Downloaded 69 times





















































The document describes techniques for synchronizing in-memory caches across multiple web servers using Redis. It discusses the problems with traditional in-process caches, such as data lag and inconsistency. The proposed solution uses Redis for the source of truth, with each web server maintaining an in-process cache. Hash slots are used to partition keys and publish updates via Redis pub/sub. When a key is requested, the server checks if its cache version is stale by comparing timestamps. This approach maintains consistency while minimizing network usage.
An introduction to synchronizing in-memory caches using Redis, highlighting the presenter and subject matter.
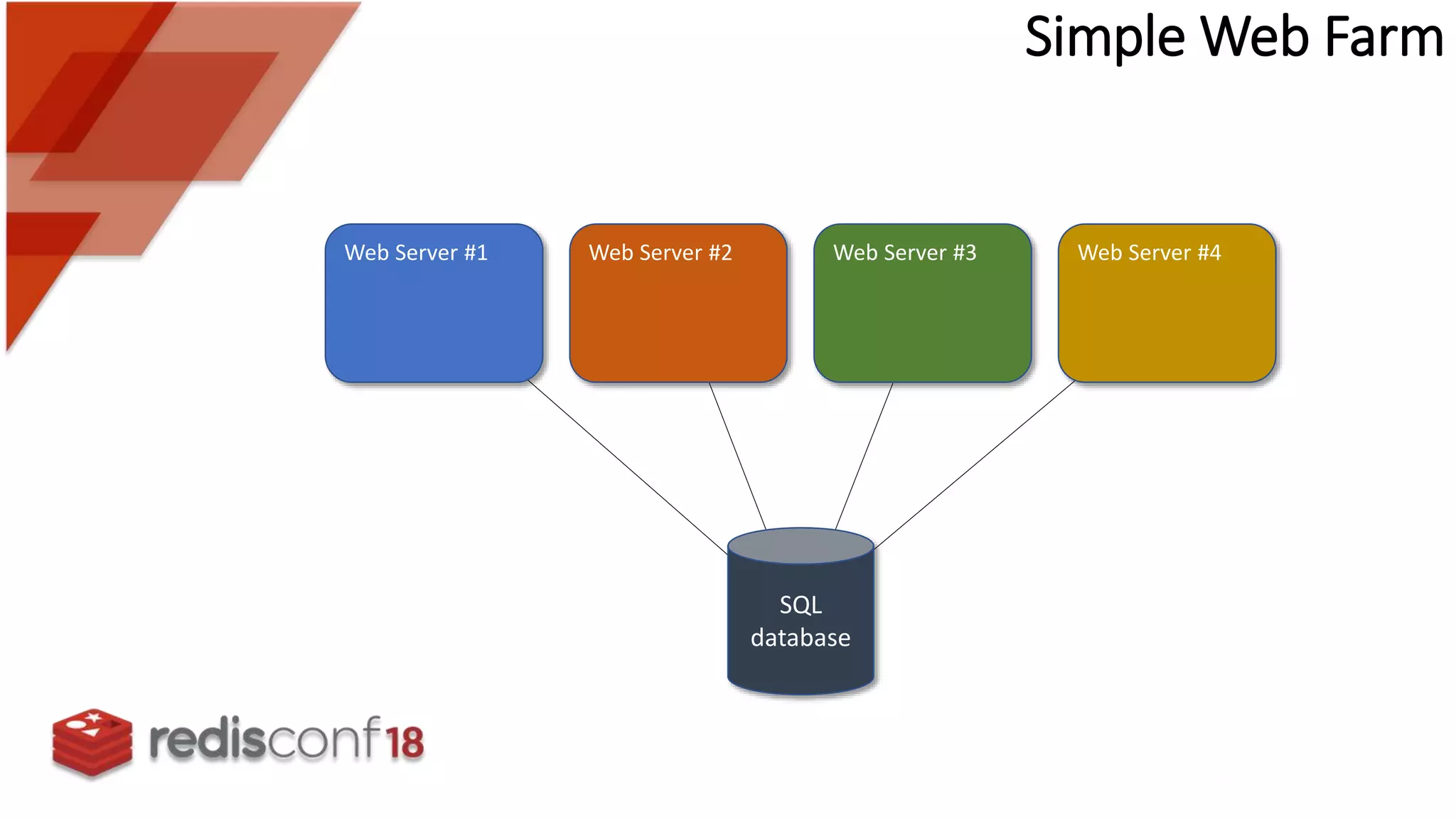
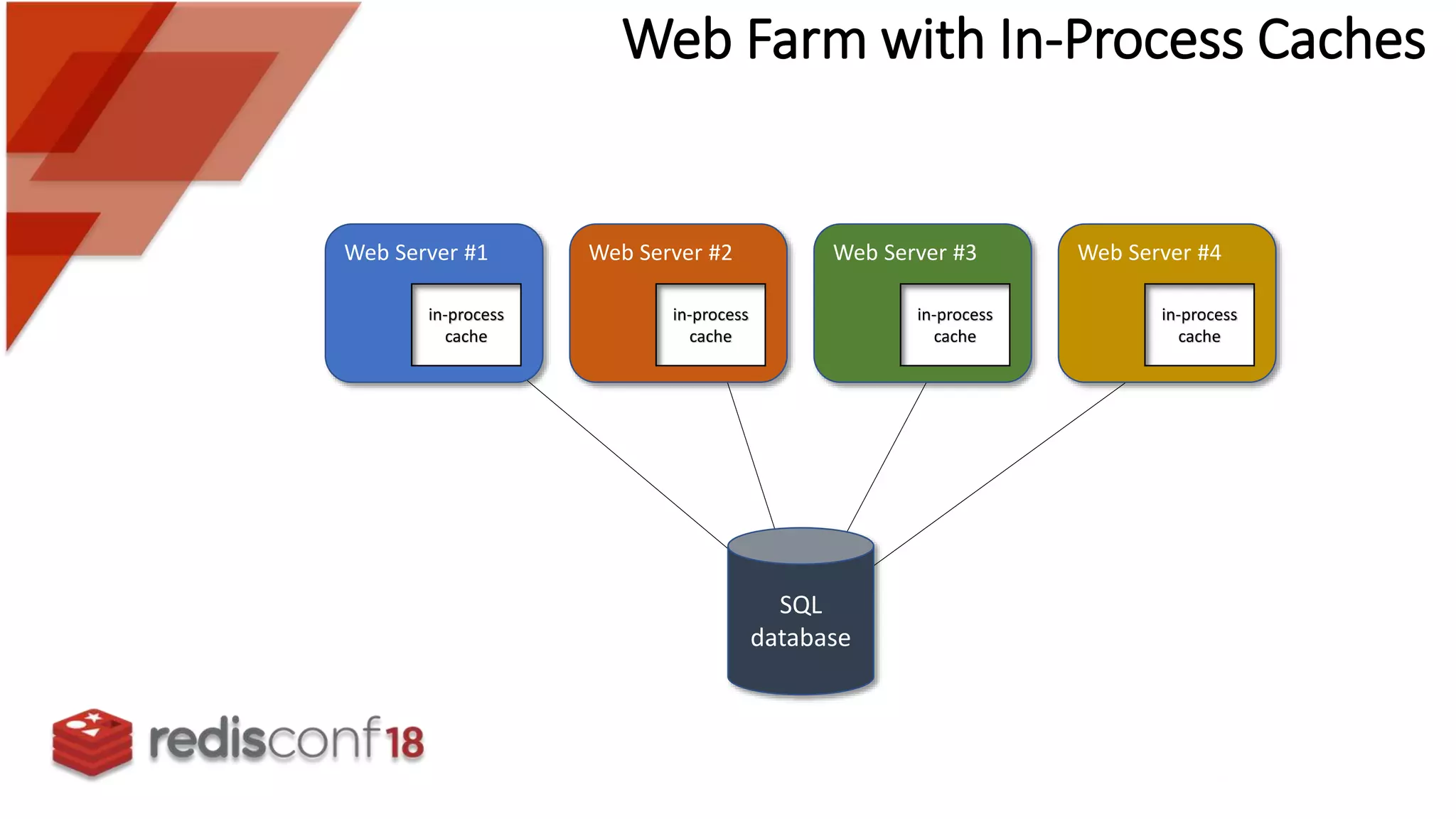
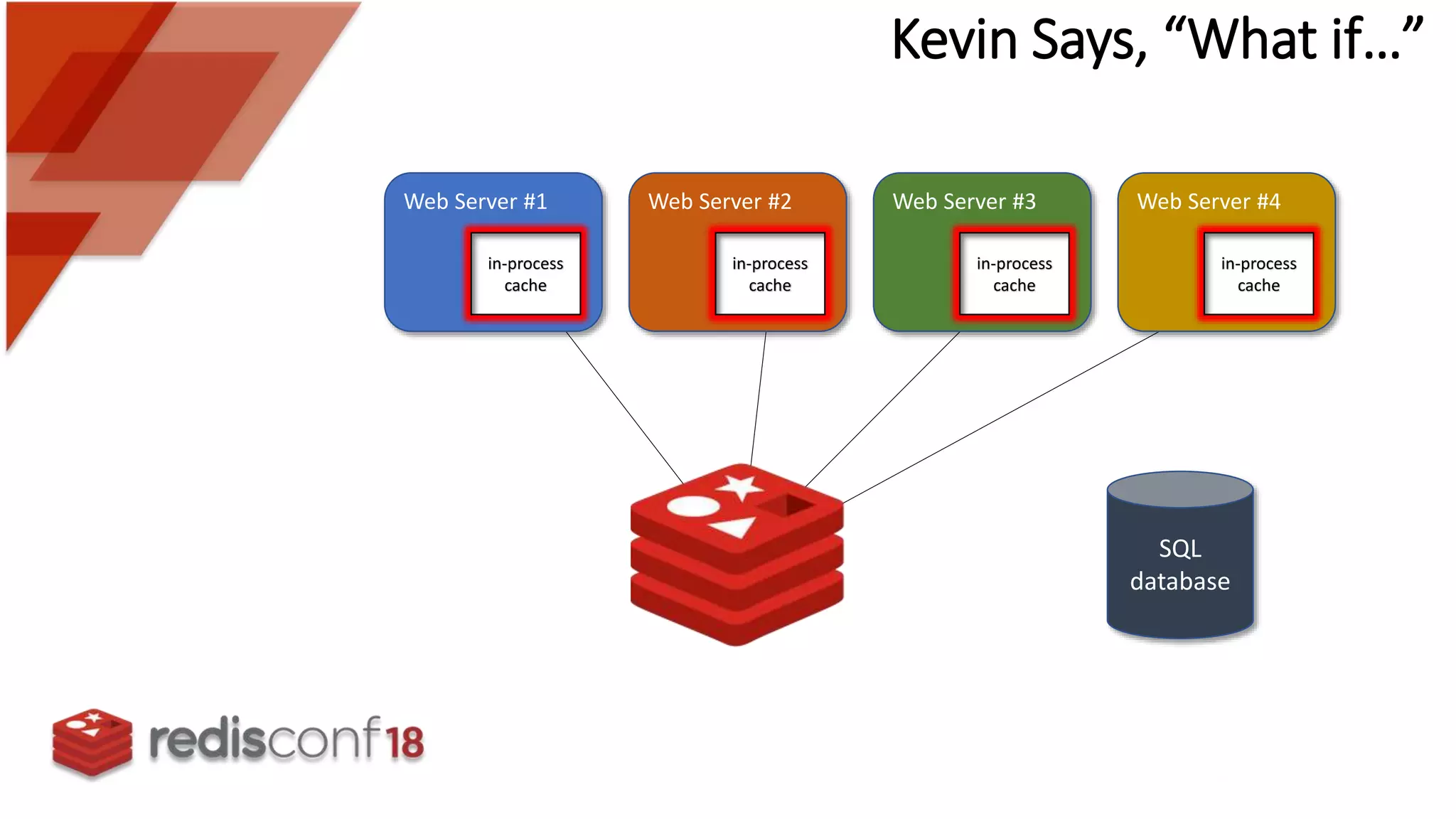
Description of a simple web farm architecture with in-process caches for multiple web servers accessing a SQL database.
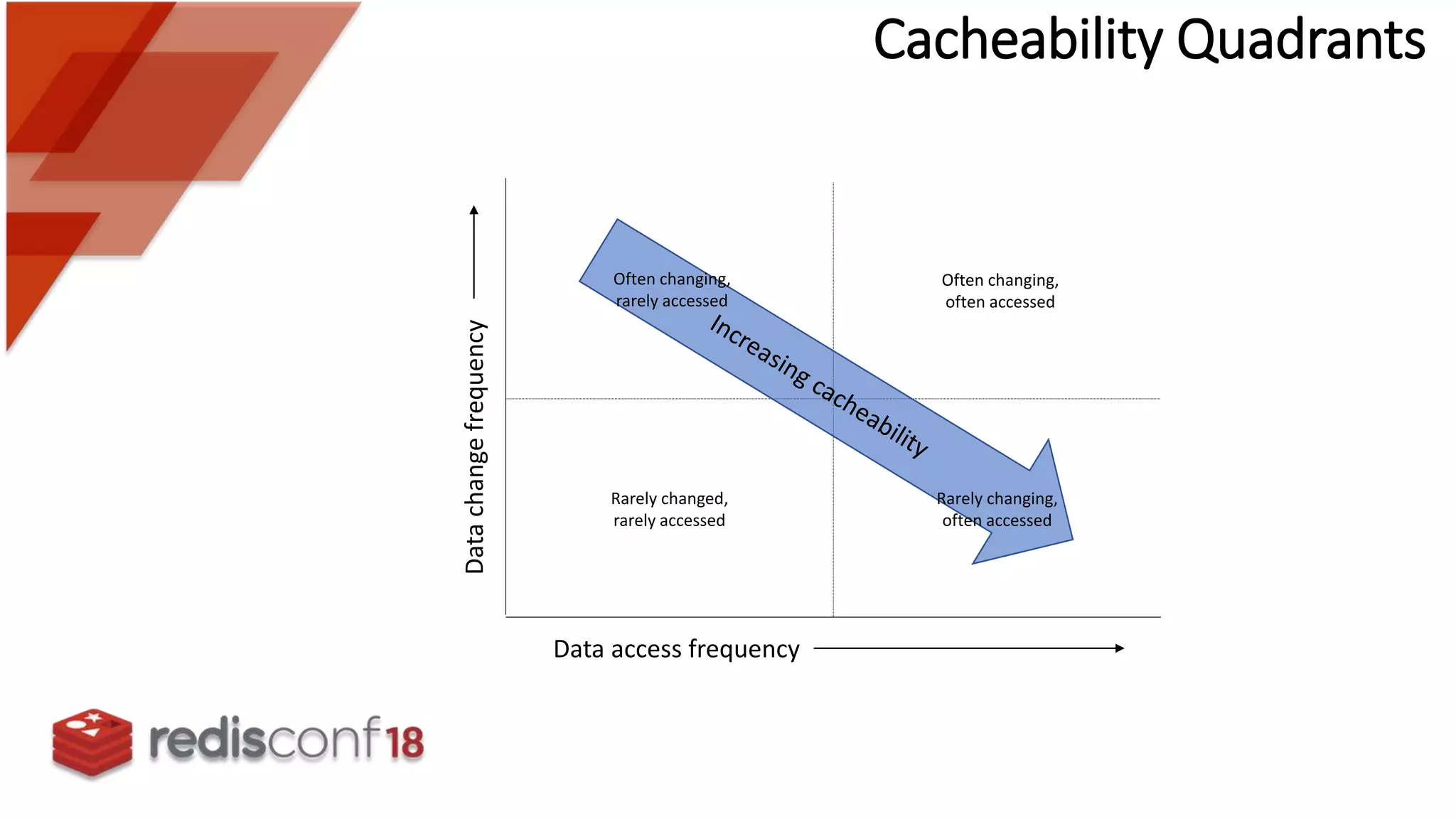
Identifies challenges in cache data lag, consistency, and cache stampede that affect web server performance.
