Download as PDF, PPTX





























































The document discusses building large-scale streaming infrastructure across multiple data centers using Apache Kafka. It outlines the reasons for multi-data center architecture, design patterns, and the trade-offs between latency and consistency. Various options for data replication and management are presented, including active-active and active-passive replication strategies.
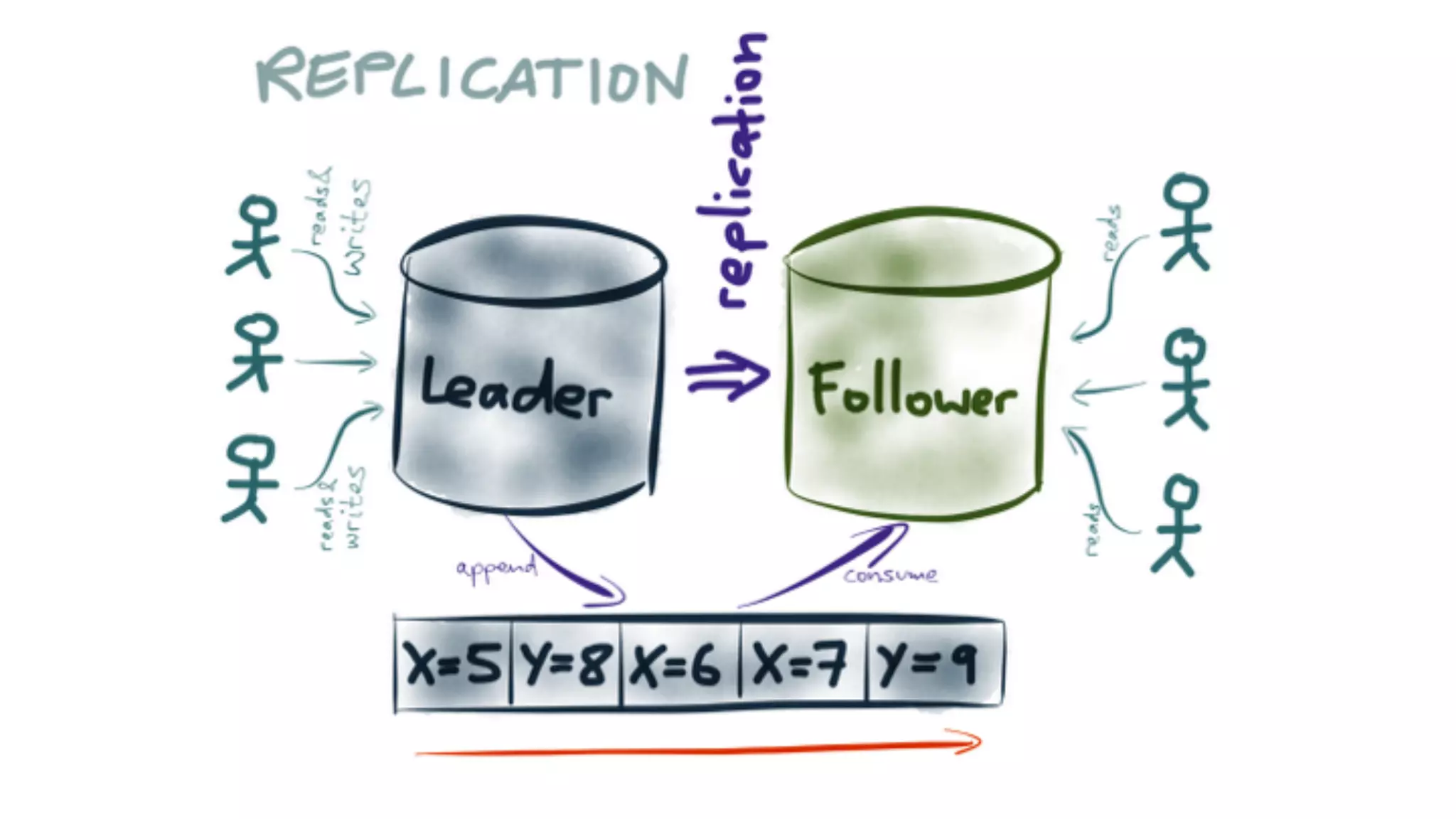
This section discusses the necessity of multi-data center setups due to failures and geo-locality, along with challenges like bandwidth, latency, and consistency.
