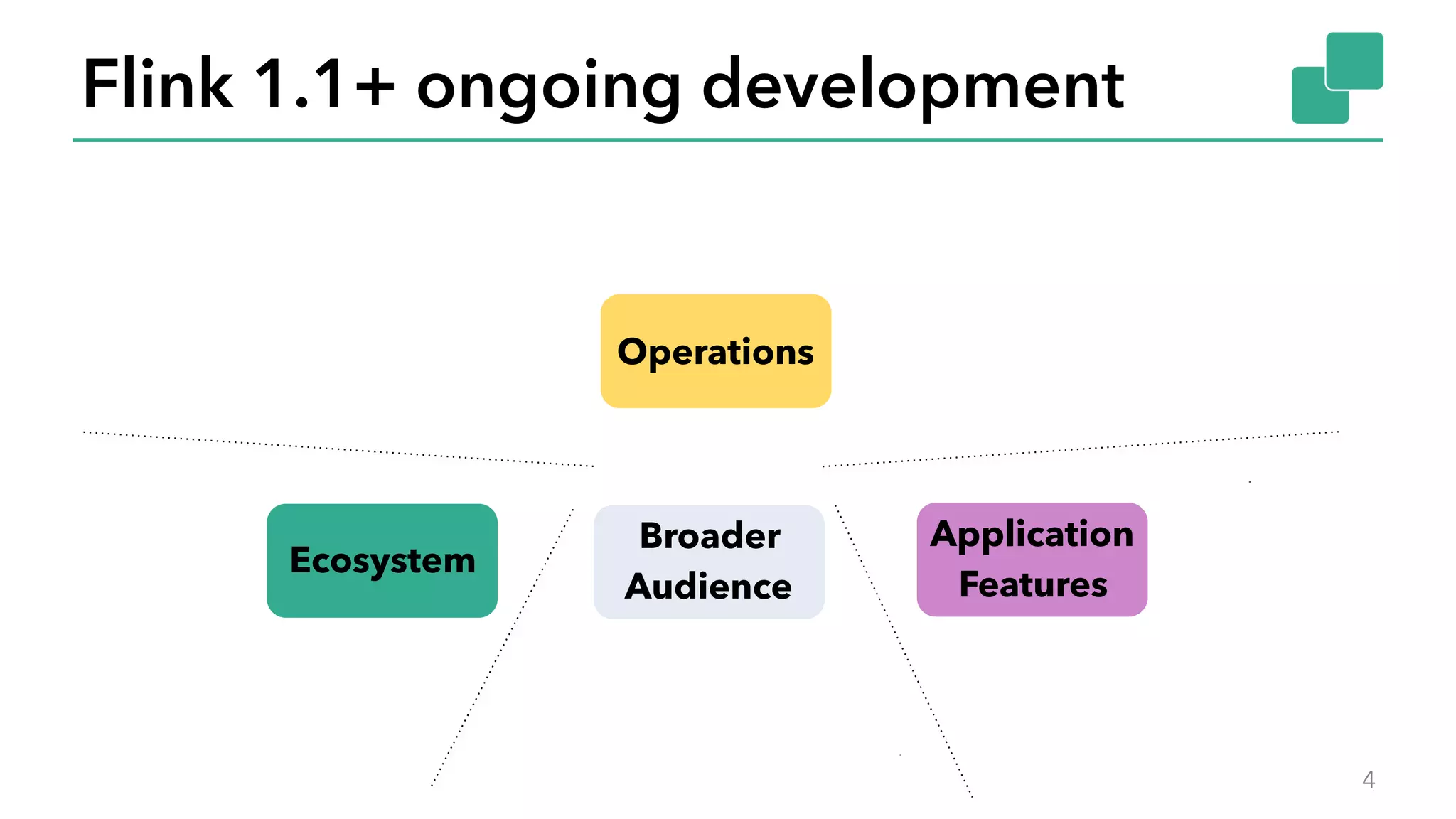
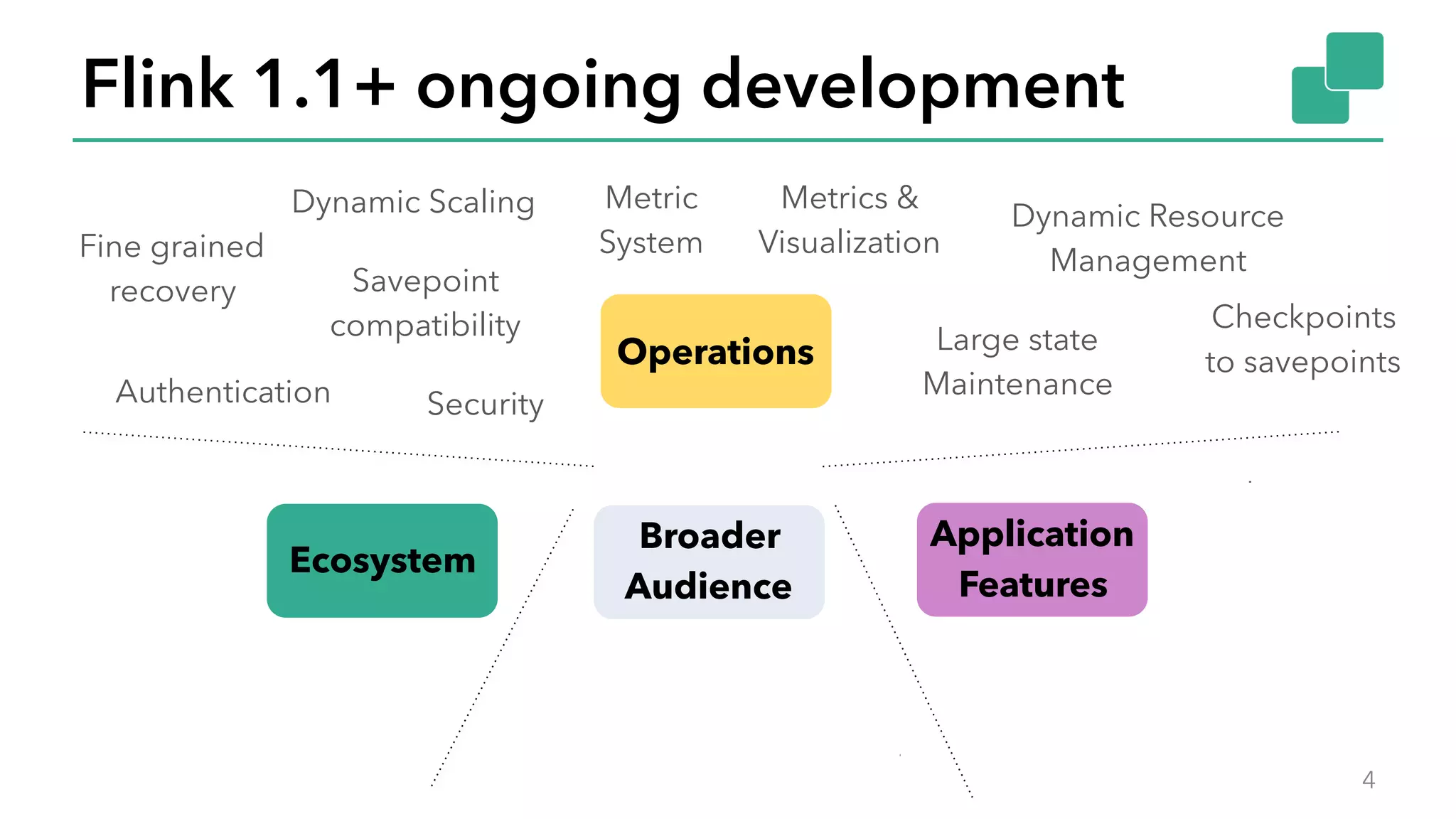
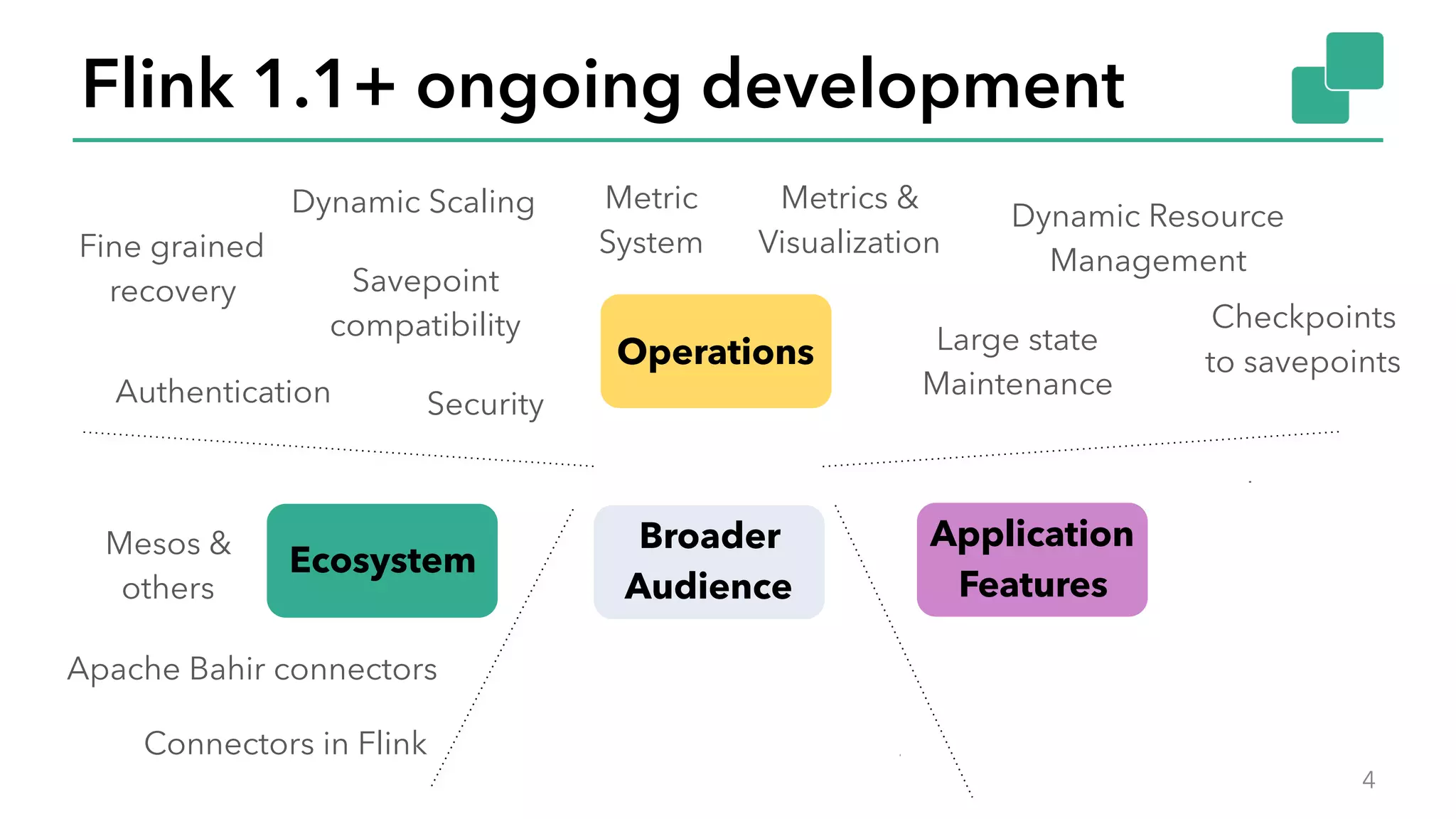
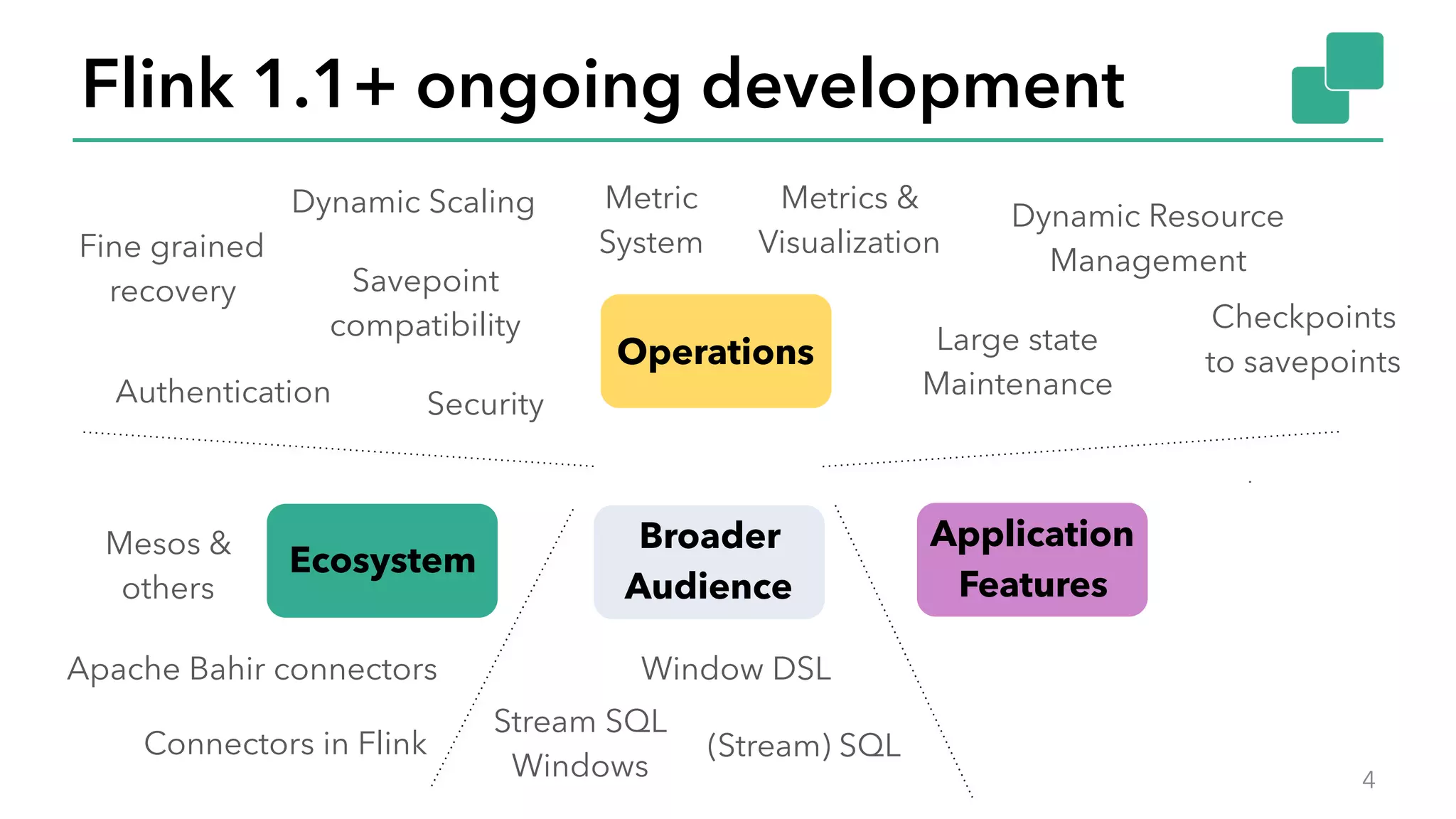
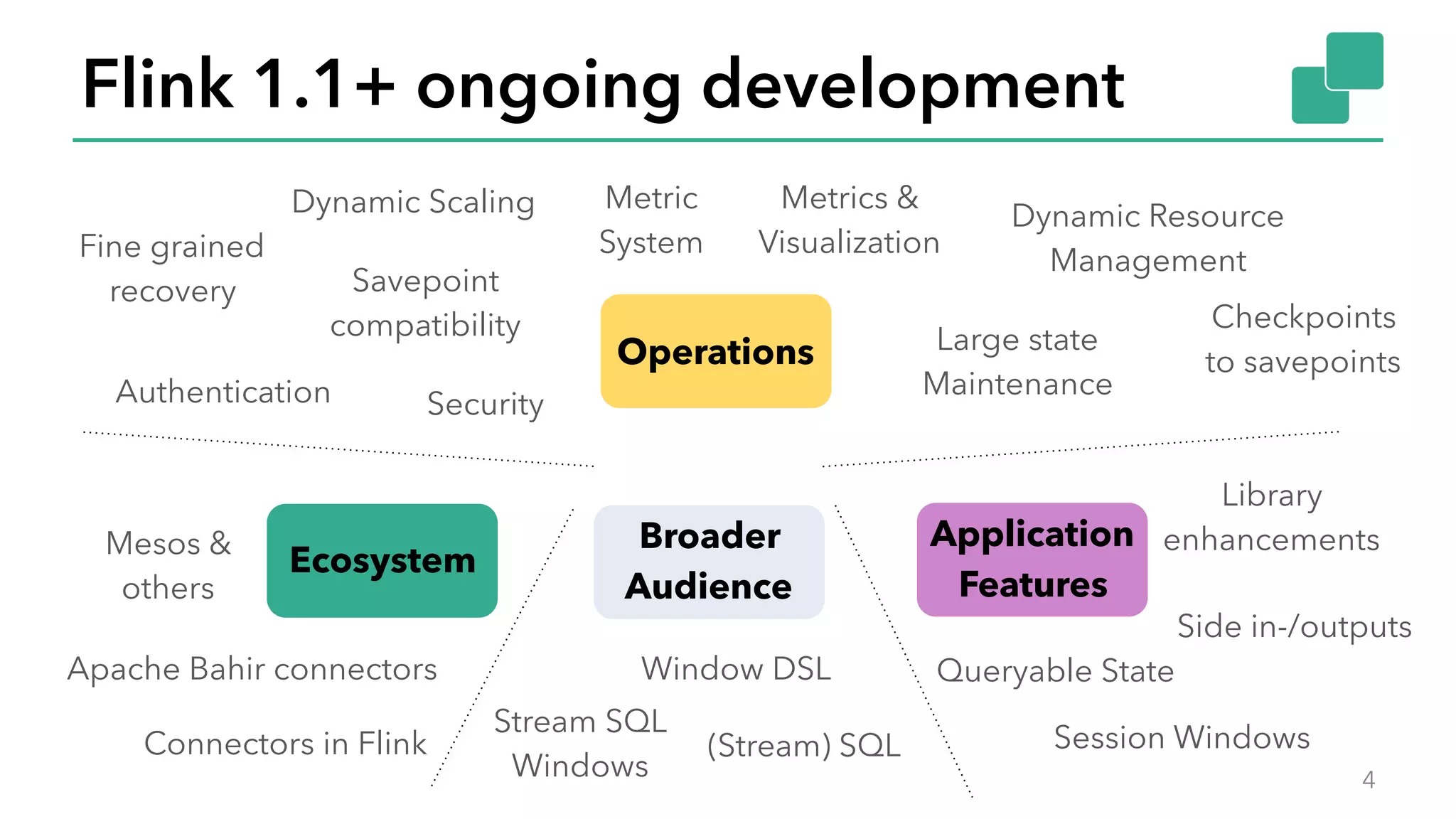
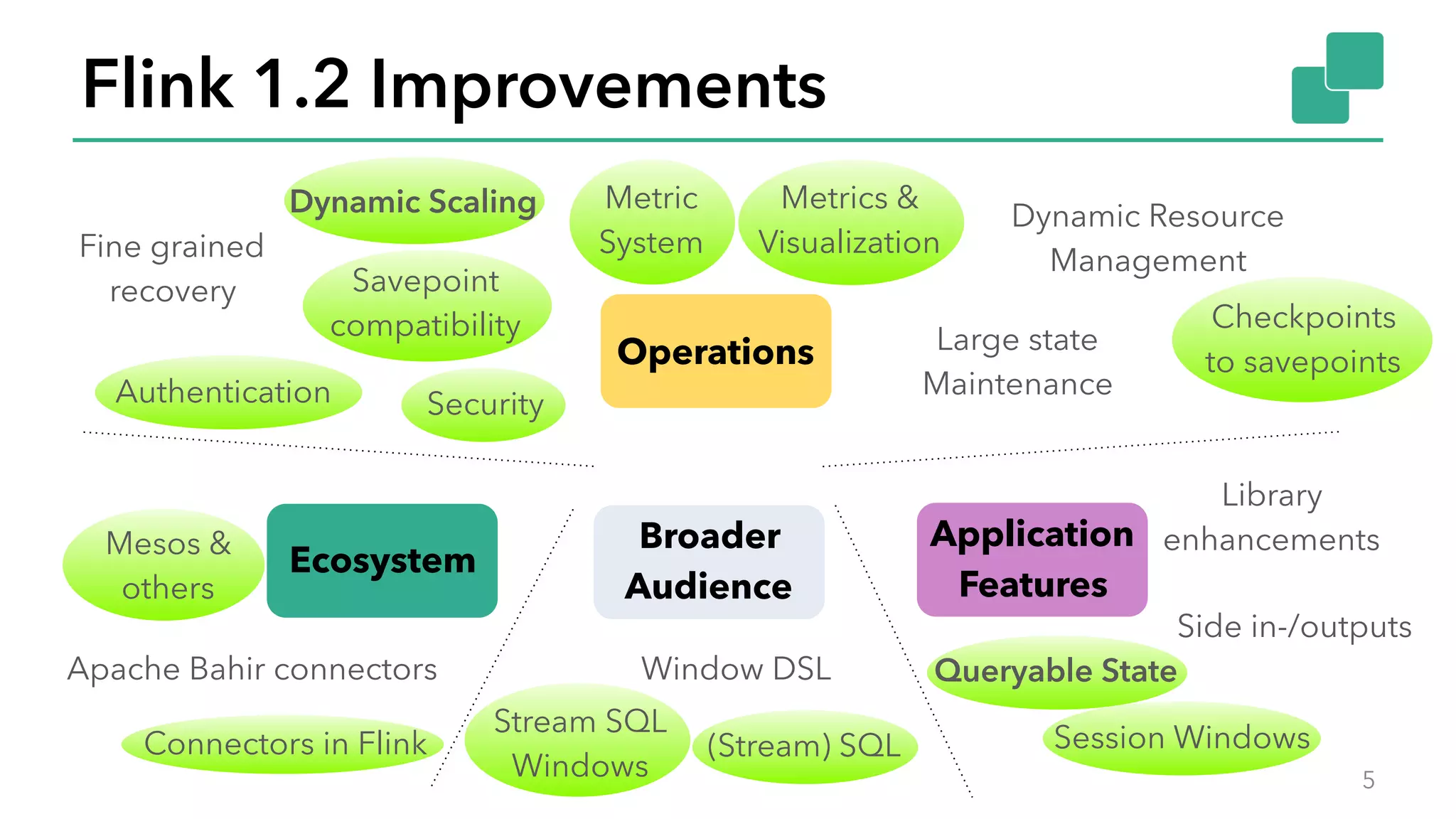
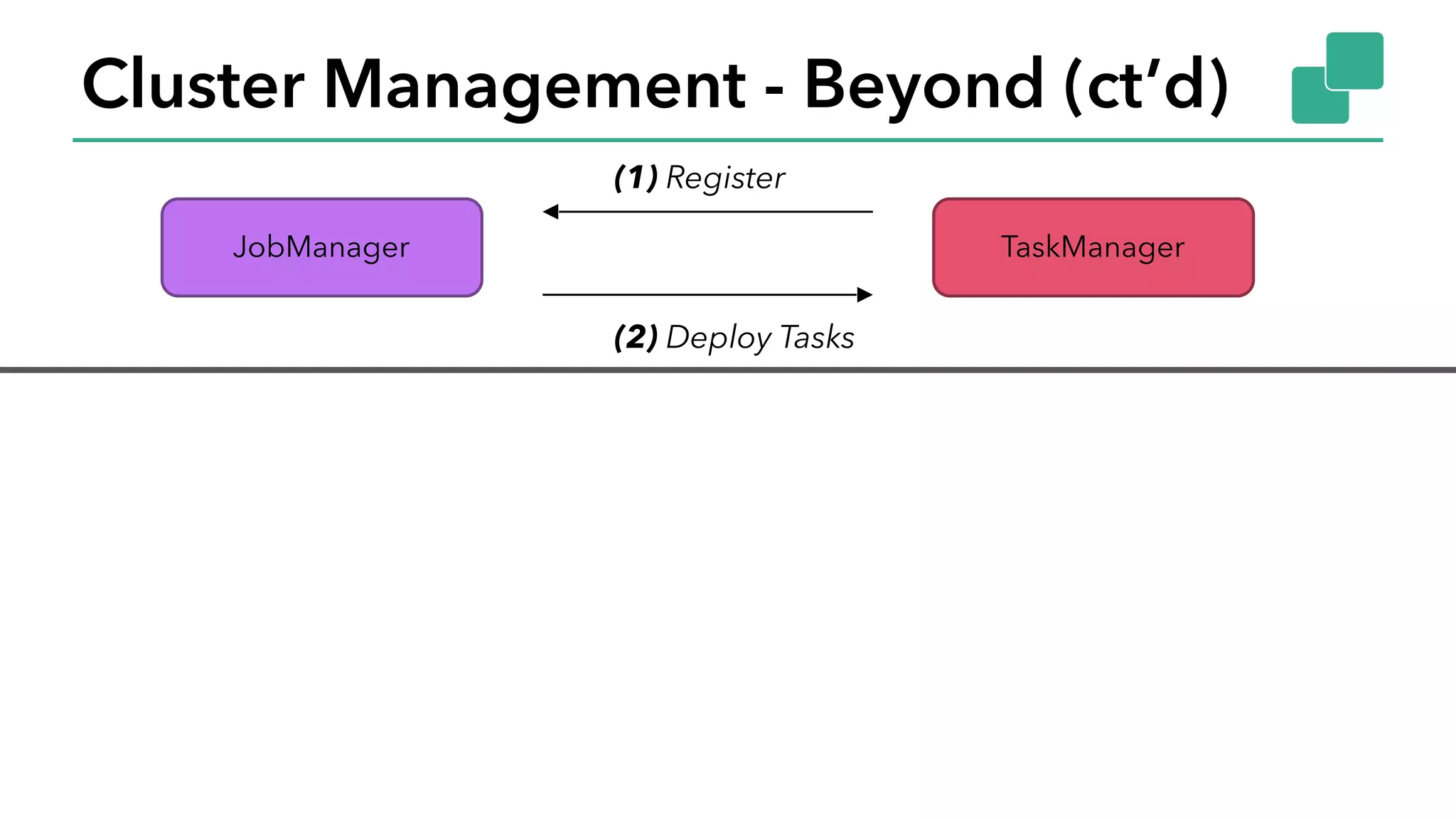
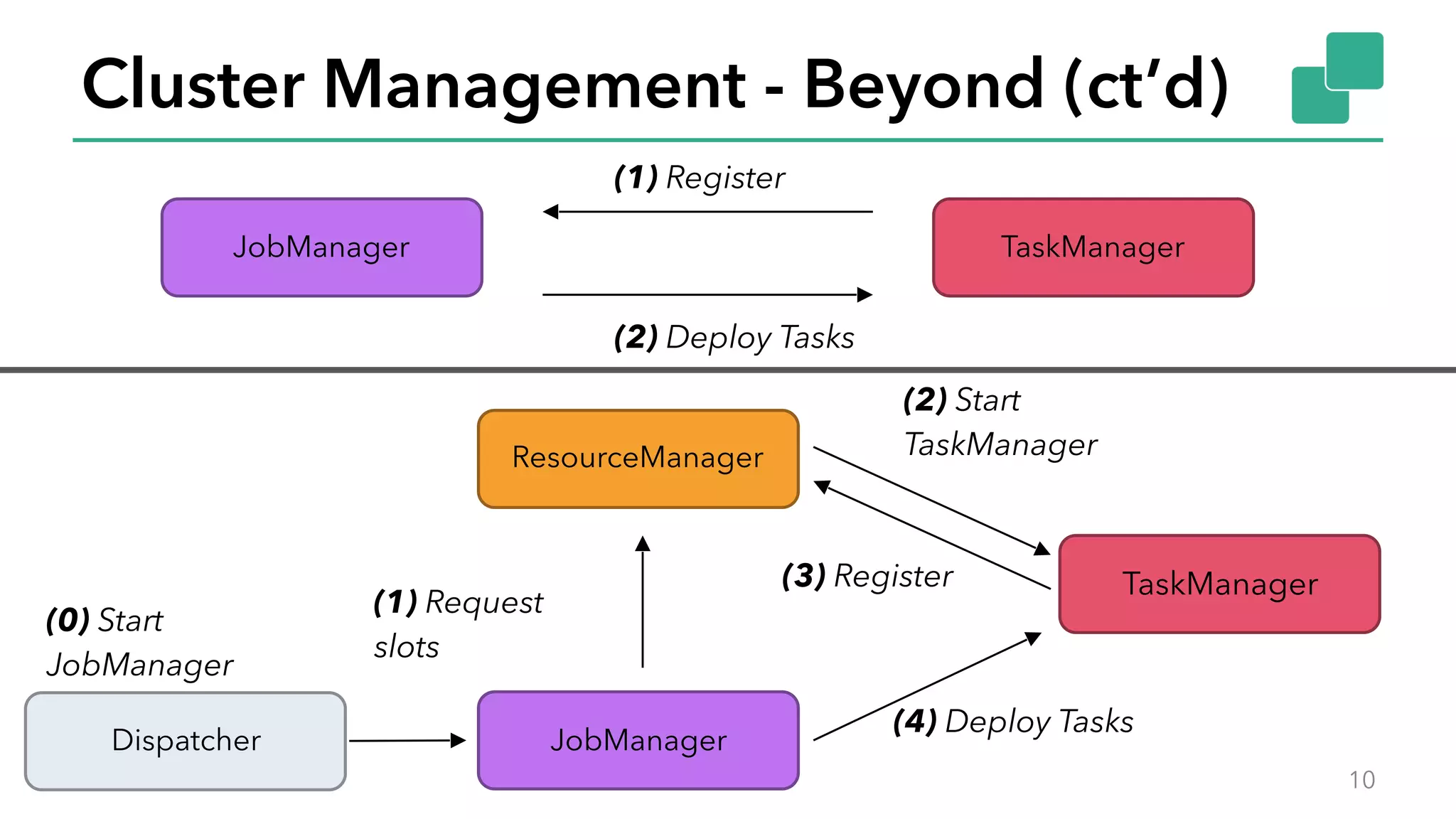
