Downloaded 16 times
















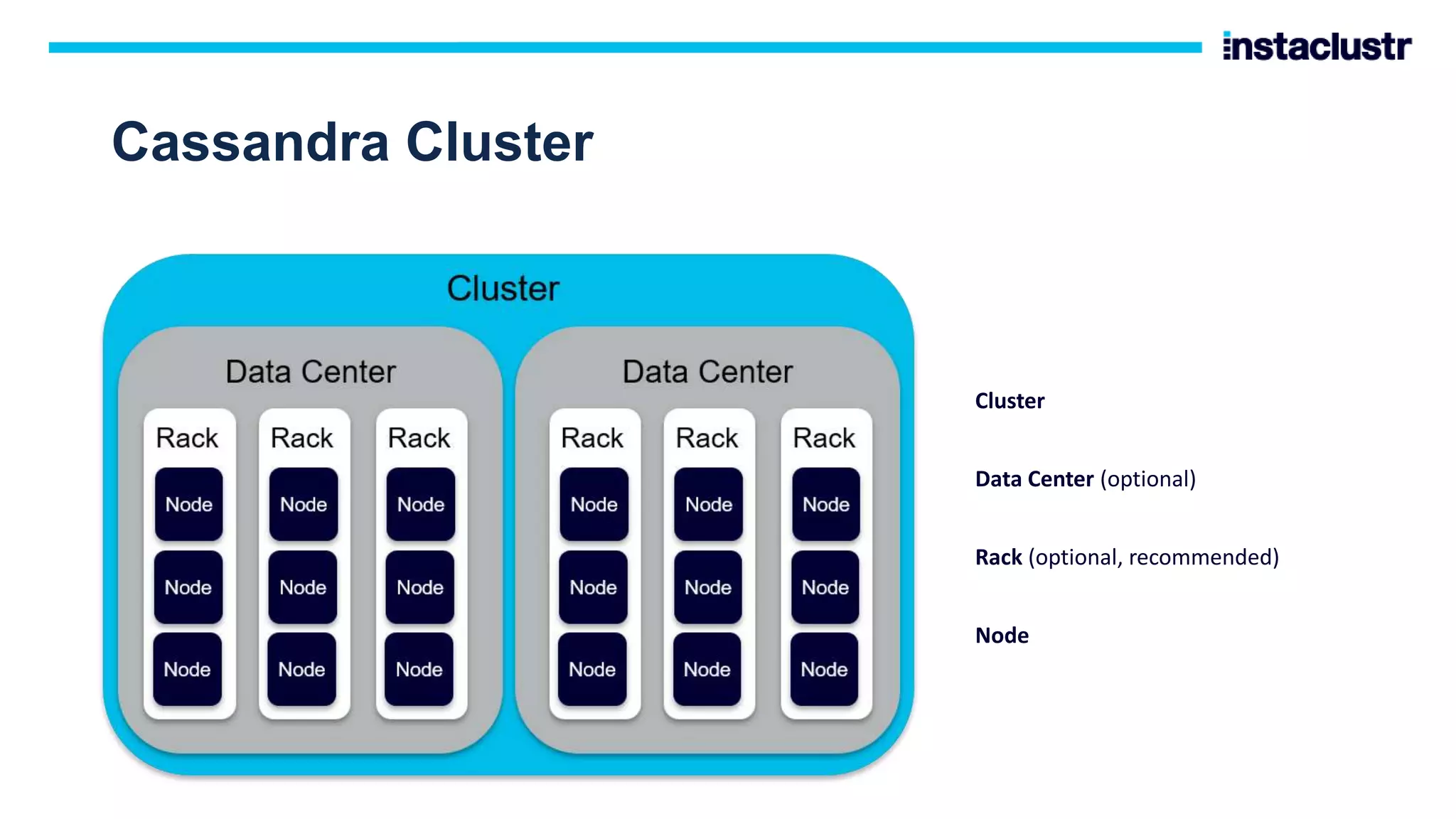
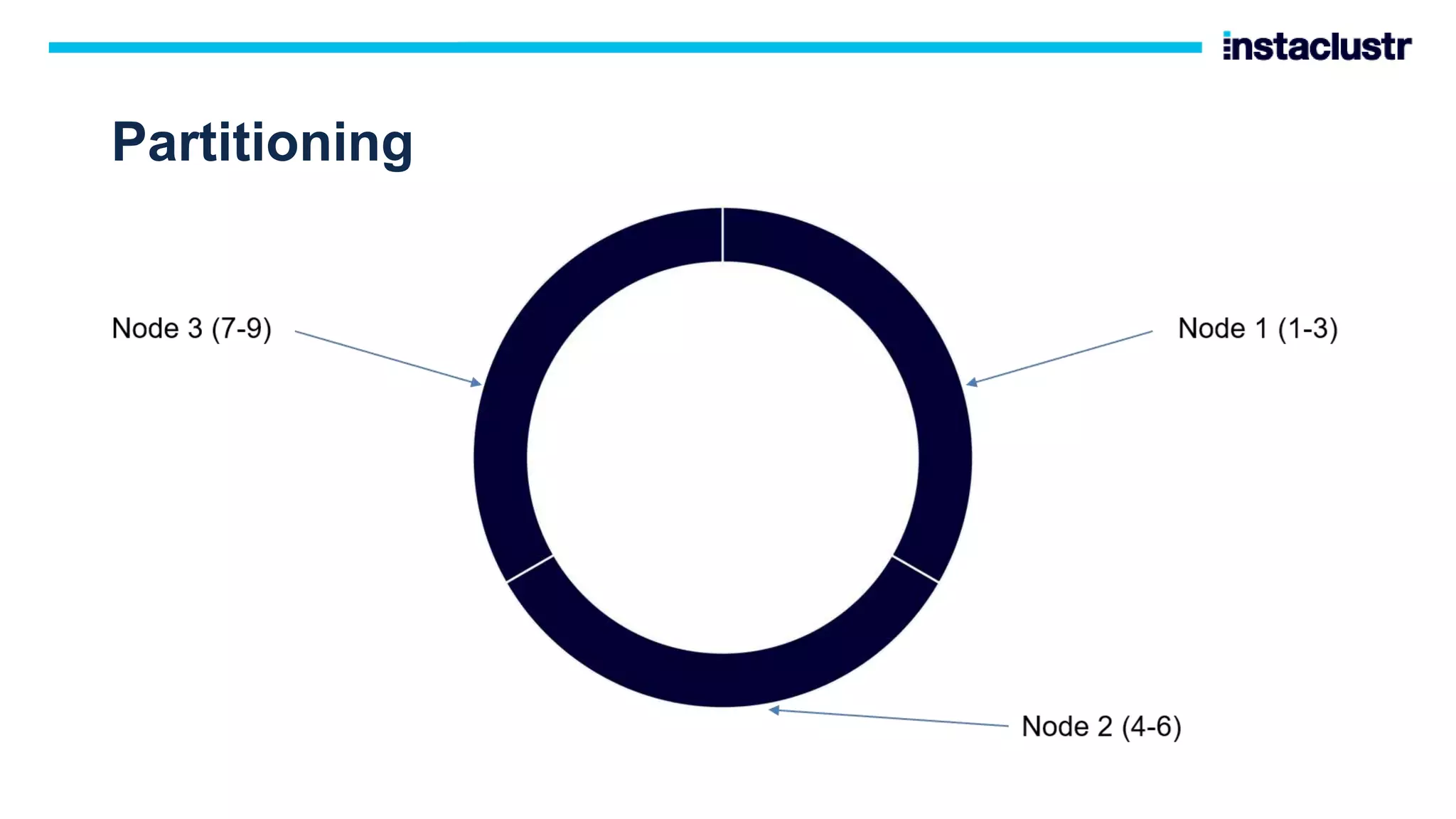
