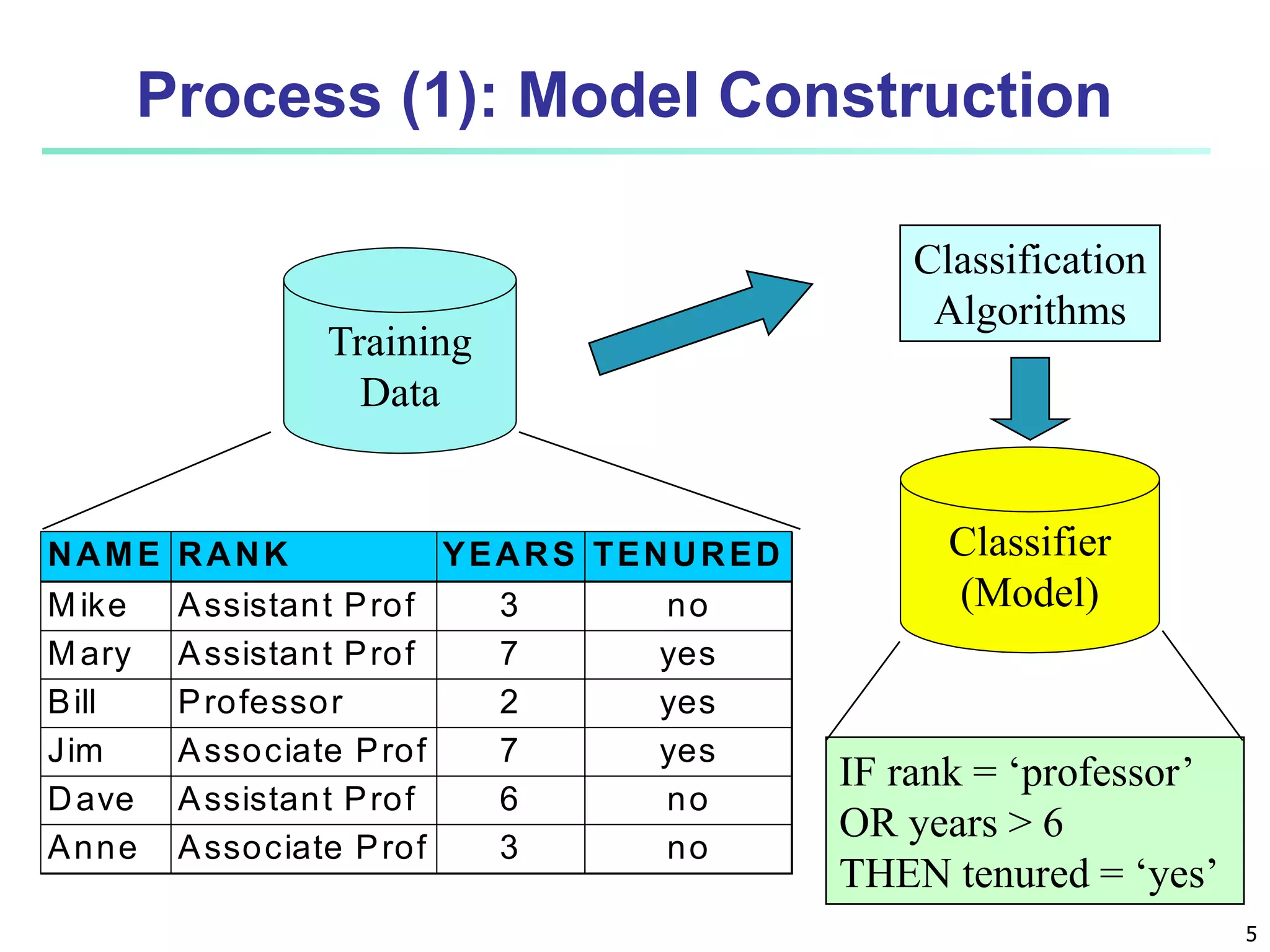
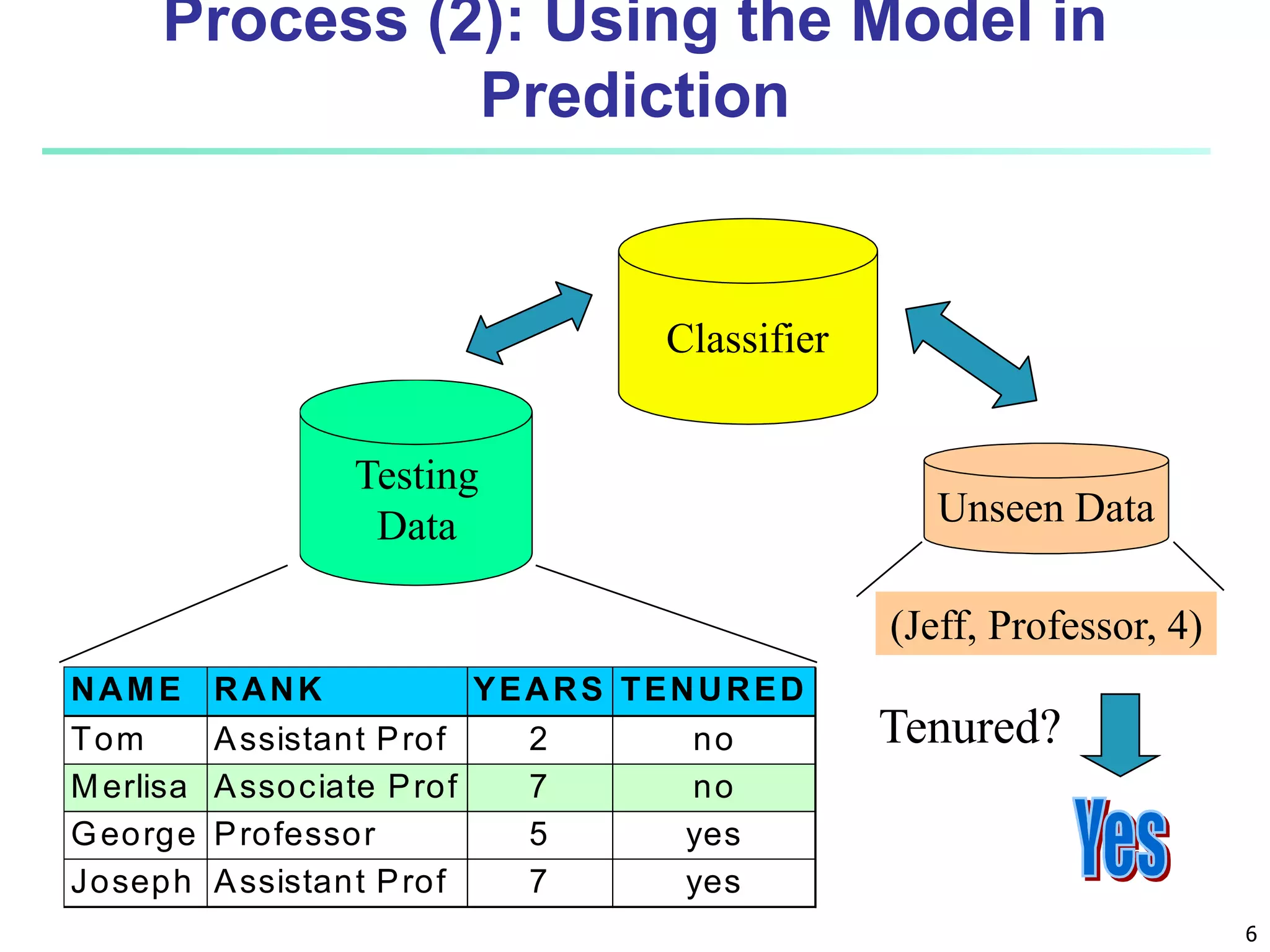
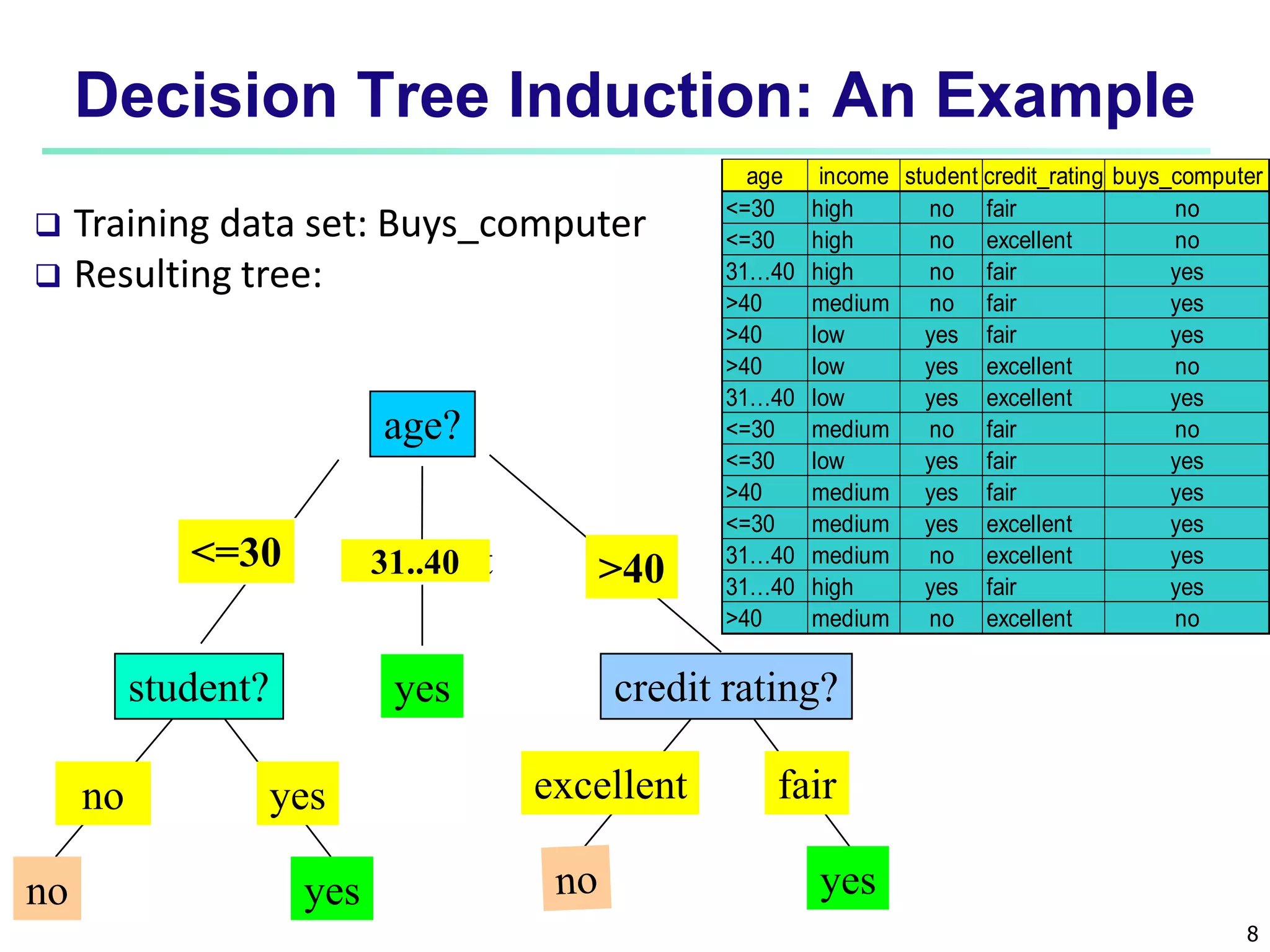
