Agenda
Introduction
Transactionand System Concepts
Properties of Transaction
Schedules and Recoverability
Serializability of Schedules
2
3.
Why We studyabout Transaction?
To understand the basic properties of a transaction
and learn the concepts underlying transaction
processing as well as the concurrent executions of
transactions.
3
4.
Introduction
One criterionfor classifying a database system is according to the number of
users who can use the system concurrently.
Single-user VS multi-user systems
A DBMS is single-user if at most one user can use the system at a time
A DBMS is multi-user if many users can use the system and access
database concurrently.
Problem
How to make the simultaneous interactions of multiple users with the
database safe, consistent, correct, and efficient?
4
5.
Introduction(cont..)
It dependson
Computing systems(CPU +programming language)
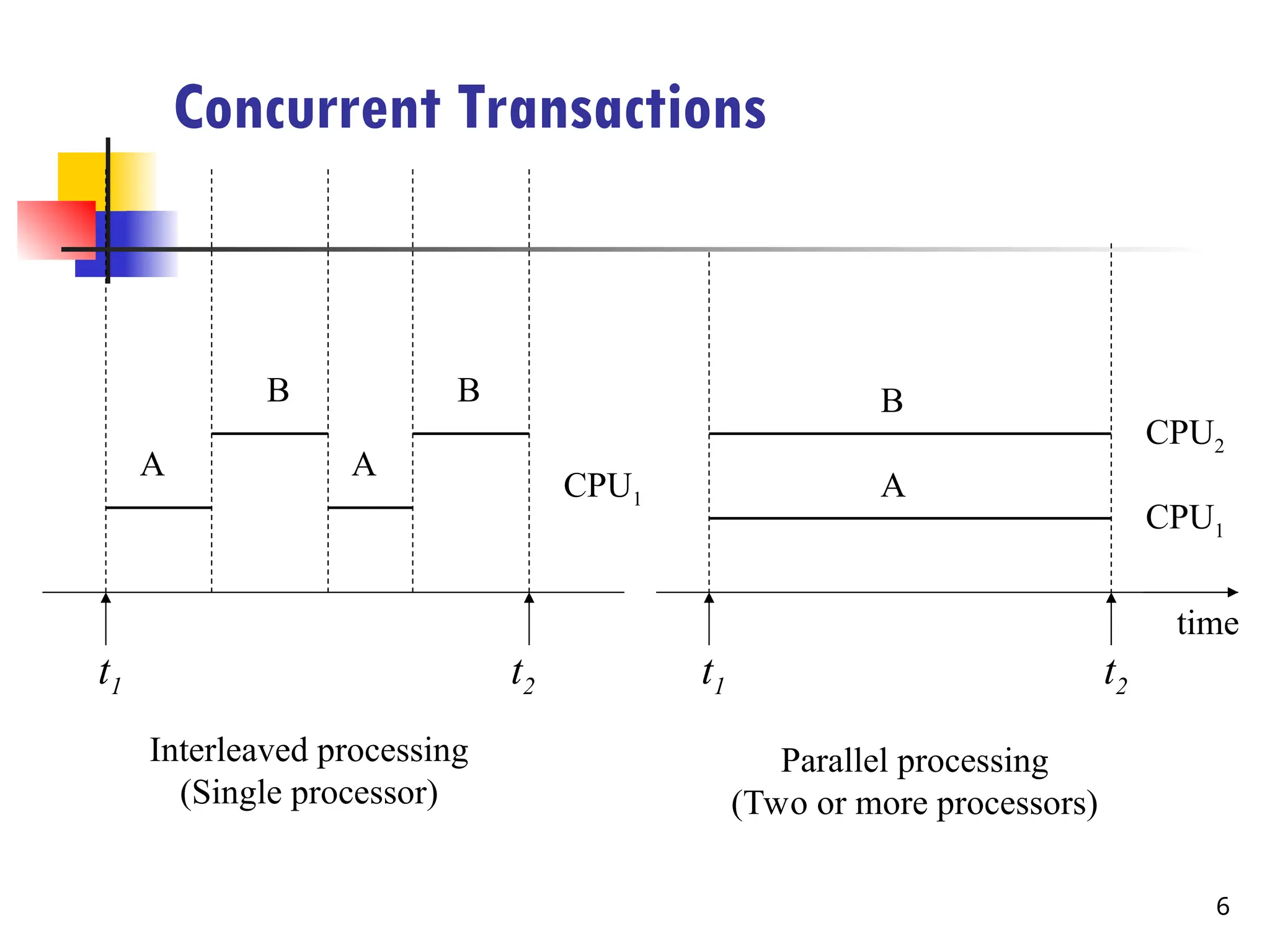
Single-processor computer system(one cpu)
Multiprogramming execute some commands from one process, then suspend that process
and execute some commands from the next process.
A process is resumed at the point where it was suspended whenever
it gets its turn to use the CPU again.
concurrent execution of processes is actually interleaved
Inter-leaved Execution
Multi-processor computer system (multiple CPUs)
Parallel processing
5
Introduction (cont..)
Whatis Transaction?
Business(money) Exchange(dictionary definition)
a unit of a program execution that accesses and possibly
modifies various data objects (tuples, relations)
Action, or series of actions, carried out by user or application,
which accesses or changes contents of database.
Basic operations a transaction can include “actions”:
Reads, writes
Special actions: commit, abort 7
8.
Transaction: Database Readand Write Operations
A database is represented as a collection of named data items
Read-item (X)
1. Find the address of the disk block that contains item X
2. Copy the disk block into a buffer in main memory
3. Copy the item X from the buffer to the program variable named X
Write-item (X)
1. Find the address of the disk block that contains item X.
2. Copy that disk block into a buffer in main memory
3. Copy item X from the program variable named X into its correct location in the
buffer.
4. Store the updated block from the buffer back to disk (either immediately or at some
later point in time).
8
9.
Transaction(example)
Example: fundTransfer
transaction to transfer $50 from account A to account B:
For a user it is one activity
To database
1. read(A)
2. A := A – 50
3. write(A)
4. read(B)
5. B := B + 50
6. write(B)
Two main issues to deal with:
Failures of various kinds, such as hardware failures and system crashes
Concurrent execution of multiple transactions 9
10.
Why concurrency control(During multiple
transaction Execution)is needed?
Process of managing simultaneous execution of transactions in a shared
database, to ensure the serializability of transactions, is known as
concurrency control
Mostly three problems are
1. The lost update problem
2. The temporary update (dirty read) problem
3. Incorrect summary problem
4. The Unrepeatable Read Problem 10
11.
A Transaction: AFormal Example
T1
read_item(X);
read_item(Y);
X:=X - 400000;
Y:=Y + 400000;
write _item(X);
write_item(Y);
t0
tk
11
12.
Problems in concurrentexecution of
Transaction(Lost Update)
Occurs when two transactions that access the same database items have their
operations interleaved in a way that makes the value of some database items
incorrect.
12
13.
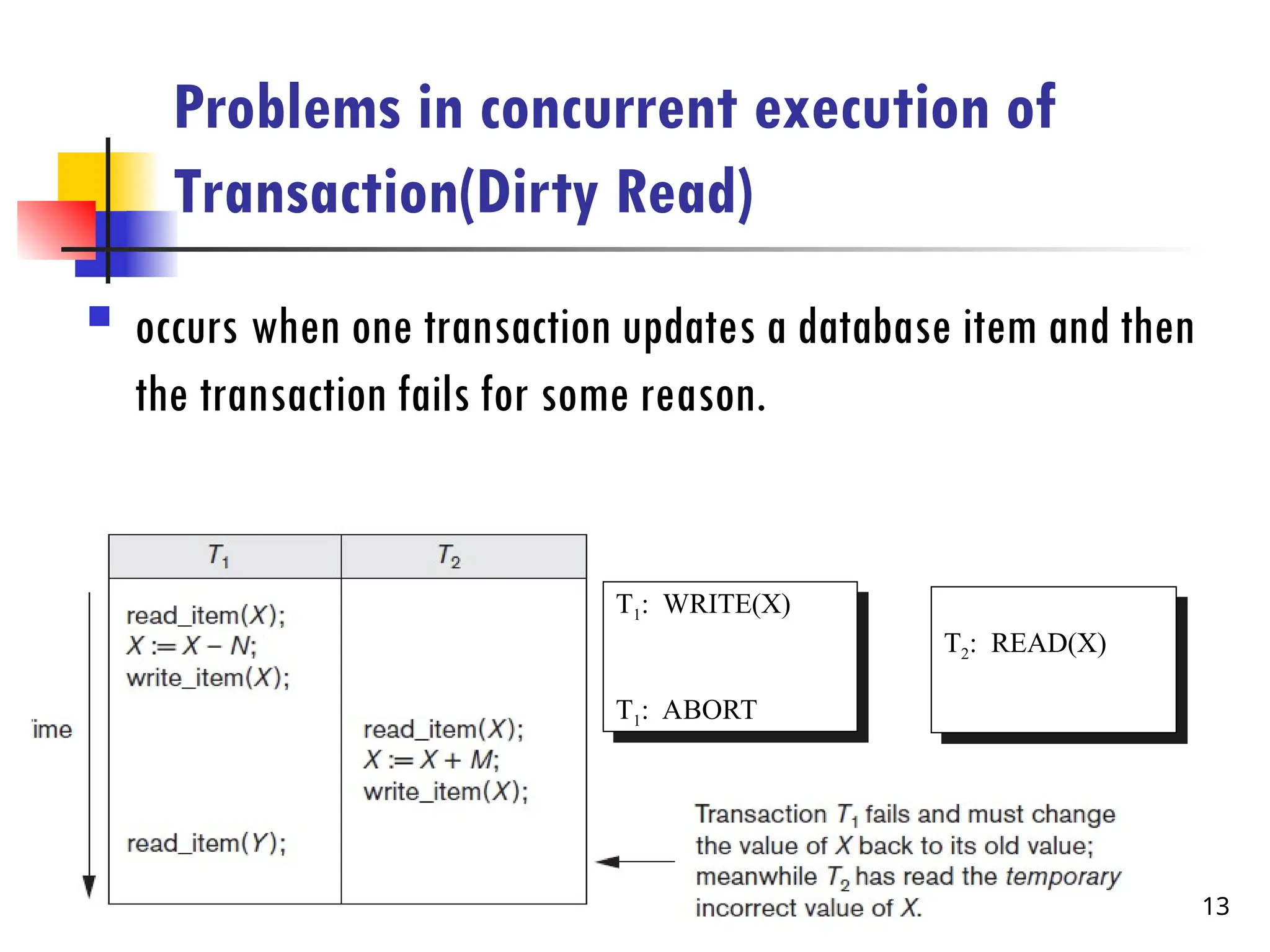
Problems in concurrentexecution of
Transaction(Dirty Read)
occurs when one transaction updates a database item and then
the transaction fails for some reason.
T1: WRITE(X)
T1: ABORT
T2: READ(X)
13
14.
Problems in concurrentexecution of Transaction
( Incorrect Summary)
Occurs if one transaction is calculating an aggregate summary function on a
number of database items while other transactions are updating some of these
items, the aggregate function may calculate some values before they are
updated and others after they are updated.
14
15.
Problems in concurrentexecution of
Transaction
(The Unrepeatable Read Problem)
a transaction T reads the same item
twice and the item is changed by
another transaction T’ between the
two reads. Hence, T receives different
values for its two reads of the same
item.
15
16.
How those problemsare solved?
DBMS has a Concurrency Control subsystem to assure database remains in consistent
state despite concurrent execution of transactions.
Other problems
System failures may occur
Types of failures:
System crash
Transaction or system error
Local errors
Concurrency control enforcement
Disk failure
Physical failures
DBMS has a Recovery Subsystem to protect database against system failures
16
17.
Why recovery isneeded?
1. A computer failure (system crash) e.g. main memory failure.
2. A transaction or system error e.g. such as integer overflow or
division by zero
3. Local errors or exception conditions detected by the transaction
e.g. data for the transaction may not be found.