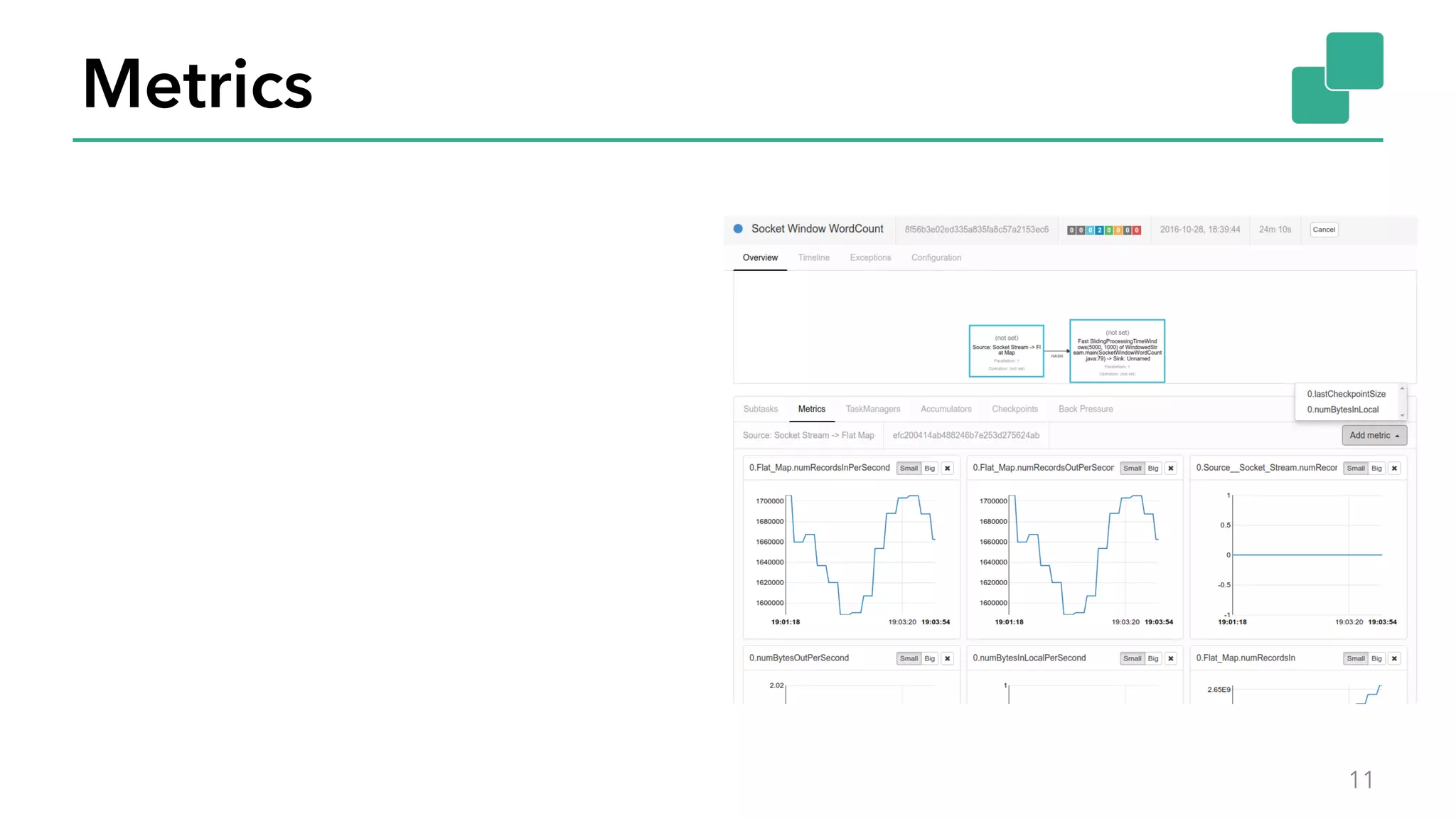
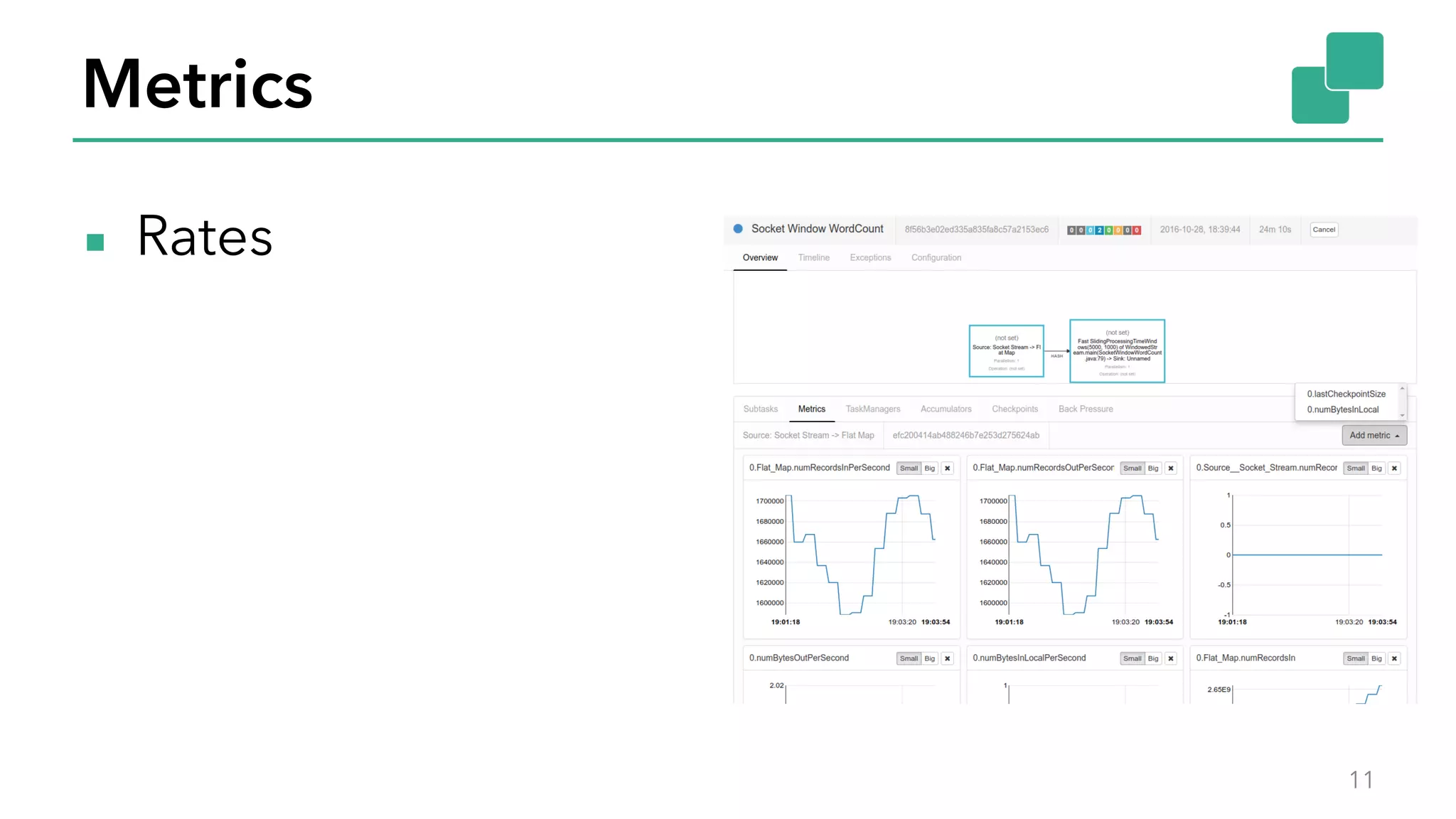
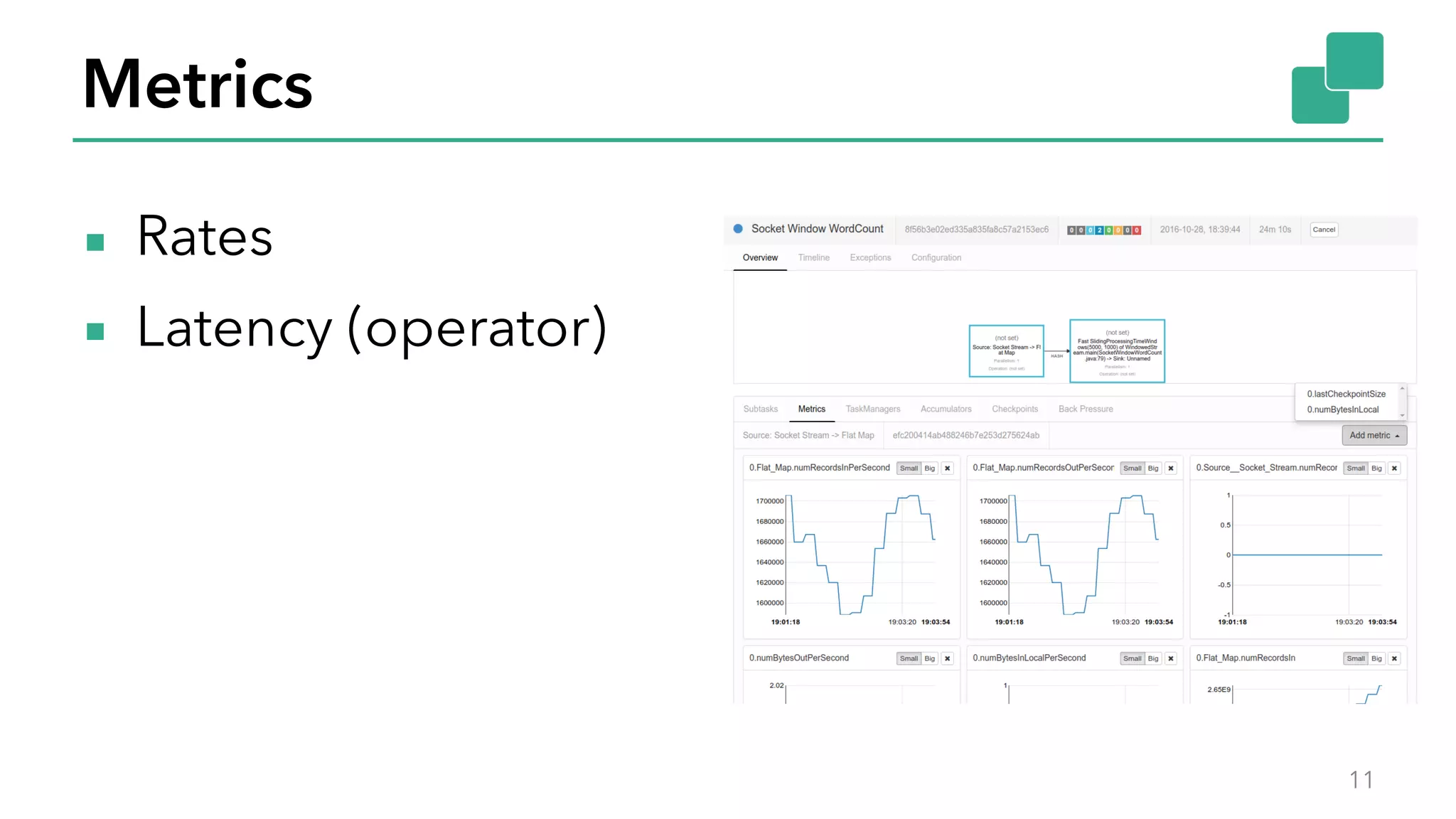
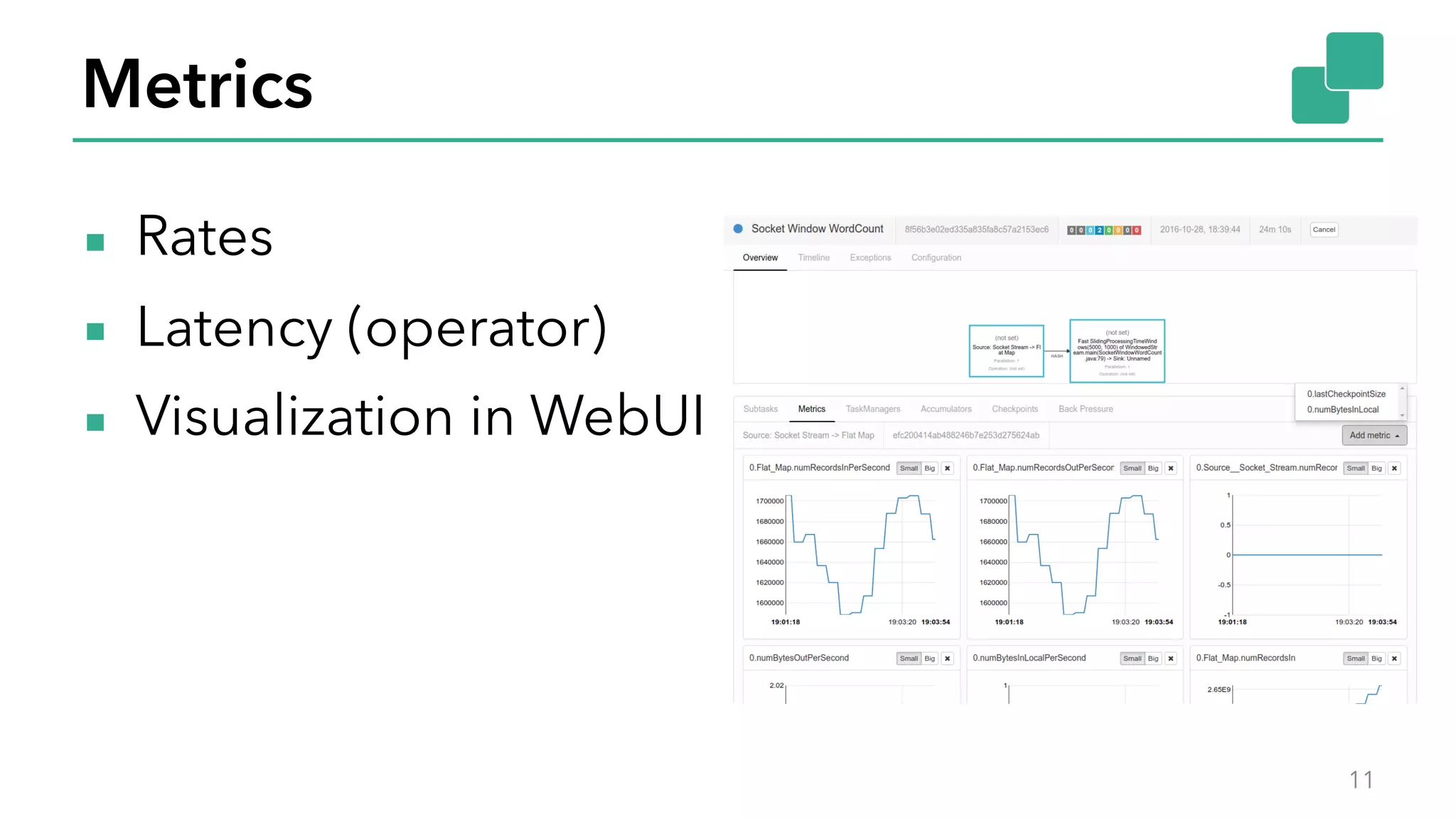
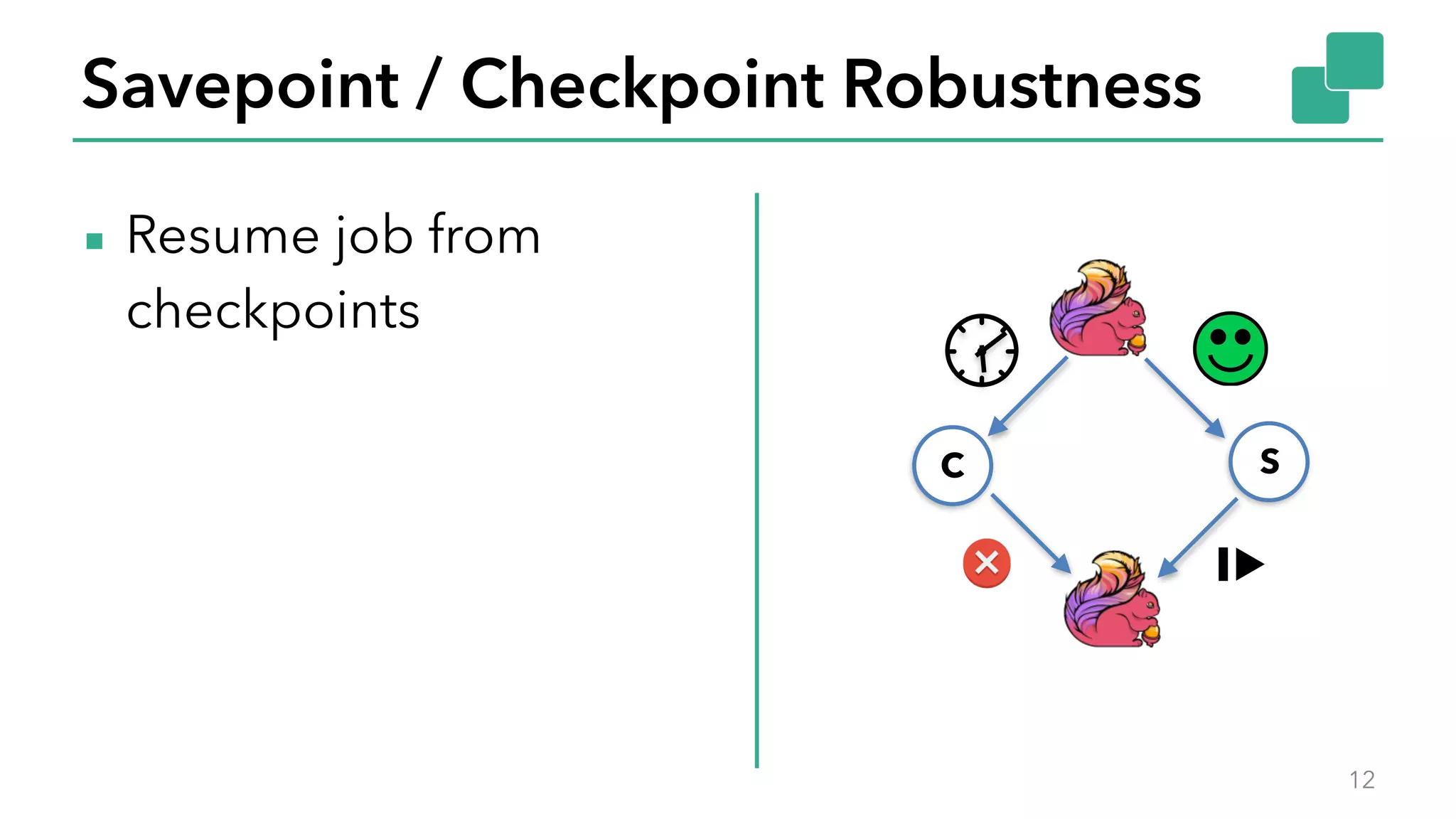
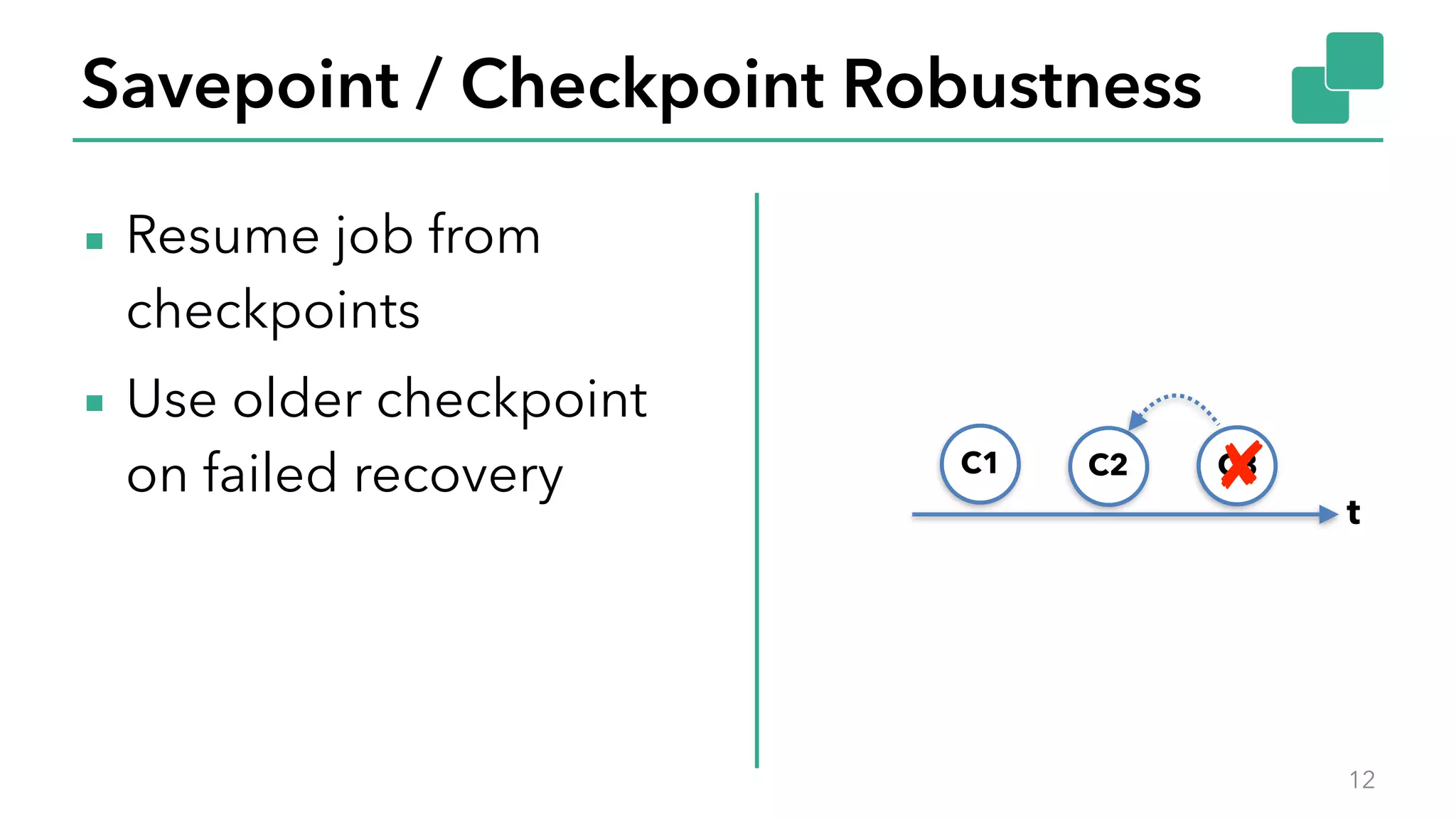
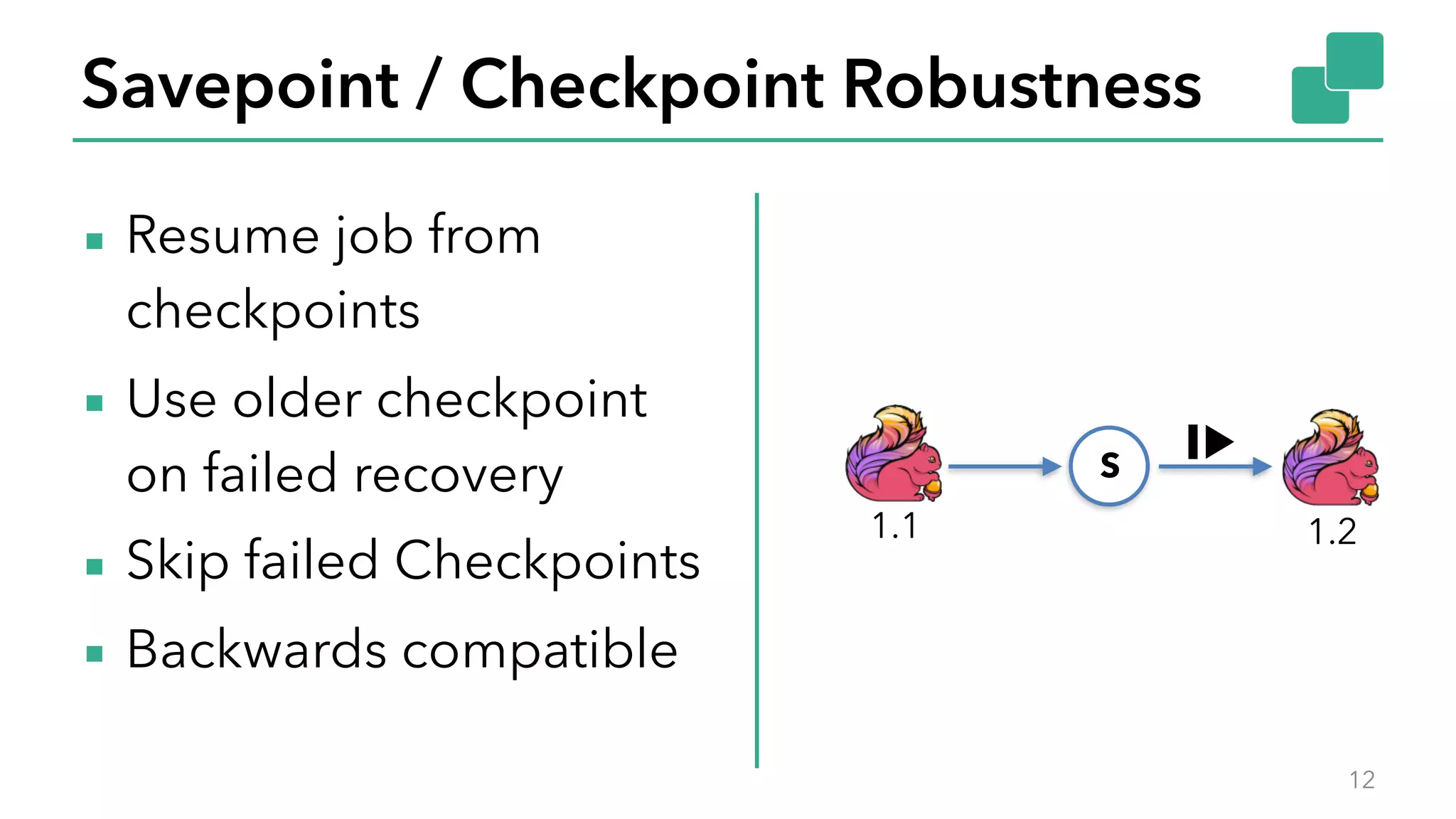
