









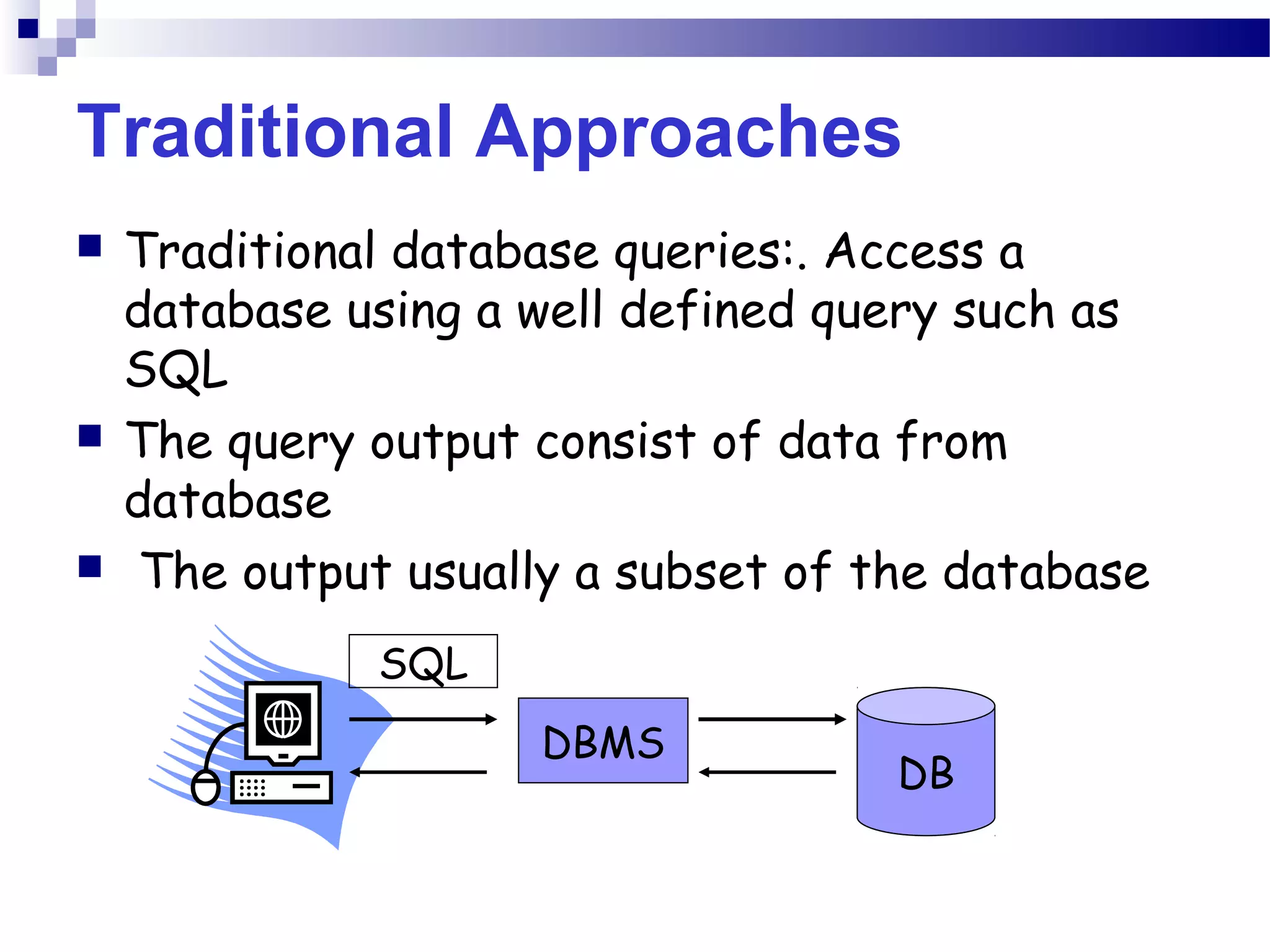
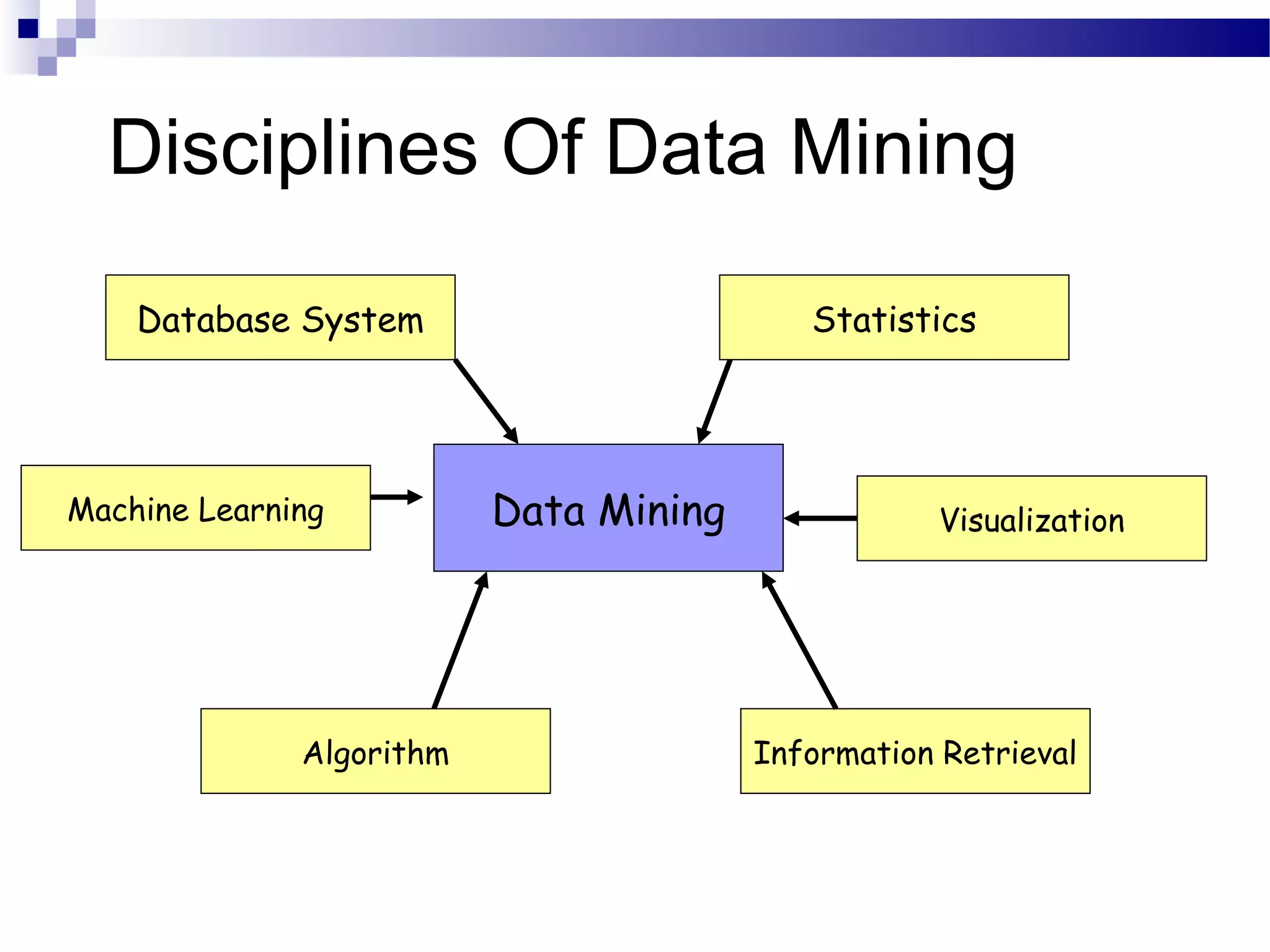
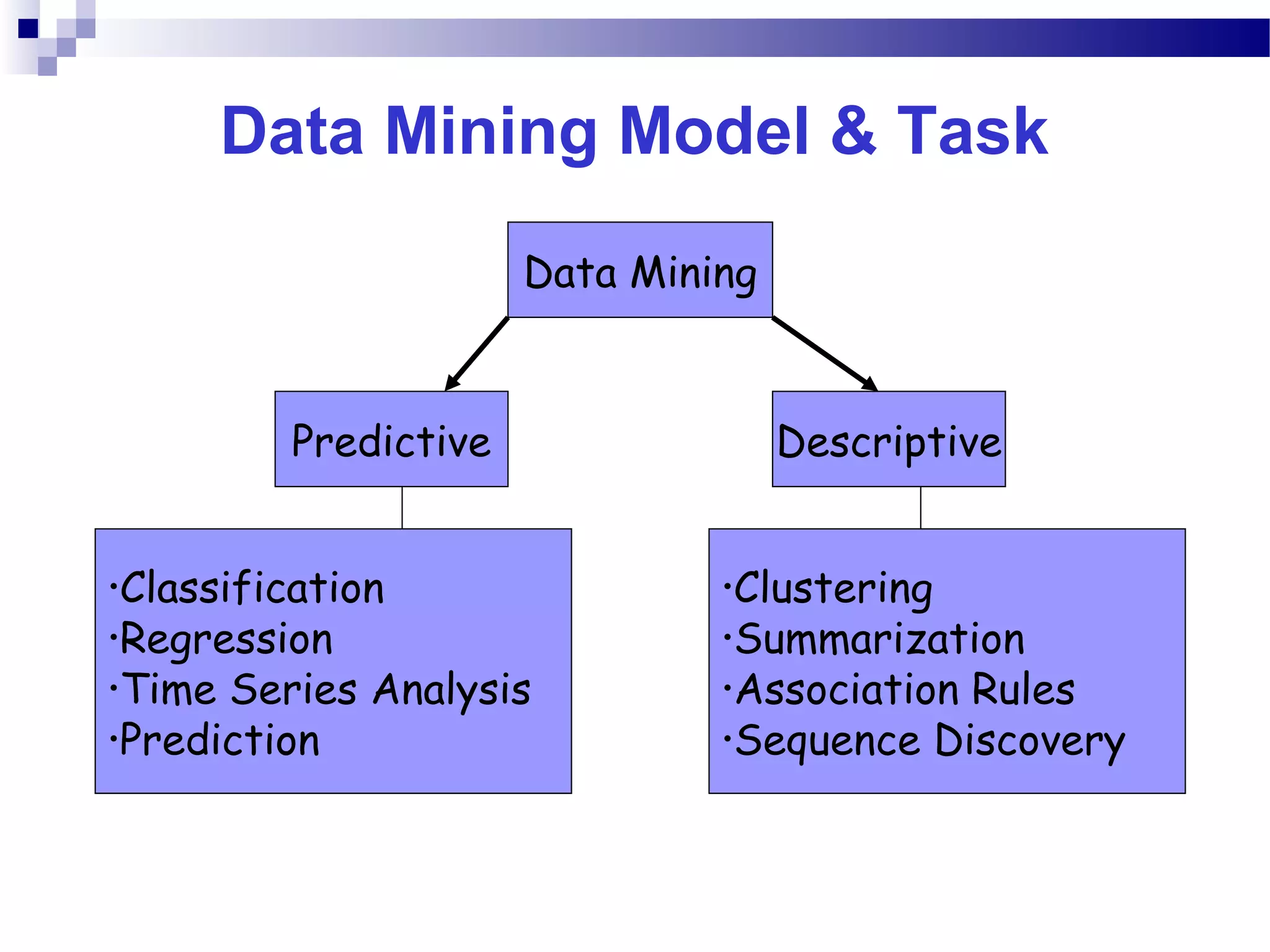



