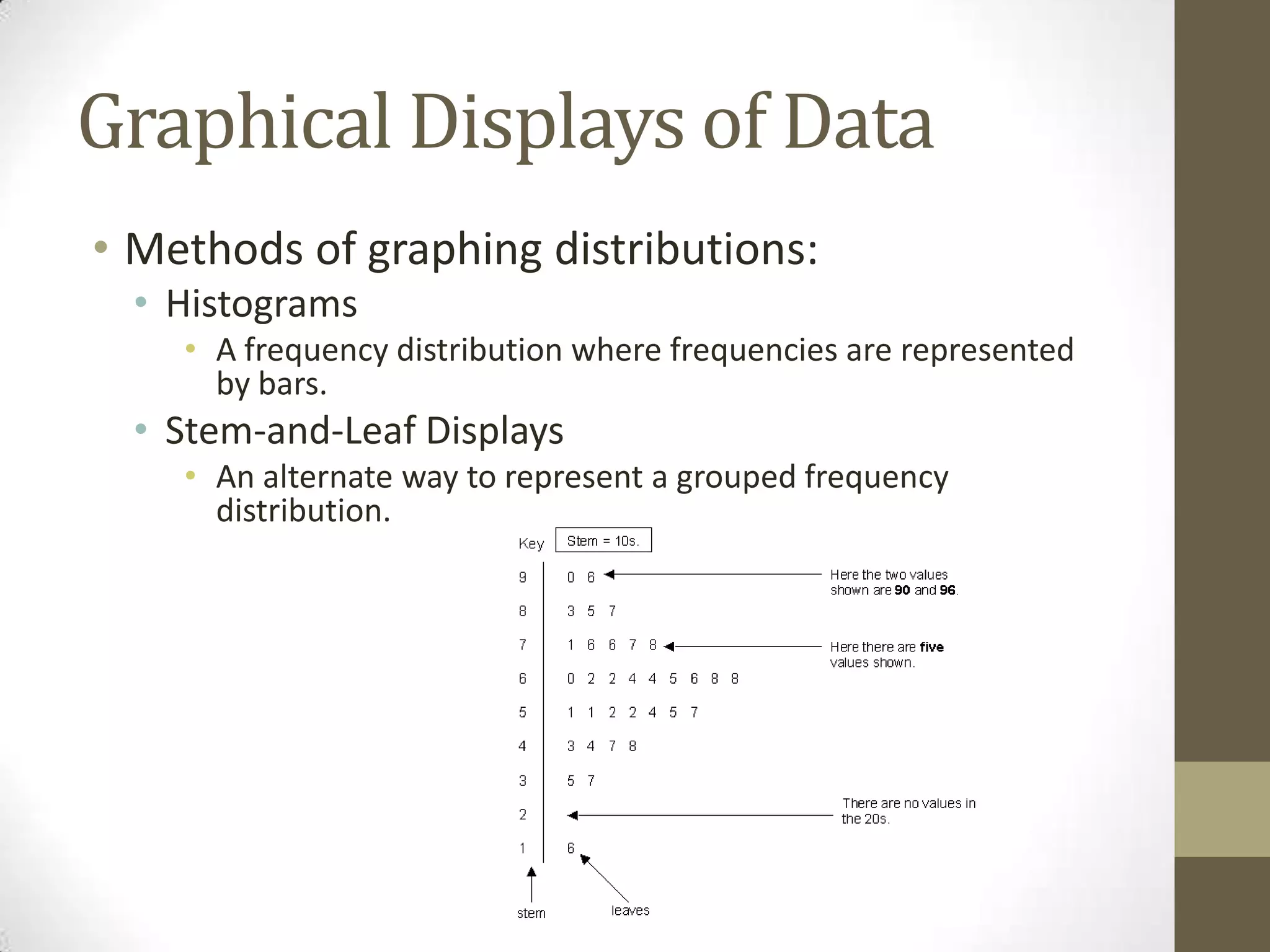
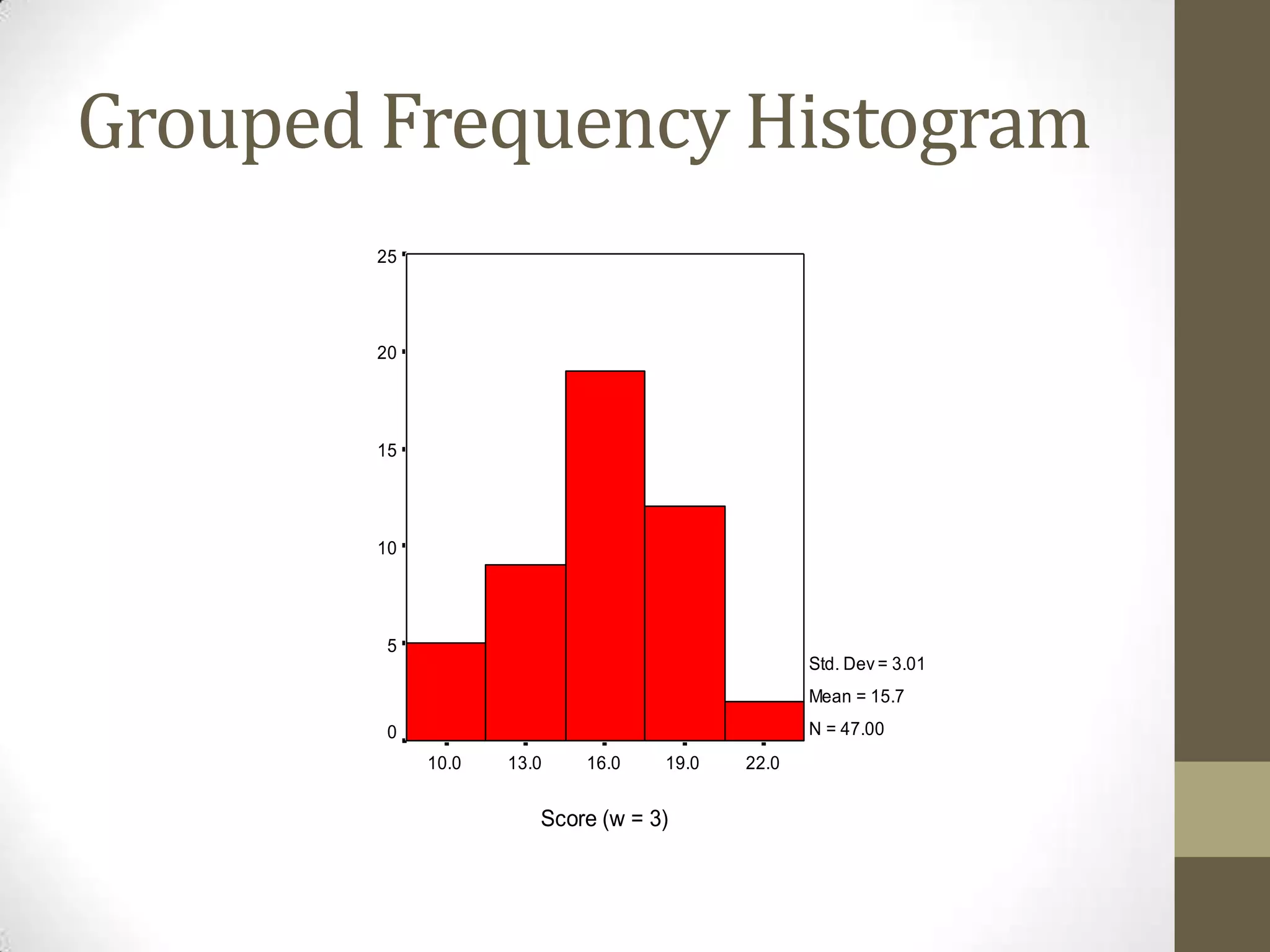
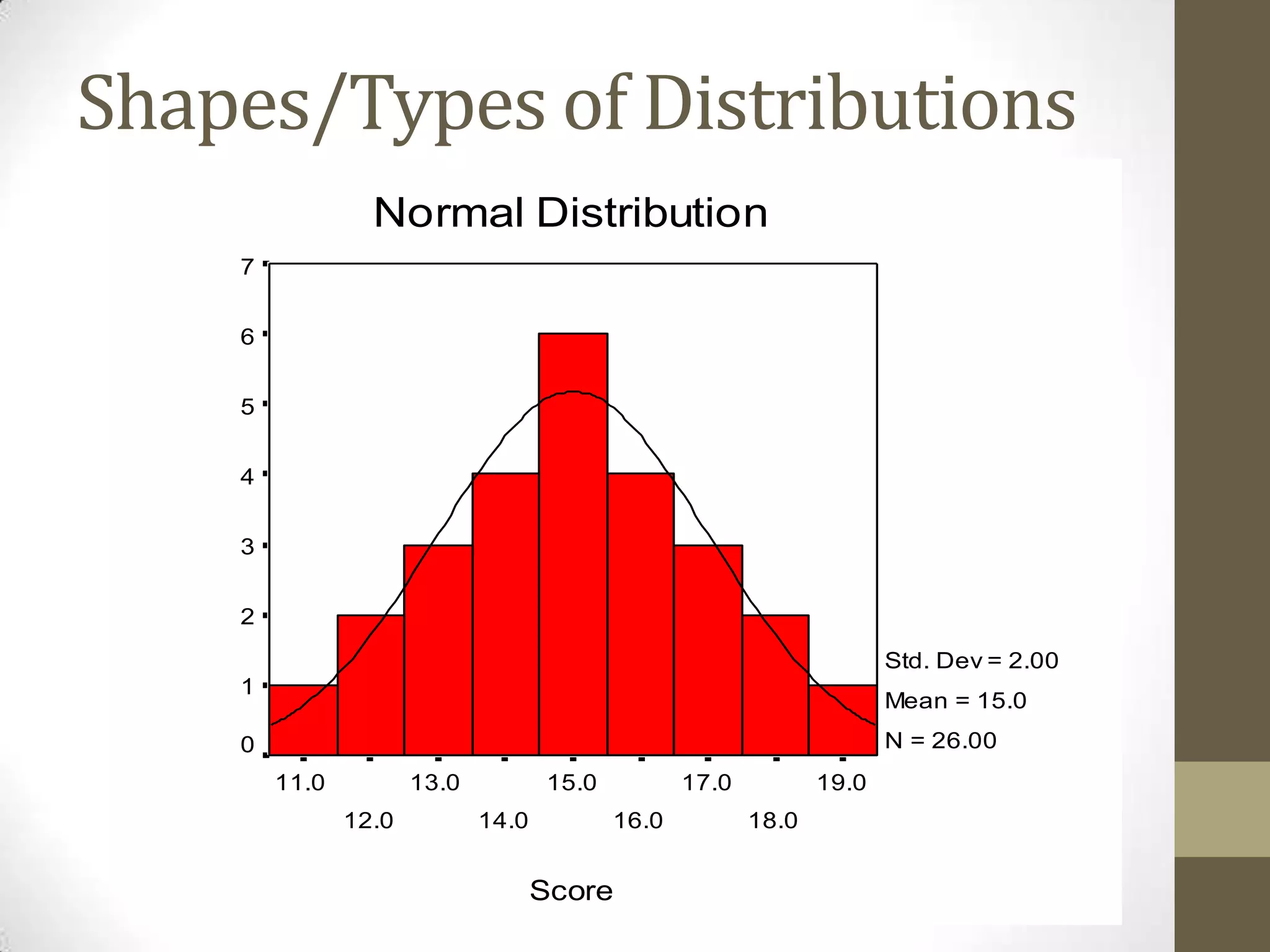