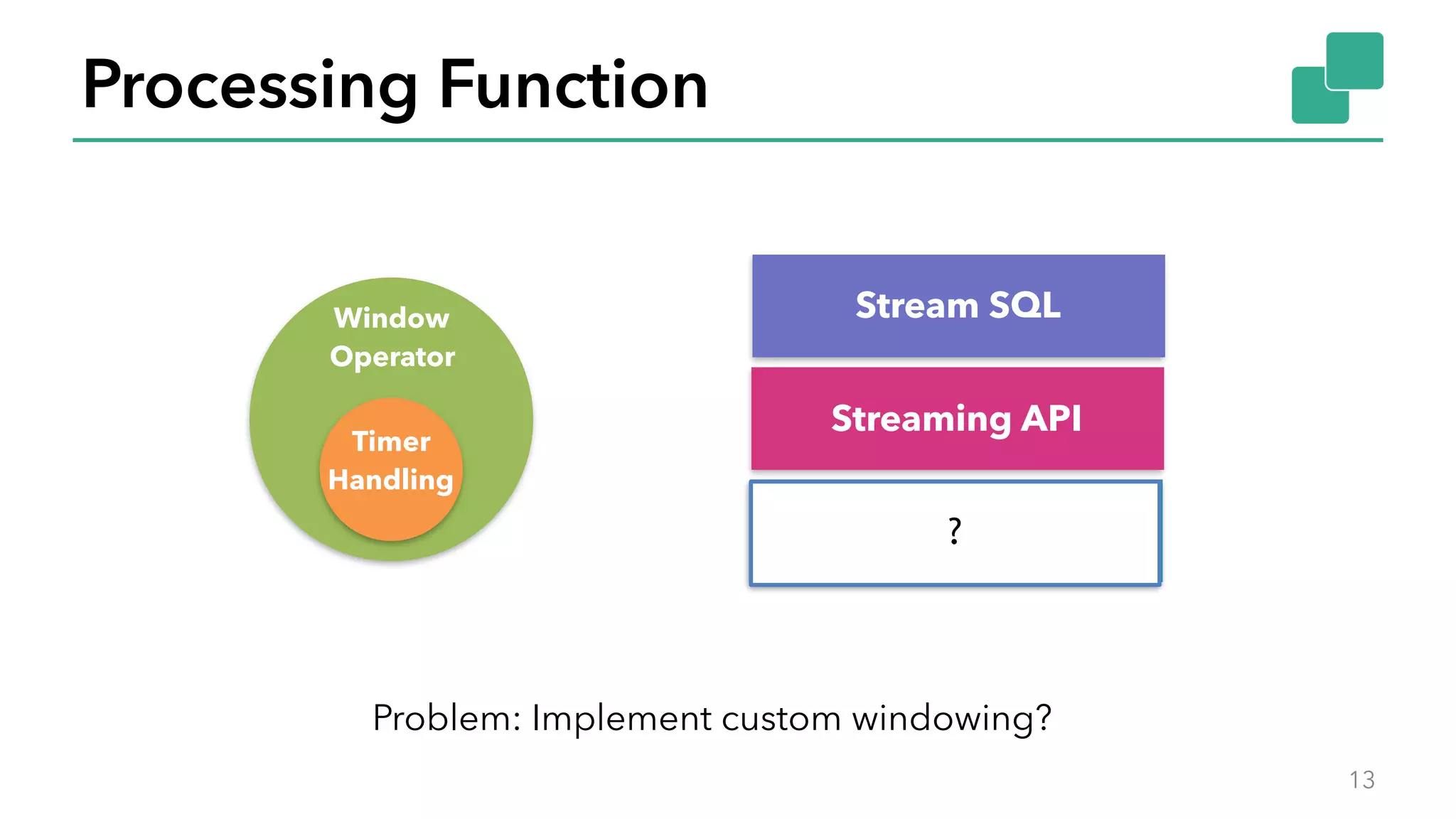
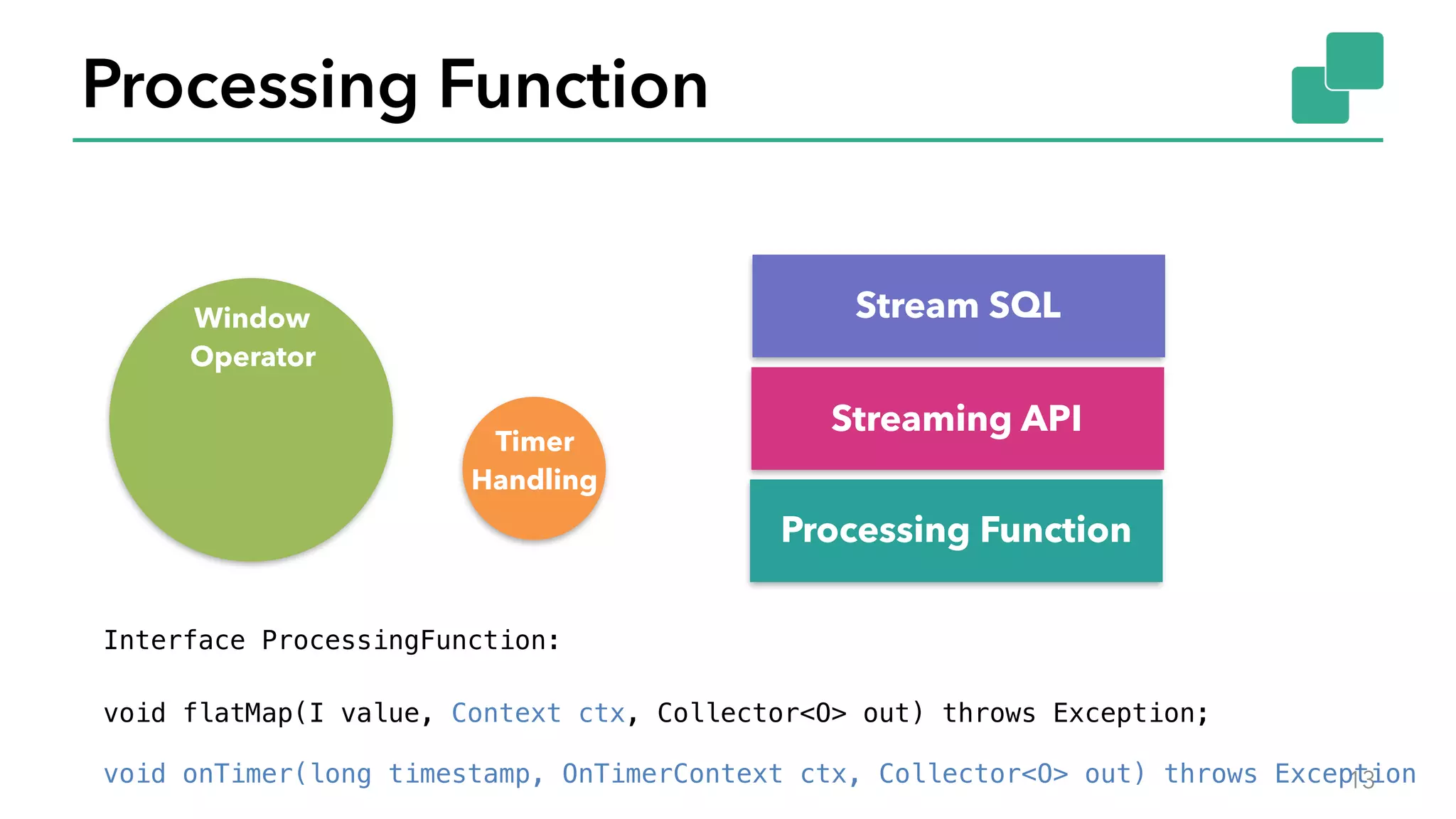
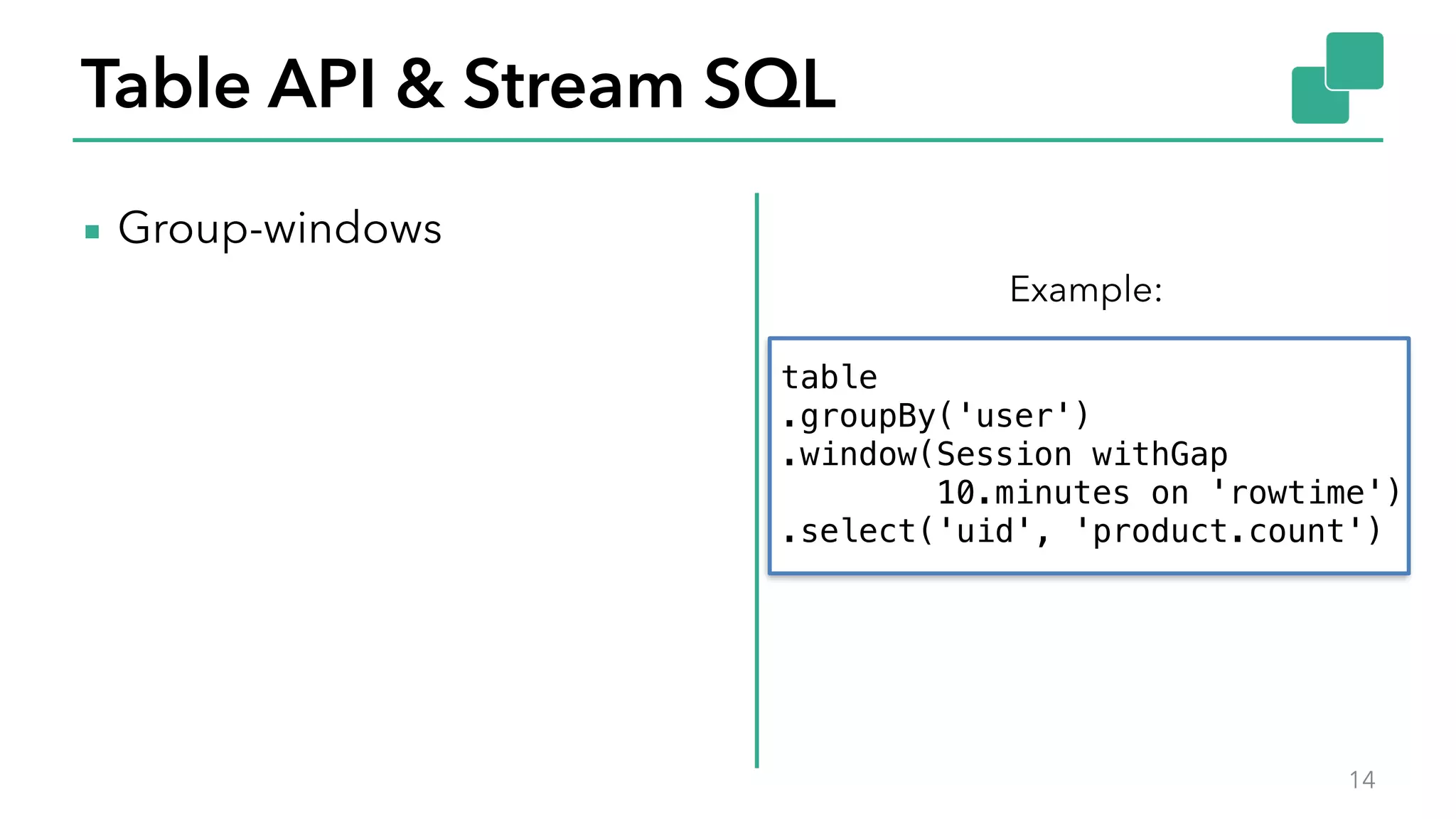
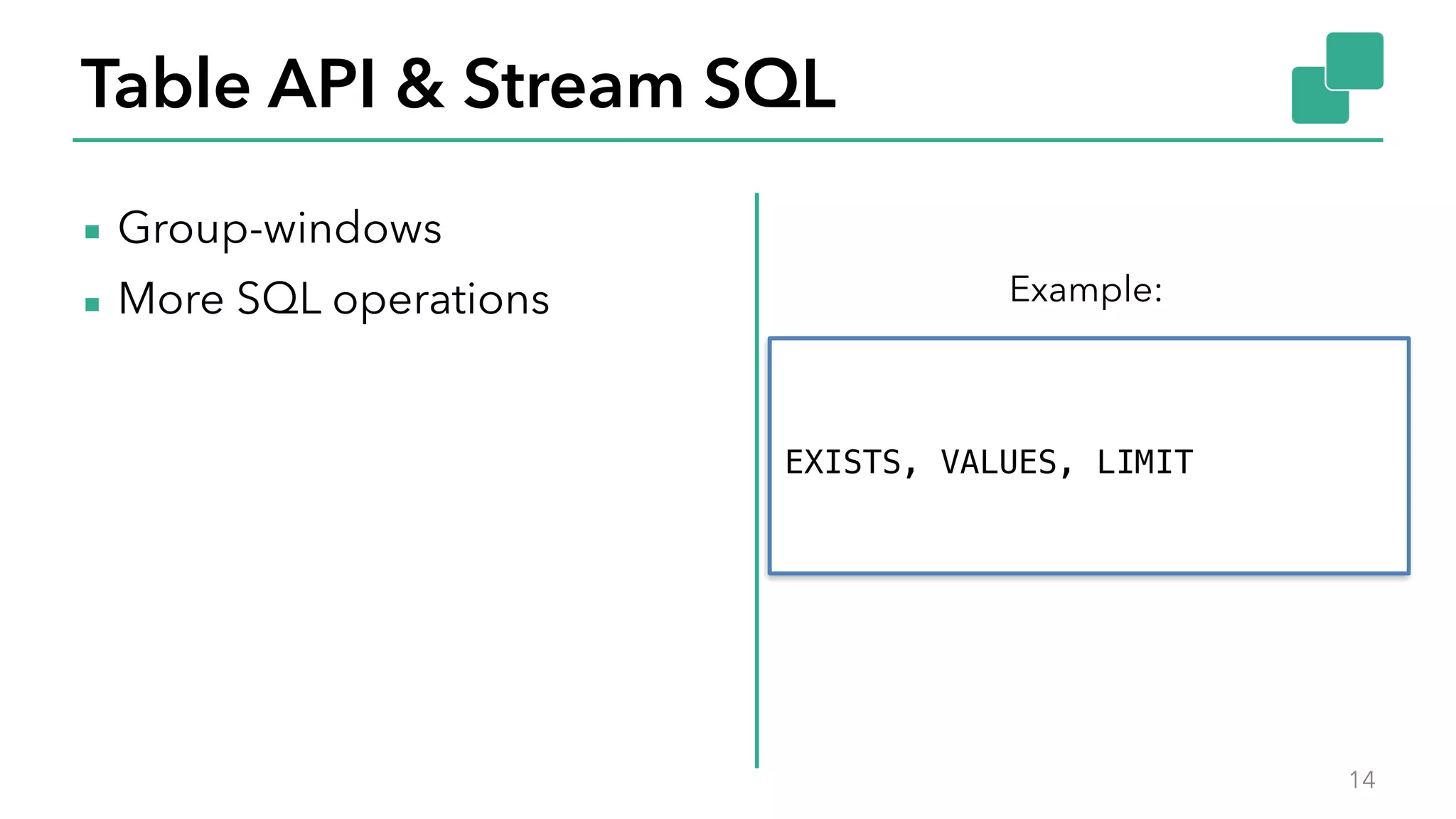
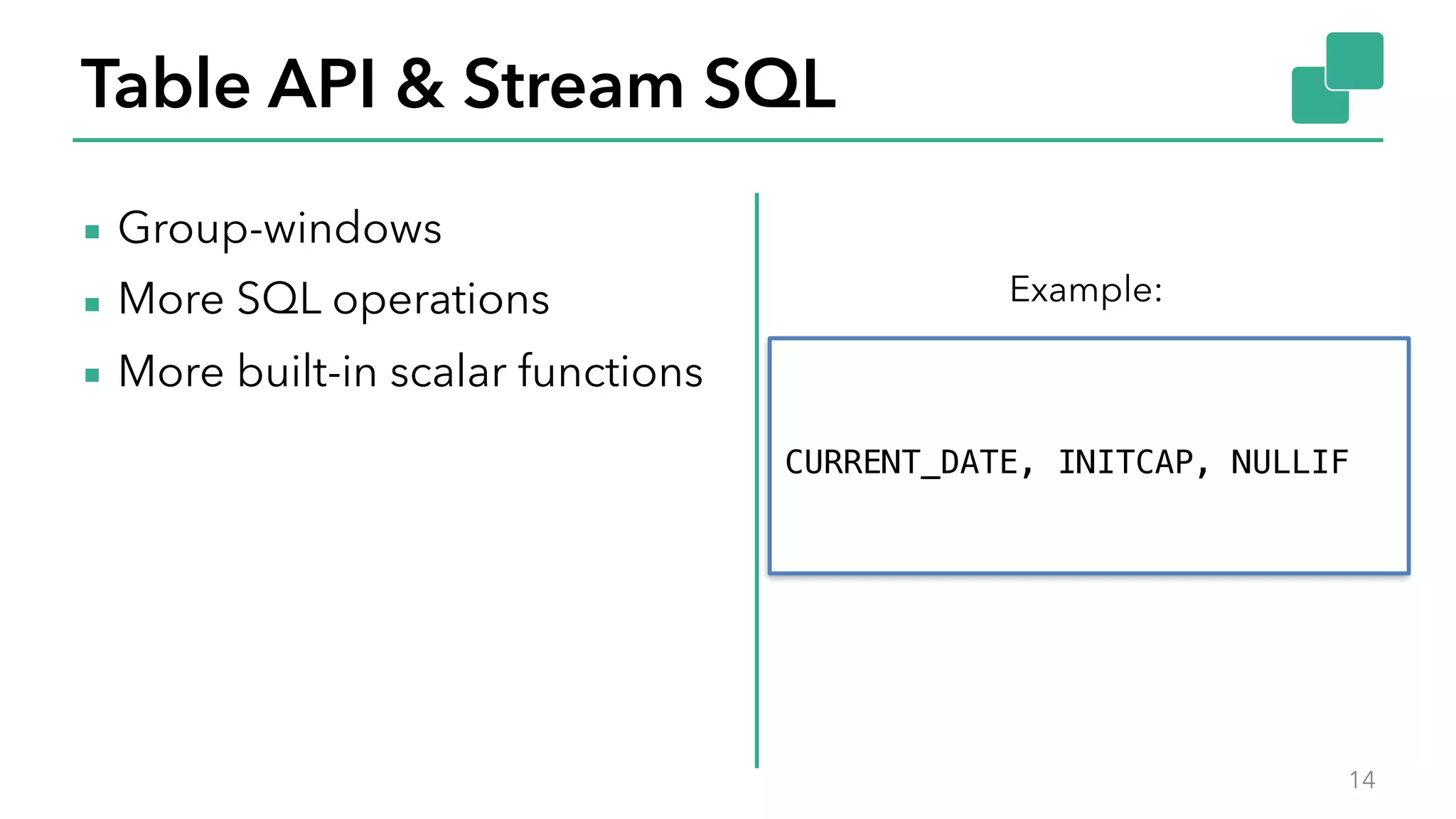
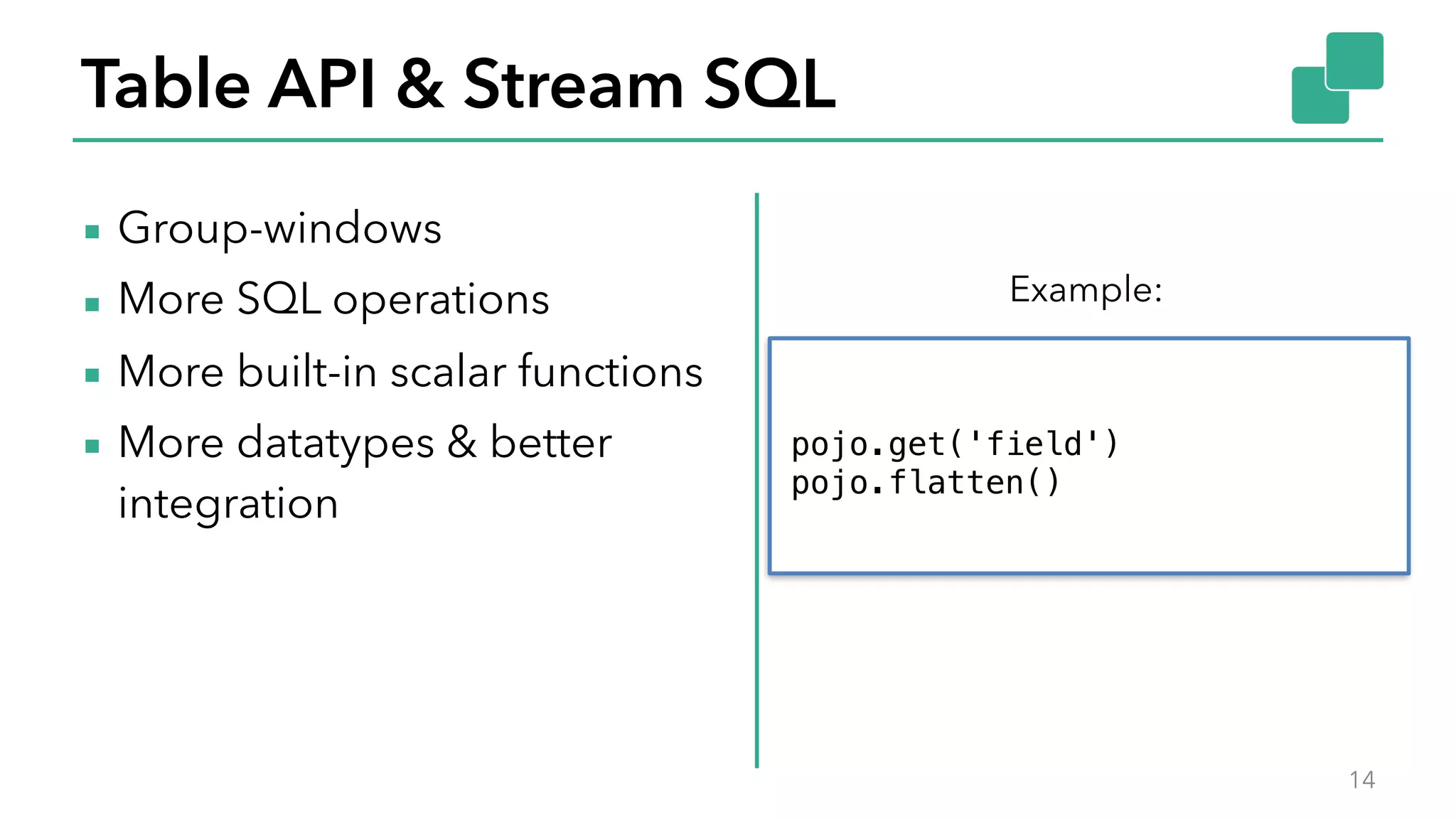
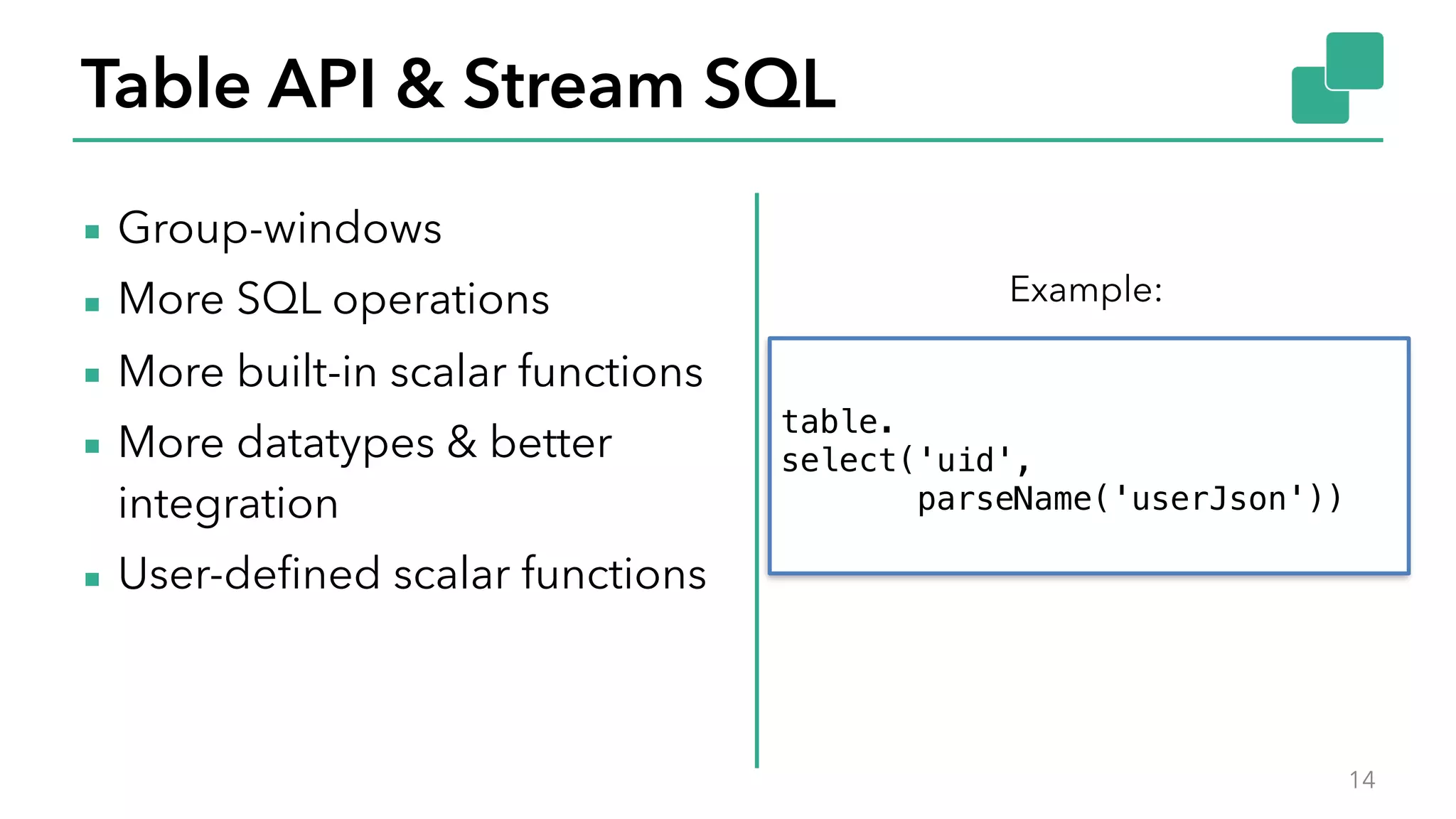
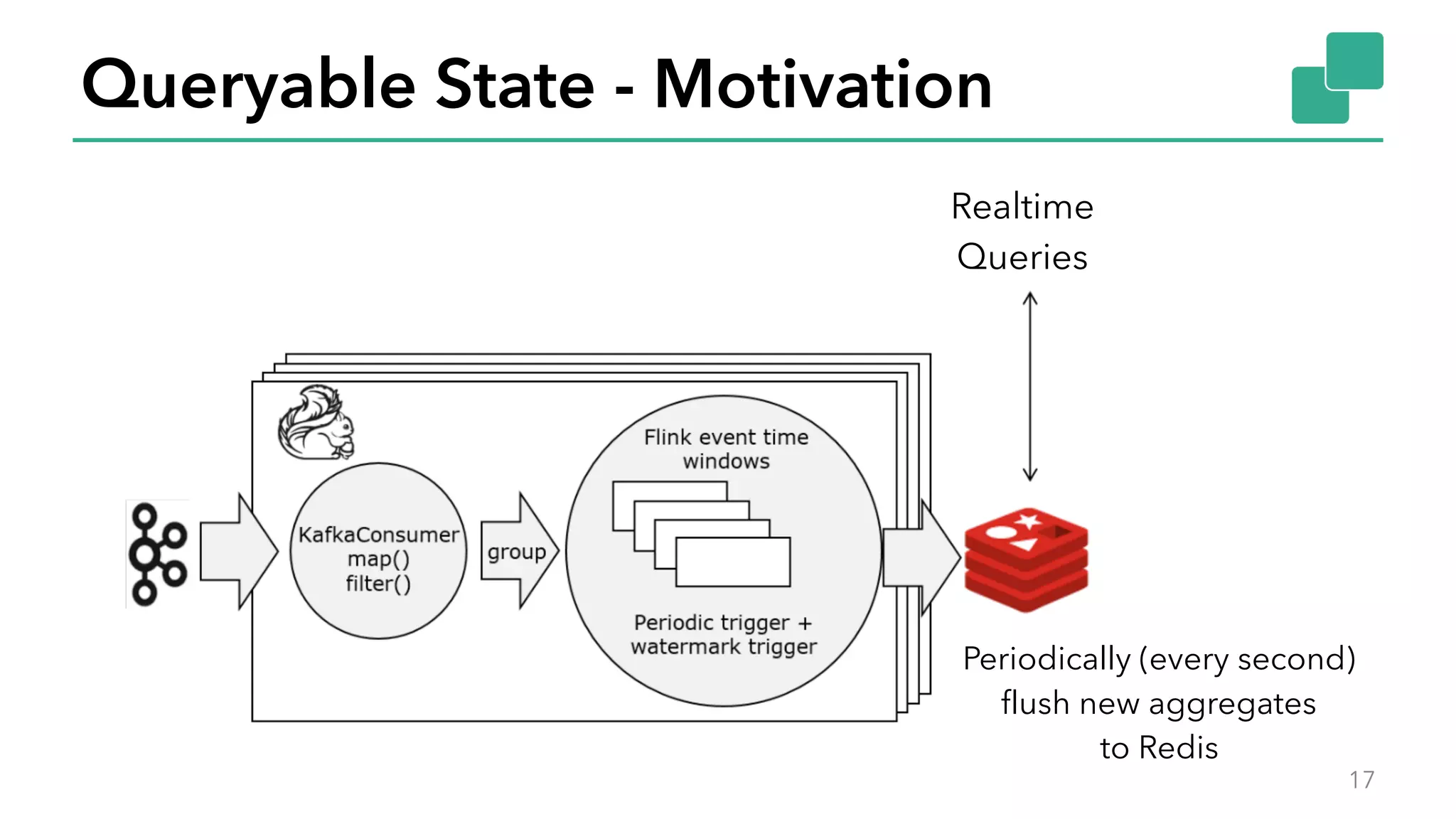