4. Concurrency control enforcement e.g. violation of serializability.
5. Disk failure e.g. disk read/write head crash.
6. Physical problems and catastrophes e.g. power or air-conditioning
failure
17
18.
Transaction and SystemConcepts
Transaction State
A transaction is an atomic unit of work that should either be completed
in its entirety (Committed) or not done at all (aborted).
For recovery purposes, the system needs to keep track of when each
transaction starts, terminates, and commits or aborts.
the recovery manager of the DBMS needs to keep track of the following
operations:
18
19.
Transaction and SystemConcepts
BEGIN_TRANSACTION: marks start of transaction
READ or WRITE: two possible operations on the data
END_TRANSACTION: marks the end of the read or write operations;
start checking whether everything went according to plan
COMIT_TRANSACTION: signals successful end of transaction; changes
can be “committed” to DB
Partially committed
ROLLBACK (or ABORT): signals unsuccessful end of transaction,
changes applied to DB must be undone
19
20.
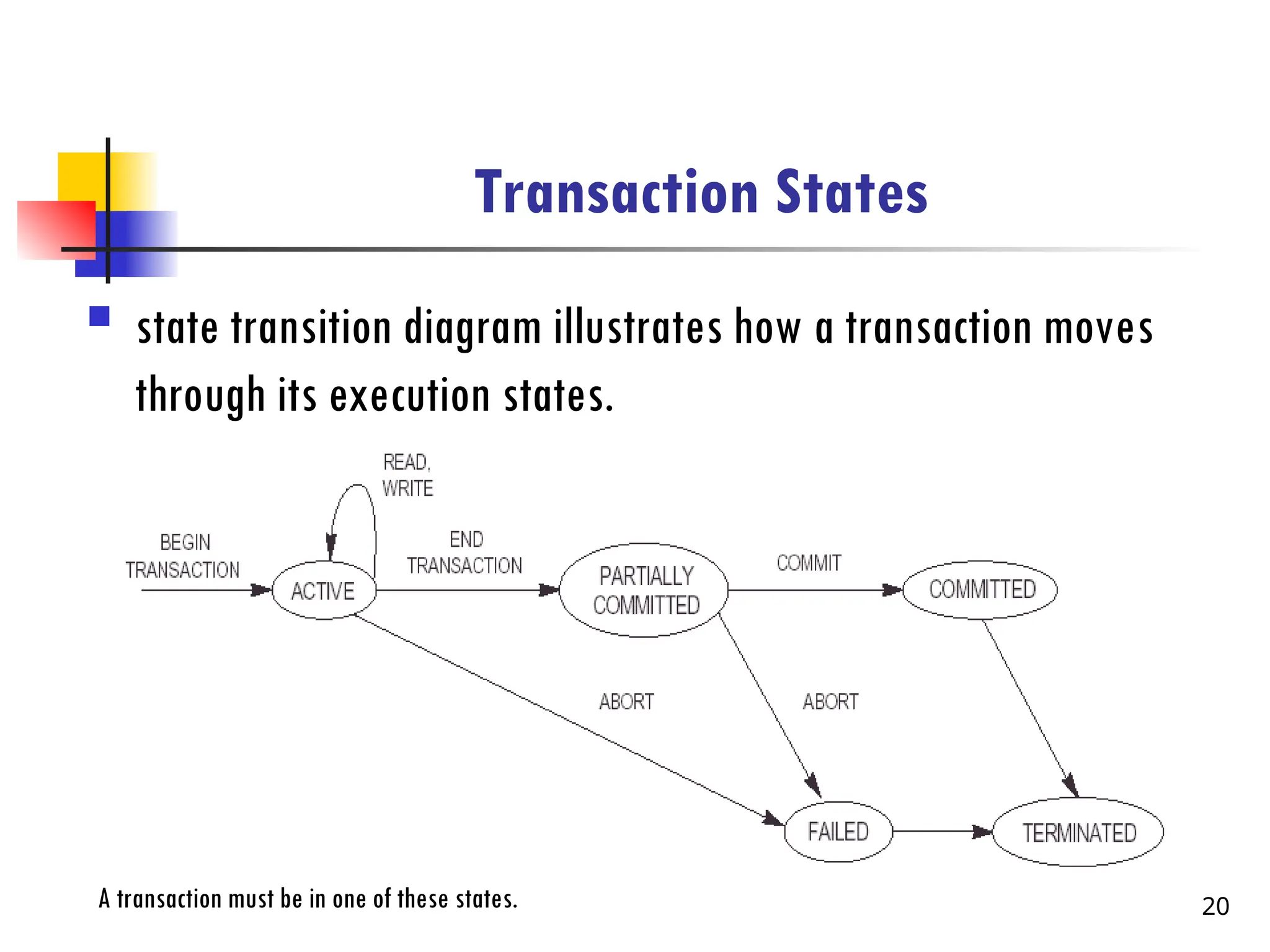
Transaction States
statetransition diagram illustrates how a transaction moves
through its execution states.
A transaction must be in one of these states. 20
Atomicity and Consistency
Atomicity
Transactions are atomic –
they don’t have parts
(conceptually)
can’t be executed partially;
it should not be detectable
that they interleave with
another transaction
Consistency
Transactions take the
database from one
consistent state into
another
In the middle of a
transaction the database
might not be consistent
22
23.
Isolation and Durability
Isolation
The effects of a transaction are
not visible to other
transactions until it has
completed
From outside the transaction
has either happened or not
Durability
Once a transaction has
completed, its changes are
made permanent
Even if the system crashes, the
effects of a transaction must
remain in place
23
24.
Properties of Transaction(cont..)
Transfer £50 from account A to account B
Read(A)
A = A - 50
Write(A)
Read(B)
B = B+50
Write(B)
Atomicity - shouldn’t take money
from A without giving it to B
Consistency - money isn’t lost or
gained
Isolation - other queries shouldn’t
see A or B change until completion
Durability - the money does not go
back to A
transaction
24
25.
Who will enforcethe ACID properties?
The transaction manager
It schedules the operations of transactions
COMMIT and ROLLBACK are used to ensure atomicity
Locks or timestamps are used to ensure consistency and isolation for concurrent
transactions (next lectures)
A log is kept to ensure durability in the event of system failure.
25
26.
COMMIT and ROLLBACK
COMMIT signals the successful
end of a transaction
Any changes made by the
transaction should be
saved
These changes are now
visible to other
transactions
ROLLBACK signals the
unsuccessful end of a
transaction
Any changes made by the
transaction should be
undone
It is now as if the
transaction never existed
26
27.
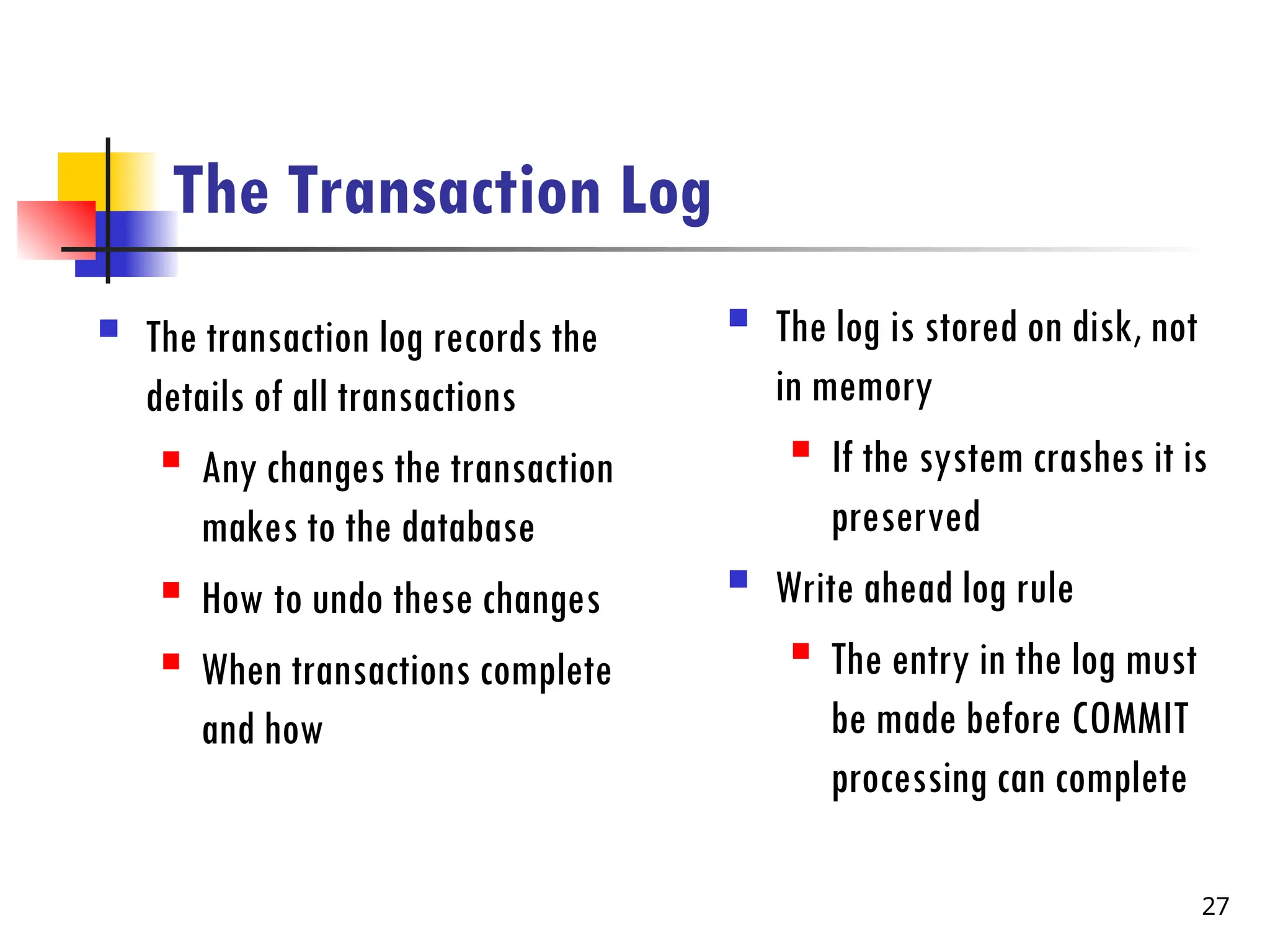
The Transaction Log
The transaction log records the
details of all transactions
Any changes the transaction
makes to the database
How to undo these changes
When transactions complete
and how
The log is stored on disk, not
in memory
If the system crashes it is
preserved
Write ahead log rule
The entry in the log must
be made before COMMIT
processing can complete
27
28.
Schedules and Recoverability
What is Schedule?
sequences that indicate the chronological order in which instructions of
concurrent transactions are executed.
Ordering of execution of operations from various transactions T1, T2,
… , Tn is called a schedule S.
Given multiple transactions,
A schedule is a sequence of interleaved actions from all
transactions
28
29.
Schedules and Recoverability(cont..)
a schedule for a set of transactions must consist of all instructions of those
transactions
must preserve the order in which the instructions appear in each individual
transaction.
Example
Transaction T1: r1(X); w1(X); r1(Y); w1(Y); c1
Transaction T2: r2(X); w2(X); c2
A schedule, S:
r1(X); r2(X); w1(X); r1(Y); w2(X); w1(Y); c1; c2
29
30.
Schedule(cont..)
Operations
read(Q,q)
read the valueof the database item Q and store in the local
variable q.
write(Q,q)
write the value of the database item Q and store in the local variable q.
other operations such as arithmetic
commit
rollback
30
31.
Example: A “Good”Schedule
• One possible schedule,
initially X = 10, Y=10
•Resulting Database: X=21,Y=21, X=Y
31
32.
Example: A “Bad”Schedule
• Another possible schedule
•Resulting Database X=21,Y=21, X=Y
32
33.
