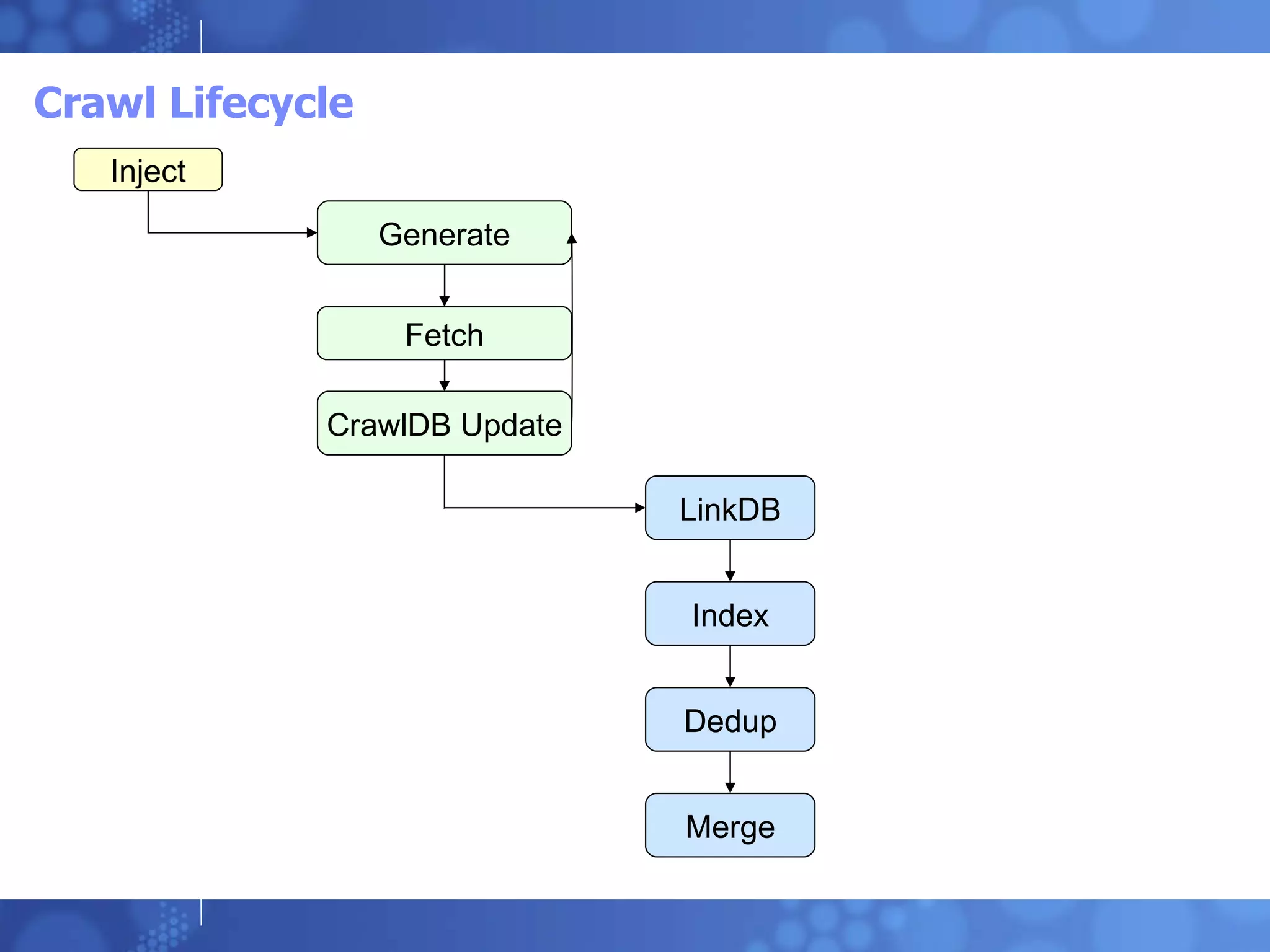
Apache Nutch is an open source web crawler built on Hadoop. It crawls websites, indexes the downloaded content using Lucene, and supports querying the index via Solr. The crawl process involves seeding, filtering, fetching pages, indexing content, and merging results. Nutch can crawl websites in a single process or distributed mode using Hadoop. It provides tools to inject URLs, read crawl segments from HDFS, and demonstrate the crawl lifecycle.
