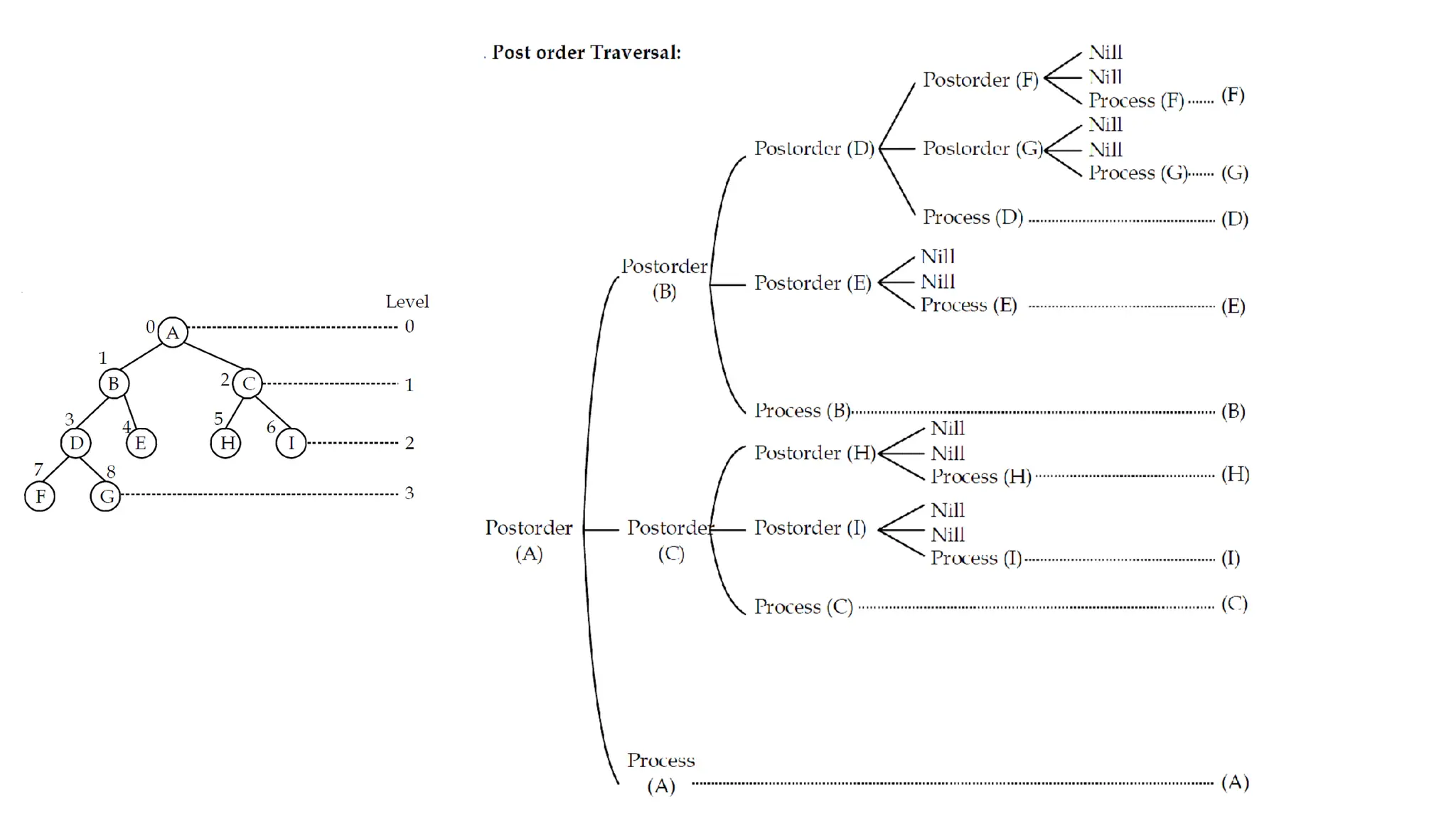
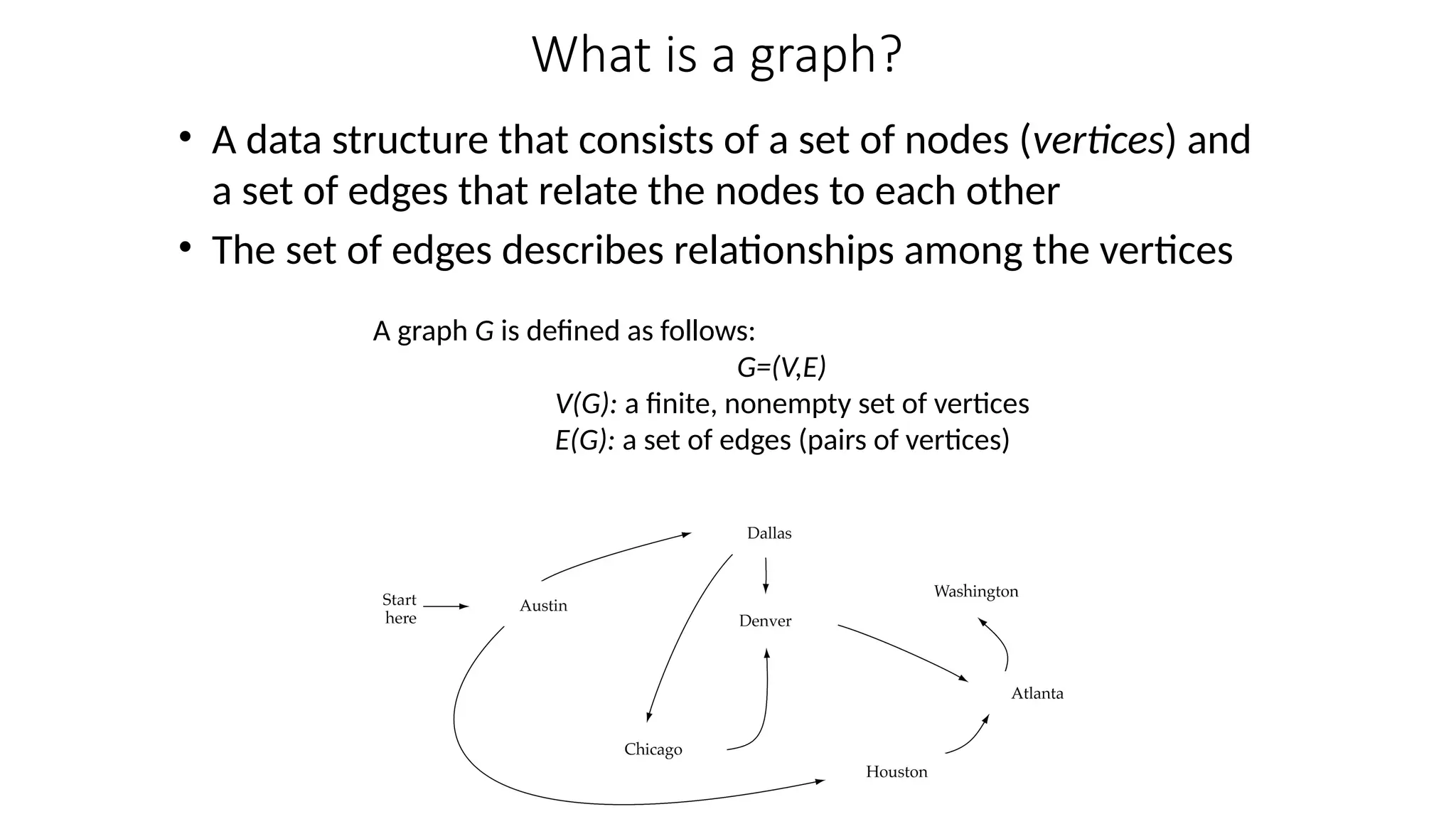
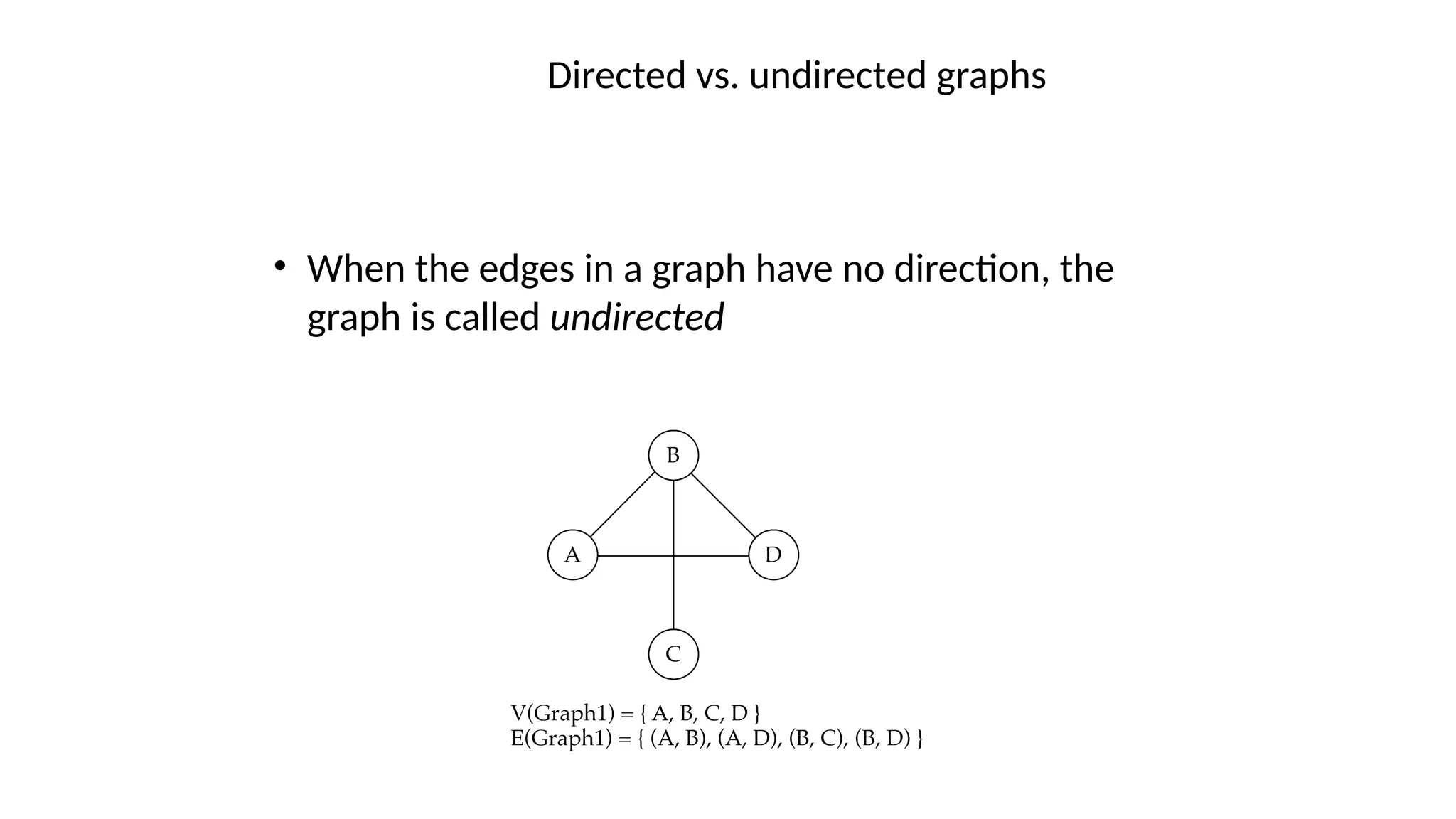
