Downloaded 25 times










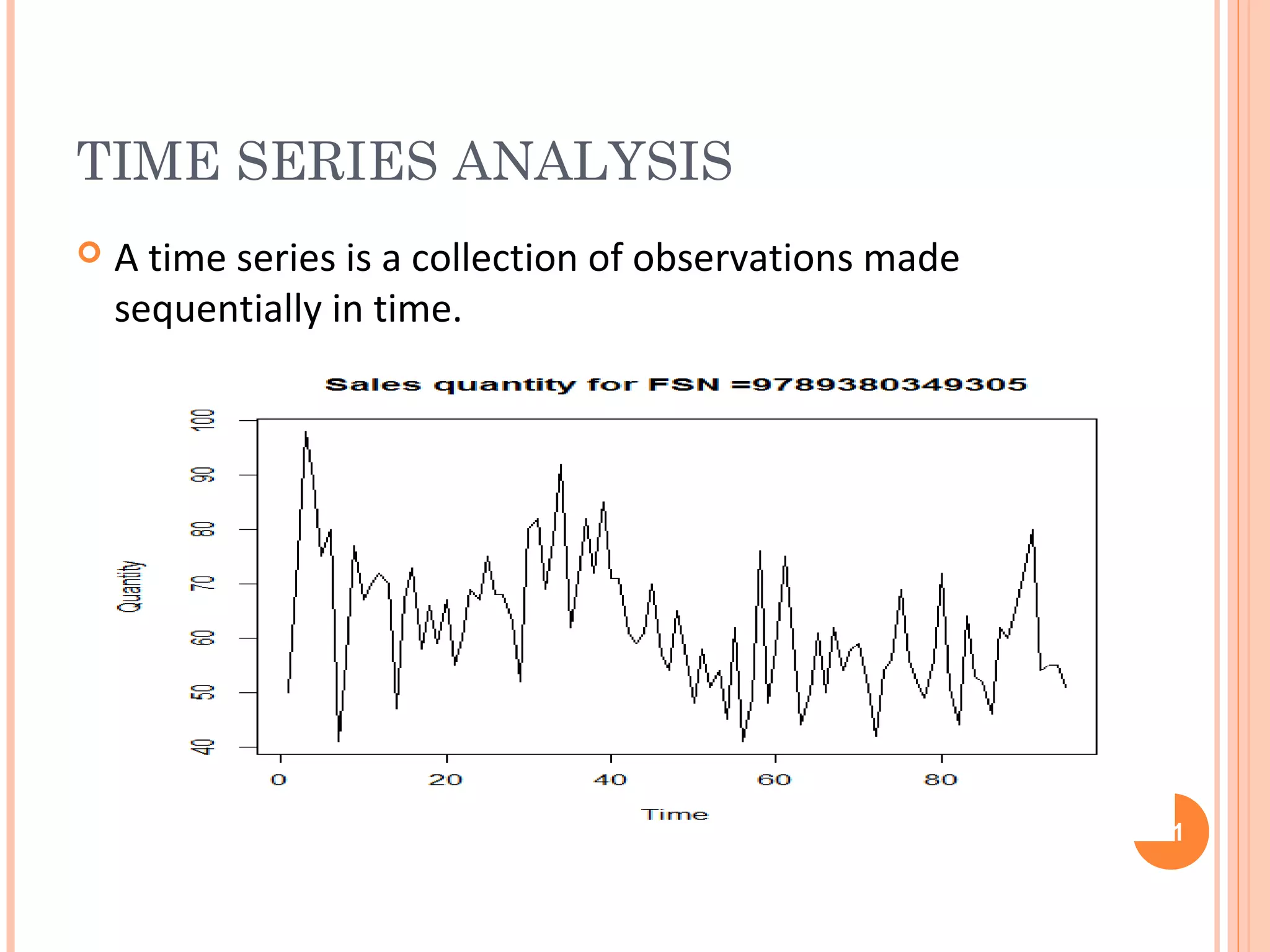

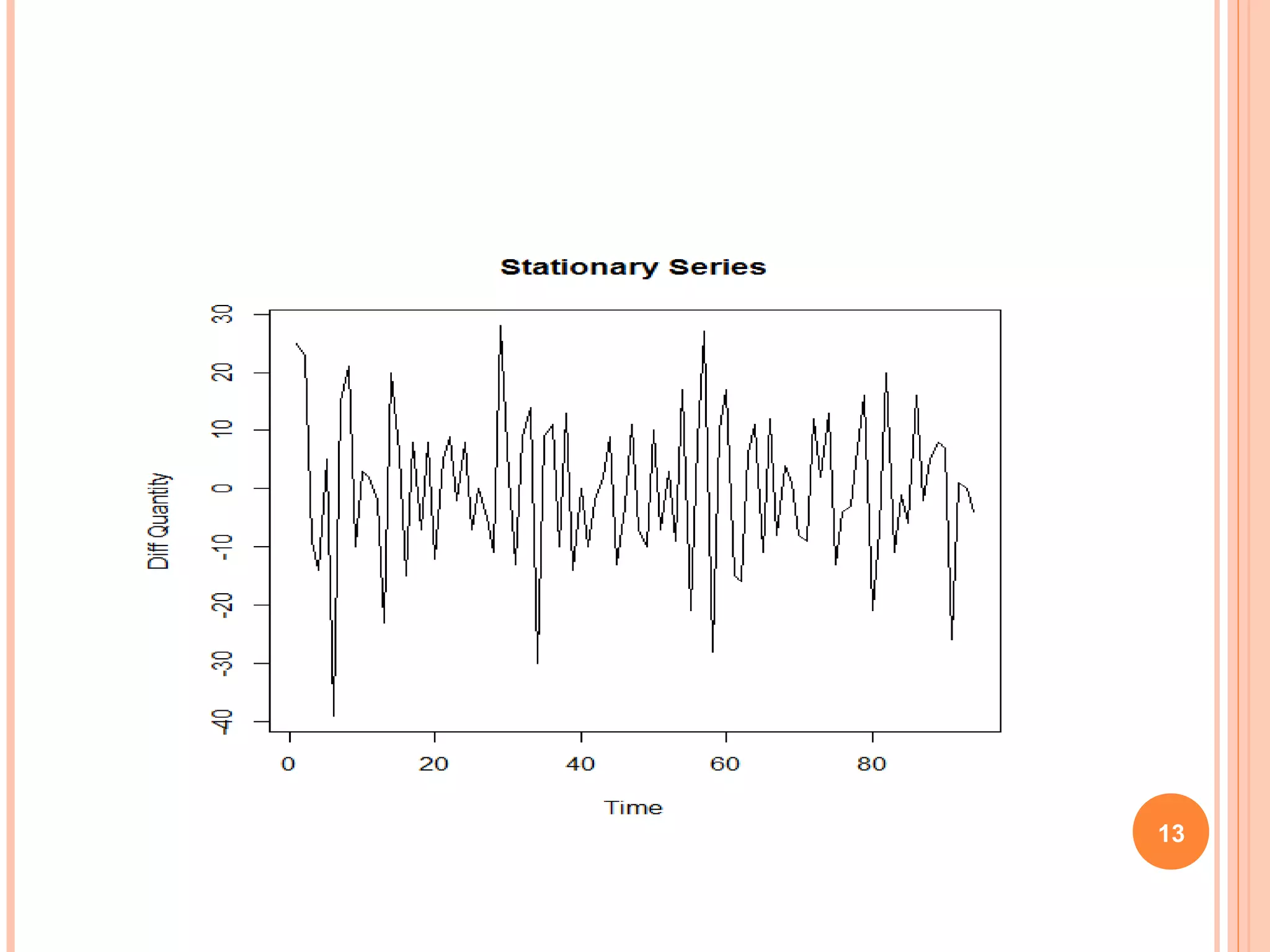
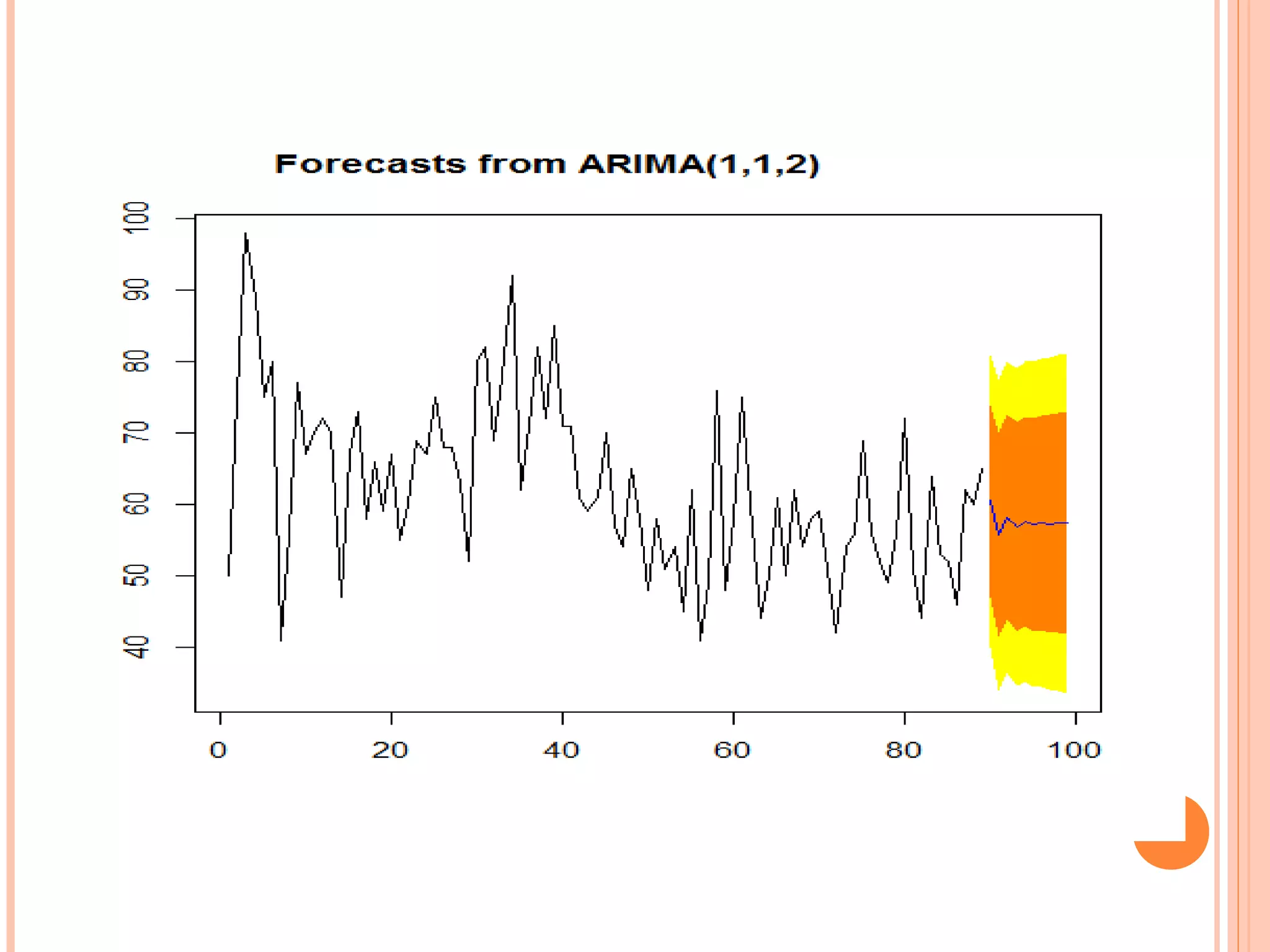
