Downloaded 1,099 times
![MySQL Cluster Wagner Bianchi – LAD Senior Principal Consulting [email_address]](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-1-2048.jpg)





![Management Node When a local data node's files are used and the option “ nostart ” is mentioned in these files, you’ll be required to start data nodes manually, using ndb_mgm as: You can START or RESTART a node, issuing mentioned statement, preceding by the node ID. Observing that it will work only for data nodes, not for SQL/API nodes; # start or restarting data nodes after its execution shell> ndb_mgm –e “4 [ START | RESTART ]”](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-8-2048.jpg)

![Management Node Downloading and installing mgm node packages: # creating directories -> BASEDIR and DATADIR [ root@node1 ~ ] mkdir -p /usr/local/mysql-cluster [ root@node1 ~ ] mkdir -p /var/lib/mysql-cluster [ root@node1 ~ ] cd /usr/local/mysql-cluster # downloading management node necessary packages [ root@node1 ~ ] wget http://downloads.mysql...management.rpm [ root@node1 ~ ] wget http://downloads.mysql...tools.rpm # installing necessary packages [ root@node1 mysql-cluster ] rpm -ivh MySQL-* Preparing... ############################################ [100%] 1:MySQL-Cluster-gpl-management ########################### [100%] 2:MySQL-Cluster-gpl-tools ################################ [100%]](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-10-2048.jpg)

![Management Node You can verify that the management server process is running by viewing the output of a system command such this one: Now we can use ndb_mgm, the management client to retrieve information about the cluster using SHOW command: [ root@node1 ]# ps aux | grep ndb_mgmd root 103467 17.3 0.7 8398 2564 ? Ssl 3:20 3:55 ndb_mgmd –f /usr/local/mysql-cluster/config.ini # SHOW command retrieves information about cluster [ root@node1 ]# ndb_mgm –e “ SHOW”](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-12-2048.jpg)







![Local Configuration File Each data or API Node in a particular cluster needs to know how to connect to the cluster Management Node(s) – another way to provide necessary information is to use local configuration file; These types of files follow similar conventions to my.cnf, are located in the same place and have the same structure; [ndbd] # local ndbd’s configuration file - /etc/my.cnf ndb-connectstring=192.168.0.101:1186,192.168.0.102:1186 NoStart # ndbd do not start after be invoked](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-21-2048.jpg)
![Global Configuration File The global configuration file is a central one that resides on one or more Management Node servers, and which provides information about the cluster as a whole Specific types of nodes can be configured globally within the sections of this file, e.g., [ndbd default] ; This file, commonly created as config.ini , is used by the Management Node to start cluster, receive nodes’ connections and start cluster’s operations;](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-22-2048.jpg)
![Global Configuration File [ndb_mgmd] NodeId=1 HostName=192.168.0.101 [ndbd default] NoOfReplicas=2 DataDir=/var/lib/mysql-cluster StopOnError=false # angel will restart failed nodes [ndbd] NodeId=2 HostName=192.168.0.102 [ndbd] NodeId=3 HostName=192.168.0.103 [mysqld] NodeIde=4 HostName=192.168.0.104 [mysqld] # free reserved slot – e.g. ndb_restore, the native cli for database restore](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-23-2048.jpg)









