Downloaded 72 times


![CURRENT SOLUTIONS
1. Lambda Architecture [2011]
• Nathan Marz (Creator of Apache Storm)
• “How to beat the CAP theorem”
• Evidence of prior art [1983]:
• Butler Lampson (Turing Award Laureate)
• “Hints for Computer System Design” – Xerox PARC
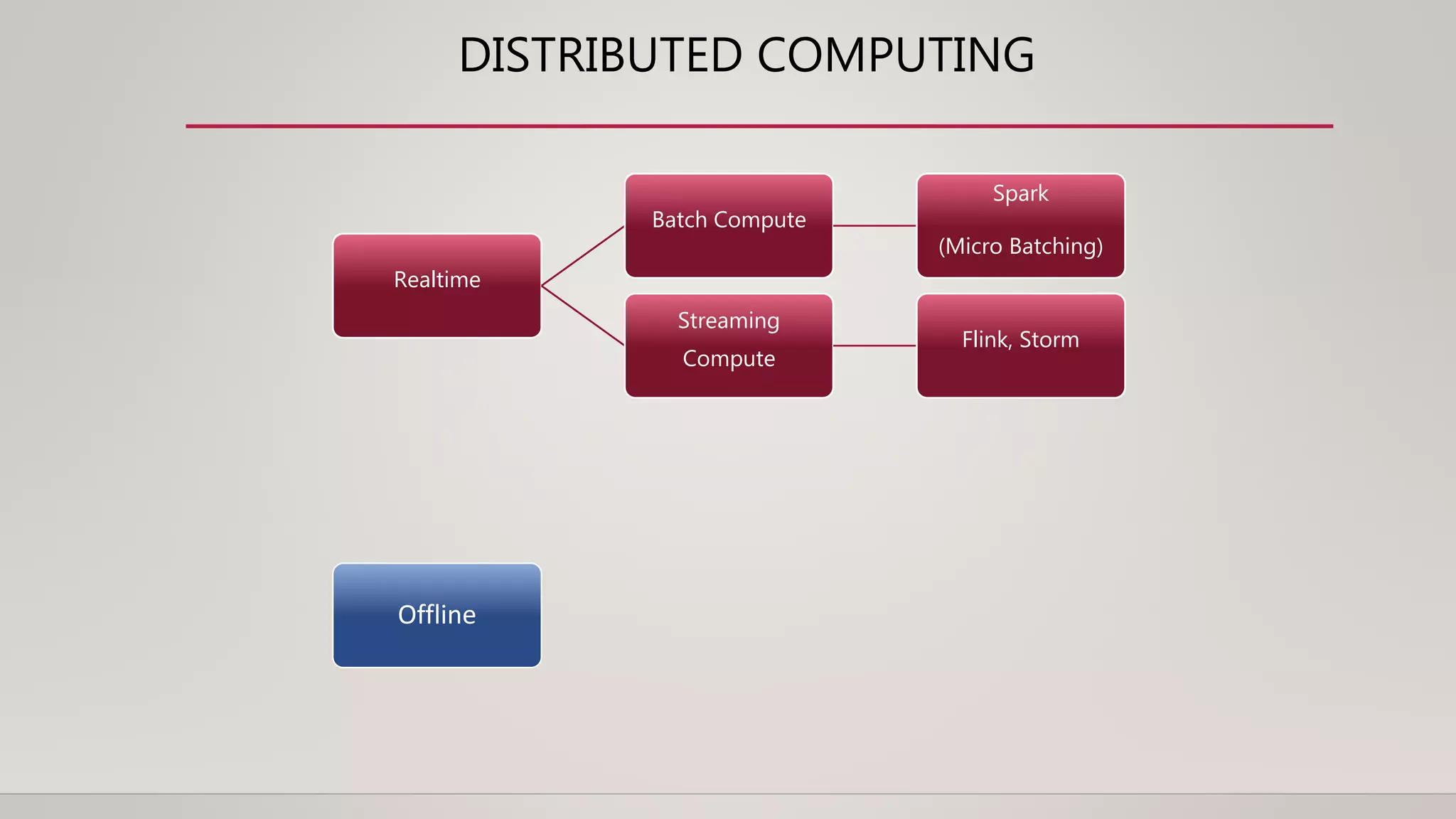
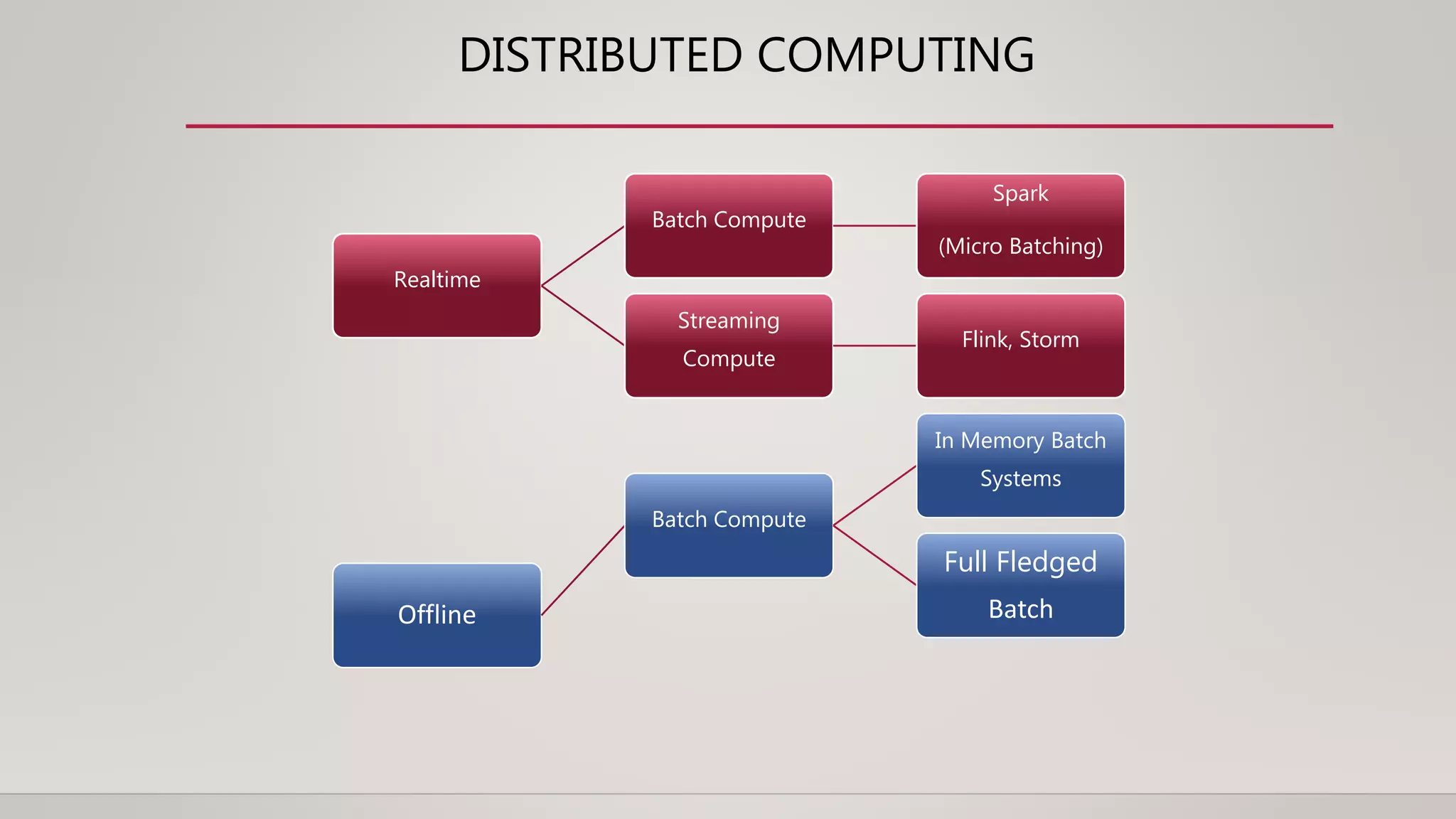
• Core Idea: Streaming job for realtime processing. Batch job for offline processing.