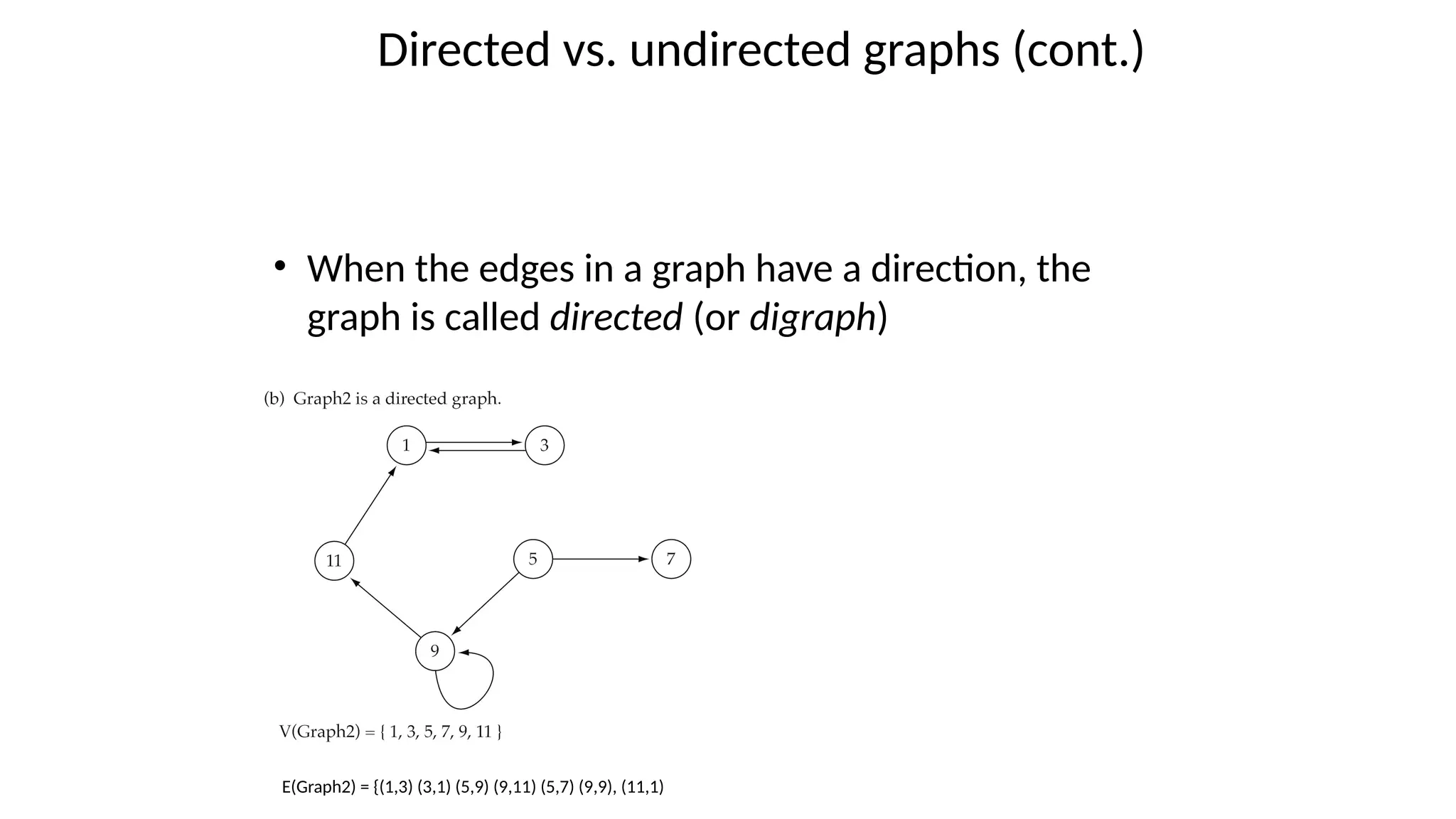
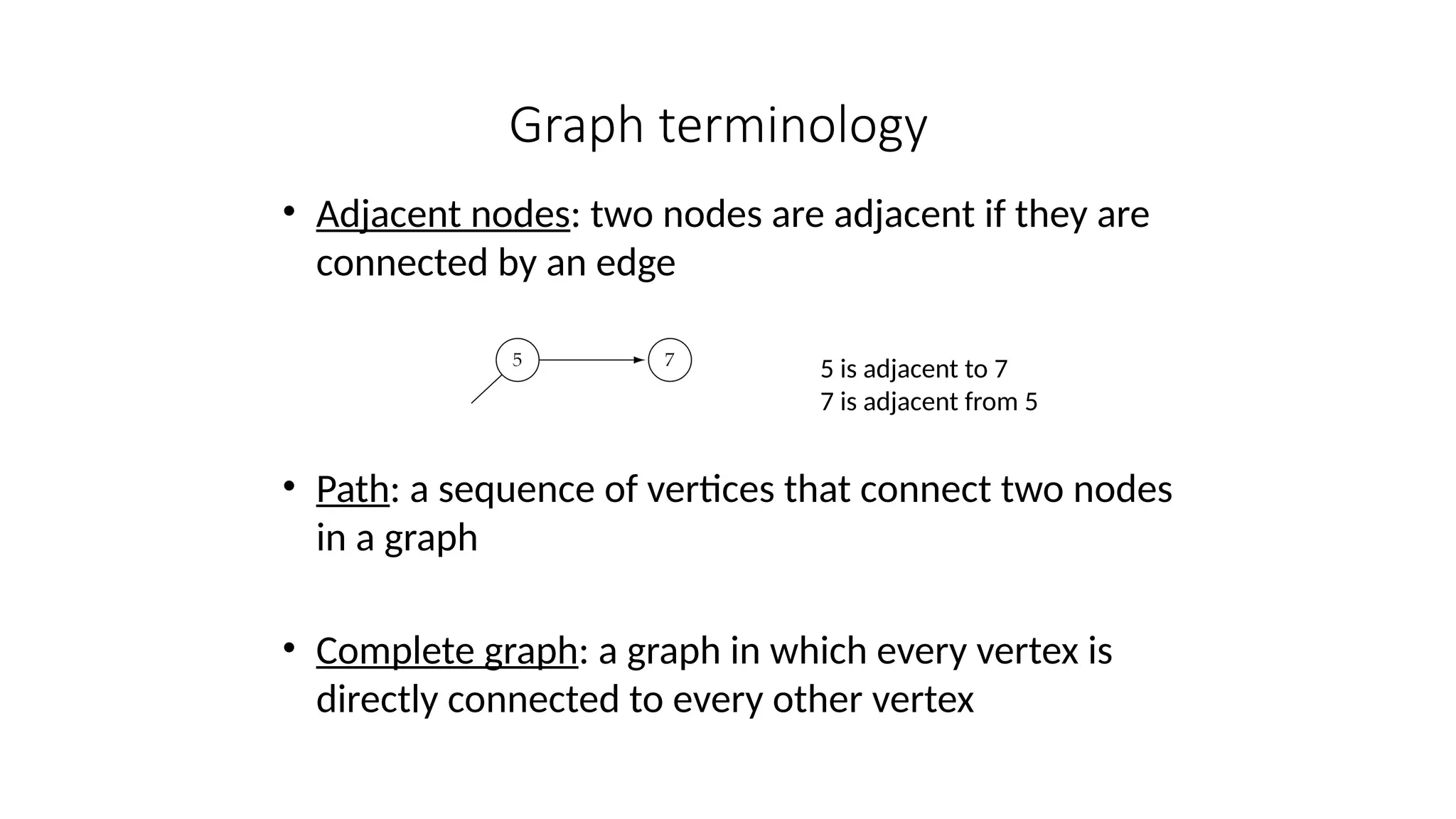
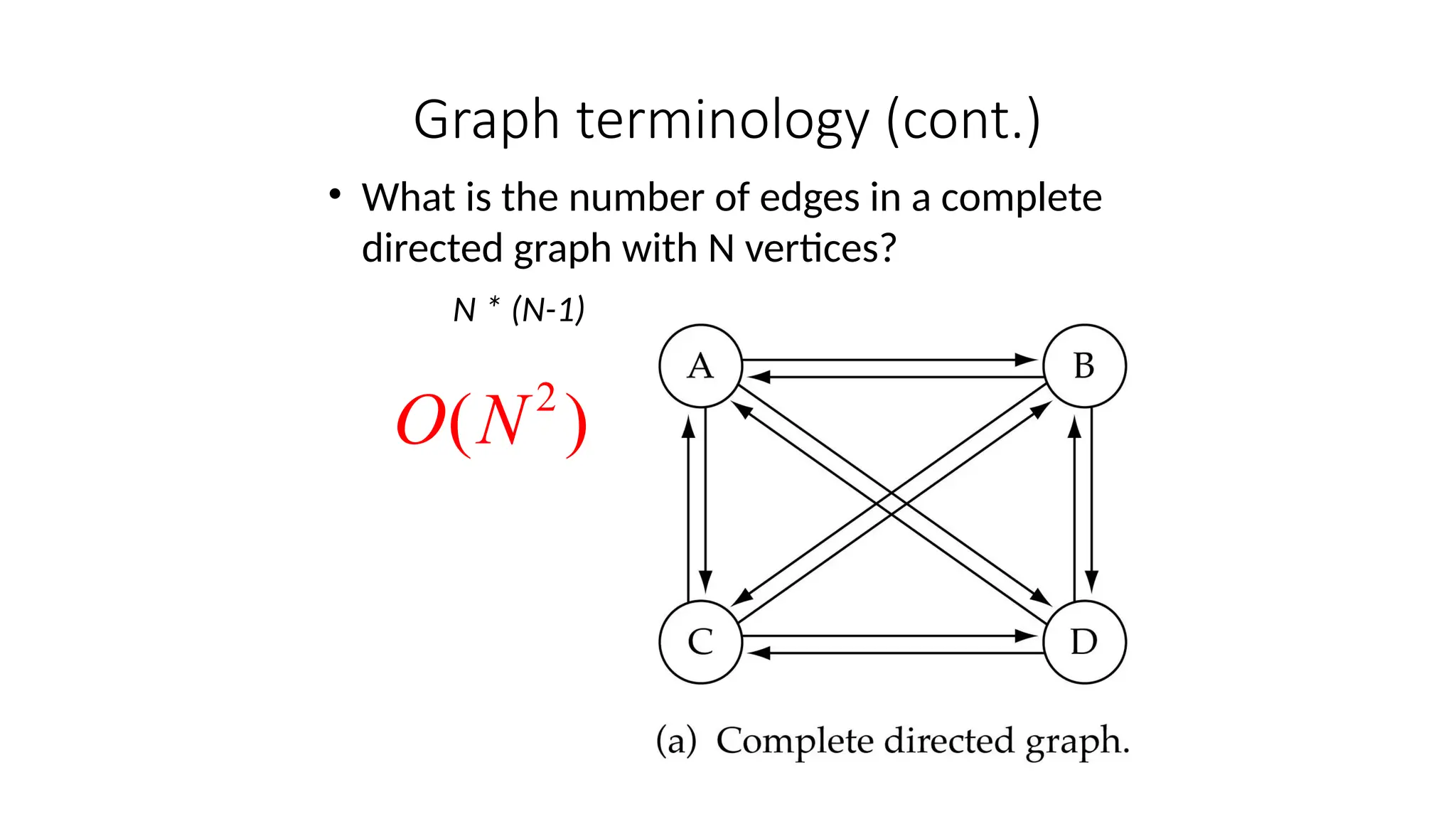
