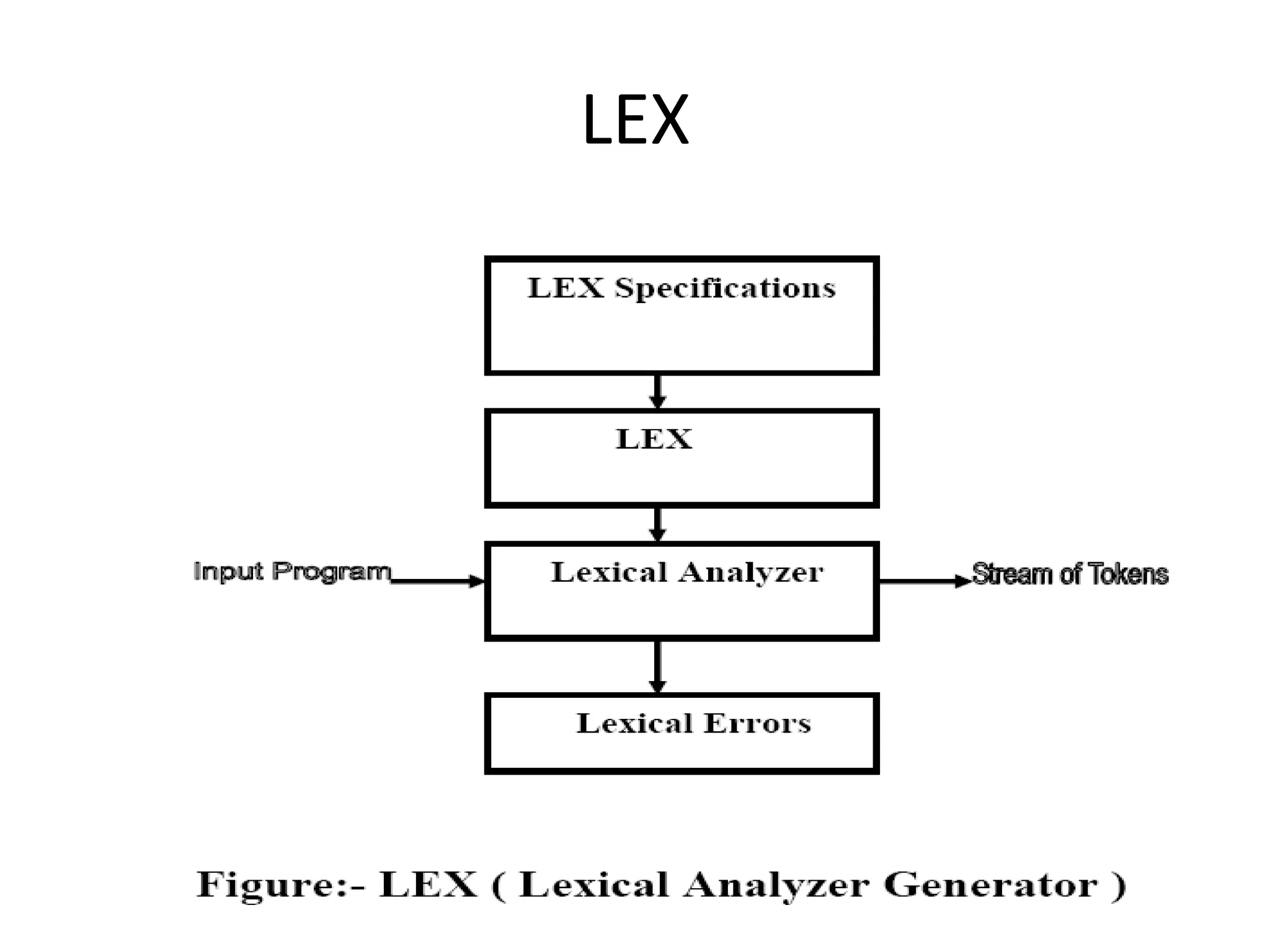
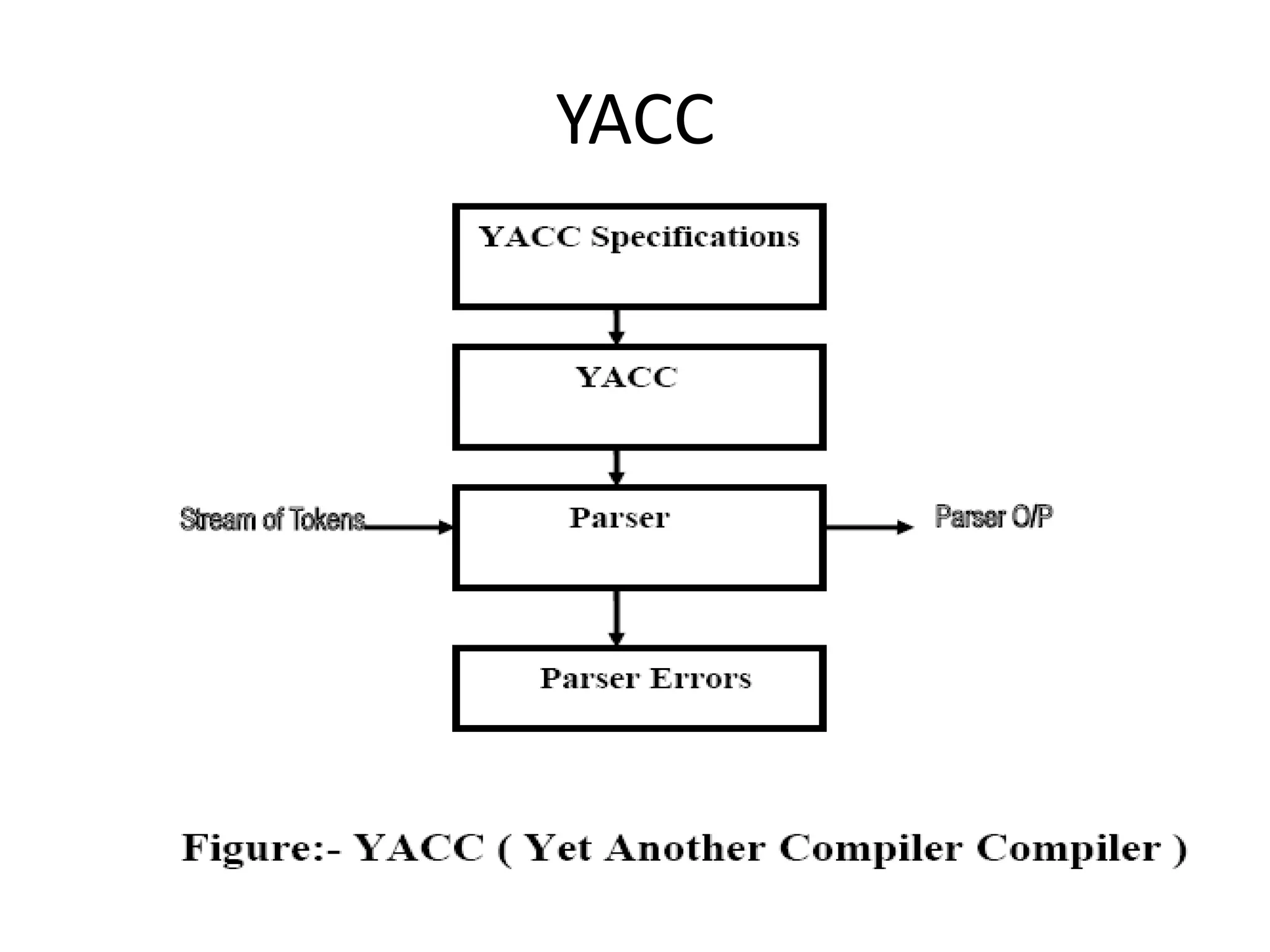
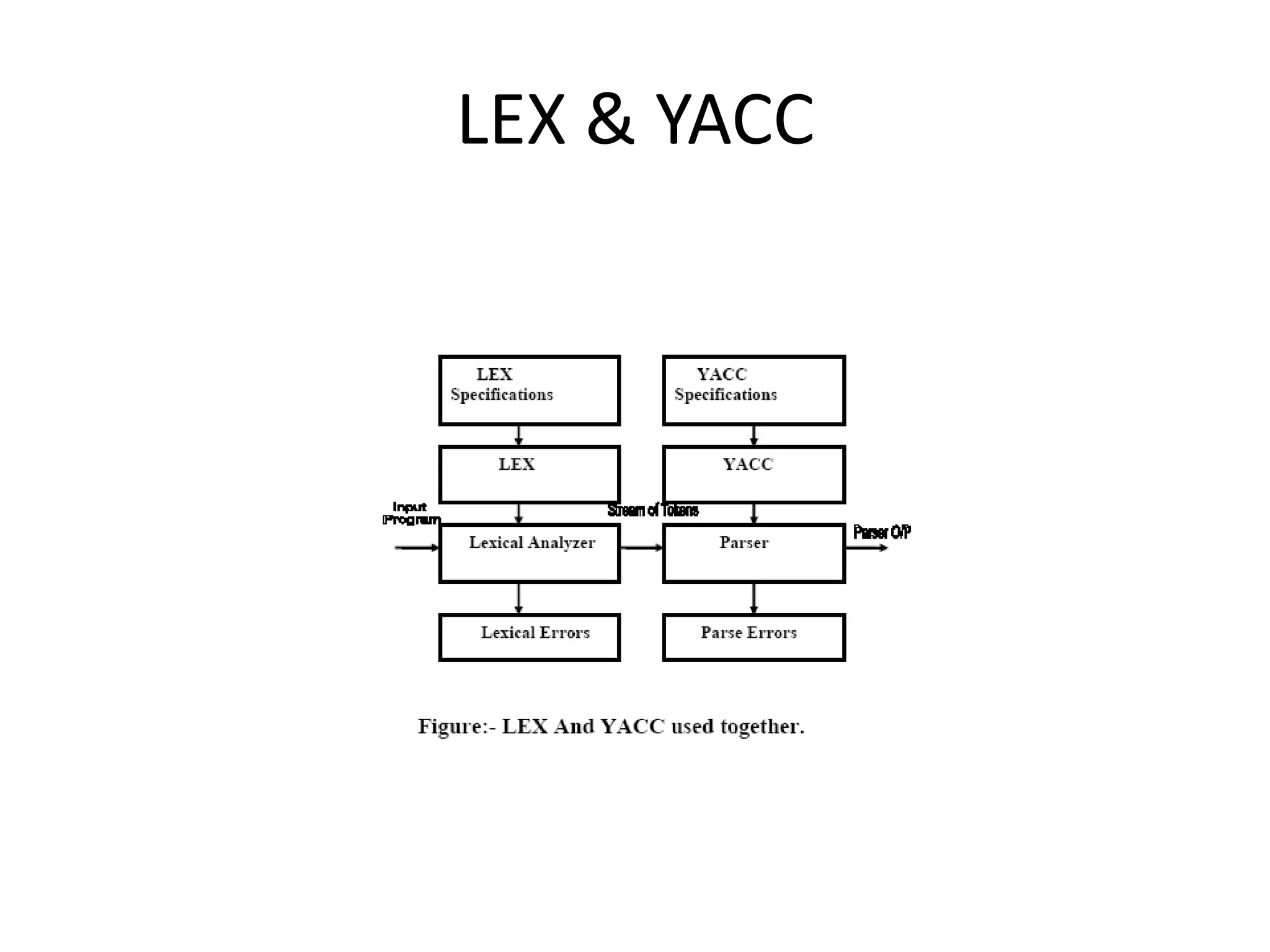
LEX and YACC are software development tools used for lexical analysis and parsing. LEX is a lexical analyzer generator that accepts an input specification defining lexical units and associated semantic