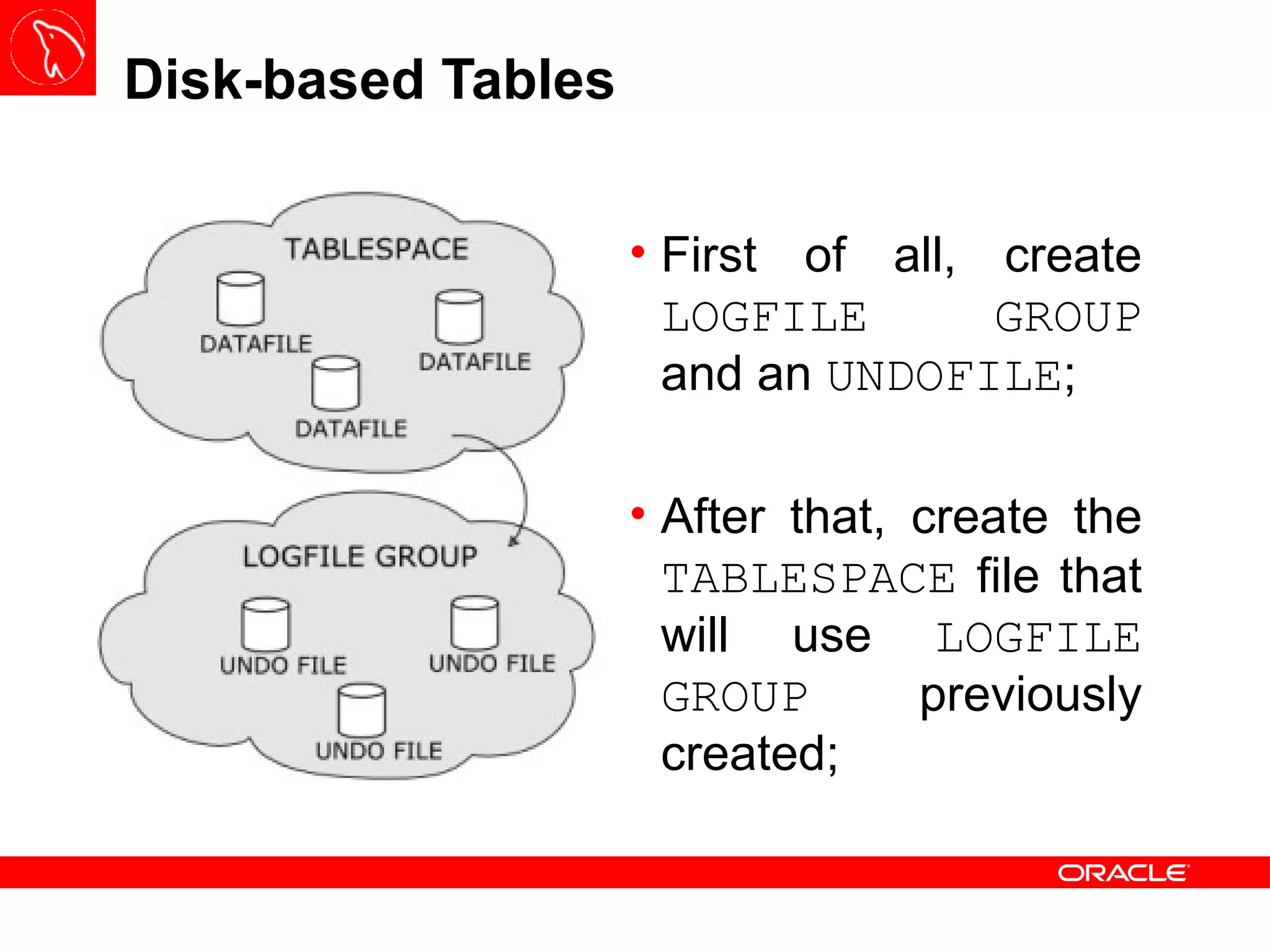








![In-memory Tables In order to store table data in-memory, no additional statements are required, instead some parameters must be configured to get the required data in main memory; Those parameters must be configured in the global configuration file (located on mgm node),l generally use the [ndbd default] section; it is not good to set up parameters individually for each Data Node;](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-46-2048.jpg)
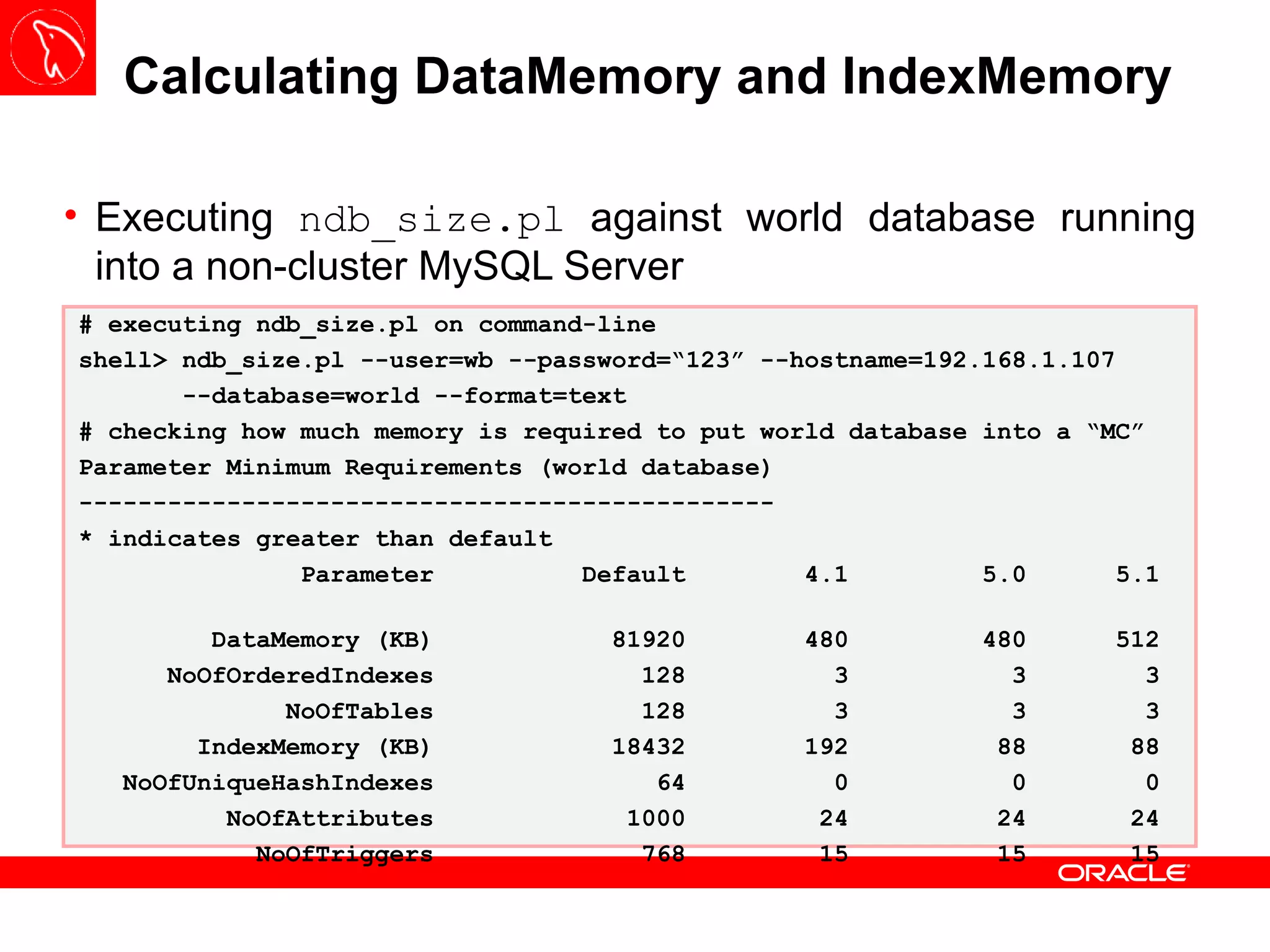
![In-memory Tables Most commonly used parameters in [ndbd] and [ndbd default]: DataMemory : amount of memory space for storing database records; IndexMemory : amount of memory space to store hash indexes (primary key and unique indexes); MaxNoOfTables; MaNoOfAttributes; MaxNoOfOrderedIndexes; MaxNoOfTriggers; MaxNoOfConcurrentOperations; MaxNoOfConcurrentIndexOperations; MaxNoOfConcurrentScans; MaxNoOfConcurrentTransactions “ …”](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-47-2048.jpg)






