Downloaded 39 times








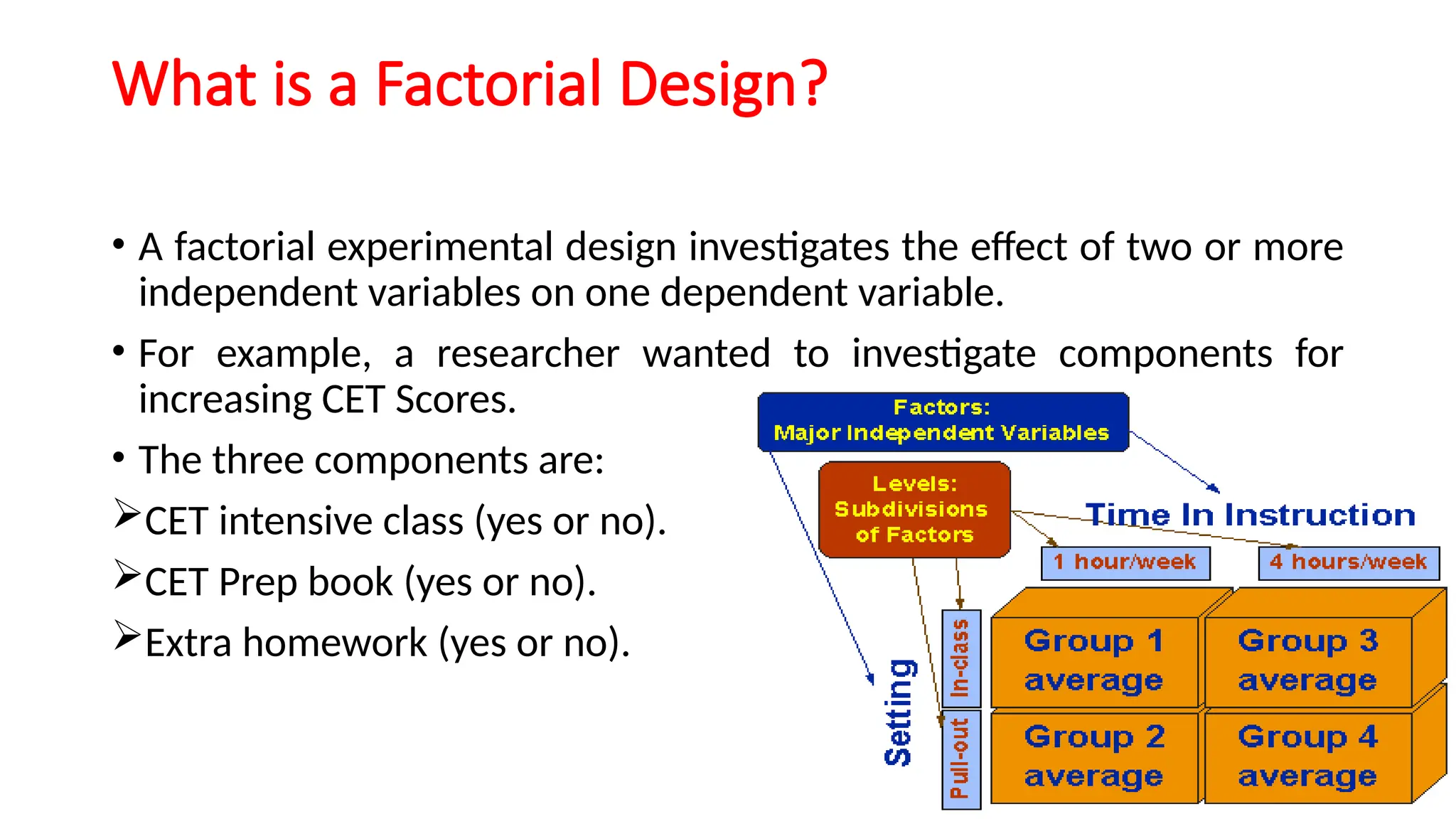










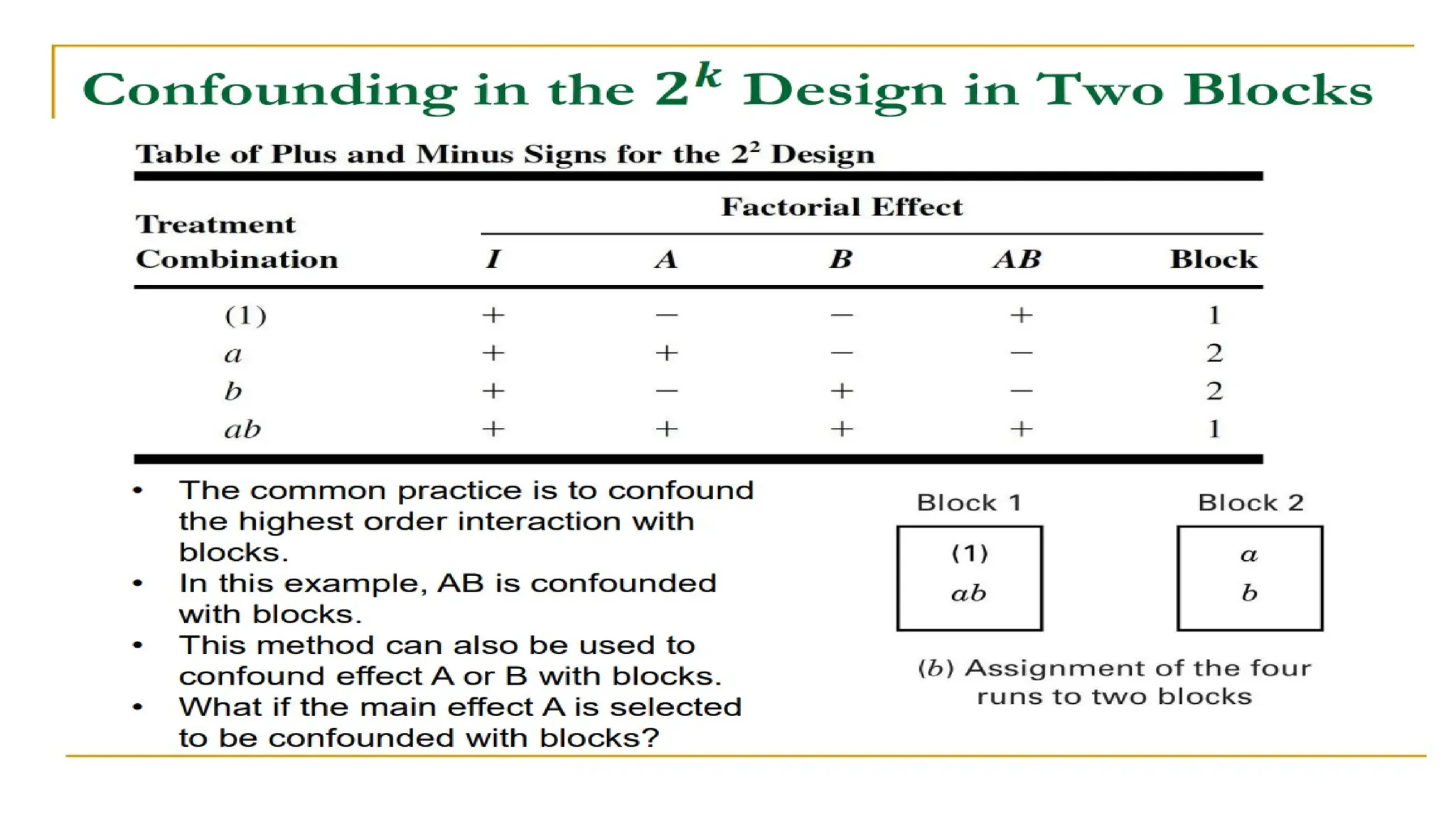