Apache Nutch WebCrawling and Data Gathering Steve Watt - @wattsteve IBM Big Data Lead Data Day Austin
2.
Topics Introduction TheBig Data Analytics Ecosystem Load Tooling How is Crawl data being used? Web Crawling - Considerations Apache Nutch Overview Apache Nutch Crawl Lifecycle, Setup and Demos
3.
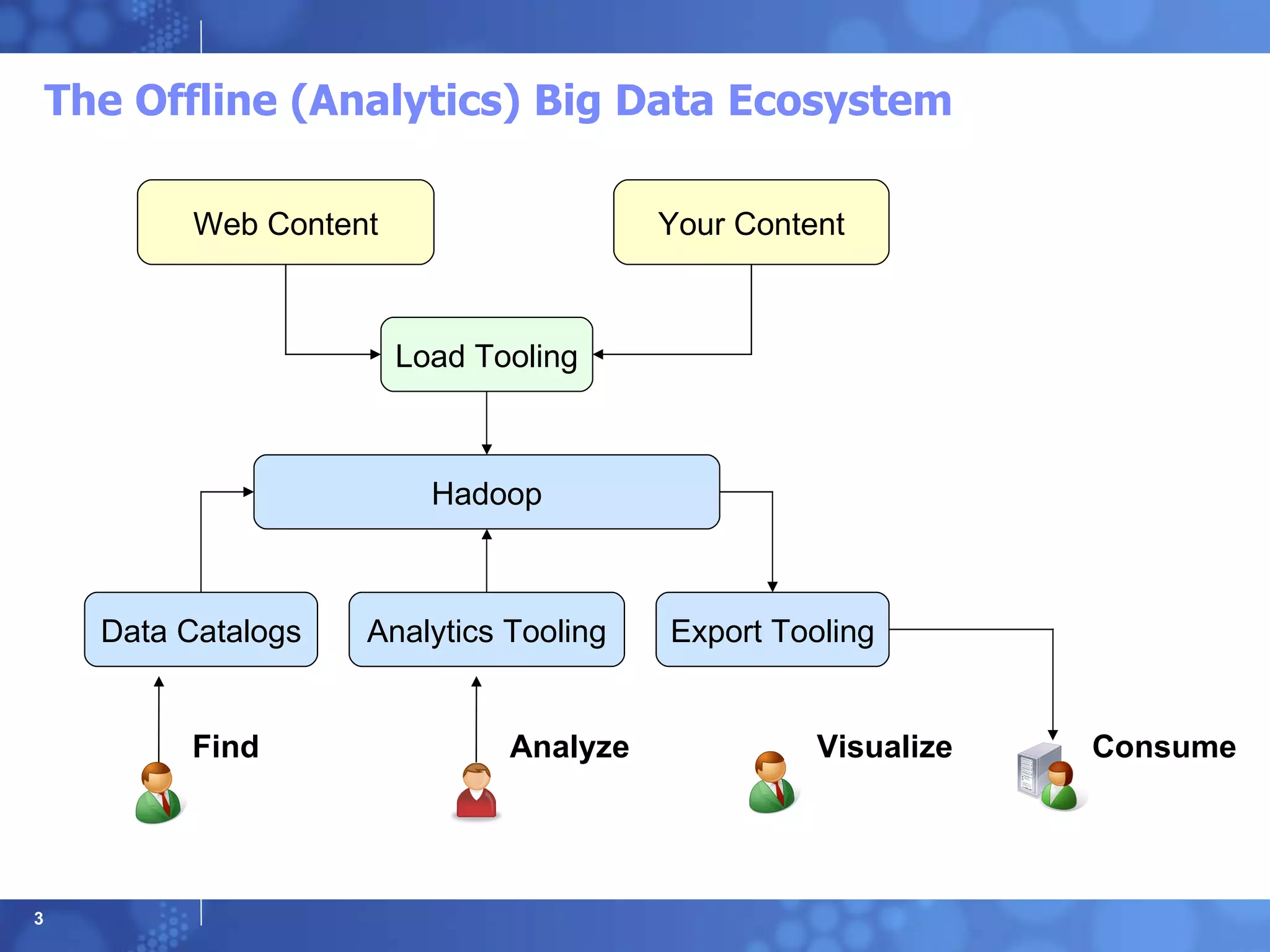
The Offline (Analytics)Big Data Ecosystem Load Tooling Web Content Your Content Hadoop Data Catalogs Analytics Tooling Export Tooling Find Analyze Visualize Consume
4.
