



![Staged
def add (!
a: Float, !
b: Float!
): Float = {!
a + b!
}!
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
Non-Staged
execution delayed
AST created
add (2,3)
add (2,3)
normal CPU
execution
Plus(2, 3)
5
2 3](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-8-2048.jpg)
![Staged
def add (!
a: Float, !
b: Float!
): Float = {!
a + b!
}!
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
Non-Staged
Float vs. Rep[Float]
LMS uses Scala Types
to control staging
T vs. Rep[T] - LMS
overloads operations on a
standard type [T] with a
staged version type Rep[T]
Staged and non-staged
code can be abstracted
using type parameters
def add [T] (!
a: T, b: T!
): T = { !
a + b!
}!
add [Rep[Float]]!
type NoRep[T] = T!
add[NoRep[Float]]!](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-9-2048.jpg)
![Building generators with staging
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
float add (!
float a, !
float b!
) = { !
return a - b;!
}!
Staging
AST Rewrites:
• Domain specific
optimizations
• Low level
optimizations
Unparsing
to C code
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b * (-1)!
}!
a
b-1
a b](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-10-2048.jpg)
![Abstracting Code Styles with Staging1
for (i <- 0 to n: Rep[Int]) { f(i) }!
for (i <- 0 to n: NoRep[Int]) { f(i) }!
n f(i)
for
ArrayApply(a, 1)!
ArrayApply(a, 3)!
val (x1, x2) = (a(1), a(3))!
val x3 = x1 + x2!
val a: Array[Rep[T]]!val a: Rep[Array[T]]!
a
x1
1
x2
3
a
x1
x2
a(0)
a(1)
a(2)
a(3)
a(4)
Looped
Code
Unrolled
Code
Arrays of Staged Elements
(i.e. array scalarization)Staged Arrays
1Spiral in Scala: towards the systematic construction of generators for performance libraries.
G. Ofenbeck, T. Rompf, A. Stojanov M. Odersky, M. Püschel. GPCE 2013
f(0)
f(1)
f(2) f(n)
…f(3)](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-11-2048.jpg)
![Scala Type Classes
used to encapsulate
implementation
abstract class NumericOps[T] {!
def plus (x: T, y: T) : T!
def minus (x: T, y: T) : T!
def times (x: T, y: T) : T!
}!
class SISDOps[T] extends NumericOps[Rep[SISD[[T]]] !
{!
type E = Rep[SISD[[T]]!
def plus (x: E, y: E) = Plus [E](x, y)!
def minus(x: E, y: E) = Minus[E](x, y)!
def times(x: E, y: E) = Times[E](x, y)!
}!
SISD (staged)
class SIMDOps[T] extends NumericOps[Rep[SIMD[[T]]]!
{ !
type E = Rep[SIMD[[T]]!
def plus (x: E, y: E) = VPlus [E](x, y)!
def minus(x: E, y: E) = VMinus[E](x, y)!
def times(x: E, y: E) = VTimes[E](x, y)!
}!
SIMD (staged, ISA independent)
abstract class ArrayOps[…] {!
def alloc (…): …!
def apply (…): …!
def update (…): …!
}!](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-12-2048.jpg)
![abstract class NumericOps[T] {!
def plus (x: T, y: T) : T!
def minus (x: T, y: T) : T!
def times (x: T, y: T) : T!
}!
Scala Type Classes
used to encapsulate
implementation
abstract class ArrayOps[…] {!
def alloc (…): …!
def apply (…): …!
def update (…): …!
}!
SISD (apply, compute, store)
1
3
2
4
1
3
2
4
apply
1
3
2
4
1
3
2
4
compute
update
1
3
2
4
1
2
3
4
1
3
2
4
SIMD (apply, compute, store - ISA dependent)
1
2
3
4
1
3
2
4
1
3
2
4
apply
compute
update](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-13-2048.jpg)

![abstract class CVector[V[_], E[_], R[_], P[_], T](...) {!
type Element = E[R[P[T]]]!
val nops: NumericOps[Element]!
val aops: ArrayOps[V[Element]]!
def size (): V[Int]!
def apply (i: V[Int]) : Element!
def update (i: V[Int], v: Element)!
}!
Staged /Non Staged Array
Type of Element:
Real Numbers
Complex Numbers
Staged / Non Staged
Element Primitives
SIMD / SISD
Array
Underlying primitive:
Float / Double / Int
class Interleaved_Scalar_Complex_SISD_Double_Vector extends!
CVector[NoRep, Complex, Rep, SISD, Double]!
Complete Abstraction](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-15-2048.jpg)
![single
codebase
def add[V[_], E[_], R[_], P[_], T] (!
(x, y, z): Tuple3[CVector[V,E,R,P,T]]!
) = for ( i <- 0 until x.size() ) { !
z(i) = x(i) + y(i) !
}!
#define T float!
#define N 4!
void add(T* x, T* y, T* z) {!
int i = 0;!
for(; i < N; ++i) {!
T x1 = x[i];!
T y1 = y[i];!
T z1 = x1 + y1;!
z[i] = z1;!
}!
}!
