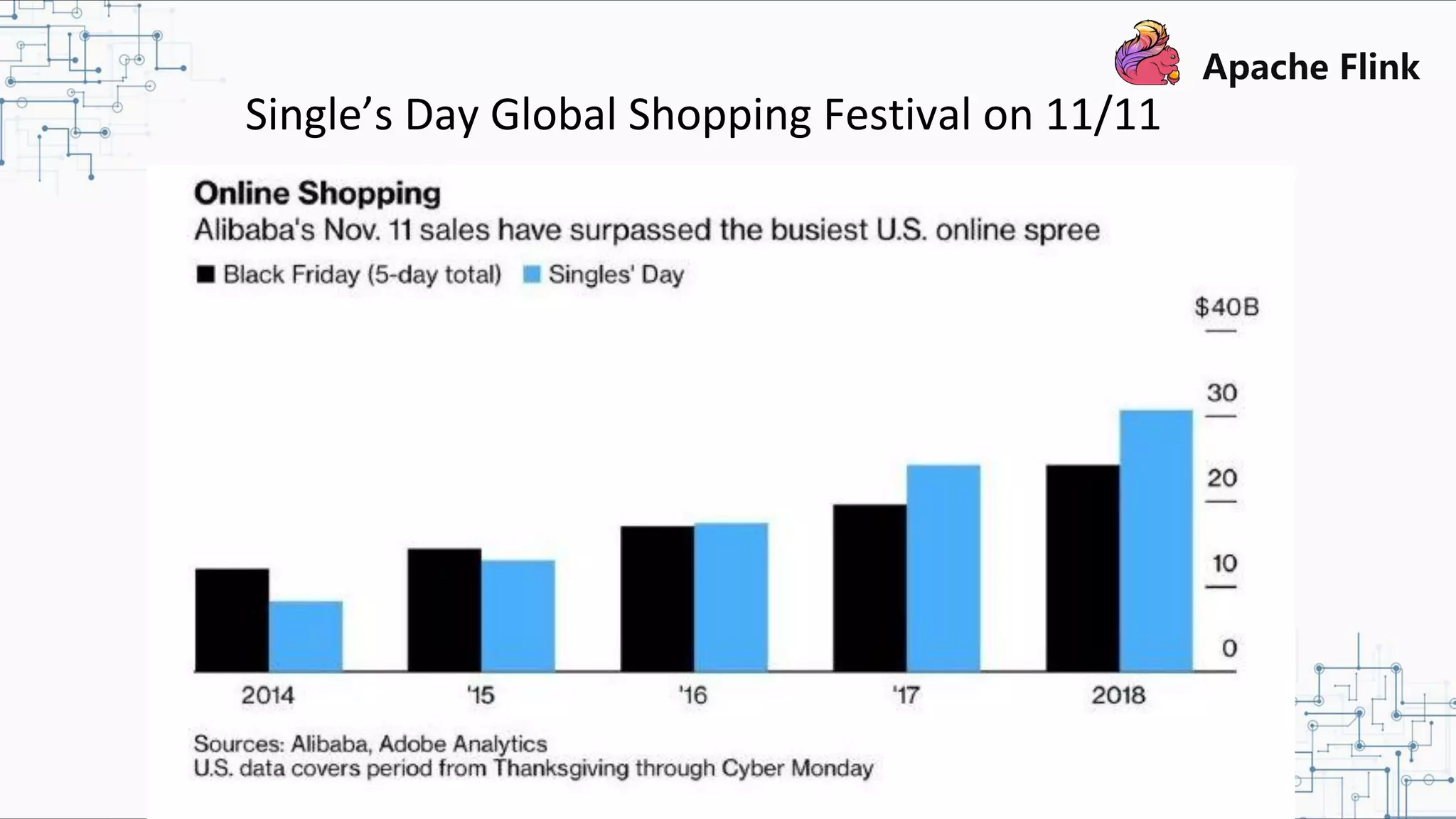
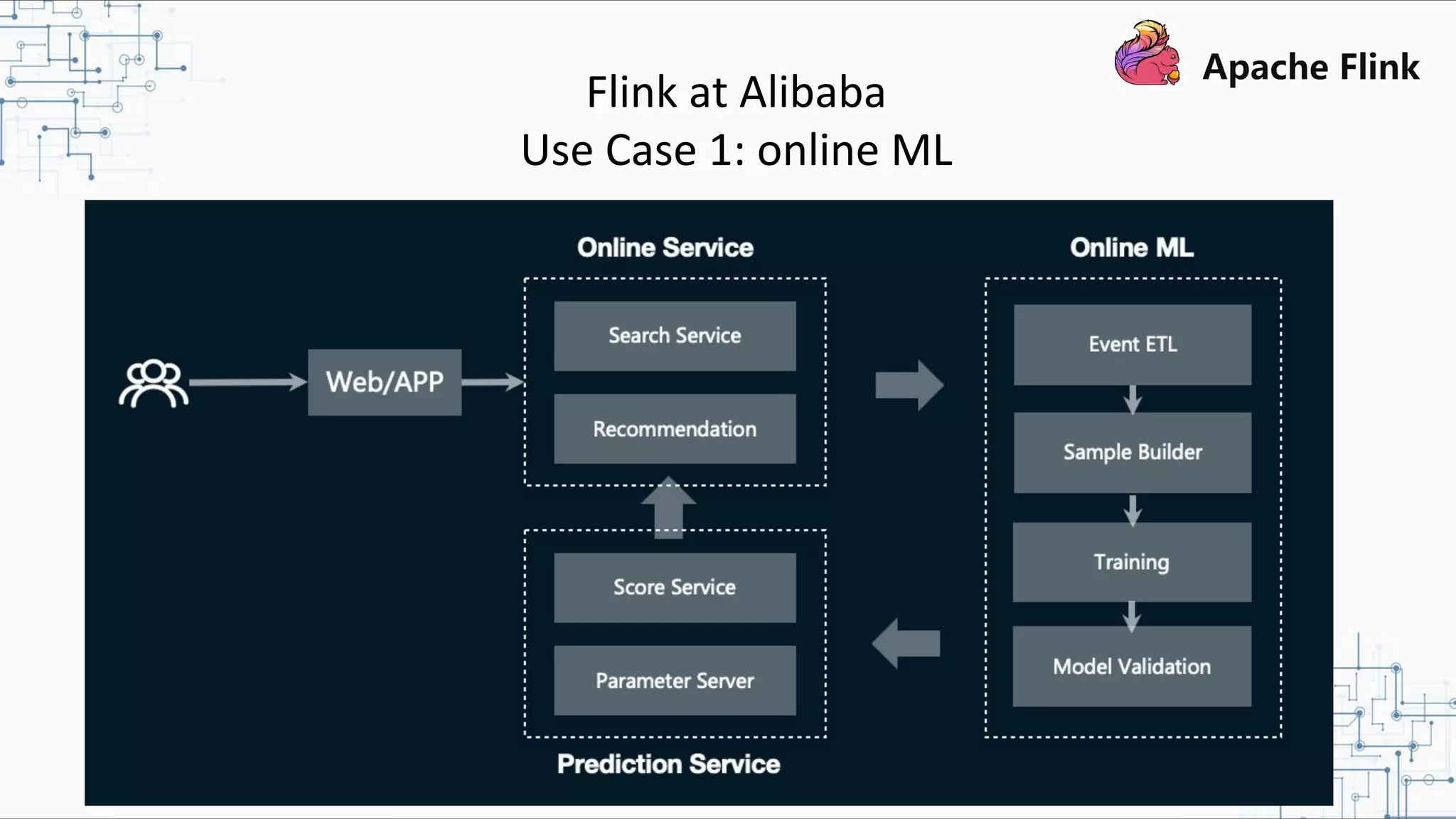
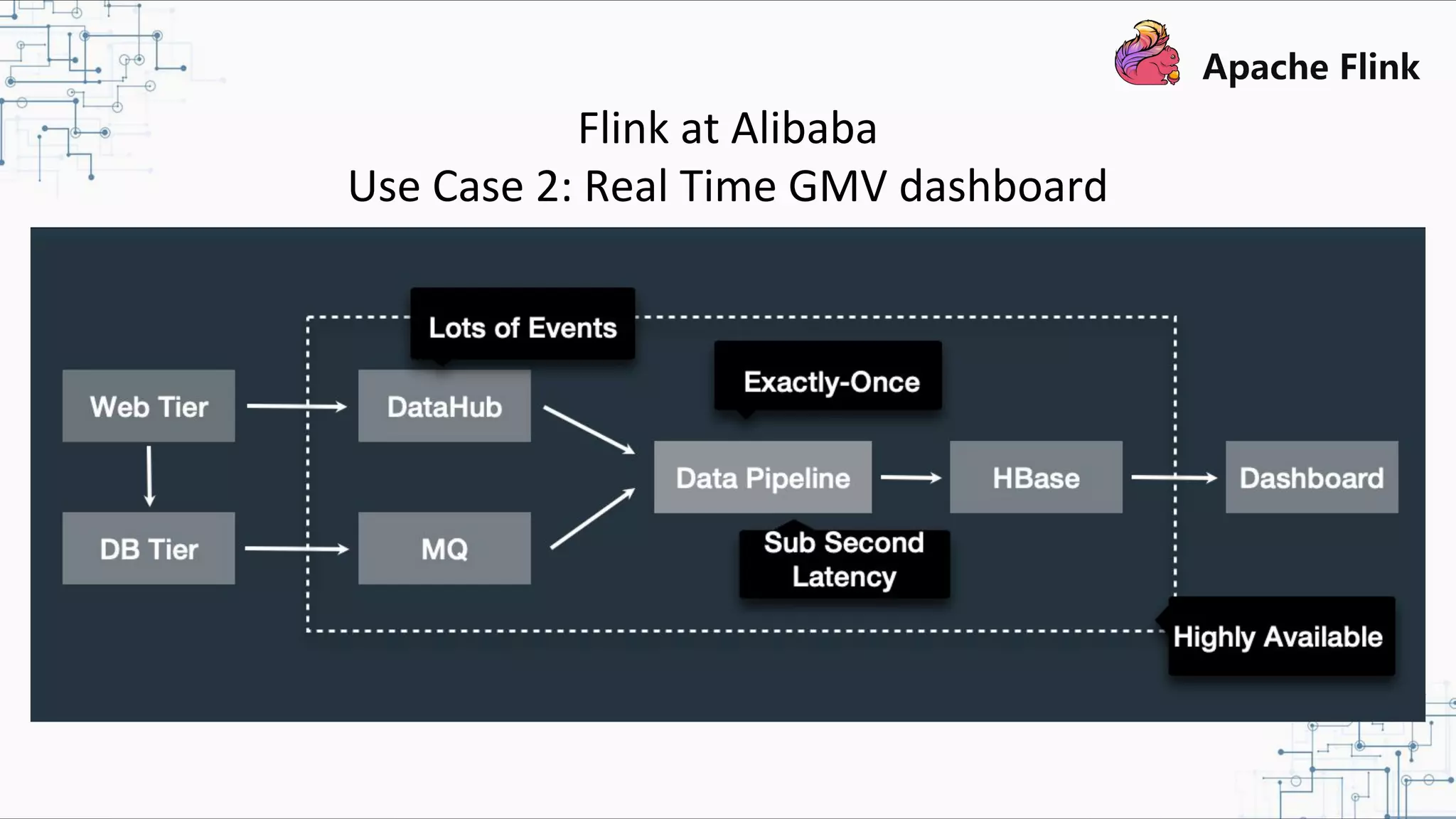
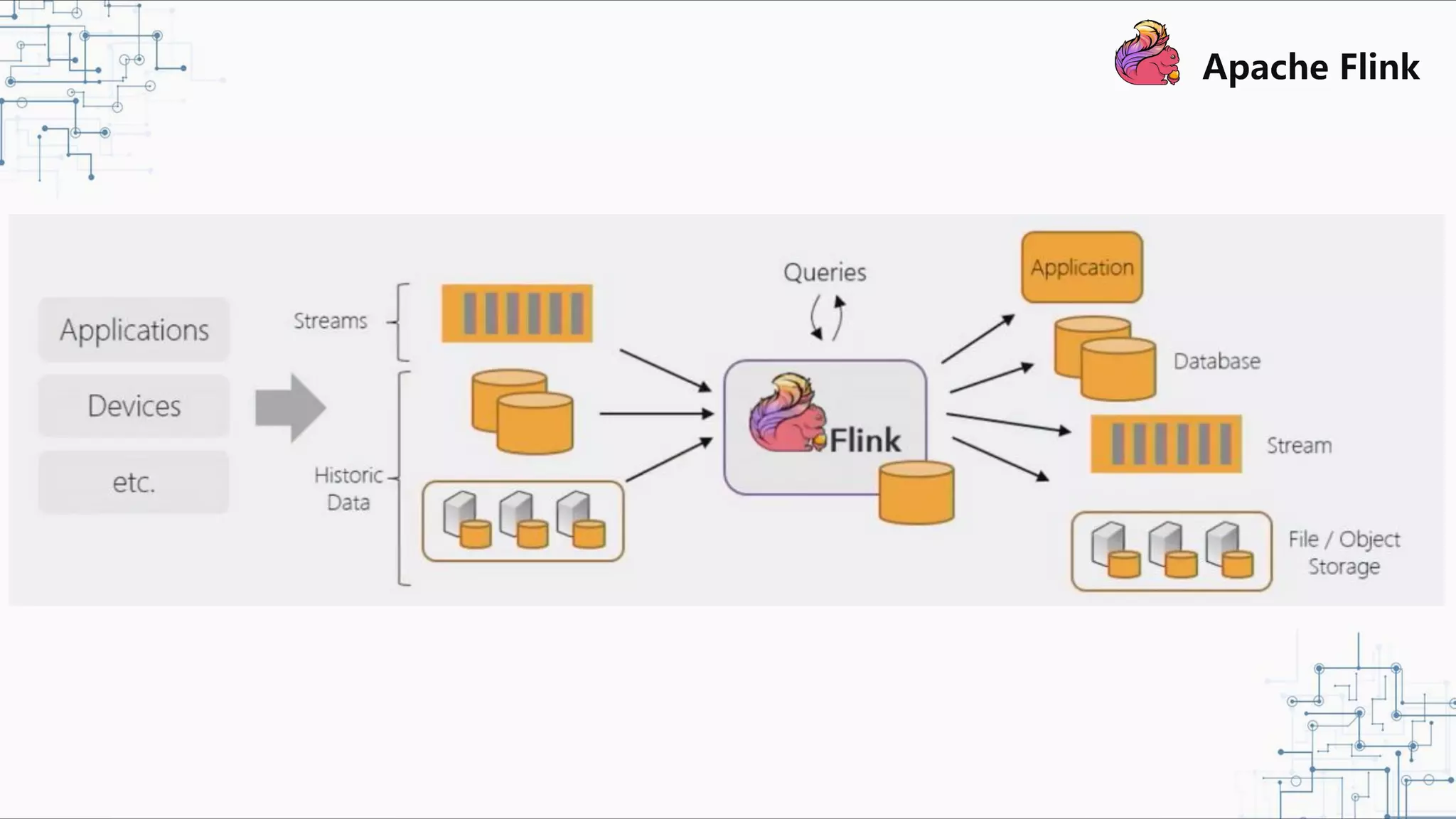
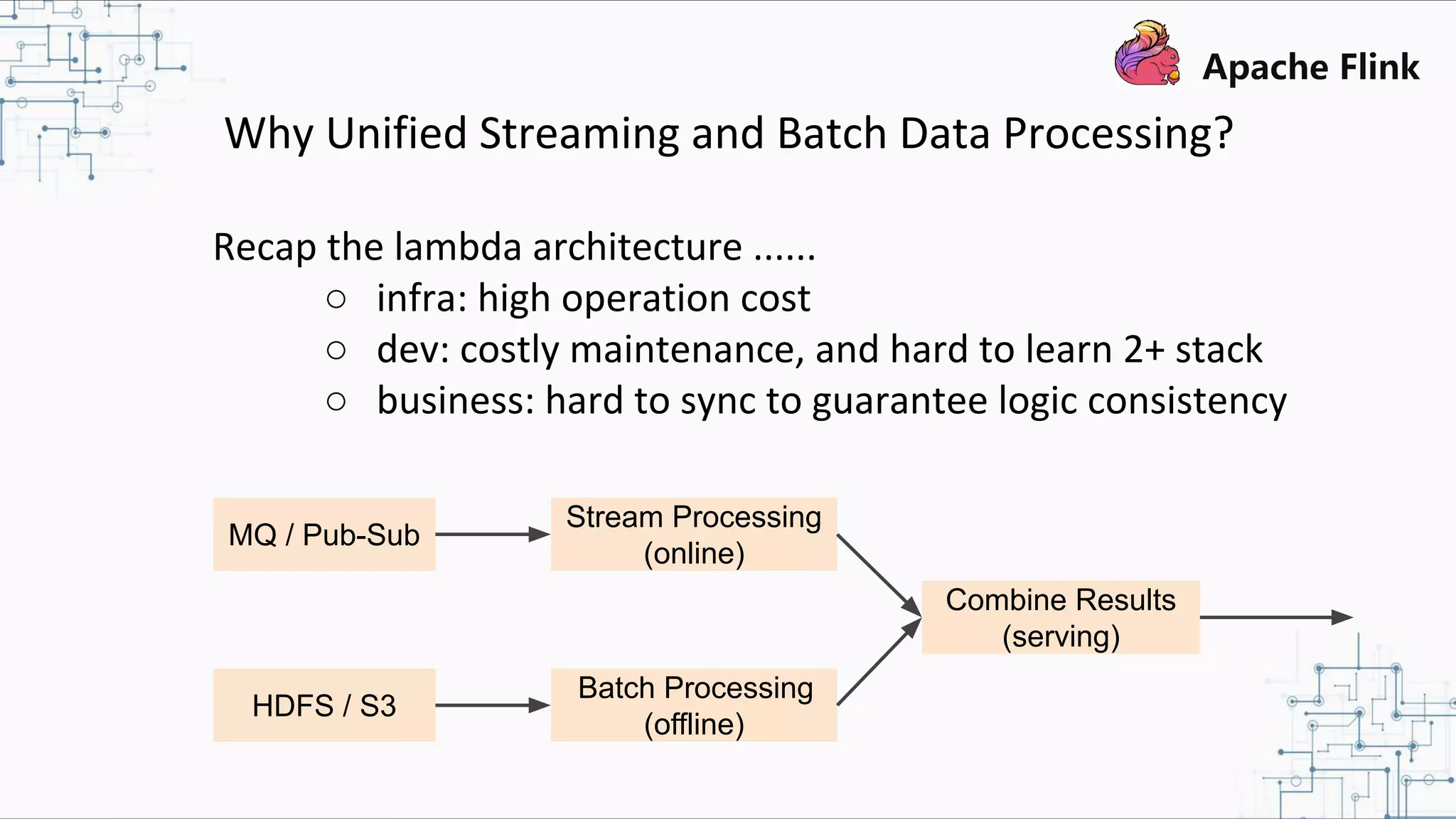