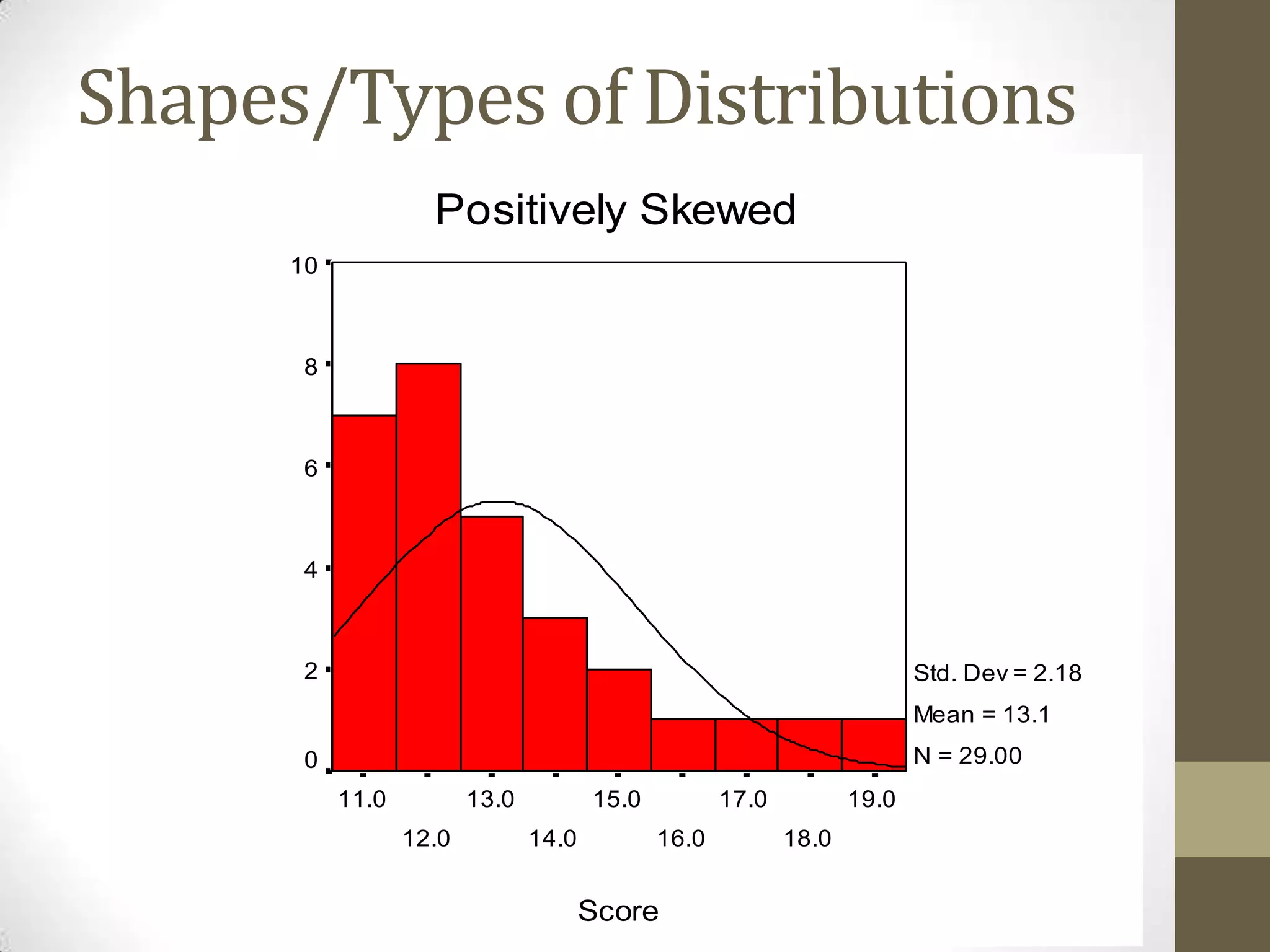
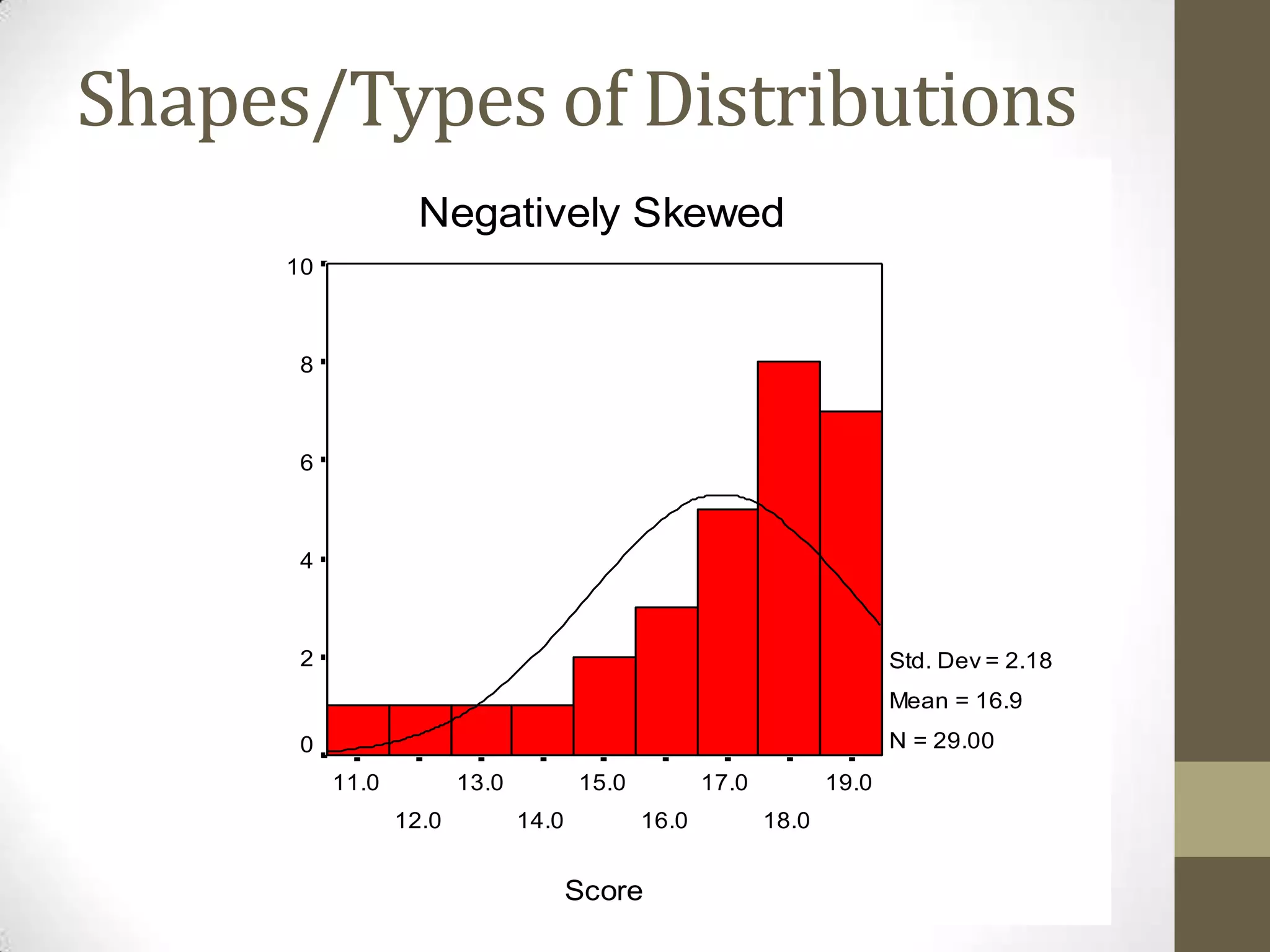
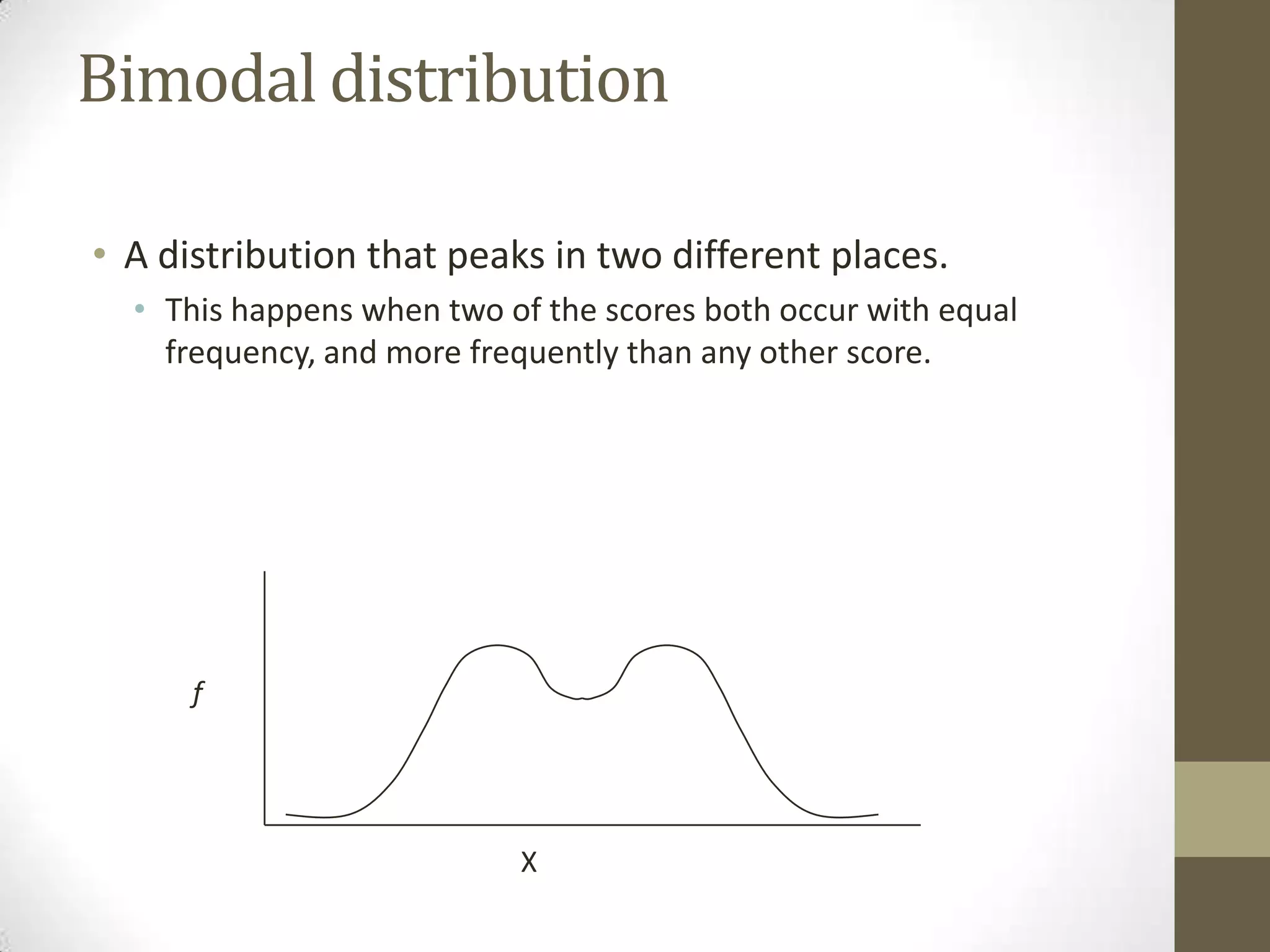
