Download as PDF, PPTX





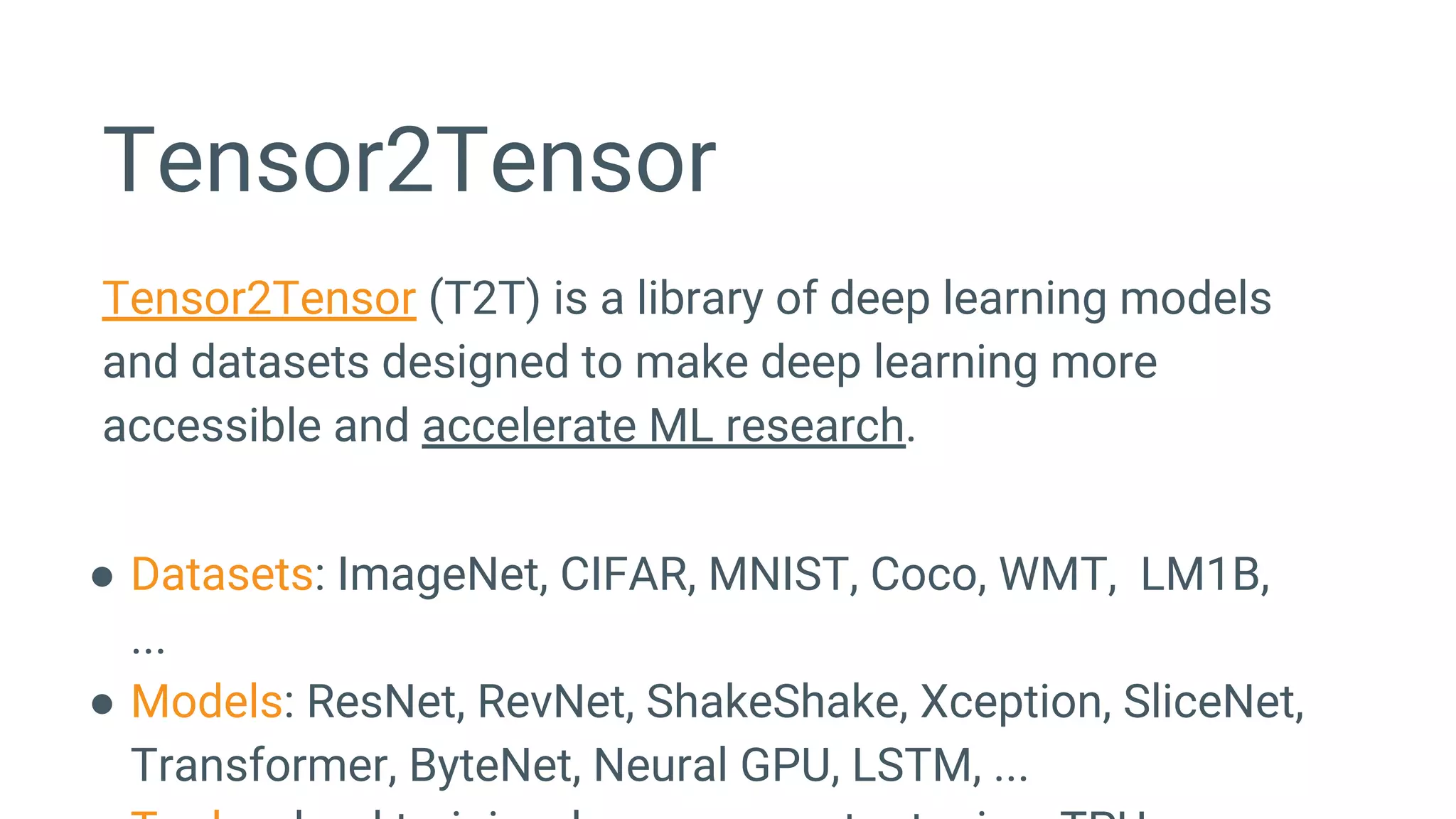
![Can deep learning solve these tasks?
● Inputs and outputs have variable size, how can neural networks handle it?
● Recurrent Neural Networks can do it, but how do we train them?
● Long Short-Term Memory [Hochreiter et al., 1997], but how to compose it?
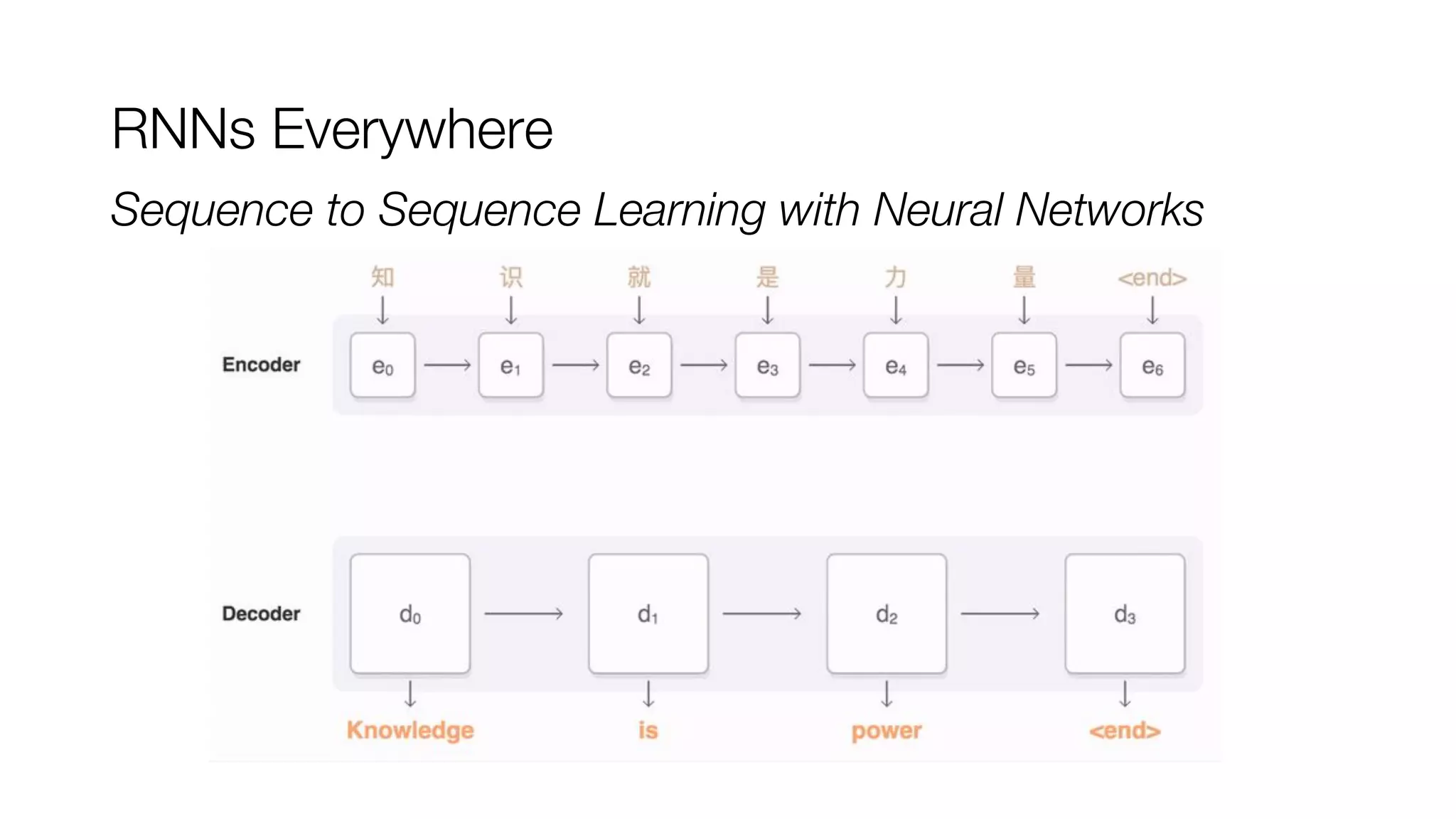
● Encoder-Decoder (sequence-to-sequence) architectures
[Sutskever et al., 2014; Bahdanau et al., 2014; Cho et al., 2014]](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-10-2048.jpg)
![Parsing with sequence-to-sequence LSTMs
(1) Represent the tree as a sequence.
(2) Generate data and train a sequence-to-sequence LSTM model.
(3) Results: 92.8 F1 score vs 92.4 previous best [Vinyals & Kaiser et al., 2014]](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-11-2048.jpg)
![Language modeling with LSTMs
Language model performance is measured in perplexity (lower is better).
● Kneser-Ney 5-gram: 67.6 [Chelba et al., 2013]
● RNN-1024 + 9-gram: 51.3 [Chelba et al., 2013]
● LSTM-512-512: 54.1 [Józefowicz et al., 2016]
● 2-layer LSTM-8192-1024: 30.6 [Józefowicz et al., 2016]
● 2-l.-LSTM-4096-1024+MoE: 28.0 [Shazeer & Mirhoseini et al., 2016]
Model size seems to be the decisive factor.](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-12-2048.jpg)
![Language modeling with LSTMs: Examples
Raw (not hand-selected) sampled sentences: [Józefowicz et al., 2016]
About 800 people gathered at Hever Castle on Long Beach from noon to 2pm ,
three to four times that of the funeral cortege .
It is now known that coffee and cacao products can do no harm on the body .
Yuri Zhirkov was in attendance at the Stamford Bridge at the start of the second
half but neither Drogba nor Malouda was able to push on through the Barcelona
defence .](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-13-2048.jpg)
![Sentence compression with LSTMs
Example:
Input: State Sen. Stewart Greenleaf discusses his proposed human
trafficking bill at Calvery Baptist Church in Willow Grove Thursday night.
Output: Stewart Greenleaf discusses his human trafficking bill.
Results: readability informativeness
MIRA (previous best): 4.31 3.55
LSTM [Filippova et al., 2015]: 4.51 3.78](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-14-2048.jpg)
![Translation with LSTMs
Translation performance is measured in BLEU scores (higher is better, EnDe):
● Phrase-Based MT: 20.7 [Durrani et al., 2014]
● Early LSTM model: 19.4 [Sébastien et al., 2015]
● DeepAtt (large LSTM): 20.6 [Zhou et al., 2016]
● GNMT (large LSTM): 24.9 [Wu et al., 2016]
● GNMT+MoE: 26.0 [Shazeer & Mirhoseini et al., 2016]
Again, model size and tuning seem to be the decisive factor.](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-15-2048.jpg)

![Translation with LSTMs: How good is it?
PBMT GNMT Human Relative improvement
English → Spanish 4.885 5.428 5.504 87%
English → French 4.932 5.295 5.496 64%
English → Chinese 4.035 4.594 4.987 58%
Spanish → English 4.872 5.187 5.372 63%
French → English 5.046 5.343 5.404 83%
Chinese → English 3.694 4.263 4.636 60%
Google Translate production data, median score by human evaluation on the scale 0-6. [Wu et al., ‘16]](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-17-2048.jpg)

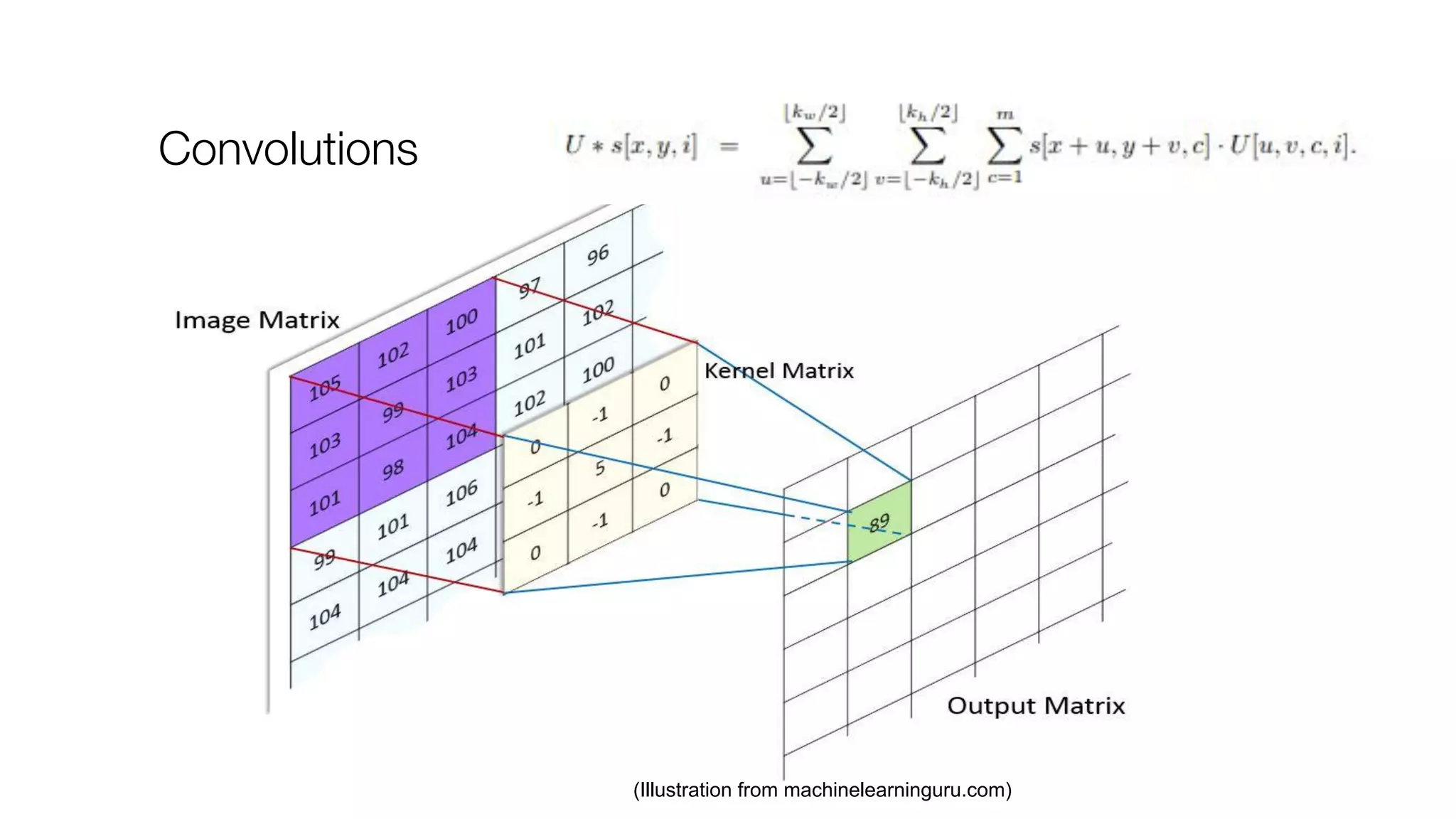
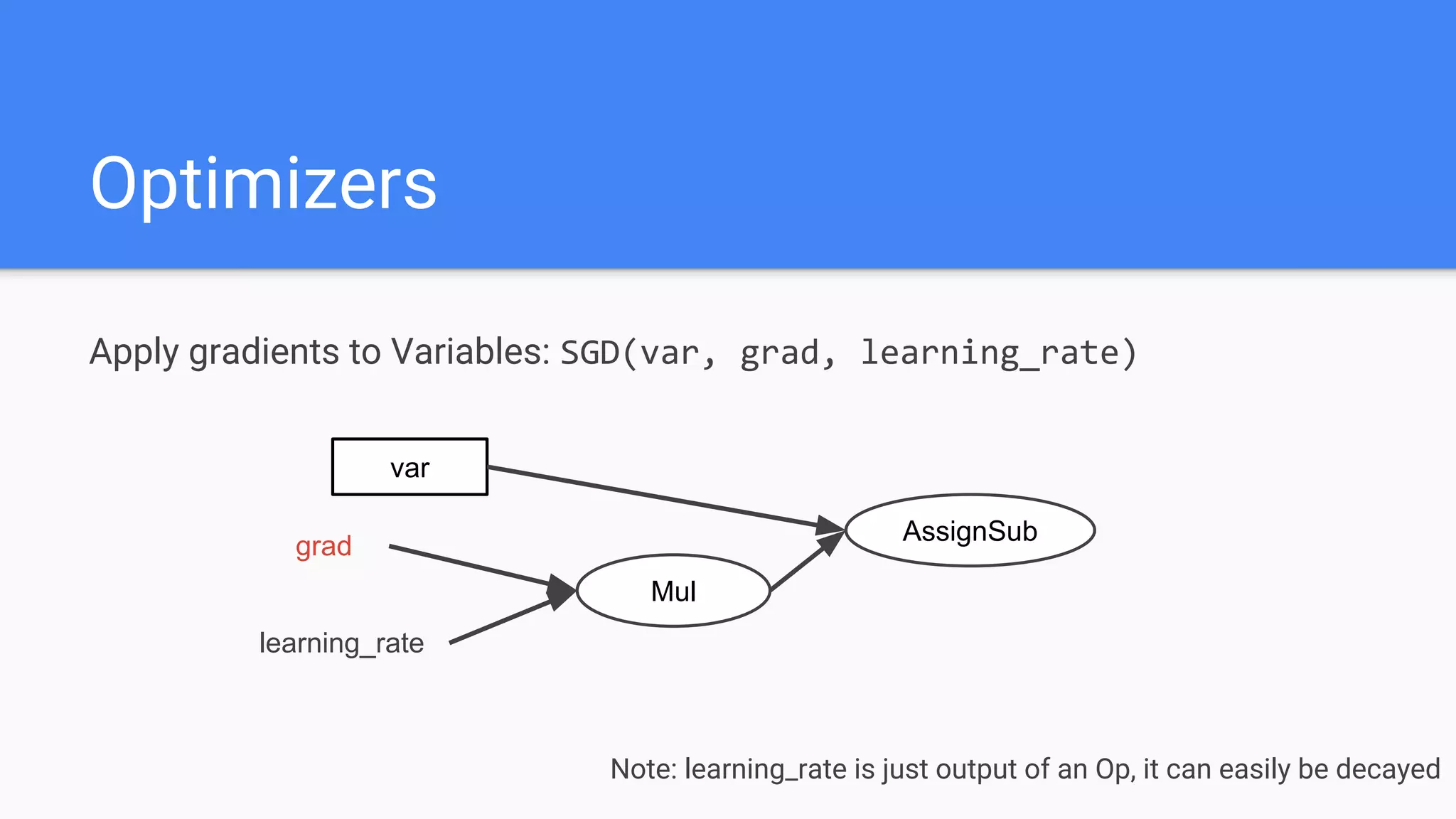
![Modern View
h = f(Wx + B) [or h = conv(W, x)]
o = f(W’h + B’)
l = -logp(o = true)
P -= lr * dl/dP where P =
{W,W’,B,B’}](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-23-2048.jpg)