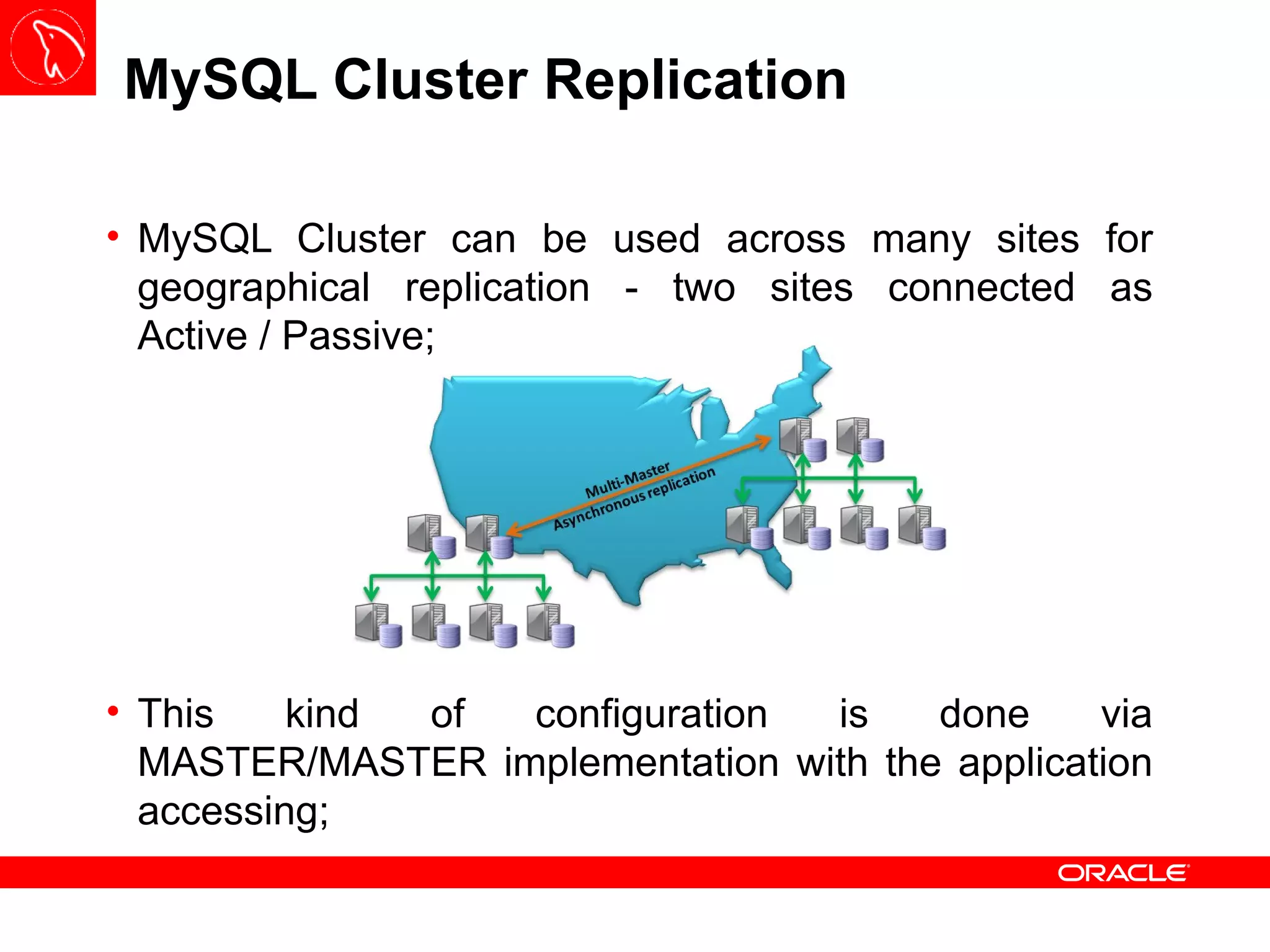


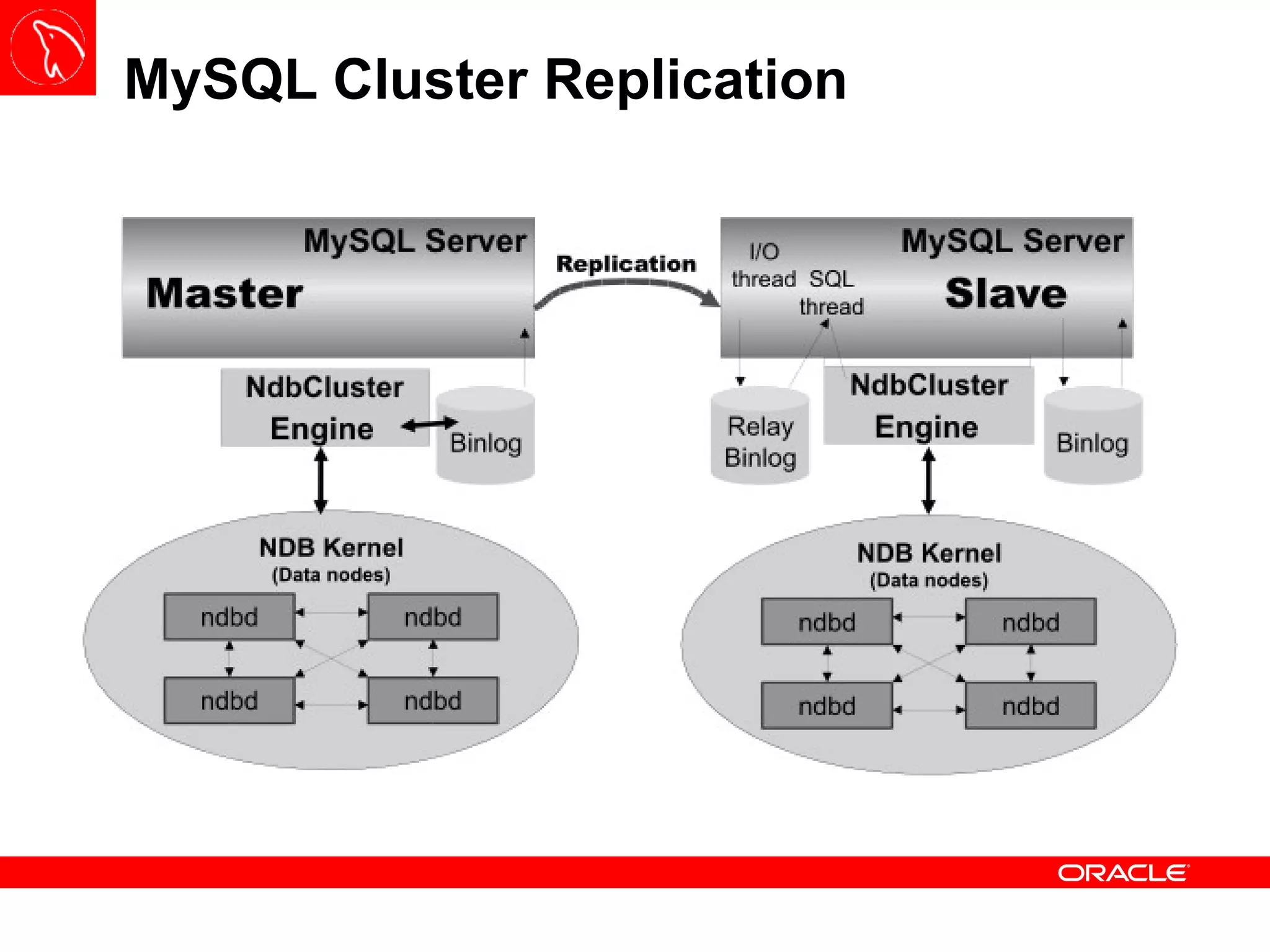




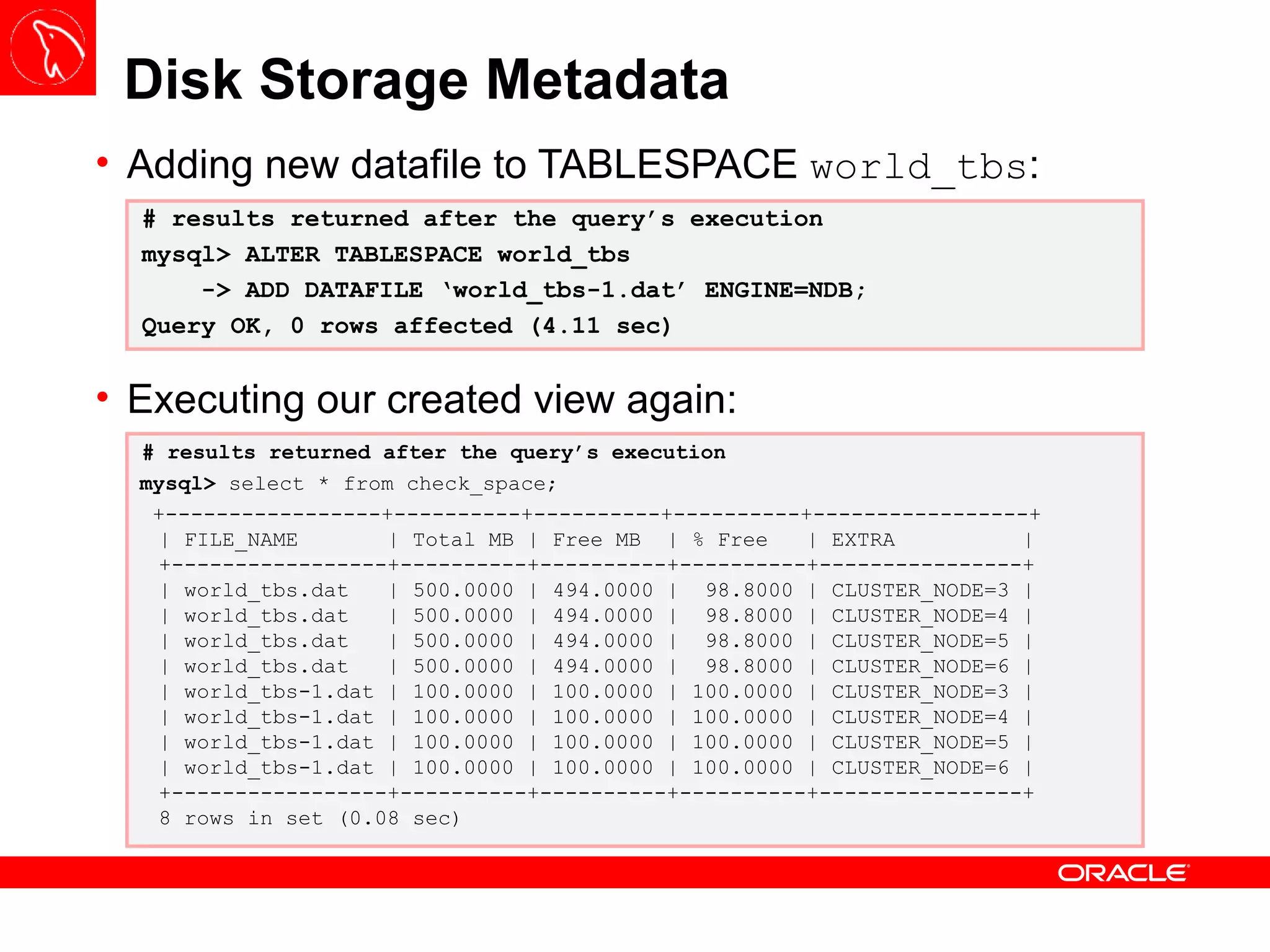
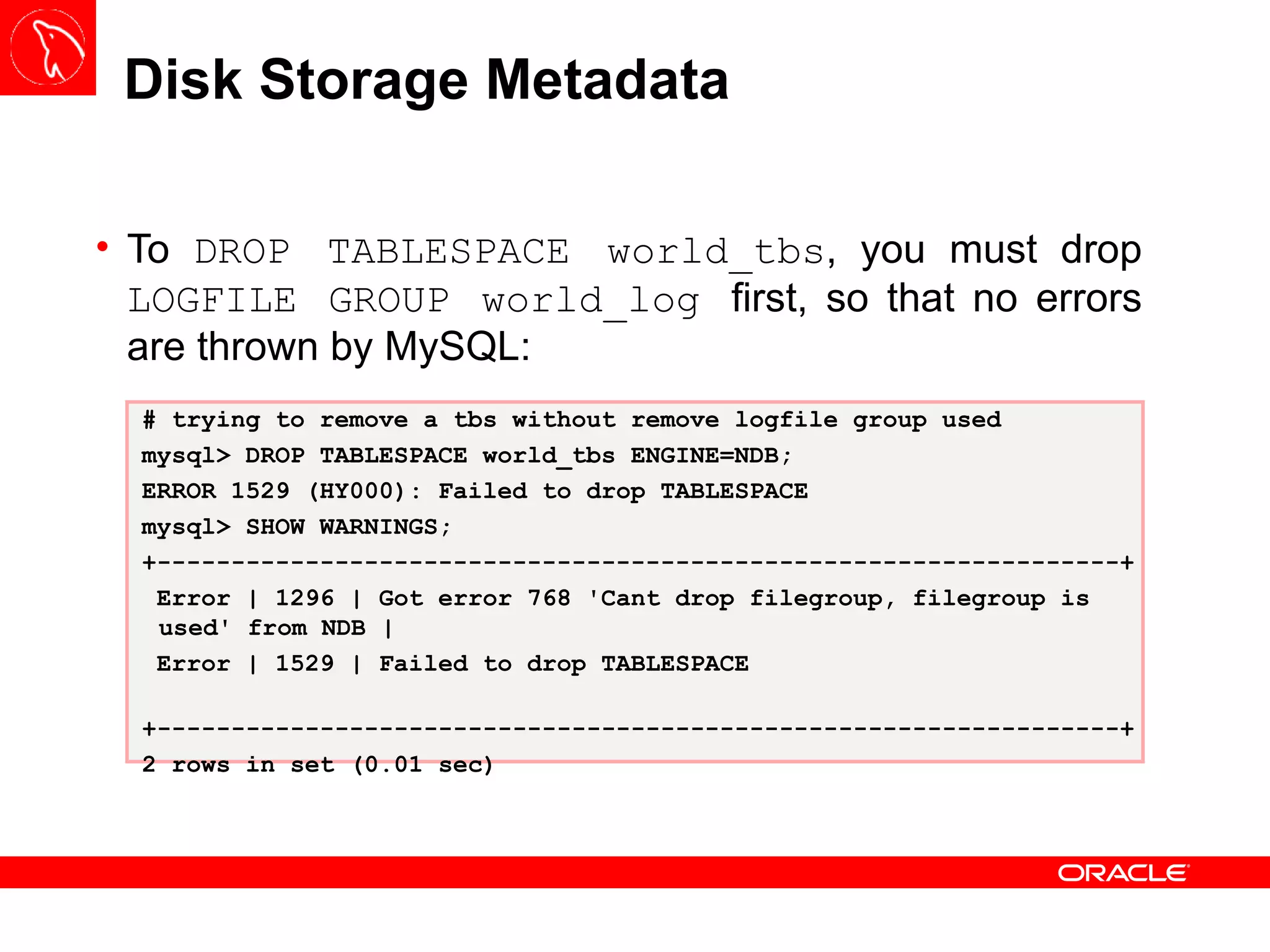
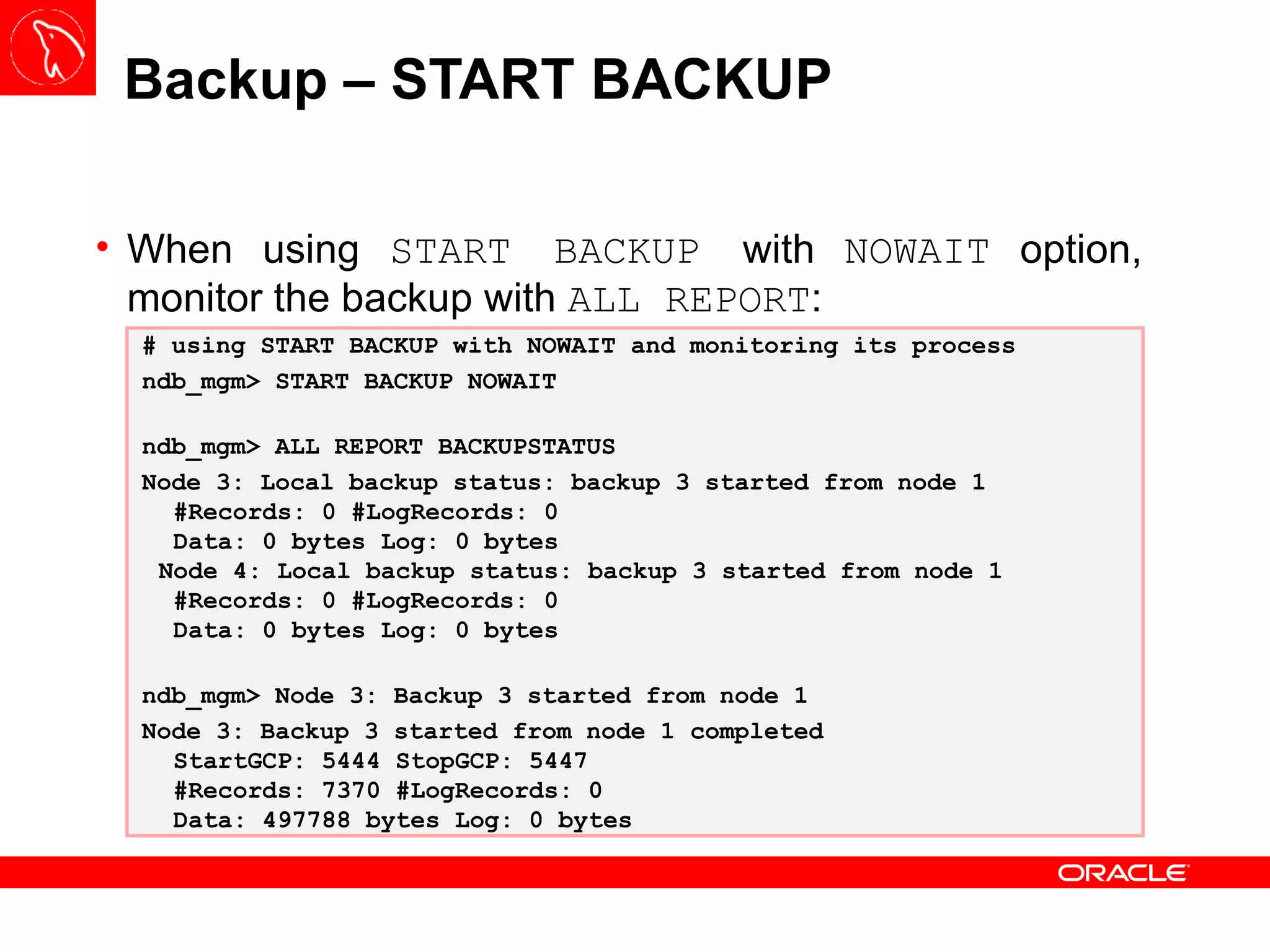
![Backup – START BACKUP The START BACKUP command execution is done through the ndb_mgm or Management Node Client and it has three interesting options: NOWAIT : present the prompt immediately to the user; WAIT STARTED : wait until the backup process starts; WAIT COMPLETE : wait until the backup process is finished; It is good practice to set up a new physical partition on Data Nodes to store all backups – this behavior can be configured using BackupDataDir variable under [ndbd default]](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-63-2048.jpg)
![Backup – START BACKUP Cluster backups are created by default in the BACKUP subdirectory of the DataDir on each Data Node as showed below: Listing files inside BACKUP-1: # listing DataDir/BACKUP subdirectories [root@node3]# ls –l BACKUP-1 # listing files from BACKUP-1 directory [root@node3 BACKUP]# ls -l BACKUP-1/ total 276 -rw-r--r-- 1 root root 253388 Jun 7 17:57 BACKUP-1-0.3.Data -rw-r--r-- 1 root root 17660 Jun 7 17:57 BACKUP-1.3.ctl -rw-r--r-- 1 root root 52 Jun 7 17:57 BACKUP-1.3.log](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-65-2048.jpg)