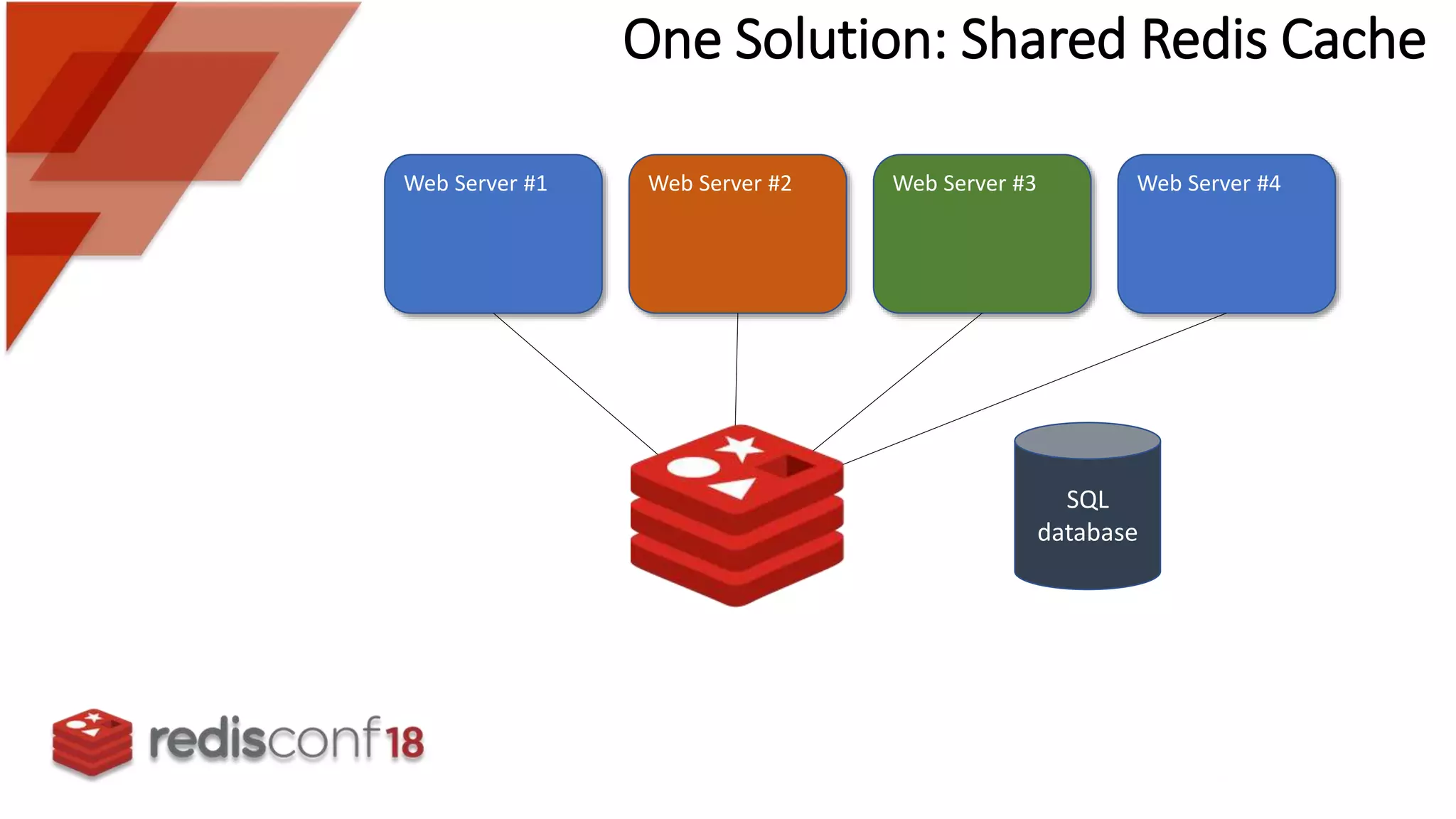
Presents a shared Redis cache solution to solve data consistency, cache lag, and cache stampede problems.
Explores different strategies for broadcasting data synchronization messages across servers to solve consistency issues.