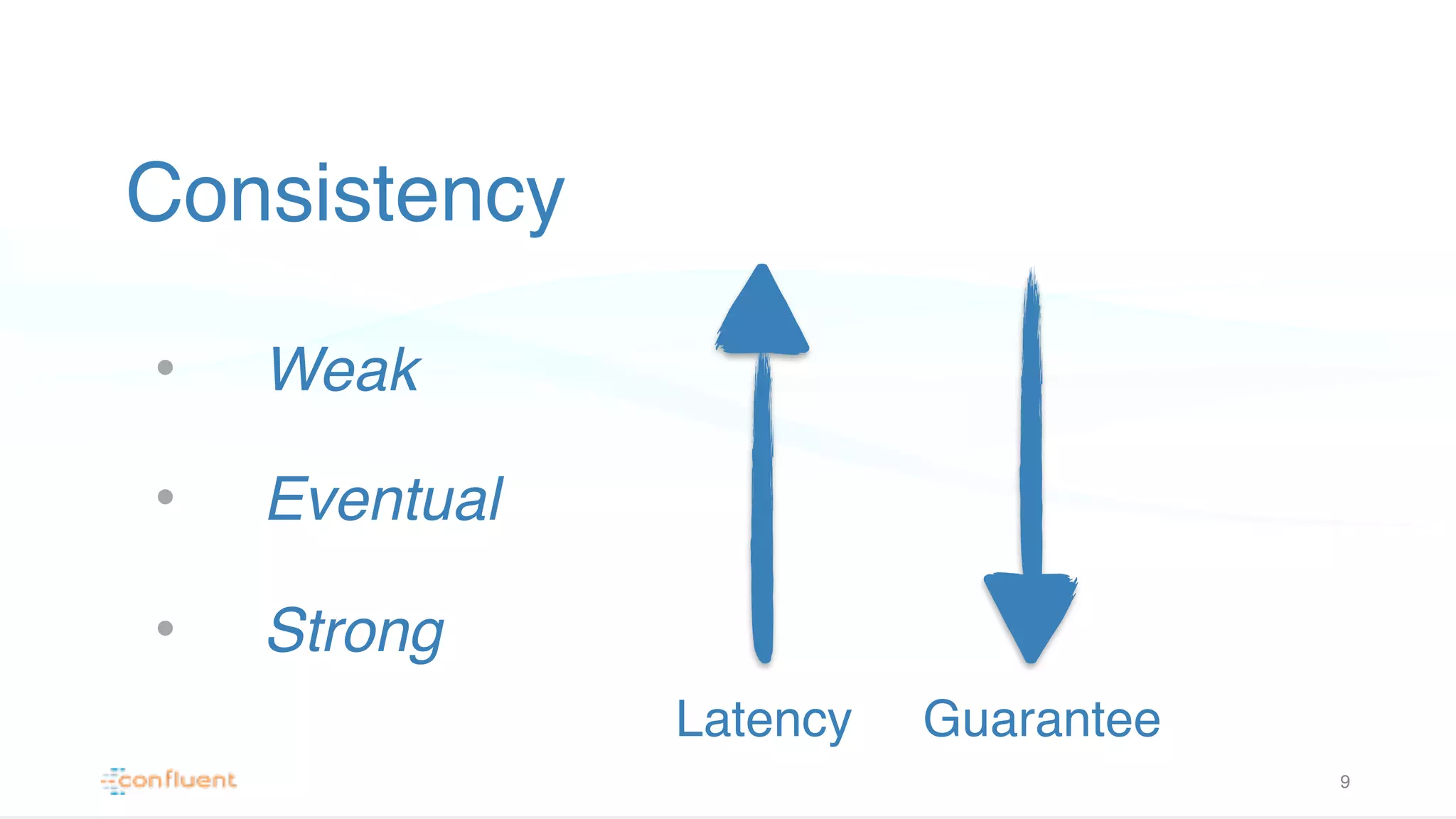
Explores different consistency models: Weak, Eventual, and Strong consistency with examples, stressing their implications for data integrity in distributed systems.
Examines the trade-offs between consistency and latency in WAN vs. LAN environments, setting the stage for the architecture design topics ahead.
Describes various strategies for data center deployment including Bunkerizing, Primary with Hot Standby, and Active-Active configurations to address failures.
Emphasizes the crucial role of ordering in distributed systems and introduces methods like vector clocks and Paxos for effective ordering.