actions. It generates a translator containing tables of lexical units and tokens. YACC is a parser generator that accepts a grammar specification and actions for the language being compiled. It produces a bottom-up parser that uses shift-reduce parsing. These tools allow programmers to specify the syntax of a language and generate code to analyze programs in that language.

























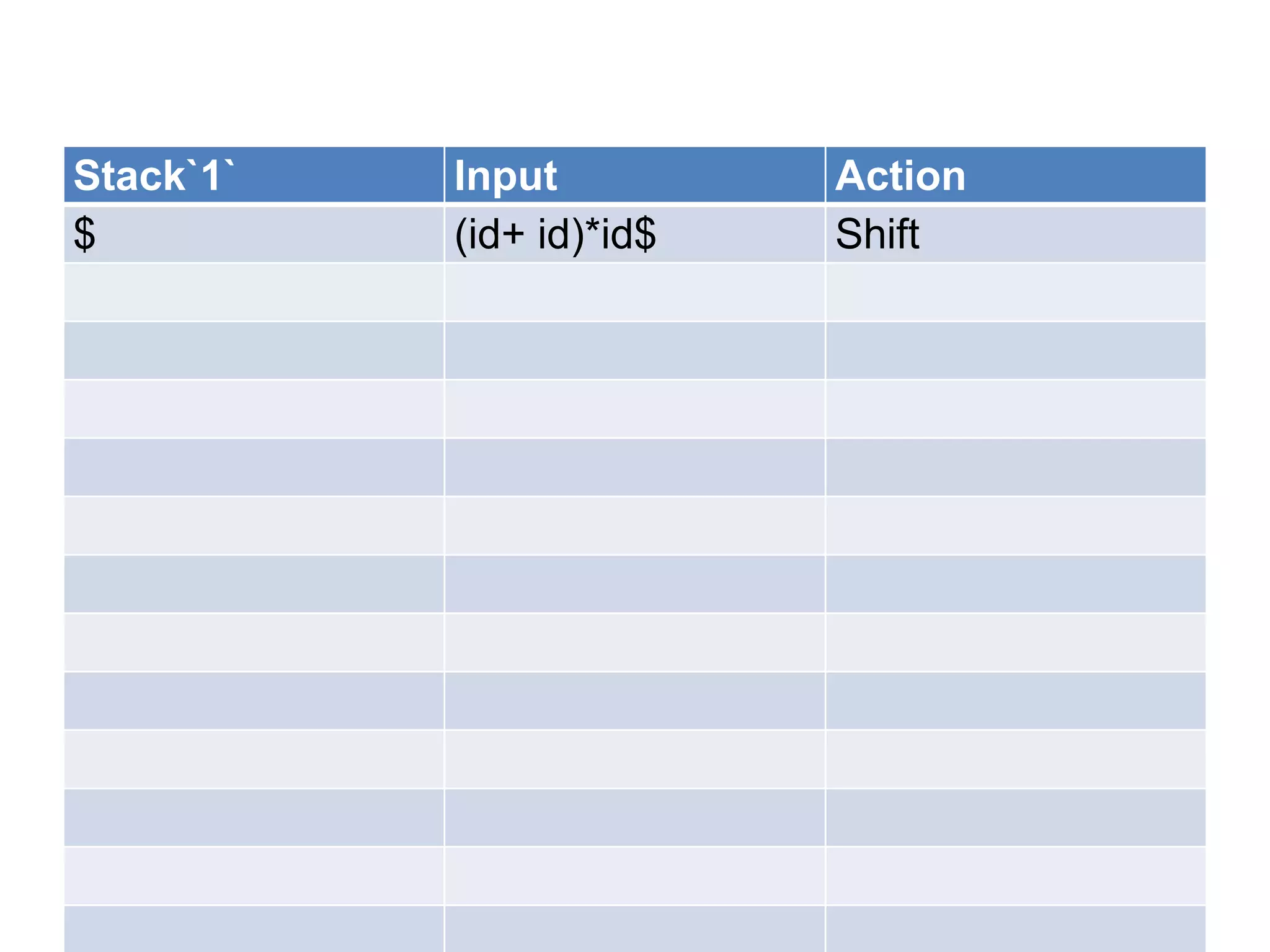
![Bottom–up Parsing [Shift Reduce
Parser]
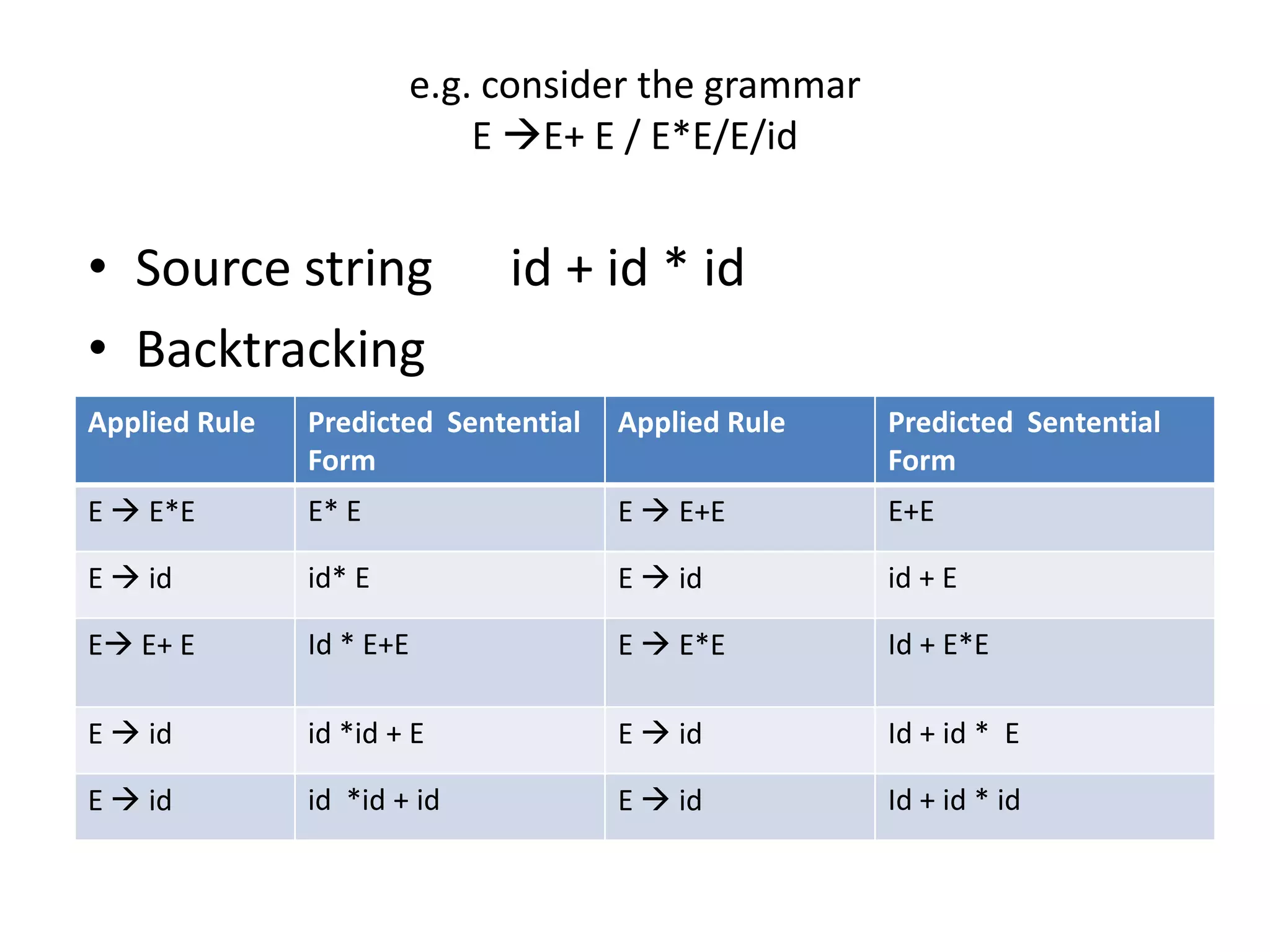
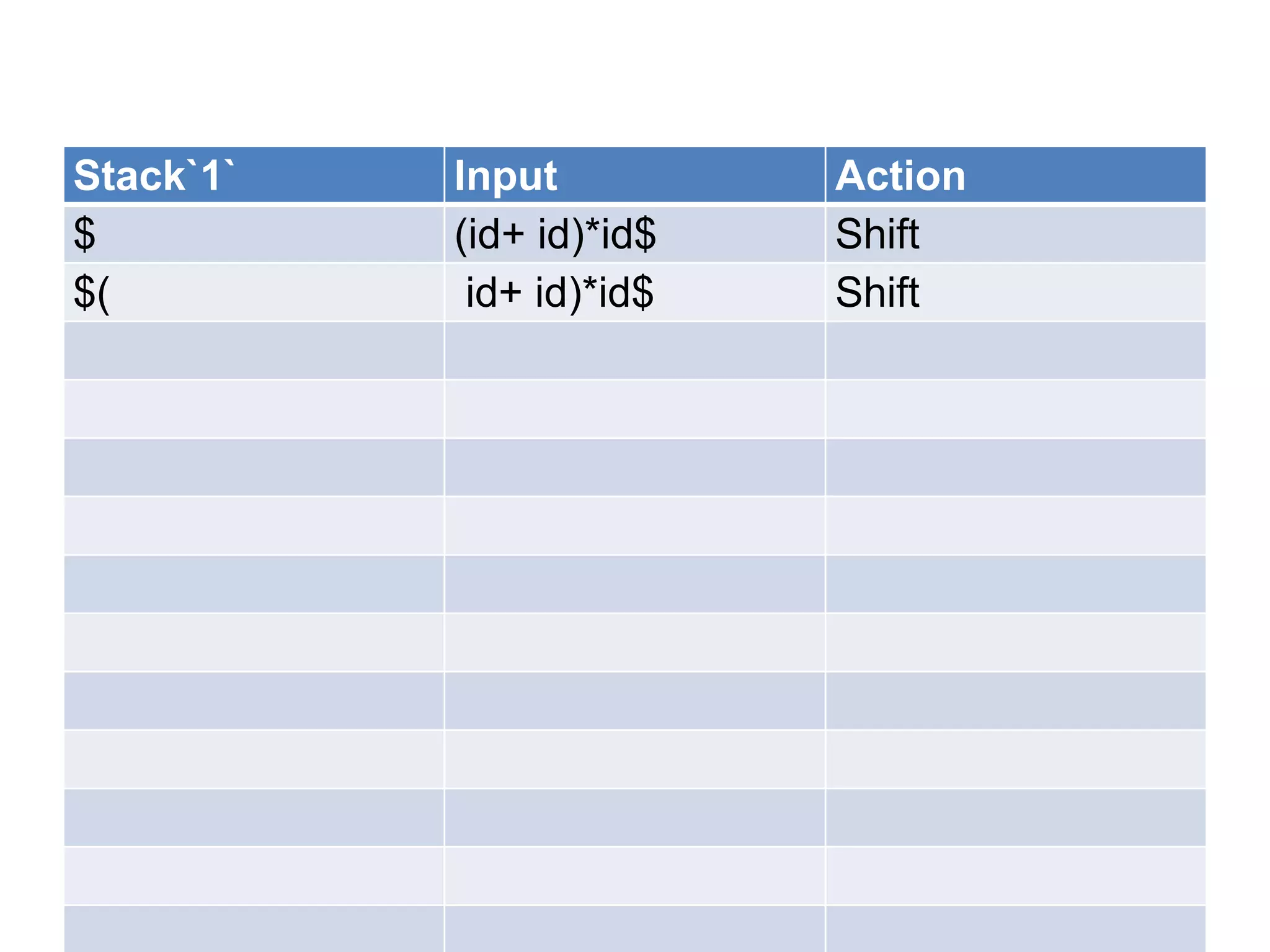
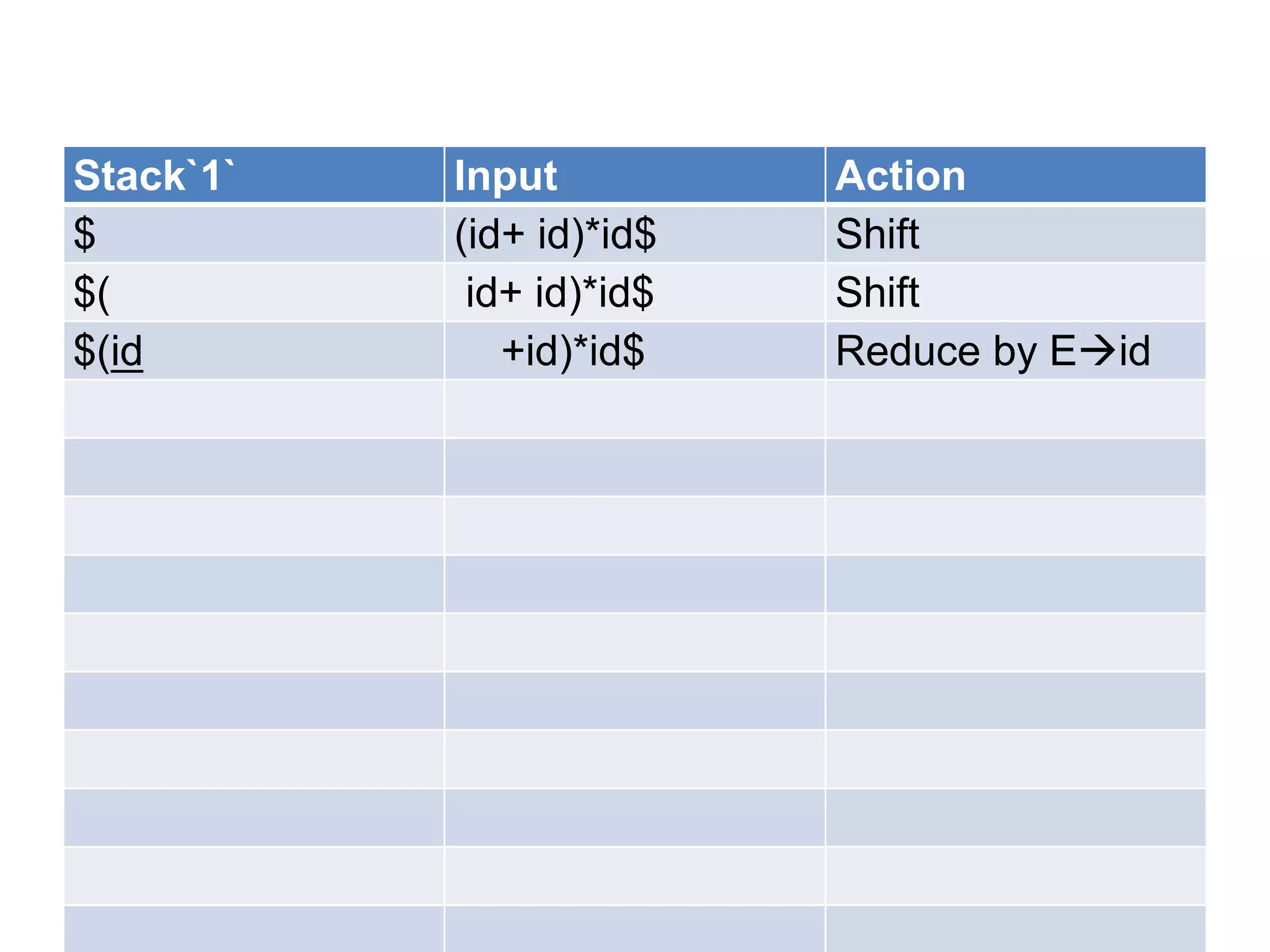
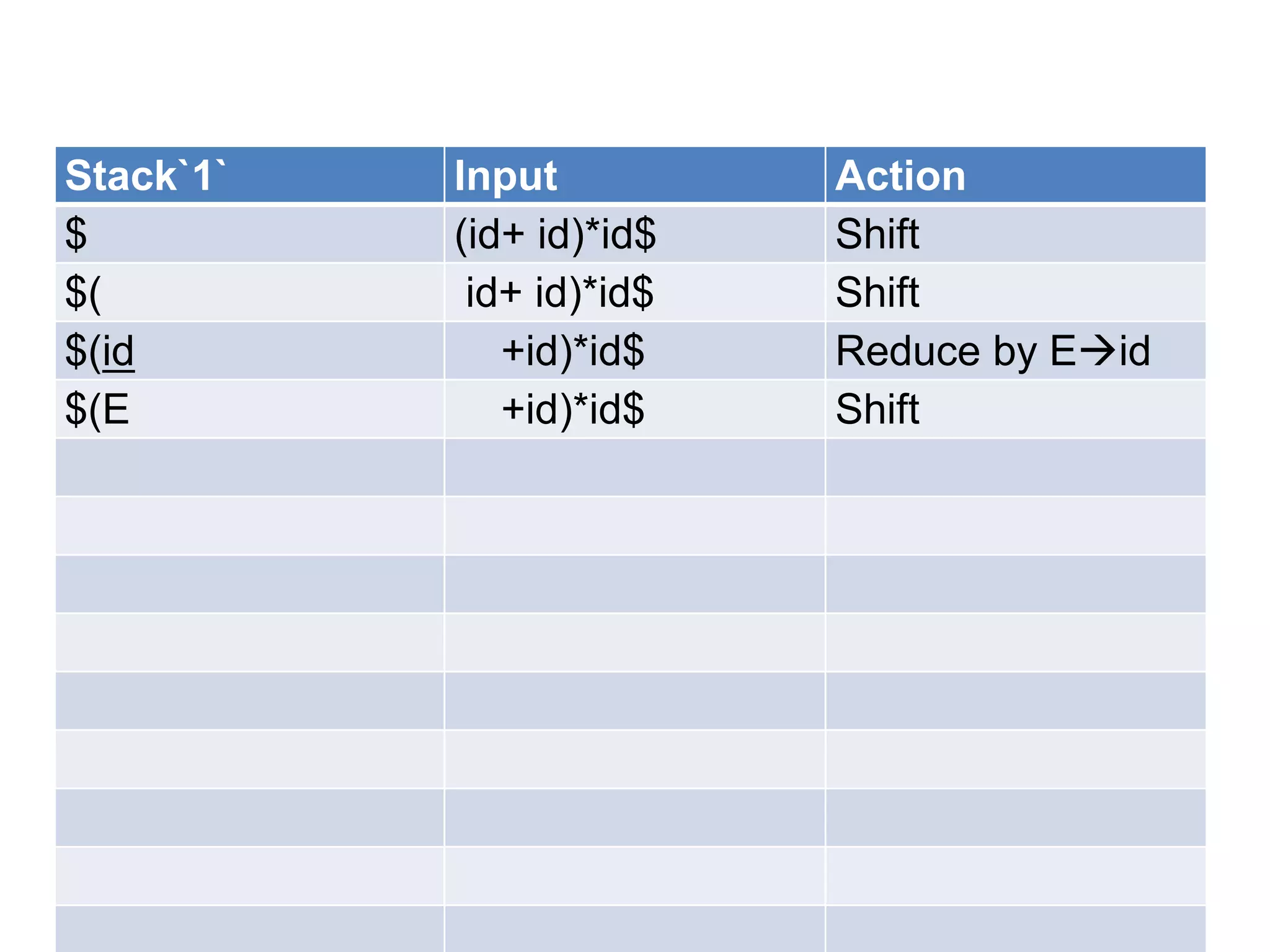