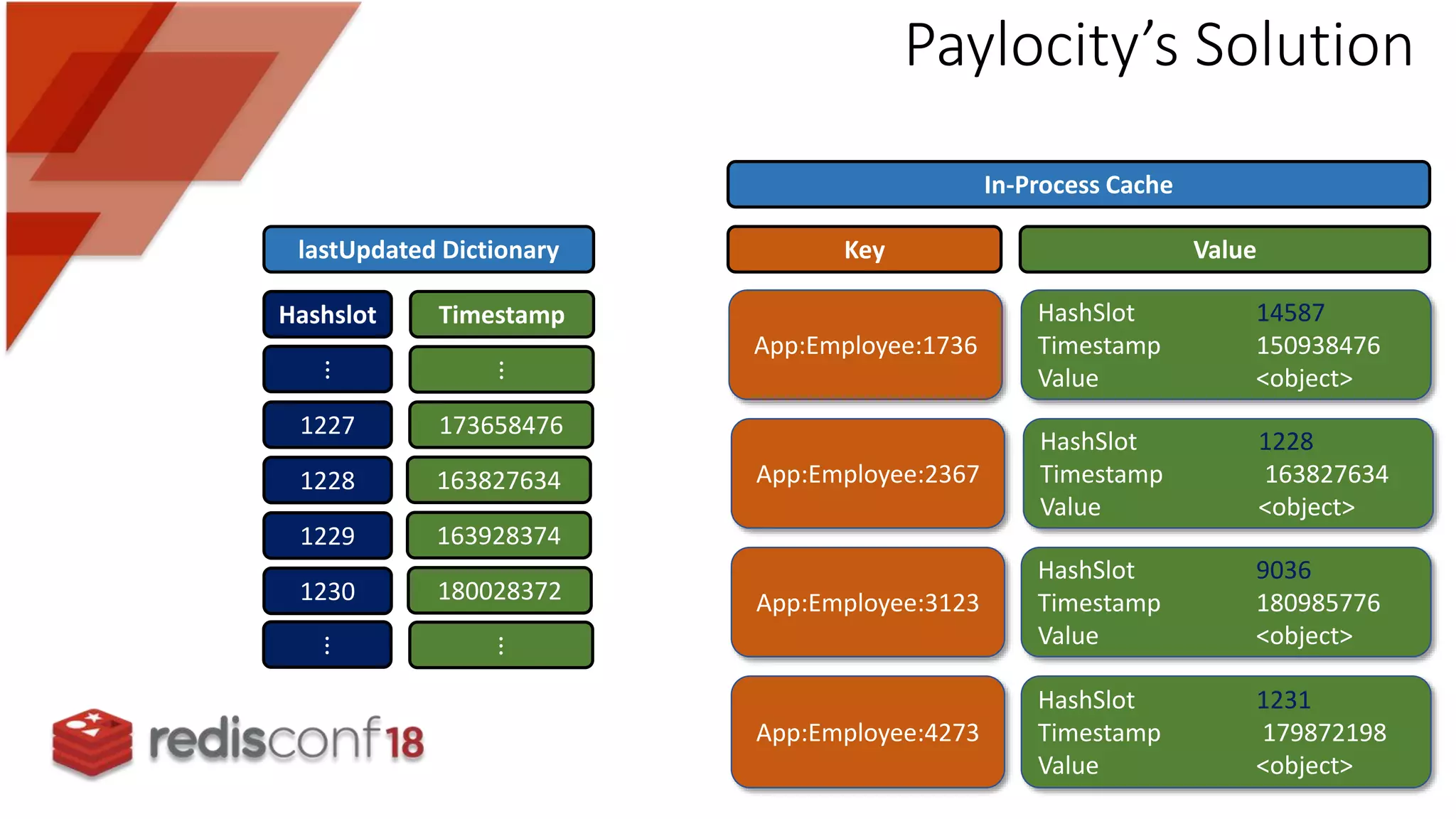
Details on challenges faced during implementation of synchronization strategies and the innovative solution by Paylocity.
