AI for Program Specifications UW PLSE 2025 - final.pdf
1.
AI for ProgramSpecifications
Shuvendu Lahiri
Research in Software Engineering (RiSE),
Microsoft Research
1
Collaborators: Sarah Fakhoury, Saikat Chakraborty, Markus Kuppe, Shan Lu, Tahina Ramananandro, Nikhil Swamy, ….
Interns: George Sakkas, Aaditya Naik, Madeline Endres, Livia Sun, ….
Trusted AI-assisted
Programming Project
UW PLSE Talk (Feb 25, 2025)
2.
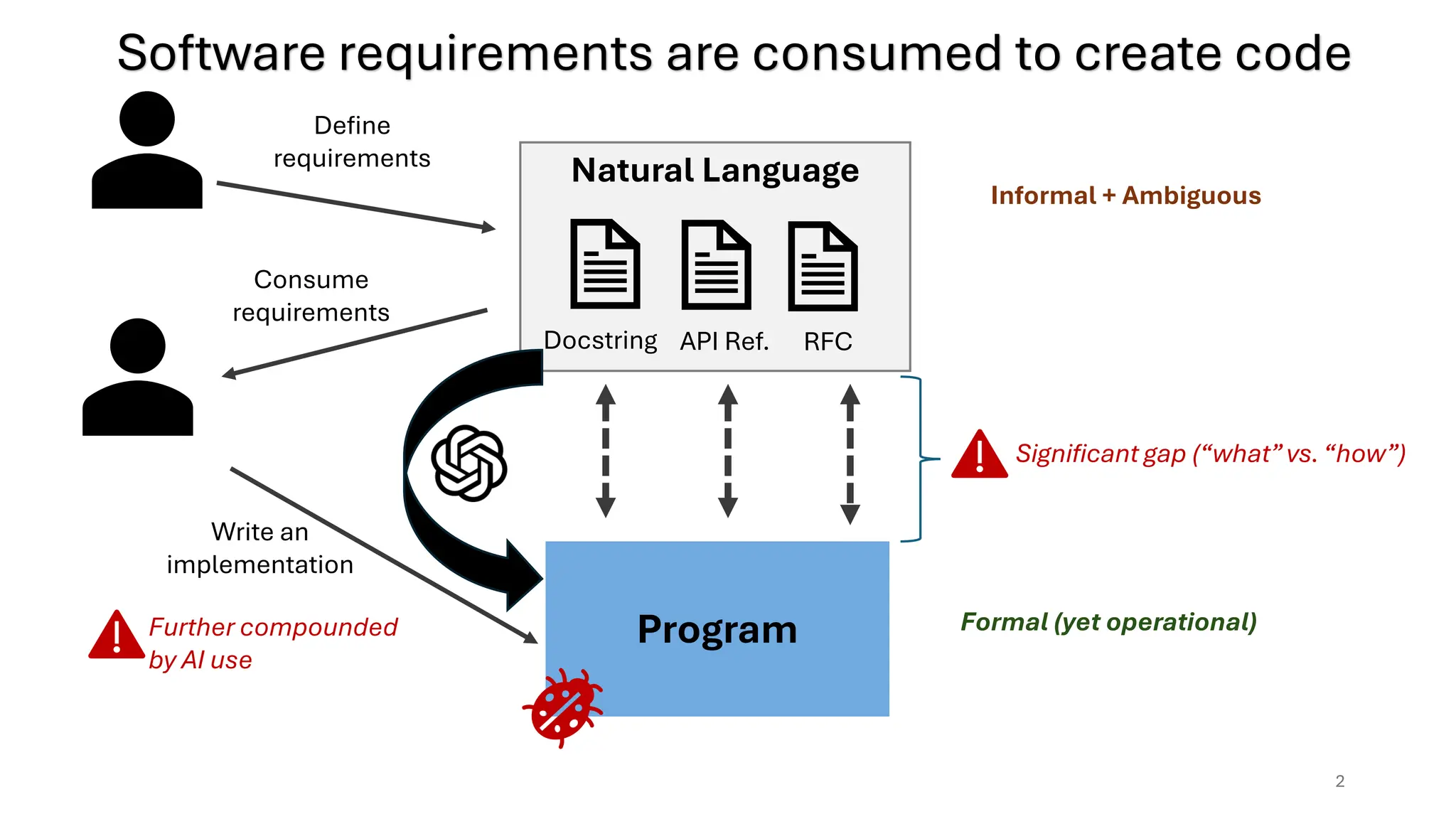
Natural Language
RFC
API Ref.
Docstring
Program
Informal+ Ambiguous
Further compounded
by AI use
Software requirements are consumed to create code
2
Formal (yet operational)
Significant gap (“what”vs. “how”)
Consume
requirements
Write an
implementation
Define
requirements
3.
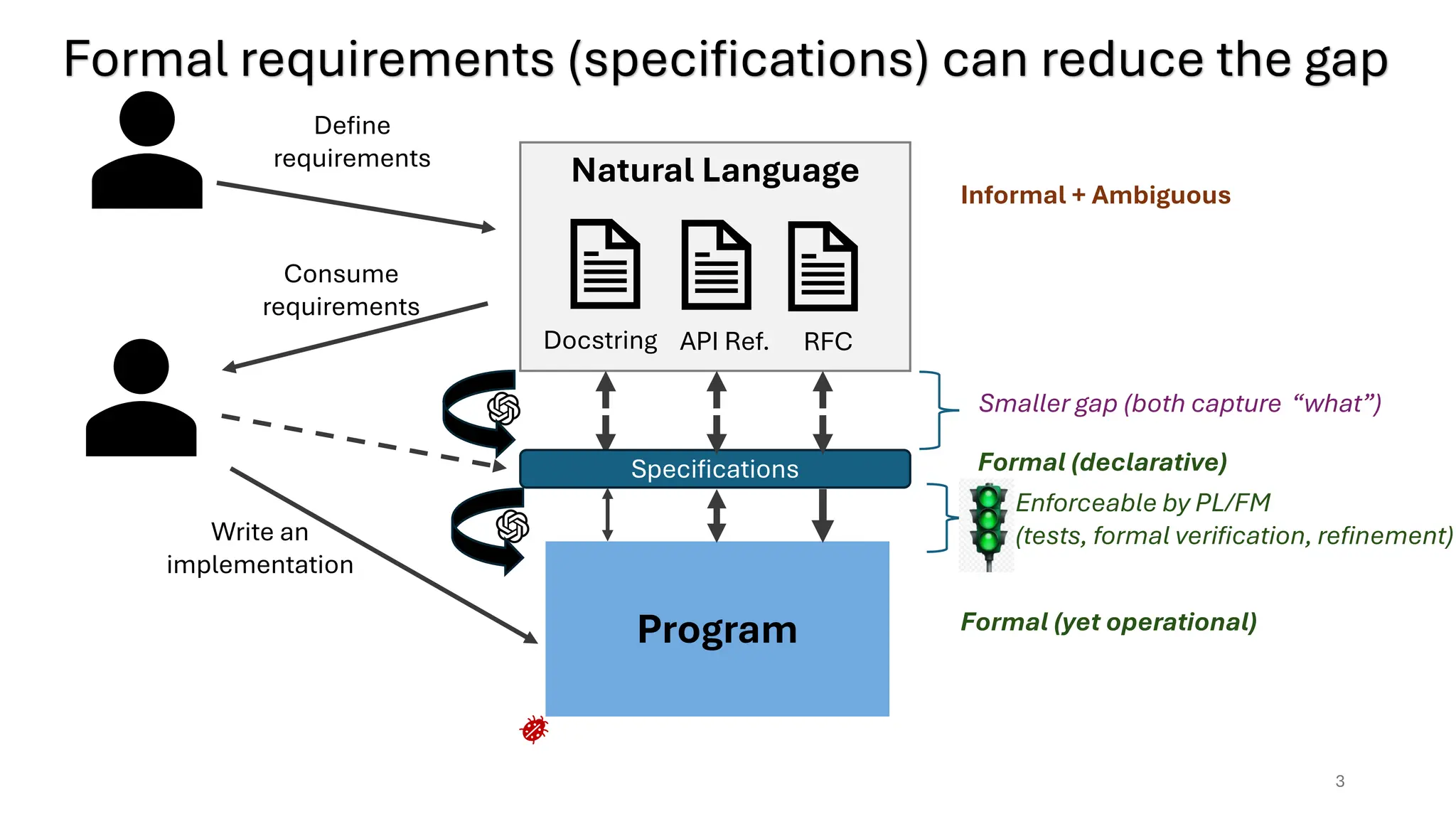
Natural Language
RFC
API Ref.
Docstring
Program
Informal+ Ambiguous
Formal requirements (specifications) can reduce the gap
3
Formal (yet operational)
Specifications
Enforceable by PL/FM
(tests, formal verification, refinement)
Formal (declarative)
Smaller gap (both capture “what”)
Write an
implementation
Consume
requirements
Define
requirements
4.
User-intent formalization forprograms:
Research Questions
• Problem statement:
• Can we automatically evaluate the correctness of a formal (requirement)
specification given an informal natural language intent?
• Applications:
• What new applications can be enabled by user-intent formalization for
programs
4
5.
User-intent formalization (UIF)for programs
• Observation
• NL2Code progress has been spurred by establishment of benchmarks and
automated metrics [MBPP (Google), HumanEval (OpenAI), …]
• Driving progress in latest large language models (LLMs) as a core task
• Uses semantic based metric through tests for evaluating correctness of generated code
(not NLP/syntactic metrics such as BLEU etc.)
• Used in mainstream programming [GitHub Copilot, Cursor, CodeWhisperer, Tabnine, …]
5
• (Revised) Problem statement:
• Can we automatically evaluate the correctness of a formal (requirement) specification
given an informal natural language intent + a diverse set of (hidden) validation tests?
6.
This talk
• UIFfor mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical
Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]
6
7.
UIF for mainstreamlanguages (Python, Java)
7
Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions?
Endres, Fakhoury, Chakraborty, Lahiri FSE’24
https://github.com/microsoft/nl-2-postcond
8.
Formal Specifications inPython
8
UIF for mainstream languages (Python, Java)
[1,2,3,2,4] -> [1,3,4]
assert all(i in return_list for i in numbers if numbers.count(i) == 1)
9.
Problem formulation (ideal)
•Given
• NL description nl for a method m
• (hidden) reference implementation I
• Generate a postcondition S of m from nl
• Evaluation metrics (intuition)
• Soundness: I satisfies S
• Completeness: S discriminates I from any buggy implementations
9
10.
Problem formulation (basedon tests)
• Given
• NL description nl for a method m
• (hidden) reference implementation I + a set of input/output tests T
• Generate a postcondition S of m from nl
• Evaluation metrics (intuition)
• Test-set Soundness: S is consistent with I for each test t in T
• Test-set Completeness: S discriminates I from any buggy implementations on some
test t in T
0 if unsound
• Score =
|buggy mutants discriminated|/|mutants|
10
11.
Buggy mutant generation
LeverageLLMs!
1. Prompt GPT-3.5 to enumerate 200 solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [natural bugs]
3. If too few distinct mutants,
1. Prompt GPT-3.5 to enumerate 200 “buggy” solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [artificial bugs]
Hypothesis
• More space of mutations (compared to traditional mutant generation through
mutating program elements)
• More natural and subtly incorrect mutants?
11
12.
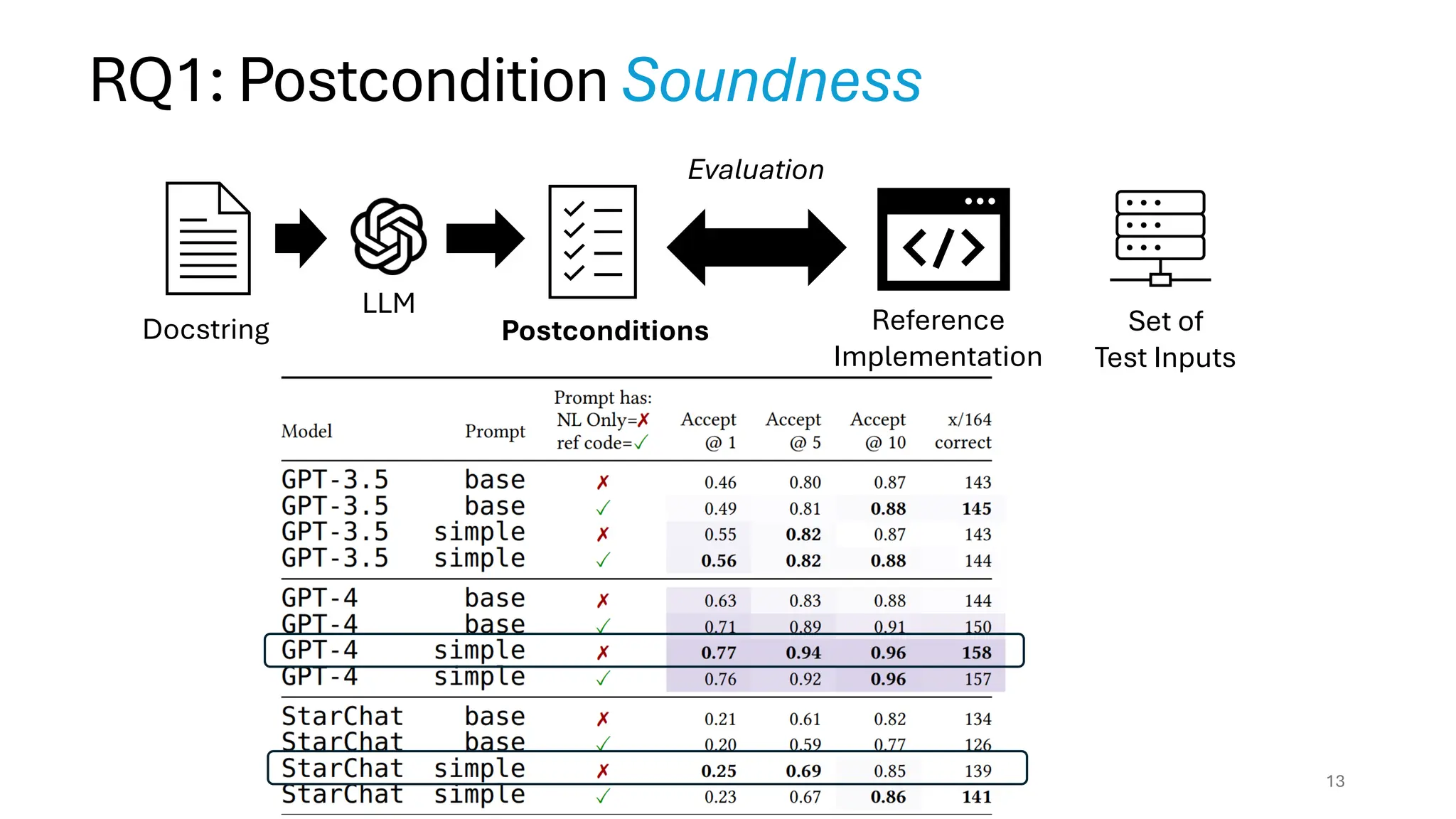
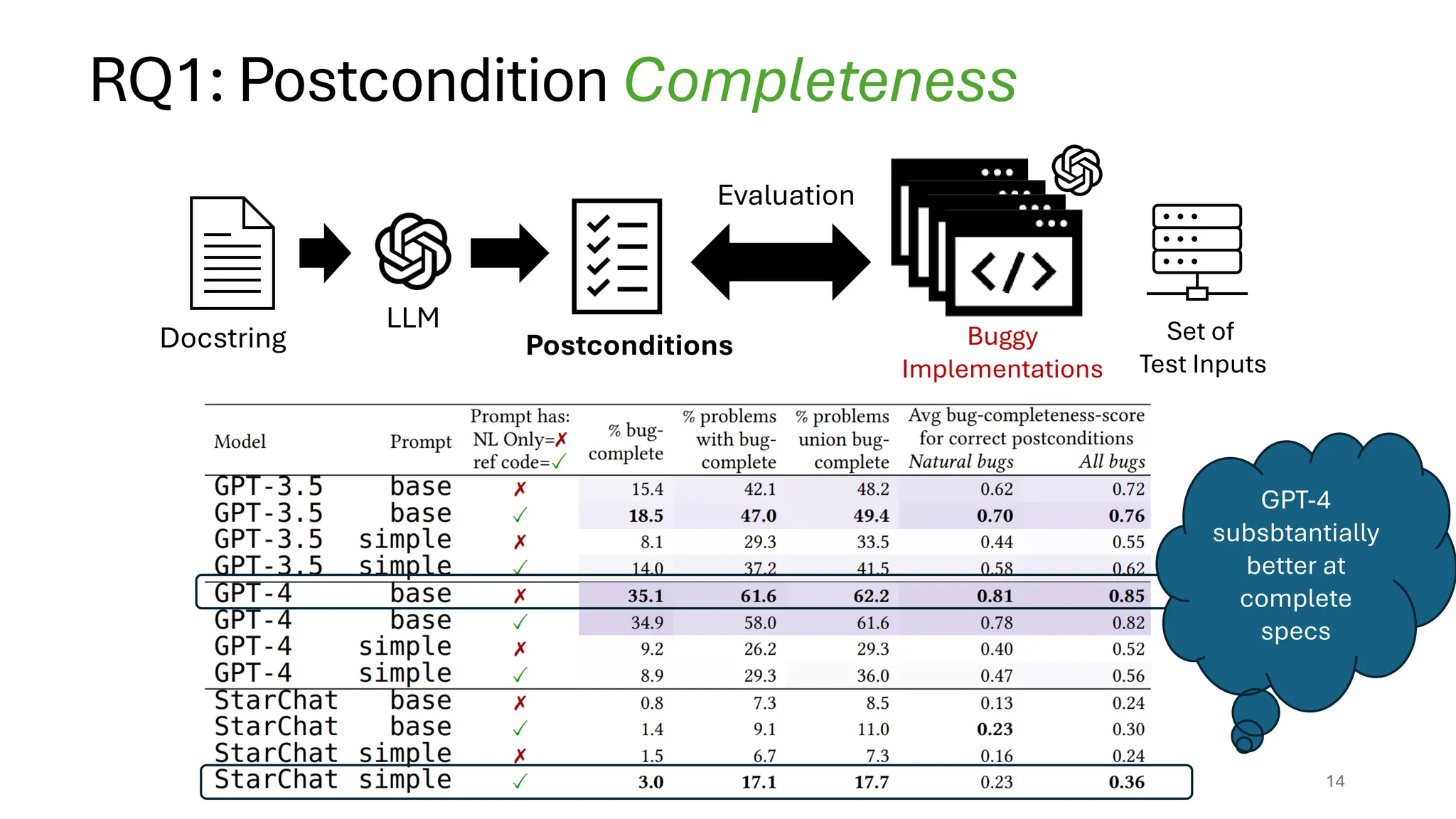
RQ1: How goodare LLMs at generating specs
from Natural Language?
Evaluation Methodology: EvalPlus
[Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code
Generation. Liu et al. NeurIPS’23]
For each problem in HumanEvall, we used LLMs to generate a set of
postconditions. We consider the following ablations1:
1. Model (GPT 3.5 and GPT 4 and StarCoder)