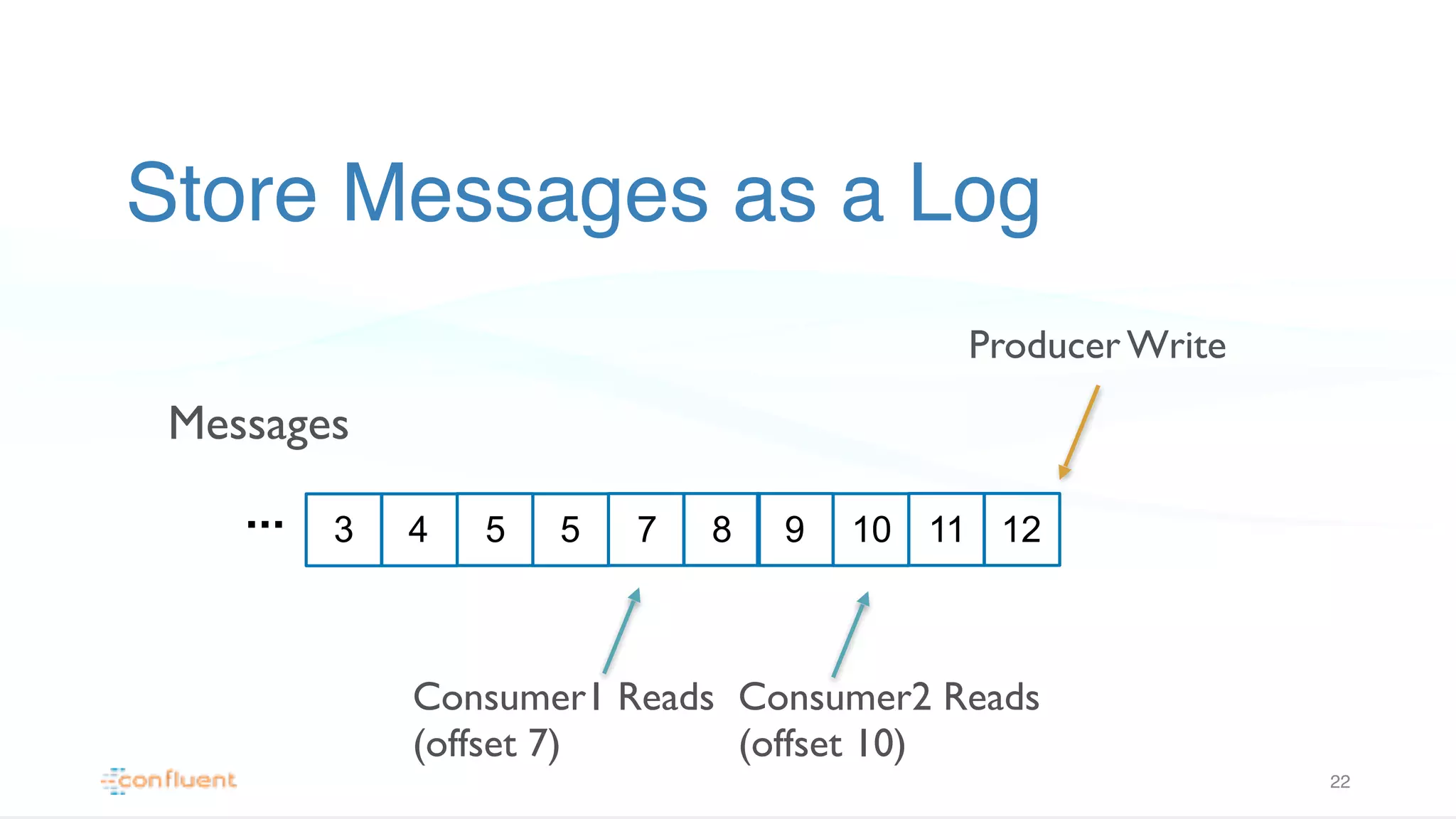
Introduces Apache Kafka as a distributed messaging system that operates on a log-based message storage mechanism for efficient data handling.
