Downloaded 33 times






![Getting to production is hard to do
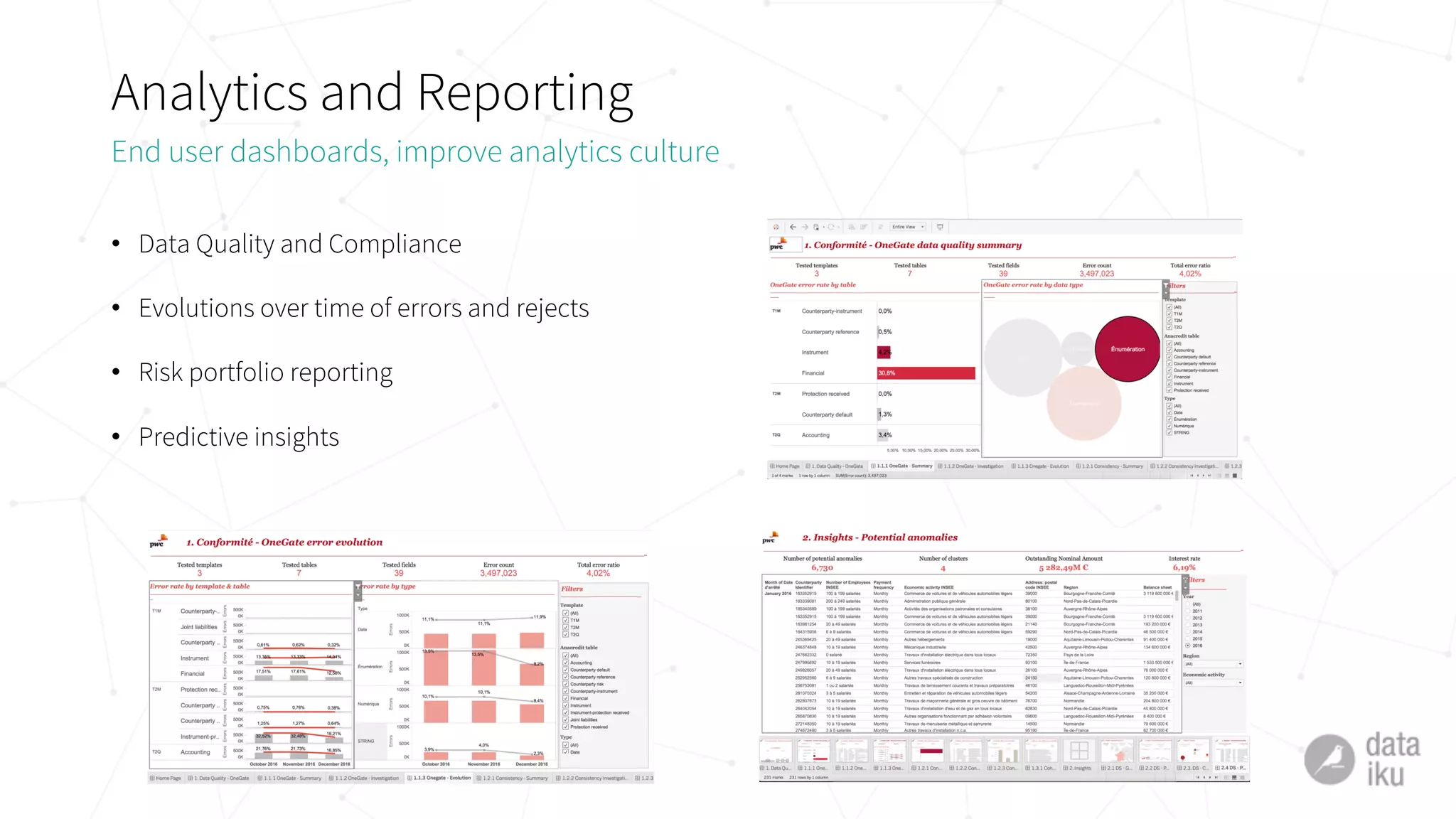
• different teams in charge
• lack of established platforms or frameworks
• overall low maturity on deployment skills and experience