2. Prompting with NL only vs. NL + reference solution
12
Evaluate on Defects4Jdataset of real-world bugs
and fixes in mature Java projects
Our postconditions leverage functional Java syntax introduced in
Java 8. Not all bugs in Defects4J are Java 8 syntax compatible.
Our NL2Spec Defects4J subset contains 525 bugs from 11
projects. These bugs implicate 840 buggy Java methods.
16
RQ2: Can GPT-4 generated specifications find
real-world bugs?
[Defects4J: a database of existing faults to enable controlled testing studies for Java programs. 2014. Rene Just, Darioush Jalali, Michael Ernst]
17.
We use GPT-4to generate 10 postconditions and 10
preconditions for each buggy function.
We consider two ablations (33,600 total GPT-4 calls)
• NL + Buggy Method Code + Relevant File Context
• NL + Relevant File Context
For each, we measure:
17
Correctness
Does the spec pass the
tests on correct code?
Bug-discriminating
If it is correct, does the
spec fail any of the tests
on buggy code?
RQ2: Bug Finding: Experiments
18.
18
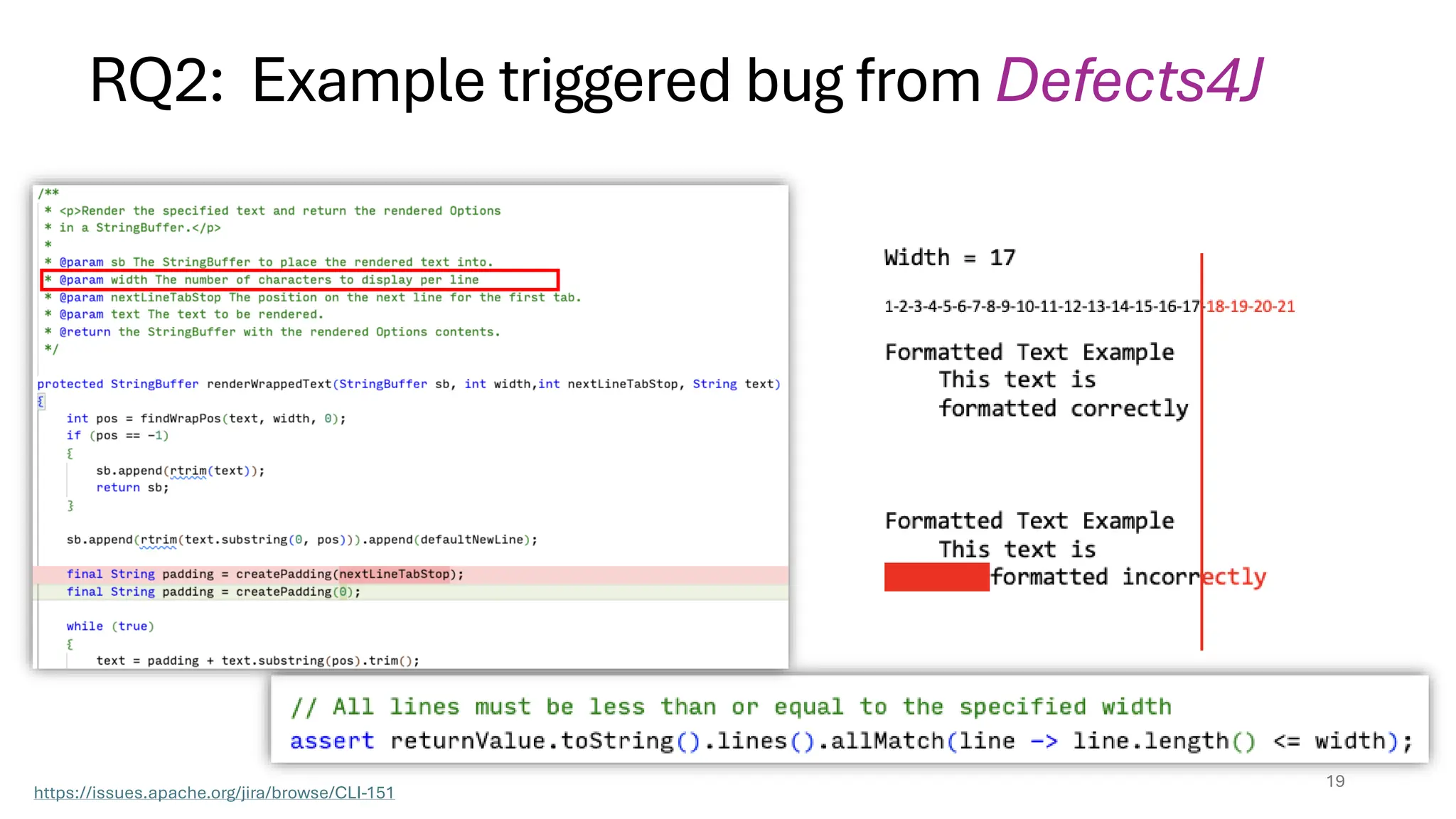
Defects4J results
Across ablations,65 bugs (12.5% of all bugs) are plausibly caught by
generated specifications
• We manually verify a subset of bug catching conditions
Complementary to prior assertion generation approaches TOGA [Dinella, Ryan,
Mytkowicz, Lahiri, ICSE’22] and Daikon [Ernst et al. ICSE’99]
• TOGA mostly finds expected exceptional bugs. TOGA can only tolerate bugs during
testing, and cannot prevent bugs in production.
• Daikon specs overfit the regression tests and bug-discriminating specs are unsound
UIF for verification-awarelanguages
(Dafny, F*, Verus, …)
20
[Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages, Lahiri, FMCAD’24]
21.
Motivating example
21
predicate InArray(a:array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
"Write a function to find the shared elements from the given two lists.“ [MBPP task#2]
GPT4 generated
specifcation.
Labeled as
“strong” by authors
[Towards AI-Assisted Synthesis of Verified Dafny Methods. Misu, Lopes, Ma, Noble. FSE’24]
"test_cases": {
"test_1": "var a1 := new int[] [3, 4, 5, 6];
var a2 := new int[] [5, 7, 4, 10];
var res1 :=SharedElements(a1,a2);
//expected[4, 5];",
"test_2": “…",
"test_3": “…"
}
Hidden (not visible to spec generator)
22.
Prior works
MBPP-DFY
[Misu, Lopes,Ma, Noble. FSE’24]
• Generates spec+code+proof in
Dafny from NL using GPT-4
• Creates 153 “verified”
examples
• Problem:
• How good are the
specifications?
• Manual/subjective (non-
automated) metric for
evaluation of specifications
22
nl2postcond
[Endres, Fakhoury, Chakraborty, Lahiri.
FSE’24]
• Creates automated metrics
for specification quality for
mainstream languages (Java,
Py) given tests and code
mutants
• Problem:
• Doesn’t work with rich
specifications (e.g.,
quantifiers, ghost variables)
in verification-aware
languages
23.
This work
• Anapproach to evaluate the correctness of formal program
specifications (given tests)
• A step towards creating a benchmark for user-intent-formalization
(specification quality) for programs in Dafny
• Leverages the dataset from MBPP-DFY
• “Adapts” the metric from nl2postcond for verification-aware languages
• Outcomes
• A “benchmark” of 64/153 examples from MBPP-DFY
• Automated metric for spec evaluation based on symbolically testing
specifications
23
24.
Our approach
• Symbolicallytest specifications (given tests as input/output
examples)
• Given
• A method signature
method Foo(x): (returns y) requires P(x) ensures Q(x, y)
• A set of input/output tests T
• Specification Soundness (for a test (i, o)) //Boolean metric
• {P} x := i; y := o; {Q} is valid
• Specification Completeness (for a test (i,o)) //Quantitative
metric (kill-set from mutation-testing)
• Fraction of mutants o’ of o, s.t. {P} x := i; y := o’; {Q} is not valid
24
25.
predicate InArray(a: array<int>,x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>)
returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) &&
InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==>
result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
25
"Write a function to find the shared
elements from the given two lists."
Should
verify
Should
fail to verify
[6];
26.
Evaluation https://github.com/microsoft/nl-2-postcond