When does Conflictsoccur between
two operations?
Two operations conflict if they satisfy ALL three conditions:
1. they belong to different transactions AND
2. they access the same item AND
3. at least one is a write_item()operation
Example.:
Transaction T1 T 2
Read(X) Read(X)
Read(X) Write(X)
Write(X) Read(X)
Write(X) Write(X)
33
34.
Serializability of Schedules
What is serializable schedules?
types of schedules that are always considered to be correct when concurrent
transactions are executing.
Suppose that two users
for example, two airline reservations agents submit to the DBMS transactions
T1 and T2 approximately at the same time.
If no interleaving of operations is permitted, there are only two possible
outcomes:
34
35.
Serializability of Schedules(cont..)
1.Execute all the operations of transaction T1 (in sequence)
followed by all the operations of transaction T2 (in
sequence).
2.Execute all the operations of transaction T2 (in sequence)
followed by all the operations of transaction T1 (in
sequence).
35
36.
Serializability of Schedules(classification)
Serial Schedule
Non-serial schedule
Serializable schedule
Conflict equivalent—all pairs of conflicting ops are
ordered the same way
View equivalent—all users get the same view
36
37.
Serializability of Schedules(classification)
Serial Schedule
Schedule where operations of each transaction are executed
consecutively without any interleaved operations from other
transactions. The opposite of serial is non serial schedule.
No guarantee that results of all serial executions of a given set of
transactions will be identical.
37
Serializability of Schedules
Objective of serializability is to find non_serial schedules that allow
transactions to execute concurrently without interfering with one another.
In other words, want to find non_serial schedules that are equivalent to
some serial schedule. Such a schedule is called serializable.
When are two schedules equivalent?
• Option 1: They lead to same result (result equivalent)
• Option 2: The order of any two conflicting operations is the same (conflict
equivalent)
39
40.
Result Equivalent Schedules
Two schedules are result equivalent if they produce the same final state
of the database
Problem: May produce same result by accident!
S1
read_item(X);
X:=X+10;
write_item(X);
S2
read_item(X);
X:=X*1.1;
write_item(X);
Schedules S1 and S2 are result equivalent for X=100 but not in general
S1
read_item(X);
X:=X+10;
write_item(X);
S1
read_item(X);
X:=X+10;
write_item(X);
40
41.
Conflict Equivalent Schedules
Let I and J be consecutive instructions by two different transactions within a schedule S.
If I and J do not conflict, we can swap their order to produce a new schedule S'.
The instructions appear in the same order in S and S', except for I and J, whose order does not matter.
Two schedules are conflict equivalent, if the order of any two conflicting operations is the same in both
schedules
A schedule is conflict serializable if it can be transformed into a serial schedule by a series of swappings of
adjacent non-conflicting actions
S and S' are termed conflict equivalent schedules.
41
42.
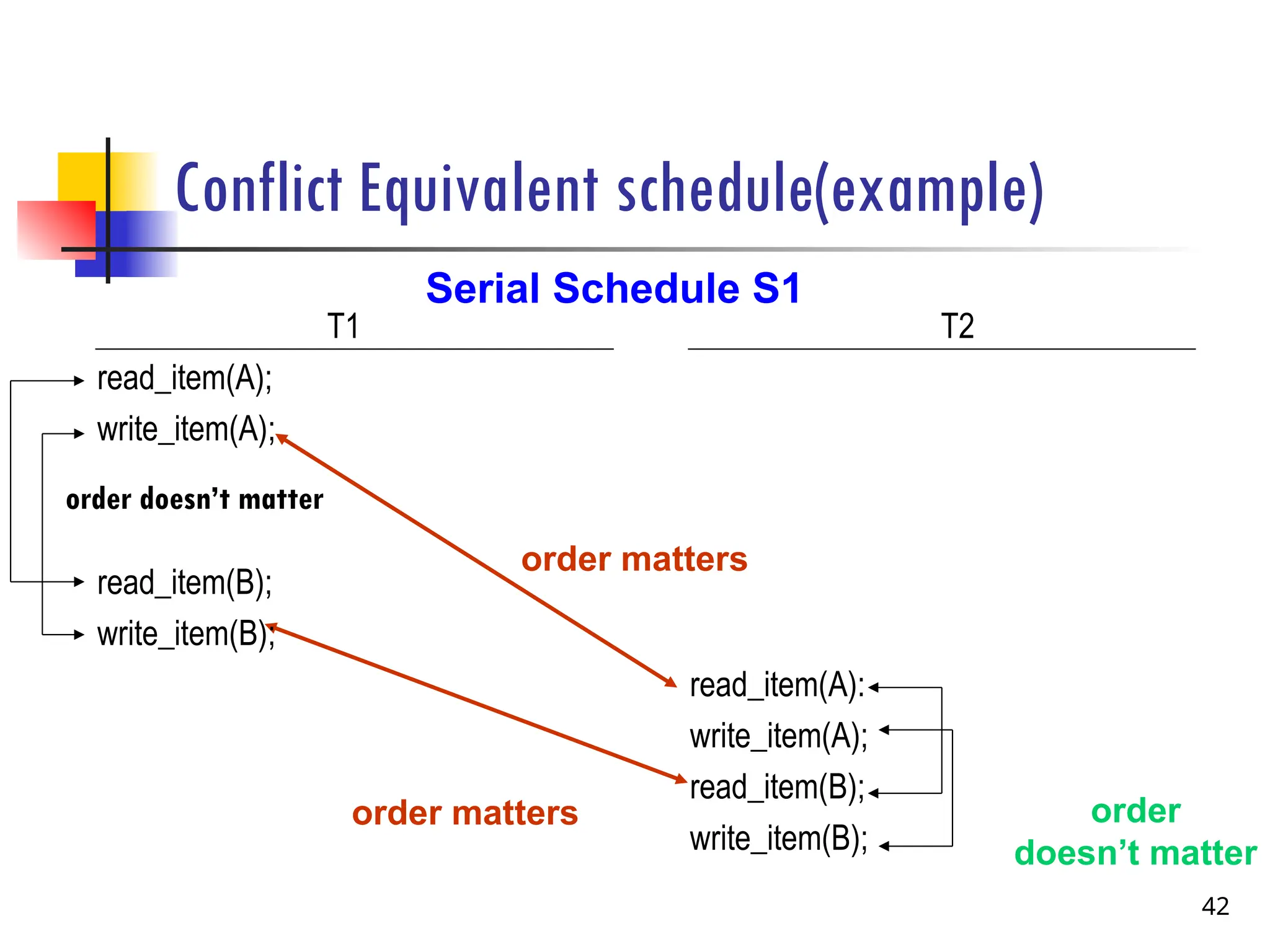
Conflict Equivalent schedule(example)
order
doesn’tmatter
order matters
order matters
Serial Schedule S1
T1
read_item(A);
write_item(A);
read_item(B);
write_item(B);
T2
read_item(A):
write_item(A);
read_item(B);
write_item(B);
order doesn’t matter
42
43.
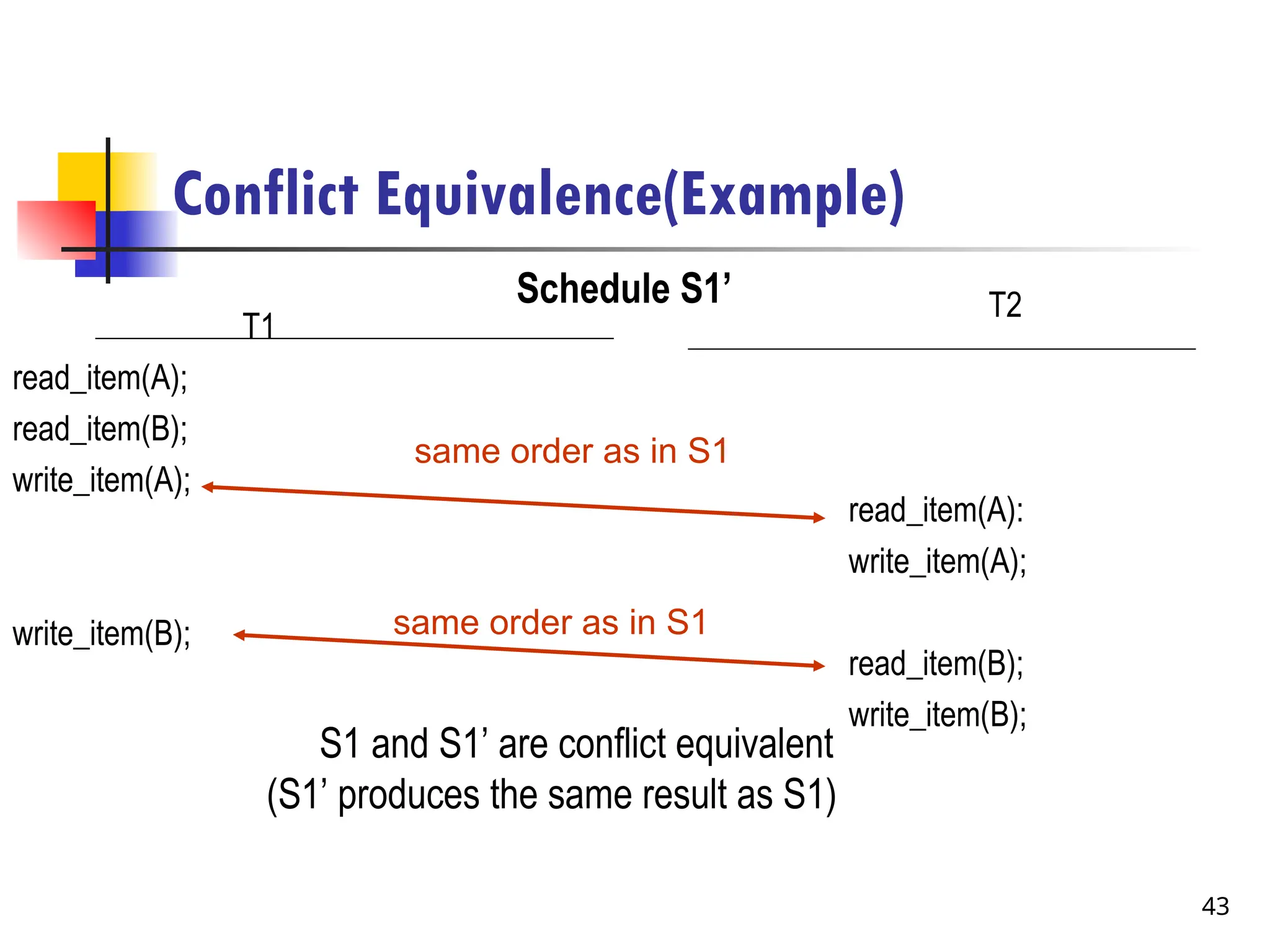
Conflict Equivalence(Example)
S1 andS1’ are conflict equivalent
(S1’ produces the same result as S1)
Schedule S1’
same order as in S1
T1
read_item(A);
read_item(B);
write_item(A);
write_item(B);
T2
read_item(A):
write_item(A);
read_item(B);
write_item(B);
same order as in S1
43
44.