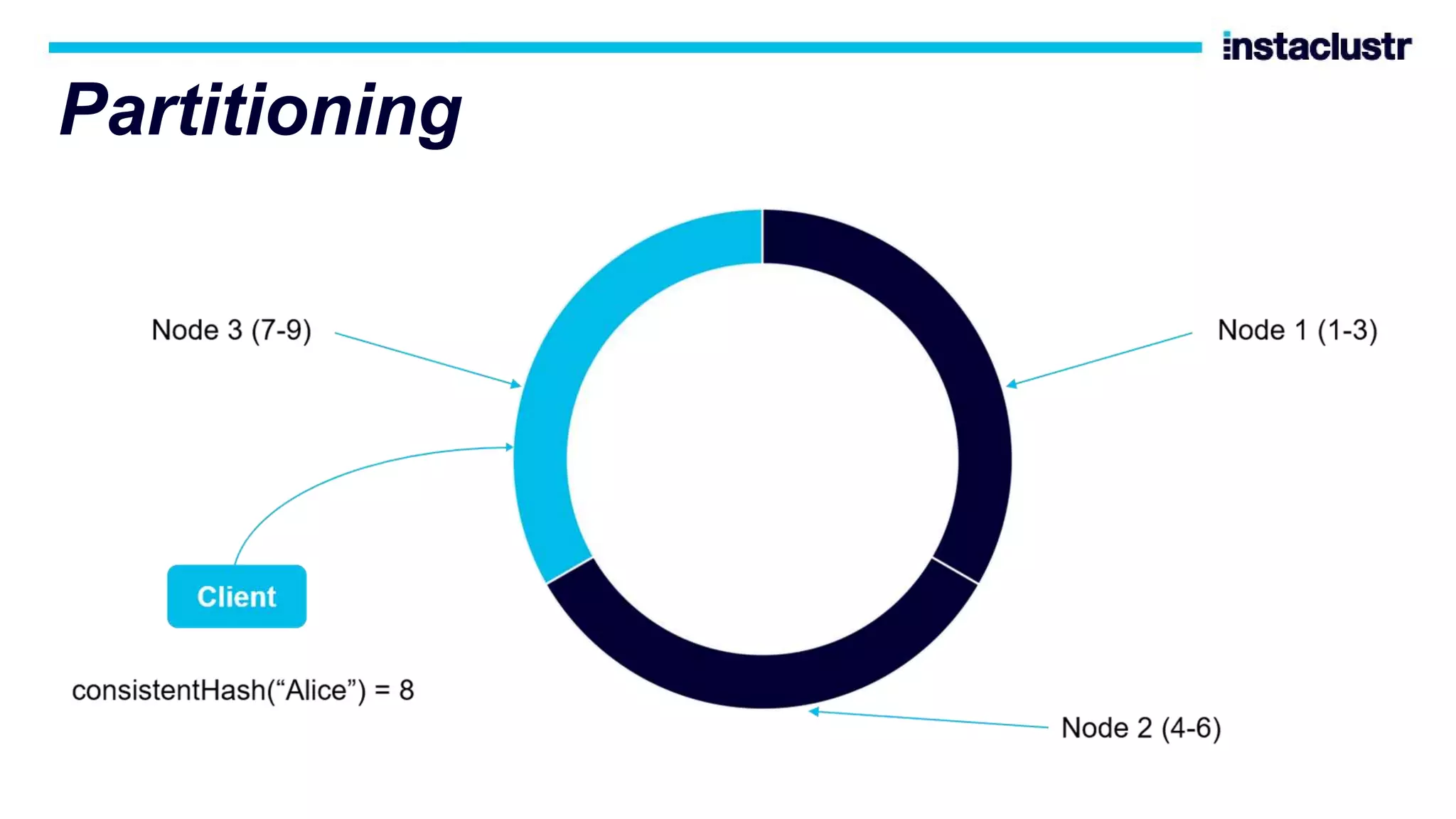
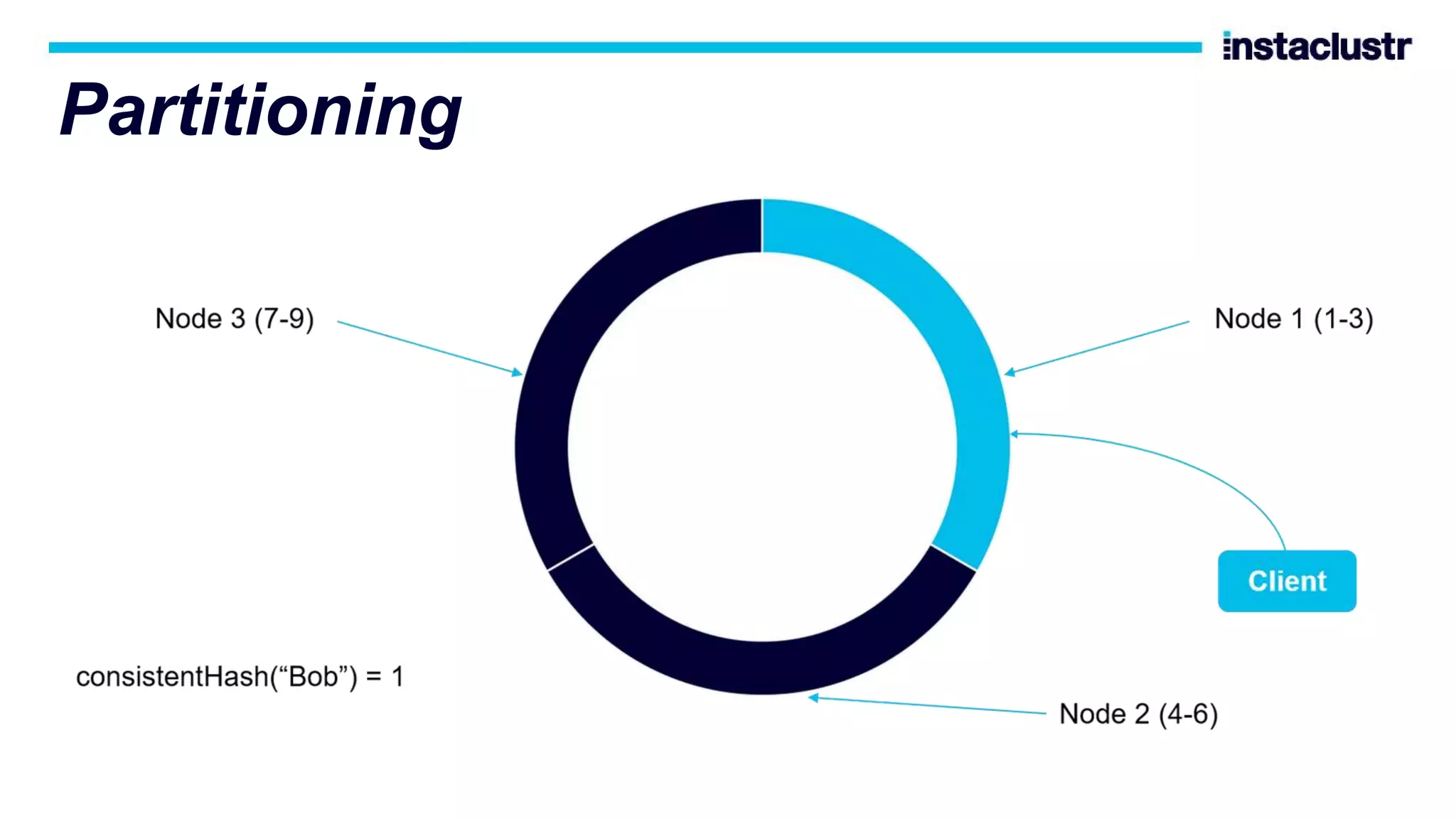
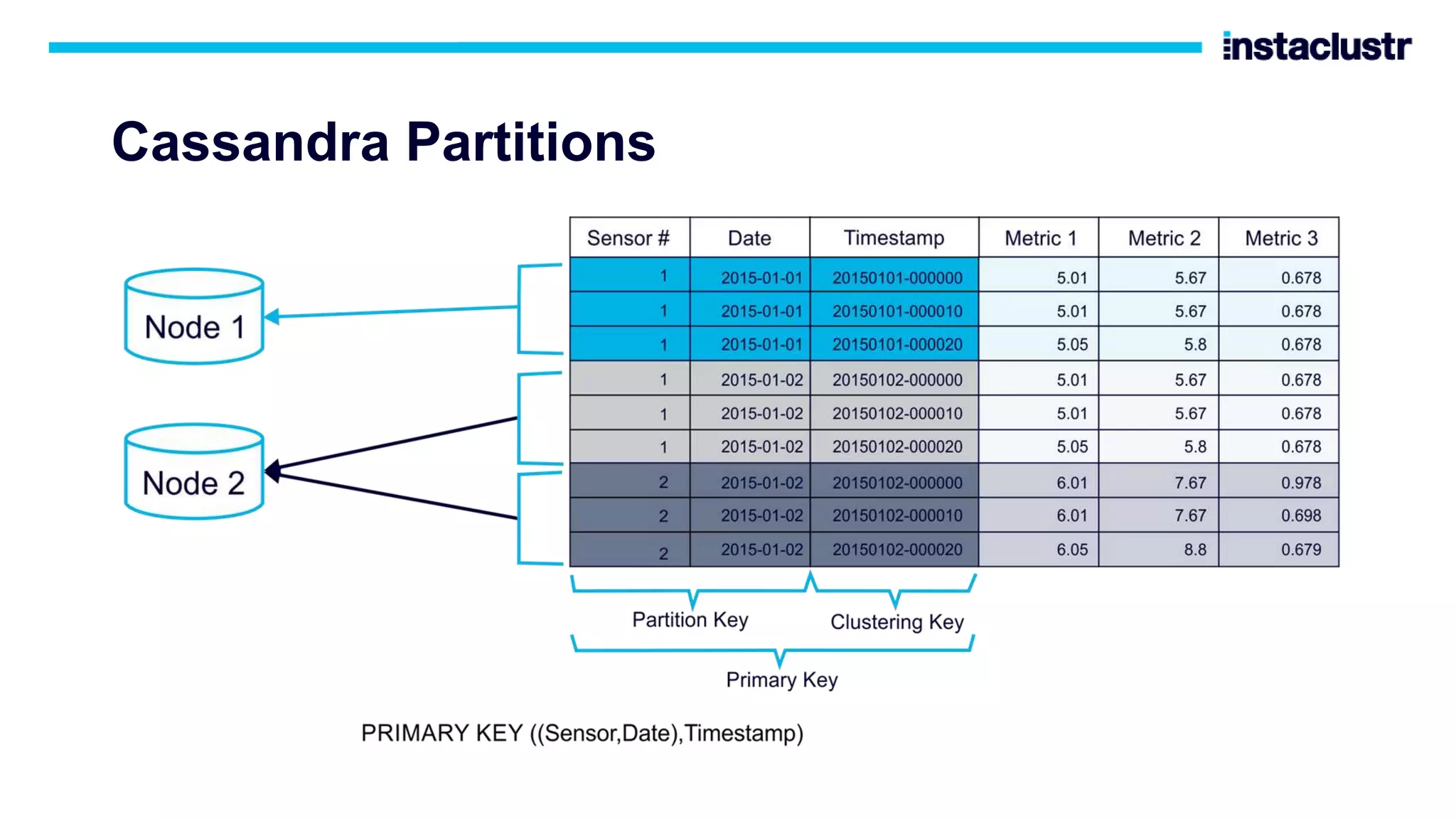