• Evaluatethe soundness/completeness metrics against human labels
• Dataset: 153 Dafny specifications for MBPP-DFY dataset
• Implemented mutation operators for simple output values (Booleans, integers,
string, lists)
• Results
• Automated metrics gets parity with the human-labeling for most examples
• Can replace manual annotation with automated checks (given tests)
• Soundness check satisfied for 64/153 examples
• Finds instances where a “strong” specification is not complete
• Finds instances of “incorrect” specifications
26
27.
predicate InArray(a: array<int>,x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
27
"Write a function to find the shared elements from the given two lists."
GPT4 generated.
Labeled as
“strong”
Our metric marks this as a
weak specification (wrt the test)
Changing ==> to <==> makes it a
strong invariant by our metric
Result 1: label weak specifications
2 more such examples in the paper detected automatically
28.
Result 2: labelincorrect specifications
"234": {
"task_id": "234",
"task_description": "Write a method in Dafny to find the
volume of a cube given its side length.",
"method_signature": "method CubeVolume(l:int) returns (int)",
"test_cases": {
"test_1": "var out1:= CubeVolume(3);nassert out1==27;",
"test_2": "var out2:= CubeVolume(2);nassert out2==8;",
"test_3": "var out3:= CubeVolume(5);nassert out3==25;"
}
28
Our metric marks this as a
Incorrect specification (wrt the tests)
Problem: authors introduced error during copy-paste from Python -> Dafny!
2 more such examples in the paper detected automatically
29.
Challenges: quantifiers, unrolling,…
• Parsing complex datatypes (e.g., 2-dimensional arrays etc.)
• Need redundant assertions to trigger the quantifiers [DONE]
assume {:axiom} a[..a.Length] == a1[..a1.Length];
assert a[0] == a1[0] && .... && a[3] == a1[3];
• Unroll (or partially evaluate) recursive predicates based on concrete
input
• Trigger for nested quantifiers in specification predicates
• method IsNonPrime(n: int) returns (result: bool)
requires n >= 2
ensures result <==> (exists k :: 2 <= k < n && n % k == 0)
29
30.
Alternate proposals forbenchmark
• Other alternatives for automated metric
• Running the reference implementation with specifications on the tests
• Compare against a reference specification
• Verifying the specification against reference implementation
• Checking for the most precise specification (given the tests)
• Check the paper for details why they do not suffice …..
30
31.
Application: Specification modeltraining for Verus
31
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
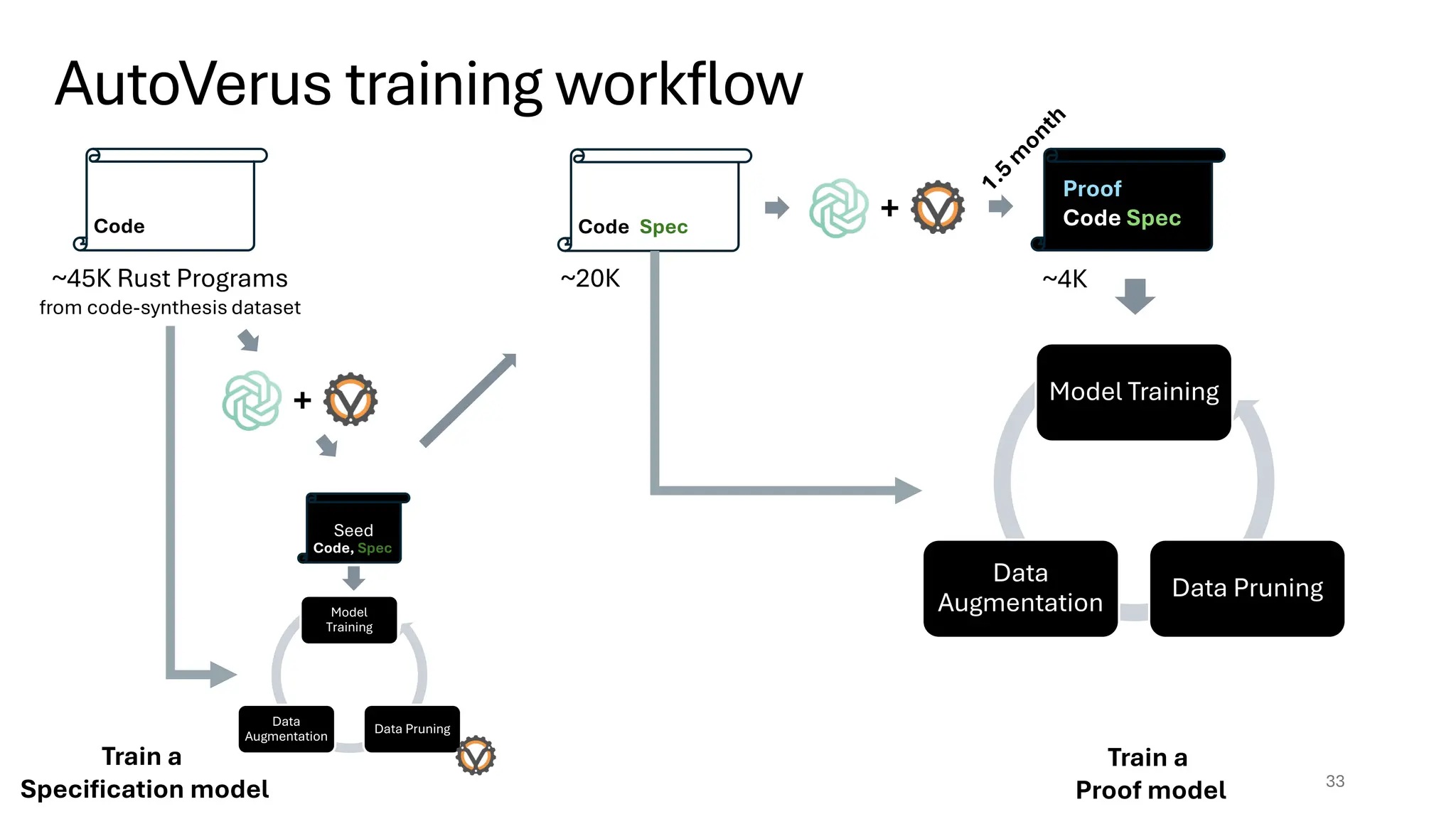
The approach of scoring specifications given tests has been ported to Verus
for boosting synthetic (spec, code, proof) generation for model training
Problem: Fine-tune an LLM to produce high-quality Proof given <DocString, Code, Spec>
• Need a high quality < DocString, Code, Spec, Proof > tuples
• Sub-Problem: Need a high quality < DocString, Code, Spec> tuples
• Approach: Fine-tune an LLM to produce high quality Spec given DocString and Tests using the
metric from earlier slide
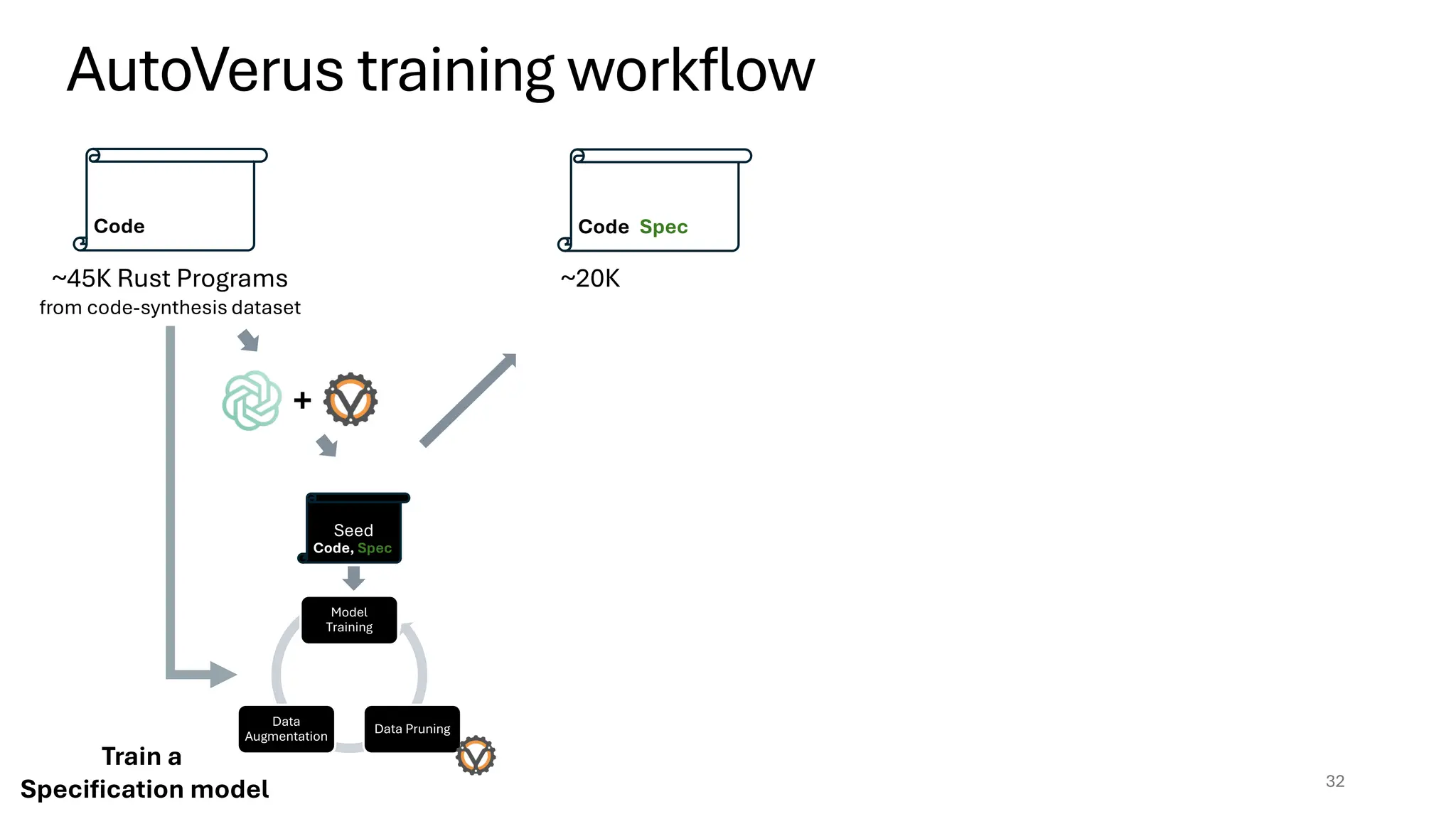
32.
Seed
AutoVerus training workflow
32
Code,Spec
Code
~45K Rust Programs
from code-synthesis dataset
Model
Training
Data
Augmentation
Data Pruning
Code, Spec
+
~20K
Train a
Specification model
33.
Seed
AutoVerus training workflow
33
Code,Spec
Proof
Code Spec
Code
~45K Rust Programs
from code-synthesis dataset
Model
Training
Data
Augmentation
Data Pruning
Code, Spec
+
~20K
+
Model Training
Data
Augmentation
Data Pruning
~4K
Train a
Specification model
Train a
Proof model
34.
Specification model training
forVerus
34
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
The approach of scoring specifications
given tests has been ported to Verus for
boosting synthetic (spec, code, proof)
generation for model training
35.
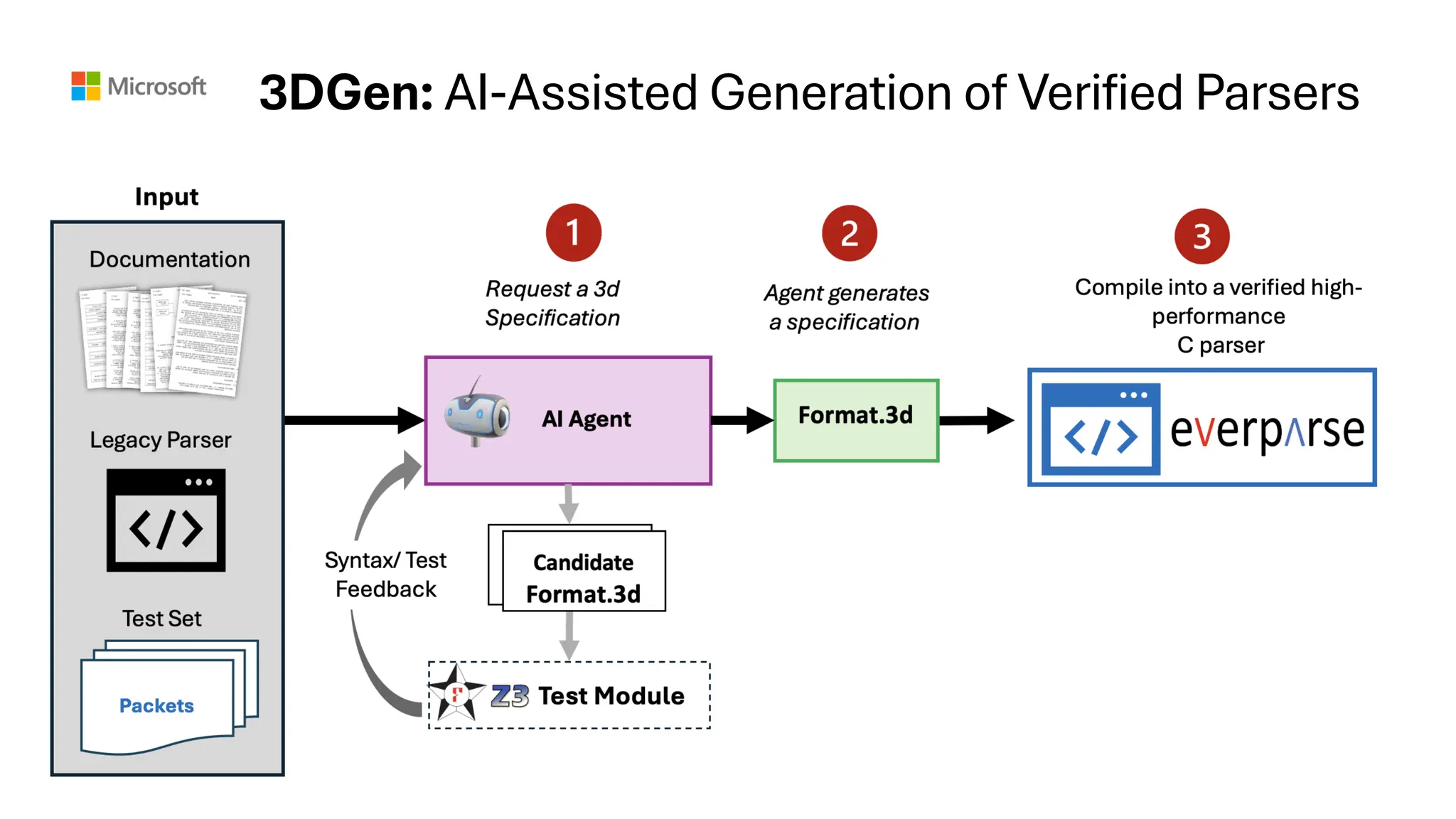
Real world applicationof UIF: Verified Parser
Generation from RFCs
[3DGen: AI-Assisted Generation of Provably Correct Binary Format Parsers. Fakhoury, Kuppe, Lahiri,
Ramananandro, Swamy, arXiv:2404.10362, ICSE’25 to appear]
35
36.
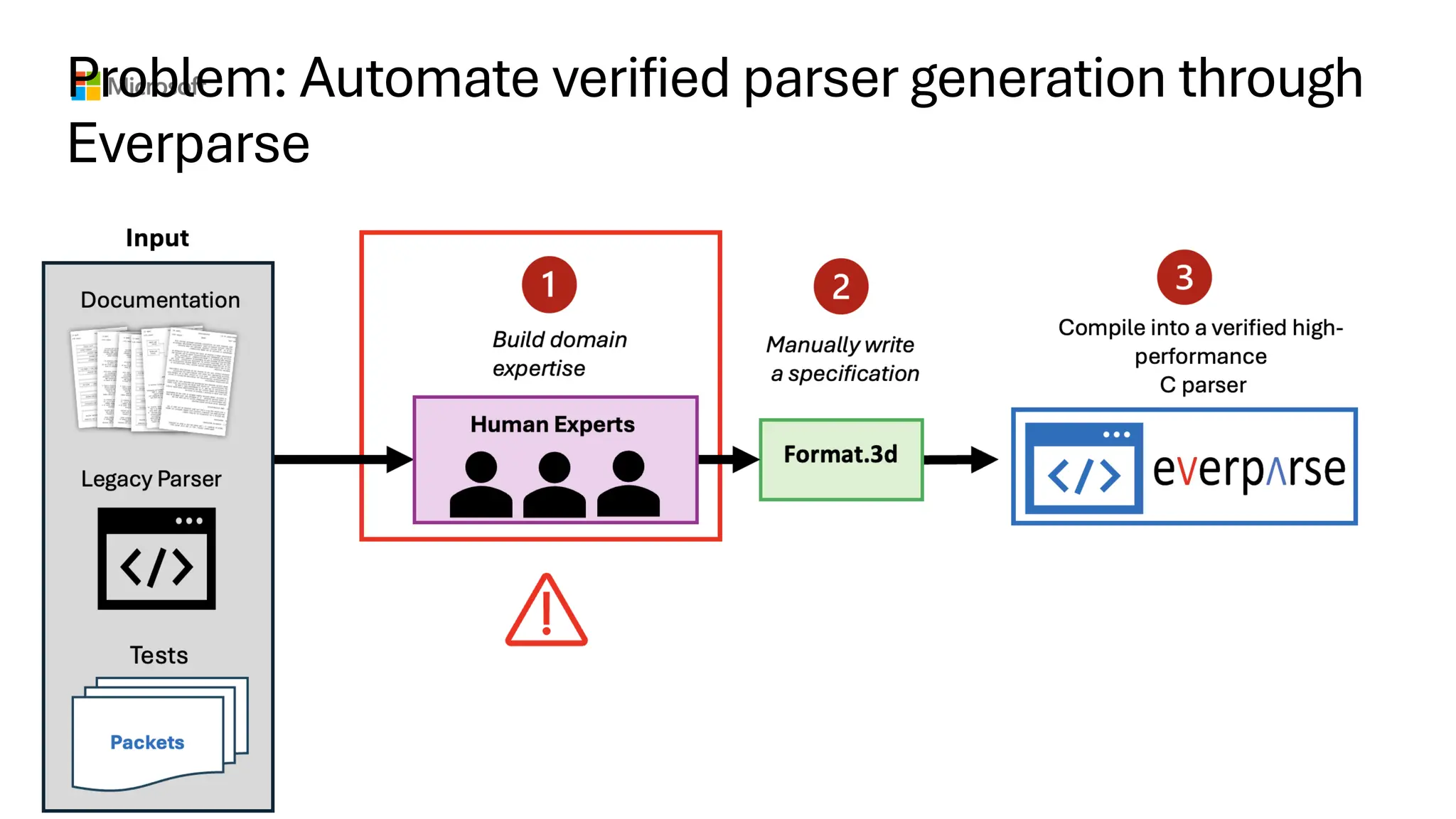
Background: verified parsergeneration from
declarative 3D specifications in Everparse
