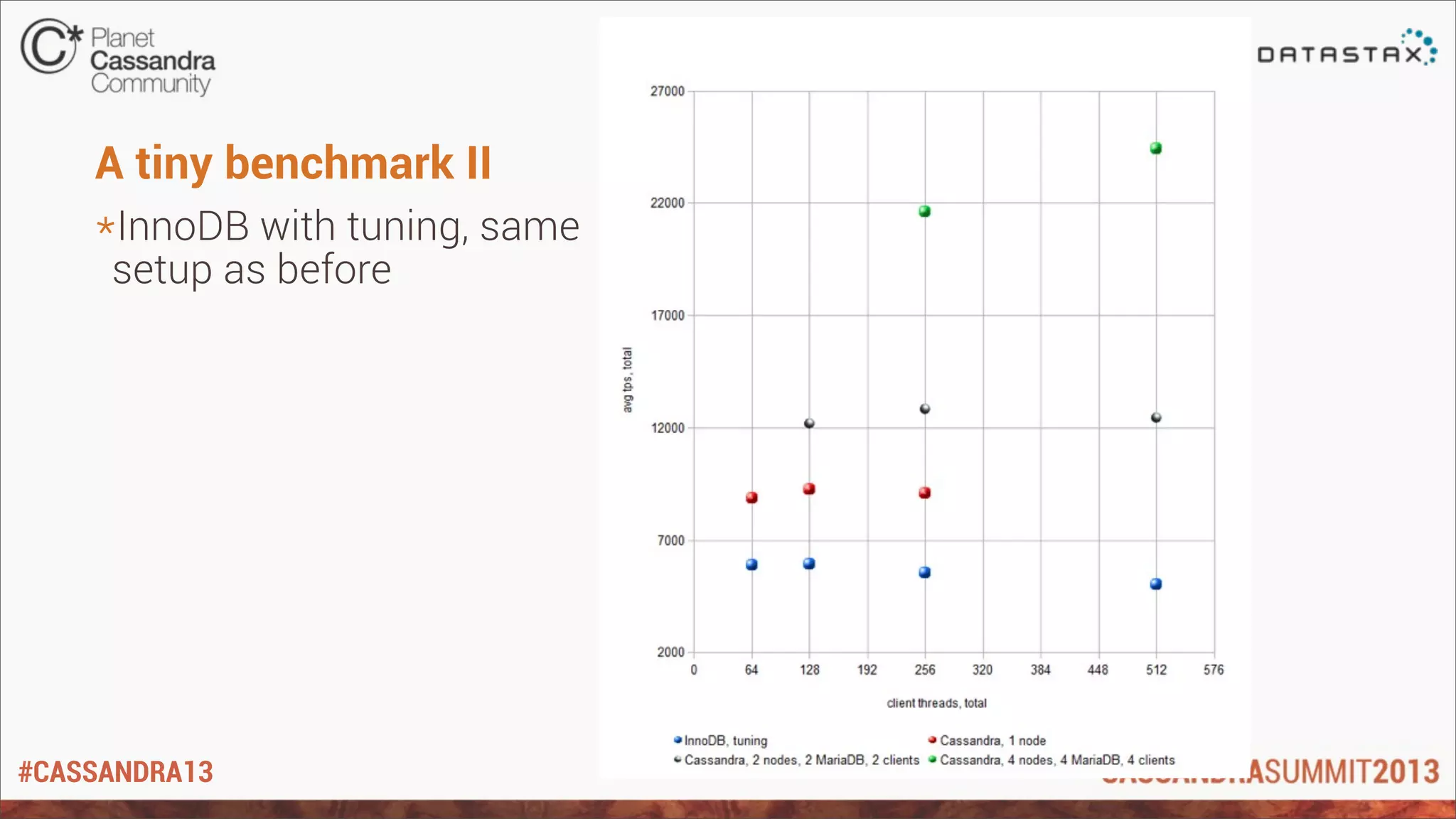
Downloaded 45 times









![#CASSANDRA13
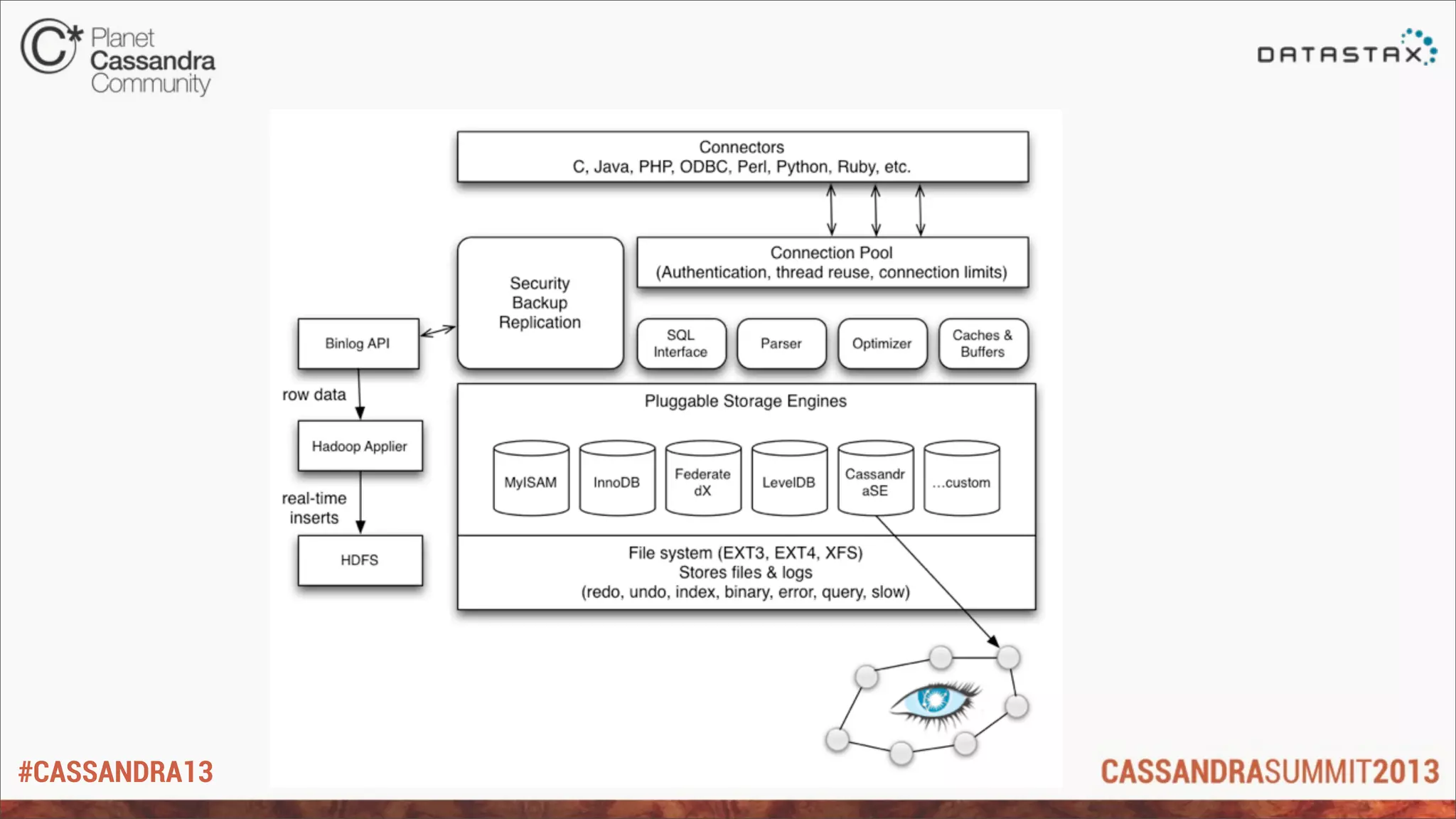
Getting started
*Get MariaDB 10.0.2 from https://downloads.mariadb.org/
*Load the Cassandra plugin
- From SQL:
MariaDB [(none)]> install plugin cassandra soname 'ha_cassandra.so';
- Or start it from my.cnf
[mysqld]
...
plugin-load=ha_cassandra.so](https://image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-11-2048.jpg)
![#CASSANDRA13
Is everything ok?
*Check to see that it is loaded - SHOW PLUGINS
MariaDB [(none)]> show plugins;
+--------------------+--------+-----------------+-----------------+---------+
| Name | Status | Type | Library | License |
+--------------------+--------+-----------------+-----------------+---------+
...
