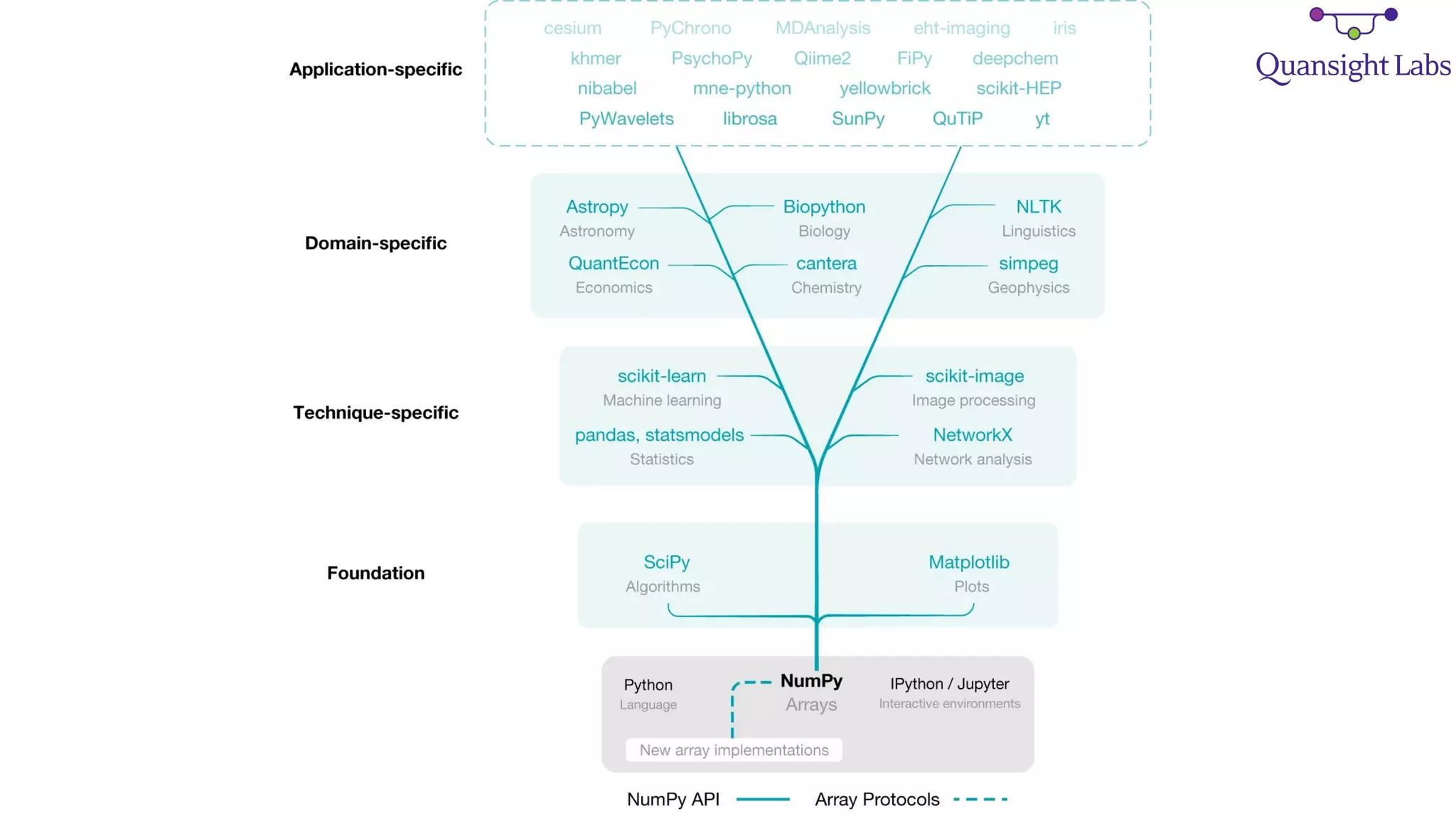
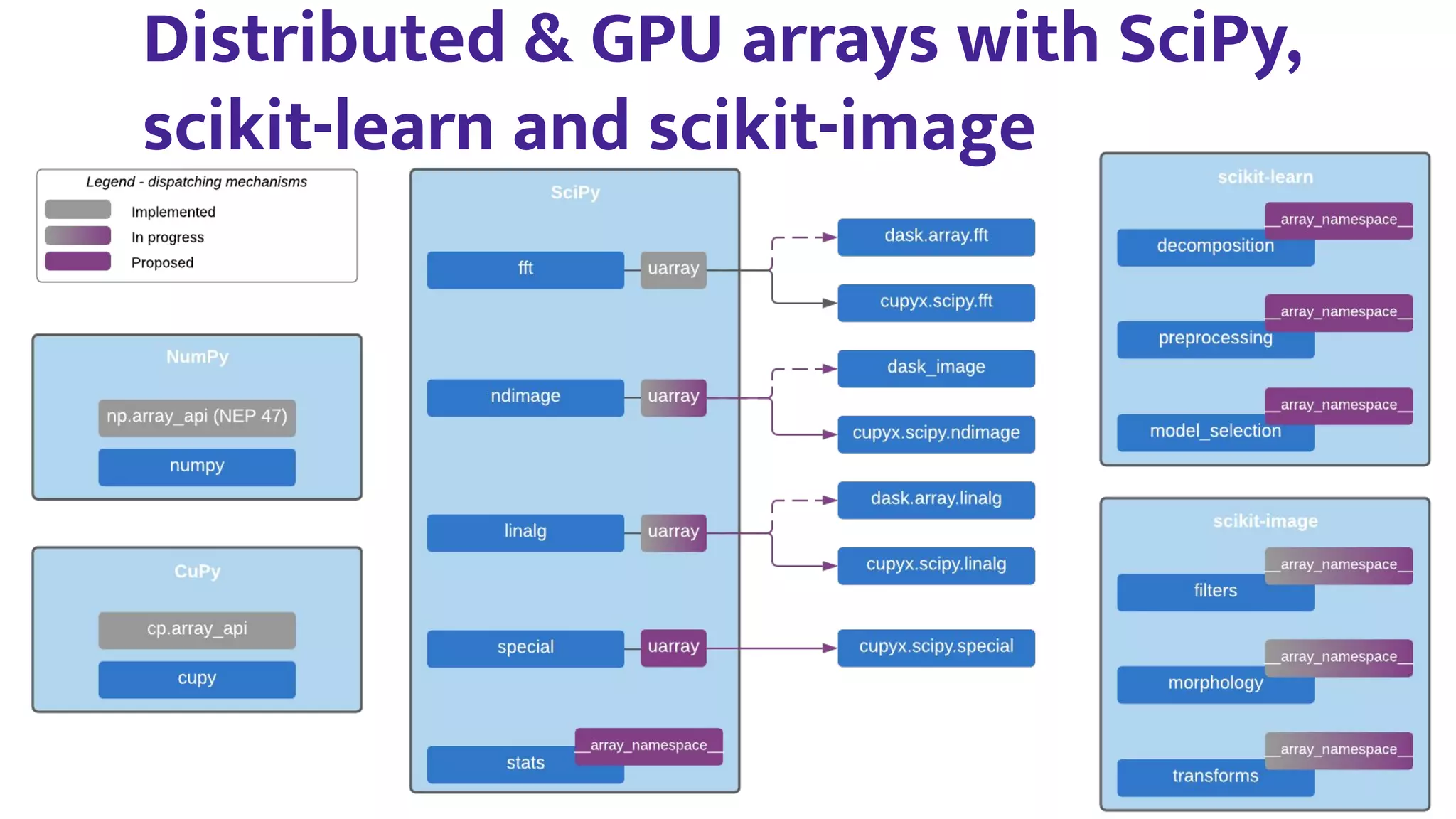
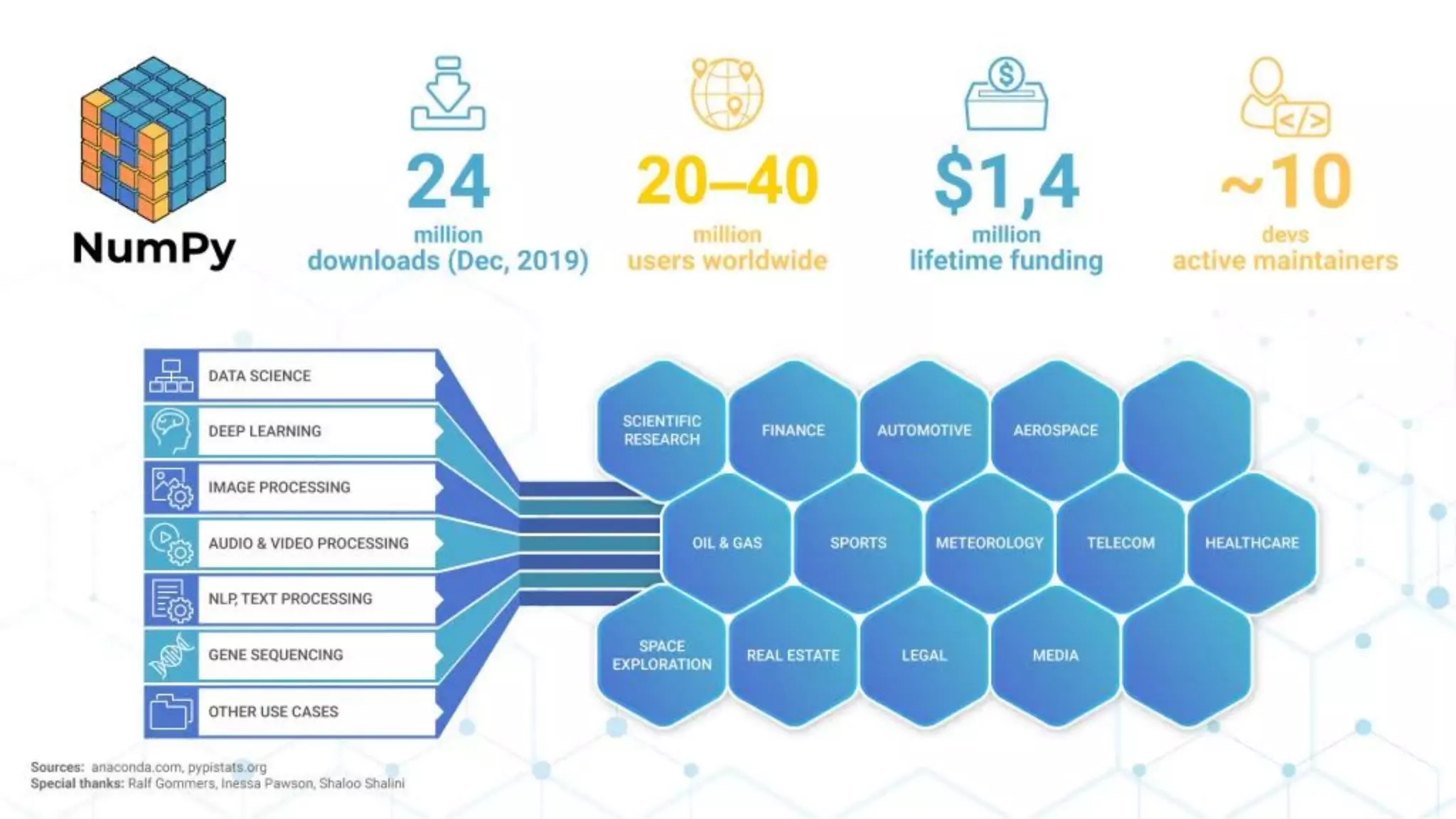
1) The PyData ecosystem, including NumPy, SciPy, and scikit-learn, faces technical challenges related to fragmentation of array libraries, lack of parallelism, packaging constraints, and performance issues for non-vectorized algorithms.