• Parsing and input validation failures: A
major root cause of software security
vulnerabilities
• `80%, according to DARPA, MITRE
• Mostly due to handwritten parsing code
• Writing functionally correct parsers is hard
(Endianness, data dependencies, size
constraints, etc.)
• Especially disastrous in memory unsafe
languages
Safe high-performance formally verified
C (or Rust) code
Functional Specification: Data Format Description (3D)
[1] Swamy, Nikhil, et al. "Hardening attack surfaces with formally
proven binary format parsers." International Conference on
Programming Language Design and Implementation (PLDI). 2022.
[2] Ramananandro, Tahina, et al. "EverParse: Verified secure zero-
copy parsers for authenticated message formats." 28th USENIX
Security Symposium (USENIX Security 19). 2019
Microsoft Research
• ThreeAgent personas collaborating:
o Planner: dictates roles, orchestrates
conversation
o Domain Expert Agent: Extracts
constraints from NL or Code, provides
feedback about generated specification
o 3D Agent: translates extracted
specifications into 3D
• Implemented with AutoGen [1]
o Composable
Retrieval Augmented (RAG) agents
o Gpt-4-32k model
Agent Implementation
[1] Wu, Qingyun, et al. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework." arXiv:2308.08155 (2023)
40.
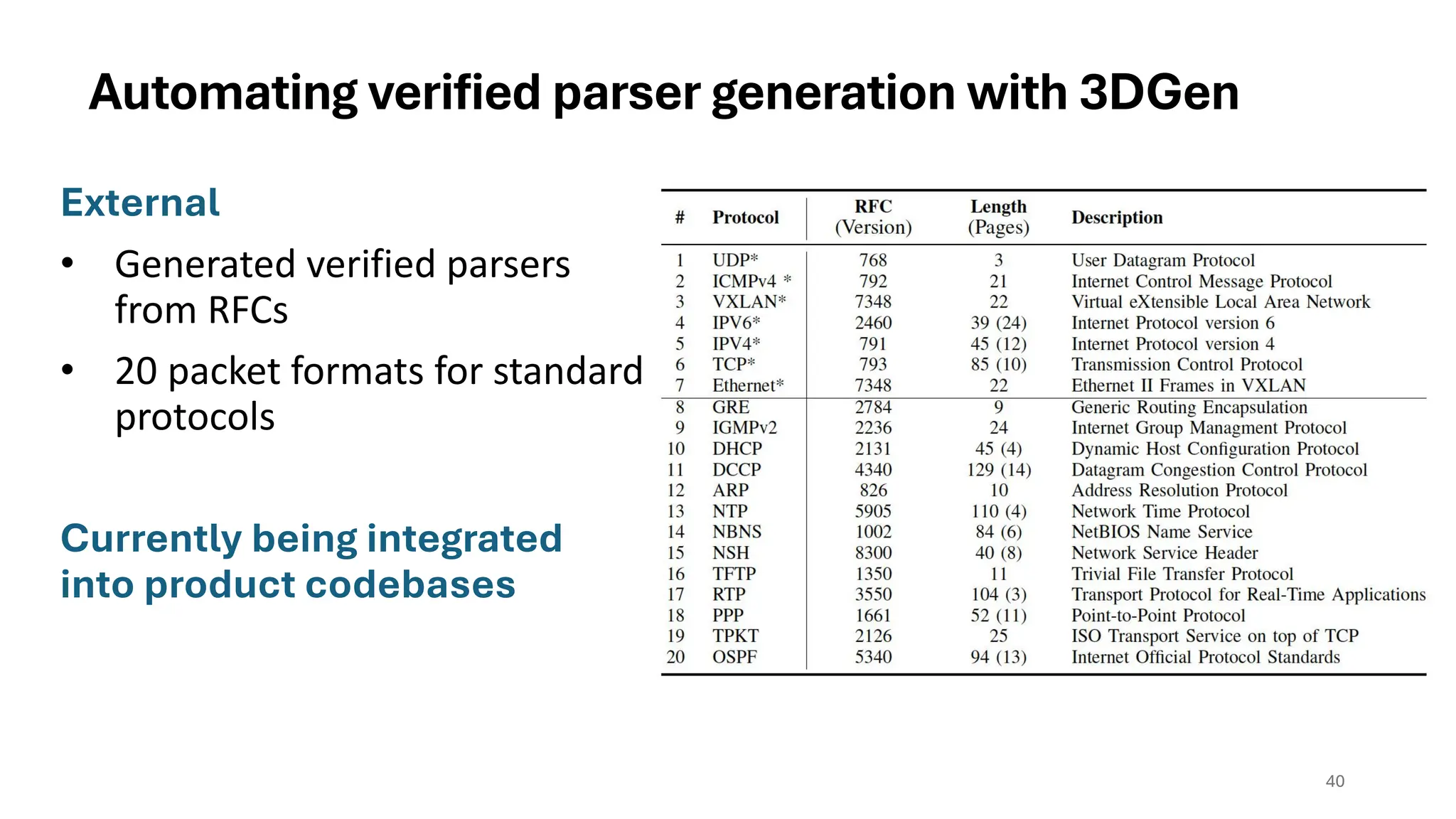
Automating verified parsergeneration with 3DGen
External
• Generated verified parsers
from RFCs
• 20 packet formats for standard
protocols
Currently being integrated
into product codebases
40
41.
UIF (tests asspec) can improve code generation
accuracy and developer productivity with user-
in-the-loop
41
[LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation, Fakhoury, Naik, Sakkas, Chakraborty,
Lahiri, TSE’24]
[Interactive Code Generation via Test-Driven User-Intent Formalization, Lahiri, Naik, Sakkas, Choudhury, Veh, Musuvathi, Inala,
Wang, Gao, arXiv:2208.05950]
42.
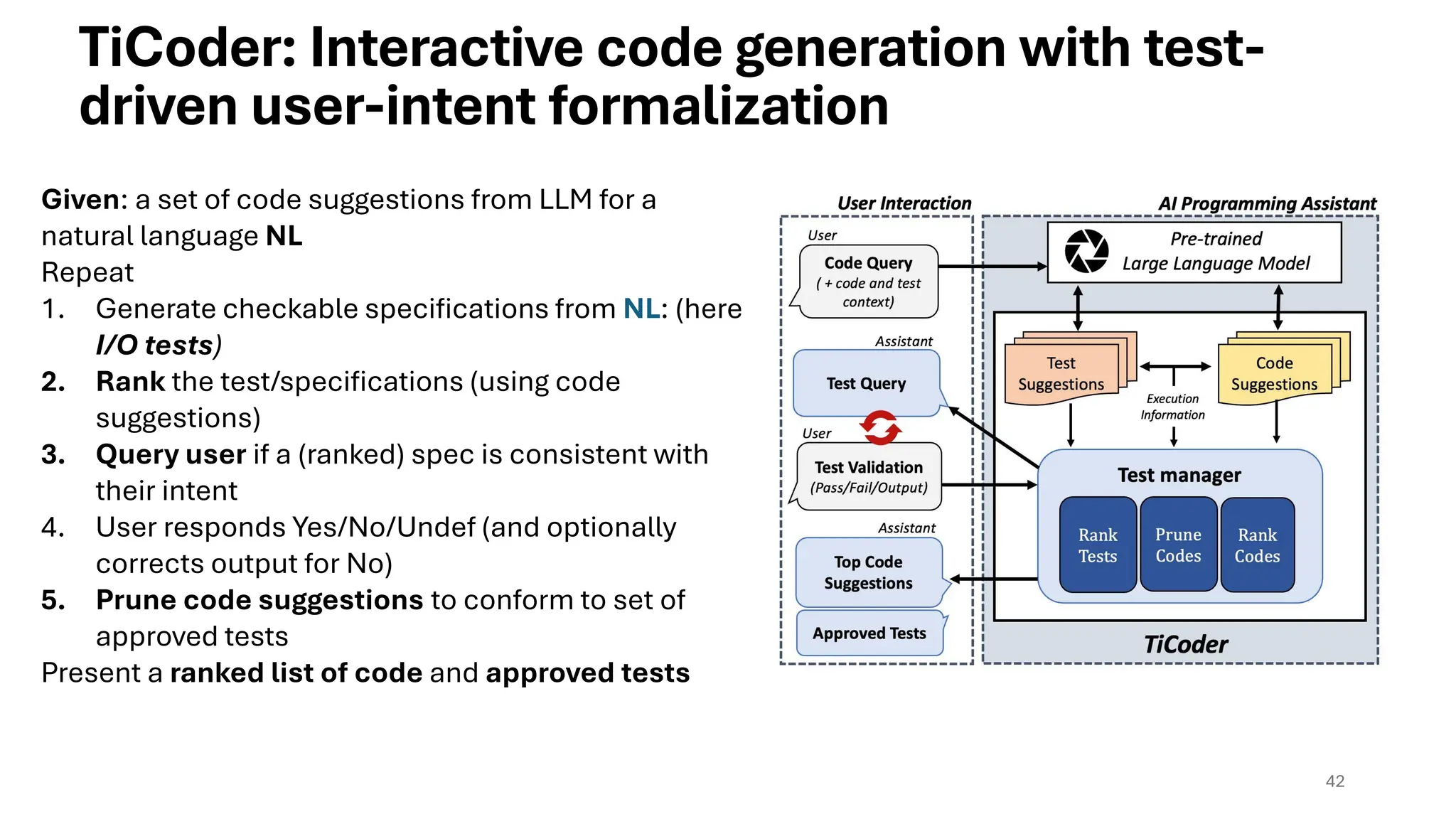
42
TiCoder: Interactive codegeneration with test-
driven user-intent formalization
Given: a set of code suggestions from LLM for a
natural language NL
Repeat
1. Generate checkable specifications from NL: (here
I/O tests)
2. Rank the test/specifications (using code
suggestions)
3. Query user if a (ranked) spec is consistent with
their intent
4. User responds Yes/No/Undef (and optionally
corrects output for No)
5. Prune code suggestions to conform to set of
approved tests
Present a ranked list of code and approved tests
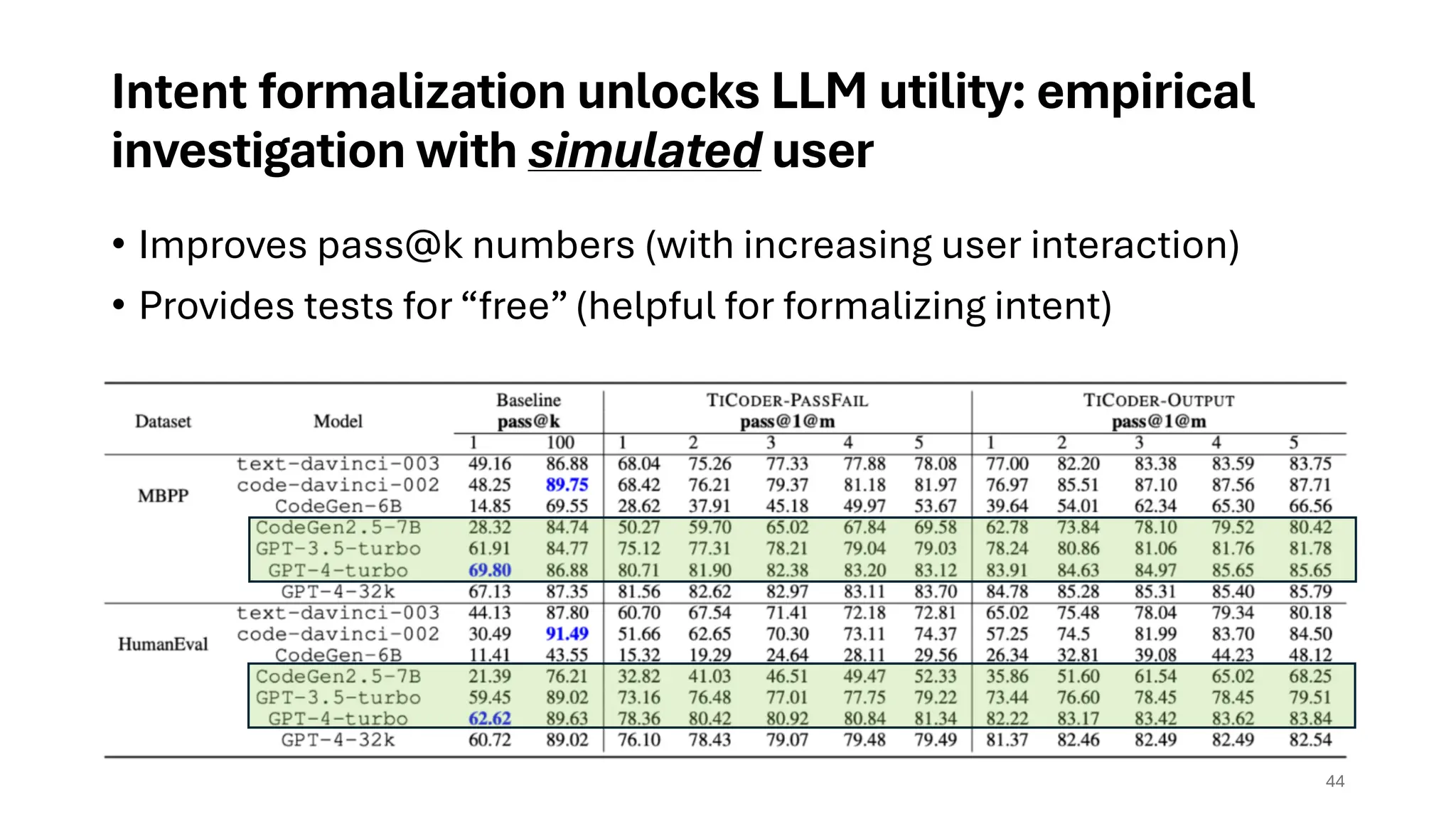
Intent formalization unlocksLLM utility: empirical
investigation with simulated user
• Improves pass@k numbers (with increasing user interaction)
• Provides tests for “free” (helpful for formalizing intent)
44
45.
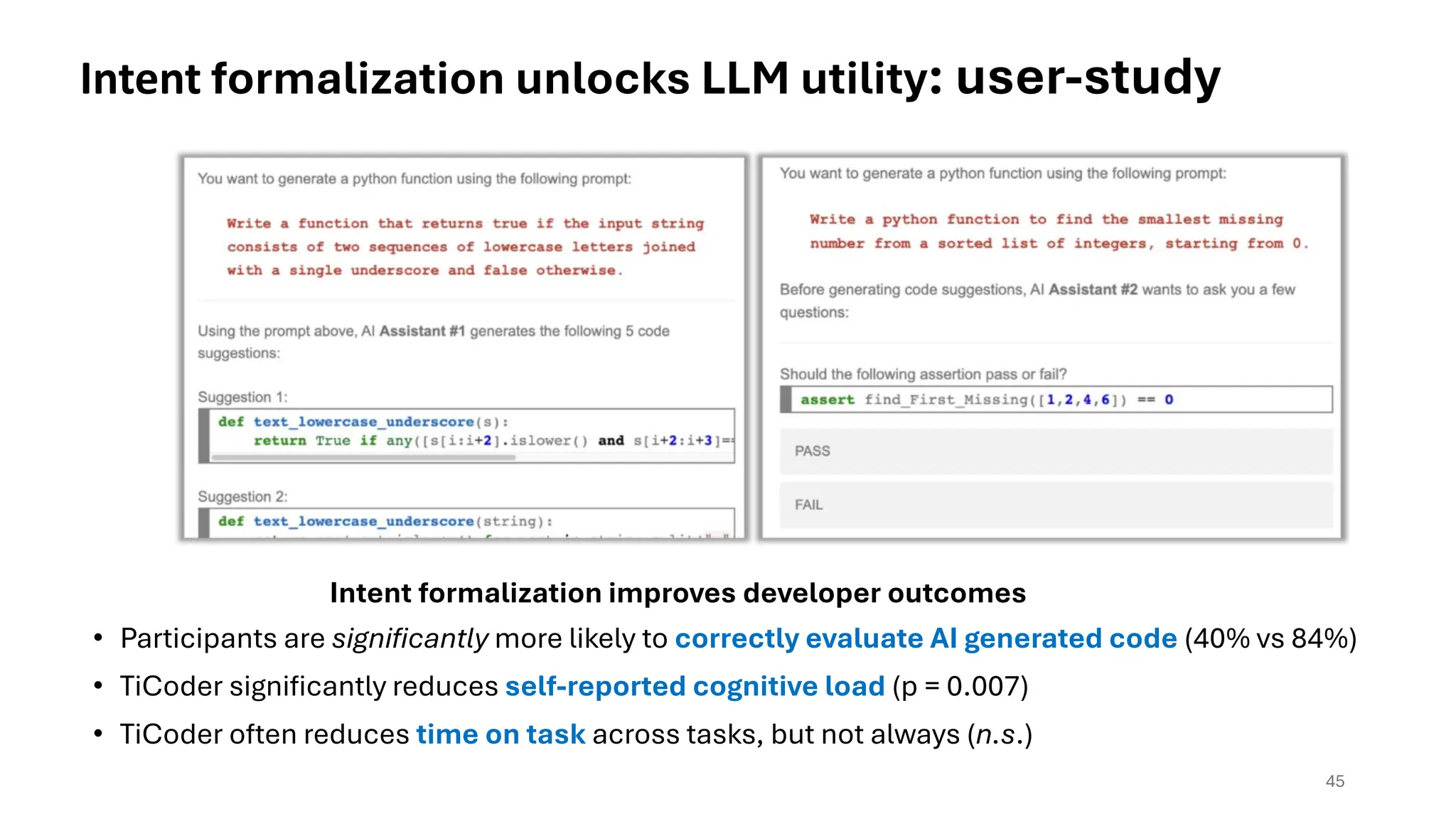
• Participants aresignificantly more likely to correctly evaluate AI generated code (40% vs 84%)
• TiCoder significantly reduces self-reported cognitive load (p = 0.007)
• TiCoder often reduces time on task across tasks, but not always (n.s.)
45
Intent formalization improves developer outcomes
Intent formalization unlocks LLM utility: user-study
46.
Other works inAI and testing/verification
46
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language
Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury,
Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis,
Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner,
Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong,
Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri
[CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri
[Sigmod '25 to appear]
Trusted AI-assisted
Programming
47.
Summary
47
Trusted AI-assisted
Programming
Related researchwith LLM and testing/verification
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury, Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis, Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner, Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to
appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong, Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri [CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri [SIGMOD '25 to appear]
RiSE
AI for Program Specifications
• UIF for mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]


