Downloaded 10 times













![Types of Reproducibility
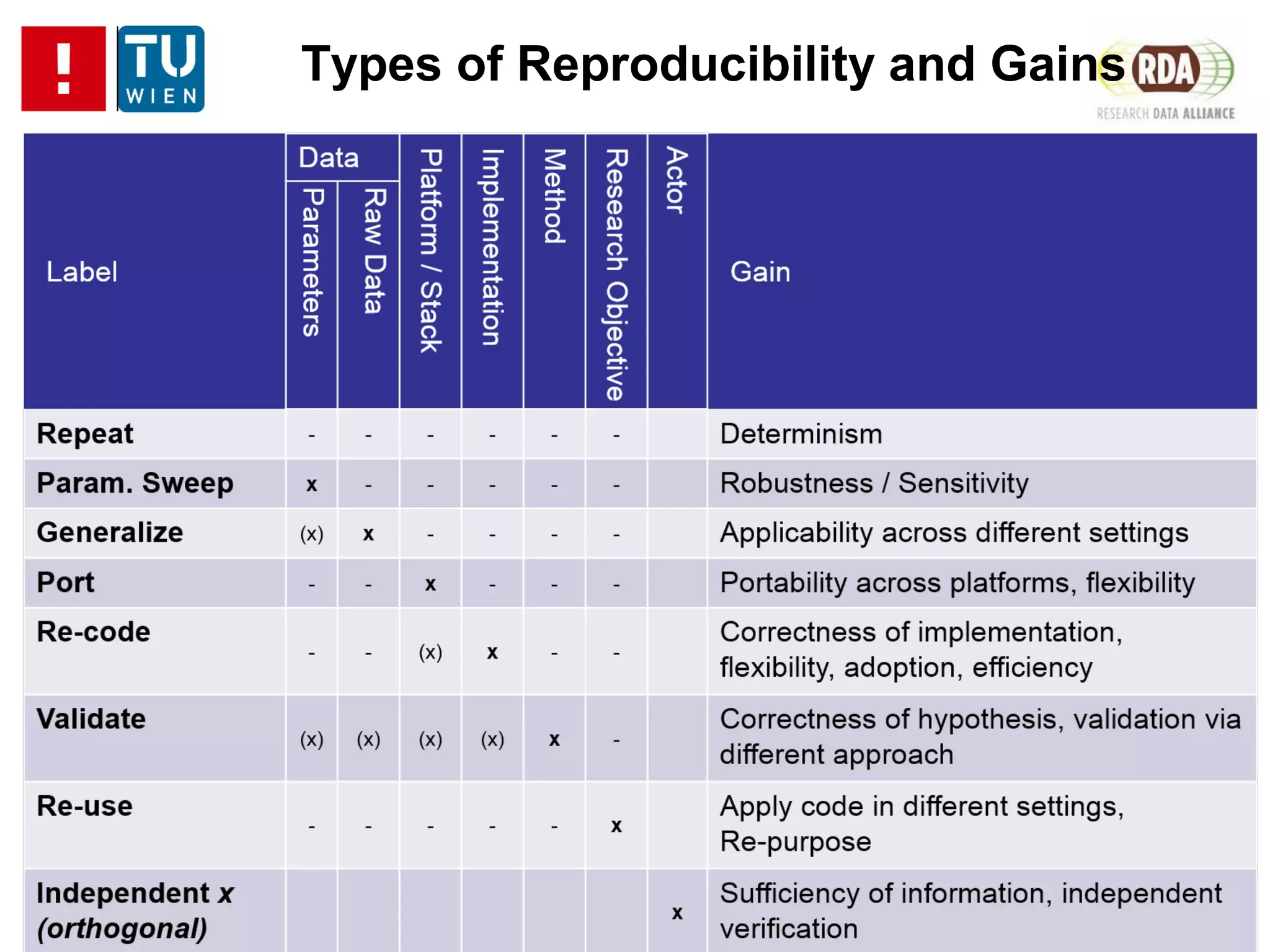
The PRIMAD1
model: which attributes can we “prime”?
- Data
• Parameters
• Input data
- Plattform
- Implementation
- Method
- Research Objective
- Actors
What do we gain by priming one or the other?
[1] Juliana Freire, Norbert Fuhr, and Andreas Rauber. Reproducibility of Data-Oriented
Experiments in eScience. Dagstuhl Reports, 6(1), 2016.](https://image.slidesharecdn.com/161114rauberrdaflorencereproducibility-161125095133/75/Reproducibility-challenges-in-computational-settings-what-are-they-why-should-we-address-them-and-how-18-2048.jpg)



































![Types of Reproducibility
The PRIMAD1
model: which attributes can we “prime”?
