Download as PDF, PPTX



































![References
[1] Lucene/Solr Revolution EU 2013. Dublin, 6-7 November 2013.
http://www.lucenerevolution.org/
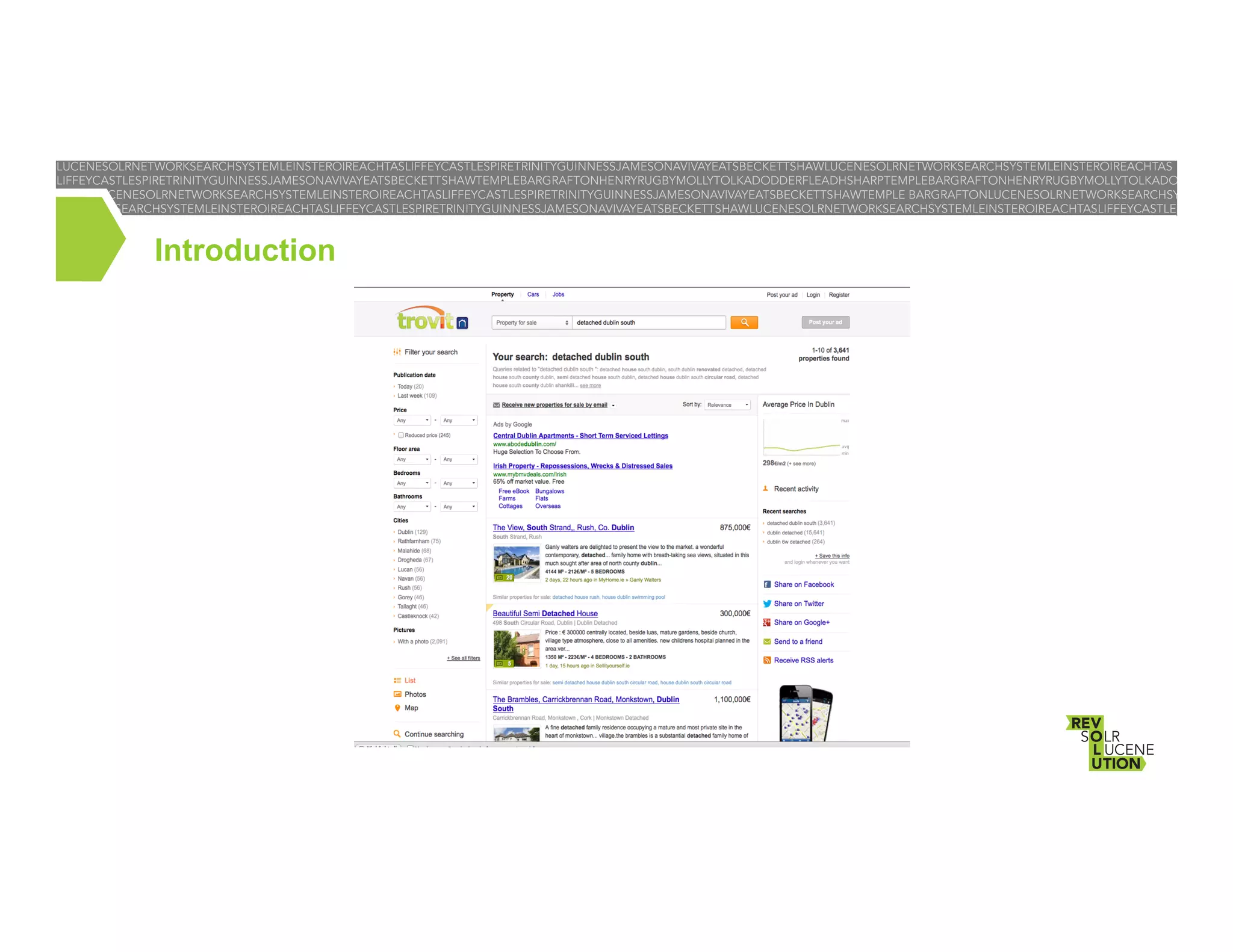
[2] Trovit – A search engine for classified ads of real estate, jobs, cars and vacation
rentals. http://www.trovit.com
[3] Apache Software Foundation. “Apache Solr” https://lucene.apache.org/solr/
[4] Apache Software Foundation. “Apache Lucene” https://lucene.apache.org
[5] Apache Software Foundation. “Spell Checking – Apache Solr Reference Guide –
Apache Software Foundation”
https://cwiki.apache.org/confluence/display/solr/Spell+Checking](https://image.slidesharecdn.com/spellcheckingintrovitslides-131118143103-phpapp01/75/Spellchecking-in-Trovit-Implementing-a-Contextual-Multi-language-Spellchecker-for-Classified-Ads-41-2048.jpg)








































![References
[1] Lucene/Solr Revolution EU 2013. Dublin, 6-7 November 2013.