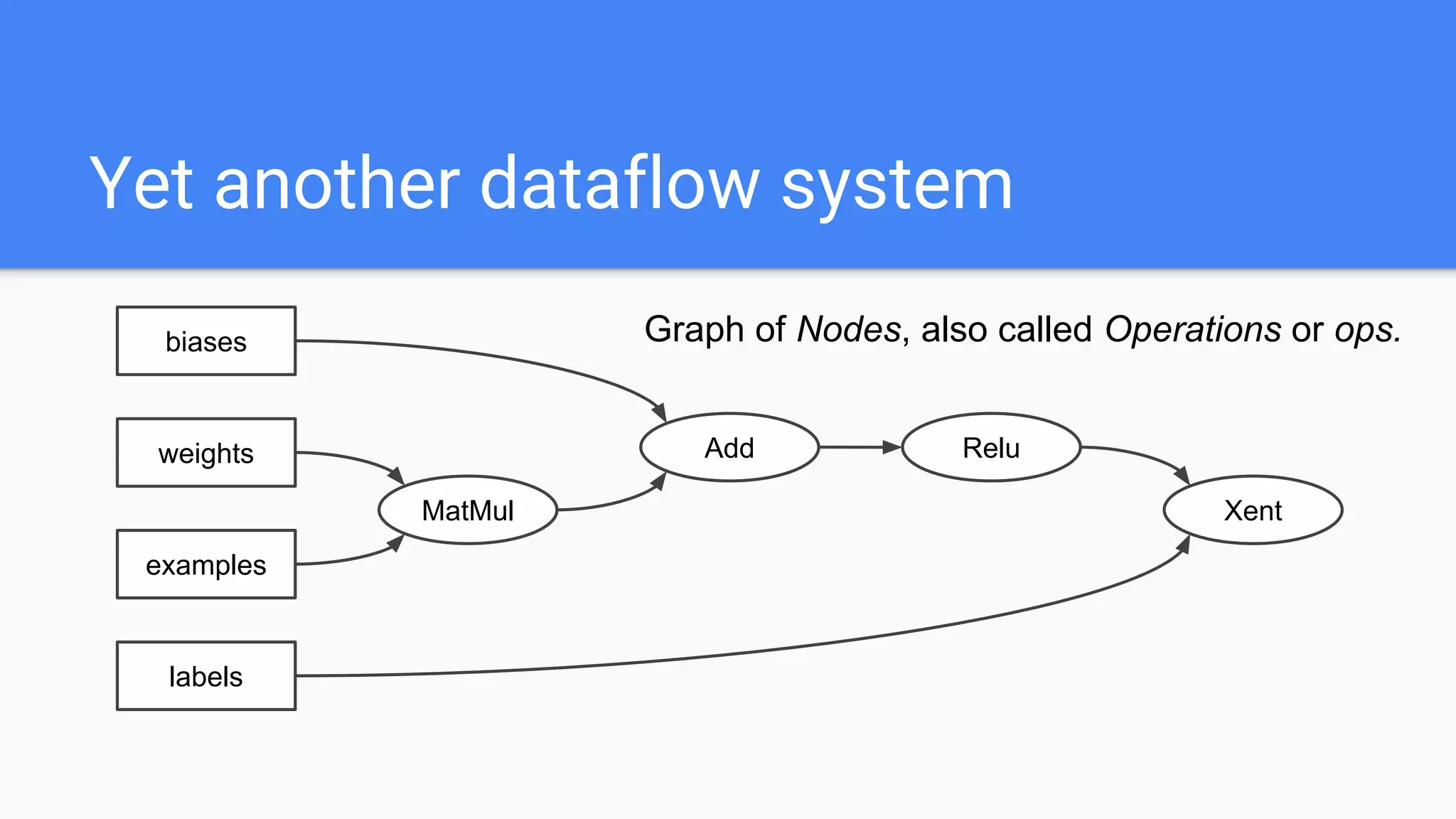
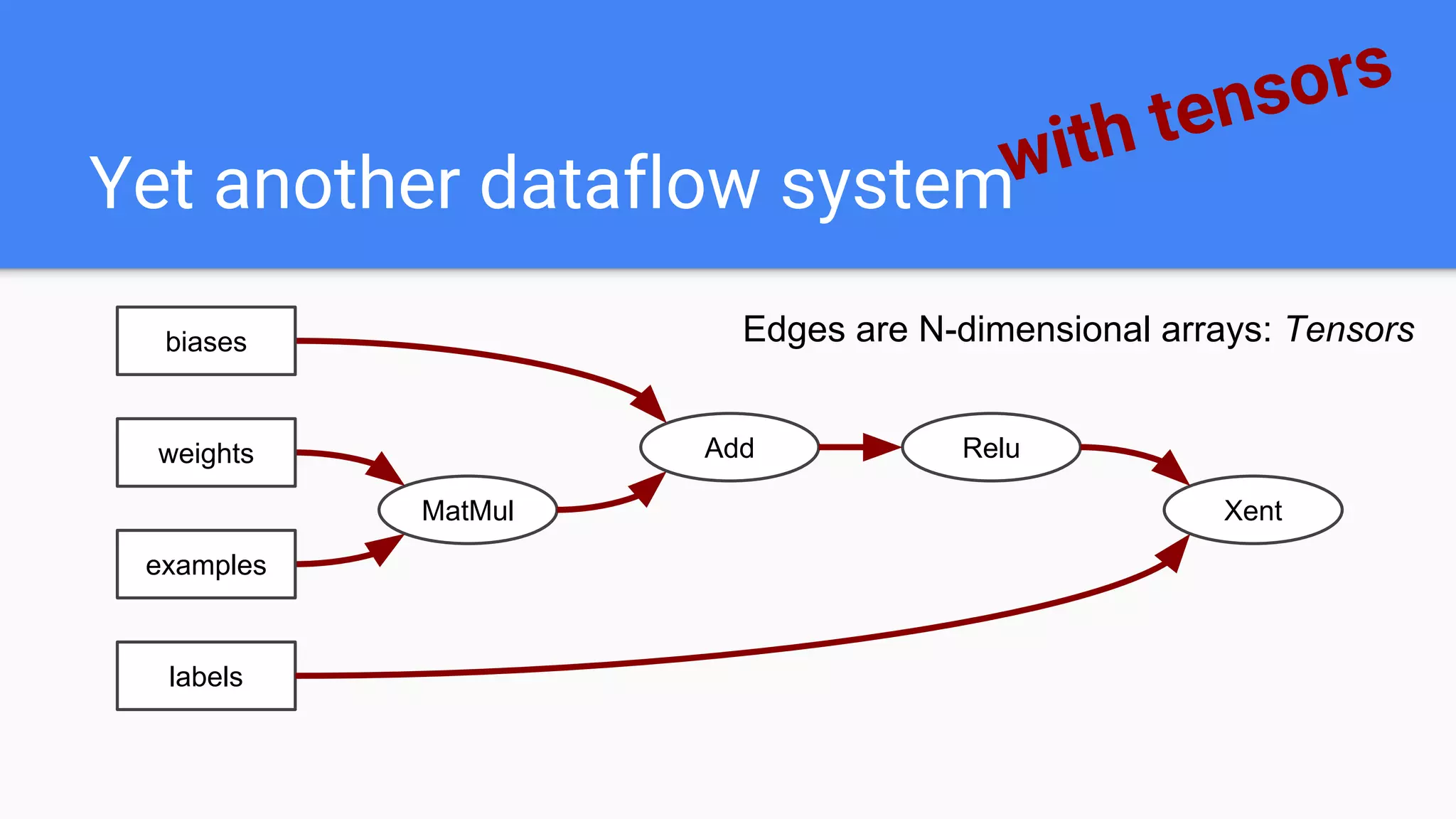
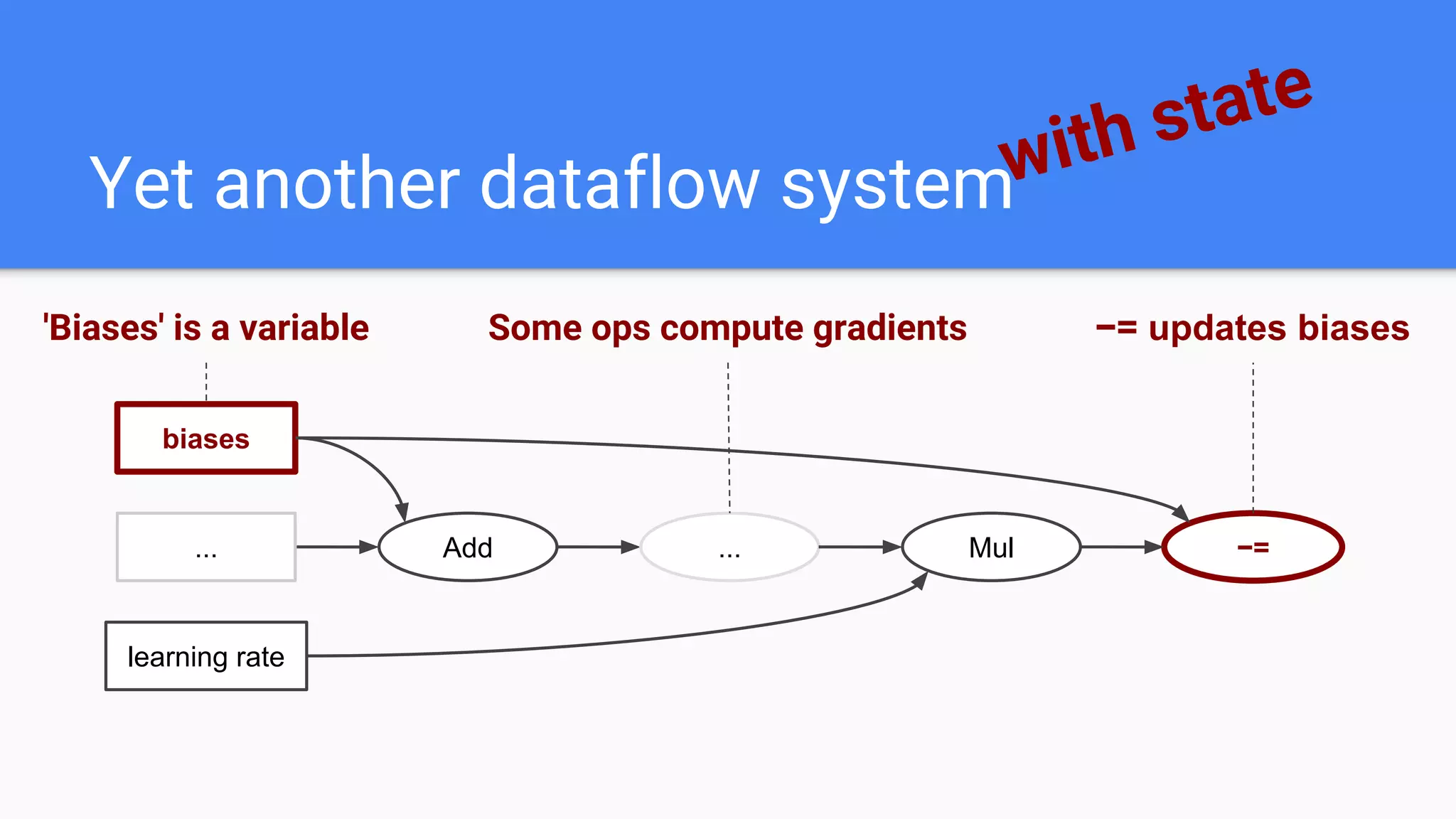
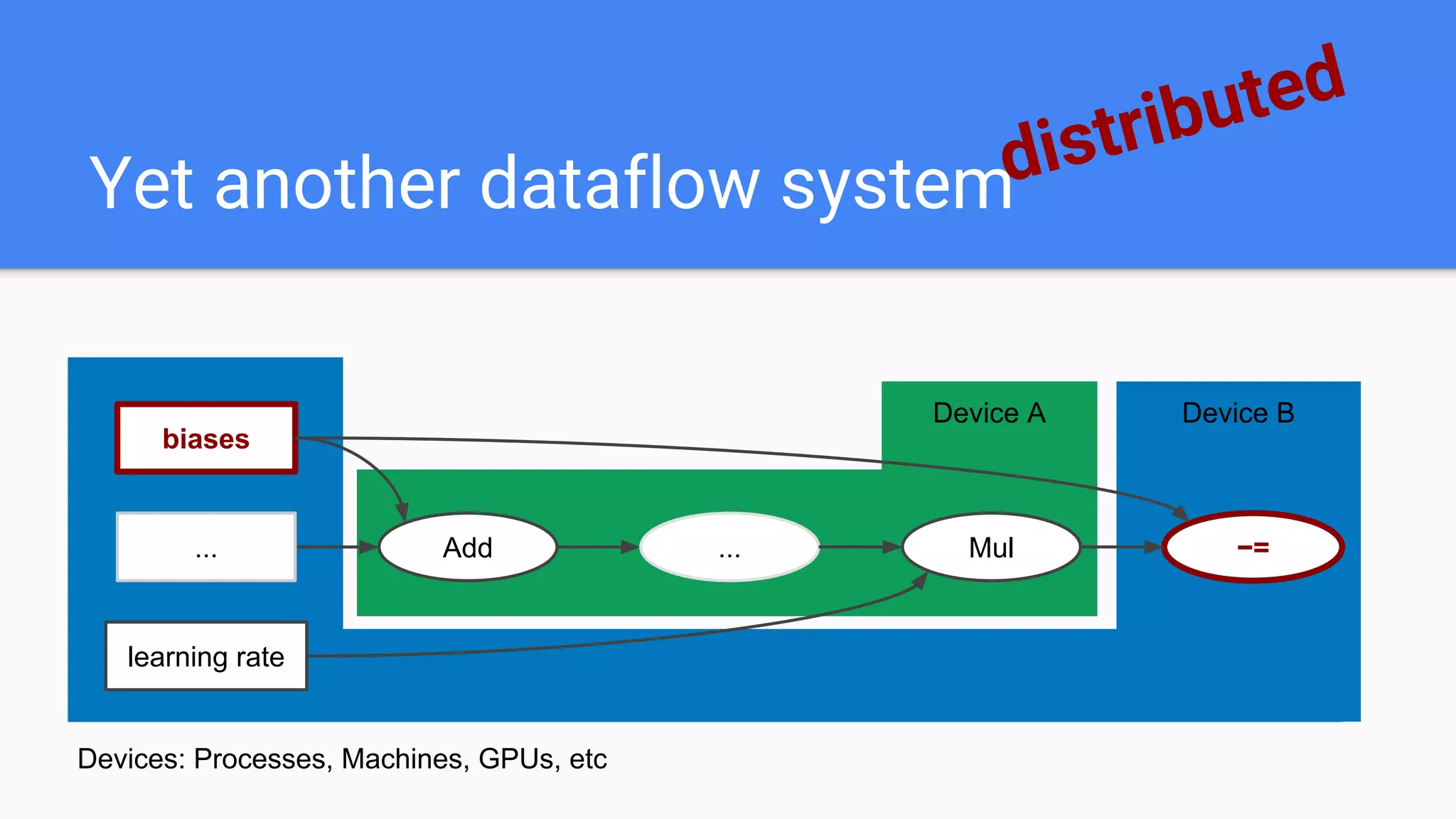