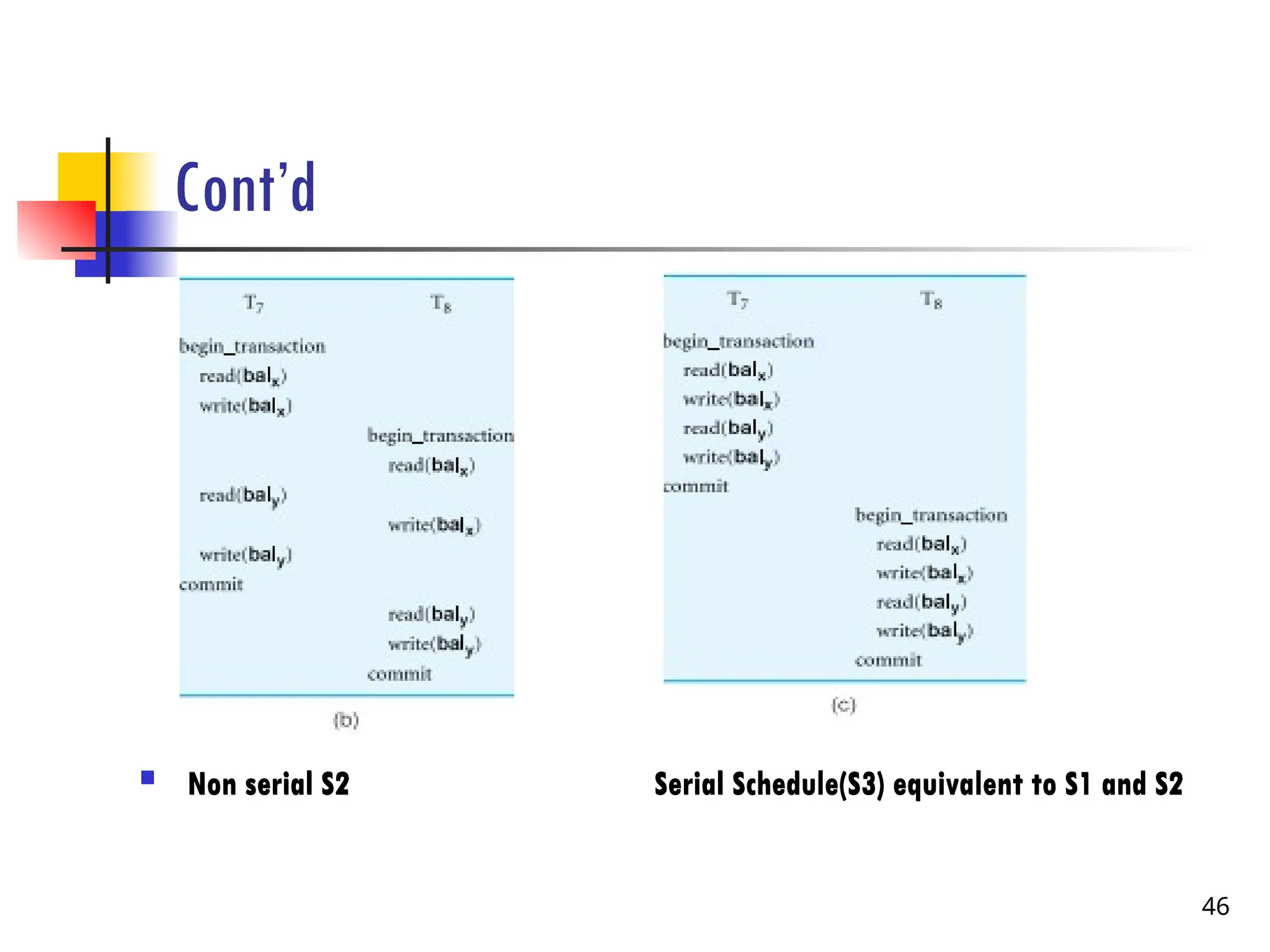
Example 2
Considerthe schedule S1 shown figure(a) in next slide containing operations from two concurrently
executing transactions T7 and T8. Since the write operation on balx in T8 does not conflict with the
subsequent read operation on baly in T7, we can change the order of these operations to produce the
equivalent schedule S2 shown in Figure (b). If we also now change the order of the following non-conflicting
operations, we produce the equivalent serial schedule S3 shown in figure (c).
44
45.
Cont’d……
Non serial S1
Change the order of the write(balx) of T8 with the
write(baly) of T7.
Change the order of the read(balx) of T8 with the
read(baly) of T7.
Change the order of the read(balx) of T8 with the
write(baly) of T7
45
46.
Cont’d
Non serialS2 Serial Schedule(S3) equivalent to S1 and S2
Non serial S2 Serial Schedule(S3) equivalent to S1 and S2
46
47.
Testing for conflictserializability
Under the constrained write rule (that is, a transaction updates a data item based on its old
value, which is first read by the transaction), a precedence (or serialization) graph can be
produced to test for conflict serializability.
For a schedule S, a precedence graph is a directed graph G = (N, E) that consists of a set of nodes N
and a set of directed edges E, which is constructed as follows:
Create a node for each transaction.
Create a directed edge Ti T
→ j, if Tj reads the value of an item written by Ti.
Create a directed edge Ti T
→ j, if Tj writes a value into an item after it has been read by Ti.
Create a directed edge Ti T
→ j, if Tj writes a value into an item after it has been written by Ti.
If an edge Ti T
→ j exists in the precedence graph for S, then in any serial schedule S’ equivalent to S,
Ti must appear before Tj. If the precedence graph contains a cycle the schedule is not conflict
serializable.
47
48.
Example….
Consider thetwo transactions shown in Figure below Transaction T9 is transferring £100 from one account
with balance balx to another account with balance baly, while T10 is increasing the balance of these two
accounts by 10%.
Does this schedule is conflict serializable? Why?
48
49.
Cont’d…
Let usdraw precedence graph
Precedence graph for figure above showing a cycle, so schedule is not conflict serializable.
49
50.
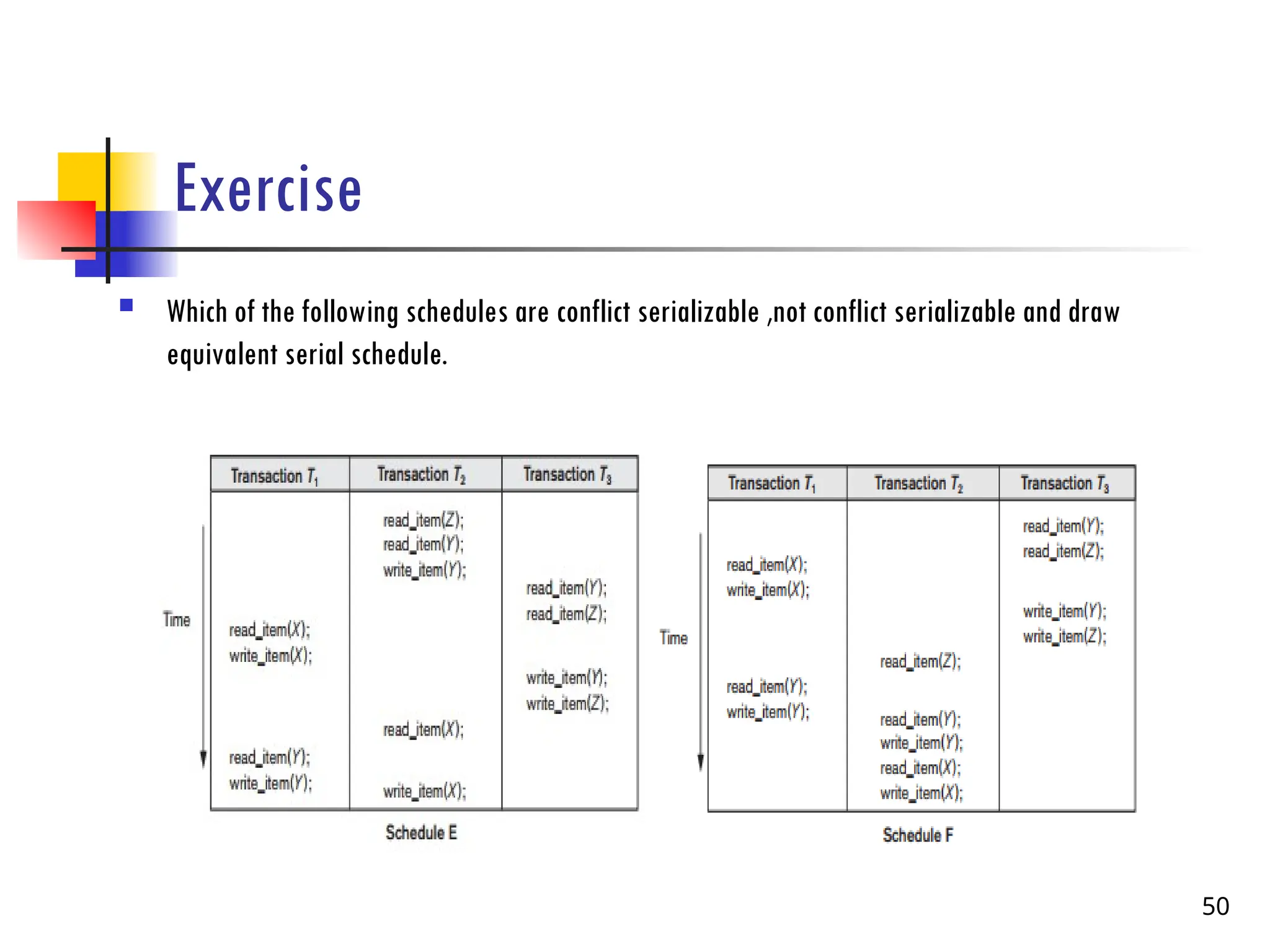
Exercise
Which ofthe following schedules are conflict serializable ,not conflict serializable and draw
equivalent serial schedule.
50
51.
View Equivalence andView Serializability
Another less restrictive definition of equivalence of schedules is called view equivalence.
This leads to another definition of serializability called view serializability.
Two schedules S and S’ are said to be view equivalent if the following three conditions hold:
1. The same set of transactions participates in S and S’, and S and S’ include the same operations of
those transactions.
2. For any operation ri(X) of Ti in S, if the value of X read by the operation has been written by an
operation wj(X) of Tj (or if it is the original value of X before the schedule started), the same condition
must hold for the value of X read by operation ri(X) of Ti in S’.
3. If the operation wk(Y) of Tk is the last operation to write item Y in S, then wk(Y) of Tk must also be
the last operation to write item Y in S’.
A schedule is view serializable if it is view equivalent to a serial schedule
51
52.
Cont’d…
Every conflictserializable schedule is view serializable, although the converse is not true.
e.g. The schedule below is view serializable, although it is not conflict serializable.
In this example, transactions T12 and T13 do not conform to the constrained write rule; in other
words, they perform blind writes.
any view serializable schedule that is not conflict serializable contains one or more blind writes.
52
53.
Recoverability
Serializability identifiesschedules that maintain the consistency of the database, assuming that none
of the transactions in the schedule fails.
An alternative perspective examines the recoverability of transactions within a schedule.
If a transaction fails, the atomicity property requires that we undo the effects of the transaction.
In addition, the durability property states that once a transaction commits, its changes cannot be
undone. This leads to recoverable schedule.
Recoverable schedule A schedule where, for each pair of transactions Ti and Tj, if Tj reads a data item
previously written by Ti, then the commit operation of Ti precedes the commit operation of Tj.
53
54.
Concurrency control techniques
Serializability can be achieved in several ways.
There are two main concurrency control techniques that allow transactions to execute safely in
parallel subject to certain constraints: locking and timestamp methods.
Locking Methods
What is Locking? A procedure used to control concurrent access to data. When one transaction is
accessing the database, a lock may deny access to other transactions to prevent incorrect results.
There are several locking variations, but all share the same fundamental characteristic, namely that a
transaction must claim a shared (read) or exclusive (write) lock on a data item before the
corresponding database read or write operation.
Shared lock: If a transaction has a shared lock on a data item, it can read the item but not update it.
Exclusive lock: If a transaction has an exclusive lock on a data item, it can both read and update the
item.
54
55.
Cont’d…
If atransaction holds the exclusive lock on the item, no other transactions can read or update that
data item.
How the locks are used?
Any transaction that needs to access a data item must first lock the item (i.e. requesting for shared
or exclusive locks.)
If the item is not already locked by another transaction, the lock will be granted.
If the item is currently locked, the DBMS determines whether the request is compatible with the
existing lock. If a shared lock is requested on an item that already has a shared lock on it, the
request will be granted; otherwise, the transaction must wait until the existing lock is released.