Load Tooling -Data Gathering Patterns and Enablers Web Content Downloading – Amazon Public DataSets / InfoChimps Stream Harvesting – Collecta / Roll-your-own (Twitter4J) API Harvesting – Roll your own (Facebook REST Query) Web Crawling – Nutch Your Content Copy from FileSystem Load from Database - SQOOP Event Collection Frameworks - Scribe and Flume
5.
How is Crawldata being used? Build your own search engine Built in Lucene Indexes for querying Solr integration for Multi-faceted search Analytics Selective filtering and extraction with data from a single provider Joining datasets from multiple providers for further analytics Event Portal Example Is Austin really a startup town? Extension of the mashup paradigm - “Content Providers cannot predict how their data will be re-purposed”
6.
Web Crawling -considerations Robots.txt Facebook lawsuit against API Harvester “ No Crawling without written approval” in Mint.com Terms of Use What if the web had as many crawlers as Apache Web Servers ?
7.
Apache Nutch –What is it ? Apache Nutch Project – nutch.apache.org Hadoop + Web Crawler + Lucene Hadoop based web crawler ? How does that work ?
8.
Apache Nutch OverviewSeeds and Crawl Filters Crawl Depths Fetch Lists and Partitioning Segments - Segment Reading using Hadoop Indexing / Lucene Web Application for Querying
Single Process WebCrawling Create the seed file and copy it into a “urls” directory Export JAVA_HOME Edit the conf/crawl-urlfilter.txt regex to constrain the crawl (Usually via domain) Edit the conf/nutch-site.xml and specify an http.agent.name bin/nutch crawl urls -dir crawl -depth 2 D E M O