#define T int!
void add(T* x, T* y, T* z) {!
T x1 = x[0]; T x2 = x[1];!
T x3 = x[2]; T x4 = x[3];!
T y1 = y[0]; T y2 = y[1];!
T y3 = y[2]; T y4 = y[3];!
T z1 = x1 + y1;!
T z2 = x2 + y2;!
T z3 = x3 + y3;!
T z4 = x4 + y4;!
z[0] = z1; z[1] = z2;!
z[2] = z3; z[3] = z4;!
}!
#define T double!
#define N 1!
void add(T* x, T* y, T* z) {!
int i = 0;!
for(; i < N; ++i) {!
__m256d x1, y1, z1;!
x1 = _mm256_loadu_pd(x + i);!
y1 = _mm256_loadu_pd(y + i);!
z1 = _mm256_add_pd(x1, y1);!
_mm256_storeu_pd(z + i, y1);!
}!
}!
#define T double!
void add(T* x, T* y, T* z) {!
__m256d x1, y1, z1;!
x1 = _mm256_loadu_pd(x + 0);!
y1 = _mm256_loadu_pd(y + 0);!
z1 = _mm256_add_pd(x1, y1);!
_mm256_storeu_pd(z + 0, y1);!
}!
Staged Loop
SISD, Floats
Unrolled Loop
SISD, Integers
Staged Loop
SIMD, Doubles
Unrolled Loop
SIMD, Doubles
type T = Float
add[Rep,Real,NoRep,SISD,T]
type T = Int
add[NoRep,Real,Rep,SISD,T]
type T = Double
add[Rep,Real,NoRep,SIMD,T]
type T = Double
add[NoRep,Real,Rep,SIMD,T]](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-16-2048.jpg)


![class SigmaLL2IIRTranslator[E[_], R[_], P[_], T] {!
type Element = E[R[P[T]]]!
def sum (in: List[Element]) =!
if (in.length == 1) in(0) else {!
val (m, e) = (in.length / 2, in.length)!
sum(in.slice(0, m)) + sum(in.slice(m, e))!
}!
def translate(stm: Stm) = stm match {!
case TP(y, PFIR(x, h)) =>!
val xV = List.tabulate(k)(i => x.apply(i))!
val hV = List.tabulate(k)!
(i => h.vset1(h.apply(k-i-1)))!
val tV = (xV, hV).zipped map (_*_)!
y.update(y(0), sum(tV))!
}!
}!
I-IR conversion
& SIMDification
1
2
3
4
1
2
3
5
6
1
2
3
4
1
1
1
1
2
2
2
2
3
3
3
3
2
3
4
5
3
4
5
6
↓](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-21-2048.jpg)
![class SigmaLL2IIRTranslator[E[_], R[_], P[_], T] {!
type Element = E[R[P[T]]]!
def sum (in: List[Element]) =!
if (in.length == 1) in(0) else {!
val (m, e) = (in.length / 2, in.length)!
sum(in.slice(0, m)) + sum(in.slice(m, e))!
}!
def translate(stm: Stm) = stm match {!
case TP(y, PFIR(x, h)) =>!
val xV = List.tabulate(k)(i => x.apply(i))!
val hV = List.tabulate(k)!
(i => h.vset1(h.apply(k-i-1)))!
val tV = (xV, hV).zipped map (_*_)!
y.update(y(0), sum(tV))!
}!
}!
I-IR conversion
& SIMDification
123
1.23
Scalar, SSE, AVX](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-22-2048.jpg)

![Intel(R) Xeon(R)
E5-2643 3.3 GHz
AVX, Ubuntu 13.10
Intel C++ Composer 2013.SP1.1.106
flags: -std=c99 -O3 –xHost
kernel v3.11.0-12-generic
Intel MKL v11.1.1
Intel IPP v8.0.1
Intel’s Hyper-Threading: Off
Intel Turbo Boost: Off
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
8 Taps, Complex Numbers
IPP
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
20 Taps, Complex Numbers
IPP
MKL
Base
● ● ● ● ●
● ● ● ● ●
● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
8 Taps, Real Numbers
IPP
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
20 Taps, Real Numbers
IPP
MKL
Base
●Base IPP v8.0.1 MKL v11.1.1 FGen](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-24-2048.jpg)
![Intel(R) Core(TM) 2 Duo
CPU L7500 1.6 GHz,
SSSE3, Debian 7
Intel C++ Composer 2013.SP1.1.106
flags: -std=c99 -O3 –xHost
kernel v3.2.0-4-686-pae
Intel MKL v11.1.1
Intel IPP v8.0.1
Intel Dynamic Acceleration: Off
●Base IPP v8.0.1 MKL v11.1.1 FGen
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
8 Taps, Complex Numbers
IPP
FGenBase
MKL
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
20 Taps, Complex Numbers
IPP
FGen
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
8 Taps, Real Numbers
FGen
MKL
IPPBase
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
20 Taps, Real Numbers
IPP
Base
FGen
MKL](https://image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-25-2048.jpg)








![Staged
def add (!
a: Float, !
b: Float!
): Float = {!
a + b!