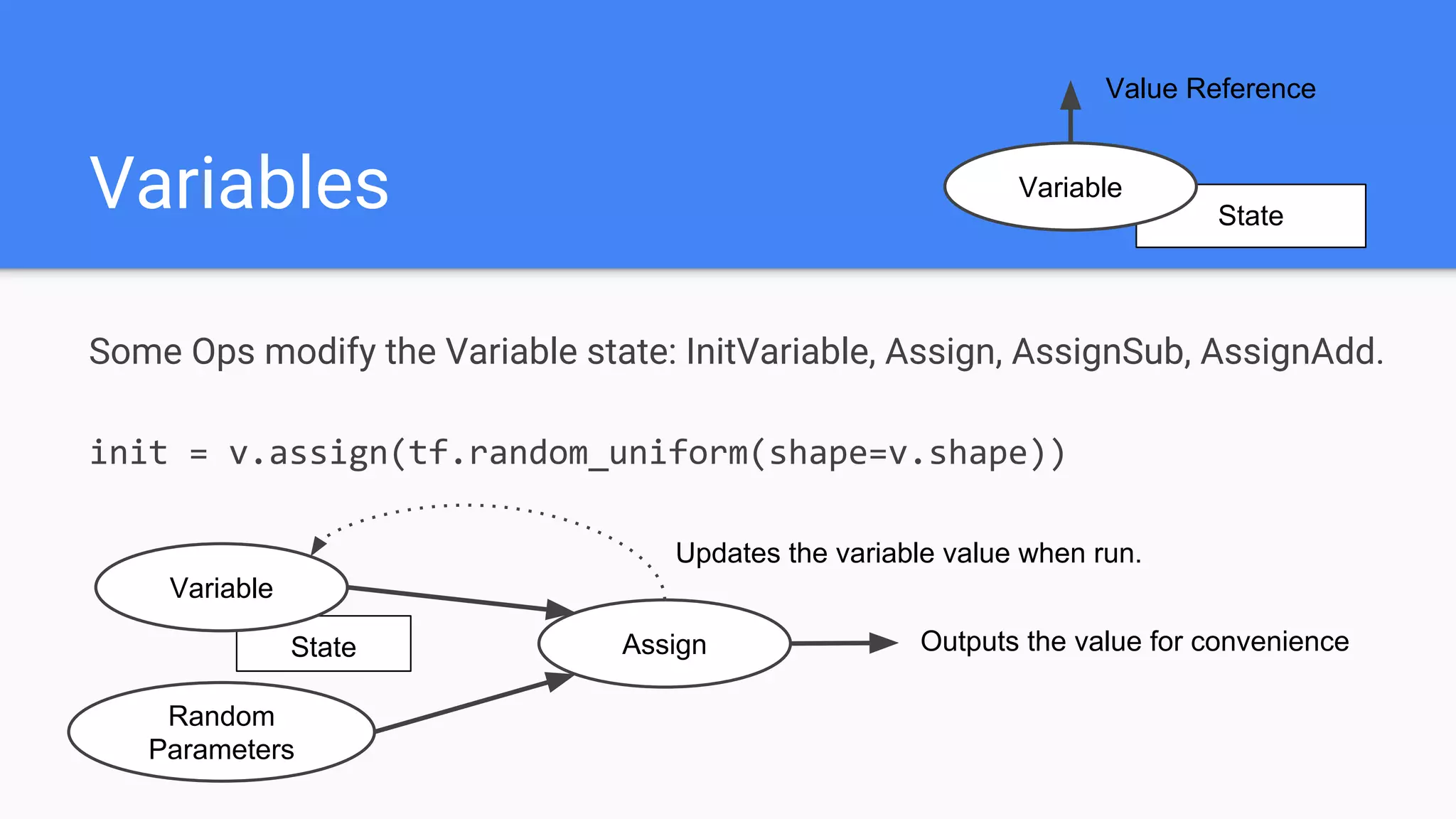
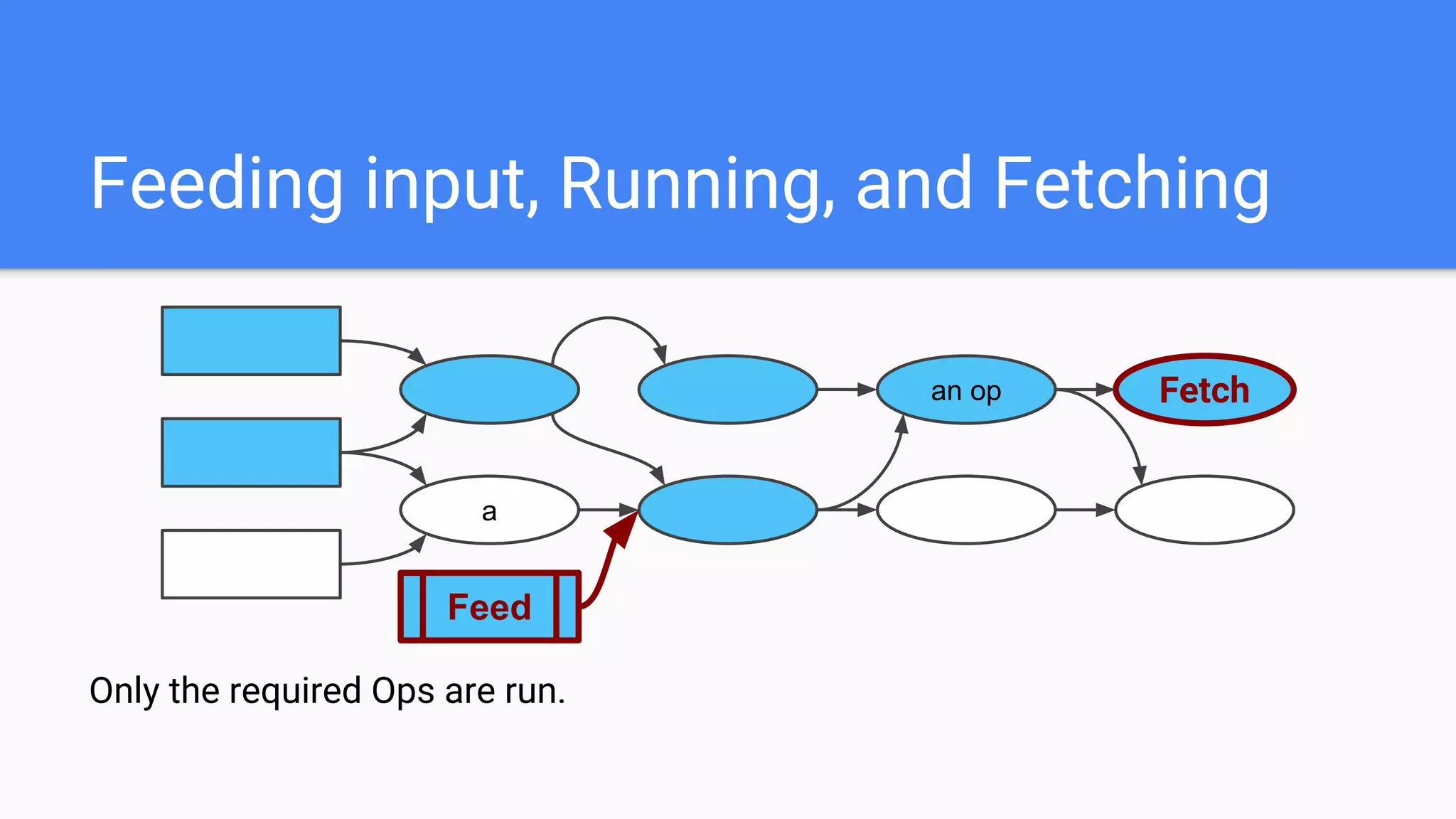
![Op that holds state that persists across calls to Run()
v = tf.get_variable(‘v’, [4, 3]) # 4x3 matrix, float by default
Variable State
Variable
Value Reference](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-36-2048.jpg)



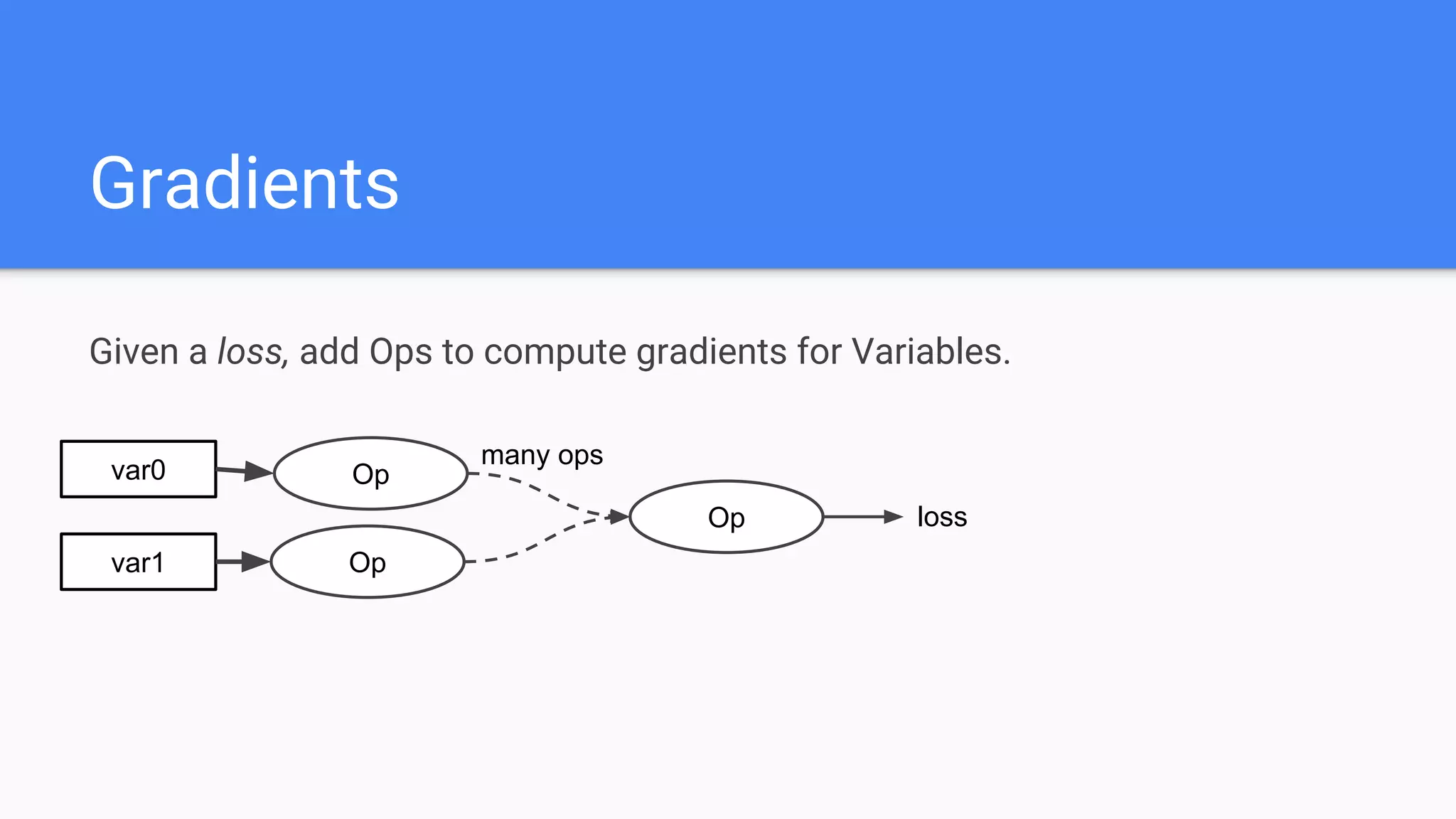
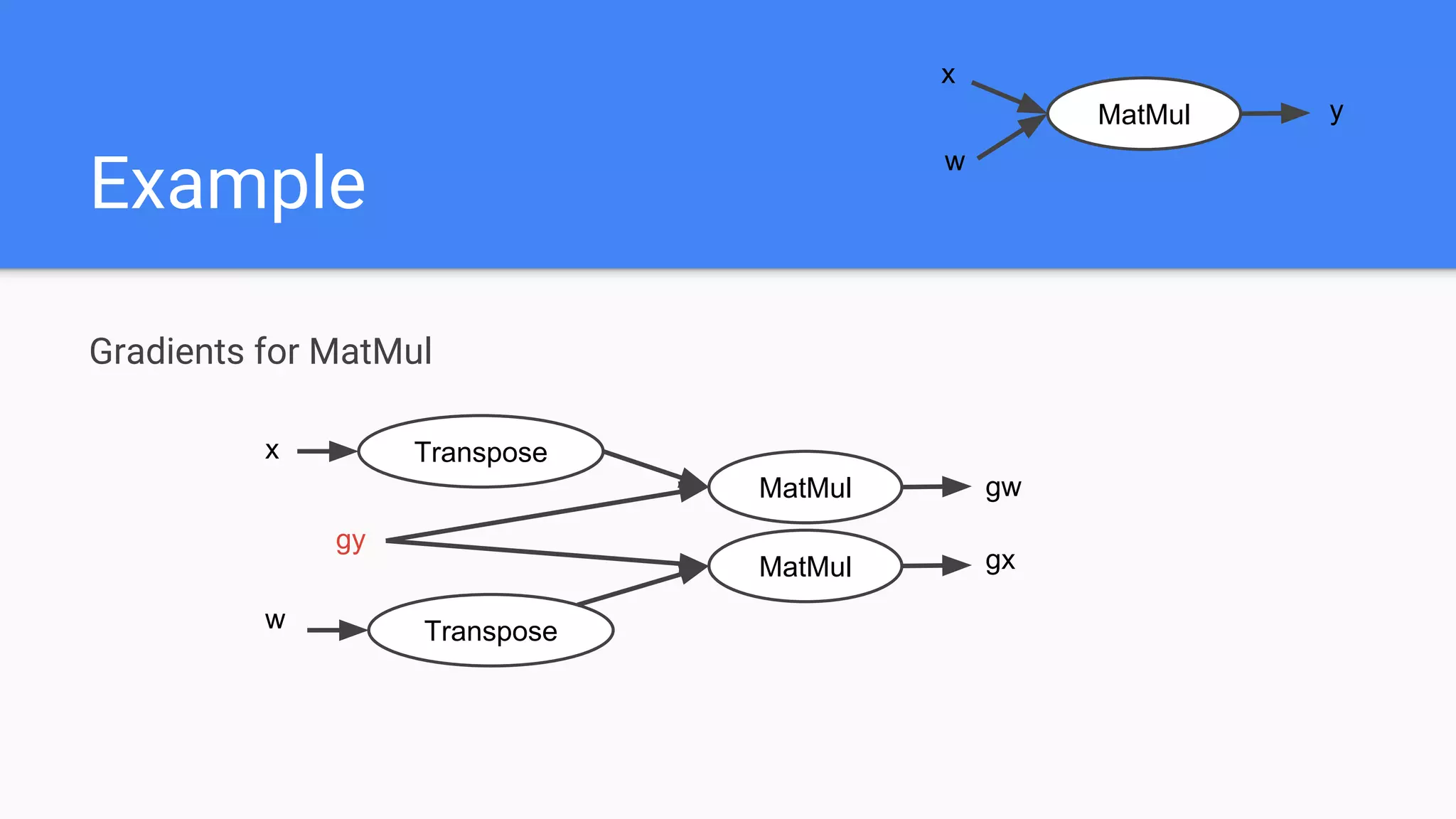
![Gradients
tf.gradients(loss, [var0, var1]) # Generate gradients
var1
var0 Op
Op
Op
loss
many ops
Op
Op
many opsGradients for var0
Gradients for var1 Op](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-42-2048.jpg)