- Data
• Parameters
• Input data
- Plattform
- Implementation
- Method
- Research Objective
- Actors
What do we gain by priming one or the other?
[1] Juliana Freire, Norbert Fuhr, and Andreas Rauber. Reproducibility of Data-Oriented
Experiments in eScience. Dagstuhl Reports, 6(1), 2016.](https://crownmelresort.com/image.slidesharecdn.com/161114rauberrdaflorencereproducibility-161125095133/75/Reproducibility-challenges-in-computational-settings-what-are-they-why-should-we-address-them-and-how-18-2048.jpg)


































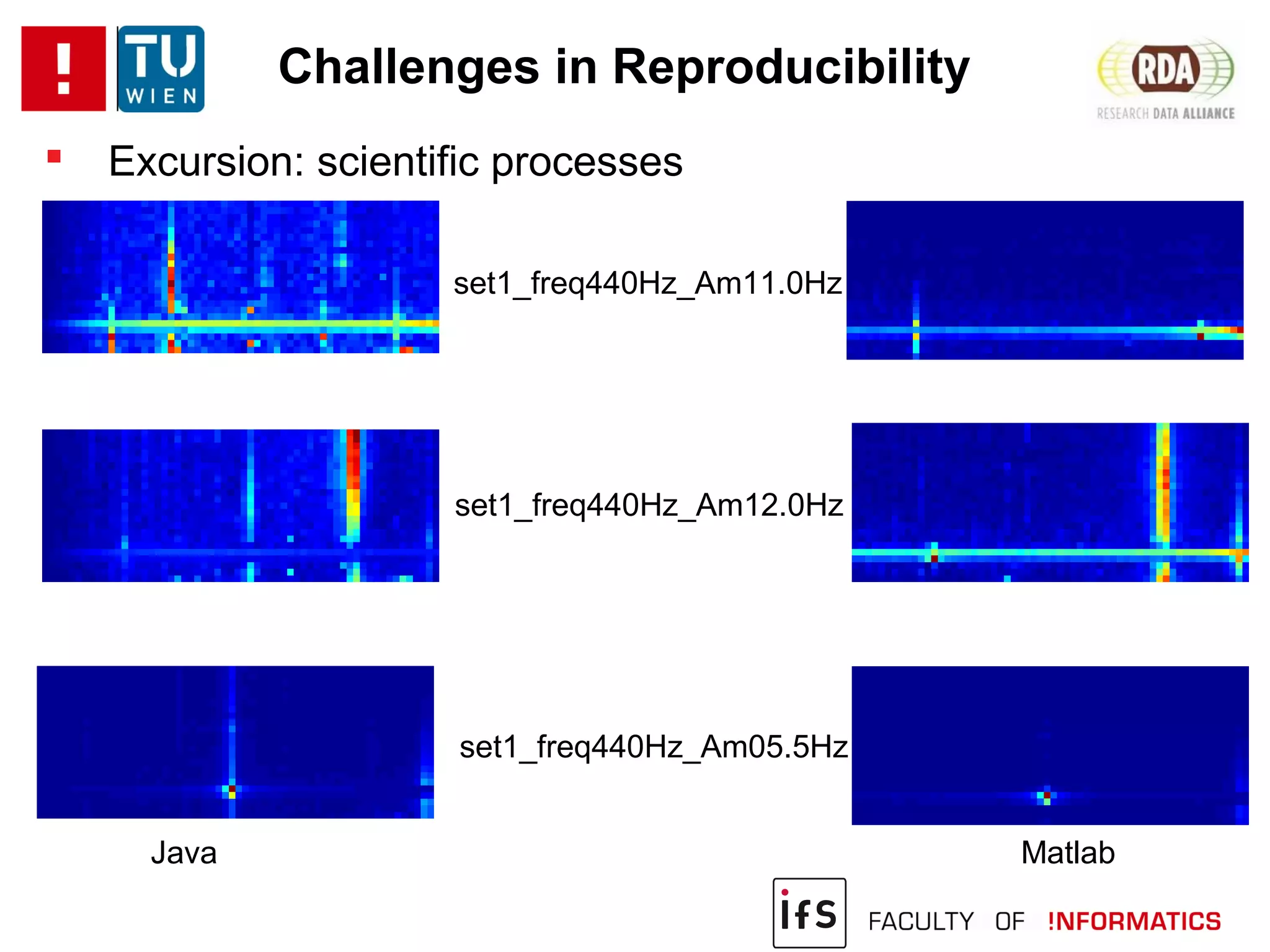
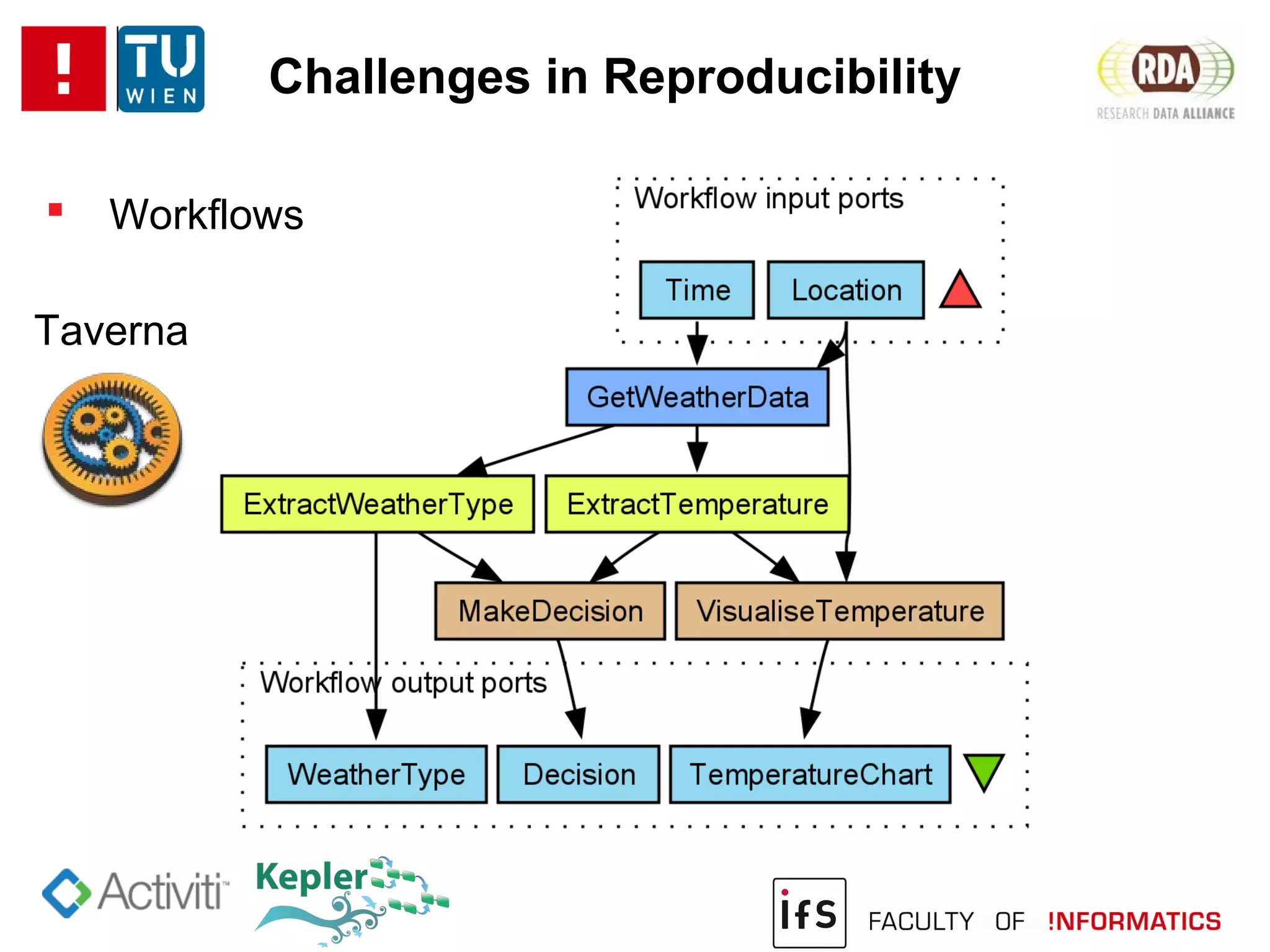
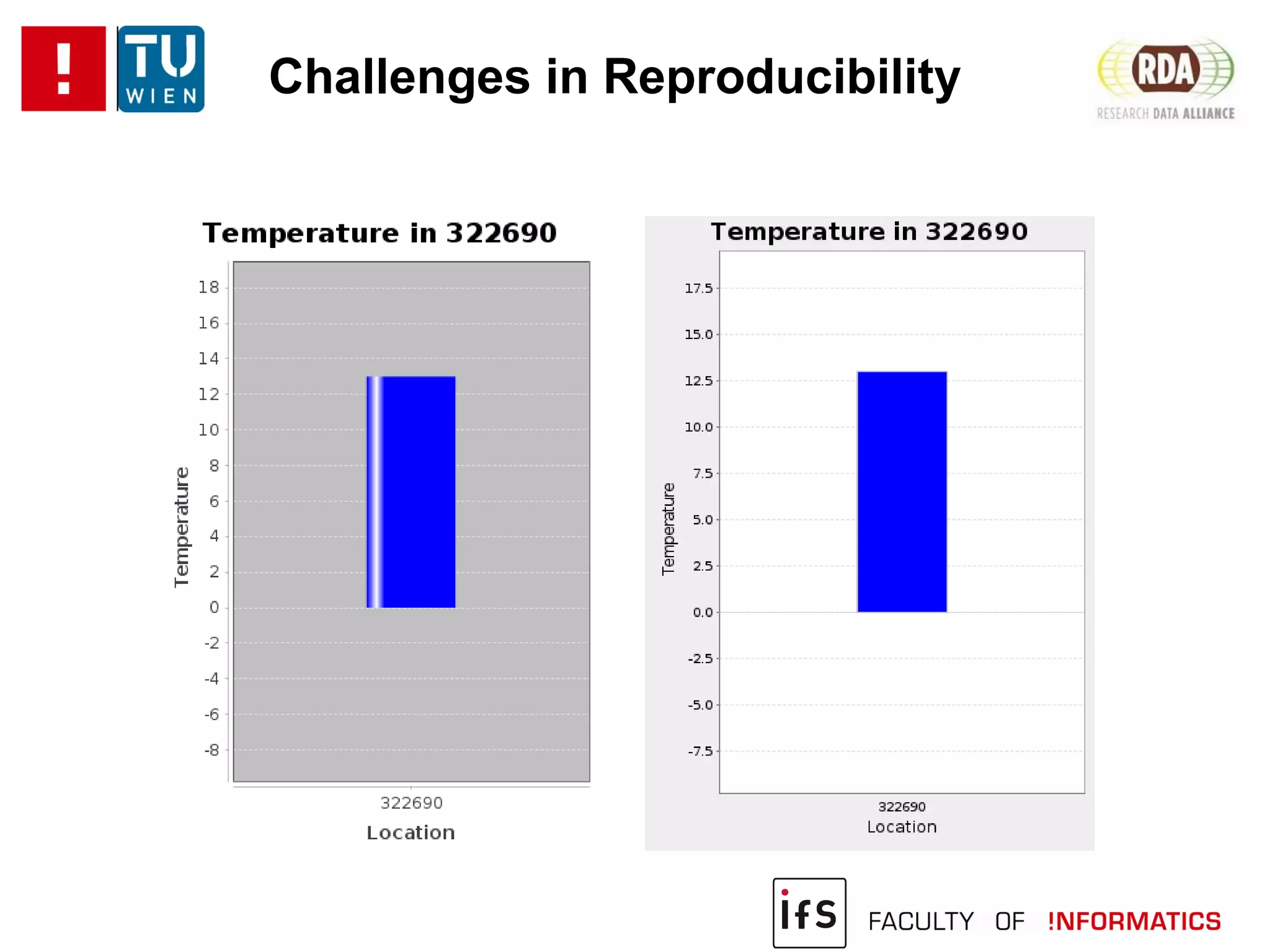