![User-intent formalization (UIF) for programs
• Observation
• NL2Code progress has been spurred by establishment of benchmarks and
automated metrics [MBPP (Google), HumanEval (OpenAI), …]
• Driving progress in latest large language models (LLMs) as a core task
• Uses semantic based metric through tests for evaluating correctness of generated code
(not NLP/syntactic metrics such as BLEU etc.)
• Used in mainstream programming [GitHub Copilot, Cursor, CodeWhisperer, Tabnine, …]
5
• (Revised) Problem statement:
• Can we automatically evaluate the correctness of a formal (requirement) specification
given an informal natural language intent + a diverse set of (hidden) validation tests?](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-5-2048.jpg)
![This talk
• UIF for mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical
Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]
6](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-6-2048.jpg)

![Formal Specifications in Python
8
UIF for mainstream languages (Python, Java)
[1,2,3,2,4] -> [1,3,4]
assert all(i in return_list for i in numbers if numbers.count(i) == 1)](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-8-2048.jpg)


![Buggy mutant generation
Leverage LLMs!
1. Prompt GPT-3.5 to enumerate 200 solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [natural bugs]
3. If too few distinct mutants,
1. Prompt GPT-3.5 to enumerate 200 “buggy” solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [artificial bugs]
Hypothesis
• More space of mutations (compared to traditional mutant generation through
mutating program elements)
• More natural and subtly incorrect mutants?
11](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-11-2048.jpg)
![RQ1: How good are LLMs at generating specs
from Natural Language?
Evaluation Methodology: EvalPlus
[Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code
Generation. Liu et al. NeurIPS’23]
For each problem in HumanEvall, we used LLMs to generate a set of
postconditions. We consider the following ablations1:
1. Model (GPT 3.5 and GPT 4 and StarCoder)
2. Prompting with NL only vs. NL + reference solution
12](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-12-2048.jpg)