A transaction continues to hold a lock until it explicitly releases it either during execution or when it
terminates (aborts or commits). It is only when the exclusive lock has been released that the effects
of the write operation will be made visible to other transactions.
55
56.
Incorrect locking schedule
Assume the following schedule that we
have seen in the earlier:
If we schedule the transactions by applying
lock it becomes
S = {write_lock(T9, balx), read(T9, balx),
write(T9, balx),
unlock(T9,balx),write_lock(T10, balx),
read(T10, balx), write(T10, balx),
unlock(T10, balx),write_lock(T10, baly),
read(T10, baly), write(T10, baly),
unlock(T10, baly), commit(T10),
write_lock(T9, baly), read(T9, baly),
write(T9, baly),unlock(T9, baly),
commit(T9)}
56
57.
cont’d…(diagrammatically)
If, priorto execution, balx = 100, baly =
400, the result should be balx = 220,
baly = 330, if T9 executes before T10, or
balx = 210 and baly = 340, if T10
executes before T9. However, the result of
executing schedule S would give balx =
220 and baly = 340. (S is not a serializable
schedule.) till the serializability isn’t
guaranteed.
To guarantee serializability, we must
follow an additional protocol i.e. 2PL
57
58.
Two-phase locking (2PL)
A transaction follows the two-phase locking protocol if all locking operations precede the first unlock
operation in the transaction.
According to the rules of this protocol, every transaction can be divided into two phases: a growing
phase and shrinking phase.
Growing phase- in which it acquires all the locks needed but cannot release any locks.
Shrinking phase - in which it releases its locks but cannot acquire any new locks.
58
59.
Preventing the lostupdate problem using 2PL
T2 blocks T1 from accessing balx because T2 issued with exclusive lock.
e.g.
59
60.
Preventing the uncommitteddependency
(Dirty read) problem using 2PL
To prevent this problem occurring, T4 first requests an exclusive lock on balx. It can then proceed to
read the value of balx from the database, increment it by £100, and write the new value back to the
database. When the rollback is executed, the updates of transaction T4 are undone and the value of
balx in the database is returned to its original value of £100.
Then the exclusive lock is released by T4 and granted by T3.
60
61.
Preventing the inconsistentanalysis
(incorrect summary) problem using 2PL
To prevent this problem occurring, T5 must precede its reads by exclusive locks, and T6 must precede
its reads with shared locks. Therefore, when T5 starts it requests and obtains an exclusive lock on
balx. Now, when T6 tries to share lock balx the request is not immediately granted and T6 has to
wait until the lock is released, which is when T5 commits.
61
62.
Cascading rollback
Isa situation, in which a single transaction leads to a series of rollbacks.
E.g. Consider a schedule consisting of the three transactions shown in Figure below, which conforms
to the two-phase locking protocol. All txns executing their database operations. Meanwhile, T14 has
failed and has been rolled back. However, since T15 is dependent on T14 (it has read an item that
has been updated by T14), T15 must also be rolled back. Similarly, T16 is dependent on T15, so it too
must be rolled back.
62
63.
Cascading rollback (cont’d…)
Are undesirable since they potentially lead to the undoing of a significant amount of work.
Clearly, it would be useful if we could design protocols that prevent cascading rollbacks.
One way to achieve this with two-phase locking is to leave the release of all locks until the end of
the transaction.
In this way, the problem illustrated earlier slide would not occur, as T15 would not obtain its
exclusive lock until after T14 had completed the rollback. This is called rigorous 2PL.
Another variant of 2PL, called strict 2PL, only holds exclusive locks until the end of the transaction.
Most database systems implement one of these two variants of 2PL.
63
64.
Concurrency control withindex structures
can be managed by treating each page of the index as a data item and applying the two-phase
locking protocol described earlier.
However, since indexes are likely to be frequently accessed, particularly the higher levels of trees
(as searching occurs from the root downwards), this simple concurrency control strategy may lead to
high lock contention.
Therefore, a more efficient locking protocol is required for indexes.
For searches, obtain shared locks on nodes starting at the root and proceeding downwards along the
required path. Release the lock on a (parent) node once a lock has been obtained on the child node.
For insertions, a conservative approach would be to obtain exclusive locks on all nodes as we
descend the tree to the leaf node to be modified. This ensures that a split in the leaf node can
propagate all the way up the tree to the root. However, if a child node is not full, the lock on the
parent node can be released. 64
65.
Latches
DBMSs alsosupport another type of lock called a latch.
It is held for a much shorter duration than a normal lock.
A latch can be used before a page is read from, or written to, disk to ensure that the operation is
atomic.
For example, a latch would be obtained to write a page from the database buffers to disk, the page
would then be written to disk, and the latch immediately unset.
65
66.
Deadlock
An impassethat may result when two (or more) transactions are each waiting for locks to be
released that are held by the other.
Once deadlock occurs, the applications involved cannot resolve the problem. Instead, the DBMS has
to recognize that deadlock exists and break the deadlock in some way.
Unfortunately, there is only one way to break deadlock: abort one or more of the transactions.
Figure in next slide shows two transactions, T17 and T18, that are deadlocked because each is
waiting for the other to release a lock on an item it holds. At time t2, transaction T17 requests and
obtains an exclusive lock on item balx, and at time t3 transaction T18 obtains an exclusive lock on
item baly. Then at t6, T17 requests an exclusive lock on item baly. Since T18 holds a lock on baly,
transaction T17 waits. Meanwhile, at time t7, T18 requests a lock on item balx, which is held by
transaction T17. Neither transaction can continue because each is waiting for a lock it cannot obtain
until the other completes.
66
67.
Example
In Figurebelow we may decide to abort transaction T18. Once this is complete, the locks held by
transaction T18 are released and T17 is able to continue again. Deadlock should be transparent to
the user, so the DBMS should automatically restart the aborted transaction(s)
67
68.
cont’d…
There arethree general techniques for handling deadlock: timeouts, deadlock prevention, and
deadlock detection and recovery.
With timeouts, the transaction that has requested a lock waits for at most a specified period of
time.
Using deadlock prevention, the DBMS looks ahead to determine if a transaction would cause
deadlock, and never allows deadlock to occur.
Using deadlock detection and recovery, the DBMS allows deadlock to occur but recognizes
occurrences of deadlock and breaks them.
Since it is more difficult to prevent deadlock than to use timeouts or testing for deadlock and
breaking it when it occurs, systems generally avoid the deadlock prevention method.
68
69.
Deadlock Prevention: WaitDie
Suppose Ti tries to lock an item locked by Tj.
If Ti is the older transaction then Ti will wait.
otherwise Ti is aborted and restarts later with the same timestamp.
69
70.
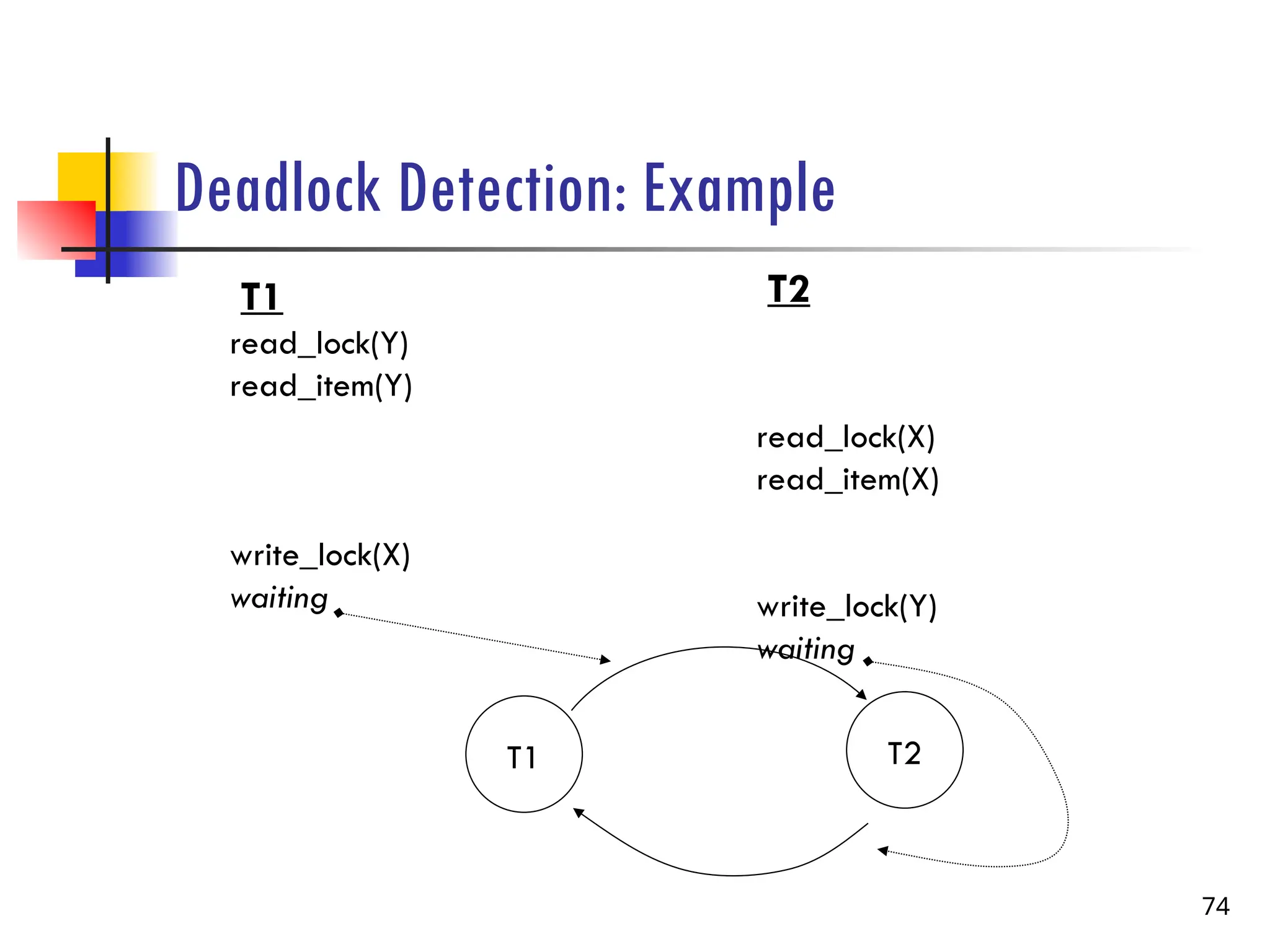
Deadlock Prevention: WaitDie(example)
70
T1
read_lock(Y)
read_item(Y)
write_lock(X)
T1 is older and so it is allowed to wait.
can resume
T2
read_lock(X)
read_item(X)
write_lock(Y)
T2 is younger and so it is aborted, which
results in its locks being released, and that
allows T1 to carry on:
abort
T1 starts before T2 so T1 is
older
71.
Deadlock Prevention: Wound-wait
Suppose Ti tries to lock an item locked by Tj
If Ti is the older transaction then Tj is aborted and restarts later with the same timestamp;
otherwise Ti is allowed to wait.
71
Deadlock Detection
Periodicallycheck for deadlock in the system.
Detection algorithm uses a wait-for graph and performs in the following
manner:
one node for each transaction
an edge (Ti Tj) is created if Ti is waiting for Tj to release a lock (the
edge is removed when Tj releases the lock and Ti is then unblocked).
If the graph has a cycle then there is deadlock.
If there is deadlock then a victim is chosen and it is aborted.
73
Deadlock and Starvation
Starvation
Occurs when a particular transaction consistently waits or restarted and never gets a chance to proceed
further.
This limitation is inherent in all priority based scheduling mechanisms.
Example
In Wound-Wait scheme a younger transaction may always be wounded (aborted) by a long running older
transaction which may create starvation.
So, what is the solution?
75
76.
Concurrency Control Technique:Timestamping
Whatis Timestamp?
A unique identifier created by the DBMS to identify a transaction.
A monotonically increasing variable (integer) indicating the age of an operation or a
transaction.
Each transaction is assigned a timestamp (TS).