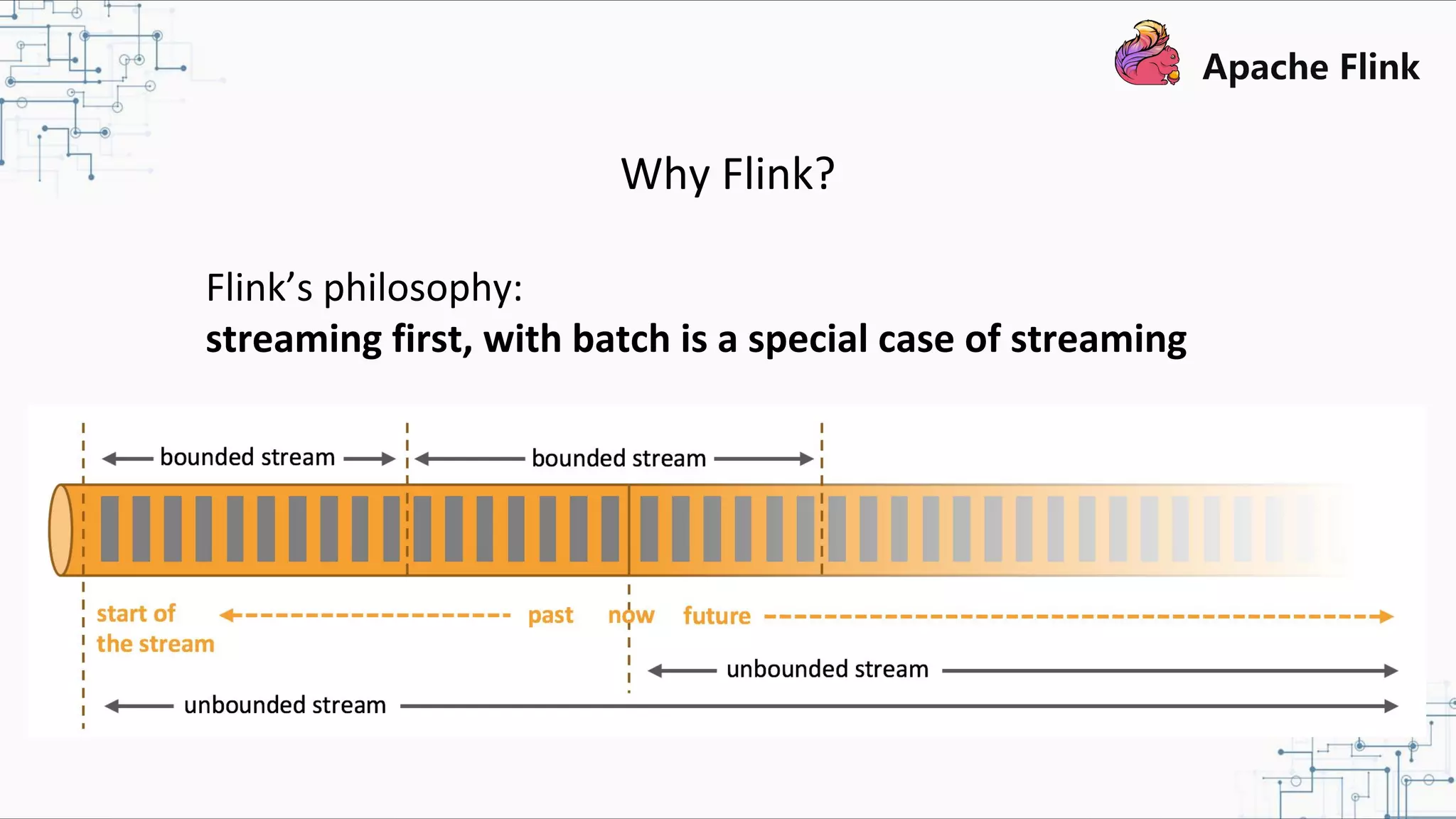
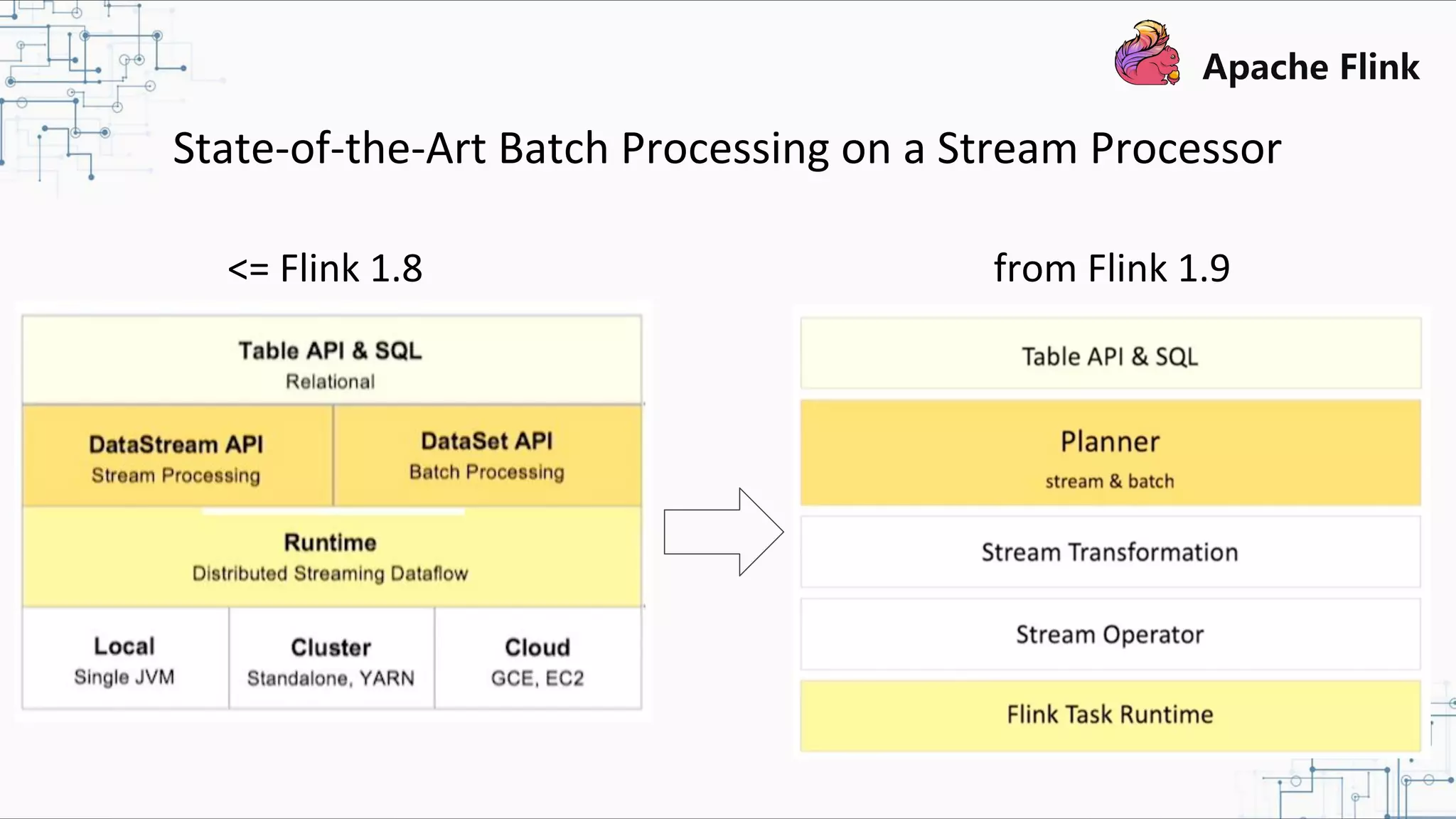
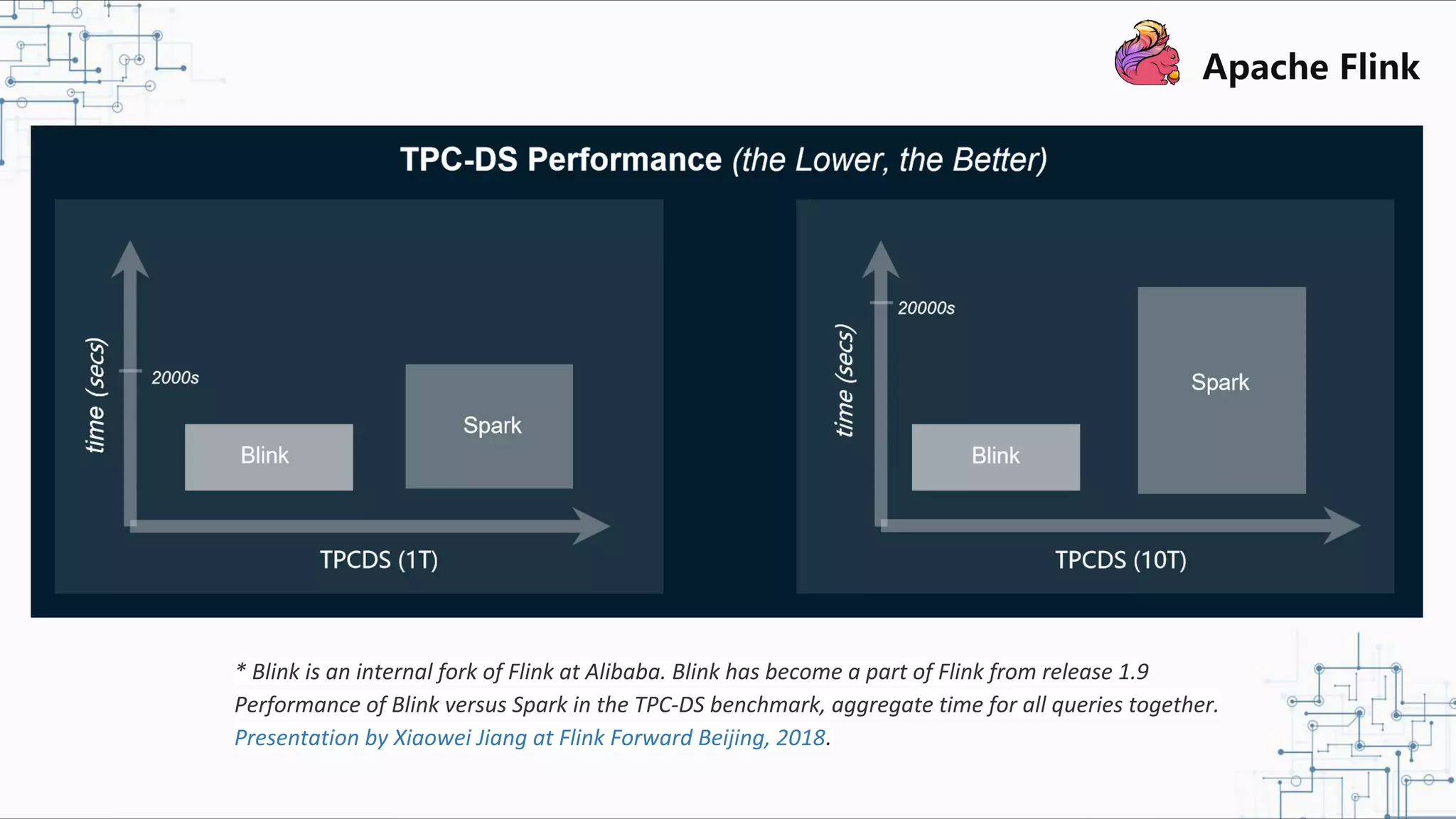
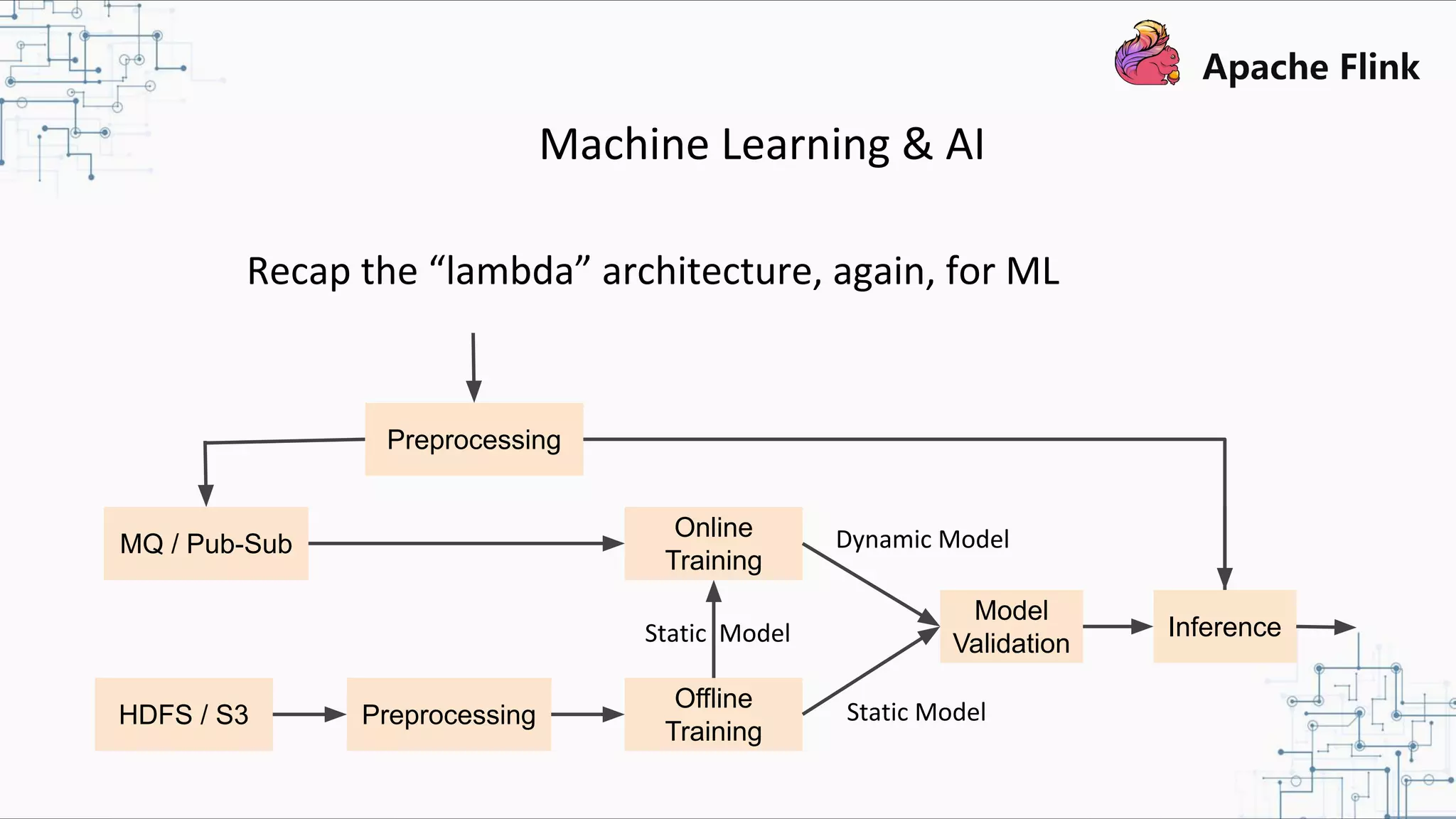
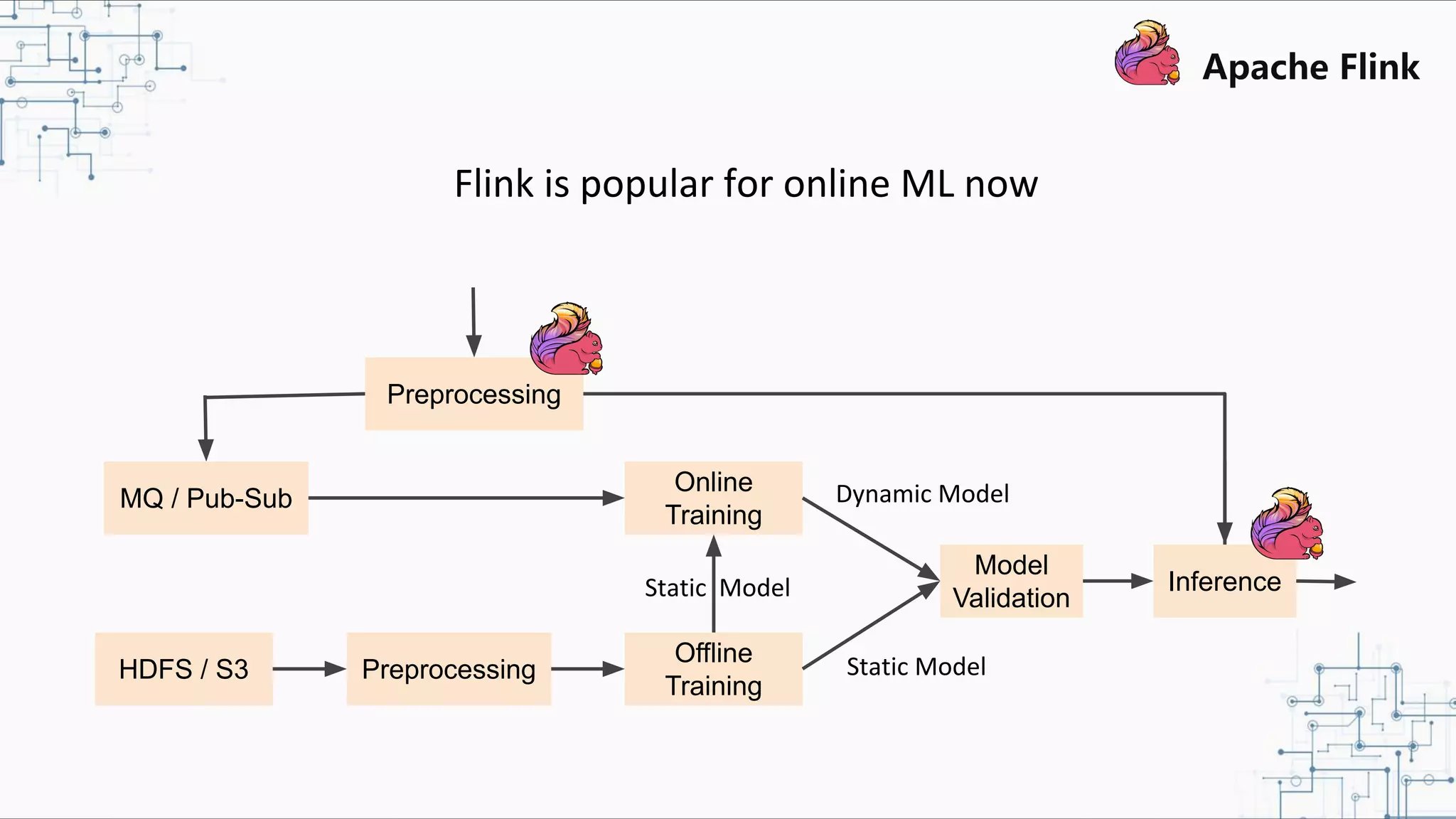
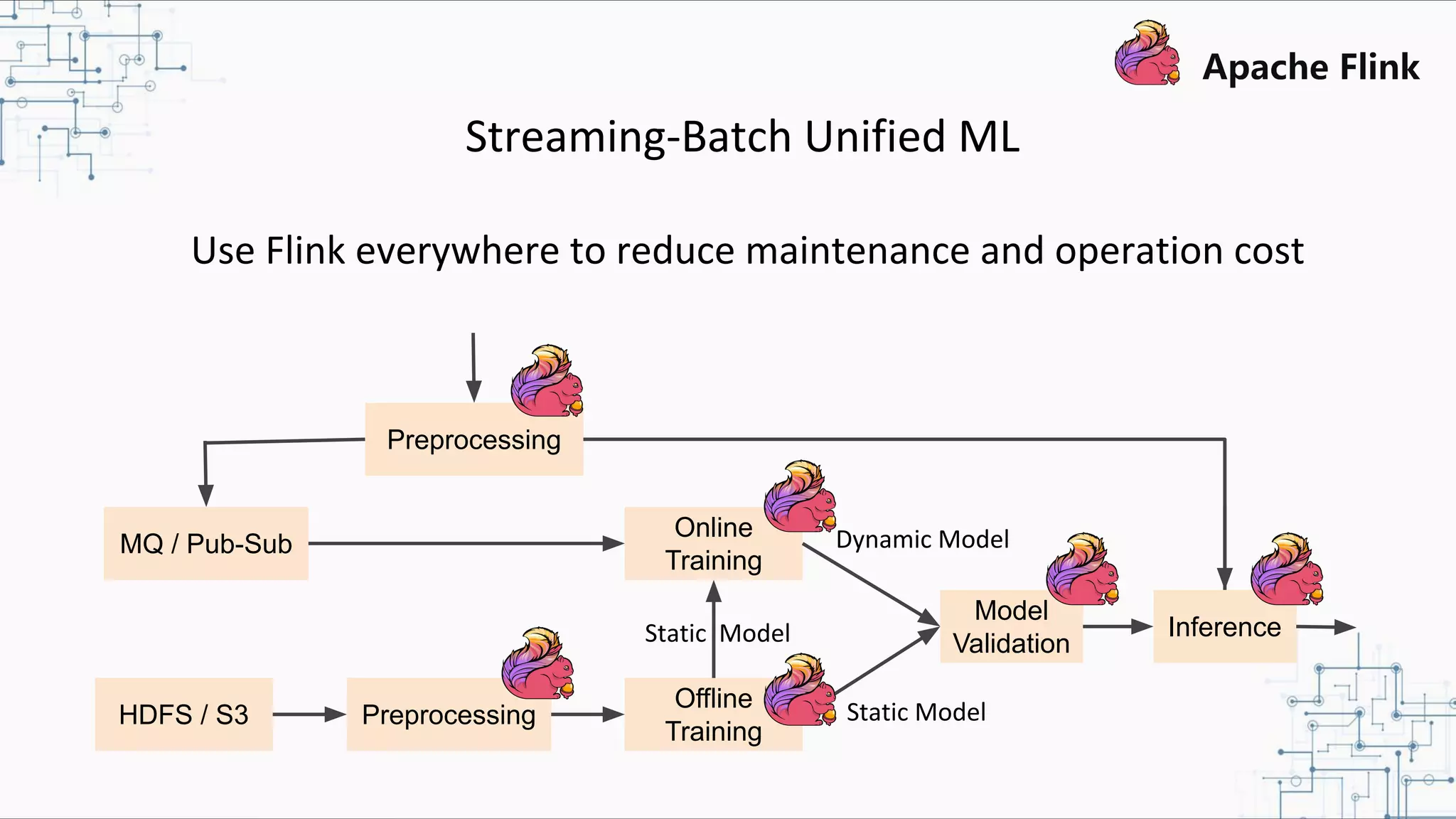
