Downloaded 29 times








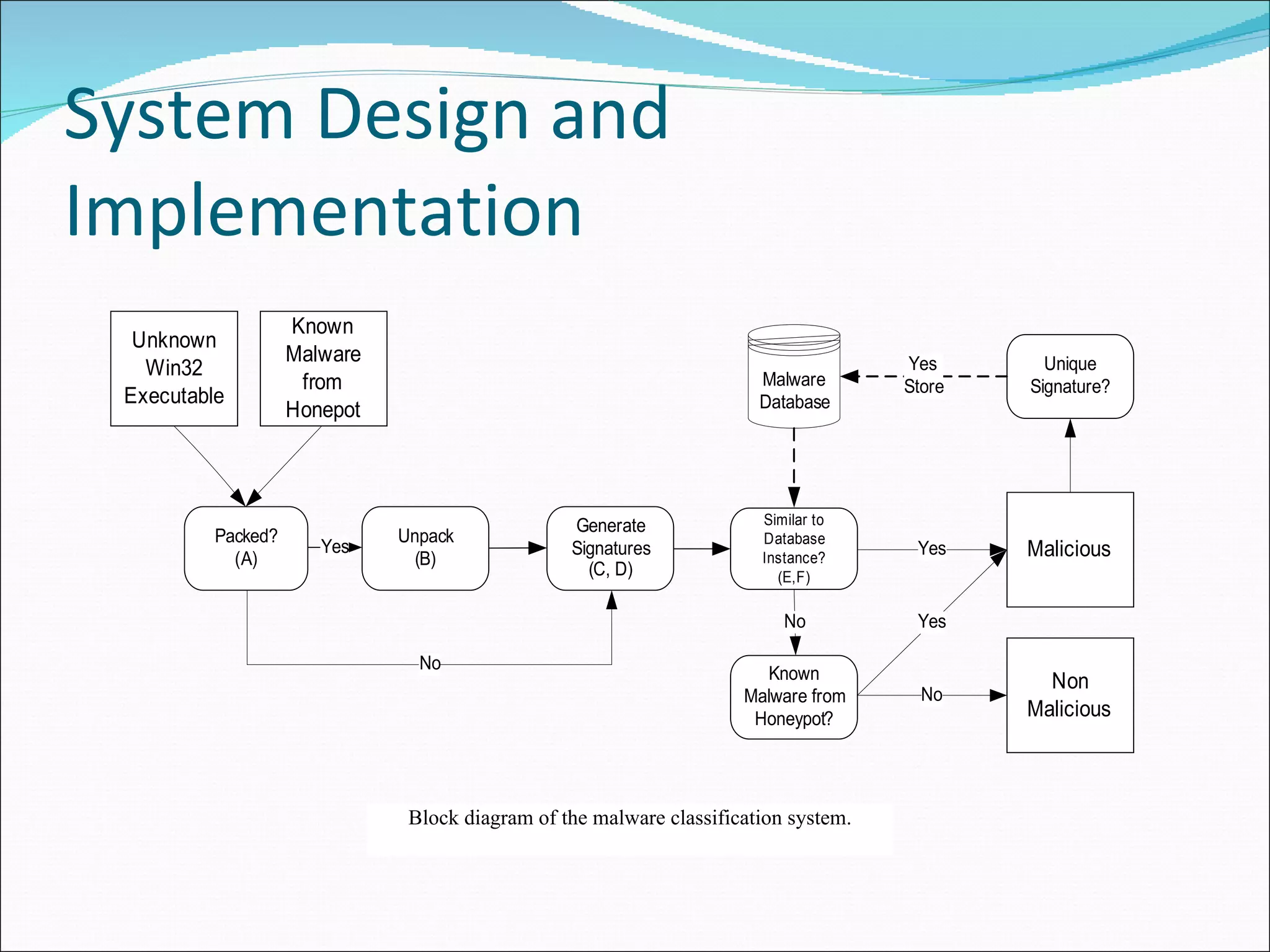





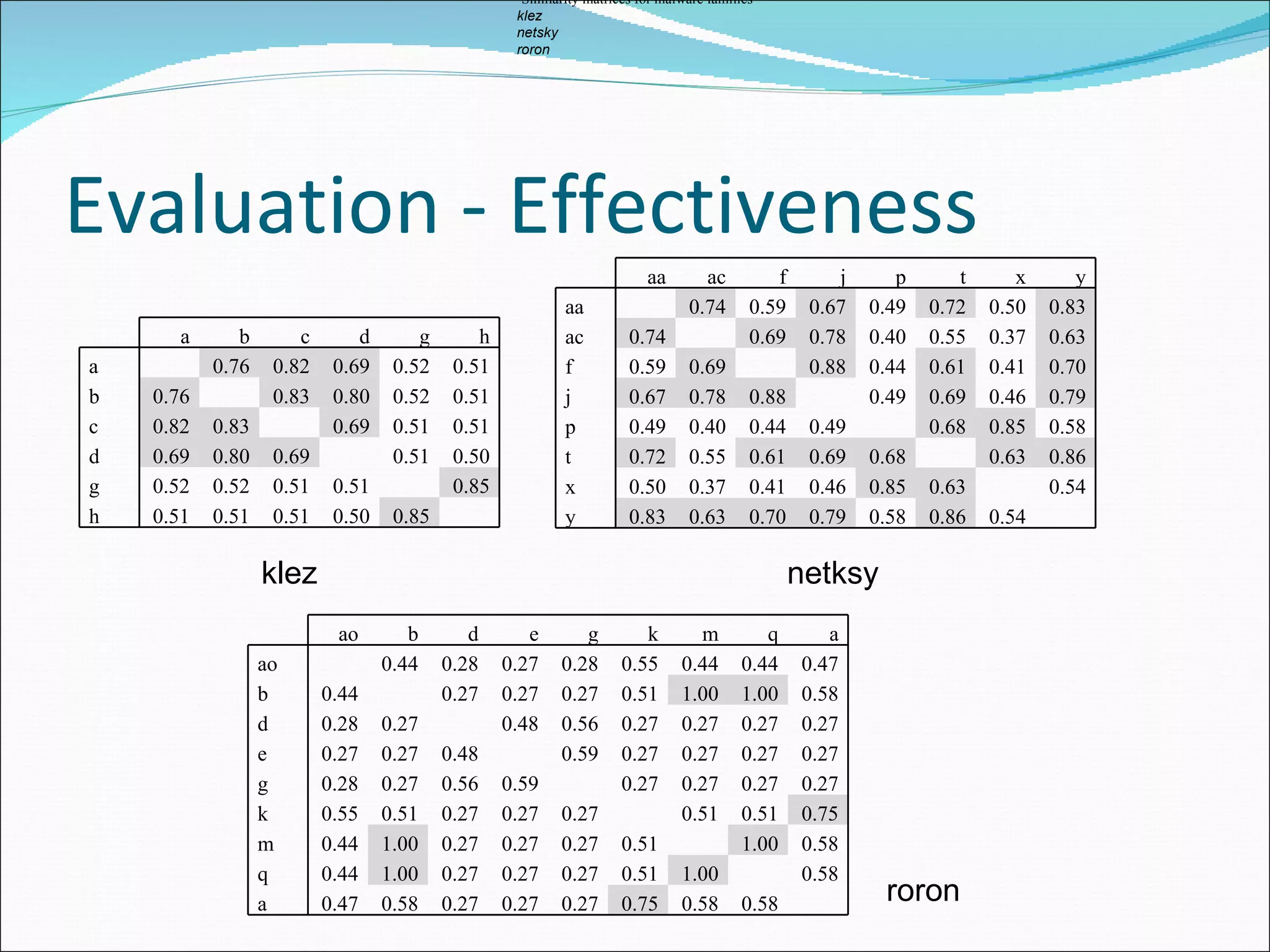


























We propose an algorithm to identify malware variants by determining program similarity through estimating isomorphic control flow graphs. We implement this approach in a prototype system that demonstrates its ability to detect real malware variants with low false positives and logarithmic performance scalability, making it suitable for endhost adoption. Control flow graphs provide a more invariant characteristic than traditional static features like byte sequences for identifying polymorphic malware variants. Our system generates signatures for control flow graphs to efficiently compare programs and classify unknown samples.



















































