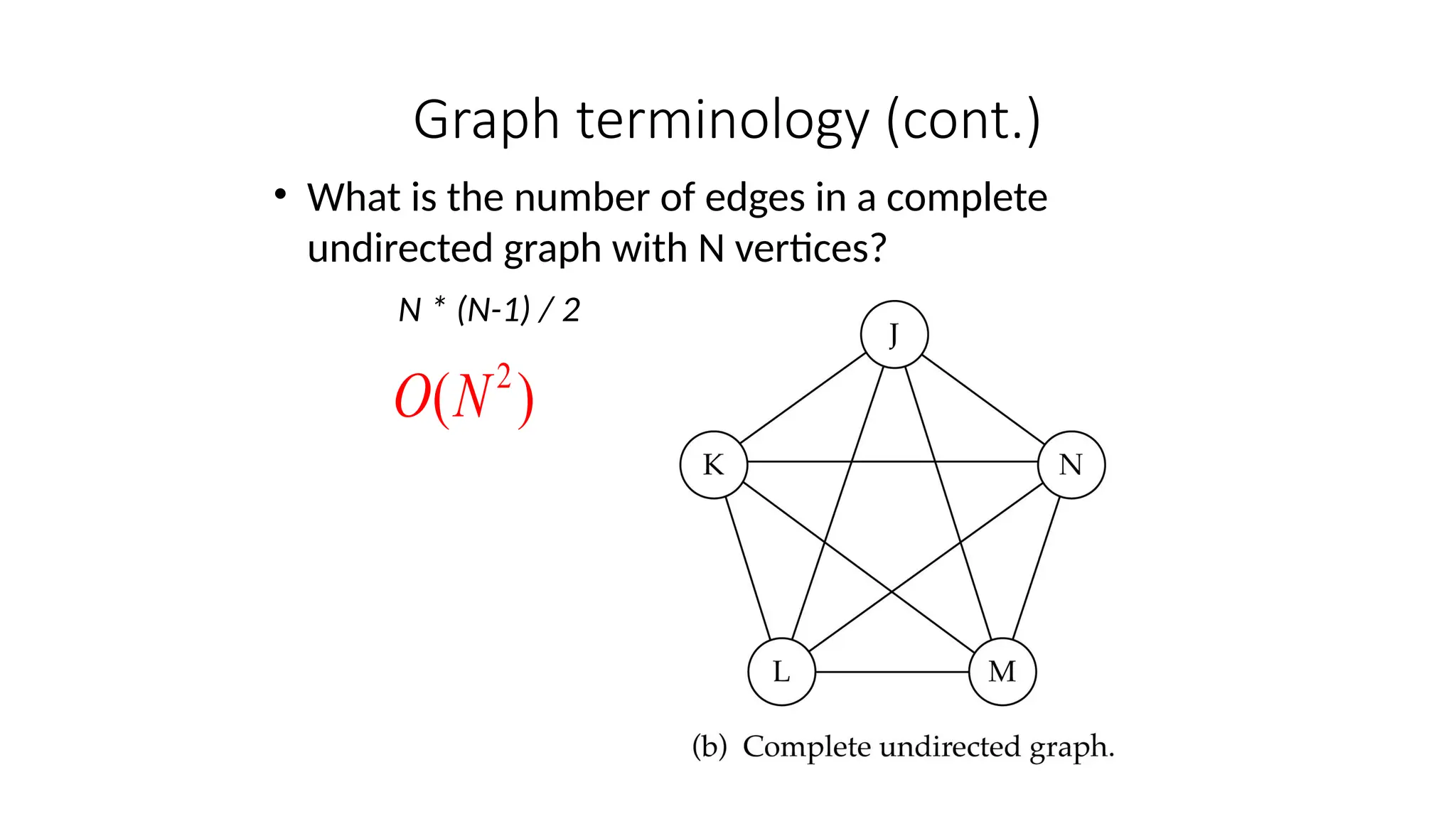
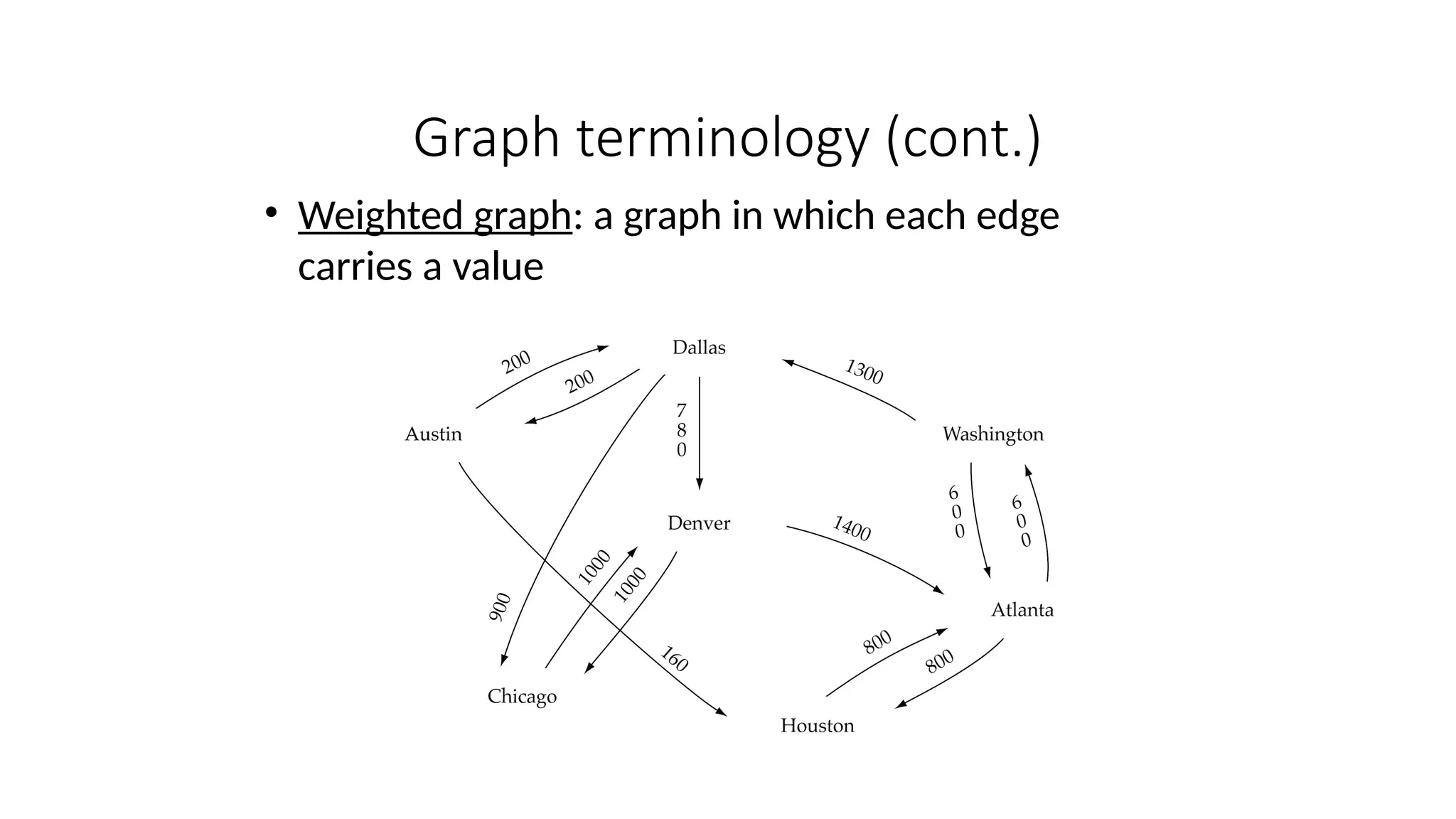
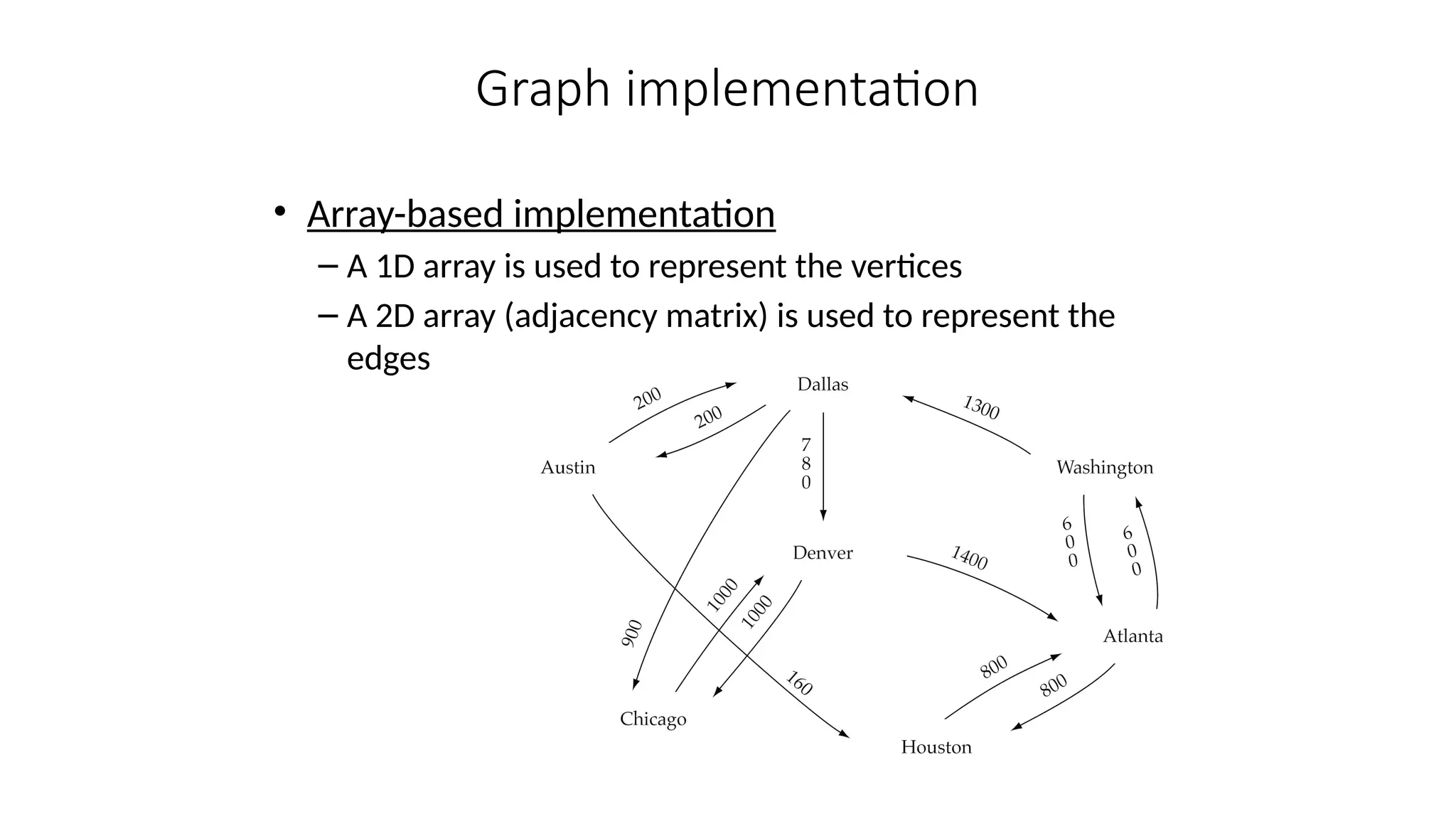
