Downloaded 141 times











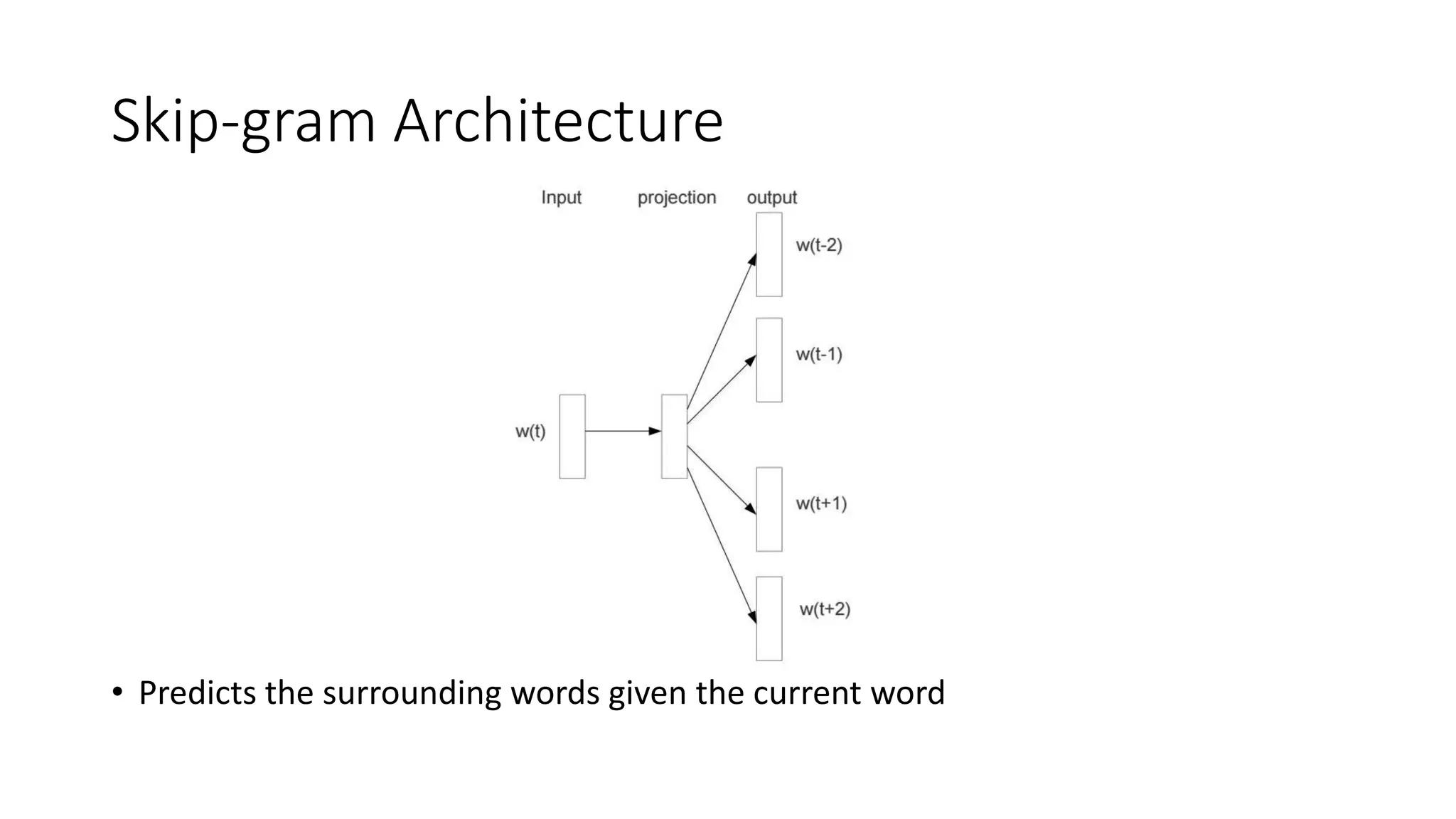
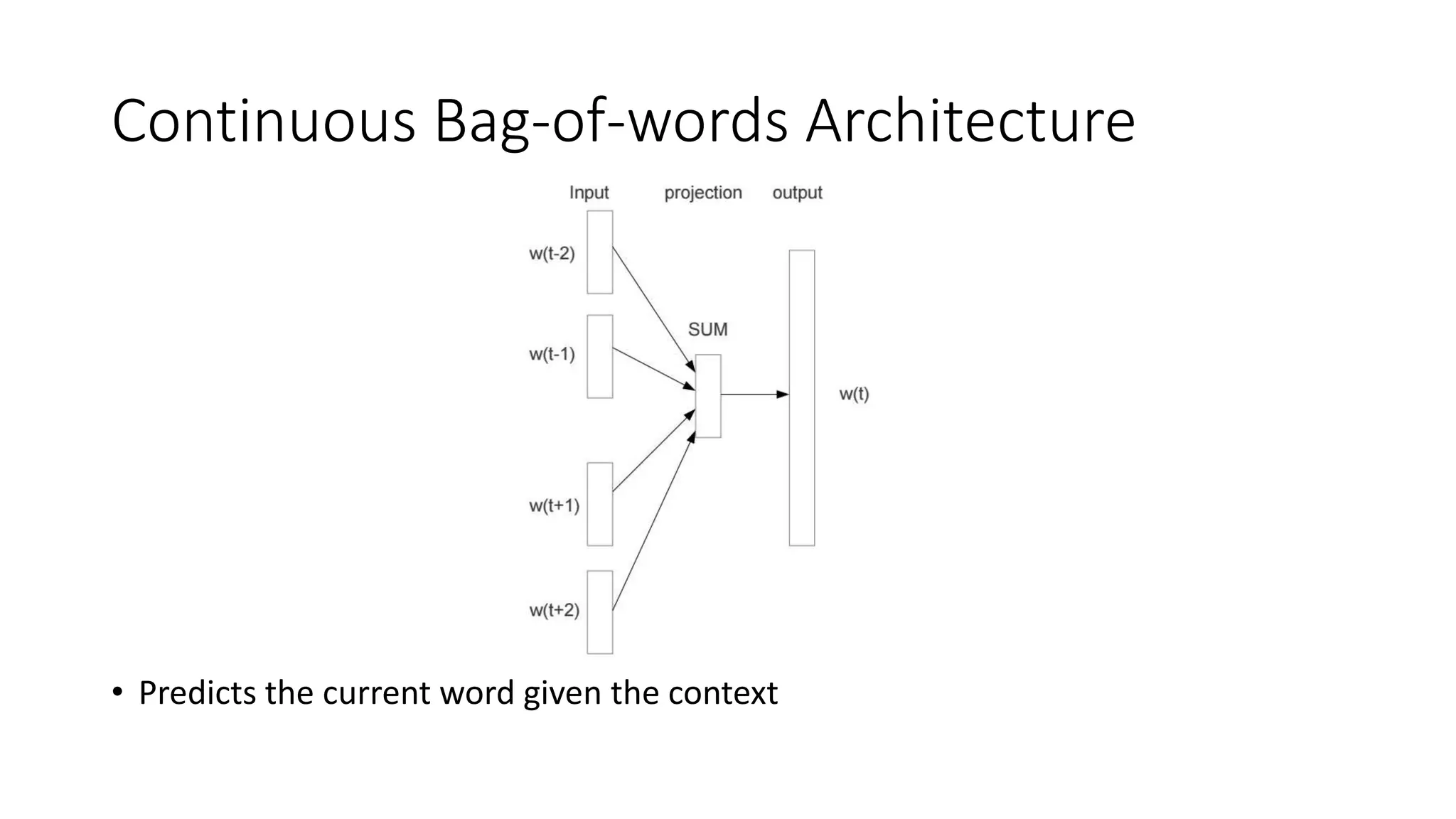
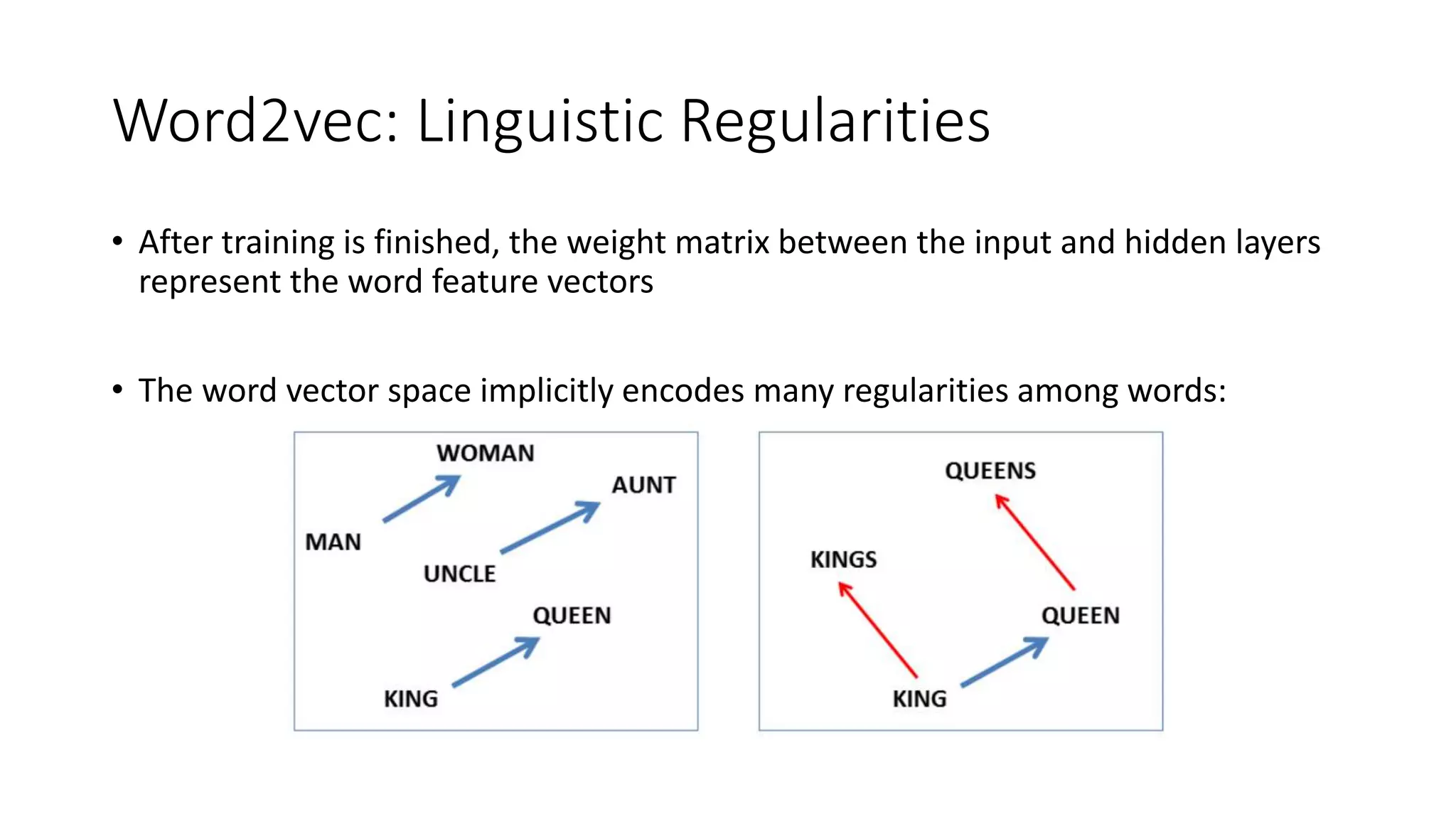


