Download as PDF, PPTX







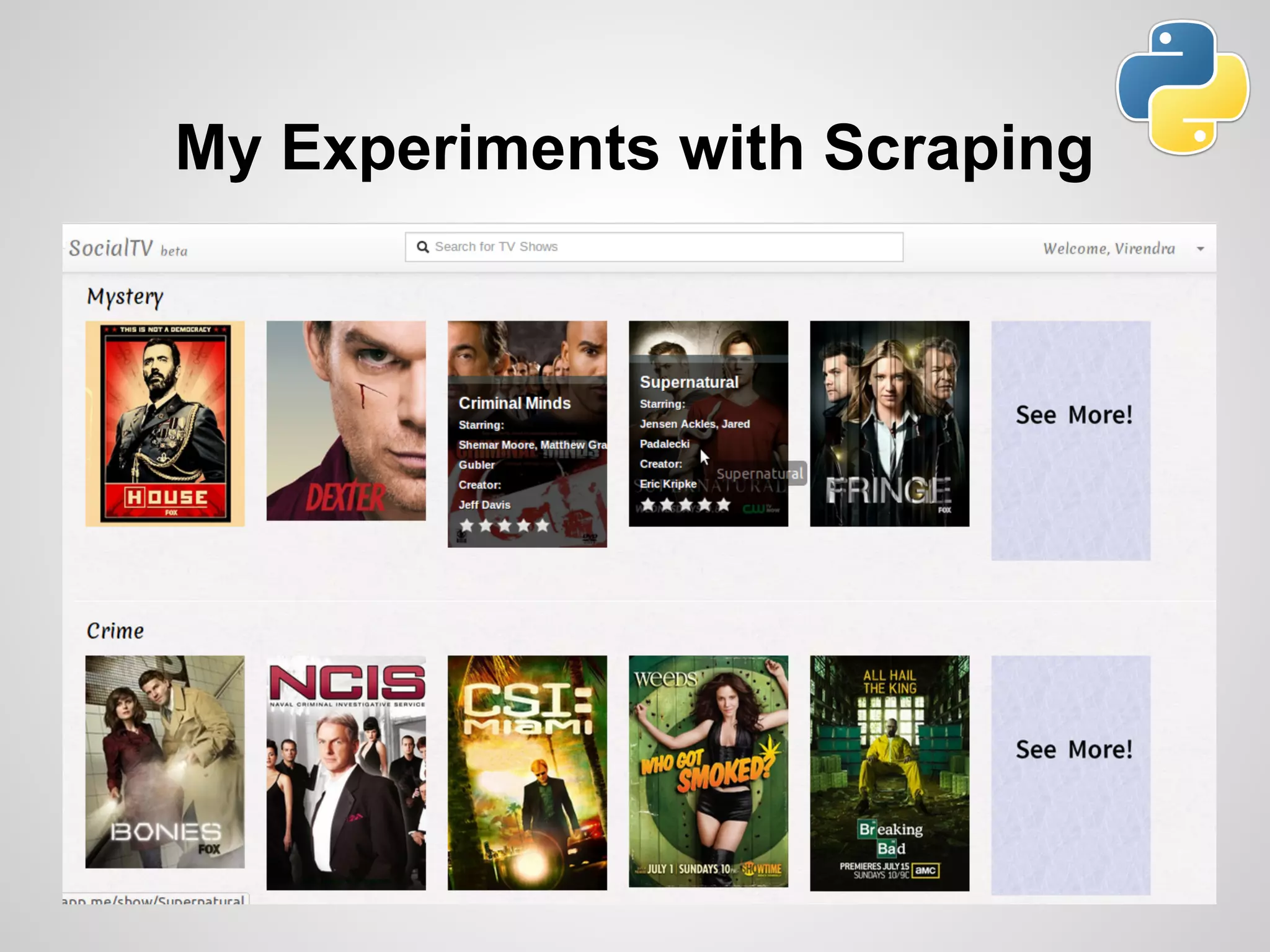


































This document discusses web scraping using Python, detailing its definition, purpose, and methods for extracting structured data from unstructured web content. It covers practical experience, tools such as BeautifulSoup and Scrapy, and highlights the importance of ethical considerations in scraping practices. The document concludes with a reminder to scrape responsibly and share knowledge, alongside links to the author's personal resources.
































![[DSC Europe 24] Domagoj Maric - Modern Web Data Extraction: Techniques, Tools...](https://cdn.slidesharecdn.com/ss_thumbnails/domagojmaric-modernwebdataextractionfinal-250218225444-c7bcad20-thumbnail.jpg?width=640&height=640&fit=bounds)


