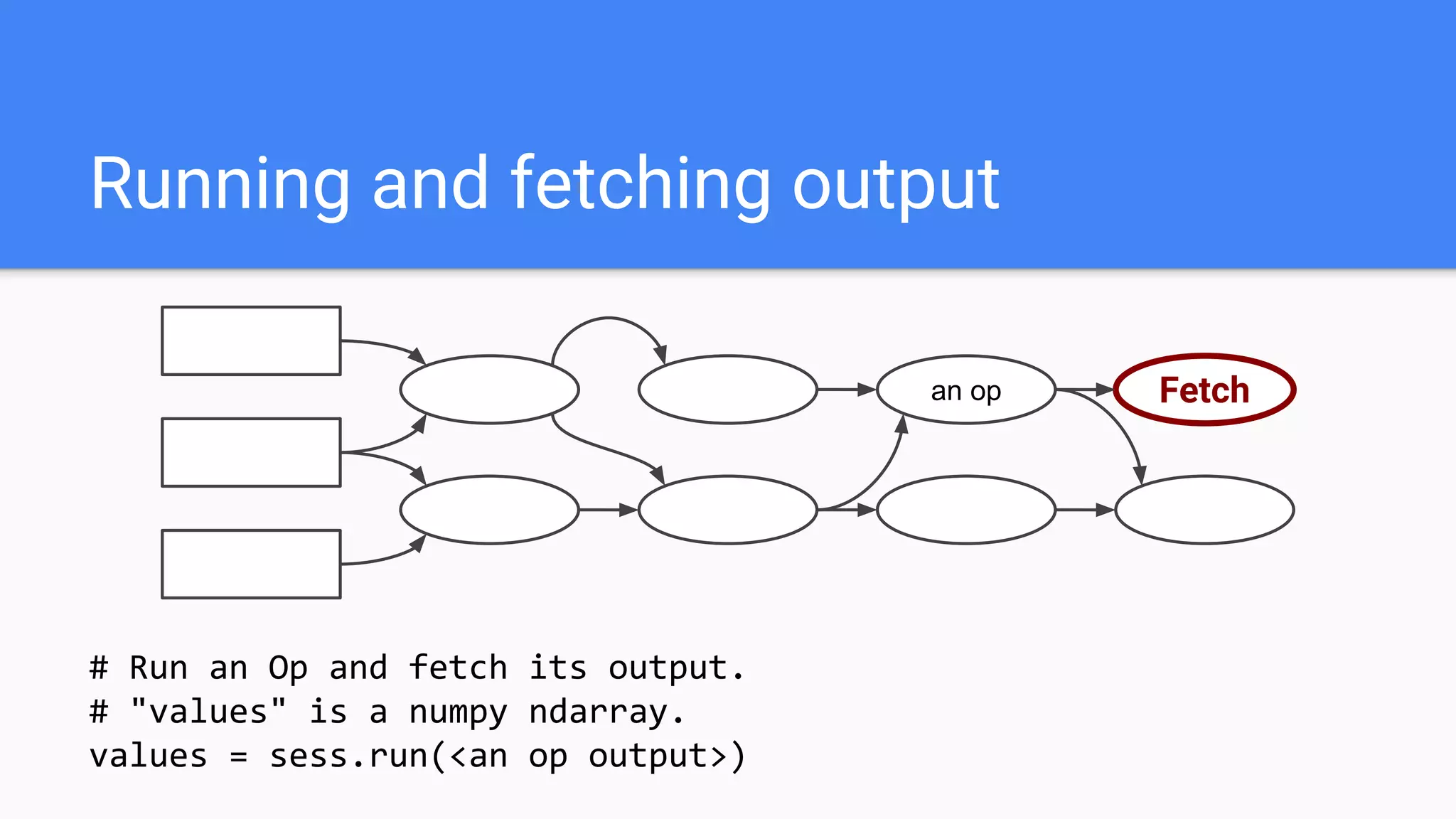
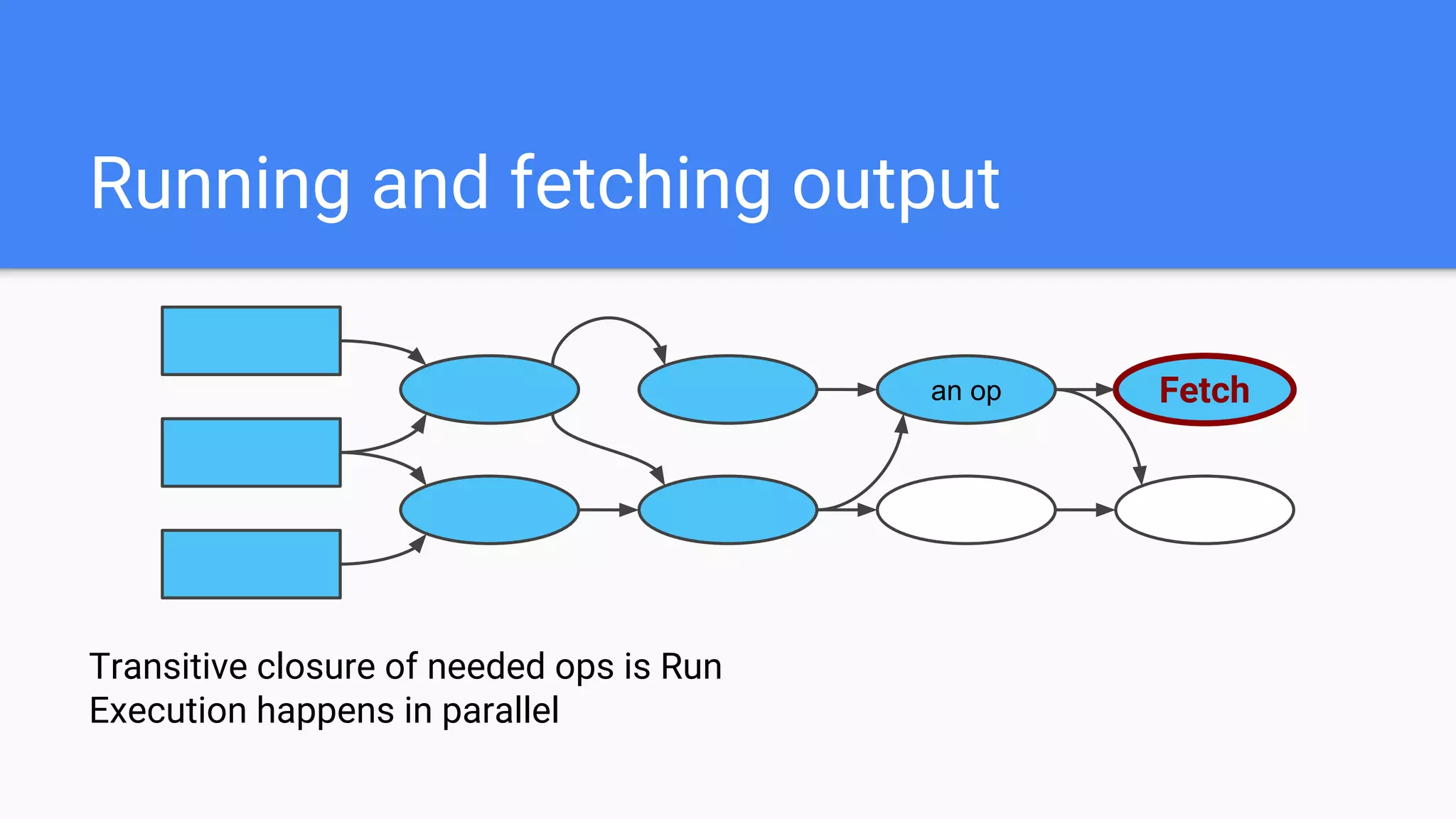
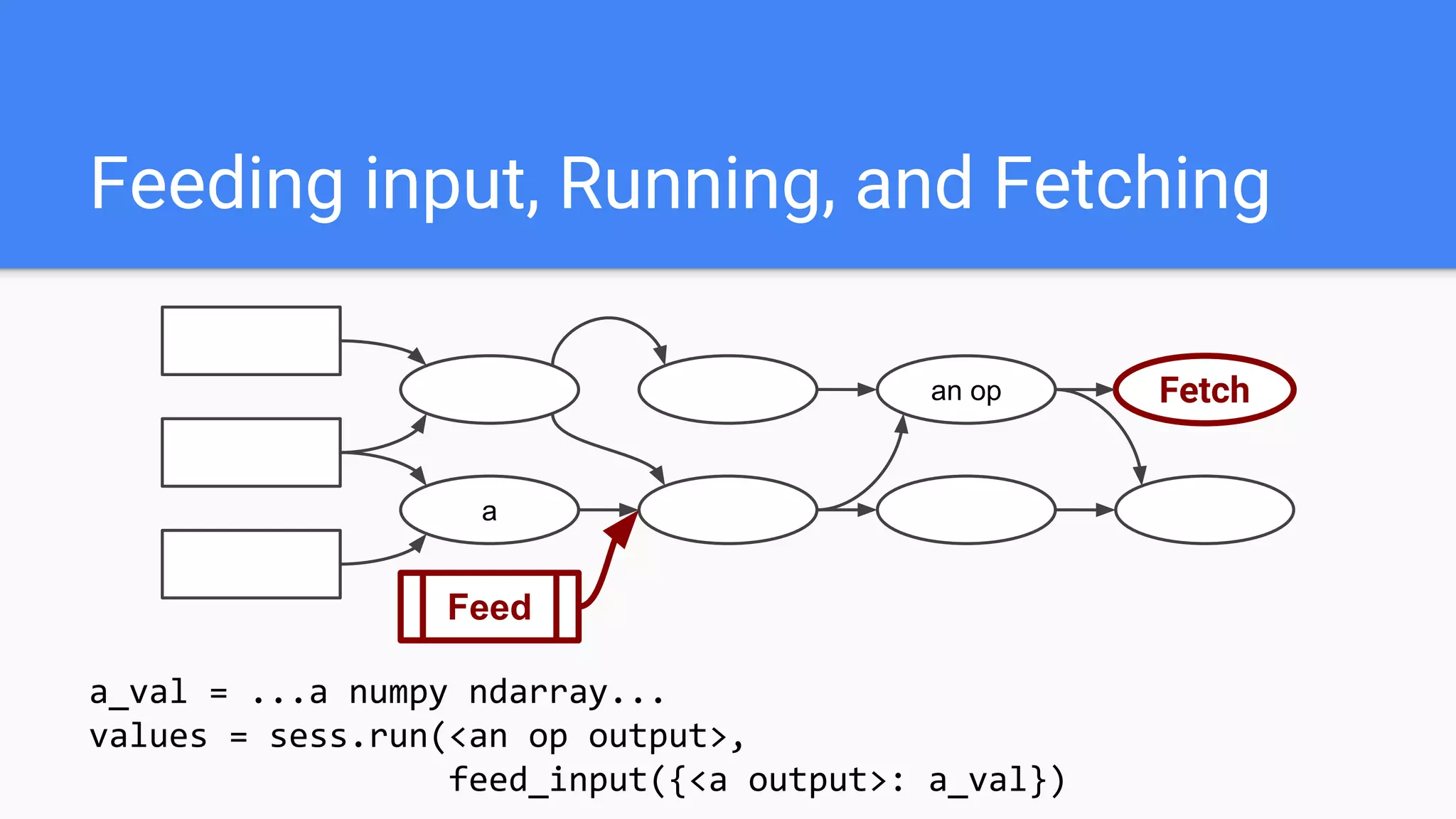
![Python Program
create graph
create session
sess.run()
Remote Runtime
Session
Master
Worker
CPU
Worker
CPU
GPU
Worker
CPU
GPU
Run([ops])
RunSubGraph()
GetTensor()
CreateGraph()](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-50-2048.jpg)

![Layers are ops that create Variables
def embedding(x, vocab_size, dense_size,
name=None, reuse=None, multiplier=1.0):
"""Embed x of type int64 into dense vectors."""
with tf.variable_scope( # Use scopes like this.
name, default_name="emb", values=[x], reuse=reuse):
embedding_var = tf.get_variable(
"kernel", [vocab_size, dense_size])
return tf.gather(embedding_var, x)](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-56-2048.jpg)
![Models are built from Layers
def bytenet(inputs, targets, hparams):
final_encoder = common_layers.residual_dilated_conv(
inputs, hparams.num_block_repeat, "SAME", "encoder", hparams)
shifted_targets = common_layers.shift_left(targets)
kernel = (hparams.kernel_height, hparams.kernel_width)
decoder_start = common_layers.conv_block(
tf.concat([final_encoder, shifted_targets], axis=3),
hparams.hidden_size, [((1, 1), kernel)], padding="LEFT")
return common_layers.residual_dilated_conv(
decoder_start, hparams.num_block_repeat,
"LEFT", "decoder", hparams)](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-57-2048.jpg)