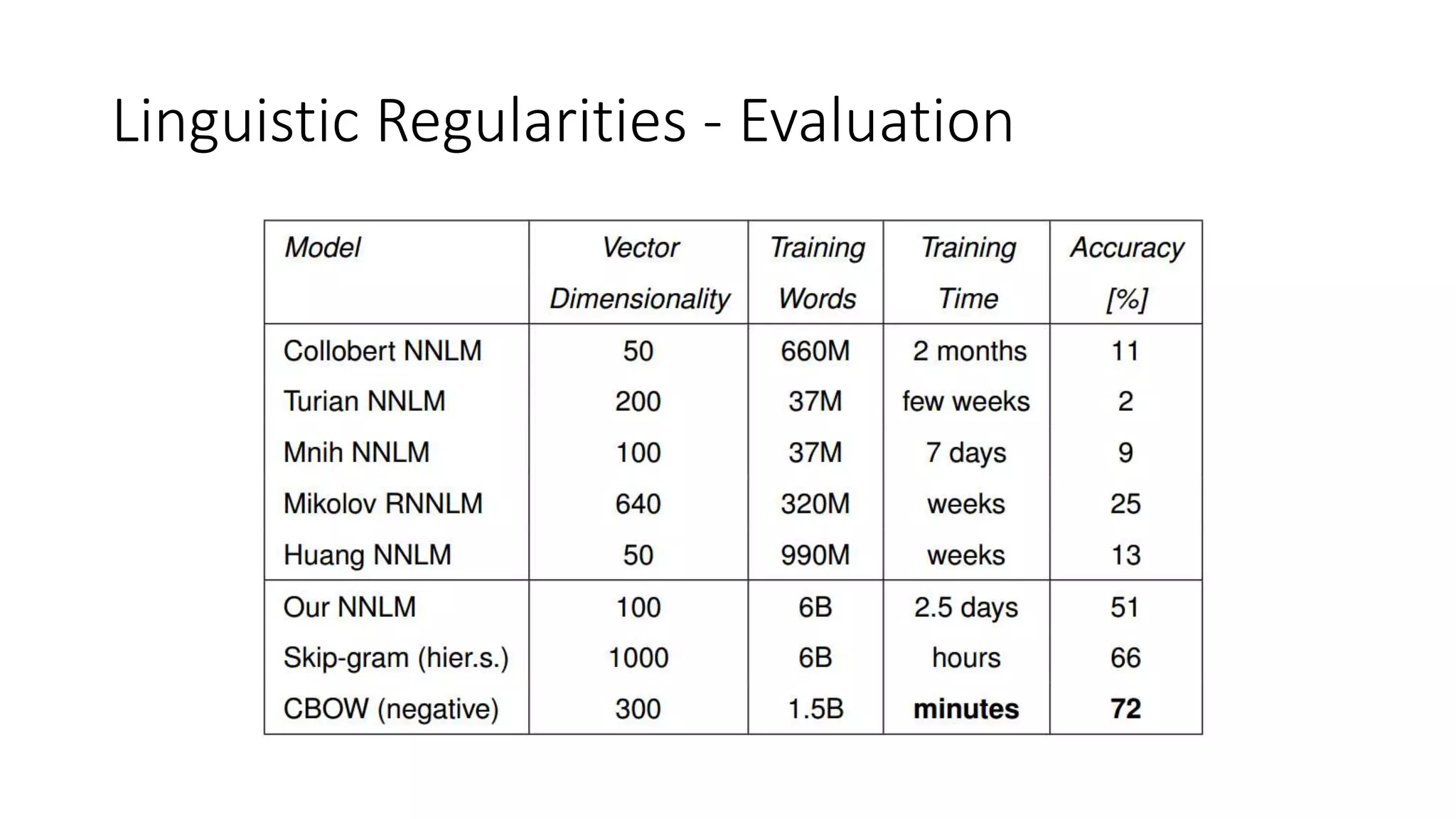
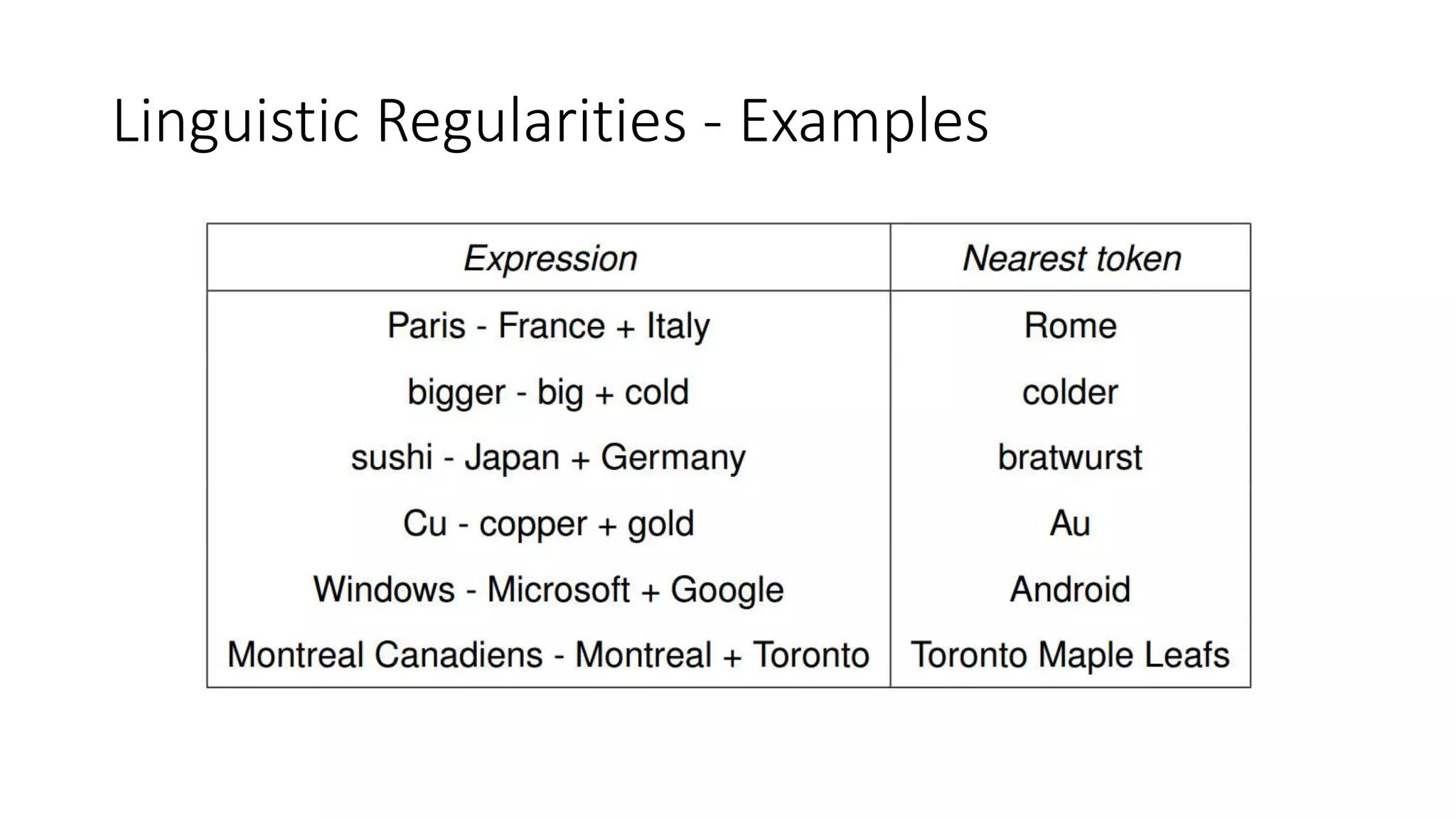
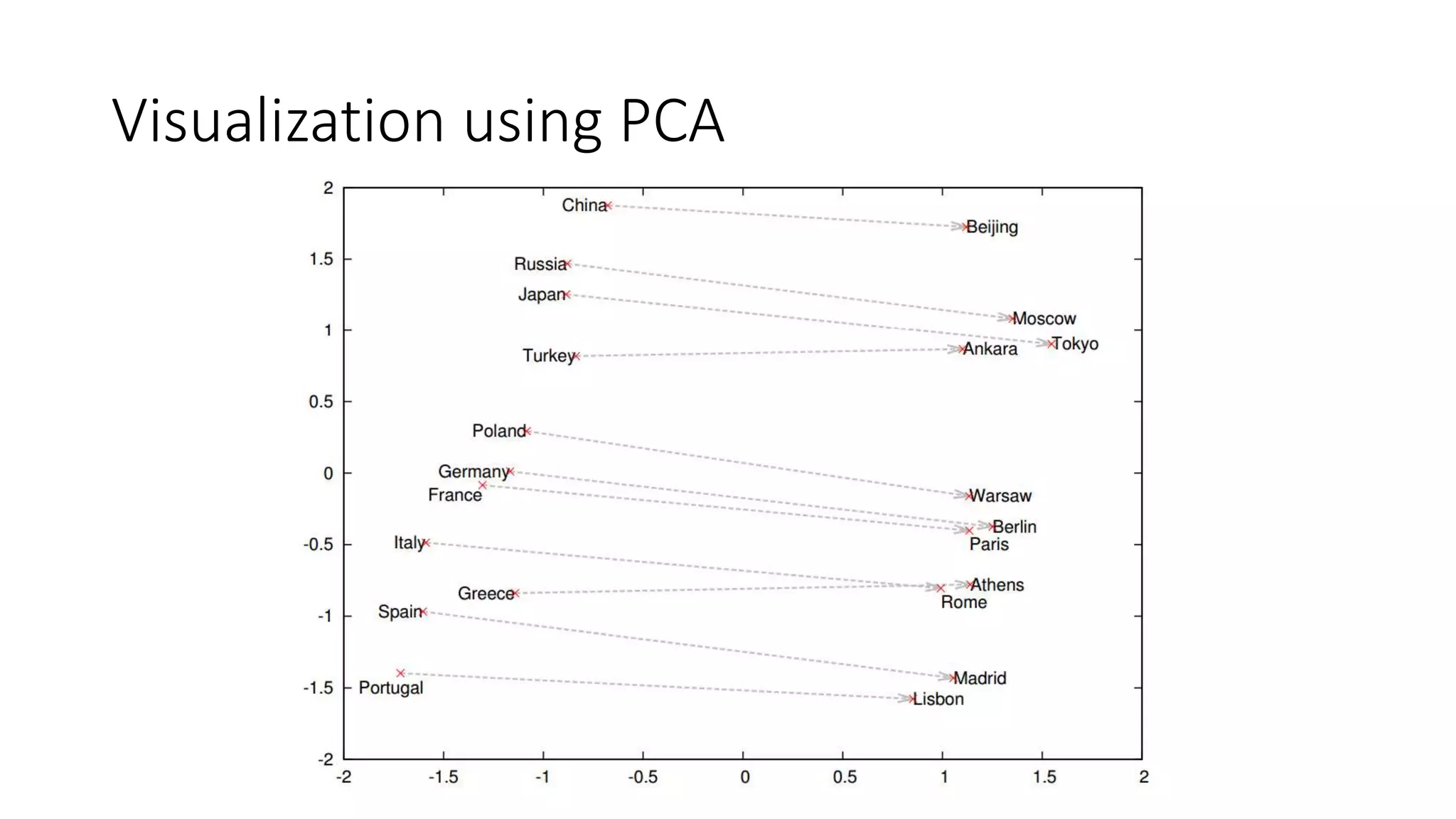
































The document discusses word embedding techniques, specifically Word2vec. It introduces the motivation for distributed word representations and describes the Skip-gram and CBOW architectures. Word2vec produces word vectors that encode linguistic regularities, with simple examples showing words with similar relationships have similar vector offsets. Evaluation shows Word2vec outperforms previous methods, and its word vectors are now widely used in NLP applications.

































































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)


