

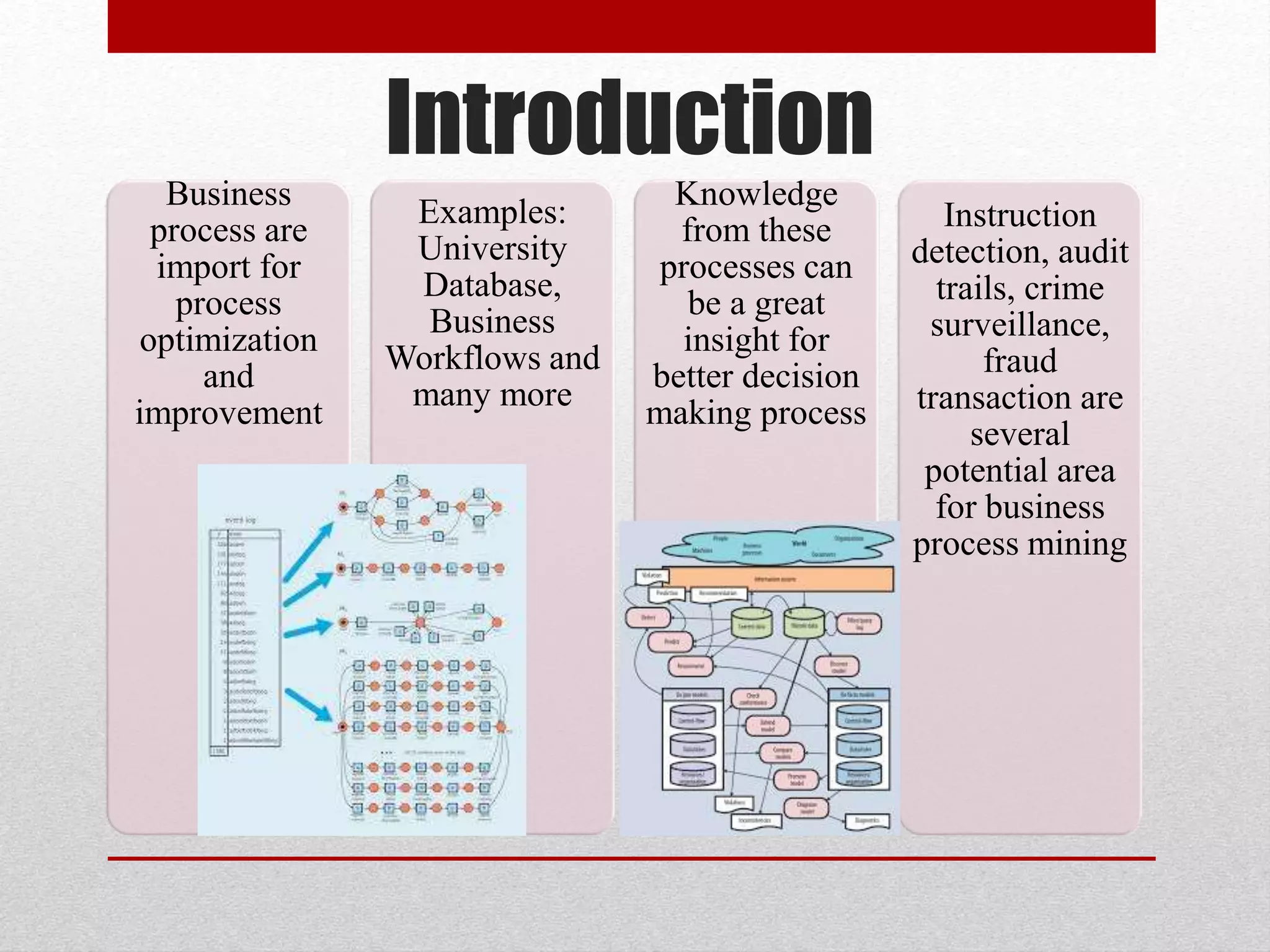

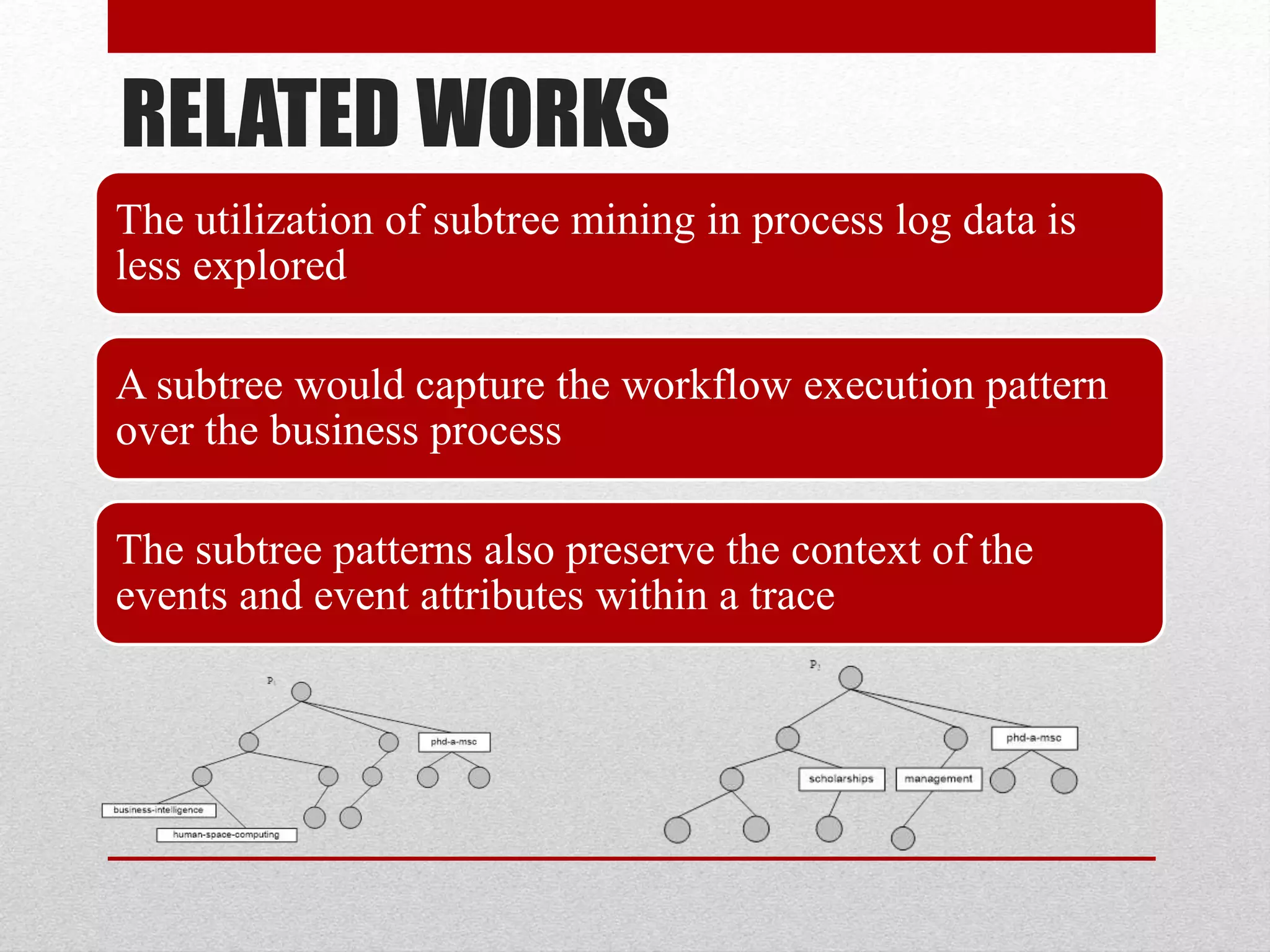
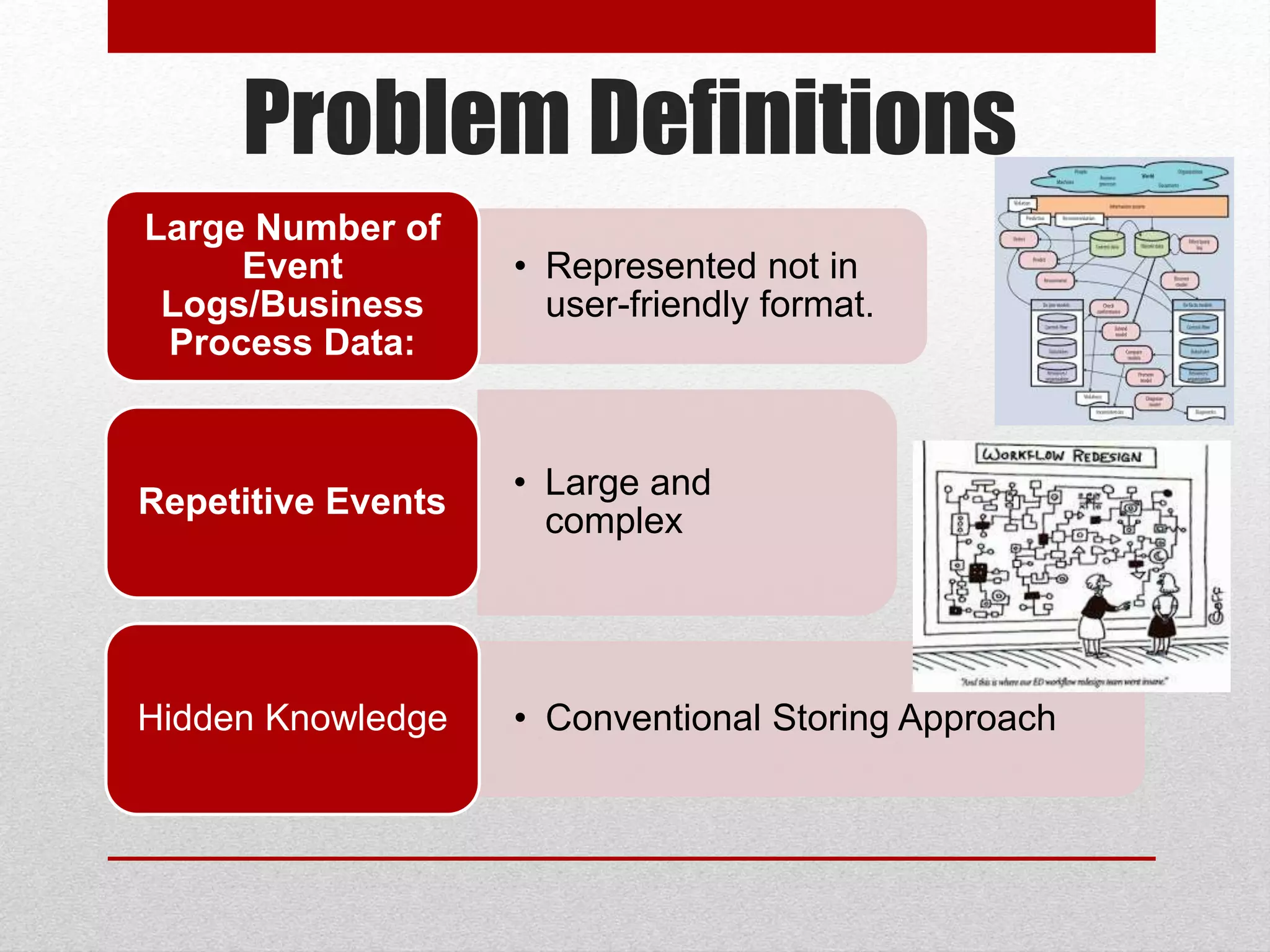


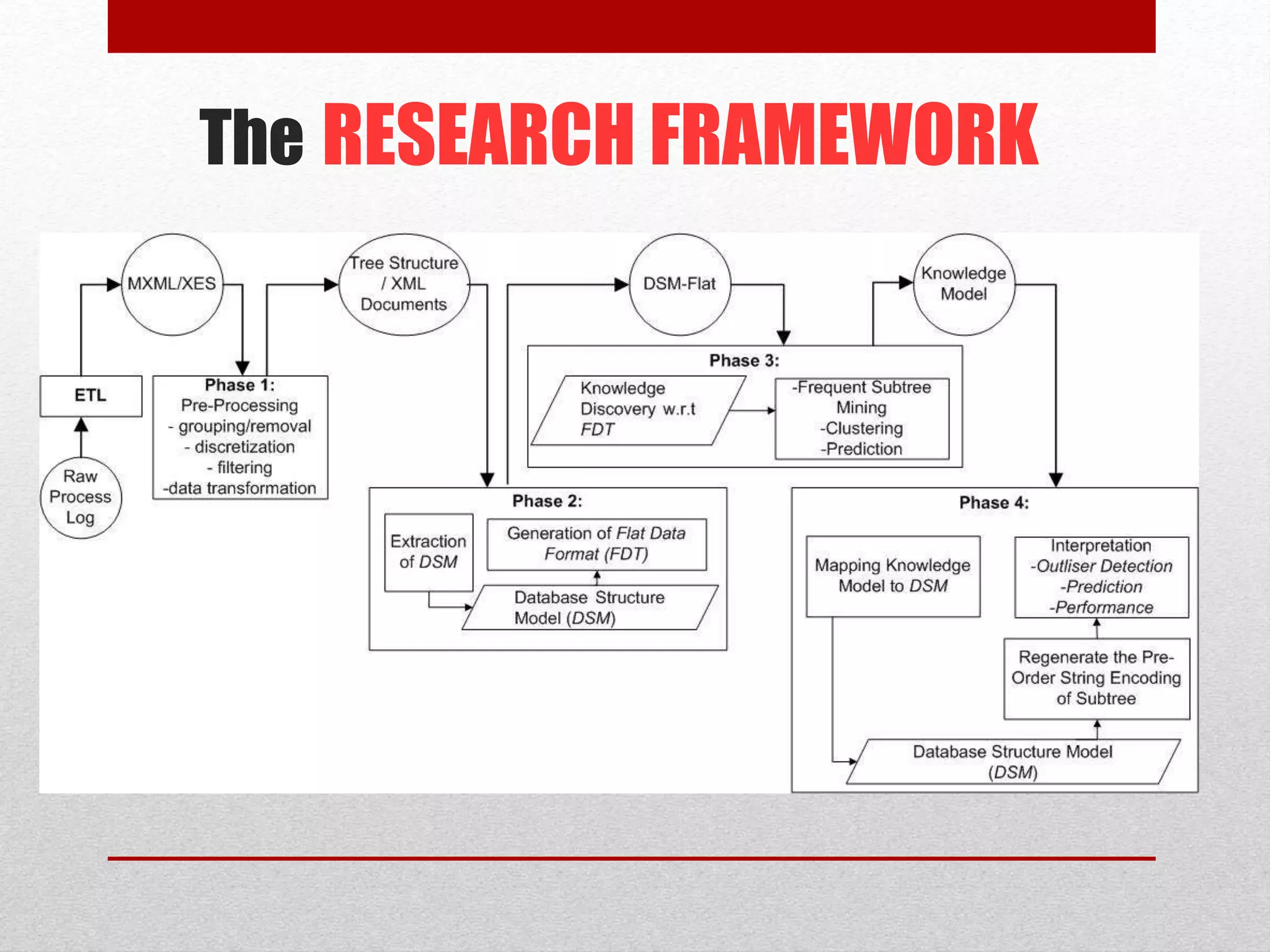



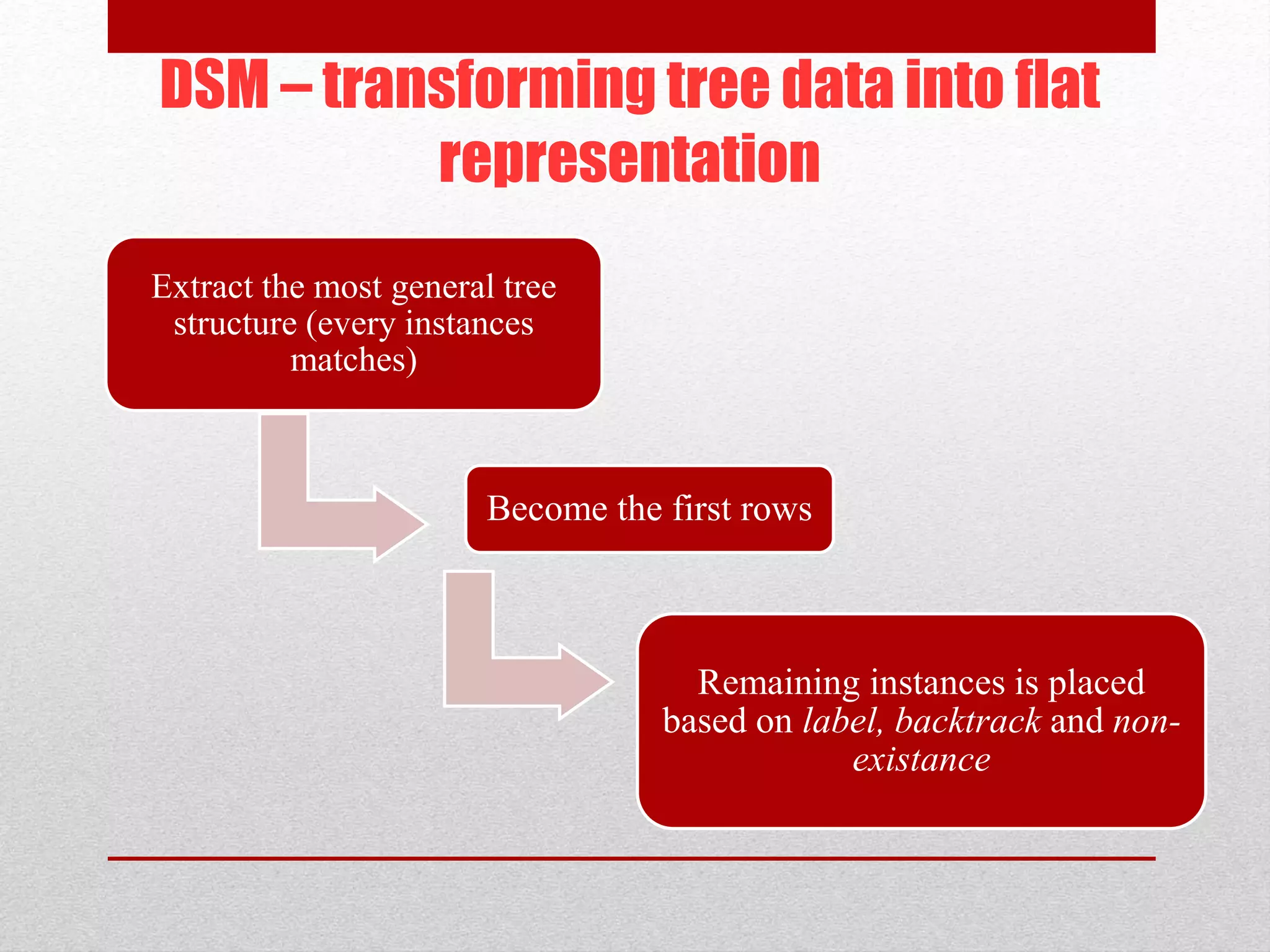