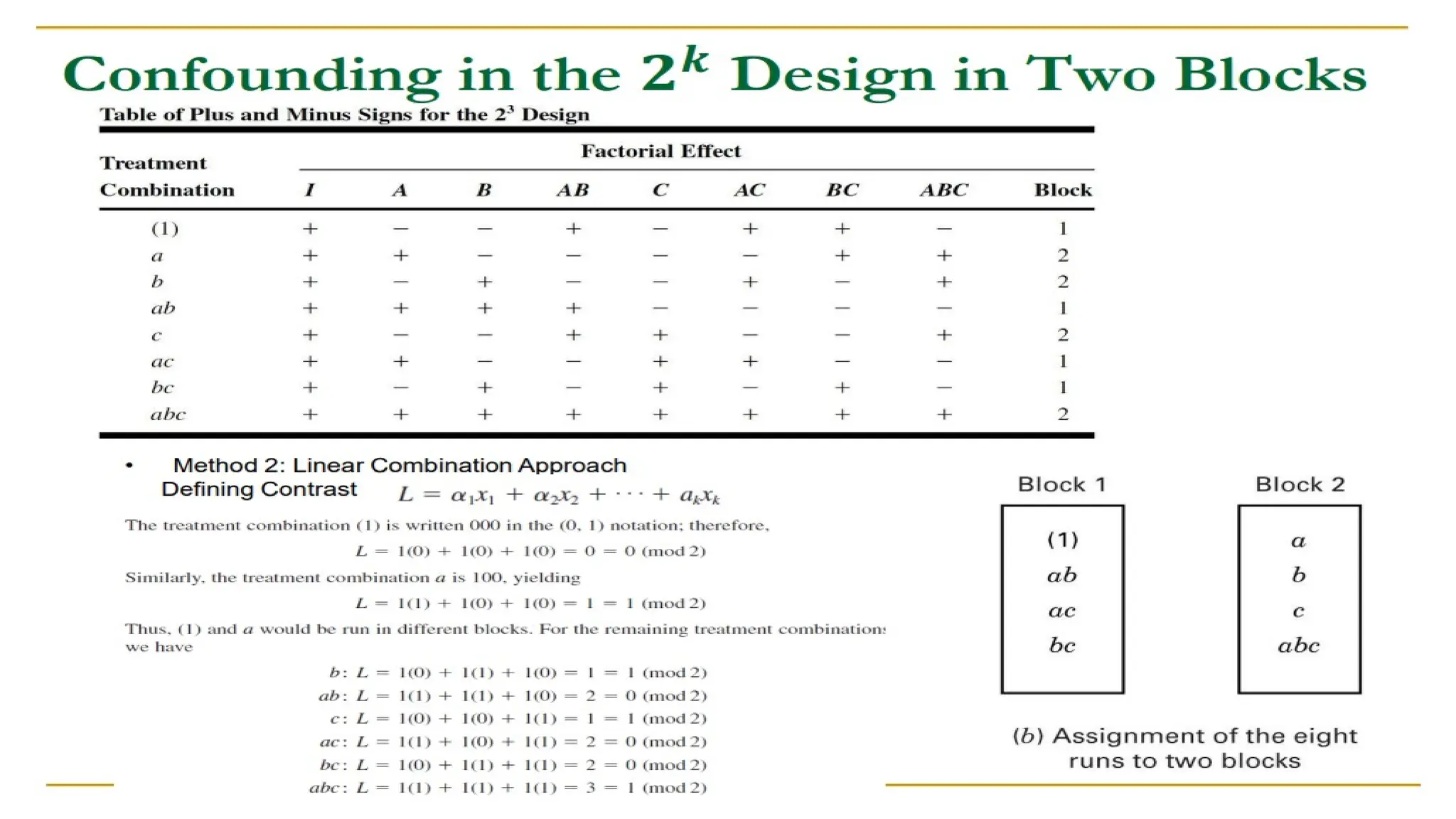






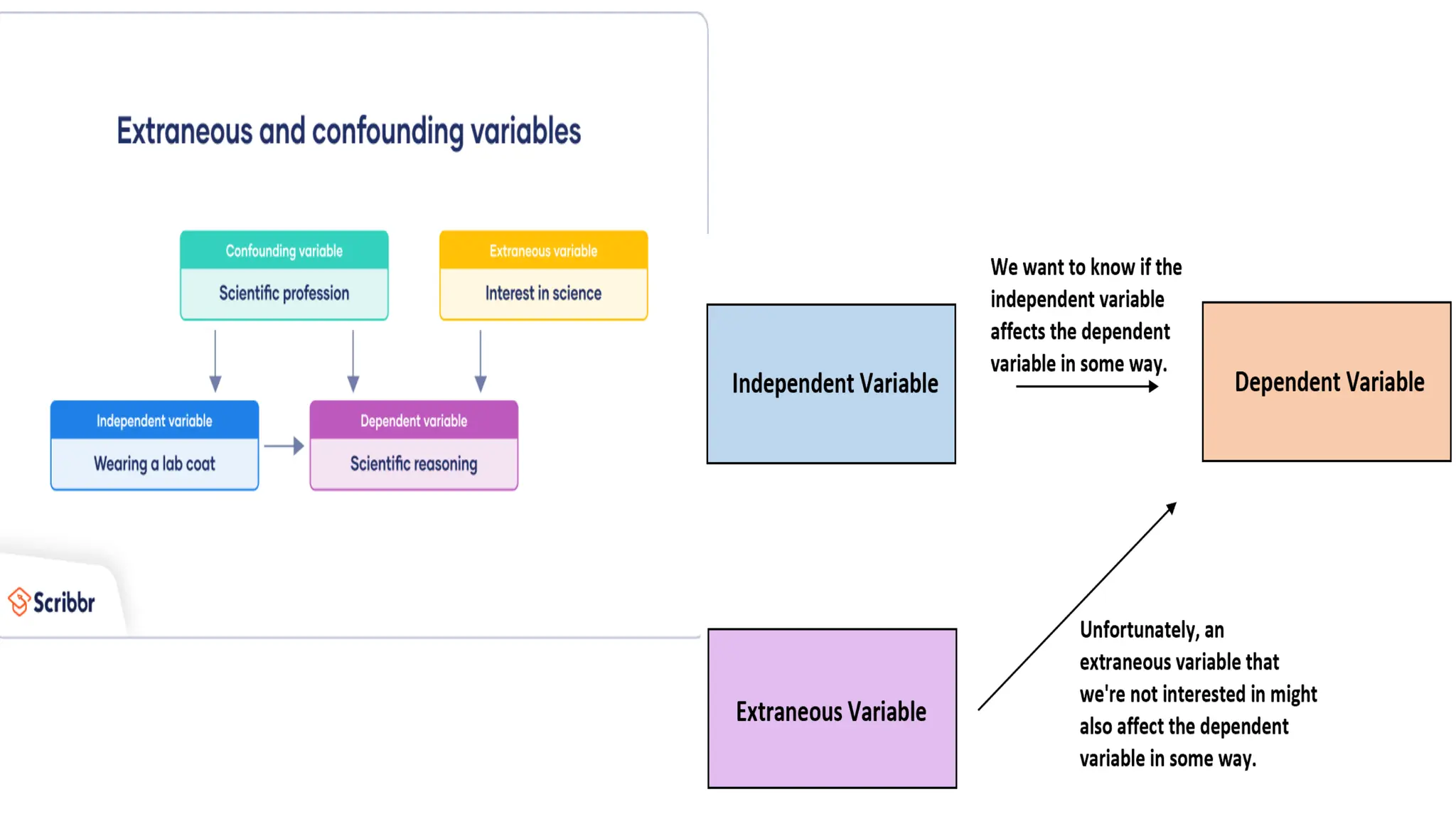






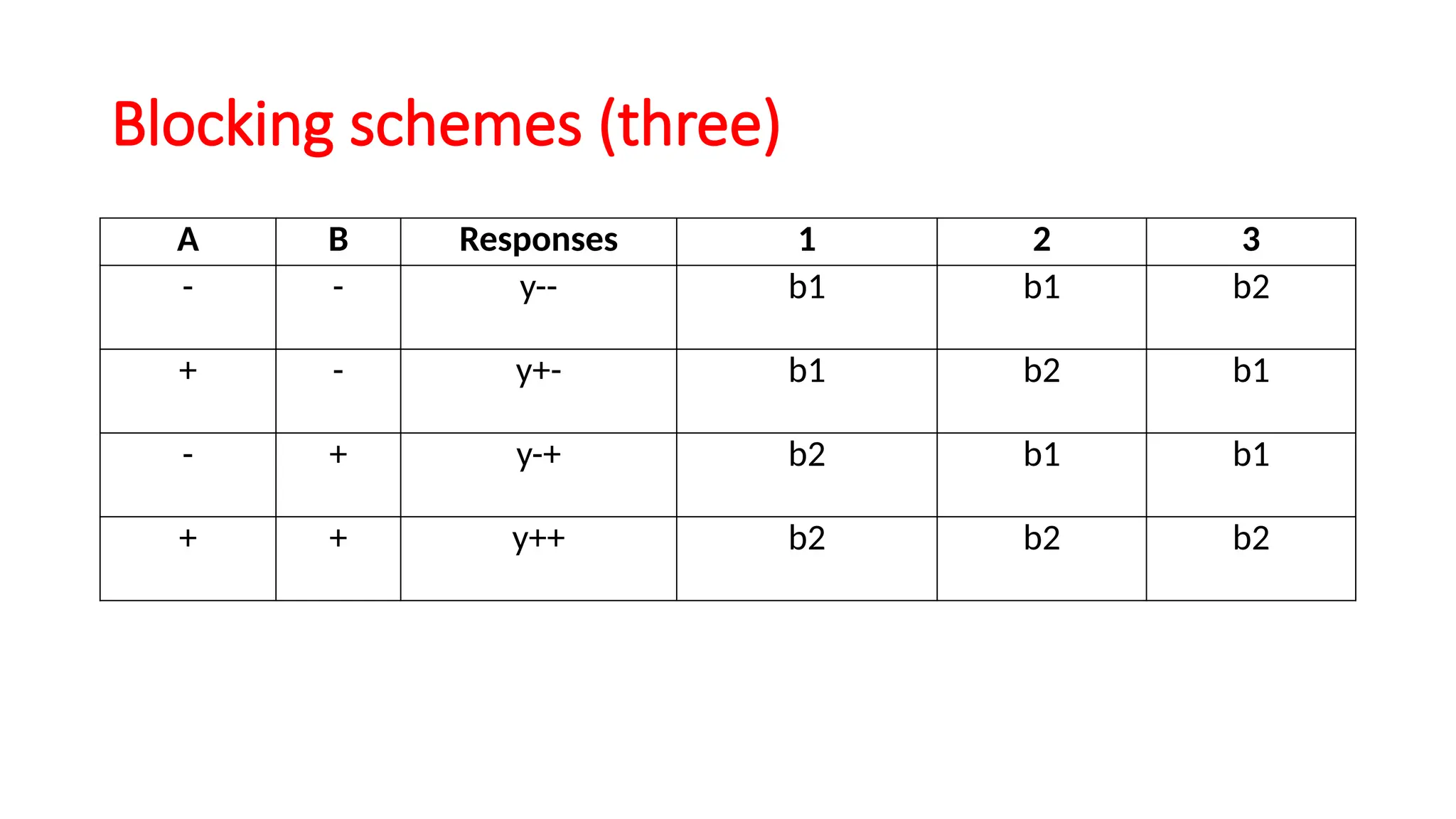