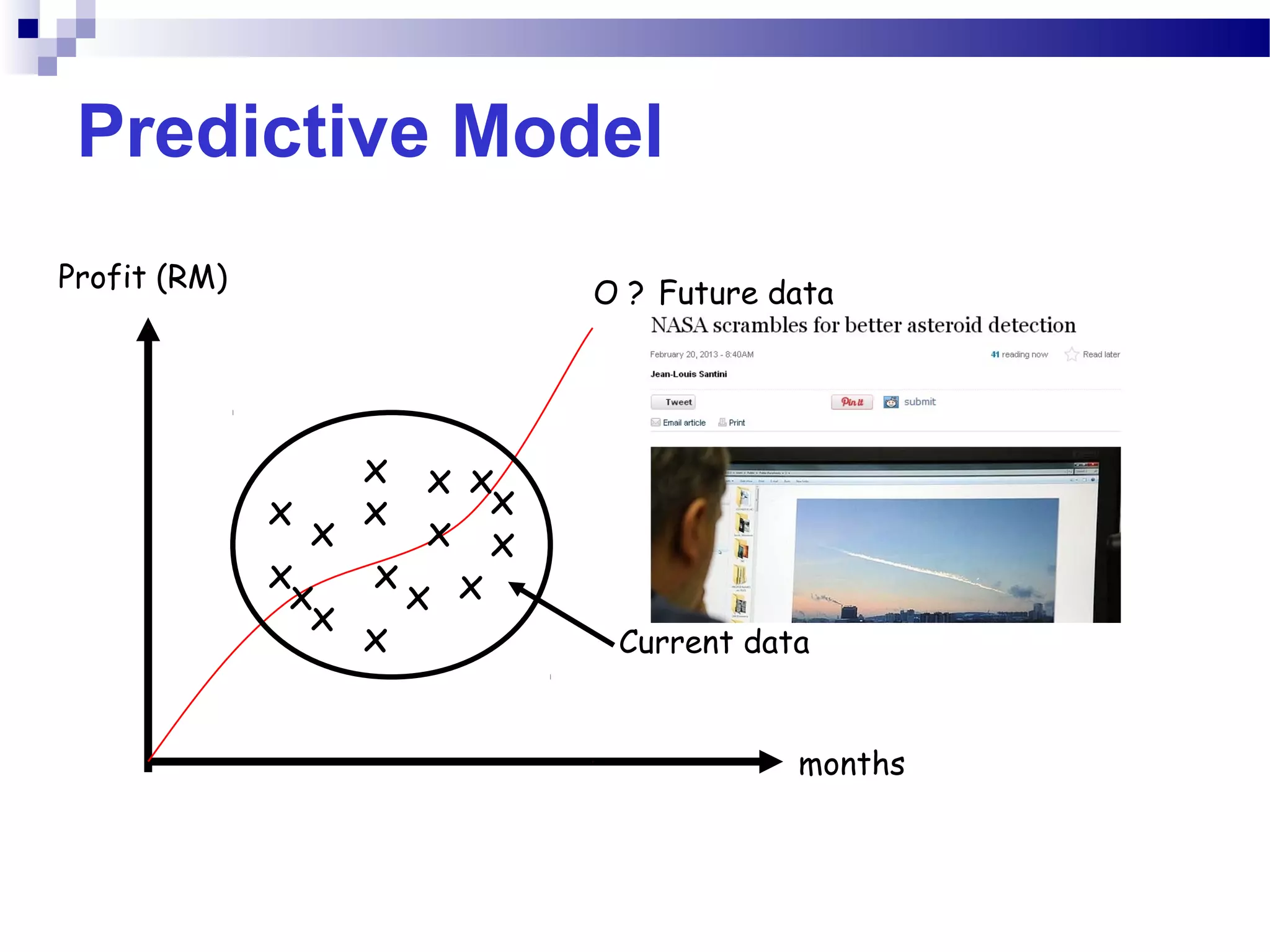


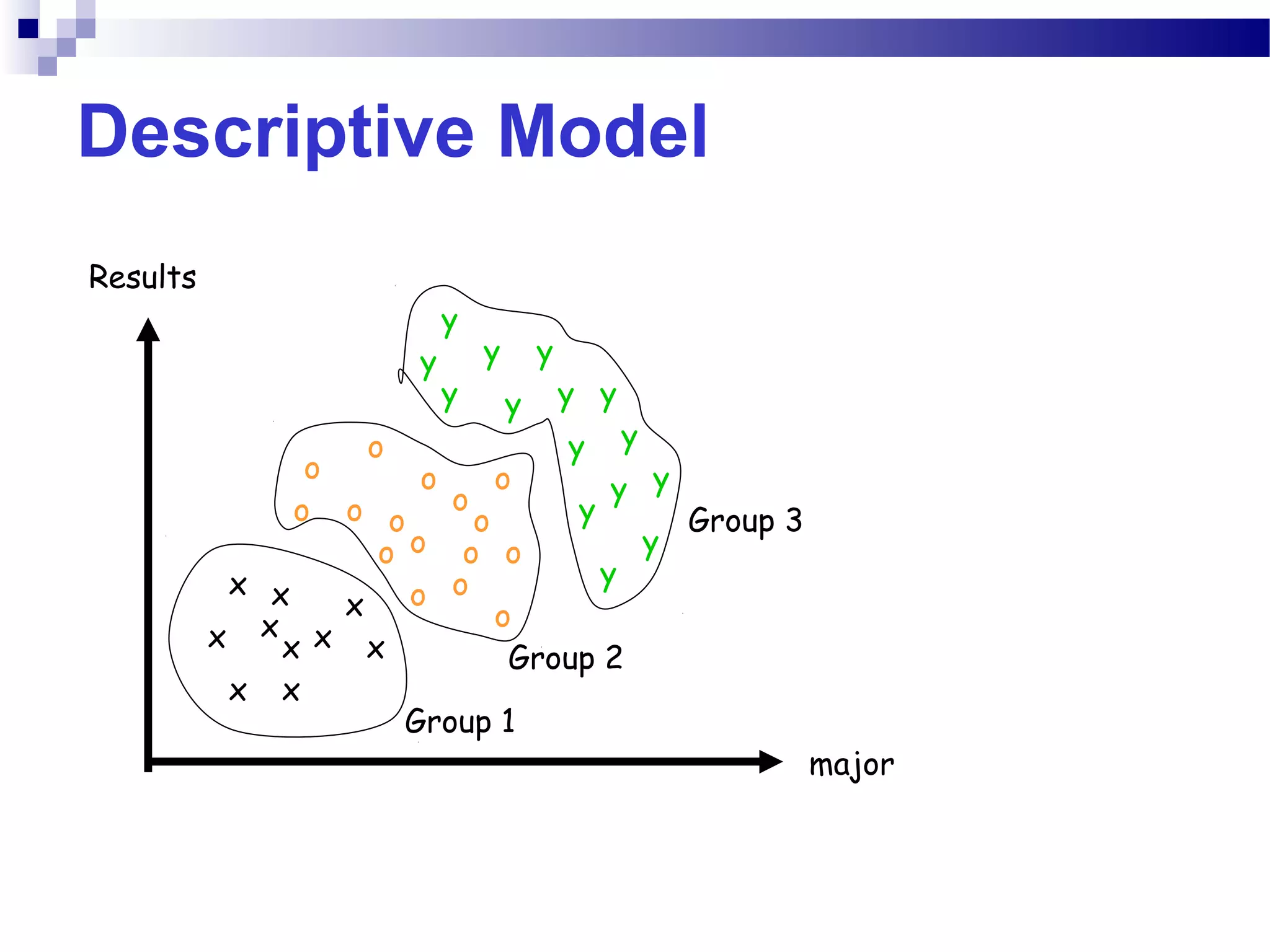






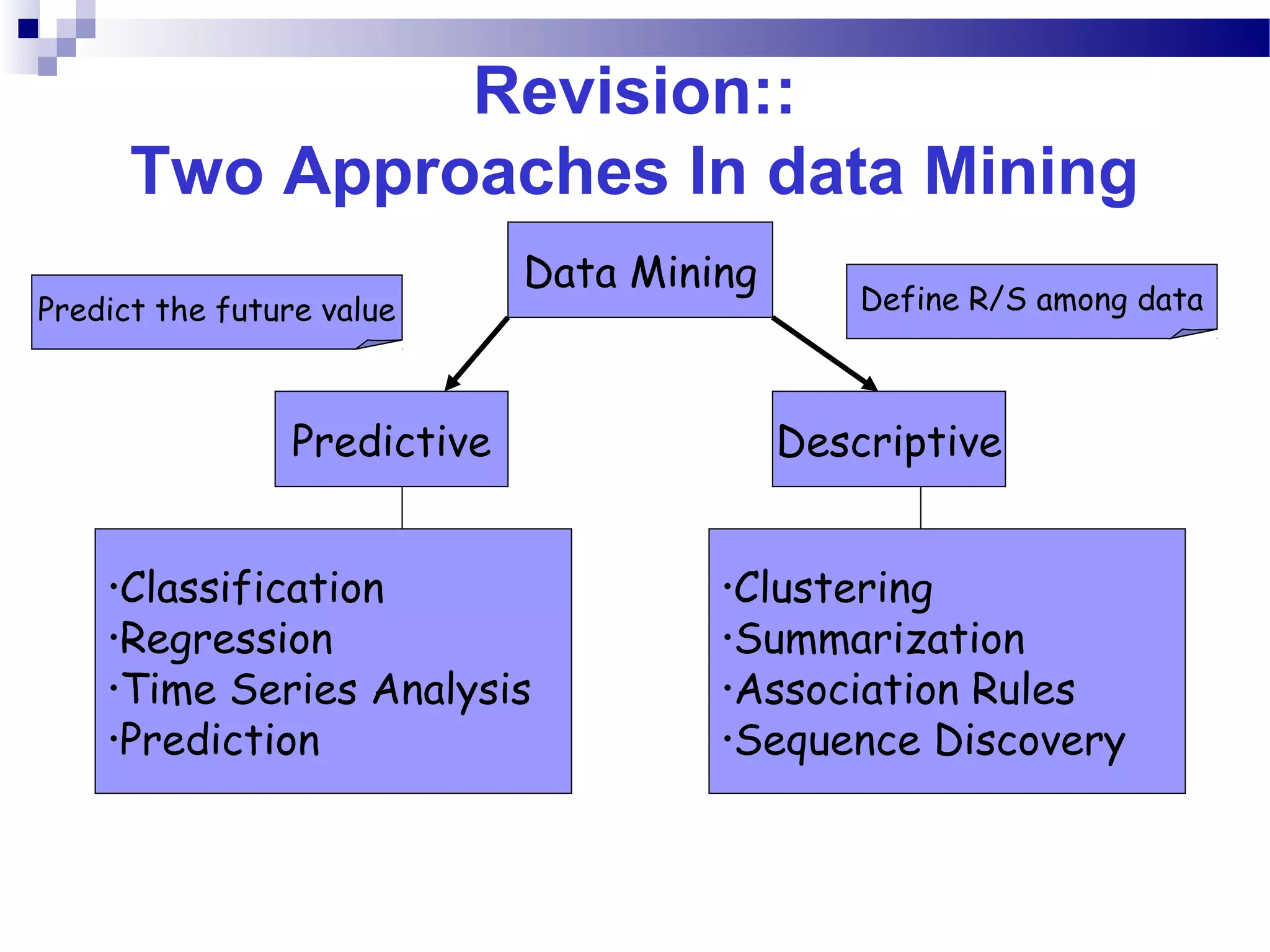