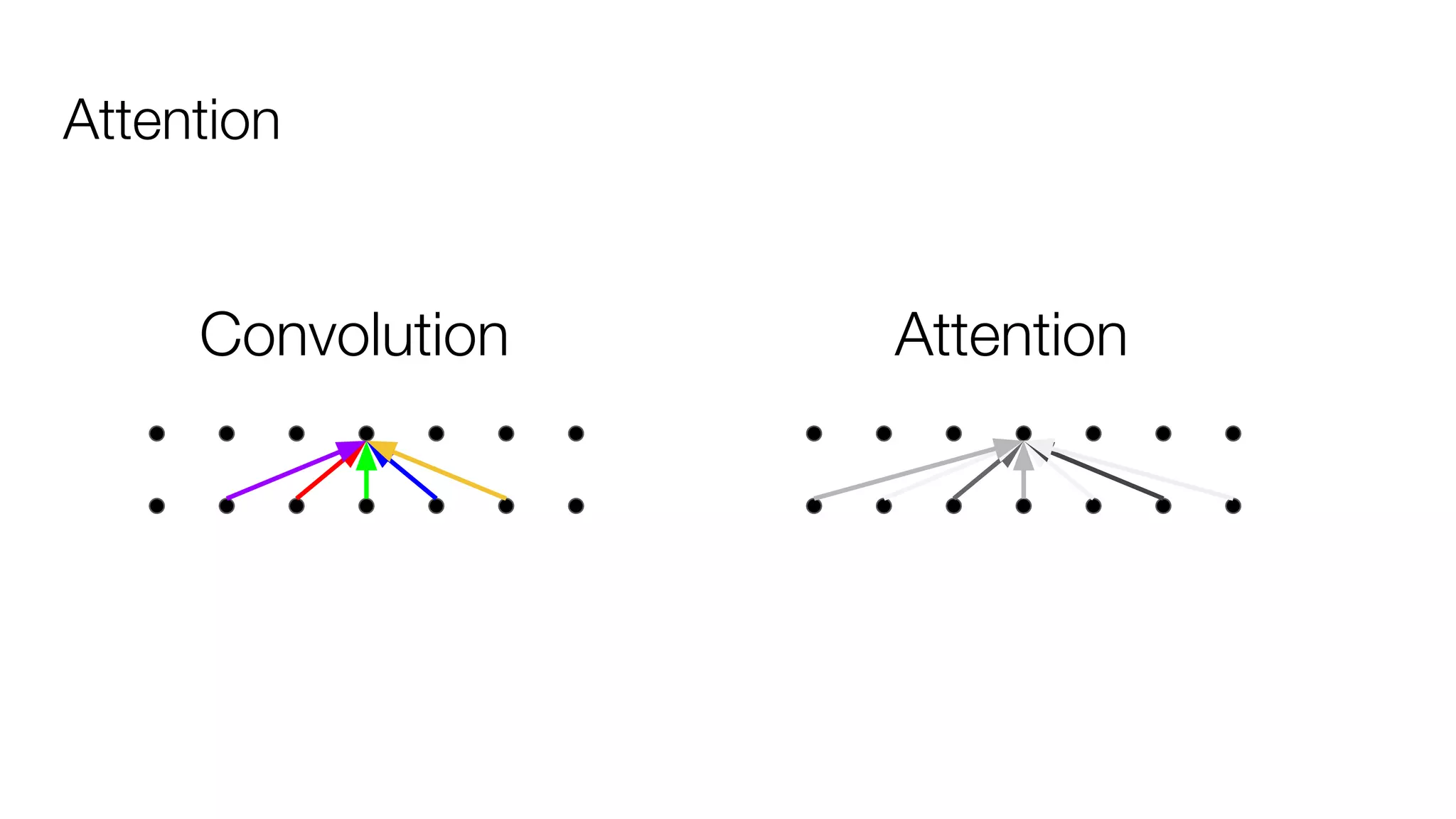
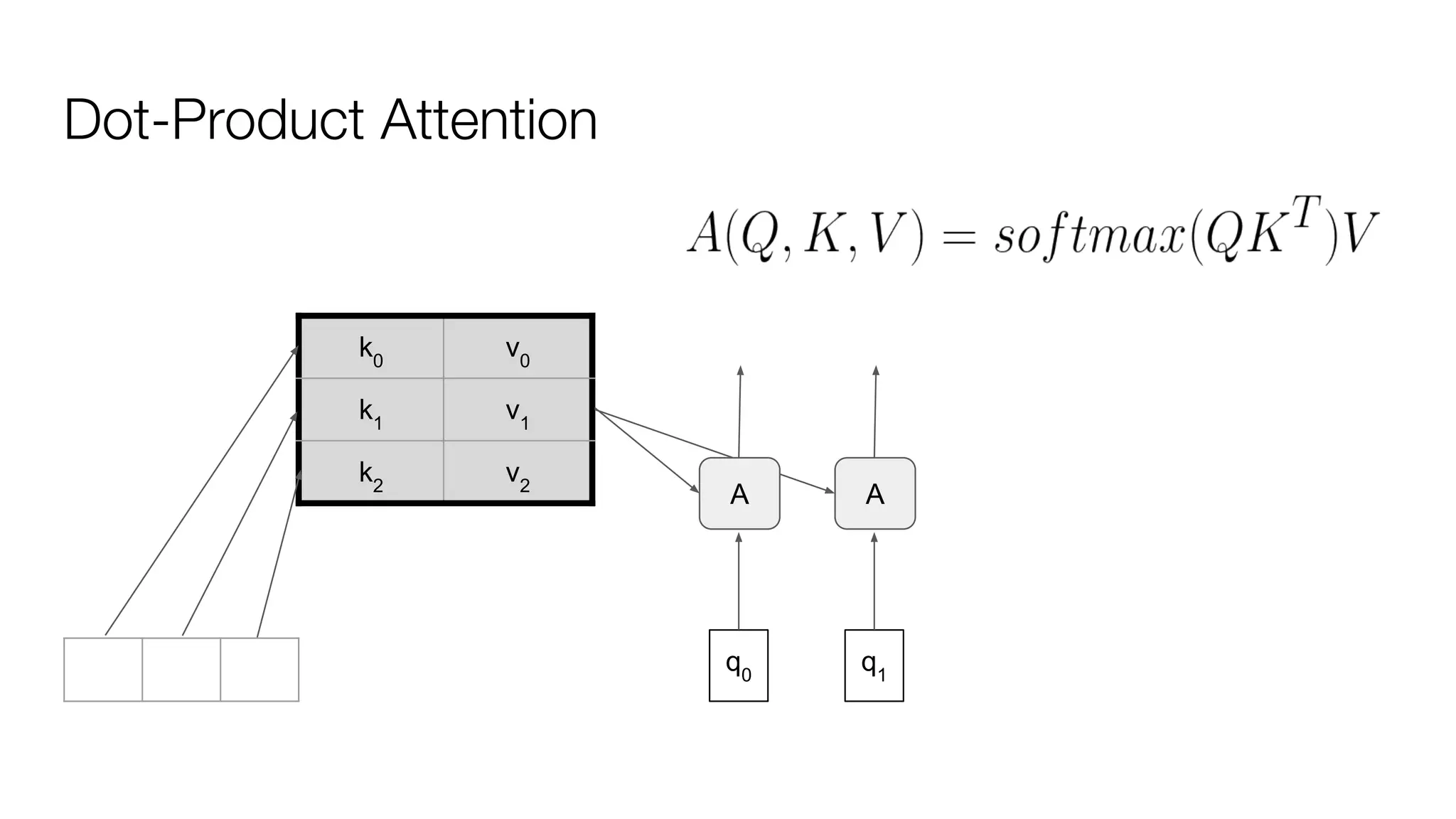
![Dot-Product Attention
def dot_product_attention(q, k, v, bias, dropout_rate=0.0, image_shapes=None, name=None,
make_image_summary=True, save_weights_to=None, dropout_broadcast_dims=None):
with tf.variable_scope(
name, default_name="dot_product_attention", values=[q, k, v]) as scope:
# [batch, num_heads, query_length, memory_length]
logits = tf.matmul(q, k, transpose_b=True)
if bias is not None:
logits += bias
weights = tf.nn.softmax(logits, name="attention_weights")
if save_weights_to is not None:
save_weights_to[scope.name] = weights
# dropping out the attention links for each of the heads
weights = common_layers.dropout_with_broadcast_dims(