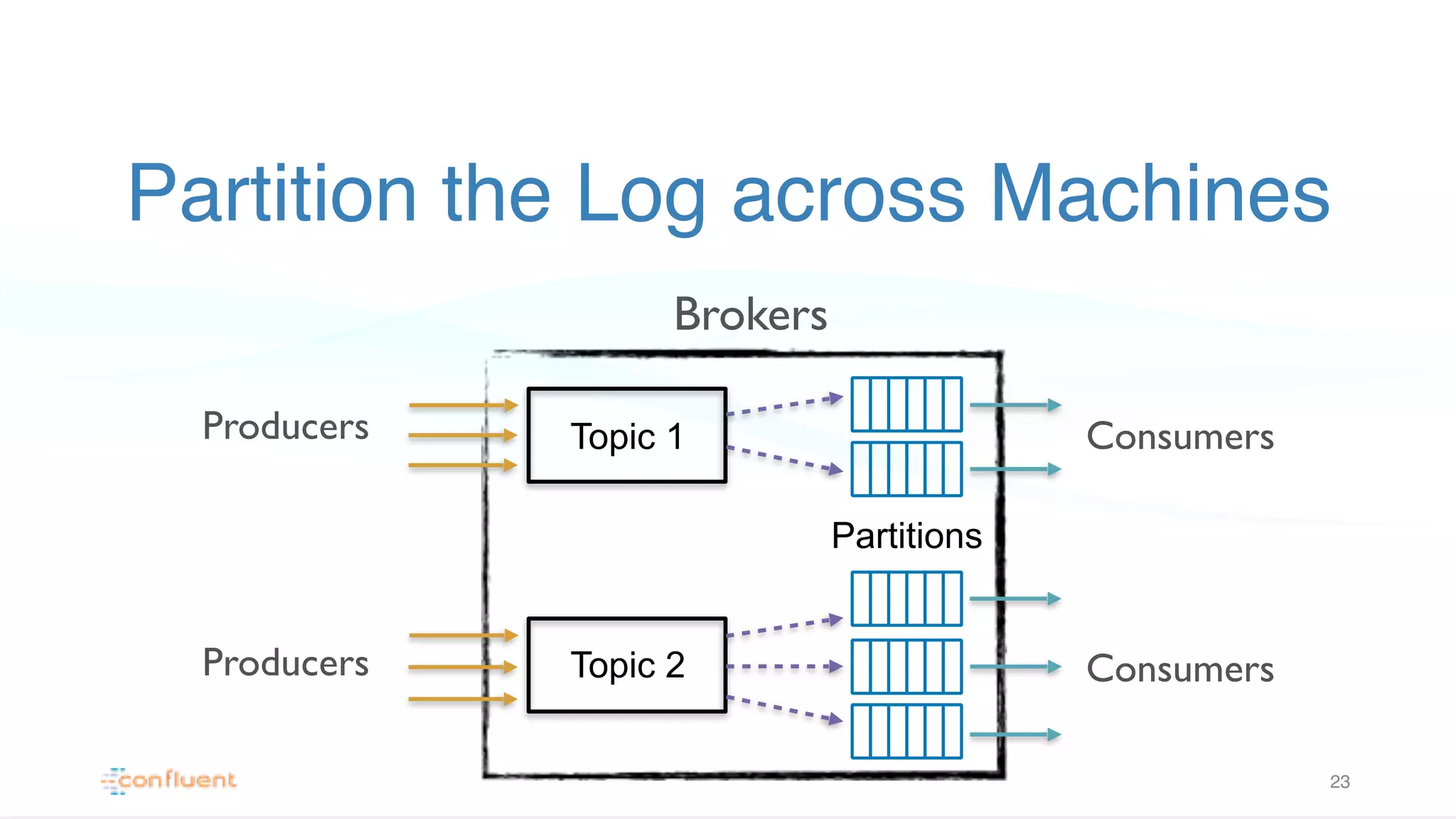
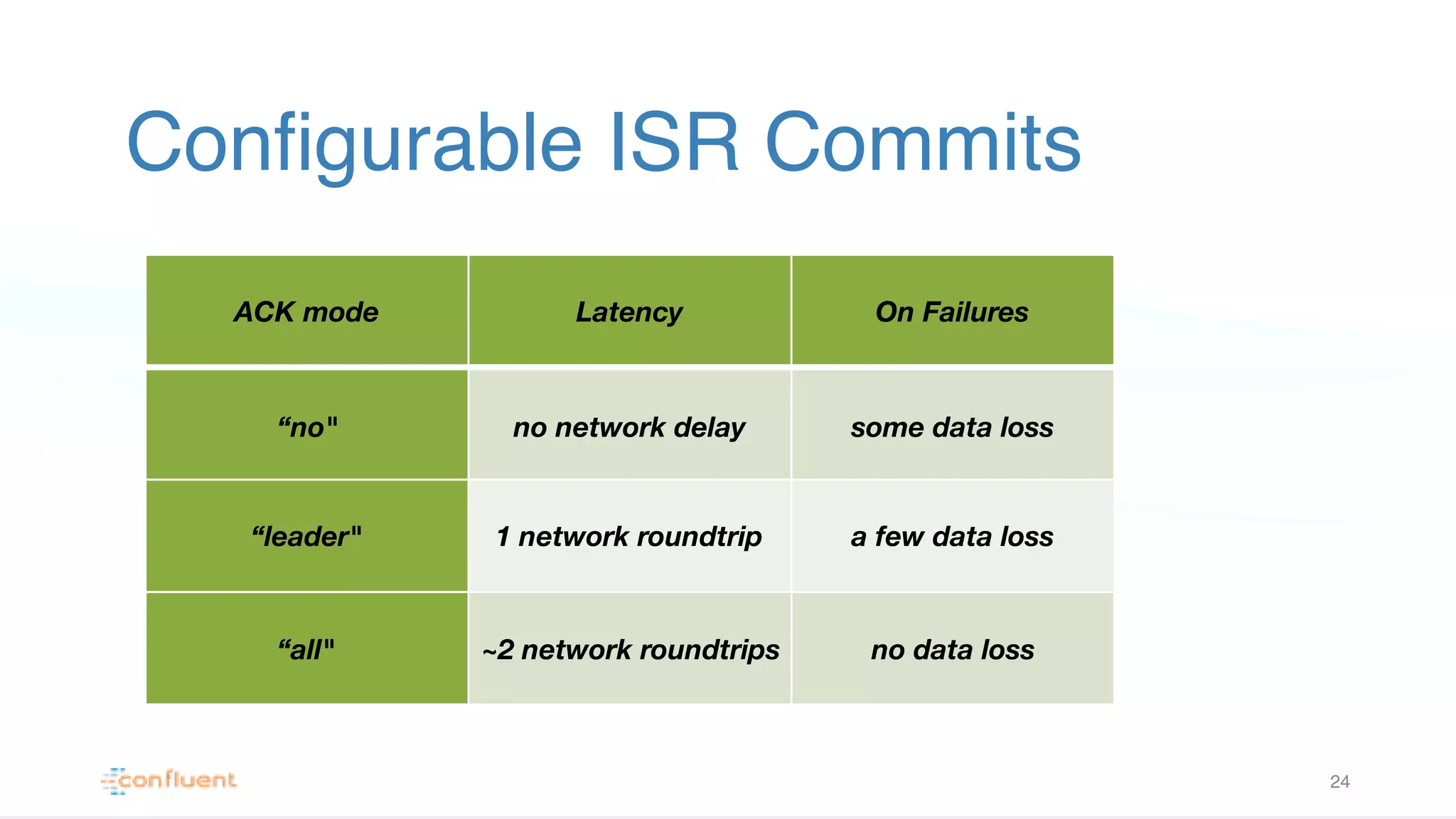
Discusses how Kafka partitions logs across various machines, enhancing performance with configurable acknowledgment modes to handle failures.