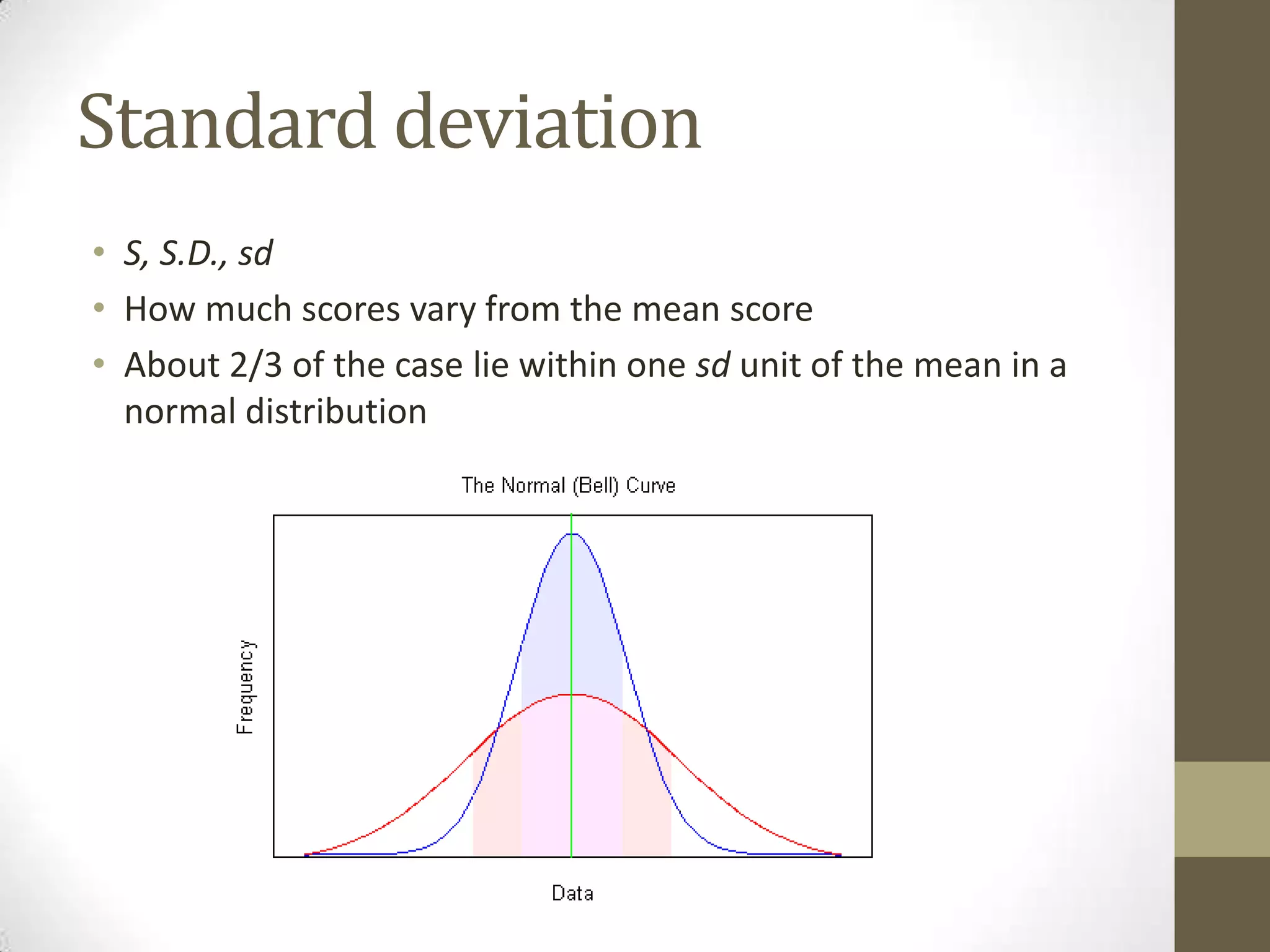
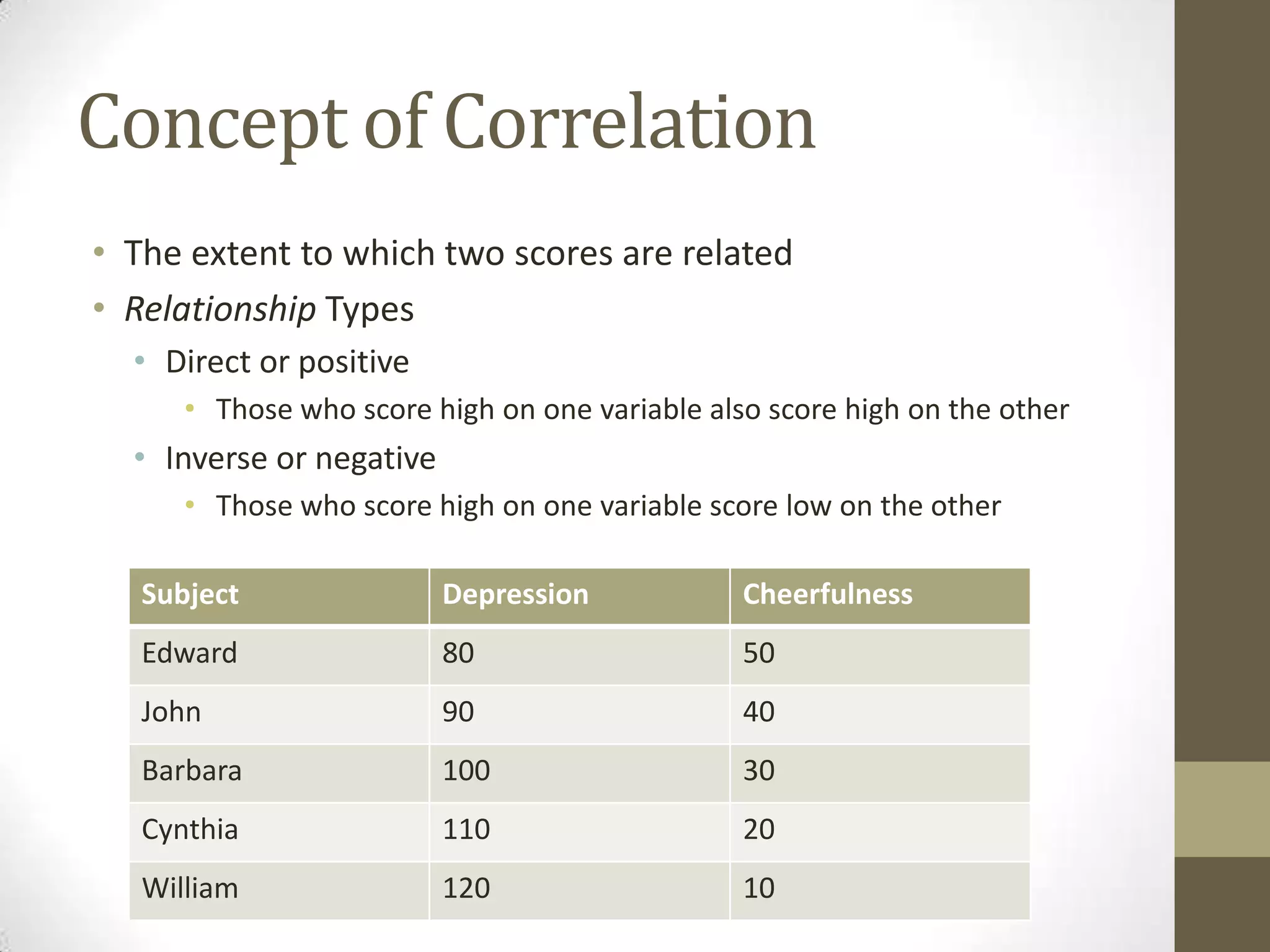
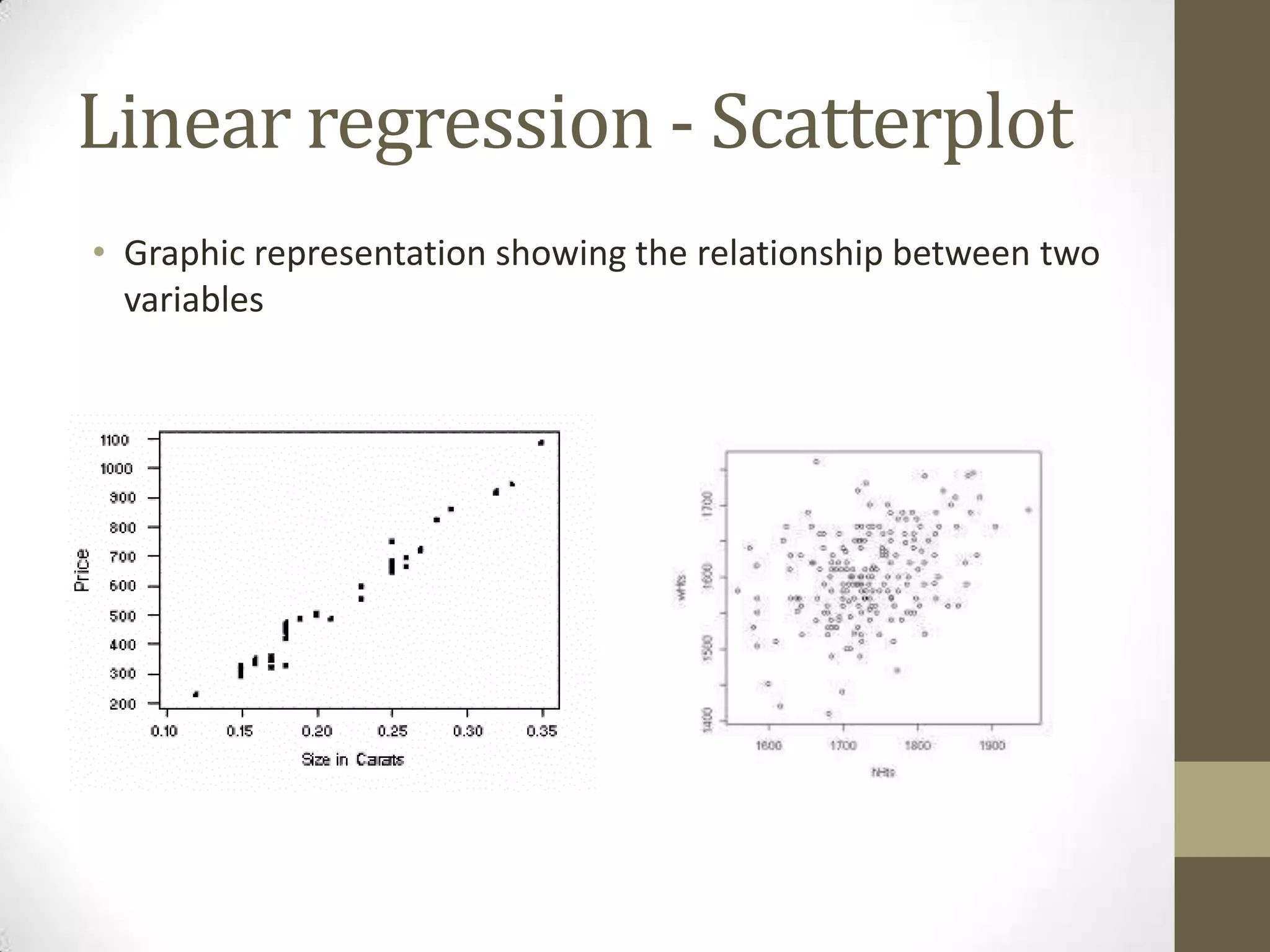