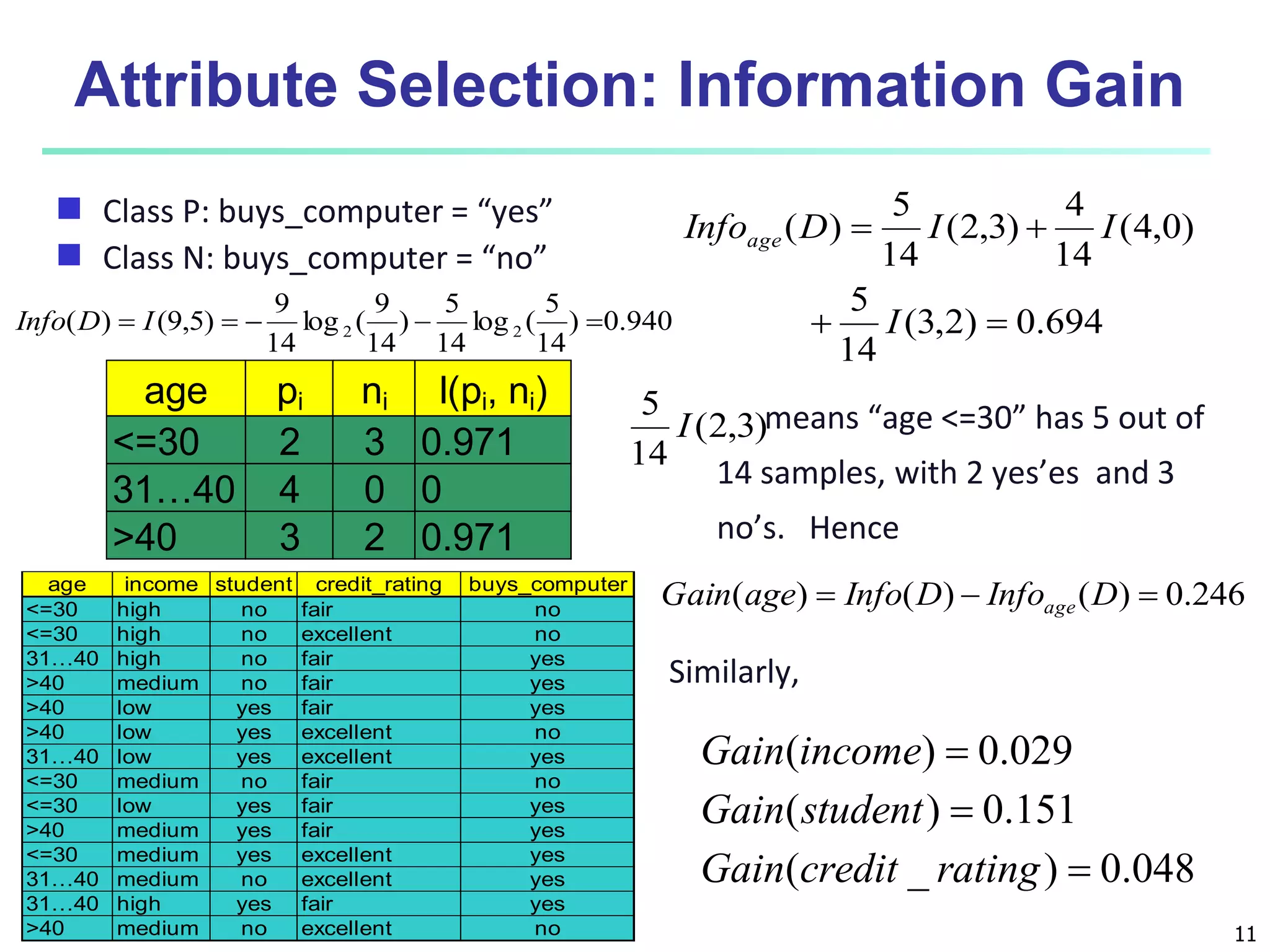
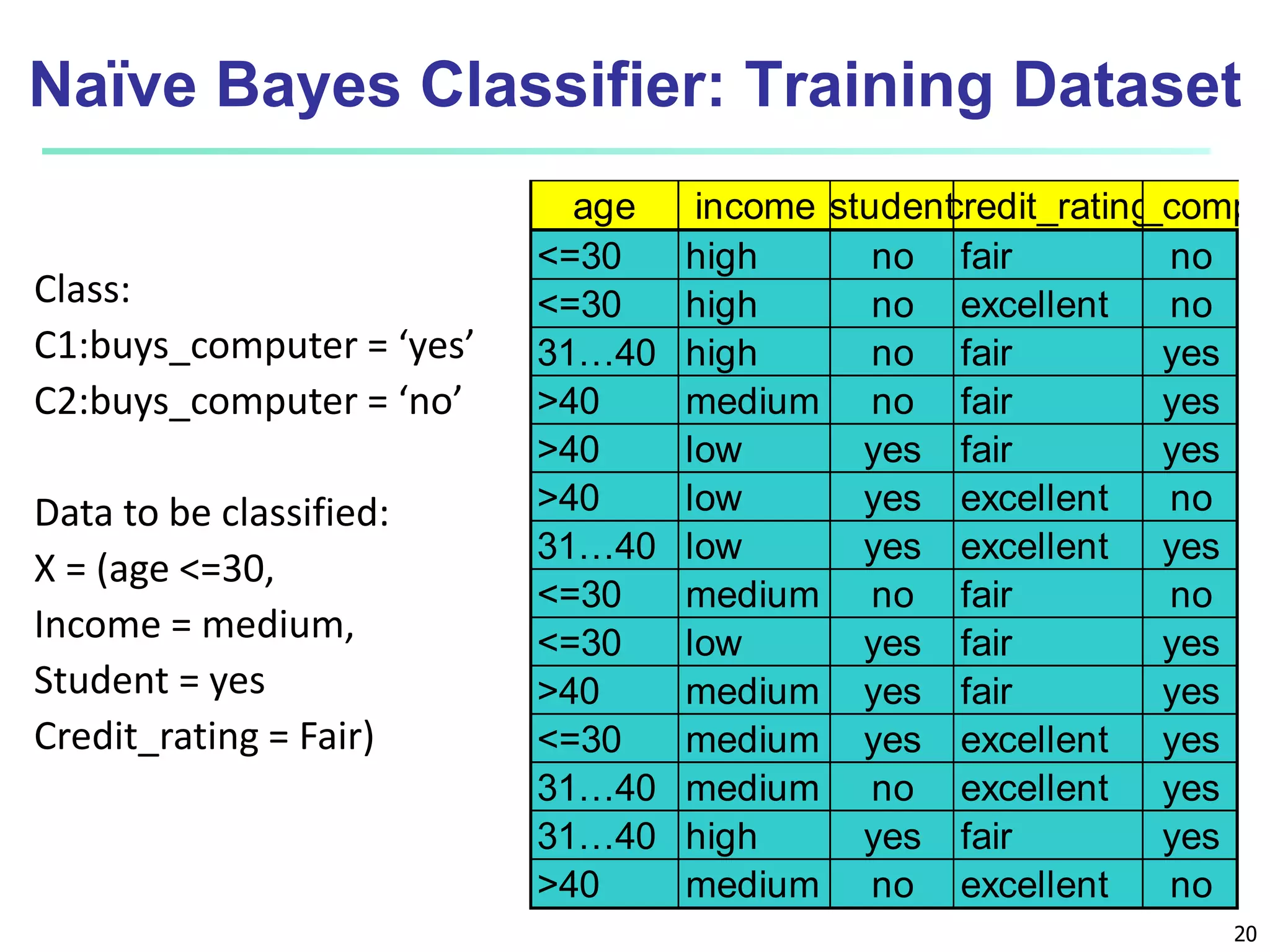
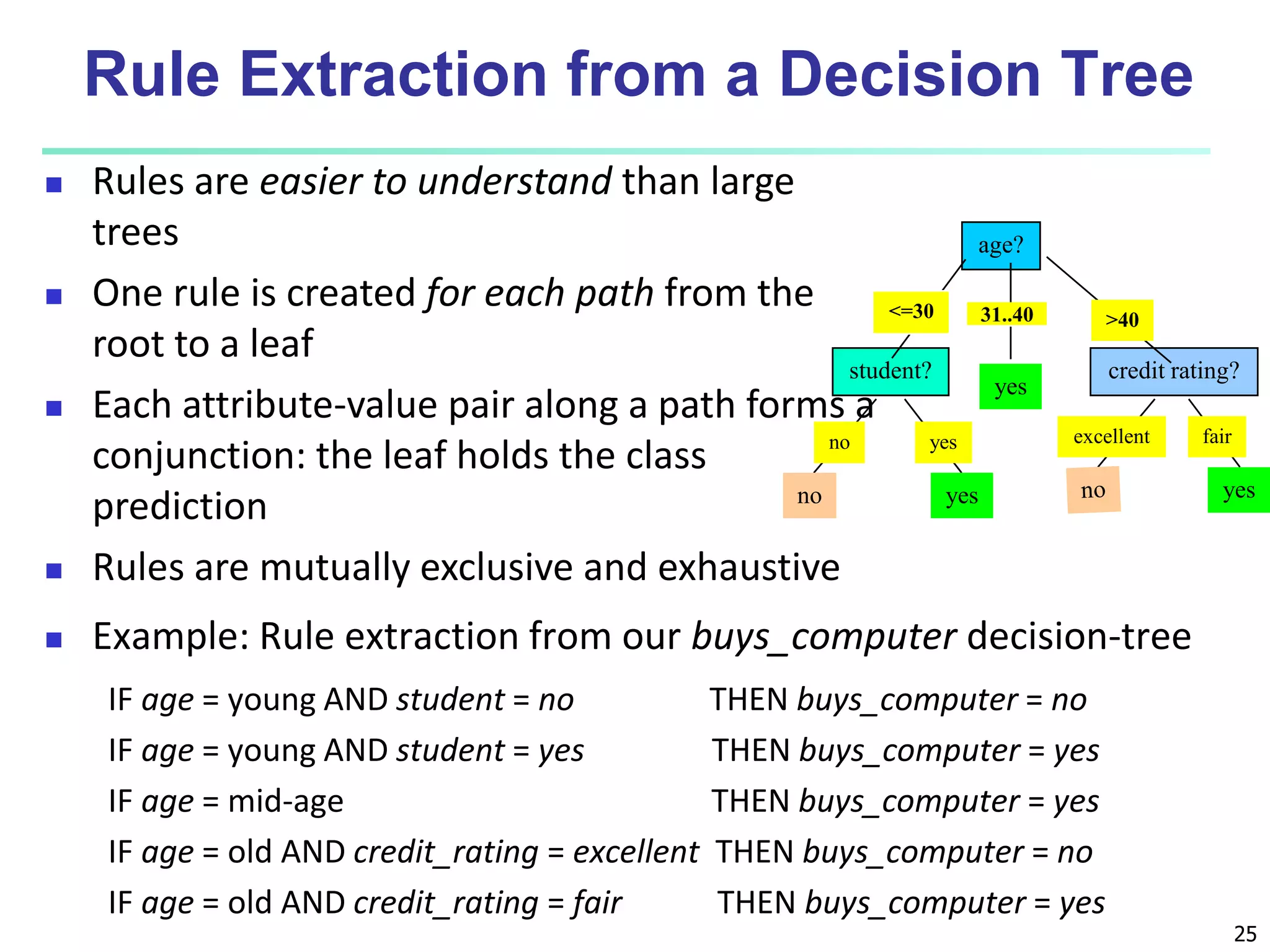