}!
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
Non-Staged
execution delayed
AST created
add (2,3)
add (2,3)
normal CPU
execution
Plus(2, 3)
5
2 3](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-8-2048.jpg)
![Staged
def add (!
a: Float, !
b: Float!
): Float = {!
a + b!
}!
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
Non-Staged
Float vs. Rep[Float]
LMS uses Scala Types
to control staging
T vs. Rep[T] - LMS
overloads operations on a
standard type [T] with a
staged version type Rep[T]
Staged and non-staged
code can be abstracted
using type parameters
def add [T] (!
a: T, b: T!
): T = { !
a + b!
}!
add [Rep[Float]]!
type NoRep[T] = T!
add[NoRep[Float]]!](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-9-2048.jpg)
![Building generators with staging
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b!
}!
float add (!
float a, !
float b!
) = { !
return a - b;!
}!
Staging
AST Rewrites:
• Domain specific
optimizations
• Low level
optimizations
Unparsing
to C code
def add (!
a: Rep[Float], !
b: Rep[Float]!
): Rep[Float] = { !
a + b * (-1)!
}!
a
b-1
a b](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-10-2048.jpg)
![Abstracting Code Styles with Staging1
for (i <- 0 to n: Rep[Int]) { f(i) }!
for (i <- 0 to n: NoRep[Int]) { f(i) }!
n f(i)
for
ArrayApply(a, 1)!
ArrayApply(a, 3)!
val (x1, x2) = (a(1), a(3))!
val x3 = x1 + x2!
val a: Array[Rep[T]]!val a: Rep[Array[T]]!
a
x1
1
x2
3
a
x1
x2
a(0)
a(1)
a(2)
a(3)
a(4)
Looped
Code
Unrolled
Code
Arrays of Staged Elements
(i.e. array scalarization)Staged Arrays
1Spiral in Scala: towards the systematic construction of generators for performance libraries.
G. Ofenbeck, T. Rompf, A. Stojanov M. Odersky, M. Püschel. GPCE 2013
f(0)
f(1)
f(2) f(n)
…f(3)](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-11-2048.jpg)
![Scala Type Classes
used to encapsulate
implementation
abstract class NumericOps[T] {!
def plus (x: T, y: T) : T!
def minus (x: T, y: T) : T!
def times (x: T, y: T) : T!
}!
class SISDOps[T] extends NumericOps[Rep[SISD[[T]]] !
{!
type E = Rep[SISD[[T]]!
def plus (x: E, y: E) = Plus [E](x, y)!
def minus(x: E, y: E) = Minus[E](x, y)!
def times(x: E, y: E) = Times[E](x, y)!
}!
SISD (staged)
class SIMDOps[T] extends NumericOps[Rep[SIMD[[T]]]!
{ !
type E = Rep[SIMD[[T]]!
def plus (x: E, y: E) = VPlus [E](x, y)!
def minus(x: E, y: E) = VMinus[E](x, y)!
def times(x: E, y: E) = VTimes[E](x, y)!
}!
SIMD (staged, ISA independent)
abstract class ArrayOps[…] {!
def alloc (…): …!
def apply (…): …!
def update (…): …!
}!](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-12-2048.jpg)
![abstract class NumericOps[T] {!
def plus (x: T, y: T) : T!
def minus (x: T, y: T) : T!
def times (x: T, y: T) : T!
}!
Scala Type Classes
used to encapsulate
implementation
abstract class ArrayOps[…] {!
def alloc (…): …!
def apply (…): …!
def update (…): …!
}!
SISD (apply, compute, store)
1
3
2
4
1
3
2
4
apply
1
3
2
4
1
3
2
4
compute
update
1
3
2
4
1
2
3
4
1
3
2
4
SIMD (apply, compute, store - ISA dependent)
1
2
3
4
1
3
2
4
1
3
2
4
apply
compute
update](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-13-2048.jpg)

![abstract class CVector[V[_], E[_], R[_], P[_], T](...) {!
type Element = E[R[P[T]]]!
val nops: NumericOps[Element]!
val aops: ArrayOps[V[Element]]!
def size (): V[Int]!
def apply (i: V[Int]) : Element!
def update (i: V[Int], v: Element)!
}!
Staged /Non Staged Array
Type of Element:
Real Numbers
Complex Numbers
Staged / Non Staged
Element Primitives
SIMD / SISD
Array
Underlying primitive:
Float / Double / Int
class Interleaved_Scalar_Complex_SISD_Double_Vector extends!
CVector[NoRep, Complex, Rep, SISD, Double]!
Complete Abstraction](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-15-2048.jpg)
![single
codebase
def add[V[_], E[_], R[_], P[_], T] (!
(x, y, z): Tuple3[CVector[V,E,R,P,T]]!
) = for ( i <- 0 until x.size() ) { !
z(i) = x(i) + y(i) !
}!
#define T float!
#define N 4!
void add(T* x, T* y, T* z) {!
int i = 0;!
for(; i < N; ++i) {!
T x1 = x[i];!
T y1 = y[i];!
T z1 = x1 + y1;!
z[i] = z1;!