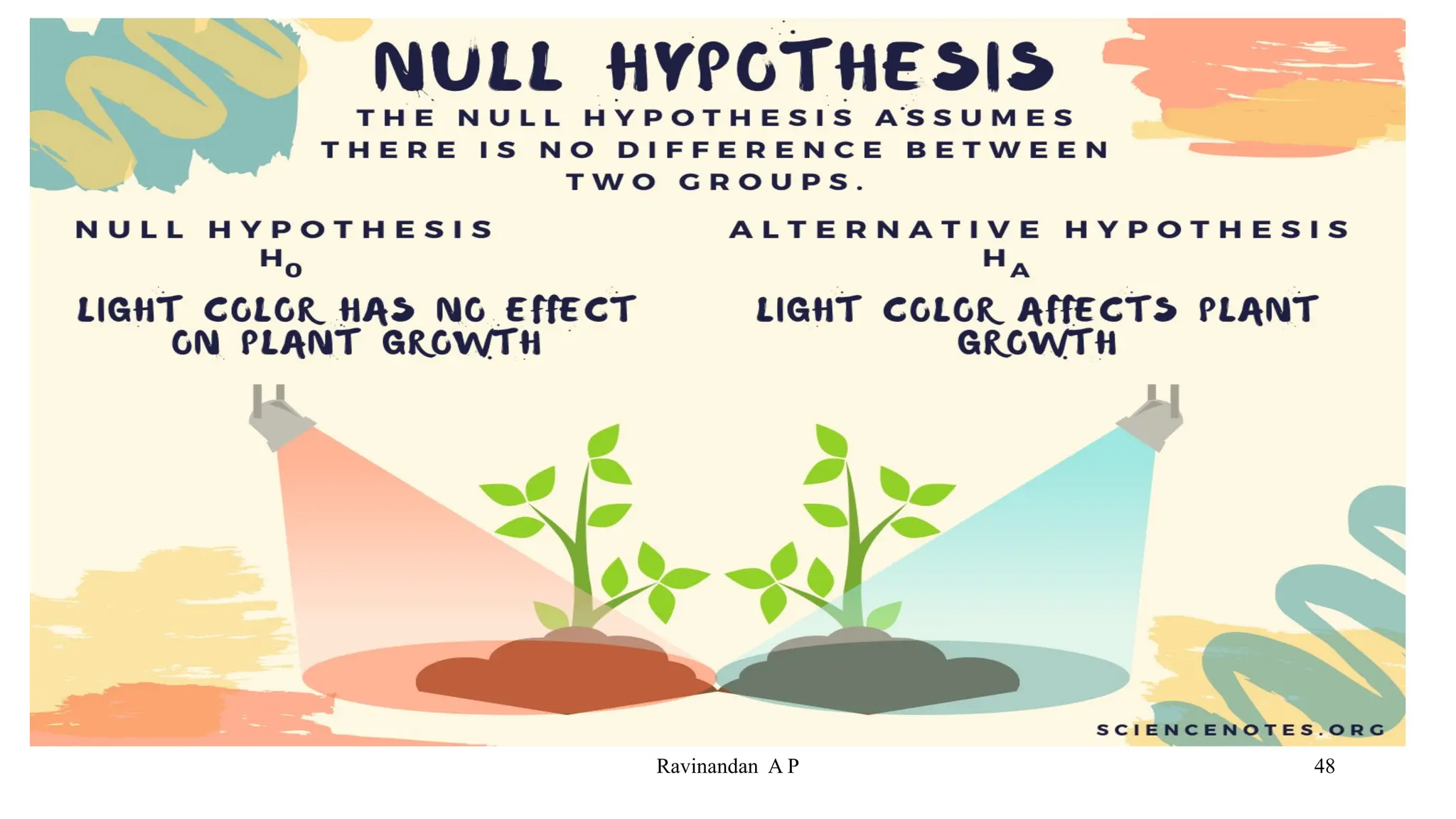
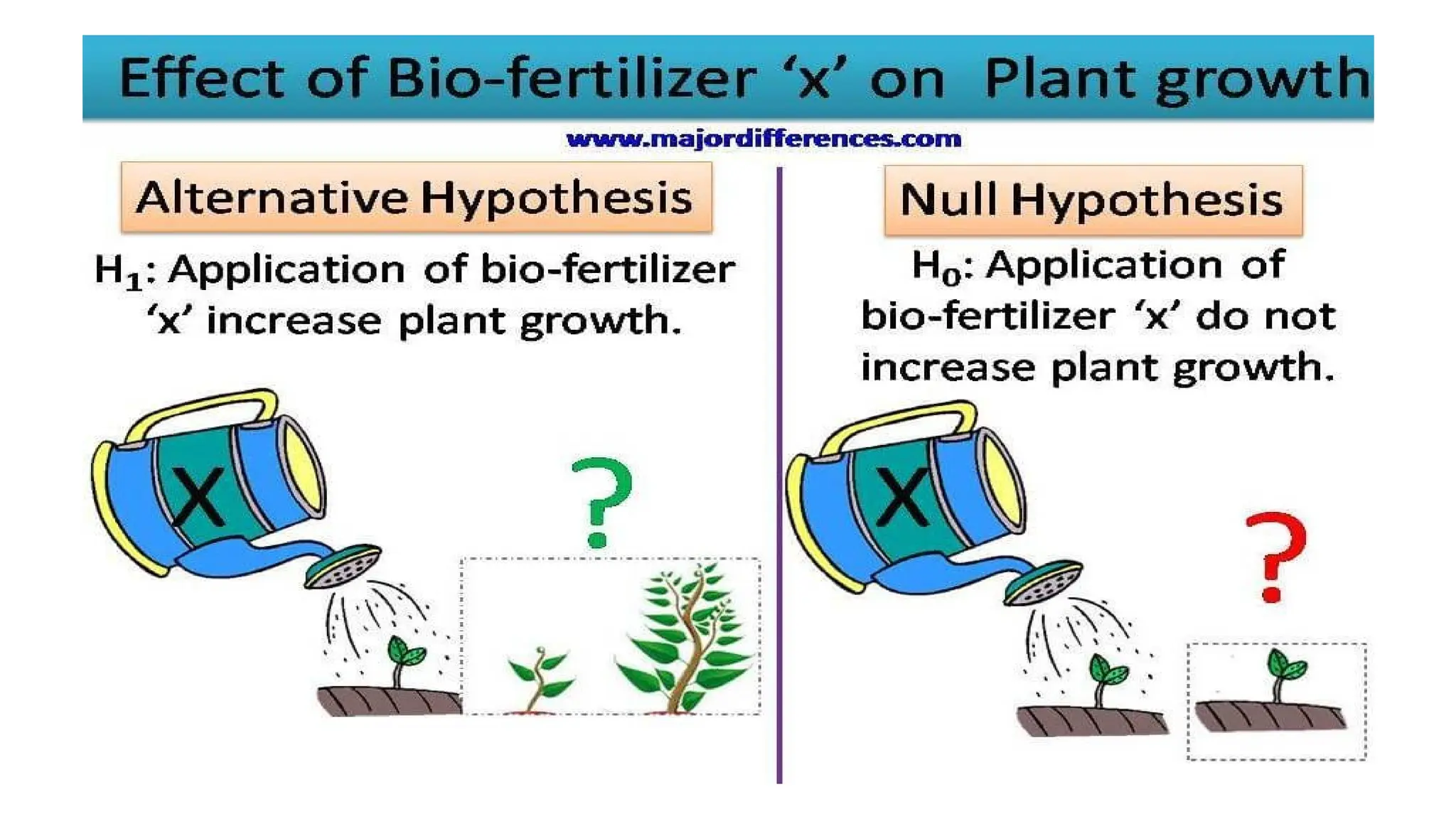










































































This document provides an overview of a biostatistics course, outlining objectives such as understanding statistical terminologies, hypothesis testing, and statistical software. It discusses factorial designs, blocking, and confounding techniques essential for analyzing experimental data efficiently. Additionally, it covers regression modeling, hypothesis testing procedures, and the importance of controlling extraneous variables in research.























































