![Restore - ndb_restore [root@node3 ~]# ndb_restore -c 192.168.1.101 -b 1 -n 3 -r /backup-cluster/BACKUP/BACKUP-1 Backup Id = 1 Nodeid = 3 backup path = /backup-cluster/BACKUP/BACKUP-1 Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1.3.ctl' File size 17660 bytes Backup version in files: ndb-6.3.11 ndb version: mysql-5.1.56 ndb-7.1.13 Stop GCP of Backup: 4747 Connected to ndb!! Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1-0.3.Data' File size 253388 bytes _____________________________________________________ Processing data in table: world/def/CountryLanguage(15) fragment 0 _____________________________________________________ Processing data in table: sys/def/NDB$EVENTS_0(3) fragment 0 _____________________________________________________ Processing data in table: mysql/def/ndb_apply_status(6) fragment 0 _____________________________________________________ Processing data in table: world/def/City(11) fragment 0 _____________________________________________________ Processing data in table: mysql/def/NDB$BLOB_4_3(5) fragment 0 _____________________________________________________ Processing data in table: sys/def/SYSTAB_0(2) fragment 0 _____________________________________________________ Processing data in table: mysql/def/ndb_schema(4) fragment 0 _____________________________________________________ Processing data in table: world/def/Country(13) fragment 0 Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1.3.log' File size 52 bytes Restored 2697 tuples and 0 log entries NDBT_ProgramExit: 0 - OK](https://image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-67-2048.jpg)