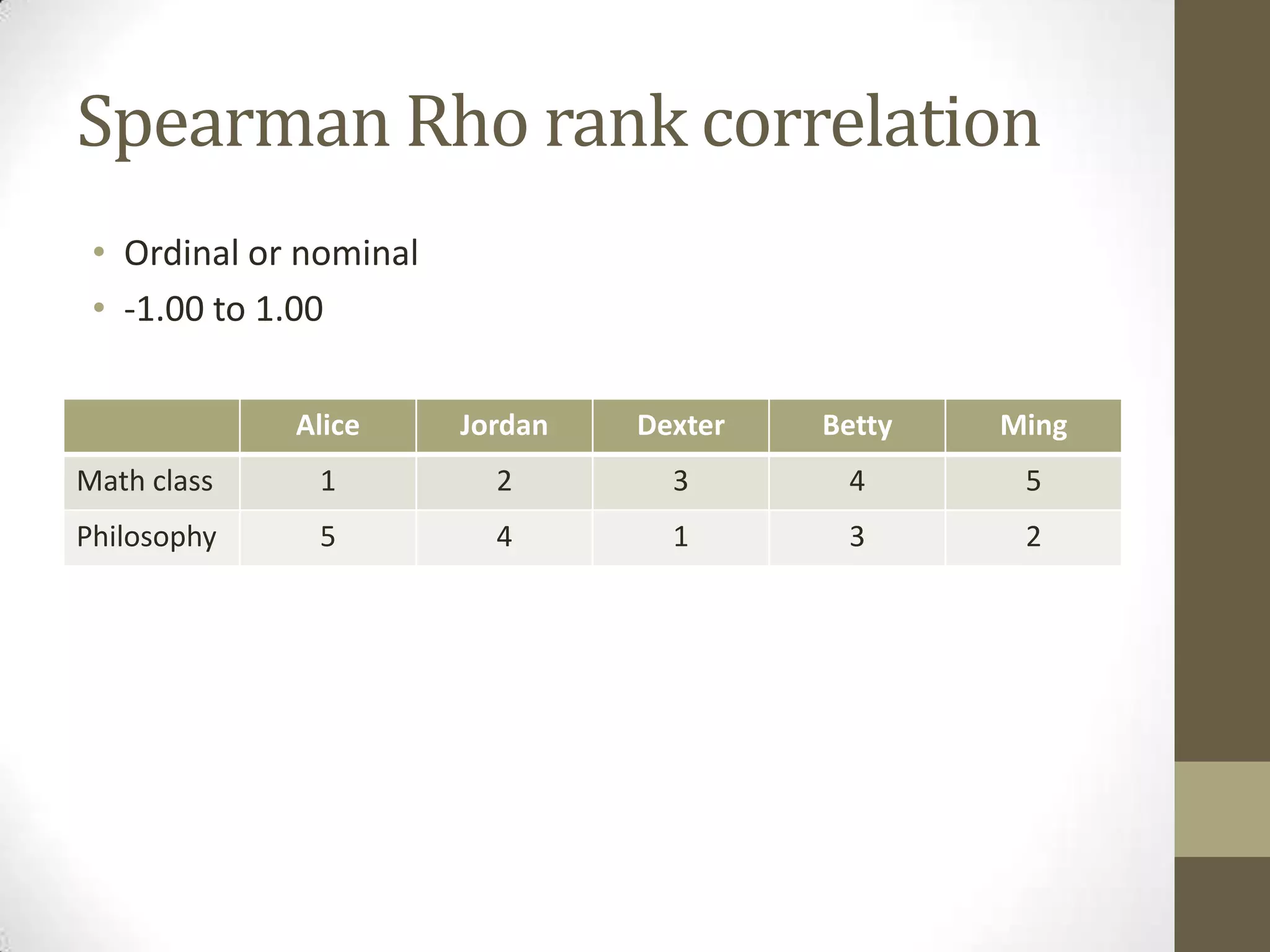
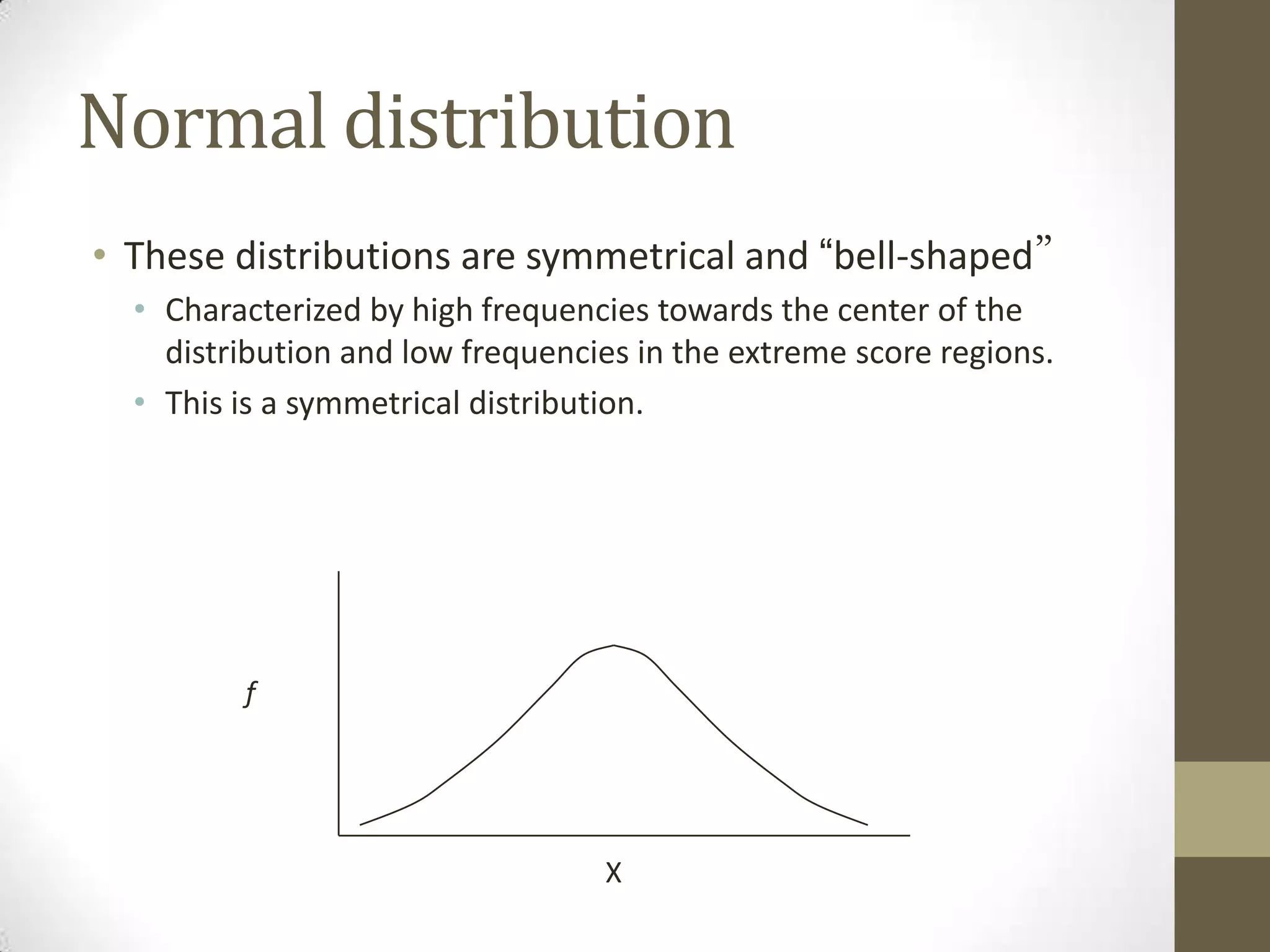
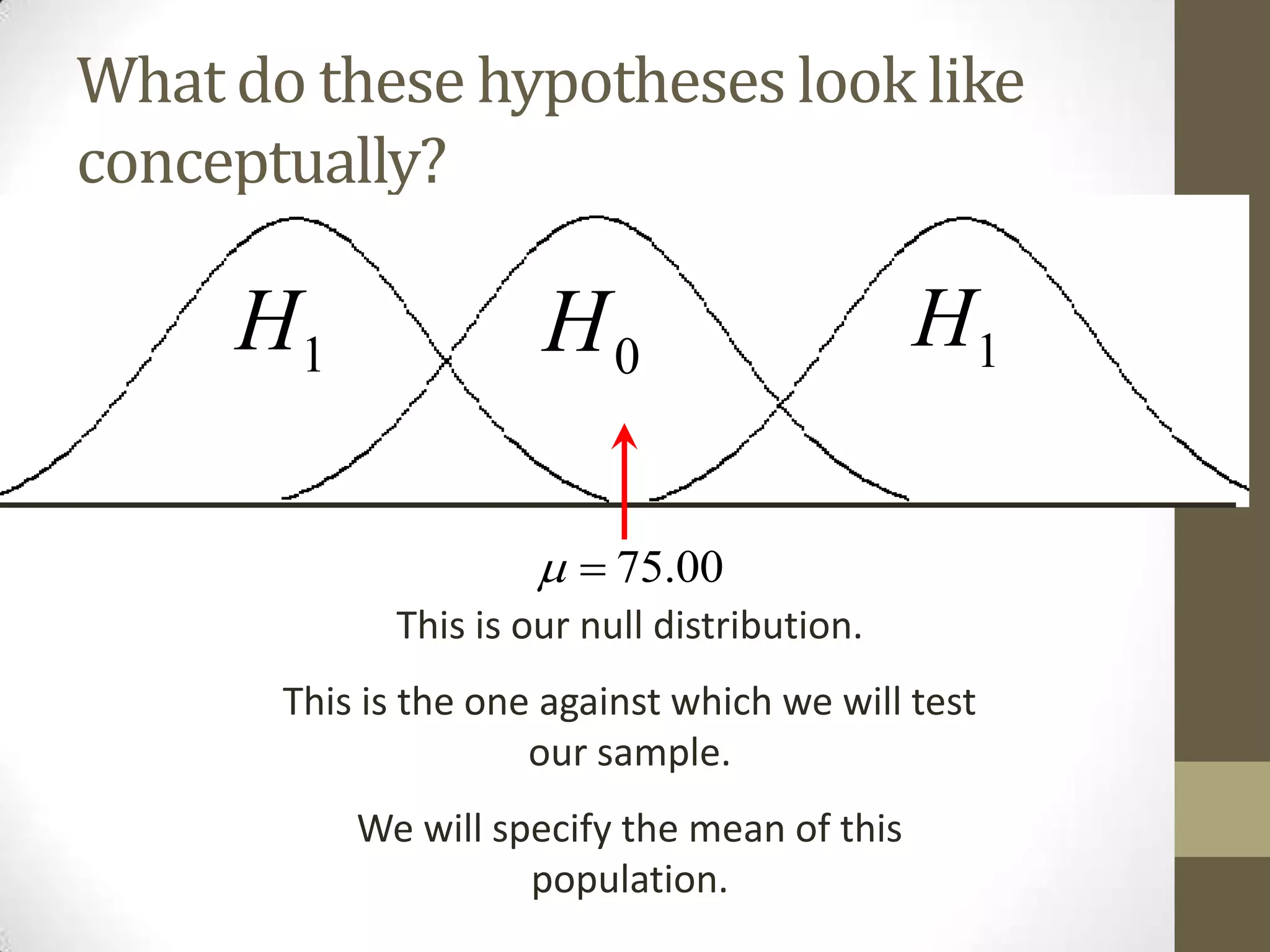
This document provides an overview of descriptive and inferential statistics concepts. It discusses parameters versus statistics, descriptive versus inferential statistics, measures of central tendency (mean, median, mode), variability (standard deviation, range), distributions (normal, positively/negatively skewed), z-scores, correlations, hypothesis testing, t-tests, ANOVA, chi-square tests, and presenting results. Key terms like alpha levels, degrees of freedom, effect sizes, and probabilities are also introduced at a high level.