If a transaction T1 starts before transaction T2, then TS(T1) < TS(T2); T1 is older
than T2.
76
77.
Timestamping cont’d….
Eachdatabase item X has 2 timestamps:
The read timestamp of X, read_TS(X), is the largest timestamp among all
transaction timestamps that have successfully read X.
The write timestamp of X, write_TS(X), is the largest timestamp among all
transaction timestamps that have successfully written X.
77
78.
Timestamp Ordering (TO)Algorithm
When a transaction T tries to read or write an item X, the timestamp of T is
compared to the read and write timestamps of X to ensure the timestamp order of
execution is not violated.
If the timestamp order of execution is violated then T is aborted and resubmitted
later with a new timestamp.
78
79.
Timestamp Ordering (TO)Algorithm - in detail
If T issues write_item(X) then
– if {read_TS(X) > TS(T) or write_TS(X) > TS(T)} then abort T.
– otherwise (*TS(T) read_TS(X) and TS(T) write_TS(X)*)
• execute write_item(X)
• set write_TS(X) to TS(T)
If T issues read_item(X) then
– if write_TS(X) > TS(T) then abort T.
otherwise (*TS(T) write_TS(X)*)
• execute read_item(X)
• set read_TS(X) to max{TS(T), read_TS(X)}
79
80.
Timestamp Ordering(example)
Whatis the schedule for T1 and T2? Assuming all initial data item timestamps
are 0, what are the various read and write timestamps? 80
T1 T2
TS 5 10
Initially, the timestamps for all the data
items are set to 0.
Time T1 T2
1 read_item(Y)
2 read_item(X)
3 write_item(X)
aborted
4 write_item(Y)
5 commit
6 could be restarted
81.
Concurrency Control Technique:Optimistic
Are based on the assumption that conflict is rare.
It is more efficient to allow transactions to proceed without imposing delays to ensure serializability.
Transactions operate on their own local copies of data items
When a transaction executes commit, i.e. it is ending, the transaction enters a validation phase
where serializability is checked.
Reduces overhead
Useful if there is little interference between transactions.
During transaction execution, all updates are applied to local copies of the data items that are kept
for the transaction.
81
82.
Optimistic (Validation) cont’d…
A transaction has three phases:
Read - reads operate on database; writes operate on local copies.
Validation - check for serializability.
Write - if serializability test is satisfied, the database is updated otherwise the transaction is
aborted.
Read set a transaction is the set of items it reads.
Write set of a transaction is the set of items it writes
82
83.
Optimistic (Validation) cont’d…
Validationphase
Suppose Ti is in its validation phase and Tj is any transaction that has committed or is also in its
validation phase, then one of 3 conditions must be true for serializability to hold:
1.Tj completes its write phase before Ti starts its read phase.
2.Ti starts its write phase after Tj completes its write phase, and the read set of Ti has no items in
common with the write set of Tj
3.Both the read set and write set of Ti have no items in common with the write set of Tj and Tj completes
its read phase before Ti completes its read phase.
If none of these conditions hold, Ti is aborted.
83
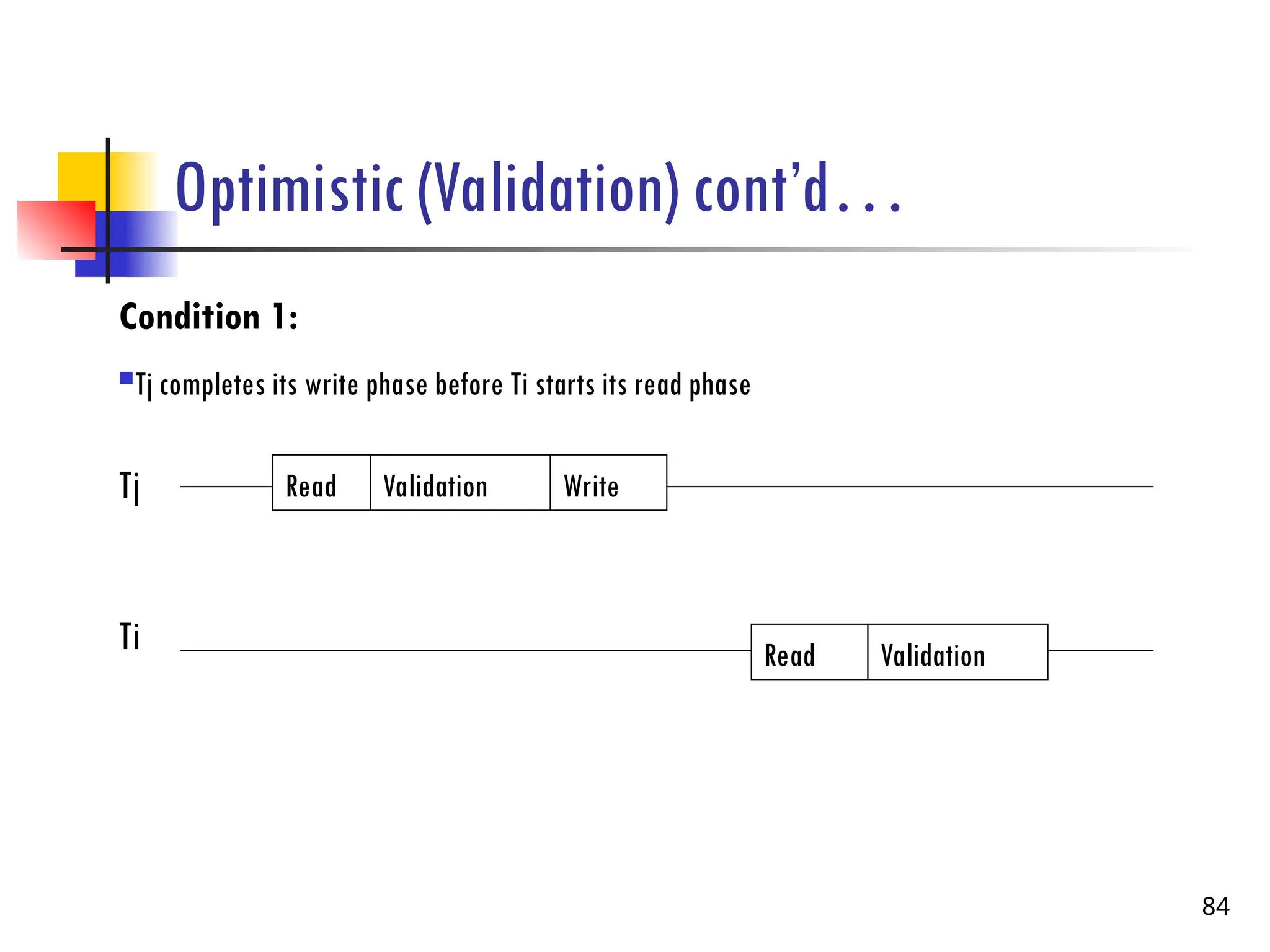
Optimistic (Validation) cont’d…
Condition2:
Ti starts its write phase after Tj completes its write phase, and the read set of Ti has no items in
common with the write set of Tj
85
Tj
Ti
Read Validation Write
Read Validation write
Ti does not read anything that Tj
writes
86.
Optimistic (Validation) cont’d…
Condition3:
both the read set and write set of Ti have no items in common with the write set of Tj, and Tj
completes its read phase before Ti completes its read phase
86
Tj
Ti
Read Validation
Read Validation
Ti does not read or write anything
that Tj writes
Validation
87.
Granularity of DataItems and Multiple
Granularity Locking
What is Granularity of data items?
A lockable unit of data.
The size of data items(data items granularity)
Granularity can be coarse (entire database or large data size ) or it can be fine (a tuple or an attribute of a
relation or small data size)
Example of data item granularity:
1.A field of a database record (an attribute of a tuple)
2.A database record (a tuple or a relation)
3.A disk block
4.An entire file
5.The entire database 87
88.
Granularity Level Considerationsfor Locking
Data item granularity significantly affects concurrency control performance.
The larger the data item size is, the lower the degree of concurrency permitted.
The smaller the data size is, the more the number of items in the database.(since
every database item associated with the locks.)
What is the best item size?
Answer: it depends on the types of transactions involved.
88
89.
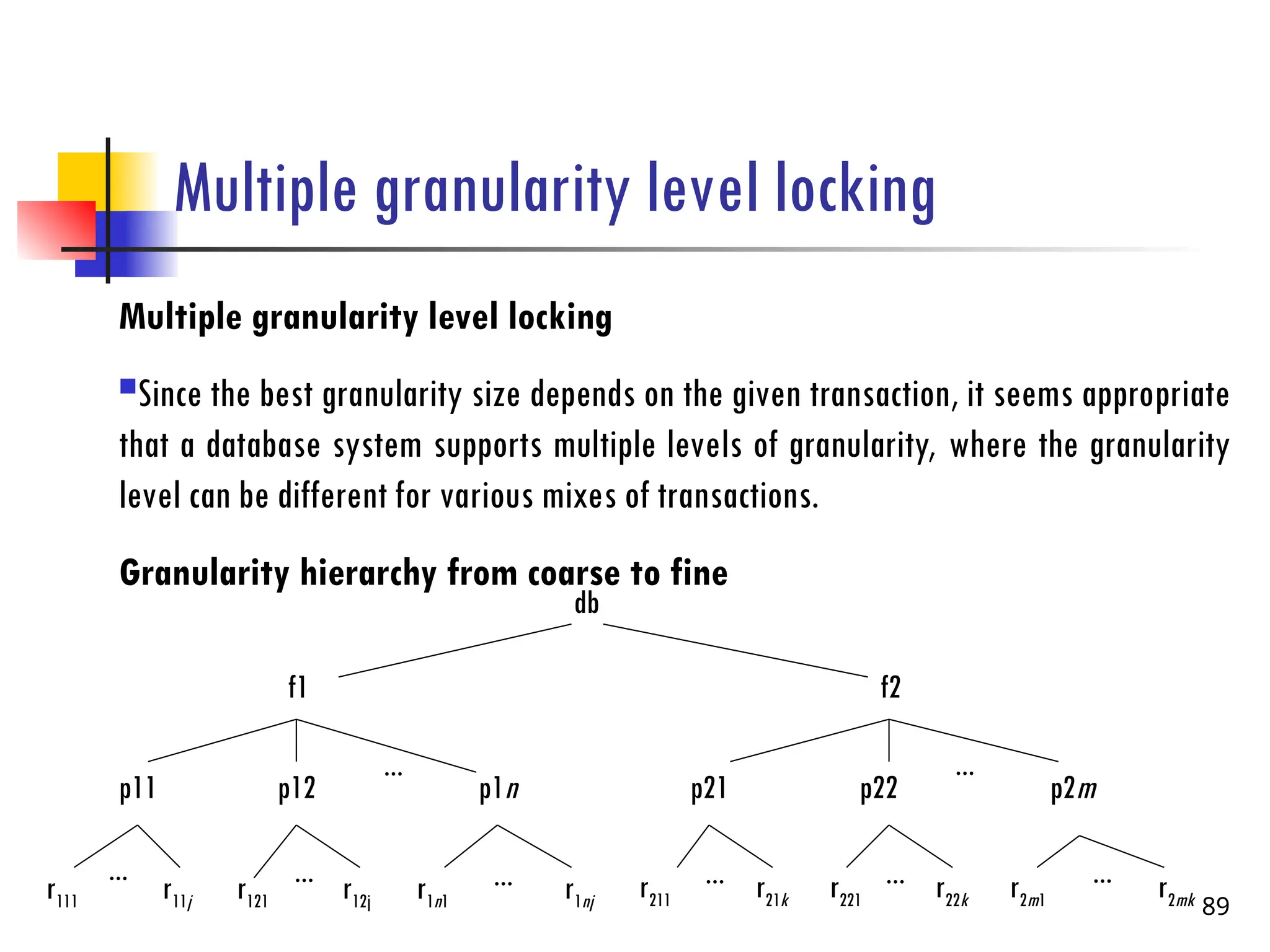
Multiple granularity levellocking
Multiple granularity level locking
Since the best granularity size depends on the given transaction, it seems appropriate
that a database system supports multiple levels of granularity, where the granularity
level can be different for various mixes of transactions.