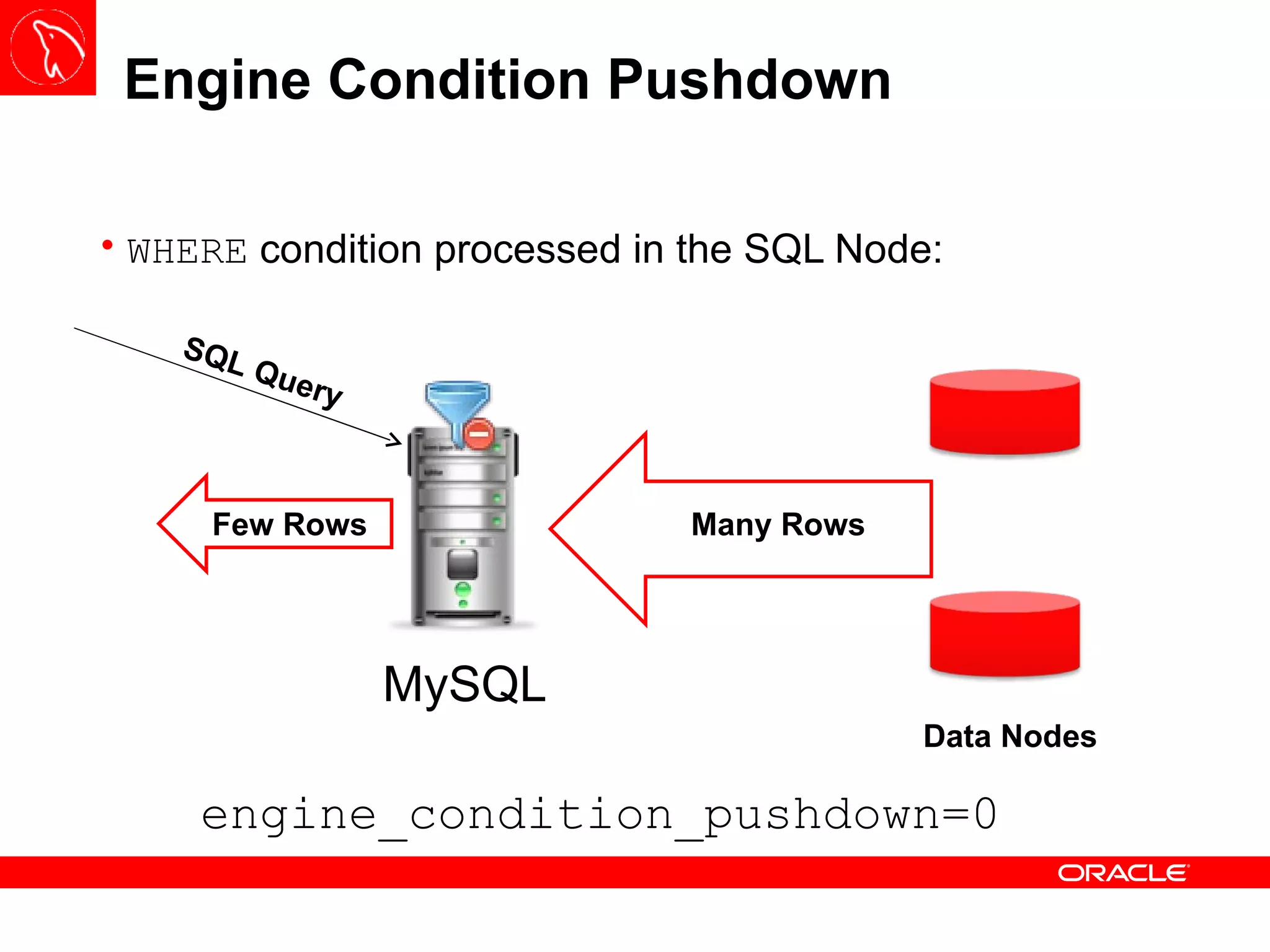





![MySQL Cluster Wagner Bianchi – LAD Senior Principal Consulting [email_address]](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-1-2048.jpg)






![Management Node When a local data node's files are used and the option “ nostart ” is mentioned in these files, you’ll be required to start data nodes manually, using ndb_mgm as: You can START or RESTART a node, issuing mentioned statement, preceding by the node ID. Observing that it will work only for data nodes, not for SQL/API nodes; # start or restarting data nodes after its execution shell> ndb_mgm –e “4 [ START | RESTART ]”](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-8-2048.jpg)

![Management Node Downloading and installing mgm node packages: # creating directories -> BASEDIR and DATADIR [ root@node1 ~ ] mkdir -p /usr/local/mysql-cluster [ root@node1 ~ ] mkdir -p /var/lib/mysql-cluster [ root@node1 ~ ] cd /usr/local/mysql-cluster # downloading management node necessary packages [ root@node1 ~ ] wget http://downloads.mysql...management.rpm [ root@node1 ~ ] wget http://downloads.mysql...tools.rpm # installing necessary packages [ root@node1 mysql-cluster ] rpm -ivh MySQL-* Preparing... ############################################ [100%] 1:MySQL-Cluster-gpl-management ########################### [100%] 2:MySQL-Cluster-gpl-tools ################################ [100%]](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-10-2048.jpg)

![Management Node You can verify that the management server process is running by viewing the output of a system command such this one: Now we can use ndb_mgm, the management client to retrieve information about the cluster using SHOW command: [ root@node1 ]# ps aux | grep ndb_mgmd root 103467 17.3 0.7 8398 2564 ? Ssl 3:20 3:55 ndb_mgmd –f /usr/local/mysql-cluster/config.ini # SHOW command retrieves information about cluster [ root@node1 ]# ndb_mgm –e “ SHOW”](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-12-2048.jpg)








![Local Configuration File Each data or API Node in a particular cluster needs to know how to connect to the cluster Management Node(s) – another way to provide necessary information is to use local configuration file; These types of files follow similar conventions to my.cnf, are located in the same place and have the same structure; [ndbd] # local ndbd’s configuration file - /etc/my.cnf ndb-connectstring=192.168.0.101:1186,192.168.0.102:1186 NoStart # ndbd do not start after be invoked](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-21-2048.jpg)
![Global Configuration File The global configuration file is a central one that resides on one or more Management Node servers, and which provides information about the cluster as a whole Specific types of nodes can be configured globally within the sections of this file, e.g., [ndbd default] ; This file, commonly created as config.ini , is used by the Management Node to start cluster, receive nodes’ connections and start cluster’s operations;](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-22-2048.jpg)
![Global Configuration File [ndb_mgmd] NodeId=1 HostName=192.168.0.101 [ndbd default] NoOfReplicas=2 DataDir=/var/lib/mysql-cluster StopOnError=false # angel will restart failed nodes [ndbd] NodeId=2 HostName=192.168.0.102 [ndbd] NodeId=3 HostName=192.168.0.103 [mysqld] NodeIde=4 HostName=192.168.0.104 [mysqld] # free reserved slot – e.g. ndb_restore, the native cli for database restore](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-23-2048.jpg)






















![In-memory Tables In order to store table data in-memory, no additional statements are required, instead some parameters must be configured to get the required data in main memory; Those parameters must be configured in the global configuration file (located on mgm node),l generally use the [ndbd default] section; it is not good to set up parameters individually for each Data Node;](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-46-2048.jpg)
![In-memory Tables Most commonly used parameters in [ndbd] and [ndbd default]: DataMemory : amount of memory space for storing database records; IndexMemory : amount of memory space to store hash indexes (primary key and unique indexes); MaxNoOfTables; MaNoOfAttributes; MaxNoOfOrderedIndexes; MaxNoOfTriggers; MaxNoOfConcurrentOperations; MaxNoOfConcurrentIndexOperations; MaxNoOfConcurrentScans; MaxNoOfConcurrentTransactions “ …”](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-47-2048.jpg)















![Backup – START BACKUP The START BACKUP command execution is done through the ndb_mgm or Management Node Client and it has three interesting options: NOWAIT : present the prompt immediately to the user; WAIT STARTED : wait until the backup process starts; WAIT COMPLETE : wait until the backup process is finished; It is good practice to set up a new physical partition on Data Nodes to store all backups – this behavior can be configured using BackupDataDir variable under [ndbd default]](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-63-2048.jpg)

![Backup – START BACKUP Cluster backups are created by default in the BACKUP subdirectory of the DataDir on each Data Node as showed below: Listing files inside BACKUP-1: # listing DataDir/BACKUP subdirectories [root@node3]# ls –l BACKUP-1 # listing files from BACKUP-1 directory [root@node3 BACKUP]# ls -l BACKUP-1/ total 276 -rw-r--r-- 1 root root 253388 Jun 7 17:57 BACKUP-1-0.3.Data -rw-r--r-- 1 root root 17660 Jun 7 17:57 BACKUP-1.3.ctl -rw-r--r-- 1 root root 52 Jun 7 17:57 BACKUP-1.3.log](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-65-2048.jpg)