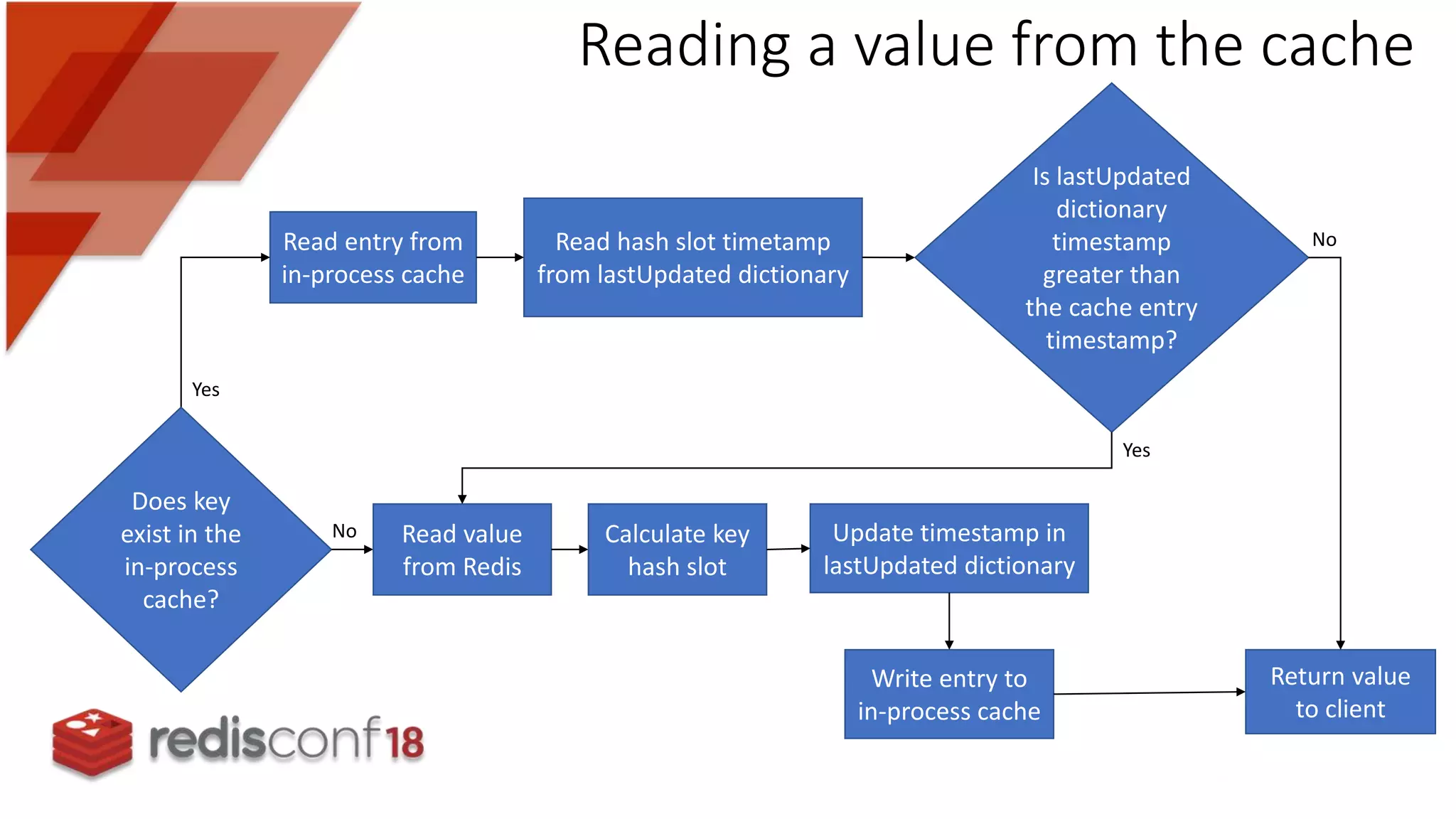
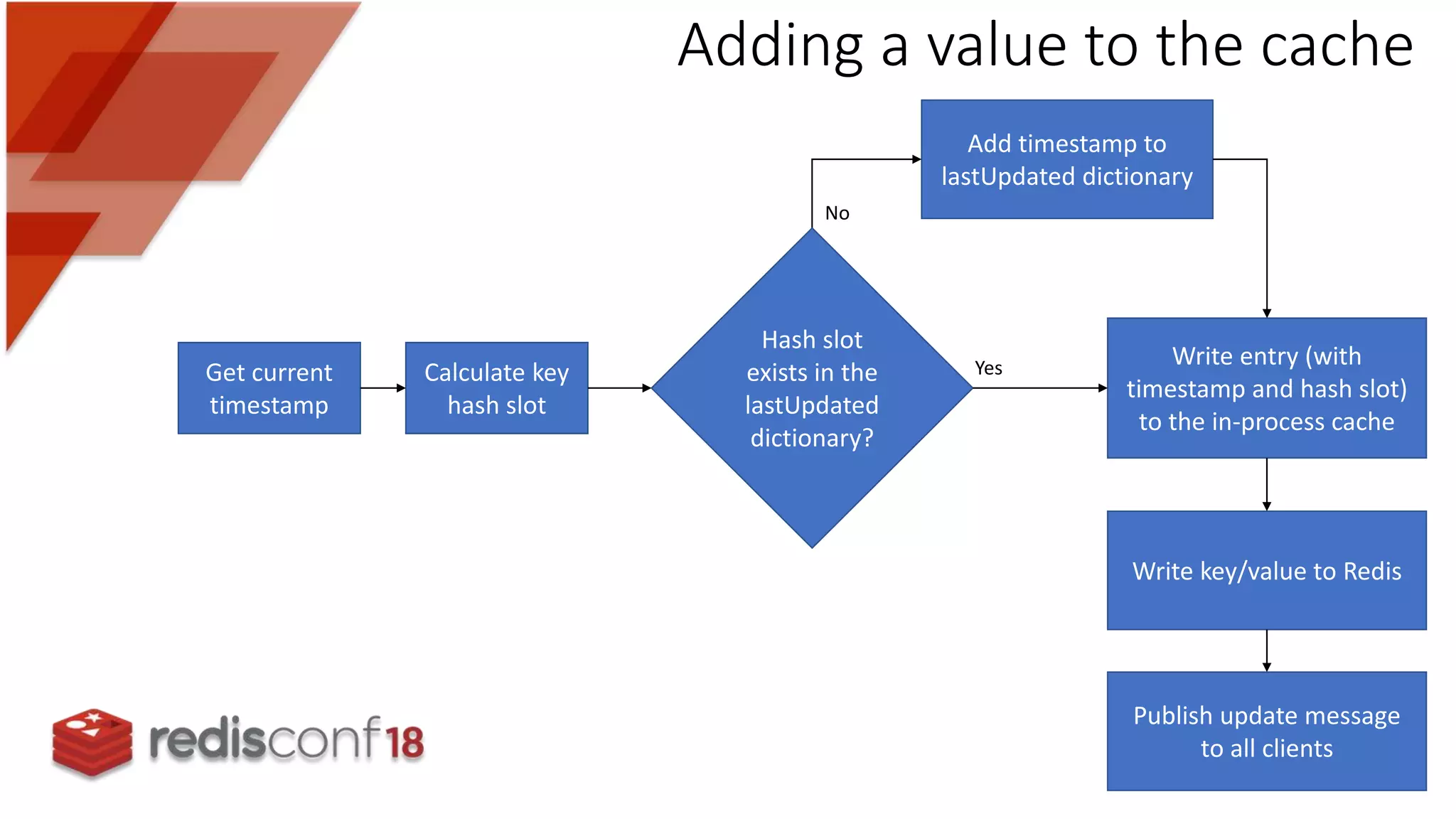
Explains the flow for reading from and adding to the in-process cache, ensuring data consistency with Redis.
