Download as PDF, PPTX






















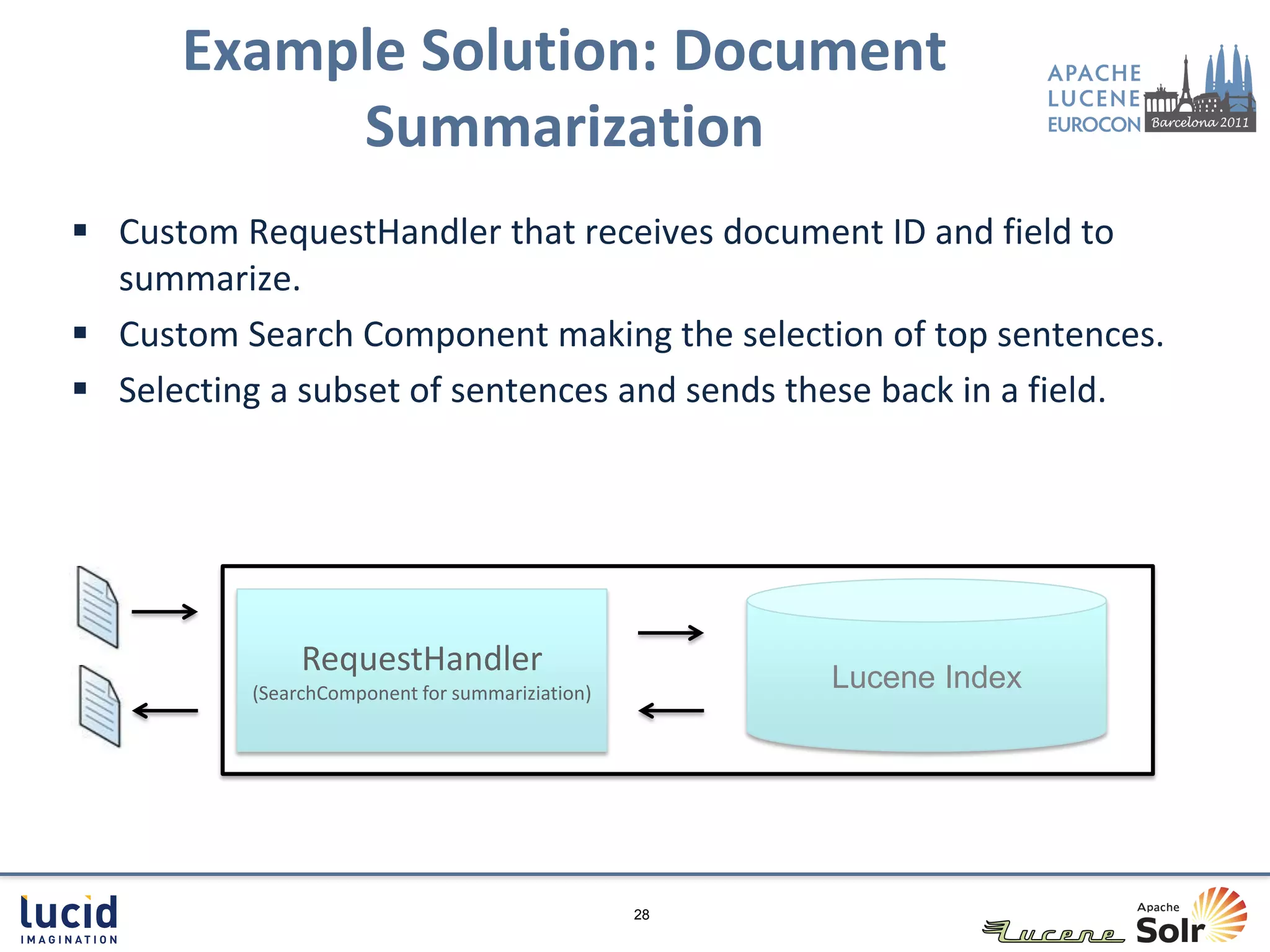
































The document discusses text analytics in enterprise search, outlining its definition, benefits, and applications such as entity extraction, document categorization, and summarization. It highlights challenges like the prevalence of unstructured data and emphasizes improvements in information discovery and findability. The author, Daniel Ling, provides insights into various frameworks and techniques, exemplifying how these can enhance user efficiency and content analysis in enterprises.






















































