![Evaluate on Defects4J dataset of real-world bugs
and fixes in mature Java projects
Our postconditions leverage functional Java syntax introduced in
Java 8. Not all bugs in Defects4J are Java 8 syntax compatible.
Our NL2Spec Defects4J subset contains 525 bugs from 11
projects. These bugs implicate 840 buggy Java methods.
16
RQ2: Can GPT-4 generated specifications find
real-world bugs?
[Defects4J: a database of existing faults to enable controlled testing studies for Java programs. 2014. Rene Just, Darioush Jalali, Michael Ernst]](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-16-2048.jpg)

![18
Defects4J results
Across ablations, 65 bugs (12.5% of all bugs) are plausibly caught by
generated specifications
• We manually verify a subset of bug catching conditions
Complementary to prior assertion generation approaches TOGA [Dinella, Ryan,
Mytkowicz, Lahiri, ICSE’22] and Daikon [Ernst et al. ICSE’99]
• TOGA mostly finds expected exceptional bugs. TOGA can only tolerate bugs during
testing, and cannot prevent bugs in production.
• Daikon specs overfit the regression tests and bug-discriminating specs are unsound](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-18-2048.jpg)
![UIF for verification-aware languages
(Dafny, F*, Verus, …)
20
[Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages, Lahiri, FMCAD’24]](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-20-2048.jpg)
![Motivating example
21
predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
"Write a function to find the shared elements from the given two lists.“ [MBPP task#2]
GPT4 generated
specifcation.
Labeled as
“strong” by authors
[Towards AI-Assisted Synthesis of Verified Dafny Methods. Misu, Lopes, Ma, Noble. FSE’24]
"test_cases": {
"test_1": "var a1 := new int[] [3, 4, 5, 6];
var a2 := new int[] [5, 7, 4, 10];
var res1 :=SharedElements(a1,a2);
//expected[4, 5];",
"test_2": “…",
"test_3": “…"
}
Hidden (not visible to spec generator)](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-21-2048.jpg)
![Prior works
MBPP-DFY
[Misu, Lopes, Ma, Noble. FSE’24]
• Generates spec+code+proof in
Dafny from NL using GPT-4
• Creates 153 “verified”
examples
• Problem:
• How good are the
specifications?
• Manual/subjective (non-
automated) metric for
evaluation of specifications
22
nl2postcond
[Endres, Fakhoury, Chakraborty, Lahiri.
FSE’24]
• Creates automated metrics
for specification quality for
mainstream languages (Java,
Py) given tests and code
mutants
• Problem:
• Doesn’t work with rich
specifications (e.g.,
quantifiers, ghost variables)
in verification-aware
languages](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-22-2048.jpg)


![predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>)
returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) &&
InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==>
result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
25
"Write a function to find the shared
elements from the given two lists."
Should
verify
Should
fail to verify
[6];](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-25-2048.jpg)

![predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
27
"Write a function to find the shared elements from the given two lists."
GPT4 generated.
Labeled as
“strong”
Our metric marks this as a
weak specification (wrt the test)
Changing ==> to <==> makes it a
strong invariant by our metric
Result 1: label weak specifications
2 more such examples in the paper detected automatically](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-27-2048.jpg)

![Challenges: quantifiers, unrolling, …
• Parsing complex datatypes (e.g., 2-dimensional arrays etc.)
• Need redundant assertions to trigger the quantifiers [DONE]
assume {:axiom} a[..a.Length] == a1[..a1.Length];
assert a[0] == a1[0] && .... && a[3] == a1[3];
• Unroll (or partially evaluate) recursive predicates based on concrete
input
• Trigger for nested quantifiers in specification predicates
• method IsNonPrime(n: int) returns (result: bool)
requires n >= 2
ensures result <==> (exists k :: 2 <= k < n && n % k == 0)
29](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-29-2048.jpg)

![Application: Specification model training for Verus
31
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
The approach of scoring specifications given tests has been ported to Verus
for boosting synthetic (spec, code, proof) generation for model training
Problem: Fine-tune an LLM to produce high-quality Proof given <DocString, Code, Spec>
• Need a high quality < DocString, Code, Spec, Proof > tuples
• Sub-Problem: Need a high quality < DocString, Code, Spec> tuples
• Approach: Fine-tune an LLM to produce high quality Spec given DocString and Tests using the
metric from earlier slide](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-31-2048.jpg)
![Specification model training
for Verus
34
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
The approach of scoring specifications
given tests has been ported to Verus for
boosting synthetic (spec, code, proof)
generation for model training](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-34-2048.jpg)
![Real world application of UIF: Verified Parser
Generation from RFCs
[3DGen: AI-Assisted Generation of Provably Correct Binary Format Parsers. Fakhoury, Kuppe, Lahiri,
Ramananandro, Swamy, arXiv:2404.10362, ICSE’25 to appear]
35](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-35-2048.jpg)
![Background: verified parser generation from
declarative 3D specifications in Everparse
• Parsing and input validation failures: A
major root cause of software security
vulnerabilities
• `80%, according to DARPA, MITRE
• Mostly due to handwritten parsing code
• Writing functionally correct parsers is hard
(Endianness, data dependencies, size
constraints, etc.)
• Especially disastrous in memory unsafe
languages
Safe high-performance formally verified
C (or Rust) code
Functional Specification: Data Format Description (3D)
[1] Swamy, Nikhil, et al. "Hardening attack surfaces with formally
proven binary format parsers." International Conference on
Programming Language Design and Implementation (PLDI). 2022.
[2] Ramananandro, Tahina, et al. "EverParse: Verified secure zero-
copy parsers for authenticated message formats." 28th USENIX
Security Symposium (USENIX Security 19). 2019](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-36-2048.jpg)
![Microsoft Research
• Three Agent personas collaborating:
o Planner: dictates roles, orchestrates
conversation
o Domain Expert Agent: Extracts
constraints from NL or Code, provides
feedback about generated specification
o 3D Agent: translates extracted
specifications into 3D
• Implemented with AutoGen [1]
o Composable
Retrieval Augmented (RAG) agents
o Gpt-4-32k model
Agent Implementation
[1] Wu, Qingyun, et al. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework." arXiv:2308.08155 (2023)](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-39-2048.jpg)
![UIF (tests as spec) can improve code generation
accuracy and developer productivity with user-
in-the-loop
41
[LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation, Fakhoury, Naik, Sakkas, Chakraborty,
Lahiri, TSE’24]
[Interactive Code Generation via Test-Driven User-Intent Formalization, Lahiri, Naik, Sakkas, Choudhury, Veh, Musuvathi, Inala,
Wang, Gao, arXiv:2208.05950]](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-41-2048.jpg)
![Other works in AI and testing/verification
46
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language
Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury,
Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis,
Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner,
Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong,
Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri
[CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri
[Sigmod '25 to appear]
Trusted AI-assisted
Programming](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-46-2048.jpg)
![Summary
47
Trusted AI-assisted
Programming
Related research with LLM and testing/verification
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury, Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis, Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner, Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to
appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong, Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri [CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri [SIGMOD '25 to appear]
RiSE
AI for Program Specifications
• UIF for mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]](https://image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-47-2048.jpg)





![User-intent formalization (UIF) for programs
• Observation
• NL2Code progress has been spurred by establishment of benchmarks and
automated metrics [MBPP (Google), HumanEval (OpenAI), …]
• Driving progress in latest large language models (LLMs) as a core task
• Uses semantic based metric through tests for evaluating correctness of generated code
(not NLP/syntactic metrics such as BLEU etc.)
• Used in mainstream programming [GitHub Copilot, Cursor, CodeWhisperer, Tabnine, …]
5
• (Revised) Problem statement:
• Can we automatically evaluate the correctness of a formal (requirement) specification
given an informal natural language intent + a diverse set of (hidden) validation tests?](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-5-2048.jpg)
![This talk
• UIF for mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical
Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]
6](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-6-2048.jpg)

![Formal Specifications in Python
8
UIF for mainstream languages (Python, Java)
[1,2,3,2,4] -> [1,3,4]
assert all(i in return_list for i in numbers if numbers.count(i) == 1)](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-8-2048.jpg)