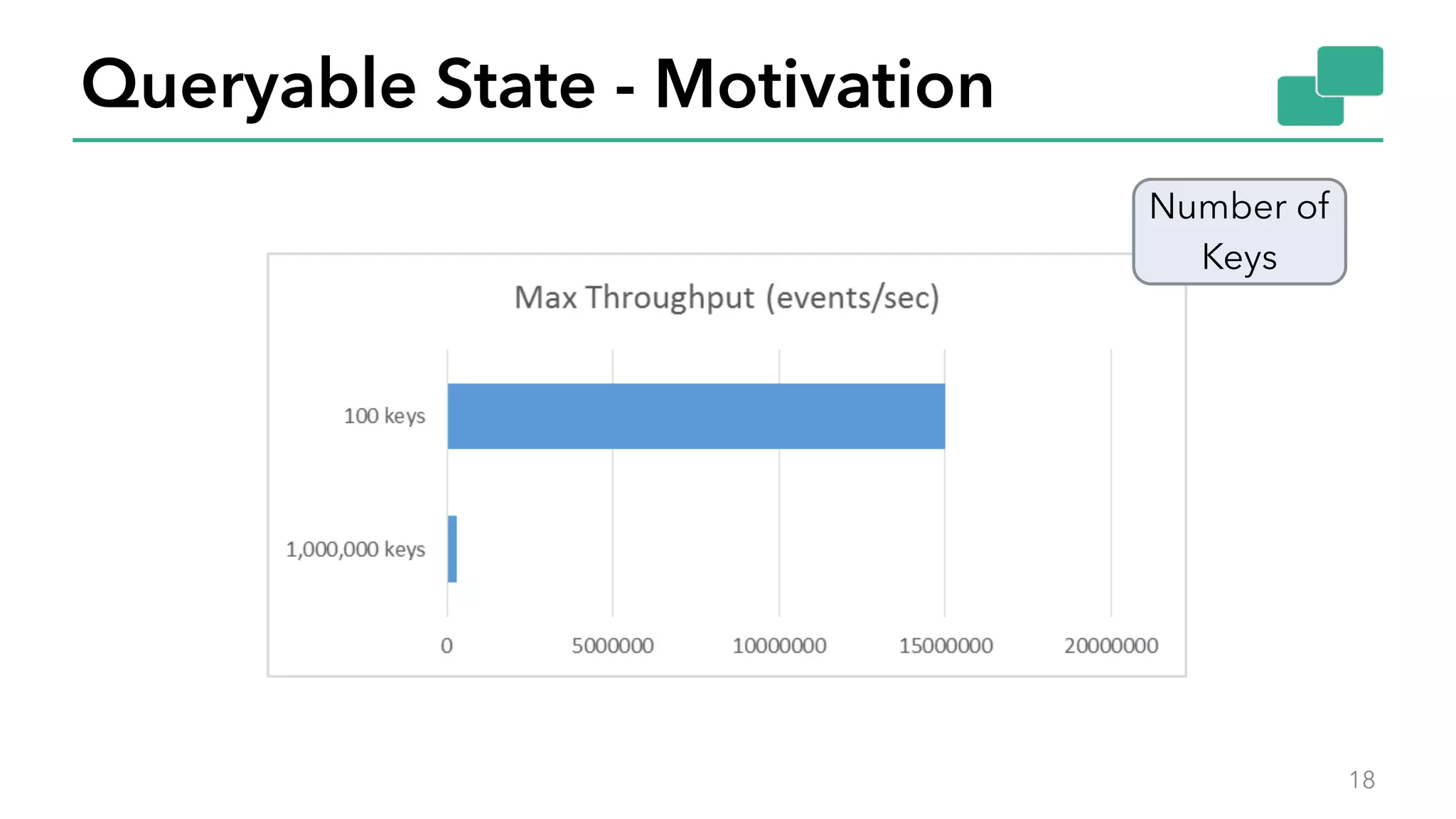
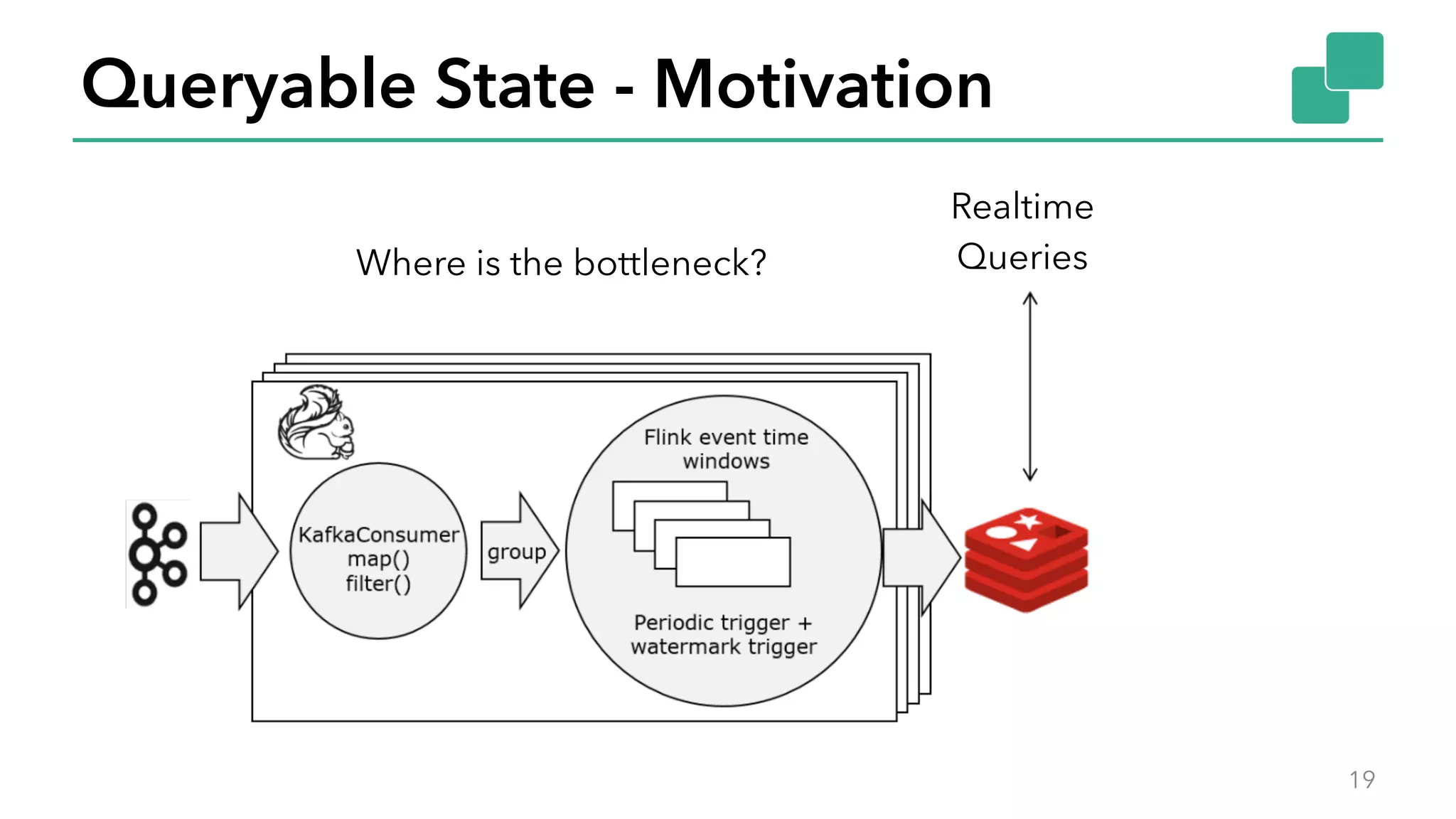
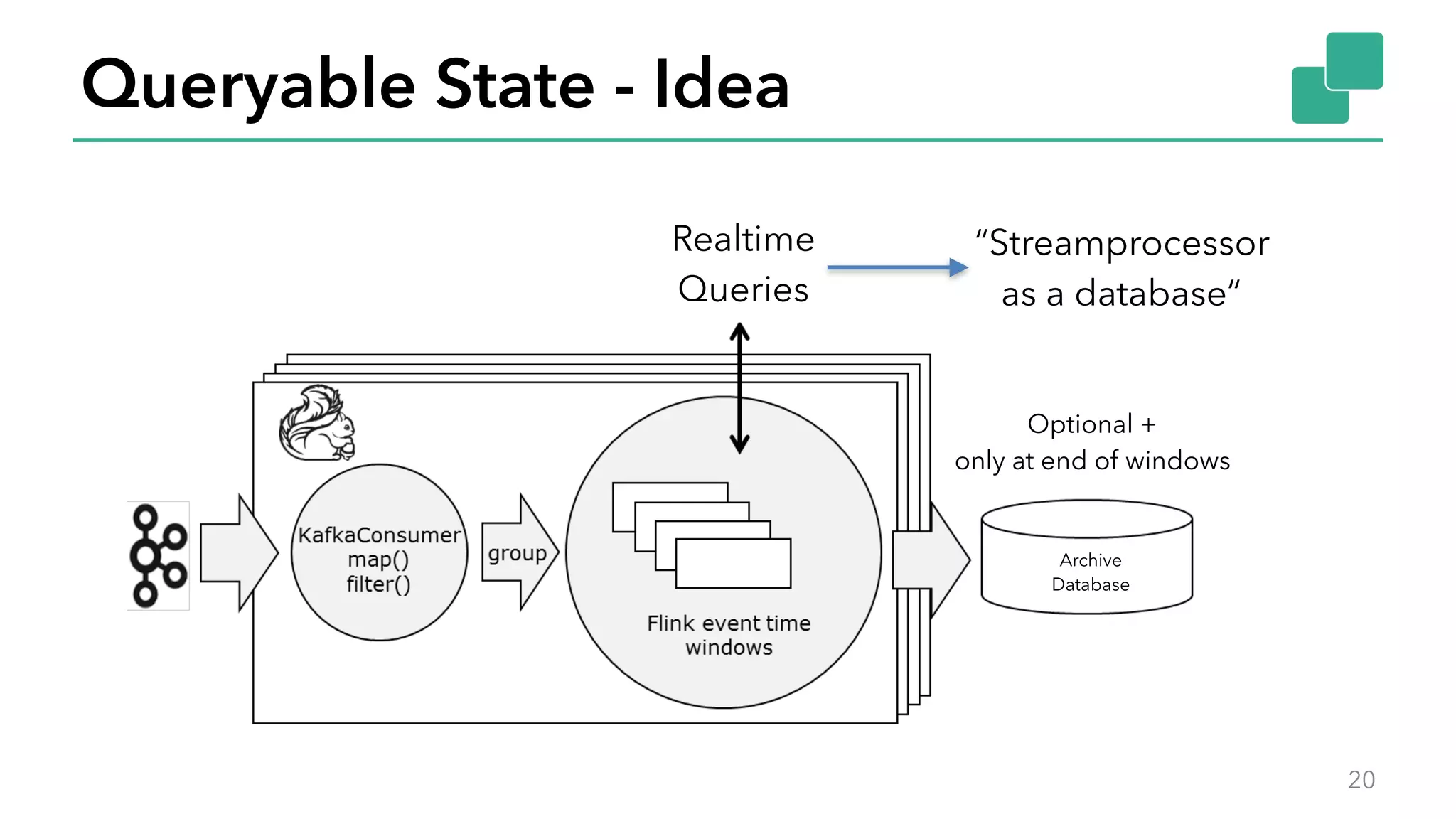
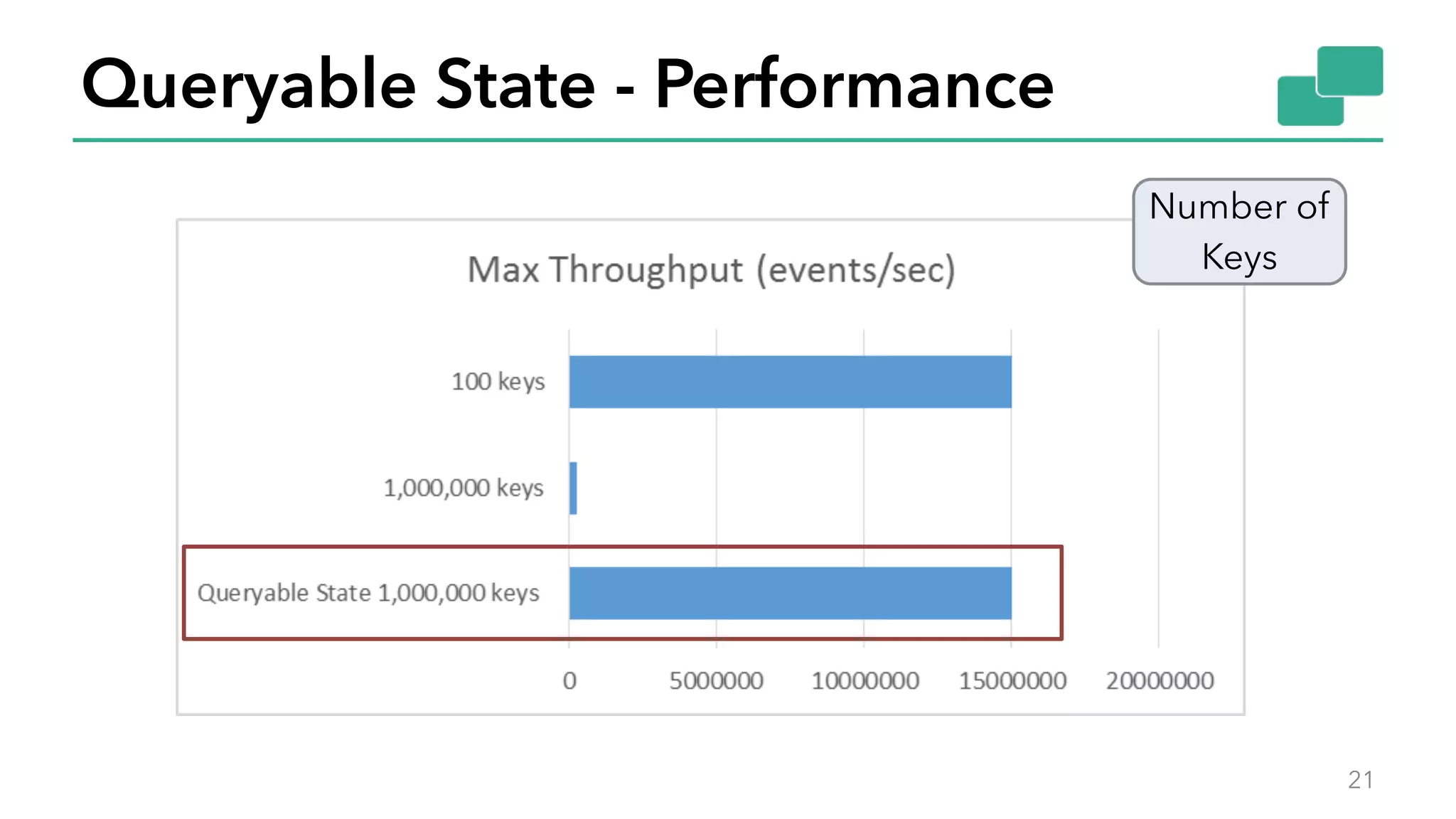
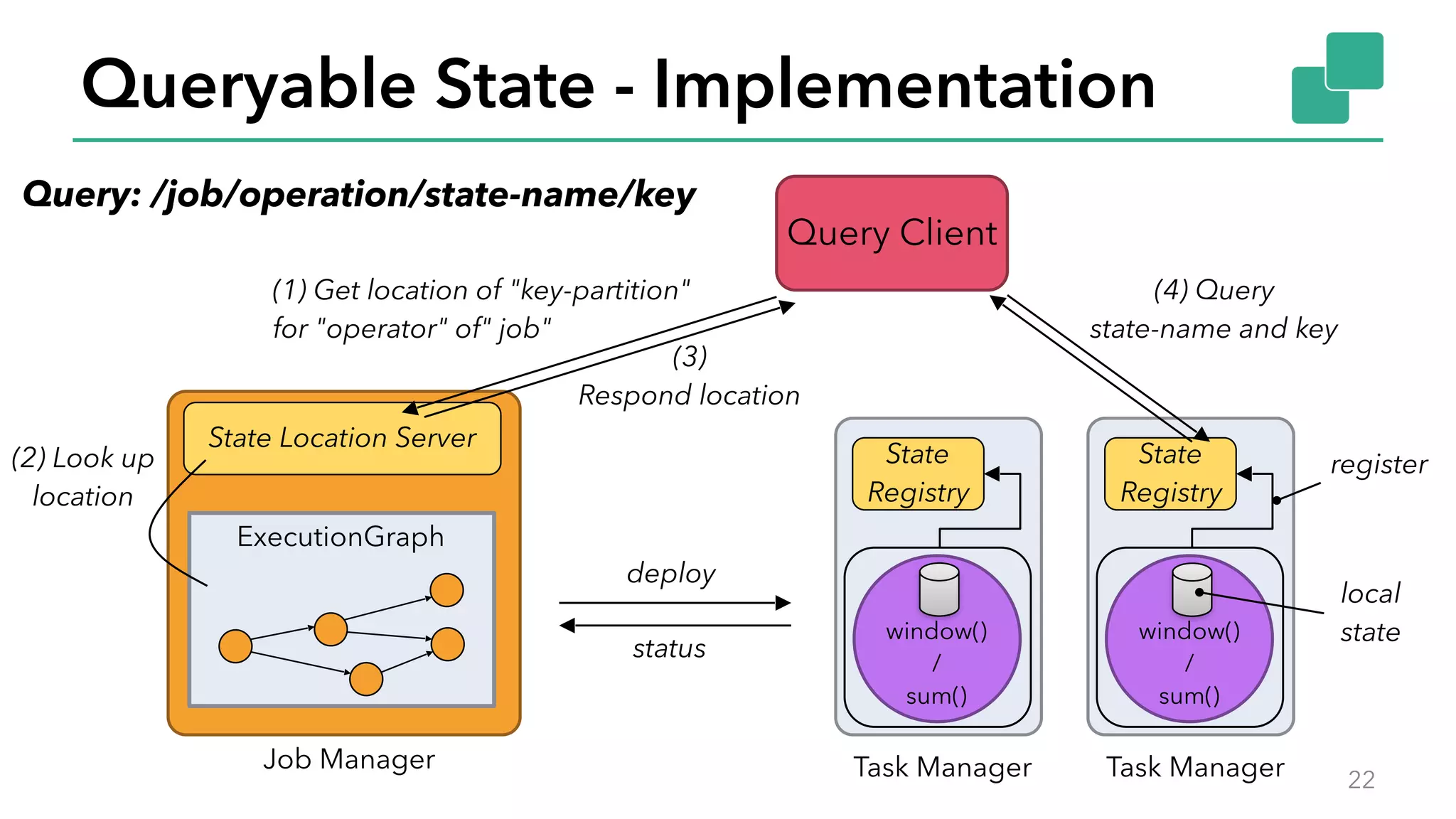
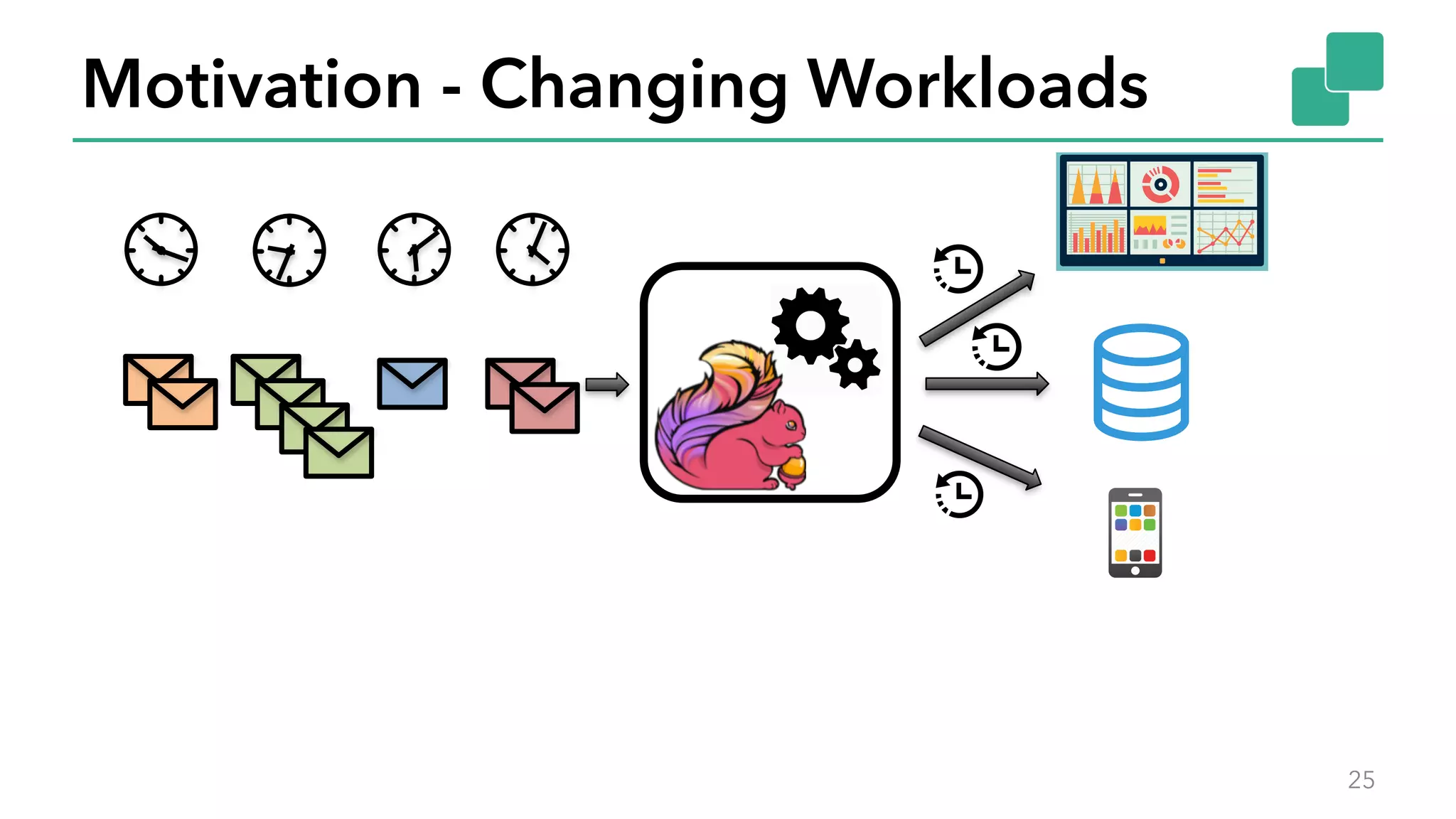
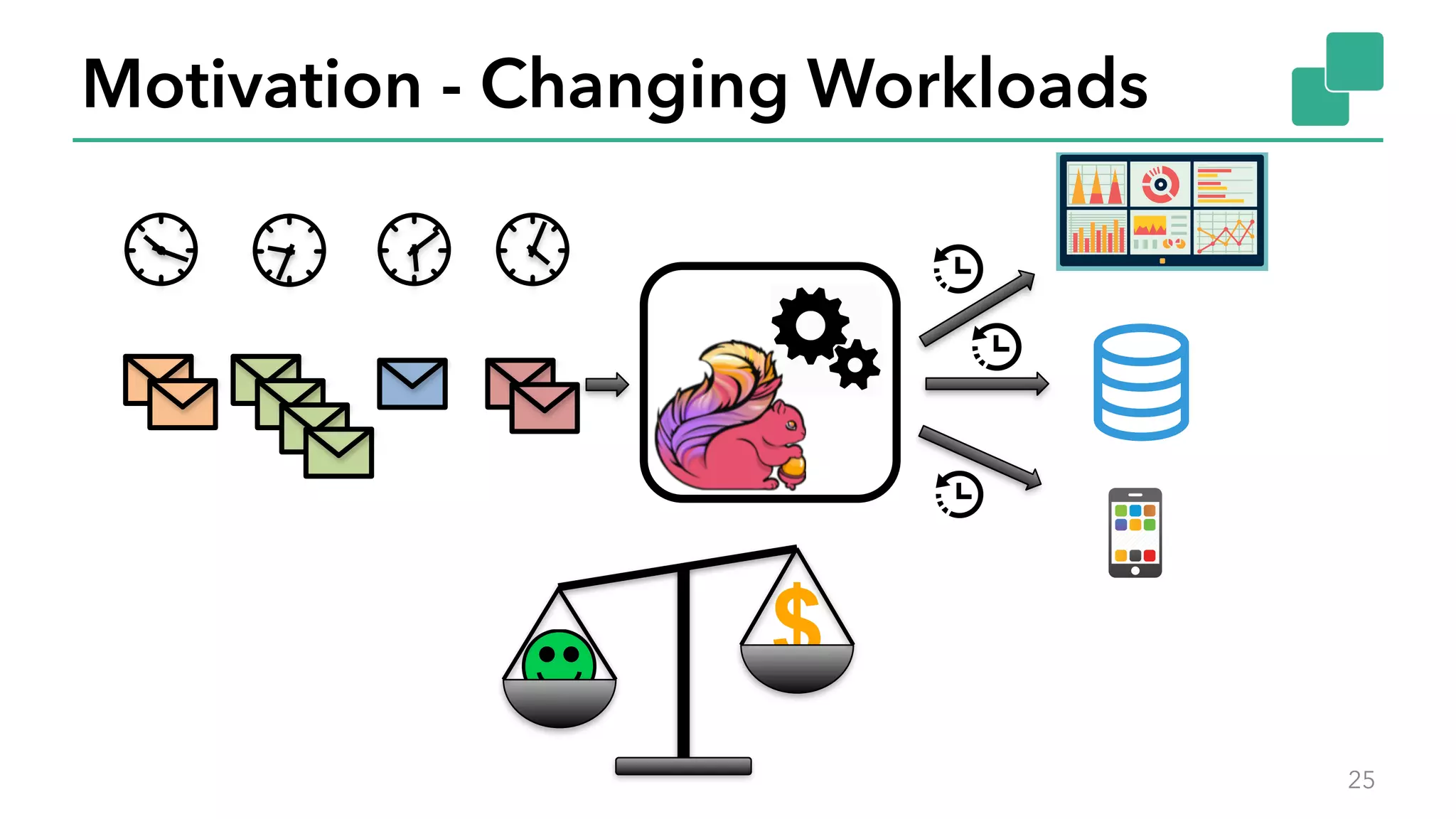
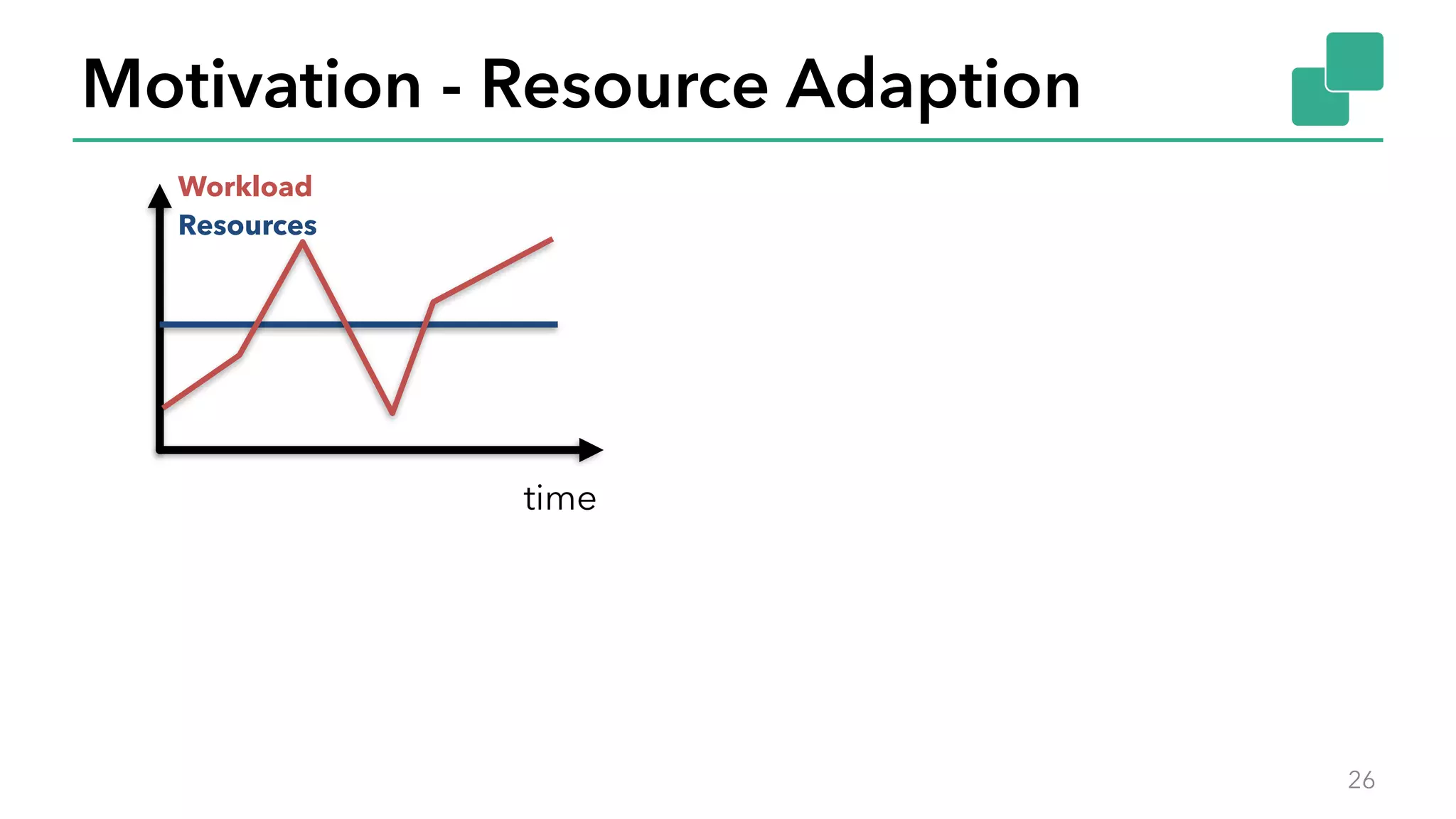