| CASSANDRA | ACTIVE | STORAGE ENGINE | ha_cassandra.so | GPL |
+--------------------+--------+-----------------+-----------------+---------+](https://image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-12-2048.jpg)
![#CASSANDRA13
Create an SQL table which is a view of a column family
MariaDB [test]> set global cassandra_default_thrift_host='10.196.2.113';
MariaDB [test]> create table t2 (pk varchar(36) primary key,
-> data1 varchar(60),
-> data2 bigint
-> ) engine=cassandra
-> keyspace='mariadbtest'
-> thrift_host='10.196.2.113'
-> column_family='cf1';
*thrift_host can be set per-table
*@@cassandra_default_thrift_host allows to re-point the table to different node
dynamically, and not change table DDL when Cassandra IP changes](https://image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-13-2048.jpg)
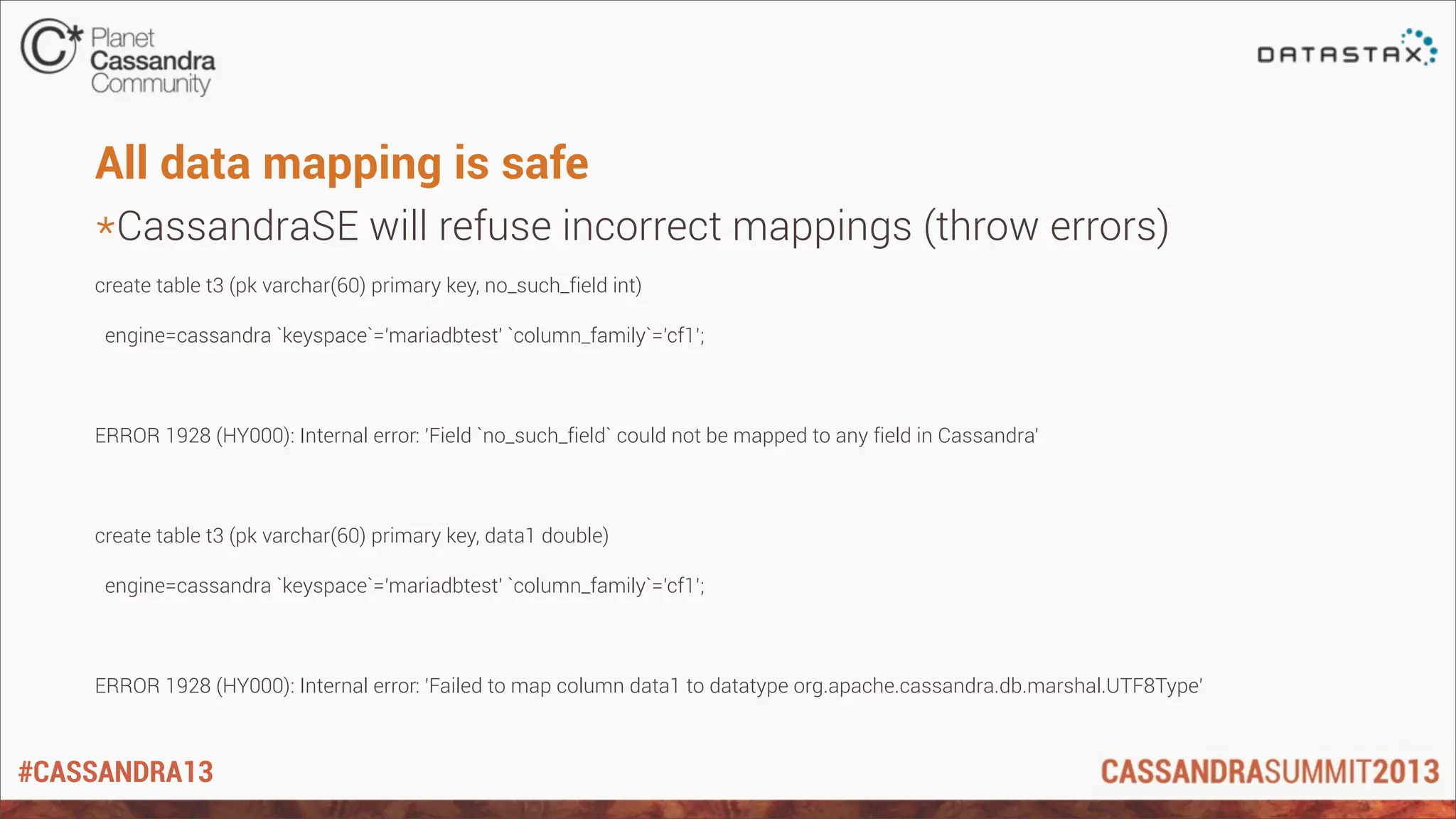
![#CASSANDRA13
Potential issues
*SELinux blocks the connection
ERROR 1429 (HY000): Unable to connect to foreign data source:
connect() failed: Permission denied [1]
*Disable SELinux: echo 0 > /selinux/enforce
*Cassandra 1.2 with Column Families (CFs) without “COMPACT
STORAGE”
ERROR 1429 (HY000): Unable to connect to foreign data source:
Column family cf1 not found in keyspace mariadbtest
*Change in Cassandra 1.2 that broke Pig as well; we’ll update this soon](https://image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-14-2048.jpg)
![#CASSANDRA13
Accessing Cassandra data from MariaDB
*Get data from Cassandra
MariaDB [test]> select * from t2;
+------+-------------------+-------+
| pk | data1 | data2 |
+------+-------------------+-------+
| row1 | data-in-cassandra | 1234 |
+------+-------------------+-------+
*Insert data into Cassandra
MariaDB [test]> insert into t2 values ('row2','data-from-mariadb', 123);
*Ensure Cassandra sees inserted data
cqlsh:mariadbtest> select * from cf1;
pk | data1 | data2
------+-------------------+-------
row1 | data-in-cassandra | 1234
row2 | data-from-mariadb | 123](https://image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-15-2048.jpg)


























![#CASSANDRA13
Getting started
*Get MariaDB 10.0.2 from https://downloads.mariadb.org/
*Load the Cassandra plugin
- From SQL:
MariaDB [(none)]> install plugin cassandra soname 'ha_cassandra.so';
- Or start it from my.cnf
[mysqld]
...