Granularity hierarchy from coarse to fine
89
db
f1 f2
p11 p12 p1n p21 p22 p2m
r111 r11j r121 r12j r1n1 r1nj r211 r21k r221 r22k r2m1 r2mk
... ...
... ... ... ... ... ...
90.
Multiple granularity levellocking cont’d…
Problem with only shared and exclusive locks
T1: updates all the records in file f1.
T2: read record r1nj.
Assume that T1 comes before T2:
T1 locks f1.
Before T2 is executed, the compatibility of the lock on r1nj with the lock on f1 should be checked.
This can be done by traversing the granularity hierarchy bottom-up (from leaf r1nj to p1n to db).
It is efficient
90
91.
Multiple granularity levellocking cont’d…
Assume that T2 comes before T1:
T2 locks r1nj.
Before T1 is executed, the compatibility of the lock on f1 with the lock on r1nj should
be checked.
It is quite difficult for the lock manager to check all nodes below f1(inefficient).
So, What is the solution to make multiple granularity level locking practical?
91
92.
Multiple granularity levellocking cont’d…
Solution: intention locks.
The idea of Intention locks is for a transaction to indicate, along the path from the
root to the desired node, what type of lock (shared or exclusive) it will require from
one of the node’s descendants.
92
93.
Multiple granularity levellocking cont’d…
Three types of intention locks:
Intention-shared (IS): indicates that a shared lock(s) will be requested on some
descendant node(s).
Intention-exclusive (IX): indicates that an exclusive lock(s) will be requested on
some descendant node(s).
Shared-intention-exclusive (SIX): indicates that the current node is locked in
shared mode but an exclusive lock(s) will be requested on some descendant node(s).
93
94.
Multiple granularity levellocking cont’d…
Lock compatibility matrix for multiple granularity locking
94
IS yes yes yes yes no
IX yes yes no no no
S yes no yes no no
SIX yes no no no no
X no no no no no
IS IX S SIX X
95.
Multiple granularity levellocking cont’d…
Multiple granularity locking (MGL) protocol:
1. The lock compatibility must be adhere to.
2. The root of the granularity hierarchy must be locked first, in any mode.
3. A node N can be locked by a transaction T in S or IS mode only if the parent of node N is already
locked by transaction T in either IS or IX mode.
4. A node N can be locked by a transaction T in X, IX, or SIX mode only if the parent of node N is
already locked by transaction T in either IX or SIX mode.
5. A transaction T can lock a node only if it has not unlocked any node (to enforce the 2PL protocol).
6. A transaction T can unlock a node N only if none of the children of node N are currently locked by
T.
95
96.
Multiple granularity levellocking cont’d…
Example:
T1: updates all the records in p12.
T2: read record r1nj.
96
T1:
IX(db)
IX(f1)
X(p12)
write-item(p12)
unlock(p12)
unlock(f1)
unlock(db)
T2:
IS(db)
IS(f1)
IS(p1n)
S(r1nj)
read-item(r1nj)
unlock(r1nj)
unlock(p1n)
unlock(f1)
unlock(db)
Database Recovery: RecoveryConcepts
What is Recovery?
The process of getting back something lost (dictionary definition).
What is Database Recovery?
It is the process of restoring the database to the most recent consistent state that
existed just before the failure.
Why Database Recovery?
To bring the database into the last consistent state which existed prior to the failure.
To preserve transaction properties (Atomicity, Consistency, Isolation and Durability).
98
99.
Recovery Concepts cont’d….
Example
Ifthe system crashes before a fund transfer transaction completes its execution,
then either one or both accounts may have incorrect value.
Thus, the database must be restored to the state before the transaction modified
any of the accounts.
99
100.
Recovery Concepts (Typesof Failure)
The database may become inconsistent or unavailable for use due to various
types of failure:
Transaction failure: Transactions may fail because of incorrect input,
deadlock, incorrect synchronization.
System failure: System may fail because of addressing error, application
error, operating system fault, RAM failure, etc.
Media failure: Disk head crash, power disruption, etc.
How to control this failures? the system must keep information about the
changes that were applied to data items by the various transactions (stored in
system log).
100
101.
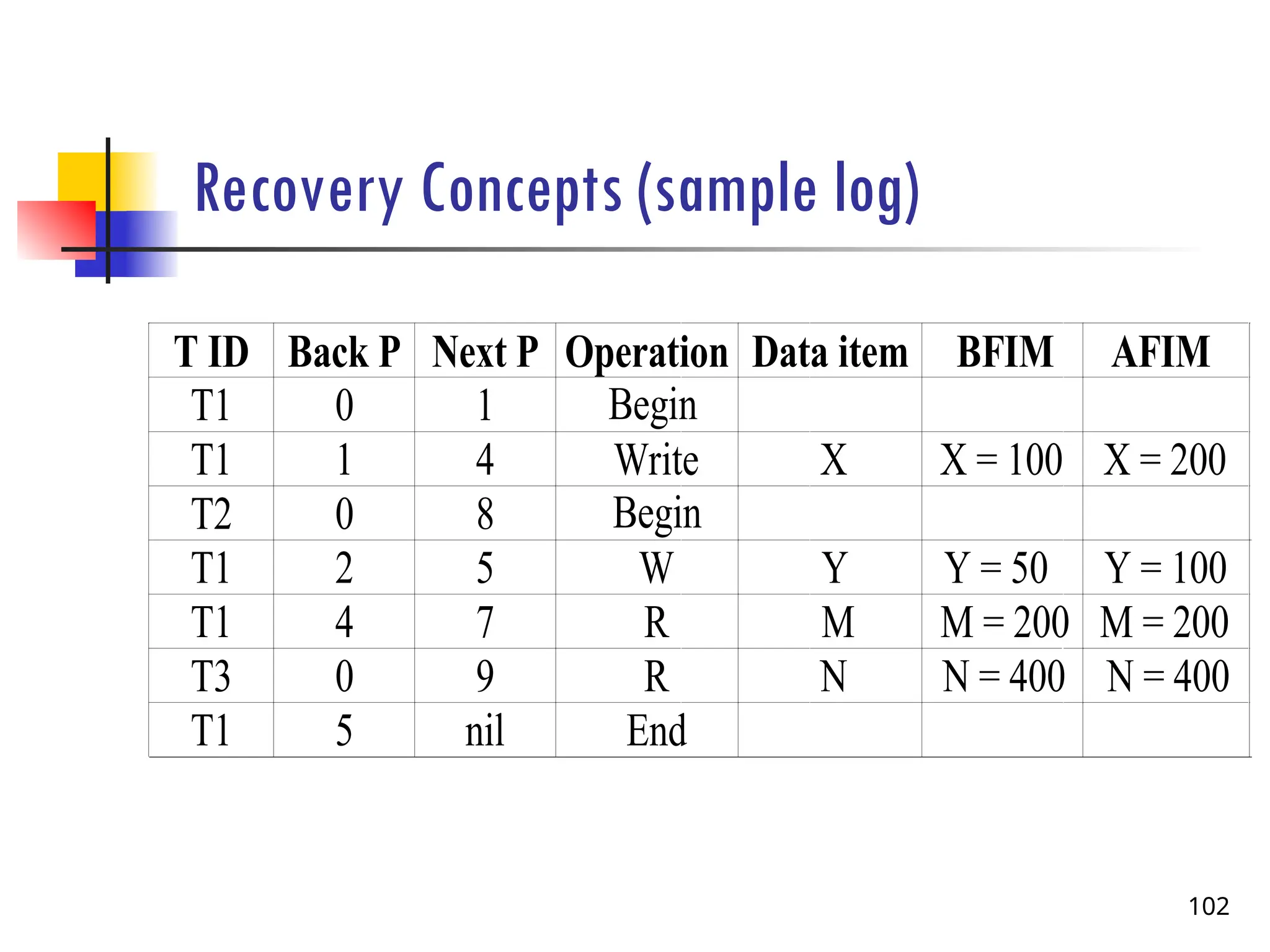
Recovery Concepts cont’d….
Whatis Transaction (system) Log?
For recovery from any type of failure,
Old value of the data item before updating (BFIM - BeFore Image) and
New value of data item after updating (AFIM – After Image) are required.
These values and other information is stored in a sequential file called
Transaction log. Example :A sample log in next slide
Back P and Next P point to the previous and next log records of the same
transaction.
101
102.
Recovery Concepts (samplelog)
102
T ID Back P Next P Operation Data item BFIM AFIM
T1 0 1
T1 1 4
T2 0 8
T1 2 5
T1 4 7
T3 0 9
T1 5 nil
Begin
Write
W
R
R
End
Begin
X
Y
M
N
X = 200
Y = 100
M = 200
N = 400
X = 100
Y = 50
M = 200
N = 400
103.
Data Caching (Buffering)of Disk Blocks
The recovery process is often closely intertwined with operating system
functions.
Data items to be modified are first stored into database cache by the Cache
Manager (CM) and after modification they are flushed (written) to the disk.
The flushing is controlled by Modified and Pin-Unpin bits.
Pin-Unpin: Instructs the operating system not to flush the data item. It cannot
be written back to disk as yet.
Modified: Indicates the AFIM of the data item.
103
104.
Write-Ahead Logging, Steal/No-Stealand
Force/No-Force
When in-place update (immediate or deferred) is used then log is necessary for
recovery and it must be available to recovery manager (in order to undo or
redo). This is achieved by Write-Ahead Logging (WAL) protocol.
WAL(Write Ahead Logging) states that:
For Undo: Before a data item is flushed to the database disk (overwriting the
BFIM) , its BFIM must be written to the log and the log must be saved on a stable
store (log disk).
For Redo: Before a transaction executes its commit operation, all its AFIMs must
be written to the log and the log must be saved on a stable store.
104
105.
Information needed toUNDO and REDO
The REDO-type log entry includes the new value (AFIM) of the item written
by the operation. Since this is needed to redo the effect of the operation from the
log (by setting the item value in the database on disk to its AFIM).
The UNDO-type log entries include the old value (BFIM) of the item. Since
this is needed to undo the effect of the operation from the log (by setting the item
value in the database back to its BFIM).
105
106.
Steal/No-Steal and Force/No-Force
Standard DBMS recovery terminology includes the terms steal/no-steal and
force/no-force. It specify the rules that govern when a page from the database
can be written to disk from the cache.
Possible ways for flushing database cache to database disk:
No_Steal: when a cache buffer page updated by a transaction cannot be written
to disk before the transaction commits.
Steal: is recovery protocol allows writing an updated buffer before the
transaction commits.
106
107.
Steal/No-Steal and Force/No-Forcecont’d…
Force: If all pages updated by a transaction are immediately written to disk
before the transaction commits.
No-Force: Caches(all pages updated) is deferred until transaction commits.
107
108.
Steal/No-Steal and Force/No-Forcecont’d…
These give rise to four different ways for handling recovery:
Steal/No-Force (Undo/Redo)
Steal/Force (Undo/No-redo)
No-Steal/No-Force (Redo/No-undo)
No-Steal/Force (No-undo/No-redo)
108
109.
Check Pointing inthe System Log
Checkpoint is a mechanism where all the previous logs are removed from the
system and stored permanently in a storage disk
Checkpoint is another type of entry in the log.
Time to time (randomly or under some criteria) the database flushes its buffer to
database disk to minimize the task of recovery.
As part of check pointing, the list of transaction ids for active transactions at the
time of the checkpoint is included in the checkpoint record. These transactions can
be easily identified during recovery.
109
110.
Transaction Roll-back (Undo)and Roll-
Forward (Redo)
To maintain atomicity, a transaction’s operations are redone or undone.
Undo: Restore all BFIMs on to disk (Remove all AFIMs).