weights, 1.0 - dropout_rate, broadcast_dims=dropout_broadcast_dims)
if expert_utils.should_generate_summaries() and make_image_summary:
attention_image_summary(weights, image_shapes)
return tf.matmul(weights, v)](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-70-2048.jpg)
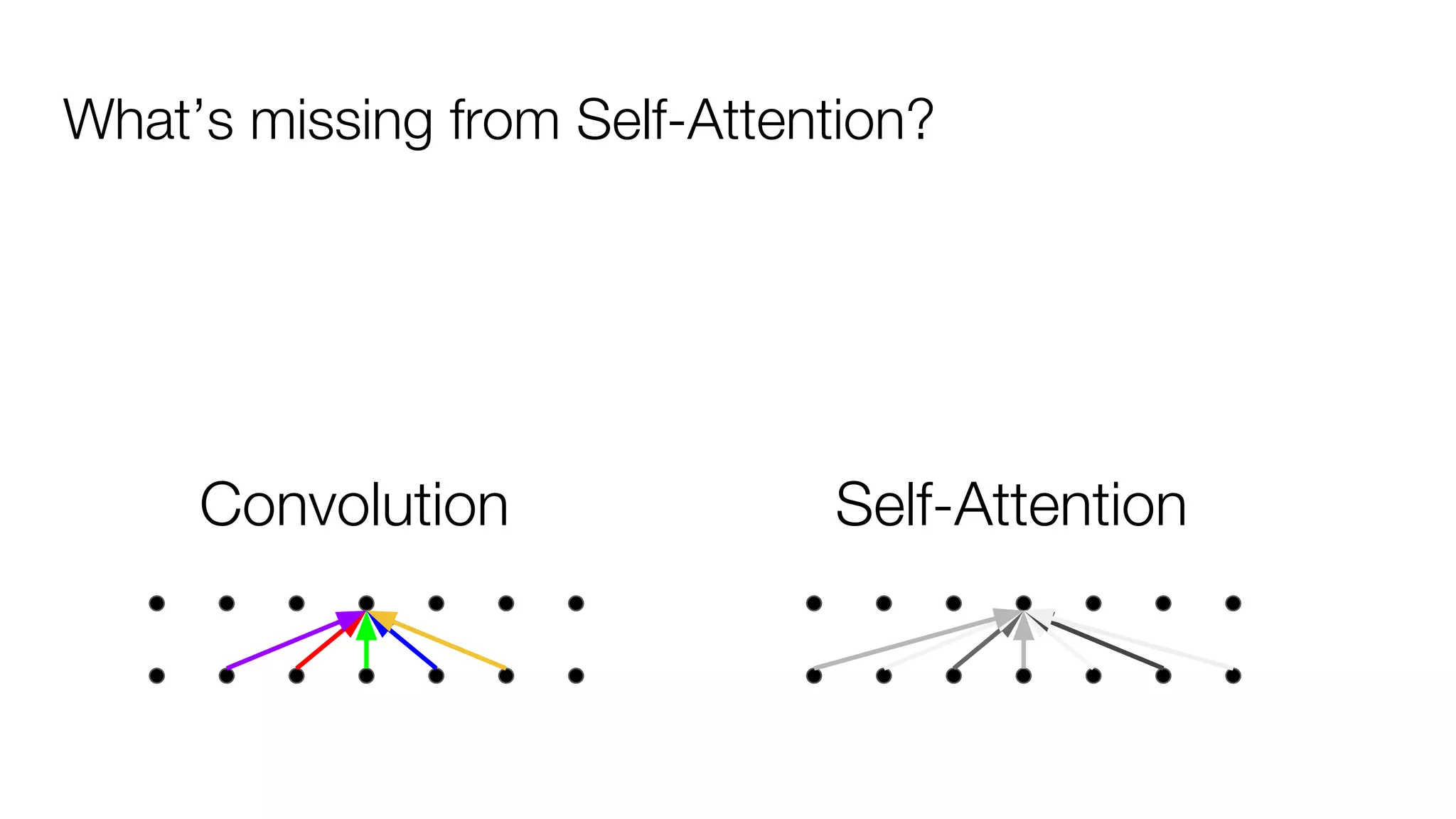
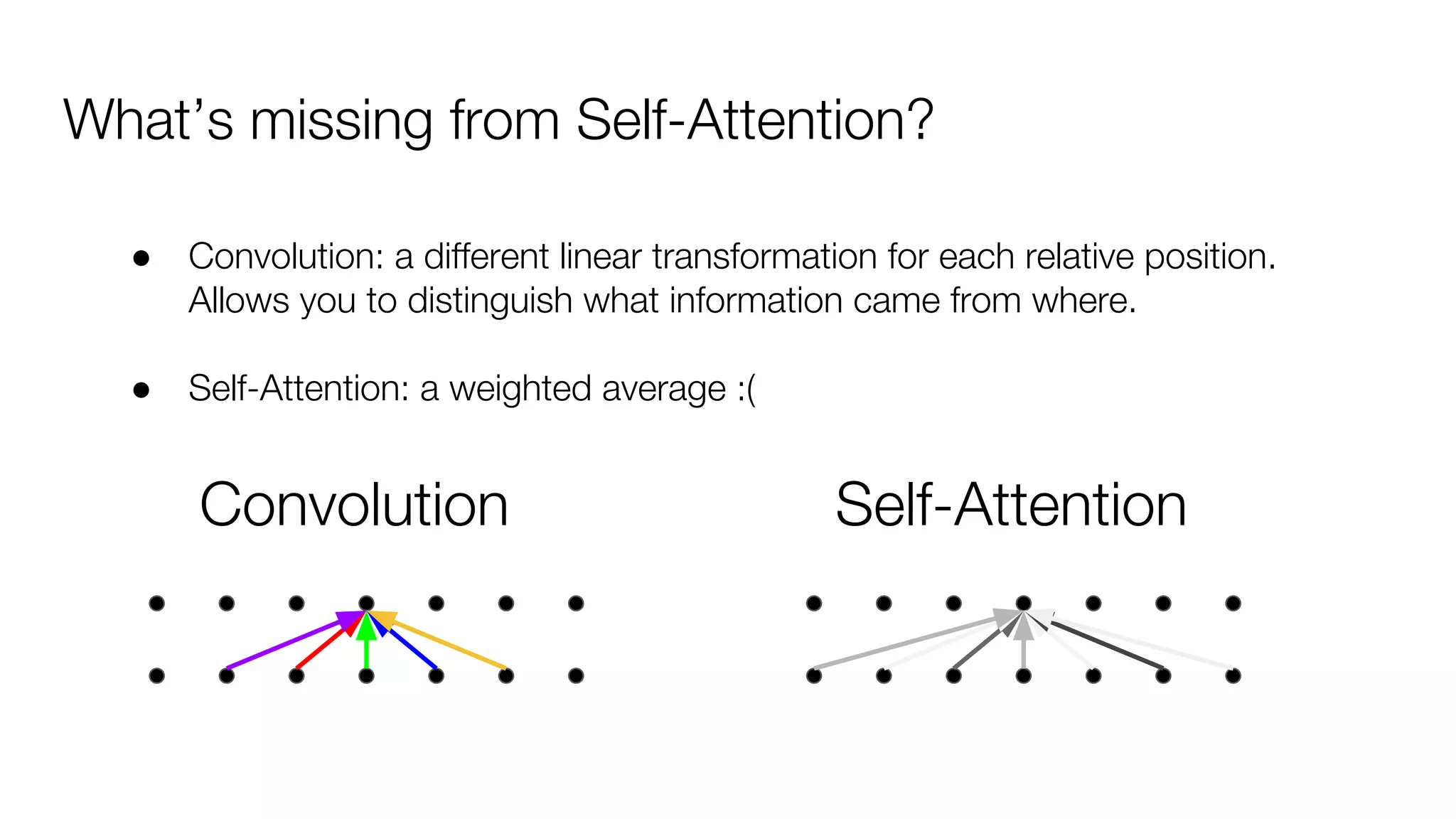
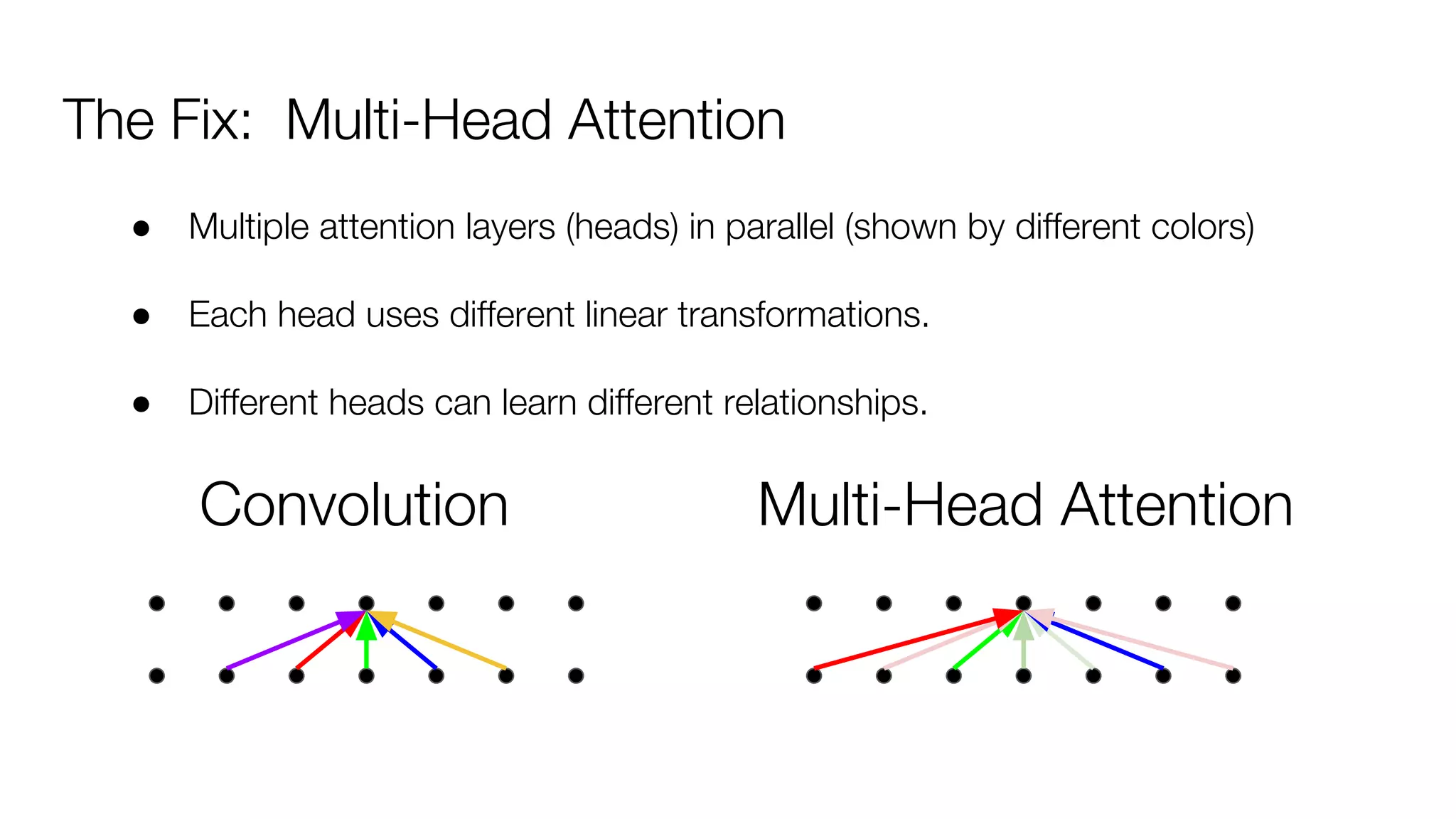
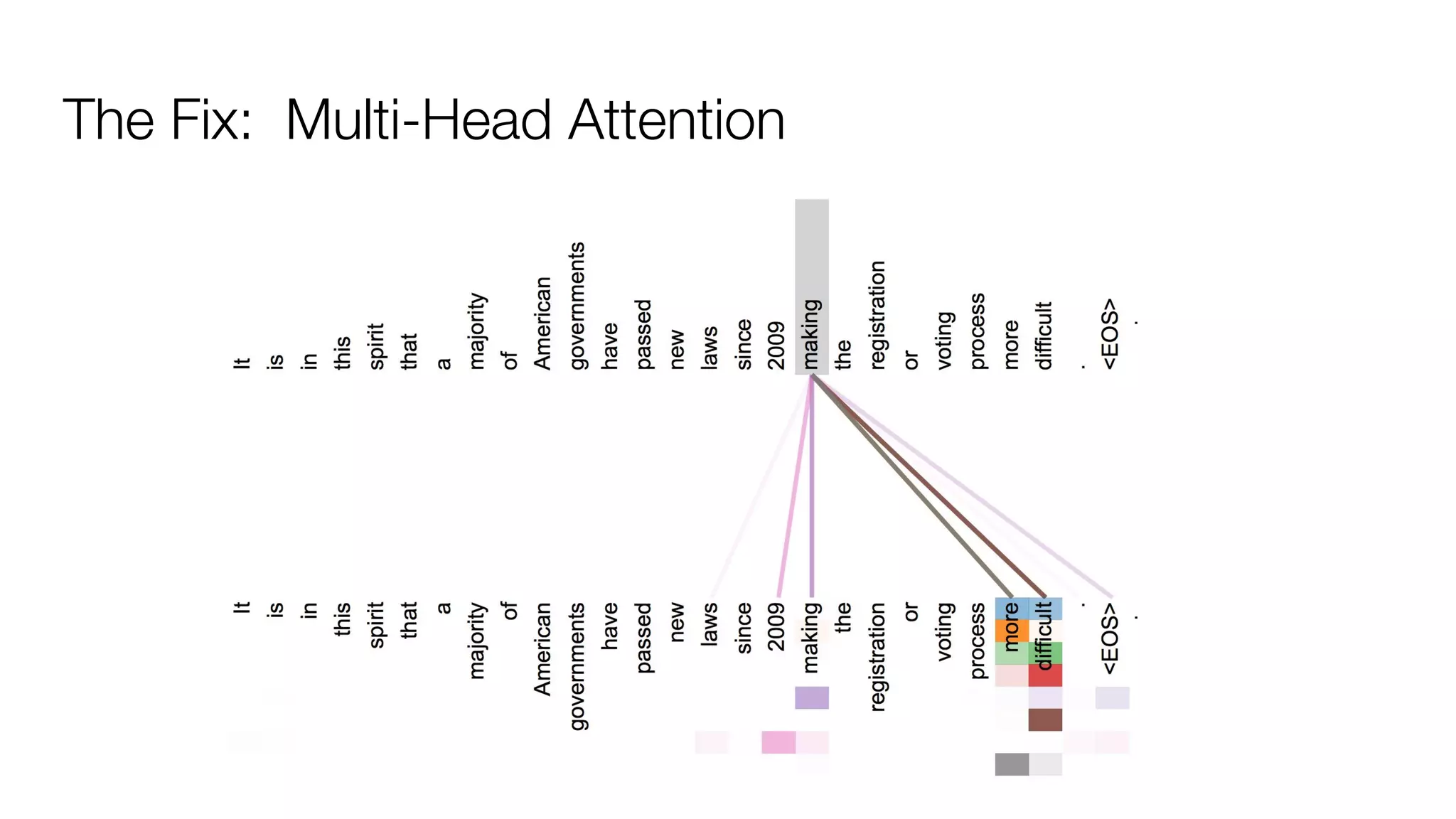
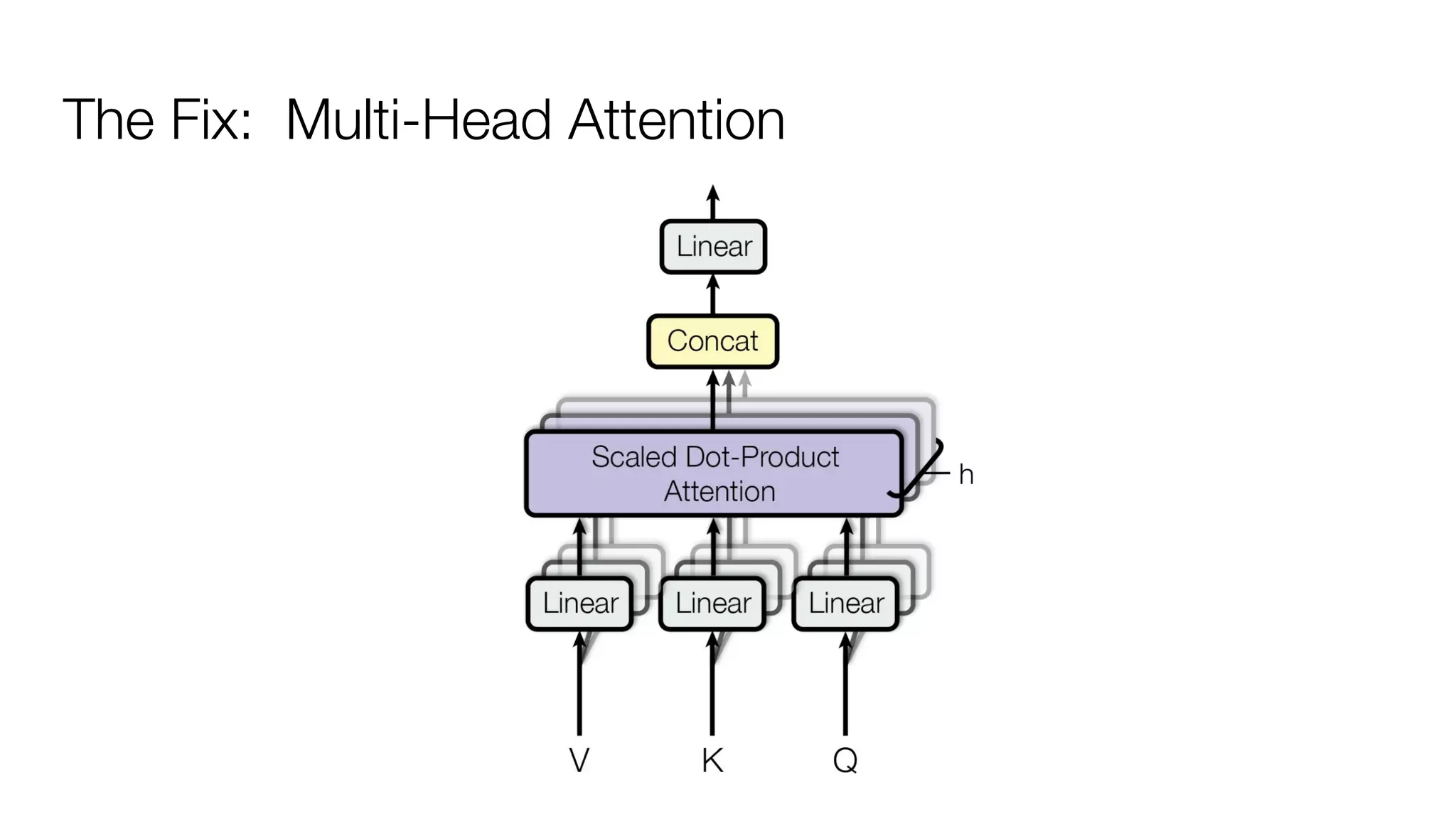
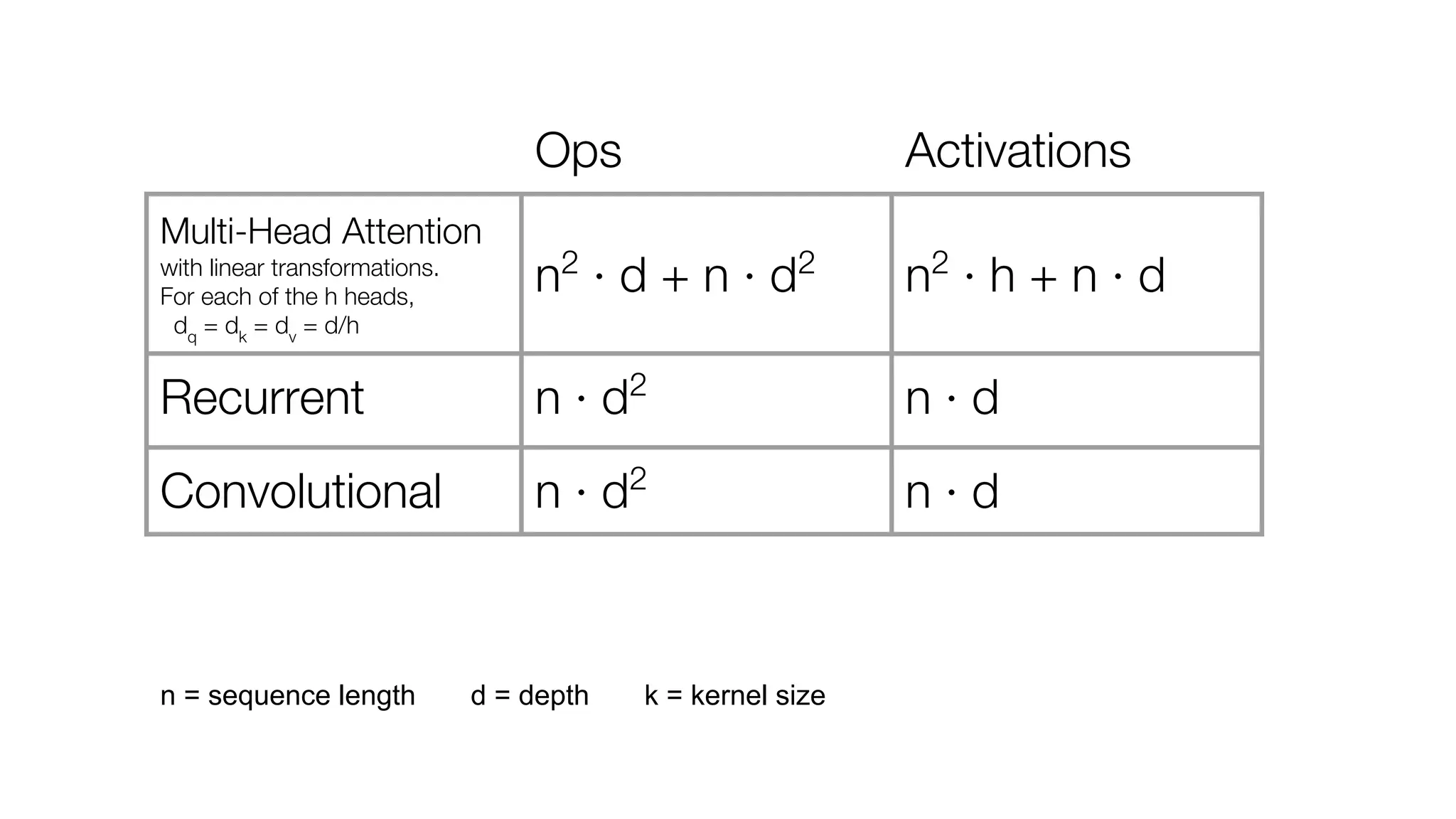
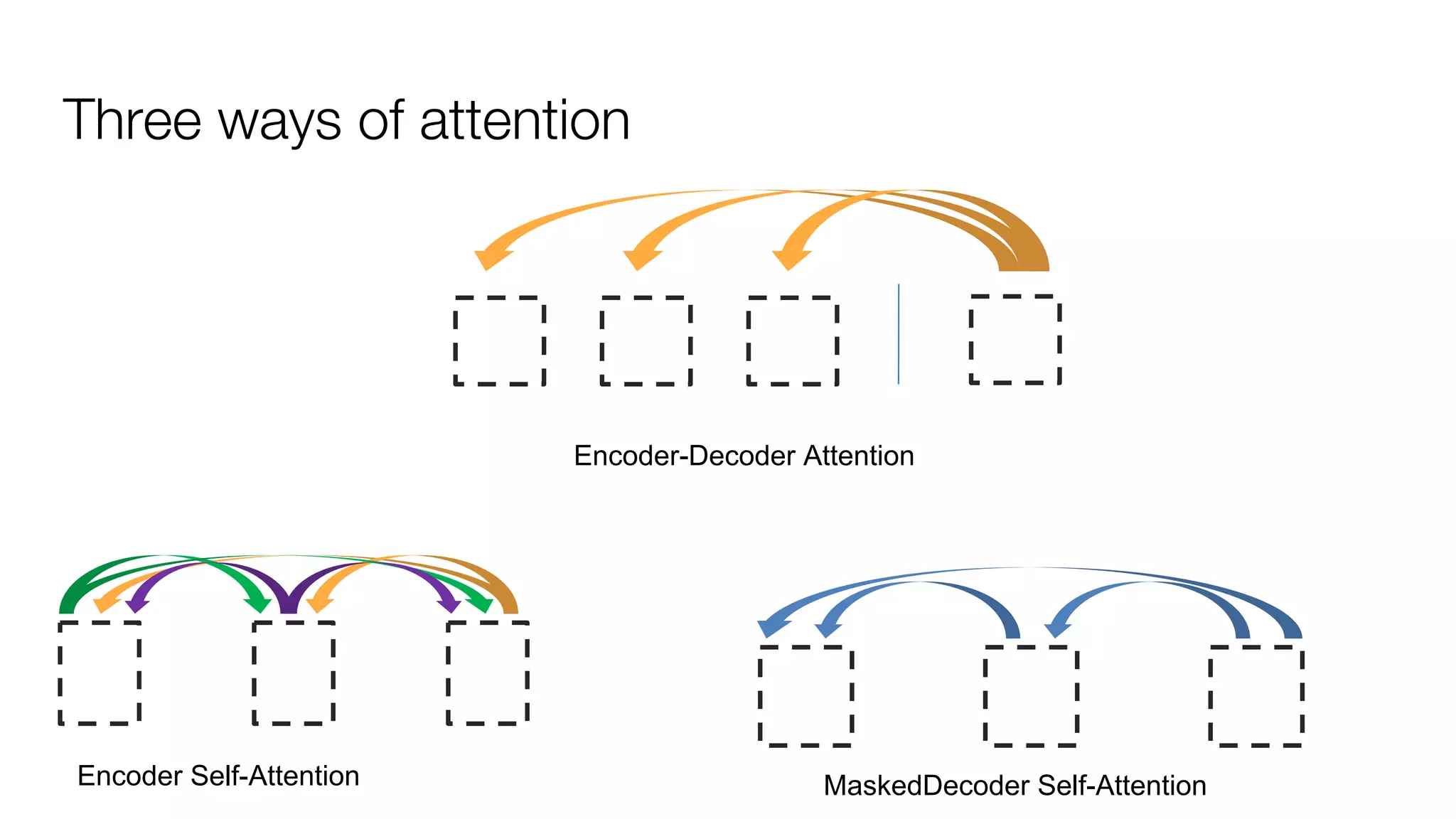
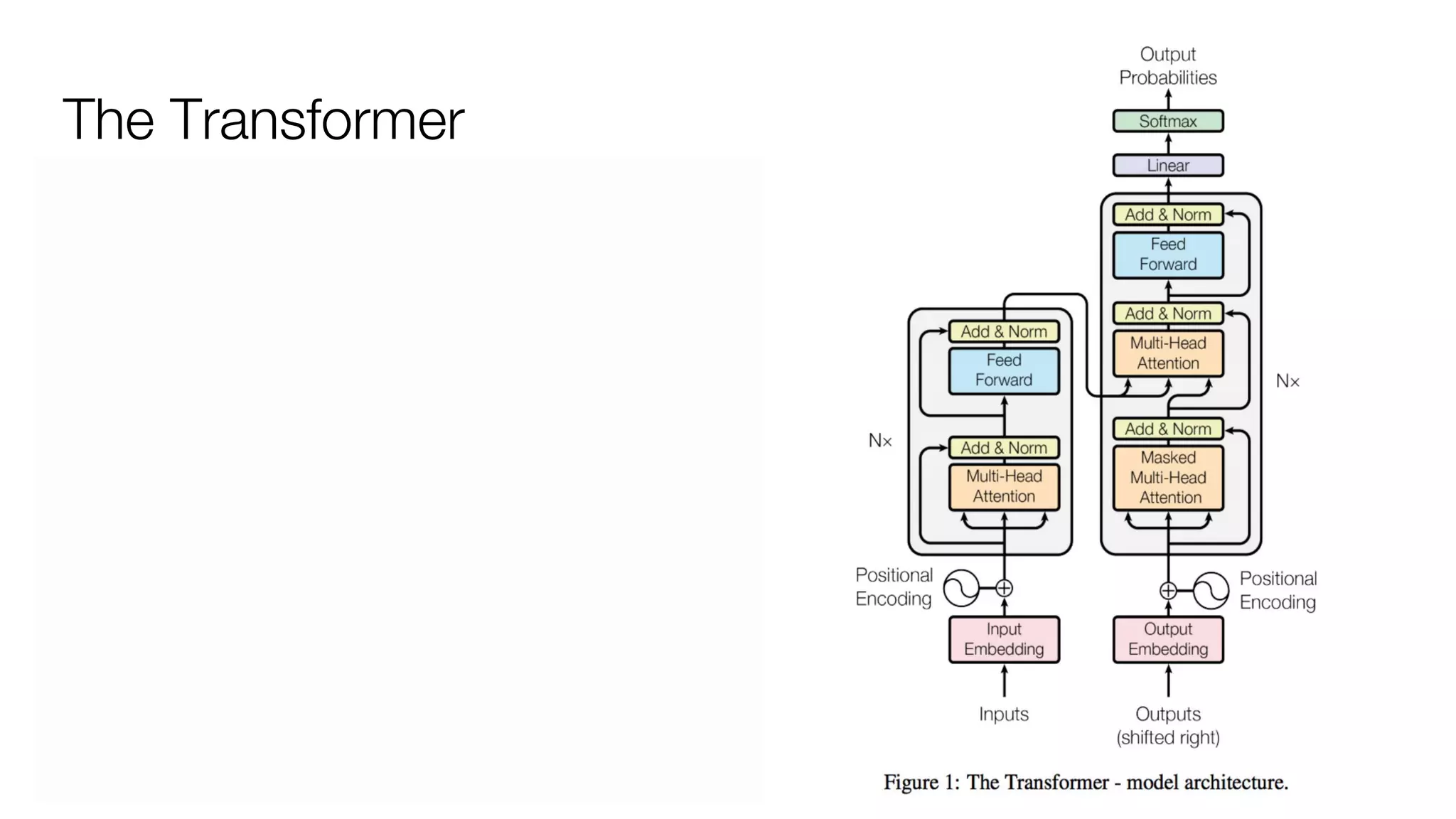
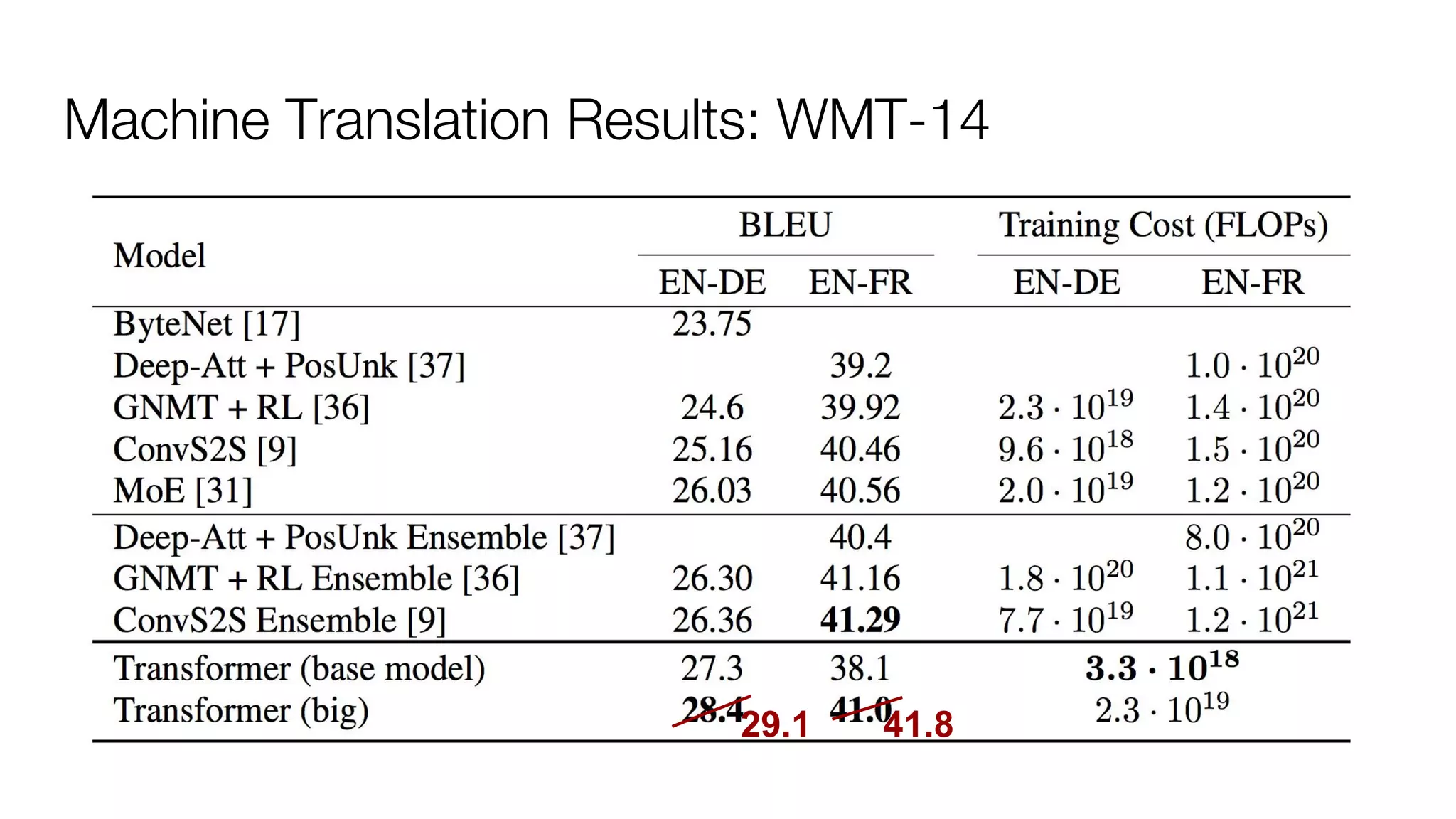
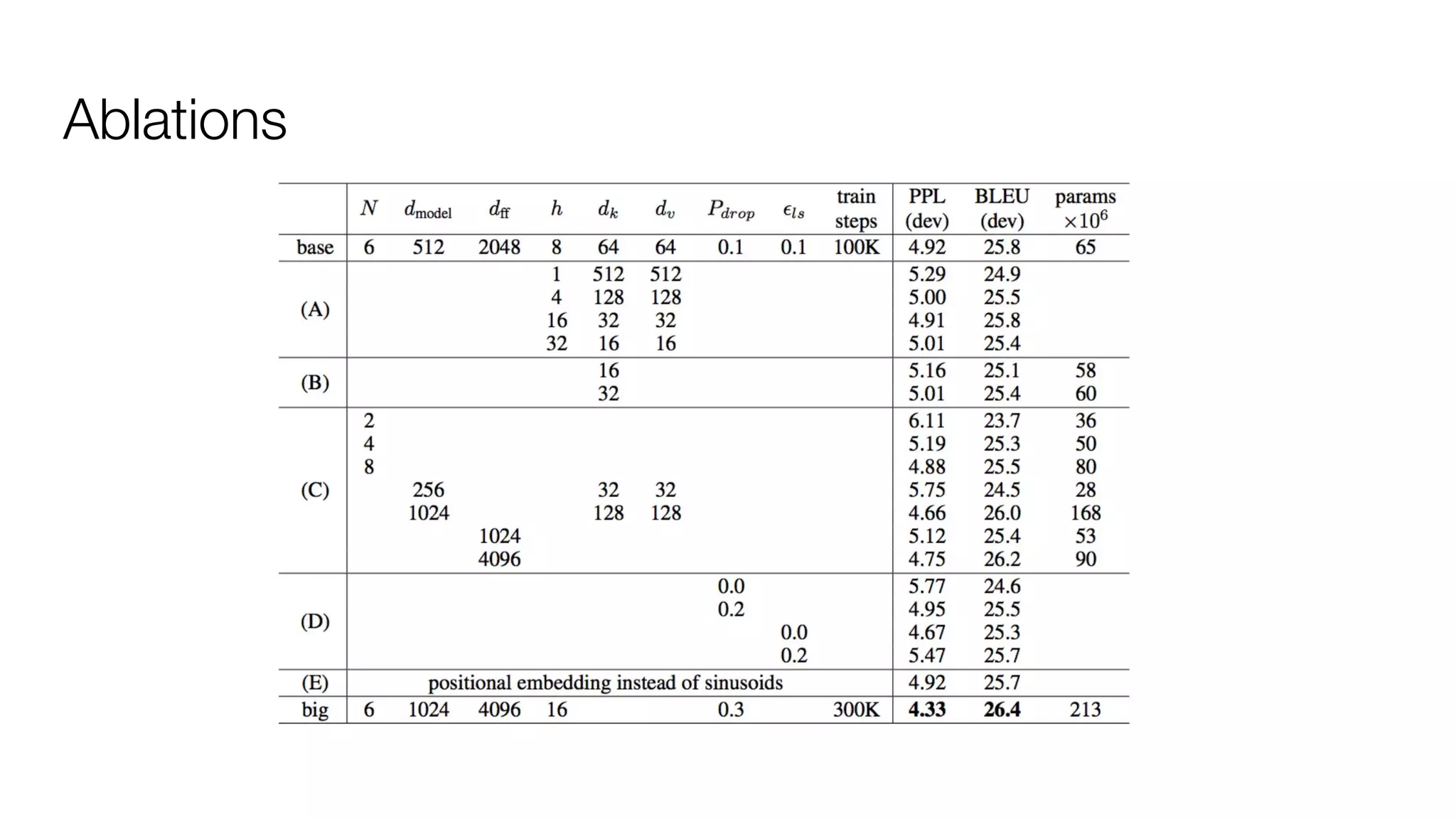
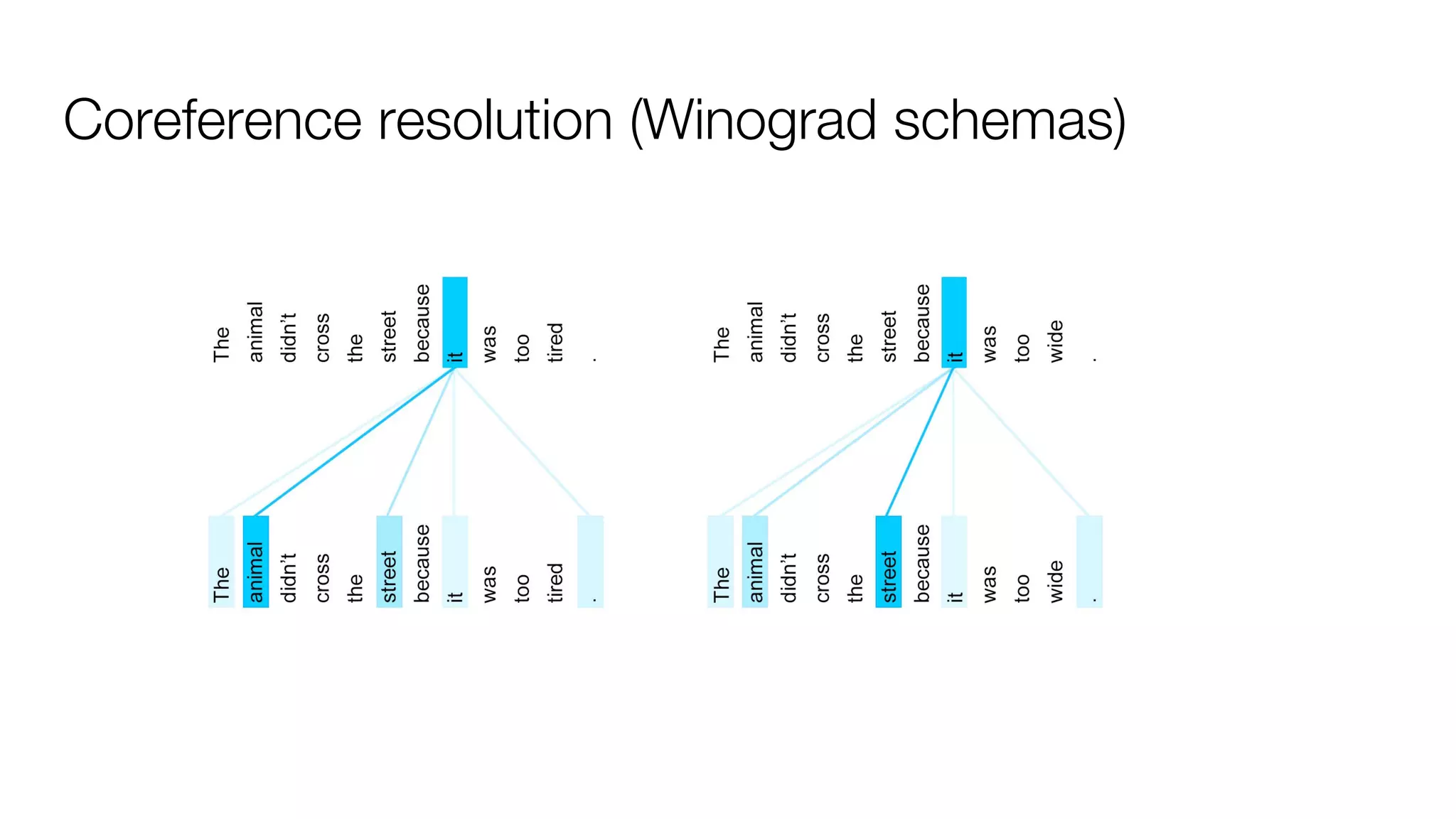