2) There are also social challenges around sustainability of key projects due to limited funding and maintainers, tensions with proprietary involvement from large tech companies, and academia's role in supporting open-source scientific software.
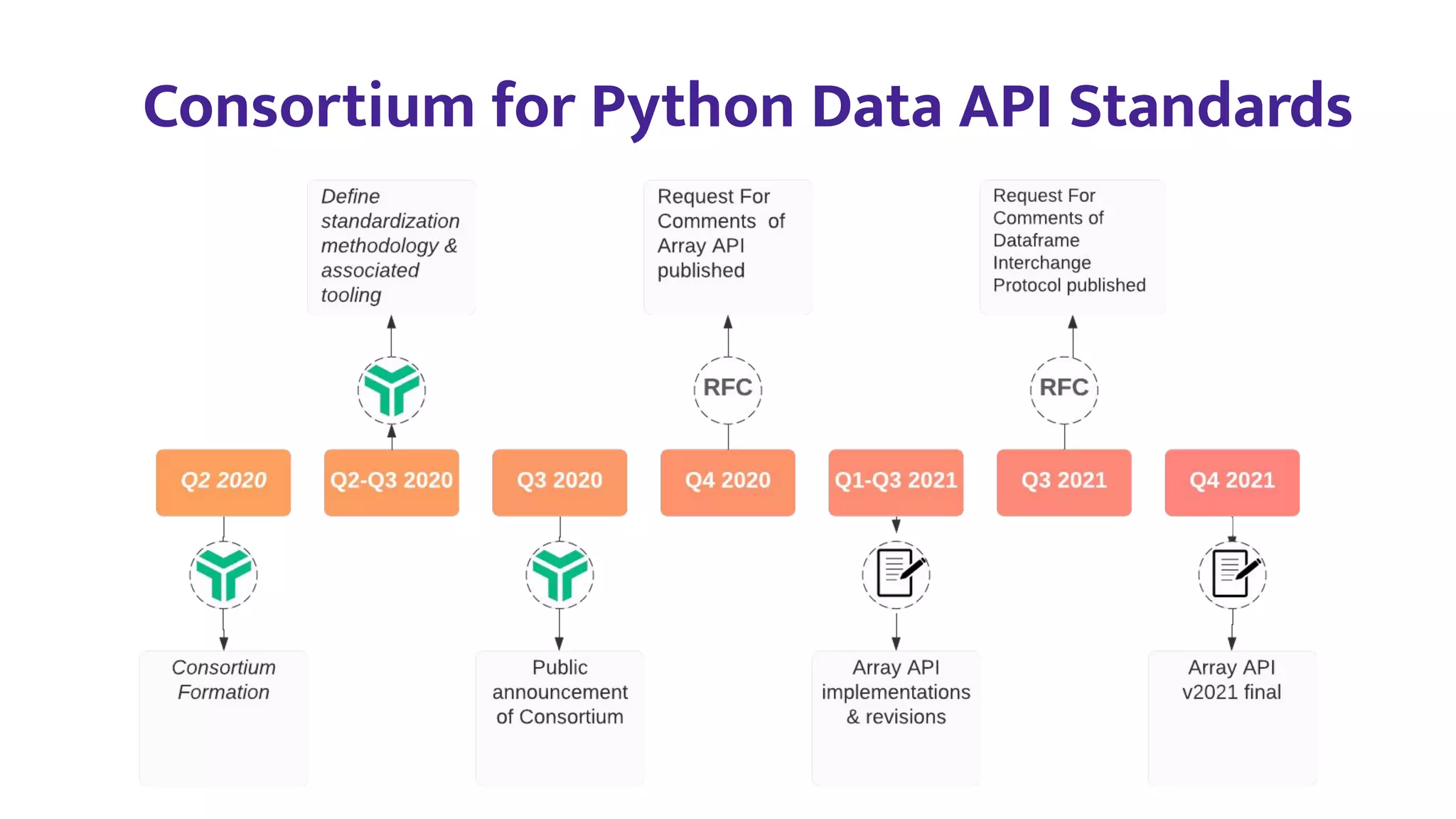