}!
}!
#define T int!
void add(T* x, T* y, T* z) {!
T x1 = x[0]; T x2 = x[1];!
T x3 = x[2]; T x4 = x[3];!
T y1 = y[0]; T y2 = y[1];!
T y3 = y[2]; T y4 = y[3];!
T z1 = x1 + y1;!
T z2 = x2 + y2;!
T z3 = x3 + y3;!
T z4 = x4 + y4;!
z[0] = z1; z[1] = z2;!
z[2] = z3; z[3] = z4;!
}!
#define T double!
#define N 1!
void add(T* x, T* y, T* z) {!
int i = 0;!
for(; i < N; ++i) {!
__m256d x1, y1, z1;!
x1 = _mm256_loadu_pd(x + i);!
y1 = _mm256_loadu_pd(y + i);!
z1 = _mm256_add_pd(x1, y1);!
_mm256_storeu_pd(z + i, y1);!
}!
}!
#define T double!
void add(T* x, T* y, T* z) {!
__m256d x1, y1, z1;!
x1 = _mm256_loadu_pd(x + 0);!
y1 = _mm256_loadu_pd(y + 0);!
z1 = _mm256_add_pd(x1, y1);!
_mm256_storeu_pd(z + 0, y1);!
}!
Staged Loop
SISD, Floats
Unrolled Loop
SISD, Integers
Staged Loop
SIMD, Doubles
Unrolled Loop
SIMD, Doubles
type T = Float
add[Rep,Real,NoRep,SISD,T]
type T = Int
add[NoRep,Real,Rep,SISD,T]
type T = Double
add[Rep,Real,NoRep,SIMD,T]