McKinsey Institute: « less than 10% of data science projects are deployed into
production […] with average deployment times of 9 to 12 months »
Why is data science hard to productionalize?](https://image.slidesharecdn.com/yashasvaidya-180212175832/75/Data-Science-Salon-Quit-Wasting-Time-Case-Studies-in-Production-Machine-Learning-9-2048.jpg)


















![Getting to production is hard to do
• different teams in charge
• lack of established platforms or frameworks
• overall low maturity on deployment skills and experience
McKinsey Institute: « less than 10% of data science projects are deployed into
production […] with average deployment times of 9 to 12 months »
Why is data science hard to productionalize?](https://crownmelresort.com/image.slidesharecdn.com/yashasvaidya-180212175832/75/Data-Science-Salon-Quit-Wasting-Time-Case-Studies-in-Production-Machine-Learning-9-2048.jpg)






















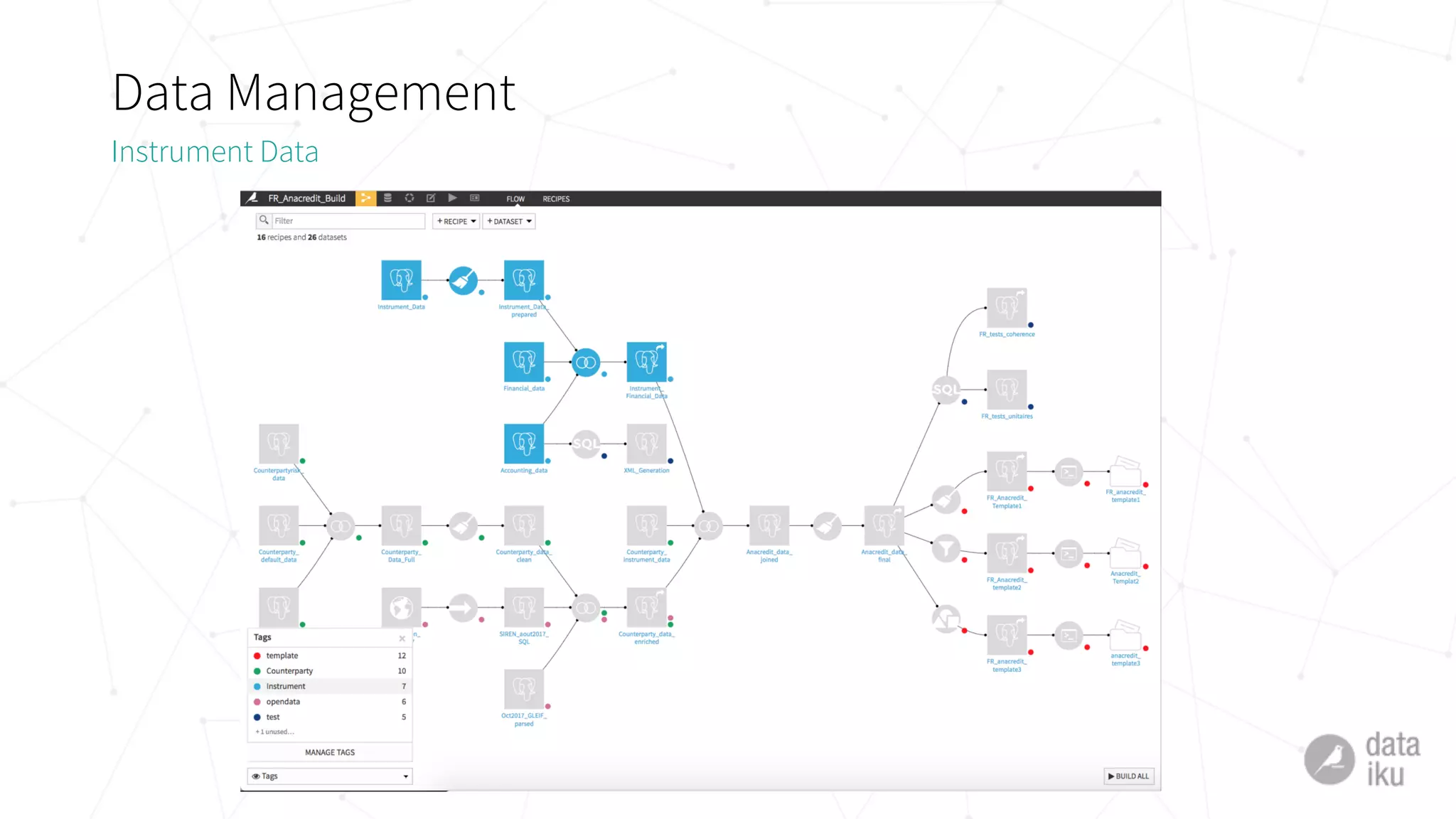
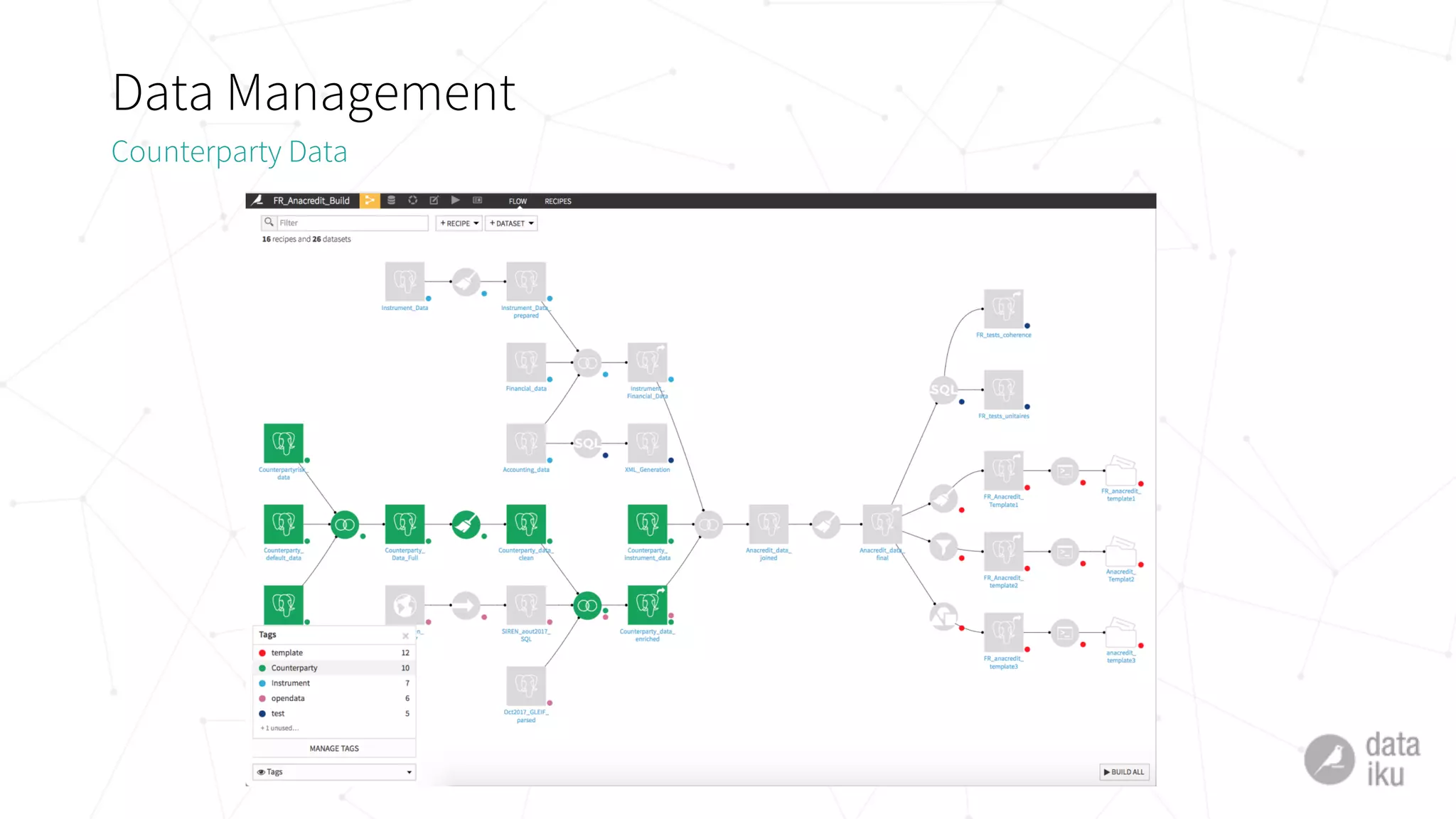
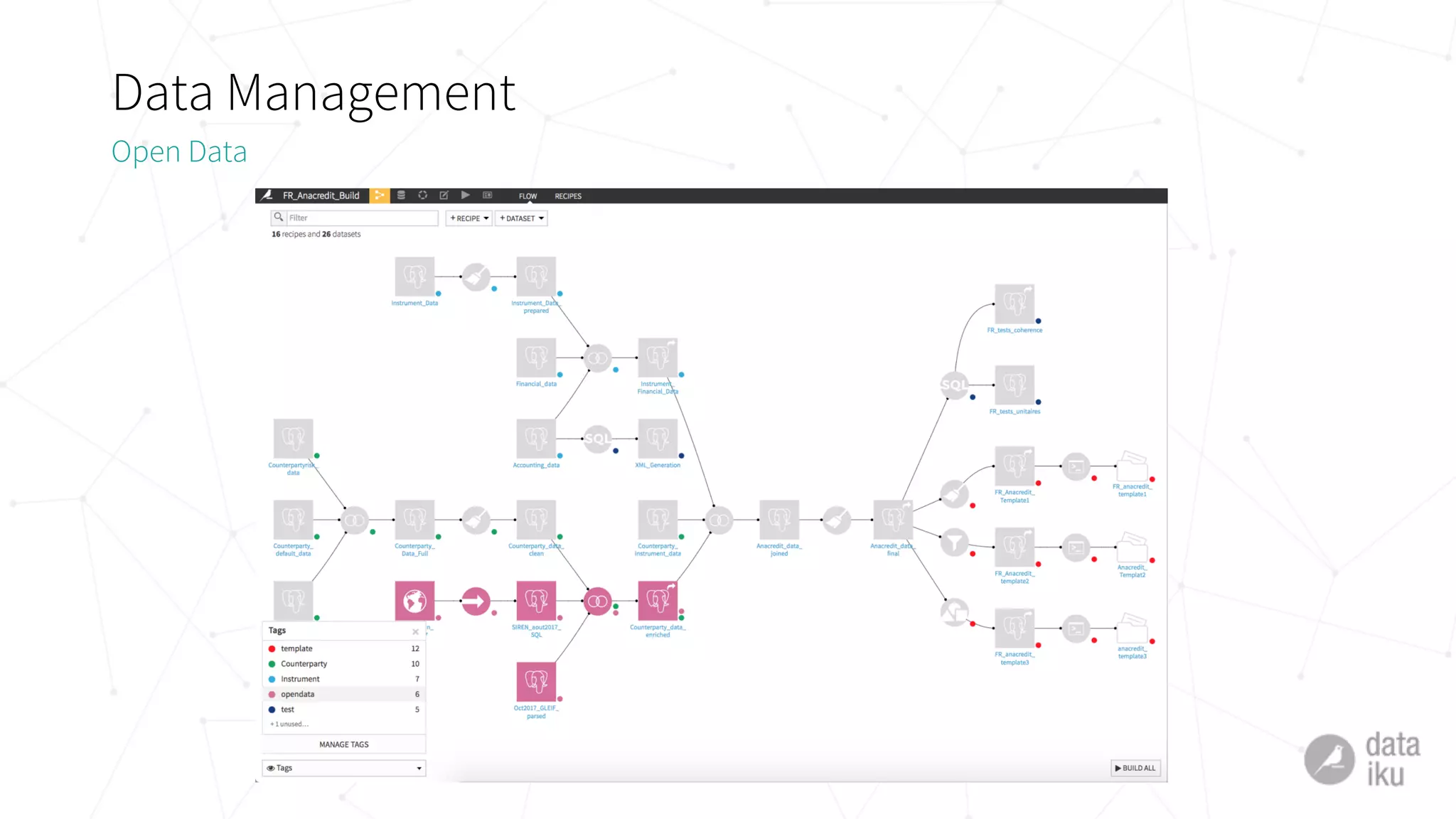