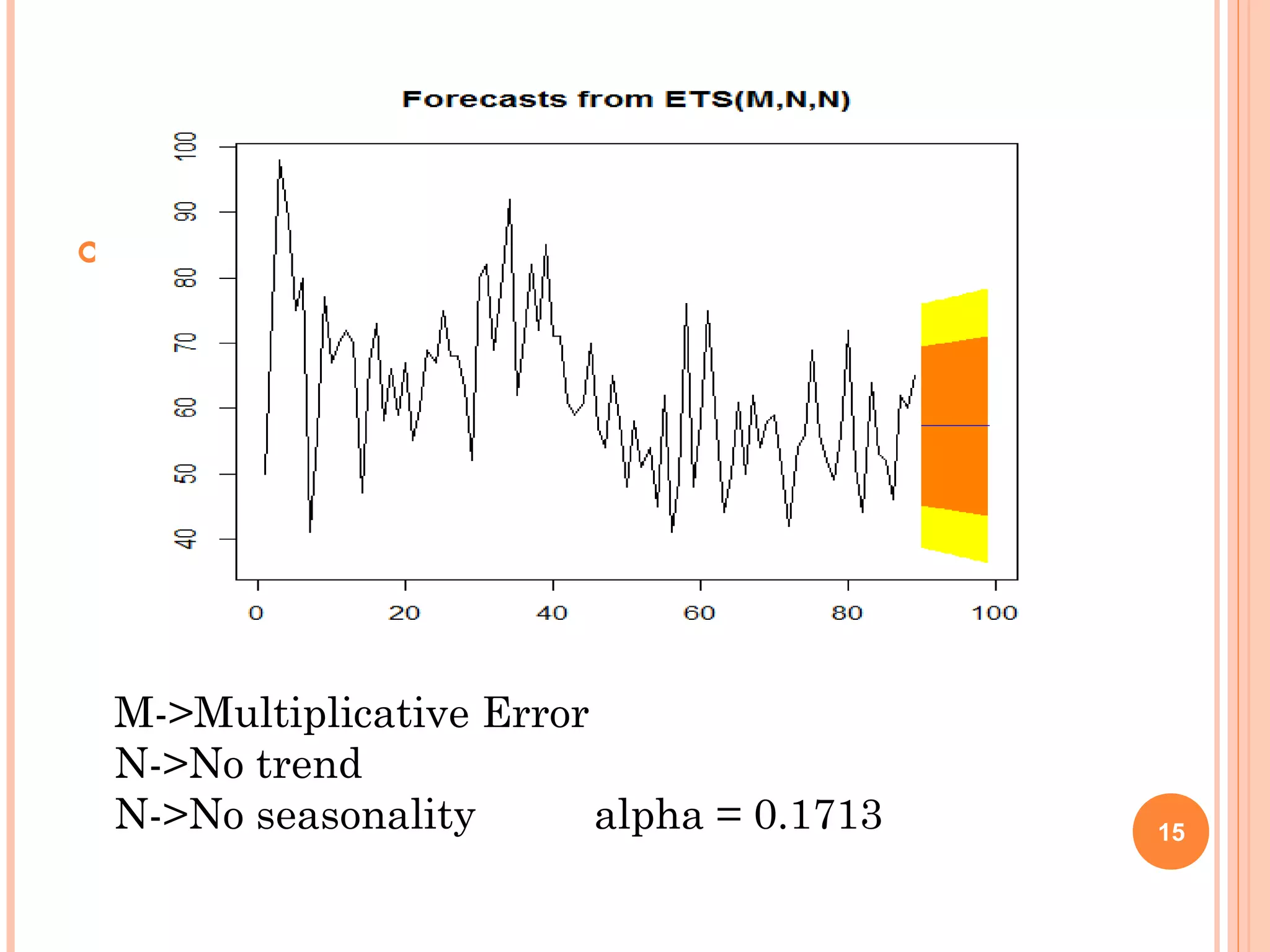


















This document provides an introduction to R, an open-source statistical software environment. It discusses key features of R including its data handling, statistical, and graphical capabilities. The document also summarizes popular statistical methods that can be performed in R like correlation, regression, time series analysis, and discusses the advantages and disadvantages of using R.



















































