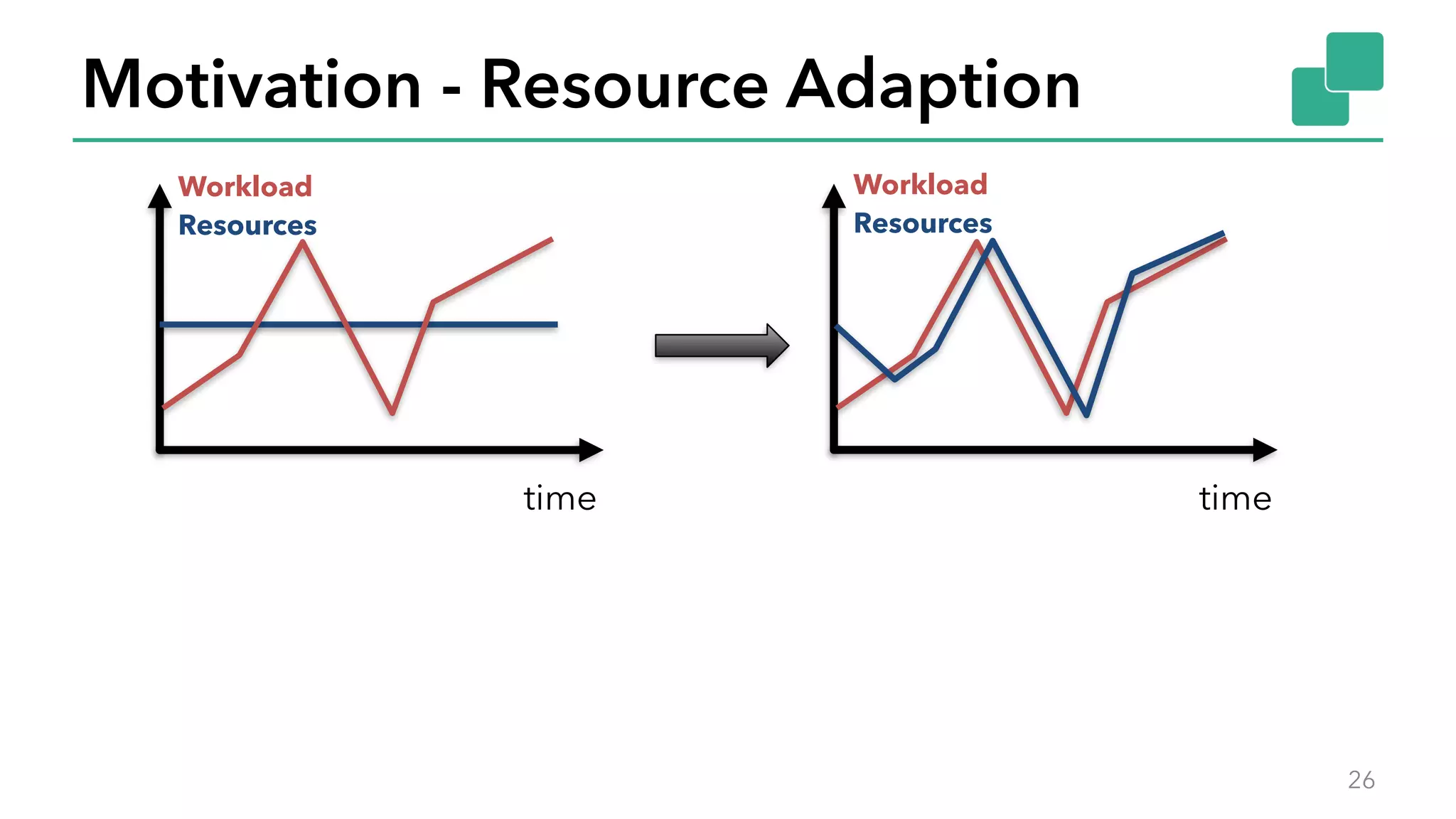
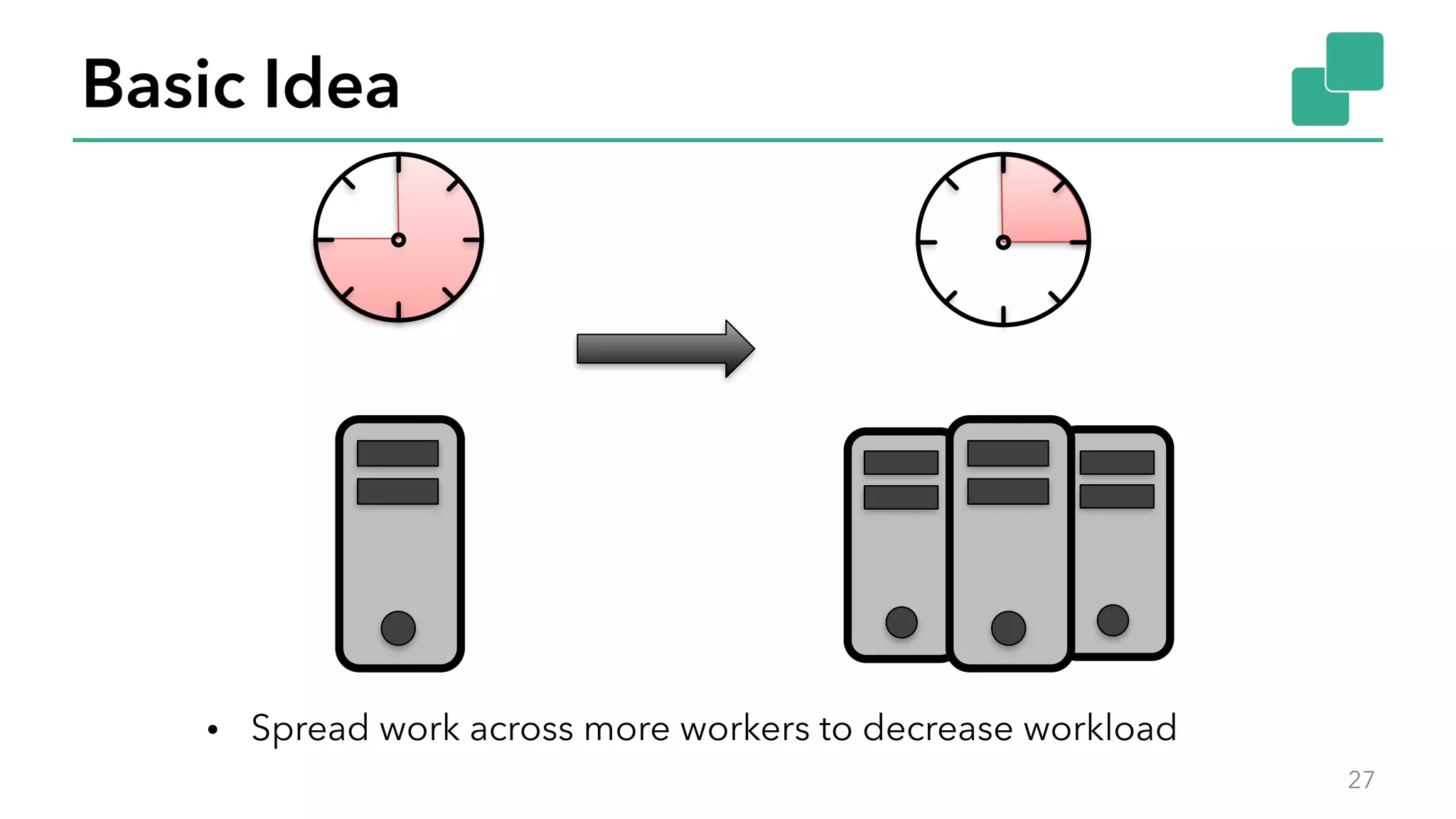
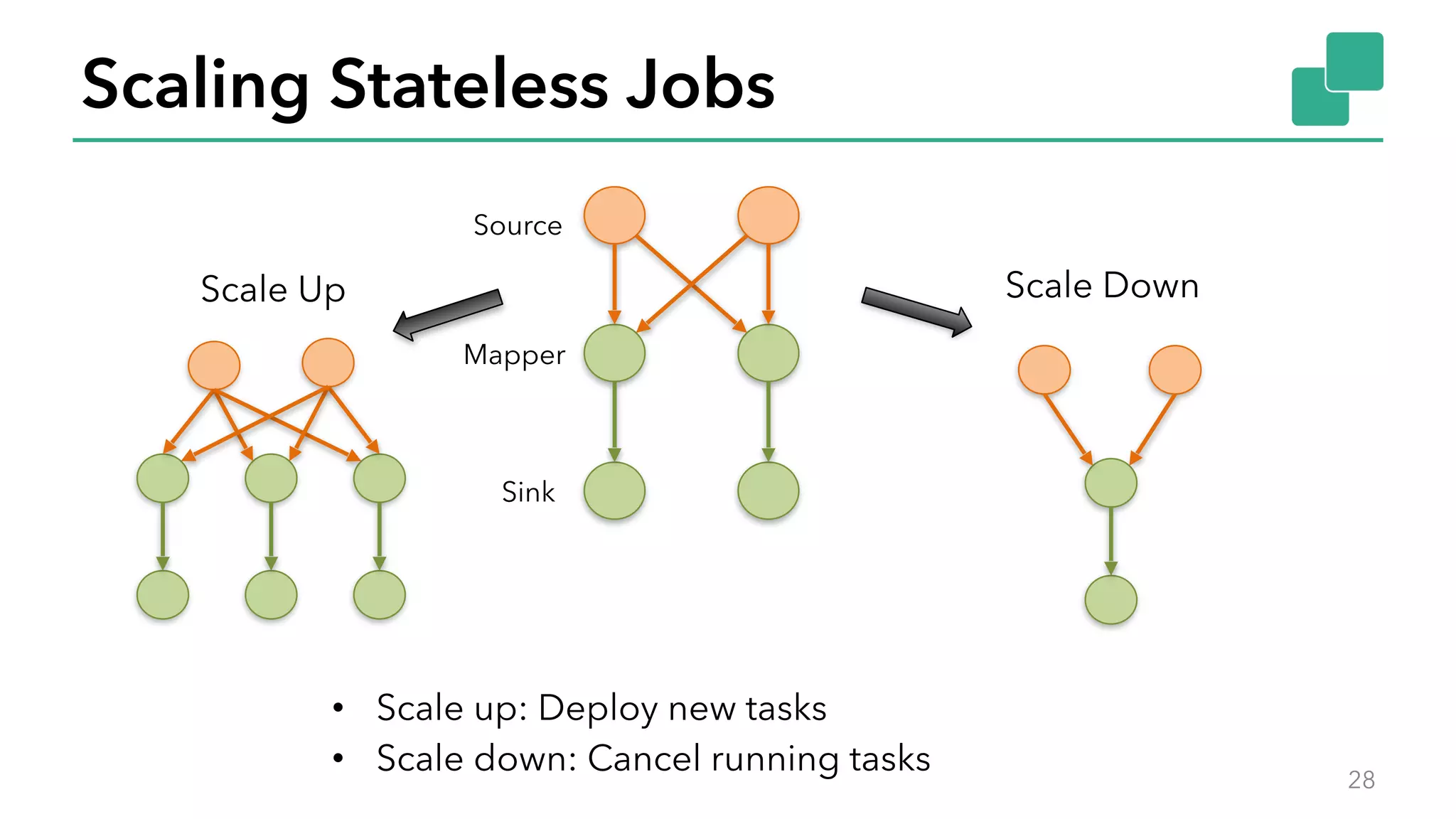
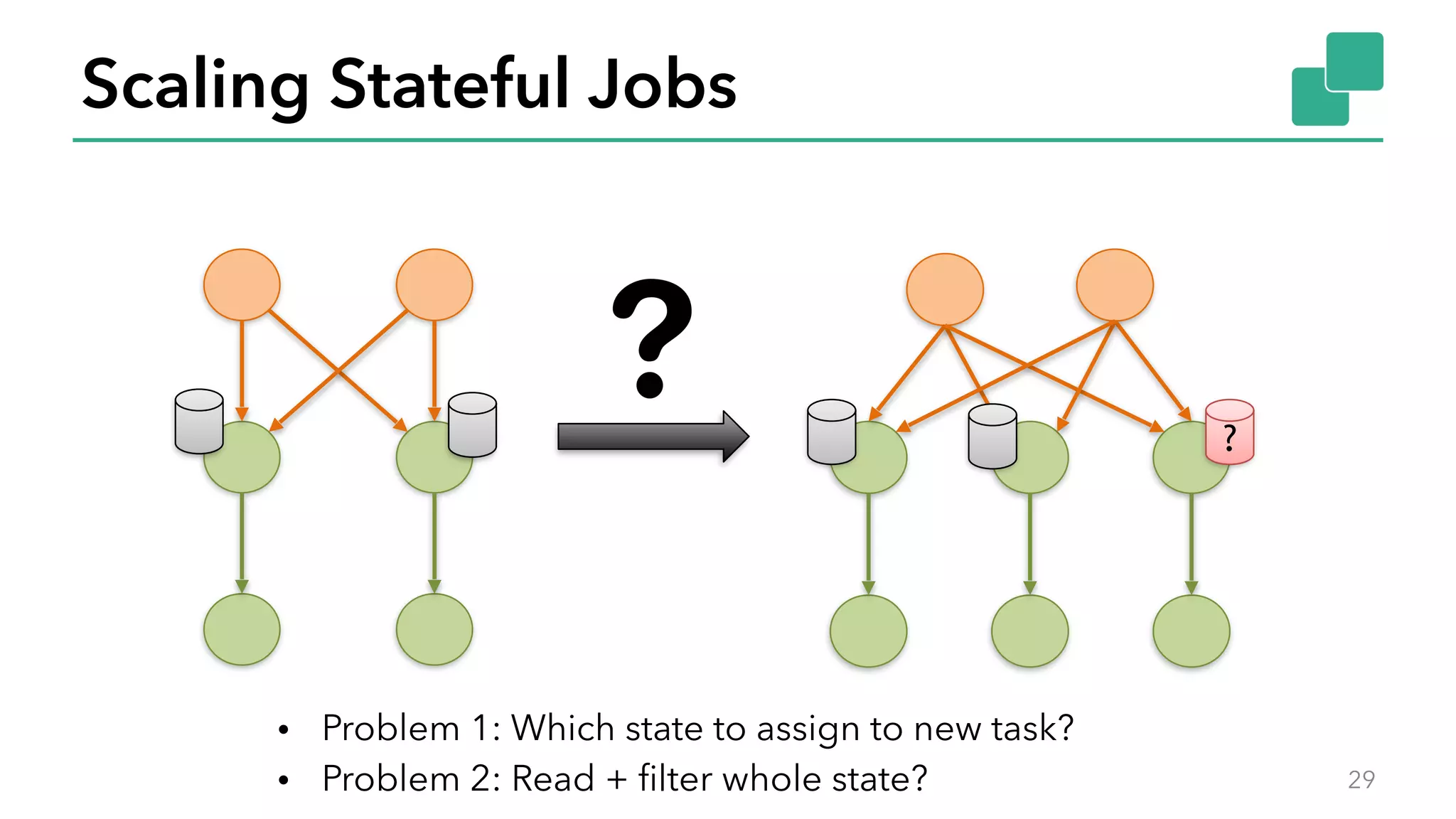
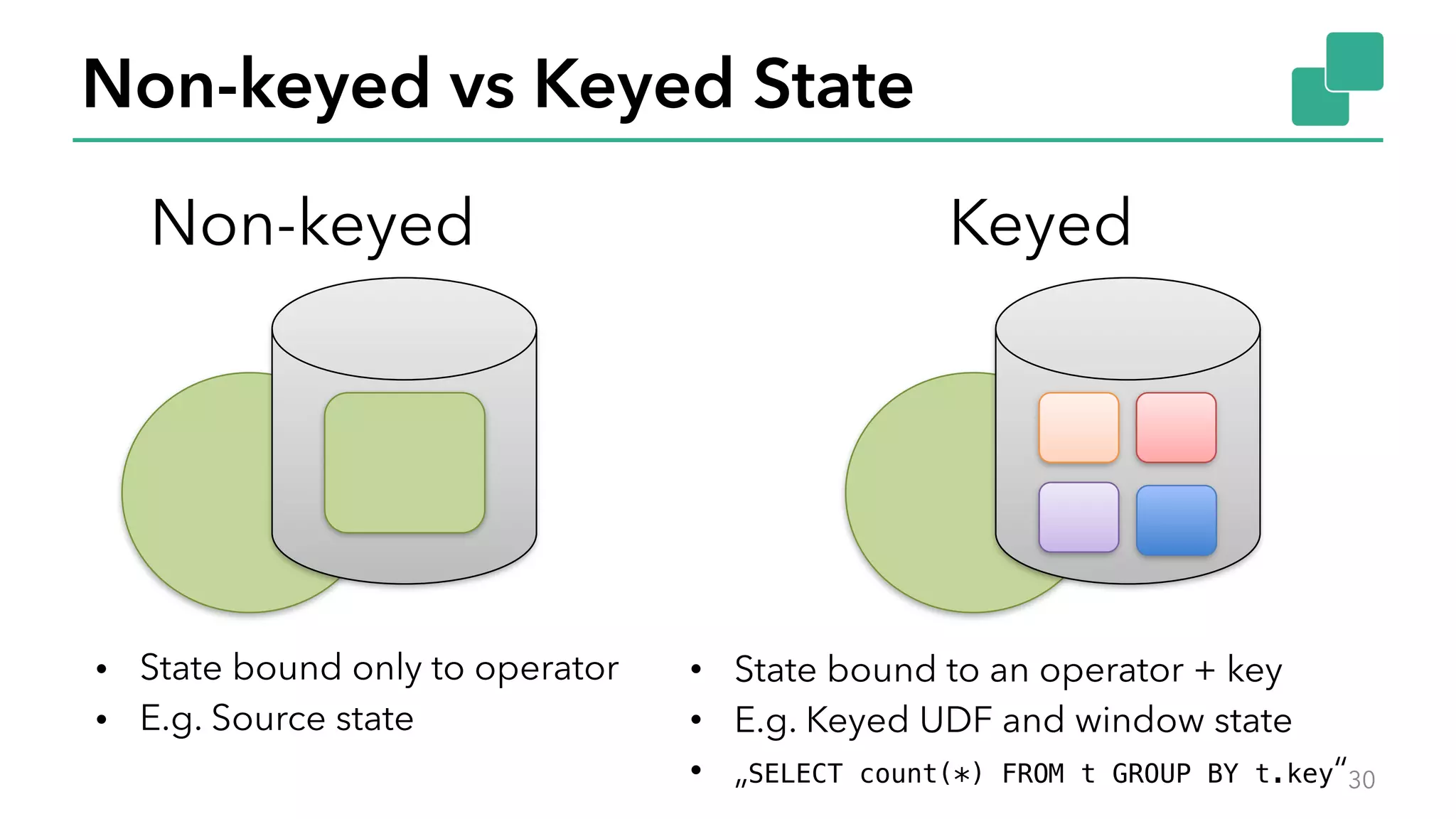
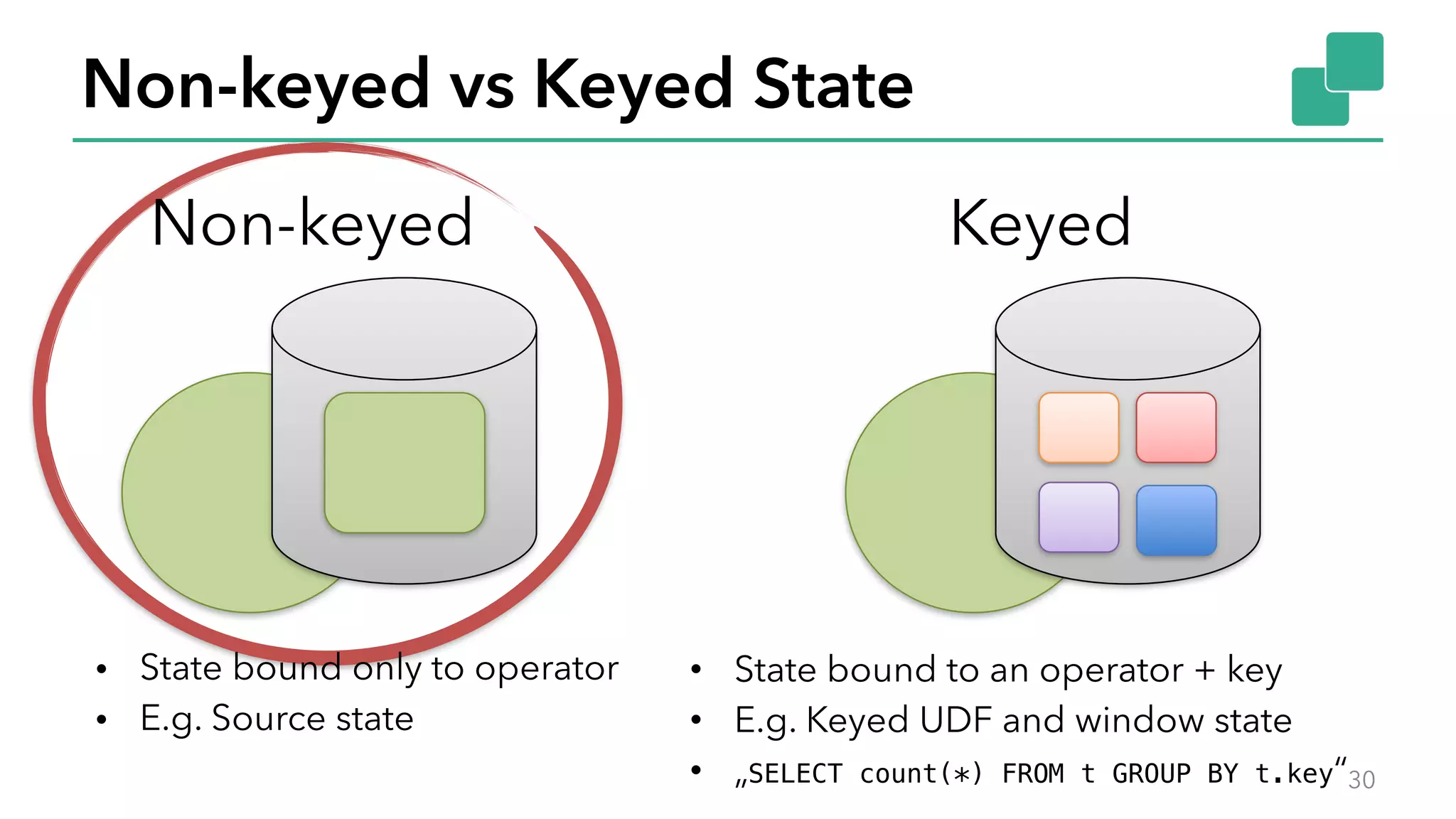
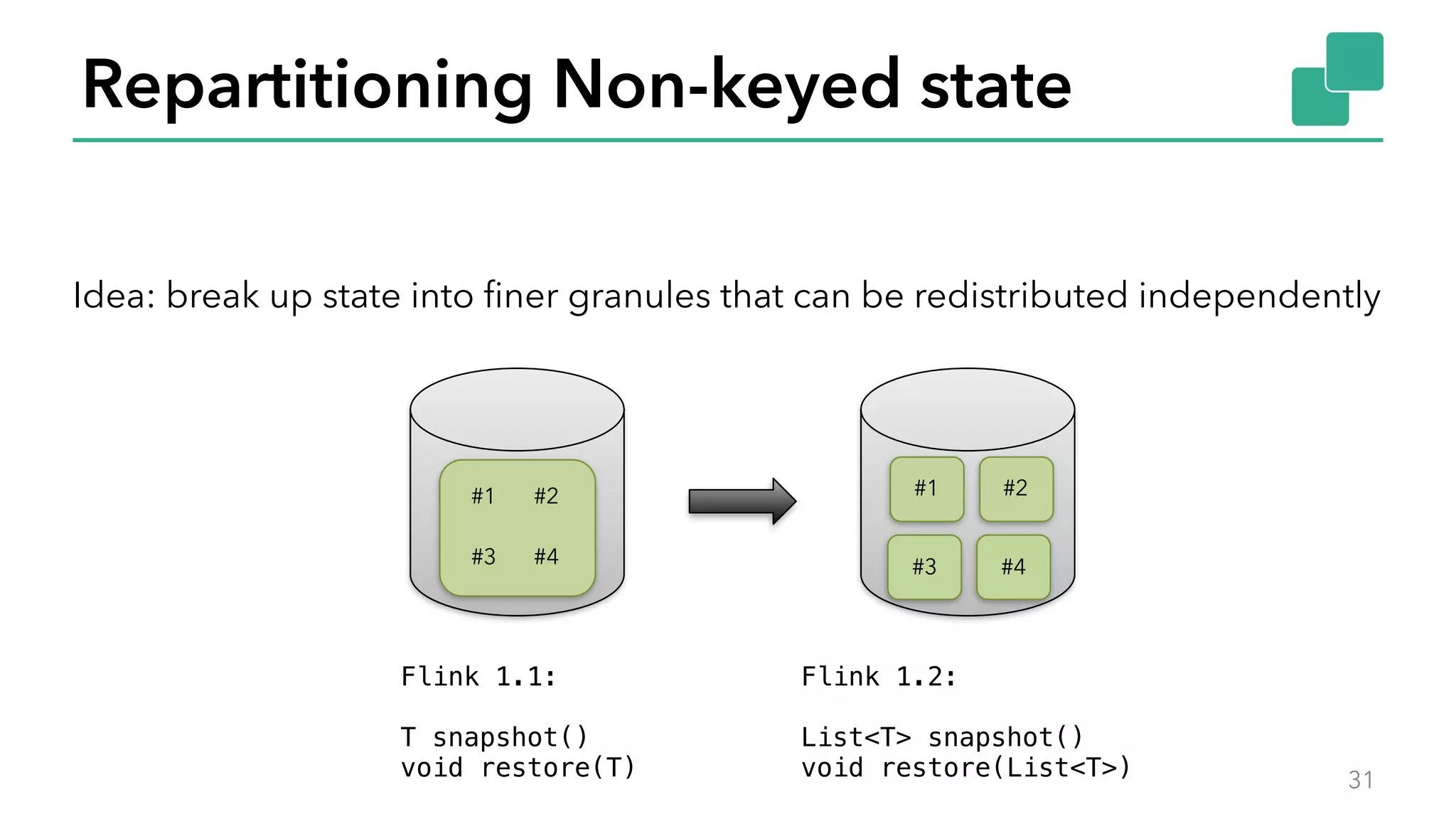
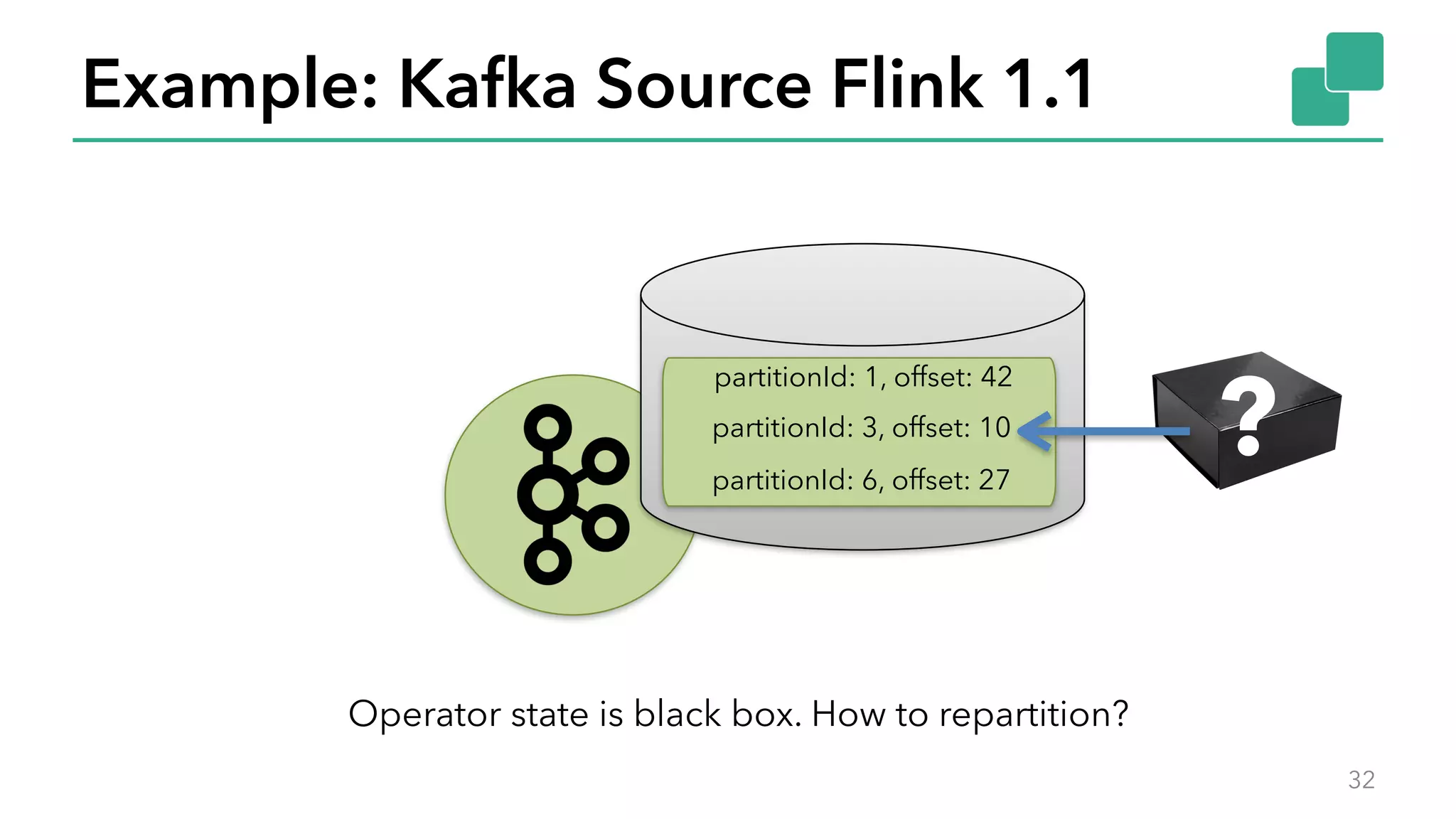