![Restore - ndb_restore [root@node3 ~]# ndb_restore -c 192.168.1.101 -b 1 -n 3 -r /backup-cluster/BACKUP/BACKUP-1 Backup Id = 1 Nodeid = 3 backup path = /backup-cluster/BACKUP/BACKUP-1 Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1.3.ctl' File size 17660 bytes Backup version in files: ndb-6.3.11 ndb version: mysql-5.1.56 ndb-7.1.13 Stop GCP of Backup: 4747 Connected to ndb!! Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1-0.3.Data' File size 253388 bytes _____________________________________________________ Processing data in table: world/def/CountryLanguage(15) fragment 0 _____________________________________________________ Processing data in table: sys/def/NDB$EVENTS_0(3) fragment 0 _____________________________________________________ Processing data in table: mysql/def/ndb_apply_status(6) fragment 0 _____________________________________________________ Processing data in table: world/def/City(11) fragment 0 _____________________________________________________ Processing data in table: mysql/def/NDB$BLOB_4_3(5) fragment 0 _____________________________________________________ Processing data in table: sys/def/SYSTAB_0(2) fragment 0 _____________________________________________________ Processing data in table: mysql/def/ndb_schema(4) fragment 0 _____________________________________________________ Processing data in table: world/def/Country(13) fragment 0 Opening file '/backup-cluster/BACKUP/BACKUP-1/BACKUP-1.3.log' File size 52 bytes Restored 2697 tuples and 0 log entries NDBT_ProgramExit: 0 - OK](https://crownmelresort.com/image.slidesharecdn.com/mysqlclustertraining-111027174029-phpapp01/75/MySQL-Cluster-Basics-67-2048.jpg)











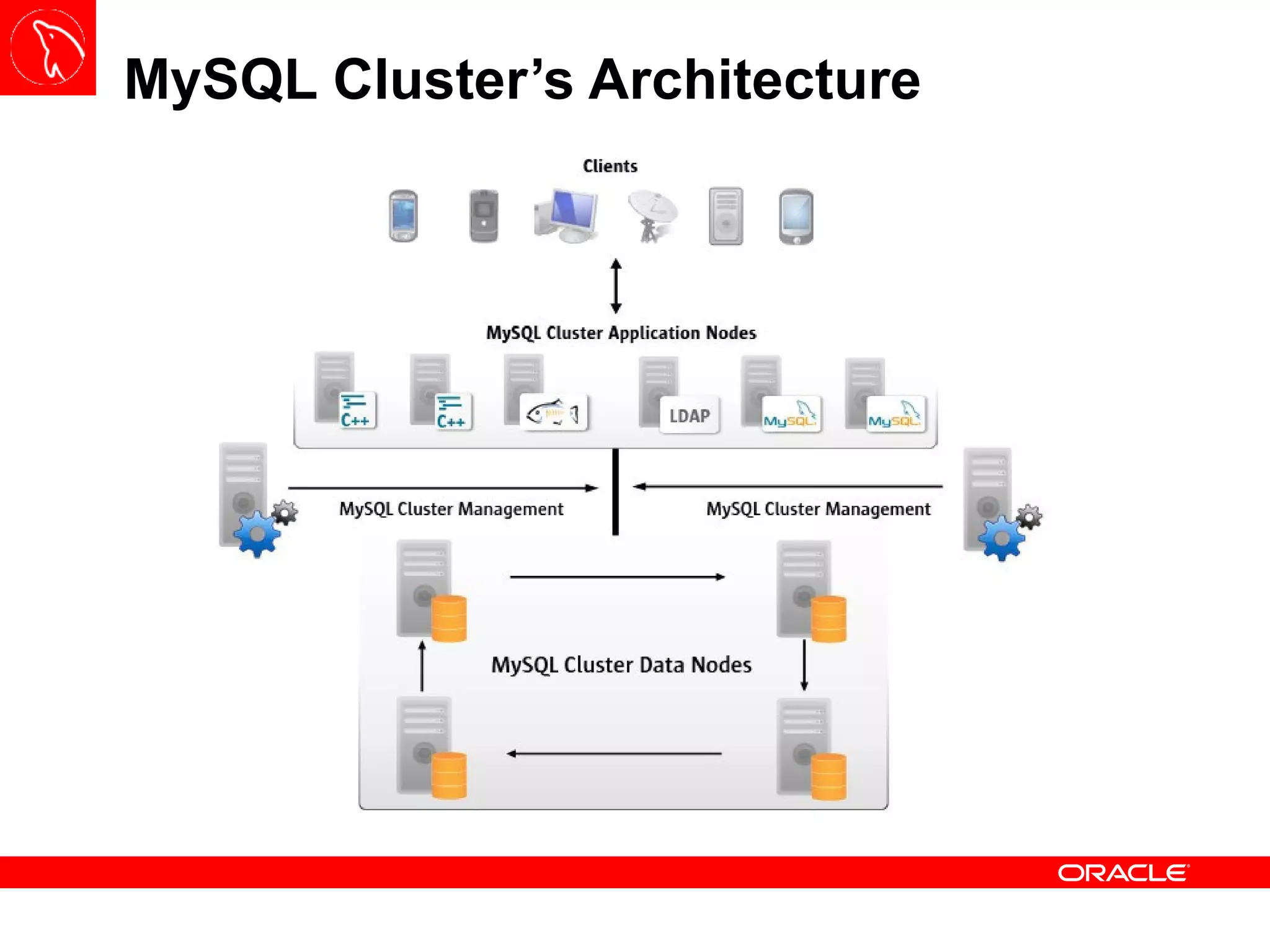
The document outlines the architecture and management processes of a MySQL Cluster, including its components like management and data/storage nodes, and SQL/api nodes. It covers configuration, partitioning, backup and restore processes, and the necessary commands for interacting with the cluster. Additionally, it details the setup for disk-based and in-memory tables, along with performance monitoring and maintenance strategies.






































































