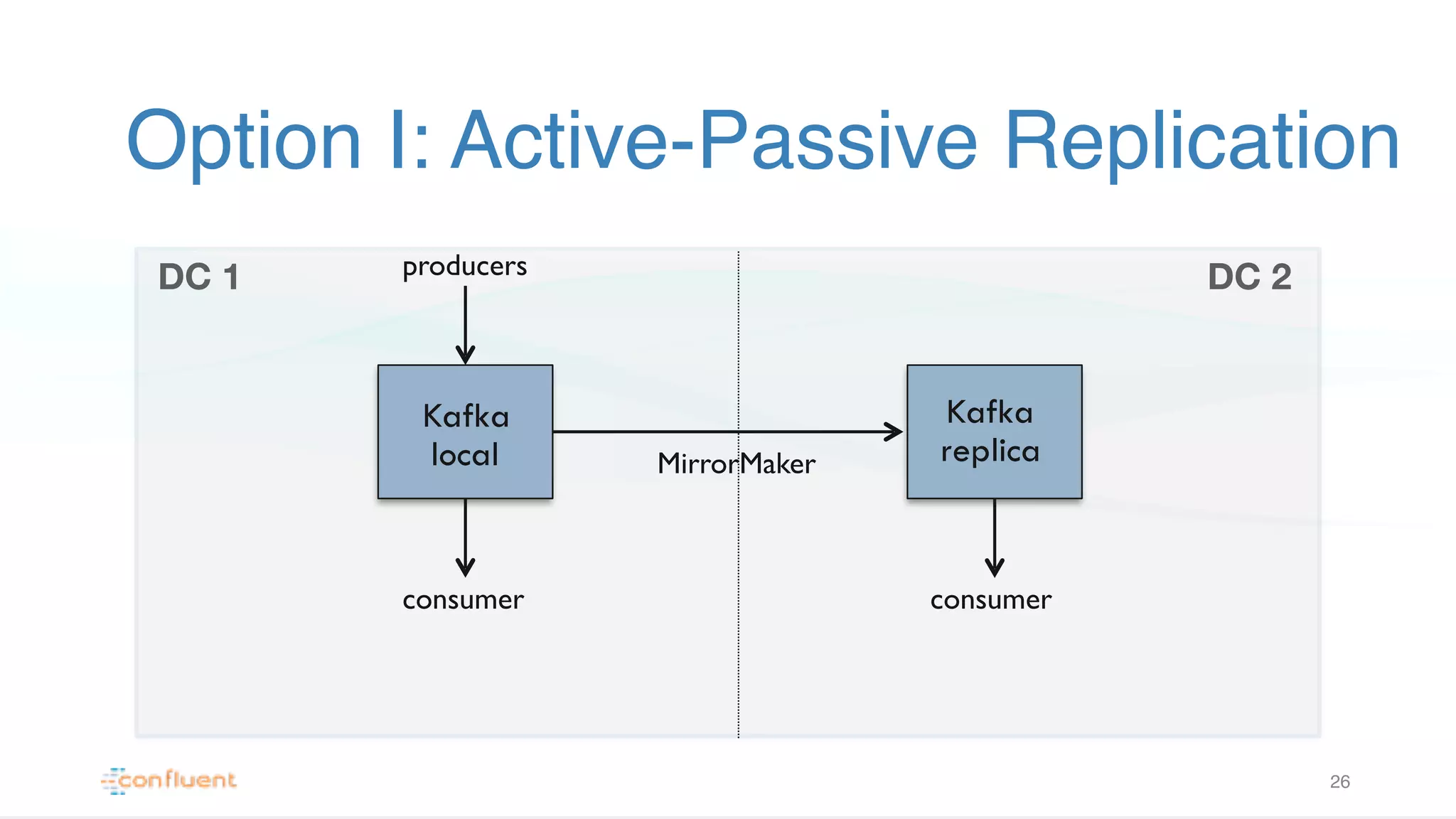
Details the Active-Passive replication method in Kafka, its use for asynchronous data replication, and trade-offs including potential data loss.