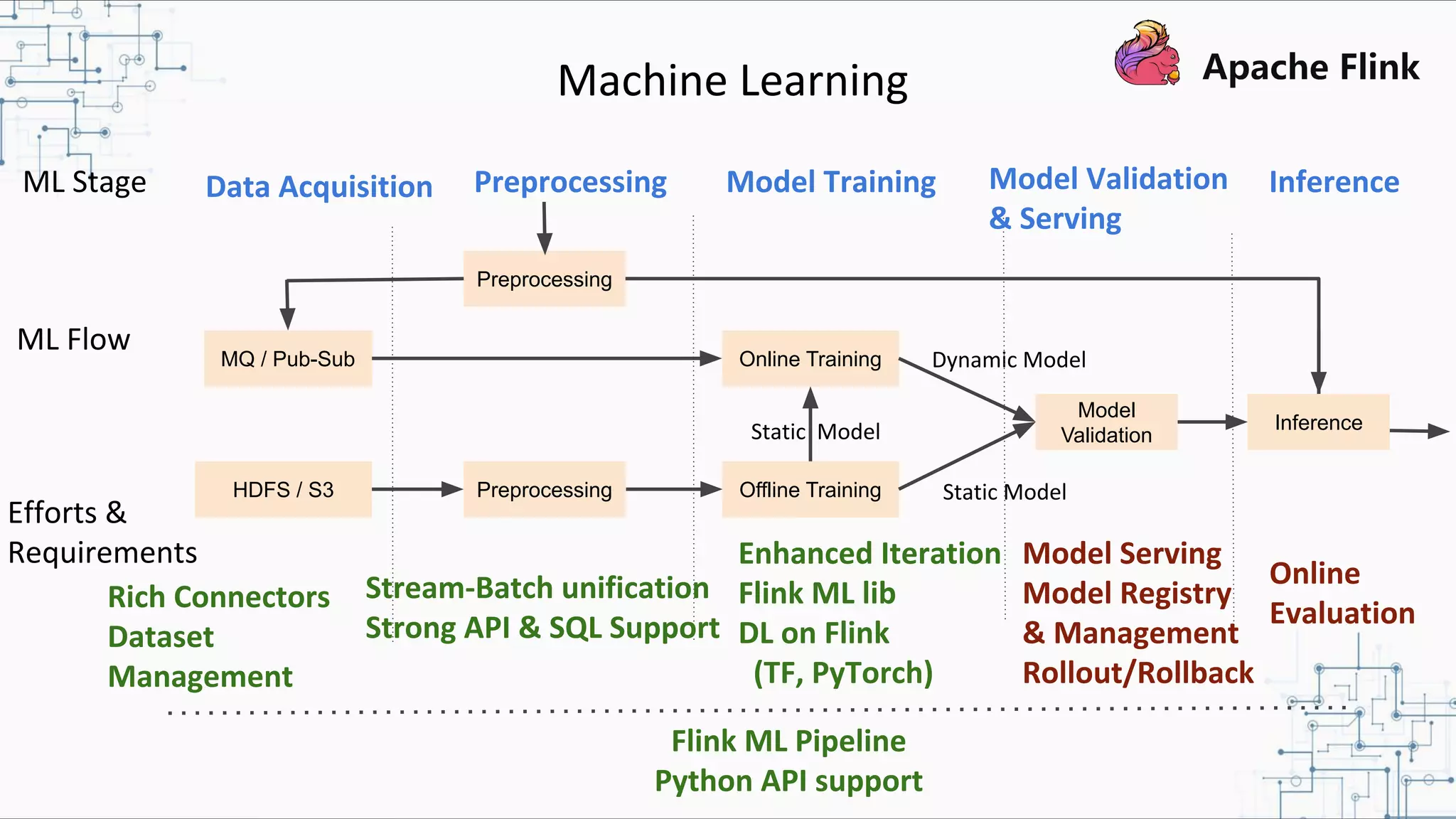
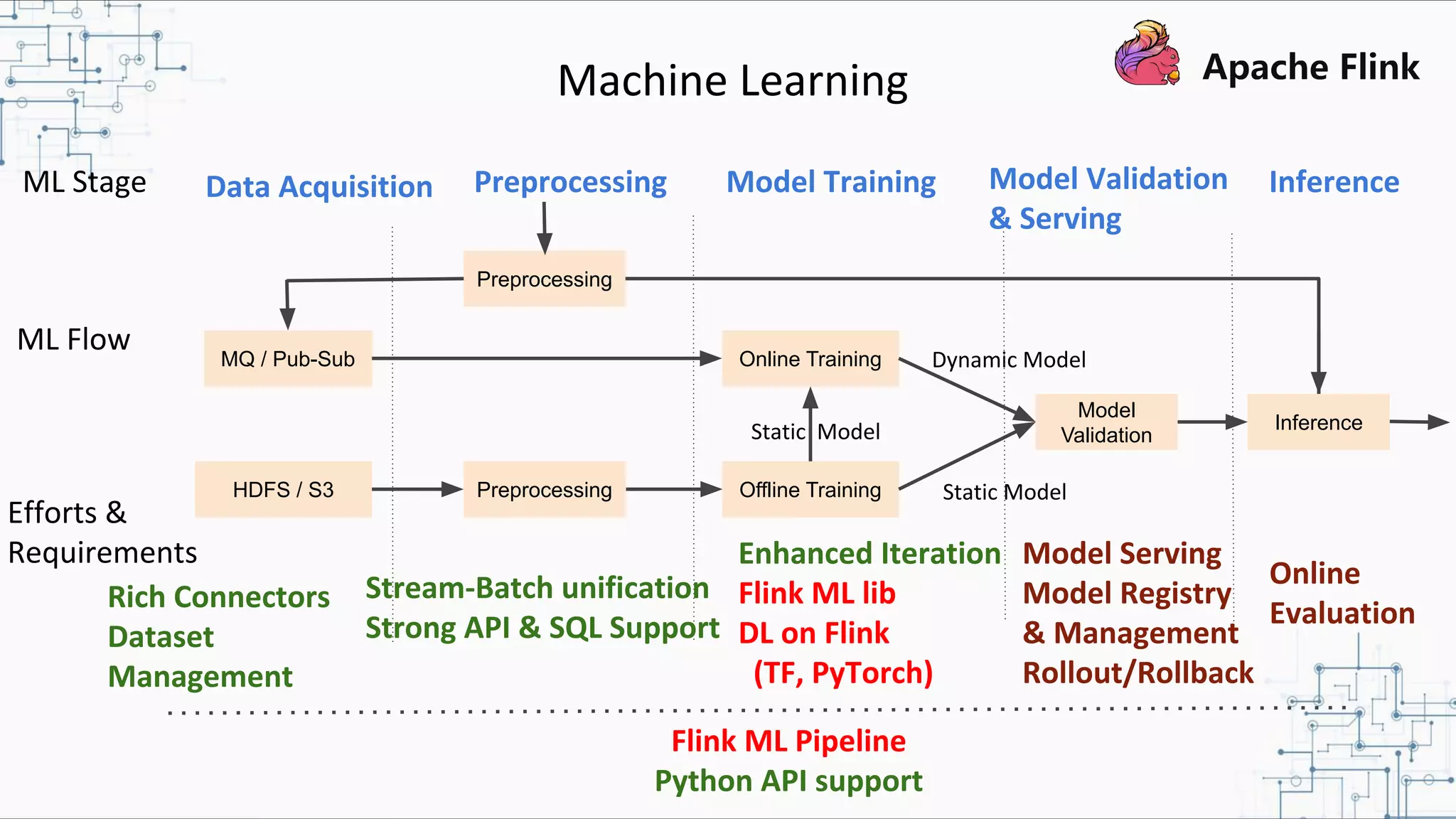
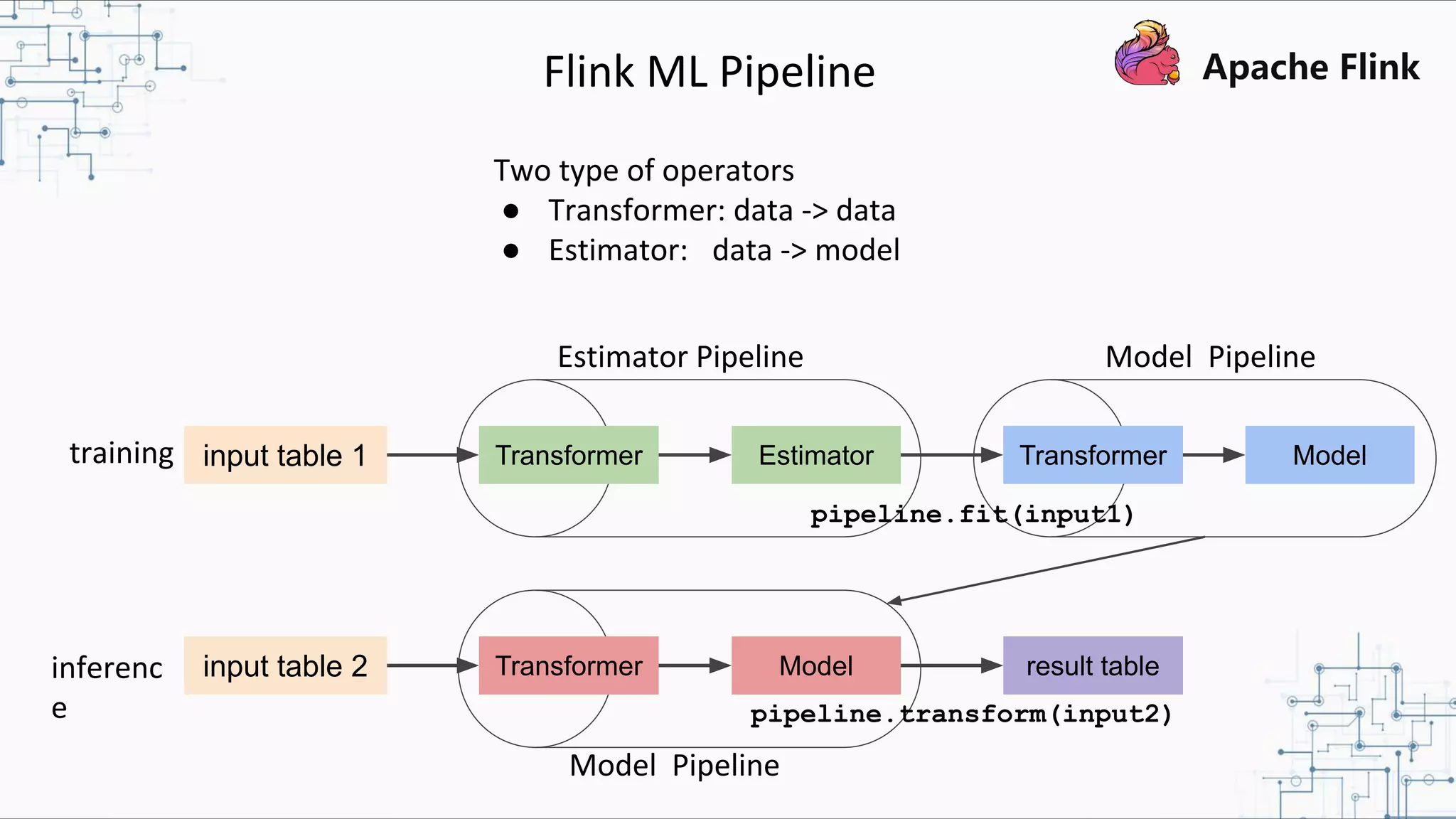
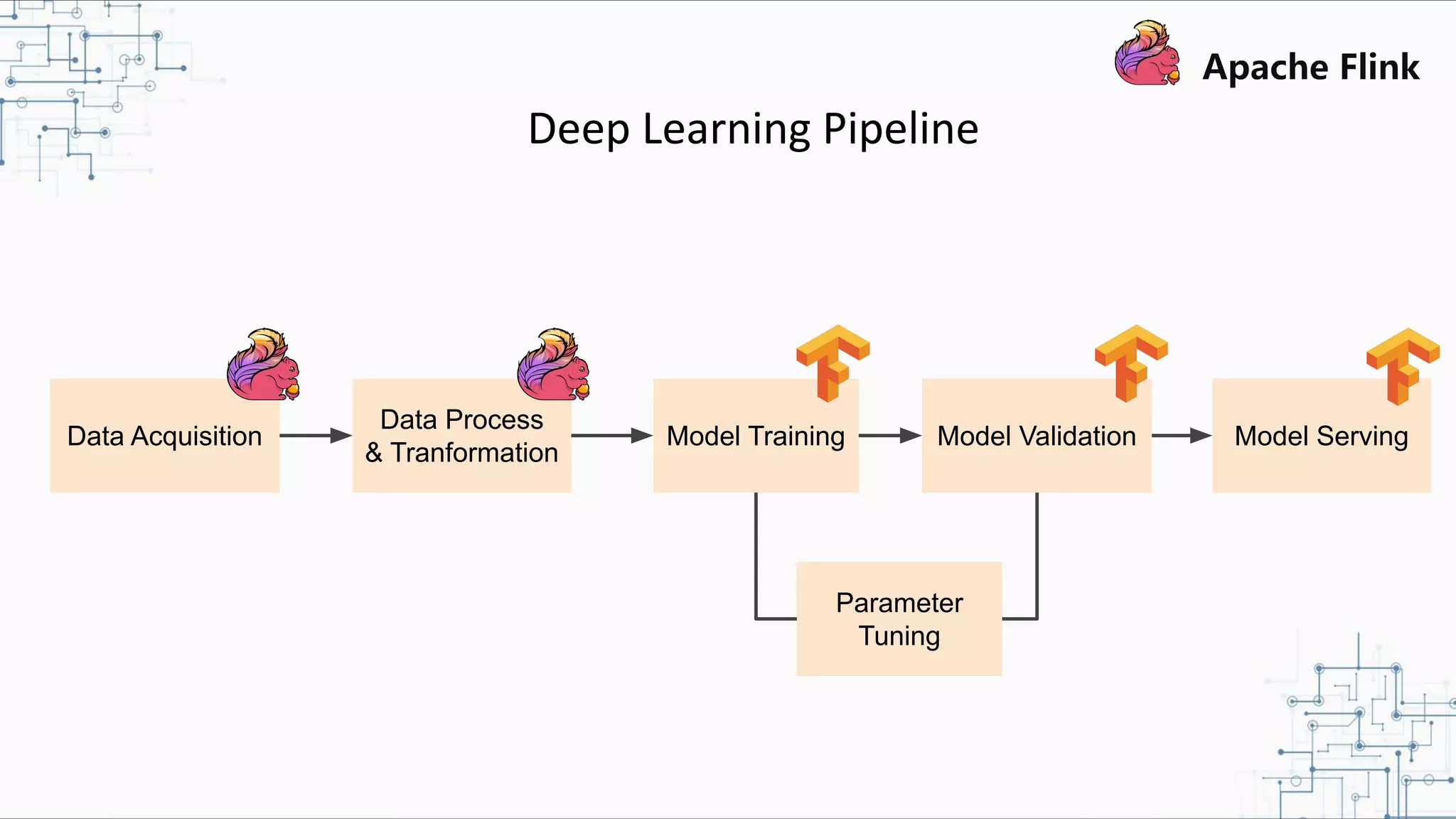
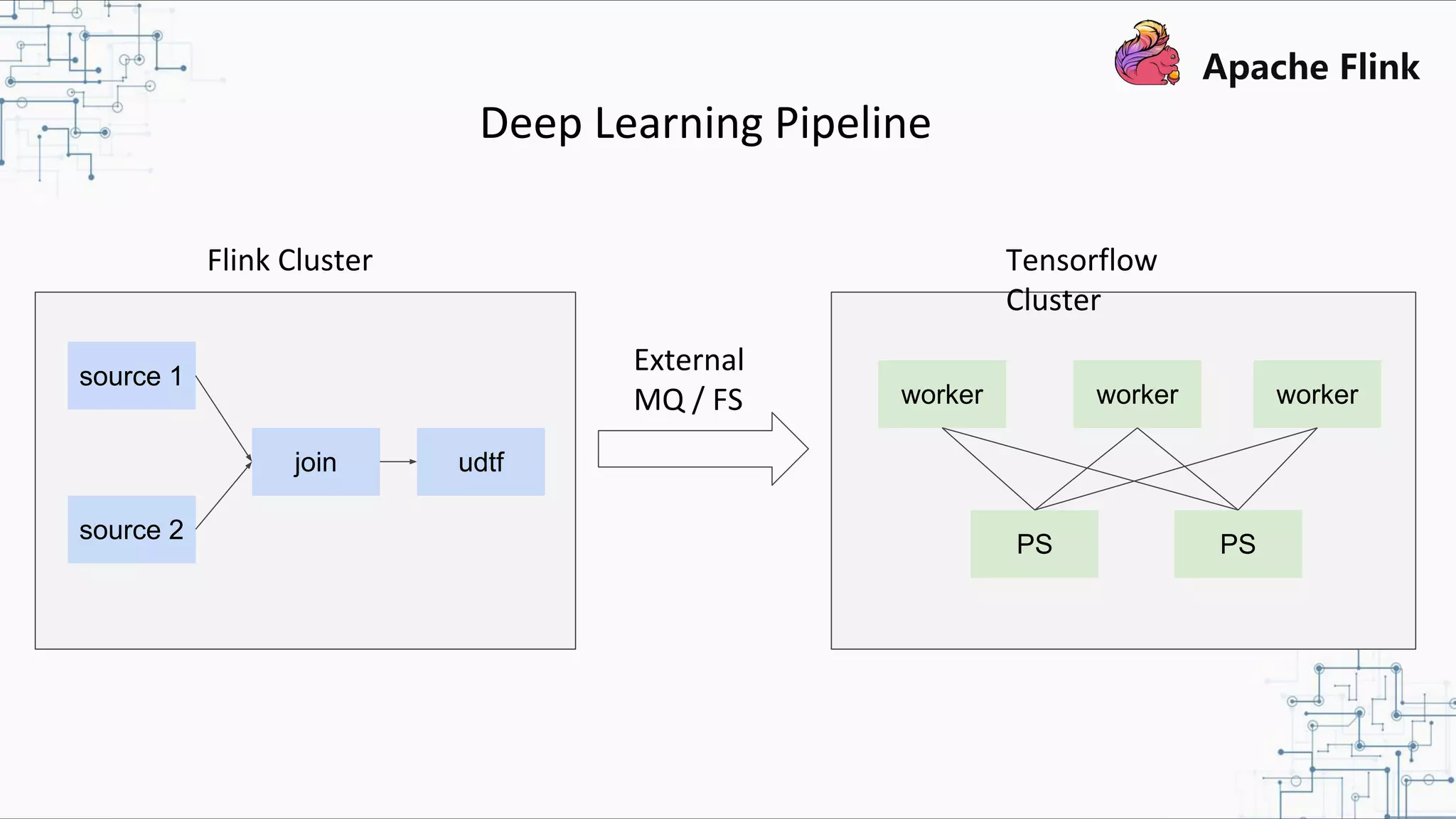