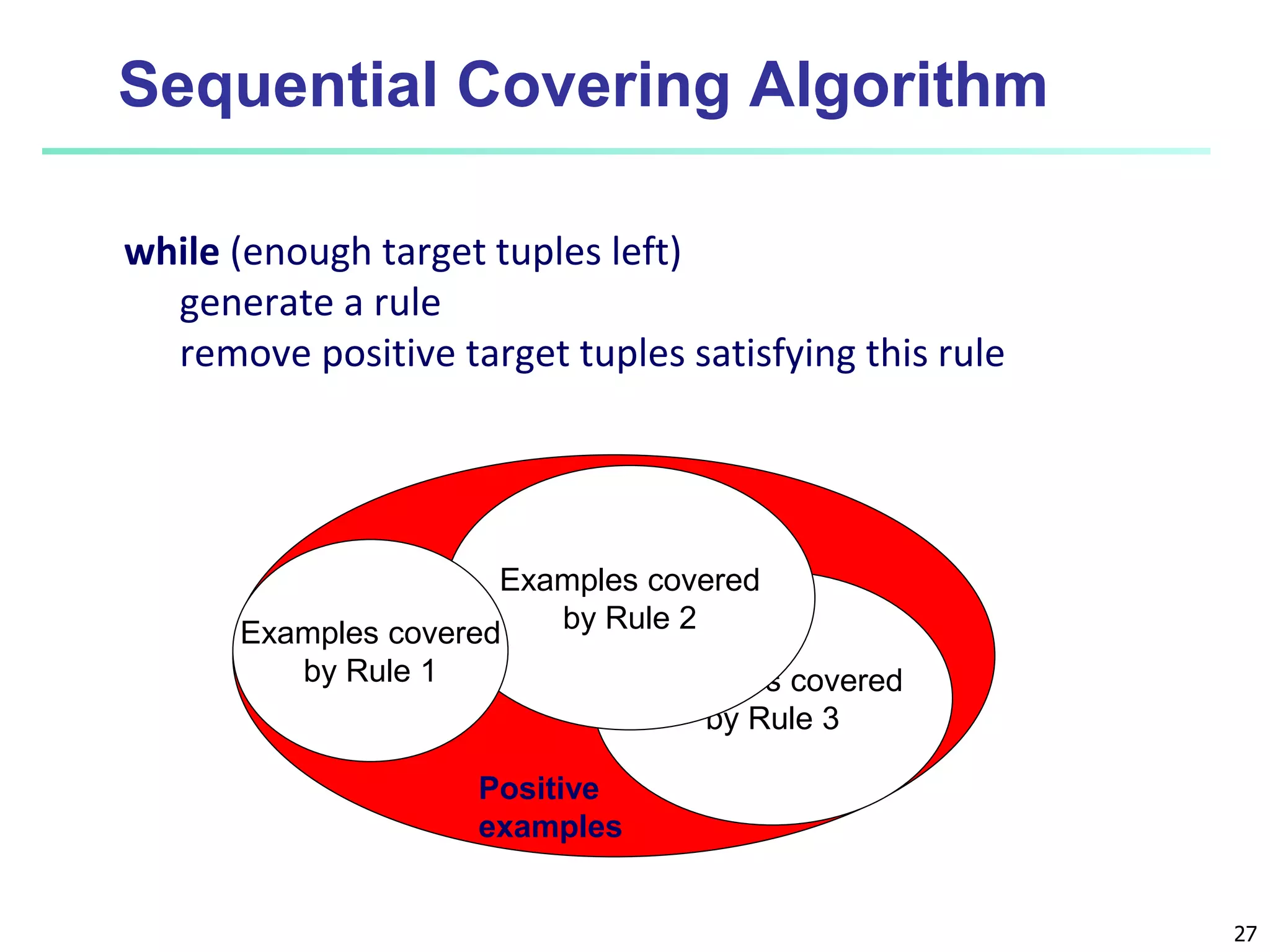
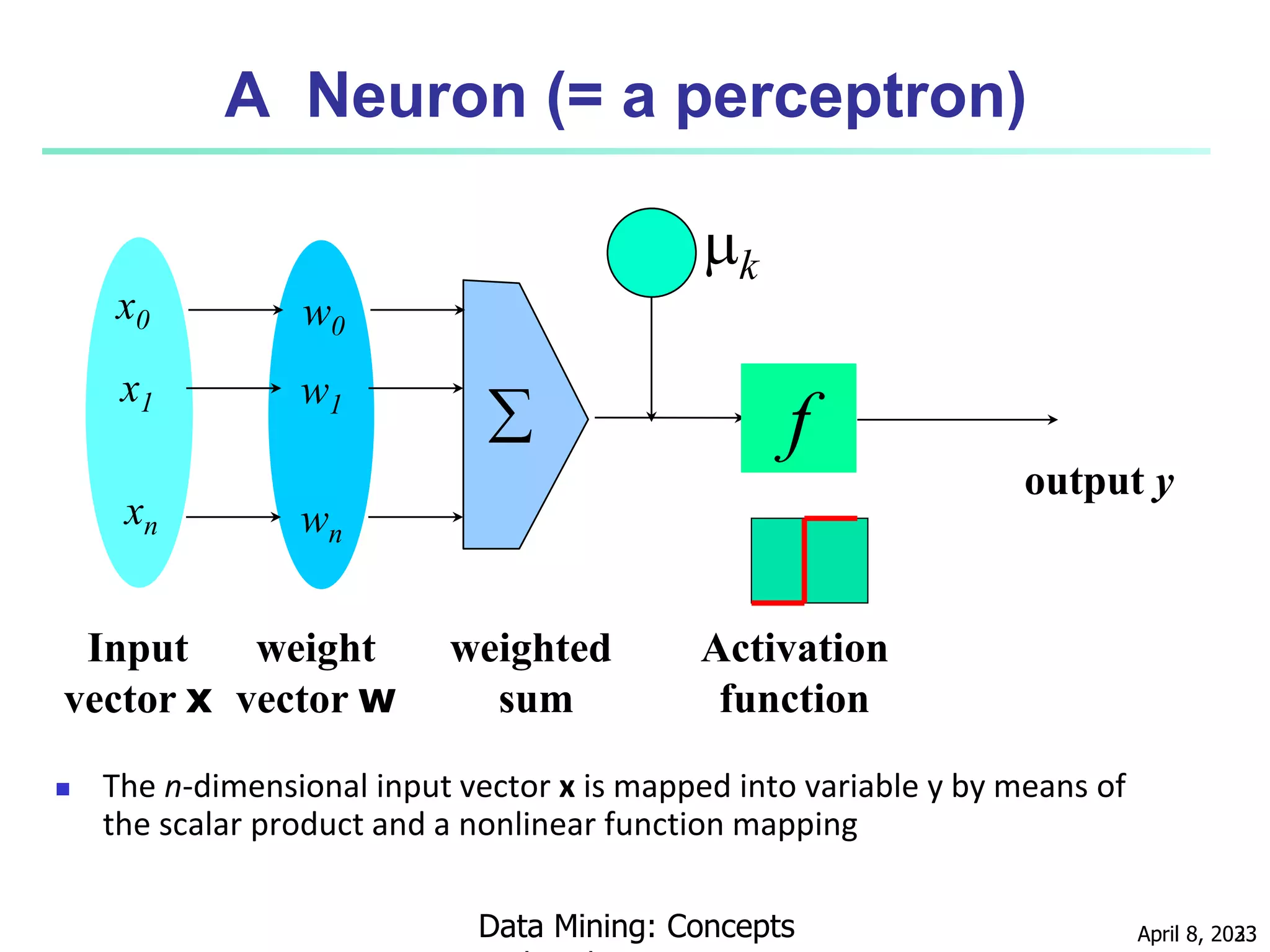
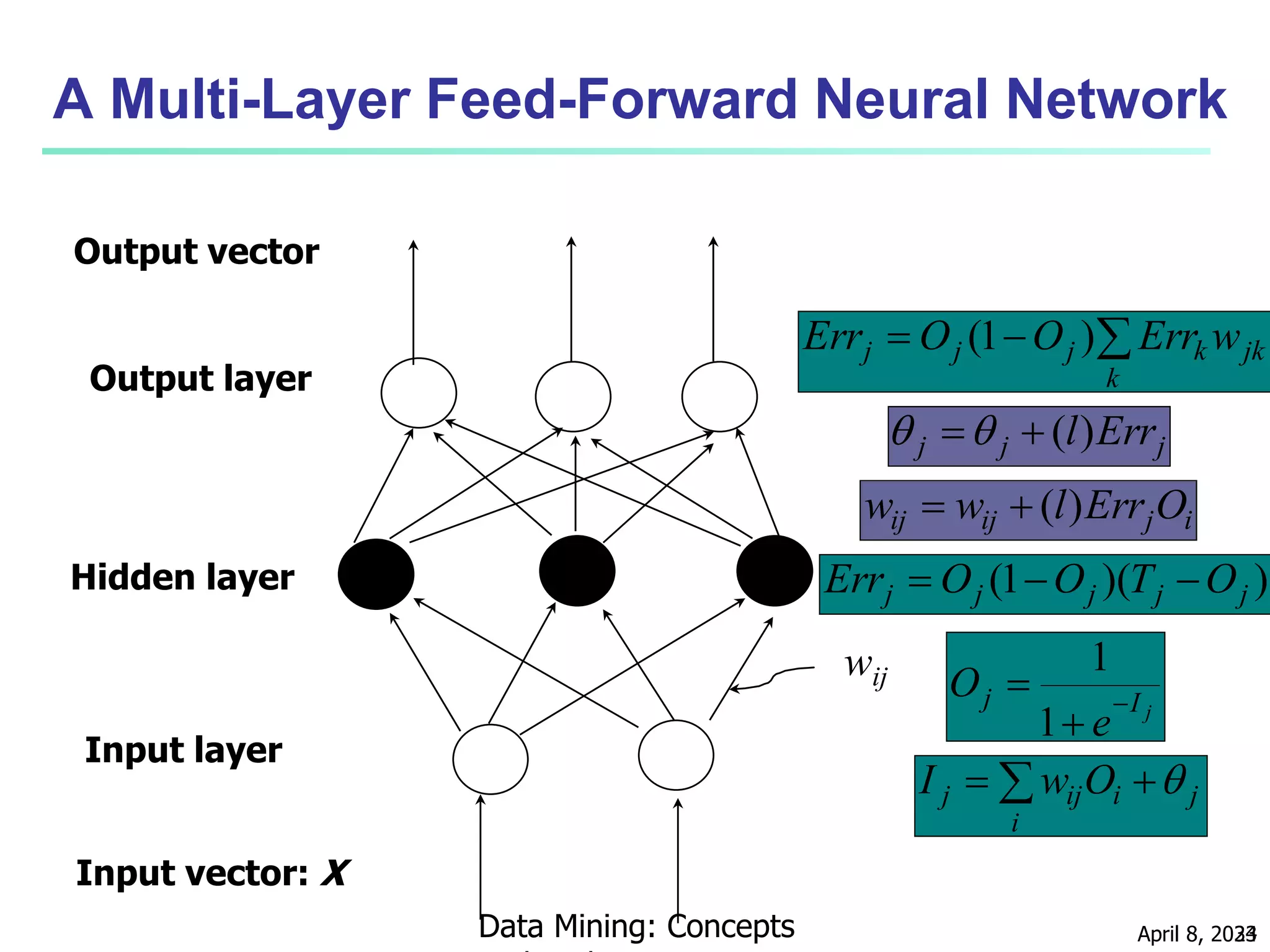
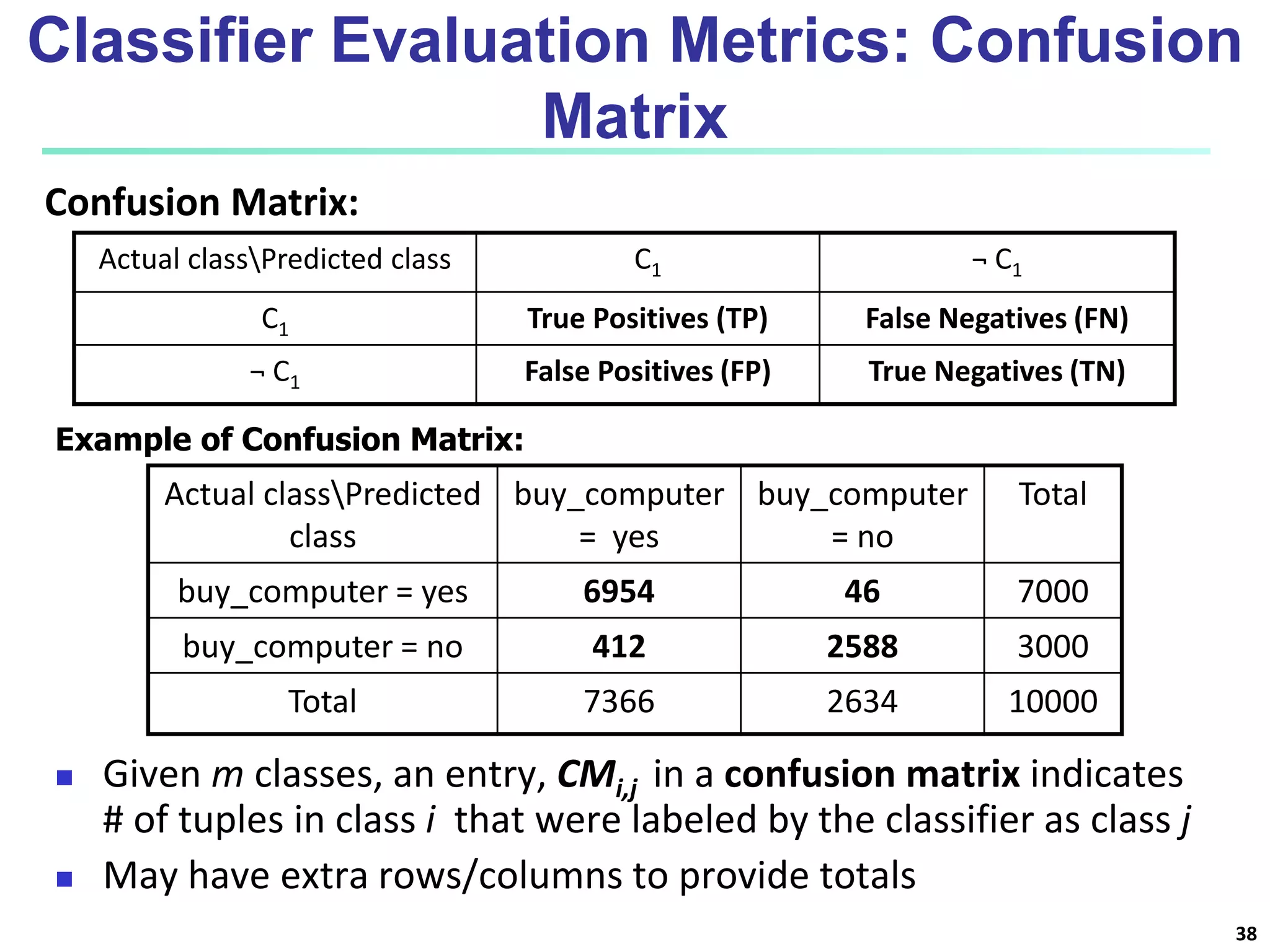