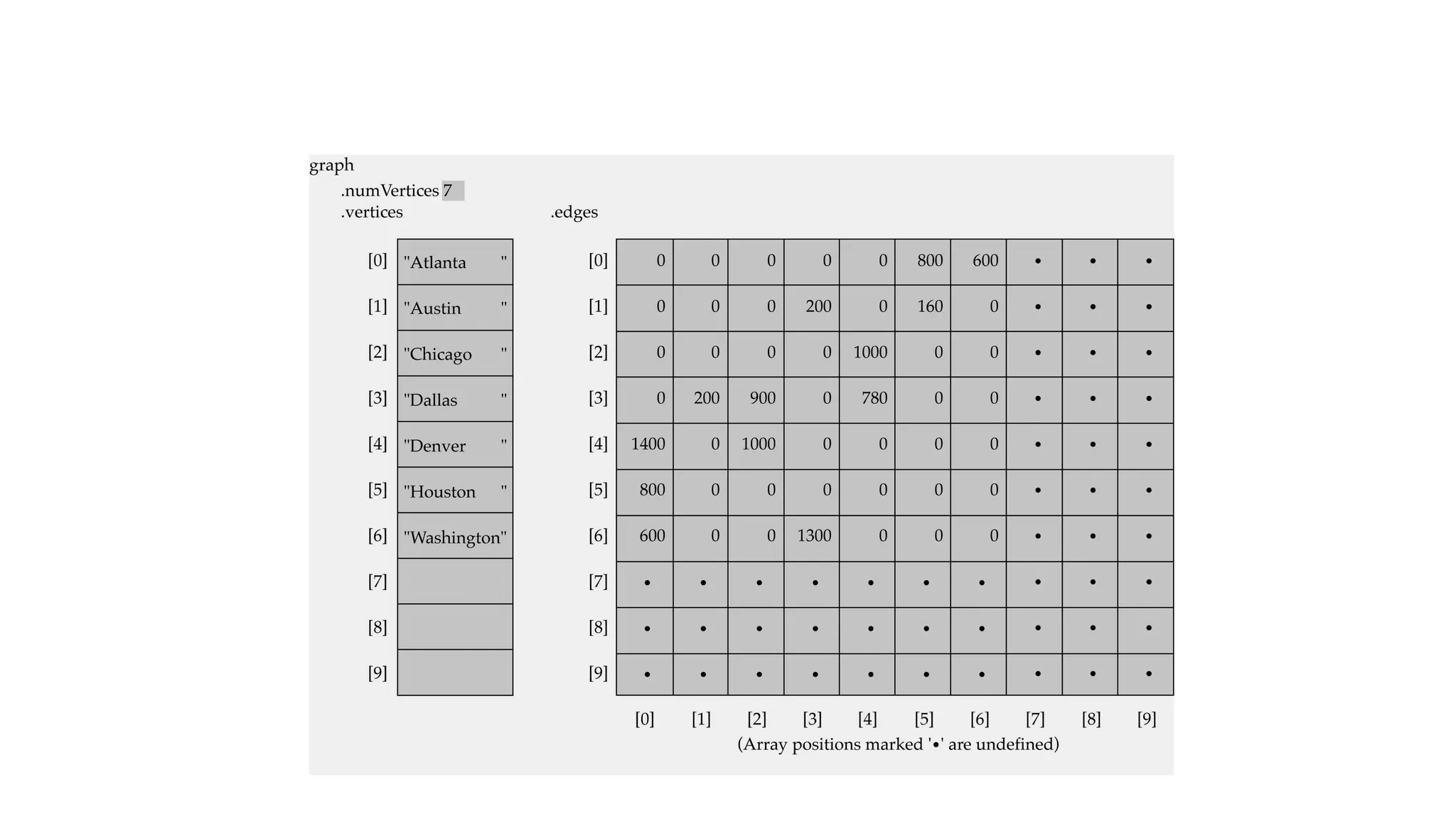
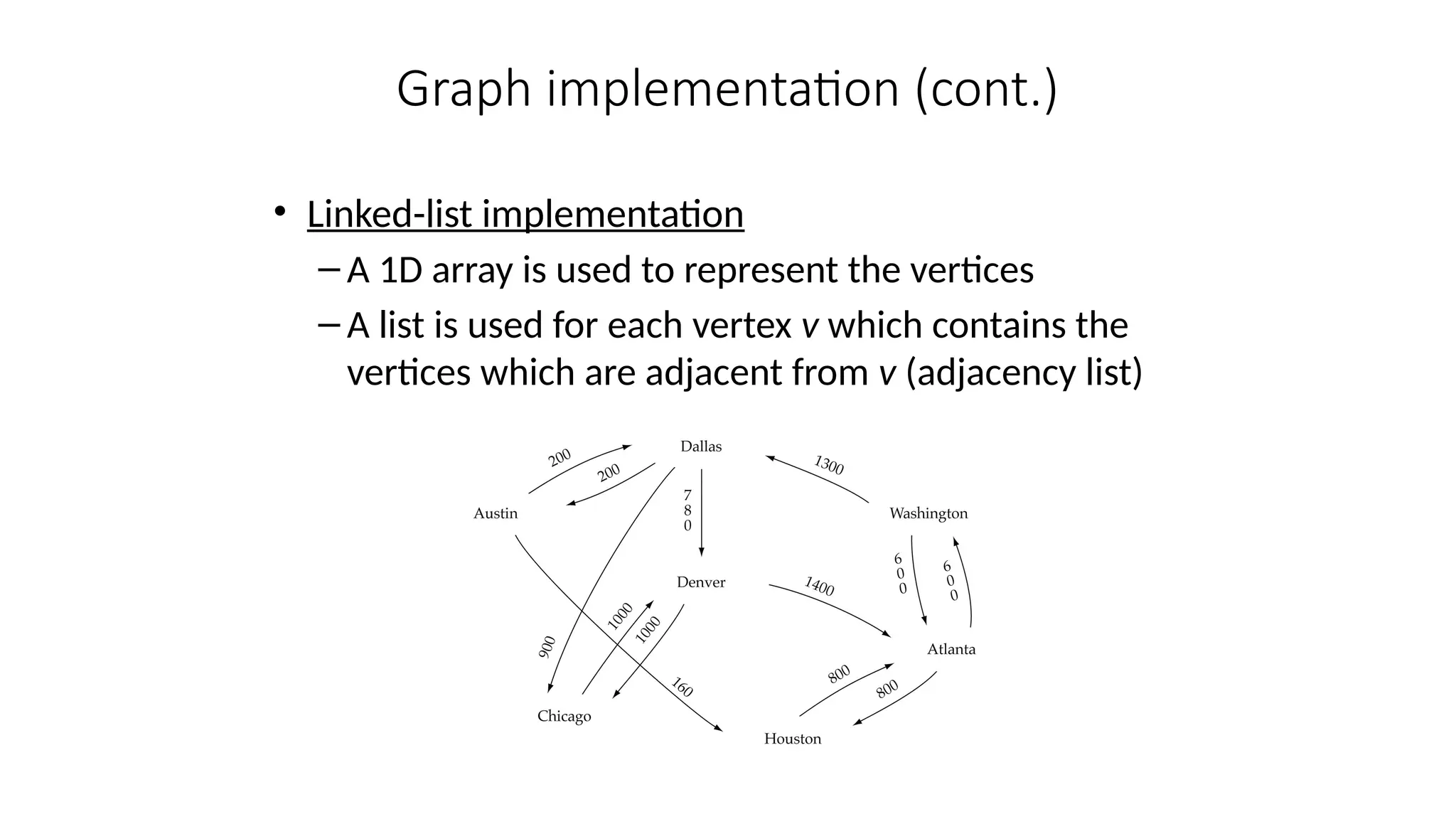
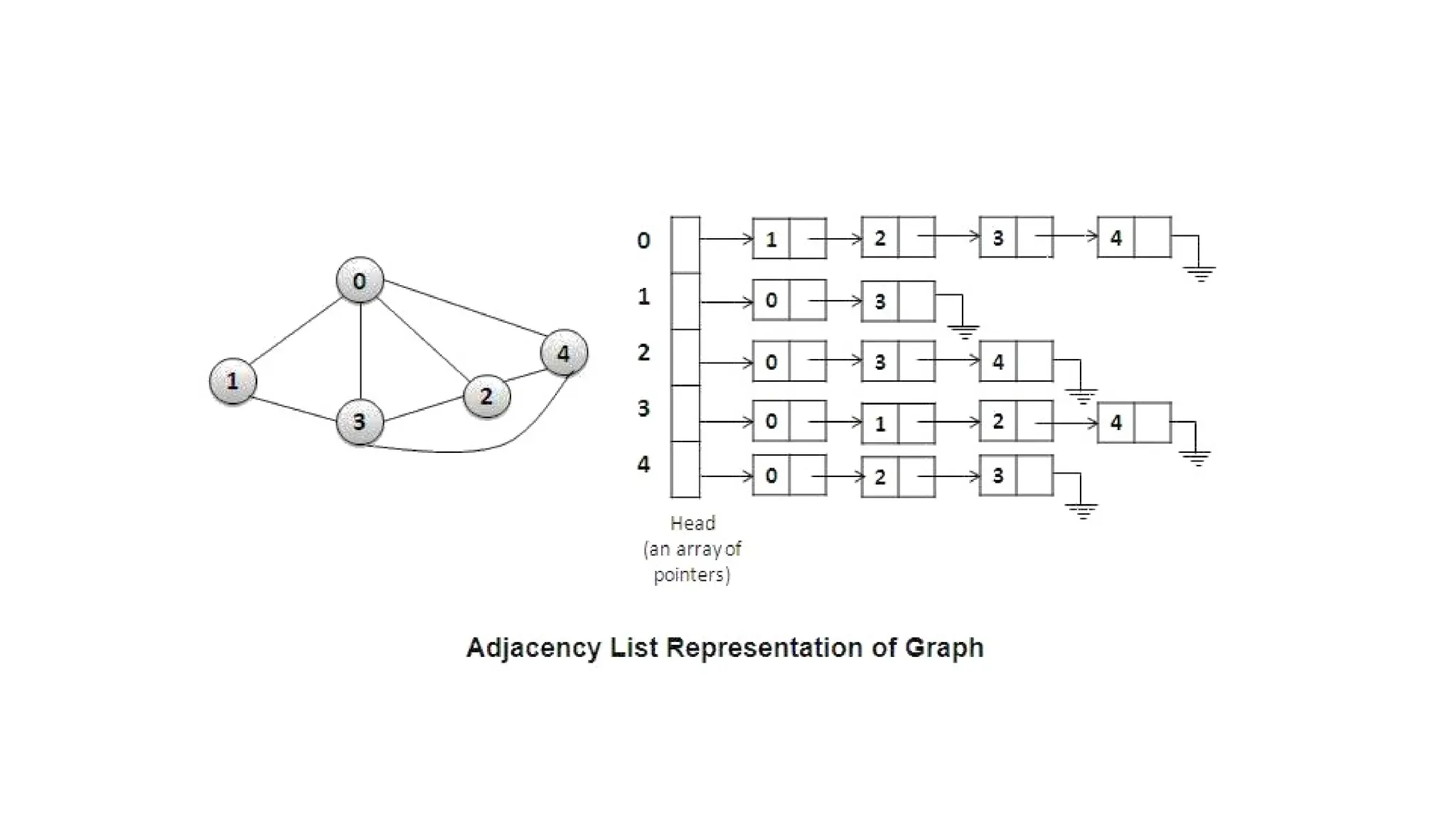