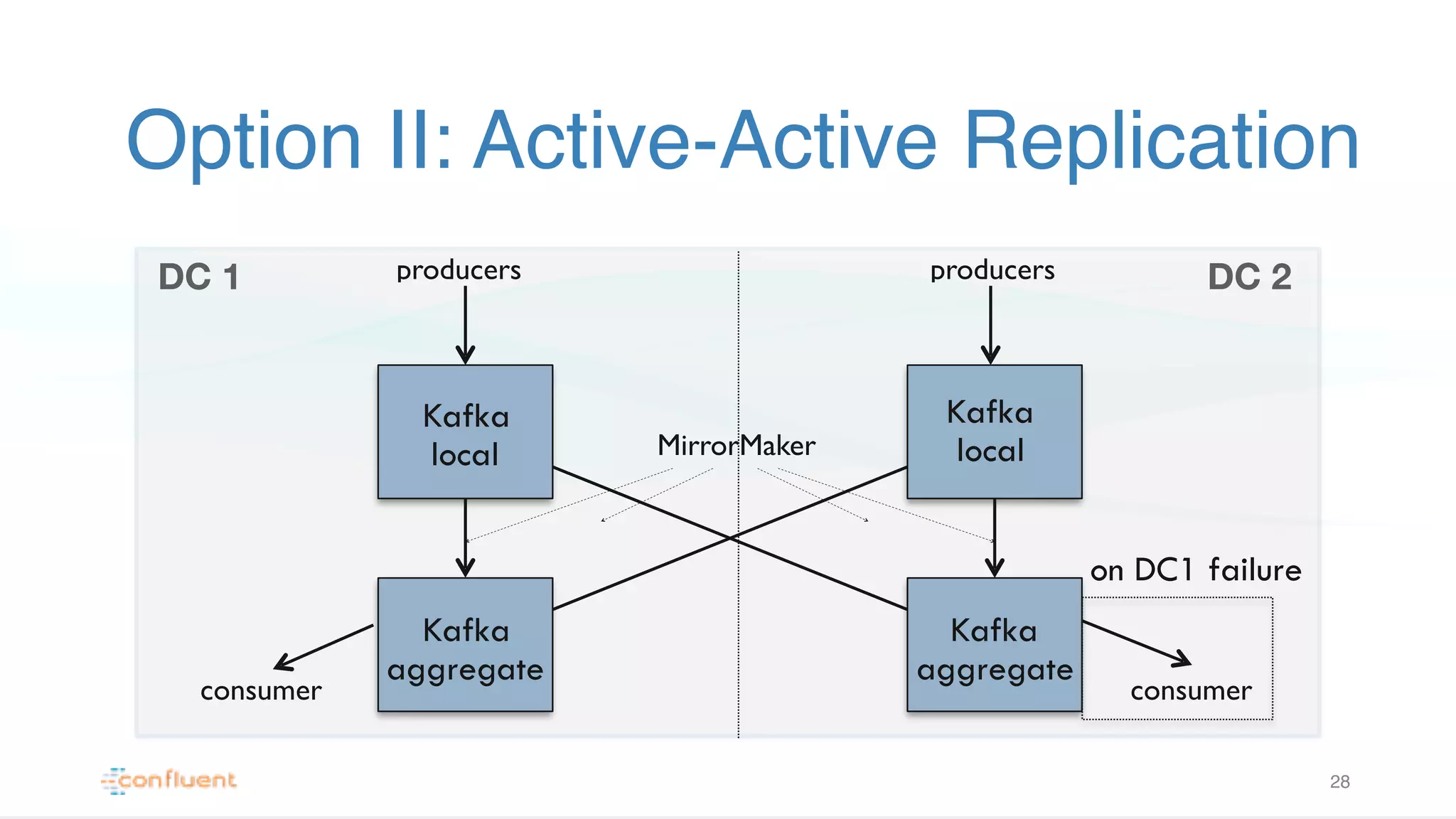
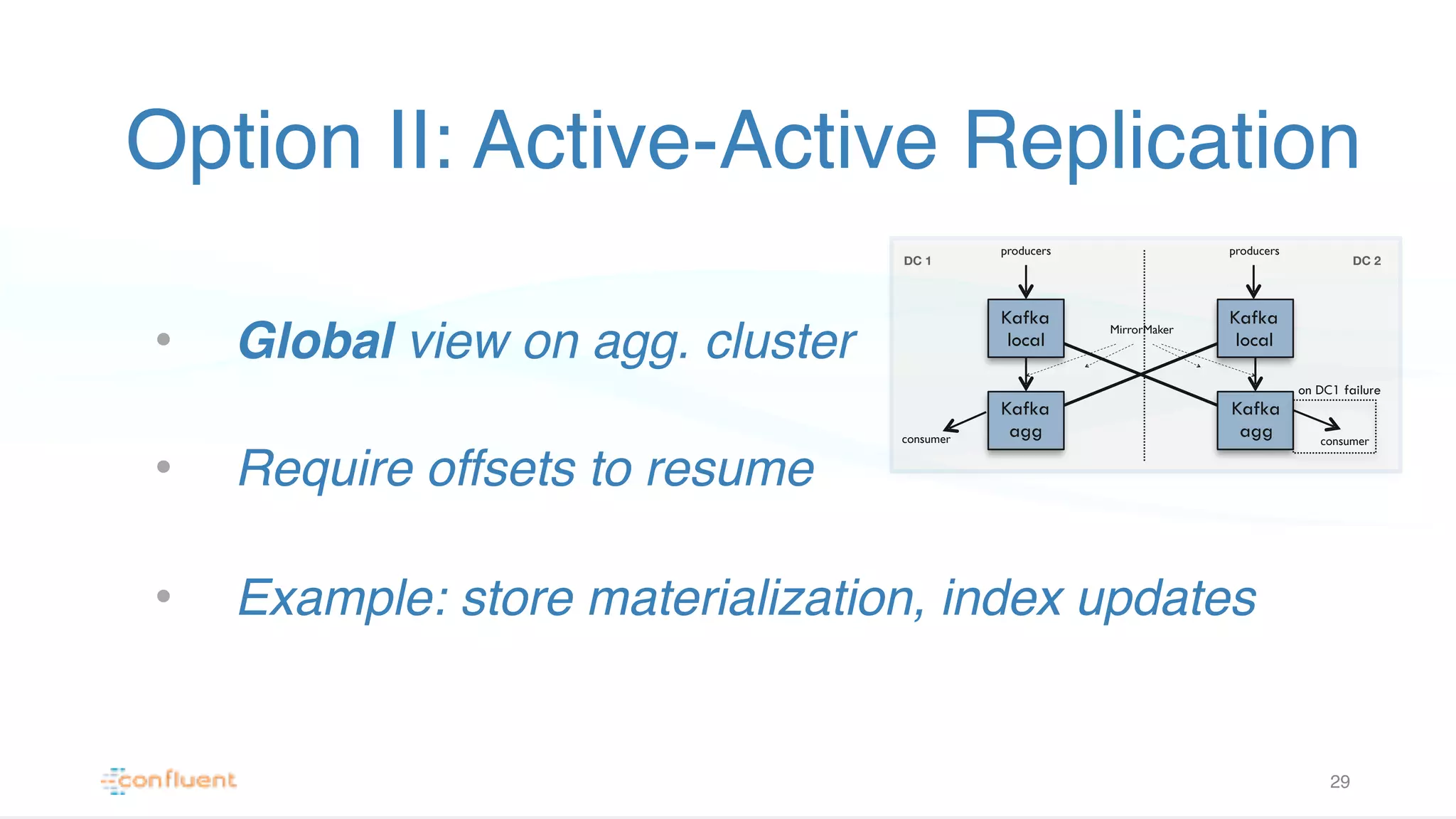
Explains Active-Active replication in Kafka with a focus on global view maintenance and challenges during failovers with examples.
Addresses challenges of deploying Kafka across data centers, including differences in offsets, potential