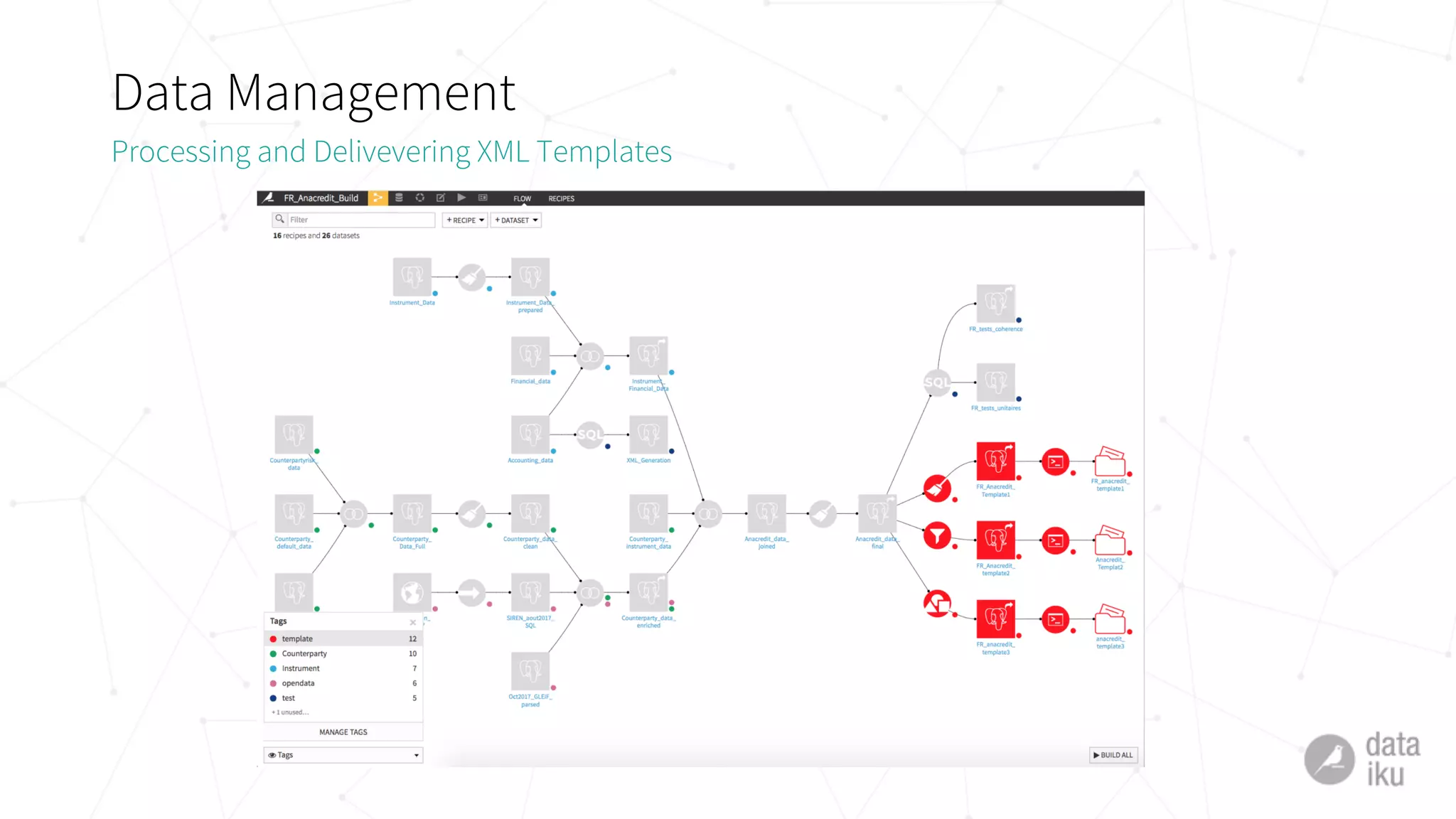
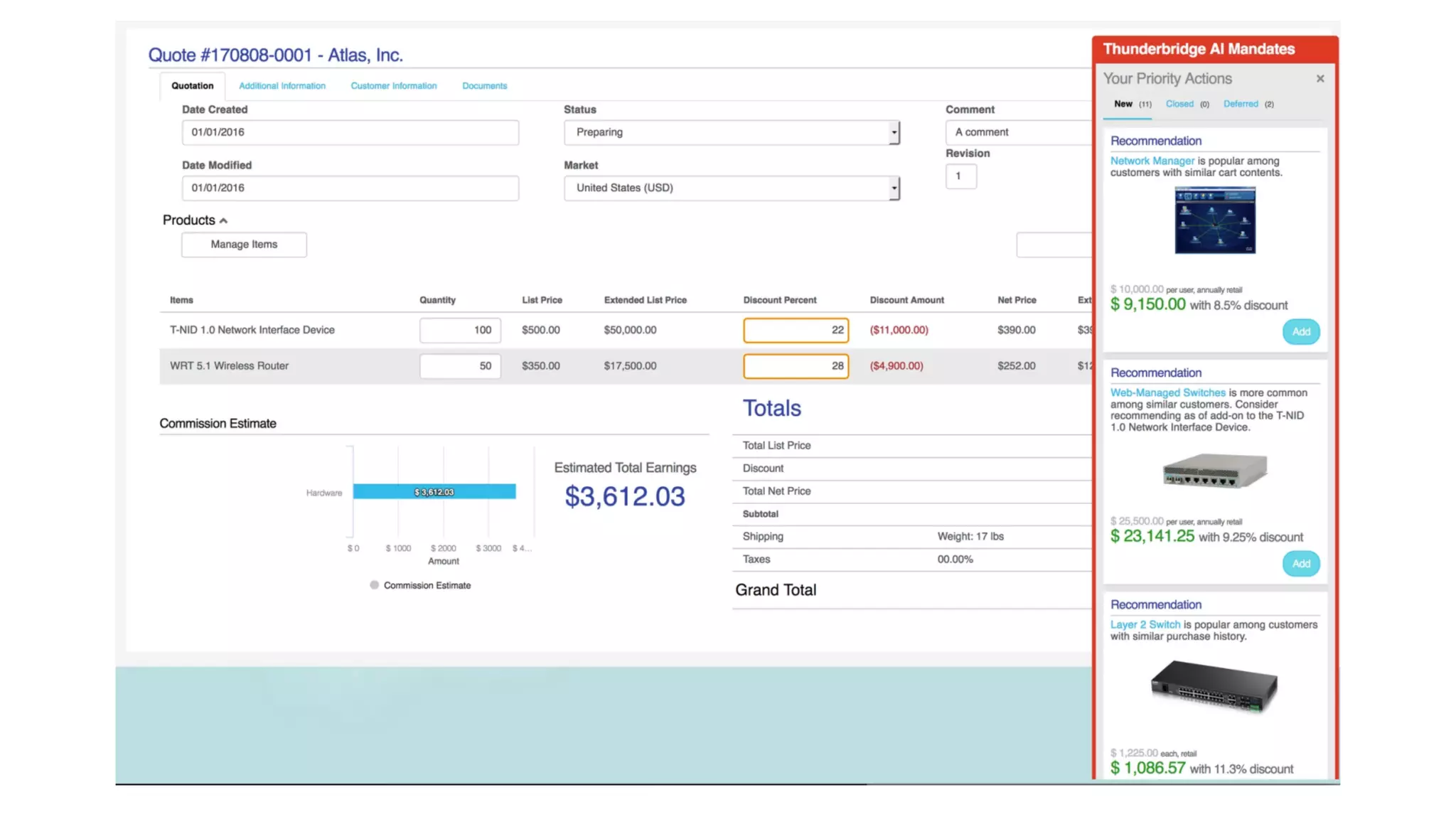
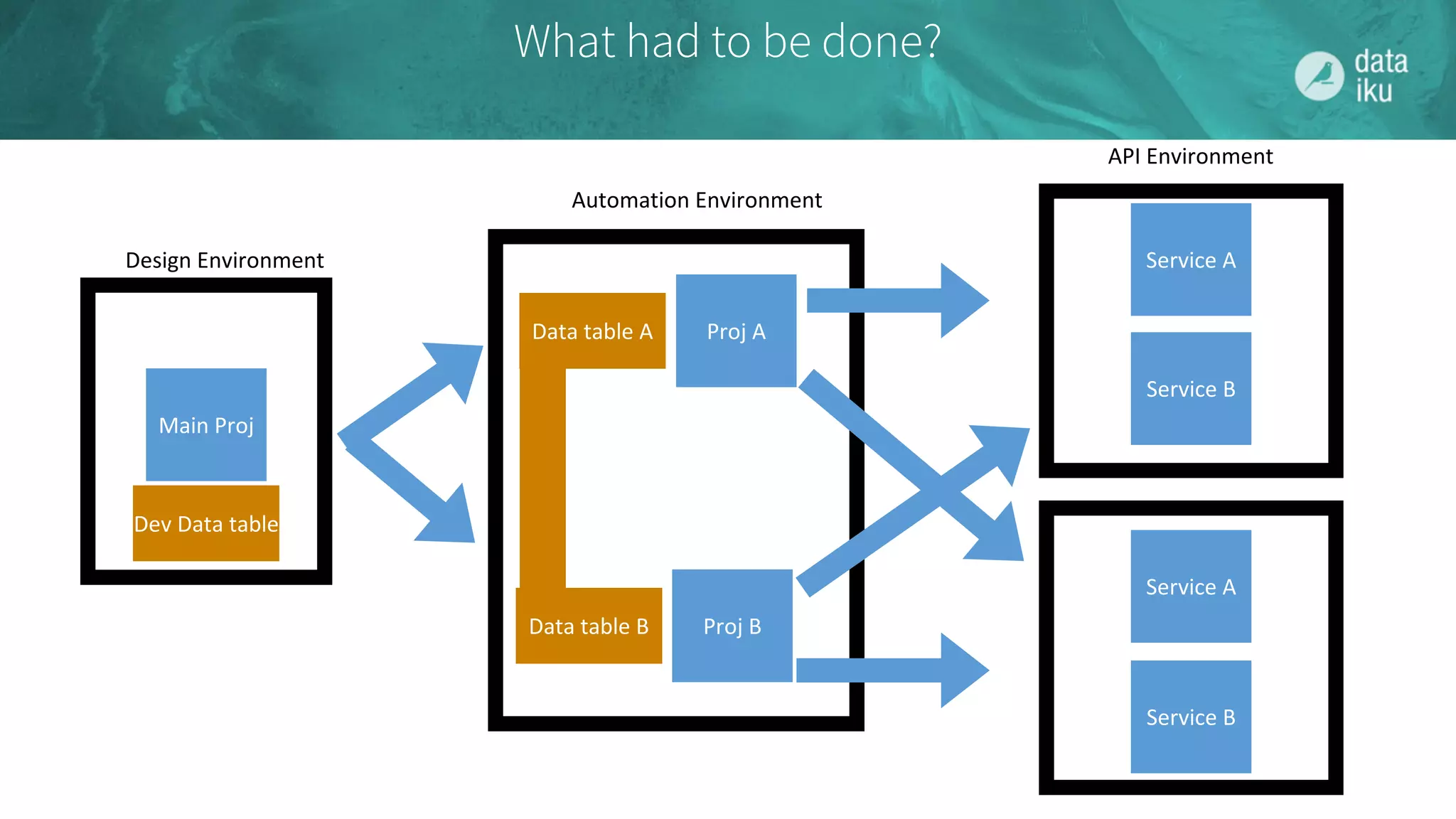
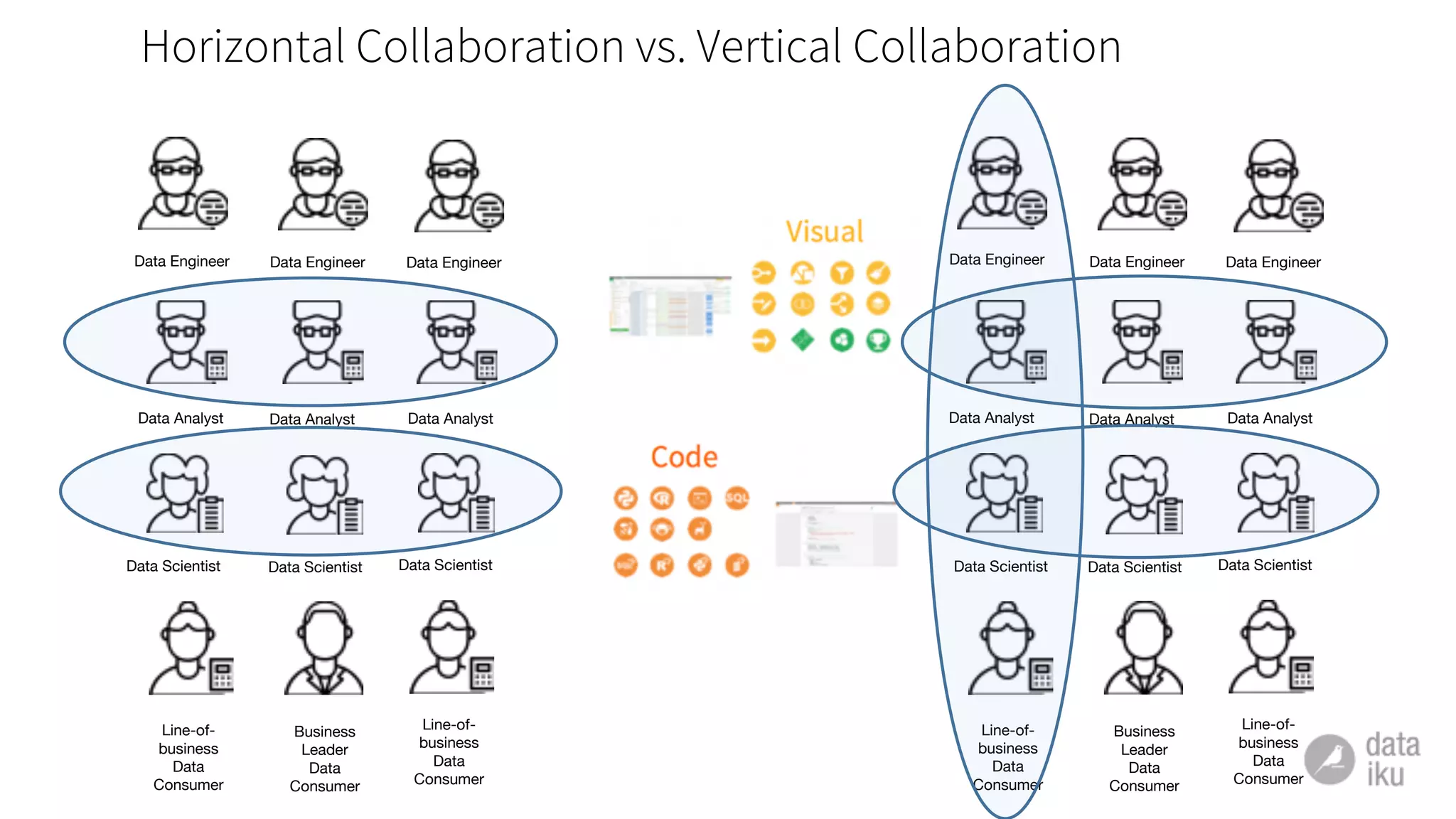
The document discusses challenges in deploying machine learning projects and presents two case studies highlighting strategies to overcome these issues. The first case study focuses on regulatory compliance within financial institutions, while the second explores the implementation of a real-time recommendation system. It emphasizes the importance of collaboration among teams and leveraging tools like Dataiku DSS to streamline processes and improve insights.



















































































![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)