type T = Double
add[NoRep,Real,Rep,SIMD,T]](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-16-2048.jpg)




![class SigmaLL2IIRTranslator[E[_], R[_], P[_], T] {!
type Element = E[R[P[T]]]!
def sum (in: List[Element]) =!
if (in.length == 1) in(0) else {!
val (m, e) = (in.length / 2, in.length)!
sum(in.slice(0, m)) + sum(in.slice(m, e))!
}!
def translate(stm: Stm) = stm match {!
case TP(y, PFIR(x, h)) =>!
val xV = List.tabulate(k)(i => x.apply(i))!
val hV = List.tabulate(k)!
(i => h.vset1(h.apply(k-i-1)))!
val tV = (xV, hV).zipped map (_*_)!
y.update(y(0), sum(tV))!
}!
}!
I-IR conversion
& SIMDification
1
2
3
4
1
2
3
5
6
1
2
3
4
1
1
1
1
2
2
2
2
3
3
3
3
2
3
4
5
3
4
5
6
↓](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-21-2048.jpg)
![class SigmaLL2IIRTranslator[E[_], R[_], P[_], T] {!
type Element = E[R[P[T]]]!
def sum (in: List[Element]) =!
if (in.length == 1) in(0) else {!
val (m, e) = (in.length / 2, in.length)!