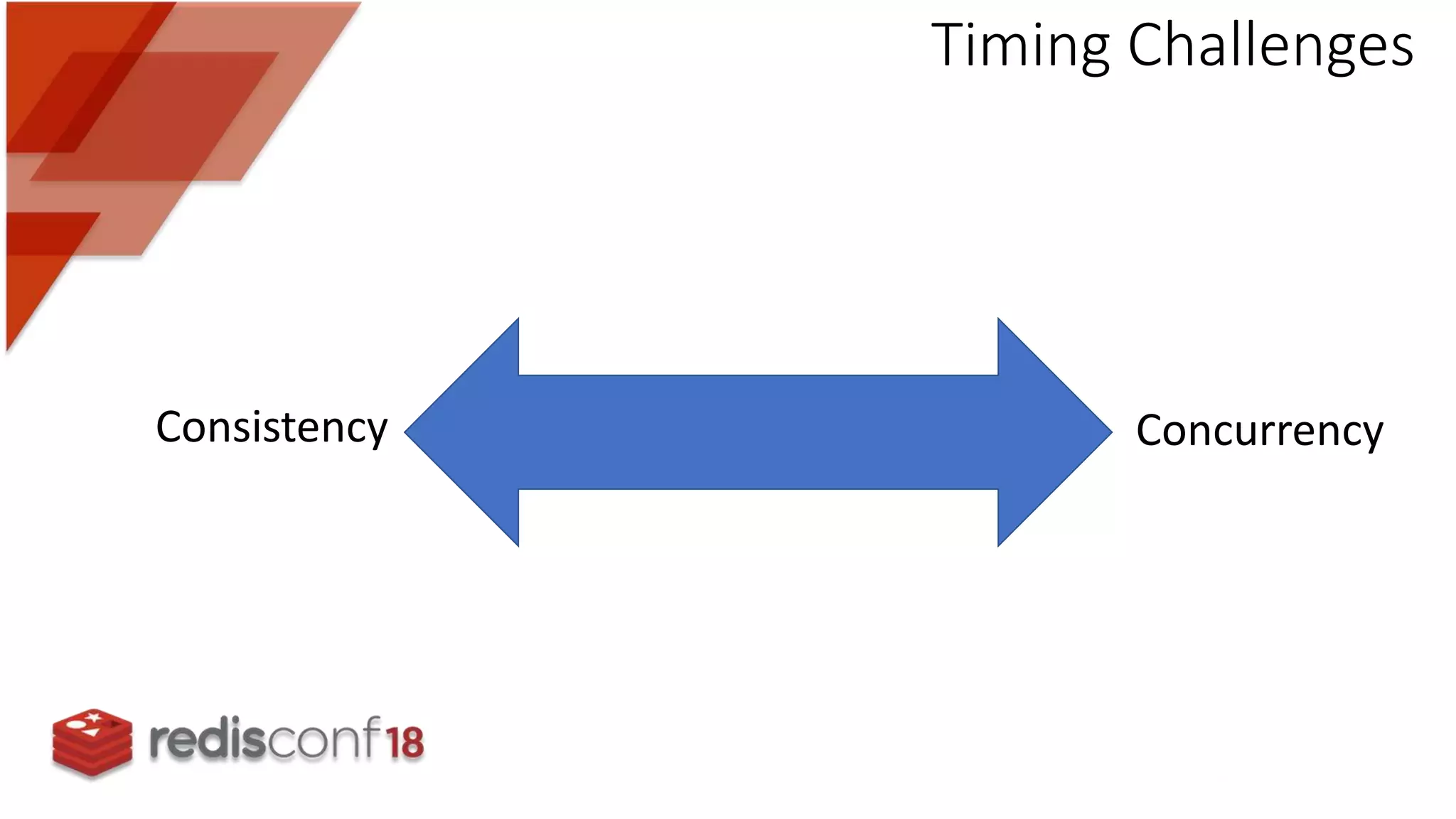
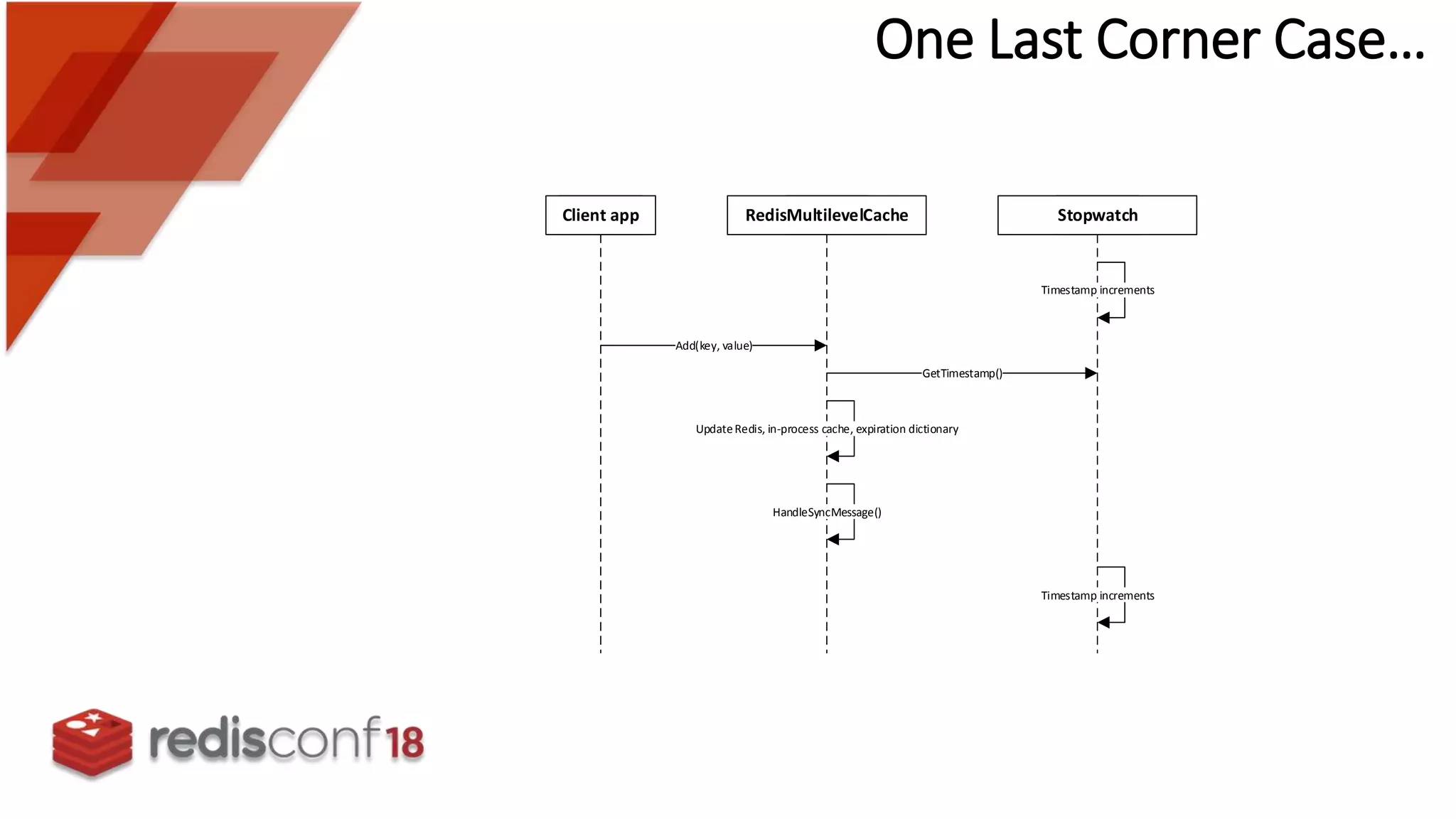
Discusses timing issues related to data consistency and concurrency in cache synchronization processes.
Focuses on leveraging order-of-operations to manage update timings effectively, preventing inconsistencies.
Reveals additional optimizations made, unresolved concerns, and future plans for enhancing the synchronization mechanism.
Final recap, resources for further exploration of the implementation, and a thank you to the audience.




















![[Webinar]: Working with Reactive Spring](https://cdn.slidesharecdn.com/ss_thumbnails/working-wth-reactive-spring-190607114059-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈테크넷서밋2022] 국내 PaaS(Kubernetes) Best Practice 및 DevOps 환경 구축 사례.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/2022paaskubernetesbestpracticedevops-220927105318-84776c9a-thumbnail.jpg?width=640&height=640&fit=bounds)














































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)