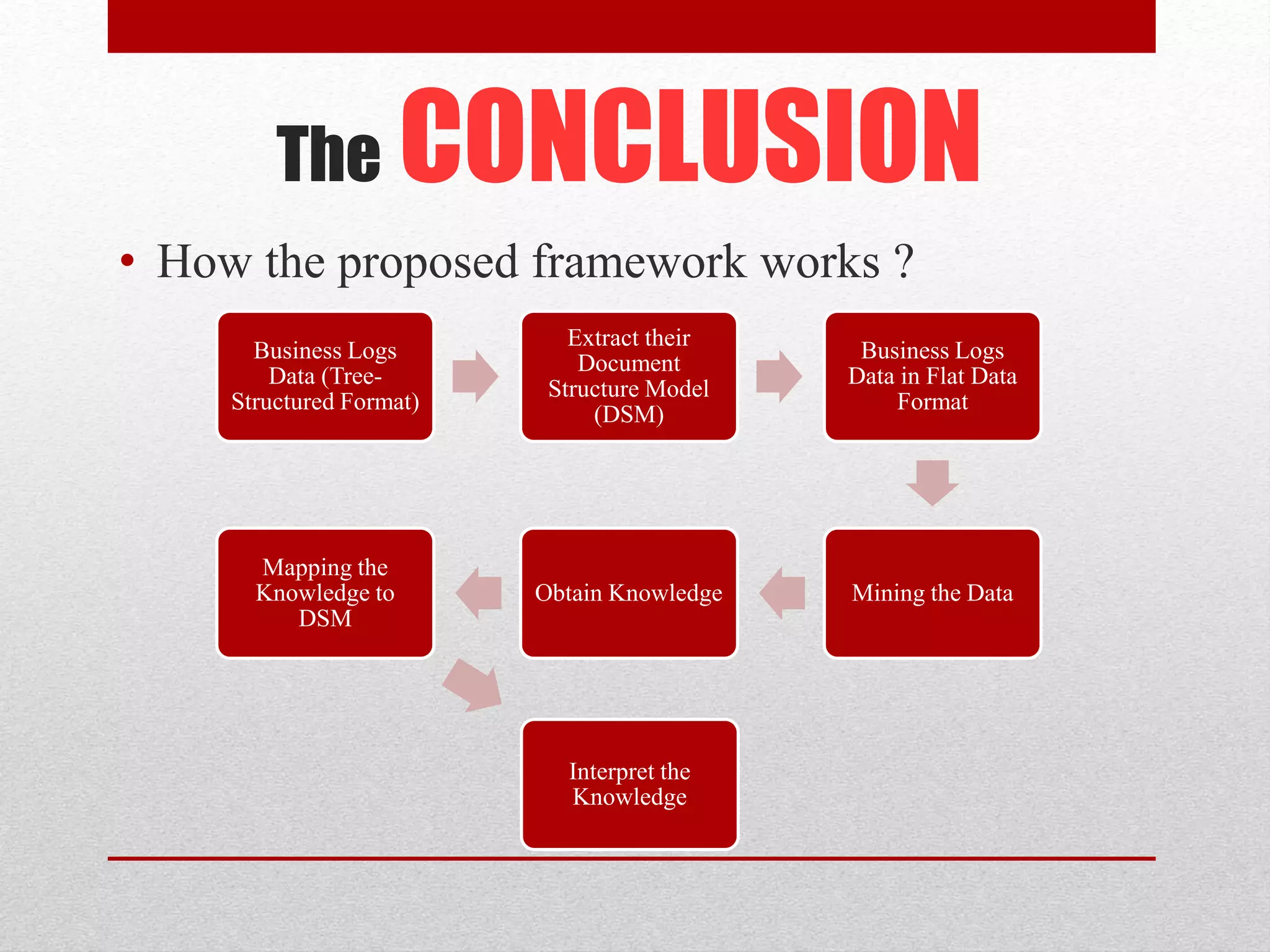



















This paper proposes an improved framework for analyzing tree-structured business process logs through data mining. The framework consists of four phases: pre-processing of raw process data, extraction of a Document Structure Model (DSM) to transform the tree data into a flat table format, knowledge discovery on the flat data table through techniques like frequent subtree mining, and interpretation of the discovered knowledge by mapping it back to the DSM. The framework aims to address challenges of large and complex business process logs typically stored in XML format by facilitating advanced data mining and knowledge extraction to optimize processes.



















![[IJET-V1I4P3] Authors :Mekhala](https://cdn.slidesharecdn.com/ss_thumbnails/ijet-v1i4p3-150728160211-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)


























![SHS_Core_CAE_Q3_LE1 FOR THIRD [FINAL].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/shscorecaeq3le1final-251116055110-e3081055-thumbnail.jpg?width=640&height=640&fit=bounds)

