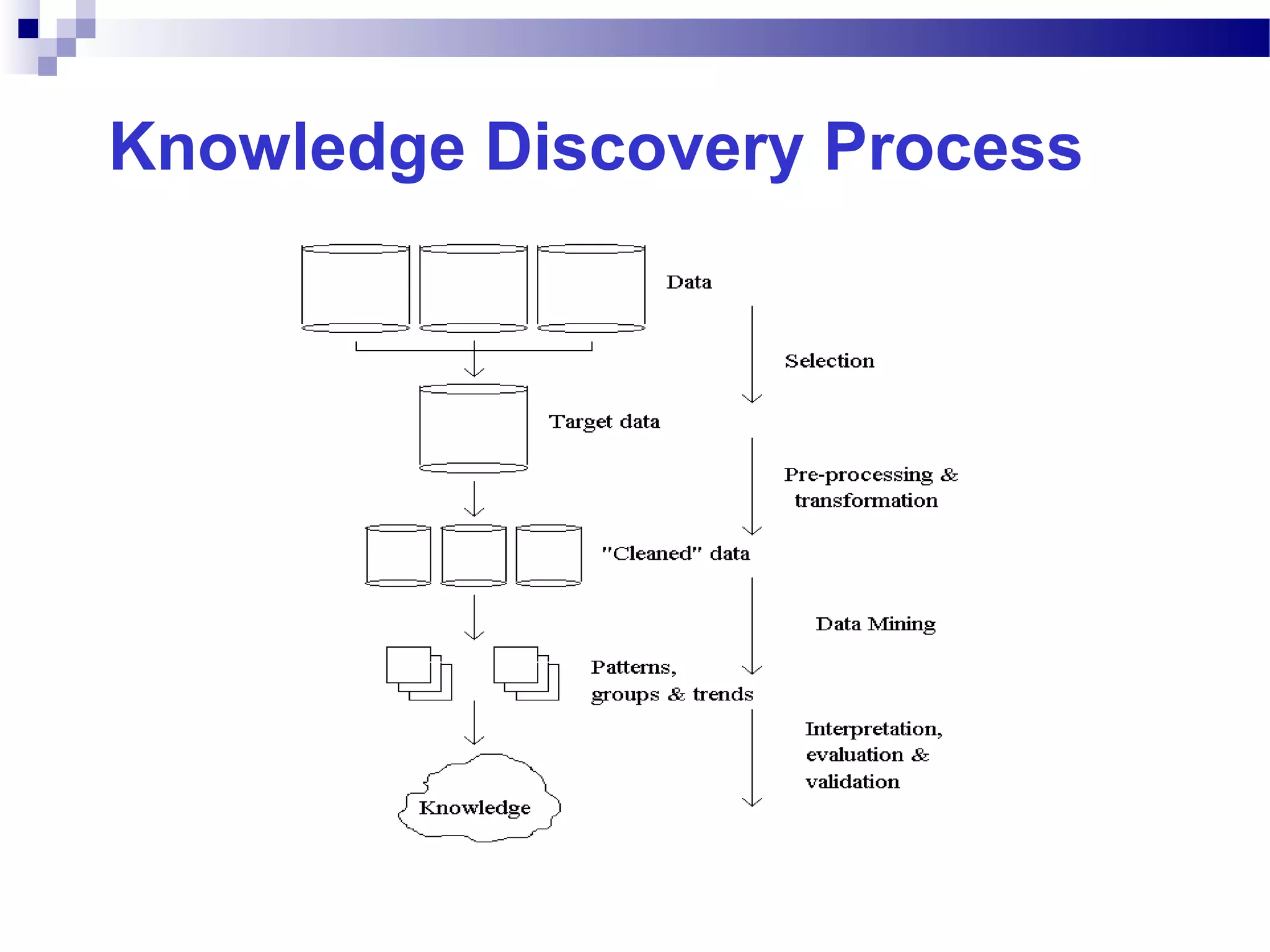
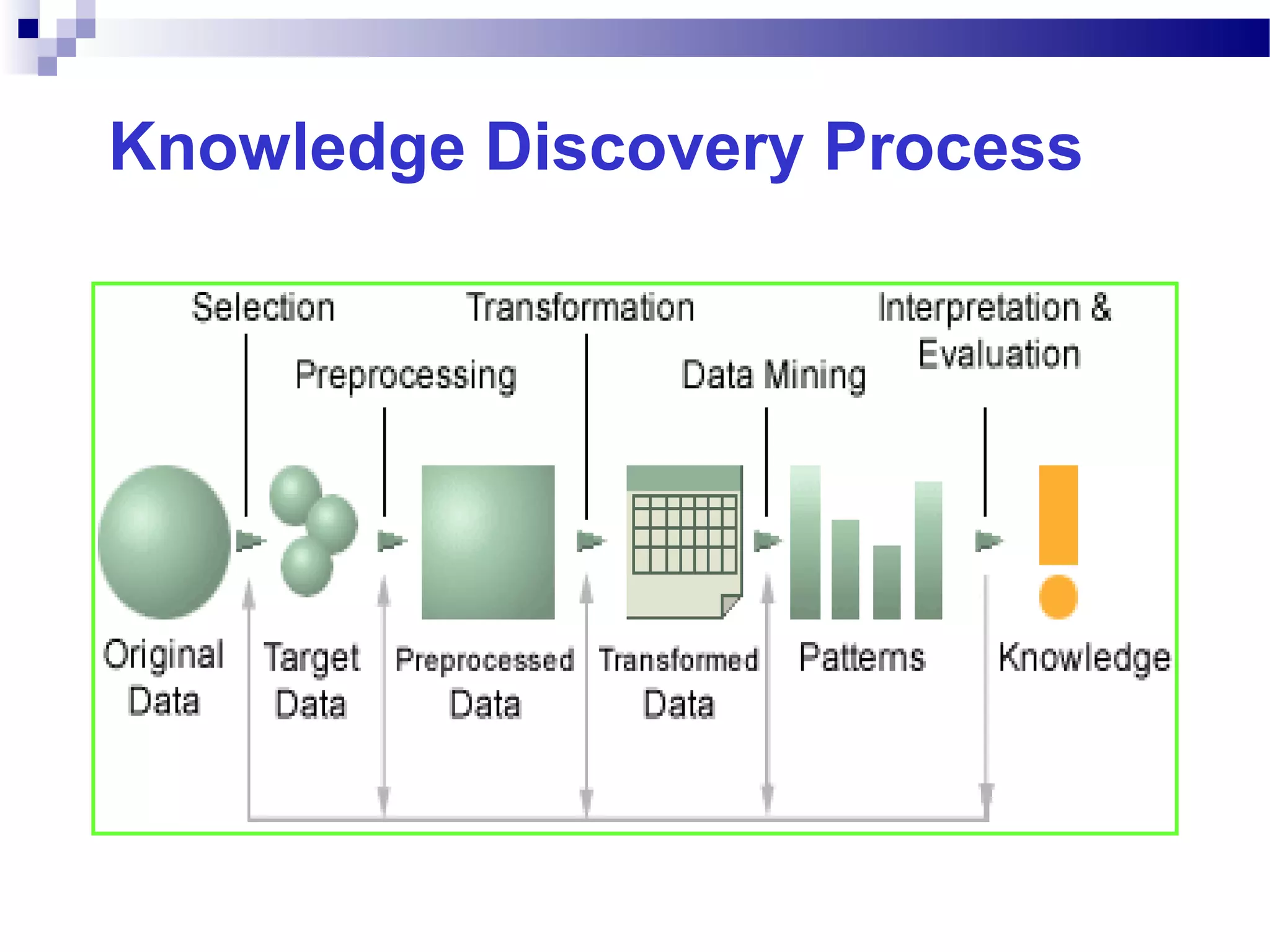





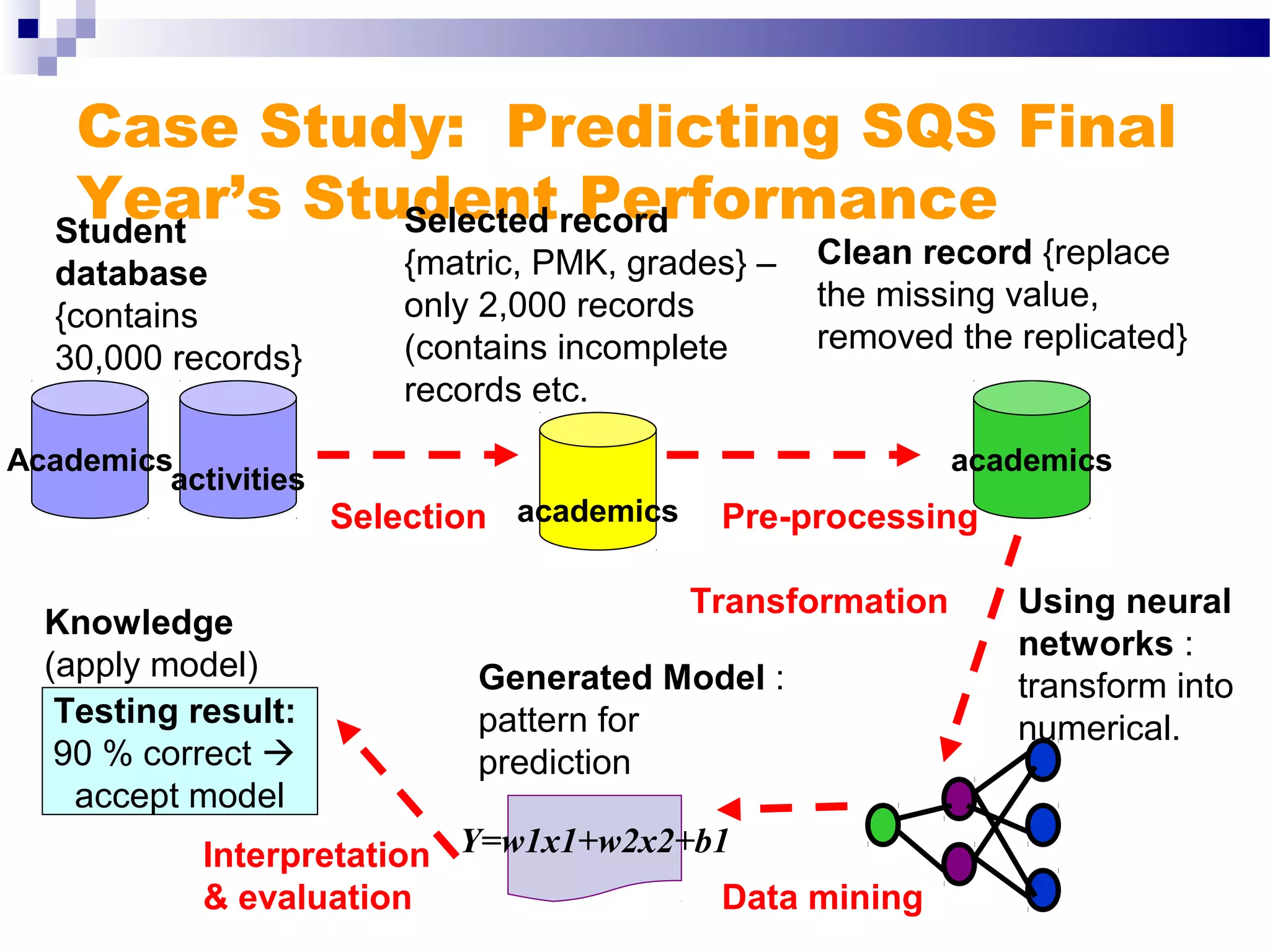








































This document outlines the objectives, content, evaluation, and prerequisites for a course on Knowledge Acquisition in Decision Making, which introduces students to data mining techniques and how to apply them to solve business problems using SAS Enterprise Miner and WEKA. The course covers topics such as data preprocessing, predictive modeling with decision trees and neural networks, descriptive modeling with clustering and association rules, and a project presentation. Students will be evaluated based on assignments, case studies, a project, quizzes, class participation, and a final exam.









































