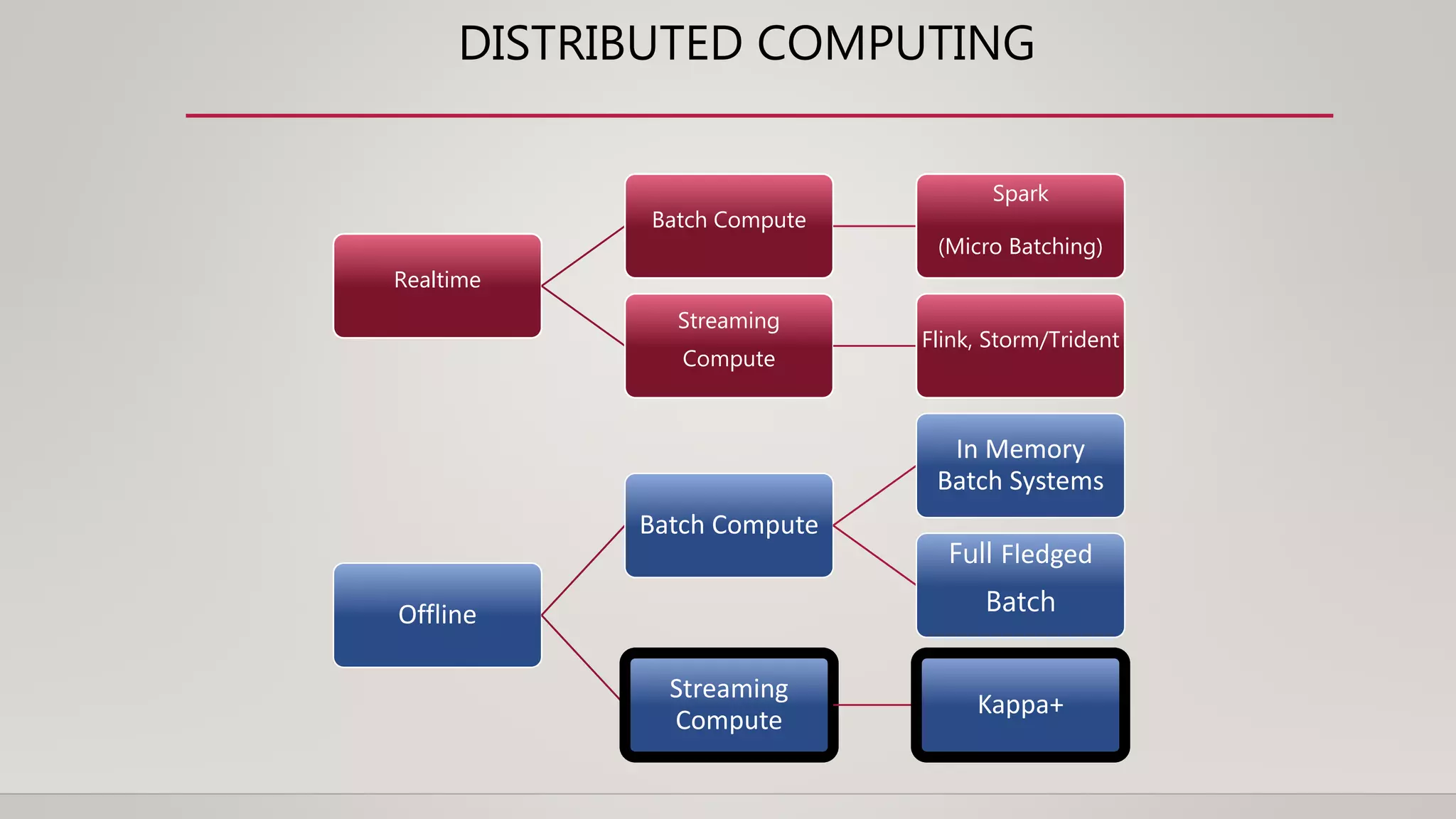
2. Kappa Architecture [2014]
• Jay Krepps (Creator of Kafka, CoFounder/CEO Confluent)
• "Questioning the Lambda Architecture”
• Core Idea: Long data retention in Kafka. Replay using realtime code from an older point.](https://image.slidesharecdn.com/movingfromlambdaandkappaarchitecturestokappaatuber-190412151223/75/Flink-Forward-San-Francisco-2019-Moving-from-Lambda-and-Kappa-Architectures-to-Kappa-at-Uber-Roshan-Naik-3-2048.jpg)















![CURRENT SOLUTIONS
1. Lambda Architecture [2011]
• Nathan Marz (Creator of Apache Storm)
• “How to beat the CAP theorem”
• Evidence of prior art [1983]:
• Butler Lampson (Turing Award Laureate)
• “Hints for Computer System Design” – Xerox PARC
• Core Idea: Streaming job for realtime processing. Batch job for offline processing.