http://www.lucenerevolution.org/
[2] Trovit – A search engine for classified ads of real estate, jobs, cars and vacation
rentals. http://www.trovit.com
[3] Apache Software Foundation. “Apache Solr” https://lucene.apache.org/solr/
[4] Apache Software Foundation. “Apache Lucene” https://lucene.apache.org
[5] Apache Software Foundation. “Spell Checking – Apache Solr Reference Guide –
Apache Software Foundation”
https://cwiki.apache.org/confluence/display/solr/Spell+Checking](https://crownmelresort.com/image.slidesharecdn.com/spellcheckingintrovitslides-131118143103-phpapp01/75/Spellchecking-in-Trovit-Implementing-a-Contextual-Multi-language-Spellchecker-for-Classified-Ads-41-2048.jpg)

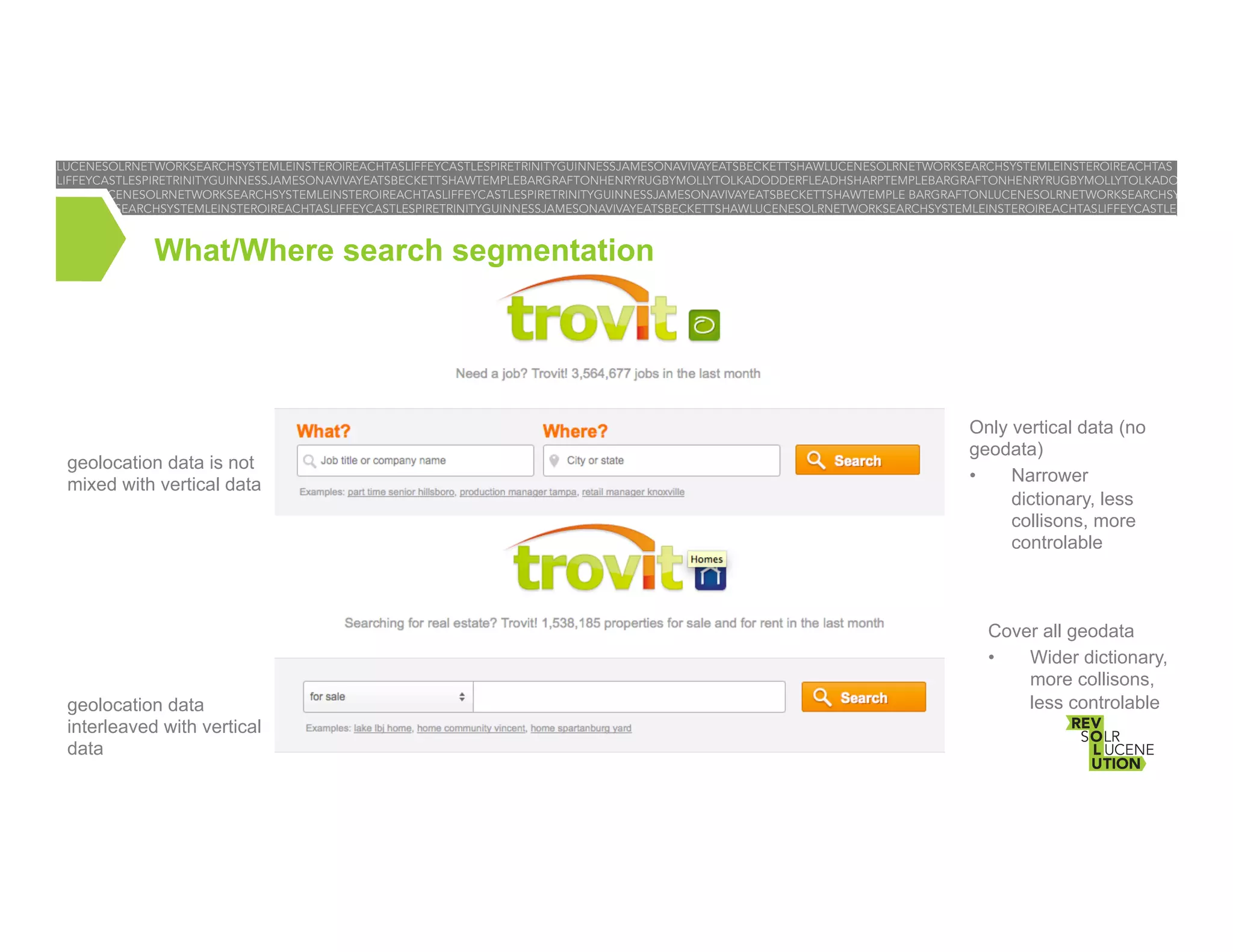
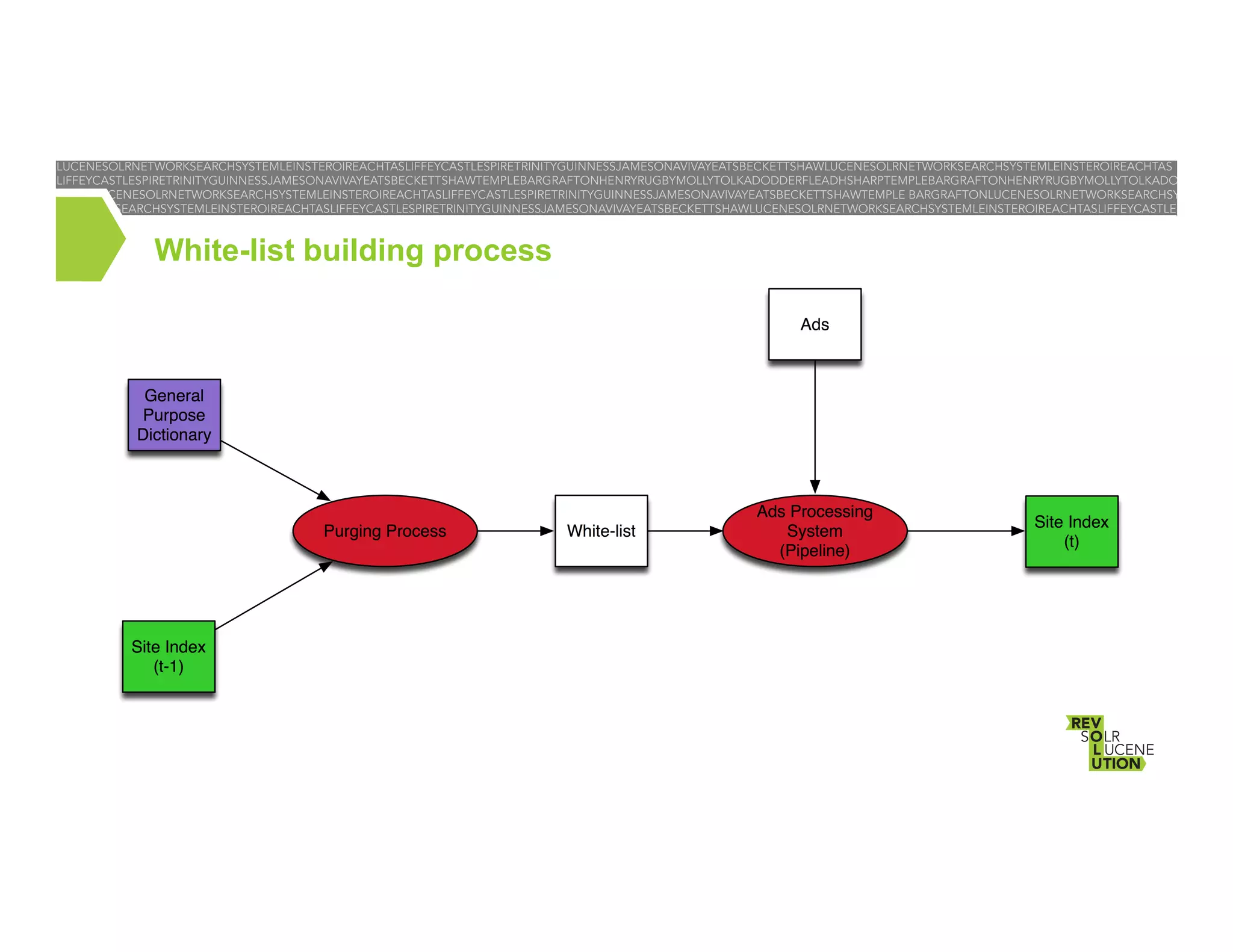
The document discusses the implementation of a multi-language contextual spellchecker for classified ads at Trovit, focusing on tailoring dictionaries based on user context, including language and type of ads. It highlights challenges in the document corpus, such as inconsistencies and noisy content from third-party sources that hinder spellchecking accuracy. The conclusion emphasizes ongoing improvements to the spellchecking process and future expansions to cover additional contexts.

































