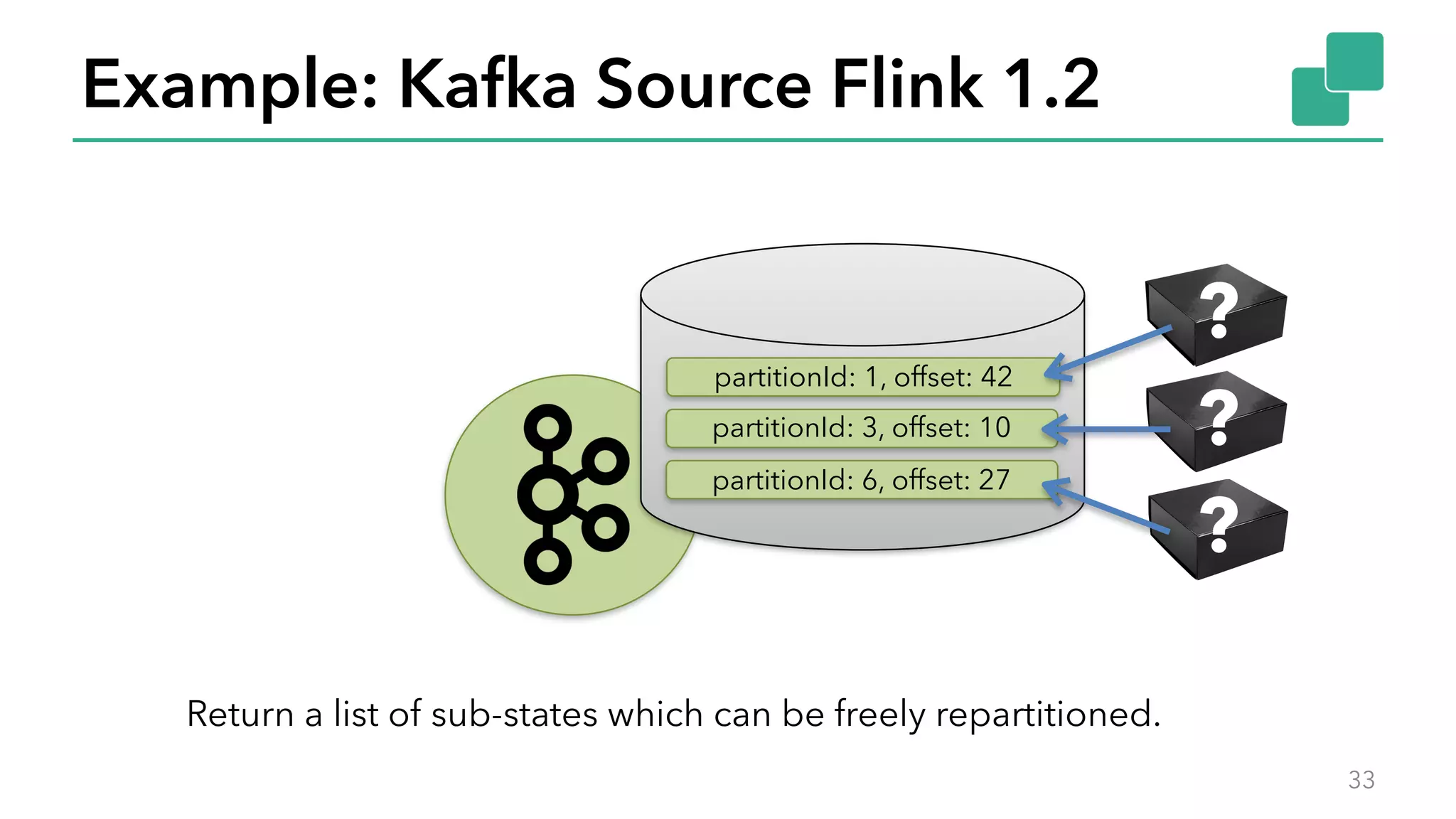
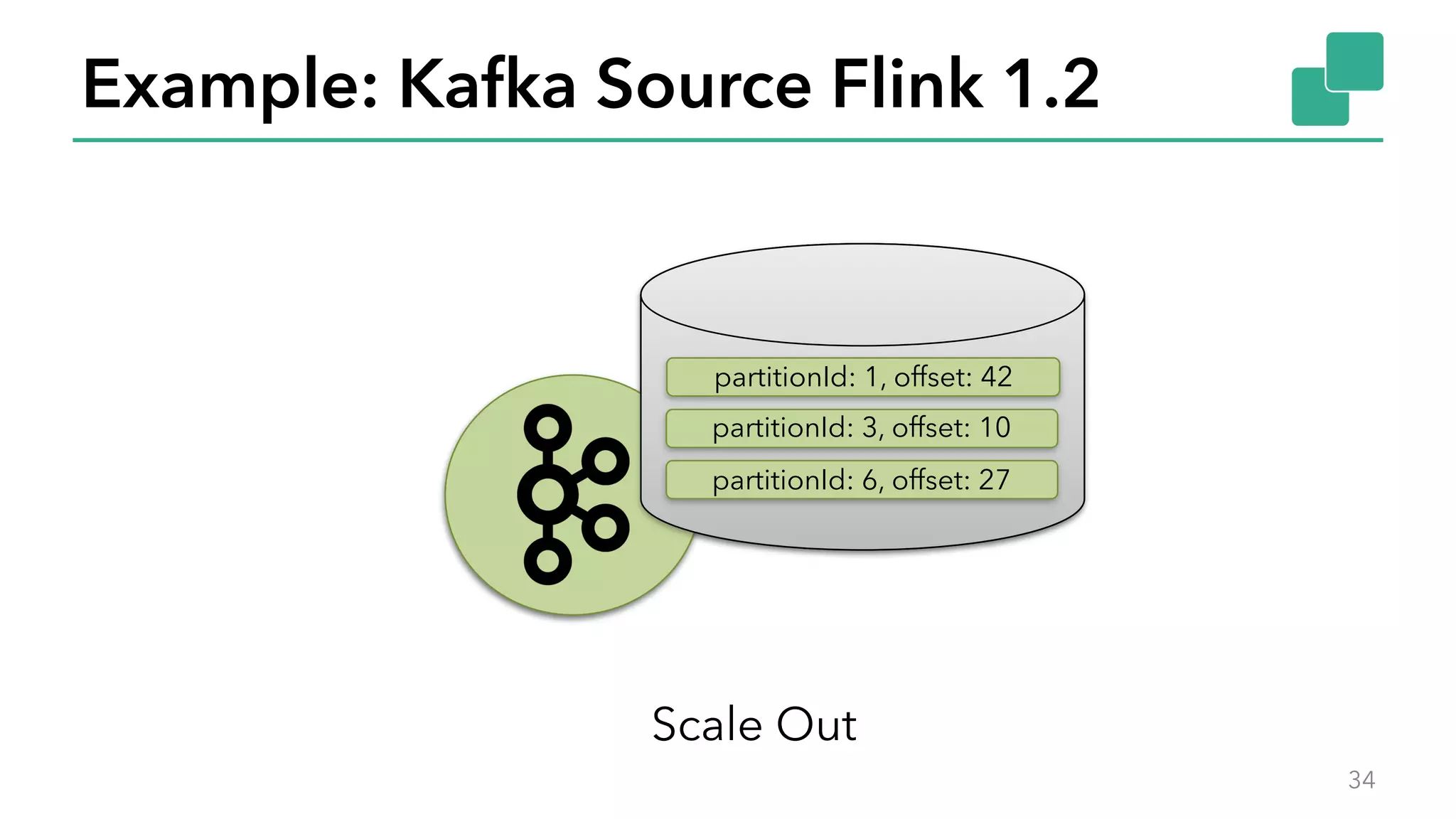
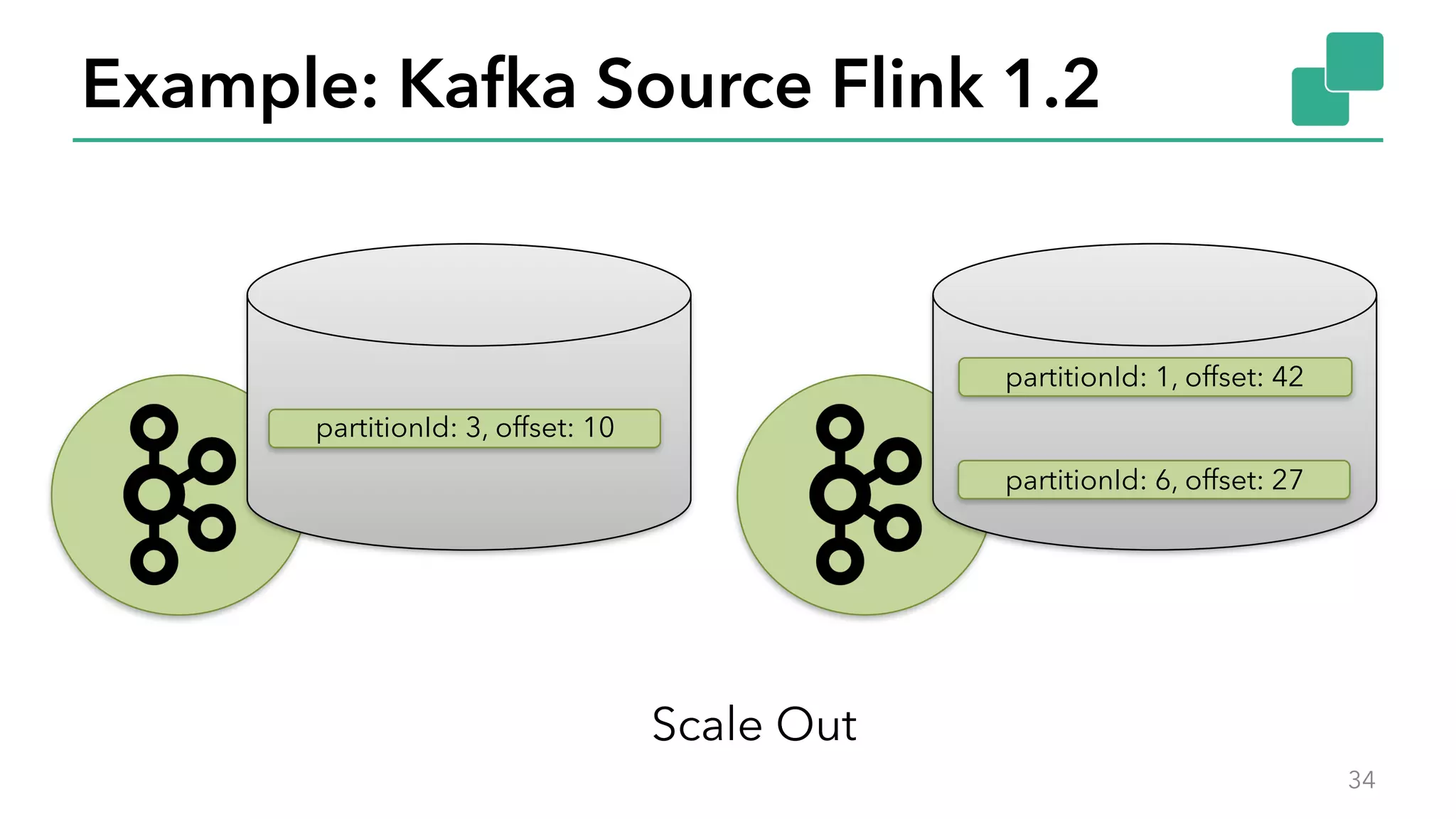
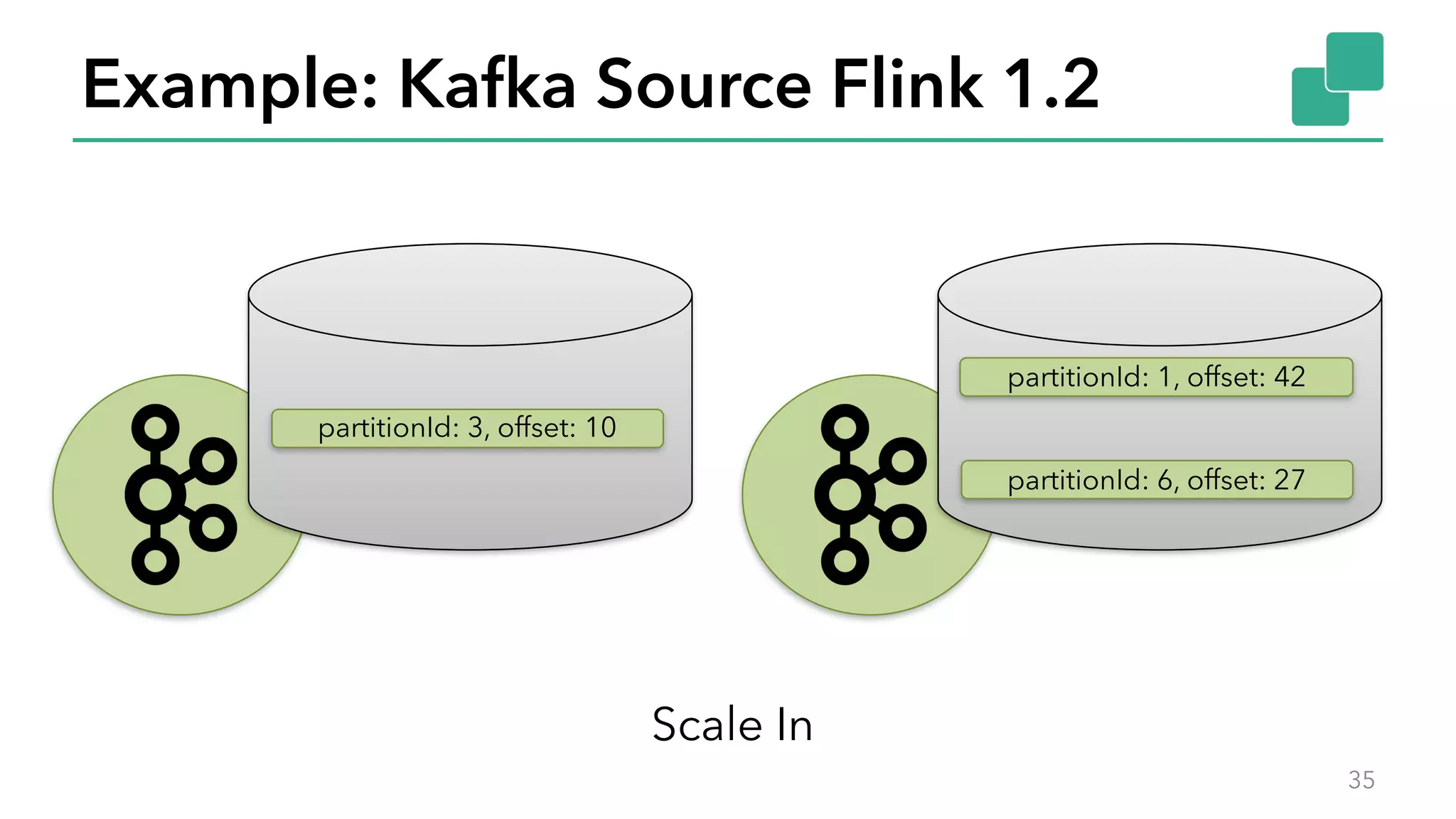
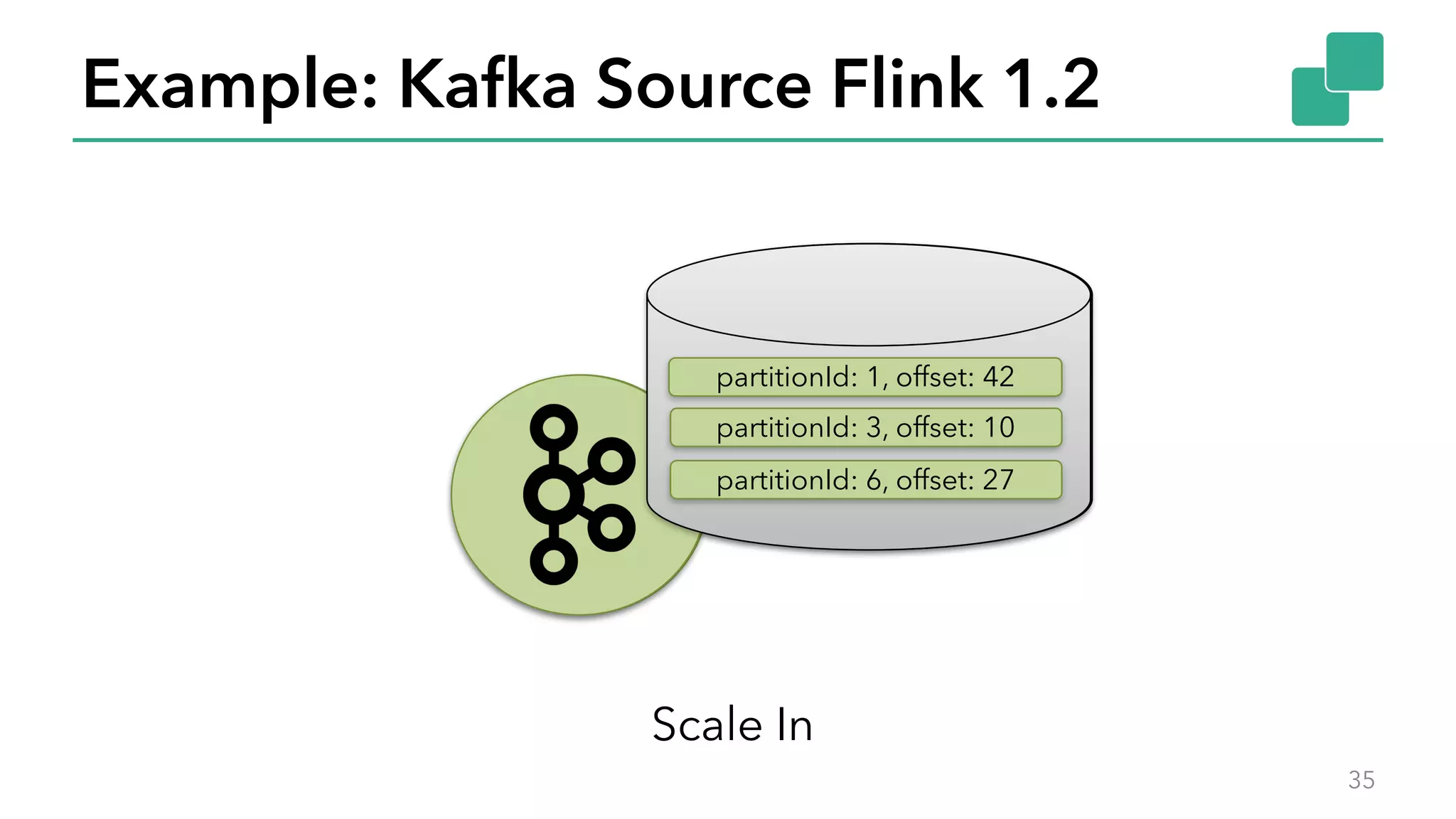
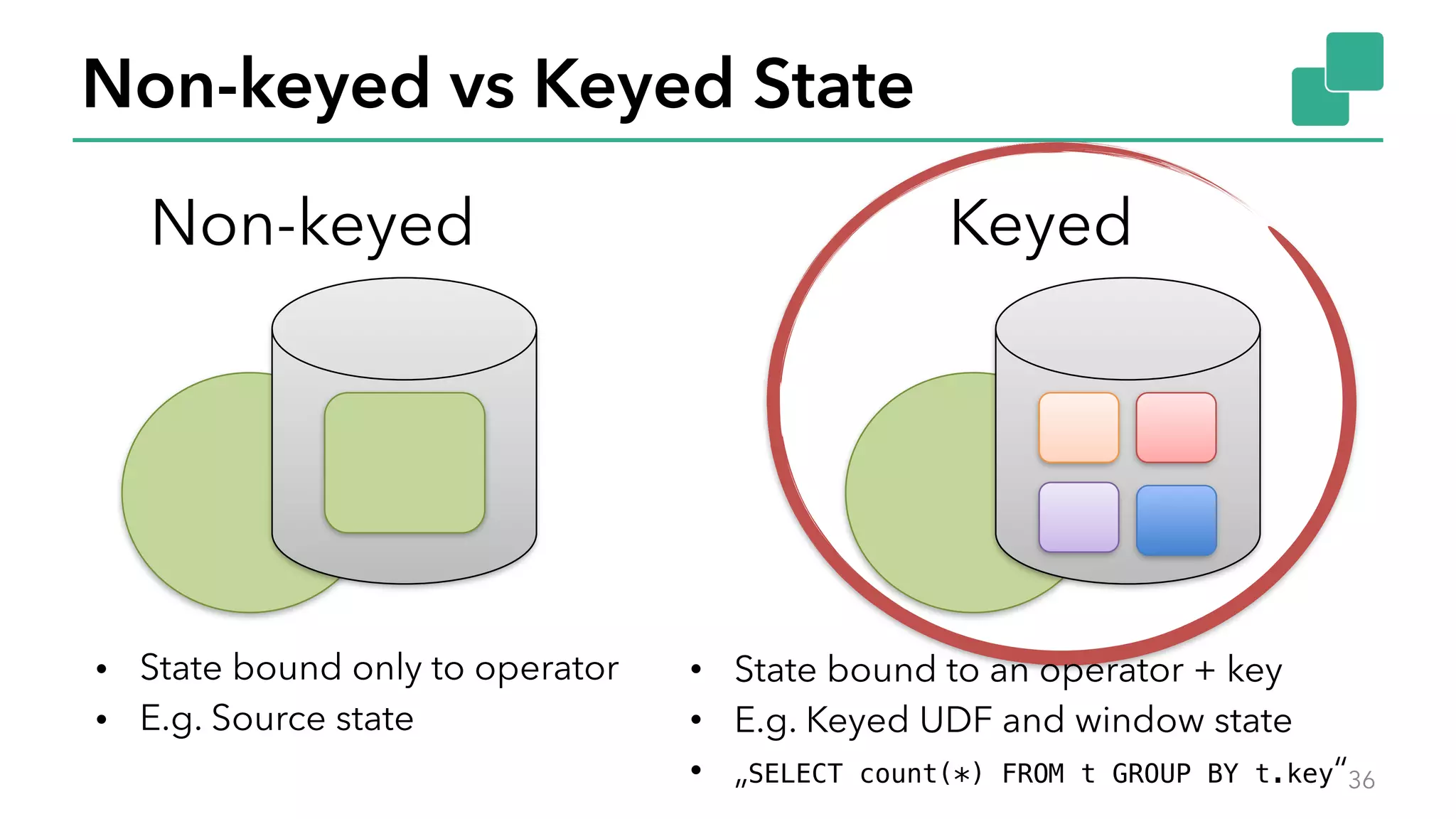
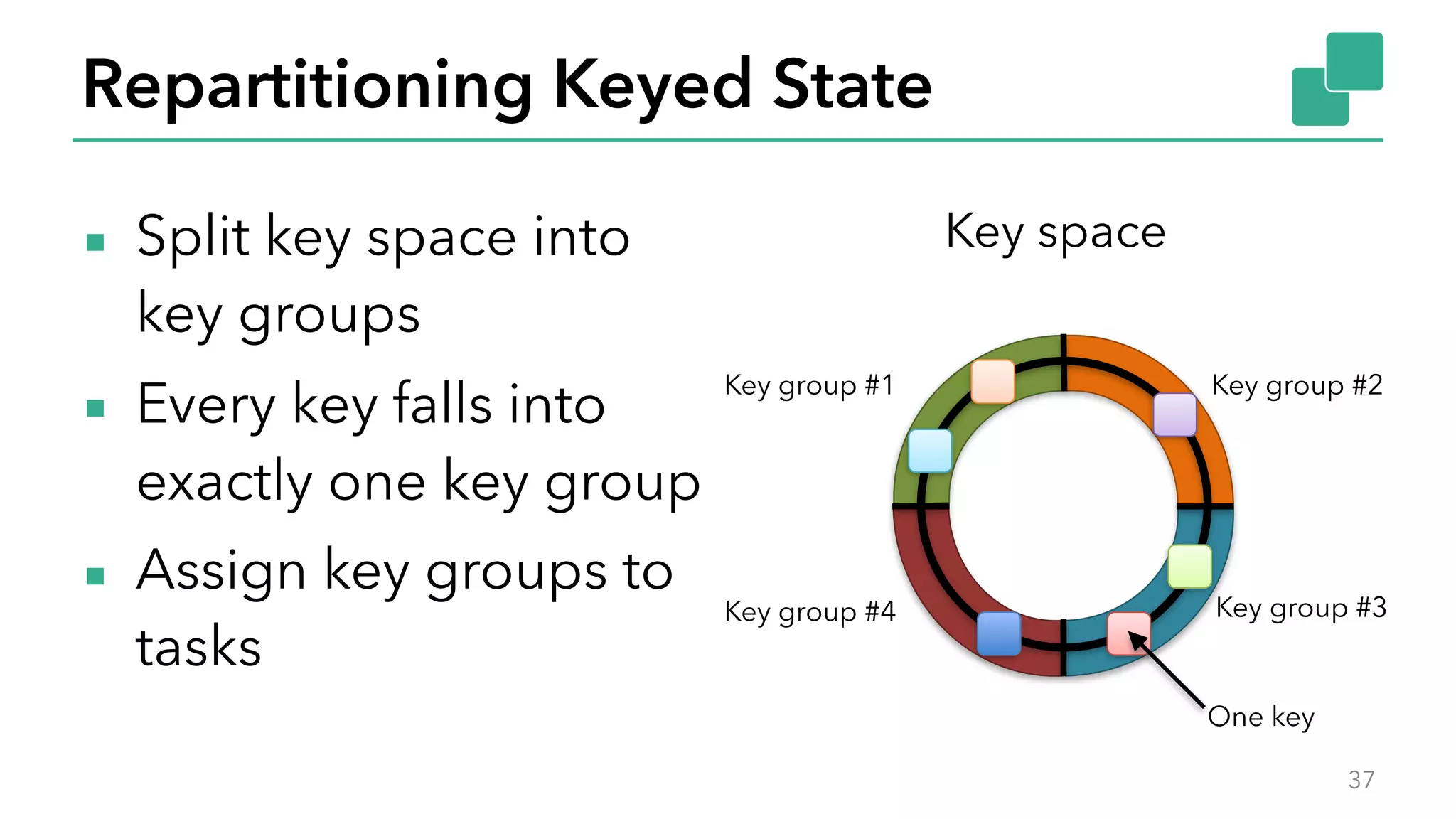
