Download to read offline






















![Couchbase tuning
● Upgrade Nonio parameter to 8 to avoid rebalance failures on high-load
clusters:
○ curl -i -u <Administrator>:<pwd> --data 'ns_bucket:update_bucket_props("<bucketname>",
[{extra_config_string, "max_num_nonio=<N>"}]).' http://<NodeIP>:8091/diag/eval
● Disable access log if you don’t need them to reduce disk usage (native in
Couchbase 4.5):
○ curl -i -u <Administrator>:<pwd> --data 'ns_bucket:update_bucket_props("<bucketname>",
[{extra_config_string, "access_scanner_enabled=false"}]).' http://<NodeIP>:8091/diag/eval](https://image.slidesharecdn.com/couchbaselive2016-161007082446/75/Couchbase-live-2016-31-2048.jpg)
































![Couchbase tuning
● Upgrade Nonio parameter to 8 to avoid rebalance failures on high-load
clusters:
○ curl -i -u <Administrator>:<pwd> --data 'ns_bucket:update_bucket_props("<bucketname>",
[{extra_config_string, "max_num_nonio=<N>"}]).' http://<NodeIP>:8091/diag/eval
● Disable access log if you don’t need them to reduce disk usage (native in
Couchbase 4.5):
○ curl -i -u <Administrator>:<pwd> --data 'ns_bucket:update_bucket_props("<bucketname>",
[{extra_config_string, "access_scanner_enabled=false"}]).' http://<NodeIP>:8091/diag/eval](https://crownmelresort.com/image.slidesharecdn.com/couchbaselive2016-161007082446/75/Couchbase-live-2016-31-2048.jpg)



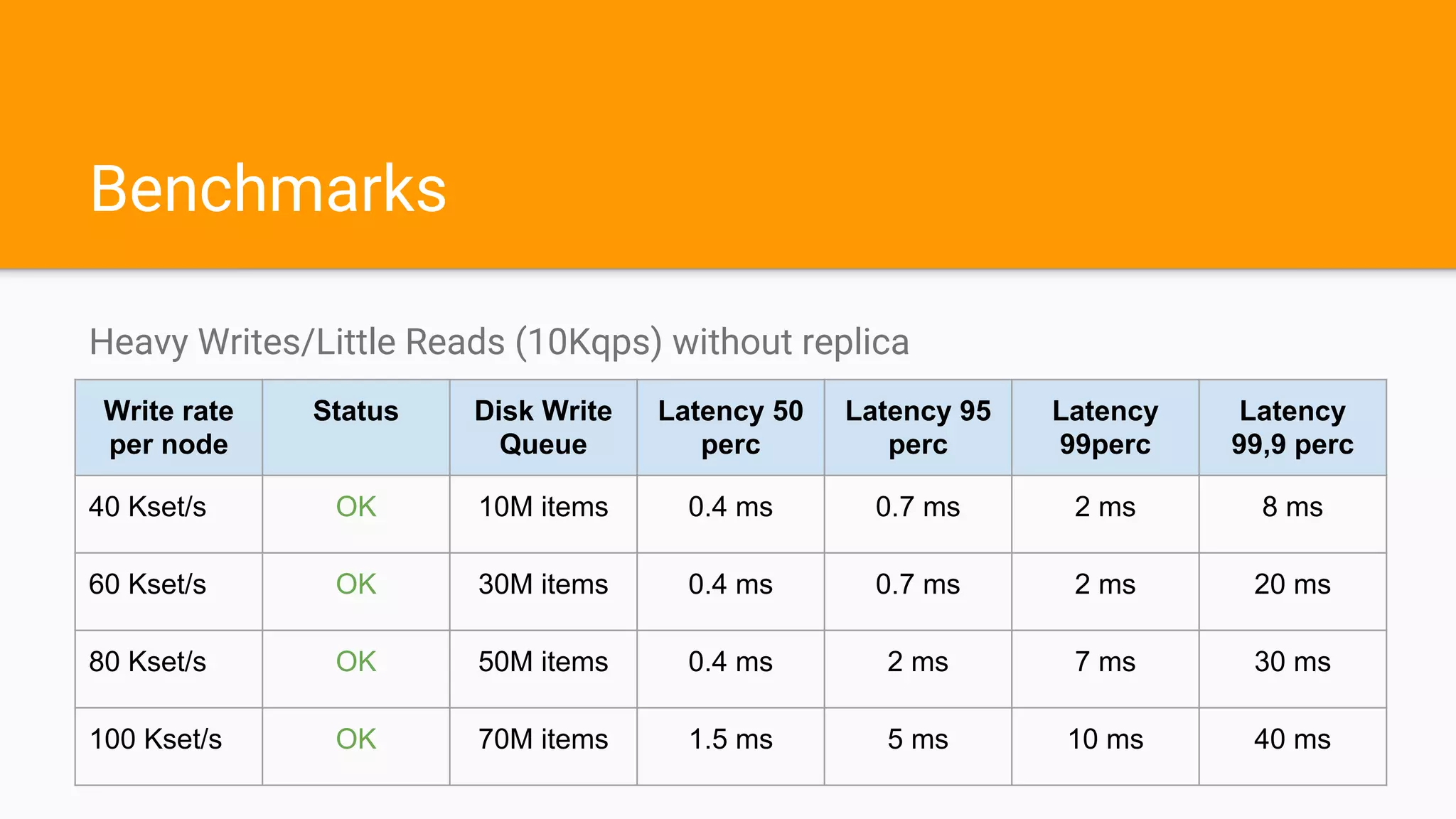
Pierre Mavro from Criteo discussed Couchbase usage at their company. Criteo has over 100 Couchbase clusters storing over 90TB of data serving up to 25 million queries per second. They benchmarked Couchbase and found network bandwidth and replicas increased latency. To improve, Criteo monitored latency, split workloads across clusters, automated operations, and tuned Couchbase and systems. Their changes helped Couchbase scale for Criteo's large workload.





























































