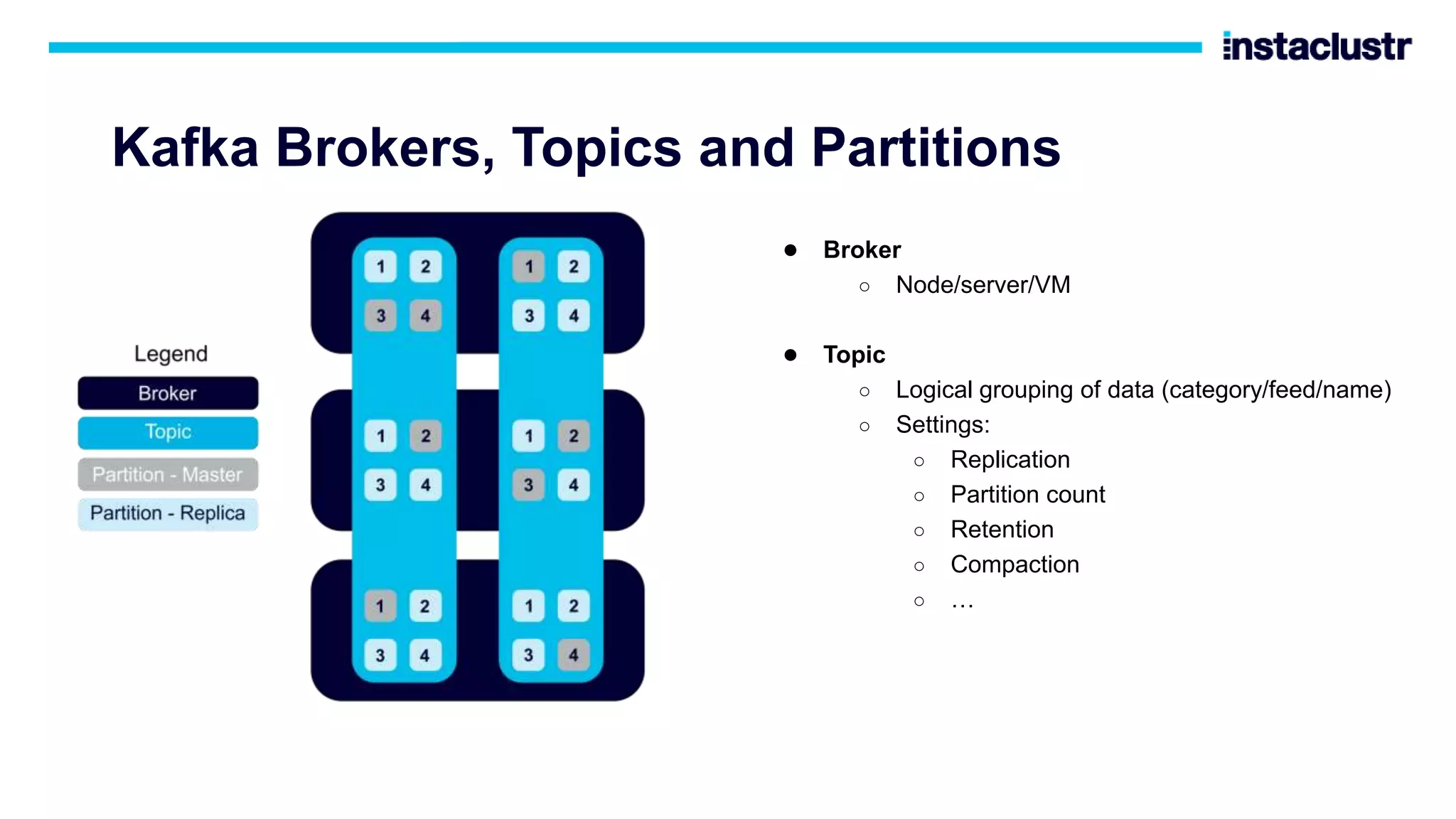
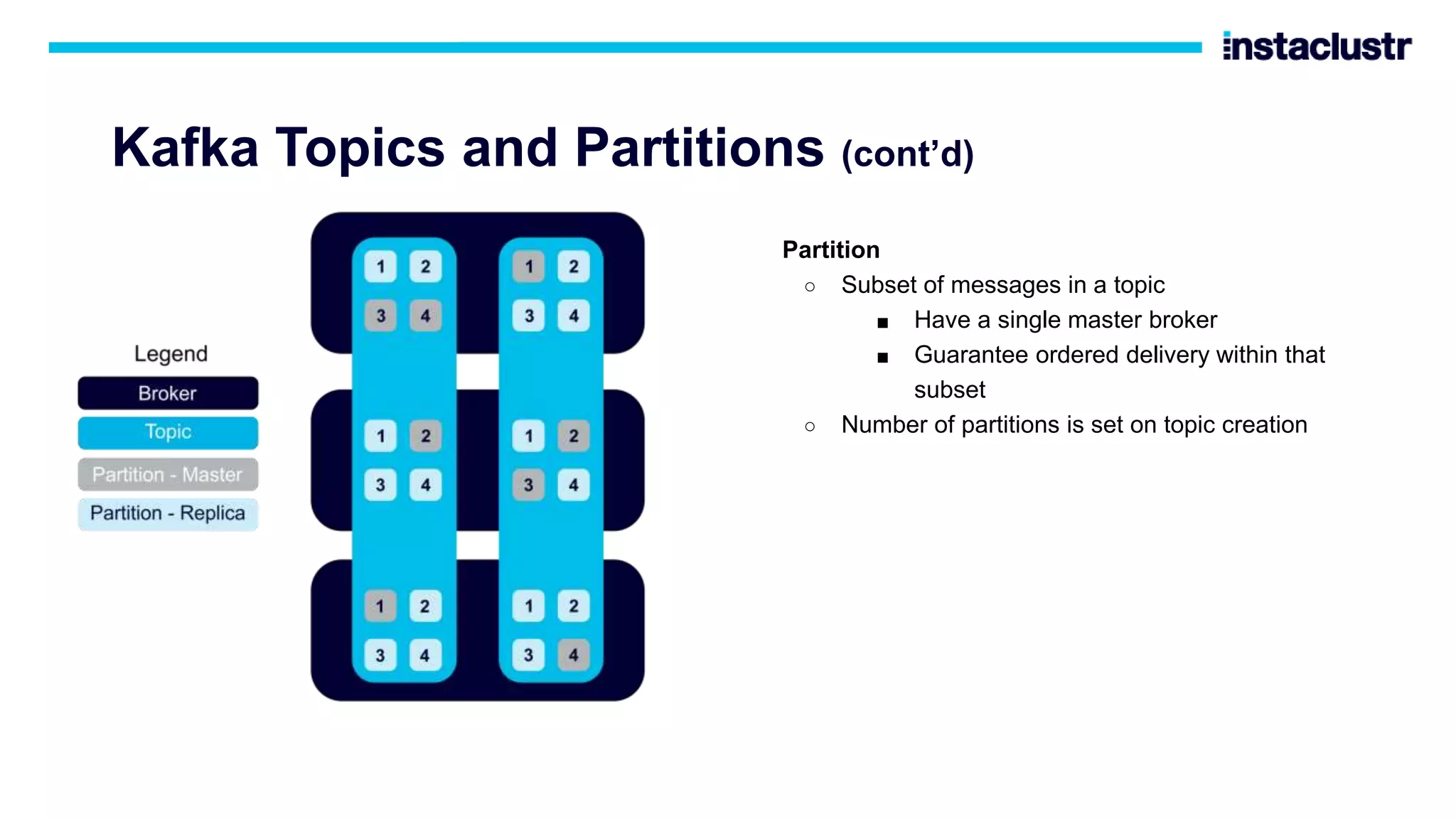
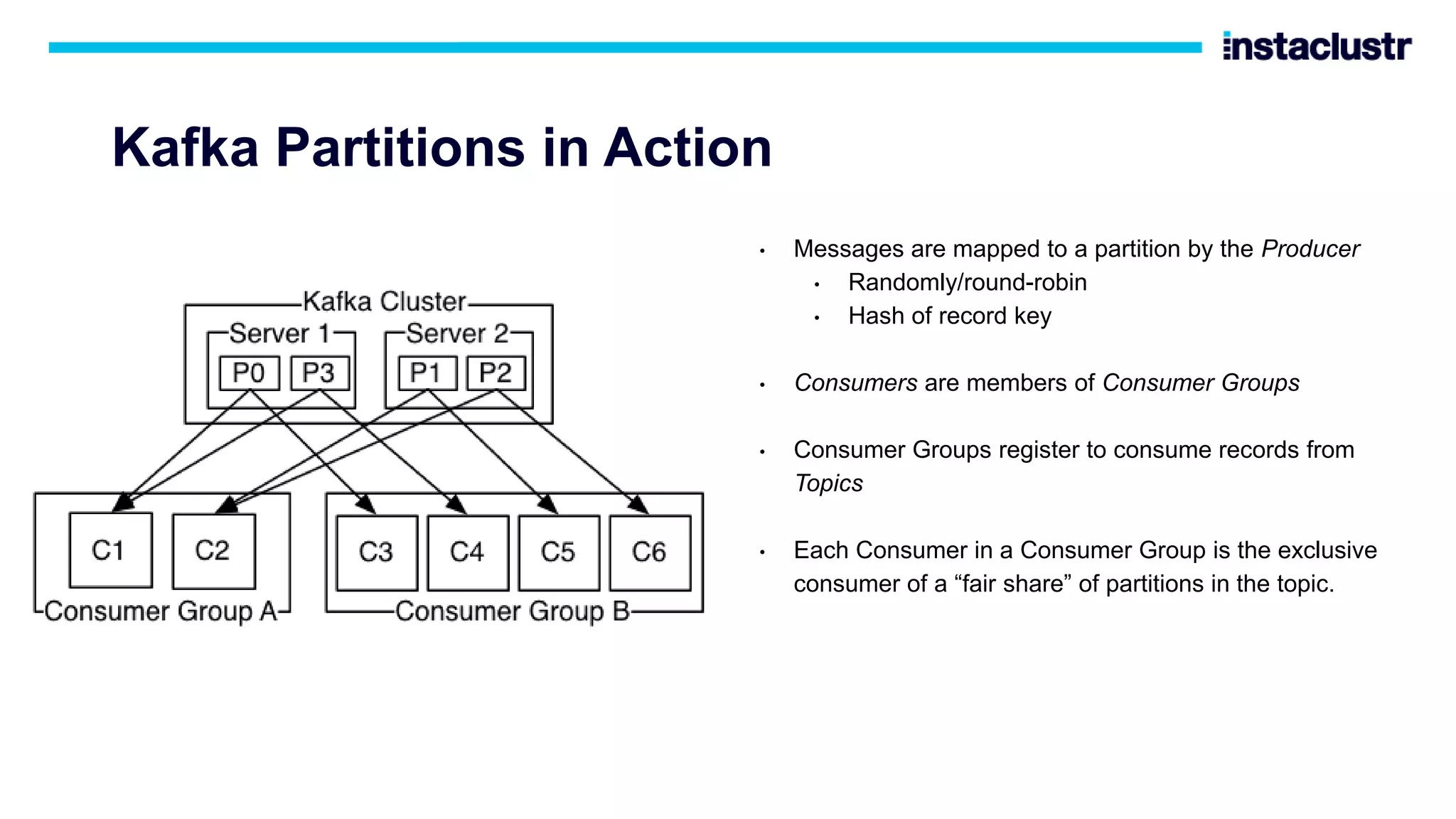

































The document discusses the use of Apache Cassandra and Apache Kafka for scaling next-generation applications, emphasizing their reliability, availability, and efficiency in handling high-volume data. It covers practical applications and case studies, highlighting companies like Worldpay and lenders in Australia that have successfully implemented these technologies. Key topics include data partitioning, integration challenges, and the architectural benefits of using managed services for optimal performance.























































