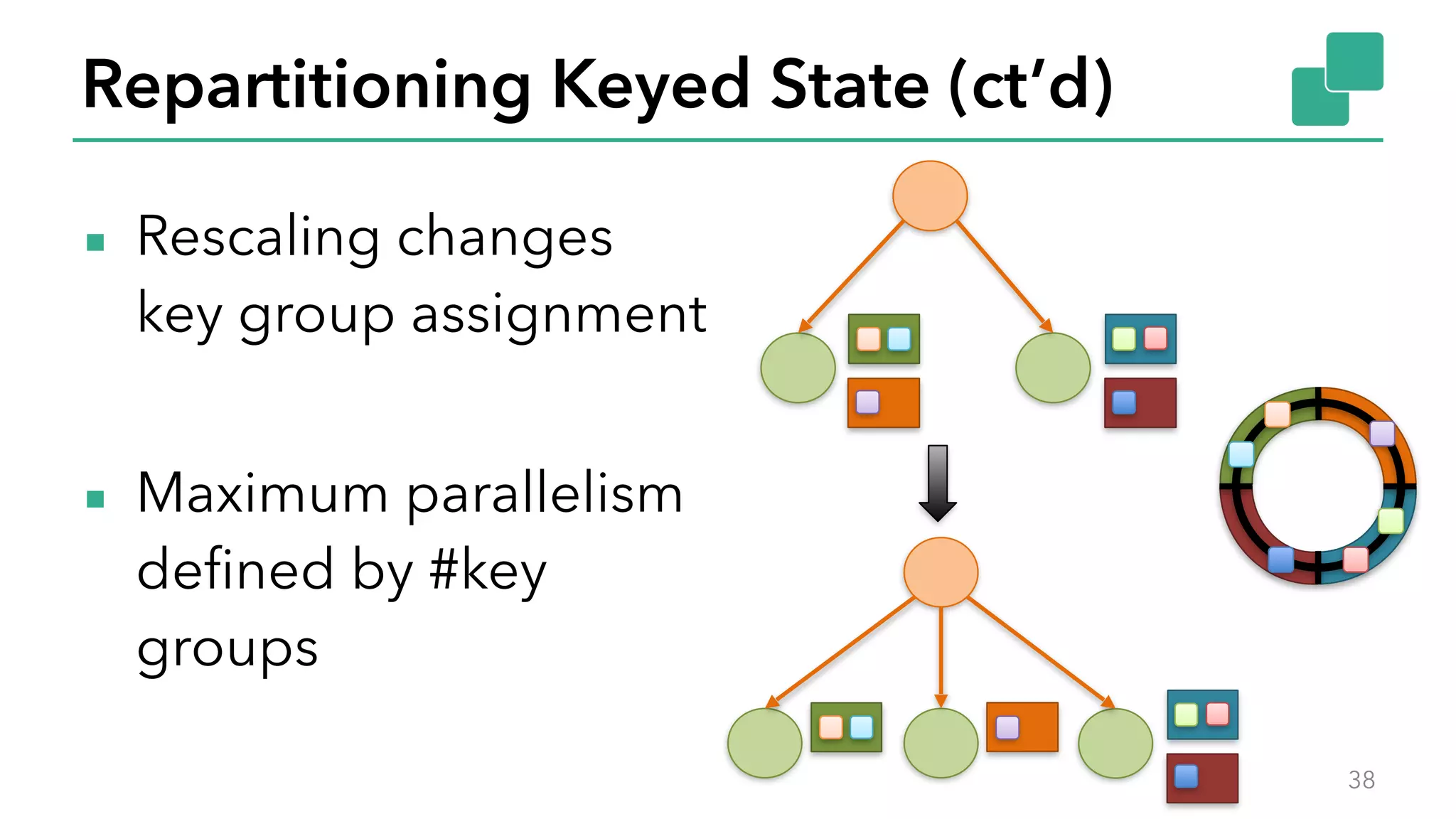
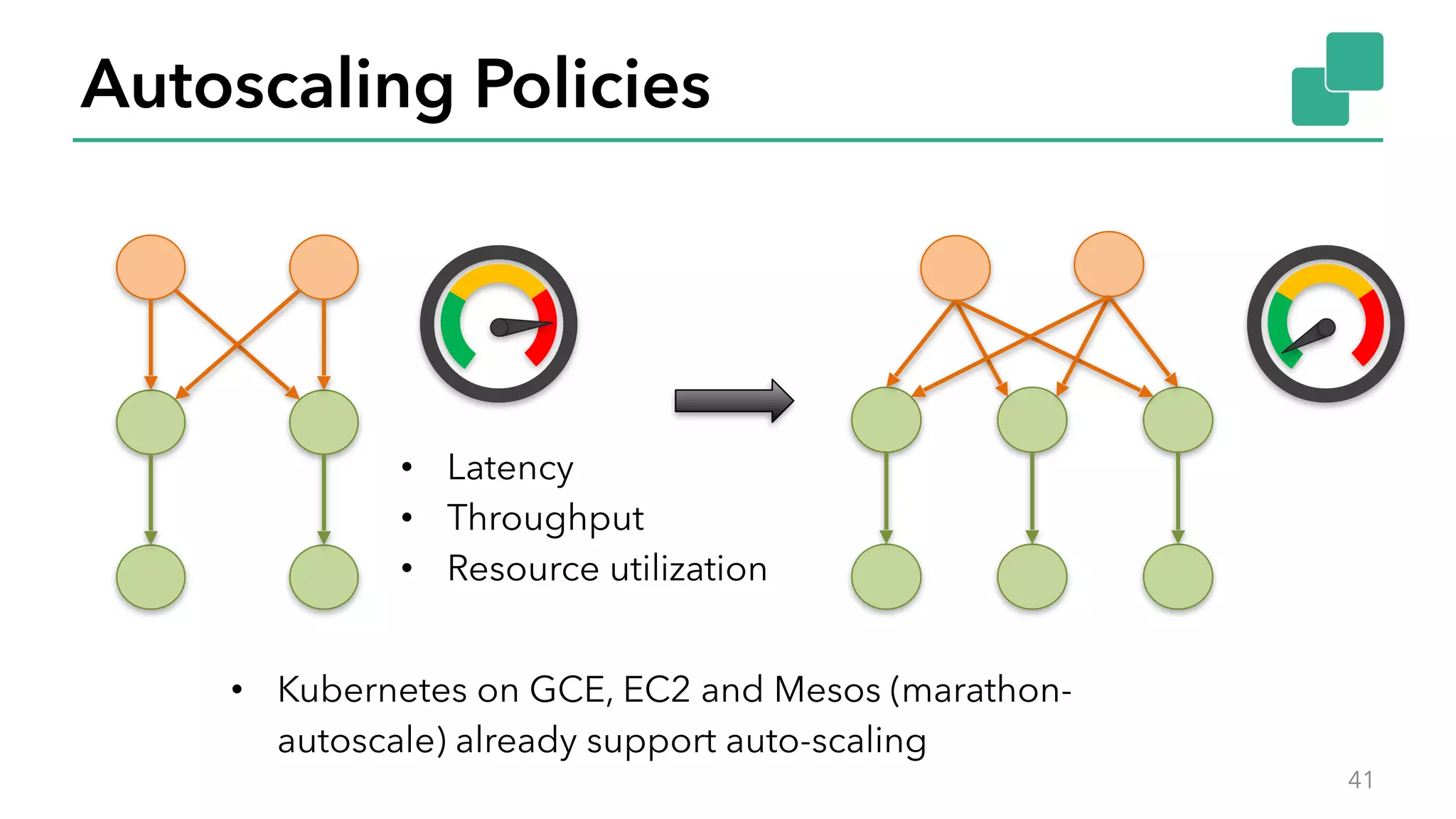
The document discusses new features in Apache Flink 1.2, including queryable state and dynamic scaling. It provides an overview of Flink 1.2 features like security enhancements, metrics, and improvements to table API and SQL. It then examines queryable state and dynamic scaling in more detail, covering motivations and implementations for making state queryable and allowing jobs to scale resources dynamically in response to changing workloads. The document concludes by looking briefly beyond Flink 1.2 to future work on automatic scaling without restarts.