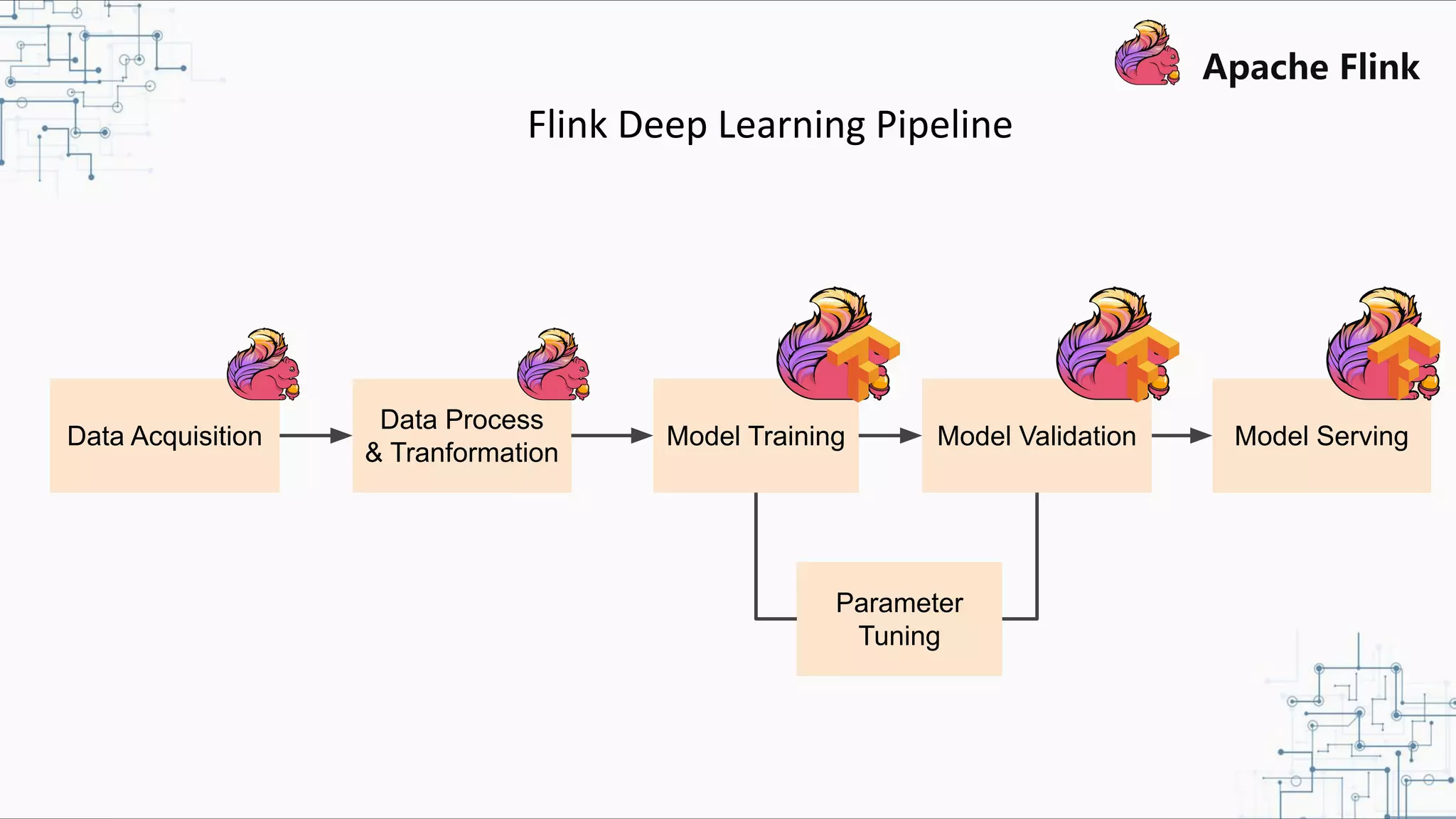
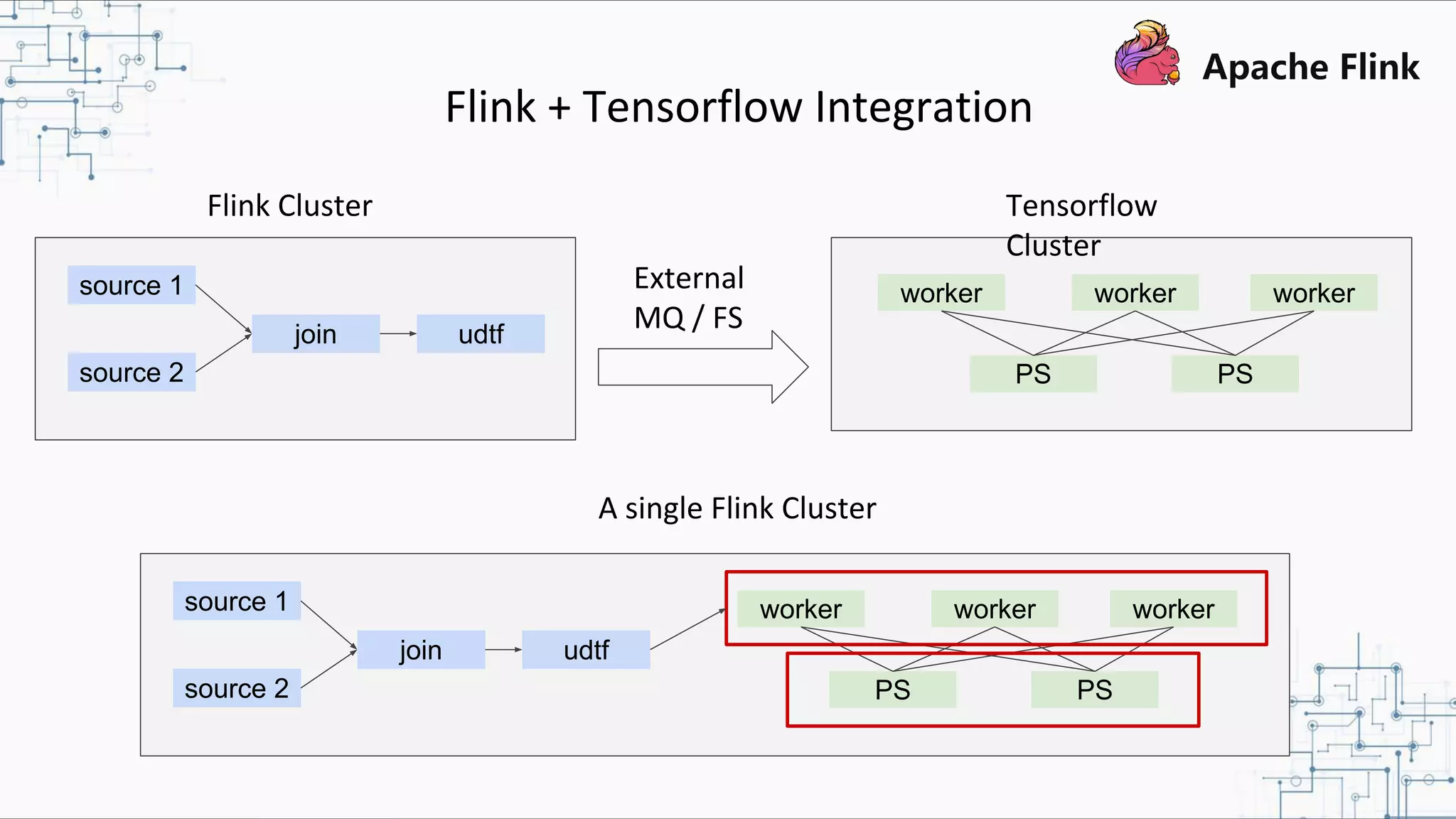
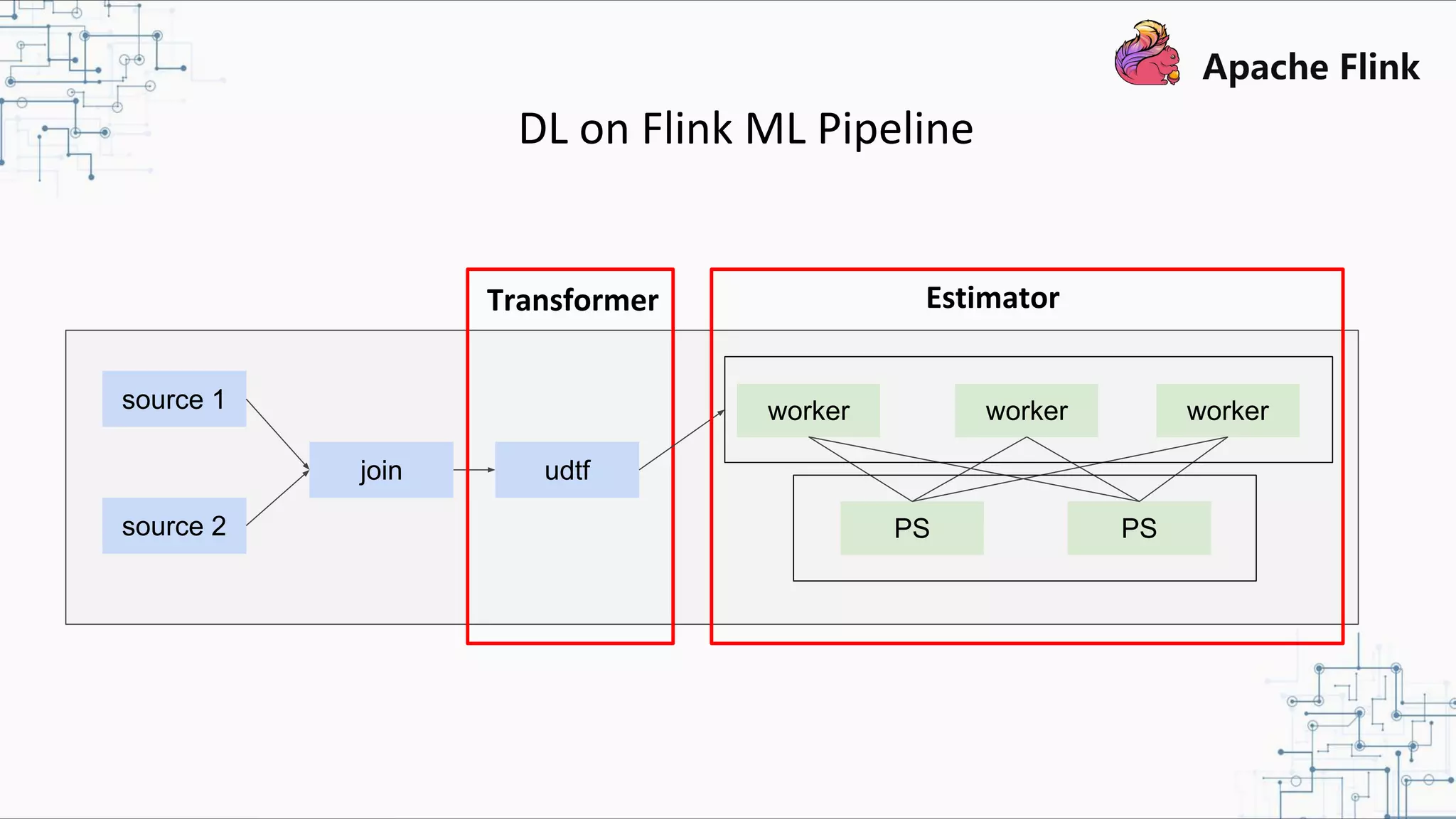
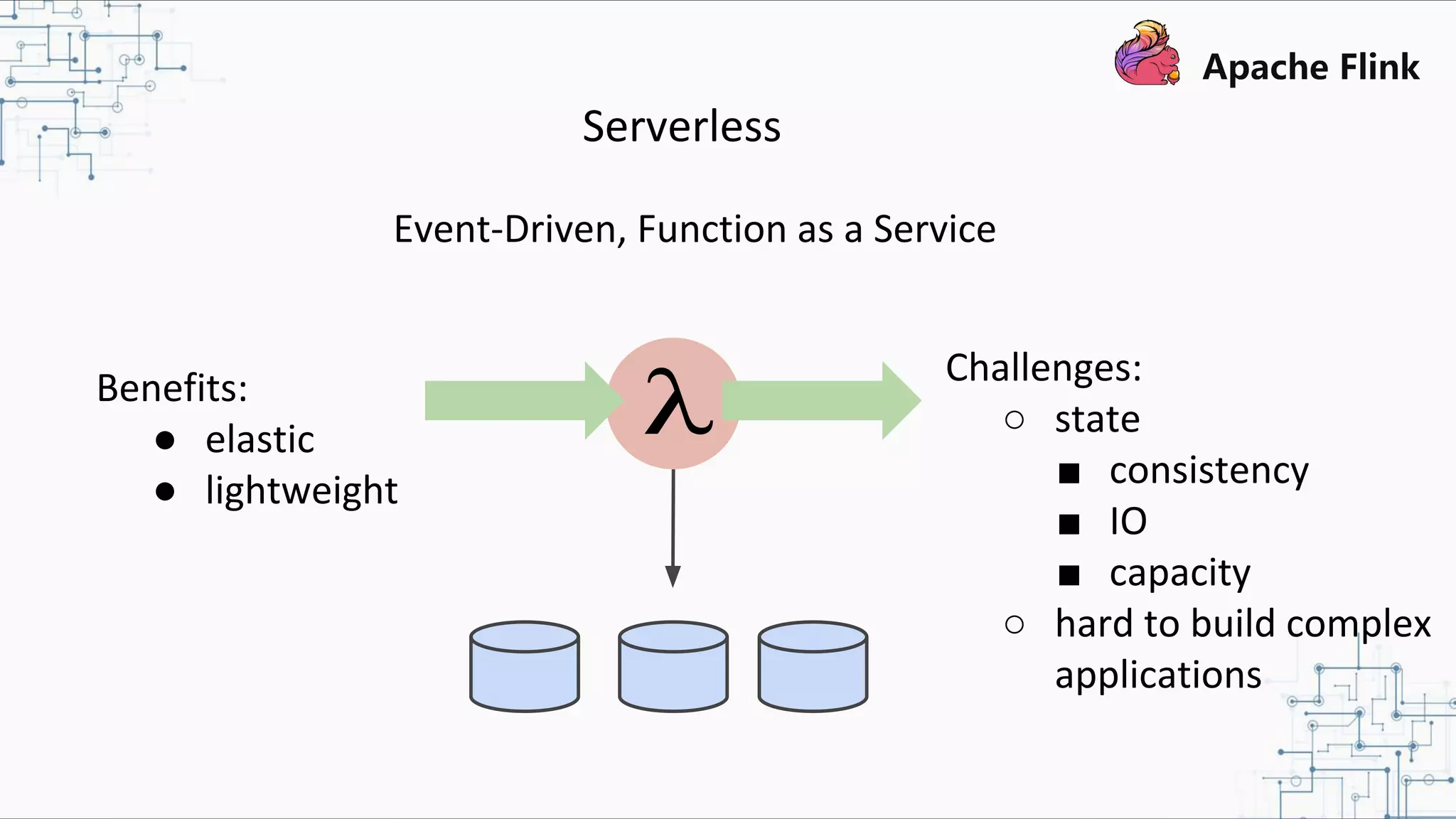
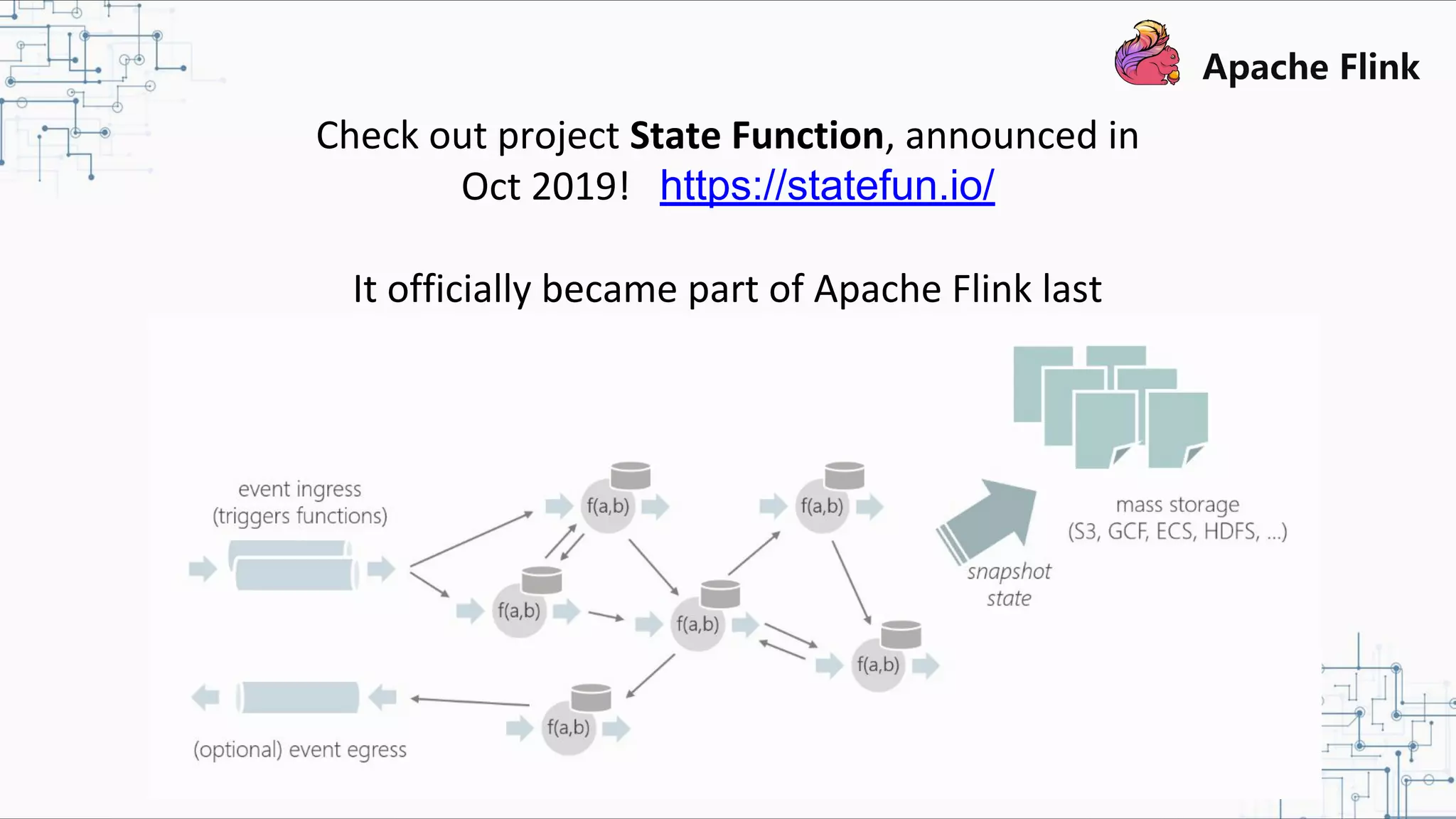
The document discusses Apache Flink 2.0, highlighting its capabilities in unified data processing, including stream and batch processing, and real-time analytics applications at Alibaba. It details how Flink supports various use cases such as online machine learning and real-time dashboards, emphasizing its stateful computations and fault-tolerant architecture. Additional insights cover the integration of Flink with machine learning frameworks and the potential of serverless event-driven functionalities.































































































































![[FFE19] Build a Flink AI Ecosystem](https://cdn.slidesharecdn.com/ss_thumbnails/ffe19flinkaiecosystem-191010100923-thumbnail.jpg?width=640&height=640&fit=bounds)








































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)