duplicates, and solutions for real-time applications.
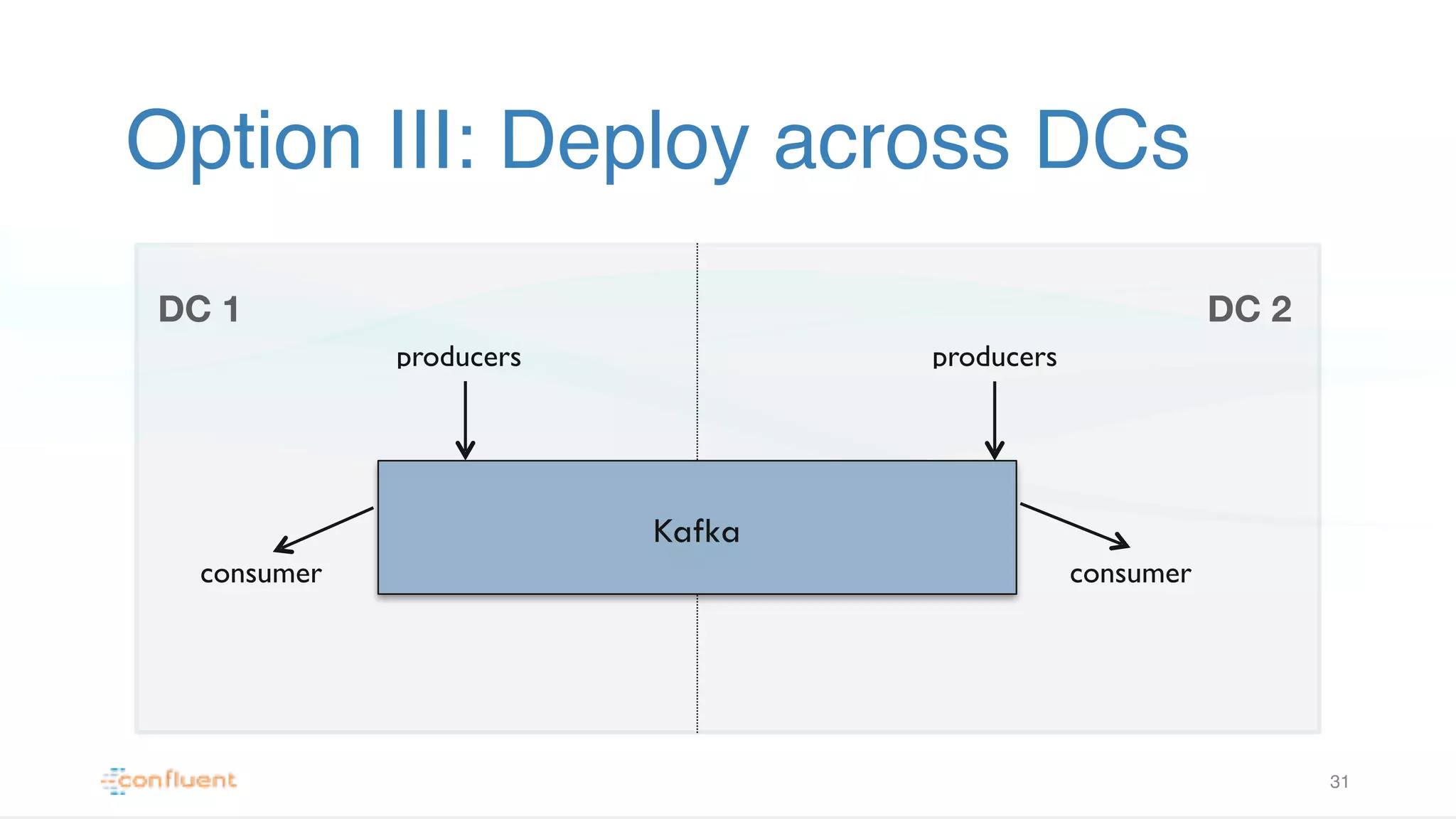
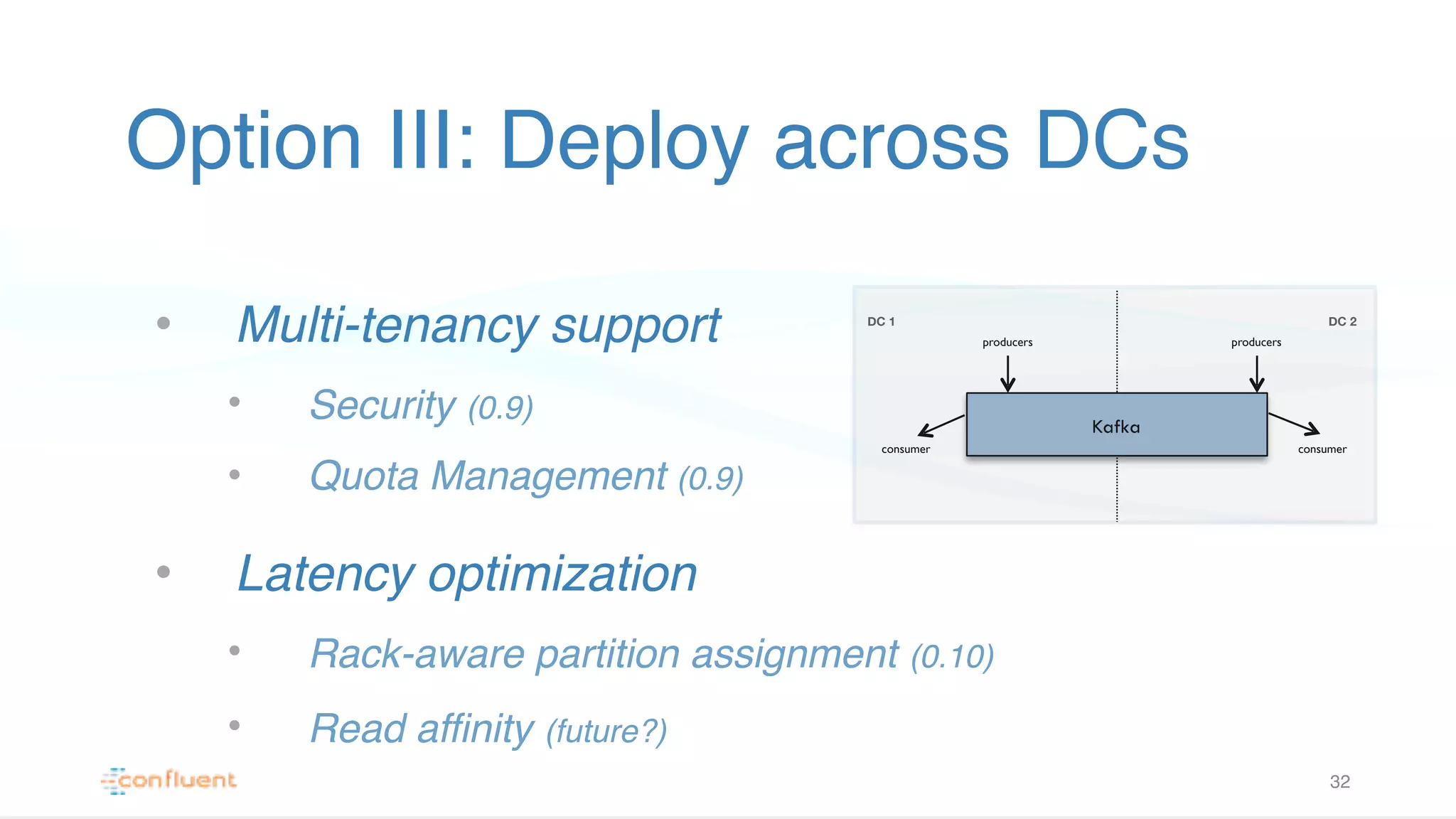
Illustrates strategies for deploying Kafka in multiple data centers, focusing on multi-tenancy, security, and optimized latency.
Provides an example of EC2 multi-AZ deployment addressing considerations like latency, Zookeeper needs, and maintaining data integrity.
Wraps up the discussion with key takeaways about multi-DC trade-offs, inviting attendees to engage with Confluent for further learning.

















































