sum(in.slice(0, m)) + sum(in.slice(m, e))!
}!
def translate(stm: Stm) = stm match {!
case TP(y, PFIR(x, h)) =>!
val xV = List.tabulate(k)(i => x.apply(i))!
val hV = List.tabulate(k)!
(i => h.vset1(h.apply(k-i-1)))!
val tV = (xV, hV).zipped map (_*_)!
y.update(y(0), sum(tV))!
}!
}!
I-IR conversion
& SIMDification
123
1.23
Scalar, SSE, AVX](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-22-2048.jpg)

![Intel(R) Xeon(R)
E5-2643 3.3 GHz
AVX, Ubuntu 13.10
Intel C++ Composer 2013.SP1.1.106
flags: -std=c99 -O3 –xHost
kernel v3.11.0-12-generic
Intel MKL v11.1.1
Intel IPP v8.0.1
Intel’s Hyper-Threading: Off
Intel Turbo Boost: Off
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
8 Taps, Complex Numbers
IPP
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
20 Taps, Complex Numbers
IPP
MKL
Base
● ● ● ● ●
● ● ● ● ●
● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
8 Taps, Real Numbers
IPP
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
2
4
6
8
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
FGen
20 Taps, Real Numbers
IPP
MKL
Base
●Base IPP v8.0.1 MKL v11.1.1 FGen](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-24-2048.jpg)
![Intel(R) Core(TM) 2 Duo
CPU L7500 1.6 GHz,
SSSE3, Debian 7
Intel C++ Composer 2013.SP1.1.106
flags: -std=c99 -O3 –xHost
kernel v3.2.0-4-686-pae
Intel MKL v11.1.1
Intel IPP v8.0.1
Intel Dynamic Acceleration: Off
●Base IPP v8.0.1 MKL v11.1.1 FGen
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
8 Taps, Complex Numbers
IPP
FGenBase
MKL
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
20 Taps, Complex Numbers
IPP
FGen
MKL
Base
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
8 Taps, Real Numbers
FGen
MKL
IPPBase
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0
1
2
3
4
5
2^10 2^13 2^16 2^19 2^22 2^25
Input size
Performance [f/c]
20 Taps, Real Numbers
IPP
Base
FGen