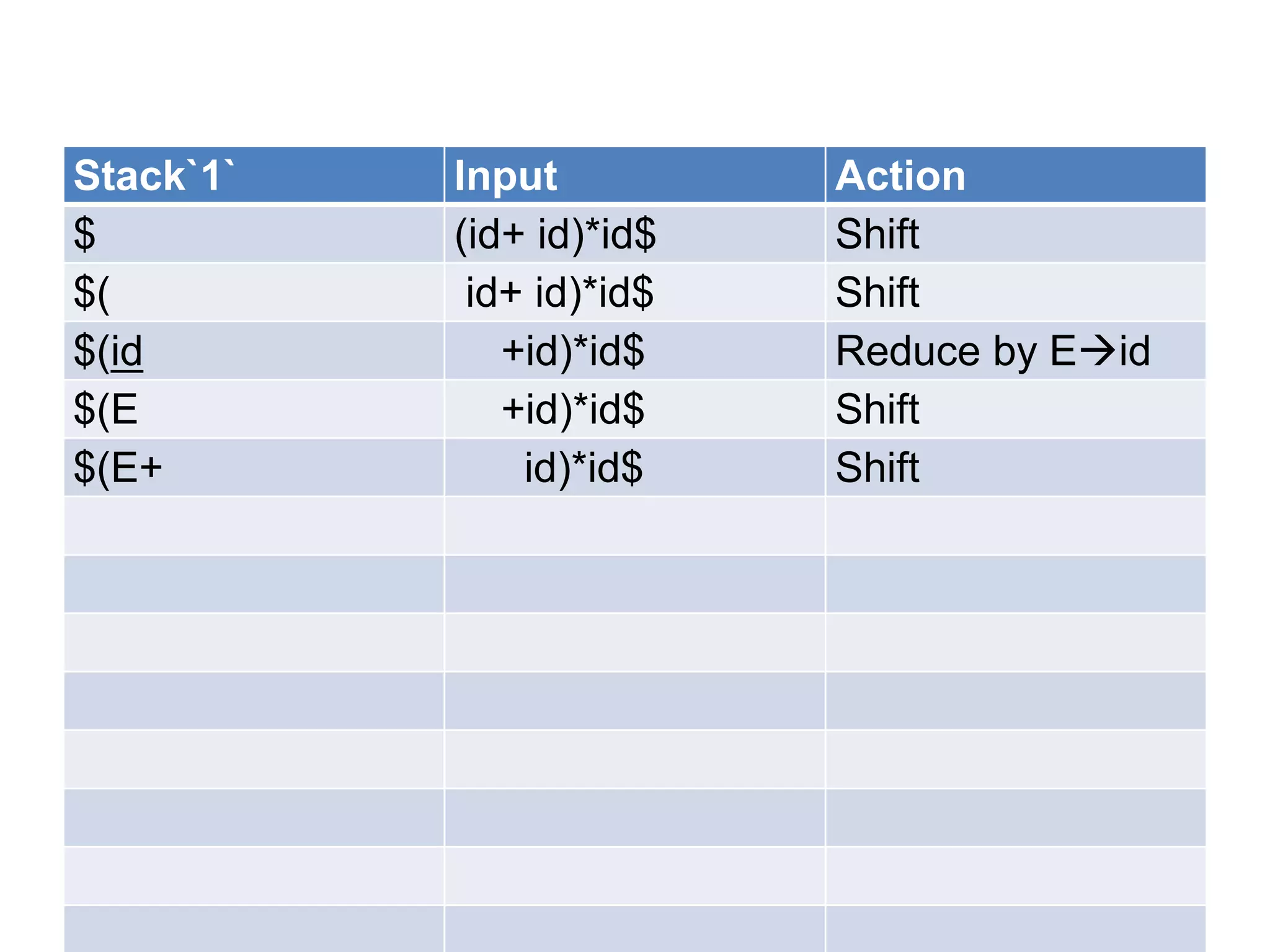
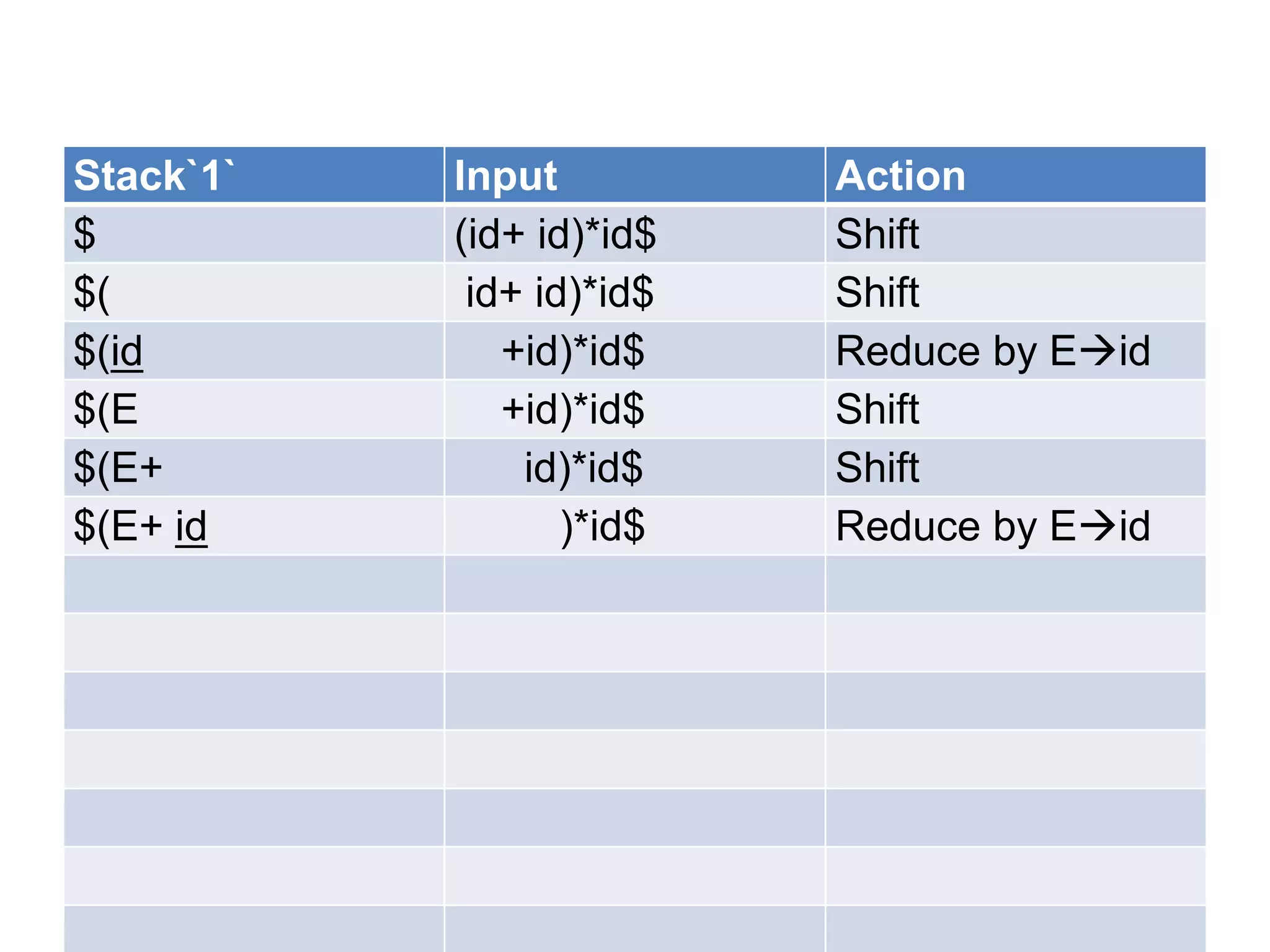
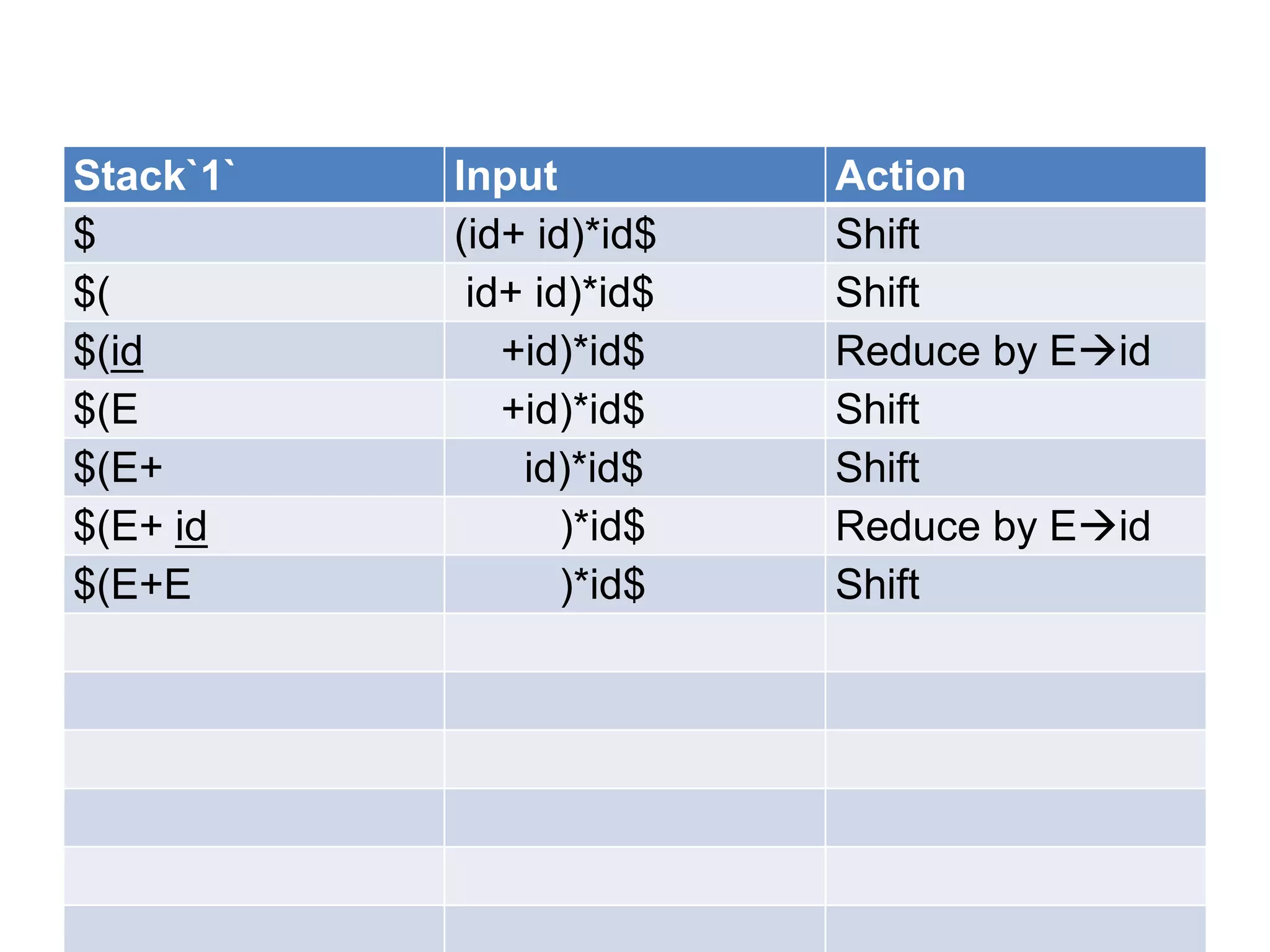
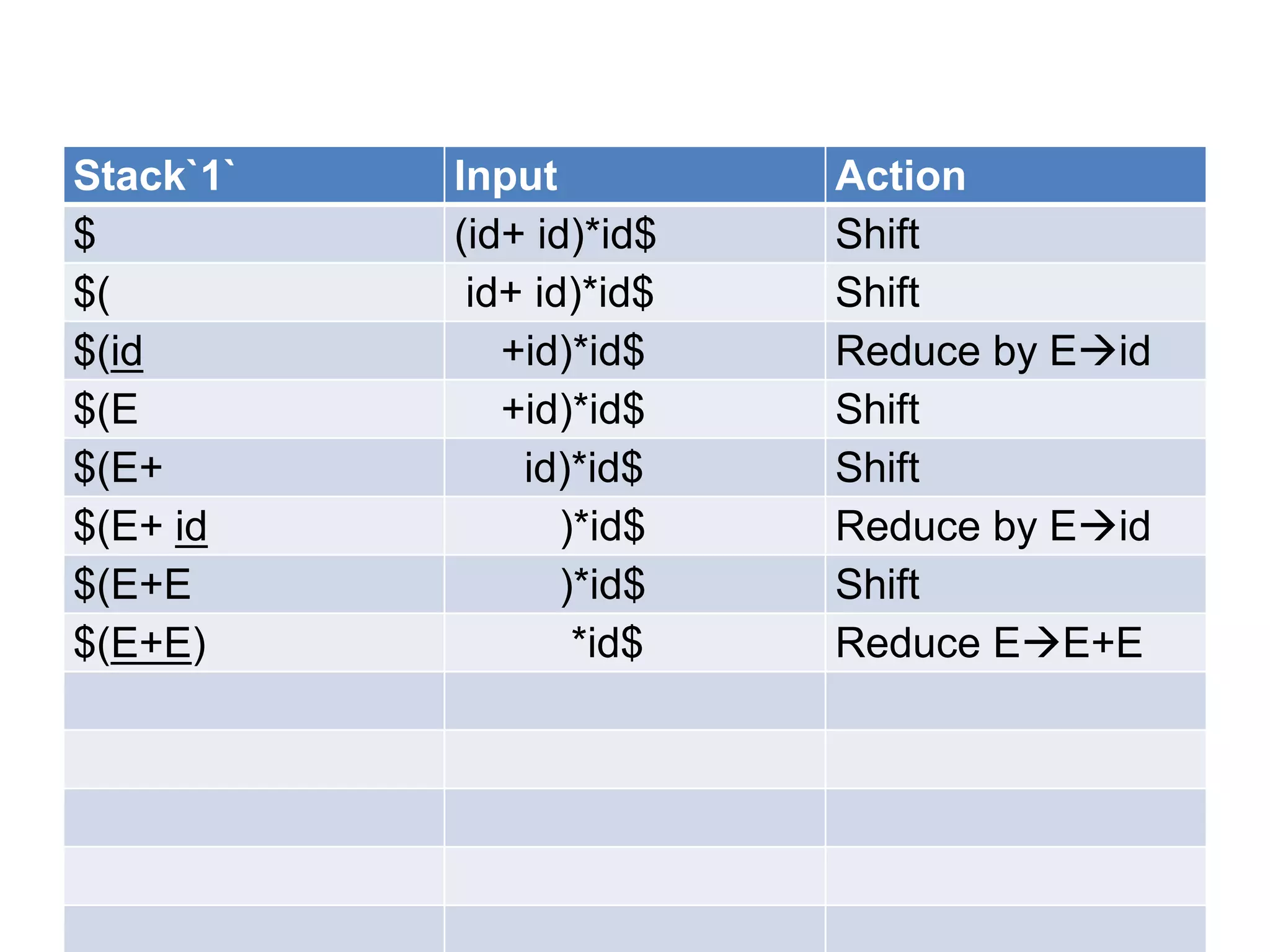
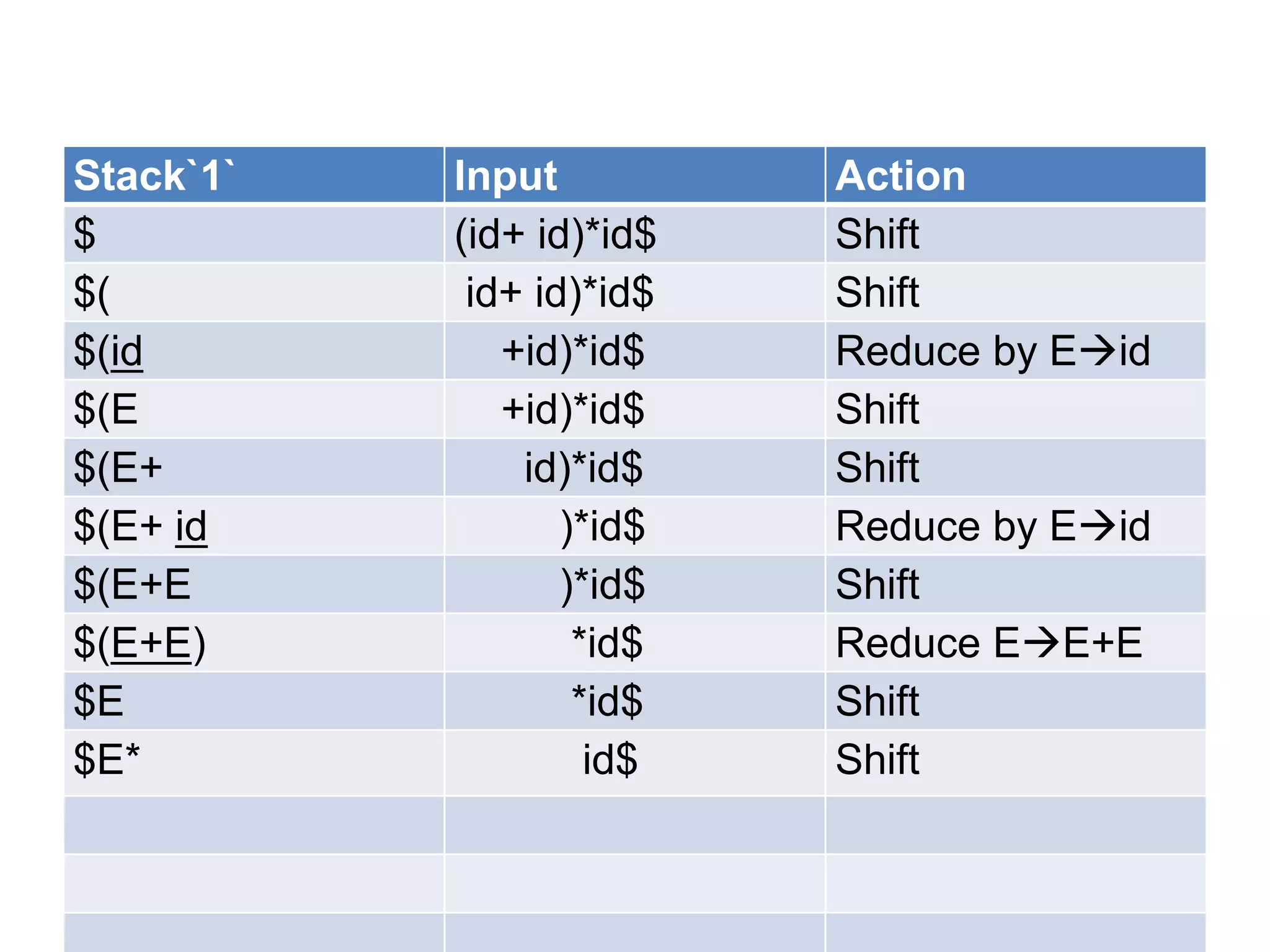
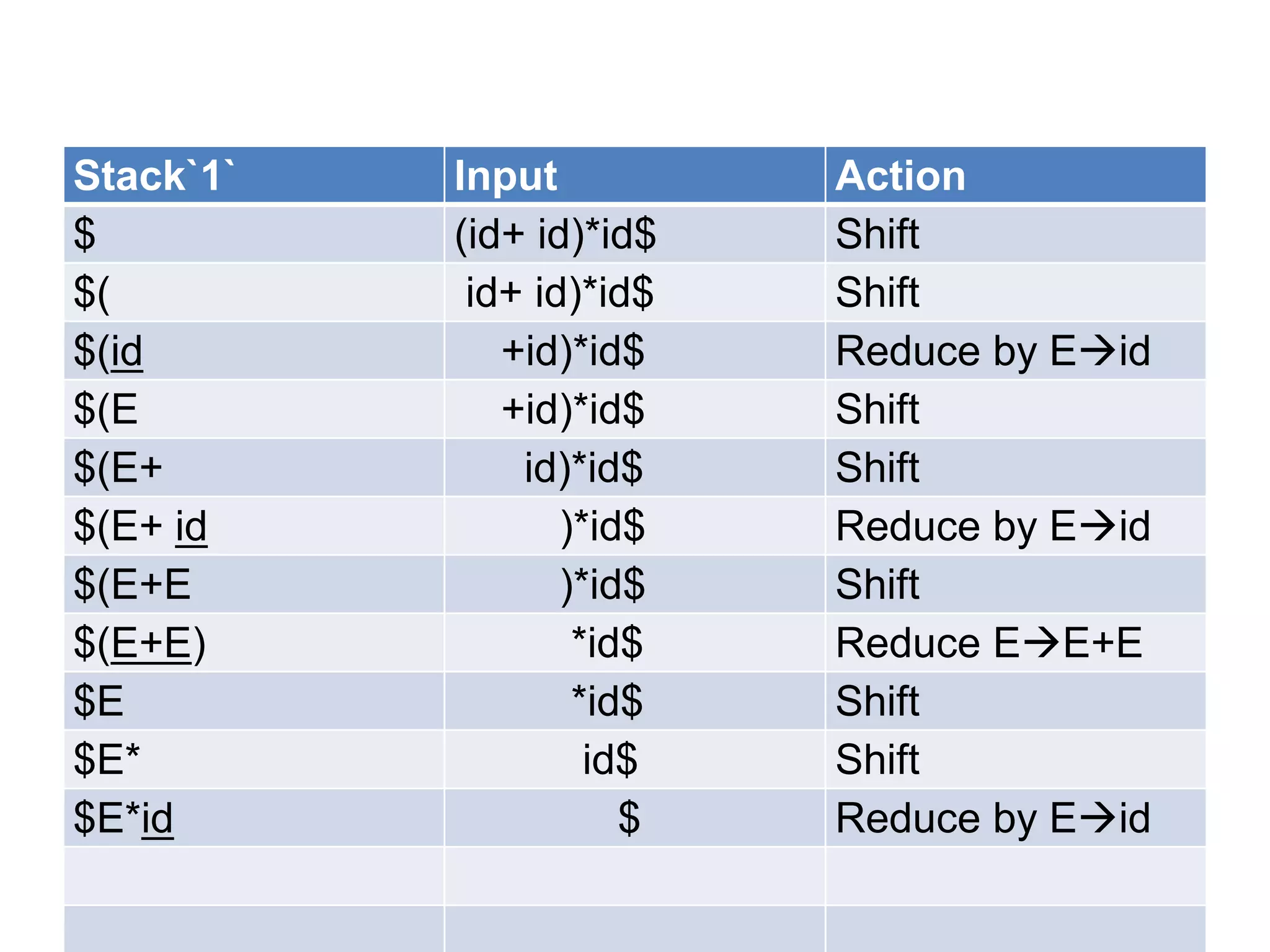
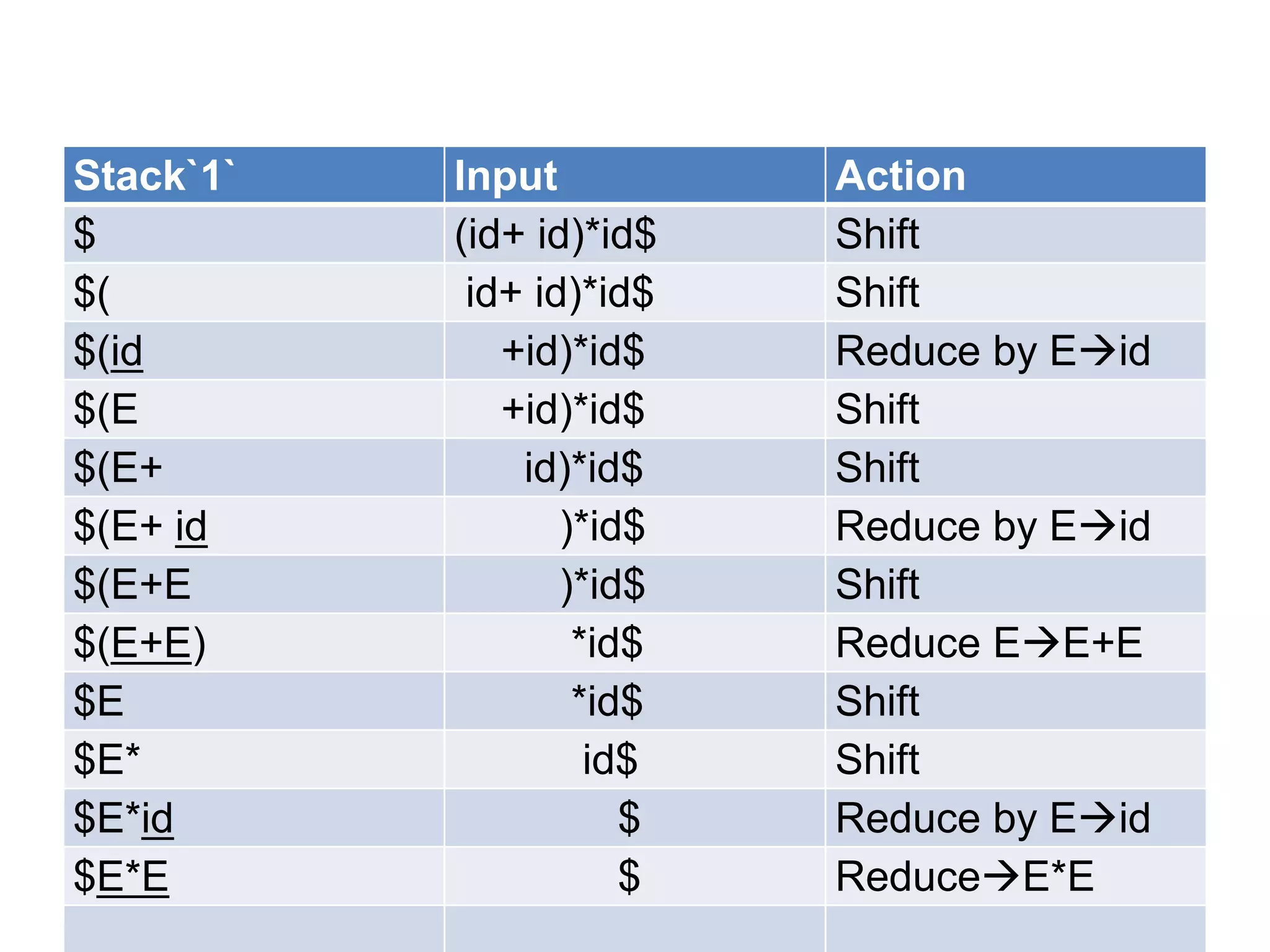
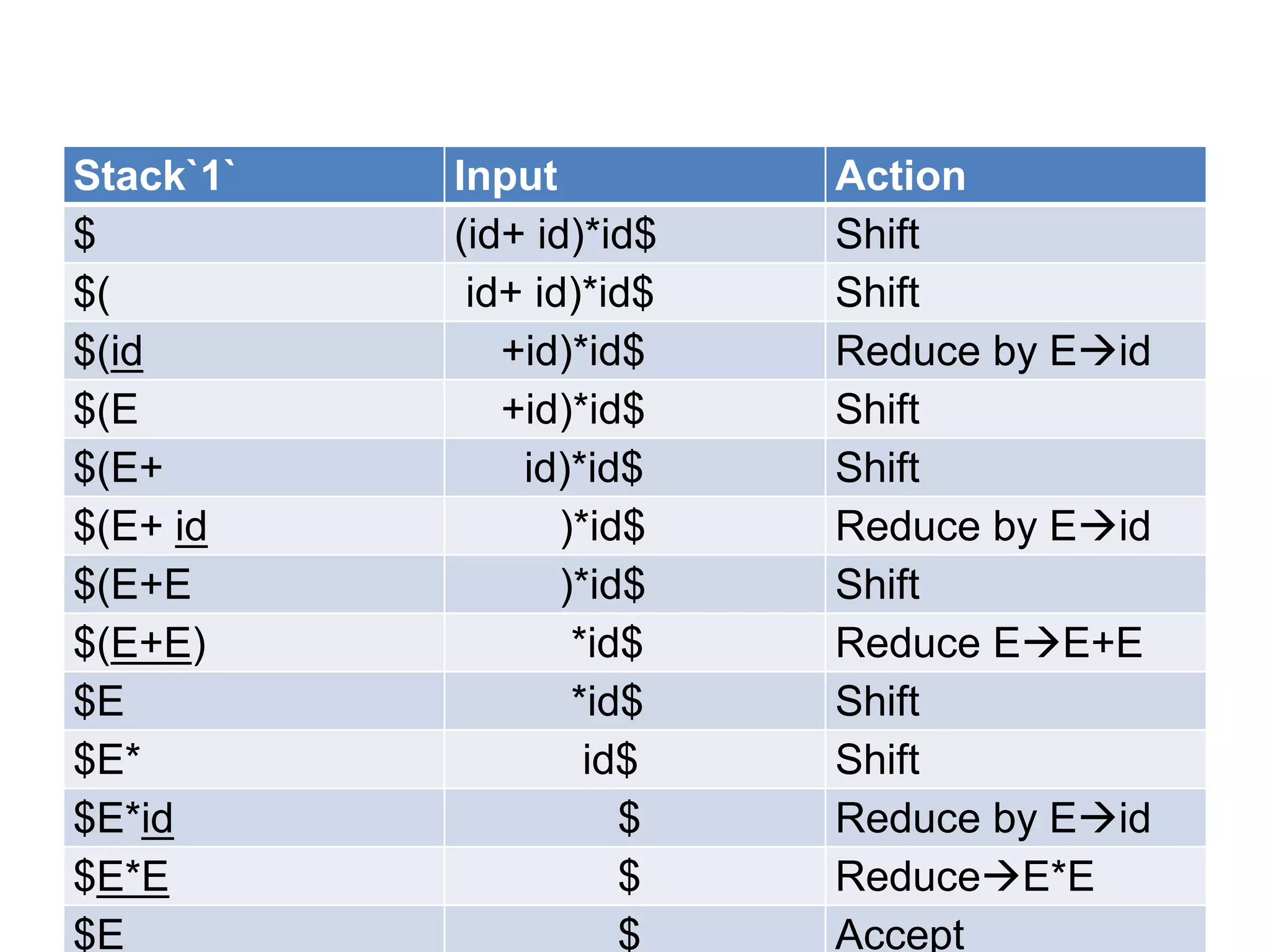
• A bottom up parser attempt to develop the
syntax tree for an input string through a
sequence of reductions.
• If the input string can be reduced to the
distinguished symbol , the string is valid. If not
, error would have be detected and indicated
during the process of reduction itself.
• Attempts at reduction starts with the first
symbol in the string and process to the right.](https://image.slidesharecdn.com/unitiv-111206005201-phpapp01/75/System-Programming-Unit-IV-33-2048.jpg)









































![Bottom–up Parsing [Shift Reduce
Parser]
• A bottom up parser attempt to develop the
syntax tree for an input string through a
sequence of reductions.
• If the input string can be reduced to the
distinguished symbol , the string is valid. If not
, error would have be detected and indicated
during the process of reduction itself.
• Attempts at reduction starts with the first
symbol in the string and process to the right.](https://crownmelresort.com/image.slidesharecdn.com/unitiv-111206005201-phpapp01/75/System-Programming-Unit-IV-33-2048.jpg)





































































![Cd2 [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/cd2autosaved-161231072301-thumbnail.jpg?width=640&height=640&fit=bounds)








