plugin-load=ha_cassandra.so](https://crownmelresort.com/image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-11-2048.jpg)
![#CASSANDRA13
Is everything ok?
*Check to see that it is loaded - SHOW PLUGINS
MariaDB [(none)]> show plugins;
+--------------------+--------+-----------------+-----------------+---------+
| Name | Status | Type | Library | License |
+--------------------+--------+-----------------+-----------------+---------+
...
| CASSANDRA | ACTIVE | STORAGE ENGINE | ha_cassandra.so | GPL |
+--------------------+--------+-----------------+-----------------+---------+](https://crownmelresort.com/image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-12-2048.jpg)
![#CASSANDRA13
Create an SQL table which is a view of a column family
MariaDB [test]> set global cassandra_default_thrift_host='10.196.2.113';
MariaDB [test]> create table t2 (pk varchar(36) primary key,
-> data1 varchar(60),
-> data2 bigint
-> ) engine=cassandra
-> keyspace='mariadbtest'
-> thrift_host='10.196.2.113'
-> column_family='cf1';
*thrift_host can be set per-table
*@@cassandra_default_thrift_host allows to re-point the table to different node
dynamically, and not change table DDL when Cassandra IP changes](https://crownmelresort.com/image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-13-2048.jpg)
![#CASSANDRA13
Potential issues
*SELinux blocks the connection
ERROR 1429 (HY000): Unable to connect to foreign data source:
connect() failed: Permission denied [1]
*Disable SELinux: echo 0 > /selinux/enforce
*Cassandra 1.2 with Column Families (CFs) without “COMPACT
STORAGE”
ERROR 1429 (HY000): Unable to connect to foreign data source:
Column family cf1 not found in keyspace mariadbtest
*Change in Cassandra 1.2 that broke Pig as well; we’ll update this soon](https://crownmelresort.com/image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-14-2048.jpg)
![#CASSANDRA13
Accessing Cassandra data from MariaDB
*Get data from Cassandra
MariaDB [test]> select * from t2;
+------+-------------------+-------+
| pk | data1 | data2 |
+------+-------------------+-------+
| row1 | data-in-cassandra | 1234 |
+------+-------------------+-------+
*Insert data into Cassandra
MariaDB [test]> insert into t2 values ('row2','data-from-mariadb', 123);
*Ensure Cassandra sees inserted data
cqlsh:mariadbtest> select * from cf1;
pk | data1 | data2
------+-------------------+-------
row1 | data-in-cassandra | 1234
row2 | data-from-mariadb | 123](https://crownmelresort.com/image.slidesharecdn.com/5colincharles-130618172522-phpapp01/75/C-Summit-2013-Can-t-we-all-just-get-along-MariaDB-and-Cassandra-by-Colin-Charles-15-2048.jpg)






















The document discusses the interoperability between MariaDB and Cassandra, outlining MariaDB as a community-developed, MySQL-compatible database that includes a Cassandra storage engine. Key topics include the architecture of MariaDB, the functionality of the Cassandra storage engine, various use cases, and data and command mapping between the two databases. It emphasizes that while Cassandra can be accessed via SQL through MariaDB, it does not aim to replace full SQL functionality, particularly for complex tasks.



















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)