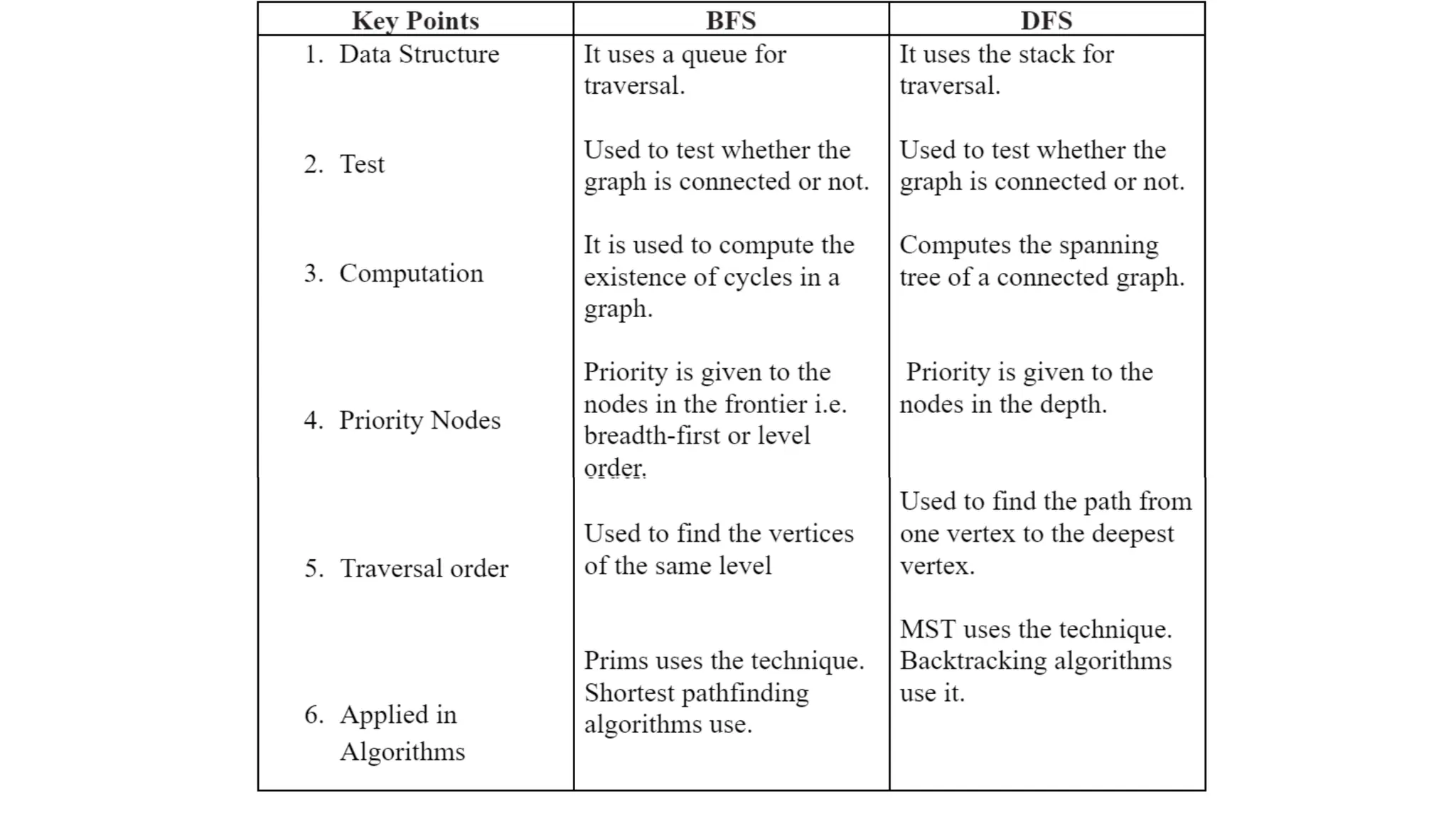
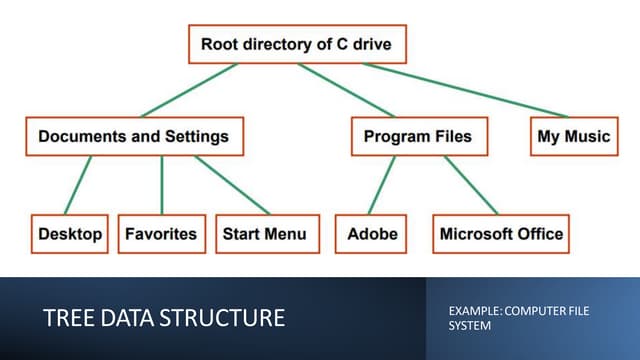
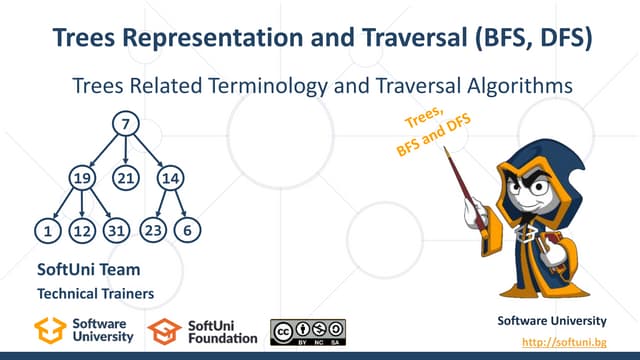
Data structures are fundamental concepts in computer science, helping in efficient data management and problem-solving. Two of the most important non-linear data structures are Trees and Graphs. These structures allow for the representation of hierarchical and networked relationships, respectively, and are widely used in various domains including databases, networking, artificial intelligence, and more.