MKL](https://crownmelresort.com/image.slidesharecdn.com/arraypdf-141224032326-conversion-gate02/75/Abstracting-Vector-Architectures-in-Library-Generators-Case-Study-Convolution-Filters-25-2048.jpg)


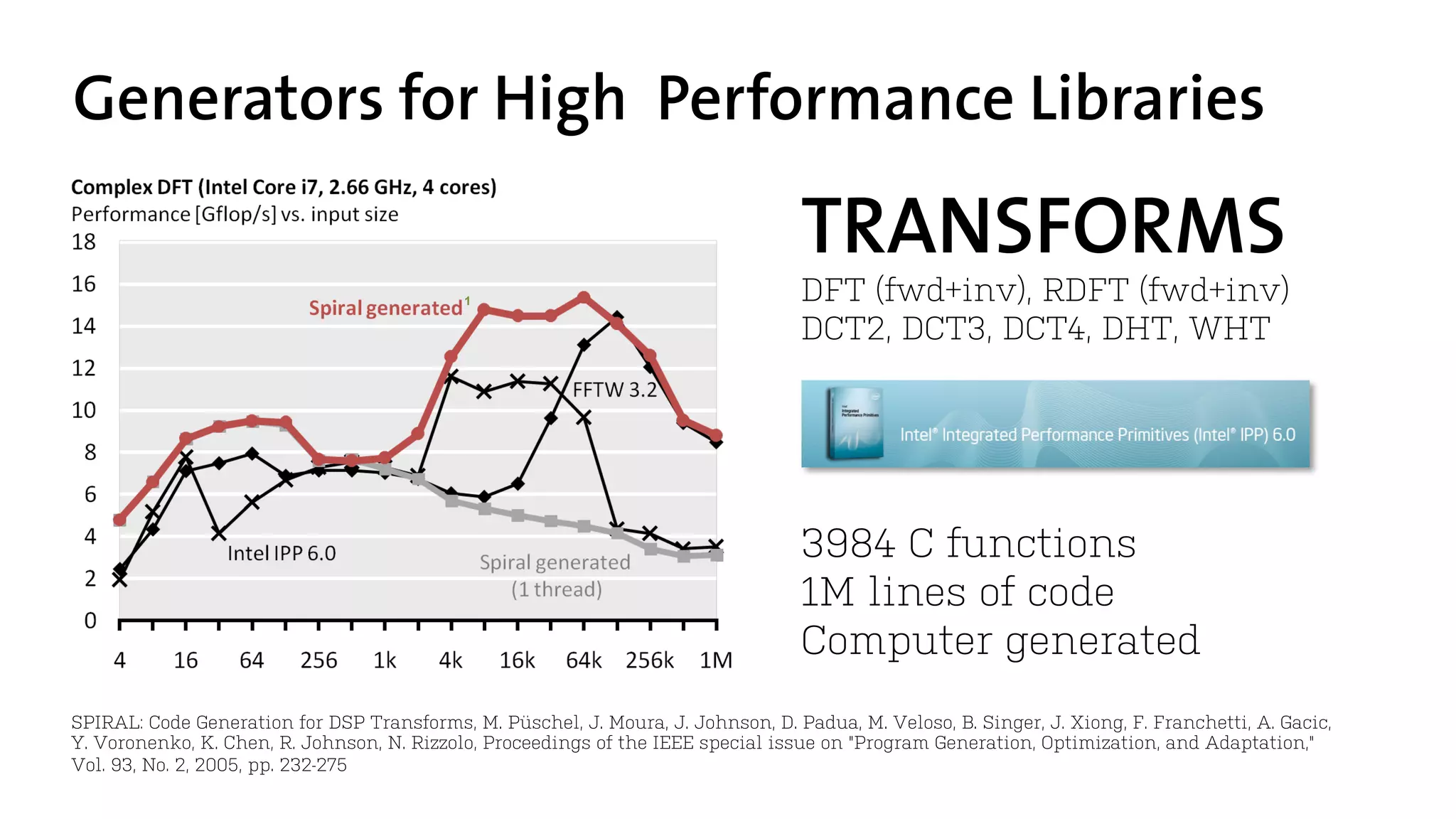
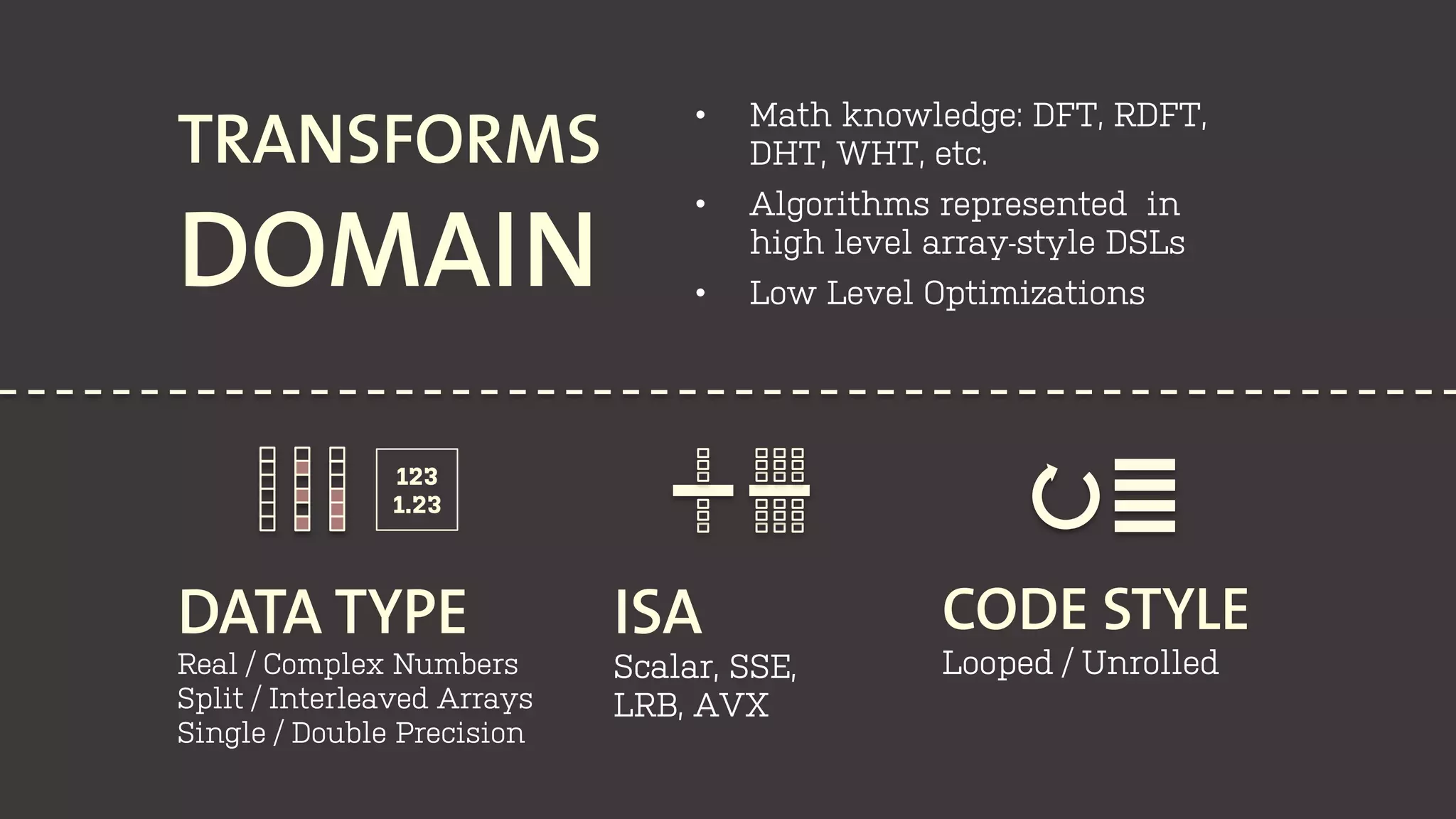
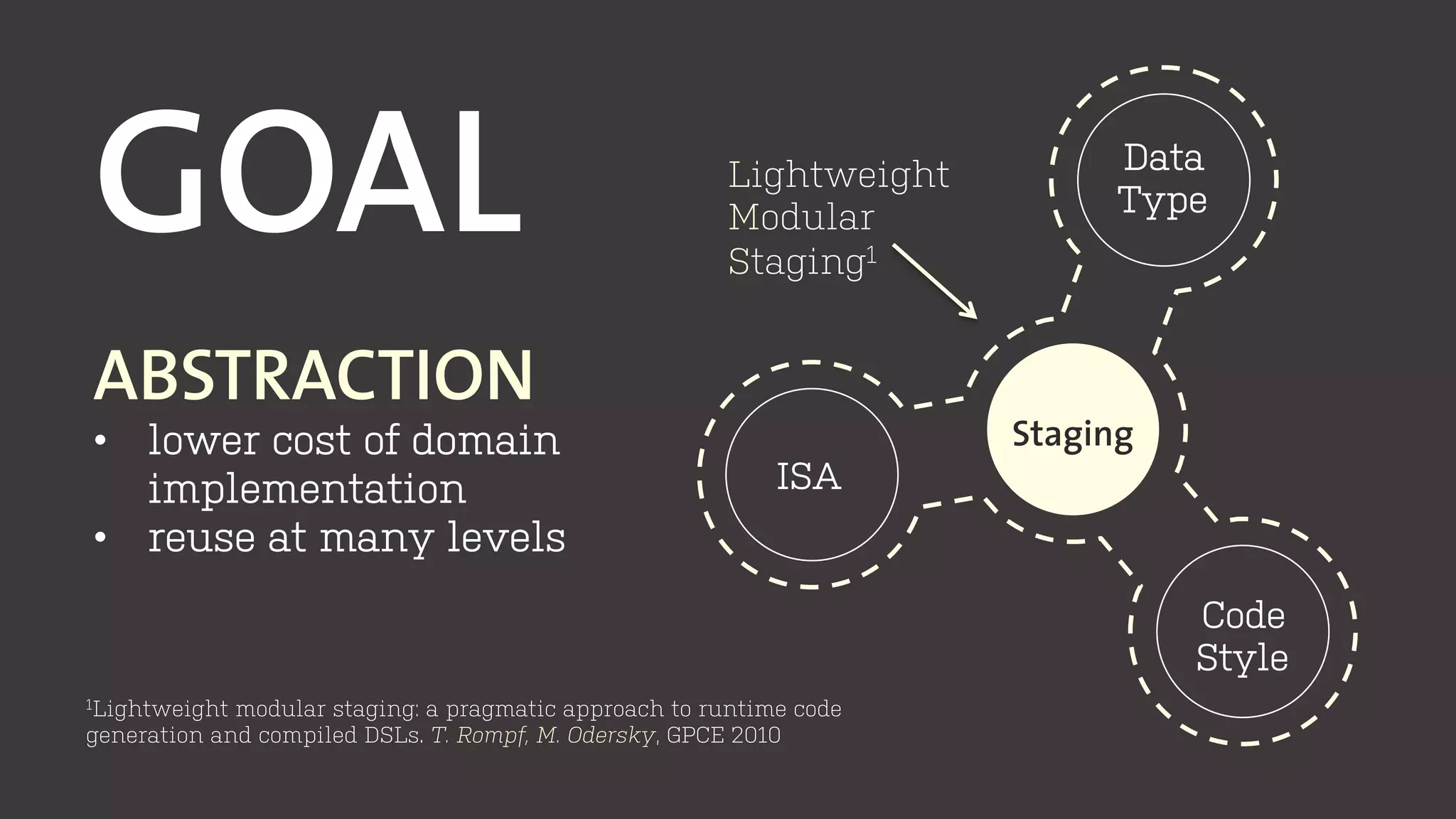
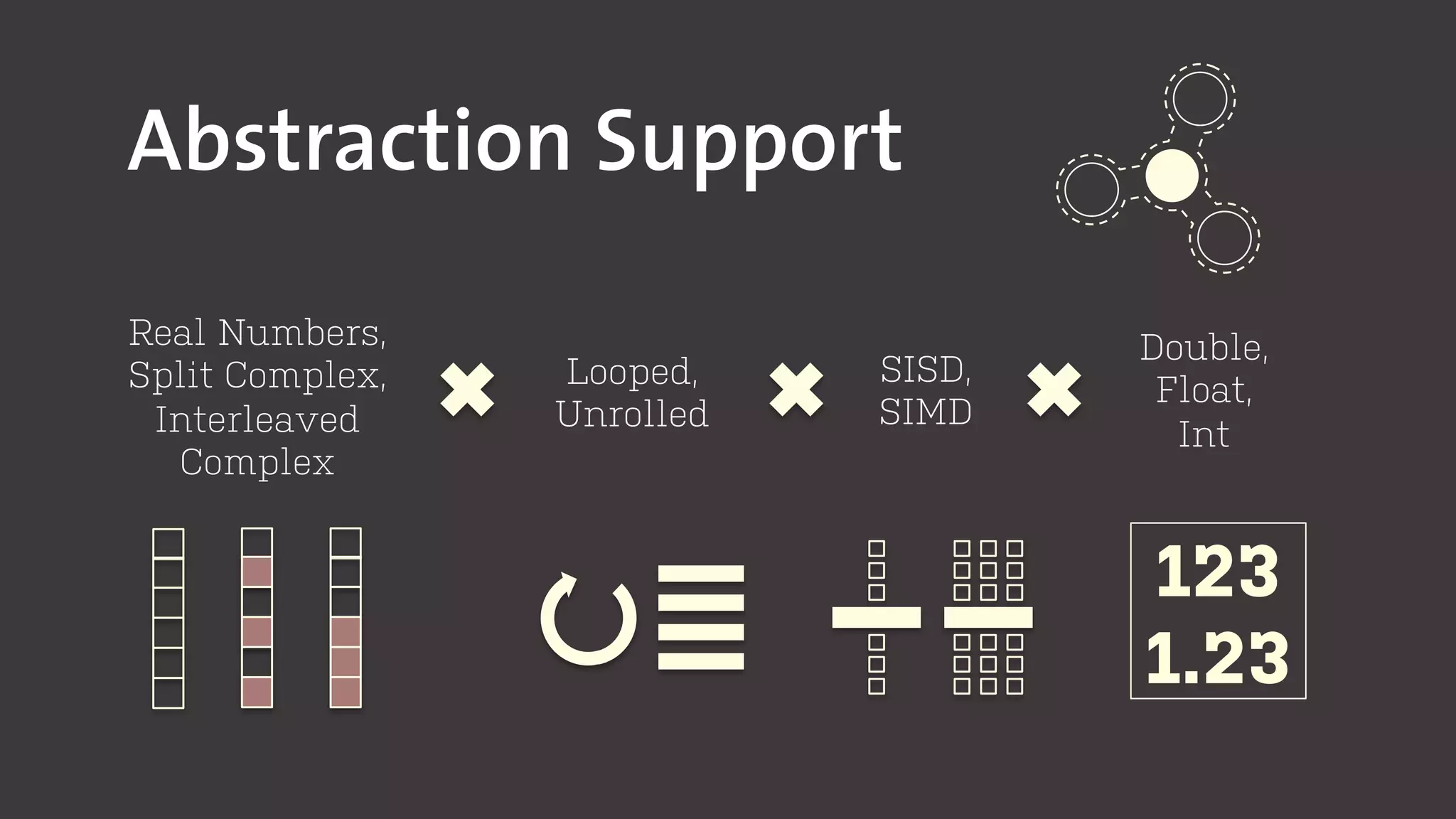
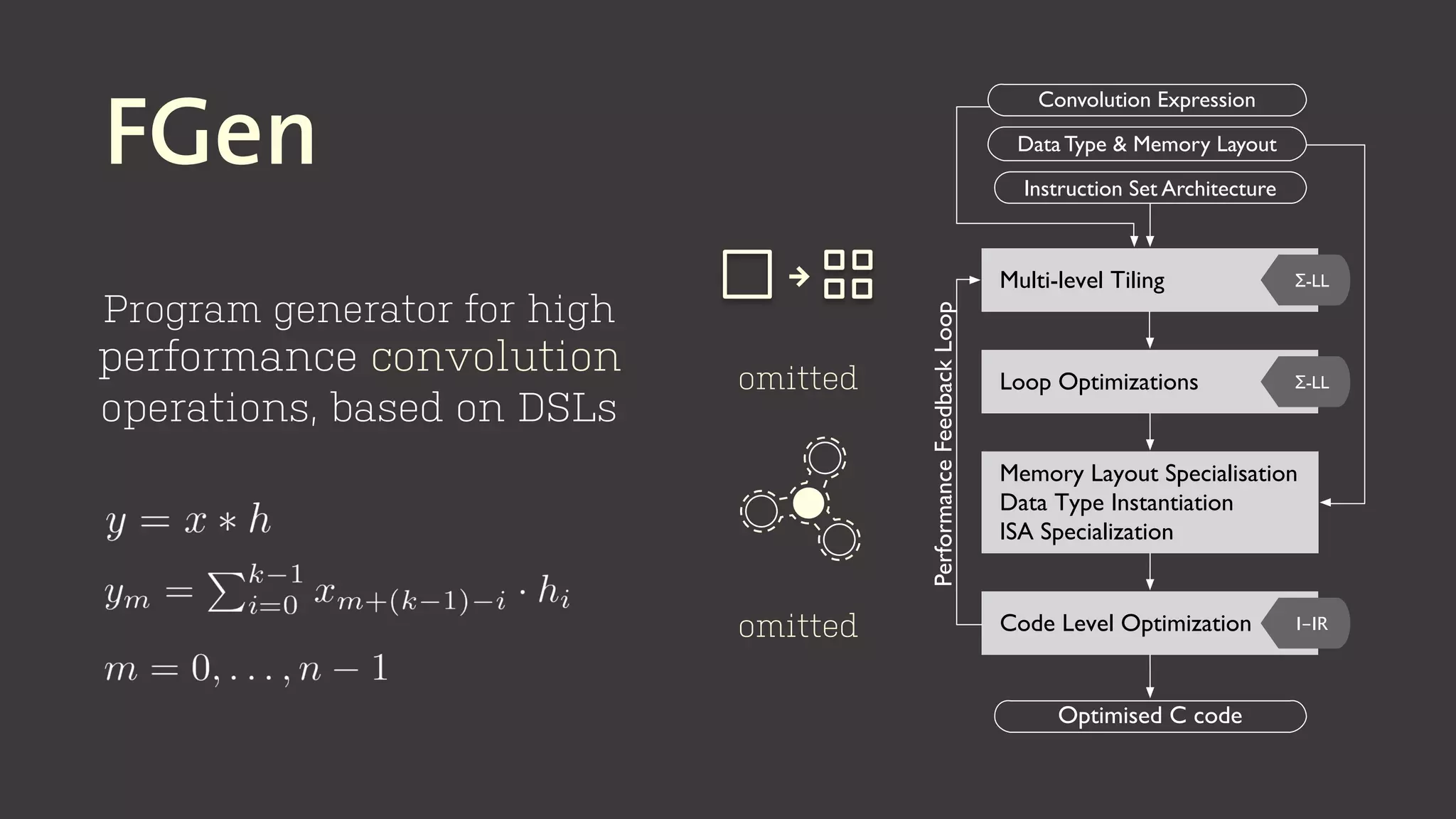
The document discusses the development of program generators for high-performance libraries using generic programming and staging techniques. It emphasizes the ability to create a single codebase that accommodates varying code styles, instruction set architectures (ISA), and data abstractions while achieving performance similar to commercial libraries. The case study focuses on convolution filters and highlights the practicality and efficiency of the approach in various domains.



































