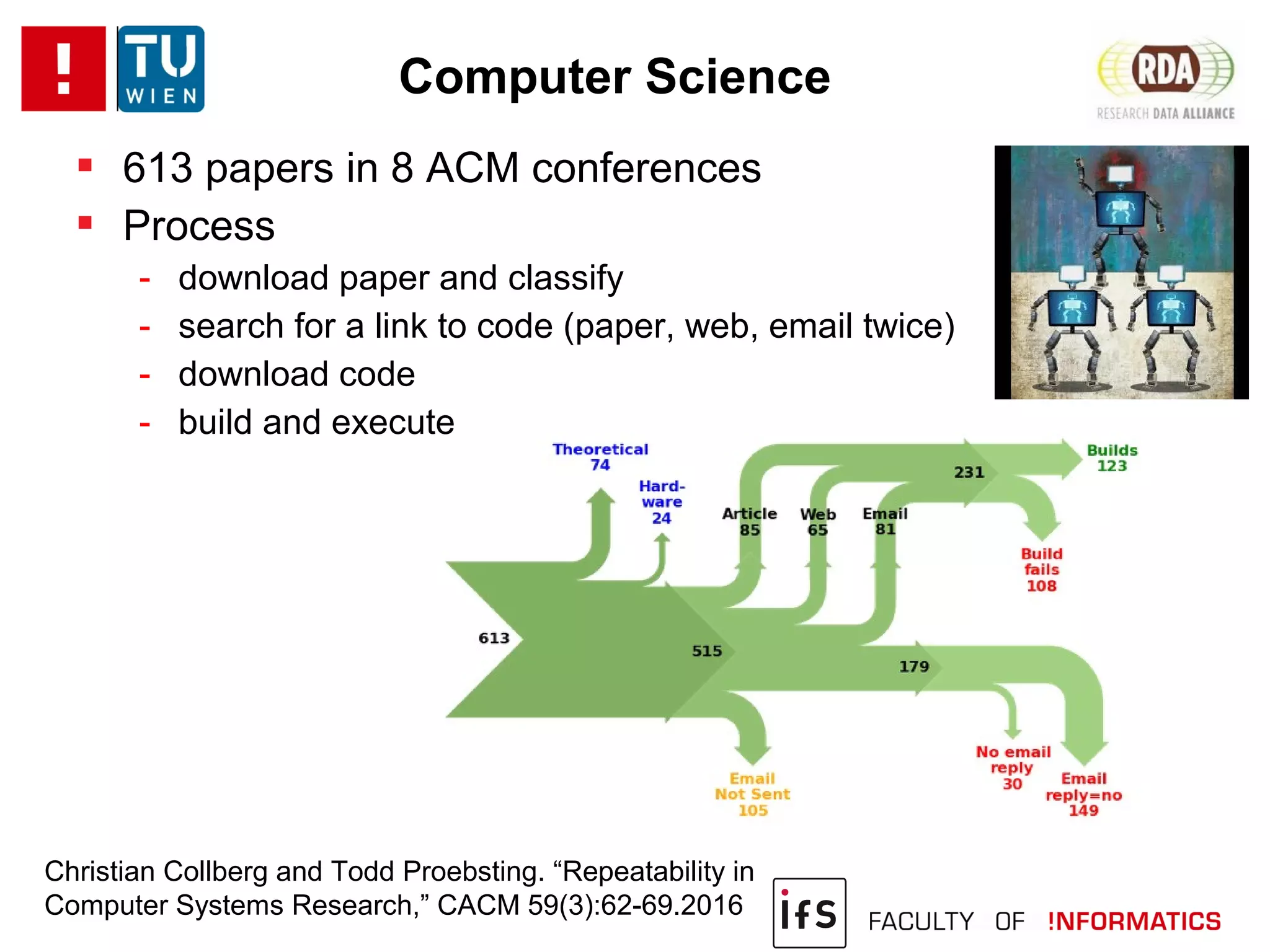
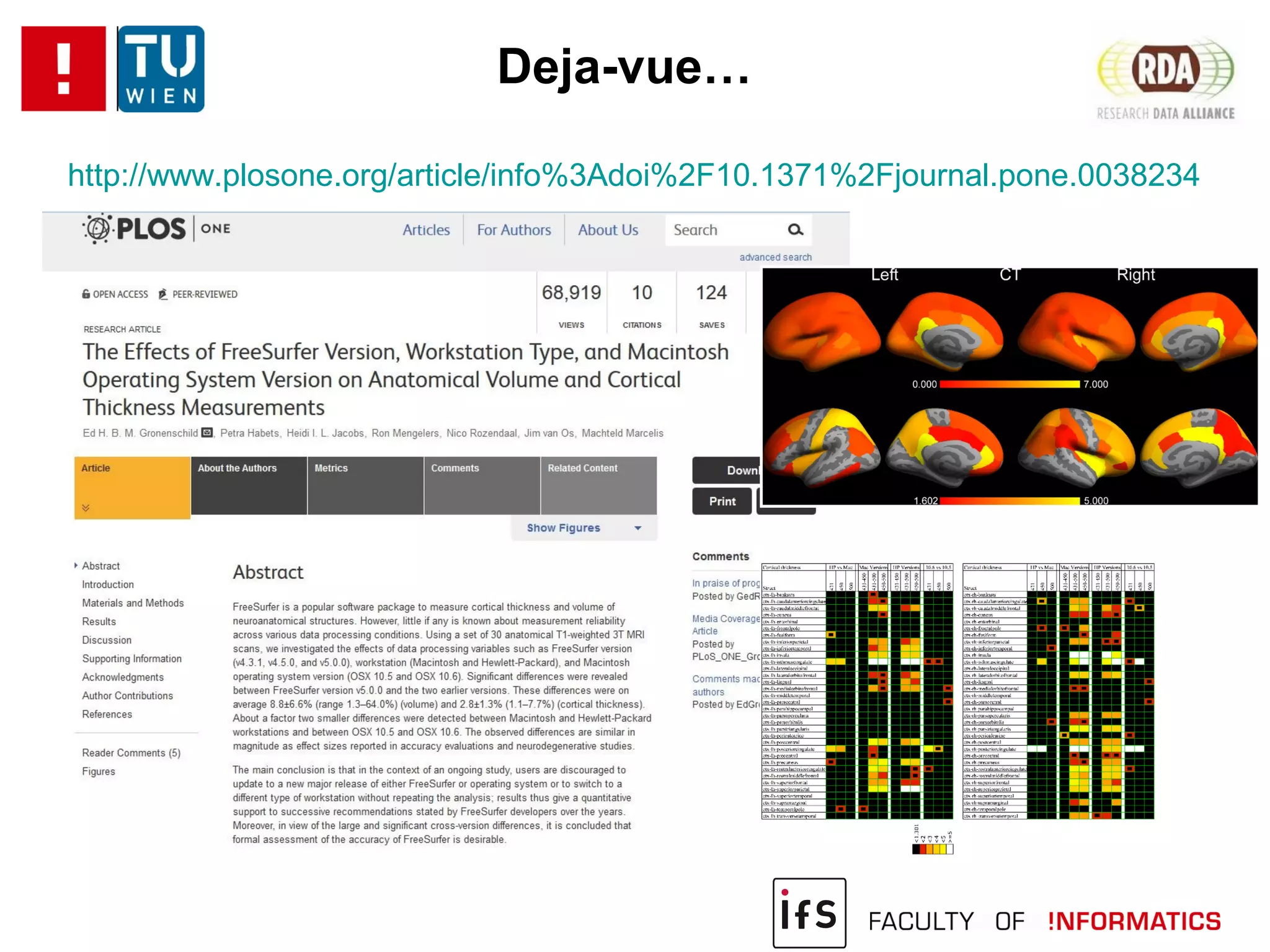
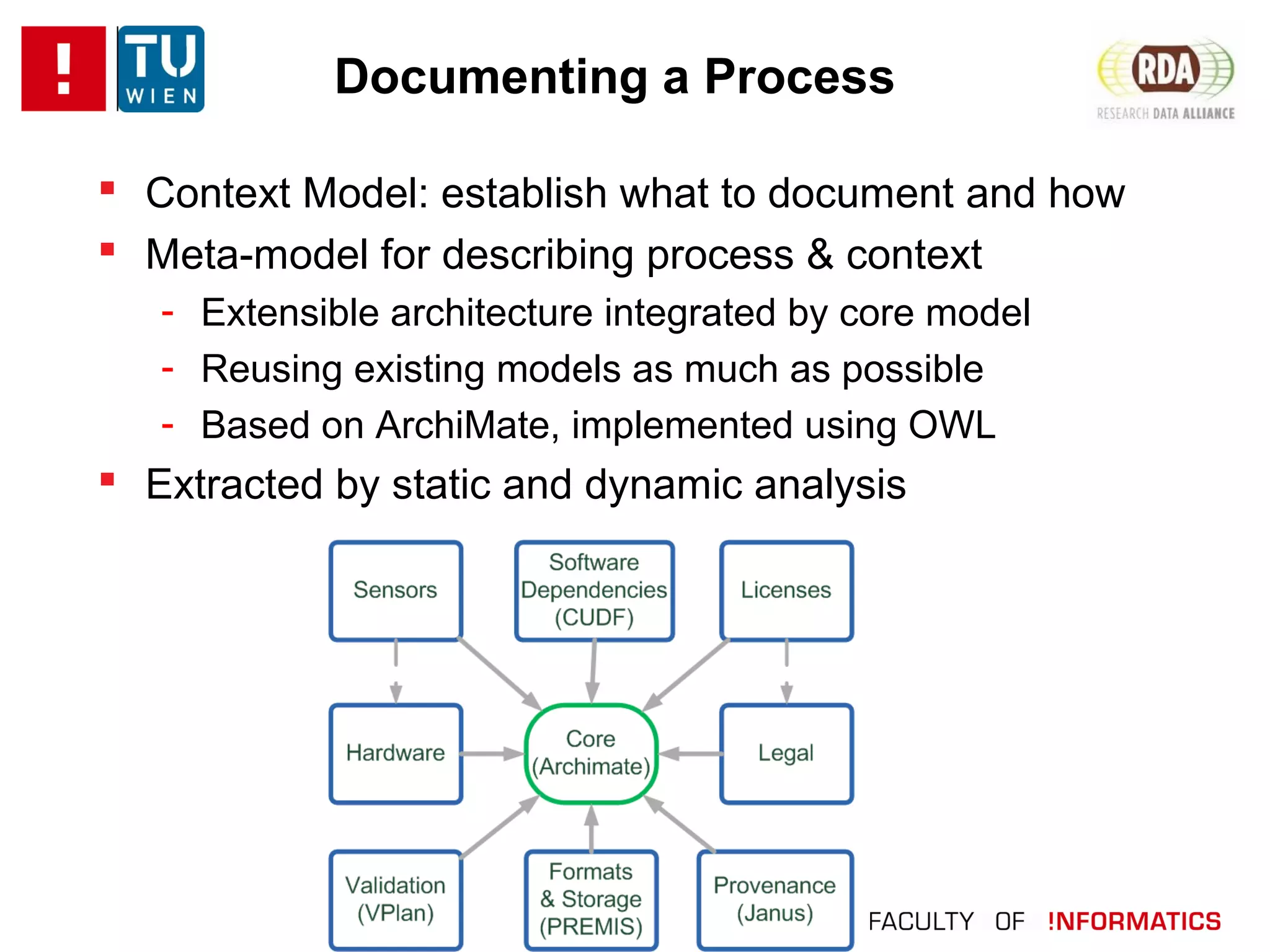
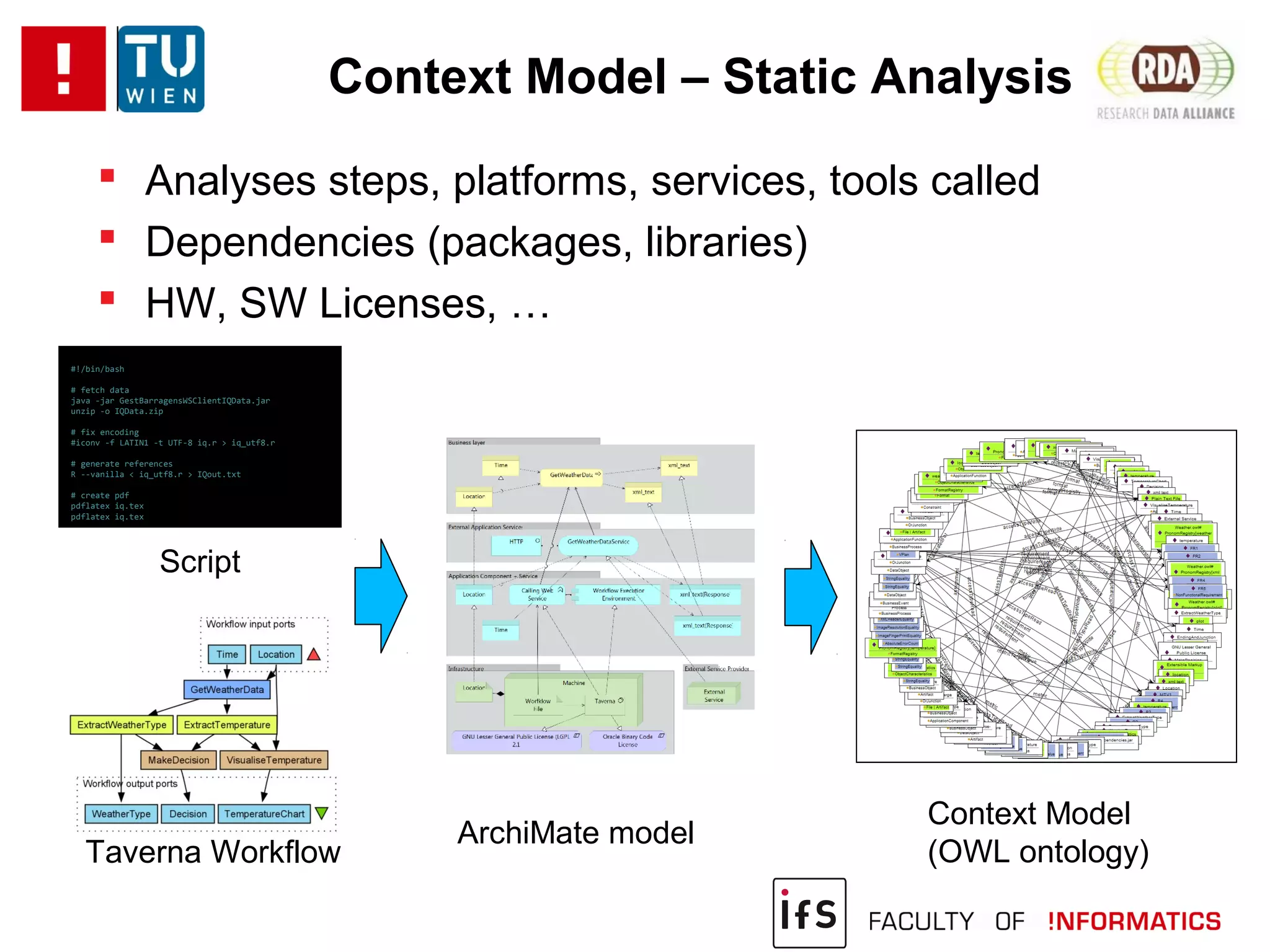
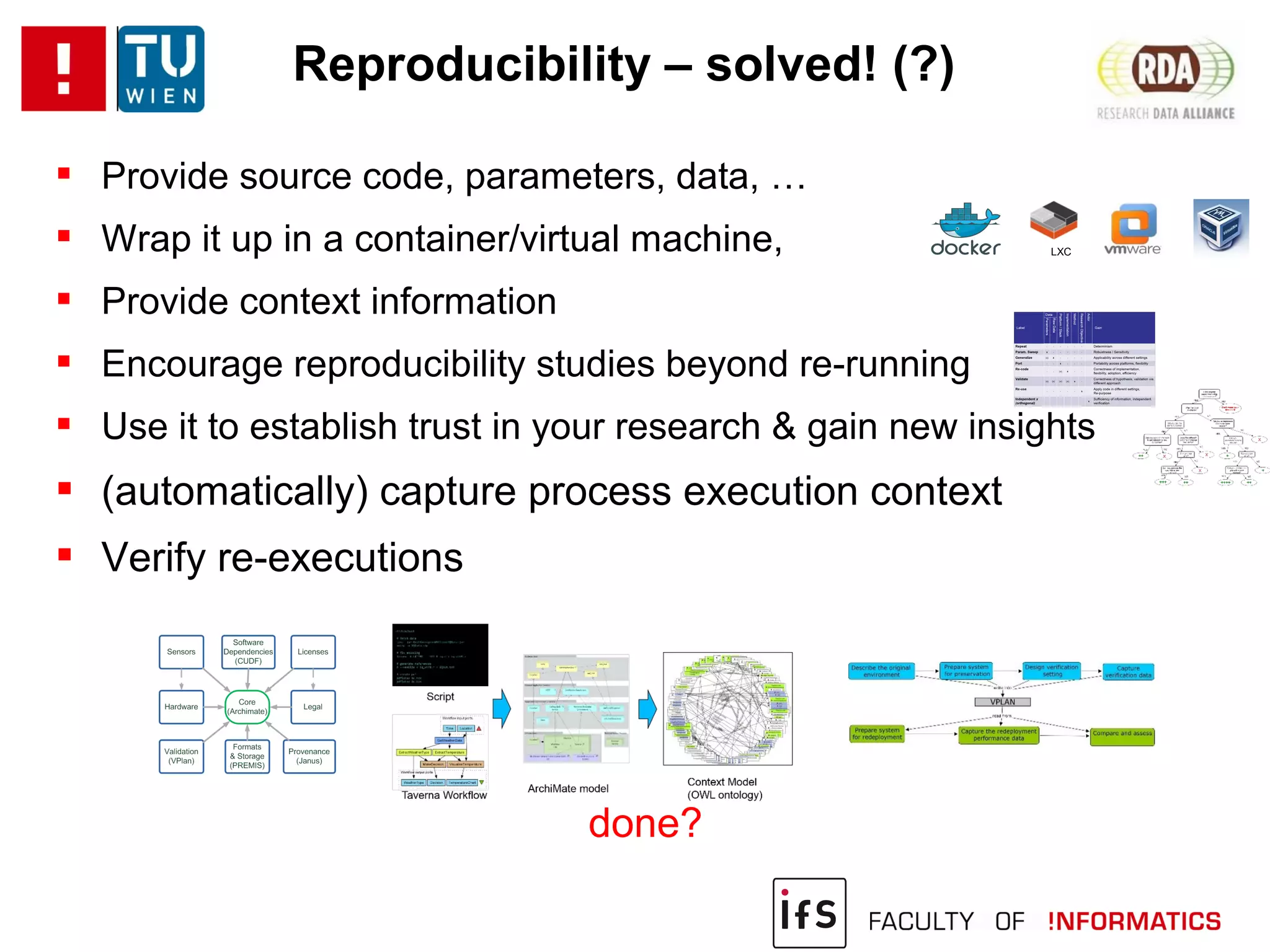
The document discusses the challenges of reproducibility in computational research, emphasizing the need for comprehensive data management, sharing of workflows, and proper documentation to enhance reproducibility. It highlights the importance of learning from non-reproducibility and addresses how to manage complex processes and big data effectively. The text advocates for better practices in research, including standardization, context capture, and active encouragement of reproducibility studies to foster trust and efficiency in e-science.



































































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