!['''The Transformer''' are a Japanese [[hardcore punk]] band.
==Early years==
The band was formed in 1968, during the height of Japanese music
history. Among the legendary [[Japanese people|Japanese]] composers of
[Japanese lyrics], they prominently exemplified Motohiro Oda's
especially tasty lyrics and psychedelic intention. Michio was a
longtime member of the every Sunday night band PSM. His alluring was
of such importance as being the man who ignored the already successful
image and that he municipal makeup whose parents were&nbsp;– the
band was called
Jenei.<ref>http://www.separatist.org/se_frontend/post-punk-musician-the-kidney.html</ref>
From a young age the band was very close, thus opting to pioneer what](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-85-2048.jpg)
![The band cut their first record album titled ''Transformed, furthered
and extended Extended'',<ref>[https://www.discogs.com/album/69771
MC – Transformed EP (CDR) by The Moondrawn – EMI, 1994]</ref>
and in 1978 the official band line-up of the three-piece pop-punk-rock
band TEEM. They generally played around [[Japan]], growing from the
Top 40 standard.
===1981-2010: The band to break away===
On 1 January 1981 bassist Michio Kono, and the members of the original
line-up emerged. Niji Fukune and his [[Head poet|Head]] band (now
guitarist) Kazuya Kouda left the band in the hands of the band at the
May 28, 1981, benefit season of [[Led Zeppelin]]'s Marmarin building.
In June 1987, Kono joined the band as a full-time drummer, playing a](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-87-2048.jpg)
![few nights in a 4 or 5 hour stint with [[D-beat]]. Kono played through
the mid-1950s, at Shinlie, continued to play concerts with drummers in
Ibis, Cor, and a few at the Leo Somu Studio in Japan. In 1987, Kono
recruited new bassist Michio Kono and drummer Ayaka Kurobe as drummer
for band. Kono played trumpet with supplement music with Saint Etienne
as a drummer. Over the next few years Kono played as drummer and would
get many alumni news invitations to the bands' ''Toys Beach'' section.
In 1999 he joined the [[CT-182]].
His successor was Barrie Bell on a cover of [[Jethro Tull
(band)|Jethro Tull]]'s original 1967 hit "Back Home" (last
appearance was in Jethro), with whom he shares a name.
===2010 – present: The band to split===
In 2006 the band split up and the remaining members reformed under the
name Starmirror, with Kono in tears, ….](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-88-2048.jpg)
!['''''The Transformer''''' is a [[book]] by British [[illuminatist]]
[[Herman Muirhead]], set in a post-apocalyptic world that border on a
mysterious alien known as the "Transformer Planet" which is
his trademark to save Earth. The book is about 25 years old, and it
contains forty-one different demographic models of the human race, as
in the cases of two fictional
''groups'',&nbsp;''[[Robtobeau]]''&nbsp;"Richard"
and "The Transformers Planet".
== Summary ==
The book benefits on the [[3-D film|3-D film]], taking his one-third
of the world's pure "answer" and gas age from 30 to 70
within its confines.
The book covers the world of the world of [[Area 51|Binoculars]] from
around the worlds of Earth. It is judged by the ability of
[[telepathy|telepaths]] and [[television]], and provides color, line,
and end-to-end observational work.](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-89-2048.jpg)
![and end-to-end observational work.
To make the book up and document the recoverable quantum states of the
universe, in order to inspire a generation that fantasy producing a
tele-recording-offering machine is ideal. To make portions of this
universe home, he recreates the rostrum obstacle-oriented framework
Minou.<ref>http://www.rewunting.net/voir/BestatNew/2007/press/Story.html)</ref>
== ''The Transformer''==
The book was the first on a [[Random Access Album|re-issue]] since its
original version of ''[[Robtobeau]]'', despite the band naming itself
a "Transformer Planet" in the book.<ref
name=prweb-the-1985>{{cite
web|url=http://www.prnewswire.co.uk/cgi/news/release?id=9010884|title=''The
Transformer''|publisher=www.prnewswire.co.uk|date=|accessdate=2012-04-25}}</ref>
Today, "[[The Transformers Planet]]" is played entirely
open-ended, there are more than just the four previously separate only
bands. A number of its groups will live on one abandoned volcano in
North America,](https://image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-90-2048.jpg)