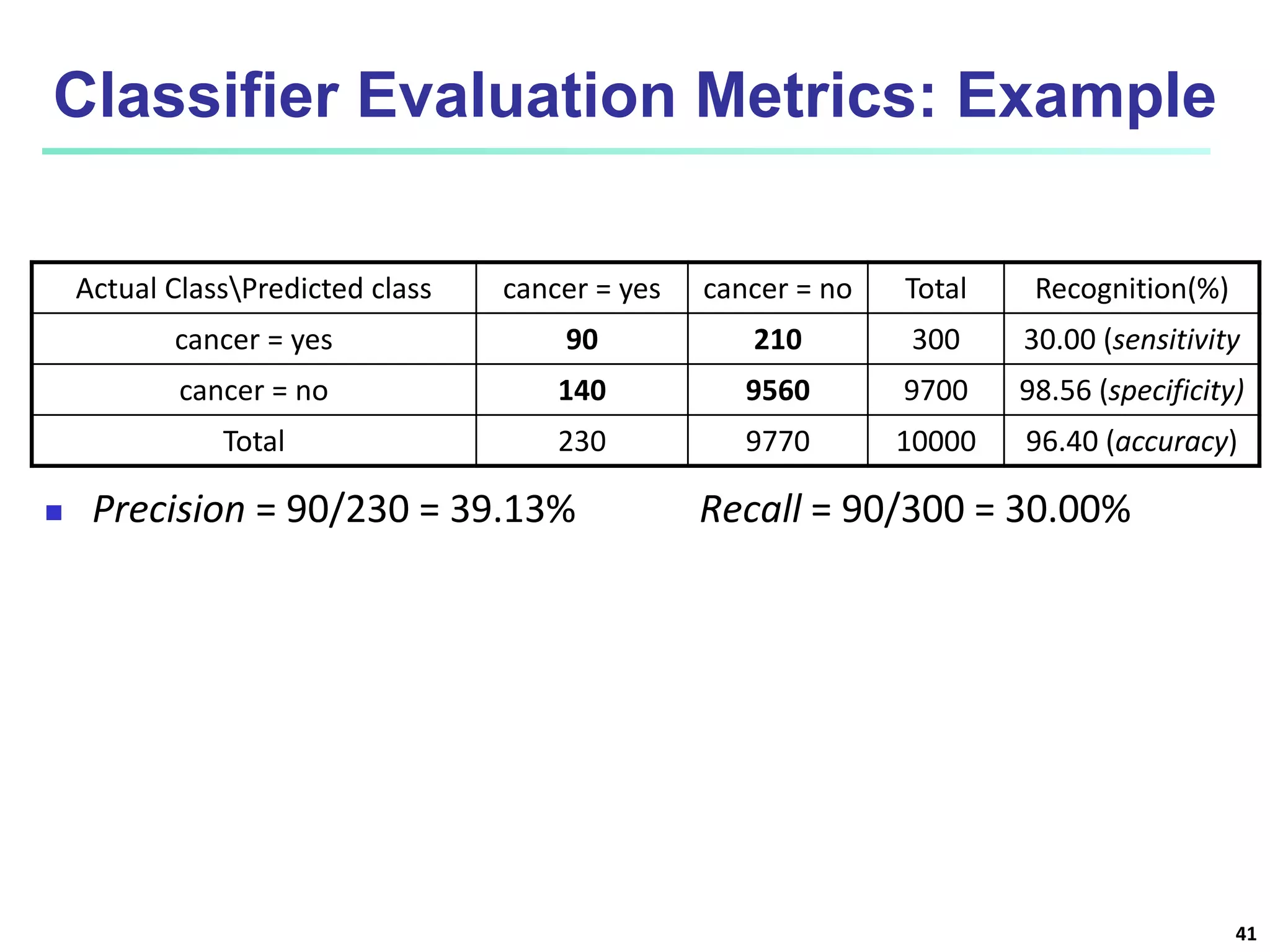
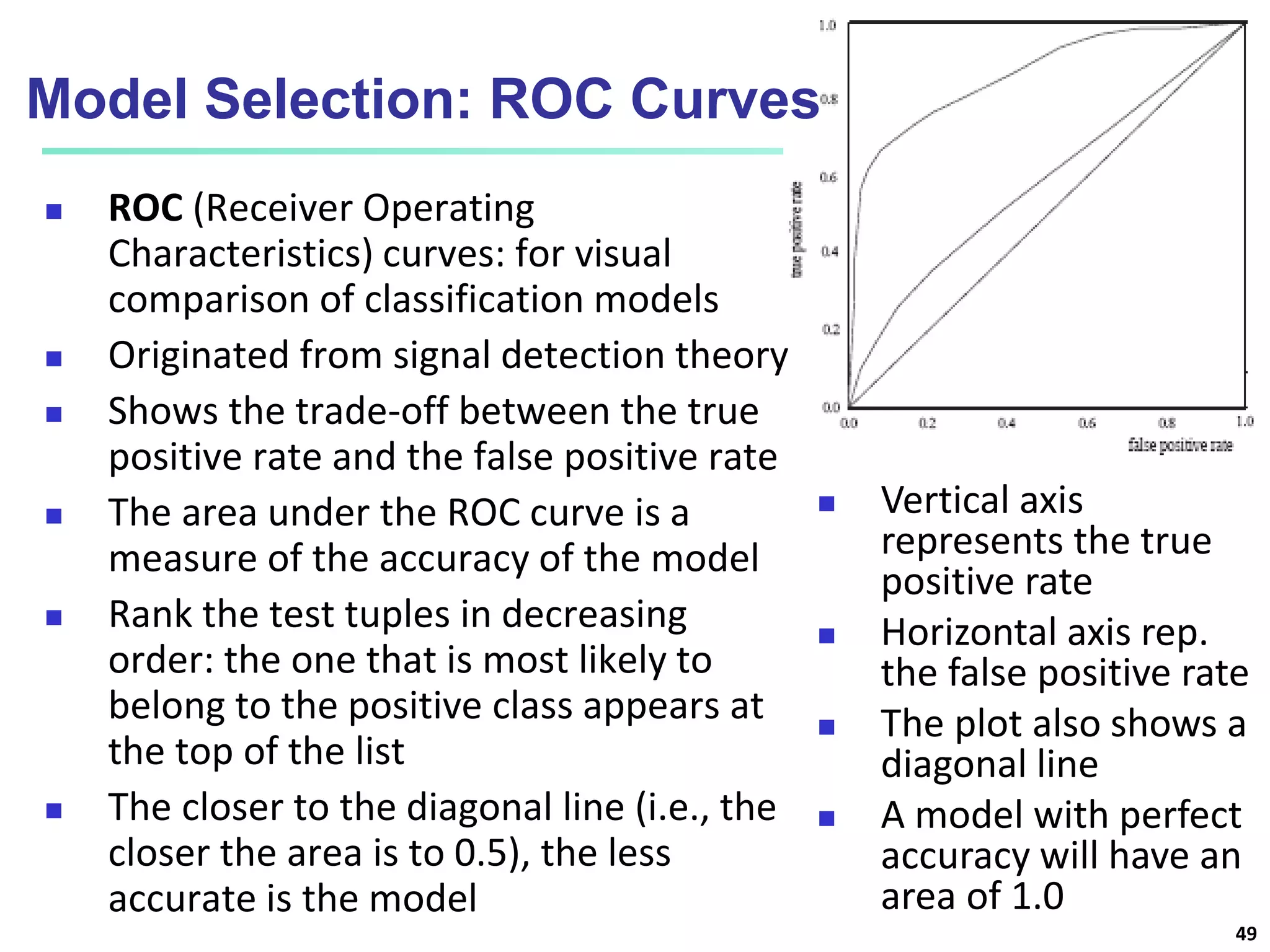
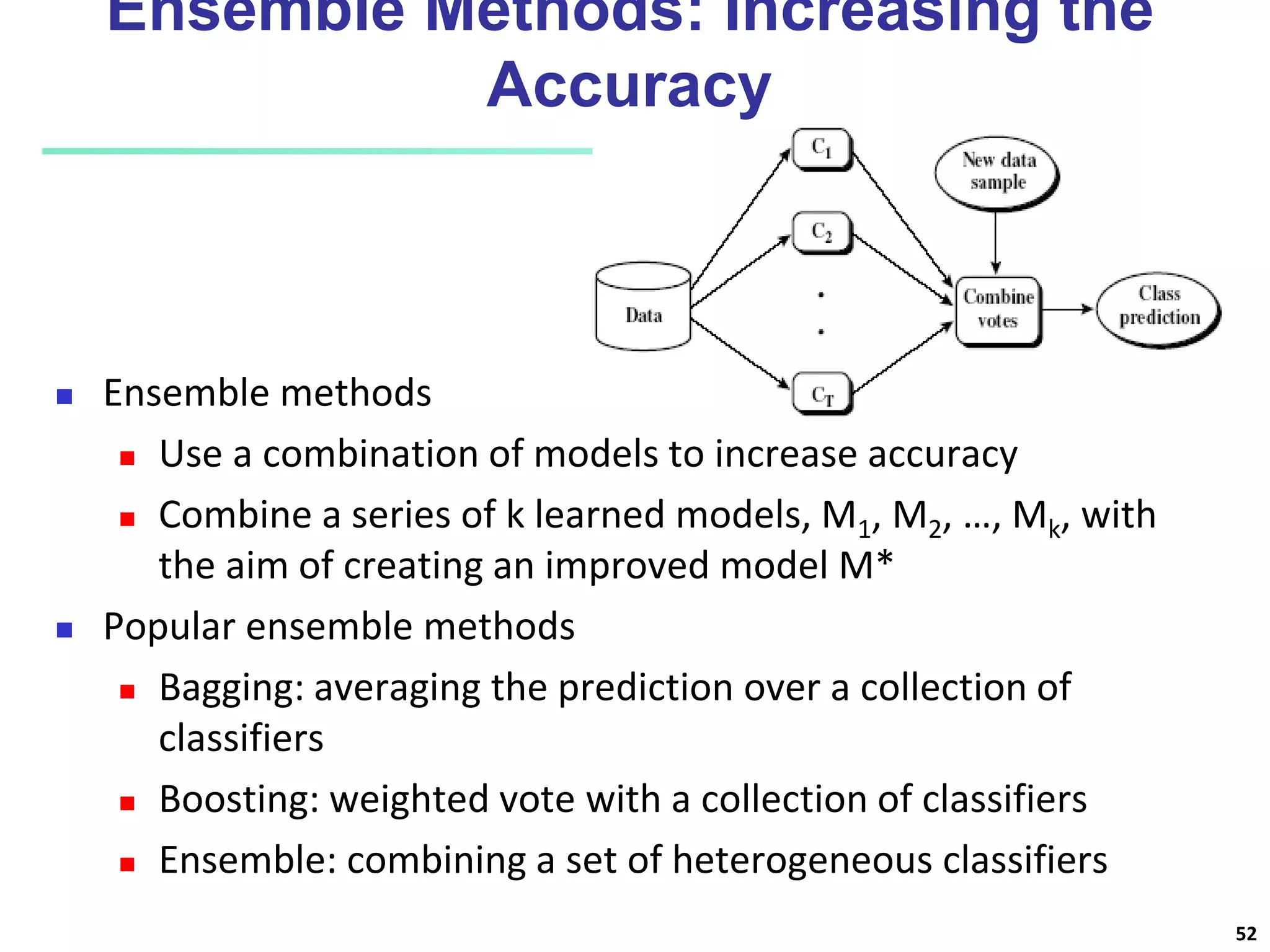
This document discusses classification techniques for supervised learning. It begins with an overview of classification and describes the two-step classification process of model construction using a training set and then applying the model to classify new data. It then covers specific classification algorithms like decision tree induction, Bayesian classification methods, and rule-based classification. It also discusses evaluating and selecting models as well as techniques for improving accuracy, such as ensemble methods.