2. Kappa Architecture [2014]
• Jay Krepps (Creator of Kafka, CoFounder/CEO Confluent)
• "Questioning the Lambda Architecture”
• Core Idea: Long data retention in Kafka. Replay using realtime code from an older point.](https://crownmelresort.com/image.slidesharecdn.com/movingfromlambdaandkappaarchitecturestokappaatuber-190412151223/75/Flink-Forward-San-Francisco-2019-Moving-from-Lambda-and-Kappa-Architectures-to-Kappa-at-Uber-Roshan-Naik-3-2048.jpg)






















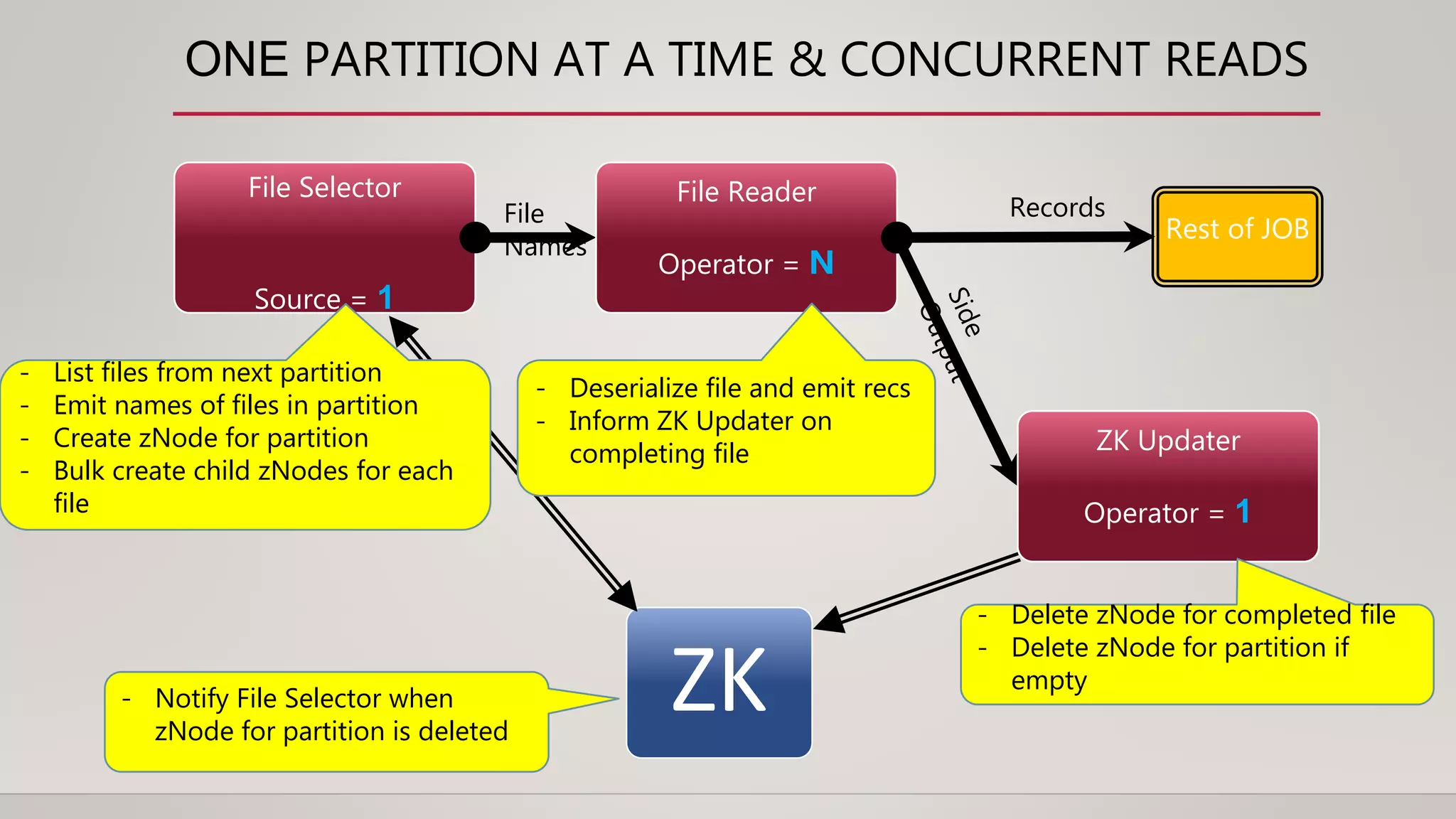
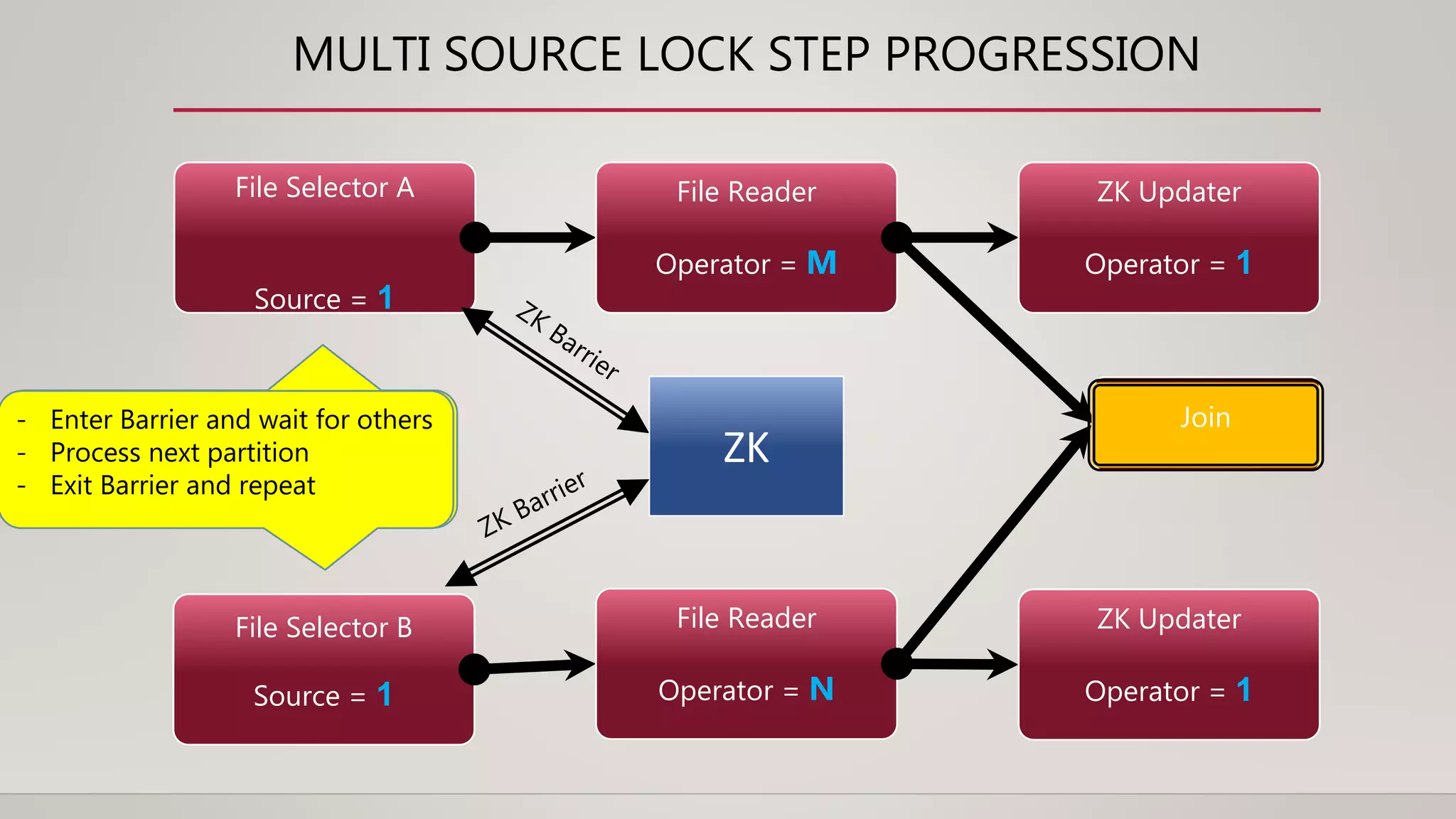
The document discusses the transition from lambda and kappa architectures to a new kappa+ architecture at Uber for handling real-time data processing. Kappa+ introduces a job classification system to efficiently process data directly from data warehouses, addressing limitations of previous architectures while allowing for improved resource management and reduced complexity. Key features include decoupling bounded vs. unbounded data processing, implementing a processing model with categorized job types, and enhancing concurrent processing capabilities.























































