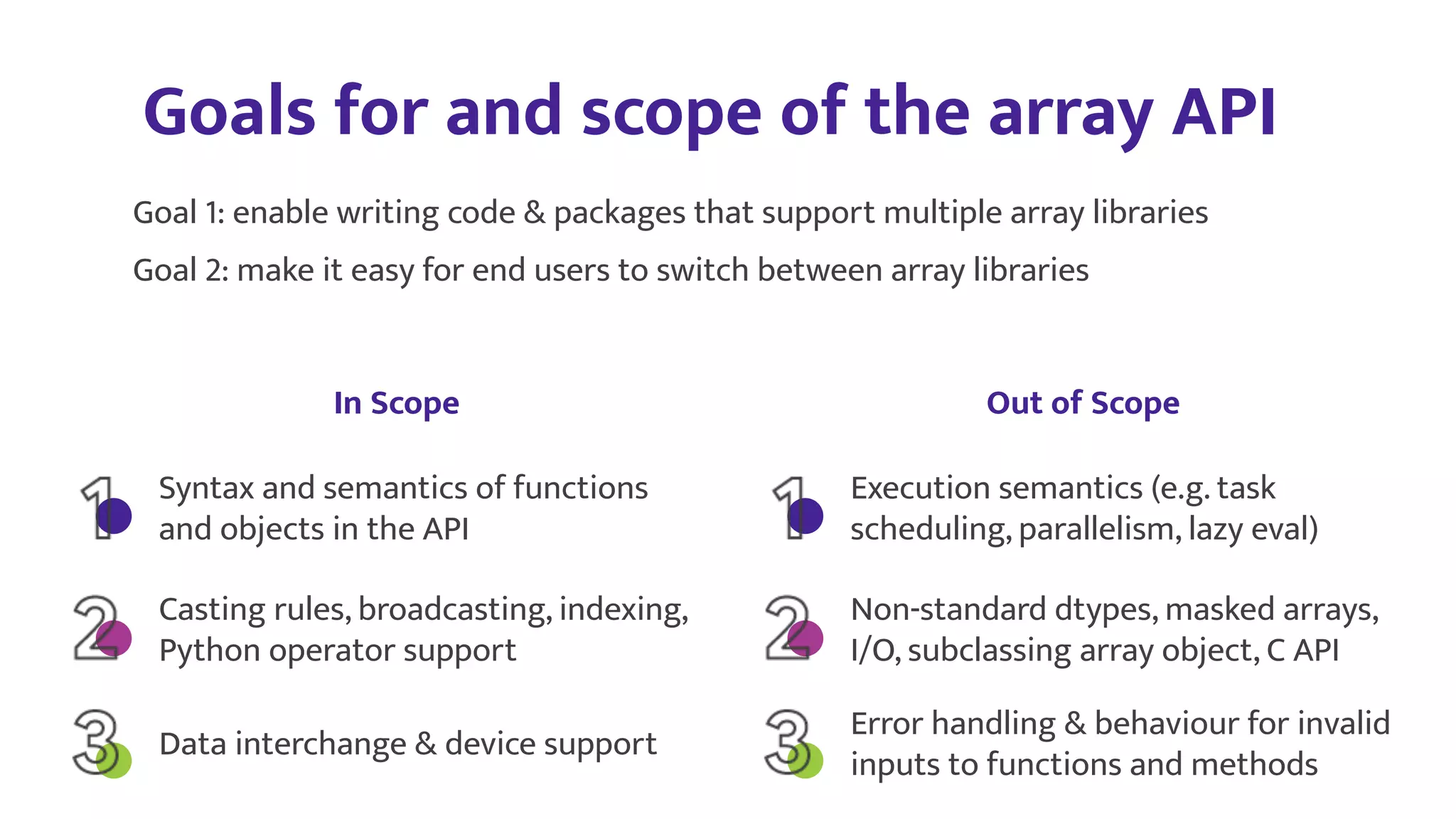
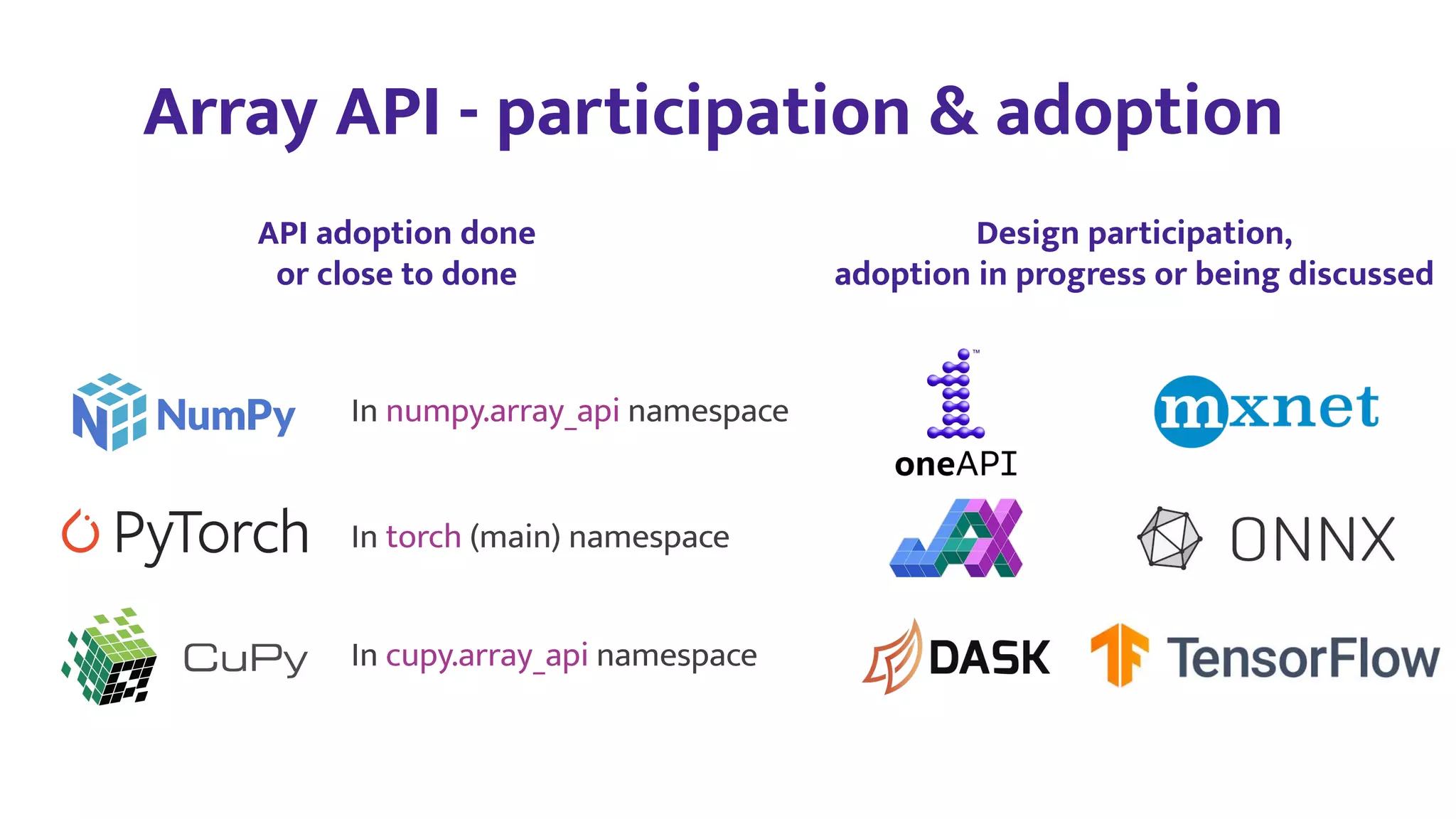
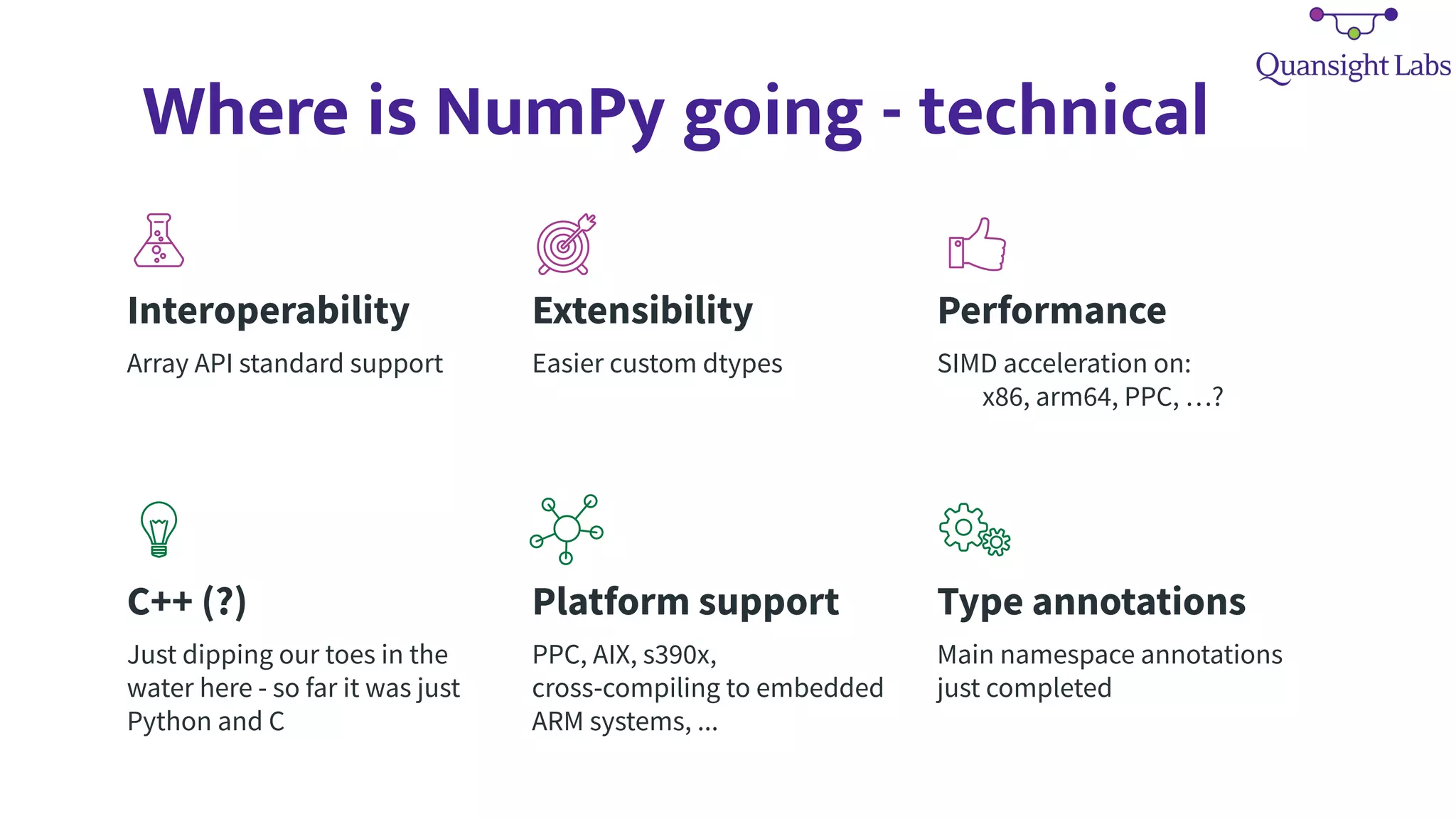
3) NumPy is working to address these issues through efforts like the Array API standardization, improved extensibility and performance, and growing autonomous teams and diversity within the community.