![Buggy mutant generation
Leverage LLMs!
1. Prompt GPT-3.5 to enumerate 200 solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [natural bugs]
3. If too few distinct mutants,
1. Prompt GPT-3.5 to enumerate 200 “buggy” solutions to nl prompt
2. Group mutants by the subset of tests in T they pass [artificial bugs]
Hypothesis
• More space of mutations (compared to traditional mutant generation through
mutating program elements)
• More natural and subtly incorrect mutants?
11](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-11-2048.jpg)
![RQ1: How good are LLMs at generating specs
from Natural Language?
Evaluation Methodology: EvalPlus
[Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code
Generation. Liu et al. NeurIPS’23]
For each problem in HumanEvall, we used LLMs to generate a set of
postconditions. We consider the following ablations1:
1. Model (GPT 3.5 and GPT 4 and StarCoder)
2. Prompting with NL only vs. NL + reference solution
12](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-12-2048.jpg)



![Evaluate on Defects4J dataset of real-world bugs
and fixes in mature Java projects
Our postconditions leverage functional Java syntax introduced in
Java 8. Not all bugs in Defects4J are Java 8 syntax compatible.
Our NL2Spec Defects4J subset contains 525 bugs from 11
projects. These bugs implicate 840 buggy Java methods.
16
RQ2: Can GPT-4 generated specifications find
real-world bugs?
[Defects4J: a database of existing faults to enable controlled testing studies for Java programs. 2014. Rene Just, Darioush Jalali, Michael Ernst]](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-16-2048.jpg)

![18
Defects4J results
Across ablations, 65 bugs (12.5% of all bugs) are plausibly caught by
generated specifications
• We manually verify a subset of bug catching conditions
Complementary to prior assertion generation approaches TOGA [Dinella, Ryan,
Mytkowicz, Lahiri, ICSE’22] and Daikon [Ernst et al. ICSE’99]
• TOGA mostly finds expected exceptional bugs. TOGA can only tolerate bugs during
testing, and cannot prevent bugs in production.
• Daikon specs overfit the regression tests and bug-discriminating specs are unsound](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-18-2048.jpg)

![UIF for verification-aware languages
(Dafny, F*, Verus, …)
20
[Evaluating LLM-driven User-Intent Formalization for Verification-Aware Languages, Lahiri, FMCAD’24]](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-20-2048.jpg)
![Motivating example
21
predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
"Write a function to find the shared elements from the given two lists.“ [MBPP task#2]
GPT4 generated
specifcation.
Labeled as
“strong” by authors
[Towards AI-Assisted Synthesis of Verified Dafny Methods. Misu, Lopes, Ma, Noble. FSE’24]
"test_cases": {
"test_1": "var a1 := new int[] [3, 4, 5, 6];
var a2 := new int[] [5, 7, 4, 10];
var res1 :=SharedElements(a1,a2);
//expected[4, 5];",
"test_2": “…",
"test_3": “…"
}
Hidden (not visible to spec generator)](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-21-2048.jpg)
![Prior works
MBPP-DFY
[Misu, Lopes, Ma, Noble. FSE’24]
• Generates spec+code+proof in
Dafny from NL using GPT-4
• Creates 153 “verified”
examples
• Problem:
• How good are the
specifications?
• Manual/subjective (non-
automated) metric for
evaluation of specifications
22
nl2postcond
[Endres, Fakhoury, Chakraborty, Lahiri.
FSE’24]
• Creates automated metrics
for specification quality for
mainstream languages (Java,
Py) given tests and code
mutants
• Problem:
• Doesn’t work with rich
specifications (e.g.,
quantifiers, ghost variables)
in verification-aware
languages](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-22-2048.jpg)


![predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>)
returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) &&
InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==>
result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
25
"Write a function to find the shared
elements from the given two lists."
Should
verify
Should
fail to verify
[6];](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-25-2048.jpg)

![predicate InArray(a: array<int>, x: int)
reads a
{exists i :: 0 <= i < a.Length && a[i] == x}
method SharedElements(a: array<int>, b: array<int>) returns (result: seq<int>)
ensures forall x :: x in result ==> (InArray(a, x) && InArray(b, x))
ensures forall i, j :: 0 <= i < j < |result| ==> result[i] != result[j]
method SharedElementsTest(){
var a1:= new int[] [3, 4, 5, 6];
var a2:= new int[] [5, 7, 4, 10];
var res1:=SharedElements(a1,a2);
//expected[4, 5];
}
27
"Write a function to find the shared elements from the given two lists."
GPT4 generated.
Labeled as
“strong”
Our metric marks this as a
weak specification (wrt the test)
Changing ==> to <==> makes it a
strong invariant by our metric
Result 1: label weak specifications
2 more such examples in the paper detected automatically](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-27-2048.jpg)

![Challenges: quantifiers, unrolling, …
• Parsing complex datatypes (e.g., 2-dimensional arrays etc.)
• Need redundant assertions to trigger the quantifiers [DONE]
assume {:axiom} a[..a.Length] == a1[..a1.Length];
assert a[0] == a1[0] && .... && a[3] == a1[3];
• Unroll (or partially evaluate) recursive predicates based on concrete
input
• Trigger for nested quantifiers in specification predicates
• method IsNonPrime(n: int) returns (result: bool)
requires n >= 2
ensures result <==> (exists k :: 2 <= k < n && n % k == 0)
29](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-29-2048.jpg)

![Application: Specification model training for Verus
31
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
The approach of scoring specifications given tests has been ported to Verus
for boosting synthetic (spec, code, proof) generation for model training
Problem: Fine-tune an LLM to produce high-quality Proof given <DocString, Code, Spec>
• Need a high quality < DocString, Code, Spec, Proof > tuples
• Sub-Problem: Need a high quality < DocString, Code, Spec> tuples
• Approach: Fine-tune an LLM to produce high quality Spec given DocString and Tests using the
metric from earlier slide](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-31-2048.jpg)


![Specification model training
for Verus
34
Automated Proof Generation for Rust Code via Self-Evolution. Chen, Lu, (Shan) Lu, Gong, Yang, Li, Misu, Yu, Duan, Cheng, Yang, Lahiri,
Xie, Zhou [arXiv:2410.15756], ICLR 2025
The approach of scoring specifications
given tests has been ported to Verus for
boosting synthetic (spec, code, proof)
generation for model training](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-34-2048.jpg)
![Real world application of UIF: Verified Parser
Generation from RFCs
[3DGen: AI-Assisted Generation of Provably Correct Binary Format Parsers. Fakhoury, Kuppe, Lahiri,
Ramananandro, Swamy, arXiv:2404.10362, ICSE’25 to appear]
35](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-35-2048.jpg)
![Background: verified parser generation from
declarative 3D specifications in Everparse
• Parsing and input validation failures: A
major root cause of software security
vulnerabilities
• `80%, according to DARPA, MITRE
• Mostly due to handwritten parsing code
• Writing functionally correct parsers is hard
(Endianness, data dependencies, size
constraints, etc.)
• Especially disastrous in memory unsafe
languages
Safe high-performance formally verified
C (or Rust) code
Functional Specification: Data Format Description (3D)
[1] Swamy, Nikhil, et al. "Hardening attack surfaces with formally
proven binary format parsers." International Conference on
Programming Language Design and Implementation (PLDI). 2022.
[2] Ramananandro, Tahina, et al. "EverParse: Verified secure zero-
copy parsers for authenticated message formats." 28th USENIX
Security Symposium (USENIX Security 19). 2019](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-36-2048.jpg)


![Microsoft Research
• Three Agent personas collaborating:
o Planner: dictates roles, orchestrates
conversation
o Domain Expert Agent: Extracts
constraints from NL or Code, provides
feedback about generated specification
o 3D Agent: translates extracted
specifications into 3D
• Implemented with AutoGen [1]
o Composable
Retrieval Augmented (RAG) agents
o Gpt-4-32k model
Agent Implementation
[1] Wu, Qingyun, et al. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework." arXiv:2308.08155 (2023)](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-39-2048.jpg)

![UIF (tests as spec) can improve code generation
accuracy and developer productivity with user-
in-the-loop
41
[LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation, Fakhoury, Naik, Sakkas, Chakraborty,
Lahiri, TSE’24]
[Interactive Code Generation via Test-Driven User-Intent Formalization, Lahiri, Naik, Sakkas, Choudhury, Veh, Musuvathi, Inala,
Wang, Gao, arXiv:2208.05950]](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-41-2048.jpg)




![Other works in AI and testing/verification
46
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language
Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury,
Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis,
Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner,
Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong,
Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri
[CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri
[Sigmod '25 to appear]
Trusted AI-assisted
Programming](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-46-2048.jpg)
![Summary
47
Trusted AI-assisted
Programming
Related research with LLM and testing/verification
• LLM and test generation
• TOGA: A Neural Method for Test Oracle Generation. Dinella, Ryan, Mytkowicz, Lahiri [ICSE ‘22]
• CODAMOSA: Escaping Coverage Plateaus in Test Generation with Pre-trained Large Language Models. Lemieux, Priya Inala, Lahiri, Sen [ICSE’23]
• LLM and proof automation
• Ranking LLM-Generated Loop Invariants for Program Verification Chakraborty, Lahiri, Fakhoury, Musuvathi, Lal, Rastogi, Swamy, Sharma [EMNLP’23]
• Leveraging LLMs for Program Verification. Kamath, Senthilnathan, Chakraborty, Deligiannis, Lahiri, Lal, Rastogi, Roy, Sharma [FMCAD’24]
• Towards Neural Synthesis for SMT-Assisted Proof-Oriented Programming Chakraborty, Ebner, Bhat, Fakhoury, Fatima, Lahiri, Swamy [ICSE’25 to
appear]
• AutoVerus: Automated Proof Generation for Rust Code. Yang, Li, Misu, Yao, Cui, Gong, Hawblitzel, Lahiri, Lorch, Lu, Yang, Zhou, Lu [arXiv]
• LLM and verified code translation
• LLM-Vectorizer: LLM-based Verified Loop Vectorizer. Taneja, Laird, Yan, Musuvathi, Lahiri [CGO’25 to appear]
• QURE: AI-Assisted and Automatically Verified UDF Inlining. Siddiqui, König, Cao, Yan, Lahiri [SIGMOD '25 to appear]
RiSE
AI for Program Specifications
• UIF for mainstream languages (Python, Java), and use case
• Endres, Fakhoury, Chakraborty, Lahiri [FSE’24]
• UIF for verification-aware languages (Dafny, F*, Verus, …)
• Lahiri [FMCAD’24]
• Application to a specification model training (for Verus) [ICLR’25]
• UIF for verified parser generation from RFCs
• 3DGen: Fakhoury, Kuppe, Lahiri, Ramananandro, Swamy [ICSE’25]
• Application to interactive code-generation (TiCoder)
• LLM-based Test-driven Interactive Code Generation: User Study and Empirical Evaluation. Fakhoury, Naik, Sakkas, Chakraborty, Lahiri [TSE’24]](https://crownmelresort.com/image.slidesharecdn.com/aiforprogramspecificationsuwplse2025-final-250410202630-cc0f8c05/75/AI-for-Program-Specifications-UW-PLSE-2025-final-pdf-47-2048.jpg)
















