Distributed Web CrawlingThe Nutch distribution is overkill if you already have a Hadoop Cluster. Its also not how you really integrate with Hadoop these days, but there is some history to consider. Nutch Wiki has Distributed Setup. Why orchestrate your crawl? How? Create the seed file and copy it into a “urls” directory. Then copy the directory up to the HDFS Edit the conf/crawl-urlfilter.txt regex to constrain the crawl (Usually via domain) Copy the conf/nutch-site,conf/nutch-default.xml, conf/nutch-conf.xml & conf/crawl-urlfilter.txt to the Hadoop conf directory. Restart Hadoop so the new files are picked up in the classpath
15.
Distributed Web CrawlingCode Review: org.apache.nutch.crawl.Crawl Orchestrated Crawl Example (Step 1 - Inject): bin/hadoop jar nutch-1.2.0.job org.apache.nutch.crawl.Injector crawl/crawldb urls D E M O
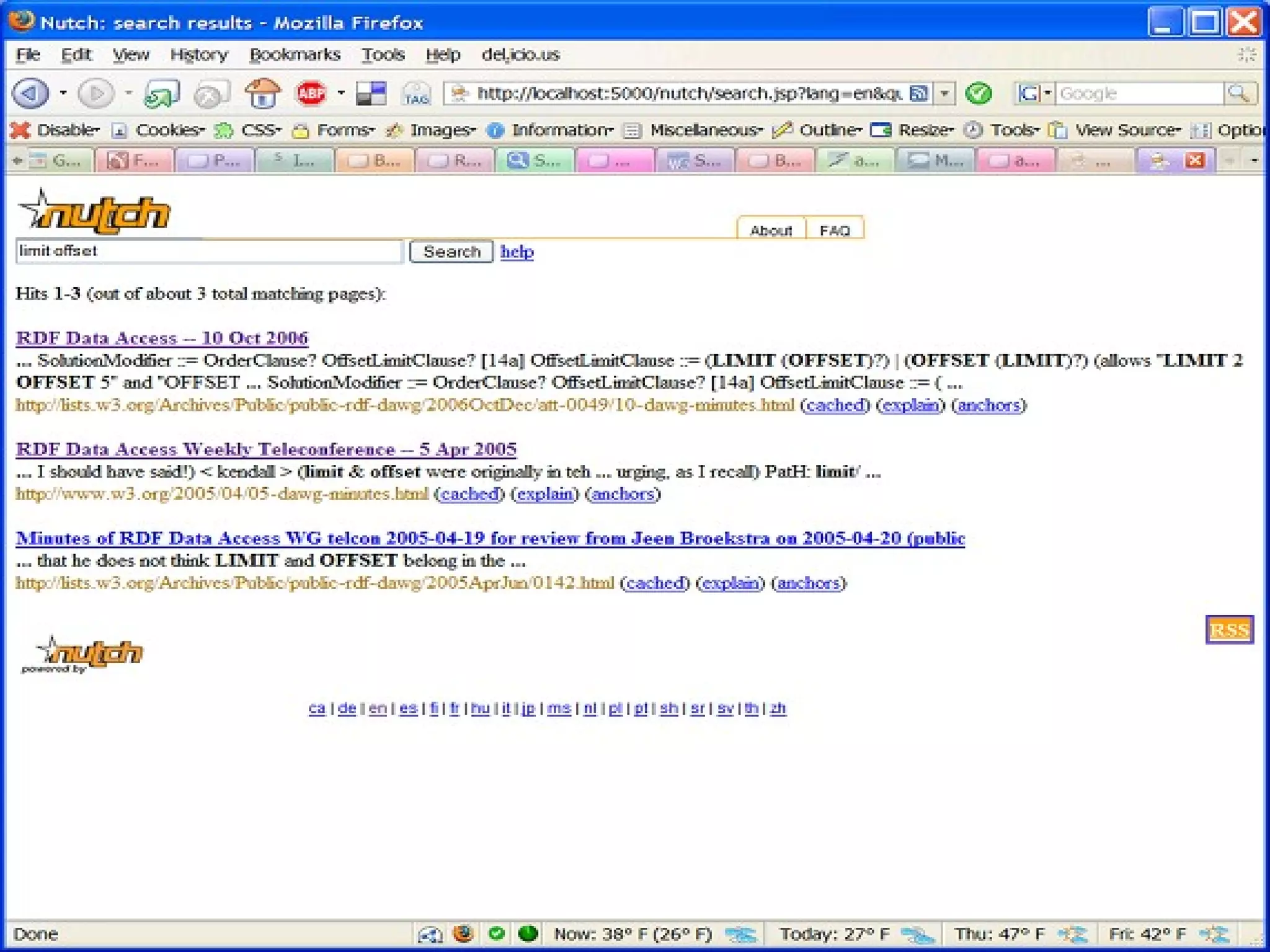
Segment Readers TheSegmentReader class is not all that useful. But here it is anyway: bin/nutch readseg -list crawl/segments/20110128170617 bin/nutch readseg -dump crawl/segments/20110128170617 dumpdir What you really want to do is process each crawled page in M/R as an individual record SequenceFileInputFormatters over Nutch HDFS Segments FTW RecordReader returns Content Objects as Value Code Walkthrough D E M O














![Thanks Questions ? Steve Watt - [email_address] Twitter: @wattsteve Blog: stevewatt.blogspot.com austinhug.blogspot.com](https://image.slidesharecdn.com/webcrawlingwithnutch-110131110925-phpapp02/75/Web-Crawling-and-Data-Gathering-with-Apache-Nutch-18-2048.jpg)

















![Thanks Questions ? Steve Watt - [email_address] Twitter: @wattsteve Blog: stevewatt.blogspot.com austinhug.blogspot.com](https://crownmelresort.com/image.slidesharecdn.com/webcrawlingwithnutch-110131110925-phpapp02/75/Web-Crawling-and-Data-Gathering-with-Apache-Nutch-18-2048.jpg)


































































