Redo: Restore all AFIMs on to disk.
Database recovery is achieved either by performing only Undos or only Redos
or by a combination of the two. These operations are recorded in the log as
they happen.
110
111.
Recovery Concepts Basedon Deferred Update
(No Undo/Redo)
Defer or postpone any actual updates to the database on disk until the
transaction completes its execution successfully and reaches its commit point and
follows no-steal approach.
The data update goes as follows:
A set of transactions records their updates in the log.
At commit point under WAL scheme these updates are saved on database disk.
After reboot from a failure the log is used to redo all the transactions affected by
this failure.
No undo is required because no AFIM is flushed to the disk before a transaction
commits. 111
112.
Recovery Concepts Basedon Deferred Update
(No Undo/Redo) cont’d…
Redo is needed in case the system fails after a transaction commits but before
all its changes are recorded in the database on disk.
112
113.
Deferred Update withsingle-user system
There is no concurrent data sharing in a single user system. The data update goes as
follows:
A set of transactions records their updates in the log.
At commit point under WAL scheme these updates are saved on database disk.
After reboot from a failure the log is used to redo all the transactions affected by
this failure.
No undo is required because no AFIM is flushed to the disk before a transaction
commits.
113
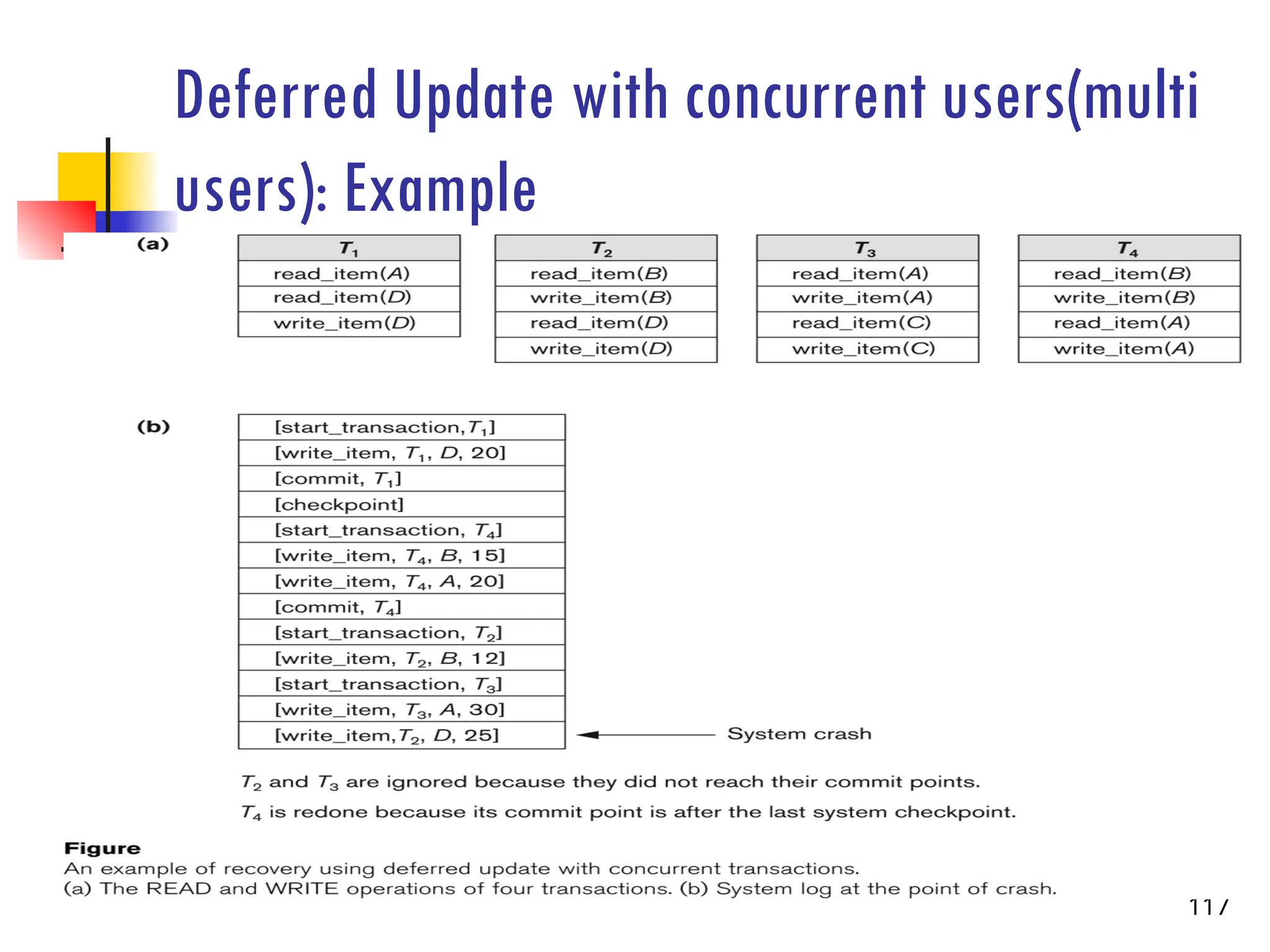
Deferred Update withconcurrent users(multi
users)
This environment requires some concurrency control mechanism to guarantee
isolation property of transactions.
In a system recovery transactions which were recorded in the log after the
last checkpoint were redone.
The recovery manager may scan some of the transactions recorded before the
checkpoint to get the AFIMs.
115
Deferred Update withconcurrent users cont’d
Two tables are required for implementing this protocol:
Active table: All active transactions are entered in this table.
Commit table: Transactions to be committed are entered in this table.
During recovery, all transactions of the commit table are redone and all
transactions of active tables are ignored since none of their AFIMs reached the
database.
118
119.
Recovery Techniques Basedon Immediate
Update(Undo/No-redo)
Follows steal strategy.
when a transaction issues an update command, the database on disk can be
updated immediately without any need to wait for the transaction to reach its
commit point.
In this algorithm AFIMs of a transaction are flushed to the database disk under
WAL before it commits. For this reason the recovery manager undoes all
transactions during recovery.
No transaction is redone.
It is possible that a transaction might have completed execution and ready to
commit but this transaction is also undone.
119
120.
Recovery Techniques Basedon Immediate
Update(Undo/No-redo)
With single user environment
Recovery schemes of this category apply undo and also redo for recovery.
In a single-user environment no concurrency control is required but a log is
maintained under WAL.
Note that at any time there will be one transaction in the system and it will be
either in the commit table or in the active table.
The recovery manager performs:
Undo of a transaction if it is in the active table.
Redo of a transaction if it is in the commit table.
120
121.
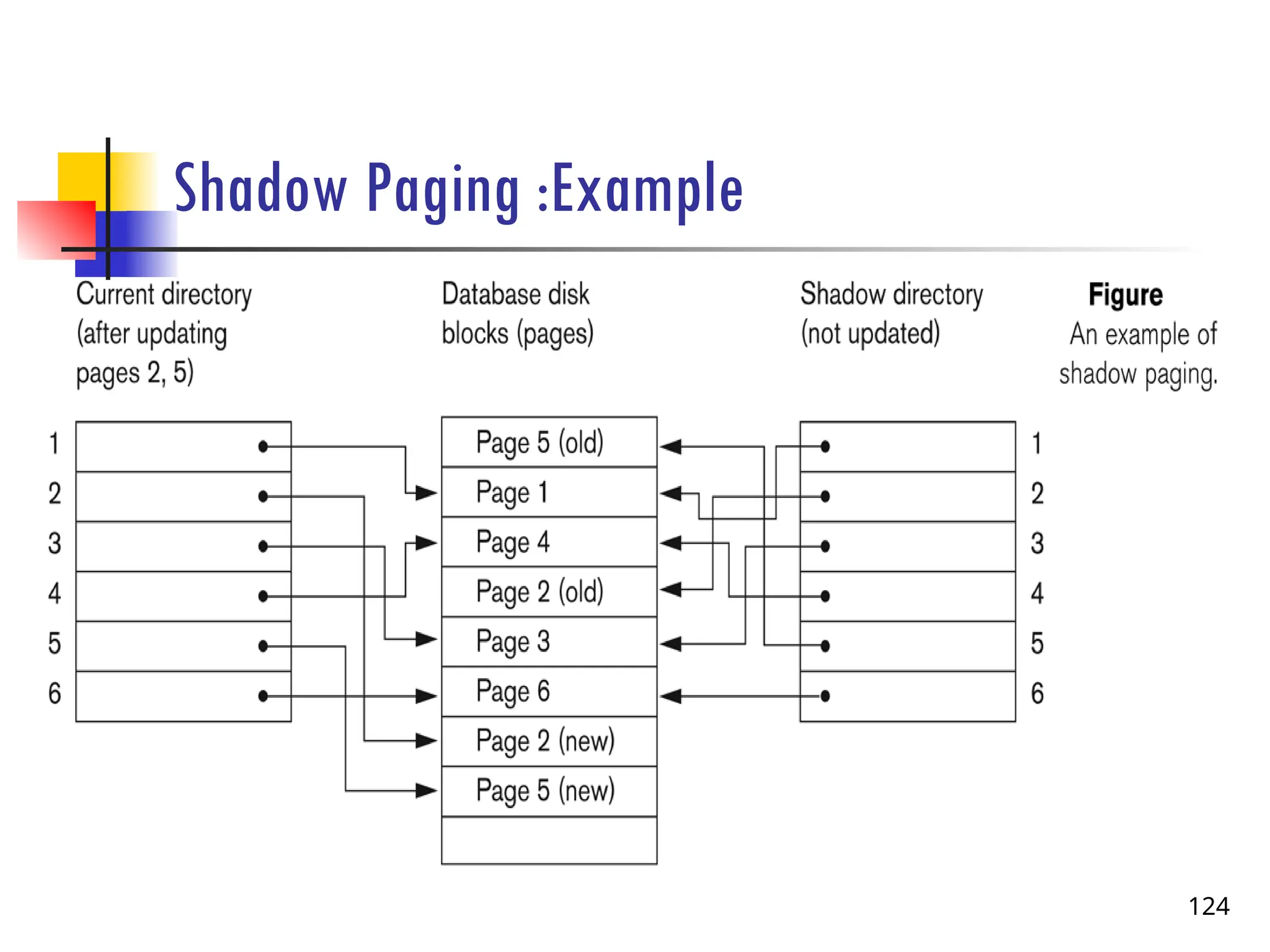
Shadow Paging
Doesnot require the use of a log in a single-user environment.
Is an alternative to log-based recovery.
The AFIM does not overwrite its BFIM but recorded at another place on the disk.
Thus, at any time a data item has AFIM and BFIM (Shadow copy of the data item) at
two different places on the disk.
X and Y: Shadow copies of data items
X' and Y': Current copies of data items 121
X Y
Database
X' Y'
122.
Shadow Paging cont’d…
Maintain two page tables during the lifetime of a transaction –the current page
table and the shadow page table.
Store the shadow page table in nonvolatile storage, such that state of the
database prior to transaction execution may be recovered.
Shadow page table is never modified during execution
122
123.
Shadow Paging cont’d…
To start with, both the page tables are identical. Only current page table is used
for data item accesses during execution of the transaction.
Whenever any page is about to be written for the first time:
A copy of this page is made onto an unused page.
The current page table is then made to point to the copy
The update is performed on the copy
123
Shadow Paging cont’d…
Howdoes Shadow Paging recover transaction when failure occurs?
To recover from a failure during transaction execution,
It is sufficient to free the modified database pages and to discard the current
directory.
The state of the database before transaction execution is available through the
shadow directory (BFIM) and that state is recovered by reinstating the shadow
directory.
125
126.
Shadow Paging cont’d…
The database is returned to its state prior to the transaction that was executing
when the crash occurred and any modified pages are discarded.
Committing a transaction corresponds to discarding the previous shadow
directory.
Shadow paging is categorized as a NO UNDO/ NO-REDO technique for
recovery.
126