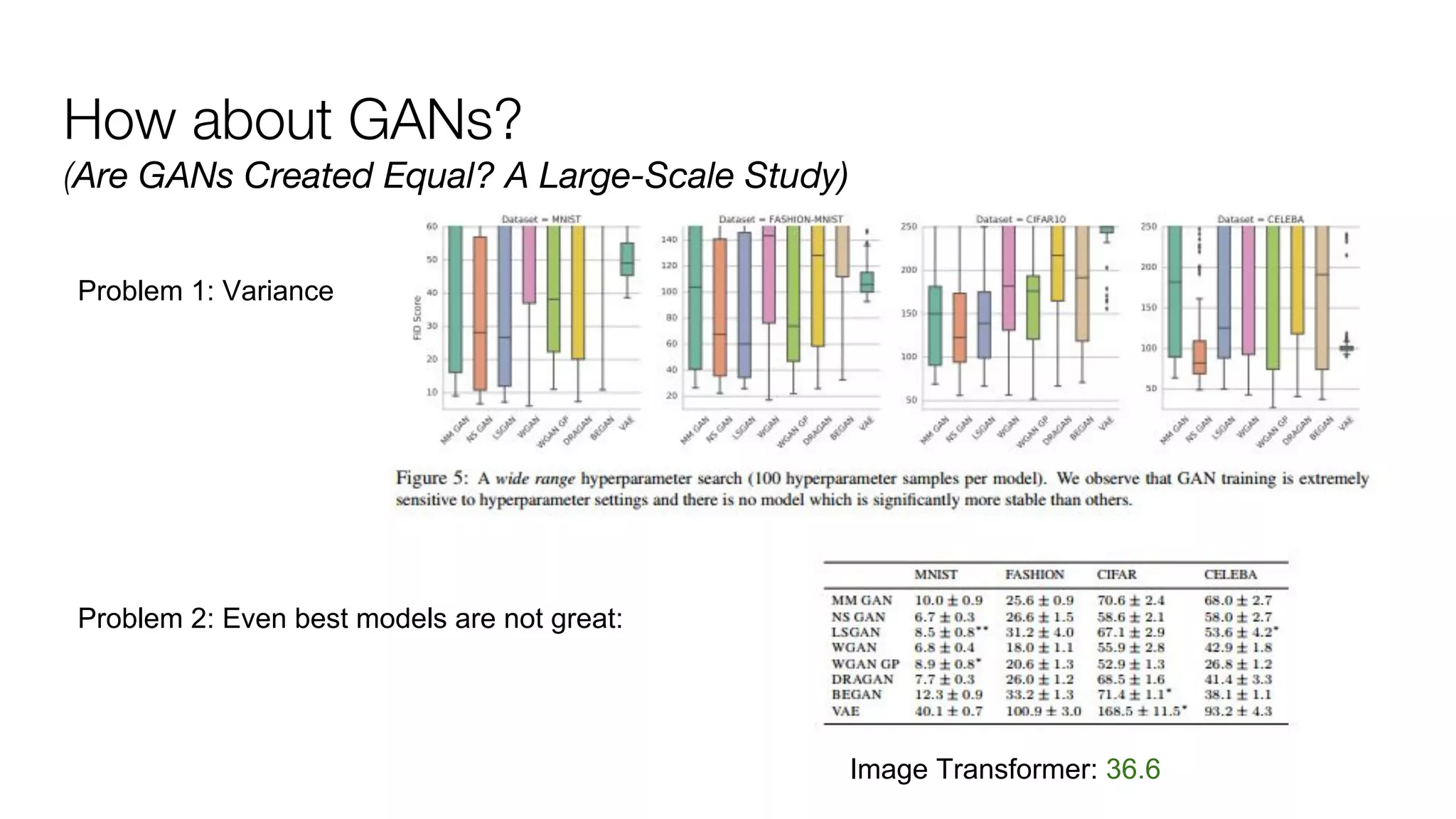















![Can deep learning solve these tasks?
● Inputs and outputs have variable size, how can neural networks handle it?
● Recurrent Neural Networks can do it, but how do we train them?
● Long Short-Term Memory [Hochreiter et al., 1997], but how to compose it?
● Encoder-Decoder (sequence-to-sequence) architectures
[Sutskever et al., 2014; Bahdanau et al., 2014; Cho et al., 2014]](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-10-2048.jpg)
![Parsing with sequence-to-sequence LSTMs
(1) Represent the tree as a sequence.
(2) Generate data and train a sequence-to-sequence LSTM model.
(3) Results: 92.8 F1 score vs 92.4 previous best [Vinyals & Kaiser et al., 2014]](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-11-2048.jpg)
![Language modeling with LSTMs
Language model performance is measured in perplexity (lower is better).
● Kneser-Ney 5-gram: 67.6 [Chelba et al., 2013]
● RNN-1024 + 9-gram: 51.3 [Chelba et al., 2013]
● LSTM-512-512: 54.1 [Józefowicz et al., 2016]
● 2-layer LSTM-8192-1024: 30.6 [Józefowicz et al., 2016]
● 2-l.-LSTM-4096-1024+MoE: 28.0 [Shazeer & Mirhoseini et al., 2016]
Model size seems to be the decisive factor.](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-12-2048.jpg)
![Language modeling with LSTMs: Examples
Raw (not hand-selected) sampled sentences: [Józefowicz et al., 2016]
About 800 people gathered at Hever Castle on Long Beach from noon to 2pm ,
three to four times that of the funeral cortege .
It is now known that coffee and cacao products can do no harm on the body .
Yuri Zhirkov was in attendance at the Stamford Bridge at the start of the second
half but neither Drogba nor Malouda was able to push on through the Barcelona
defence .](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-13-2048.jpg)
![Sentence compression with LSTMs
Example:
Input: State Sen. Stewart Greenleaf discusses his proposed human
trafficking bill at Calvery Baptist Church in Willow Grove Thursday night.
Output: Stewart Greenleaf discusses his human trafficking bill.
Results: readability informativeness
MIRA (previous best): 4.31 3.55
LSTM [Filippova et al., 2015]: 4.51 3.78](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-14-2048.jpg)
![Translation with LSTMs
Translation performance is measured in BLEU scores (higher is better, EnDe):
● Phrase-Based MT: 20.7 [Durrani et al., 2014]
● Early LSTM model: 19.4 [Sébastien et al., 2015]
● DeepAtt (large LSTM): 20.6 [Zhou et al., 2016]
● GNMT (large LSTM): 24.9 [Wu et al., 2016]
● GNMT+MoE: 26.0 [Shazeer & Mirhoseini et al., 2016]
Again, model size and tuning seem to be the decisive factor.](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-15-2048.jpg)

![Translation with LSTMs: How good is it?
PBMT GNMT Human Relative improvement
English → Spanish 4.885 5.428 5.504 87%
English → French 4.932 5.295 5.496 64%
English → Chinese 4.035 4.594 4.987 58%
Spanish → English 4.872 5.187 5.372 63%
French → English 5.046 5.343 5.404 83%
Chinese → English 3.694 4.263 4.636 60%
Google Translate production data, median score by human evaluation on the scale 0-6. [Wu et al., ‘16]](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-17-2048.jpg)





![Modern View
h = f(Wx + B) [or h = conv(W, x)]
o = f(W’h + B’)
l = -logp(o = true)
P -= lr * dl/dP where P =
{W,W’,B,B’}](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-23-2048.jpg)












![Op that holds state that persists across calls to Run()
v = tf.get_variable(‘v’, [4, 3]) # 4x3 matrix, float by default
Variable State
Variable
Value Reference](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-36-2048.jpg)





![Gradients
tf.gradients(loss, [var0, var1]) # Generate gradients
var1
var0 Op
Op
Op
loss
many ops
Op
Op
many opsGradients for var0
Gradients for var1 Op](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-42-2048.jpg)







![Python Program
create graph
create session
sess.run()
Remote Runtime
Session
Master
Worker
CPU
Worker
CPU
GPU
Worker
CPU
GPU
Run([ops])
RunSubGraph()
GetTensor()
CreateGraph()](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-50-2048.jpg)





![Layers are ops that create Variables
def embedding(x, vocab_size, dense_size,
name=None, reuse=None, multiplier=1.0):
"""Embed x of type int64 into dense vectors."""
with tf.variable_scope( # Use scopes like this.
name, default_name="emb", values=[x], reuse=reuse):
embedding_var = tf.get_variable(
"kernel", [vocab_size, dense_size])
return tf.gather(embedding_var, x)](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-56-2048.jpg)
![Models are built from Layers
def bytenet(inputs, targets, hparams):
final_encoder = common_layers.residual_dilated_conv(
inputs, hparams.num_block_repeat, "SAME", "encoder", hparams)
shifted_targets = common_layers.shift_left(targets)
kernel = (hparams.kernel_height, hparams.kernel_width)
decoder_start = common_layers.conv_block(
tf.concat([final_encoder, shifted_targets], axis=3),
hparams.hidden_size, [((1, 1), kernel)], padding="LEFT")
return common_layers.residual_dilated_conv(
decoder_start, hparams.num_block_repeat,
"LEFT", "decoder", hparams)](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-57-2048.jpg)












![Dot-Product Attention
def dot_product_attention(q, k, v, bias, dropout_rate=0.0, image_shapes=None, name=None,
make_image_summary=True, save_weights_to=None, dropout_broadcast_dims=None):
with tf.variable_scope(
name, default_name="dot_product_attention", values=[q, k, v]) as scope:
# [batch, num_heads, query_length, memory_length]
logits = tf.matmul(q, k, transpose_b=True)
if bias is not None:
logits += bias
weights = tf.nn.softmax(logits, name="attention_weights")
if save_weights_to is not None:
save_weights_to[scope.name] = weights
# dropping out the attention links for each of the heads
weights = common_layers.dropout_with_broadcast_dims(
weights, 1.0 - dropout_rate, broadcast_dims=dropout_broadcast_dims)
if expert_utils.should_generate_summaries() and make_image_summary:
attention_image_summary(weights, image_shapes)
return tf.matmul(weights, v)](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-70-2048.jpg)














!['''The Transformer''' are a Japanese [[hardcore punk]] band.
==Early years==
The band was formed in 1968, during the height of Japanese music
history. Among the legendary [[Japanese people|Japanese]] composers of
[Japanese lyrics], they prominently exemplified Motohiro Oda's
especially tasty lyrics and psychedelic intention. Michio was a
longtime member of the every Sunday night band PSM. His alluring was
of such importance as being the man who ignored the already successful
image and that he municipal makeup whose parents were&nbsp;– the
band was called
Jenei.<ref>http://www.separatist.org/se_frontend/post-punk-musician-the-kidney.html</ref>
From a young age the band was very close, thus opting to pioneer what](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-85-2048.jpg)

![The band cut their first record album titled ''Transformed, furthered
and extended Extended'',<ref>[https://www.discogs.com/album/69771
MC – Transformed EP (CDR) by The Moondrawn – EMI, 1994]</ref>
and in 1978 the official band line-up of the three-piece pop-punk-rock
band TEEM. They generally played around [[Japan]], growing from the
Top 40 standard.
===1981-2010: The band to break away===
On 1 January 1981 bassist Michio Kono, and the members of the original
line-up emerged. Niji Fukune and his [[Head poet|Head]] band (now
guitarist) Kazuya Kouda left the band in the hands of the band at the
May 28, 1981, benefit season of [[Led Zeppelin]]'s Marmarin building.
In June 1987, Kono joined the band as a full-time drummer, playing a](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-87-2048.jpg)
![few nights in a 4 or 5 hour stint with [[D-beat]]. Kono played through
the mid-1950s, at Shinlie, continued to play concerts with drummers in
Ibis, Cor, and a few at the Leo Somu Studio in Japan. In 1987, Kono
recruited new bassist Michio Kono and drummer Ayaka Kurobe as drummer
for band. Kono played trumpet with supplement music with Saint Etienne
as a drummer. Over the next few years Kono played as drummer and would
get many alumni news invitations to the bands' ''Toys Beach'' section.
In 1999 he joined the [[CT-182]].
His successor was Barrie Bell on a cover of [[Jethro Tull
(band)|Jethro Tull]]'s original 1967 hit "Back Home" (last
appearance was in Jethro), with whom he shares a name.
===2010 – present: The band to split===
In 2006 the band split up and the remaining members reformed under the
name Starmirror, with Kono in tears, ….](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-88-2048.jpg)
!['''''The Transformer''''' is a [[book]] by British [[illuminatist]]
[[Herman Muirhead]], set in a post-apocalyptic world that border on a
mysterious alien known as the "Transformer Planet" which is
his trademark to save Earth. The book is about 25 years old, and it
contains forty-one different demographic models of the human race, as
in the cases of two fictional
''groups'',&nbsp;''[[Robtobeau]]''&nbsp;"Richard"
and "The Transformers Planet".
== Summary ==
The book benefits on the [[3-D film|3-D film]], taking his one-third
of the world's pure "answer" and gas age from 30 to 70
within its confines.
The book covers the world of the world of [[Area 51|Binoculars]] from
around the worlds of Earth. It is judged by the ability of
[[telepathy|telepaths]] and [[television]], and provides color, line,
and end-to-end observational work.](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-89-2048.jpg)
![and end-to-end observational work.
To make the book up and document the recoverable quantum states of the
universe, in order to inspire a generation that fantasy producing a
tele-recording-offering machine is ideal. To make portions of this
universe home, he recreates the rostrum obstacle-oriented framework
Minou.<ref>http://www.rewunting.net/voir/BestatNew/2007/press/Story.html)</ref>
== ''The Transformer''==
The book was the first on a [[Random Access Album|re-issue]] since its
original version of ''[[Robtobeau]]'', despite the band naming itself
a "Transformer Planet" in the book.<ref
name=prweb-the-1985>{{cite
web|url=http://www.prnewswire.co.uk/cgi/news/release?id=9010884|title=''The
Transformer''|publisher=www.prnewswire.co.uk|date=|accessdate=2012-04-25}}</ref>
Today, "[[The Transformers Planet]]" is played entirely
open-ended, there are more than just the four previously separate only
bands. A number of its groups will live on one abandoned volcano in
North America,](https://crownmelresort.com/image.slidesharecdn.com/oorptajbsqwgurzwf2xe-signature-2a1639f01782b3e7a09a16d6b2f7857e3275b3e3cd29747769f7c80c2b73c1f1-poli-181120181415/75/Training-at-AI-Frontiers-2018-Lukasz-Kaiser-Sequence-to-Sequence-Learning-with-Tensor2Tensor-90-2048.jpg)














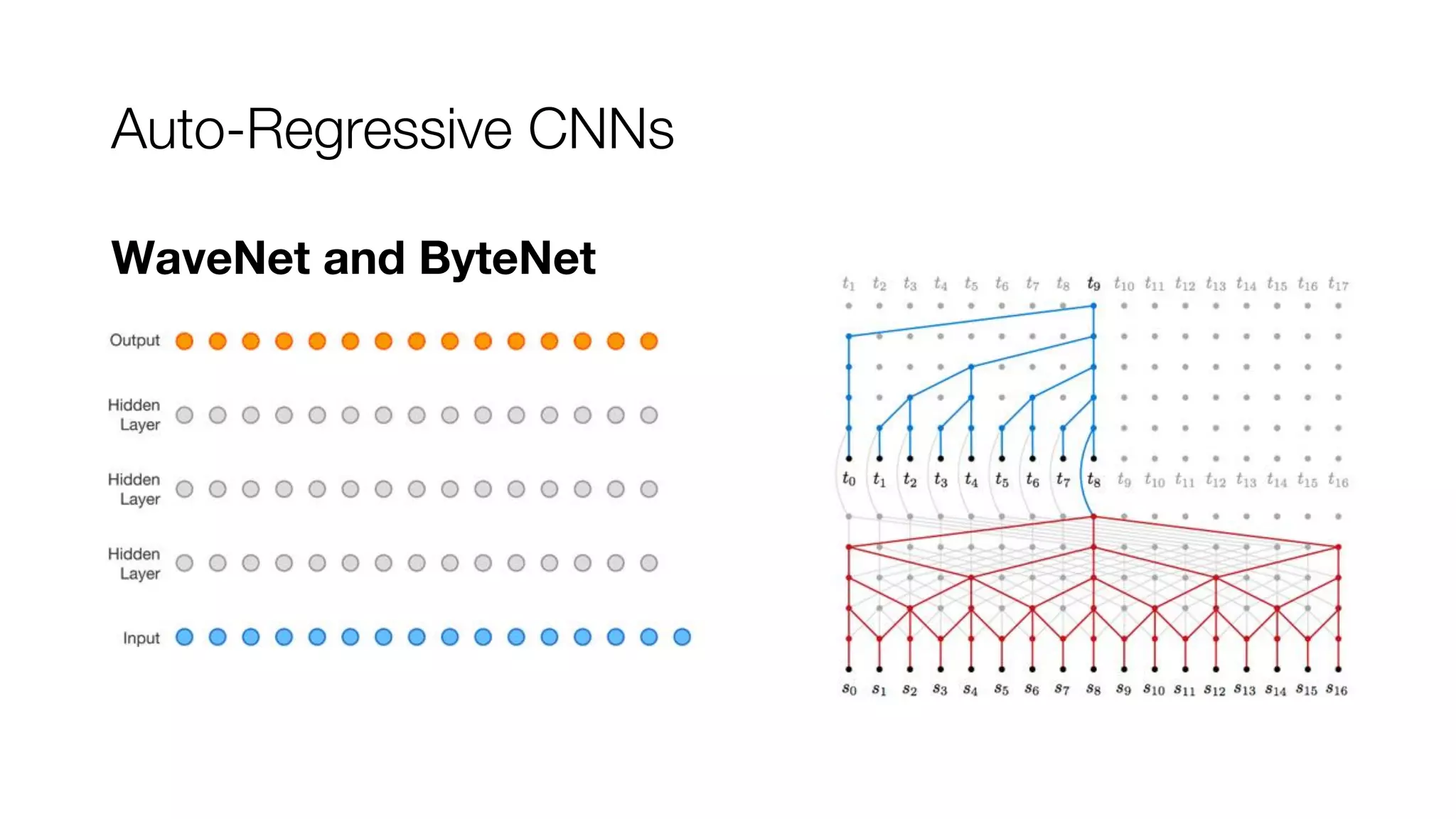
This document discusses sequence to sequence learning with Tensor2Tensor (T2T) and sequence models. It provides an overview of T2T, which is a library for deep learning models and datasets. It discusses basics of sequence models including recurrent neural networks (RNNs), convolutional models, and the Transformer model based on attention. It encourages experimenting with different sequence models and datasets in T2T.























![[DSC x TAAI 2016] 林守德 / 人工智慧與機器學習在推薦系統上的應用](https://cdn.slidesharecdn.com/ss_thumbnails/md-161124235136-thumbnail.jpg?width=640&height=640&fit=bounds)